Материалы по тегу: nvidia
|
08.01.2026 [14:43], Руслан Авдеев
Valor Equity Partners привлекла $5,4 млрд на покупку ускорителей NVIDIA для xAI — часть денег снова дала сама NVIDIAИнвестиционная группа Valor Equity Partners привлекла $5,4 млрд для покупки ИИ-ускорителей NVIDIA в интересах xAI. Инвестиционная компания основала дочернюю компанию Valor Compute Infrastructure (VCI), которая будет покупать и сдавать в аренду ИИ-инфраструктуру для стартапа Илона Маска (Elon Musk), сообщает Datacenter Dynamics. Предусмотрена закупка ускорителей NVIDIA GB200, причём часть денег на них дала сама NVIDIA. Фонды, управляемые инвестиционной компанией Apollo Capital, внесут вклад в общие инвестиции в объёме $3,5 млрд. Сделка предусматривает «тройную чистую аренду» (triple net lease) — это происходит на фоне недавних новостей о привлечении xAI $20 млрд в раунде финансирования серии E, одним из инвесторов также является Valor. NVIDIA тоже вложила средства в этом раунде, но в виде акций. Средства будут потрачены на строительство дата-центров. Создание VCI является новым шагом в партнёрстве Valor и xAI. Фонд обеспечивает инвесторам возможность вкладывать средства в критическую вычислительную ИИ-инфраструктуру с ежеквартальными выплатами. При этом инвестор будет владеть и самими вычислительными активами. Тройная чистая аренда означает, что xAI будет платить не только за аренду ускорителей, но и оплачивать любые расходы, связанные с их использованием. 
Источник изображения: NVIDIA В числе институциональных спонсоров VCI названа и NVIDIA. Это означает, что лидер рынка ускорителей подписал очередное циклическое финансовое соглашение — средства NVIDIA будут потрачены на покупку её же продуктов. Такие соглашения NVIDIA также заключала с компаниями, включая OpenAI и неооблачных партнёров — это подогревает опасения, что рынок ИИ по сути является самоподдерживающимся пузырём. В результате NVIDIA пришлось даже выпустить памятку для финансовых аналитиков, в которой убеждает тех, что всё в порядке и ни о каком очередном пузыре не может быть и речи.
08.01.2026 [13:35], Руслан Авдеев
«Дата-центр в чемодане»: Odinn представила переносной нано-ЦОД Omnia с четырьмя NVIDIA H200Громоздкость оборудования для дата-центров не позволяет легко переносить его с места на место, но у стартапа Odinn своё видение этой проблемы. Компания представила на днях своеобразный «нано-ЦОД» с четырьмя ИИ-ускорителями NVIDIA H200 (NVL), сообщает The Register. По данным компании, 35-кг платформа Odinn Omnia помимом ускорителей включает до двух CPU AMD EPYC 9965 (Turin), до 6 Тбайт DDR5 ECC, 1 Пбайт NVMe SSD, 400GbE-адаптер, встроенный 23,8″ 4K-дисплей и откидную клавиатуру. Шасси снабжено рукоятками для переноски. Фактически речь идёт об устройстве размером с чемодан, хотя Omnia не позиционируется как портативный ПК или даже мобильная рабочая станция. «Чемоданный» ЦОД предлагается в нескольких конфигурациях, включая AI, Creator, Search и X. Использовать их можно для критически важных периферийных вычислений, военных миссий, симуляций корпоративного уровня, работы с киноматериалами буквально в любой локации. Кроме того, Omnia могут использоваться как модули для создания более масштабных структур, объединённых в кластеры Infinity Racks. 
Источник изображения: Odinn Конечно, всё это обойдётся недёшево — один NVIDIA H200 стоит около $32 тыс. Можно предположить, что немногие компании позволят сотрудникам разгуливать с такими дорогими «чемоданами», которые довольно легко похитить. Впрочем, Odinn пока ничего не сообщает о цене устройств. Внешне, со встроенным дисплеем и откидной клавиатурой, Omnia отчасти напоминает портативные ПК далёкого прошлого. 
Источник изображения: Odinn Если же встроенные дисплей и клавиатура не нужны, то есть решения попроще и в буквально смысле полегче. Так, 25-кг модульная платформа GigaIO Gryf объединяет в одном шасси-чемодане до пяти узлов различной конфигурации (плюс один обязательный модуль питания), в том числе с H200 NVL. Gryf тоже можно объединять в мини-кластеры.
