Материалы по тегу: nvidia
|
23.12.2025 [13:40], Руслан Авдеев
NVIDIA намерена начать поставки в Китай ИИ-чипов H200 к середине февраляКомпания NVIDIA заявила китайским клиентам о намерении начать поставки ИИ-ускорителей NVIDIA H200 в середине февраля 2026 года, сообщает Reuters со ссылкой на источники, знакомые с ситуацией. Утверждается, что первые заказы из КНР выполнят из уже имеющихся запасов. По данным источников, объём поставок составит 5–10 тыс. ИИ-модулей, т.е. приблизительно 40–80 тыс. ИИ-ускорителей H200. Также китайским покупателям якобы объявили о планах нарастить производственные мощности для выпуска таких чипов, заказы на них начнут принимать во II квартале 2026 года. Источники свидетельствуют, что пока Пекин не одобрил ни одной закупки, а расписание поставок может зависеть от решений китайского правительства. В заявлении для Reuters NVIDIA сообщила, что постоянно контролирует цепочку поставок и лицензионные продажи ускорителей H200 в КНР никак не повлияют на продажи клиентам в США. Это первые официальные партии поставок чипов H200 в Китай после того, как Вашингтон разрешил подобные продажи с пошлиной 25 %. На днях сообщалось, что администрацией США начата межведомственная проверка заявок на получение разрешений на продажу H200 в КНР. H200 не относится к самым передовым моделям. При этом чип входит в линейку Hopper, которая до сих пор широко востребована на рынке ИИ, хотя на смену ей пришли Blackwell и уже готовятся Rubin. Это затрудняет организацию поставок H200, поскольку ресурсы выделены уже на другие решения. 
Источник изображения: NVIDIA Решение США во многом принято из опасений, вызванных активными действиями Китая по развитию собственного производства ИИ-полупроводников. Поскольку китайские ИИ-ускорители пока значительно слабее американских вариантов, разрешение на продажи H200 может замедлить развитие ИИ-технологий КНР. Недавно появилась информация, что китайские власти провели ряд экстренных совещаний в начале декабря для обсуждения политики в отношении закупок и производства полупроводников в новых условиях. Рассматривается возможность разрешения поставок в Китай, но при этом не исключается обязательная покупка китайскими клиентами нескольких чипов «домашнего» производства на каждый купленный H200. Для китайских IT-гигантов вроде Alibaba Group и ByteDance, выразивших заинтересованность в покупке H200, вариант будет значительно более привлекательным, чем поставки «ослабленных» для Китая ускорителей H20, продававшихся ранее. Модель H200 приблизительно в шесть раз более производительна и искусственному ухудшению не подвергалась.
22.12.2025 [14:36], Руслан Авдеев
Японское неооблако Datasection предоставит китайской Tencent десятки тысяч подсанкционных чипов NVIDIA B200/B300Хотя некоторые международные игроки стремятся ограничить доступ Китая к передовым американским чипам, в дата-центре близ Осаки (Япония) современные ИИ-ускорители используются единственным клиентом — китайской Tencent, сообщает The Financial Times. Чипы NVIDIA B200 принадлежат японской Datasection, недавно переключившейся с маркетинговых решений на управление ИИ ЦОД. С тех пор компания заключила соглашение с клиентом на сумму $1 млрд, а тот получил доступ к значительной части из 15 тыс. ИИ-ускорителей NVIDIA Blackwell. По словам источников издания, этим клиентом и является Tencent. Сделка позволяет китайскому техногиганту использовать довольно сложную, но вполне легальную стратегию для доступа к передовым ИИ-чипам на фоне санкций США. В результате сделки Datasection превратилась в одну из крупнейших «неооблачных» компаний в Азии. По словам представителя компании, менее полугода назад для обеспечения работы ИИ-моделей было достаточно 5 тыс. чипов B200, а теперь требуется минимум 10 тыс. Правила, которые вводили при прошлом президенте США, должны были закрыть юридическую лазейку, позволяющую китайским компаниями получать доступ к передовым ИИ-ускорителями в ЦОД и облаках за пределами КНР, но в мае новый президент отменил их. Теперь же одобрена поставка в Китай чипов NVIDIA H200, поэтому компании вроде Tencent, возможно, снова смогут строить собственные ИИ ЦОД на более современных ускорителях. Однако по словам Bernstein Research, использование зарубежных облаков вместо покупки чипов может оказаться для китайских технологических групп даже более привлекательным вариантом. 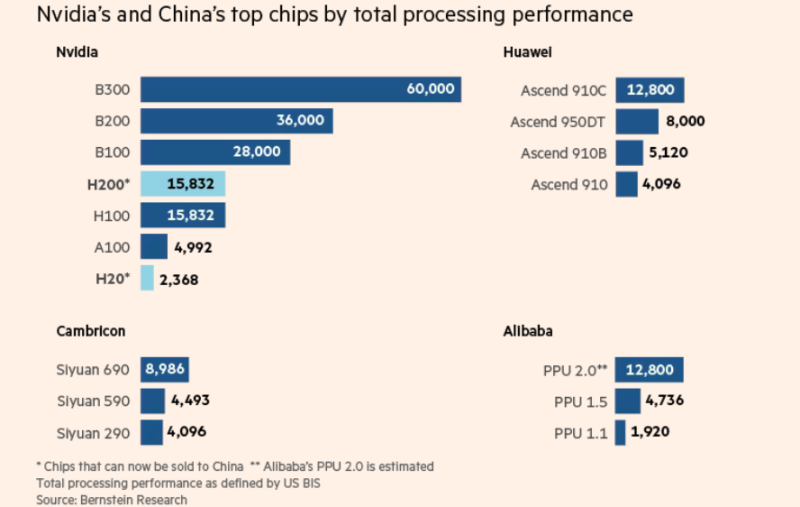
