Материалы по тегу: сбой
|
26.07.2026 [17:10], Руслан Авдеев
Сбой в «Аллее дата-центров» привёл к мгновенному отключению 3 ГВт мощностей — рекорд для энергосистемы СШАНеисправность ЛЭП в Ашберне (Ashburn, Вирджиния) привела к крупнейшему падению нагрузки в истории американской энергосистемы. После того, как сбой заставил гиперскейлеров в «Аллее дата-центров» ненадолго включить резервные генераторы, нагрузка в сети PJM за считанные секунды упала на более чем 3 ГВт, сообщает Datacenter Knowledge. Это редкая возможность увидеть, как крупные ИИ-кампусы реагируют на неполадки в магистральной энергосистеме. Фактически изменение нагрузки инициировано не энергокомпанией, а системами защиты самих ЦОД. По данным PJM, более 3 ГВт — это около 3 % потребностей энергосистемы на тот момент. Резкое отключение столь большой нагрузки вызвало заметно изменение частоты тока в сети, но общая надёжность энергосистемы не пострадала. Компания Dominion Energy, работающая в сети PJM, объявила, что события начались с автоматического отключения ЛЭП в Ашберне, работоспособность которой была восстановлена в течение нескольких минут. Сколько и какие именно объекты в результате этого сбоя были переведены на резервное питание, не разглашается. Примечательно, что пару недель назад, во время рекордной жары, PJM впервые предупредила операторов ЦОД о том, что их могут попросить перейти на локальную генерацию, если состояние энергосети ухудшится, но подобных запросов так и не поступило. При этом сейчас PJM находится под давлением властей, которые упрекают её в недостаточной скорости обеспечения питанием новых ИИ ЦОД и грозятся разделить компанию. Однако у компании мало возможностей для манёвра — в «Аллее дата-центров», согласно данным Data Center Map, работают 278 дата-центров, а проектируются и строятся — ещё 121 ЦОД. 
Источник изображения: Nhan Hoang/unspalsh.com PJM пока не опубликовала никаких выводов, а причина неисправности ЛЭП, которых и так не хватает, не раскрыта. Нет данных и о том, связано ли падение нагрузки с одним крупных клиентом или несколькими кампусами. Однако это уже не первый инцидент в сети PJM и Dominion. Два года назад из-за миллисекундного сбоя ЛЭП сразу 60 ЦОД общей мощностью 1,5 ГВт разом отключились от энергосети, перейдя на резервные генераторы. Хуже того, автоматическое переключение на основное питание не произошло, так что ЦОД несколько часов были отключены от сети. PJM разрабатывает новые протоколы действия в чрезвычайных ситуациях с перепадами нагрузок гигаваттного масштаба. Десятилетиями коммунальные компании и операторы энергосетей планировали действия на случай неожиданной потери крупных генерирующих мощностей. Теперь они должны готовиться и к внезапной потере нагрузки из-за ИИ ЦОД и столь же скоротечному восстановлению энергопотребления. По мнению экспертов, кампусы гиперскейл-уровня становятся достаточно значимыми для общей энергосистемы, чтобы выдвигать к ним специальные требования по устойчивости при кратковременных сбоях и корректному возврату в энергосистему — внезапное подключение 3 ГВт к сети ничем не лучше внезапного отключения. Коммунальные компании и PJM также нуждаются в инструментах мониторинга в режиме реального времени, чтобы определить, какая часть нагрузки оказалась «за счётчиком», сколько работает резервных генерирующих мощностей и когда нагрузка восстановится. В течение прошлого года североамериканский регулятор NERC изучал вопросы моделирования и интеграции быстрорастущих нагрузок ЦОД в процесс планирования магистральных энергосистем. Впрочем, уже сейчас дата-центры в Вирджинии негативно влияют на качество энергоснабжения обычных потребителей — риск возгораний становится всё выше. Более того, недавно китайские специалисты по кибербезопасности сообщили, что злоумышленники могут использовать облачные ЦОД как оружие для атаки на энергосети, удалённо управляя поведением энергоёмких ИИ-нагрузок.