07.01.2026 [12:23], Руслан Авдеев
xAI привлекла $20 млрд в раунде финансирования, возглавленном NVIDIA и CiscoИИ-стартап xAI, основанный и поддерживаемой Илоном Маском (Elon Musk), объявил о том, что привлёк $20 млрд в ходе раунда позднего финансирования. В раунде серии E приняли участие NVIDIA и Cisco, сообщает Silicon Angle. К ним присоединились Valor Equity Partners, Stepstone Group, Fidelity Management & Research, Qatar Investment Authority, MGX, Baron Capital Group и другие инвестиционные структуры. В ноябре сообщалось, что следующий раунд финансирования позволит оценить компанию в $230 млрд. Компания намерена использовать капитал для расширения своей ИИ-инфраструктуры. Она обучает флагманские ИИ-модели серии Grok с использованием суперкомпьютеров Colossus. Недавно Маск анонсировал, что компания приобрела новый дата-центр для увеличения вычислительной мощности. По слухам, ЦОД находится недалеко от электростанции, которую xAI строит, чтобы удовлетворить растущие потребности Colossus в энергии. По данным Маска, запланированные доработки Colossus увеличат энергопотребление до 2 ГВт. Маск уже похвалил недавно представленные ускорители NVIDIA Rubin. Судя по новостям об участии NVIDIA в финансировании xAI, высока вероятность, что новые чипы будут активно применяться для расширения проекта Colossus. Помимо строительства новой инфраструктуры, xAI будет использовать собранные средства для запуска новых продуктов. Компания объявила, что речь идёт о разработках как для пользовательского, так и для корпоративного рынков. 
Источник изображения: xAI В декабре 2025 года xAI представила корпоративную версию Grok, предусматривающую интеграцию Google Drive. Сотрудники компаний могут использовать чат-бот для поиска материалов, хранящихся в облачном хранилище. Тариф Grok Enterprise также предусматривает доступ к инструментам по обеспечению кибербезопасности. Использующие его организации могут задавать настройки доступа и использовать собственные ключи шифрования для защиты бизнес-данных. В ближайшие месяцы xAI намерена обеспечить интеграцию со сторонними сервисами помимо Google Drive. Компания также добавит и новые функции, включая возможность создания кастомных ИИ-агентов. Обновления должны выйти одновременно с премьерой флагманской ИИ-модели Grok 5. Компания сообщила, что её обучение уже началось. Последний раунд финансирования состоялся всего через неделю после того, как OpenAI, по слухам, получила $22,5 млрд от ключевого инвестора SoftBank Group. Средства поступили в рамках раунда финансирования на $40 млрд, объявленного ещё в марте 2025 года. Как и xAI, компания OpenAI активно строит инфраструктуру ИИ ЦОД для поддержки обучения ИИ-моделей нового поколения.
07.01.2026 [07:01], Владимир Мироненко
Lenovo показала концепт ИИ-хаба Lenovo Personal AI Hub Concept для обработки ИИ-приложений в экосистеме устройств пользователяLenovo продемонстрировала на выставке CES 2026 концепт ИИ-хаба Lenovo Personal AI Hub Concept, получивший кодовое название Project Kubit. Как сообщает компания, персональный ИИ-хаб — периферийное облачное устройство для поддержки ИИ-приложений в экосистеме потребителя, включающей ПК, смартфоны, носимые устройства и решения для умного дома. В частности, Lenovo Personal AI Hub собирает данные с различных платформ, предоставляя пользователю доступ к новым уровням аналитики и ИИ-приложениям, обеспечивая высокопроизводительные персональные вычисления с использованием ИИ. 
Источник изображения: Lenovo Lenovo Personal AI Hub Concept представляет собой систему из двух рабочих станций Lenovo ThinkStation PGX, соединённых с помощью адаптера NVIDIA ConnectX-7. Lenovo ThinkStation PGX использует для вычислений суперчип NVIDIA GB10, включающий ускоритель с архитектурой Blackwell и 20-ядерный Arm-процессор. Объём унифицированной оперативной памяти LPDDR5X-9400 составляет 128 Гбайт, ёмкость накопителя NVMe M.2 составляет до 4 Тбайт. Станция обеспечивает производительность 1 PFLOPS в вычислениях FP4. Система из двух станций поддерживает работу с ИИ-моделями размером до 405 млрд параметров. ИИ-хаб Lenovo Personal AI Hub поддерживает управление как с помощью касаний сенсорного экрана, так и с использованием голосовых команд.
