Лента новостей
|
29.07.2022 [14:18], Алексей Степин
Бесславный конец Optane: полмиллиарда убытков и полный отказ от технологииВ своё время совместная инициатива Intel и Micron, целью которой стало создание принципиально нового типа энергонезависимой памяти 3D XPoint, наделало много шума. Первые же выпущенные на основе данной технологии SSD показали великолепные результаты. Эту память сегодня мы знаем как Optane, и, увы, с надеждами на появление новых решений на её основе придётся распрощаться. Тревожные звонки раздавались давно: в 2018 году Micron вышла из бизнеса, уступив своё производство 3D XPoint партнёру, а сама Intel отказалась от идеи выпуска потребительских накопителей на базе Optane. Но, по крайней мере, на тот момент она сосредоточила усилия на выпуске серверных решений. В их число вошёл и принципиально новый продукт: энергонезависимые модули DCPMM/PMem.  Они устанавливались в обычные слоты DIMM, не слишком сильно уступали в производительности классической оперативной памяти и позволяли кардинально нарастить объём доступной памяти за меньшую стоимость, нежели при использовании только DRAM. Казалось бы, память Optane нашла свою, пусть и довольно экзотическую нишу, что подтверждалось и многочисленными результатами тестов систем с Optane DCPMM, в том числе, в научных задачах. Но грянул гром! По результатам II квартала 2022 года Intel сообщила, что изрядно похудевшее к этому моменту подразделение Optane принесло $559 млн убытков. Решение списать текущие запасы готовых решений и чипов по графе «убытки» окончательно доказывает то, что Intel действительно намеревается покончить с этой страницей своей истории. Равно как и с SSD — соответствующее подразделение продано компании SK Hynix.  На данный момент сама Intel официально подтвердила отказ от Optane: в рамках новой стратегии оптимизации бизнеса IDM 2.0 компания закроет подразделения, не являющиеся решающими в стратегическом отношении, либо просто недостаточно прибыльные. Впрочем, поддержка клиентов, уже вложившихся в Optane будет продолжена. Сама же Intel отметила, что переход на CXL позволит хотя бы отчасти заменить Optane PMem. Из альтернатив технологии Optane, тоже не слишком популярных, можно вспомнить Samsung Z-SSD и Toshiba/Kioxia XL-Flash. Таким образом, приходится расстаться с мечтой о твердотельных накопителях не просто надёжных, но и лишённых традиционной медлительности NAND при операциях записи, особенно мелкоблочных. Стоимость производства чипов 3D XPoint даже во втором поколении, когда память удалось сделать четырёхслойной, всё же оказалась слишком высокой для того, чтобы устройства на её основе стали действительно выгодными для Intel.
28.07.2022 [23:13], Алексей Степин
Microsoft и Plug Power успешно протестировали водородные топливные элементы для резервного питания ЦОДДизель-генератор — неотъемлемая часть подсистемы резервного питания любого серьёзного ЦОД, но по природе своей он не может похвастаться нейтральностью выхлопа. Многие ищут традиционным генераторам замену, и в их числе Microsoft. На днях компания сообщила, что ей удалось достичь важной вехи в освоении водородных топливных элементов, которые, по замыслу Microsoft, и должны заменить традиционные дизель-генераторы в принадлежащих ей центрах обработки данных. Компания начала тестирование новой генераторной станции мощностью 3 МВт, построенной на базе топливных ячеек с протонообменной мембраной (PEM). Она способна обеспечивать питание 10 тыс. серверов. С топливными элементами компания экспериментирует давно, ещё с 2013 года, но более ранние разработки использовали природный газ и не по факту не являлись такими уж экологичными. 
