Материалы по тегу: cdna
|
08.11.2021 [20:00], Игорь Осколков
AMD анонсировала Instinct MI200, самые быстрые в мире ускорители вычислений на базе CDNA 2В прошлом году AMD окончательно развела ускорители для графики и вычислений, представив Instinct MI100, первый продукт на базе архитектуры CDNA, который позволил компании противостоять NVIDIA. Теперь же AMD подготовила новую версию архитектуры CDNA 2 и ускорители MI200 на неё основе. Новинки, согласно внутренним тестам, в ряде задач на голову выше того, что сейчас может предложить NVIDIA. 
AMD Instinct MI200 в OAM-варианте (Здесь и ниже изображения AMD) Циркулировавшие ранее слухи оказались верны — MI200 являются двухчиповыми решениями с 2.5D-упаковкой кристаллов (GCD) самих ускорителей, четырёх линий Infinity Fabric между ними и восьми стеков памяти HBM2e (8192 бит, 1600 МГц, 128 Гбайт, 3,2 Тбайт/c). В данном случае используется мостик EFB (Elevated Fanout Bridge), который позволяет задействовать стандартные подложки, что удешевляет и упрощает производство и тестирование ускорителей, не потеряв при этом в производительности и, что важнее, без существенного увеличения задержек в обмене данными. 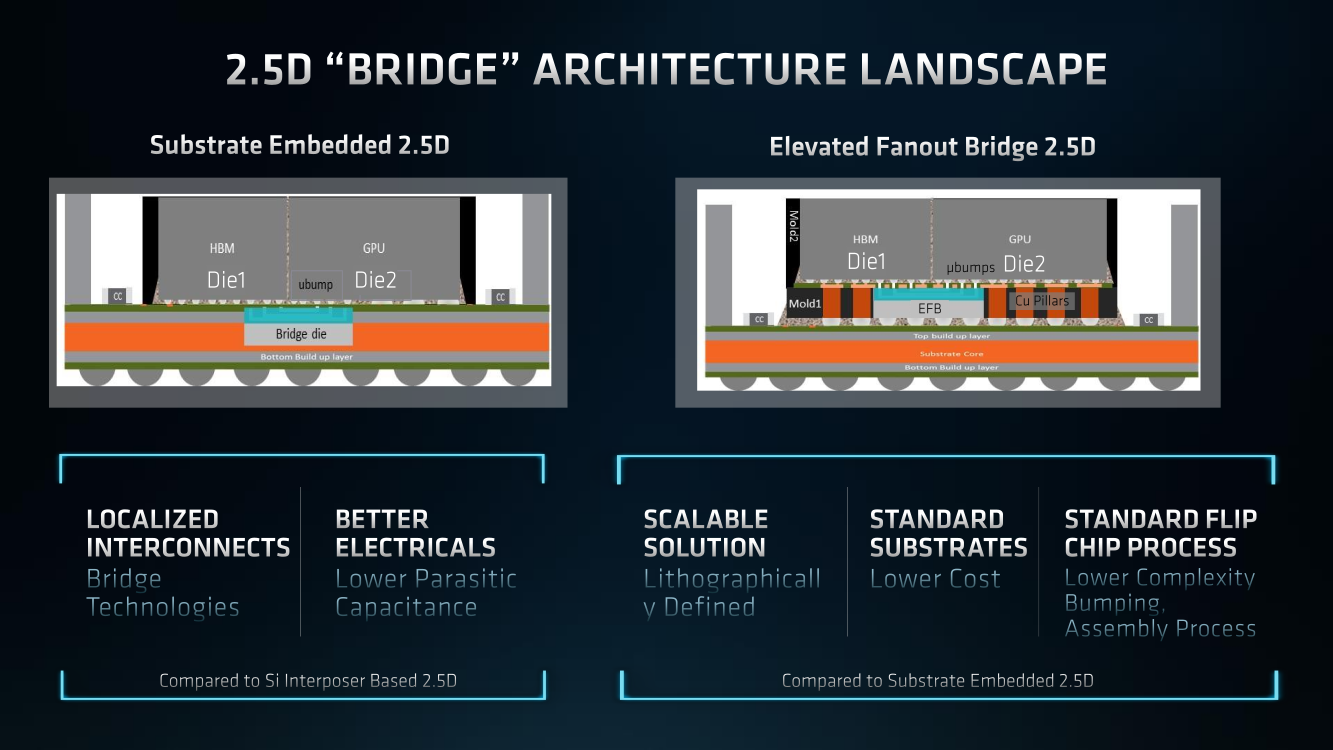 Несмотря на то, что в составе ускорителя два GCD, системе они представляются как единое целое с общей же памятью. Каждый GCD в случае CDNA 2 включает 112 CU (Compute Unit), но в конечных продуктах они задействованы не все. CU разбиты на четыре группы (с индивидуальным планировщиком) с общим L2-кешем объёмом 8 Мбайт и пропускной способностью 6,96 Тбайт/с, который поделён на 32 отдельных блока. А сами блоки имеют индивидуальные подключения к контроллерам памяти в GCD.  