Материалы по тегу: c
|
29.01.2025 [12:17], Сергей Карасёв
Spectra Logic представила SAS-коммутатор OSW-2400 для ленточных СХДКомпания Spectra Logic анонсировала коммутатор Spectra OSW-2400, предназначенный для подключения ленточных накопителей в дата-центрах. Новинка, выполненная на основе стандарта Serial-Attached SCSI 4.0 (SAS-4), уменьшает или полностью устраняет необходимость в развёртывании более дорогой сетевой инфраструктуры Fibre Channel. Коммутатор предоставляет до 48 линий 24G, работающих на скорости 22,5 Гбит/с. Таким образом, обеспечивается пропускная способность до 1,08 Тбит/с, а совокупная скорость передачи данных достигает 108 Гбайт/с. Отмечается, что затраты на подключение оборудования в случае Spectra OSW-2400 до 70 % ниже, чем при использовании сопоставимой инфраструктуры Fibre Channel. 
Источник изображения: Spectra Logic По заявлениям Spectra Logic, благодаря использованию активных оптических кабелей новинка обеспечивает возможность организации соединений протяжённостью до 100 м. Это позволяет охватывать ЦОД площадью до 10 тыс. м2, а также организовывать передачу данных между несколькими этажами и даже между отдельно стоящими зданиями. Коммутатор поддерживает ленточные приводы SAS-3, включая LTO-9 и IBM TS1170 Enterprise. Кроме того, заявлена обратная совместимость с устройствами SAS-2, в том числе LTO-6, LTO-7, LTO-8 и IBM TS1160 Enterprise. Поддерживаются ленточные библиотеки TFinity, T950, Spectra Cube и Spectra Stack. Изделие оборудовано 12 портами Mini-SAS HD (24/12 Gb), к каждому из которых можно подключить до четырёх устройств, например, серверов или ленточных накопителей. Кроме того, имеется сетевой порт управления 1GbE. Коммутатор выполнен в форм-факторе 1U с размерами 439,7 × 304,8 × 44,5 мм. Предусмотрены два блока питания мощностью 220 Вт с возможностью горячей замены. За охлаждение отвечают три вентилятора, которые также допускают горячую замену.
28.01.2025 [23:00], Руслан Авдеев
Первый ЦОД Stargate получит собственные газовые турбины, солнечную электростанцию и энергохранилище
caterpillar
crusoe energy
general electric
hardware
openai
oracle
softbank
stargate
аккумулятор
ибп
ии
кадры
сша
цод
электропитание
энергетика
Для бесперебойного снабжения электроэнергией американского суперпроекта Stargate, помимо подключения к энергосети, будут использоваться солнечная энергия, природный газ, аккумуляторные энергохранилища и дизель-генераторы, сообщает Datacenter Dynamics. Строительство первого ЦОД уже начато в Техасе. По данным источников Bloomberg, знакомых с планами развития Stargate, часть энергии, вероятно, будет поступать от SB Energy, дочерней структуры компании SoftBank, предлагающей солнечные и аккумуляторные решения. SB Energy уже довольно давно планировала запитать ЦОД в Техасе. В прошлом году компания объявила о трёх соответствующих проектах для дата-центров Google. Речь идёт о «солнечном поясе» Orion Solar Belt — солнечных электростанциях Orion I, Orion II и Orion III суммарной мощностью почти 900 МВт (258 МВТ, 302 МВт и 315 МВт соответственно). OpenAI сообщила журналистам, что рассматриваются различные варианты модернизации энергосистемы Соединённых Штатов с использованием самых разных технологий — от атомной энергетики до аккумуляторных энергохранилищ. Поскольку одной только солнечной энергии для Stargate вряд ли хватит, OpenAI будет использовать и другие источники. Подрядчики Stargate уже подали заявку на строительство электростанции на природном газе мощностью 360,5 МВт и стоимостью около $500 млн. Всего будет задействовано десять газовых турбин — по пять от GE Vernova и Solar Turbines («дочка» Caterpillar). Они напрямую будут питать дата-центр. Заявку подала компания, работающая в интересах Crusoe Energy, которая, в свою очередь, ещё летом начала строительство 205-МВт ИИ ЦОД для Oracle и OpenAI в техасском Абилине (Abilene), также известного как Project Ludicrous. Именно этот кампус, как ожидается, станет первой действующей площадкой Stargate. Кроме того, уже получено разрешение на установку резервных дизель-генераторов. 
Источник изображения: Thomas Richter/unsplash.com Дополнительно появилась информация о том, что OpenAI ищет для Stargate менеджера по закупкам, ответственного за оборудованиее и работу с поставщиками, и технического руководителя программ, отвечающий за инфраструктурную стратегию. Обе вакансии предполагают широкий круг обязанностей, от соискателей требуется не менее пяти лет опыта работы в крупных проектах. Не так давно OpenAI уже переманила из Meta✴ специалиста по цепочкам поставок для помощи в реализации проекта Stargate.
28.01.2025 [15:38], Руслан Авдеев
Газ и атом: NextEra с GE Vernova развернут газовые турбины и перезапустят АЭС, чтобы запитать ИИ ЦОДАмериканский производитель энергии NextEra Energy заключил соглашение с поставщиком энергетического оборудования GE Vernova — компании совместно организуют поставки энергии газовых электростанций для ЦОД. Кроме того, NextEra намерена перезапустить АЭС Duane Arnold Energy Center (DAEC) в Айове, сообщает Datacenter Dynamics. Об этом NextEra рассказала во время публикации финансового отчёта за IV квартал и 2024 год в целом. По словам NextEra, рамочное соглашение с GE Vernova будет действовать четыре года. Компании будут вместе искать узловые точки в энергосистеме США, которые выиграют от новых генерирующих мощностей. Новое сотрудничество позволит поставить до нескольких гигаватт дата-центрам и другим промышленным объектам, перенести производство энергии и улучшить обслуживание коммунальных предприятий, муниципалитетов, коммерческих и иных структур. Партнёрство рассчитано на крупных клиентов и обеспечит комплексное решение, предусматривающее использование газовых генерирующих мощностей, возобновляемых источников энергии и энергохранилищ, которыми партнёры намерены владеть в равных долях. Клиенты смогут рассчитывать на долгосрочное сотрудничество. В NextEra даже допускают возможность передачи права собственности на газовую генерацию, если это станет частью более масштабной сделки, которая будет включать возобновляемые источники энергии. 
