Материалы по тегу: nvidia
|
11.07.2025 [09:09], Сергей Карасёв
В облаке AWS появились инстансы EC2 P6e-GB200 UltraServer на базе ИИ-суперускорителей NVIDIA GB200 NVL72Облачная платформа AWS объявила о доступности высокопроизводительных инстансов EC2 P6e-GB200 UltraServer, рассчитанных на наиболее ресурсоёмкие нагрузки ИИ. В основу экземпляров положены суперускорители NVIDIA GB200 NVL72. Система GB200 NVL72 объединяет в одной стойке 18 узлов 1U, каждый из которых содержит два ускорителя GB200, что даёт в общей сложности 72 чипа B200 и 36 процессоров Grace. Задействована шина NVLink 5. Инстансы u-p6e-gb200-x72 предоставляют доступ к 72 чипам поколения Blackwell в одном домене NVLink, включая примерно 13,4 Тбайт памяти HBM3e. Производительность в режиме FP8 достигает 360 Пфлопс. Количество vCPU составляет до 2592, объём памяти — до 17 280 ГиБ. Кроме того, предоставляется до 405 Тбайт пространства для хранения данных. Используются адаптеры AWS Elastic Fabric Adapter (EFAv4) с низкой задержкой, агрегированной скоростью передачи данных 28,8 Тбит/с и поддержкой NVIDIA GPUDirect RDMA. Пропускная способность EBS достигает 1080 Гбит/с. Также доступны u-p6e-gb200-x36 с вдвое меньшими характеристиками. 
Источник изображений: AWS Применяется система AWS Nitro, которая переносит функции виртуализации, хранения и сетевые операции на выделенное оборудование и ПО для повышения производительности и улучшения безопасности. Инстансы EC2 P6e-GB200 UltraServer объединяются в кластеры EC2 UltraCluster, что обеспечивает возможность безопасного и надёжного масштабирования до десятков тысяч ускорителей. 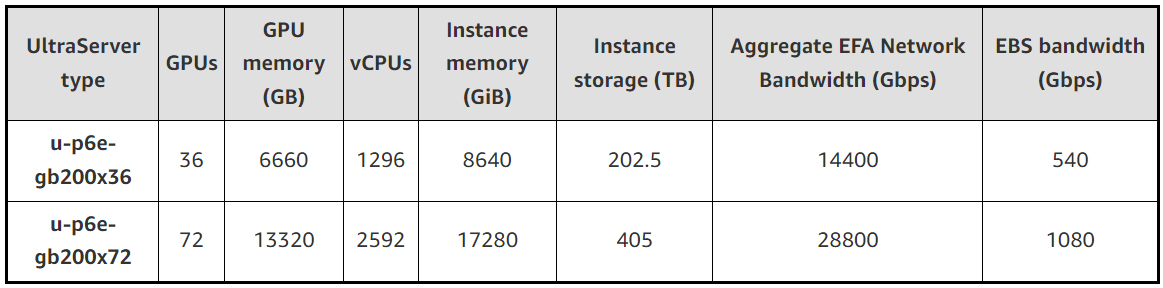 AWS отмечает, что новые экземпляры подходят для работы с передовыми ИИ-моделями, насчитывающими триллионы параметров. При этом может использоваться сочетание экспертных и рассуждающих моделей. После резервирования ёмкости стоимость за инстанс списывается авансом, и цена не меняется после оплаты.
10.07.2025 [17:30], Сергей Карасёв
Bloomberg: Китай строит в пустыне гигантский комплекс ИИ ЦОД для 115 тыс. ускорителей NVIDIA, поставки которых запрещены СШАНа окраине пустыни Гоби в Синьцзяне (автономный район на северо-западе Китая), по сообщению Bloomberg News, ведутся активные работы по строительству кампуса ЦОД для ИИ-задач. Согласно имеющейся информации, в этих дата-центрах будут применяться серверы с ускорителями NVIDIA, поставки которых запрещены в КНР в соответствии с американскими санкциями. Специалисты Bloomberg News проанализировали сведения, содержащиеся в инвестиционных одобрениях, тендерных документах и заявках китайских компаний. Утверждается, что масштабные планы Китая в отношении развития ИИ прямо предусматривают использование «запрещённых» продуктов NVIDIA, а не только местных решений вроде Huawei Ascend. В частности, в IV квартале 2024 года власти Синьцзяна (Xinjiang) и соседней провинции Цинхай (Qinghai) одобрили создание в общей сложности 39 дата-центров, в которых будет