22.07.2026 [16:38], Руслан Авдеев
Зона недоступности: сбой облака Google Cloud в Нидерландах продлился почти 15 часов из-за проблем питания и охлаждения в ЦОДОблачная платформа Google Cloud пострадала от масштабного сбоя, вызванного перебоями в электроснабжении и охлаждении одного из дата-центров в Нидерландах. По данным гиперскейлера, речь идёт о зоне доступности в регионе Europe-West4, неполадки в которой длились 14 ч. 55 м., сообщает Datacenter Dynamics. Проблемы начались 15 июля в 16:39 PST — 02:39 16 июля МСК. Пострадали сервисы Google Cloud VMware Engine, Bare Metal Solution, и Google Cloud NetApp Volumes, которые восстановили работу лишь 16 июля 07:34 PST (17:34 МСК). Судя по докладу компании об инциденте, проблемы были связаны с отключением электропитания и последовавшим сбоем работы систем охлаждения. Компания ссылается на аварию во внешней энергосети — в результате нарушилась работа распределительного электрооборудования, что повлекло отключение части систем ЦОД. Сбой охлаждения привело к быстрому критическому «потеплению» в машинных залах. Серверы, хранилища и коммутаторы отключили, чтобы избежать их повреждения. Данные о работе резервных генераторов и даже их наличии отсутствуют. Как утверждает The Register, одна из основных проблем заключается в «привязке» ряда ключевых сервисов к одному дата-центру. Google советует распределять нагрузки по разным зонам доступности, но оказалось, что сама зависела от одной зоны в обеспечении работы критически важных сервисов. Формально зона продолжила работу, но клиенты пострадали всё равно. В этом году IT-гигант также столкнулся с проблемами в Индии. Пожар в стороннем ЦОД под управлением STT GDC/Tata привёл к аварийному отключению сетевого оборудования, изоляции локальной точки присутствия (Point of Presence) в Дели и снижению доступной сетевой ёмкости в местной агломерации. 
Источник изображения: Google По мнению экспертов, во многом облачному бизнесу не хватает прозрачности. Клиентам просто не сообщают, насколько конкретный сервис зависит от единственного дата-центра. В итоге те полностью полагаются на провайдера, хотя архитектура подобных облаков нередко весьма уязвима. В Gartner, например, напомнили, что в 2023 году у Google случился сбой, когда сервис Spanner отказал из-за протечки и пожара в части здания, арендованного сторонней компанией. Google извинилась и пообещала представить отчёт о мерах по предотвращению аварий, но это не поможет клиентам узнать, какие ещё скрытые конструктивные изъяны есть в архитектуре облака. Datacenter Dynamics напоминает, что в Нидерландах Google управляет несколькими ЦОД, последний открылся в Винсхотен (Winschoten) в провинции Гронинген (Groningen) в ноябре 2025 года. В 2018 году заработал ЦОД Google в Эмсхавене (Eemshaven), а в 2020 году — в Мидденмере (Middenmeer). Также компания купила землю в промышленной зоне Вестпорта (Westpoort) в Гронингене, где начала строительство в апреле 2024 года.
22.07.2026 [13:55], Руслан Авдеев
Удар по мёртвому облаку: Иран объявил, что уничтожил ЦОД AWS в Бахрейне, который и так не работал месяцамиПредставители иранских силовых ведомств заявили, что снова нанесли удар крылатыми ракетами по дата-центру AWS в Бахрейне и уничтожили его, хотя сам ЦОД был выведен из строя ещё во время весенней атаки, сообщает The Register. Сообщается, что новая атака стала ответом на действия США. Достоверность утверждений Ирана о повторном успешном ударе по объекту в Бахрейне пока трудно поддаётся проверке, поскольку сервисы AWS в стране и без того недоступны в течение нескольких месяцев. В самой AWS информацию пока не комментируют. Последнее обновление статусов инфраструктуры AWS в ОАЭ и Бахрейне после атак весной этого года было сделано 30 апреля. Оба региона, me-central-1 (ОАЭ) и me-south-1 (Бахрейн), фактически недоступны с начала марта. В числе компаний, пользовавшихся мощностями AWS, назывались Snowflake и Red Hat, которые позже предложили пострадавшим от ударов клиентам или переключиться на резервные мощности, или перенести рабочие нагрузки в другие облачные регионы. 
