Материалы по тегу: интерконнект
|
16.02.2026 [09:35], Сергей Карасёв
Мировой рынок оптических коммутаторов к 2029 году достигнет $2,5 млрд, но львиная доля всё равно придётся на GoogleИсследовательская компания Cignal AI повысила прогноз по глобальному рынку оптических коммутаторов (OCS). Связано это с ускоренным развёртыванием кластеров ИИ на базе тензорных ускорителей (TPU) Google. Аналитики пришли к выводу, что сектор OCS имеет гораздо больший потенциал, нежели предполагалось ранее. Google применяет оптические коммутаторы собственной разработки Apollo на базе MEMS-переключателей для формированя ИИ-кластеров. По заявлениям Google, решения OCS быстрее, дешевле и потребляют меньше энергии по сравнению с InfiniBand. Cignal AI полагает, что объём мирового рынка OCS в 2026 году окажется в три раза больше, чем ожидалось ранее. Прогноз на 2029 год повышен более чем на 40 % по сравнению с цифрами, опубликованными в декабре: аналитики считают, что к этому времени продажи оптических коммутаторов увеличатся как минимум до $2,5 млрд. 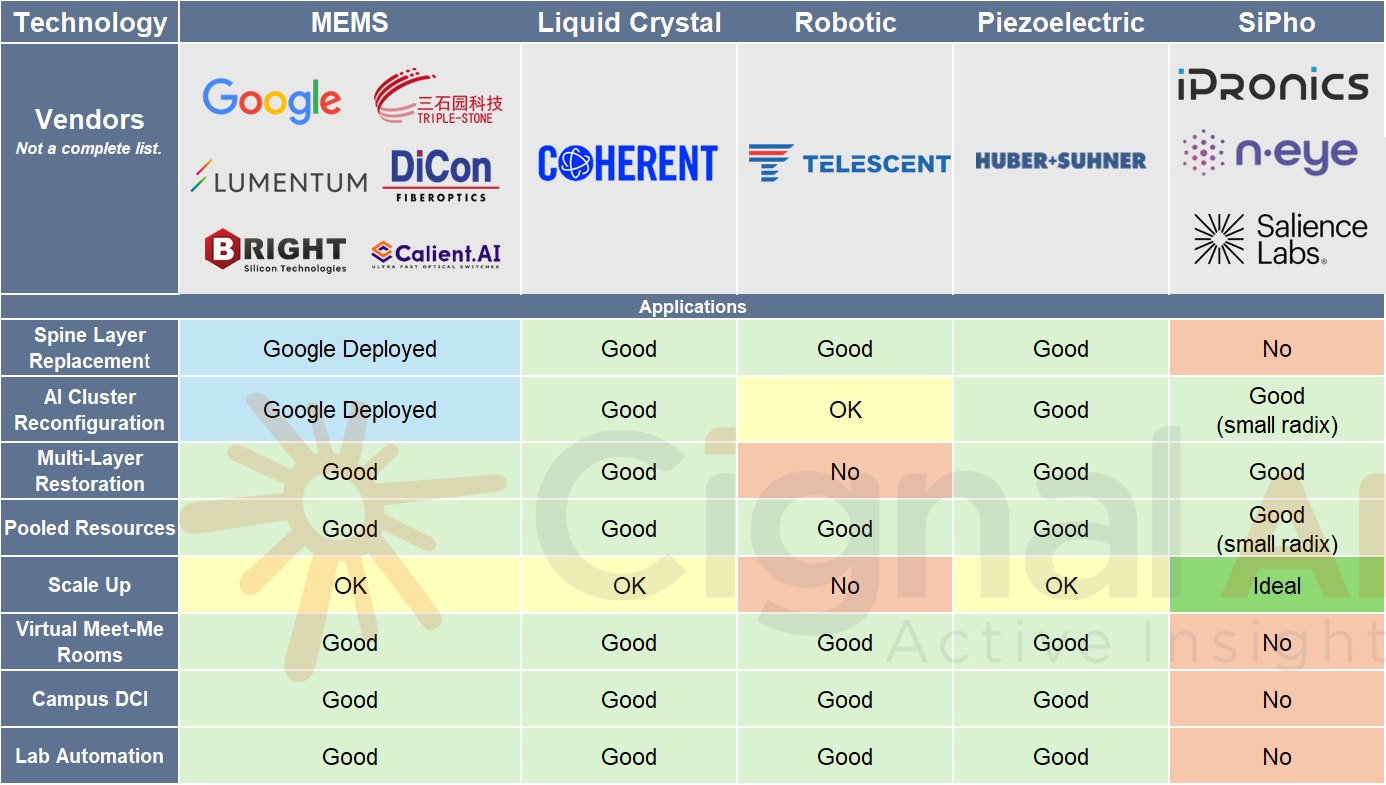
Источник изображения: Cignal AI Предполагается, что до конца десятилетия большинство развёртываний OCS будут по-прежнему сосредоточены в инфраструктуре Google. При этом в ЦОД на основе GPU-ускорителей применение OCS окажется ограниченным: связано это с тем, что в таких экосистемах переход на оптические коммутаторы сопряжён со значительными техническими сложностями. В целом, внедрение OCS за пределами дата-центров Google пока находится на стадии проверки концепции и раннего тестирования. «Общий потенциал рынка, безусловно, исчисляется миллиардами долларов, но основная часть краткосрочных инвестиций останется в пределах внутренних проектов Google», — говорит Скотт Уилкинсон (Scott Wilkinson), ведущий аналитик Cignal AI. Ранее эксперименты в этом направлении проводила Meta✴. Впрочем, не так давно в рамках OCP появилась отдельный проект OCS (Optical Circuit Switching), направленный на ускорение внедрения технологий оптической коммутации в ИИ ЦОД, что потенциально может ускорить развитие рынка.
07.02.2026 [13:53], Сергей Карасёв
Montage Technology представила активные кабели PCIe 6.x/CXL 3.xКомпания Montage Technology объявила о разработке активных электрических кабелей (AEC) PCIe 6.x/CXL 3.x, предназначенных для организации высокоскоростного интерконнекта с низкой задержкой в дата-центрах, ориентированных на ресурсоёмкие задачи ИИ и НРС. Отмечается, что на фоне стремительного внедрения ИИ и продолжающегося развития облачных вычислений