Материалы по тегу: c
|
18.02.2025 [14:04], Сергей Карасёв
Уязвимости в процессорах AMD EPYC обеспечивают выполнение произвольного кодаКомпания AMD сообщила о выявлении шести уязвимостей в процессорах EPYC различных поколений. Некоторые из этих «дыр» могут использоваться с целью выполнения произвольного кода в атакуемой системе. Наибольшую опасность представляют уязвимости CVE-2023-31342, CVE-2023-31343 и CVE-2023-31345, которые получили 7,5 балла (High) из 10 по шкале CVSS. Проблемы связаны с неправильной проверкой входных данных в обработчике SMM (System Management Mode). Успешная эксплуатация «дыр» позволяет злоумышленнику перезаписать SMRAM, что потенциально может привести к выполнению произвольных операций. Брешь CVE-2023-31352 с рейтингом CVSS 6,0 (Medium) связана с защитным механизмом AMD SEV (Secure Encrypted Virtualization), который применяется в системах виртуализации. Ошибка даёт атакующему возможность читать незашифрованную память, что может привести к потере гостевых данных. 
Источник изображения: AMD Уязвимость CVE-2023-20582 с рейтингом CVSS 5,3 (Medium) затрагивает технологию AMD Secure Encrypted Virtualization — Secure Nested Paging (SEV-SNP). Злоумышленник может обойти проверку RMP (Reverse Map Table), что может привести к потере целостности памяти виртуальной машины. Наконец, «дыра» CVE-2023-20581 с низким уровнем опасности CVSS 2,5 (Low) связана с ошибкой управления доступом к IOMMU (Input/Output Memory Management Unit). Привилегированный злоумышленник может обойти проверку RMP, что приведёт к потере целостности гостевой памяти. Уязвимости затрагивают процессоры EPYC Milan и Milan-X, EPYC Genoa и Genoa-X, а также EPYC Bergamo и Siena. Необходимые исправления уже выпущены: для устранения проблем необходимо обновить прошивку. Добавим, что ранее была выявлена опасная уязвимость в проверке подписи микрокода для процессоров AMD на архитектуре от Zen1 до Zen4. Успешная эксплуатация этой «дыры» может привести к потере защиты конфиденциальности.
12.02.2025 [23:28], Руслан Авдеев
Евросоюз направит €200 млрд на развитие ИИ, чтобы не отстать от США и Китая в этой сфереЕвросоюз объявил о намерении направить €200 млрд (около $206 млрд) на развитие ИИ в рамках инициативы InvestAI — это, как ожидается, позволит конкурировать с США и Китаем на рынке систем искусственного интеллекта, сообщает The Verge. По словам главы Еврокомиссии Урсулы фон дер Ляйен (Ursula von der Leyen), €50 млрд (около $51 млрд) будет выделено надгосударственными структурами союза, ещё €150 млрд (около $154 млрд) потратит группа частных инвесторов European AI Champions Initiative. По её мнению, Европа должна стать одним из ведущих «ИИ-континентов», а это значит, что необходимо принять образ жизни, где ИИ используется повсюду. Чиновница не согласилась с утверждениями, что Европа «опоздала» к гонке между США и Китаем — она уверена, что гонка далека от завершения. По словам фон дер Ляйен, инициатива InvestAI на €200 млрд поможет ускорить строительство в ЕС «гигафабрик», необходимых для обучения сложных моделей непосредственно в Европе. Как отмечает Euronews, ещё в декабре прошлого года в рамках EuroHPC было объявлено о строительстве семи первых «гигафабрик», а вскоре будет объявлено о ещё пяти. Они получат порядка 100 тыс. самых современных ускорителей. Это примерно вчетверо больше, чем у ИИ-фабрик, строящихся сегодня. Основная цель — обеспечить доступ к высокопроизводительным вычислениям даже мелким компаниям. 