Важное отличие CDNA 2 заключается в «подтягивании» производительности векторных FP64- и FP32-вычислений — они исполняются с одинаковой скоростью в отличие от CDNA первого поколения. Кроме того, появилась поддержка сжатых (packed) инструкций для операций FMA/FADD/FMUL для FP32-векторов. Второй крупный апдейт касается матричных вычислений. Для них теперь тоже есть отдельная поддержка FP64, и с той же производительностью, что и для FP32. Новые инструкции рассчитаны на блоки 16×16×4 и 4×4×4. 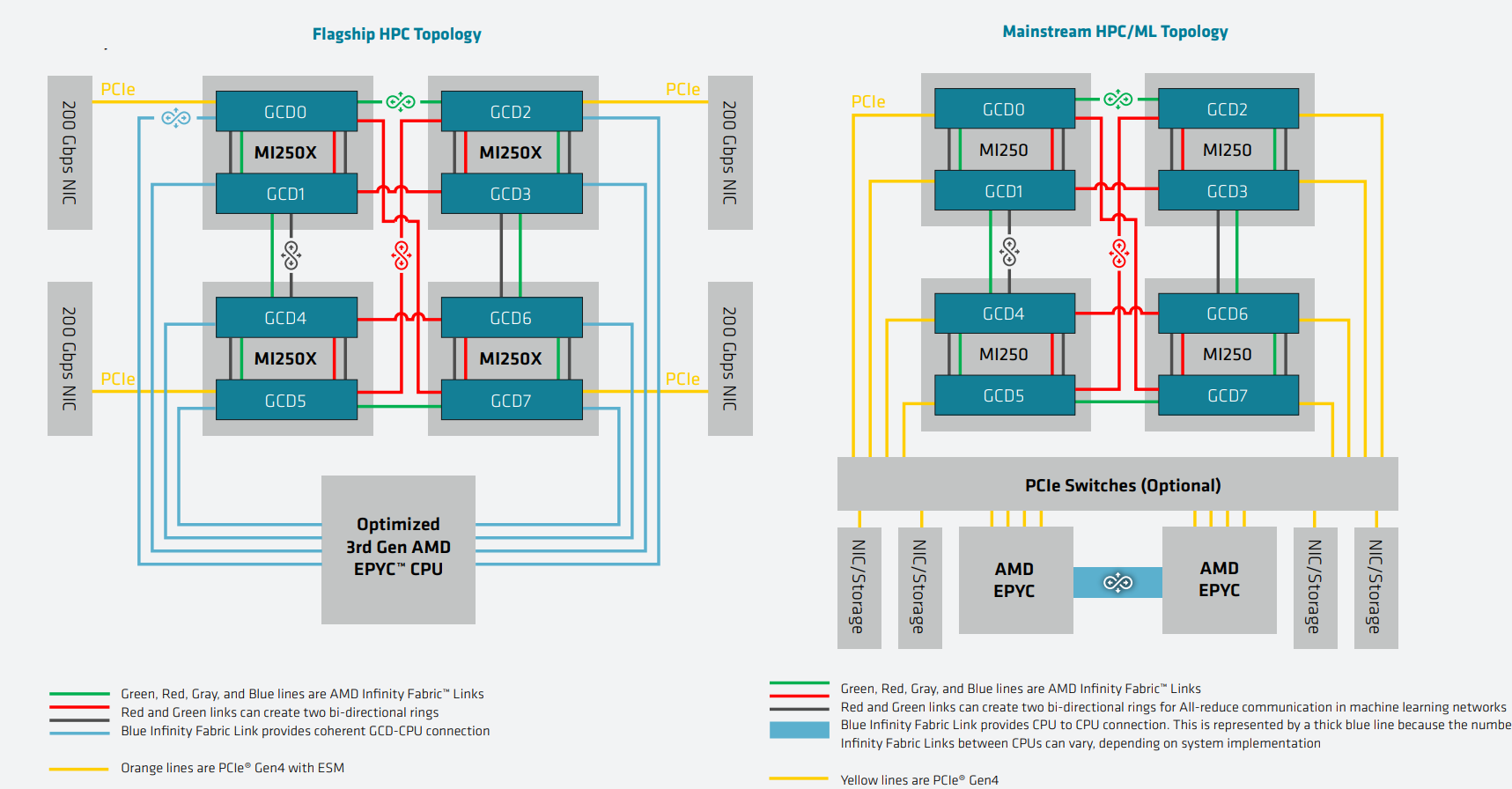 Поддержка FP16/BF16 в матричных ядрах, конечно, тоже есть, что позволяет задействовать их и для ИИ-задач, а не только HPC. Подспорьем для них в некоторых задачах будут два блока VCN (Video Codec Next) в каждом GCD. Они поддерживают декодирование H.264/AVC, H.265/HEVC, VP9 и JPEG, а также кодирование H.264/H.265, что потенциально позволит более эффективно работать ИИ-алгоритмам с изображениями и/или видео. 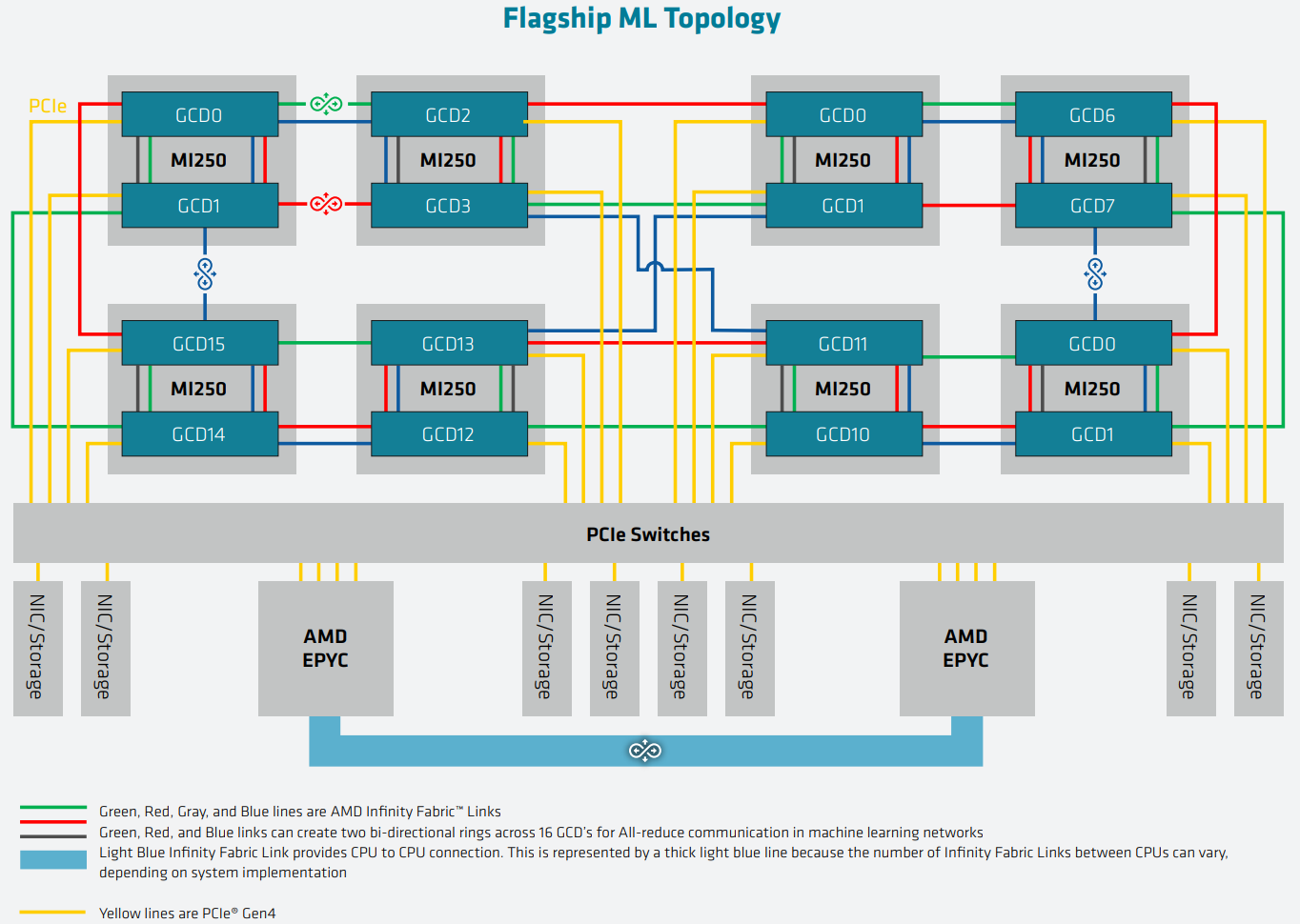 Для обмена данными между ускорителями и CPU используется единая шина Infinity Fabric (IF) с поддержкой кеш-когерентности. Всего на ускоритель приходится до восьми внешних линий IF, а суммарная скорость обмена данными может достигать 800 Гбайт/c. В наиболее плотной компоновке из четырёх MI200 и одного EPYC каждый ускоритель имеет по две линии для связи с CPU и со своим