Источник изображения: Todd Gardner/unsplash.com AWS отменила в регионе me-central-1 оплату использования сервисов в марте 2026 года. Иран также называл легитимными целями все объекты, ассоциированные с Google, IBM, Microsoft, NVIDIA, Oracle, и Palantir, ссылаясь на поддержку IT-гигантами военных операций в отношении страны. В числе прочего он грозил уничтожить строящийся дата-центр Stargate в ОАЭ.
21.07.2026 [15:32], Руслан Авдеев
ЦОД как оружие: злоумышленники могут вывести из строя энергосети с помощью облачных ИИ-сервисовИИ ЦОД уже создают серьёзные нагрузки на энергосети даже в обычных условиях, но гораздо хуже, если злоумышленники захотят использовать их ресурсы во вред. Специалисты по кибербезопасности из Китая разработали атаку Bit2Watt, позволяющую вызвать веерные отключения электричества или повредить оборудование, сообщает The Register. Исследование призвано продемонстрировать необходимость распространить киберзащиту на планирование рабочих нагрузок в ЦОД. Исследователи из Чжэцзянского университета в Ханчжоу (Zhejiang University, ZSU) описали новую методику атак в статье «Bit2Watt: Киберфизическая уязвимость, эксплуатирующую нагрузки GPU в энергетических и вычислительных инфраструктурах» (Bit2Watt: A Cyber-Physical Vulnerability Exploiting GPU Workloads Across Power and Computing Infrastructures). Связанные с обучением ИИ нагрузки уже представляют собой проблему для операторов ЦОД. В исследовании 2025 года Microsoft, NVIDIA и OpenAI отметили необходимость стабилизации энергоснабжения в процессе обучения ИИ. Компании подчеркнули, что во время перехода ускорителей от вычислений к синхронизации данных и обратно, случаются огромные перепады энергопотребления, иногда на десятки мегаватт и более. Если частотный спектр колебаний в процессе «сочетается» с критическими частотами энергосистем, то возможно повреждение инфраструктуры энергосети, да и другим потребителям от этого будет только хуже. 
Источник изображения: dhahi alsaeedi/unsplash.com В работе Meta✴, посвящённой обучению ИИ-модели Llama, также упоминается о риске энергосетям в процессе обучения. Подчёркивается, что десятки тысяч ускорителей способны одновременно увеличивать или снижать энергопотребление в определённые моменты рабочих циклов. Это способно привести к немедленным колебаниям энергопотребления в масштабе ЦОД, в таких случаях энергосеть эксплуатируется на грани её возможностей. Чтобы избежать таких колебаний, разработчики вынужденно нагружали ускорители бессмысленными, но энергоёмкими счётными задачами. Атака Bit2Watt позволяет превратить такой сценарий в