Материалы по тегу: интерконнект
|
29.10.2025 [11:55], Сергей Карасёв
NVIDIA представила интерконнект NVQLink для гибридных вычислений на базе GPU и QPUКомпания NVIDIA анонсировала NVQLink — открытую системную архитектуру, предназначенную для тесной интеграции графических (GPU) и квантовых (QPU) процессоров с целью создания гибридных вычислительных платформ. В разработке интерконнекта NVQLink приняли участие Брукхейвенская национальная лаборатория (BNL), Национальная ускорительная лаборатория им. Ферми (Fermilab), Национальная лаборатория имени Лоуренса в Беркли (LBNL), Лос-Аламосская национальная лаборатория (LANL), Национальная лаборатория Ок-Ридж (ORNL), Национальные лаборатории Сандия (SNL) и Тихоокеанская северо-западная национальная лаборатория (PNNL), которые принадлежат Министерству энергетики США (DoE). Кроме того, были вовлечены специалисты Линкольнской лаборатории Массачусетского технологического института (MIT Lincoln Laboratory). 
Источник изображения: NVIDIA Отмечается, что NVQLink обеспечивает открытый подход к квантовой интеграции. Максимальная пропускная способность в системах GPU — QPU заявлена в 400 Гбит/с, тогда как минимальная задержка (FPGA-GPU-FPGA) составляет менее 4 мкс. Интерконнект может применяться в составе ИИ-платформ, обладающих производительностью до 40 Пфлопс (FP4). Решение NVQLink оптимизировано для крупномасштабных квантовых вычислений в реальном времени. В целом, NVQLink обеспечивает возможность непосредственного взаимодействия QPU разных типов и систем управления квантовым оборудованием с ИИ-суперкомпьютерами. Технология предоставляет готовое унифицированное решение для преодоления ключевых проблем интеграции, с которыми сталкиваются исследователи в области квантовых вычислений при масштабировании своих систем. Разработчики могут получить доступ к NVQLink благодаря интеграции с программной платформой NVIDIA CUDA-Q. В число партнёров, вносящих вклад в NVQLink, входят разработчики квантового оборудования Alice & Bob, Anyon Computing, Atom Computing, Diraq, Infleqtion, IonQ, IQM Quantum Computers, ORCA Computing, Oxford Quantum Circuits, Pasqal, Quandela, Quantinuum, Quantum Circuits, Quantum Machines, Quantum Motion, QuEra, Rigetti, SEEQC и Silicon Quantum Computing, а также разработчики квантовых систем управления, включая Keysight Technologies, Quantum Machines, Qblox, QubiC и Zurich Instruments.