06.01.2026 [14:28], Владимир Мироненко
NVIDIA объявила о запуске платформы Vera Rubin NVL72NVIDIA объявила о запуске платформы следующего поколения Rubin, которая приходит на смену Blackwell Ultra. Компания отметила, что платформа Rubin объединяет сразу пять инноваций, включая новейшие поколения интерконнекта NVIDIA NVLink, Transformer Engine, Confidential Computing и RAS Engine, а также процессор NVIDIA Vera. Примечательно, что NVIDIA снова решила вернуться к именованию на основе количества суперчипов (NVL72), а не ускорителей (NVL144), как обещала в прошлом году. Созданная с использованием экстремального совместного проектирования на аппаратном и программном уровнях, NVIDIA Vera Rubin обеспечивает десятикратное снижение стоимости токенов для инференса и четырёхкратное сокращение количества ускорителей для обучения моделей MoE по сравнению с платформой NVIDIA Blackwell. Коммутационные системы NVIDIA Spectrum-X Ethernet Photonics обеспечивают пятикратное повышение энергоэффективности и времени безотказной работы. 
Источник изображений: NVIDIA Платформа Rubin построена на шести чипах — Arm-процессоре Vera, ускорителе Rubin, коммутаторе NVLink 6, адаптере ConnectX-9 SuperNIC, DPU BlueField-4 и Ethernet-коммутаторе NVIDIA Spectrum-6. Ускорители Rubin поначалу будут доступны в двух форматах. В первом случае — в составе стоечной платформы DGX Vera Rubin NVL72, которая объединяет 72 ускорителя Rubin и 36 процессоров Vera, NVLink 6, ConnectX-9 SuperNIC и BlueField-4. Также ускорители Rubin будут доступны в составе платформы DGX/HGX Rubin NVL8 на базе x86-процессоров. Обе платформы будут поддерживаться кластерами NVIDIA DGX SuperPod, сообщил ресурс CRN.  Как отметила NVIDIA, разработанный для агентного мышления, процессор NVIDIA Vera является самым энергоэффективным процессором для крупномасштабных ИИ-фабрик. Он оснащён 88 кастомными Armv9.2-ядрами Olympus с 176 потоками с новой технологией пространственной многопоточности NVIDIA, 1,5 Тбайт системной памяти SOCAMM LPDDR5x (1,2 Тбайт/с), возможностями конфиденциальных вычислений и быстрым интерконнектом NVLink-C2C (1,8 Тбайт/с в дуплексе). 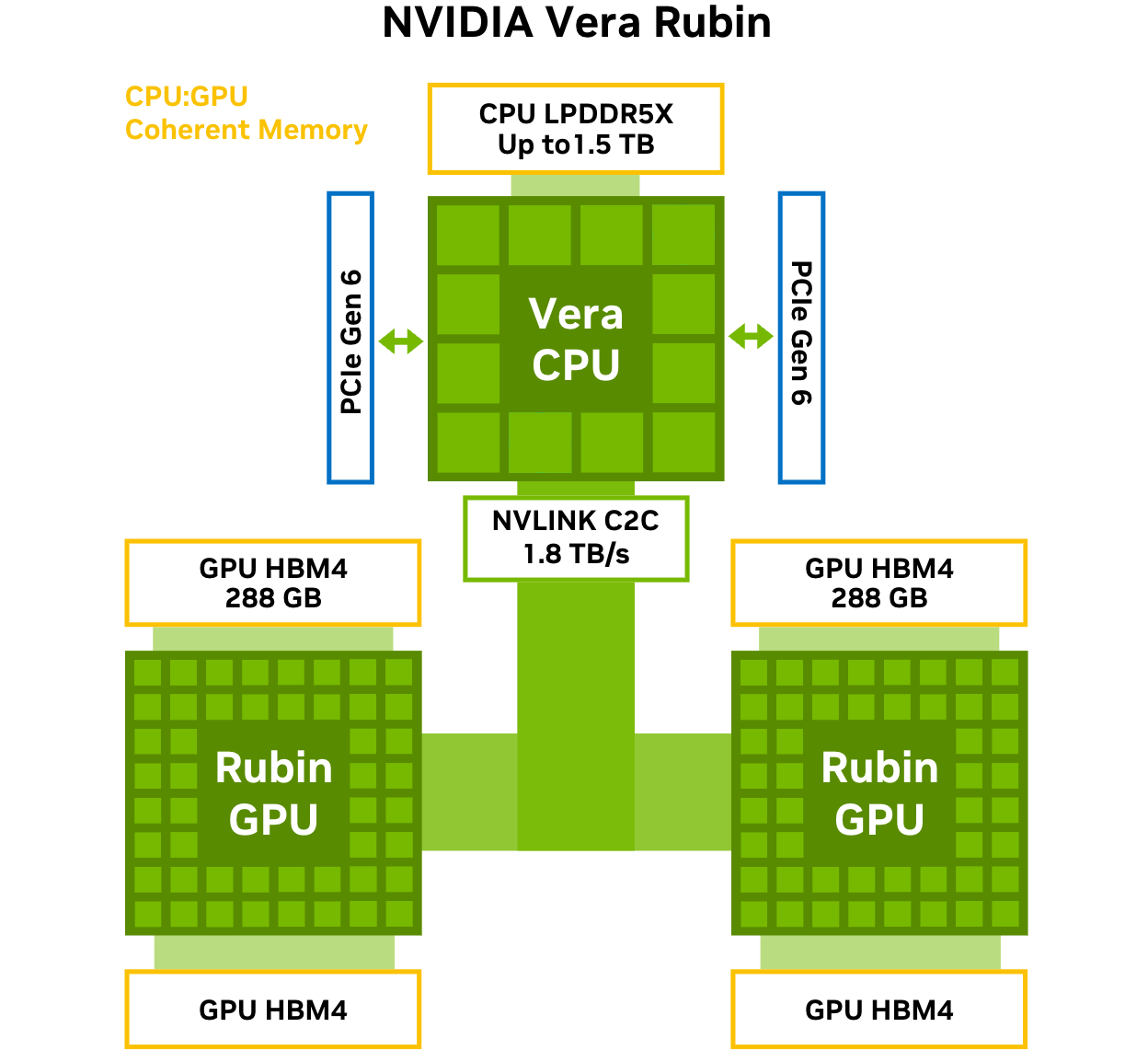 NVIDIA Rubin с аппаратным адаптивным сжатием данных обеспечивает до 50 Пфлопс (NVFP4) для инференса, что в пять раз быстрее, чем Blackwell. Он также обеспечивает до 35 Пфлопс (NVFP4) в режиме, что в 3,5 раза быстрее, чем его предшественник. Пропускная способность 288 Гбайт HBM4 составляет 22 Тбайт/с, что в 2,8 раза быстрее предшественника, а пропускная способность NVLink на один ускоритель вдвое выше — 3,6 Тбайт/с (в дуплексе).  