соседом. Причём внутренние и внешние IF-линии образуют два двунаправленных кольца между ускорителями. Каждая IF-линия опирается на x16-подключение PCIe 4.0, но в данном случае есть ряд оптимизаций конкретно под HPC-системы HPE Cray.  Дополнительно у каждого ускорителя есть собственный root-комплекс, что позволяет напрямую подключить сетевой адаптер класса 200G. И это явный намёк на возможность непосредственного RDMA-соединения с внешними хранилищами, поскольку в такой схеме на локальные NVMe-накопители линий попросту не остаётся. Более простые топологии уже предполагают использование половины линий IF в качестве обычного PCIe-подключения и задействуют коммутатор(-ы) для связи с CPU и NIC. В этом случае IF-подключение остаётся только между процессорами. Зато в одной системе можно объединить восемь MI200.  Чипы ускорителей MI250X изготовлены по 6-нм техпроцессу FinFet, содержат 58 млрд транзисторов и предлагают 220 CU, включающих 880 ядер для матричных вычислений и 14080 шейдерных ядер второго поколения. У MI250 их 208, 832 и 13312 соответственно. Для обеих моделей уровень TDP составляет 500 или 560 Вт, поэтому поддерживается как воздушное, так и жидкостное охлаждение. В дополнение к OAM-версиям MI250(X) чуть позже появится и более традиционная PCIe-модель MI210.  Для сравнения — у NVIDIA A100 объём и пропускная способность памяти (тоже HBM2e) составляют до 80 Гбайт и 2 Тбайт/с соответственно. Шина же NVLink 3.0 имеет пропускную способность 600 Гбайт/c, а коммутатор NVSwitch для связи между