задействовано более 115 тыс. ИИ-ускорителей NVIDIA. Причём во всех случаях речь идёт об H100 и H200. Операторы ЦОД в Синьцзяне намерены разместить львиную долю этих ускорителей в одном крупном комплексе, который будет использоваться для обучения передовых ИИ-моделей и других ресурсоёмких нагрузок. Строительные работы организованы в уезде Иу (Yìwū). Сотрудникам Bloomberg News не удалось установить, каким способом китайские компании намерены приобретать изделия NVIDIA, закупки которых запрещены без получения специальных лицензий от правительства США. Местные операторы дата-центров, государственные чиновники и представители центрального правительства в Пекине отказались давать какие-либо комментарии по данному вопросу. Между тем, как отмечается в публикации, стоимость 115 тыс. указанных ИИ-ускорителей может составить миллиарды долларов, исходя из цен на чёрном рынке Китая. 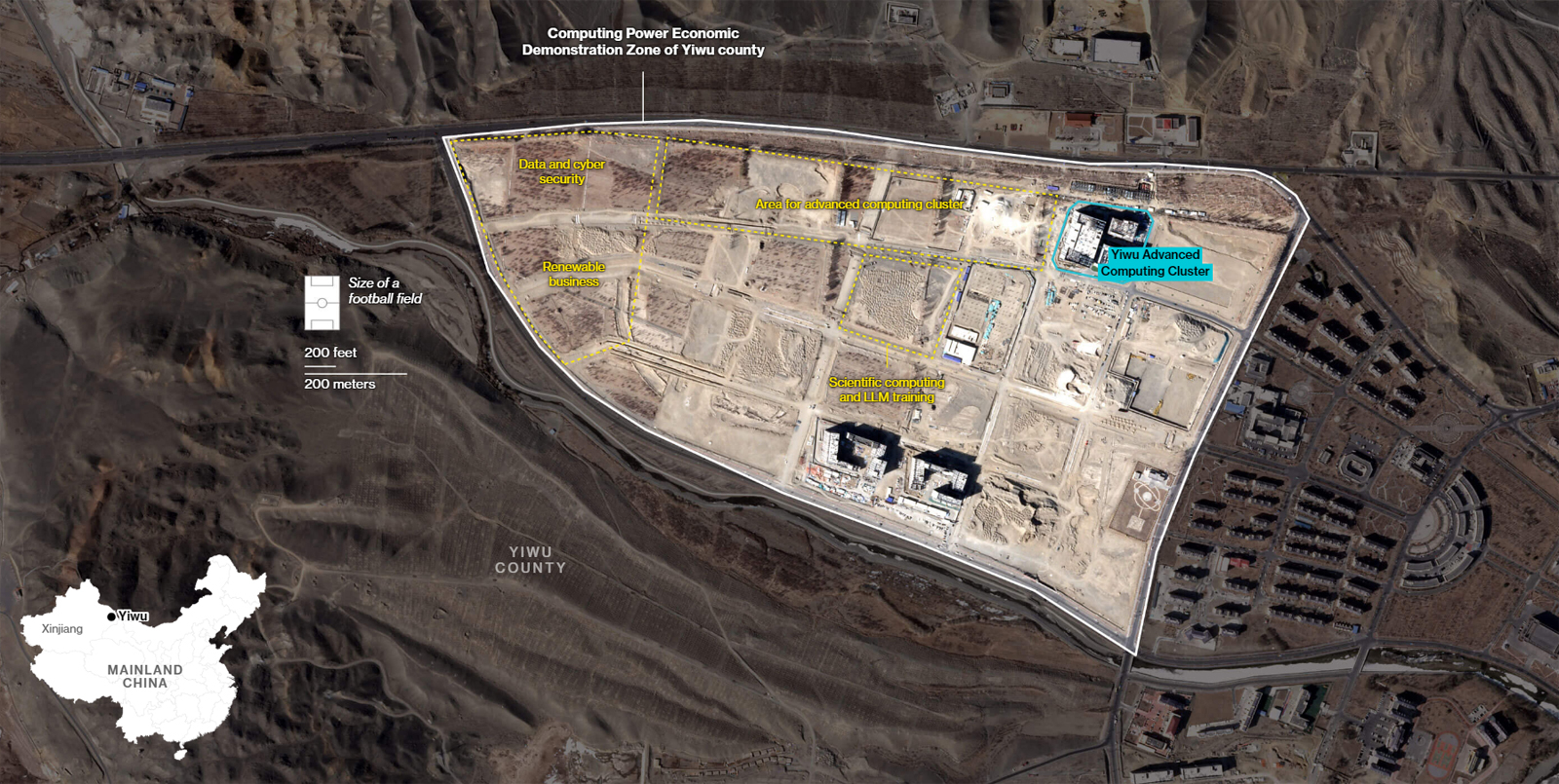
Источник изображения: Bloomberg И всё же строительство комплекса ЦОД продолжается. Синьцзян, и особенно регион Хами (Hāmì), включающий уезд Иу, богаты ветровой и солнечной энергией, а также углём. Это позволит решить вопросы, связанные с энергообеспечением дата-центров. Дополнительными достоинствами выбранного региона являются доступность больших территорий, низкая стоимость земли и прохладный климат в высотных районах. Согласно тендерной документации, полученной Bloomberg, по состоянию на июнь 2025 года по семи проектам ЦОД в Синьцзяне либо начаты строительные работы, либо выиграны тендеры на услуги ИИ-вычислений. В частности, один из крупнейших проектов связан с энергокомпанией Nyocor из Тяньцзиня (Tianjin), которая специализируется на солнечной и ветровой энергетике. Инициатива предусматривает создание дата-центра на базе 625 серверов с ускорителями H100. Nyocor продаёт вычислительные мощности корпорации Infinigence AI — одной из крупнейших организаций в сфере ИИ-инфраструктуры в Китае. В документах по 27 другим проектам ЦОД, одобренным в Синьцзяне и Цинхае в прошлом году, упоминаются в общей сложности более 9 тыс. серверов и около 72 тыс. ускорителей H100/H200. Два высокопоставленных чиновника американской администрации заявили, что по их оценкам, в Китае имеется примерно 25 тыс. запрещенных ИИ-ускорителей NVIDIA: такое количество, как утверждается, не вызывает серьёзного беспокойства. Более того, даже в случае приобретения ещё 115 тыс. карт NVIDIA масштабы соответствующих ИИ-платформ в КНР окажутся несопоставимы с мощью развитой инфраструктурой ИИ в США. Нужно отметить, что за последние годы власти Китая потратили $6,1 млрд на строительство крупных кампусов ЦОД, тогда как ещё $28 млрд вложили частные инвесторы. Площадки дата-центров появились в регионе Внутренняя Монголия, провинциях Нинся, Ганьсу, Гуйчжоу, регионе Пекин-Тяньцзинь-Хэбэй, а также в дельте Янцзы и на других территориях. Однако многие подобные объекты оказались невостребованными из-за переоценённого спроса и архитектурных недоработок.