Источник изображения: The Financial Times Datasection намерена создать ИИ ЦОД с более 100 тыс. ускорителей NVIDIA. По некоторым данным, первые 15 тыс. чипов в основном зарезервированы для Tencent на три года. Впрочем, в самой Datasection вероятную сделку не комментируют, упоминая лишь о «крупном клиенте». По данным The Financial Times, в июле Datasection заключила контракт с «одним из крупнейших в мире поставщиков облачных услугу» на $406 млн, согласившись заплатить $272 млн за 5 тыс. B200 для объекта в Осаке, а уже в августе оборудование прибыло в Японию. Вскоре партнёры заключили ещё одну сделку, на этот раз на $800 млн с расчётом на второй ИИ ЦОД в Сиднее, где будут развёрнуты десятки тысяч B300. В декабре Datasection объявила, что первые 10 тыс. ускорителей B300 для сиднейского дата-центра обойдутся в $521 млн. В компании утверждают, что речь идёт о первом в мире ИИ-кластере гиперскейл-уровня на базе B300. По данным источников, мощности австралийского ЦОД тоже будут использоваться преимущественно Tencent. Контракт с «крупным клиентом» заключён на пять лет, с возможным продлением на два года. По сведениям источников, посредником (для защиты данных) выступает токийская NowNaw. Datasection может расторгнуть соглашения, если США вновь изменят правила работы с КНР. 
Источник изображения: Datasection Все участники сделки уверяют, что соблюдают все применимые законы, в том числе относительно использования зарубежных облачных сервисов. По словам Datasection, Министерство торговли Соединённых Штатов и NVIDIA одобрили использование ей ИИ-ускорителей. Кроме того, принимаются меры, чтобы компания не попадала под действие некоторых японских законов, в том числе о валютном контроле. В будущем Datasection рассчитывает выйти на рынок высокодоходных облачных сервисов, в частности, она нацелена на экспансию в Европу. В прошлом году она привлекла в совет директоров испанского и американского политиков. В Datasection уверены, что даже если ограничения США на экспорт ослабят, дав китайскому бизнесу доступ к самым передовым чипам NVIDIA, ей это не помешает. Как считают представители неооблачной компании, спрос на вычислительные мощности так высок, что новых клиентов найти будет несложно. В худшем случае деятельность придётся остановить «скажем, на неделю». В 2025 году акции Datasection выросли почти на 185 %, хотя и успели упасть с лета на фоне опасений по поводу избыточных инвестиций в ИИ и торговых атак на ценные бумаги со стороны участников фондового рынка.
19.12.2025 [18:35], Сергей Карасёв
NVIDIA выпустила ускоритель RTX Pro 5000 Blackwell с 72 Гбайт памяти для рабочих станцийКомпания NVIDIA сообщила о доступности ускорителя RTX Pro 5000 Blackwell с 72 Гбайт памяти GDDR7 (ECC) для мощных рабочих станций, ориентированных на ИИ-задачи, включая «тонкую» настройку больших языковых моделей (LLM). Новинка является собратом ранее выпущенной версии RTX Pro 5000 Blackwell с 48 Гбайт GDDR7, по сравнению с которой объём памяти увеличился в полтора раза. Оба ускорителя построены на чипе Blackwell с 14 080 ядрами CUDA. Задействованы тензорные ядра пятого поколения и RT-ядра четвёртого поколения. Говорится об использовании 512-бит шины памяти; пропускная способность — 1344 Гбайт/с. Новинка выполнена в виде двухслотовой карты расширения полной высоты с интерфейсом PCIe 5.0 x16. 
