Материалы по тегу: c
|
17.01.2025 [01:07], Алексей Степин
США готовятся к созданию суперкомпьютера нового поколения с 10 Пбайт RAMСуперкомпьютеру Crossroads (ATS-3), расположенному в Лос-Аламосской национальной лаборатории (LANL) Министерства энергетики США (DoE), не так уж много лет. Система мощностью 30 Пфлопс запущена в 2023 году, но ей уже готовится замена в лице суперкомпьютера нового поколения под кодовым названием ATS-5. Министерство энергетики совместно с Национальным управлением по ядерной безопасности (NNSA) раскрыли некоторые детали, касающиеся этого проекта. Главной задачей ATS-5 станет запуск высокоточных 3D-симуляций для оценки перспектив модернизации и поддержания в актуальном состоянии ядерного арсенала США. Симуляции со столь высокой детализацией очень сложны и относятся к классу «геройских» (hero-class). Их прогон может занимать несколько месяцев, но ATS-5 должен не только сократить это время до дней, но и обеспечить обработку нескольких таких симуляций параллельно. 
Монтаж Crossroads. Источник здесь и далее LANL NNSA не сообщает о том, будет ли ATS-5 относится к системам экзафлопсного класса, но судя по употреблению термина «post-exascale system» и сложности планируемых для запуска симуляций, новый суперкомпьютер будет достаточно мощным. Известен уровень его энергопотребления — порядка 20 МВт. Для сравнения, Frontier (1,35 Эфлопс FP64) потребляет 21 МВт, а El Capitan (1,74 Эфлопс FP64) — около 30 МВт. По замыслу DoE, ATS-5 станет модульной системой со смешанной архитектурой, сфокусированной не только на HPC-задачах (FP64), но и на ИИ-сценариях с их упрощёнными форматами вычислений. Упор делается на размещении данных ближе к вычислительным узлам, увеличении объёмов памяти (в настоящее время заявлено 10,1 Пбайт) и ускорении её работы.  В качестве интерконнекта может быть применена смесь технологий InfiniBand и Ethernet, развивающая от 100 до 300 Гбайт/с в каждом направлении. Модульность означает возможность замены ускорителей и процессоров на протяжении всего срока эксплуатации ATS-5. Помимо ускорителей NVIDIA рассматривается возможность использования квантовых ускорителей, а также чипов Cerebras, Groq и SambaNova. ПО практически целиком должно быть open source, но и от CUDA при необходимости отказываться не будут. Министерство энергетики США надеется разместить контракт на постройку ATS-5 в мае текущего года. Поставки оборудования должны начаться в конце 2026 или начале 2027 гг, а ввод системы в строй намечен на август-сентябрь 2027 года. Тогда же будет выведен из строя Crossroads (ATS-3).
16.01.2025 [17:10], Руслан Авдеев
Австралийская Macquarie выделит до $5 млрд на ИИ ЦОД Applied DigitalВенчурные капиталисты пока не боятся возможного финансового «пузыря», связанного с ИИ-технологиями, поэтому вливают миллиарды долларов в новые ИИ ЦОД. Так, австралийская финансовая компания Macquarie сообщила о намерении вложить $5 млрд в проекты американского оператора дата-центров Applied Digital, сообщает The Register. Техасский оператор работает на рынке ИИ и HPC относительно недавно, но это не мешает ему на равных соперничать с сильными конкурентами с более богатой историей. Во многом история компания напоминает путь CoreWeave, вышедшей на рынок HPC-объектов приблизительно в 2022 году и свернувшей бизнес по майнингу криптовалют. Applied Digital, как и CoreWeave и Lambda Labs, предлагает услуги ЦОД и облачные сервисы на базе ускорителей NVIDIA. Австралийские инвестиции, в том числе в ходе начального раунда финансирования в объёме $900 млн, позволят компании продолжить работу над кампусом Ellendale High Performance Computing в Северной Дакоте мощностью 100 МВт (до 400 МВт в перспективе), а также вернуть порядка $300 млн, ранее инвестированных в объект в виде акционерного капитала. 