Источник изображения: Chad Peltola/unsplash.com Что касается 601-МВт АЭС Duane Arnold, о перезапуске которой сообщалось ранее, компания уже обратилась в Комиссию по ядерному регулированию (NRC). Ожидается, что станция, проработавшая 45 лет и закрытая в 2020 году, сможет снова заработать уже к концу 2028 года. Впрочем, NextEra признаёт, что перезапуск не сможет в действительно значимой степени удовлетворить рост спроса на энергию для ЦОД. Поэтому приходится рассчитывать на возобновляемые источники энергии и энергохранилища, а постепенно к ним добавится и генерация энергии на природном газе. Заявления соответствуют распространённой в последнее время среди коммунальных служб концепции — на фоне роста спроса на электричество они готовы использовать все доступные источники энергии. В результате природный газ всё больше востребован в сегменте энергетики для ЦОД, несколько производителей электричества объявили об инвестициях в соответствующий рынок. Ранее в январе поддерживаемая Сэмом Альтманом (Sam Altman) компания Oklo совместно с RPower объявили о трёхэтапном подходе к питанию, который предусматривает установку генераторов на природном газе в течение 24 месяцев для удовлетворения насущных потребностей ИИ ЦОД. Позже, по мере коммерческой готовности, будут установлены малые модульные реакторы (SMR) компании Oklo, а газовые генераторы будут использоваться только в качестве резервных питания.
28.01.2025 [00:14], Владимир Мироненко
Дороговизна и высокое энергопотребление ИИ-ускорителей NVIDIA открыли новые горизонты для Marvell и BroadcomВзрывной рост популярности ChatGPT и других решений на базе генеративного ИИ вызвал беспрецедентный спрос на вычислительные мощности, что привело к дефициту ИИ-ускорителей, пишет DIGITIMES. NVIDIA занимает львиную долю рынка ИИ-чипов, а ведущие поставщики облачных услуг, такие как Google, Amazon и Microsoft, активно занимаются проектами по разработке собственных ускорителей, стремясь снизить свою зависимость от внешних поставок. Всё большей популярностью у крупных облачных провайдеров пользуются ASIC, поскольку они стремятся оптимизировать чипы под свои конкретные требования, отметил DIGITIMES. ASIC обеспечивают высокую производительность и энергоэффективность в узком спектре задач, что делает их альтернативой универсальным ускорителям NVIDIA. Несмотря на доминирование NVIDIA на рынке, высокое энергопотребление её чипов в сочетании с высокой стоимостью позволило ASIC занять конкурентоспособную нишу. Особенно хорошо ASIC подходят для обучения и инференса ИИ-моделей, предлагая значительно более высокие показатели производительности в пересчёте на 1 Вт по сравнению с GPU общего назначения. Также ASIC предоставляют заказчикам больший контроль над своим технологическим стеком. На рынке разработки ASIC основными конкурентами являются Broadcom и Marvell, которые используют разные технологии и стратегические подходы. 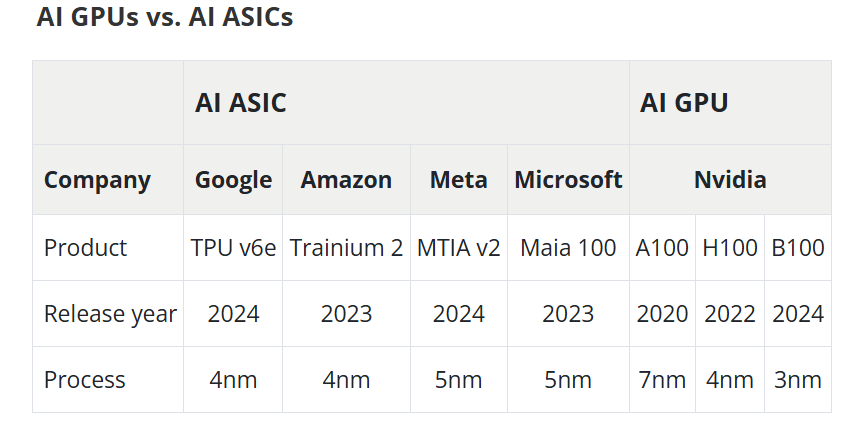
Источник изображений: DIGITIMES Marvell укрепила свои позиции на рынке, в частности, благодаря партнёрству с Google в разработке серверных Arm-чипов, расширив при этом стратегическое сотрудничество со своим основным клиентом — Amazon. TPU v6e от Google представляет собой самую передовую ASIC ИИ среди чипов, разработанных четырьмя ведущими облачными провайдерам, приближаясь по производительности к H100. Однако она всё ещё отстает от ускорителей NVIDIA примерно на два года, утверждает DIGITIMES. Созданный Marvell и Amazon ускоритель Trainium 2 по производительности находится между NVIDIA A100 и H100. В ходе последнего отчёта о финансовых результатах Marvell поделилась прогнозом значительного роста выручки от ASIC, начиная с 2024 года (2025 финансовый год), обусловленного Trainium 2 и Google Axion. В частности, совместный с Amazon проект Marvell Inferential ASIC предполагается запустить в массовое производство в 2025 году (2026 финансовый год), в то время как Microsoft Maia, как ожидается, начнет приносить доход с 2026 года (2027 финансовый год). 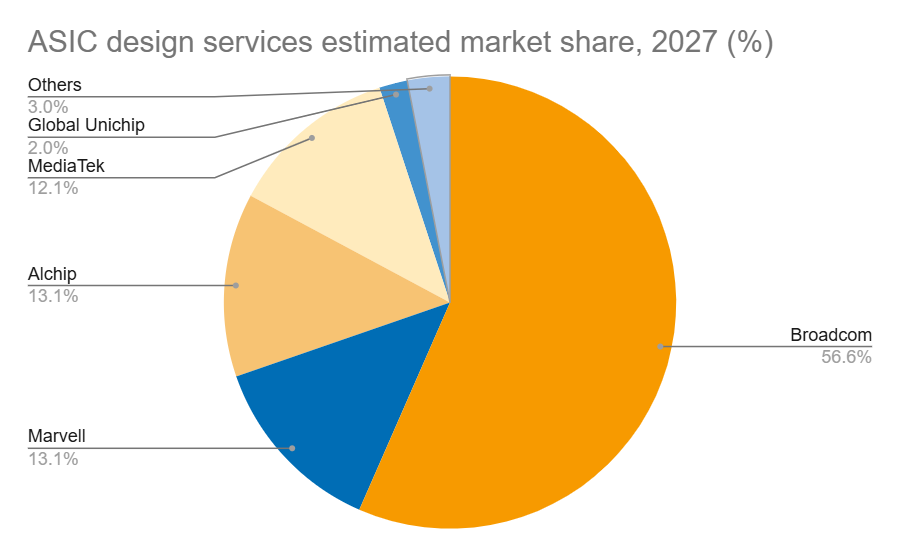 Как утверждают в Morgan Stanley, хотя бизнес Marvell по производству кастомных чипов является ключевым драйвером роста его подразделения по разработке решений для ЦОД, он также несёт в себе значительную неопределённость. Краткосрочные прогнозы Morgan Stanley для продуктов Marvell/Trainium положительны, что подтверждается возросшими мощностями TSMC по упаковке чипов методом CoWoS, планами Amazon по расширению производства и уверенностью Marvell в рыночном спросе. Однако в долгосрочной перспективе конкурентная среда создает проблемы. Появление компаний вроде WorldChip Electronics в секторе вычислительных чипов может заставить Marvell переориентироваться на сетевые решения. Кроме того, потенциальное снижение прибыли от Trainium после 2026 года означает, что Marvell нужно будет обеспечить запуск новых проектов для поддержания динамики роста, говорят аналитики. Broadcom и Marvell являют собой примеры разных стратегий развития в секторе ASIC, отмечает DIGITIMES. Broadcom отдаёт приоритет крупномасштабной интеграции и проектированию платформ, подкрепляя свой подход значительными инвестициями в НИОКР и сложной технологической интеграцией. В свою очередь, Marvell развивается за счёт стратегических приобретений, например, Cavium, Avera и Innovium, благодаря чему расширяет своё портфолио технологий.