22.10.2025 [17:09], Владимир Мироненко
AWS пожертвовала компактностью GB300 NVL72, лишь бы снизить зависимость от NVIDIAAmazon Web Services (AWS) нашла выход, как использовать собственные Nitro DPU K2v5/6 (EFA) в новейших стоечных системах NVIDIA GB300 NVL72, которые, как считает гиперскейлер, превосходит адаптеры NVIDIA ConnectX-7/8 по производительности. В связи с тем, что в стойках NVIDIA Oberon используются укороченные лотки высотой 1U, AWS размещает NIC в отдельной стойке JBOK, предназначенной только для сетевых карт, пишет SemiAnalysis. Причина кроется в невозможности установить в 1U сразу девять фирменных адаптеров (8 × EFA + 1 × ENA/EBS). Для серверных систем GB200 NVL предыдущего поколения AWS выбрала вариант NVL36×2, поскольку только в этом случае использовались 2U-узлы, где достаточно места для всех NIC. Однако сдвоенная конфигурация менее эффективна, чем нативная конструкция NVL72. NVIDIA сама была не очень довольна вариантами NVL36. Meta✴, например, и вовсе «растянула» NVL36×2 на шесть стоек, чтобы обойтись воздушным охлаждением. 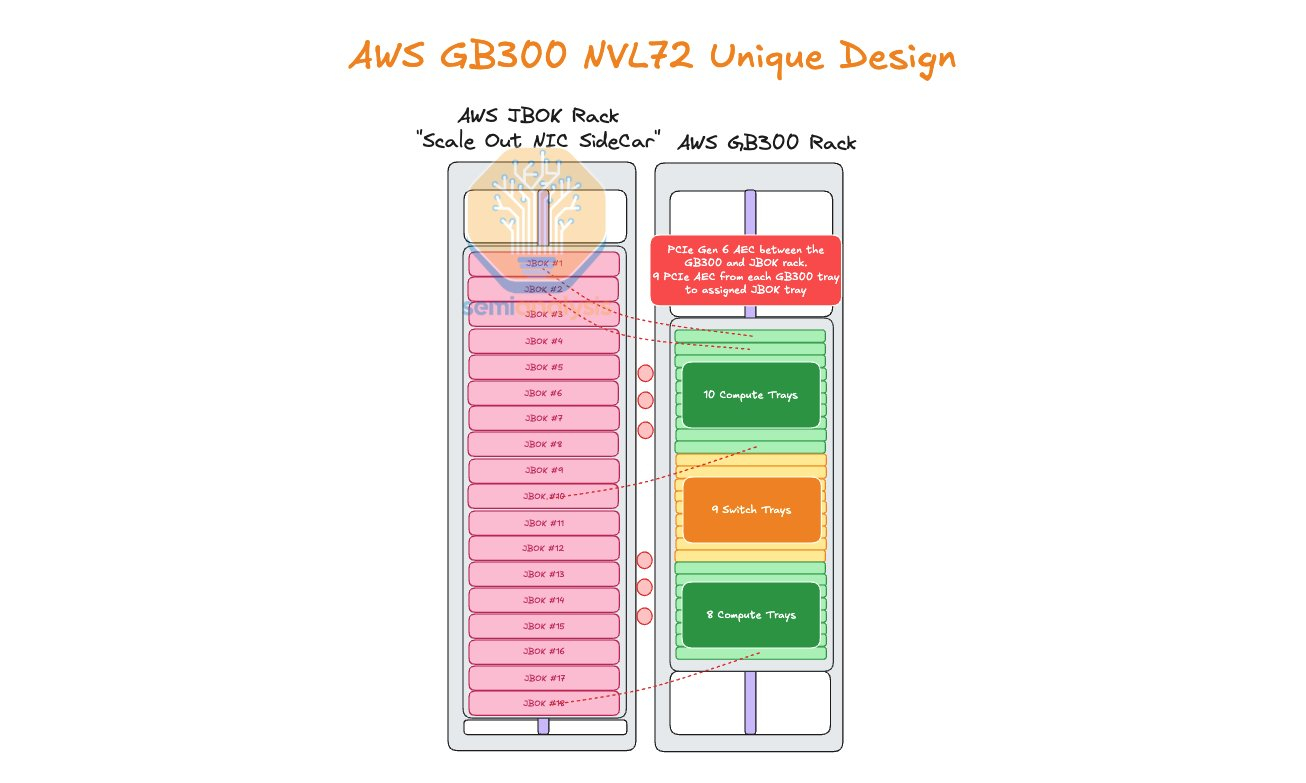
Источник изображения: SemiAnalysis AWS в случае Blackwell Ultra предпочла остановиться на NVL72-варианте, а DPU вынести в отдельную стойку — всего 18 узлов высотой 2U, по 9 NIC в каждом. С узлами NVIDIA они соединены активными электрическими кабелями (AEC) и портами OSFP-XD для передачи сигналов PCIe 6.0. По словам AWS, её адаптеры лучше справляются с нагрузками, чем ConnectX-8 (RoCEv2), что отчасти спорно. В любом случае таким образом компания снижается зависимость от NVIDIA. 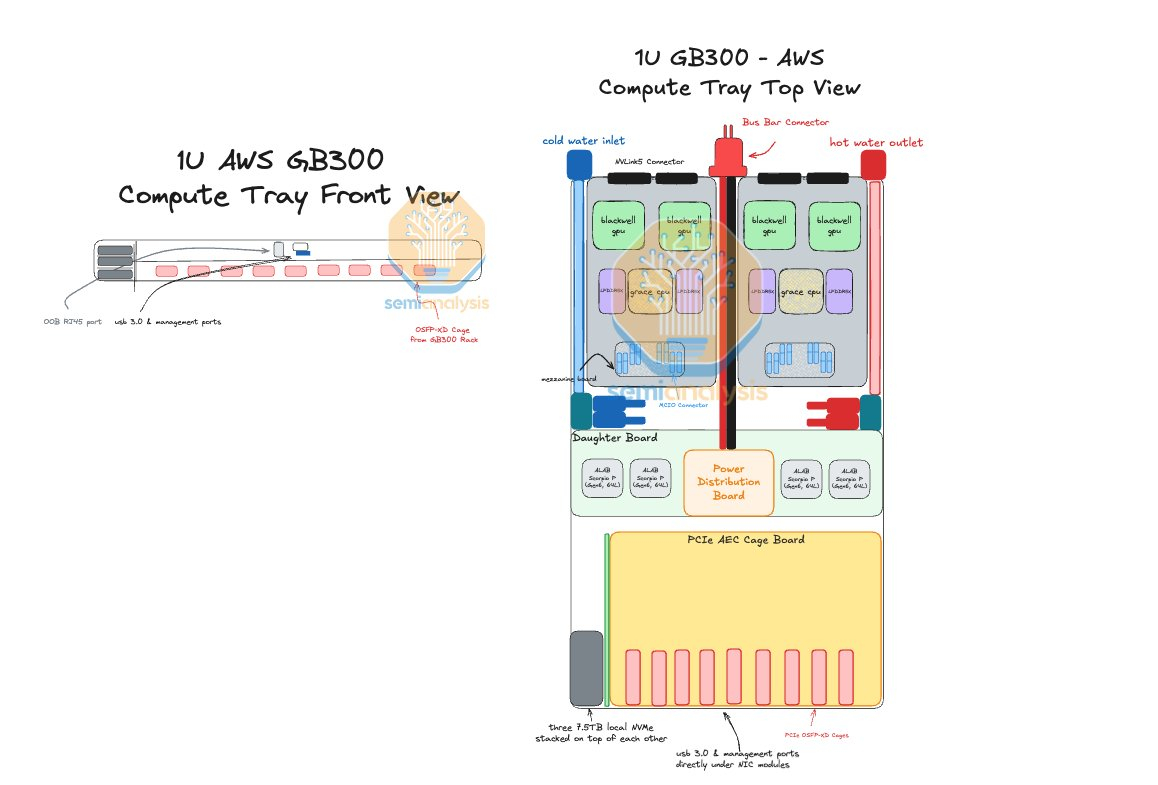
Источник изображения: SemiAnalysis С точки зрения SemiAnalysis, доработка GB300 в AWS помогает устранить единую точку отказа в референсной архитектуре NVIDIA, где каждый ускоритель взаимодействует только с одним сетевым адаптером ConnectX-8, тогда как в конфигурации AWS каждый ускоритель общается с двумя NIC. У AWS накоплен богатый опыт разработки собственного оборудования для ЦОД. Ранее компания в партнёрстве с Broadcom разрабатывала специализированные сетевые коммутаторы. Также недавно представленные ею EC2-инстансы P6-B200 и P6e-GB200 оснащены собственным сетевым стеком Elastic Fabric Adapter (EFAv4) на базе собственных контроллеров Nitro, который оптимизирует обработку сетевых пакетов и снижает задержки для высокопроизводительных приложений.