08.07.2025 [17:09], Владимир Мироненко
Российский суперкомпьютер «Говорун» получил два узла «РСК Экзастрим ИИ» с NVIDIA H100 и фирменной СЖО
emerald rapids
h100
h200
hpc
intel
nvidia
sapphire rapids
xeon
россия
рск
сделано в россии
сервер
суперкомпьютер
ГК РСК продемонстрировала 2U-узел (912 × 508 × 88 мм) собственной разработки «РСК Экзастрим ИИ» на базе восьми ускорителей NVIDIA H100 с прямым жидкостным охлаждением. Два таких узла были установлены в суперкомпьютере «Говорун» в Дубне. «РСК Экзастрим ИИ» включает:
«РСК Экзастрим ИИ» имеет локальную подсистему хранения «тёплых данных», сетевую подсистему с доступом на основе технологии GPUDirect. Также есть возможность расширения ресурсов путём подключения дополнительных пар ускорителей или системы внешнего хранения данных на базе пула JBOF, подключаемой напрямую. Производительность «РСК Экзастрим ИИ» составляет до 208 Тфлопс (FP64). При установке 21 сервера в шкаф «РСК Экзастрим» пиковая производительность достигает 4,26 Пфлопс (FP64). Сервер отличается высокой энергоэффективностью, сверхвысокой плотностью монтажа и надёжной работой. Он может использоваться для решения ресурсоёмких задач в области машинного обучения и ИИ, создания мощных вычислительных ресурсов облачных провайдеров и в частных облаках и т.д. 
Источник изображений: РСК Два узла «РСК Экзастрим ИИ» были установлены в суперкомпьютере «Говорун» в Лаборатории информационных технологий им М.Г. Мещерякова Объединенного института ядерных исследований (ЛИТ ОИЯИ) в Дубне в рамках нового этапа модернизации, проведенной силами специалистов ГК РСК и лаборатории.  Как сообщается, новые серверы «РСК Экзастрим ИИ» уникальны и были сконструированы и изготовлены для СК «Говорун» с учётом его архитектурных особенностей. При этом пиковая FP64-производительность GPU-компоненты суперкомпьютера «Говорун» выросла на 36 % и достигла 1,4 Пфлопс, пиковая суммарная FP64-производительность суперкомпьютера теперь составляет 2,2 Пфлопс. Характеристики серверов «РСК Экзастрим ИИ», установленных в ОИЯИ:
 В конце 2024 года было проведено расширение СХД суперкомпьютера «Говорун», после чего её ёмкость увеличилась до 10 Пбайт. В СХД вычислительного комплекса ОИЯИ были добавлены два узла хранения данных RSC Tornado AFS ёмкостью 1 Пбайт каждый. Обновленная модификация СХД RSC Tornado AFS включает серверную плату на базе процессоров Intel Xeon Sapphire Rapids, а также коммутатор с интерфейсом PCIe 4.0, что позволило установить по два адаптера интерконнекта с пропускной способностью 200 Гбит/с каждый.  СХД RSC Tornado AFS поддерживает технологию GPUDirect Storage (GDS), которая обеспечивает прямую передачу данных между локальным или удалённым хранилищем и памятью ускорителя. Две СХД, установленные ранее специалистами РСК в суперкомпьютере «Говорун» входят в мировой рейтинг IO500 самых высокопроизводительных системам хранения данных. В суперкомпьютере «Говорун» используются интегрированный программный комплекс «РСК БазИС 4» и модуль «РСК БазИС СХД» (включены в Реестр российского ПО). Микроагентная архитектура «РСК БазИС 4» обеспечивает функционирование объектов системы, позволяя также взаимодействовать с ними. «РСК БазИС» в сочетании с аппаратными платформами РСК позволяет создавать гиперконвергентные решения для HPC и эффективной обработки больших объёмов данных.
