Материалы по тегу: hpc
|
29.07.2018 [13:00], Геннадий Детинич
Американские ВВС получили самый большой в мире нейроморфный суперкомпьютерЗвучит громко, но это именно так. Лаборатория Air Force Research Laboratory (AFRL) в городе Ром, штат Нью-Йорк, получила в своё распоряжение самый большой в мире компьютер по числу задействованных в системе нейроморфных процессоров IBM TrueNorth. Система представлена полочными компьютерами высотой 4U (7 дюймов) для стандартной серверной стойки. Каждый компьютер располагает 64 процессорами IBM TrueNorth. В пересчёте на человеческие в буквальном смысле единицы измерения мозга — это 64 млн нейронов и 16 млрд синапсов. Всего в стойке может разместиться 512 млн цифровых нейронов. Примерно столько нейронов в коре головного мозга собаки. 
AFRL Система под именем «Blue Raven» на базе IBM TrueNorth для Лаборатории ВВС США представлена пока 64-процессорным решением с общим потреблением 40 Вт. Это, кстати, в 4 раза больше ожидаемого. Аналогичный 16-процессорный компьютер, переданный в 2016 году Ливерморской национальной лаборатории им. Лоуренса, потреблял всего 2,5 Вт или 156 мВт на один процессор. Возможно таким образом была повышена производительность системы, которая при потреблении 70 мВт способна работать с производительностью 46 млрд синаптических операций в секунду. 
IBM По оценкам IBM, работа процессоров TrueNorth с необозначенным датасетом на CIFAR-100 по распознаванию наборов изображений характеризуется производительностью свыше 1500 кадров в секунду с потреблением 200 мВт или свыше 7000 кадров в секунду на ватт. Ускоритель NVIDIA Tesla P4 (Pascal GP104), например, обрабатывает датасет Resnet-50 с производительностью 27 кадров в секунду на ватт. 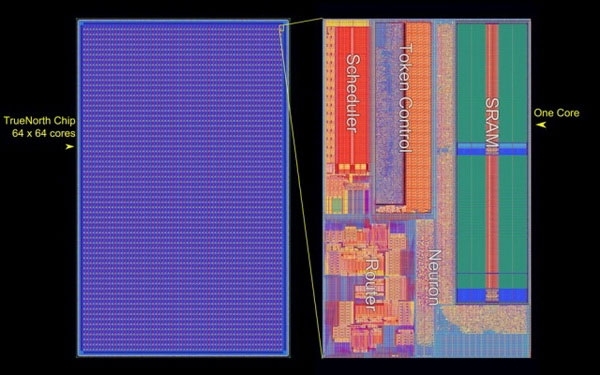
Структура процессора IBM TrueNorth Вообще, в Лаборатории AFRL, похоже, работают увлечённые люди. Новым проектом «Blue Raven» руководит тот же человек (Mark Barnell), который несколько лет назад отметился запуском суперкомпьютера Condor Cluster на базе сотен игровых консолей Sony PlayStation 3. Какими расчётами в AFRL будет заниматься суперкомпьютер с «мозгами» не уточняется. Пока учёные будут изучать круг задач, решаемый подобными системами. Ожидается, что принятая на «вооружение» научным отделом ВВС США вычислительная система обеспечит дальнейшее приоритетное развитие технологий в этой стране.