20.01.2025 [12:32], Сергей Карасёв
IDC: квартальные расходы на облачную инфраструктуру взлетели на 115 %Компания International Data Corporation (IDC) обнародовала результаты исследования мирового рынка облачных инфраструктур в III квартале 2024 года. Затраты в годовом исчислении взлетели на 115,3 %, достигнув $57,3 млрд. При этом необлачный сегмент показал рост на 28,6 % — до $19,6 млрд. Аналитики учитывает поставки серверов и СХД для выделенных и публичных облачных платформ. Расходы на публичную инфраструктуру в III квартале 2024 года достигли $47,9 млрд, увеличившись на 136,5 % по сравнению с тем же периодом в 2023-м. Сегменты выделенных систем показал рост на 47,6 % в годовом исчислении — до $9,3 млрд. При этом на публичные платформы пришлось 62,3 % от суммарных затрат. 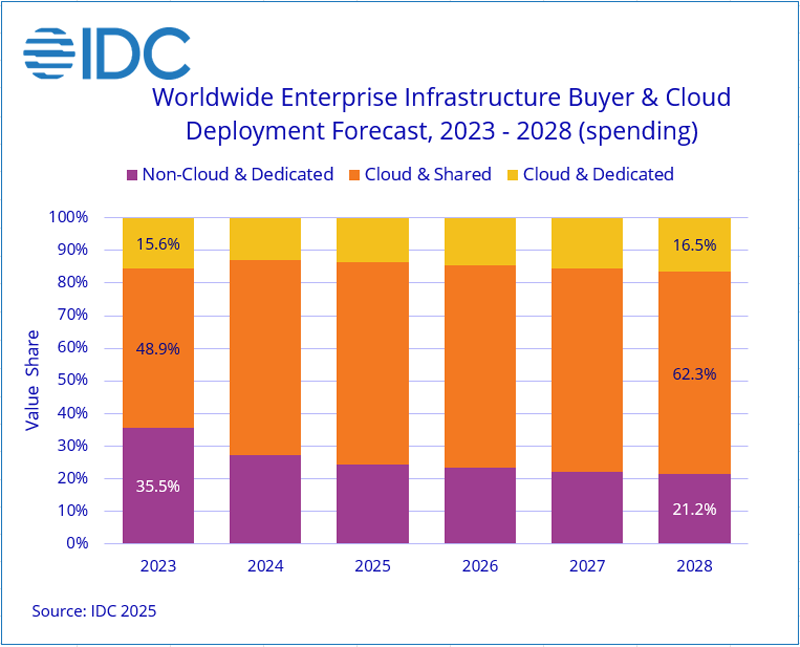
Источник изображения: IDC С географической точки зрения рост в III четверти 2024 года показали практически все регионы. Самые высокие показатели зафиксированы в США и Китае — плюс 148,3 % и 100 % соответственно. В Азиатско-Тихоокеанском регионе (исключая Китай и Японию) отмечена прибавка в 90,3 % по сравнению с III кварталом 2023-го. Япония, Западная Европа, Канада и Латинская Америка продемонстрировали рост на 73,5 %, 40,1 %, 38,5 % и 34,8 % соответственно. На Ближнем Востоке и в Африке зарегистрирован рост на уровне 6,7 %. Отрицательная динамика зафиксирована только в Центральной и Восточной Европе — минус 1,7 % год к году. IDC прогнозирует, что в 2024 году расходы на облачные инфраструктуры в мировом масштабе вырастут на 74,3 % по сравнению с 2023-м, достигнув $192,0 млрд. В сегменте публичных облаков ожидается рост на 88,9 % в годовом исчислении — до $157,8 млрд. Выделенные облака, по мнению аналитиков IDC, покажут прибавку в 28,6 % — до $34,2 млрд. При этом необлачная инфраструктура, как прогнозируется, вырастет на 17,9 % — до $71,4 млрд долларов США. IDC прогнозирует, что в долгосрочной перспективе расходы на облачные инфраструктуры продемонстрируют показатель CAGR (среднегодовой темп роста в сложных процентах) на уровне 24,2 %: объём рынка к 2028 году достигнет $325,5 млрд. Расходы на публичные платформы составят 79,1 % от общей суммы: в данном сегменте величина CAGR ожидается в размере 25,2 % с результатом $257,4 млрд в 2028 году. Затраты на выделенные облака будут расти с величиной CAGR на уровне 20,7 %, достигнув $68,2 млрд. Расходы на необлачную инфраструктуру покажут значение CAGR в 7,6 % и достигнут $87,5 млрд к 2028 году.
