Материалы по тегу: nvidia
|
20.01.2026 [10:02], Владимир Мироненко
FP64 у вас ненастоящий: AMD сомневается в эффективности эмуляции научных расчётов на тензорных ядрах NVIDIAВместо создания специализированных чипов для аппаратных FP64-вычислений NVIDIA использует эмуляцию для повышения производительности HPC на ИИ-ускорителях, пишет The Register. Компания отказалась от развития FP64-блоков в поколении Blackwell Ultra, а в новейших ускорителях Rubin пиковая заявленная производительность векторных FP64-вычислений составляет 33 Тфлопс, тогда как у H100, вышедшего четыре года назад, она была равна 34 Тфлопс, а у Blackwell — около 40 Тфлопс. Если включить программную эмуляцию в библиотеках CUDA от NVIDIA, ускоритель, как утверждается, может достичь производительности до 200 Тфлопс в матричных FP64-вычислениях. Впрочем, и Blackwell с эмуляций способен выдать в этом случае до 150 Тфлопс, тогда как у Hopper были «честные» 67 Тфлопс. «В ходе многочисленных исследований с партнёрами и собственных внутренних изысканий мы обнаружили, что точность, достигаемая с помощью эмуляции, как минимум не уступает точности, получаемой от аппаратных тензорных ядер», — сообщил ресурсу The Register Дэн Эрнст (Dan Ernst), старший директор по суперкомпьютерным продуктам NVIDIA. В свою очередь, в AMD считают, что это утверждение справедливо не для всех сценариев. «В некоторых бенчмарках она показывает довольно хорошие результаты, но в реальных физических научных симуляциях это не очевидно», — говорит Николас Малайя (Nicholas Malaya), научный сотрудник AMD. Он выразил мнение, что, хотя эмуляция FP64, безусловно, заслуживает дальнейших исследований и экспериментов, такое решение ещё не готово к широкому применению. AMD и сама изучает возможность программной эмуляции FP64 на Instinct MI355X, чтобы определить области её возможного применения. 
Источник изображения: Hilda Trinidad / Unsplash Хотя чипы всё чаще используют типы данных с более низкой точностью, FP64 остаётся золотым стандартом для научных вычислений, и на то есть веские причины — FP64 не имеет себе равных по динамическому диапазону. Современные же LLM обучаются с использованием FP8-вычислений, а компактные типы данных MXFP8/MXFP4 или NVFP4 позволяют получить достаточный для ИИ диапазон значений. Это хорошее решение для нечёткой математики больших языковых моделей, но это не замена FP64 для HPC. ИИ-нагрузки обладают высокой устойчивостью к ошибкам, а HPC-задачи требуют высокой точности. AMD указала на то, что эмуляция FP64 у NVIDIA не совсем соответствует стандарту IEEE. Алгоритмы NVIDIA не учитывают такие понятия, как положительные и отрицательные нули, ошибки NaN (Not a Number) и ошибки infinite number (бесконечное число). Из-за этого небольшие ошибки в промежуточных вычислениях, используемых для эмуляции более высокой точности, могут привести к искажениям, способным повлиять на точность конечного результата, пояснил Малайя. По его словам, целесообразность использования эмуляции FP64 зависит от конкретного приложения. Эмуляция FP64 лучше всего работает для хорошо обусловленных проблем, где малые изменения «на входе» приводят к малым же изменениям в конечном результате. Ярким примером такой задачи является бенчмарк Linpack (HPL). «Но если вы посмотрите на материаловедение, коды для расчёта процессов горения, системы ленточых матриц и т.п., то увидите, что это гораздо менее обусловленные системы, и внезапно всё начинает давать сбои», — сказал он. 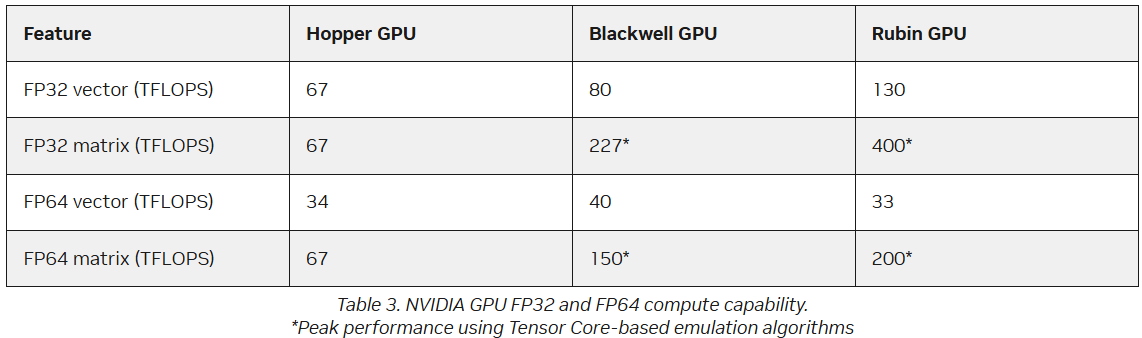
Источник изображения: NVIDIA Точность можно повысить, увеличив количество используемых операций, однако после определённого предела никаких преимуществ от эмуляции уже не будет. Вдобавок все эти операции требуют память. «У нас есть данные, которые показывают, что алгоритму Озаки требуется примерно вдвое больше памяти для эмуляции матриц FP64», — сказал Малайя. Поэтому компания готовит специализированные ускорители MI430X c повышенной FP64/FP32-производительностью, но, как опасаются учёные, она может оказаться не слишком в них заинтересована, поскольку ИИ-ускорители приносят больше денег. Эрнст утверждает, что для большинства специалистов в области HPC неполное соответствие стандарту IEEE не представляет большой проблемы. Всё во многом зависит от конкретного приложения. Тем не менее, NVIDIA разработала дополнительные алгоритмы для обнаружения и смягчения указанных выше ошибок и неэффективных операций эмуляции. Эрнст также признал, что использование памяти при эмуляции может быть несколько выше, но подчеркнул, что эти накладные расходы относятся к расчётам, а не к самому приложению — в большинстве случаев речь идёт о матрицах размером не более нескольких Гбайт. Впрочем, всё это не меняет того, что эмуляция полезна только для подмножества HPC-задач, которые полагаются на операции умножения плотных матриц (DGEMM). По словам Малайи, для 60–70 % рабочих нагрузок HPC эмуляция дает незначительные преимущества или ничего не меняет. «По нашим оценкам, подавляющее большинство реальных рабочих нагрузок HPC полагаются на векторное умножение (FMA), а не на DGEMM», — сказал он, отметив, что это действительно нишевый сегмент, хотя и не крошечная доля рынка. Для рабочих нагрузок, интенсивно использующих векторы, таких как вычислительная гидродинамика (CFD), ускорители Rubin по-прежнему будут полагаться на медленные векторные FP64-блоки.