NVIDIA также сообщила, что Vera Rubin NVL72 обладает 54 Тбайт памяти LPDDR5x, что в 2,5 раза больше, чем у Blackwell, и 20,7 Тбайт памяти HBM4, что на 50 % больше, чем у предшественника. Агрегированная пропускная способность HBM4 достигает 1,6 Пбайт/с, что в 2,8 раза больше, а скорость интерконнекта составляет 260 Тбайт/с, что вдвое больше, чем у платформы Blackwell NVL72, и «больше, чем пропускная способность всего интернета». Ожидаемый уровень энергопотребления составит от 190 до 230 кВт на стойку.  Компания отметила, что Vera Rubin NVL72 — первая стоечная платформа, обеспечивающая конфиденциальные вычисления, которая поддерживает безопасность данных на уровне доменов CPU, GPU и NVLink. Коммутатор NVLink 6 с жидкостным охлаждением оснащён 400G-блоками SerDes, обеспечивает пропускную способность 3,6 Тбайт/с на каждый GPU для связи между всеми GPU, общую пропускную способность 28,8 Тбайт/с и 14,4 Тфлопс внутрисетевых вычислений в формате FP8.  Хотя NVIDIA заявила, что Rubin находится в «полномасштабном производстве», аналогичные продукты от партнёров появятся только во II половине этого года. Среди ведущих мировых ИИ-лабораторий, поставщиков облачных услуг, производителей компьютеров и стартапов, которые, как ожидается, внедрят Rubin, компания назвала Amazon Web Services (AWS), Anthropic, Black Forest Labs, Cisco, Cohere, CoreWeave, Cursor, Dell Technologies, Google, Harvey, HPE, Lambda, Lenovo, Meta✴, Microsoft, Mistral AI, Nebius, Nscale, OpenAI, OpenEvidence, Oracle Cloud Infrastructure (OCI), Perplexity, Runway, Supermicro, Thinking Machines Lab и xAI.  ИИ-лаборатории, включая Anthropic, Black Forest, Cohere, Cursor, Harvey, Meta✴, Mistral AI, OpenAI, OpenEvidence, Perplexity, Runway, Thinking Machines Lab и xAI, рассматривают платформу NVIDIA Rubin для обучения более крупных и мощных моделей, а также для обслуживания мультимодальных систем с длинным контекстом с меньшей задержкой и стоимостью по сравнению предыдущими поколениями ускорителей. Партнёры по инфраструктурному ПО и хранению данных AIC, Canonical, Cloudian, DDN, Dell, HPE, Hitachi Vantara, IBM, NetApp, Nutanix, Pure Storage, Supermicro, SUSE, VAST Data и WEKA работают с NVIDIA над разработкой платформ следующего поколения для инфраструктуры Rubin.  