Источник изображения: NVIDIA Выпущенный ускоритель располагает четырьмя разъёмами DisplayPort 2.1b. Возможен одновременный вывод изображения на несколько мониторов в следующих конфигурациях: четыре с разрешением до 4096 × 2160 пикселей и частотой обновления 120 Гц, четыре с разрешением 5120 × 2880 точек и частотой 60 Гц или два с разрешением 7680 × 4320 пикселей и частотой 60 Гц. Заявлена поддержка DirectX 12, Shader Model 6.6, OpenGL 4.63, Vulkan 1.33, а также CUDA 12.8, OpenCL 3.0 и DirectCompute. Заявленная ИИ-производительность достигает 2142 TOPS. Карта оборудована 16-контактным разъёмом дополнительного питания. Энергопотребление находится на уровне 300 Вт. Применено активное охлаждение с вентилятором. Ускоритель RTX Pro 5000 Blackwell с 72 Гбайт памяти предлагается через партнёрские каналы, включая Ingram Micro, Leadtek, Unisplendour и xFusion.
17.12.2025 [10:11], Сергей Карасёв
SK hynix и NVIDIA объединили усилия для создания сверхбыстрых SSD для ИИ-системКомпании SK hynix и NVIDIA, по сообщениям сетевых источников, занимаются совместной разработкой сверхбыстрых SSD, которые, как ожидается, помогут устранить узкие места современных ИИ-платформ. Проект получил название Storage Next: он предполагает создание чипов флеш-памяти NAND и сопутствующих контроллеров следующего поколения. По информации ресурса ZDNet, первые прототипы изделий партнёры намерены представить к концу следующего года. Речь идёт о накопителях с интерфейсом PCIe 6.0, которые смогут демонстрировать показатель IOPS (операций ввода/вывода в секунду) на уровне 25 млн. Более того, в 2027-м, как ожидается, будет выпущено устройство с величиной IOPS до 100 млн. Для сравнения, современные высокопроизводительные SSD корпоративного класса имеют значение IOPS на уровне 2–3 млн. 
Источник изображения: SK hynix В основу накопителей Storage Next лягут наработки SK hynix в области памяти AI-N (AI-NAND), оптимизированной для ИИ. В частности, упоминаются решения AI-N P: предполагается, что такие устройства будут выполнены в форм-факторе EDSFF E3.x. Они получат контроллер, предназначенный для выполнения как обычных рабочих нагрузок, так и с высоким показателем IOPS. По мере того, как ИИ-платформы переходят от обучения к инференсу, возможностей памяти HBM с высокой пропускной способностью оказывается недостаточно: наблюдается разрыв между объёмом и производительностью HBM и вычислительными возможностями ИИ-ускорителей на базе GPU. Цель проекта Storage Next состоит в том, чтобы решить эту проблему путём использования инноваций в области NAND. По сравнению с современными SSD накопители Storage Next смогут демонстрировать увеличение показателя IOPS в 30–50 раз. Кроме того, SK hynix разрабатывает память AI DRAM (AI-D) для ИИ-платформ: эти изделия, как предполагается, помогут справиться с нехваткой памяти.
16.12.2025 [01:05], Владимир Мироненко
NVIDIA купила разработчика Slurm, пообещав не забрасывать open source решениеNVIDIA объявила о приобретении SchedMD — ведущего разработчика открытой системы оркестрации Slurm для высокопроизводительных вычислений (HPC) и ИИ. Финансовые условия сделки не разглашаются. Созданная SchedMD система Slurm обеспечивает планирование и управление большими вычислительными задачами в ЦОД, позволяя уменьшить количество ошибок, ускорить вывод продукции на рынок и снизить затраты. Как сообщает NVIDIA, сделка поможет укрепить экосистему ПО с открытым исходным кодом и стимулировать инновации в области ИИ для исследователей, разработчиков и предприятий. Компания отметила, что рабочие нагрузки HPC и ИИ включают сложные вычисления с выполнением параллельных задач на кластерах, для чего требуется организация очередей, планирование и распределение вычислительных ресурсов. По мере увеличения размеров и мощности кластеров HPC и ИИ задача эффективного использования ресурсов становится критически важной. 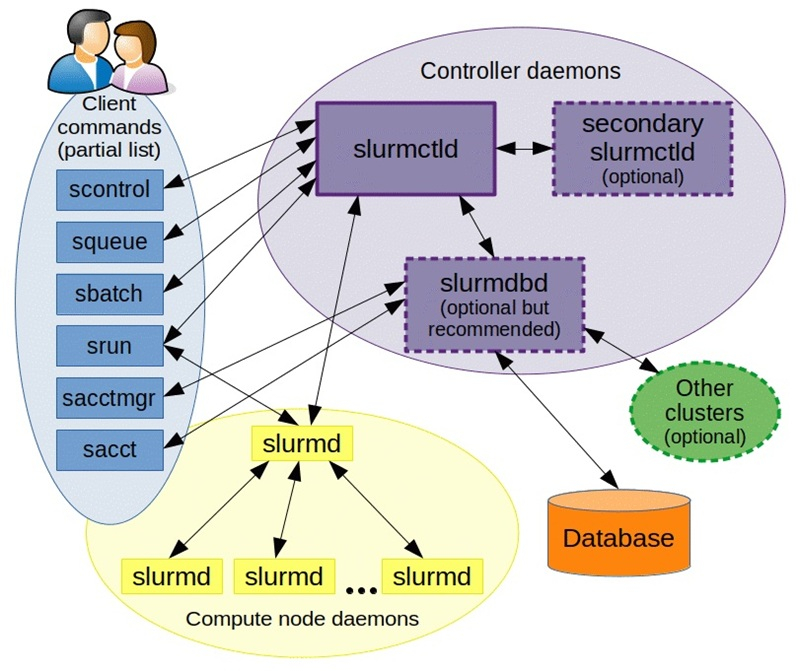