14.10.2025 [20:58], Владимир Мироненко
Oracle анонсировала крупнейший в мире зеттафлопсный ИИ-кластер OCI Zettascale10: до 800 тыс. ускорителей NVIDIA в нескольких ЦОД
800gbe
ethernet
hardware
hpc
nvidia
oracle
oracle cloud infrastructure
stargate
ии
интерконнект
кластер
сша
цод
Oracle анонсировала облачный ИИ-кластер OCI Zettascale10 на базе сотен тысяч ускорителей NVIDIA, размещённых в нескольких ЦОД, который имеет пиковую ИИ-производительность 16 Зфлопс (точность вычислений не указана). OCI Zettascale10 — это инфраструктура, на которой базируется флагманский ИИ-суперкластер, созданный совместно с OpenAI в техасском Абилине (Abilene) в рамках проекта Stargate и основанный на сетевой архитектуре Oracle Acceleron RoCE нового поколения. OCI Zettascale10 использует NVIDIA Spectrum-X Ethernet — первую, по словам NVIDIA, Ethernet-платформу, которая обеспечивает высокую масштабируемость, чрезвычайно низкую задержку между ускорителями в кластере, лидирующее в отрасли соотношение цены и производительности, улучшенное использование кластера и надежность, необходимую для крупномасштабных ИИ-задач. Как отметила Oracle, OCI Zettascale10 является «мощным развитием» первого облачного ИИ-кластера Zettascale, который был представлен в сентябре 2024 года. Кластеры OCI Zettascale10 будут располагаться в больших кампусах ЦОД мощностью в гигаватты с высокоплотным размещением в радиусе двух километров, чтобы обеспечить наилучшую задержку между ускорителями для крупномасштабных задач ИИ-обучения. Именно такой подход выбран для кампуса Stargate в Техасе. Oracle отметила, что помимо возможности создавать, обучать и развёртывать крупнейшие ИИ-модели, потребляя меньше энергии на единицу производительности и обеспечивая высокую надёжность, клиенты получат свободу работы в распределённом облаке Oracle со строгим контролем над данными и суверенитетом ИИ. 
Источник изображения: OpenAI Изначально кластеры OCI Zettascale10 будут рассчитаны на развёртывание до 800 тыс. ускорителей NVIDIA, обеспечивая предсказуемую производительность и высокую экономическую эффективность, а также высокую пропускную способность между ними благодаря RoCEv2-интерконнекту Oracle Acceleron со сверхнизкой задержкой. Acceleron предлагает 400G/800G-подключение со сверхнизкой задержкой, двухуровневую топологию, множественное подключение одного NIC к нескольким коммутатором с физической и логической изоляцией сетевых потоков, поддержку LPO/LRO и гибкость конфигурации. DPU Pensando от AMD в Acceleron место тоже нашлось. 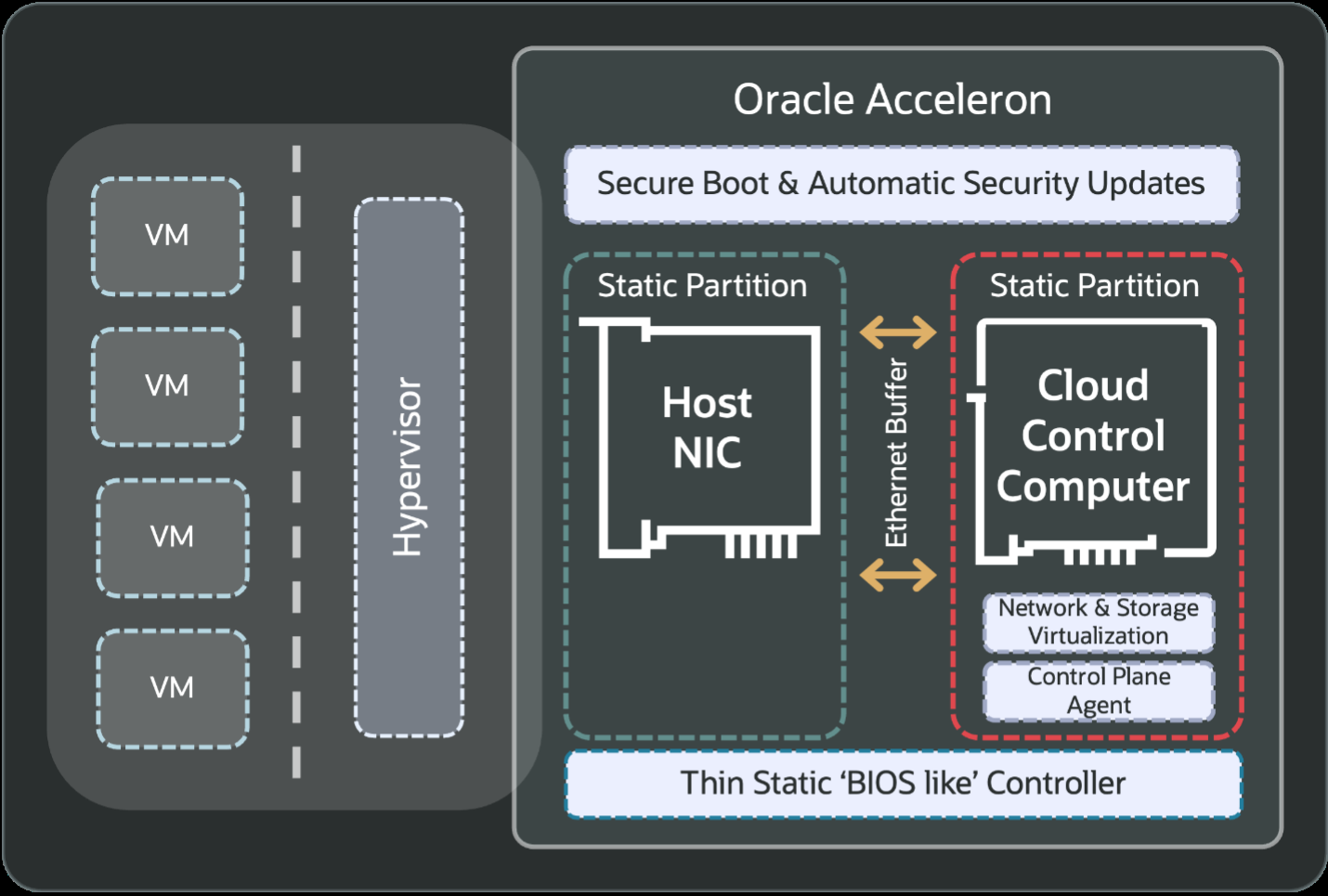
Источник изображения: Oracle OCI уже принимает заказы на OCI Zettascale10, который поступит в продажу во II половине следующего календарного года. В августе NVIDIA анонсировала решение Spectrum-XGS Ethernet для объединения нескольких ЦОД в одну ИИ-суперфабрику, которым, по-видимому, воспользуется не только Oracle, но и Meta✴.