Источник изображения: Anthony DELANOIX/unsplash.com Из €200 млрд на строительство «гигафабрик» выделят €20 млрд. По словам руководства ЕС, «гигафабрики», финансируемые в рамках InvestAI, должна стать крупнейшими в мире государственно-частными партнёрствами по разработке надёжных решений в сфере искусственного интеллекта. Изначально средства для InvestAI будут поступать от действующих программ с «цифровым» компонентом, вроде Horizon Europe и InvestEU. Вклад могут внести и государства — члены Евросоюза. Примечательно, что в понедельник президент Франции Эммануэль Макрон (Emmanuel Macron) объявил об инвестициях в одни только французские ИИ-проекты €109 млрд (около $112 млрд). Он отметил, что эти проекты смогут составить конкуренцию американскому $500-млрд проекту Stargate, на них Франция сразу выделит гигаватт атомной энергии. Кроме того, вложиться во французские ЦОД обещали и представители ОАЭ. Евросоюз стал одним из первых мировых игроков, принявших всеобъемлющие правила для рынка ИИ — «Закон об ИИ» был подписан 2024 году. США раскритиковали эти нормы, назвав нормативную среду Евросоюза «авторитарной цензурой». За океаном считают, что чрезмерное регулирование способно буквально убить отрасль. Примечательно, что США и Великобритания отказались подписывать декларацию на Парижском ИИ-саммите, которая обязывает страны-участницы обеспечить «открытость, инклюзивность, прозрачность, этичность, безопасность, надежность» искусственного интеллекта и т. д.
12.02.2025 [00:50], Владимир Мироненко
AMD и французские атомщики вместе займутся развитием технологий для ИИ-инфраструктур будущегоAMD объявила о подписании соглашения о намерениях с французским Комиссариатом по атомной энергии и альтернативным источникам энергии (CEA) с целью совместной работы над созданием передовых технологий, компонентов и системных архитектур, которые определят будущее ИИ-вычислений. Сотрудничество позволит использовать сильные стороны обеих организаций в разработке энергоэффективных систем и технологий для вычислительной инфраструктуры следующего поколения, необходимых для поддержки самых ресурсоёмких в мире рабочих ИИ-нагрузок в различных областях — от энергетики до медицины. AMD и CEA планируют провести в 2025 году симпозиум, посвящённый будущему ИИ-вычислений, который соберёт европейских и глобальных разработчиков технологий, стартапы, суперкомпьютерные центры, университеты и политиков с целью укрепления сотрудничества в разработке современных вычислительных технологий ИИ. В CEA отметили, что сотрудничество с AMD является значительным шагом на пути к укреплению международного партнёрства в области HPC, позволяя объединить экспертные знания мирового уровня для удовлетворения растущих потребностей в обслуживании ИИ-нагрузок. В свою очередь, в AMD подчеркнули, что в сотрудничестве с CEA и ведущими французскими инженерами компания стремится приблизить передовые исследования в области ИИ к реальным приложениям, развивая системные архитектуры, которые отвечают требованиям будущих рабочих нагрузок, одновременно расширяя возможности для совместных исследований и разработок США и Франции. 
Источник изображения: AMD Большая часть электроэнергии во Франции производится АЭС, что позволяет обеспечивать внутренние потребности, а также поставлять излишки за рубеж. Франция рассматривает это как ключевой фактор для привлечения инвесторов, стремящихся развивать инфраструктуру энергоёмких ЦОД в стране. По словам президента Франции Эммануэля Макрона (Emmanuel Macron), это позволит разместить в стране 20 % всех ЦОД в мире. В понедельник Макрон объявил, что объём частных инвестиций в ИИ-сектор страны составит в ближайшие несколько лет около €109 млрд.