20.01.2025 [07:53], Владимир Мироненко
SRAM, да и только: d-Matrix готовит ИИ-ускоритель CorsairСтартап d-Matrix создал ИИ-ускоритель Corsair, оптимизированный для быстрого пакетного инференса больших языковых моделей (LLM). Архитектура ускорителя основана на модифицированных ячейках SRAM для вычислений в памяти (DIMC), работающих на скорости порядка 150 Тбайт/с. Новинка, по словам компании, отличается производительностью и энергоэффективностью, пишет EE Times. Массовое производство Corsair начнётся во II квартале. Среди инвесторов d-Matrix — Microsoft, Nautilus Venture Partners, Entrada Ventures и SK hynix. d-Matrix фокусируется на пакетном инференсе с низкой задержкой. В случае Llama3-8B сервер d-Matrix (16 четырёхчиплетных ускорителей в составе восьми карт) может производить 60 тыс. токенов/с с задержкой 1 мс/токен. Для Llama3-70B стойка d-Matrix (128 чипов) может производить 30 тыс. токенов в секунду с задержкой 2 мс/токен. Клиенты d-Matrix могут рассчитывать на достижение этих показателей для размеров пакетов порядка 48–64 (в зависимости от длины контекста), сообщила EE Times руководитель отдела продуктов d-Matrix Шри Ганесан (Sree Ganesan). 
Источник изображений: d-Matrix Производительность оптимизирована для исполнения моделей в расчёте до 100 млрд параметров на одну стойку. По словам Ганесан, это реалистичный сценарий использования LLM. В таких сценариях решение d-Matrix обеспечивает 10-кратное преимущество в интерактивности (время до получения токена) по сравнению с решениями на базе традиционных ускорителей, таких как NVIDIA H100. Corsair ориентирован на модели размером менее 70 млрд параметров, подходящих для генерации кода, интерактивной генерации видео или агентского ИИ, которые требуют высокой интерактивности в сочетании с пропускной способностью, энергоэффективностью и низкой стоимостью.  