В связи с тем, что рабочие нагрузки агентного ИИ генерируют огромные объёмы контекстных данных, NVIDIA также представляла новую платформу хранения контекста инференса NVIDIA Inference Context Memory Storage Platform — новый класс инфраструктуры хранения, разработанной для масштабирования контекста инференса.  Сообщается, что платформа, работающая на базе BlueField-4, обеспечивает эффективное совместное использование и повторное применение данных KV-кеша в рамках всей ИИ-инфраструктуры, повышая скорость отклика и пропускную способность, а также обеспечивая предсказуемое и энергоэффективное масштабирование агентного ИИ. Дион Харрис (Dion Harris), старший директор NVIDIA по высокопроизводительным вычислениям и решениям для ИИ-инфраструктуры, сообщил, что по сравнению с традиционными сетевыми хранилищами для данных контекста инференса, новая платформа обеспечивает до пяти раз больше токенов в секунду, в пять раз лучшую производительность на доллар и в пять раз лучшую энергоэффективность.
31.12.2025 [18:30], Владимир Мироненко
Потребность китайских компаний в H200 в несколько раз выше запасов NVIDIAПосле того, как США дали NVIDIA добро на поставку ИИ-ускорителей H200 в Китай, выяснилось, что потребности ключевого для компании рынка в этих чипах гораздо выше имеющихся у неё запасов. По данным источников Reuters, компания уже обратилась к TSMC с запросом на увеличение производства H200. Однако существует определённый риск, что правительство КНР может не дать разрешение на ввоз в страну H200, хотя и официального заявления по поводу запрета пока тоже не поступало. Как сообщают источники, сейчас у NVIDIA насчитывается на складах порядка 700 тыс. ускорителей H200, включая 100 тыс. суперчипов GH200, в то время как поступило заказов от китайских технологических компаний более чем на 2 млн ускорителей. Газета South China Morning Post сообщила со ссылкой на источники, что только ByteDance планирует потратить в 2026 году около ¥100 млрд (около $14,3 млрд) на чипы NVIDIA, по сравнению с примерно ¥85 млрд (около $12,2 млрд) в 2025 году, если, опять же, Китай разрешит поставки H200. Власти КНР пока не определились с тем, стоит ли разрешать ли импорт H200, опасаясь, что доступ к передовым зарубежным чипам может замедлить развитие местной полупроводниковой промышленности в ИИ-сфере. Один из рассматриваемых вариантов предполагает, что могут в качестве условия поставки потребовать комплектовать закупки H200 определённым количеством чипов китайского производства. 