восемью ускорителями — 1,8 Тбайт/с. Потребление SXM3-версии составляет 400 Вт. Стоит также отметить, что первая версия A100 появилась ещё весной 2020 года, и скоро ожидается анонс следующего поколения ускорителей на базе архитектуры Hopper. На носу и выход ускорителей Intel Xe Ponte Vecchio.  И если про первые мы пока ничего толком не знаем, то вторые, похоже, уже проиграли MI250X в «голой» производительности как минимум по одной позиции (FP32). AMD говорит, что создавала Instinct MI200 как серию универсальных ускорителей, пригодных и для «классических» HPC-задач, и для ИИ. Отсюда и практически пятикратная разница в пиковой FP64-производительности с NVIDIA A100. 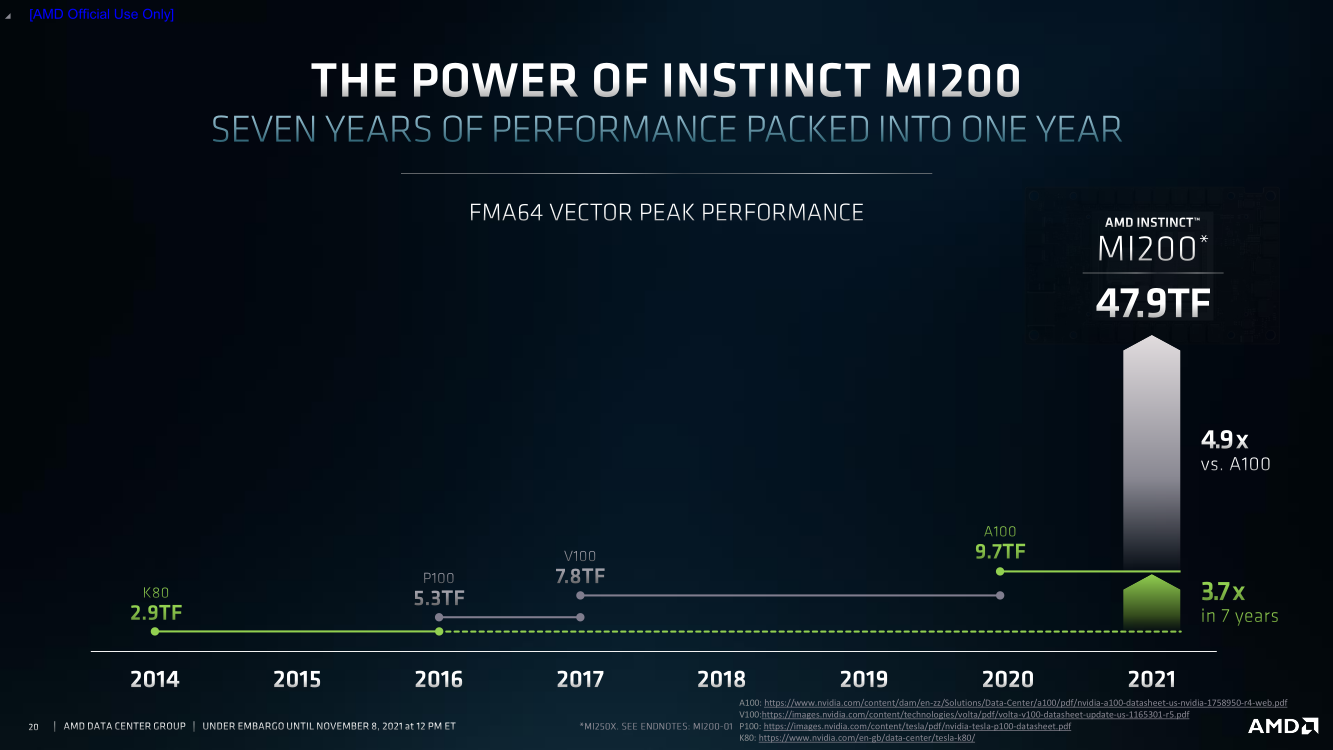 Но вот с нейронками всё не так однозначно. Предпочтительным форматом для обучения у NVIDIA является собственный TF32, поддержка которого есть в Tensor-ядрах Ampere. Ядра для матричных вычислений в CDNA2 про него ничего не знают, поэтому сравнить производительность в лоб нельзя. Разница в BF16/FP16 между MI250X и A100 уже не так велика, так что AMD говорит о приросте в 1,2 раза для обучения со смешанной точностью. 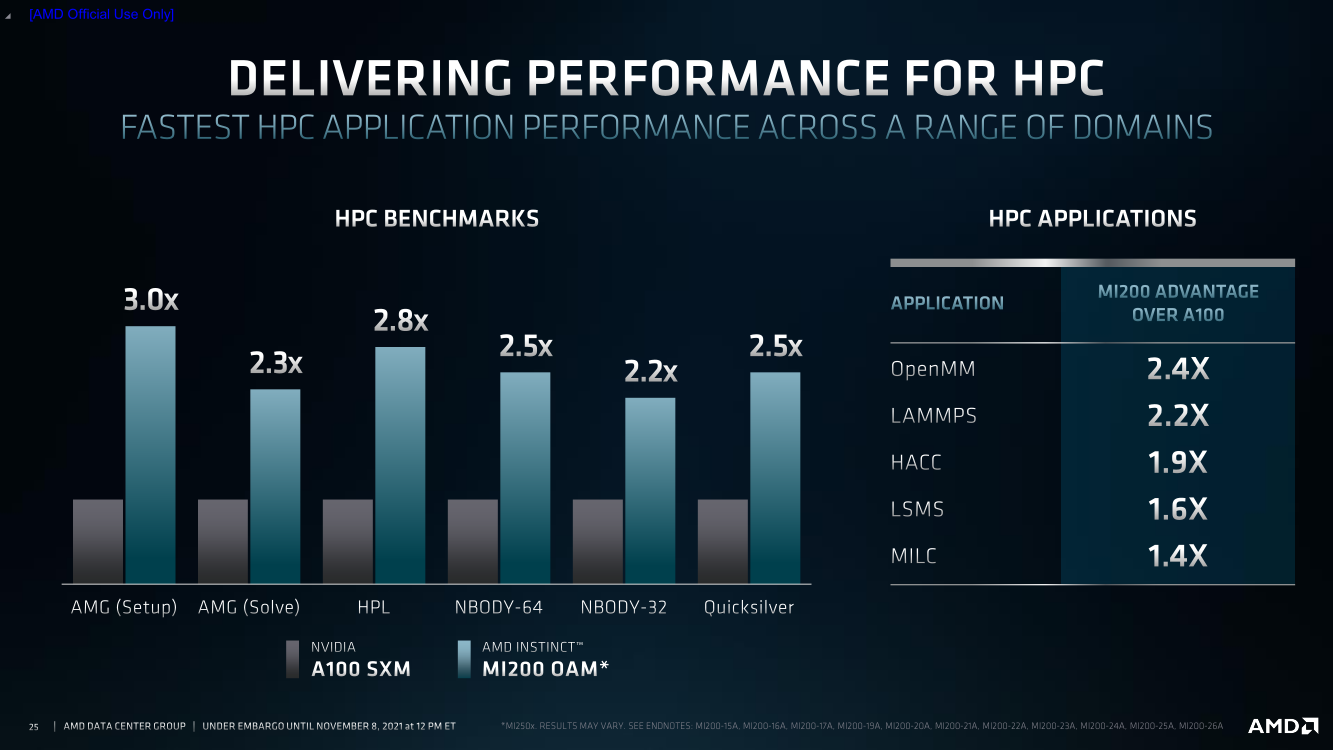 Данные по INT8 и INT4 в презентацию не вынесены, что неудивительно. Пиковый показатель для обоих форматов у MI250X составляет 383 Топс, тогда как тензорные ядра NVIDIA A100 выдают 624 и 1248 Топс соответственно. В данном случае больший объём памяти сыграл бы на руку MI200 в задачах инференса для крупных моделей. Наконец, у A100 есть ещё одно преимущество — поддержка MIG (Multi-Instance GPU), которая позволяет более эффективно задействовать имеющиеся ресурсы, особенно в облачных системах.  