Ранние версии архитектуры d-Matrix использовали MAC-блоки на базе SRAM-ячеек, дополненных большим количеством транзисторов для операций умножения. Сложение же выполнялось в аналоговом виде с использованием разрядных линий, измерения тока и аналого-цифрового преобразования. В 2020 году компания выпустила чиплетную платформу Nighthawk на основе этой архитектуры. «[Nighthawk] продемонстрировал, что мы можем значительно повысить точность по сравнению с традиционными аналоговыми решениями, но мы всё ещё отстаем на пару процентных пунктов от традиционных решений типа GPU», — сказал EE Times генеральный директор d-Matrix Сид Шет (Sid Sheth). 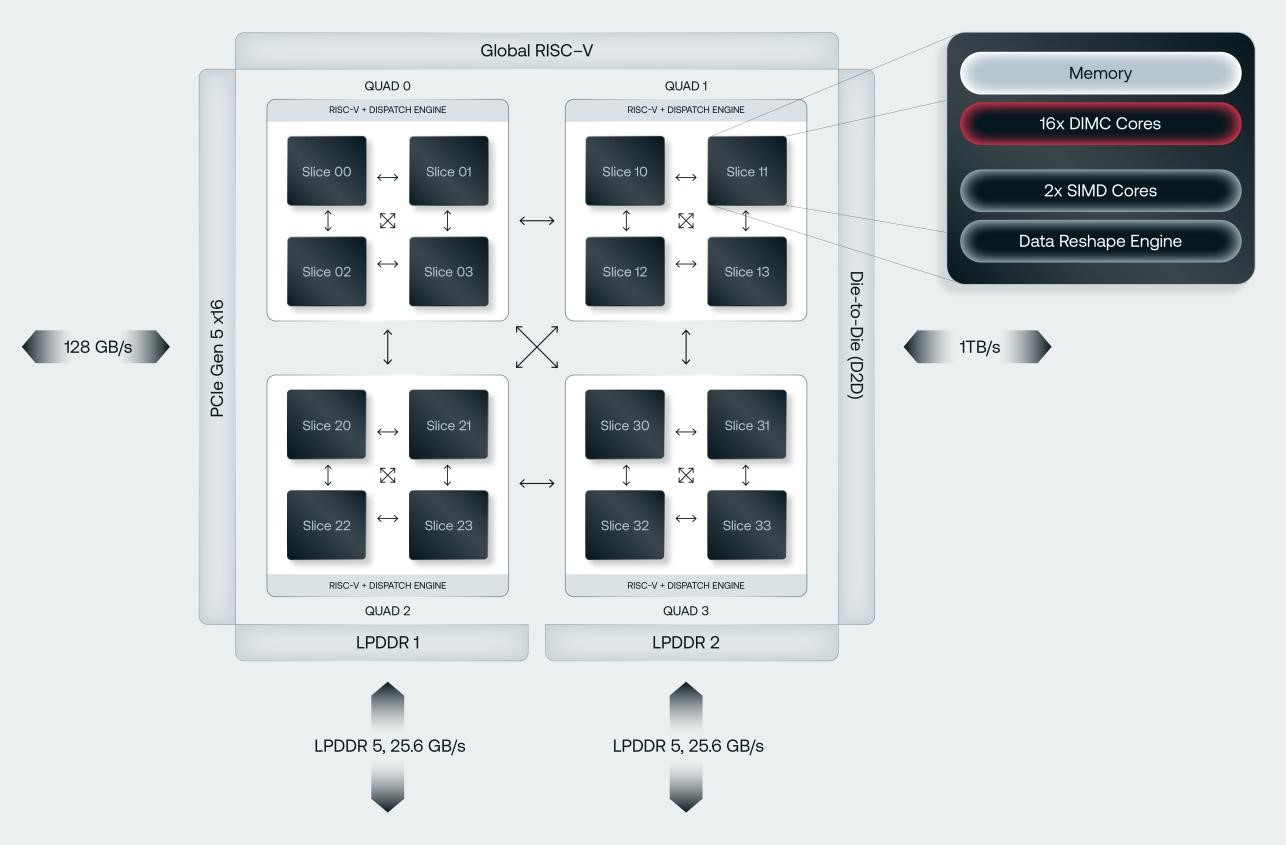 Однако потенциальным клиентам не понравилось, что при таком подходе возможно снижение точности, так что в Corsair компания вынужденно сделала выбор в пользу полностью цифрового сумматора. ASIC d-Matrix включает четыре чиплета, каждый из которых содержит по четыре вычислительных блока, объединённых посредством DMX Link по схеме каждый-с-каждым, и по одному планировщику и RISC-V ядру. Внутри каждого вычислительного блока есть 16 DIMC-ядер, состоящих из наборов SRAM-ячеек (64×64), а также два SIMD-ядра и движок преобразования данных. Суммарно доступен 1 Гбайт SRAM с пропускной способностью 150 Тбайт/с. 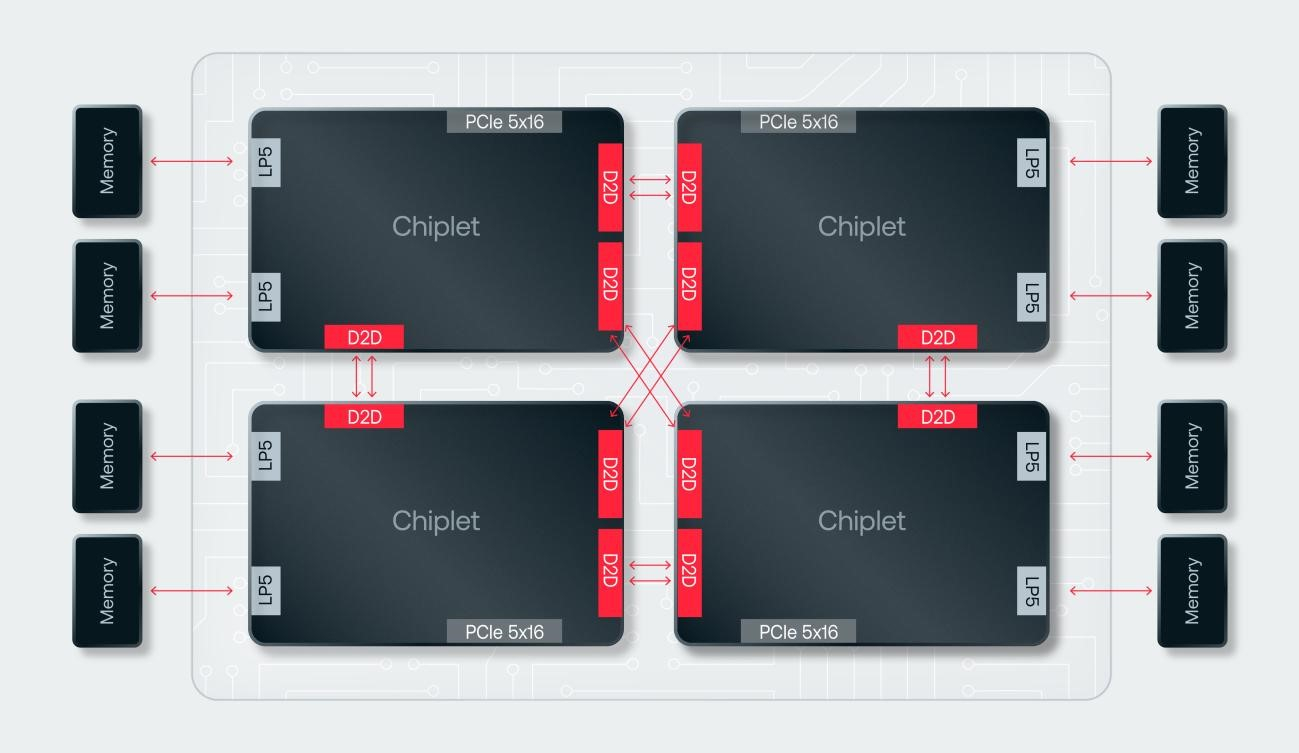 ASIC объединён со 128 Гбайт LPDDR5 (до 400 Гбайт/с) посредством органической подложки (без дорогостоящего кремниевого интерпозера). Хотя текущее поколение ASIC включает только четыре чиплета именно из-за ограничений подложки, в будущем их количество увеличится. Внешние интерфейсы ASIC представлены стандартным PCIe 5.0 x16 (128 Гбайт/с) и фирменным интерконнектом DMX Link (1 Тбайт/с) для объединения чиплетов. 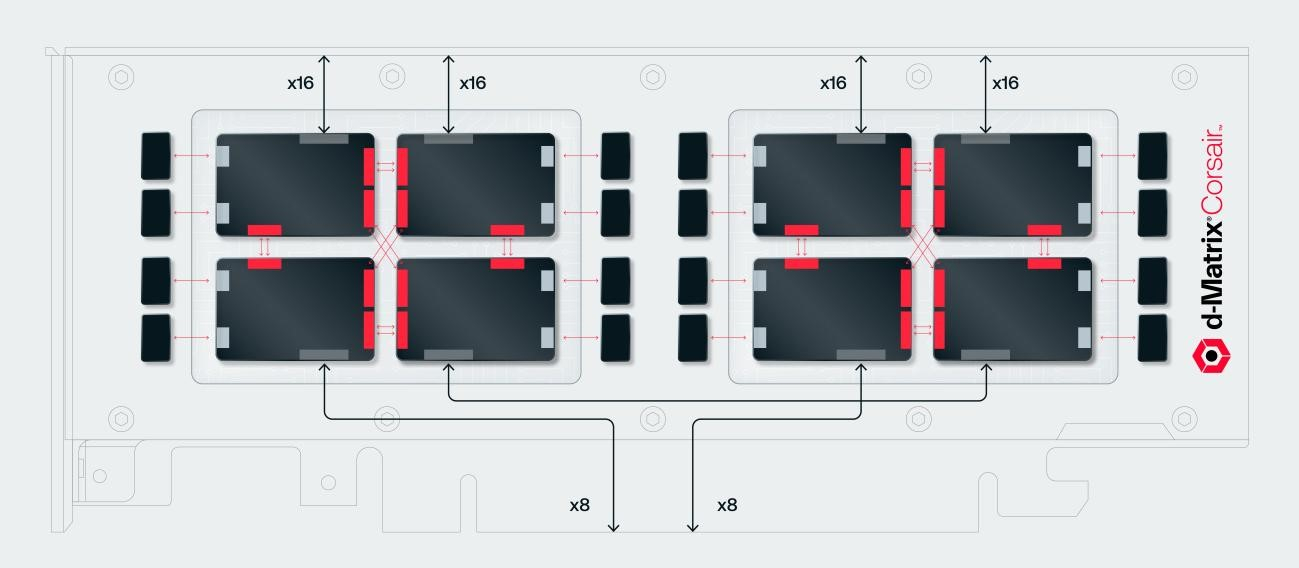 FHFL-карта Corsair включает два ASIC d-Matrix (т.