29.06.2018 [13:00], Геннадий Детинич
Опубликованы финальные спецификации CCIX 1.0: разделяемый кеш и PCIe 4.0Чуть больше двух лет назад в мае 2016 года семёрка ведущих компаний компьютерного сектора объявила о создании консорциума Cache Coherent Interconnect for Accelerators (CCIX, произносится как «see six»). В число организаторов консорциума вошли AMD, ARM, Huawei, IBM, Mellanox, Qualcomm и Xilinx, хотя платформа CCIX объявлена и развивается в рамках открытых решений Open Compute Project и вход свободен для всех. В основе платформы CCIX лежит дальнейшее развитие идеи согласованных (когерентных) вычислений вне зависимости от аппаратной реализации процессоров и ускорителей, будь то архитектура x86, ARM, IBM Power или нечто уникальное. Скрестить ежа и ужа — вот едва ли не буквальный смысл CCIX. 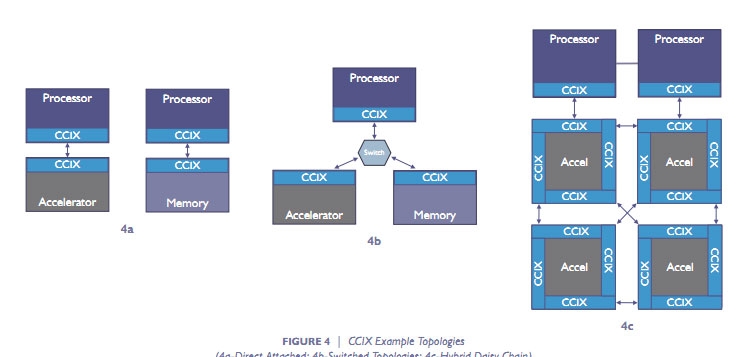
Варианты топологии CCIX На днях консорциум сообщил, что подготовлены и представлены финальные спецификации CCIX первой версии. Это означает, что вскоре с поддержкой данной платформы на рынок может выйти первая совместимая продукция. По словам разработчиков, CCIX позволит организовать новый класс подсистем обмена данными с согласованием кеша с низкими задержками для следующих поколений облачных систем, искусственного интеллекта, больших данных, баз данных и других применений в инфраструктуре ЦОД. Следующая ступенька в производительности невозможна без эффективных гетерогенных (разнородных) вычислений, которые смешают в одном котле исполнение кода общего назначения и спецкода для ускорителей на базе GPU, FPGA, «умных» сетевых карт и энергонезависимой памяти. 
Решение CCIX IP компании Synopsys Базовые спецификации CCIX Base Specification 1.0 описывают межчиповый и «бесшовный» обмен данными между вычислительными ресурсами (процессорными ядрами), ускорителями и памятью во всём её многообразии. Все эти подсистемы объединены разделяемой виртуальной памятью с согласованием кеша. В основе спецификаций CCIX 1.0, добавим, лежит архитектура PCI Express 4.0 и собственные наработки в области быстрой коррекции ошибок, что позволит по каждой линии обмениваться данными со скоростью до 25 Гбайт/с. 
Тестовая платформа с поддержкой CCIX Synopsys на FPGA матрице Но главное, конечно, не скорость обмена, хотя это важная составляющая CCIX. Главное — в создании программируемых и полностью автономных процессов по обмену данными в кешах процессоров и ускорителей, что реализуется с помощью новой парадигмы разделяемой виртуальной памяти для когерентного кеша. Это радикально упростит создание программ для платформ CCIX и обеспечит значительный прирост в ускорении работы гетерогенных платформ. Вместо механизма прямого доступа к памяти (DMA), со всеми его тонкостями для обмена данными, на платформе CCIX достаточно будет одного указателя. Причём обмен данными в кешах будет происходить без использования драйвера на уровне базового протокола CCIX. Ждём в готовой продукции. Кто первый, AMD, ARM или IBM? 
Тестовый набор CCIX 
Рабочая демо-система с неназванным CPU и FPGA, соединённых шиной CCIX
30.09.2017 [00:15], Алексей Степин
Терафлопс в космосе: на МКС тестируется компьютер HPE SpaceborneБытует мнение, что в космической отрасли используется всё самое лучшее, включая компьютерные компоненты. Это не совсем так: вы не встретите в космических аппаратах 18-ядерных Xeon и ускорителей Tesla. Во-первых, энергетические резервы за пределами Земли строго ограничены, и даже на МКС никто не будет тратить несколько киловатт на питание «космического суперкомпьютера». Во-вторых, практически вся электроника, работающая за пределами атмосферы, выпускается в специальном радиационно-стойком исполнении. Чаще всего за счёт техпроцессов «кремний на диэлектрике» (SOI) и «сапфировая подложка» (SOS), используется также биполярная логика вместо менее стойкой к внешним излучениям CMOS. 