Тестовая станция мощностью 3 мВт. Источник: Microsoft/John Brecher Разработать водородные PEM-ячейки компании удалось в сотрудничестве с Plug Power. В течение нескольких недель июня компании совместно протестировали прототип генератора нового поколения. Новая система, выбрасывающая в атмосферу лишь нагретый водяной пар, сработала успешно, так что Plug Power уже работает над созданием коммерческой версии системы. 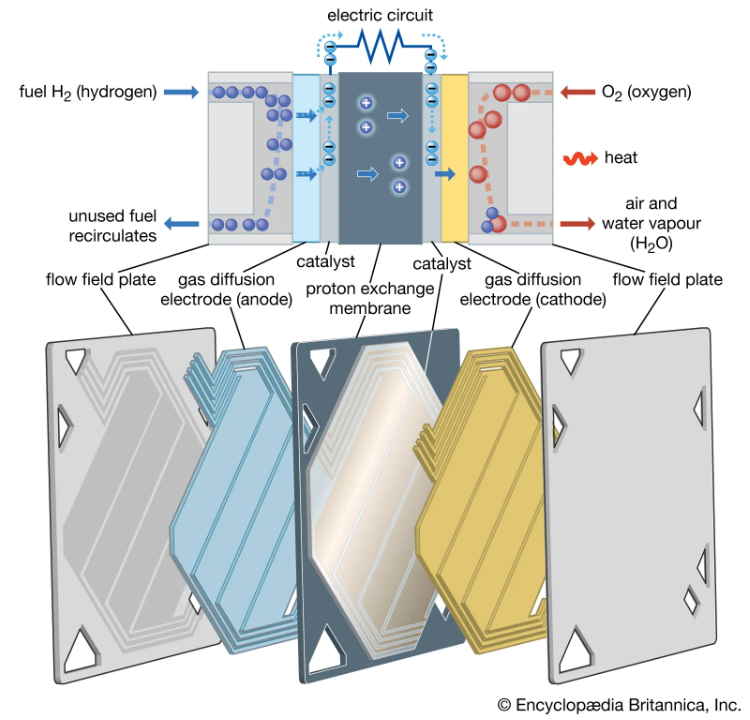
Протонообменная мембрана: конструкция и принцип действия. Источник: Encyclopedia Britannica Первый же экземпляр будет установлен научно-исследовательском центре Microsoft, но пока конкретных сроков пока озвучено не было. У IT-гиганта большие надежды на подобные технологии: к 2030 году компания планирует обновить системы резервного питания во всех своих ЦОД. 
В работе система выделяет только горячий водяной пар. Источник: Microsoft/John Brecher Правда, в полной экологичности водородных топливных элементов есть сомнения: работают они без вредных выбросов, но само их производство может оказаться далеко не таким чистым, как эксплуатация. Тем не менее, администрация США одобрила план стоимостью $8 млрд по развитию производства водорода в рамках программы альтернатив ископаемому топливу. В Европе есть аналогичные инициативы — как совсем скромные (€2,5 млн), так и весьма крупные (€1 млрд).
28.07.2022 [18:12], Руслан Авдеев
Европейские дата-центры хотят снизить потребление воды до 400 мл/кВт·ч, но только к 2040 годуГруппа Climate Neutral Data Centre Pact (CNDCP), объединяющая 90 % европейских операторов ЦОД, предложила добровольно снизить потребление воды до 400 мл на 1 кВт·ч к 2040 году и добиться углеродной нейтральности намного раньше 2050 года. Соответствующая цель уже поставлена ЕС, но операторы намерены добиваться её без законодательного принуждения и с опережением графика, — сообщает Data Center Dynamics. Хотя использование воды способно оказать значительное влияние на экологию, этот фактор часто недооценивают, учитывая только расход энергии. При этом многие ЦОД активно используют воду для охлаждения оборудования, благодаря чему снижается расход всё той же энергии, но растут затраты самой жидкости, что имеет критическое значение для некоторых регионов. Группу CNDCP сформировали в 2021 году с намерением достичь углеродной нейтральности европейских ЦОД к 2030 году, а также обеспечить достойный ответ прочим экологическим вызовам, в том числе снизить расход воды. Для оценки эффективности использования воды используется коэффициент WUE, который отражает расход воды на каждый затраченный киловатт·час электричества. Например, исследование 2016 года показало, что на тот момент WUE для ЦОД в США составлял в среднем 1,8 л/кВт·ч. 
Источник изображения: Christian Lue/unsplash.com Цели поставлены с учётом жизненного цикла уже действующих систем охлаждения, поскольку их немедленная массовая замена может принести больше вреда, чем пользы из-за ущерба экологии в процессе производства самих систем. Поэтому в CNDCP заявили, что все 74 оператора ЦОД, участвовавшие в заключении пакта, добьются потребления не более 400 мл/кВт·ч только к 2040 году. Такой показатель вывели с учётом разницы технологий, климатических и иных условий, характерных для тех или иных ЦОД. 