Вместе с Instinct MI200 была анонсирована и новая версия открытой (open source) платформы ROCm 5.0, которая обзавелась поддержкой и различными оптимизациями не только для этих ускорителей, но и, например, Radeon Pro W6800. В этом релизе компания уделит особое внимание расширению программной экосистемы и адаптации большего числа приложений. Кроме того, будет развиваться и новый портал Infinity Hub, где будет представлено больше готовых к использованию контейнеров с популярным ПО с рекомендациями по настройке и запуску.  AMD Instinct MI200 появятся в I квартале 2022 года. Новинки, в первую очередь MI210, будут доступны у крупных OEM/ODM-производителей: ASUS, Atos (X410-A5 2U1N2S), Dell Technologies, Gigabyte (G262-ZO0), HPE, Lenovo и Supermicro. Ускорители Instinct MI250X пока остаются эксклюзивом для систем HPE Cray Ex. Именно они вместе с «избранными» процессорами AMD EPYC (без уточнения, будут ли это Milan-X) станут основой для самого мощного в США суперкомпьютера Frontier.  Окончательный ввод в эксплуатацию этого комплекса запланирован на будущий год. Ожидается, что его пиковая производительность превысит 1,5 Эфлопс. При этом он должен стать самой энергоэффективной системой подобного класса. А адаптация ПО под него позволит несколько потеснить NVIDIA CUDA в некоторых областях. И это для AMD сейчас, пожалуй, гораздо важнее, чем победа по флопсам.