08.07.2025 [13:54], Сергей Карасёв
«Инферит» выпустил российскую рабочую станцию для ИИ-задач с четырьмя GPU и СЖОРоссийский поставщик IT-решений «Инферит» (ГК Softline) представил рабочую станцию Inferit, разработанную для ресурсоёмких ИИ-задач, включая обучение больших языковых моделей (LLM). Устройство, как утверждается, сочетает в себе надёжность, компактность, низкий уровень шума и высокую производительность. Новинка выполнена в форм-факторе 4U с габаритами 439 × 681 × 177 мм (без ручек и выступающих элементов) и массой 45 кг. Допускается настольное размещение или монтаж в 19″ серверную стойку. Задействована материнская плата типоразмера E-ATX. В зависимости от модификации предусматривается установка процессоров AMD или Intel и до 2 Тбайт RAM. Машина допускает использование до четырёх ИИ-ускорителей на базе GPU. Могут применяться карты AMD W7800 и W7900 или NVIDIA RTX 5090, RTX 6000 ADA, L40, L40S, H100, H200 и RTX Pro 6000. Рабочая станция изначально спроектирована под жидкостное охлаждение: этот контур охватывает зоны CPU (включая VRM) и GPU (включая DDR и VRM). Благодаря СЖО, по заявлениям компании «Инферит», достигается стабильное функционирование системы на повышенных частотах, что обеспечивает высокую производительность и небольшой уровень шума при максимальных нагрузках. Диапазон рабочих температур — от +3 до +38 °C. 
Источник изображений: «Инферит» Возможна установка до восьми NVMe SSD формата M.2, а также двух LFF-накопителей и шести SFF-изделий с интерфейсом SATA. Питание обеспечивают три блока SFX-L мощностью 1200 Вт каждый. Упомянуты два сетевых порта 10GbE. Заявлена совместимость с «МСВСфера» разработки «Инферит», Ubuntu, Windows 10 и Windows Server.  «Рабочая станция Inferit ориентирована на самые ресурсоёмкие сценарии в области искусственного интеллекта, научных исследований и графики. Это мощный инструмент для тех, кто каждый день работает с технологическими задачами», — сообщает «Инферит Техника».
08.07.2025 [09:44], Руслан Авдеев
В гонке за лидерство в сфере ИИ поможет инфраструктура, а не хайпВ докладе AI Space Race («Космическая гонка ИИ») NetApp собрала мнения топ-менеджмента компаний нескольких стран относительно возможности стать лидерами в сфере ИИ-инноваций. Судя по представленным данным, для победы игрокам потребуется развитая ИИ-инфраструктура. Выводы вполне ожидаемые для поставщика подобных решений, сообщает Blocks & Files. В представленном материале гонка за лидерство в сфере ИИ сравнивается с космической гонкой с участием СССР и США 1960-х годов, когда государства активно инвестировали в научные изыскания и инновации. Предполагается, что результат «космической гонки» в сфере ИИ определит мироустройство на десятилетия вперёд. NetApp опросила 400 генеральных директоров и IT-руководителей из китайских, индийских, британских и американских компаний в мае текущего года. 43 % из них заявили, что в следующие пять лет лидером в сфере ИИ будут США. Гораздо меньше из них сделали ставку на Китай, Индию или Великобританию. В докладе сообщается, что 92 % китайских генеральных директоров сообщили об активной реализации ИИ-проектов, но только 74 % китайских IT-руководителей согласны с ними. В США 77 % CEO доложили об активных ИИ-проектах, а едины с ними во мнениях 86 % IT-руководителей. 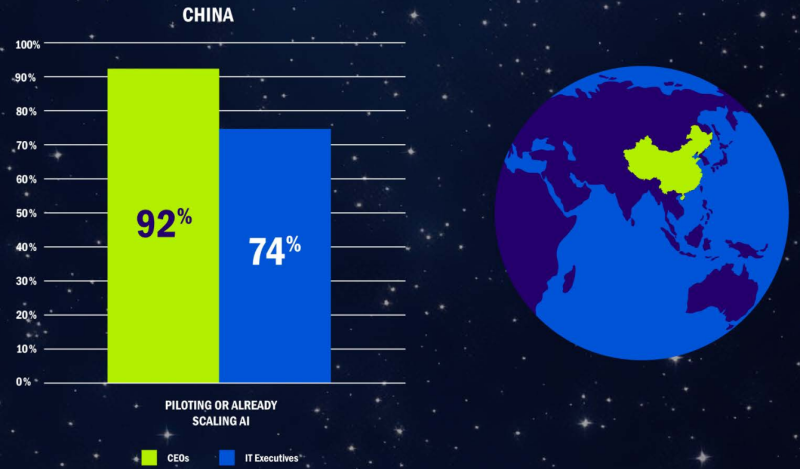