Источник изображений: Applied Digital Кампус в Эллендейле (Ellendale) — лишь одна из площадок Applied Digital, в которые Macquarie готова вложить средства. В соответствии с новым соглашением, она получила преимущественное право участвовать в новых проектах, связанных с ИИ ЦОД в следующие 30 месяцев на сумму $4,1 млрд. В Applied Digital заявляют, что с сегодняшними ценами на строительство у компании будет значительная часть средств, необходимых для создания HPC-объектов мощностью более 2 ГВт, включая кампус в Эллендейле. Место, по-видимому, привлекательное для таких объектов — две неизвестных компании готовы потратить до $250 млрд на строительство в штате гигаваттных ИИ ЦОД. Пока не сообщается, когда, где и сколько дата-центров Applied Digital в итоге построят, но, согласно пресс-релизу, объекты получат жидкостное охлаждение. Вероятнее всего, как и в Северной Дакоте, другие объекты получат ускорители NVIDIA. Не исключено даже использование 120-кВт GB200 NVL72. В сентябре NVIDIA вместе с другими инвесторами сама вложила в оператора $160 млн. Большая часть инвестиций, вероятно, вернётся в виде заказов на чипы и подписки AI Enterprise. Что касается Macquarie, она фактически выкупила себе 15 % в бизнесе Applied HPC, а оператор сохранил за собой 85 %. 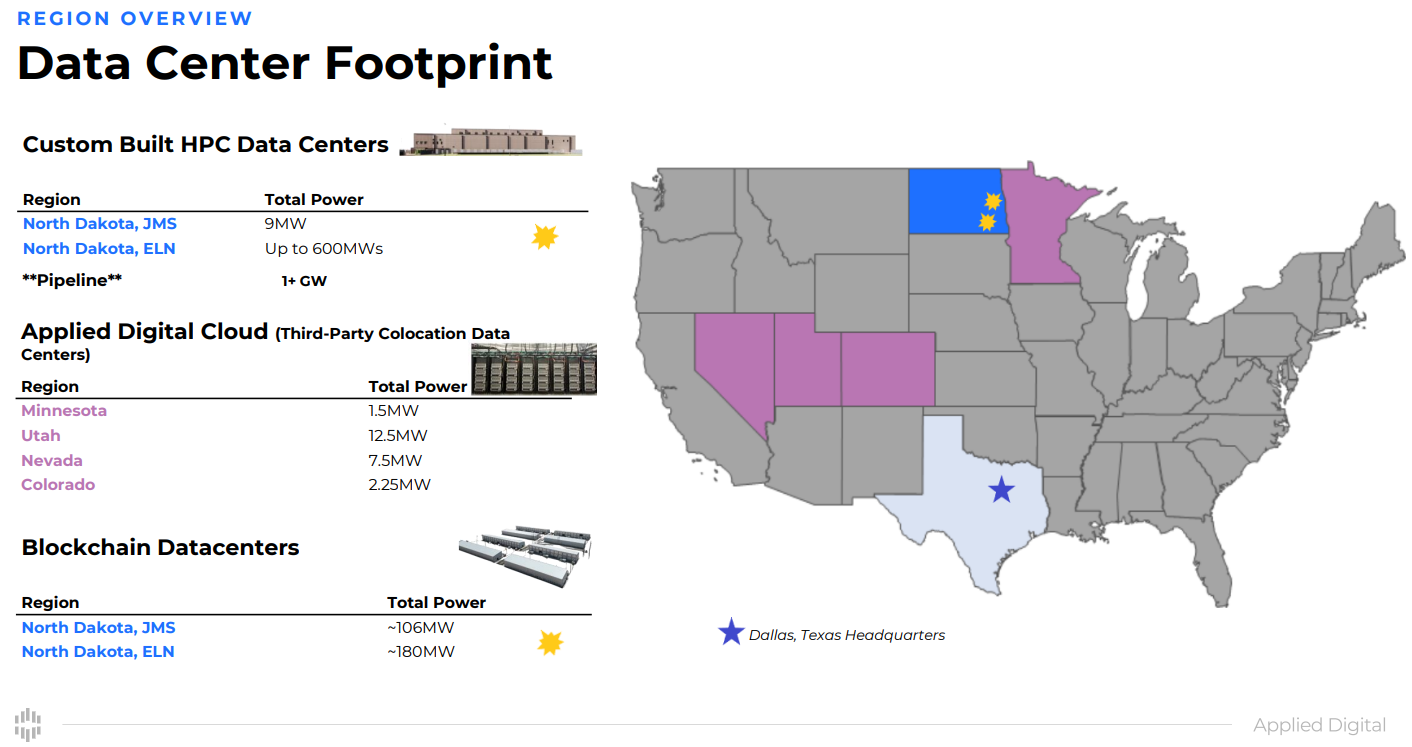 $1,5 млрд обычно достаточно для создания ЦОД с 16 тыс. ускорителей уровня NVIDIA H100 для последующей сдачи в аренду. В течение четырёх лет это принесёт около $5,27 млрд выручки при благоприятных условиях. С учётом уровня окупаемости инвестиций нетрудно понять, почему многие инвесторы желают участвовать в подобных проектах. Не мешает и высокий спрос на ускорители — иногда они используются в качестве залога при крупных кредитах. Так, в апреле 2024 года Macquarie помогла привлечь Lambda порядка $500 млн заёмного финансирования под залог ускорителей NVIDIA. Среди крупнейших бенефициаров таких сделок — CoreWeave, по данным Crunchbase, только в 2024 году получившая $9,9 млрд финансирования и заёмных средств. Деньги под залог ускорителей она брала ещё в 2023 году.
16.01.2025 [16:16], Руслан Авдеев
США вводят очередные ограничения на выпуск и экспорт современных чиповМинистерство торговли США вводит новый пакет экспортных ограничений, призванных помешать Китаю и другим странам закупать передовые чипы, сообщает Silicon Angle. В частности, ограничения коснутся предприятий, выпускающих микросхемы, а также работающих по заказу других организаций. Так, новые меры коснутся TSMC и Samsung Electronics, а также упаковщиков чипов, включая ту же TSMC. Новые правила предусматривают получение производителями чипов и упаковщиками полупроводников лицензий на экспорт «определённых передовых чипов» в ряд регионов. Власти откажутся от подобных требований, если производитель чипов получит технические аттестации от доверенных участников цепочек поставок. Так, разработчики чипов могут получить от американских властей статус «одобренных» или «авторизованных». Если разработчик подтверждает, что его чипы не достигают по своим характеристикам установленных США порогов производительности, лицензионные требования к ним отменяются. То же касается фабрик и компаний-упаковщиков. Если характеристики производимых чипов не превышают определённого порога, новые экспортные ограничения не применяются. 