оружие — злоумышленник может злонамеренно использовать нагрузки на ИИ-ускорители для дестабилизации работы ЦОД и энергетической инфраструктуры. Китайские учёные утверждают, что нагрузки на ускорители могут достичь частот модуляции более 6 кГц, для сравнения — при обычных бытовых нагрузках устройств вроде кондиционеров частоты составляют всего несколько Гц. Подобные высокочастотные модуляции могут вызвать нарушения в работе электросетей. По словам авторов исследования, атака на 1-МВт локальную энергосеть, состоящую в основном из распределённых энергоресурсов вроде солнечных панелей, достаточно 1 тыс. ИИ-ускорителей для создания суммарного коэффициента гармонических искажений в 46,8 %. В результате почти половина тока будет потрачена на «непроизводительную» работу и приведёт к выделению на 20 % больше тепла, чем обычно. Специалисты утверждают, что под угрозой окажется не только доступность вычислительного оборудования — создаётся отрицательный коэффициент демпфирования, что вводит энергосистему в нестабильный режим. При этом срабатывание защиты и сброс вычислительных нагрузок могут стать триггерами каскадных сбоев. 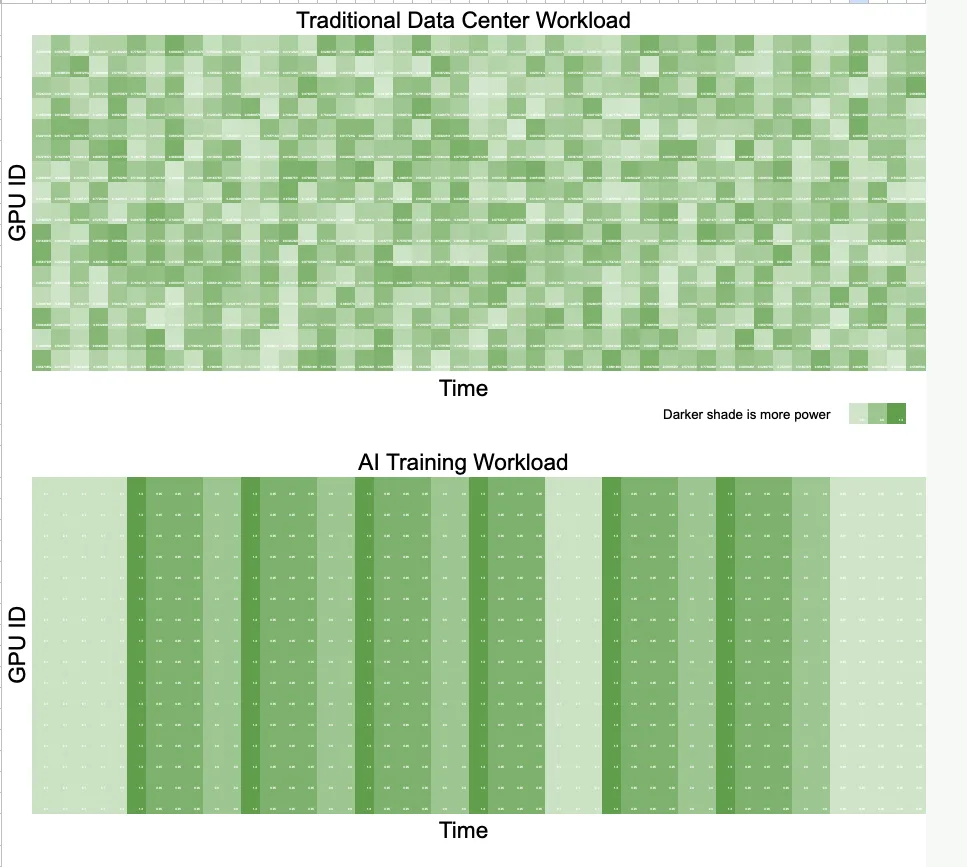
Источник изображения: NVIDIA Эксперты уверены, что атаку можно осуществить довольно скрытно, поскольку её можно запустить в рамках разрешённых механизмов выполнения рабочих нагрузок и она, вероятно, не будет выявлена системами мониторинга облачных провайдеров своевременно. Провайдерам ИИ-инфраструктуры предлагается координировать защиту от «вредоносных шаблонов вычислений» на кибернетическом и физическом уровнях. Также необходимо создание локальных систем буферизации энергии, чтобы сглаживать пики спроса на электричество. Впрочем, операторы и поставщики уже озаботились этим вопросом — стойки NVIDIA GB300 NVL72 снабжены конденсаторным модулем для сглаживания скачков энергопотребления. Что интересно, Bit2Watt открывает дверь атакам по побочным каналам, получившим название Watt2Bit. По словам исследователей, «вредоносные» задачи, создающие электрическую и тепловую нагрузку на оборудование, вызывают отказы и позволяют скрыто организовать утечки данных с помощью модуляции энергии. Исследователи даже продемонстрировали возможность восстановления 50-бит тестовой последовательности посредством частотной манипуляции (FSK). В итоге эксперты призывают создавать координированную защиту, учитывающей статус рабочих нагрузок, состояние силовой электроники и динамики электросети — по мере слияния энергетических и вычислительных инфраструктур безопасность должна обеспечиваться на стыке дисциплин.