Источник изображений: NetApp Другими словами, в Китае отмечается критическое несоответствие мнений CEO и IT-руководителей, что может ослабить потенциал в КНР в будущем. Успешная реализация проектов зависит не только от амбиций руководства, но и от согласованности реализации ИИ-стратегий на разных уровнях. Тем не менее, не исключается, что китайские организации просто активнее реализуют ИИ-проекты под патронажем CEO, опережая в этом США. Ещё одно отличие Китая от других стран в том, что КНР делает ставку на масштабируемость — 35 % компаний фокусируются на этом (против 24 % в среднем по миру), что отражает стремление к быстрому развёртыванию ИИ-решений. Другие страны больше ориентированы на интеграцию — встраивание ИИ в существующие системы и процессы. Безопасность и иные факторы оказались наименее важными для всех участников опроса — лишь 10 % директоров и IT-руководителей считают эти вопросы приоритетными.  Утверждается, что больше респондентов считают, что США, а не Китай в долгосрочной перспективе будут лидировать в сфере ИИ. 64 % респондентов в США назвали Соединённые Штаты вероятным лидером в ИИ-инновациях в следующие пять лет, в среднем в мире на США делают ставку 43 % респондентов (считая и американских). В Китае будущим лидером считают родину 43 % опрошенных, и только 22 % от общего числа респондентов. У Индии и Великобритании ситуация ещё хуже. Эти страны считают будущими лидерами 40 % и 34 % местных респондентов соответственно. В целом по миру шансы Индии и Соединённого Королевства стать лидерами дают 16 % и 19 % от всех опрошенных соответственно. 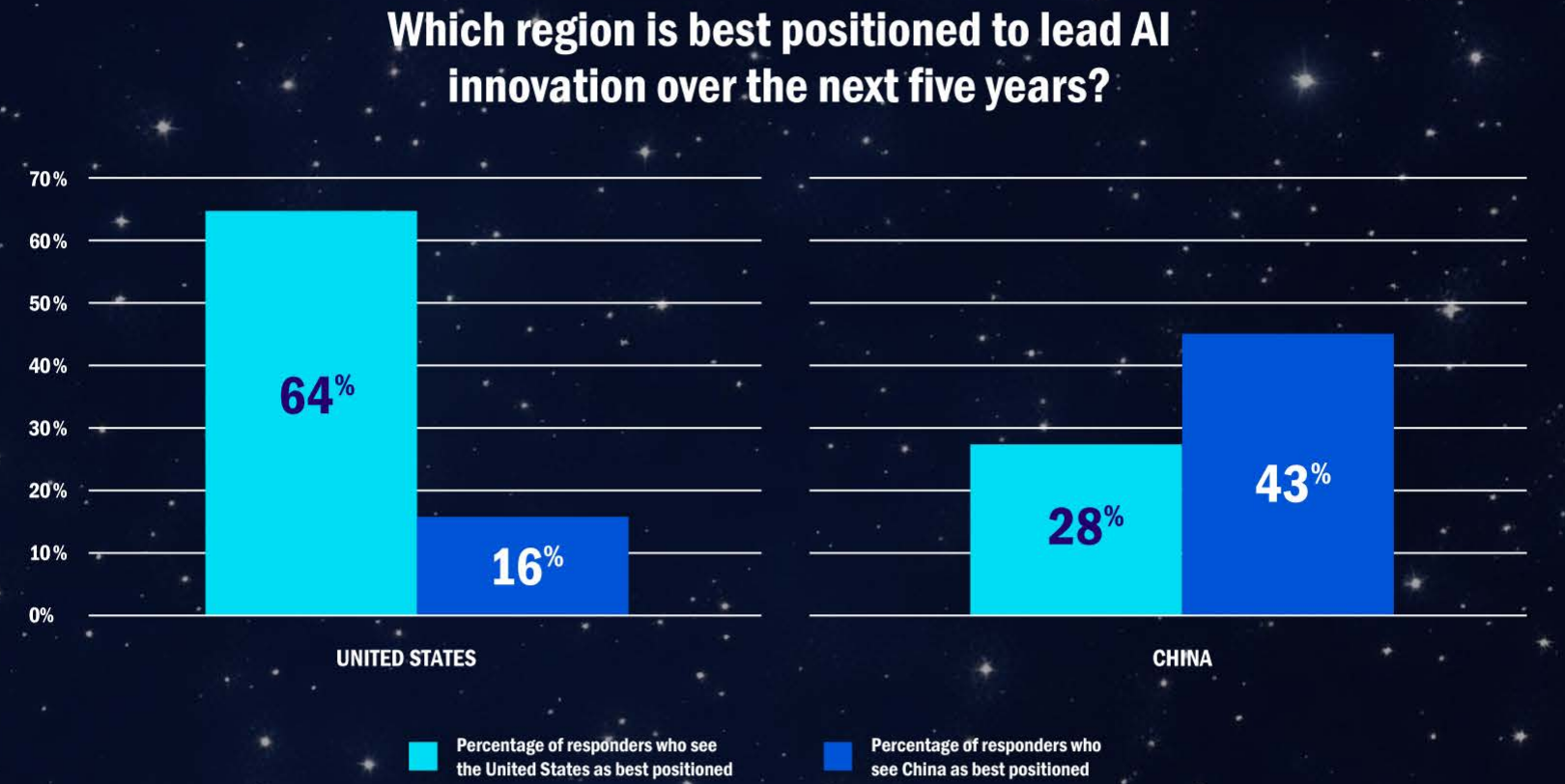 Главным драйвером для внедрения ИИ CEO и IT-руководители видят необходимость использования ИИ для принятия решений и сохранения конкурентоспособности (26 %). Индия (29 %) и Великобритания (32 %) ощущают необходимость догонять явных лидеров — США и КНР. Примечательно, что в Китае одним из главных драйверов является реальный пользовательский спрос (21 % против 13 % в среднем по миру). На деле речь идёт о практическом внедрении 83% пилотных решений и программ в Китае против 81% в мире (разница не очень большая). 51 % респондентов назвали собственные организации конкурентоспособными в сфере ИИ, но, похоже, никто не видит себя безусловным лидером. 88 % считают, что их организации в основном или полностью готовы поддержать ИИ-трансформацию, а 81 % уже реализуют пилотные ИИ-проекты или масштабируют ИИ.  