16.11.2020 [20:44], Алексей Степин
Подробности об архитектуре AMD CDNA ускорителей Instinct MI100Лидером в области использования графических архитектур для вычислений долгое время была NVIDIA, однако давний соперник в лице AMD вовсе не собирается сдавать свои позиции. В ответ на анонс архитектуры Ampere и ускорителей нового поколения A100 на её основе компания AMD сегодня ответила своим анонсом первого в мире ускорителя на основе архитектуры CDNA — сверхмощного процессора Instinct MI100. Достаточно долго подход к проектированию графических чипов оставался унифицированным, однако быстро выяснилось, что то, что хорошо для игр, далеко не всегда хорошо для вычислений, а некоторые возможности для областей применения, не связанных с рендерингом 3D-графики, попросту избыточны. Примером могут служить модули растровых операций (RBE/ROP) или наложения текстур. Произошло то, что должно было произойти: слившиеся на какое-то время воедино ветви эволюции «графических» и «вычислительных» процессоров вновь начали расходиться. И новый процессор AMD Instinct MI100 относится к чисто вычислительной ветви развития подобного рода чипов.  Теперь AMD имеет в своём распоряжении две основных архитектуры, RDNA и CDNA, которые и представляют собой вышеупомянутые ветви развития GPU. Естественно, новый процессор Instinct MI100 унаследовал у своих собратьев по эволюции многое — в частности, блоки исполнения скалярных и векторных инструкций: в конце концов, всё равно, работают ли они для расчёта графики или для вычисления чего-либо иного. Однако новинка содержит и ряд отличий, позволяющих ей претендовать на звание самого мощного и универсального в мире ускорителя на базе GPU. 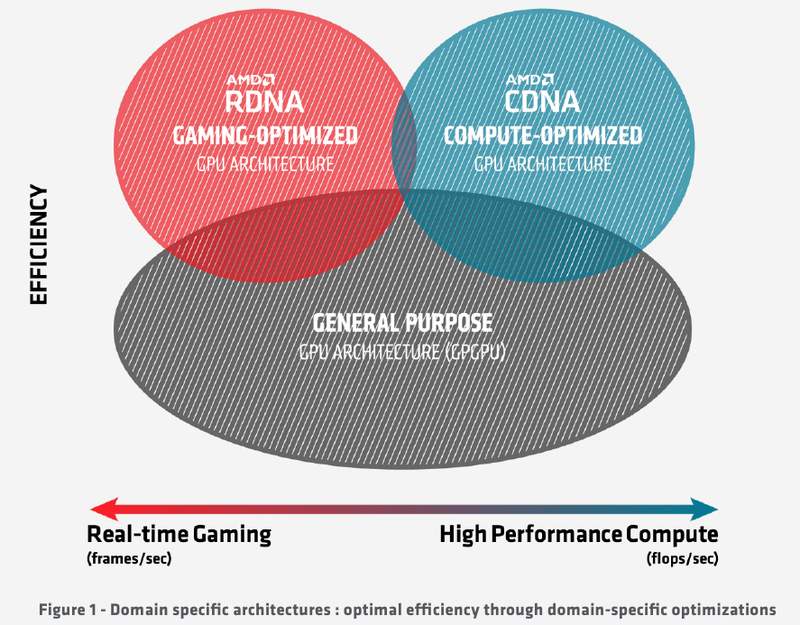
Схема эволюции графических процессоров: налицо дивергенция признаков AMD в последние годы существенно укрепила свои позиции, и это отражается в создании собственной единой IP-инфраструктуры: новый чип выполнен с использованием 7-нм техпроцесса и все системы интерконнекта, как внутренние, так и внешние, в MI100 базируются на шине AMD Infinity второго поколения. Внешние каналы имеют ширину 16 бит и оперируют на скорости 23 Гт/с, однако если в предыдущих моделях Instinct их было максимум два, то теперь количество каналов Infinity Fabric увеличено до трёх. Это позволяет легко организовывать системы на базе четырёх MI100 с организацией межпроцессорного общения по схеме «все со всеми», что минимизирует задержки. 