14.10.2025 [19:00], Сергей Карасёв
OCP поможет в унификации чиплетов с применением открытых стандартов: Arm и Eliyan поделились наработкамиНекоммерческая организация Open Compute Project Foundation (OCP) сообщила о расширении так называемой «открытой чиплетной экономики» (Open Chiplet Economy). Свои наработки в данной сфере сообществу передали компании Arm и Eliyan. Open Chiplet Economy — это инициатива OCP Server Project Group. Она позволяет разработчикам чиплетов посредством открытого рынка взаимодействовать с производителями продукции. Речь идет о формировании унифицированной экосистемы, за поддержание которой в актуальном состоянии отвечает OCP. В рамках проекта компания Arm передала организации OCP и её участникам архитектуру FCSA (Foundation Chiplet System Architecture), основанную на CSA (Chiplet System Architecture). Она определяет общие базовые стандарты для разделения монолитных систем на чиплеты, которые затем могут использоваться в составе различных изделий, включая память, устройства ввода-вывода и ускорители. Такой подход, как ожидается, упростит создание новых продуктов благодаря повторному использованию уже разработанных блоков. Кроме того, повысится гибкость за счёт отказа от привязки к проприетарным стандартам чиплетов. 
Источник изображения: OCP В свою очередь, Eliyan предоставит сообществу разработки, которые помогут расширить спецификацию интерконнекта для чиплетов OCP BoW 2.0 (Bunch of Wires). В частности, будут добавлены функции для систем, которым требуется высокая пропускная способность: это могут быть приложения ИИ, НРС, игры, автомобильные платформы и пр. Целевым показателем является поддержка скоростей памяти HBM4 (2 Тбайт/с для чтения или записи) вместе с дополнительным каналом связи для сигналов ECC и управления.
14.10.2025 [13:26], Руслан Авдеев
«Нервная система» ИИ-фабрик: Meta✴ и Oracle развернут сетевые платформы NVIDIA Spectrum-X Ethernet в своих ЦОДNVIDIA объявила, что Meta✴ и Oracle развернут в своих ИИ ЦОД Ethernet-платформы NVIDIA Spectrum-X. В NVIDIA подчёркивают, что модели на триллионы параметров трансформируют дата-центры в ИИ-фабрики гигаваттного уровня, а лидеры индустрии стандартизируют использование решений Spectrum-X Ethernet в качестве одного из драйверов промышленной революции. По словам компании, речь идёт не просто о быстром Ethernet, а о «нервной системе» ИИ-фабрик, позволяющей гиперскейлерам объединять миллионы ИИ-ускорителей в гигантские кластеры для обучения крупнейших за всю историю моделей. Oracle намерена строить ИИ-гигафабрики из ускорителей NVIDIA Vera Rubin с интерконнектами Spectrum-X Ethernet. В Oracle подчёркивают, что инфраструктура Oracle Cloud «с нуля» строится для ИИ-задач, и партнёрство с NVIDIA способствует лидерству Oracle в сфере ИИ. Использование Spectrum-X Ethernet позволит клиентам связывать миллионы ускорителей и быстрее обучать, внедрять и пользоваться благами генеративных и «рассуждающих» ИИ нового поколения. Meta✴ намерена интегрировать коммутаторы в свою сетевую инфраструктуру для программной платформы Facebook✴ Open Switching System (FBOSS), как раз разработанной для управления и контроля массивами сетевых коммутаторов. Интеграция решений ускорит масштабное внедрение для повышения эффективности ИИ-проектов. Интеграция NVIDIA Spectrum Ethernet в коммутатор Minipack3N и использование FBOSS позволит повысить эффективность и предсказуемость, необходимые для обучения крупнейших в истории ИИ-моделей и доступа к ИИ-приложениям миллионам людей. 
Источник изображения: NVIDIA Платформа NVIDIA Spectrum-X Ethernet включает как собственно коммутаторы Spectrum-X Ethernet, так и адаптеры Spectrum-X Ethernet SuperNIC. Spectrum-X Ethernet уже продемонстрировала рекордную эффективность, позволившую крупнейшему в мире суперкомпьютеру Colossus компании xAI добиться использования 95 % возможной полосы, тогда как обычные Ethernet-платформы обеспечивают лишь 60 %, утверждает NVIDIA. 
Источник изображения: Meta✴ В июне сообщалось, что продажи Ethernet-коммутаторов NVIDIA за год выросли на 760 % благодаря росту спроса на ИИ, а в последнем квартале рост составил +98 %. Акции Arista, одного из ключевых поставщиков коммутаторов для Meta✴, упали после анонса NVIDIA и объявления Meta✴, что коммутаторы Minipack3N теперь используют ASIC Spectrum-4 и производятся Accton.