В NetApp пришли к выводу, что одним из важнейших факторов успеха в новой «космической гонке» будет наличие инфраструктуры и эффективное управление данными при поддержке гибких, безопасных и масштабируемых облачных решений. Просто «хайп» не поможет вне зависимости от размера компании, отрасли, её местоположения и др. Хотя по материалам NetApp очевидно, что ключевым поставщиком инфраструктуры компания видит себя, в Blocks & Files напоминают, что сильные позиции занимают и другие игроки в разных сферах, включая Dell, HPE, IBM, Pure Storage, VAST Data и др. — они также активно развивают решения для хранения неструктурированных данных, векторных баз данных и интеграции с ускорителями NVIDIA. Особое внимание уделяется технологиям вроде GPUDirect, IO500-оптимизированным системам, а также поставщикам систем резервного копирования и облачных файловых сервисов, которые всё чаще внедряют ИИ в свои продукты. Кроме того, практически все крупные IT-игроки вообще — от поставщиков баз данных до гигантов вроде Huawei активно развивают ИИ-направление, часто в партнёрстве с NVIDIA. Это связано с тем, что любое отставание в поддержке ИИ-инициатив клиентов может привести к потере целых направлений в пользу конкурентов. За пределами США значительную роль играют китайские вендоры, например, всё та же Huawei, что только усиливает глобальную конкуренцию. В июне учёные Оксфордского университета пришли к выводу, что в обозримом будущем недоступность ИИ-инфраструктуры усилит цифровое, экономическое и политическое неравенство.
06.07.2025 [23:08], Сергей Карасёв
Giga Computing представила ИИ-серверы на базе NVIDIA HGX B200 с воздушным и жидкостным охлаждениемКомпания Giga Computing, подразделение Gigabyte, представила серверы G4L3-SD1-LAX5, G4L3-ZD1-LAX5, G894-AD1-AAX5 и G894-SD1-AAX5 для приложений ИИ, инференса и других ресурсоёмких нагрузок. В основу новинок положена платформа NVIDIA HGX B200 в конфигурации 8 × SXM. Модель G4L3-SD1-LAX5 типоразмера 4U оснащена системой прямого жидкостного охлаждения (DLC) с отдельными зонами CPU и GPU. Допускается установка двух процессоров Intel Xeon Sapphire Rapids или Xeon Emerald Rapids с показателем TDP до 385 Вт. Предусмотрены 32 слота для модулей DDR5-5600, восемь фронтальных отсеков для SFF-накопителей (NVMe/SATA), а также два коннектора для SSD типоразмера M.2 2280/22110 (PCIe 3.0 x2 и PCIe 3.0 x1). Доступны восемь разъёмов для однослотовых карт расширения FHHL PCIe 5.0 x16 и четыре разъёма для карт FHHL PCIe 5.0 x16 двойной ширины. В оснащение входят контроллер ASPEED AST2600, два сетевых порта 10GbE на базе Intel X710-AT2 и выделенный сетевой порт управления 1GbE. Питание обеспечивают восемь блоков мощностью 3000 Вт с сертификатом 80 PLUS Titanium. Диапазон рабочих температур простирается от +10 до +35 °C. Вариант G4L3-ZD1-LAX5 рассчитан на два чипа AMD EPYC 9004 (Genoa) или EPYC 9005 (Turin) с TDP до 500 Вт. Этот сервер также выполнен в формате 4U и оборудован DLC-охлаждением. Есть 24 слота для модулей DDR5-6400, восемь фронтальных отсеков для SFF-накопителей NVMe и два внутренних коннектора для SSD стандартов M.2 2280/22110 (PCIe 3.0 x4 и PCIe 3.0 x1). Прочие характеристики аналогичны предыдущей модели. 