17.01.2026 [13:07], Сергей Карасёв
Huawei сравняла долю с NVIDIA на китайском рынке ИИ-чиповРезкий рост спроса на вычислительные мощности, геополитическое давление и ограничения в цепочках поставок приводят к трансформации китайского рынка ИИ-ускорителей. По оценкам Bernstein, которые приводит ресурс DigiTimes, позиции в КНР резко укрепила компания Huawei, которой удалось сравнять свою долю с NVIDIA. Объём сектора ИИ-чипов в Китае по итогам 2025 года достиг приблизительно $20,4 млрд. Примерно по 40 % от этой суммы, или по $8,16 млрд, приходится на Huawei и NVIDIA. Годом ранее доля Huawei составляла одну треть от показателей NVIDIA. Таким образом, сообща эти две компании контролируют около 80 % китайского рынка ИИ-ускорителей, что эквивалентно $16,32 млрд. Если не рассматривать двух лидеров, рынок ИИ-чипов в КНР является сильно фрагментированным. Так, Hygon и Cambricon занимают примерно по 4 %, при этом Hygon выигрывает от совместимости с архитектурой x86. T-Head Semiconductor, принадлежащая Alibaba, и Kunlunxin (Baidu) занимают по 3 % отрасли. Ещё около 2 % приходится на AMD. Все прочие игроки вместе взятые, включая Zixiao (Tencent), MetaX, Moore Threads и Biren, контролируют менее 4 % отрасли. 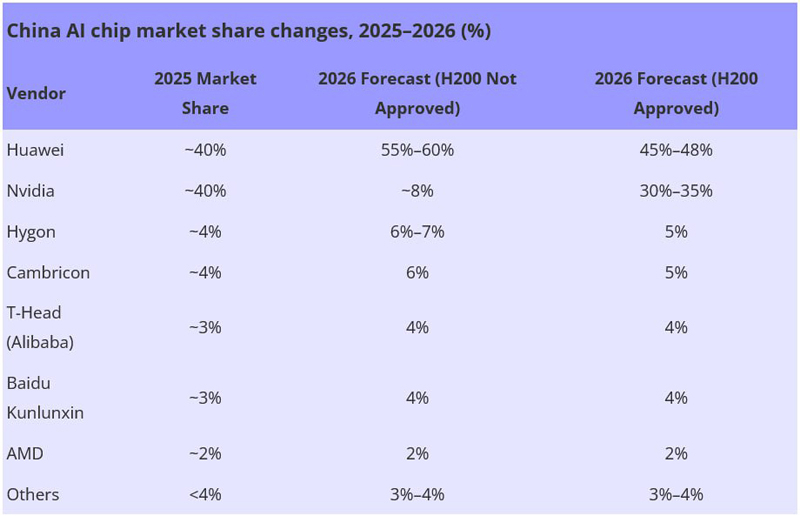
Источник изображения: DigiTimes Аналитики полагают, что в случае запрета поставок в Китай ускорителей H200 доля NVIDIA на местном рынке в 2026 году может сократиться до 8 %. При этом Huawei, как ожидается, укрепит позиции до 55–60 %. Если же поставки H200 в КНР будут одобрены, NVIDIA может занять 30–35 %, а Huawei — 45–48 %. При этом суммарная доля всех прочих игроков будет колебаться в пределах 24–27 %. По словам самой NVIDIA, запрет поставок ускорителей в Китай был большой ошибкой. В целом, считают эксперты, китайский рынок ИИ-чипов в период с 2023-го по 2028 году будет демонстрировать среднегодовой темп роста в сложных процентах (CAGR) на уровне 50 %. В результате, его объём за этот период увеличится с $11 млрд до $88 млрд.
16.01.2026 [23:14], Владимир Мироненко
NVIDIA добралась до RISC-V: NVLink Fusion пропишется в серверных процессорах SiFiveПродолжая укреплять свои лидирующие позиции на ИИ-рынке NVIDIA не скрывает стремления построить целую экосистему ИИ-платформ с привязкой к своим решениям. Эти усилия активизировались в прошлом году с анонсом технологии NVLink Fusion, позволяющей использовать NVLink в чипах сторонних производителей. Как стало известно, вслед за Arm, Intel и AWS, присоединившимися к программе в прошлом году, экосистема NVLink Fusion пополнилась первым поставщиком чипов на архитектуре RISC-V — компанией SiFive, которая объявила о планах внедрить NVLink Fusion в свои будущие чипы для ЦОД. SiFive отметила, что ИИ-вычисления вступают в фазу, когда архитектурная гибкость и энергоэффективность так же важны, как и пиковая пропускная способность. Нагрузки обучения и инференса растут быстрее, чем энергетические бюджеты, заставляя операторов ЦОД переосмыслить способы подключения и управления CPU, GPU и ASIC. Теперь производительность на Вт и эффективность перемещения данных стали первостепенными ограничениями при проектировании чипов. Патрик Литтл (Patrick Little), президент и генеральный директор SiFive заявил, что ИИ-инфраструктура больше не строится из универсальных компонентов, а разрабатывается совместно с нуля: «Интегрируя NVLink Fusion с высокопроизводительными вычислительными подсистемами SiFive, мы предоставляем клиентам открытую и настраиваемую платформу CPU, которая легко интегрируется с ИИ-инфраструктурой NVIDIA, обеспечивая исключительную эффективность в масштабах ЦОД». 