Источник изображения: Clemens van Lay / Unsplash Ранее сообщалось, что первая партия NVIDIA H200 может поступить в Китай в середине февраля. По данным источников Reuters, NVIDIA уже решила, какие варианты H200 она будет предлагать китайским клиентам, установив цену около $27 тыс./шт.. При этом цена будет зависеть от объёма закупок и конкретных договорённостей с клиентами. Сообщается, что восьмичиповый модуль с H200 будет стоить около ¥1,5 млн (около $214 тыс.), что немного дороже, чем поставлявшийся до введения запрета Китаем по цене ¥1,2 млн (около $172 тыс.) модуль с ускорителями H20. Однако, с учётом того, что H200 обеспечивает примерно в шесть раз большую производительность, чем H20, китайские интернет-компании считают цену привлекательной, отметили источники. Также это дешевле цены серого рынка примерно на 15 %. Хотя потенциальный заказ означает значительное расширение производства H200, в комментарии для Reuters в NVIDIA сообщили, что «лицензионные продажи H200 авторизованным клиентам в Китае никак не повлияют на способность компании поставлять продукцию клиентам в США». «Китай — это высококонкурентный рынок с быстрорастущими местными поставщиками чипов. Блокировка всего экспорта из США подорвала нашу национальную и экономическую безопасность и лишь пошла на пользу иностранным конкурентам», — отметили в компании.
30.12.2025 [12:49], Руслан Авдеев
NVIDIA потратила $5 млрд на акции Intel, но уже заработала на этом $2,5 млрдСентябрьская сделка NVIDIA с Intel, в ходе которой первая потратила на акции своего конкурента $5 млрд в сентябре, уже принесла ей ощутимую выгоду — пакет купленных акций Intel теперь оценивается в $7,58 млрд, сообщает The Register. В сентябре глава NVIDIA Дженсен Хуанг (Jensen Huang) и руководитель Intel Лип-Бу Тан (Lip-Bu Tan) заключили соглашение, в рамках которого NVIDIA зафиксировала цену покупки акций Intel по $23,28 за ценную бумагу. Сделка привлекла пристальное внимание Федеральной торговой комиссии (FTC) США, заинтересовавшейся, не противоречит ли покупка NVIDIA доли конкурента в объёме приблизительно 4 % антимонопольному законодательству Соединённых Штатов. 18 декабря сделке дали «зелёный свет». Согласно документам, поданным Intel американским регуляторам, сделка по покупке 214 млн простых акций завершена 26 декабря. В понедельник торги акциями компании закрылись на отметке $36,68. 
Источник изображения: Brock Wegner/unsplash.com По условиям сделки, компании будут вместе разрабатывать несколько поколений чипов для ЦОД и ПК, увеличивая долю на всех профильных рынках, от ПК до крупных корпоративных клиентов. Ранее уже сообщалось, что партнёры обеспечат объединение архитектур NVIDIA и Intel с использованием NVIDIA NVLink. Так, ожидается появление x86-процессоров, специально разработанных для NVIDIA. Также Intel будет способна создавать x86-чипсеты (SoC) с интегрированными GPU NVIDIA RTX. Соглашение Intel и NVIDIA похоже на то, что вызвало недовольство регуляторов ещё в 2021 году, когда NVIDIA попыталась целиком купить британского разработчика Arm за $40 млрд. На тот момент FTC заявила, что сделка обеспечила бы крупному игроку на рынке чипов контроль над одним из своих конкурентов — это могло бы стать крупнейшей сделкой в полупроводниковой сфере за всю историю. Подчёркивалось, что такая покупка обеспечила бы одному из крупнейших производителей чипов контроль над разработками конкурентов, поэтому компания получила бы «средства и стимулы» для «удушения» технологий следующего поколения Тогда FTC подала в суд, и через два месяца NVIDIA приняла решение отказаться от сделки. На тот момент FTC отметила, что речь идёт о «редкой внесудебной победе» для ведомства.
29.12.2025 [23:06], Владимир Мироненко
Ни один сотрудник Groq не останется внакладе в результате сделки с NVIDIAЗаключение NVIDIA соглашения с Groq, своим конкурентом в области производства ИИ-ускорителей, вызвало вопросы, что означает эта сделка для самих компаний, а также их сотрудников. Структура сделки, оцениваемой, по данным источников Axios, в $20 млрд, призвана свести к минимуму возможность столкновения с обвинениями в нарушении антимонопольного законодательства со стороны регуляторов, поскольку формально нигде на бумаге не зафиксирован факт покупки. Подобного рода сделки заключались на ИИ-рынке и ранее. Согласно условиям соглашения, Groq продолжит действовать как самостоятельная компания под руководством нового гендиректора Саймона Эдвардса (Simon Edwards), ранее исполнявшего обязанности финансового директора. А нынешний генеральный директор Groq Джонатан Росс (Jonathan Ross) и президент Санни Мадра (Sunny Madra) присоединятся к NVIDIA. Оставшиеся сотрудники, по-видимому, будут ответственны за обслуживание ускорителей на Ближнем Востоке и в Европе. Согласно данным источников Axios, большинство акционеров Groq получат выплаты на акцию, привязанные к оценке рыночной стоимости стартапа в $20 млрд. Около 85 % назначенной суммы будет выплачено авансом, еще 10 % — в середине 2026 года, а оставшаяся часть — в конце 2026 года. 