Ускорители Instinct MI100 получили третий канал Infinity Fabric Общую организацию внутренней архитектуры процессор MI100 унаследовал ещё от архитектуры GCN; его основу составляют 120 вычислительных блоков (compute units, CU). При принятой AMD схеме «64 шейдерных блока на 1 CU» это позволяет говорить о 7680 процессорах. Однако на уровне вычислительного блока архитектура существенно переработана, чтобы лучше отвечать требованиям, предъявляемым современному вычислительному ускорителю. В дополнение к стандартным блокам исполнения скалярных и векторных инструкций добавился новый модуль матричной математики, так называемый Matrix Core Engine, но из кремния MI100 удалены все блоки фиксированных функций: растеризации, тесселяции, графических кешей и, конечно, дисплейного вывода. Универсальный движок кодирования-декодирования видеоформатов, однако, сохранён — он достаточно часто используется в вычислительных нагрузках, связанных с обработкой мультимедийных данных. 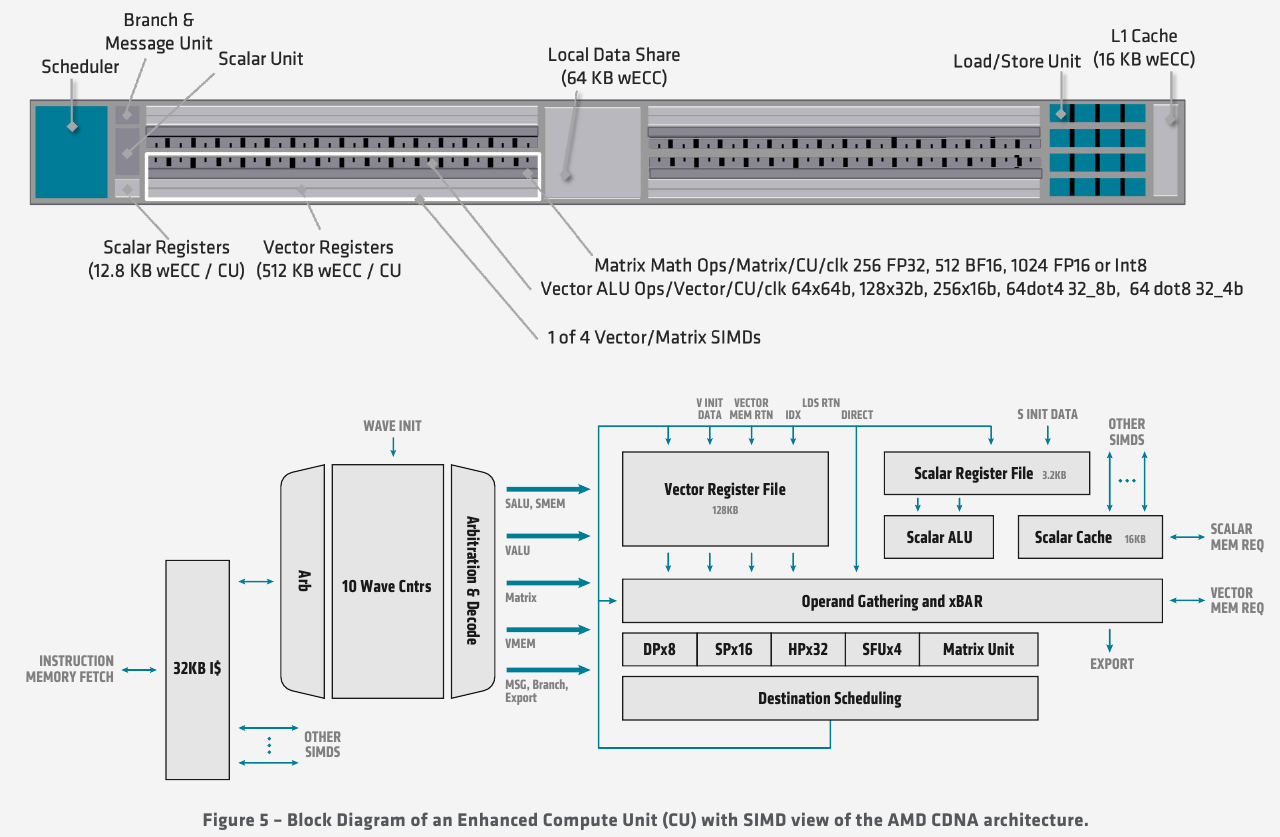
Структурная схема вычислительных модулей в MI100 Каждый CU содержит в себе по одному блоку скалярных инструкций со своим регистровым файлом и кешем данных, и по четыре блока векторных инструкций, оптимизированных для вычислений в формате FP32 саналогичными блоками. Векторные модули имеют ширину 16 потоков и обрабатывают 64 потока (т.н. wavefront в терминологии AMD) за четыре такта. Но самое главное в архитектуре нового процессора — это новые блоки матричных операций. Наличие Matrix Core Engines позволяет MI100 работать с новым типом инструкций — MFMA (Matrix Fused Multiply-Add). Операции над матрицами размера KxN могут содержать смешанные типы входных данных: поддерживаются режимы INT4, INT8, FP16, FP32, а также новый тип Bfloat16 (bf16); результат, однако, выводится только в форматах INT32 или FP32. Поддержка столь многих типов данных введена для универсальности и MI100 сможет показать высокую эффективность в вычислительных сценариях разного рода. 