быстро растёт нагрузка на ЦОД. При этом PCIe остаётся основным стандартом для обмена данными между CPU, GPU, сетевыми картами и высокопроизводительными хранилищами. Интерконнект на базе PCIe применяется как в рамках серверных стоек, так и в составе суперузлов, в связи с чем требуется увеличивать протяжённость соединений. В таких условиях, подчёркивает Montage Technology, медные линии на базе AEC имеют решающее значение для обеспечения целостности сигнала на больших расстояниях. 
Источник изображения: Montage Technology Кабели Montage Technology PCIe 6.x/CXL 3.x с ретаймером используют фирменные блоки SerDes и передовую архитектуру DSP. Применён высокоплотный форм-фактор OSFP-XD. Говорится о развитых функциях мониторинга и диагностики каналов связи, что упрощает обслуживание систем и повышает их эффективность. Возможно использование в инфраструктурах с различными топологиями. В разработке решения, как утверждается, принимали участие ведущие китайские производители кабелей. Проведены успешные тесты на совместимость с CPU, xPU, коммутаторами PCIe, сетевыми адаптерами и другими устройствами. В дальнейшем компания Montage Technology намерена развивать направление высокоскоростного интерконнекта, включая выпуск ретаймеров PCIe 7.0.
30.01.2026 [10:43], Сергей Карасёв
Lightmatter представила оптический VLSP-движок Guide для ИИ-платформ нового поколенияКомпания Lightmatter, специализирующаяся на разработке ИИ-ускорителей и других продуктов на основе фотоники, объявила о «фундаментальном прорыве» в лазерной архитектуре для систем передачи данных: представлена т.н. платформа сверхмасштабируемой фотоники — Very Large Scale Photonics (VLSP). Первым изделием на её основе стал оптический движок Guide, ориентированный на ИИ-системы следующего поколения. Отмечается, что современные решения CPO (Co-Packaged Optics) и NPO (Near-Package Optics) базируются на дискретных лазерных диодах на основе фосфида индия (InP), интегрированных в модули ELSFP (External Laser Small Form Factor Pluggable). Однако эти архитектуры сталкиваются с трудностями, обусловленными ограничениями по мощности. Компоненты, при изготовлении которых используется эпоксидная смола, уязвимы к термическому повреждению. Вместе с тем для удвоения полосы пропускания требуется кратное увеличение количества ELSFP, что приводит к соответствующему повышению стоимости и энергопотребления, а также к увеличению занимаемого пространства. Кроме того, в случае дискретных лазеров могут возникать проблемы с обеспечением точного разнесения длин волн. 