Источник изображений: Gigabyte Двухпроцессорные серверы G894-AD1-AAX5 и G894-SD1-AAX5 типоразмера 8U наделены воздушным охлаждением, включая 15 вентиляторов диаметром 80 мм в зоне GPU. Вариант G894-AD1-AAX5 поддерживает установку чипов Intel Xeon 6900 с показателем TDP до 500 Вт и 24 модулей DDR5 (RDIMM-6400 или MRDIMM-8800).  Модификация G894-SD1-AAX5, в свою очередь, рассчитана на процессоры Intel Xeon 6700/6500 с TDP до 350 Вт и 32 модуля DDR5 (RDIMM-6400 или MRDIMM-8000). Оба сервера оборудованы двумя портами 10GbE (Intel X710-AT2), сетевым портом управления 1GbE, контроллером ASPEED AST2600, восемью фронтальными отсеками для SFF-накопителей NVMe, двумя коннекторами M.2 2280/22110 (PCIe 5.0 x4 и PCIe 5.0 x2). Имеются восемь разъёмов для карт расширения FHHL PCIe 5.0 x16 одинарной ширины и четыре разъёма для карт FHHL PCIe 5.0 x16 двойной ширины. Установлены 12 блоков питания мощностью 3000 Вт с сертификатом 80 PLUS Titanium. Серверы могут эксплуатироваться при температурах от +10 до +30 °C.
05.07.2025 [02:13], Владимир Мироненко
CoreWeave первой в отрасли развернула кластер на базе NVIDIA GB300 NVL72Облачный провайдер CoreWeave объявил о первом в отрасли развёртывании кластера на базе передовой платформы NVIDIA GB300 NVL72, размещённой в интегрированной стоечной системе, поставленной Dell. Развёртыванием кластера занимался оператор ЦОД Switch. Dell заявила, что стоечные системы поставляются собранными и протестированными. Они изначально разработаны для быстрой установки и развёртывания. GB300 NVL72 в исполнении Dell представляет собой интегрированное стоечное решение на базе серверов PowerEdge XE9712 с жидкостным охлаждением, которое объединяет 72 ускорителя NVIDIA Blackwell Ultra, 36 Arm-процессоров NVIDIA Grace на базе Arm-архитектуры, интерконнект NVLink и 18 или 36 DPU NVIDIA BlueField-3 в одну мощную платформу, использующую в работе широкий спектр передовых решений NVIDIA. 
Источник изображения: CoreWeave/Switch Каждая стойка GB300 NVL72 оснащена 21 Тбайт HBM3E и 40 Тбайт RAM. В решении используются 800G-сеть с коммутаторами Quantum-X800 InfiniBand и адаптерами ConnectX-8 SuperNIC. Каждая стойка GB300 NVL72 обеспечивает производительность 1,1 Эфлопс в FP4-вычислениях для инференса и 0,36 Эфлопс в FP8 (без разреженности) для обучения, что на 50 % выше по сравнению с GB200 NVL72. 
Источник изображения: Dell Программная инфраструктура NVIDIA DOCA, работающая на NVIDIA BlueField-3, ускоряет рабочие нагрузки ИИ, обеспечивая пользователям скорость сети до 200 Гбит/с и высокопроизводительный доступ к данным ускорителей. Как отметила CoreWeave, новое оборудование означает для клиентов значительный рост производительности при обработке рабочих нагрузок рассуждающих ИИ-моделей.
04.07.2025 [12:56], Сергей Карасёв
«Инферит» представил российские GPU-серверы с СЖО на платформах AMD и IntelРоссийский поставщик IT-решений «Инферит» (ГК Softline) анонсировал отечественные GPU-серверы, предназначенные для работы с ИИ-моделями, инференса, глубокого обучения и других ресурсоёмких задач. Новинки оснащены системой жидкостного охлаждения. Серверы предлагаются в одно- и двухпроцессорных конфигурациях. В первом случае могут применяться чипы AMD Threadripper Pro 5000 WX, 7000 WX, EPYC 9004 (Genoa) и EPYC 9005 (Turin) или изделия Intel Xeon W-2400/2500/3400/3500, Xeon Sapphire Rapids, Xeon Emerald Rapids и Xeon 6. Двухсокетные версии несут на борту процессоры AMD EPYC 9004/9005 или Xeon Sapphire Rapids / Emerald Rapids и Xeon 6. Объём оперативной памяти достигает 2 Тбайт. Максимальная конфигурация предполагает установку до восьми PCIe-ускорителей. Могут использоваться карты AMD W7800 и W7900 или NVIDIA RTX 5090, RTX 6000 ADA, L40, L40S, H100, H200 и RTX Pro 6000. Подсистема хранения данных выполнена на основе высокоскоростных SSD. Для охлаждения задействованы два контура — жидкостный и воздушный с тремя вентиляторами (6200 об/мин). За питание отвечают до четырёх блоков мощностью 2000 Вт в режимах 4+0, 3+1, 2+2. Серверы наделены средствами удалённого мониторинга, которые позволяют анализировать работу охлаждения и других компонентов в реальном времени. 