Источник изображения: SiFive Пресс-релиз SiFive не содержит каких-либо конкретных планов по продуктам, кроме сообщения о добавления поддержки NVLink к «высокопроизводительным решениям для ЦОД» SiFive. Предположительно, речь идёт о чипах платформы Vera Rubin или более поздних, т.е. о NVLink 6. Для SiFive — как поставщика IP-блоков RISC-V CPU — интерес заключается в использовании интерконнекта NVLink-C2C, который обеспечивает высокоскоростную, полностью кеш-когерентную связь между CPU и GPU, и это предпочтительный способ подключения к ускорителям NVIDIA в высокоинтегрированных системах. В рамках экосистемы NVLink Fusion NVIDIA предлагает NVLink-C2C в качестве лицензируемого IP-ядра, что упростит интеграцию шины в будущие чипы SiFive. Для SiFive это может стать конкурентным преимуществом. Кроме того, NVIDIA объявила о поддержке RISC-V — на эту архитектуру портируют CUDA и драйверы, что со временем откроет для компании новые рынки.
14.01.2026 [15:39], Руслан Авдеев
США разрешили экспорт NVIDIA H200 в Китай, а Китай импорт H200 не разрешилСША официально разрешили поставки чипов NVIDIA H200 китайским клиентам несмотря на неодобрение некоторых политиков. Впрочем, как оказалось, в Китае эти ускорители не очень ждут, сообщает Reuters. Параллельно США прикрыли лазейку в законах, позволявшую КНР пользоваться передовыми ИИ-чипами в зарубежных ЦОД и облаках. Согласно новым американским правилам, продаваемые в КНР чипы должны перед поставками проверяться независимыми лабораториями для подтверждения их технических характеристик. При этом в Поднебесную запрещено продавать более 50 % от общего объёма чипов, продаваемых американским клиентам. NVIDIA придётся доказать, что в США достаточно ускорителей H200, а китайские клиенты должны пройти «необходимые процедуры безопасности» и не должны использовать полупроводники в военных целях. Ранее об этих условиях не сообщалось. В NVIDIA подчёркивают, что критики новых правил непреднамеренно продвигают интересы конкурентов компании, находящихся в американском «чёрном списке». В декабре было объявлено о возможности продавать чипы NVIDIA H200 в КНР с условием уплаты в американский бюджет пошлины в объёме 25 % от их стоимости. Китайским технологическим компаниям нужно порядка 2 млн H200, причём каждый из ускорителей стоит около $27 тыс. Это превышает запасы NVIDIA, на складах которой имеется не более 700 тыс. таких чипов. Глава NVIDIA Дженсен Хуанг (Jensen Huang) заявил, что компания нарастит производство H200. 
Источник изображения: Veronica Dudarev/unsplash.com По словам Reuters, пожелавшие остаться анонимными сотрудники китайской таможни заявили, что ввоз чипов NVIDIA H200 в Китай пока не разрешён. Также, по некоторым данным, китайские власти пригласили представителей местных технологических компаний на встречу, в ходе которой недвусмысленно указали не покупать H200 без крайней необходимости. Фактически, по данным источников СЧМИ, речь идёт о временном запрете закупок, который может стать постоянным. H200 в последнее время находится в центре обсуждений американо-китайских отношений. Хотя спрос со стороны китайского бизнеса велик, есть вероятность, что Пекин вовсе запретит ввоз таких чипов, чтобы местные разработчики ИИ-чипов могли развивать собственные проекты. Также возможно, что вопросы, касающиеся поставок H200, станут предметом торга с Вашингтоном. Пока нет данных, касается ли запрет уже сделанных заказов, или только новых. Желая замедлить развитие Китая в сфере ИИ и технологий в целом, США с 2022 года ввела ограничения на экспорт в КНР передовых полупроводников. В 2025 году США сначала запретили, а позже разрешили экспорт ускорителей H20, но поставки с августа фактически заблокировал сам Китай. Дженсен Хуанг заявлял, что доля NVIDIA на рынке ИИ-чипов КНР уменьшилась до нуля. H200 приблизительно в шесть раз производительнее H20 и отказаться от такого предложения полностью КНР будет весьма затруднительно, особенно с учётом того, что собственные чипы китайской разработки далеко не столь производительны.
14.01.2026 [09:45], Владимир Мироненко
Самая загадочная сделка 2025 года: зачем NVIDIA потратила $20 млрд на Groq?Сделка NVIDIA с ИИ-стартапом Groq, фактически означающая его поглощение, вызвала вопросы по поводу целей, которые преследует лидер ИИ-рынка. Для того, чтобы избежать волокиты с одобрением сделки регулирующими органами и антимонопольных расследований, NVIDIA провела её под видом приобретения неисключительной лицензии на технологии Groq. В результате сделки ключевые кадры Groq перешли в NVIDIA, а остатки команды во главе с финансовым директором продолжат управлять инфраструктурой GroqCloud и вряд ли смогут сохранить былую конкурентоспособность стартапа. Похожую сделку NVIDIA провела немногим ранее, фактически поглотив стартап Enfabrica, занимавшийся разработкой интерконнекта. В случае с Enfabrica, по слухам, сумма сделки составила $900 млн. Это большая сумма для стартапа, находящегося на ранней стадии, но вполне обоснованная в нынешних условиях, пишет EE Times. Groq — более крупный стартап, но и стоимость сделки гораздо выше — $20 млрд при последней оценке стартапа на уровне $6,9 млрд. Если в отношении Enfabrica предполагалось, что сделка была связана, хотя бы частично, с наймом персонала, то для Groq такая большая сумма вряд ли выглядит оправданной, если речь идёт только о привлечении квалифицированных кадров. Можно допустить, что NVIDIA планирует выпускать чипы Groq. Их упомянул в электронном письме сотрудникам гендиректор NVIDIA Дженсен Хуанг: «Мы планируем интегрировать процессоры Groq с низкой задержкой в архитектуру NVIDIA AI Factory, расширив платформу для обслуживания ещё более широкого спектра задач ИИ-инференса и рабочих нагрузок в реальном времени». 