Источник изображения: Google Отдельные участники рынка уже заявили о намерении добиться положительного водного баланса для своих дата-центров — ЦОД будут отдавать больше чистой воды, чем потреблять. Так, Meta✴ и Microsoft планируют добиться этой цели к 2030 году. Последняя также начала устанавливать станции для очистки сточных вод ЦОД. А вот Google отметилась тем, что пыталась всеми возможными способами скрыть расход воды своими дата-центрами даже от властей. Помимо ограничения расхода воды, подписанты CNDCP предложили ввести и другие цели для дата-центров. Например, уже сформированы две рабочие группы для подготовки к переходу на «циркулярную экономику» со вторичным использованием материалов и переработкой различных ресурсов. В частном порядке аналогичную инициативу уже несколько лет развивает Microsoft в рамках проекта Circular Center.
27.07.2022 [17:11], Руслан Авдеев
Жители Северной Вирджинии ополчились против крупных дата-центровЖители Северной Вирджинии всё более и более недовольны распространению дата-центров гиперскейл-класса и готовы активно противостоять их строительству. По данным DataCenter Dynamics, вслед за жителями округа Принс-Уильям (Prince William), жалующихся на невыносимый уровень шума ЦОД Amazon, обитатели округа Фокир (Fauquier) потребовали от властей запретить строительство дата-центра той же компании, которая за последний десяток лет вложила в местные ЦОД более $35 млрд. Примечательно, что Северная Вирджиния десятилетиями является едва ли не крупнейшим хабом для строительства дата-центров в мире, последовательно привлекающим новые компании, объекты и инвестиции. Изначально ЦОД концентрировались преимущественно в округе Лаудон, а теперь распространяются на территорию округов Калпепер (Culpeper), Фокир и Принс-Уильям, жители которых начали вести организованную борьбу с инициативами IT-гигантов и местных властей. 
Фото: Taylor Vick / Unsplash.com В наиболее «пострадавшем» округе Лаудон предложили новые правила зонирования для дата-центров, определяющих, где будущие ЦОД можно строить так, чтобы не побеспокоить местных жителей. Кроме того, предложено пересмотреть экологические стандарты строительства и допустимого уровня шума. Ожидается, что в определённых местах будет прекращено и одобрение строительства ЦОД в ускоренном порядке. Жители округа Калпепер подали в суд, требуя аннулировать разрешение на перезонирование и развитие ЦОД Amazon. В округе Фокир Amazon уже купила более 16 га земли, подала заявку на строительство нового дата-центра и договорилась с местной энергосбытовой компанией Dominion Energy. Изначально местные жители протестовали против строительства 230-кВ линий электропередач над их домами, но потом поняли, что они вообще не понадобятся, если дата-центра не будет. Местных жителей беспокоит не только экология и комфортность окружающей среды, но и экономика — скупка земли для ЦОД поднимает её цены. Кроме того, всё чаще задаётся вопрос, почему налоги для жителей не падают по мере развития дата-центров. О полном отказе от ЦОД речь не идёт, поскольку они обеспечивают около трети местных налоговых поступлений.
26.07.2022 [10:56], Сергей Карасёв
Kioxia представила корпоративные SSD серии CM7 с PCIe 5.0 и NVMe 2.0Компания Kioxia анонсировала твердотельные накопители CM7 корпоративного класса, оптимизированные для использования в высокопроизводительных и высокоэффективных серверах, а также системах хранения данных. Уже начаты отгрузки устройств некоторым заказчикам. Изделия серии CM7 доступны в двух вариантах исполнения: EDSFF E3.S и SFF толщиной 15 мм. Задействован интерфейс PCIe 5.0 (спецификация NVMe 2.0): утверждается, что по сравнению с накопителями предыдущего поколения производительность увеличилась в два раза. Заявленная скорость чтения информации достигает 14 Гбайт/с; скорость записи не уточняется. Заказчики смогут выбирать между устройствами с разным уровнем надёжности: 1 DWPD (полных перезаписей в сутки) и 3 DWPD. В первом случае вместимость достигает 30,72 Тбайт, во втором — 12,80 Тбайт. 
Источник изображения: Kioxia Накопители CM7 имеют двухпортовую конструкцию. Среди поддерживаемых функций названы SR-IOV, CMB, Multistream writes, SGL. Говорится о поддержке TCG-Opal в соответствии со стандартом FIPS 140-3. Наконец, упомянуты средства обеспечения безопасности Flash Die Failure Protection.