е. всего восемь чиплетов) и имеет TDP на уровне 600 Вт. Ускоритель работает с форматами данных OCP MX (Microscaling Formats) и обеспечивает до 2400 Тфлопс в MXINT8-вычислениях или 9600 Тфолпс в случае MXINT4. Две карты Corsair можно объединить посредством 512-Гбайт/с мостика DMX Bridge. Их, по словам компании, достаточно для задействования тензорного параллелизма. Дальнейшее масштабирование возможно посредством PCIe-коммутации. Именно поэтому d-Matrix работает с GigaIO и Liqid. В одно шасси можно поместить восемь карт Corsair, а в стойку, которая будет потреблять порядка 6–7 кВт — 64 карты. 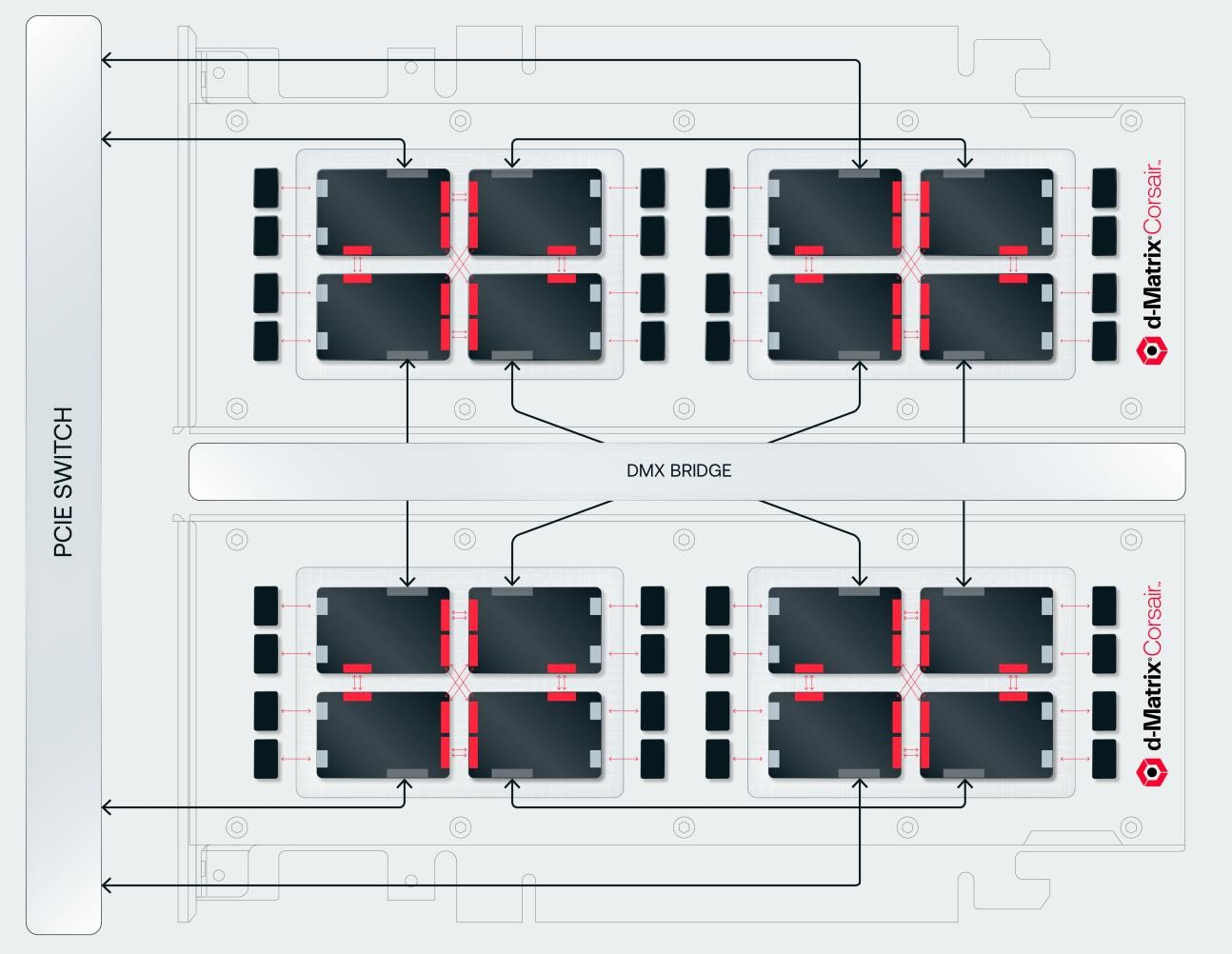 d-Matrix уже разрабатывает ASIC следующего поколения Raptor, который должен выйти в 2026 году. Raptor будет ориентирован на «думающие» модели и получит ещё больше памяти за счёт размещения DRAM непосредственно поверх вычислительных чиплетов. SRAM-чиплеты Raptor также перейдут с 6-нм техпроцесса TSMC, который используется при изготовлении Corsair, к 4 нм без существенных изменений микроархитектуры. По словам компании, она потратила два года на работу с TSMC, чтобы создать 3D-упаковку для нового поколения ASIC. 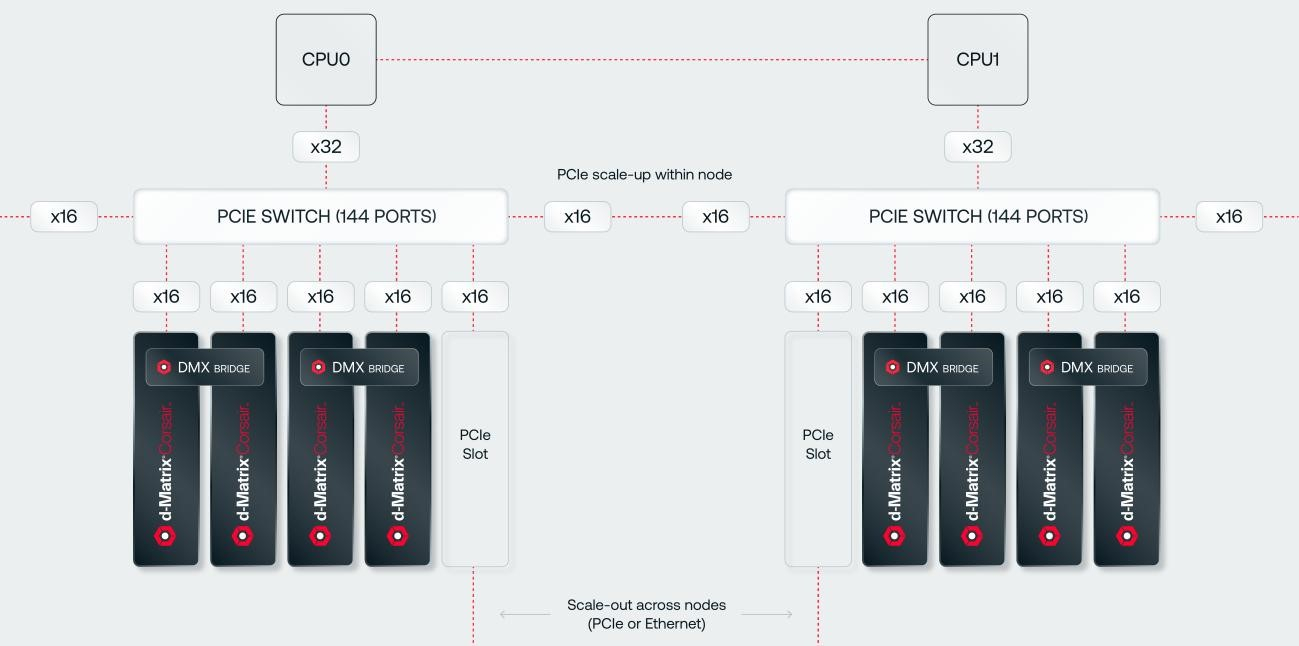 Как отмечает EETimes, команда разработчиков ПО d-Matrix в два раза больше команды разработчиков оборудования (120 против 60). Стратегия компании в области ПО заключается в максимальном использовании open source экосистемы, включая PyTorch, OpenAI Triton, MLIR, OpenBMC и т.д. Вместе они образуют программный стек Aviator, который отвечает за конвертацию моделей в числовые форматы d-Matrix, применяет к ним фирменные методы разрежения, компилирует их, распределяет нагрузку по картам и серверам, а также управляет исполнением моделей, включая обслуживание большого количества запросов.