14.10.2025 [12:46], Владимир Мироненко
OpenAI и Broadcom совместно разработают и развернут ИИ-ускорители на 10 ГВтOpenAI и Broadcom объявили о заключении соглашения о стратегическом сотрудничестве с целью совместного создания и дальнейшего развёртывания кастомных ИИ-ускорителей общей мощностью 10 ГВт. Речь идёт об вертикально интегрированных решениях уровня стоек и ЦОД. OpenAI отметила в пресс-релизе, что при разработке собственных чипов и систем сможет интегрировать имеющиеся достижения в создании передовых моделей и продуктов непосредственно в аппаратное обеспечение. «Стойки, полностью масштабируемые с использованием Ethernet и других сетевых решений Broadcom, удовлетворят растущий глобальный спрос на ИИ и будут развёрнуты на объектах OpenAI и в партнёрских ЦОД», — сообщила компания. Начало развертывания систем запланировано на II половину 2026 года, а завершение — на конец 2029 года. «Партнёрство с Broadcom — критически важный шаг в создании инфраструктуры, необходимой для раскрытия потенциала ИИ и предоставления реальных преимуществ людям и бизнесу», — заявил Сэм Альтман (Sam Altman), соучредитель и генеральный директор OpenAI. Он отметил, что разработка собственных ускорителей дополняет более широкую экосистему партнёров, которые вместе создают потенциал, «необходимый для расширения возможностей ИИ на благо всего человечества». 
Источник изображений: Broadcom Чарли Кавас (Charlie Kawwas), президент группы полупроводниковых решений Broadcom сообщил, что кастомные ускорители «прекрасно сочетаются со стандартными сетевыми решениями Ethernet для масштабирования и горизонтального масштабирования», позволяя создать оптимизированную по стоимости и производительности ИИ-инфраструктуру нового поколения. По его словам, стойки будут включать комплексный набор решений Broadcom для Ethernet, PCIe и оптических соединений. Как пишет The Register, президент OpenAI Грег Брокман (Greg Brockman) рассказал, что при разработке ускорителя компания смогла использовать собственные ИИ-модели, которые позволили оптимизировать и ускорить процесс. По его словам, благодаря этому удалось увеличить плотность размещения компонентов. «Вы берёте компоненты, которые уже оптимизированы людьми, просто указываете для них вычислительные мощности, и модель сама предлагает решение», — цитирует Брокмана SiliconANGLE. Компании не уточнили, какие именно продукты Broadcom будут использоваться в рамках партнёрства. Вполне возможно, что это будет анонсированный на прошлой неделе Ethernet-коммутатор TH6-Davisson, оптимизированный для ИИ-кластеров и обеспечивающий пропускную способность до 102,4 Тбит/с, что, по заявлению компании, вдвое превышает показатели изделий ближайшего конкурента. Также Broadcom поставляет линейку PCIe-коммутаторов серии PEX и ретаймеры.  Ранее в этом месяце OpenAI заключила соглашение с AMD на поставку ИИ-ускорителей AMD нескольких поколений общей мощностью 6 ГВт для обеспечения своей ИИ-инфраструктуры. По предварительным оценкам, стоимость контракта составляет $60–$80 млрд. В сентябре NVIDIA объявила о соглашении с OpenAI на поставку ускорителей для развёртывания ИИ-инфраструктуры мощностью не менее 10 ГВт с сопутствующими инвестициями в размере $100 млрд. Broadcom в сентябре сообщила о получении заказа от нового клиента на разработку и поставку кастомного ИИ-чипа на сумму более $10 млрд. По мнению аналитиков, речь шла как раз об OpenAI. Создание сети взаимозависимостей означает, что несколько технологических компаний с оборотом в миллиарды долларов кровно заинтересованы в успехе OpenAI, отметил The Register. При этом OpenAI заявляет, что у неё не будет положительного денежного потока ещё четыре года и вместе с тем планирует в течение этого периода значительно увеличить расходы на инфраструктуру ЦОД. Такой подход вызывает опасения у экспертов, заявляющих, что подобные сделки указывают на своего рода пузырь на ИИ-рынке, поскольку компании оперируют такими терминами, как гигаватты и токены, вместо таких «скучных старых терминов», как выручка или доход.
09.10.2025 [11:42], Сергей Карасёв
Broadcom представила 102,4-Тбит/с СРО-коммутатор TH6-DavissonКомпания Broadcom анонсировала коммутационную систему платформу с интегрированной оптикой CPO (Co-Packaged Optics) третьего поколения Tomahawk 6 — Davisson (TH6-Davisson) для современных кластеров ИИ. Решение обеспечивает пропускную способность до 102,4 Тбит/с. В основу новинки положен чип-коммутатор Tomahawk 6. Утверждается, что TH6-Davisson устанавливает новый стандарт производительности для дата-центров, рассчитанных на наиболее ресурсоёмкие нагрузки. Поддерживаются оптические соединения с пропускной способностью 200 Гбит/с на линию. В случае вертикального масштабирования в один кластер могут быть объединены до 512 XPU. В двухуровневых горизонтально масштабируемых сетях количество XPU может превышать 100 тыс. Решение TH6-Davisson обеспечивает гибкие возможности в плане конфигурации портов. Возможны варианты 64 × 1,6 Тбит/с, 128 × 800 Гбит/с, 256 × 400 Гбит/с, 512 × 200 Гбит/с, 512 × 100 Гбит/с или 512 × 50 Гбит/с. Среди других преимуществ платформы названы возможность замены лазерных модулей ELSFP в полевых условиях и совместимость с DR-оптикой. 
Источник изображения: Broadcom При изготовлении TH6-Davisson задействована технология TSMC Compact Universal Photonic Engine (TSMC COUPE) вкупе с усовершенствованной многокристальной компоновкой на уровне подложки. Благодаря этому значительно снижаются потери, в результате чего энергопотребление оптического интерконнекта уменьшается на 70 % по сравнению с традиционными решениями. Таким образом, обеспечивается сокращение совокупной стоимости владения, что важно в случае масштабных инфраструктур, ориентированных на ИИ.