11.02.2025 [16:24], Владимир Мироненко
ИИ ЦОД за 20 недель: G42 и DataOne построят крупнейший во Франции суперкомьютер на чипах AMD InstinctХолдинг G42 из Абу-Даби (ОАЭ) объявил о стратегических инвестициях во Франции в партнёрстве с недавно образованной DataOne, которая сама себя называет первым в Европе оператором гига-ЦОД для ИИ. Вместе компании в кратчайшие сроки построят в Гренобле ИИ ЦОД, оснащённый ускорителями AMD Instinct. Ожидается, что объект будет полностью введён в эксплуатацию к середине 2025 года. Вычислительные возможности нового ЦОД позволят французским компаниям и учёным разрабатывать передовые модели ИИ, агентов и приложения, а также проводить различные исследования. Реализацией проекта будет заниматься компания Core42, дочернее предприятие G42, совместно с DataOne. По словам главы DataOne Шарля-Антуана Бейни (Charles-Antoine Beyney), на развёртывание крупнейшего ИИ-суперкомпьютера в Европе потребуется всего 20 недель. Для сравнения: кластер xAI Colossus был построен за 122 дня. Как заявила Лиза Су (Lisa Su), председатель и генеральный директор AMD, стратегическое сотрудничество с G42 поможет активизировать французскую экосистему ИИ, предоставив вычислительную мощность, необходимую для поддержки местных стартапов и новаторов, занимающихся передовыми разработками, которые укрепляют французскую экономику. «Работа с G42 является ещё одним примером нашей приверженности объединению открытых экосистем с ведущими в отрасли технологиями ИИ AMD, что обеспечивает возможность государственным учреждениям и частным предприятиям использовать весь потенциал ИИ», — подчеркнула Лиза Су. 
Источник изображения: AMD Инвестиции G42 входят в пакет частных инвестиций в ИИ-инфраструктуру страны на €109 млрд, анонсированный президентом Франции Эммануэле Макроном (Emmanuel Macron) в качестве ответа на представленный в США проект Stargate. Ранее было объявлено о планах ОАЭ вложить при участии фонда MGX €30–50 млрд в проект по созданию кампуса ИИ ЦОД во Франции. В G42 называют инвестиции в ИИ одним из главных направлений своей деятельности. Деятельность холдинга получила поддержку Microsoft, инвестировавшей в него $1,5 млрд. В прошлом году G42 договорился с Cerebras о строительстве в Техасе ИИ-суперкомпьютера со 173 млн ядер.
04.02.2025 [13:52], Сергей Карасёв
Уязвимость в процессорах AMD позволяет загрузить модифицированный микрокодСпециалисты Google Security Team сообщили об обнаружении опасной уязвимости в проверке подписи микрокода для процессоров AMD на архитектуре от Zen1 до Zen4. Уязвимость даёт возможность загрузить модифицированный микрокод, позволяющий скомпрометировать технологию виртуализации с шифрованием SEV (Secure Encrypted Virtualization) и SEV-SNP (Secure Nested Paging), а также вмешаться в работу Dynamic Root of Trust for Measurement (DRTM). Успешная эксплуатация «дыры» может привести к потере защиты конфиденциальности. Проблема заключается в том, что процессоры используют небезопасную хеш-функцию при проверке подписи обновлений микрокода. Брешь позволяет злоумышленнику с привилегиями локального администратора загрузить вредоносный микрокод CPU. Исследователи подготовили пример атаки на AMD EPYC 7B13 (Milan) и Ryzen 9 7940HS (Phoenix), в результате которой функция RDRAND вместо возврата случайного числа всегда возвращает 4. AMD подготовила патчи для защиты функций SEV в EPYC 7001 (Naples), EPYC 7002 (Rome), EPYC 7003 (Milan и Milan-X), а также EPYC 9004 (Genoa, Genoa-X и Bergamo/Siena) и Embedded-вариантов EPYC 7002/7003/9004. Для устранения проблемы требуется обновление микрокода чипов. Уязвимость получила идентификатор CVE-2024-56161. Они признана достаточно опасной — 7.2 (High) по шкале CVSS. 
Источник изображения: AMD Отмечается, что Google впервые уведомила AMD об уязвимости 25 сентября 2024 года. При этом в связи с широкой распространённостью процессоров AMD и разветвлённой сетью их поставок Google сделала единовременное исключение из стандартной политики раскрытия информации об уязвимостях и отложила публичное уведомление до 3 февраля 2025-го. Кроме того, Google не стала раскрывать полные детали о «дыре», чтобы предотвратить возможные атаки. Все подробности и инструменты будут опубликованы 5 марта 2024 года.