Источник изображения: CHUTTERSNAP/unsplash.com Объявлено и о ряде других нормативных изменений. В частности, запускается процесс утверждения компаний в перечне одобренных дизайн-центров и поставщиков чипов и услуг OSAT (Outsourced Semiconductor Assembly and Test). Также оптимизированы процедуры раскрытия информации в случаях, если производитель принимает заказ клиента, потенциально способного перенаправить продукцию в Китай. В связи с новыми правилами в чёрный список Entity List отправятся 16 новых организаций, включая некоторые ИИ-компании, поддерживающие развитие производства передовых чипов в Китае. Одной из таких компаний стала Sophgo — в прошлом году выяснилось, что она якобы передала выпущенную для неё продукцию компании Huawei, давно пребывающей в американском чёрном списке, после чего TSMC прекратила выполнение её заказов и поставки. Министерство торговли вводит новые правила всего через несколько дней после того, как администрация уходящего президента США ввела глобальные ограничения на поставки ИИ-чипов и передовых моделей ИИ. Ранее американские власти уже вводили санкции, ограничивающие возможности китайской полупроводниковой индустрии. Речь идёт о закупках чипов NVIDIA, памяти HBM и других компонентов. Не щадят и союзников. Нидерландской ASML запрещено поставлять в КНР оборудование для DUV-литографии, на котором можно изготавливать 5- и 7-нм полупроводники.
15.01.2025 [11:24], Владимир Мироненко
В совет директоров UALink вошли представители Alibaba, Apple и SynopsysКонсорциум Ultra Accelerator Link (UALink) объявил о расширении состава совета директоров представителями Alibaba Cloud, Apple и Synopsys. Новые члены совета будут использовать свои отраслевые знания для продвижения разработки и внедрения в отрасли UALink — высокоскоростного масштабируемого интерконнекта для производительных ИИ-кластеров следующего поколения, указано в пресс-релизе. Фактически UALink занят созданием более открытой альтернативы NVLink. С момента основания в конце октября 2024 года количество участников UALink выросло до более чем 65 компаний, сообщил Куртис Боуман (Kurtis Bowman), председатель совета директоров UALink. Новые участники совета директоров заявили, что совместная работа над интерконнектом для ускорителей будет способствовать повышению эффективности выполнения рабочих нагрузок ИИ. Представитель Apple отметил, что UALink демонстрирует большие перспективы в решении проблем подключения и создании новых возможностей ИИ-индустрии. В консорциум входит широкий круг компаний, от поставщиков облачных услуг и OEM-производителей до разработчиков ПО и полупроводниковых компонентов во главе с AMD, AWS, Astera Labs, Cisco, Google, HPE, Intel, Meta✴ и Microsoft, представляющих основные области разработки решений для повышения производительности нагрузок ИИ. 
Источник изображения: UALink Ожидается, что выпуск спецификации UALink 1.0 состоится в I квартале 2025 года. Она предусматривает пропускную способность до 200 Гбит/с на линию и возможность объединения до 1024 ИИ-ускорителей в пределах одного домена.
15.01.2025 [08:38], Руслан Авдеев
Новые ЦОД стоимостью £14 млрд помогут Великобритании превратиться в ИИ-сверхдержавуВ рамках нового плана британского правительства по развитию ИИ-проектов анонсированы инициативы по созданию ЦОД на общую сумму £14 млрд ($16,96 млрд). Так, Vantage, Nscale и Kyndryl обязались инвестировать в местную цифровую инфраструктуру и создать 13 тыс. рабочих мест. Планом предусмотрено и строительство нового ИИ-суперкомпьютера, сообщает Datacenter Dynamics. Ещё до объявления новой программы правительства об инвестициях в британские ЦОД сообщили Blackstone (£10 млрд) и DC01UK (£3,75 млрд), а также Cloud HQ, CyrusOne, CoreWeave и ServiceNow (суммарно £6,3 млрд) В рамках программы AI Opportunities Action Plan, некоторые детали которой появились ещё в ноябре, по всей стране будут созданы «Зоны роста ИИ» с приоритетным доступом к технологиям и энергии, призванные привлечь инвестиции со всего мира. Зоны станут и полигоном для энергетических проектов, связанных с ЦОД. Особая роль отведена атомной энергетике. Первую зону построят в Калхэме (графство Оксфордшир), где находится Управление по атомной энергии Великобритании и расположены кампусы AWS и CloudHQ. Оператор NScale объявил о намерении инвестировать в Великобританию £2,5 млрд ($3 млрд), где построит свой первый ИИ ЦОД в графстве Эссекс мощностью 50 МВт с возможностью расширения до 90 МВт. В компании надеются ввести дата-центр в эксплуатацию в IV квартале 2026 года, разместив в нём до 45 тыс. NVIDIA GB200 и наняв 250 постоянных сотрудников. В других графствах NScale начнёт строить модульные ЦОД во II половине 2025 года, а впоследствии будет развивать и стационарные дата-центры. 