Источник изображения: Lightmatter Изделие Guide VLSP, как утверждается, устраняет существующие ограничения. Новая интегрированная архитектура по сравнению с дискретными лазерными модулями позволяет сократить количество компонентов, предлагая при этом значительно более высокую производительность и улучшенную надёжность. Технология предусматривает возможность масштабирования от 1 до 64+ длин волн при одновременном снижении сложности сборки. В результате значительно повышается плотность компоновки: платформа Guide первого поколения обеспечивает коммутационную способность до 100 Тбит/с в 1U-шасси. Для сравнения, в случае обычных решений потребовалось бы 18 модулей ELSFP в шасси высотой 4U. Движок Guide используется в валидационных платформах Passage M-Series и L-Series (Bobcat). Говорится, что изделие обеспечивает пропускную способность до 51,2 Тбит/с на лазерный модуль в случае NPO и CPO. Выходная мощность составляет не менее 100 мВт в расчёте на оптическое волокно. Возможна генерация 16 длин волн с мультиплексированием. Поддерживаются двунаправленные фотонные каналы связи, в которых две сетки длин волн с шагом 400 ГГц чередуются с точным смещением на 200 ГГц (±20 ГГц). Новая платформа уже доступна заказчикам для тестирования. Между тем компания Lightmatter сообщила о заключении сразу нескольких партнёрских соглашений. В частности, планируется интеграция решений Synopsys в платформу Lightmatter Passage 3D Co-Packaged Optics. В сотрудничестве с Global Unichip Corp. (GUC) Lightmatter намерена заняться разработкой CPO-продуктов для гиперскейлеров, ориентированных на ИИ. Кроме того, Lightmatter и Cadence объединили усилия с целью ускорения разработки передового интерконнекта для ИИ-инфраструктур.
22.01.2026 [16:04], Владимир Мироненко
Upscale AI привлёк $200 млн для запуска ИИ-интерконнекта и коммутатора SkyHammerСтартап Upscale AI, специализирующий на разработке ИИ-интерконнекта, объявил о привлечении $200 млн в рамках раунда финансирования серии А. С учётом предыдущего раунда общая сумма инвестиций в Upscale AI достигла $300 млн, а оценка его рыночной стоимости превысила $1 млрд, что придало ему статус «единорога». Это большая сумма для любой технологической компании со 150 сотрудниками, большинство из которых инженеры. Раунд серии А возглавили Tiger Global, Premji Invest и Xora Innovation, также в нём приняли участие Maverick Silicon, StepStone Group, Mayfield, Prosperity7 Ventures, Intel Capital и Qualcomm Ventures. Upscale AI отметил, что поддержка инвесторов отражает растущее в отрасли мнение, что сети являются критически узким местом для масштабирования ИИ, а традиционные сетевые архитектуры, предназначенные для соединения вычислительных ресурсов общего назначения и хранилищ, принципиально не подходят для эпохи ИИ. Устаревшие сетевые решения для ЦОД были разработаны до появления ИИ, и слабо подходят для масштабного, синхронизированного масштабирования на уровне стоек. Когда Upscale AI был основан в начале 2024 года, консорциум UALink и стандарт ESUN, предложенный Meta✴ Platforms, ещё не были обнародованы, но идея гетерогенной инфраструктуры, безусловно, уже была, отметил ресурс The Next Platform. Созданная Upscale AI платформа объединяет GPU, ИИ-ускорители, память, хранилище и сетевые возможности в единый синхронизированный ИИ-движок. Для этого стартап разработал ASIC SkyHammer, который поддерживает ESUN, UALink, Ultra Ethernet, SONiC и Switch Abstraction Interface (SAI). Фактически Upscale AI хочет составить конкуренцию NVIDIA NVSwitch, дав возможность выбора интерконнекта при создании ИИ-инфраструктур. 