03.02.2025 [15:06], Сергей Карасёв
Разработчик гипермасштабируемых аналитических хранилищ Ocient выбрал чипы AMD EPYC GenoaКомпания Ocient, специализирующаяся на разработке гипермасштабируемых аналитических хранилищ данных, объявила о заключении соглашения о сотрудничестве с AMD с целью повышения производительности, снижения затрат и максимизации эффективности ресурсоёмких вычислений и рабочих нагрузок ИИ. Ocient была основана в 2016 году. Компания предлагает платформу на основе реляционной базы данных с массовым параллелизмом, которая способна анализировать огромные объёмы информации (триллионы строк) за секунды или минуты. Хранилище Ocient Hyperscale Data Warehouse (OHDW) использует архитектуру Compute Adjacent Storage Architecture (CASA) для устранения узких мест в сетевой инфраструктуре и обеспечения максимально быстрого доступа к данным. Функция Zero Copy Reliability отвечает за высокую надёжность хранения информации без репликации с помощью кодирования с контролем чётности. 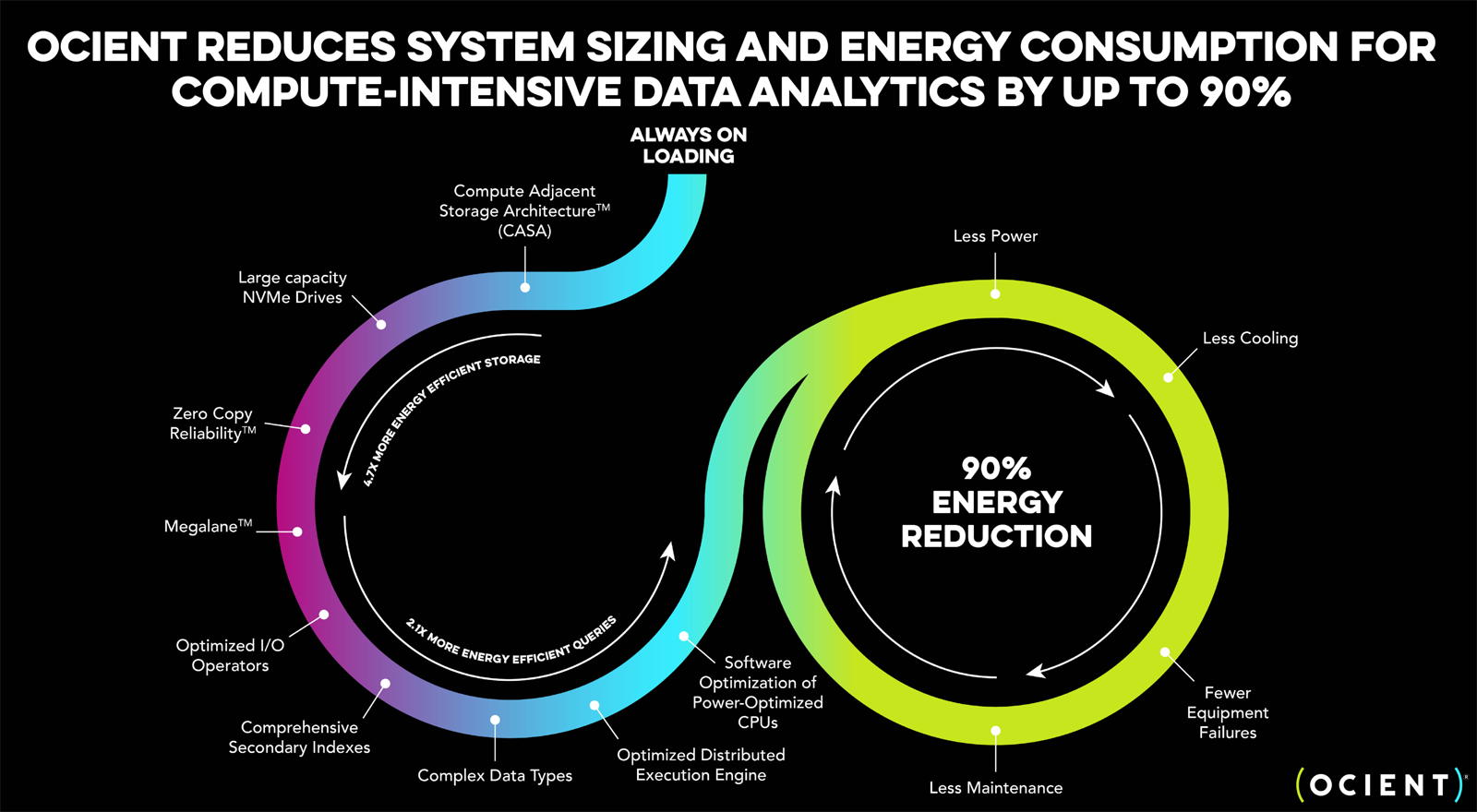
Источник изображения: Ocient Генеральный директор Ocient Крис Гладвин (Chris Gladwin) отмечает, что задачи ИИ и аналитики больших данных создают огромную вычислительную нагрузку на ЦОД по всему миру. Это означает, что повышение эффективности оборудования и программного обеспечения имеет решающее значение для снижения расходов, уменьшения энергопотребления и улучшения производительности. В этой связи Ocient сделала выбор в пользу процессоров AMD EPYC 9654 поколения Genoa с 96 вычислительными ядрами, которые придут на смену 28-ядерным чипам Intel Xeon Gold 6348 семейства Ice Lake-SP. Говорится, что благодаря более высокой плотности ядер изделия AMD обеспечат трёхкратный рост производительности для ресурсоёмких вычислительных задач. При этом снизятся эксплуатационные расходы, что обусловлено повышением быстродействия и энергоэффективности. Плюс к этому достигается гибкость масштабирования.
31.01.2025 [07:02], Сергей Карасёв