07.10.2025 [09:13], Сергей Карасёв
«Росатом» создал российский интерконнет «Альфа»: до 80 Гбит/с на порт и до 4096 узловНаучно-производственное объединение «Критические информационные системы» (НПО КИС), входящее в «Росатом», представило коммуникационную сеть Альфа, предназначенную для передачи данных между узлами вычислительных систем с высокой скоростью и малой задержкой. В качестве сфер применения сети «Альфа» названы СХД, СУБД, суперкомпьютеры и кластеры (в том числе на основе GPU), бортовые вычислительные комплексы и пр. Архитектура «Альфы» предполагает использование чипа на базе ПЛИС и хост-интерфейса PCIe 3.0 x16. Топология — 5D-тор, Fat Tree, Dragonfly+. Реализована поддержка медных и оптических кабелей, прямого доступа в память удалённого узла (RDMA), атомарных операций и вызовов удалённых прерываний, а также счётчиков производительности и исключительных ситуаций. Передача данных происходит без участия ядра ОС (в пространстве пользователя). 
Источник изображения: «Росатом» Заявленная пропускная способность достигает 80 Гбит/с на порт, пропускная способность MPI (Message Passing Interface) — 72,5 Гбит/с. Задержка между соседними узлами составляет 1,7 мкс, задержка узла — 0,5 мкс. Темп выдачи сообщений — 50 МТ/с. Возможно масштабирование до 4096 узлов. 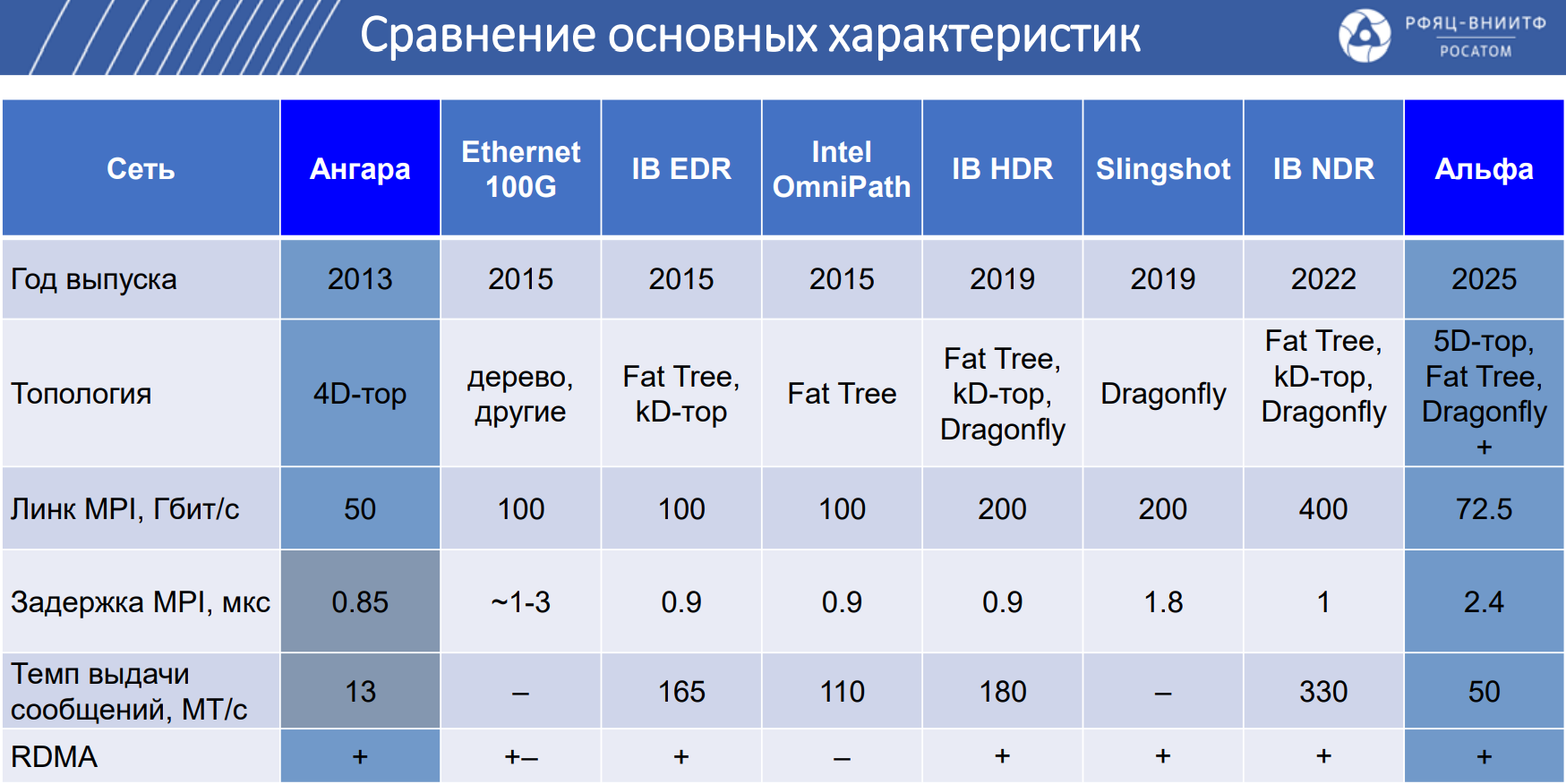
Источник изображения: «Росатом» Для сети «Альфа» разработаны адаптер и коммутатор. Первый выполнен в виде HHHL-карты с интерфейсом PCIe 3.0 x16. Предусмотрены два порта QSFP-DD. Применяется пассивная система охлаждения, потребляемая мощность — до 29,5 Вт. Изделие имеет размеры 142,25 × 68,9 × 17,25 мм. Возможно объединение в кольцо до восьми адаптеров без использования коммутатора. 
Источник изображения: НПО КИС В свою очередь, коммутатор располагает 32 портами QSFP-DD: устройство представляет собой четыре модуля коммутации, соединённых в кольцо. Решение выполнено в форм-факторе 1U с габаритами 650 × 43,6 × 440 мм. Используется активное воздушное охлаждение, а энергопотребление не превышает 300 Вт. Коммутатор получил блок питания с резервированием.