Источник изображения: SchedMD SchedMD была основана в 2010 году разработчиками ПО Slurm Моррисом «Мо» Джеттом (Morris «Moe» Jette) и Дэнни Оублом (Danny Auble) в Ливерморе (Livermore, штат Калифорния). В настоящее время персонал компании насчитывает 40 человек. Сейчас Slurm — ведущий менеджер рабочих нагрузок и планировщик заданий по масштабируемости, пропускной способности и управлению сложными политиками, который используется более чем в половине из десяти и ста лучших систем в списке TOP500 суперкомпьютеров. NVIDIA сообщила, что сотрудничает с SchedMD более десяти лет и продолжит инвестировать в разработку Slurm, чтобы сохранить его поизиции как ведущего планировщика с открытым исходным кодом для HPC и ИИ. NVIDIA обеспечит доступ SchedMD к новым системам, чтобы клиенты могли запускать гетерогенные кластеры с использованием последних инноваций Slurm. Также NVIDIA пообещала и далее поддерживать open source ПО, вкладываться в разработку Slurm и обучение. NVIDIA делает ставку на технологии с открытым исходным кодом и наращивает инвестиции в ИИ-экосистему, чтобы противостоять растущей конкуренции, отметил ресурс Reuters. В конце прошлого года NVIDIA завершила приобретение стартапа Run:ai, разрабатывающего ПО для управления рабочими нагрузками ИИ и оркестрации на базе Kubernetes. А в 2022 году она купила фирму Bright Computing, ещё одного известного разработчика инструментов оркестрации и управления кластерами.
14.12.2025 [14:40], Руслан Авдеев
NVIDIA рассматривает увеличение выпуска ускорителей H200 из-за большого спроса на них в КитаеПо данным отраслевых источников, NVIDIA сообщила клиентам в Китае, что уже рассматрвиает возможность нарастить производство ИИ-ускорителей H200. По данным Reuters, объёмы заказов уже превышают доступный сегодня уровень производства. Ранее сообщалось, что руководство США рассматривает разрешение поставок H200 в КНР, а в минувший вторник президент страны объявил о том, что этот вопрос решён положительно. При этом власти будут получать комиссию в 25 % с продаж ускорителей в Китай. Спрос на современные ИИ-чипы в Китае столь высок, что NVIDIA допускает расширение их производства. В самой NVIDIA прокомментировали слух, заявив, что управляют цепочкой поставок таким образом, чтобы продажи авторизованным клиентам в Китае не повлияли на способность поставлять продукцию покупателям из США. Пока чипов H200 производится очень немного, поскольку NVIDIA сосредоточилась на выпуске передовых ускорителей Blackwell, а также будущего семейства — Rubin. Крупные китайские компании, включая Alibaba и ByteDance уже связались с NVIDIA на днях по поводу закупок H200 и, как утверждается, заинтересованы в размещении крупных заказов. Впрочем, пока неопределённость сохраняется, поскольку закупки H200 не одобрили в самом Китае. По словам источников, в прошлую среду китайские чиновники провели ряд экстренных совещаний для обсуждения вопроса и принятия решения о том, стоит ли в принципе разрешать поставки H200. 