Источник изображений: Groq Вместе с тем в ходе CES 2026 Хуанг заявил, что технология Groq не станет частью основного портфолио NVIDIA для ЦОД. «[Groq] — это совсем, совсем другое, и я не ожидаю, что что-либо заменит то, что мы делаем с Vera Rubin и нашим следующим поколением, — сказал Хуанг. — Однако мы могли бы добавить его технологию таким образом, чтобы что-то постепенно улучшить, чего мир ещё не смог сделать». Судя по фразе «могли бы», NVIDIA пока окончательно не определилась с тем, что будет делать с активами Groq. Технология Groq позволит решать задачи, которые недоступны для Vera Rubin, в частности, сверхбыстрый инференс в реальном времени, пишет EE Times. Можно предположить, что NVIDIA будет производить и развёртывать чипы Groq как отдельное решение в ЦОД. Хотя Хуанг и сказал об интеграции чипов Groq с архитектурой NVIDIA AI Factory, это всё ещё кажется несколько надуманным, так как означает признание NVIDIA в том, что её GPU не вполне подходят для некоторых рабочих нагрузок. Однако Дженсен Хуанг в очередной раз подчеркнул на CES 2026, что гибкости GPU вполне хватит для любых нагрузок. Впрочем, анонс соускорителей Rubin CPX говорит скорее об обратном.  У Groq есть собственный программный стек, но насколько он хорош, сказать трудно. Для перезапуска технологий Groq в качестве продукта NVIDIA потребуется немало работы над ПО, а полноценная интеграция в программную экосистему может оказаться очень сложной. Более реалистичным вариантом может быть использование чиплета Groq вместе с большим чиплетом GPU для обработки определённых нагрузок, но и в этом случае ПО станет камнем преткновения, поскольку аппаратная часть принципиально слабо совместима с CUDA. Возникает вопрос: «Что же есть у Groq, чего нет у NVIDIA?». Одним из ответов может быть детерминизм — концепция, лежащая в основе архитектуры LPU Groq, которую компания пыталась продвинуть в автомобильной промышленности в 2020 году. Детерминизм имеет существенные преимущества для приложений, требующих функциональной безопасности, включая робототехнику — Хуанг в письме, упомянутом выше, говорит о «приложениях реального времени». Но для этого NVIDIA придется изменить свою риторику, признав, что для периферийных вычислений её ускорители подходят не всегда. В любом случае, у NVIDIA имеются огромные ресурсы и команда квалифицированных специалистов. Если бы она захотела создать ИИ-ускоритель, ориентированный на работу со SRAM, а не HBM, это обошлось бы гораздо дешевле уплаченных за Groq $20 млрд. Кроме того, утверждает EE Times, она могла бы за существенно меньшую сумму пробрести d-Matrix или даже SambaNova, которая готова продаться Intel всего за $1,6 млрд.  Как полагают аналитики EE Times, помимо лицензирования технологии и найма специалистов Groq, в принятии решения купить стартап также сыграли роль коммерческие факторы. Groq имеет обширные партнёрские отношения с крупными компаниями стран Персидского залива. У стартапа также есть соглашения о суверенном ИИ и в других странах, что могло показаться привлекательным для NVIDIA. Тем не менее, одним из главных аргументов в пользу покупки Groq до сих пор было то, что это вполне жизнеспособная и недорогая альтернатива NVIDIA для построения суверенной ИИ-инфраструктуры. То есть покупку Groq можно также объяснить желанием помешать одному из клиентов-гиперскейлеров купить Groq, будь то из-за аппаратной интеллектуальной собственности или уже развёрнутой инфраструктуры. Это может быть Meta✴, Microsoft или даже OpenAI, чьи планы по созданию собственного ИИ-оборудования всё ещё находятся на стадии подготовки или пока имеют умеренный успех, тогда как Google уже готов отдать «на сторону» свои ускорители TPU, а AWS со своими Trainium всё-таки готова сотрудничать с NVIDIA по аппаратной части.  В свою очередь, аналитики ресурса The Register объясняют покупку Groq за столь крупную сумму интересом NVIDIA к «конвейерной архитектуре» (dataflow) стартапа, которая, по сути, создана специально для ускорения вычислений линейной алгебры, выполняемых в ходе инференса. Стоит отметить, что архитектуры с управляемым потоком данных не ограничиваются проектами, ориентированными на SRAM. Например, NextSilicon использует HBM. Groq выбрал SRAM только потому, что это упростило задачу, но нет никаких причин, по которым NVIDIA не могла бы создать dataflow-ускоритель на основе IP-блоков Groq, используя SRAM, HBM или GDDR, пишет The Register. Правильно реализовать такую архитектуру очень сложно, но Groq удалось заставить её работать надлежащим образом, по крайней мере, для инференса, утверждает The Register. Таким образом, Groq даст NVIDIA оптимизированную для инференса вычислительную архитектуру, чего ей так сильно не хватало, полагают аналитики ресурса. Именно этого и не хватает NVIDIA, поскольку у неё фактически нет выделенных чипов для этой задачи. Ситуация изменится с запуском NVIDIA Rubin в 2026 году и их «напарников» Rubin CPX. При этом ускорители Groq LPU в силу малого объёма SRAM для обработки современных LLM необходимо объединять в кластеры из десятков и сотен чипов. Это верно и для других ускорителей примерно того же типа, включая Cerebras. Вместе с тем LPU, по мнению The Register, теоретически могут пригодиться для т.н. спекулятивного декодирования, когда малая модель, не больше нескольких миллиардов параметров, используется для предсказания ответов большой модели. Если малая модель правильно «угадывает» их, общая производительность инференса может вырасти в два-три раза. Стоит ли такая опция $20 млрд, вопрос отдельный, но Хуанг, по-видимому, играет вдолгую.
