Материалы по тегу: sc21
|
16.11.2021 [03:33], Игорь Осколков
TOP500: уж ноябрь на дворе, а экзафлопса не видатьПоследняя версия публичного рейтинга самых производительных в мире суперкомпьютеров TOP500 так и осталась без экзафлопсных машин. Китай не захотел включать в него две системы такого класса и пошёл обходным путём, номинировав работы своих учёных на премию Гордона Белла — в соответствующих научных работах даны неполные характеристики машин и показатели их производительности. Поэтому лидером списка остаётся обновлённая японская система Fugaku, 7,6 млн ядер которой выдают 442 Пфлопс. И она всё ещё втрое быстрее своего ближайшего конкурента Summit. Первые результаты сборки Frontier в список попасть не успели. Всего в ноябрьском рейтинге есть порядка 70 новых систем, но, как и прежде, больше половины из них — однотипные системы Lenovo, массово устанавливаемые в Китае. На Китай вообще приходится более трети (34,6%) систем в списке. На втором месте находятся США (29,8%), а на третьем — Япония (6,4%). По суммарной производительности Топ-3 тот же, но порядок иной: США (32,5%), Япония (20,7%), Китай (17,5%). В число лидеров также входят Германия, Франция, Нидерланды, Канада, Великобритания, Южная Корея и Россия. У РФ теперь есть сразу семь машин в списке с суммарной производительностью 73,715 Пфлопс. Для сравнения — Perlmutter (5 место) после апгрейда выдаёт 70,87 Пфлопс, а у Южной Кореи тоже есть семь машин, но с чуть более высокой суммарной производительностью в 82,177 Пфлопс. 
Суперкомпьютер Chervonenkis (Фото: Яндекс) К уже имевшимся в TOP500 российским системам MTS GROM (294 место), Lomonosov-2 (Ломоносов-2, 241 место) и Christofari (Кристофари, 72 место) добавились Christofari Neo (Кристофари Нео, 43 место), а также сразу три системы Яндекса: Ляпунов (Lyapunov, 40 место), Галушкин (Galushkin, 36 место) и Червоненкис (Chervonenkis, 19 место). Примечательно, что все российские системы этого года используют AMD EPYC Rome и NVIDIA A100, а также интерконнект Infininiband. Машины для МТС и Сбера сделала сама NVIDIA (это всё DGX), а вот у Яндекса путь особый. Ляпунов (12,81 Пфлопс) создан китайским Национальным университетом оборонных технологий (National University of Defense Technology, NUDT) и Inspur на базе серверов NF5488A5 (AMD EPYC 7662@2 ГГц + A100 40 Гбайт). Червоненкис (21,53 Пфлопс) и Галушкин (16,02 Пфлопс) разработаны IPE, NVIDIA и Tyan. В этих системах используются EPYC 7702 (тоже 64-ядерные с базовой частотой 2 ГГц) и более новые A100 (80 Гбайт). Среди прочих новых систем TOP500 особо выделяется Voyager-EUS2, которая замыкает Топ-10. Это ещё система на базе обновлённых инстансов Microsoft Azure ND A100 v4 с 80-Гбайт версией A100. Однако ещё одной облачной машиной уже никого не удивить, в отличие от совершенно неожиданного возврата японской PEZY, пропавшей с радаров после скандала 2017 года. Новая ZettaScaler3.0 занимает 453 место и базируется на AMD EPYC 7702P и фирменных ускорителях PEZY-SC3. 
Изображение: OGAWA, Tadashi (twitter.com/ogawa_tter) В целом, последний год был удачным и для AMD, и для NVIDIA. Первая почти втрое нарастила число систем на базе EPYC — их теперь в списке 74 (или почти треть новых участников списка), если учитывать Naples/Hygon (таких систем 3). Если же смотреть более детально именно на CPU, то тут лидером всё равно остаётся Intel, хотя она и потеряла несколько процентных пунктов за последние полгода — всего 408 машин используют её процессоры. Правда, новейших Ice Lake-SP среди них всего 10, тогда как у EPYC Milan уже 17. Без акселераторов обходятся 350 суперкомпьютеров списка, зато из 150 оставшихся 143 используют различные поколения ускорителей NVIDIA. Удивительно, но ни одной системы с ускорителями AMD Instinct в ноябрьском рейтинге нет. Остальные акселераторы представлены в единичном экземпляре. И это либо устаревшие системы, либо экзотика из Китая и Японии. Последняя в лице MN-3 всё ещё лидирует по энергоэффективности в Green500. Систем с Infiniband в списке 178, с Ethernet — 242. Как обычно, по производительности систем лидирует именно IB — 44,5% против 22,4% у Ethernet. Это, к слову, несколько отличается от показателей HPC-индустрии в целом, где в количественном выражении у них практически равные доли. На Omni-Path пришлось 40 систем в TOP500, и столько же на проприетарные интерконнекты. Тут интересно разве что появление второй машины с Atos BXI V2. 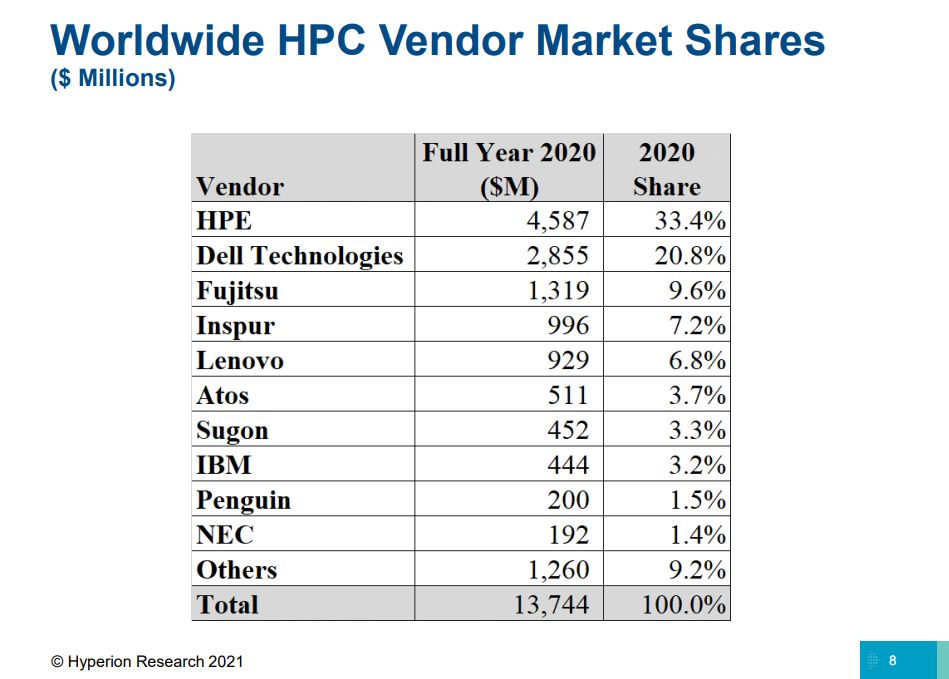 Среди производителей по количеству машин лидируют Lenovo (180 шт., это в основном уже упомянутые типовые развёртывания в Китае), HPE (84 шт., сюда же входит наследие Cray и SGI) и Inspur (50 шт.). По производительности картина иная, в Топ-3 входят HPE, Fujitsu (во многом благодаря Fugaku) и Lenovo. По HPC-рынку в целом, согласно данным Hyperion Research, в денежном выражении тройка лидеров включает HPE, Dell и Fujitsu (да, опять «виноват» Fugaku). |
|