Источник изображения: Groq Также сообщается, что около 90 % персонала Groq перейдёт в NVIDIA. Всем им причитается выплата наличными за все полностью принадлежащие (vested) акции в стартапе. Акции, которые будут им принадлежать после выполнения определённых условий (unvested), будут оплачены согласно оценке стартапа в $20 млрд акциями NVIDIA, которые перейдут в их полную собственность согласно графику. Около 50 человек, перешедших в NVIDIA, получат выплату за все пакеты акций наличными в ускоренном порядке. Остальные сотрудники Groq также получат выплаты за имеющиеся акции стартапа, а также пакет, обеспечивающий экономические стимулы участия в деятельности стартапа. Всем сотрудникам Groq, проработавшим менее года, будет отменен «период ожидания» (vesting period) для закреплённых за ними акций. Благодаря этому ценные бумаги перейдут в их полное владение раньше срока, и они смогут их продать при желании. Также сообщается, что с момента своего основания в 2016 году Groq привлёк около $3,3 млрд венчурного капитала. В число его инвесторов вошли Social Capital, Disruptive, BlackRock, Neuberger Berman, Deutsche Telekom Capital Partners, Samsung, 1789 Capital, Cisco, D1, Cleo Capital, Altimeter, Firestreak Ventures, Conversion Capital и Modi Venture. Кроме того, известно, что Groq ни разу не проводил вторичный тендер, то есть у него не было случаев, когда не были достигнуты намеченные цели по финансированию.
25.12.2025 [14:48], Руслан Авдеев
В 2026 году ByteDance увеличит инвестиции в ИИ-инфраструктуру до $23 млрдВладеющая TikTok китайская ByteDance рассчитывает нарастить свои инвестиции в ИИ-проекты, чтобы не отстать от американских конкурентов — компания намерена увеличить капитальные затраты до ¥160 млрд ($23 млрд) в 2026 году, сообщает The Financial Times. Для сравнения, в 2025 году инвестиции компании в ИИ-инфраструктуру составили порядка ¥150 млрд. ¥85 млрд планируется потратить на закупку передовых ИИ-ускорителей, хотя вопрос с доступом к чипам NVIDIA пока не решён окончательно. Сама NVIDIA рассчитывает начать поставки H200 уже в феврале следующего года. ByteDance — один из крупнейших китайских строителей ИИ-инфраструктуры, компания стремится стать одним из мировых лидеров в этой сфере. Впрочем, в сравнении с инвестициями в ИИ ЦОД, на которые ушли уже сотни миллиардов долларов, расходы ByteDance относительно невелики. Пока китайские компании не могут приобретать передовые чипы NVIDIA из-за ограничений со стороны американских властей. В результате они стремятся к программным оптимизациям и к обучению ИИ-моделей за рубежом. При этом аренда обычно учитывается не как капитальные затраты, а как операционные расходы. 
Источник изображения: ByteDance В декабре 2025 года США отменили запрет на продажу ускорителей NVIDIA H200 некоторым клиентам в Китай. Такие чипы менее производительны, чем самые современные модели. Кроме того, определённые круги в Пекине и Вашингтоне выступают против продаж по разным причинам. Так или иначе, источники свидетельствуют, что в случае разрешения поставок ByteDance и другие китайские технологические группы будут охотно покупать H200 в больших масштабах. Так, ByteDance якобы намерена закупить 20 тыс. H200 в рамках «пробного» заказа, стоимость каждого ускорителя может составить порядка $20 тыс. Если гигант получит неограниченные квоты для закупки, он может значительно нарастить капитальные затраты на 2026 год. По словам экспертов, в сравнении с другими китайскими техногигантами ByteDance выигрывает потому, что её акции не торгуются публично, т.ч. она лучше защищена от инвестиционных манипуляций и способна играть «вдолгую» на рынке ИИ. Хотя, по данным The Financial Times, производительность открытых ИИ-моделей ByteDance Doubao отстаёт от Alibaba Qwen и DeepSeek, компания доминирует в сфере ИИ-приложений, рассчитанных на потребителей. Так, по статистике QuestMobile, чат-бот Doubao обогнал DeepSeek и уже стал самым популярным в КНР по количеству ежемесячных активных пользователей. Компания активно конкурирует и с Alibaba, продвигая облачный сервис Volcano Engine для бизнеса. По информации Goldman Sachs, предложенные ByteDance ИИ-продукты обеспечили себе статус самых востребованных в Китае. По статистике, в октябре ByteDance отметила существенный рост спроса — более 30 трлн токенов в день. Для сравнения, у Google тот же показатель составил 43 трлн.