14.01.2026 [01:29], Владимир Мироненко
Безоблачно: США запретили Китаю удалённый доступ к передовым ИИ-ускорителямПалата представителей США приняла подавляющим большинством «Закон о безопасности удалённого доступа» (Remote Access Security Act). Как сообщается на сайте Специального комитета Палаты Представителей США по стратегическому соперничеству между Соединёнными Штатами и Компартией Китая (CCP), этот закон расширяет действие «Закона о реформе экспортного контроля», позволяя федеральным властям «ограничивать возможности иностранных противников получать удалённый доступ к технологиям, включая ИИ-чипы, через облачные вычислительные сервисы». Проще говоря, теперь китайским компаниям запрещён доступ к передовым ускорителям в ЦОД и облаках за пределами КНР. Хотя экспорт ускорителей NVIDIA H200 теперь разрешён, поставка в Китай более мощных чипы на базе архитектуры Blackwell по-прежнему запрещена, как и ускорителей с новой архитектурой Vera Rubin. Новый закон призван перекрыть пробелы в законодательстве США, которыми с успехом пользуются китайские компании, получая доступ к находящимся под санкциями ИИ-ускорителям, покупая или арендуя их для использования на территории США. О таких обходных путях стало известно в 2024 году, когда выяснилось, что ByteDance, китайский владелец TikTok, арендовал передовые чипы NVIDIA у Oracle, пишет Data Center Dynamics. 
Источник изображения: yang ma / Unsplash Как передаёт The Register, китайские компании обходят экспортные ограничения на высокопроизводительные ускорители NVIDIA и другие чипы, получая к ним доступ через такие платформы, как AWS и Azure, по крайней мере, с 2023 года. The Register также ранее сообщал, что китайские облачные провайдеры, такие как Alibaba и Tencent, могут предоставлять доступ к находящимся под экспортными ограничениями GPU клиентам в Китае, арендуя облачное оборудование, размещённое за пределами страны. В свою очередь, Microsoft и AWS предлагают в Китае через местных партнёров облачные услуги, в целом аналогичные тем, что доступны в других странах. «Амбиции КПК в области ИИ подпитываются доступом к американским чипам, размещённым в ЦОД за пределами Китая, — заявил председатель Специального комитета по Китаю, один из соавторов законопроекта. — Этот законопроект переводит наши законы в цифровую эпоху и ясно даёт понять, что облачные вычисления подпадают под действие американского законодательства об экспортном контроле, так же как и физические чипы. Устранение этих лазеек укрепит национальную безопасность США и защитит американские инновации». Новый закон теоретически может целиком перекрыть бизнес некоторых азиатских компаний. После появления сообщения о том, что NVIDIA потребует от китайских клиентов, приобретающих ускорители H200, полной предоплаты, чипмейкер выступил с опровержением, заявив агентству Reuters, которое первым сообщило об этом что «никогда не будет требовать от клиентов оплаты за продукцию, которую они не получают». В начале декабря администрация Трампа разрешила NVIDIA продавать H200 «одобренным клиентам» в Китае и других странах при условии выплаты 25-% пошлины. В свою очередь, китайское правительство попросило технологические компании страны приостановить оформление заказов на ускорители, пока регулирующие органы не определятся с соотношением приобретаемых чипов H200 и отечественных чипов «в нагрузку» к ним.
13.01.2026 [09:03], Руслан Авдеев
Lenovo представила серверы для ИИ-инференса: ThinkSystem SR675i V3/SR650i V4 и ThinkEdge ThinkEdge SE455i V4Lenovo представила новые серверные системы серии Lenovo Hybrid AI Advantage, оптимизированные для ИИ-инференса: ThinkSystem SR675i V3, ThinkSystem SR650i V4 и ThinkEdge SE455i V4. Если ранее акцент делался на решениях для обучения всё более производительных ИИ-моделей, то теперь бизнес обращает всё больше внимания на продукты для инференса. Новинки предлагаются параллельно с ПО для оптимизации инференса — для унификации и получения данных из разных источников для использования ИИ-моделями. 