19.07.2026 [23:00], Руслан Авдеев
Экоактивисты забросали кислотными «бомбочками» строящийся ЦОД Microsoft в НидерландахВыступающие против строительства ЦОД экоактивисты Extinction Rebellion забросали надувными шарами, наполненными кислотной смесью, строящийся в Амстердаме объект Microsoft — утверждается, что химикаты призваны навредить бетону и стали, ускорив их коррозию и разрушение сообщает The Register. В Extinction Rebellion заявили, что дата-центры и ИИ усугубляют климатический кризис, лишают человечество работы, воруют контент и даже повинны в гибели людей, поэтому активисты готовят новые акции. Объект строит британская Pure Data Centres Group (Pure DC). Если и когда его закончат, он будет состоять из трёх 85-метровых 26-МВт башен. Общая мощность площадки составит 78 МВт. На территории объекта имеется собственная электроподстанция, которая уже работает, строительство собственно ЦОД стартовало в январе 2026 года. И хотя имя арендатора компания прямо не называлось, местные СМИ сообщают, что единственным клиентом стала Microsoft. В целом в Амстердаме давно действуют ограничения на строительство новых ЦОД гиперскейл-уровня, но особенности конструкции ЦОД позволили обойти ограничения. 
Источник изображения: Gaurav Jain/unsplash.com До сих пор нет данных, какие последствия вызвала эта довольно наивная атака. Pure DC и экстренные службы подтвердили факт забрасывания площадки шарами, но о содержимом не сообщалось. Застройщик заявил, что произошедшее никак не сказалось на ходе строительства, а компания намерена подать в суд на виновных. Тем временем в США протесты проходят более радикально — например, в апреле неизвестные обстреляли дом чиновника, принимавшего активное участие в одобрении строительства крупного дата-центра. В ноябре 2025 года в отчёте крупного голландского банка ING сообщалось, что если в Нидерландах не будет возможностей для дальнейшего роста, страна потеряет знания и опыт, что скажется на экономическом росте в будущем. Сегодня сектор обеспечивает 150–250 тыс. рабочих мест в сфере цифровой инфраструктуры и вносит порядка €26 млрд в годовой оборот Нидерландов. Строительству новых ЦОД препятствуют перегрузка сетей из-за не слишком удачного планирования развития возобновляемой энергетики, нехватка земли и возможный дефицит энергии.
18.07.2026 [01:28], Владимир Мироненко
Ошибочка вышла: AWS выставила клиентам счета на миллиарды и триллионы долларов из-за проблем с биллингом17 июля клиенты облачных сервисов AWS получили по электронной почте предварительные счета за оказанные услуги, которые вызвали шок, поскольку суммы к оплате исчислялись миллиардами и даже триллионами долларов. «Я только что увидел сумму в $1,5 трлн в своем счёте за AWS, и у меня отошла душа от тела», — сообщил один из пользователей ресурсу The Guardian. Amazon подтвердила наличие ошибок в биллинге AWS, из-за которой некоторые клиенты оказались «должны» миллионы или триллионы долларов за облачные услуги. Amazon уточнила, что неточные данные биллинга начали появляться вечером в четверг. К утру пятницы компания признала, что «откат недавнего изменения не решил проблему». В пятницу в 22:56 МСК компания сообщила, что выявила первопричину и устранила основную проблему, из-за которой отображались некорректные данные. Также компания сообщила, что начала корректировать информации о затратах для всех клиентов, пообещав полностью восстановить сведения к 10:00 МСК 19 июля. 
Источник изображения: Towfiqu barbhuiya / Unsplash «Отображаемые расчётные суммы не отражают фактическое использование и начисления», — заверила клиентов Amazon. Этот инцидент произошёл через день после сбоя AWS CloudFront, в результате которого вместо веб-сайтов отображались ошибки, отметил ресурс TNW.