Источник изображений: «Инферит» Говорится о совместимости с «МСВСфера Сервер» 9, Ubuntu, Windows 10 и Windows Server. В качестве потенциальных заказчиков «Инферит» называет ИИ-разработчиков, аналитиков данных, конструкторов и других специалистов, которым требуется высокая производительность для решения различных задач. На машины предоставляется двухлетняя гарантия, которую можно расширить до трёх или пяти лет. Клиентская поддержка осуществляется специалистами «Инферит» на всей территории России.  «Новый Multi-GPU сервер Inferit — это ответ на запрос рынка на надёжные, производительные и при этом удобные в эксплуатации решения. Благодаря партнёрству с разработчиком систем жидкостного охлаждения нам удалось реализовать модель, которая справляется с самыми требовательными задачами, сохраняя эффективность и доступность», — говорит руководитель департамента продуктовых решений «Инферит Техника».
02.07.2025 [08:35], Руслан Авдеев
Arm-чипы захватывают рынок, но до доминирования в ЦОД им пока далекоСерверы на базе Arm-чипов стремительно набирают популярность — в 2025 году их поставки должны вырасти на 70 %. Тем не менее, этого не хвататит, чтобы к концу года добиться планируемого Arm Holdings охвата рынка в 50 %, сообщает The Register. Аналитики IDC утверждают, что Arm-серверы пользуются массовым спросом в основном благодаря стоечным системам вроде NVIDIA GB200 NVL72. В новейшем отчёте Worldwide Quarterly Server Tracker эксперты IDC подсчитали, что в текущем году на Arm-серверы придётся 21,1 % от общего объёма мировых поставок. Ожидается, что поставки серверов с хотя бы одним ИИ-ускорителем вырастут на 46,7 %, на них придётся в текущем году около половины рыночной стоимости. Всего за три года, по оценкам IDC, рынок серверов должен вырасти втрое благодаря гиперскейлерам и облачным провайдерам. В целом рынок серверов достиг в I квартале 2025 года $95,2 млрд, увеличившись год к году на 134,1 %. В результате IDC повысила прогноз на год до $366 млрд, на 44,6 % выше год к году — исторический максимум для данного сегмента. При этом поставки «стандартных» x86-серверов должны вырасти в 2025 году на 39,9 % до $283,9 млрд. При этом доля AMD непрерывно растёт. Сегмент альтернативных систем вырастет на 63,7 % год к году, а их общий прогнозируемый объём составит $82 млрд. 
Источник изображения: NVIDIA / CoreWeave По прогнозам IDC, наибольший рост, на 59,7 % год к году ожидается в США. К концу 2025 года на данный рынок будет приходиться почти 62 % общей выручки от продаж серверов. Ещё одной точкой роста является Китай. IDC прогнозирует рост на 39,5 % — более 21 % квартального дохода во всём мире. Регионы EMEA и Латинская Америка могут рассчитывать на 7 % и 0,7 % соответственно, а Канаду, вероятно, ожидает спад на 9,6 % из-за некой «очень крупной сделки» 2024 года. В IDC подчёркивают, что спрос на большие вычислительные мощности для ИИ, вероятно, сохранится — эволюция от старых чат-ботов к рассуждающим моделям и агентному ИИ потребует роста производительности на несколько порядков, особенно для инференса.
29.06.2025 [21:11], Сергей Карасёв
Таёжное облако: ИИ-кластер Northern Data Njoerd вошёл в рейтинг TOP500
h100
hardware
hpc
hpe
intel
northern data
nvidia
sapphire rapids
xeon
великобритания
ии
облако
суперкомпьютер
Немецкая компания Northern Data Group, поставщик решений в области ИИ и НРС, объявила о том, что её система Njoerd вошла в июньский рейтинг мощнейших суперкомпьютеров мира TOP500. Этот вычислительный комплекс, расположенный в Великобритании, построен на платформе HPE Cray XD670. Машина Njoerd попала на 26-е место списка TOP500. Она объединяет 244 узла, каждый из которых содержит восемь ускорителей NVIDIA H100. В общей сложности задействованы примерно 28,5 млн ядер CUDA. Кроме того, в составе системы используются процессоры Intel Xeon Platinum 8462Y+ (32C/64C, 2,8–4,1 ГГц, 300 Вт). Применён интерконнект Infiniband NDR400. FP64-производительность Njoerd достигает 78,2 Пфлопс, а теоретическое пиковое быстродействие составляет 106,28 Пфлопс. При рабочих нагрузках ИИ суперкомпьютер демонстрирует производительность 3,86 Эфлопс в режиме FP8 и 1,93 Эфлопс в режиме FP16. Заявленный показатель MFU (Model FLOPs Utilization) при предварительном обучении современных больших языковых моделей (LLM) находится на уровне 50–60 %. Таким образом, как утверждается, система Njoerd на сегодняшний день представляет собой наиболее эффективный кластер H100 подобного размера, оптимизированный для ресурсоёмких рабочих нагрузок ИИ и HPC. Суперкомпьютер входит в состав Taiga Cloud — одной из крупнейших в Европе облачных платформ, ориентированных на задачи генеративного ИИ. Эта вычислительная инфраструктура использует на 100 % безуглеродную энергию. Показатель PUE варьируется от 1,15 до 1,06. Доступ к ресурсам предоставляется посредством API или через портал самообслуживания. Одним из преимуществ Taiga Cloud компания Northern Data Group называет суверенитет данных. 
Источник изображения: Northern Data Group |
|