06.10.2025 [10:54], Владимир Мироненко
250 Тбит/с на чип: Ayar Labs, Alchip и TSMC предложили референс-дизайн для упаковки ASIC, памяти и оптических модулей в одном чипеКомпания Ayar Labs (США), занимающаяся разработкой интерконнекта на базе кремниевой фотоники, и тайваньский производитель ASIC-решений Alchip Technologies представили референсную платформу проектирования ИИ ASIC с несколькими оптическими IO-модулями на основе технологии кремниевой фотоники TSMC COUPE (Compact Universal Photonic Engine). В начале сентября компании объявили о стратегическом партнёрстве с целью ускорения масштабирования ИИ-инфраструктуры благодаря объединению технологии CPO компании Ayar Labs, экспертизы Alchip в области создания и упаковки кастомных ASIC, а также технологии упаковки и техпроцесса компании TSMC. Как сообщил технический директор Ayar Labs Владимир Стоянович (Vladimir Stojanovic) в интервью EE Times, платформа предназначена для устранения узких мест в передаче данных, замедляющих работу ИИ-инфраструктуры, путём эффективного сокращения времени простоя системы и создания крупных высокопроизводительных ИИ-кластеров нового поколения. Партнёры отметили, что по мере роста ИИ-моделей и размеров кластеров традиционные медные соединения достигают своих физических и энергетических пределов. Путём замены меди на интегрированную оптику (CPO) решение Alchip и Ayar Labs обеспечивает расширенную дальность связи, низкую задержку, энергоэффективность и высокий радикс, необходимые для масштабных развертываний ИИ-ускорителей. «Масштабируемые сети ИИ-кластеров ограничены расстоянием медных соединений. В то же время энергоэффективность сети ограничена плотностью мощности и возможностями систем охлаждения», — пояснил Эрез Шайзаф (Erez Shaizaf), технический директор Alchip, добавив, что CPO снимает эти ограничения. 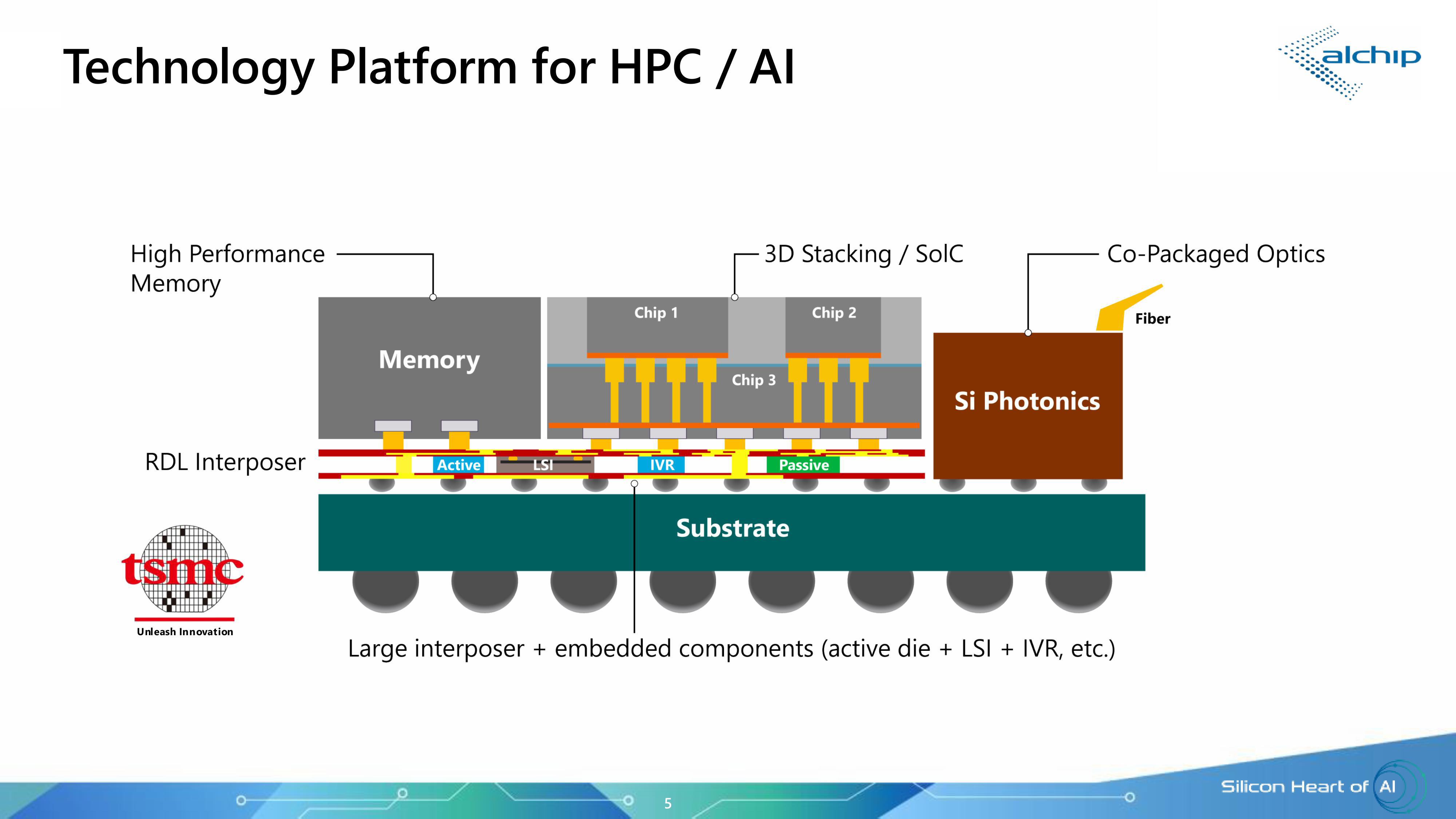
Источник изображений: Ayar Labs Новое совместное решение включает оптические модули Ayar Labs TeraPHY, размещённые вместе с решениями Alchip на общей подложке, обеспечивая прямой доступ ИИ-ускорителя к оптическому интерфейсу. Такая интеграция обеспечивает пропускную способность 100+ Тбит/с на каждый ускоритель и поддерживает более 256 оптических портов на устройство. TeraPHY не привязан к какому-либо протоколу и обеспечивает гибкую интеграцию с кастомными чиплетами. Референсный дизайн позволяет партнёрам «заложить основу» для быстрого создания подобной системы. Платформа референсного проекта включает два вычислительных кристалла с чиплетами HBM и другими чиплетами, в сочетании с восемью оптическими IO-модулями на базе чиплета TeraPHY. Такая конструкция обеспечит двустороннюю пропускную способность 200–250 Тбит/с для каждой сборки (SiP), что значительно превышает показатели современных крупных GPU, сообщил Стоянович. Это позволит масштабировать систему, а также значительно расширить объём памяти, имеющей пропускную способность, сопоставимую с HBM, добавил он. Оптический модуль Ayar Labs основан на чиплете TeraPHY PIC с двумя дополнительными слоями чиплетов, собранными с помощью TSMC COUPE. Два слоя электронных чиплетов собраны по технологии TSMC SoIC (System on Integrated Chips), которая использует вертикальное размещение нескольких кристаллов друг над другом, чтобы обеспечить более плотное соединение между ними, позволяя снизить энергопотребление, увеличить производительность и уменьшить задержки. По словам Стояновича, такой дизайн будет масштабироваться до уровня UCIe-A и выше как минимум в течение следующего десятилетия. 