10.07.2026 [23:41], Владимир Мироненко
Microsoft, Google, Amazon и Oracle попали под пристальный надзор британских регуляторов
aws
google cloud platform
microsoft azure
oracle cloud infrastructure
software
банк
великобритания
ии
информационная безопасность
кии
облако
регулирование
сбой
финансы
Со следующей недели Microsoft, Google, Amazon и Oracle будут находиться под прямым надзором британских регуляторов после того, как Министерство финансов признало четыре крупнейшие американские технологические группы критически важными поставщиками услуг для британского сектора финансовых услуг. Министерство заявило, что применяет «целенаправленный и соразмерный подход» и что со временем в список могут быть включены и другие компании, «если это будет необходимо для защиты устойчивости Великобритании». Сообщается, что эта мера направлена на повышение устойчивости финансовых компаний за счёт снижения риска масштабных сбоев в результате кибератак или технологических перебоев. «Поскольку банки, страховые компании и инфраструктуры финансовых рынков всё больше зависят от облачных сервисов, сбой у крупного поставщика может одновременно затронуть множество компаний, потенциально влияя на услуги, от которых зависят клиенты», — указано в заявлении правительства Великобритании, опубликованном в пятницу, о чём сообщило агентство Reuters. Решением британского правительства статус критически важных сторонних организаций с 13 июля присвоен Microsoft Ireland Operations Ltd, Google Cloud EMEA Ltd, Amazon Web Services EMEA SARL и Oracle Corporation UK Ltd. Надзор ними будет осуществляться Банком Англии (BoE) совместно с Управлением пруденциального регулирования (PRA) и Управлением по финансовому регулированию и надзору (FCA). Право определять компании, предоставляющие жизненно важные услуги финансовому сектору Великобритании, как «критически важных третьих лиц», Министерство финансов Великобритании имеет с января 2025 года. Этот режим позволяет регуляторам предъявлять к поставщикам облачных услуг и ИИ-моделей более жёсткие требования по поводу раскрытия информации, включая проведение ежегодной самооценки и регулярное «сценарное тестирование» своей способности предоставлять критически важные услуги во время серьёзных сбоев, а также необходимость сообщать о крупных инцидентах. 
Источник изображения: Chanel Chomse/unsplash.com Рэйчел Блейк (Rachel Blake), экономический секретарь Казначейства Великобритании, заявила: «Эти определения помогут обеспечить устойчивость критически важных услуг, на которые полагаются финансовые компании, защищая потребителей и предприятия и поддерживая рост экономики в целом», пишет The Financial Times. Вместе с тем финансовые компании по-прежнему будут нести ответственность за управление рисками, возникающими в связи с их сторонними поставщиками. Надзор регуляторов за поставщиками ИТ-сервисов будет ограничен системными услугами, которые они предоставляют сектору. Регуляторы обеспокоены тем, в какой мере финансовые компании зависят от услуг, предоставляемых на аутсорсинге небольшим числом технологических гигантов, в том числе в области облачных вычислений, хранения данных и ИИ-моделей. Согласно исследованию, проведенному Банком Англии и FCA два года назад, на три крупнейшие группы компаний, предоставляющие ИТ-услуги — Amazon, Google и Microsoft — приходилось 73 % услуг облачных вычислений, предоставляемых британским финансовым компаниям. Обеспокоенность по этому вопросу усилилась после конфликта Anthropic с администрацией президента США и последующим запретом предоставлять европейским компаниям доступ к своим самым продвинутым моделям Fable 5 и Mythos 5. Подход Великобритании заметно отличается от ЕС, выбравшего в ноябре прошлого года целых 19 поставщиков ИТ-услуг для прямого надзора со стороны регуляторов блока, включая Bloomberg, Accenture, IBM, NTT Data, SAP и Tata Consultancy Services. Депутаты парламента начали настаивать на том, чтобы минфин начал включать такие компании в свой список после прошлогоднего сбоя в облачном бизнесе Amazon, который лишил британцев доступа к некоторым банковским услугам и вызвал проблемы в работе налоговой службы Королевства. Комментируя решение правительства, Amazon, Microsoft, Google и Oracle заявили о своей приверженности обеспечению устойчивости финансовой системы Великобритании и готовности соблюдать требования усиленного надзора со стороны британских регуляторов.