Источник изображений: Lenovo Флагманской версией серии является ThinkSystem SR675i V3 в исполнении 3U на платформе AMD EPYC Turin 9535 (64C/128T, 2,4 ГГц, TDP 300 Вт). Сервер получил 1,5 Тбайт DDR5-6400 (24 × 64 Гбайт). За хранение данных отвечают до двух E3.S NVMe SSD по 3,84 Тбайт (PCIe 5.0 x4) и до двух M.2 NVMe SSD по 960 Гбайт (PCIe 4.0 x4). Возможна установка восьми ускорителей NVIDIA RTX PRO 6000 Blackwell Server Edition, а также пяти DPU NVIDIA BlueField-3 (4 × 400G, 1 × 200G). IPMI в данной модели не доступен. Для карт расширения доступно до шести слотов PCIe 5.0 х16 и один слот OCP 3.0 x8/x16. За питание отвечают четыре блока Titanium второго поколения (по 2300 Вт), а за охлаждение — пять вентиляторов.  ThinkSystem SR650i V4 позиционируется в качестве системы для инференса и корпоративных рабочих нагрузок. Этот 2U-сервер получил два Intel Xeon Granite Rapids-SP 6530P (32C/64T, 2,3 ГГц, TDP 225 Вт), 512 Гбайт DDR5-6400 (8 × 64 Гбайт), два ускорителя RTX PRO 6000 Blackwell Server Edition. За хранение отвечают два 3,84-Тбайт U.2 NVMe SSD (PCIe 5.0 x4), хотя всего таких слотов восемь, а также RAID1-массив из пары 960-Гбайт M.2 SATA SSD. Всего доступно шесть слотов расширения PCIe 5.0 x16 и два слота OCP 3.0 x8/x16. Имеется двухпортовый 25GbE-адаптер Broadcom 57414 (SFP28). За питание отвечают два Titanium-блока мощностью 2700 Вт каждый, а за охлаждение шесть вентиляторов, но есть и опция установки фирменной СЖО Neptune.  Наконец, Lenovo ThinkEdge SE455i V3 (2U) глубиной всего 440 мм представляет собой компактную модель, предназначенную для периферийного инференса — в ретейле, телекоммуникациях и промышленности. Сервер имеет защищённую конструкцию и может работать при температурах от -5 до +40 °C. Сервер построен на базе одного процессора AMD EPYC Embedded 8534P (64C/128T, 2,3 ГГц, TDP 200 Вт), дополненного 576 Гбайт DDR5-4800 (6 × 96 Гбайт) и двумя ускорителями NVIDIA L4 24 Гбайт (PCIe 4.0 x16). В комплекте идёт один 3,84-Тбайт NVMe SSD и один 960-Гбайт SATA SSD. Имеется два блока питания Platinum второго поколения с возможностью горячей замены. Для карт расширения есть до двух слотов PCIe 5.0 x16 и до четырёх слотов PCIe 4.0 x8, а также один слот OCP 3.0 (PCIe 5.0 x16). Установлен двухпортовый OCP-адаптер Broadcom 57416 (10GbE). IPMI отключён.  Фактически компания предлагает готовые конфигурации, которые можно переконфигурировать лишь слегка, чаще всего добавив накопители и/или сетевые адаптеры. Платформы будут доступны в рамках подписки TruScale. Также компания анонсировала новые сервисы Hybrid AI Factory Services, в том числе консультации по инференсу, которые помогают развёртывать оборудование и управлять им для оптимизации ИИ-производительности.
12.01.2026 [14:41], Сергей Карасёв
ASRock Rack показала ИИ-сервер на базе NVIDIA HGX B300 с СЖО ZutaCore HyperCoolКомпания ASRock Rack на выставке CES 2026 продемонстрировала ИИ-сервер 4U16X-GNR2/ZC, первая информация о котором была раскрыта в октябре прошлого года. Новинка создана в партнёрстве с разработчиком систем жидкостного охлаждения ZutaCore. Устройство выполнено в форм-факторе 4U. Возможна установка двух процессоров Intel Xeon 6700E (Sierra Forest-SP) или Xeon 6500P/6700P (Granite Rapids-SP). Доступны 32 слота для модулей оперативной памяти DDR5, три разъёма PCIe 5.0 x16 для карт FHHL и два сетевых порта 1GbE на базе контроллера Intel I350-AM2. Задействована аппаратная платформа NVIDIA HGX B300. Для отвода тепла используется система прямого жидкостного охлаждения ZutaCore HyperCool. Это двухфазное решение основано на применении специальной диэлектрической жидкости, которая не вызывает коррозии. Утверждается, что конструкция HyperCool безопасна для IT-оборудования и гарантирует сохранение работоспособности даже в случае утечки. СЖО поставляется в полностью собранном виде, что сокращает время монтажа в стойку.  