Источник изображения: Ben Seymour/unsplash.com Vantage Data Centers построит кампус на 10 зданий на месте бывшего автозавода Ford в Уэльсе. Речь идёт об инвестициях £12 млрд ($14,55 млрд) и создании 11,5 тыс. рабочих мест. Ещё в 2020 году Vantage приобрела Next Generation Data, управляющую дата-центрами в Уэльсе и Лондоне. Наконец, Kyndryl создаст 1 тыс. рабочих мест, связанных с ИИ, в новом технологическом центре в Ливерпуле, который построят в следующие три года. Ранее власти отнесли дата-центры к критически важной инфраструктуре (CNI) и пообещали реформировать законы о планировании, чтобы упростить строительство новых объектов. Более того, заново рассматриваются заявки, которые были отклонены. Например, в декабре дали «зелёный свет» отменённому годом ранее проекту в Бакингемшире. 
Источник изображения: Serena Repice Lentini/unsplash.com По словам премьер-министра Кира Стармера (Keir Starmer), индустрии ИИ нужно правительство, которое примет её сторону и не позволит упустить возможности развития. По словам министра, план сделает Великобританию мировым лидером в области ИИ, даст отрасли опору и импульс. Благодаря этому появится больше рабочих мест, больше денег у населения и, наконец, будет реформирована система государственных услуг. Подробнее о плане рассказывается на сайте самого британского правительства. Также Великобритания планирует построить ИИ-суперкомпьютер. Данных о нём пока немного, но Департамент науки, инноваций и технологий (DSIT) сообщил, что его создание — один из элементов плана по двадцатикратному увеличению вычислительных мощностей страны к 2030 году. Примечательно, что в прошлом году власти отложили реализацию HPC-проектов на £1,3 млрд, сославшись на нехватку средств. В том числе было отменено создание первого в стране экзафлопсного суперкомпьютера при Эдинбургском университете.
13.01.2025 [10:00], Игорь Осколков
Криптозамок Fplus — новое слово в защите КИИКриптозамками или, говоря бюрократическим языком, аппаратно-программными модулями доверенной загрузки (АПМДЗ), предназначенными для идентификации и аутентификации пользователей и защиты от несанкционированного доступа, никого не удивить. Как правило, выполнены они в виде PCI(e)-карт или M.2-модулей с тем или иным вариантом считывателя для токенов/смарт-карт/USB-ключей, датчиком вскрытия корпуса, «врезками» в линии PWR и RST и т.д. Основные функции их сводятся к определению, кто есть кто ещё до загрузки ОС, разграничению доступа к аппаратным ресурсам, контролю целостности самого модуля, BIOS/UEFI, настроек, ОС, реестра или отдельного ПО/файлов, автономному журналированию и блокировке системы в случае выявления неправомерного доступа. Всё это замечательно работает до того момента, когда возникает потребность в хоть сколько-нибудь большом пуле серверов, да ещё и геораспределённых, а в худшем случае и вовсе установленных где-нибудь в разбросанных edge-локациях или на производстве. Обновлять конфигурации, прошивки да ключи, а то и просто перезагружать машины (иногда это всё-таки нужно) — не набегаешься. Для этого у любых приличных серверов есть BMC с выделенным сетевым портом для удалённого управления. Однако BMC как правило иностранного производства и не лишены уязвимостей, что без доступа к исходникам хотя бы прошивки усложняет процесс защиты системы. 
Источник изображений: Fplus Сегментация с вынесением BMC в отдельную подсеть (желательно физически изолированную от других) — подход верный, но не избавляющий от атак с участием неблагонадёжного системного администратора в случае размещения на сторонних площадках. BMC — это в принципе целый отдельный контур, который нужно или отключать на корню, или защищать, а вот игнорировать никак нельзя. Для множества решений СКЗИ доступен только первый путь, но Криптозамок Fplus реализует второй. И не только его — это не просто АПМДЗ, а многофункциональная система, которая больше напоминает модуль DC SCM для контроля над аппаратной частью сервера. Собственно говоря, разработчики и не скрывают, что развивают решение именно в этом направлении.  Криптозамок выполнен в виде HHHL-платы, которая, впрочем, к PCIe не подключается. Для защиты удалённого доступа модуль подключается к сетевому интерфейсу на самой плате, при этом внешний разъём для BMC отключается. Таким образом, весь трафик до BMC проходит исключительно через криптозамок. Этот трафик заворачивается в IPSec-туннель с ГОСТ’овскими шифрами. Ответной частью являются дешифратор (фактически микрокомпьютер) с двумя портам, один из которых «смотрит» в сеть, где находятся BMC, а второй нужен для подключения, например, к ноутбуку, откуда и будет доступ к интерфейсам BMC и UEFI. Для собственно защиты в криптозамке и дешифраторе прописываются ключи. Ключ совпал с обеих сторон — доступ есть.  За работу с ключами и шифрованием отвечает отдельный шифратор отечественного производства, что резко повышает стабильность цепочки поставок. Сам блок шифратора изначально был разработан российской компанией, которая впоследствии стала частью компании Fplus. Если точнее, то шифратора в криптозамке сразу два. Один отвечает за сетевое общение, а второй за более традиционные функции защиты UEFI, инвентаризации, доверенное флеш-хранилища и т.п. Криптозамок умеет проверять подлинность и целостность прошивки UEFI (до старта основного хоста), а также загрузчика и ядра ОС привычным путём расчёта контрольных сумм (с ГОСТ 34.11-2018). Кроме того, до старта хоста можно проверить сервер антивирусом.