26.06.2026 [16:45], Руслан Авдеев
Британская больница Queen Alexandra объявила о критическом инциденте — чиллеры её ЦОД отказали на фоне рекордной жарыНа фоне рекордной жары больница Queen Alexandra Hospital в британском Портсмуте (Portsmouth) объявила о критическом инциденте в своём ЦОД. В расположенном на территории больницы объекте перестали функционировать чиллеры, что вызвало сбои в работе цифровых сервисов, сообщает Datacenter Dynamics. В результате пришлось перенести часть плановых приёмов и процедур, а посетителей предупреждают, что в госпитале «очень жарко». При этом в Великобритании температура воздуха достигает 35 °C и более из-за мощного антициклона и климатических изменений антропогенного характера. Британские метеорологи объявили красный уровень опасности в связи с экстремальной жарой. В 2022 году лондонские дата-центры тоже столкнулись со сбоями из-за жары. Тогда даже пришлось поливать из шланга охлаждающее оборудование на крышах. 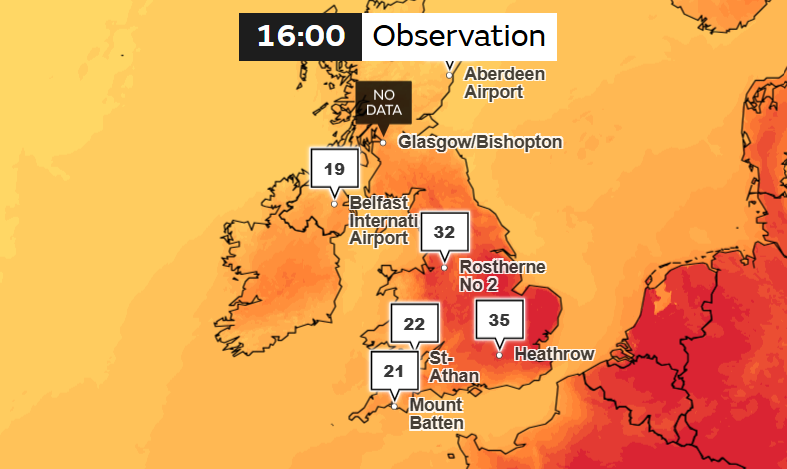
Источник изображения: Met Office Согласно заявлению больницы, текущий сбой в работе охлаждающих мощностей привёл к росту температуры в ряде помещений, что сказалось и на работе цифровых систем, и критически важных служб больницы, в т.ч. операционных, отделений диагностики и др. По словам организации Portsmouth Hospitals University NHS Trust, курирующей больницу, специалисты прилагают все усилия для ремонта повреждённого оборудования и обеспечения дальнейшего оказания медицинской помощи. Ранее расследование Национаной системы здравоохранения (NHS) показало, что сбой в работе двух лондонских больницы из-за жары в 2022 году обошёлся в £1,4 млн ($1,7 млн). Тогда из строя вышли дата-центры, поддерживавшие работу больниц, находившихся в ведении Guy’s and St Thomas’ NHS Foundation Trust. В результате зарегистрировано более 100 задержек с оказанием медицинской помощи, а один из пациентов не дождался своевременной трансплантации органа, что принесло «умеренный вред» его здоровью. На полное восстановление сервисов ушло шесть недель. Ещё в декабре 2025 года исследование Rest of World показало, что около 80 % всех дата-центров мира построены в не слишком подходящих климатических условиях. В июне компания First Street, занимающаяся финансовым моделированием климатических рисков, пришла к тем же выводам, объявив, что 79 % мировых мощностей ЦОД подвержены «серьёзным климатическим угрозам». В категории с наибольшим уровнем климатического риска — Северная Вирджиния, Джохор и Марсель.
25.06.2026 [14:43], Руслан Авдеев
Пожар из-за литиевых АКБ в индийском ЦОД STT GDC нанёс масштабный ущерб Google и другим компаниямНедавний пожар в одном из дата-центров в Индии привёл к значительному ущербу и затронул интересы сразу нескольких клиентов. В начале июня Tata Communications опубликовала краткую информацию для акционеров, сообщив о возгорании на площадке в здании Next-Gen Tower, расположенном в районе Greater Kailash-1 в Нью-Дели, сообщает Datacenter Dynamics. Пожар, причиной которого, как предварительно считается, стало возгорание литиевых аккумуляторов, своевременно взяли под контроль пожарные, поэтому никто не пострадал. Дата-центр STT Delhi 2 мощностью всего 1,1 МВт используется STT GDC. В результате инцидента пострадали сервисы Google Cloud, поскольку возгорание заставило отключить сетевое оборудование, обеспечивавшее работу локальной точки присутствия Google. Полностью работу сетевых сервисов восстановить до сих пор не удалось. В обновлении 23 июня Google сообщала, что её команда получила доступ к пострадавшей площадке и будет наращивать сетевые мощности в течение недели. Компания оптимизировала доступную ёмкость и намерена расширить магистральную ёмкость в Дели. Она продолжает отслеживать проблемы с задержками и потерями пактов данных. Следующий отчёт об инциденте будет выпущен в понедельник. 