Сервер 4U16X-GNR2/ZC оборудован 12 фронтальными отсеками для SFF-накопителей с интерфейсом PCIe 5.0 x4 (NVMe); допускается горячая замена. Кроме того, есть внутренний разъём для одного SSD типоразмера М.2 (PCIe 5.0 x2). За питание отвечают десять блоков мощностью 3000 Вт с сертификатом 80 Plus Titanium. Габариты машины составляют 900 × 448 × 175 мм. Отмечается, что в стандартной стойке 42U могут быть размещены до восьми подобных серверов, что обеспечивает высокую плотность вычислительной мощности для наиболее ресурсоёмких нагрузок ИИ.
12.01.2026 [09:54], Владимир Мироненко
От NVMe к GPU: NVIDIA представила платформу хранения контекста инференса ICMSPВместе с официальным анонсом ИИ-платформы следующего поколения Rubin компания NVIDIA также представила платформу хранения контекста инференса NVIDIA Inference Context Memory Storage Platform (ICMSP), позволяющую решить проблемы хранения KV-кеша, который становится всё крупнее по мере роста LLM и решаемых задач. При выполнении инференса контекст растёт по мере генерации новых токенов, часто превышая доступную память ускорителя. В этом случае старые записи вытесняются из памяти, сначала в системную память, а потом на диск, чтобы не пересчитывать всё заново, когда они снова понадобятся. Проблемы существенно усугубляются при работе с агентным ИИ и обработке рабочих нагрузок с большим контекстом. Агентный ИИ приводит к появлению контекстных окон в миллионы токенов, а объём моделей может составлять уже триллионы параметров. В настоящее время эти системы полагаются на долговременную память для хранения контекста, позволяя агентам опираться на предыдущие рассуждения и расширять их на протяжении многих шагов, а не начинать с нуля при каждом запросе. По мере увеличения контекстных окон растут требования к ёмкости KV-кеша, делая эффективное хранение и повторное использование данных, в том числе совместное использование различными сервисами инференса, крайне важными для повышения производительности системы. Контекст инференса является производным и пересчитываемым, что требует архитектуры хранения, которая отдаёт приоритет энергоэффективности и экономичности, а также скорости и масштабируемости, а не традиционной надёжности хранения данных. 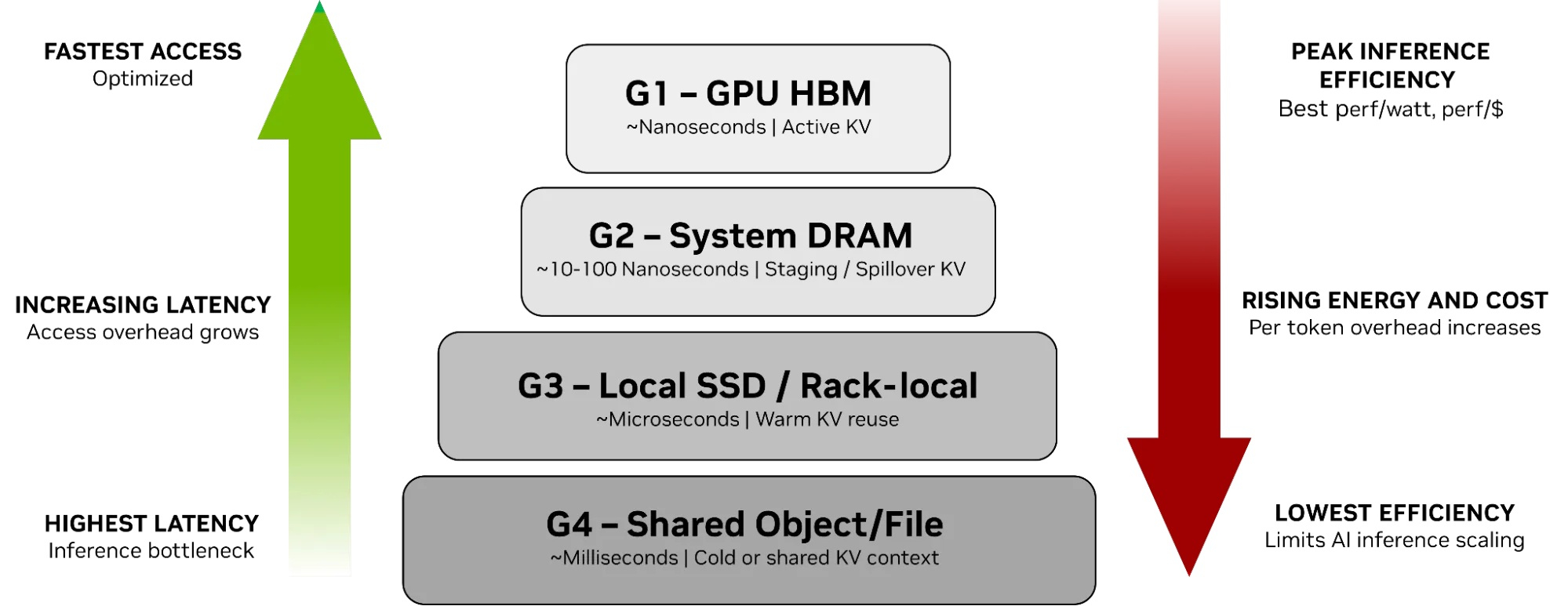
Источник изображений: NVIDIA NVIDIA отметила, что ИИ-фабрикам необходим дополнительный, специально разработанный уровень контекста, который рассматривает KV-кеш как собственный класс данных, предназначенный для ИИ, а не принудительно помещает его в дефицитную память HBM или в хранилище общего назначения. Платформа ICMSP использует DPU BlueField-4 для создания специализированного уровня памяти, чтобы преодолеть разрыв между высокоскоростной памятью GPU и масштабируемым общим хранилищем. Хранилище KV-кеша на основе NVMe должно эффективно обслуживать ускорители, узлы, стойки и кластеры целиком, говорит компания. Платформа ICMSP создаёт новый уровень (G3.5 на схеме выше) — флеш-память, подключённая через Ethernet и оптимизированная специально для KV-кеша. Этот уровень выступает в качестве долговременной агентной памяти на уровне ИИ-инфраструктуры, достаточно большой для одновременного хранения общего, развивающегося контекста многих агентов, но при этом достаточно близко расположенной для частой работы с памятью ускорителей и хостов. BlueField-4 отвечает за аппаратное ускорение размещения кеша и устранение накладных расходов на подготовку и перемещение данных и обеспечение безопасного, изолированного доступа к ним узлов с GPU, снижая зависимость от CPU хоста и минимизируя сериализацию и работу с системной памятью хоста. Программные продукты, такие как фреймворк DOCA, механизм разгрузки KV-кеша Dynamo и входящее в комплект ПО NIXL (Nvidia Inference Transfer Library), обеспечивают интеллектуальное, ускоренное совместное использование данных KV-кеша между ИИ-узлами. А Spectrum-X Ethernet обеспечивает оптимизированный RDMA-интерконнект, который связывает ICMS и узлы GPU. 