Криптозамок также отслеживает изменения аппаратной конфигурации сервера и перехватывает управление джамперами, ответственными за сброс и возможность локального обновления UEFI. Естественно, есть и датчик вскрытия корпуса, который позволяет выключить и фактически заблокировать систему, равно как и при любых других нарушениях в отслеживаемых криптозамком программной или аппаратной составляющих. Решение в целом позволяет снизить необходимость физического доступа к оборудованию, что само по себе повышает защищённость. 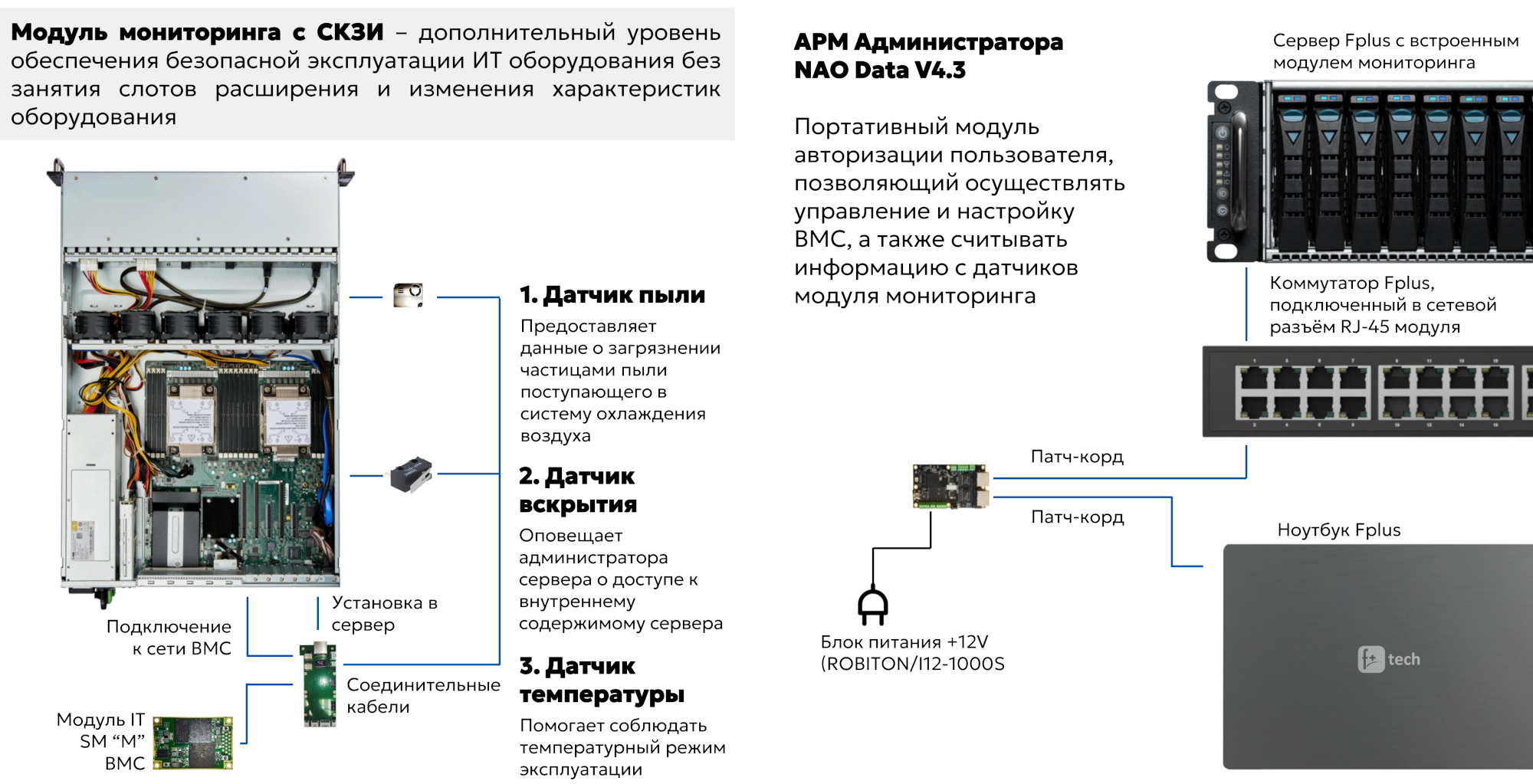 Но этим функциональность криптозамка не ограничивается. В доверенное флеш-хранилище объёмом 32 или 64 Гбайт можно поместить ISO-образ LiveCD со средствами самодиагностики, инструментами удалённой поддержки или же использовать его в качестве вообще единственного накопителя для загрузки ОС и выполнения на сервере какого-то узкого списка задач. Криптозамок также обладает собственным аккумулятором (до двух месяцев автономной работы) и часами реального времени (RTC), что важно для автономного журналирования и отслеживания состояния сервера (например, не был ли он вскрыт) даже при отсутствии внешнего питания. Для контроля физических параметров среды также есть температурный датчик и лазерный датчик запылённости шасси с точностью измерения до 0,1 мкм. Последнее особенно актуально в случае edge-развёртывания. В данный момент решение совместимо с серверами Fplus «Спутник», но компания уже работает над интеграцией новинки с другими сериями своих продуктов. А вот совместимости с серверами и СХД других вендоров ждать не стоит. Всё-таки в данном случае речь идёт о контроле над собственной цепочкой поставок, включая прошивки UEFI и BMC, что упрощает интеграцию и сертификацию — устройство относится к СКЗИ класса защиты КС3. В наличии у Fplus имеется уже более сотни устройства, а заказчики, которым важно защищать свою КИИ, уже проводят первые пилотные испытания новинки. В дальнейшем компания планирует целиком вынести TPM и RoT в модуль криптозамка, добавить дополнительные драйверы для его взаимодействия с ОС, упростить управление ключами, разрешить пользователям самостоятельно формировать цифровые подписи для защиты ПО и прошивок и т.д.