Использование Infinity Fabric 2.0 позволило ещё более увеличить производительность MI100 Каждый блок CU имеет свой планировщик, блок ветвления, 16 модулей load-store, а также кеши L1 и Data Share объёмами 16 и 64 Кбайт соответственно. А вот кеш второго уровня общий для всего чипа, он имеет ассоциативность 16 и объём 8 Мбайт. Совокупная пропускная способность L2-кеша достигает 6 Тбайт/с. Более серьёзные объёмы данных уже ложатся на подсистему внешней памяти. В MI100 это HBM2 — новый процессор поддерживает установку четырёх или восьми сборок HBM2, работающих на скорости 2,4 Гт/с. Общая пропускная способность подсистемы памяти может достигать 1,23 Тбайт/с, что на 20% быстрее, нежели у предыдущих вычислительных ускорителей AMD. Память имеет объём 32 Гбайт и поддерживает коррекцию ошибок. 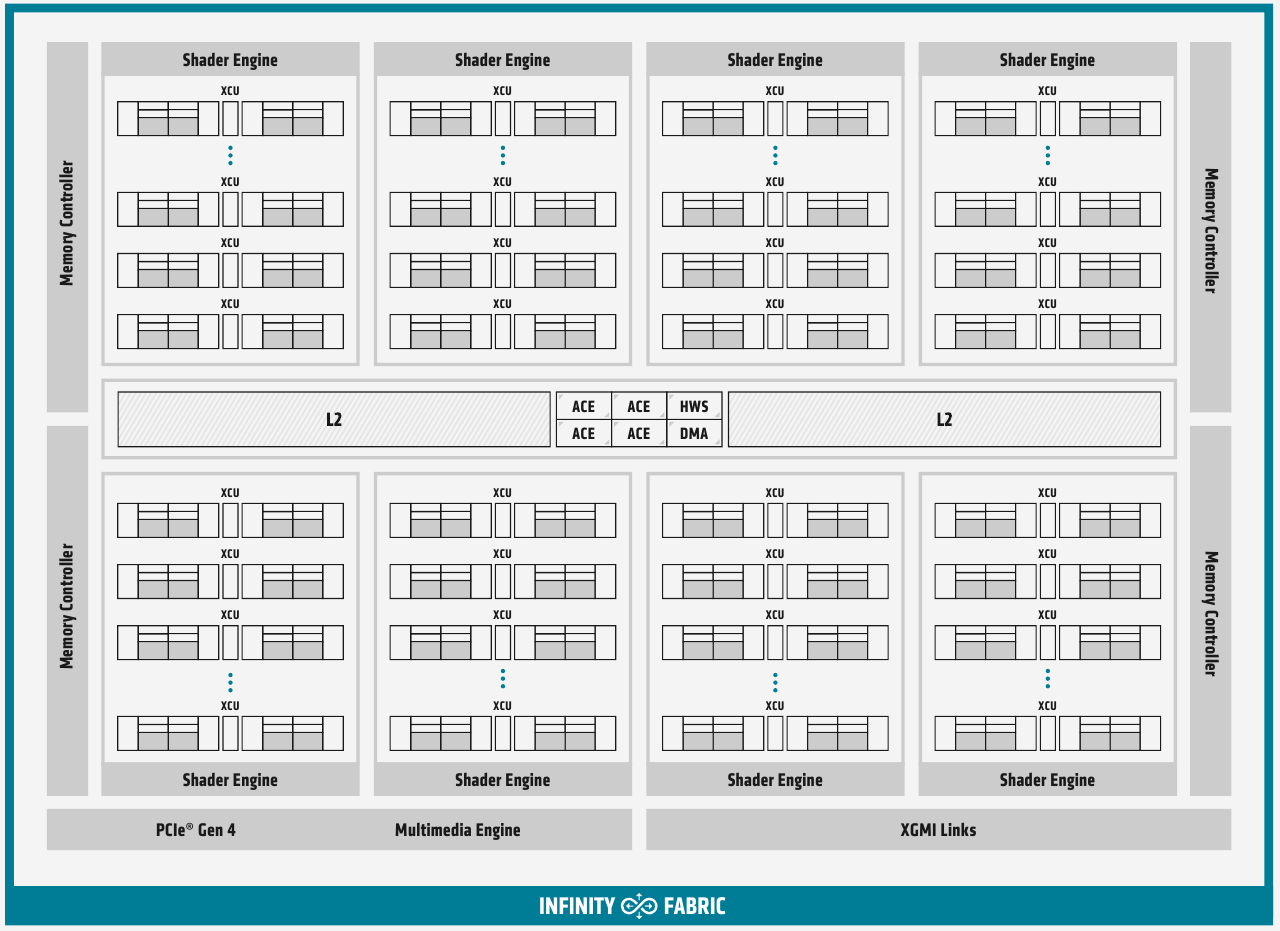
Общая блок-схема Instinct MI100 «Мозг» чипа Instinct MI100 составляют четыре командных процессора (ACE на блок-схеме). Их задача — принять поток команд от API и распределить рабочие задания по отдельным вычислительным модулям. Для подключения к хост-процессору системы в составе MI100 имеется контроллер PCI Express 4.0, что даёт пропускную способность на уровне 32 Гбайт/с в каждом направлении. Таким образом, «уютнее всего» ускоритель Instinct MI100 будет чувствовать себя совместно с ЦП AMD EPYC второго поколения, либо в системах на базе IBM POWER9/10. Избавление от лишних архитектурных блоков и оптимизация архитектуры под вычисления в как можно более широком числе форматов позволяют Instinct MI100 претендовать на универсальность. Ускорители с подобными возможностями, как справедливо считает AMD, станут важным строительным блоком в экосистеме HPC-машин нового поколения, относящихся к экзафлопсному классу. AMD заявляет о том, что это первый ускоритель, способный развить более 10 Тфлопс в режиме двойной точности FP64 — пиковый показатель составляет 11,5 Тфлопс. 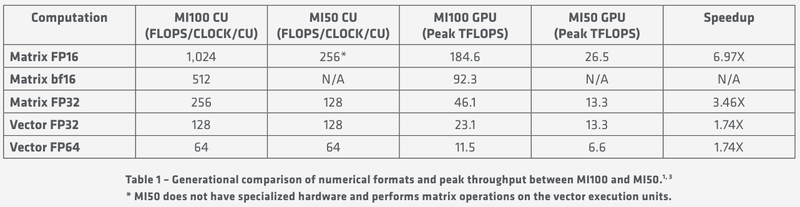
Удельные и пиковые показатели производительности MI100 В менее точных форматах новинка пропорционально быстрее, и особенно хорошо ей даются именно матричные вычисления: для FP32 производительность достигает 46,1 Тфлопс, а в новом, оптимизированном под задачи машинного обучения bf16 — и вовсе 92,3 Тфлопс, причём, ускорители Instinct предыдущего поколения таких вычислений выполнять вообще не могут. В зависимости от типов данных, превосходство MI100 перед MI50 варьируется от 1,74х до 6,97x. Впрочем, NVIDIA A100 в этих задача всё равно заметно быстрее, а вот в FP64/FP32 проигрывают. |
|