22.07.2022 [21:52], Алексей Степин
Бразильская нефтегазовая компания Petrobras получит самый мощный суперкомпьютер в Латинской Америке — PegasusСовременный суперкомпьютер, а лучше несколько, стремится иметь любая страна или корпорация, и гонка HPC-решений проходит не только между США и Китаем — так, крупнейшая бразильская нефтегазовая компания Petrobras анонсировала создание нового кластера в Рио-де-Жанейро. Будущий суперкомпьютер получил имя Pegasus, и он должен стать самой мощной HPC-системой в латиноамериканском регионе с производительностью около 21 Пфлопс. Система будет включать в себя 2016 ускорителей неизвестной пока модели и 678 Тбайт оперативной памяти, а в качестве интерконнекта планируется использовать 400-Гбит/с сеть. Вероятно, это будeт InfiniBand NDR. 
Рио-де-Жанейро. Источник: Pixabay Суперкомпьютеры активно применяются в нефтегазовой отрасли в самых различных сценариях, от поиска новых месторождений до повышения эффективности существующих процессов переработки природных ресурсов. Petrobras уже располагает солидными вычислительными мощностями, составляющими 42 Пфлопс. Главной задачей Pegasus будет обработка обширных массивов данных в рамках геологоразведывательного проекта EXP100, а также поиск способов ускорить начало разработок новых нефтегазовых полей в проекте PROD1000. 
Машинный зал Dragão. Источник: Agência Petrobras В июне 2021 года компания Petrobras запустила систему Dragão с 200 Тбайт памяти и 100G-интерконнектом. Система на базе процессоров Xeon Gold 6230R занимает 60 место в TOP500 с пиковой теоретической производительностью 14,01 Пфлопс. Также у Petrobras есть машины Atlas (8,84 Пфлопс) и Fênix (5,37 Пфлопс). Для сравнения — система HPC5, принадлежащая итальянской нефтегазовой компании Eni S.p.A., сейчас находится на 12 месте TOP500 и имеет пиковую теоретическую производительность 51,72 Пфлопс. До момента ввода в строй Pegasus, который запланирован на декабрь 2022 года, Dragão продолжит оставаться мощнейшей латиноамериканской HPC-системой. К концу 2022 года компания намеревается нарастить свой пул вычислительных мощностей до 80 Пфлопс, но пока явно отстаёт от графика. Впрочем, темпы роста впечатляют: ещё в 2018 году в распоряжении Petrоbras было лишь 3 Пфлопс.
21.07.2022 [17:27], Руслан Авдеев
Жители Северной Вирджинии жалуются на «катастрофический шум» от дата-центровКак сообщает портал Data Center Dynamics, домовладельцы и гражданские активисты округа Принс-Уильям (Prince William County) в Северной Вирджинии (США), пожаловались на «катастрофический» шум, издаваемый местными ЦОД. Шум доносится из принадлежащих Amazon дата-центров, расположенных на территории кампуса Tanner Way. Сейчас техногигант ведёт строительство в городе Манассасе, но речь идёт не о шуме стройки. По словам активистов, непрекращающийся шум вызван работой систем воздушного охлаждения на крышах ЦОД, создающих неблагоприятную среду обитания для жильцов района Great Oak, состоящего из 291 домохозяйства. 
Источник изображения: Elyas Pasban/unsplash.com Круглый стол ассоциации домовладельцев округа совместно с ассоциацией города Манассас направили жёсткую жалобу в Наблюдательный совет округа, сообщив о «чрезвычайном промышленном шуме», продолжающемся круглосуточно и без выходных, никаких мер по устранению которого не принимается. По словам местных активистов, шум загрязняет окрестности непрерывно, чему есть аудио- и видеодоказательства. От наблюдательного совета требуют найти решение проблемы. Активисты напоминают о прецедентах — аналогичные жалобы в Аризоне в 2018 году привели к прекращению развития ЦОД в регионе решением местных властей. По данным активистов, пока руководство совета не смогло напрямую решить проблему с ЦОД, и теперь жители требуют приостановки разрешений на работу дата-центров в округе Принс-Уильям до тех пор, пока проблема не будет устранена.  Основная беда в том, что Наблюдательный совет округа намеренно исключил шум от промышленных кондиционеров из правил 1989 года, в соответствии с которыми и строились дата-центры, в результате чего округ потерял законную возможность контролировать работу ЦОД в этом отношении, независимо от того, какой громкости звук издают объекты. Местные жители жалуются на проблемы как с собственным здоровьем, так и с состоянием домашних питомцев. Благодаря местным регуляциям Северная Вирджиния крайне привлекательна для строителей и операторов дата-центров. Текущая ёмкость ЦОД в штате составляет порядка 1,7 ГВт, а через два года, как ожидается, она достигнет 2 ГВт. И это самый крупный в мире рынок ЦОД. Для сравнения — суммарная ёмкость сразу четырёх европейских рынков FLAP только-только добралась до 2 ГВт. Та же Amazon за последний десяток лет вложила в постройку дата-центров в Северной Вирджинии более $35 млрд.