Источник изображения: bruce mars/unsplash.com H200 поступили в массовое производство в 2024 году и являются самыми быстрыми ускорителями NVIDIA поколения Hopper. Высокий спрос на H200 в Китае обусловлен тем, что это самый производительный чип, который будет доступен китайскому бизнесу на данный момент. Он приблизительно вшестеро производительнее «урезанной» модели H20. Решение США принято на фоне стремления Китая активно развивать собственную полупроводниковую индустрию для ИИ-проектов. Поскольку продукция, сопоставимая с H200 в продаже пока отсутствует, в Китае уже возникли опасения, что выход американских чипов на локальный рынок может затормозить развитие местной отрасли. По мнению некоторых китайских экспертов, вычислительная мощность H200 в два-три раза выше, чем у самых передовых чипов из КНР — многие поставщики облачных услуг и корпоративные клиенты активно размещают заказы и лоббируют ослабление ограничений. При этом отмечается, что спрос в Китае в любом случае превышает возможности местного производства. По сведениям источников, в ходе экстренных совещаний предлагалось разрешить покупать каждый ускоритель H200 только при условии покупки определённого количества чипов китайского производства. При этом у китайских IT-гигантов теоретически остаётся запасной вариант — размещение H200 в собственных ЦОД за пределами Китая. Они и так обучают модели в дата-центрах вне КНР, пусть и не своих. Для NVIDIA же наращивать производственные мощности тоже непросто, поскольку она занята наладкой массового производства Rubin и конкурирует за мощности TSMC с компаниями уровня Google.
12.12.2025 [17:21], Руслан Авдеев
Никаких закладок: NVIDIA анонсировала новое ПО для мониторинга и продления жизни ИИ-ускорителей в ЦОД
dcim
nvidia
open source
software
амортизация
ии
мониторинг
охлаждение
цод
электропитание
энергоэффективность
NVIDIA разрабатывает новое открытое ПО, благодаря которому операторы ЦОД смогут получать более подробные данные о тепловом состоянии и иных параметрах работы ИИ-ускорителей. Предполагается, что это поможет решать проблемы, связанные с перегревом оборудования и его надёжностью, увеличив его срок службы и производительность. NVIDIA отдельно подчёркивает, что телеметрия собирается только в режиме чтения без слежки за оборудованием, а в ПО нет «аварийных выключателей» и бэкдоров. Да и в целом использование новинки опционально. ПО обеспечивает операторам ЦОД доступ к мониторингу потребления энергии, загрузки, пропускной способности памяти и других ключевых параметров в масштабах всего парка ускорителей. Это помогает выявлять на ранних стадиях риски и проблемные компоненты и условия работы, отслеживать использование ИИ-ускорителей, их конфигурации и ошибки. Детализированная телеметрия становится всё важнее для планирования и управления масштабными инфраструктурами, говорит компания. ПО позволит:

Источник изображения: NVIDIA Такой мониторинг особенно важен на фоне недавнего отчёта учёных Принстонского университета, в котором сообщается, что интенсивные тепловые и электрические нагрузки способны сократить срок службы ИИ-чипов до года-двух, хотя обычно предполагается, что они способны стабильно проработать до трёх лет. Современные ускорители потребляют 700 Вт и более, а высокоплотные системы — от 6 кВт. Из-за этого формируются зоны перегрева, происходят колебания энергопотребления и растёт риск деградации интерконнектов в высокоплотных стойках. Телеметрия, позволяющая оценить потребление энергии в реальном времени, состояние интерконнектов, систем воздушного охлаждения и др. позволяет перейти от реактивного мониторинга к проактивному проектированию. Рабочие нагрузки можно размещать с учётом теплового режима, быстрее внедрять СЖО или гибридные системы охлаждения, оптимизировать работу сетей с уменьшением тепловыделения. Также ПО может помочь операторам ЦОД выявлять скрытые ошибки, вызванные несоответствием версий прошивки или драйверов. Благодаря этому можно повысить общую стабильность парка ускорителей. Кроме того, без задержек передаваемые данные об ошибках и состоянии компонентов могут значительно сократить среднее время восстановления работы и упростить анализ причин сбоев. Соответствующие данные могут влиять на решения о тратах на инфраструктуру и стратегию её развития на уровне предприятия. 
Источник изображения: NVIDIA Как заявляют в Gartner, современный ИИ представляет собой «энергоёмкого и сильно нагревающегося монстра», разрушающего экономику и принципы работы ЦОД. В результате, предприятиям нужны специальные инструменты мониторинга и управления для того, чтобы ситуация не вышла из-под контроля. В ближайшие годы использование подобных решений, вероятно, станет обязательным. Кроме того, прозрачность на уровне всего парка оборудования становится необходимой для обоснования роста бюджетов на ИИ-инфраструктуру. По словам экспертов, такие программные инструменты позволяют оптимизировать капитальные и операционные затраты на ЦОД и инфраструктуру, запланированные на ближайшие годы. «Каждый доллар и каждый ватт» должны быть учтены при эффективном использовании ресурсов.