Tesla наращивает вычислительные мощности для обучения человекоподобного робота OptimusГлава Tesla Илон Маск (Elon Musk) сообщил о том, что компания расширяет вычислительную инфраструктуру, необходимую для обучения человекоподобного робота Optimus. По словам Маска, в долгосрочной перспективе этот проект может принести более $10 трлн. Предполагается, что антропоморфные машины Optimus смогут выполнять самые разные задачи в быту и на производствах, взаимодействия с людьми. Но для разработки ИИ-систем робота требуются огромные вычислительные ресурсы. Маск подчёркивает, что обучение такой машины — гораздо более сложная задача, нежели обучение интеллектуальных автомобилей с автопилотом. Глава Tesla говорит, что у человекоподобного робота, вероятно, в 1000 раз больше функций, чем у транспортного средства. Это не означает, что обучение масштабируется в 1000 раз, но прирост вычислительных мощностей на порядок всё же необходим. «Потребности в обучении для гуманоидного робота Optimus, по всей видимости, как минимум в 10 раз превышают то, что требуется для создания полнофункционального умного автомобиля», — заявил Маск. 
Источник изображения: channeliam.com Он не стал вдаваться в подробности о том, какая инфраструктура нужна компании для обучения Optimus. Ранее сообщалось, что Tesla планирует ввести в эксплуатацию дата-центр с 50 тыс. ускорителей NVIDIA H100. Кроме того, у компании есть кластер Dojo на базе собственных ускорителей D1. Маск говорит, что с учётом потенциала проекта Optimus даже инвестиции в размере $500 млрд в вычислительные ресурсы могут быть оправданными, хотя такую сумму Tesla на текущем этапе вкладывать не планирует. Вероятно, указанная сумма — это отсылка к проекту Stargate. Tesla потратила более $10 млрд на капитальные затраты в 2024 году. Примерно столько же средств компания намерена выделить в 2025 и 2026 годах. Ранее Маск говорил, что небольшое количество роботов Optimus будет задействовано на предприятиях Tesla до конца 2024-го. На коммерческом рынке эти человекоподобные машины, как ожидается, появятся в 2026 году.