11.01.2025 [02:00], Алексей Степин
До 2280 ядер и 42 Тбайт RAM на стойку: Oracle представила СУБД-платформу Exadata X11MКомпания Oracle анонсировала новую версию СУБД-платформы Exadata. Ещё в предыдущем поколении, Exadata X10M, Oracle приняла решение отказаться от использования процессоров Intel Xeon. В Exadata X11M упор сделан на гибкость развёртывания: on-premise; в виде локального сервиса, управляемого Oracle; в сторонних облаках, в том числе в составе мультиоблачных конфигураций. Но и прирост производительности тоже заявлен солидный: новое поколение должно продемонстрировать на 55% возросшую скорость векторного поиска, который важен для обучения ИИ-моделей. Скорость сканирования данных выросла в 2,2 раза, а скорость обработки транзакций — на четверть. А на некоторых операциях прирост быстродействия достигает 32 раз. При этом новая платформа стоит столько же, сколько и предыдущая, говорит Oracle. 
Источник здесь и далее: Oracle Прирост производительности во многом обусловлен программными оптимизациями, но и аппаратную составляющую компания тоже подтянула. Основой Oracle Exadata X11M являются AMD EPYC, DDR5-6400, NVMe SSD и двухпортовые 100G-адаптеры. Каждый ДБ-сервер X11M содержит два 96-ядерных процессора AMD EPYC и 512 Гбайт RAM с возможностью расширения до 3 Тбайт. Впрочем, есть и конфигурация попроще — X11M-Z имеет один 32-ядерный EPYC и 768 Гбайт или 1,152 Тбайт памяти. В Exadata активно используется механизм RDMA, в том числе кеширующий слой Exadata RDMA Memory (XRMEM), на который уходит большая часть RAM.  Серверы хранения данных представлены в трёх вариантах: с одним (HC-Z) либо двумя 32-ядерными процессорами (EF и HC) и памятью объёмом 768 Гбайт либо 1,5 Тбайт соответственно. Узлы хранения HC (High Capacity) включают четыре кеширующих 6,8-Тбайт NVMe-накопителя Flash Accelerator F680 v2 (PCIe 5.0) и двенадцать 22-Тбайт SAS HDD (7200 RPM). В узлах EF (Extreme Flash) вместо HDD используются четыре 30,72-Тбайт NVMe SSD. А узлы HC-Z от HC отличаются тем, что имеют лишь пару 6,8-Тбайт кеширующих NVMe SSD и шесть 22-Тбайт HDD.  Минимальная конфигурация Exadata X11M состоит из двух серверов БД и трёх серверов хранения. Она обеспечивает скорость сканирования 135 Гбайт/с и предоставляет 1,9 Пбайт для хранения данных. Последнее достигнуто благодаря использованию гибридного сжатия Oracle Database Hybrid Columnar Compression.  В максимальной конфигурации каждая стойка X11M может содержать до 2880 процессорных ядер, 42 Тбайт RAM, 462 Тбайт высокопроизводительной флеш-памяти и 2,2 Пбайт (SSD) или 4,4 Пбайт (HDD) общего дискового пространства. Сетевая часть представлена RoCE-фабрикой на базе двухпортовых адаптеров, работающих в режиме Active–Active. Всего в стойку можно установить от 3 до 15 серверов БД и от 3 до 17 серверов хранения данных.  Конфигурация может быть расширена дополнительными стойками, подключаемыми посредством RoCE-интерконнекта, причём поддерживаются смешанные варианты, в которых совместно трудятся стойки Exadata X8M, X9M, X10M и X11M. Простоту масштабирования обеспечивают технологии Oracle Real Application Clusters (RAC) и Exadata Exascale and Automatic Storage Management (ASM). 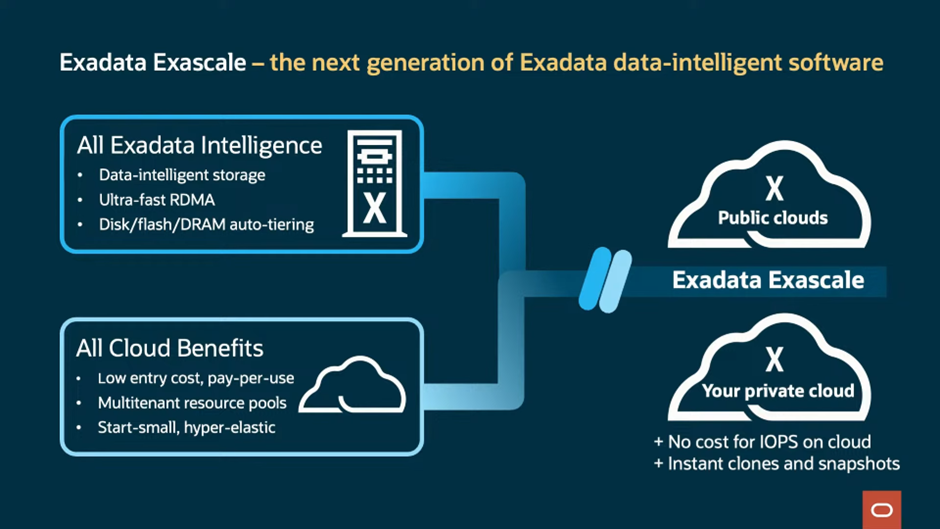 На сегодня Exadata X11M является наиболее продвинутой БД-платформой, сочетающей в себе высочайшую производительность работы с базами данных Oracle, гибкость конфигурации и широкие возможности выбора варианта развёртывания, будь то использование платформы в рамках AWS, Microsoft Azure и Google Cloud или размещение в ЦОД заказчика, говорит Oracle.