12.12.2025 [15:43], Владимир Мироненко
В МФТИ изучили альтернативы ИИ-ускорителям NVIDIA — китайские Moore Threads и MetaX оказались неплохиВ связи с прекращением поставок в Россию ускорителей NVIDIA, ограничениями на загрузку драйверов и отсутствием их техподдержки Институт искусственного интеллекта МФТИ провёл исследование рынка альтернативных ускорителей, включая продукты китайских производителей Moore Threads и MetaX с целью оценки их способности обеспечить полный цикл работы современных ИИ-моделей. Исследование включало анализ архитектурных особенностей ускорителей, драйверов, совместимости с фреймворками и тестирование под нагрузкой при работе с LLM, инференсом, задачами компьютерного зрения и распределённых вычислений. Проведена оценка скорости и воспроизводимости вычислений, устойчивости при росте нагрузки и стабильности поведения моделей на разных типах ускорителей. Исследователи пришли к выводу, что ускорители Moore Threads s4000 и MetaX C500 могут применяться в широком спектре сценариев, обеспечивая стабильный запуск популярных LLM, корректную работу современных фреймворков, предсказуемую производительность и устойчивость работы при длительных нагрузках. В отдельных типах вычислений альтернативные ускорители не уступали или даже обгоняли NVIDIA A100. Особое внимание было уделено возможности работы альтернативных ускорителей в составе вычислительных узлов и кластеров. Разработанный стек ПО позволяет эффективно распределять ресурсы, объединять мощности для работы с крупными моделями и создавать кластерные конфигурации, сообщили в МФТИ. В МФТИ планируют и дальше тестировать новые поколения ускорителей, расширив перечень поддерживаемых моделей, а также намерены подготовить отраслевые рекомендации для создания автономной ИИ-инфраструктуры. 
Источник изображения: Walter Frehner / Unsplash На основе исследования в МФТИ был создан Центр компетенций по решениям, не зависящим от NVIDIA, который объединяет лучшие инженерные практики, методики тестирования, оптимизированные конфигурации и опыт взаимодействия с поставщиками. Он будет оказывать помощь компаниям в подборе оборудования, проведении нагрузочного тестирования под конкретные задачи, настройке вычислительных цепочек, а также может сопровождать платформы в процессе эксплуатации.
10.12.2025 [18:14], Руслан Авдеев
Omdia: капитальные затраты на ЦОД вырастут до $1,6 трлн к 2030 году — если раньше не лопнет ИИ-пузырьСогласно прогнозам аналитиков Omdia, капитальные затраты на дата-центры будут расти на 17 % ежегодно до 2030 года. В итоге они достигнут $1,6 трлн, а ограничения в цепочках поставок вызовут рост цен на компоненты вычислительной инфраструктуры. В своём последнем обзоре рынка облаков и дата-центров (Cloud and Data Center Market Snapshot) компания сообщила, что инвестиции в ИИ-инфраструктуру продолжают расти быстрыми темпами, хотя разговоры о том, что на рынке формируется готовый лопнуть пузырь, не утихают. Впрочем, уровень внедрения ИИ пока остаётся относительно низким, в будущем ожидается, что вырастет как количество пользователей, так и средняя интенсивность использования ими ИИ-инструментов. В то же время ИИ-модели становятся всё более громоздкими и используют больше вычислительных ресурсов для инференса. В результате операторы наращивают производительность инфраструктуры. Вместе с этим растёт потребление