30.01.2025 [17:59], Руслан Авдеев
Chevron и Engine No. 1 построят в США газовые электростанции мощностью до 4 ГВт для прямого питания ИИ ЦОДАмериканский нефтегазовый гигант Chevron и хедж-фонд Engine No. 1 объединились для масштабного строительства электростанций, работающих на природном газе, которые будут использоваться для питания дата-центров на юго-востоке, Среднем Западе и западе США, сообщает Datacenter Dynamics. Поставщиком оборудования вновь станет GE Vernova, чьи газовые турбины запитают и другие ЦОД, в том числе Stargate. Ожидается, что стоимость проекта составит до $8 млрд. Целью является создание мощностей до 4 ГВт, ввод в эксплуатацию намечен в конце 2027 года. Вырабатываемая турбинами энергия будет использоваться в автономной системе, напрямую питая ЦОД. Проект разработан с возможностью интеграции систем улавливания и хранения углерода (CCS). Chevron уже инвестировала в некоторые из подобных проектов очистки, например — в CCS ION Clean Energy. По словам основателя Engine No. 1 Криса Джеймса (Chris James), энергия является ключом к доминированию США в области ИИ. Используя большие собственные запасы природного газа для генерации электричества станциями, напрямую подключенными к ЦОД, можно будет обеспечить лидерство в сфере ИИ. 
Источник изображения: Andreas Felske/unsplash.com Инвестиционная компания Engine No. 1, основанная в 2020 году, в 2021 году выступила против ориентации гиганта ExxonMobil на ископаемое топливо, заявив, что это ставит под угрозу будущие доходы. Хотя компания владела лишь долей 0,02 % в ExxonMobil, её поддержали три крупнейших акционера, включая Blackrock, Vanguard и Slate Street. После этого Exxon была вынуждена расширить совет директоров, добавить в него директора по устойчивому инвестированию и вкладывать средства в CCS. Однако с приходом нового правительства США политика изменилась, теперь в приоритете ископаемое топливо. Та же ExxonMobil впервые построит 1,5-ГВт электростанцию на природном газе специально для питания ИИ ЦОД. В конце прошлого года Meta✴ также объявила о новом ЦОД на северо-востоке Луизианы (по другим данным $5 млрд), который будет запитан от 2,26-ГВт газовой электростанции Entergy Louisiana. Заявления компаний отражают более общие тенденции на рынке, поскольку спрос на природный газ увеличивается в связи с ростом потребности в энергии для ИИ ЦОД.
30.01.2025 [08:58], Владимир Мироненко
Суперкомпьютер Aurora стал доступен исследователям со всего мираАргоннская национальная лаборатория (ANL) Министерства энергетики США объявила о доступности суперкомпьютера Aurora экзафлопсного класса для исследователей по всему миру. Как указано в пресс-релизе, благодаря широким возможностям моделирования, ИИ и анализа данных, Aurora будет способствовать прорывам в целом ряде областей, включая проектирование самолётов, космологию, разработку лекарств и исследования в сфере ядерной энергетики. Майкл Папка (Michael Papka), директор Argonne Leadership Computing Facility (ALCF), вычислительного центра Управления науки Министерства энергетики США, отметил, что уже первые проекты с использованием Aurora продемонстрировали его огромным потенциал. «С нетерпением ждём, как более широкое научное сообщество будет использовать систему для преобразования своих исследований», — заявил он. Aurora уже зарекомендовала себя как один мировых лидеров по производительности ИИ, заняв первое место в бенчмарке HPL-MxP в ноябре 2024 года, отметила ANL. Возможности машины для выполнения ИИ-задач используются учёными для открытия новых материалов для аккумуляторов, разработки новых лекарств и ускорения исследований в области термоядерной энергии. Перед его развёртыванием команда под руководством ANL продемонстрировала потенциал Aurora, используя его для обучения моделей ИИ для моделирования белков. 