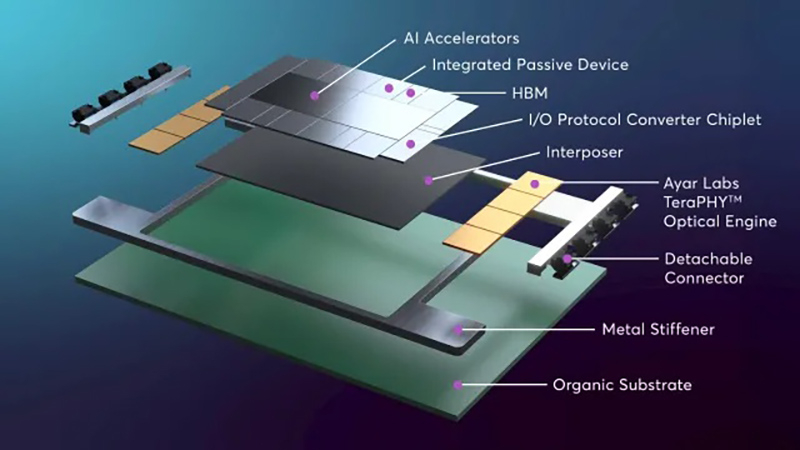 Совместное решение Alchip и Ayar Labs позволяет масштабировать многостоечную сетевую фабрику без потерь мощности и задержек, характерных для подключаемых оптических кабелей, за счёт минимизации длины электрических трасс и размещения оптических соединений вблизи вычислительного ядра. Благодаря поддержке UCIe для межкомпонентных соединений и гибкому размещению конечных точек на границе чипов, команды разработчиков могут интегрировать масштабируемое решение Alchip и Ayar Labs с существующими вычислительными блоками, стеками памяти и ускорителями, обеспечивая при этом соблюдение требований к производительности, целостности сигнала и температурному режиму на уровне всей сборки. Как сообщается, компании предоставят командам разработчиков дополнительные материалы, референсные архитектуры и варианты сборки. Платформа референсного дизайна включает в себя тестовые программы, позволяющие тестировать сборку и прошивку управления модулем, что облегчает его интеграцию в сборку. «Заказчику нужна поддержка, чтобы он понимал процессы оценки надёжности и испытаний, поэтому мы тесно сотрудничаем с Alchip, чтобы предоставить заказчику доступ ко всему этому пакету», — рассказал Стоянович.
06.10.2025 [09:19], Сергей Карасёв
Corning и GlobalFoundries создадут оптические коннекторы для кремниевой фотоникиАмериканский контрактный производитель полупроводниковых изделий GlobalFoundries и компания Corning, специализирующаяся на производстве стёкол, керамики и т.п., объявили о сотрудничестве. Совместными усилиями партнёры разработают разъёмные волоконно-оптические коннекторы для кремниевой фотоники. Речь идёт о решении GlassBridge для платформы GF Fotonix. Коннектор на основе стеклянного волновода совместим с V-образными канавками GF Fotonix. Система предназначена для удовлетворения растущих потребностей ИИ ЦОД в высокой пропускной способности каналов связи. Разрабатываются также другие механизмы соединения, включая вертикальное разъёмное решение типа Fibre-to-PIC (Photonic Integrated Circuit). Сотрудничество предусматривает использование передовых разработок Corning в области материалов, оптического волокна и средств связи. Это, в частности, стёкла специального состава, стеклянные подложки и методы лазерной обработки. Кроме того, будут применяться оптоволоконные массивы (Fibre Array Unit — FAU) с волокнами со сверхточным выравниванием сердцевины, благодаря которому минимизируются потери. 
Источник изображения: Corning В перспективе разъёмы нового типа помогут повысить удобство развёртывания и эксплуатации высокоскоростного интерконнекта на основе кремниевой фотоники в дата-центрах, ориентированных на ресурсоёмкие приложения ИИ и НРС. Не так давно GlobalFoundries объявила о том, что её платформа кремниевой фотоники выделена в отдельное продуктовое семейство. При этом компания увеличила объём инвестиции в соответствующей сфере в два раза. |
|