электроэнергии, увеличивается энергетическая плотность серверов, стоек и самих дата-центров. Окупятся ли все эти гигантские инвестиции, никто пока точно сказать не может. Bain & Company полагает, что к 2030 году доходы отрасли должны вырасти до $2 трлн/год, чтоб окупить прогнозируемый уровень инвестиций. Окупаемость затрат под вопросом как для поставщиков услуг, так и для пользователей. Как сообщает The Register, на днях представители ряда технологических компаний заявили, что ИИ — не пузырь, не находя аналогий с крахом «доткомов». 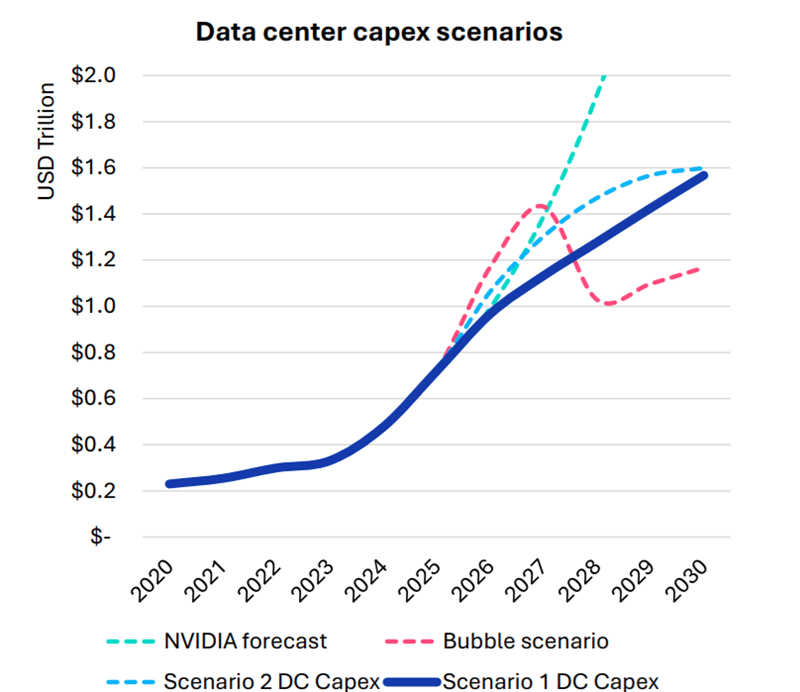
Источник изображения: Omdia Omdia рассмотрела четыре сценария развития рынка:
Рост расходов на ЦОД обусловлен и увеличением поставок серверов, цикл обновления которых начался в 2025 году и продолжится 6–8 кварталов. Ранее Omdia сообщала, что крупные операторы ЦОД, в основном гиперскейлеры, откладывали замену серверов разных типов. Новые серверы способны заменить оборудование сразу нескольких поколений. При этом ожидается, что к 2030 году серверы с Blackwell будут ещё в ходу. Рост инвестиций ожидается во всех сегментах, включая ниши неооблаков (CoreWeave, Nebius, xAI и др.), колокейшн-провайдеров первого и второго уровней, гиперскейлеров и корпоративных пользователей. 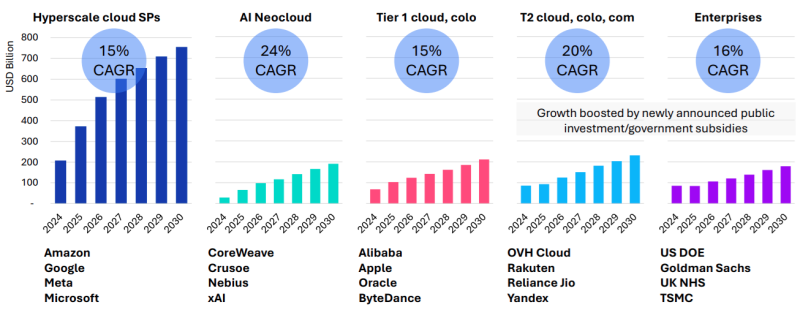
Источник изображения: Omdia Ограничения в цепочках поставок ведут к росту стоимости некоторых компонентов, например, памяти. По данным источников The Register, это, вероятно, приведёт к росту цен на серверы на 15 %. Omdia утверждает, что новые ЦОД, вероятно, будут проектироваться не так, как сегодня — спрос на ИИ приводит к быстрой смене внутренней инфраструктуры. Это касается всех компонентов, от микросхем до серверов и стоек, систем терморегуляции, распределения энергии, резервного питания и др. В докладе имеются рекомендации на будущее как для вендоров, так и для пользователей. Кроме того, Omdia прогнозирует, что, несмотря на спекуляции относительно ИИ-пузыря, быстрое внедрение ИИ-технологий и инвестиции продолжатся, а мощности по-прежнему будут в дефиците.
09.12.2025 [22:15], Владимир Мироненко
Дефицит добрался и до лазеров: NVIDIA зарезервировала чуть ли не всю продукцию ключевых поставщиковВ настоящее время высокоскоростные оптические соединения играют ключевую роль в обеспечении производительности и масштабируемости ИИ ЦОД, особенно по мере того, как они превращаются в крупные кластеры, сообщается в исследовании TrendForce. Согласно её прогнозу, в 2025 году мировые поставки оптических трансиверов с поддержкой скорости 800 Гбит/с и выше составят 24 млн шт. с последующим ростом в 2,6 раза почти до 63 млн шт. в 2026 году. Аналитики отметили, что резкий рост спроса на оптические трансиверы привёл к значительному дефициту в сфере производства источников лазерного излучения на глобальном рынке. NVIDIA в рамках стратегии развития зарезервировала крупные объёмы продукции у ключевых поставщиков EML-лазеров, что привело к увеличению сроков поставки — не ранее 2027 года. В связи с этим производители оптических модулей и провайдеры облачных услуг (CSP) вынуждены заниматься поиском вторичных поставщиков и альтернативных решений, что ведёт к изменениям в отрасли, отметили в TrendForce. Помимо лазеров VCSEL, используемых в линиях связи малой и средней дальности, оптические модули для линий средней и большой дальности в