20.07.2022 [15:56], Владимир Мироненко
Аномальная жара привела к сбоям в лондонских дата-центрах Google и Oracle
google cloud platform
hardware
oracle cloud infrastructure
великобритания
облако
охлаждение
сбой
цод
Во вторник, 19 июля, в ЦОД Google Cloud Platform (GCP) в Лондоне произошёл сбой в системе охлаждения, в связи с чем несколько сервисов компании временно вышло из строя. В лондонском регионе облака Oracle тоже возникли проблемы с охлаждением оборудования ЦОД. Сбои произошли из-за рекордной жары в Великобритании — температура превысила +40°C. Некоторые операторы дата-центров были вынуждены принять нестандартные меры, начав обрызгивать водой внешние модули систем кондиционирования, установленные на крыше. Отключение ряда сервисов Google произошло в 18:13 по местному времени (20:13 мск). В журнале статуса оборудования сбой описан как «связанный с охлаждением». Google заявила, что сбой затронул лишь небольшое количество клиентов. В частности, отключение коснулось сервисов Persistent Disk и Autoscaling. Хотя Google утверждает, что сбой продолжался до 22:00 BST (24:00 мск), в означенное время всё ещё поступали жалобы на ошибки в работе Persistent Disk. 
Изображение: pixabay.com / Gam-Ol С подобными проблемами в Лондоне столкнулась и облачная служба Oracle. Проблемы с перегревом у неё начались примерно в 17:00 по местному времени (19:00 мск). Oracle ранее арендовала ресурсы в ЦОД Equinix в лондонском кампусе Слау, но сейчас не раскрывает местонахождение своих мощностей. «В результате несезонных температур в регионе возникла проблема с частью инфраструктуры охлаждения в центре обработки данных на юге Великобритании (в Лондоне), — говорится в сообщении компании. — Это привело к тому, что часть нашей сервисной инфраструктуры пришлось отключить, чтобы предотвратить неконтролируемые сбои оборудования».
20.07.2022 [00:56], Владимир Мироненко
Из-за жары лондонские дата-центры вынуждены охлаждать оборудование на крыше, поливая его водой из шланговВ этом году в Великобритании наблюдается аномальная жара. 19 июля температура воздуха в стране установила новый рекорд, превысив 40° С. Как сообщает Bloomberg, в некоторых британских ЦОД выбрали оригинальный способ борьбы с перегревом оборудования, используя обрызгивание водой внешних модулей систем кондиционирования, установленных на крыше. По словам Адриана Тревельяна (Adrian Trevelyan), директора по послепродажному обслуживанию компании Airedale International, которая поставляет и обслуживает системы охлаждения для ЦОД, многие лондонские дата-центры вынуждены прибегнуть к такому необычному способу охлаждения. Небольшие ЦОД в густонаселённых городских районах, работающие почти на полную мощность, просто требуют экстренного орошения во время жары. 
Изображение: pixabay.com / Gam-Ol Тревельян сообщил, что орошение позволяет снизить температуру воздуха вокруг змеевиков внешнего контура охлаждения, чтобы они продолжали эффективно рассеивать тепло. Он отказался назвать конкретные компании, применяющие такой способ охлаждения, но сказал, что это делают «в пределах (кольцевой автомагистрали) M25 и в городе». Однако от жары страдают не только малые, но и крупные дата-центры, которые всё же имеют запас по охлаждению ключевых подсистем — 10 июля в лондонском ЦОД AWS произошёл перебой питания из-за так называемого «теплового события» (thermal event). Использование полива шлангами может выручить в очень жаркий день, но негативно отразится на сроке службы оборудования, сообщила София Флюкер (Sophia Flucker), директор консалтинговой фирмы Operational Intelligence, отметив, что если используется вода повышенной жёсткости (как в Лондоне), это может привести к накоплению накипи. Флюкер также рассказала, что многие операторы колокации, сдающие мощности в аренду третьим лицам, сталкиваются со штрафами за несоблюдение температурного режима в машинных залах.