Источник изображения: ANL В числе первых проектов, реализуемых с помощь Aurora, — разработка высокоточных моделей сложных систем, таких как кровеносная система человека, ядерные реакторы и сверхновые звезды. Кроме того, способность суперкомпьютера к обработке огромных наборов данных имеет решающее значение для анализа растущих потоков данных из крупных исследовательских установок, таких как Усовершенствованный источник фотонов (APS) Аргоннской национальной лаборатории, научные объекты Управления науки Министерства энергетики США (DoE) и Большой адронный коллайдер Европейской организации ядерных исследований (CERN). Чтобы гарантировать готовность Aurora к использованию для научных исследования с первого дня запуска, при его создании применили так называемое совместное проектирование. Используя этот подход, команда Aurora разработала в тандеме аппаратное и программное обеспечение для оптимизации производительности и удобства использования. Это потребовало многолетнего сотрудничества между ALCF, Intel, HPE и исследователями по всей стране, участвующими в проекте Exascale Computing Project (ECP) Министерства энергетики США и программе Aurora Early Science Program (ESP) центра. Пока велись работы по монтажу Aurora, команды ECP и ESP запускали приложения для стресс-тестирования оборудования, одновременно оптимизируя свой код для максимально эффективной работы в системе. В результате десятки научных приложений, а также широкий спектр ПО и инструментов разработки были готовы ещё до того, как Aurora ввели в строй, говорится в пресс-релизе.
29.01.2025 [12:21], Сергей Карасёв
System76 представила мини-компьютер Meerkat на базе Intel Meteor Lake, Linux и CorebootКомпания System76 анонсировала компьютер небольшого форм-фактора Meerkat следующего поколения, который построен на аппаратной платформе Intel Meteor Lake и ОС с ядром Linux. Новинка уже доступна для заказа по ориентировочной цене от $800. Устройство заключено в корпус с размерами 117,5 × 110 × 49 мм. В зависимости от модификации применяется процессор Core Ultra 7 155H с 16 ядрами (6P+8E+2LPE; 22 потока; до 4,8 ГГц) или чип Core Ultra 5 125H с 14 ядрами (4P+8E+2LPE; 18 потоков; до 4,5 ГГц). В обоих случаях задействован графический ускоритель Intel Arc. Объём оперативной памяти DDR5-5600 может достигать 96 Гбайт. Допускается установка SSD формата M.2 (PCIe 4.0 NVMe) вместимостью до 8 Тбайт, а также SFF-накопителя с интерфейсом SATA-3, ёмкость которого также может достигать 8 Тбайт. В оснащение входят адаптеры Wi-Fi 6E (802.11ax) и Bluetooth 5.3, двухпортовый сетевой контроллер 2.5GbE (Intel). Во фронтальной части расположены по одному порту USB 3.2 Gen2 Type-A, USB 4/Thunderbolt 4 (с поддержкой DP 2.1) и USB 3.2 Gen2x2 Type-C (с поддержкой DP1.4a), 3,5-мм аудиогнездо. Сзади находятся два разъёма HDMI 2.1, два гнезда RJ-45 для сетевых кабелей и два порта USB 3.2 Gen2 Type-A. Возможен вывод изображения одновременно на четыре монитора. 
Источник изображения: System76 На мини-компьютер может быть установлена ОС Pop!_OS 22.04 LTS, Ubuntu 22.04/24.04 LTS. Используется открытый загрузчик Coreboot (альтернатива BIOS/UEFI) с прошивкой System76 Open Firmware. Разработчик подчёркивает, что конструкция Meerkat допускает возможность апгрейда ключевых компонентов, таких как модули ОЗУ и накопители. Питание обеспечивает внешний адаптер мощностью 90 или 120 Вт (в зависимости от конфигурации компьютера). Новинка поставляется в более чем 60 стран по всему миру и обеспечивается пожизненной поддержкой. При этом System76 предоставляет гарантию сроком один год. Если устройство по какой-то причине не подойдёт покупателю, его можно будет вернуть в течение 30 дней, обещает производитель. |
|