06.01.2025 [15:39], Владимир Мироненко
NVIDIA начала переманивать тайваньских специалистов для будущего центра по разработке ASICТайваньскому изданию Commercial Times стало известно о планах NVIDIA создать подразделение для разработки специализированных ASIC. В публикации газеты сообщается, что американская компания выбрала Тайвань в качестве базы для своего центра исследований и разработок, и сейчас она активно переманивает квалифицированные кадры из крупных местных компаний по проектированию интегральных схем (ИС), что вызвало опасения у руководства отрасли по поводу потенциальной утечки мозгов. По данным источников Commercial Times, в тайваньских фирмах по производству ИС, в середине 2024 года был отмечен резкий рост предложений с целью переманивания талантов. Поскольку NVIDIA запускает центр исследований и разработок ASIC, она может усилить попытки по переманиванию квалифицированных кадров, что вынуждает крупные компании, включая MediaTek, Alchip Technologies и дочернюю компанию TSMC GUC, принимать ответные меры в рамках подготовки к предстоящему противостоянию. Источник изображения: NVIDIA Как отметил ресурс TrendForce, технологические гиганты активно занимаются разработкой альтернатив ускорителям NVIDIA, чтобы ослабить свою зависимость от неё. В июле 2024 года Apple сообщила, что ее ИИ-модели для Apple Intelligence были обучены на Google TPU. А в декабре старший директор Apple по машинному обучению и искусственному интеллекту Бенуа Дюпен (Benoit Dupin) сообщил, что компания будет также использовать для обучения ИИ чипы Amazon Trainium2. А сейчас Apple совместно с Broadcom работает над созданием собственного серверного ИИ-ускорителя. Реагируя на этот тренд, NVIDIA создаёт собственный центр ASIC, расширяя спектр своих услуг, пишет Commercial Times. Согласно её публикации, компания планирует нанять на Тайване более тысячи специалистов в таких областях, как проектирование микросхем, разработка ПО, а также исследования и разработки в сфере ИИ. С учётом того, что тайваньские компании по выпуску ASIC сыграли важную роль в разработке Microsoft Cobalt и Maia, Google TPU и кастомных чипов AWS, это делает их специалистов идеальными целями для привлечения, отметила Commercial Times.
30.12.2024 [14:10], Владимир Мироненко
Первый Office — бесплатно: FTC подозревает Microsoft в антиконкурентном поведении ради сохранения правительственных контрактов
ftc
microsoft
microsoft azure
microsoft office
software
информационная безопасность
конкуренция
облако
сша
Федеральная торговая комиссия США (FTC) занялась изучением деловых практик Microsoft на предмет нарушения антимонопольного законодательства в рамках широкомасштабного расследования, сообщил ресурс Ars Technica. По словам источников Ars Technica, в последние недели юристы FTC проводили встречи с конкурентами Microsoft, чтобы выяснить, какие у них есть претензии к технологическому гиганту. Особое внимание уделялось тому, как компания объединяет продукты Office с услугами по обеспечению кибербезопасности и облачными сервисами. Это объединение стало предметом недавнего расследования ProPublica, в котором описывается, как, начиная с 2021 года, Microsoft использовала эту тактику для значительного расширения своего бизнеса с правительством США, одновременно оттесняя конкурентов от выгодных федеральных контрактов. После серии кибератак на правительственные сервисы, администрация Байдена попросила в 2021 году Microsoft, Amazon, Apple, Google и другие компании предложить конкретные решения, чтобы помочь США укрепить свою защиту от хакеров. В ответ генеральный директор Microsoft Сатья Наделла (Satya Nadella) пообещал предоставить правительству $150 млн на технические услуги для модернизации его цифровой безопасности. 