13.07.2022 [16:13], Алексей Степин
128-ядерный Arm-процессор Alibaba T-Head Yitian 710 показал отличные результаты в SPEC CPU2017Не секрет, что китайские гиганты, такие, как Huawei и Alibaba Cloud, разрабатывают собственные серверные процессоры на базе архитектуры Arm. Однако информации об этих чипах, как правило, не очень много и пользоваться общепринятыми на западе тестами и рейтингами разработчики не спешат, что, к слову, характерно и для китайских суперкомпьютеров. Alibaba Cloud представила чип Yitian 710 ещё осенью прошлого года. Этот процессор построен на базе архитектуры Armv9 и максимально может иметь 128 ядер с частотой до 3,2 ГГц. Однако результаты проверки чипа в популярном тесте SPEC CPU2017 были опубликованы только сейчас. 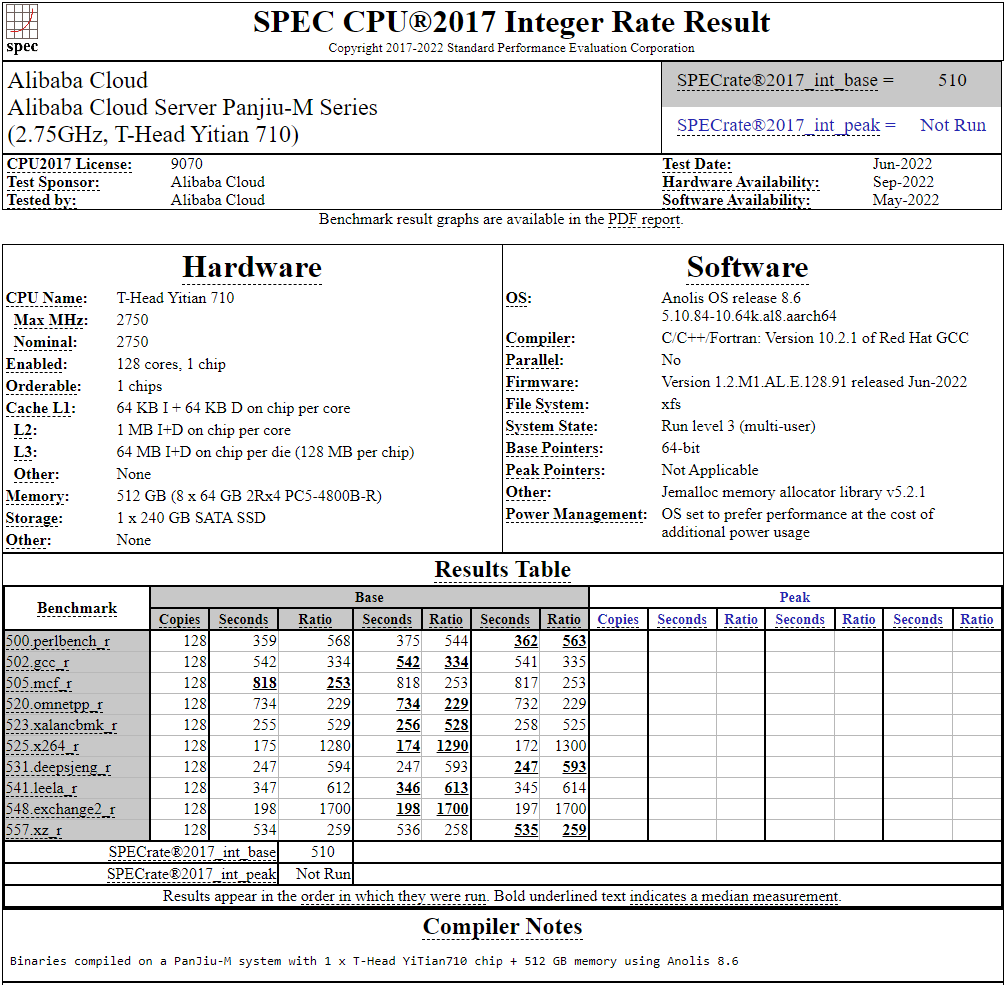 Процессор тестировался в составе референс-сервера Panjiu. Применялась 128-ядерная версия с частотой 2,75 ГГц, 1 Мбайт кеша L2 на ядро и 64 Мбайт кеша L3 на кристалл (128 Мбайт на сборку). Последнее позволяет говорить о том, что Alibaba также использует в своих процессорах чиплетную компоновку. 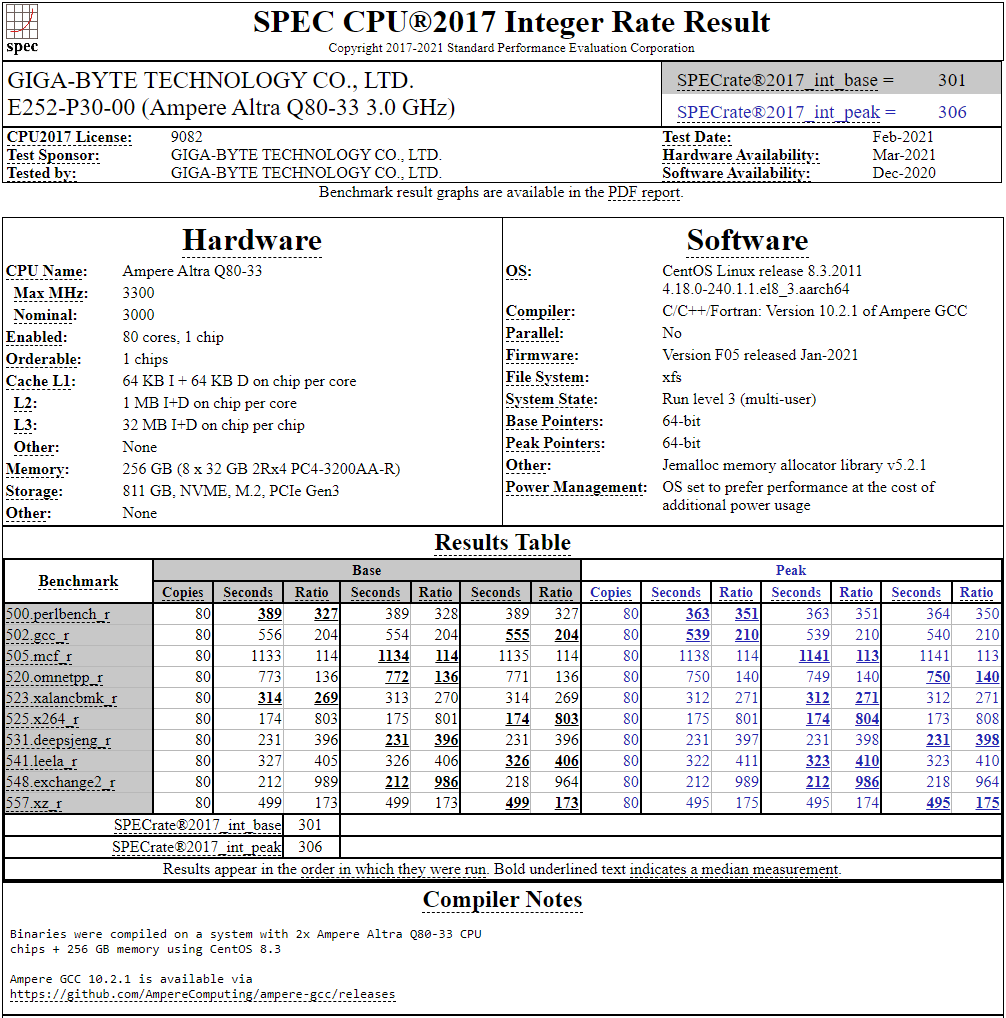 Результаты оказались существенно более высокими, нежели у Ampere Altra Q80-33; правда, стоит сделать скидку на то, что у Ampere использовалась 80-ядерная версия, а не более новая 128-ядерая Altra Max. Но в аутсайдерах оказался также и AMD EPYC 7773X (64 ядер/128 потоков, 2,2-3,5 ГГц, 768 Мбайт L3), показавший 440 очков против 510 у Yitian 710. Увеличенный объём кеша не слишком помог детищу «красных». 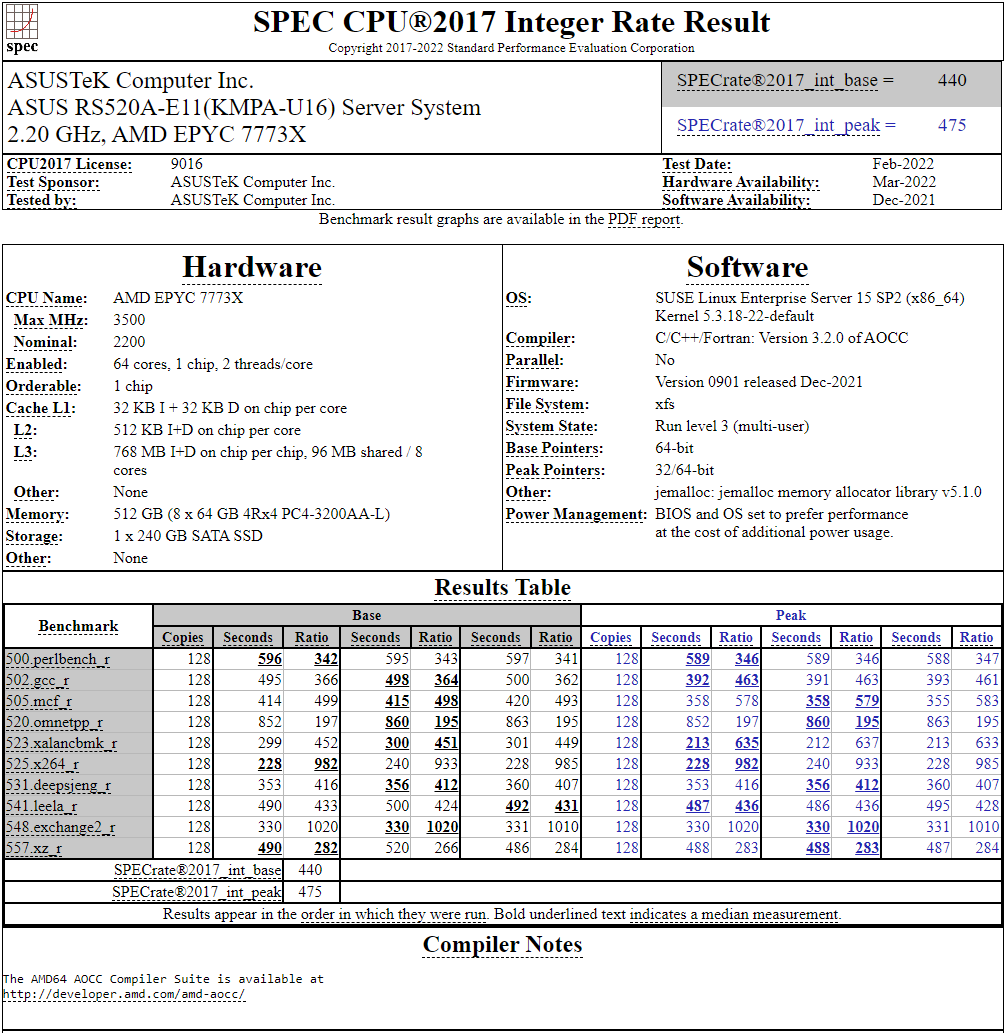 Таким образом, процессор на базе архитектуры Armv9 занял первое место там, где традиционно господствовали решения с архитектурой x86 — достаточно взглянуть на Топ-20 в рейтинге CPU2017 Integer. Можно сказать, что 128-ядерный процессор не вполне корректно сравнивать с 64-ядерным с поддержкой SMT, однако если технологии и архитектура позволяют разместить вдвое больше полноценных ядер в сопоставимом по размеру с AMD EPYC корпусе, так ли это важно? 
Текущий Tоп-20 целочисленной производительности в SPEC CPU2017 К сожалению, пока речь идёт только о целочисленных вычислениях. По неизвестной причине, Alibaba Cloud не опубликовала результаты CPU2017 Floating Point, где сравнение вышло бы существенно интереснее. В любом случае, монополия AMD на первые места пошатнулась; что же касается Intel, то в классе однопроцессорных систем самым мощным вариантом является 36-ядерный Xeon Platinum 8351N, который заведомо проиграет 64-128 ядерным монстрам AMD, Ampere, а теперь уже и Alibaba Cloud. |
|