25.12.2025 [02:15], Игорь Осколков
NVIDIA купит за $20 млрд активы разработчика ИИ-ускорителей Groq — это самая дорогая покупка в истории компанииNVIDIA приобретёт активы Groq, своего конкурента в области ИИ-ускорителей, за $20 млрд, передаёт CNBC. Сама Groq заявила, что «заключила неисключительное лицензионное соглашение с NVIDIA на технологии инференса» и что основатель и генеральный директор Groq Джонатан Росс (Jonathan Ross), а также президент компании Санни Мадра (Sunny Madra) и другие высокопоставленные сотрудники «присоединятся к NVIDIA, чтобы помочь продвижению и масштабированию лицензированной технологии». При этом Groq продолжит свою деятельность как независимая компания под руководством Саймона Эдвардса (Simon Edwards). Финансовый директор Nvidia Колетт Кресс (Colette Kress) отказалась комментировать сделку. По-видимому, речь фактически идёт о поглощении Groq, а столь необычная форма сделки выбрана, по примеру других, в попытке снизить внимание к ней регулирующих органов. Стоимость сделки официально не называется, однако Алекс Дэвис (Alex Davis), глава Disruptive, которая инвестировала в Groq более $500 млн, называет сумму в $20 млрд, причём «живыми» деньгами. Дэвис сообщил CNBC, что NVIDIA получит все активы Groq, за исключением её облачного бизнеса. Groq заявила, что «GroqCloud продолжит работать без перебоев». В электронном письме сотрудникам, полученном CNBC, глава NVIDIA Дженсен Хуанг (Jensen Huang) заявил, что сделка расширит возможности NVIDIA: «Мы планируем интегрировать ускорители Groq в архитектуру NVIDIA AI Factory, расширив платформу для обслуживания ещё более широкого спектра задач инференса и рабочих нагрузок в реальном времени». Хуанг добавил: «Хотя мы пополняем наши ряды талантливыми сотрудниками и лицензируем интеллектуальную собственность Groq, мы не приобретаем Groq как компанию». 
Источник изображения: Groq Эта сделка является крупнейшей покупкой NVIDIA за всю историю. До этого самой крупной сделкой была покупка Mellanox почти за $7 млрд в 2019 году. В конце октября у NVIDIA было $60,6 млрд наличных средств и краткосрочных инвестиций, что на $13,3 млрд больше, чем в начале 2023 года. По схожей с Groq схеме была организована и сделка c Enfabrica, в рамках которой NVIDIA заплатила $900 млн деньгами и акциями за лицензирование технологий и переход главы Enfabrica Рочана Санкара (Rochan Sankar) и других ключевых в NVIDIA. Всего три месяца назад Groq, основанная в 2016 году разработчиками ИИ-ускорителей Google TPU, привлекла $750 млн при оценке примерно в $6,9 млрд. Раунд возглавила Disruptive, к которой присоединились Blackrock, Neuberger Berman, Deutsche Telekom Capital Partners, Samsung, Cisco, D1, Altimeter, 1789 Capital и Infinitum. Повлияло ли на решение NVIDIA слухи о намерении Intel купить разработчика ИИ-ускорителей для инференса SambaNova, который наряду с Cerebras является одним из немногих стартапов, способных составить хоть какую-то серьёзную конкуренцию NVIDIA, не уточняется. Сама Groq планировала достичь выручки в $500 млн в этом году. По словам Дэвиса, компания не планировала продажу, когда к ней обратилась NVIDIA. В сентябре NVIDIA объявила о намерении вложить $5 млрд в Intel, а также инвестировать до $100 млрд в OpenAI. Впрочем, последняя сделка носит циклический характер и пока далеко не продвинулась. |
|