Источник изображения: Dave Hoefler/unsplash.com По данным СМИ, пожар вызвал «масштабный ущерб», письма об этом направлены клиентам и аналитикам. В частности, Matrix Cellular, занимающаяся международными SIM-картами, заявила, что имеет трудности с восстановлением данных за 20 лет, потерянных в результате пожара. По оценкам индийского интернет-провайдера R2 Net, ущерб компании составил $2 млн, а сейчас она теряет из-за сбоя корпоративных клиентов. Ранее пожары в ЦОД привели к крупным сбоям телеком-систем целых стран в Бангладеш и Иране. Также европейские сервисы Google Cloud серьёзно пострадали в 2023 году в результате пожара в парижском ЦОД Global Switch. Tata продала 74 % бизнеса ЦОД в Индии и Сингапуре компании STT GDC в 2016 году и до сих пор хранит оставшуюся часть акций. Совместное предприятие управляет десятками дата-центров в Индии. Услуги в сфере информационно-телекоммуникационных технологий до сих пор предоставляются Tata из десятков ЦОД по всему миру, многие из которых арендованы. В том числе речь идёт об облачных сервисах. Недавно было объявлено о намерении вернуться к бизнесу в сфере ЦОД и построить до 1 ГВт мощностей в Индии при посредничестве дочерней структуры HyperVault.
18.06.2026 [16:38], Руслан Авдеев
Сирия подозревает, что подводный интернет-кабель, связывающий страну с Египтом, повреждён в результате «систематического саботажа»По данным принадлежащей сирийскому государству телеком-структуры Syrian Telecommunications Company (SyTC), подводный кабель, связывающий Сирию и Египет, оборван — на его ремонт уйдёт некоторое время. Хотя официальных виновников не называли, СМИ сообщают, что власти в Дамаске называют причиной происшествия «систематическую кампанию саботажа», сообщает Tom’s Hardware. Пока трафик направляется через другую подводную магистраль, ведущую на Кипр, и через наземный кабель, пролегающий через Турцию. Тем не менее, инцидент сказался на качестве связи во всей стране. Несмотря на критическую важность кабелей для любого государства, эта инфраструктура довольно уязвима и зачастую кабели буквально лежат на морском дне или заглублены в грунт на 0,5–1,5 м. В результате их довольно легко повредить преднамеренно или даже случайно, в том числе рыболовными тралами, якорями и др. Охранять подобные цифровые магистрали довольно сложно, поскольку они тянутся на огромные расстояния, а для полноценной охраны каждого километра нет ресурсов ни у одного государства в мире. 
Источник изображения: JOE Planas/unspalsh.com По данным Datacenter Dynamics, в последние годы кабели несколько раз повреждались судами, которые западные СМИ относят к т.н. «теневому флоту». Например, в конце января 2025 года зафиксировано повреждение подводного оптоволоконного кабеля компании LVRTC, соединяющего Латвию и Швецию. Ещё раньше получили повреждения четыре интернет-кабеля и один силовой. А ещё раньше, в ноябре 2024 года, были повреждены интернет-кабели, связывающие Финляндию и Германию, Литву и Швецию. Впрочем, финские спецслужбы сомневаются, что Россия стала бы преднамеренно повреждать кабели. Повреждения неоднократно регистрировались и на Ближнем Востоке, особенно в Красном море, являющемся ключевым узлом связи между Европой и Азией. Тайвань также наращивает патрулирование подконтрольной акватории вблизи 24 подводных кабелей, особенно в свете того, что сотни внесённых в «чёрный список» связанных с материковым Китаем судов постоянно находятся вблизи от островной инфраструктуры и один из инцидентов даже закончился тюремным заключением для китайского капитана. |
|