19.01.2025 [23:24], Сергей Карасёв
Synology представила системы резервного копирования ActiveProtectКомпания Synology анонсировала устройства для бесшовного резервного копирования и быстрого восстановления данных семейства ActiveProtect. Решение объединяет специализированное ПО, серверы и хранилища резервных копий в единую унифицированную платформу. Утверждается, что ActiveProtect обеспечивает надёжную защиту всех корпоративных рабочих нагрузок. Это могут быть приложения SaaS, виртуальные машины, физические серверы, компьютеры с Windows и macOS, файловые серверы и базы данных. Благодаря встроенному гипервизору ActiveProtect пользователи могут в любое время тестировать резервные копии, а интуитивно понятный интерфейс упрощает управление. ActiveProtect предполагает применение стратегии 3-2-1-1-0, где:
Платформа ActiveProtect, как утверждается, позволяет выполнять резервное копирование с максимальной скоростью, устранять дублирование данных, увеличивать ёмкость хранилища и мгновенно восстанавливать информацию в случае необходимости. Консоль ActiveProtect Manager (APM) даёт возможность просматривать до 150 тыс. рабочих нагрузок, а также контролировать до 2500 систем. Возможно формирование среды с физической изоляцией (air-gap). 
Источник изображений: Synology В семейство устройств резервного копирования ActiveProtect вошли модели в настольном форм-факторе DP320 и DP340 на процессоре AMD Ryzen R1600. Первая оснащена 8 Гбайт RAM и двумя отсеками для LFF-накопителей (установлены два HDD по 8 Тбайт каждый). Возможна защита до 20 систем или 50 пользователей SaaS.  Вторая модификация располагает 16 Гбайт ОЗУ и четырьмя отсеками для LFF-накопителей (установлены четыре HDD по 8 Тбайт каждый). Эта версия укомплектована двумя кеширующими SSD вместимостью по 400 Гбайт. Возможна защита до 60 систем или 150 пользователей SaaS. Младшая версия получила два сетевых порта 1GbE, старшая — по одному порту 1GbE и 10GbE.  Кроме того, представлено стоечное устройство DP7400 типоразмера 2U с процессором AMD EPYC 7272 (12 ядер) и 64 Гбайт RAM (расширяется до 512 Гбайт). В оснащение входят десять LFF HDD ёмкостью 20 Тбайт каждый и два SFF SSD на 3,84 Тбайт. Есть один порт 1GbE и два порта 10GbE. Это решение может работать 2500 серверами или 150 тыс. рабочими нагрузками в кластере. Сетевые источники также сообщают, что к выпуску готовятся стоечные системы DP5200 и DP7300 в форм-факторе 1U и 2U соответственно, но их описание на момент подготовки материала отсутствовало на сайте производителя.
19.01.2025 [22:43], Сергей Карасёв
Германия запустила «переходный» 48-Пфлопс суперкомпьютер Hunter на базе AMD Instinct MI300AЦентр высокопроизводительных вычислений HLRS при Штутгартском университете в Германии объявил о вводе в эксплуатацию НРС-системы Hunter. Этот суперкомпьютер планируется использовать для решения широко спектра задач в области инженерии, моделирования погоды и климата, биомедицинских исследований, материаловедения и пр. Кроме того, комплекс будет применяться для крупномасштабного моделирования, ИИ-приложений и анализа данных. О создании Hunter сообщалось в конце 2023 года: соглашение на строительство системы стоимостью примерно €15 млн было заключено с HPE. Проект финансируется Федеральным министерством образования и исследований Германии и Министерством науки, исследований и искусств Баден-Вюртемберга. Hunter базируется на той же архитектуре, что El Capitan — самый мощный в мире суперкомпьютер. Задействована платформа Cray EX4000, а каждый из узлов оснащён четырьмя адаптерами HPE Slingshot. Суперкомпьютер использует комбинацию из APU Instinct MI300A и процессоров EPYC Genoa. Как отмечает The Register, в общей сложности система объединяет 188 узлов с жидкостным охлаждением и насчитывает суммарно 752 APU и 512 чипов Epyc с 32 ядрами. Применена СХД HPE Cray Supercomputing Storage Systems E2000, специально разработанная для суперкомпьютеров HPE Cray. 
Источник изображения: HLRS HLRS оценивает пиковую теоретическую FP64-производительность Hunter в 48,1 Пфлопс на операциях двойной точности, что практически вдвое выше, чем у предшественника Hawk. В режимах BF16 и FP8 быстродействие, как ожидается, будет варьироваться от 736 Пфлопс до 1,47 Эфлопс. При этом Hunter потребляет на 80% меньше энергии, нежели Hawk. 
Источник изображения: Штутгартский университет Отмечается, что Hunter задуман как переходная система, которая подготовит почву для суперкомпьютера HLRS следующего поколения под названием Herder. Ввести этот комплекс в эксплуатацию планируется в 2027 году. Предполагается, что он обеспечит производительность «в несколько сотен петафлопс».