Источник изображения: Microsoft Также компания предложила бесплатно обновить лицензии на ПО, которое включало ОС Windows, Word, Outlook, Excel и т.д., предоставив правительству на ограниченное время бесплатный доступ к своим более продвинутым продуктам кибербезопасности и консультантов для установки обновлений. Этим предложением воспользовались многие государственные агентства, а также все военные подразделения в Министерстве обороны США, которые затем начали платить за эти улучшенные сервисы после завершения срока бесплатного предоставления услуг, поскольку стали фактически привязанными к обновлениям после их установки. Благодаря этой тактике Microsoft не только вытеснила некоторых существующих поставщиков услуг кибербезопасности для правительства, но и отняла долю рынка у облачных провайдеров, поскольку правительство начало использовать продукты, работающие на платформе Microsoft Azure. Некоторые эксперты допустили в интервью ProPublica, что подобная тактика может идти вразрез с законами, регулирующими порядок заключения контрактов с целью обеспечения свободной конкуренции, и это вызывает беспокойство даже у собственных юристов Microsoft из-за возможного нарушения антимонопольного законодательства. Данное законодательство запрещают госструктурам принимать «подарки» от подрядчиков и требует открытой конкуренции. Microsoft утверждает, что её предложение было «структурировано так, чтобы избежать антимонопольных проблем». «Единственной целью компании в этот период было поддержать срочный запрос администрации об усилении безопасности федеральных агентств, которые постоянно подвергались хакерским атакам», — сообщил руководитель по безопасности федерального бизнеса Microsoft. 
Источник изображения: Microsoft Edge/unsplash.com Впрочем, некоторые из взломов были уже результатом собственных упущений в безопасности Microsoft. В частности, хакеры использовали уязвимость в продукте Microsoft, чтобы украсть конфиденциальные данные из Национального управления по ядерной безопасности (NNSA) и Национальных институтов здравоохранения (NIH). При этом за несколько лет до взлома инженер Microsoft предупредил руководителей об этой уязвимости, но они отказались её устранять из-за страха оттолкнуть федеральное правительство и уступить позиции конкурентам, сообщает ProPublica. Предложенный патч обеспечил бы безопасность клиентов, но в то же время увеличил бы продолжительность идентификации пользователей при входе в систему. По словам источника, знакомого с расследованием FTC, Entra ID (ранее — Azure Active Directory) является одним из объектов расследования FTC. Эксперты отметили, что новое антимонопольное расследование FTC перекликается с делом десятилетней давности, когда Министерство юстиции США подало в суд на компанию Microsoft с обвинением в незаконной монополии на рынке операционных систем с помощью антиконкурентного поведения, которое не позволяло конкурентам закрепиться в этом сегменте. 
Источник изображения: Surface Источники сообщили, что в рамках нового расследования FTC направила Microsoft запрос о предоставлении необходимой информации. Компания подтвердила получение документа. Вместе с тем представитель Microsoft отказался предоставить подробности расследования, но отметил, что запрос FTC о предоставлении информации «широкий, широкомасштабный» и содержит требования, которые «выходят за рамки возможного даже с точки зрения логики». С связи с избранием нового президента США ожидается смена руководства FTC, поэтому о перспективах расследования регулятором деятельности Microsoft можно будет говорить после кадровых перестановок в комиссии и её последующих официальных заявлений.
28.12.2024 [12:42], Сергей Карасёв
Итальянская нефтегазовая компания Eni запустила суперкомпьютер HPC6 с производительностью 478 ПфлопсИтальянский нефтегазовый гигант Eni запустил вычислительный комплекс HPC6. На сегодняшний день это самый мощный суперкомпьютер в Европе и один из самых производительных в мире: в свежем рейтинге TOP500 он занимает пятую позицию. О подготовке HPC6 сообщалось в начале 2024 года. В основу системы положены процессоры AMD EPYC Milan и ускорители AMD Instinct MI250X. Комплекс выполнен на платформе HPE Cray EX4000 с хранилищем HPE Cray ClusterStor E1000 и интерконнектом HPE Slingshot 11. В общей сложности в состав HPC6 входят 3472 узла, каждый из которых несёт на борту 64-ядерный CPU и четыре ускорителя. Таким образом, суммарное количество ускорителей Instinct MI250X составляет 13 888. Суперкомпьютер обладает FP64-быстродействием 477,9 Пфлопс в тесте Linpack (HPL), тогда как пиковый теоретический показатель достигает 606,97 Пфлопс. Максимальная потребляемая мощность системы составляет 10,17 МВА. Комплекс HPC6 смонтирован на площадке Eni Green Data Center в Феррера-Эрбоньоне: это, как утверждается, один из самых энергоэффективных и экологически чистых дата-центров в Европе. Новый суперкомпьютер оснащён системой прямого жидкостного охлаждения, которая способна рассеивать 96 % вырабатываемого тепла. ЦОД, где располагается HPC6, оборудован массивом солнечных батарей мощностью 1 МВт. 
Источник изображения: Eni Как отмечает ресурс Siliconangle, на создание суперкомпьютера потрачено более €100 млн. Применять комплекс планируется, в частности, для оптимизации работы промышленных предприятий, повышения точности геологических и гидродинамических исследований, разработки источников питания нового поколения, оптимизации цепочки поставок биотоплива, создания инновационных материалов и моделирования поведения плазмы при термоядерном синтезе с магнитным удержанием. |
|