Мини-кластер в космическом исполнении. Охлаждение жидкостное Мощными в космосе считаются такие решения, как BAE Systems серии RAD, особенно новая RAD5500 (от 1 до 4 ядер, 45-нм SOI, PowerPC, 64 бита). Четырёхъядерный вариант RAD5545 развивает производительность более 3,7 гигафлопс при потреблении около 20 ватт. Иными словами, вычислительные мощности в космосе тоже растут, но совсем иными темпами, нежели на Земле. Тому подтверждением служит недавно вступивший в строй на борту Международной космической станции компьютер HPE Spaceborne. Если на Земле мощность суперкомпьютеров измеряется десятками и сотнями петафлопс, то Spaceborne куда скромнее — судя по проведённым тестам, его вычислительная мощность достигает 1 терафлопса. Достигнута она путём сочетания современных процессоров Intel с ускорителями NVIDIA Tesla P100 (NVLink-версия). 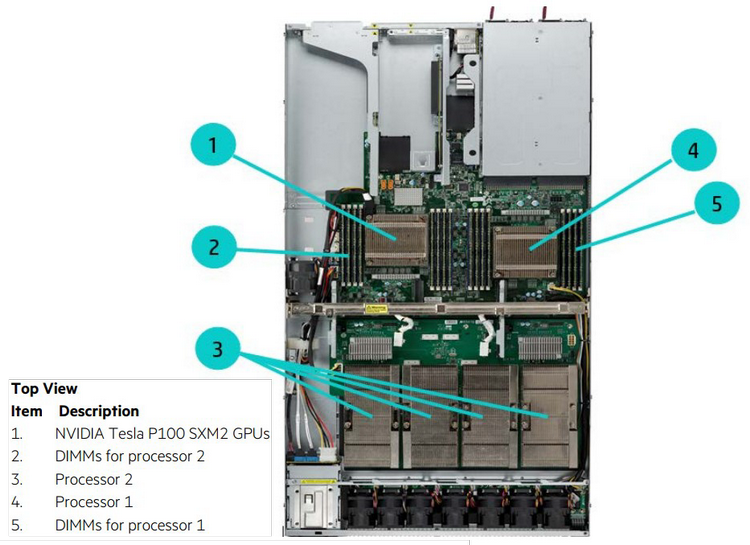
Конфигурация каждого из узлов Spaceborne Для космических систем это большое достижение, и не стоит иронизировать над этим показателем производительности. Интересно, что сама по себе система Spaceborne, доставленная на борт станции миссией SpaceX CRS-12, является своего рода экспериментом на тему «как чувствуют себя в космосе обычные компьютерные комплектующие». Это связка из двух серверов HPE Apollo 40 на базе Intel Xeon, объединённая сетью со скоростью 56 Гбит/с. 14 сентября на систему было подано питание (48 и 110 вольт), а недавно проведены первые тесты High Performance LINPACK. 
Системы охлаждения и электропитания Spaceborne Пока Spaceborne не будет использоваться для анализа научных данных или управления какими-либо системами станции. Его миссия — продемонстрировать то, насколько живучи обычные серверы в космосе. Результаты постоянных тестов будут сравниваться с аналогичной системой, оставшейся на Земле. Тем не менее, достижение первого терафлопса в космосе является своеобразным мировым рекордом. Это маленький шаг для супервычислений, но большой для всей космической индустрии, поскольку за Spaceborne явно последуют его более совершенные и мощные потомки. |
|