18.01.2025 [22:48], Сергей Карасёв
ASRock представила индустриальные мини-ПК и материнские платы на базе Intel Arrow Lake-H и AMD Ryzen 300 AIКомпания ASRock Industrial, по сообщению ресурса CNX-Software, представила индустриальные компьютеры небольшого форм-фактора NUC(S) Ultra 200 Box и материнские платы NUC Ultra 200 на новейших процессорах Intel Core Ultra 200H (Arrow Lake-H). Кроме того, дебютировали аналогичные устройства 4X4 Box AI300 и платы 4X4 AI300 на чипах AMD Ryzen AI 300. Модели NUC Ultra 200 Box, NUCS Ultra 200 Box и платы NUC Ultra 200 в зависимости от модификации комплектуются процессором Core Ultra 7 255H (6P+8E) с частотой до 5,1 ГГц или Core Ultra 5 225H (4P+8E) с частотой до 4,9 ГГц. В первом случае используется узел Intel Arc 140T GPU (74 TOPS), во втором — Intel Arc 130T GPU (63 TOPS). Оба чипа оснащены блоком Intel AI Boost с производительностью 13 TOPS. Новинки поддерживают до 96 Гбайт оперативной памяти DDR5-6400 в виде двух модулей SO-DIMM. Есть по одному разъёму M.2 Key M 2242 (PCIe 4.0 x4) и M.2 Key M 2242/2280 (PCIe 4.0 x4) для NVMe SSD, а также M.2 Key E 2230 (PCIe x1, USB 2.0, CNVi) для контроллера Wi-Fi/Bluetooth. Модели с обозначением NUC и материнские платы также снабжены портом SATA-3. В оснащение входят звуковой кодек Realtek ALC256 и сетевой адаптер 2.5GbE на базе Intel I226LM. Платы и модели NUC оснащены дополнительным портом 2.5GbE на основе Intel I226V. Кроме того, мини-компьютеры несут на борту комбинированный адаптер Wi-Fi 6E (802.11ax) + Bluetooth 5.3. 
Источник изображений: CNX-Software Все изделия располагают двумя выходами HDMI 2.1 TMDS (4096 × 2160 точек @ 60 Гц) и двумя портами DisplayPort 2.1/1.4a, интерфейсом DP++/USB Type-C (4096 × 2160 @ 60 Гц), аудиогнездом на 3,5 мм, портами USB 3.2 Gen2 Type-A (три у NUCS и четыре у NUC), интерфейсом USB4/Thunderbolt 4, портом USB 3.2 Gen2 x2 Type-C. На плате есть разъёмы для двух портов USB 2.0 и последовательного порта RS232/RS422/RS485. Габариты NUC составляют 117,5 × 110,0 × 49 мм, NUCS — 117,5 × 110,0 × 38 мм, плат — 104 × 102 мм. Диапазон рабочих температур у мини-компьютеров простирается от 0 до +40 °C, у плат — от -20 до +70 °C.  В свою очередь, компьютеры 4X4 Box AI300 и платы 4X4 AI300 могут комплектоваться процессором AMD Ryzen AI 7 350 (8 ядер; до 5,0 ГГц; AMD Radeon 860M) или AMD Ryzen AI 5 340 (6 ядер; до 4,8 ГГц; AMD Radeon 840M). В обоих случаях задействован нейропроцессор Ryzen AI на архитектуре XDNA 2 с производительностью до 50 TOPS. Объём памяти DDR5-5600 может достигать 96 Гбайт (два модуля SO-DIMM). Изделия наделены коннекторами M.2 Key M 2242 (PCIe 4.0 x4) и M.2 Key M 2242/2280 (PCIe 4.0 x4) для NVMe SSD, а также слотом M.2 Key E 2230 (PCIe x1, USB 2.0) для адаптера Wi-Fi/Bluetooth (мини-компьютеры несут на борту модуль Wi-Fi 6E). В оснащение входят сетевые адаптеры 2.5GbE (Realtek RTL8125BG) и 1GbE (Realtek RTL8111H), звуковой кодек Realtek ALC256. Набор разъёмов включает по два интерфейса HDMI 2.1 (7680 × 4320 @ 60 Гц) и DisplayPort 1.4a / USB Type-C (4096 × 2160 @ 60 Гц), аудиогнездо на 3,5 мм, три порта USB 3.2 Gen2 Type-A, два порта USB4/Thunderbolt 4, два порта USB 2.0 (через коннекторы на плате). Размеры компьютеров составляют 117,5 × 110,0 × 49 мм, плат — 104 × 102 мм. Диапазон рабочих температур — от 0 до +40 °C и от 0 до +70 °C соответственно.
17.01.2025 [22:46], Руслан Авдеев
Aligned Data Centers получила $12 млрд на расширение парка ИИ ЦОДТехасский оператор ЦОД Aligned Data Centers объявил о привлечении $12 млрд на постройку ИИ ЦОД мощностью 5 ГВт в Северной и Южной Америках. $5 млрд поступило в виде акционерного капитала из фондов, подконтрольных Macquarie Asset Management, ещё $7 млрд — в виде долговых обязательств, сообщает SiliconAngle. В Aligned заявляют, что у неё уникальное положение на рынке — у компании более 10 лет опыта в создании систем охлаждения энергоёмких дата-центров. Последнее поколение фирменных СЖО DeltaFlow~ позволяет повысить плотность размещения ресурсов до 300 кВт на стойку. Также компания разработала систему воздушного охлаждения Delta3 (Delta Cube). Aligned Data Centers управляет многочисленными колокейшн-объектами. Также она строит дата-центры для гиперскейлеров и корпоративных клиентов. В США компания управляет объектами в Чикаго, Далласе, Финиксе, Солт-Лейк-Сити и Северной Вирджинии. Новые площадки строятся в Вирджинии, Иллинойсе, Мэриленде и Огайо. В мае 2024 года Aligned купила бразильского оператора ЦОД OData, у которого уже были объекты в Бразилии, Чили, Мексике и Колумбии. Наконец, компания инвестировала в канадского оператора QScale SEC. 
Источник изображения: Aligned Data Centers Быстрый рост ИИ в последние годы вызвал и рост спроса на высокопроизводительные дата-центры, способные вместить тысячи ускорителей одновременно. В результате бизнес Aligned значительно вырос. Упомянутая австралийская Macquarie совсем недавно сообщила, что выделит до $5 млрд на ИИ ЦОД Applied Digital — ещё одного американского оператора дата-центров. |
|