основном включают два типа лазеров: EML, отличающиеся большой дальностью действия и целостностью сигнала, и лазеры непрерывного излучения (CW). В EML-лазерах все ключевые функции объединены на одном кристалле, что делает их чрезвычайно сложными и трудоёмкими в изготовлении. Их производством занимается всего лишь несколько поставщиков, таких как Lumentum, Coherent (Finisar), Mitsubishi, Sumitomo и Broadcom. Впрочем, о дефиците Mitsubishi предупреждала более года назад. А Broadcom, вероятно, будет отдавать приоритет собственным продуктам. 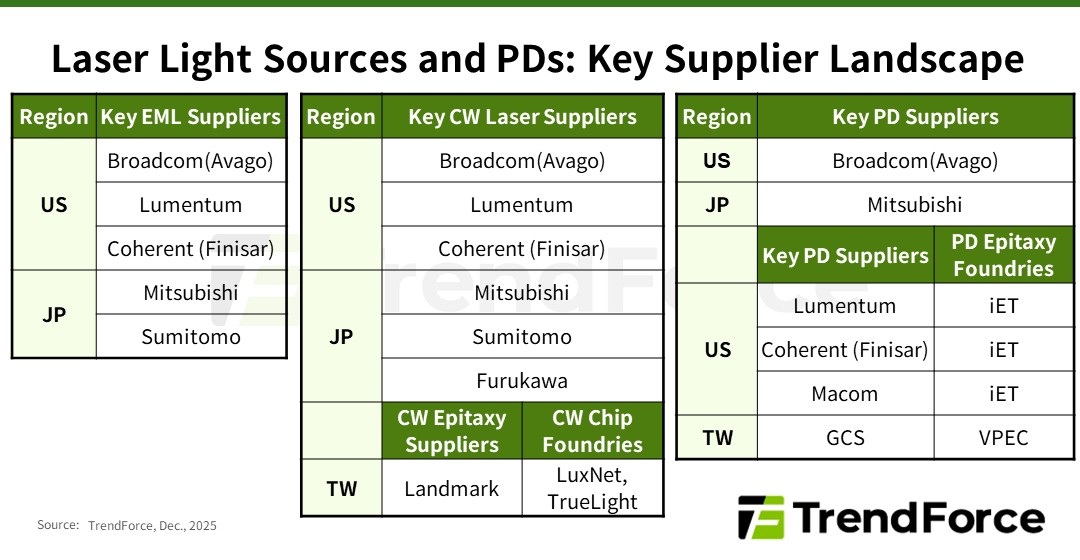
Источник изображения: TrendForce EML-лазеры играют важную роль в масштабировании вычислительных кластеров с увеличением расстояния между ЦОД. Планы NVIDIA по развитию кремниевой фотоники и интегрированной оптики (CPO) реализуются медленнее, чем предполагалось, что приводит к постоянной зависимости от подключаемых модулей для расширения кластеров. Чтобы обеспечить стабильную работу в этом направлении, NVIDIA заранее зарезервировала значительную часть мощностей по производству EML-лазеров, что отразилось на доступности компонента для остальных компаний. CW-лазеры, используемые в паре с кремниевыми фотонными чипами, отличаются более простой конструкцией, обусловленной отсутствием встроенной возможности модуляции, что упрощает производство и расширяет круг поставщиков. В результате CW-лазеры в сочетании с кремниевой фотоникой стали основным альтернативным решением для провайдеров облачных услуг в связи с дефицитом EML-лазеров. Впрочем, здесь тоже наблюдаются проблемы. Производство CW-лазеров сталкивается с растущими ограничениями, обусловленными рядом факторов: длительные сроки поставки оборудования ограничивают расширение производства, а строгие стандарты надёжности требуют трудоемких тестов. В результате многие поставщики передают эти этапы на аутсорсинг, что создает дополнительные узкие места в производственной цепочке. Ввиду того, что экосистема производства CW-лазеров приближается к дефициту мощностей, поставщики вынуждены форсировать усилия по расширению производства. 
Источник изображения: NVIDIA Помимо лазерных передатчиков, для изготовления оптических модулей требуются высокоскоростные фотодиоды (PD) для приёма сигналов. Ведущие поставщики, такие как Coherent, MACOM, Broadcom и Lumentum, выпускают фотодиоды PD 200G с поддержкой скорости передачи данных 200 Гбит/с на канал. Фотодиоды производятся на эпитаксиальных пластинах из фосфида индия (InP), аналогично EML- и CW-лазерам. Поскольку производители лазеров стремятся расширить мощности для эпитаксии, многие из них передают заказы на InP-эпитаксию (процесс выращивания эпитаксиальных листов из фосфида индия на подложке) специализированным заводам, таким как IntelliEPI и VPEC, сообщили в TrendForce. TrendForce прогнозирует, что спрос, обусловленный ИИ, приведёт не только к сокращению предложения модулей памяти, но и отразится на экосистеме производства лазеров в целом. Стремление NVIDIA обеспечить необходимые объёмы поставок EML-лазеров привело к ускорению перехода к CW-решениям и кремниевой фотоники среди других производителей. В то же время общеотраслевая гонка за производственными мощностями меняет роли в цепочке поставок и стимулирует рост производства у поставщиков технологий эпитаксии и обработки полупроводниковых соединений, говорят аналитики. |
|