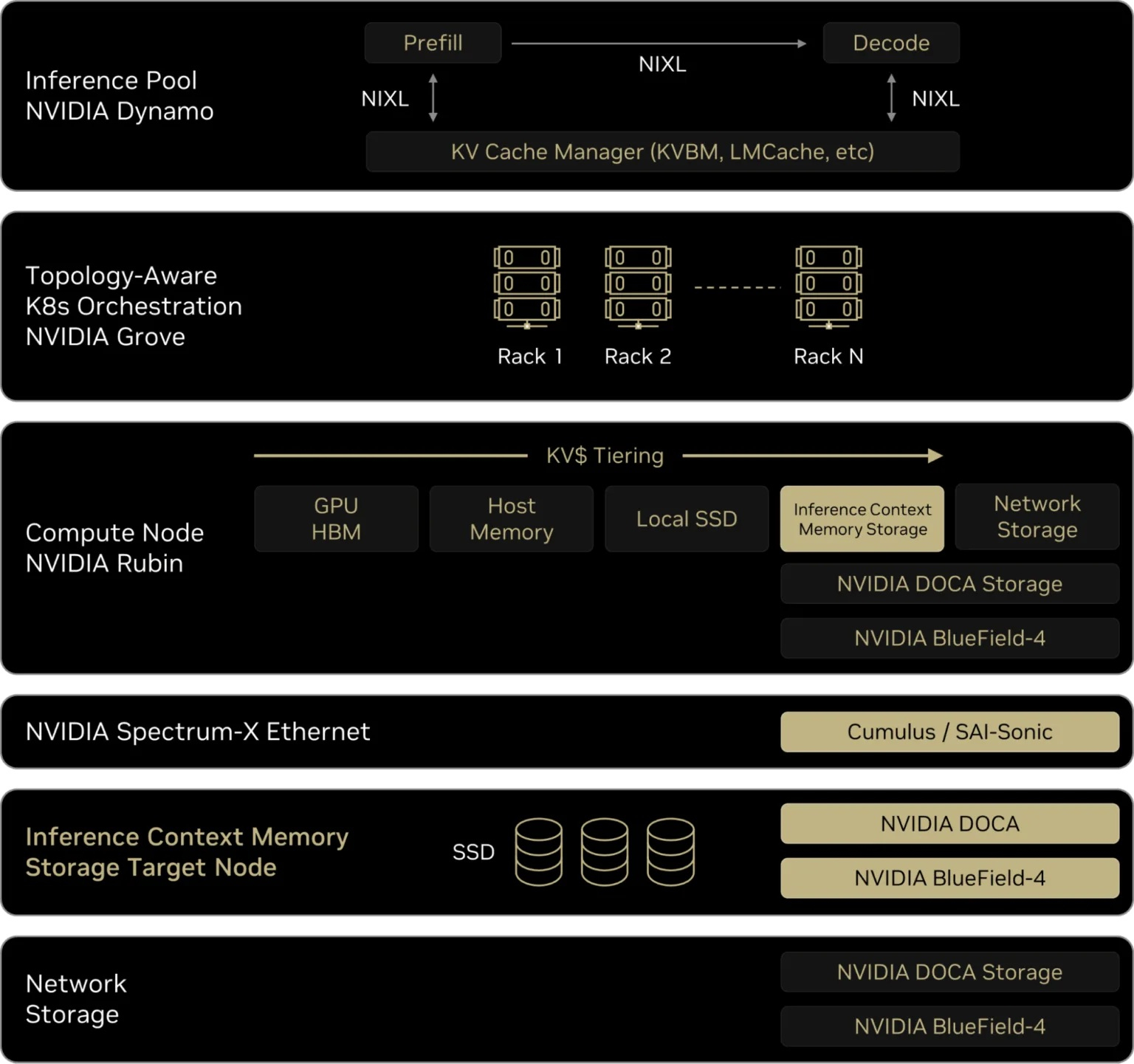 KV-кеш принципиально отличается от корпоративных данных: он является временным, производным и может быть пересчитан в случае потери. В качестве контекста инференса он не требует надёжности, избыточности или обширных механизмов защиты данных, разработанных для долговременных записей. Выделяя KV-кеш как отдельный, изначально предназначенный для ИИ класс данных, ICMS устраняет избыточные накладные расходы, обеспечивая повышение энергоэффективности до пяти раз по сравнению с универсальными подходами к хранению данных, сообщила NVIDIA. А своевременная подготовка и отдача данных более полно нагружает ускорители, что позволяет увеличить темп генерации токенов до пяти раз. Как сообщила NVIDIA, первоначальный список её партнёров, готовых обеспечить поддержку ICMSP с BlueField-4, который будет доступен во II половине 2026 года, включает AIC, Cloudian, DDN, Dell, HPE, Hitachi Vantara, IBM, Nutanix, Pure Storage, Supermicro, VAST Data и WEKA.
09.01.2026 [19:23], Владимир Мироненко
Pay 'n' Pray: NVIDIA требует полную предоплату за поставку H200 в КитайПосле того, как США дали NVIDIA добро на поставку ИИ-ускорителей H200 в Китай в обмен на выплату 25 % от суммы продаж, китайские компании выразили готовность приобрести у чипмейкера более 2 млн ускорителей. Это в несколько раз превышает имеющиеся запасы на складах NVIDIA. Ранее сообщалось, что NVIDIA готова отгрузить первые партии H200 в середине февраля до наступления лунного Нового года. Китайские власти пока не дали разрешение на импорт этих чипов, но, как утверждает Bloomberg со ссылкой на проверенные источники, правительство готово уже в этом квартале разрешить приобретение H200 для отдельных коммерческих целей. При этом из-за соображений безопасности под запретом окажутся закупки чипов для военных организаций, госучреждений, объектов критической инфраструктуры и предприятий с госсобственностью. По словам источника, власти КНР попросили некоторые китайские технологические компании приостановить на время размещение заказов на чипы H200, поскольку регуляторами пока не решено, в каком соотношении к покупке ускорителей американской компании они должны будут приобрести чипы отечественного производства. 
Источник изображения: NVIDIA Для NVIDIA возобновление поставок означает возврат на ключевой рынок. Генеральный директор NVIDIA Дженсен Хуанг (Jensen Huang) заявил, что спрос клиентов в Китае на чипы H200 «довольно высок» и что компания «запустила свою цепочку поставок» для наращивания производства. Хуанг отметил, что вне зависимости от официального заявления правительства Китая об одобрении, поступление заявок от китайских компаний на покупку «будет означать, что они могут размещать заказы». По словам источников агентства Reuters, в случае с поставками H200 компания решила полностью переложить на клиентов риски, связанные с неопределённостью ситуации, потребовав полную предоплату за заказ. NVIDIA и раньше требовала предоплату, хотя могла в порядке исключения согласиться и на размещение депозита. При полной предоплате поставок, если Китай вдруг изменит решение и заблокирует импорт чипов, возврата предоплаты не будет и убытки полностью лягут на плечи китайских клиентов американской компании. UPD 13.01.2026: NVIDIA опровергла сообщения о предоплате, заявив, что «никогда не стал бы требовать от клиентов оплаты за товары, которые они не получают». |
|