Источник изображения: Upscale AI Upscale AI сообщил, что благодаря дополнительному финансированию представит первую полнофункциональную, готовую к использованию платформу, охватывающую кремниевые компоненты, системы и ПО. Также полученные средства будут направлены на расширение инженерных, торговых и операционных команд по мере перехода к коммерческому внедрению решения. По словам Арвинда Шрикумара (Arvind Srikumar), старшего вице-президента по продуктам и маркетингу компании, поставки образцов SkyHammer клиентам начнутся в конце 2026 года, а массовые поставки — в 2027 году, когда в это же время выйдут новые поколения GPU, XPU, коммутаторов и стоек. Коммутаторы должны быть у OEM/ODM-производителей за два квартала до того, как вычислительные ядра будут готовы к поставкам, чтобы они могли собрать системы и протестировать их. «Я всегда считал, что гетерогенные вычисления — это правильный путь, и гетерогенные сети — это тоже правильный путь», — сообщил Шрикумар изданию The Next Platform. Он отметил, что Upscale AI фокусируется на демократизации интерконнекта для ИИ. Шрикумар признал, что у NVIDIA отличные технологии, и что это «потрясающая» компания, когда дело касается инноваций. Вместе с тем он считает, что в будущем, с учётом темпов развития ИИ, вряд ли одна компания сможет предоставить все необходимые технологии для ИИ. Шрикумар считает, что PCIe-коммутация хорошо работает, когда несколько СPU взаимодействуют с несколькими GPU, относительная пропускная способность памяти GPU довольно низкая, а СPU и GPU расположены довольно близко друг к другу в серверном узле. В то же время Upscale AI скептически относится к попыткам создания коммутаторов UALink, ESUN или SUE путем использования ASIC-чипов для PCIe или путём извлечения начинки ASIC-чипов Ethernet-коммутаторов. «Те, кто давно занят в сфере ASIC, знают, что можно удалить много блоков, но основные элементы остаются прежними. Базовая ДНК каждого ASIC остается неизменной», — отметил Шрикумар. Поэтому в Upscale AI решили создать ASIC с нуля, а затем обеспечить поддержку протоколов семантики памяти по мере их появления.
16.01.2026 [23:14], Владимир Мироненко
NVIDIA добралась до RISC-V: NVLink Fusion пропишется в серверных процессорах SiFiveПродолжая укреплять свои лидирующие позиции на ИИ-рынке NVIDIA не скрывает стремления построить целую экосистему ИИ-платформ с привязкой к своим решениям. Эти усилия активизировались в прошлом году с анонсом технологии NVLink Fusion, позволяющей использовать NVLink в чипах сторонних производителей. Как стало известно, вслед за Arm, Intel и AWS, присоединившимися к программе в прошлом году, экосистема NVLink Fusion пополнилась первым поставщиком чипов на архитектуре RISC-V — компанией SiFive, которая объявила о планах внедрить NVLink Fusion в свои будущие чипы для ЦОД. SiFive отметила, что ИИ-вычисления вступают в фазу, когда архитектурная гибкость и энергоэффективность так же важны, как и пиковая пропускная способность. Нагрузки обучения и инференса растут быстрее, чем энергетические бюджеты, заставляя операторов ЦОД переосмыслить способы подключения и управления CPU, GPU и ASIC. Теперь производительность на Вт и эффективность перемещения данных стали первостепенными ограничениями при проектировании чипов. Патрик Литтл (Patrick Little), президент и генеральный директор SiFive заявил, что ИИ-инфраструктура больше не строится из универсальных компонентов, а разрабатывается совместно с нуля: «Интегрируя NVLink Fusion с высокопроизводительными вычислительными подсистемами SiFive, мы предоставляем клиентам открытую и настраиваемую платформу CPU, которая легко интегрируется с ИИ-инфраструктурой NVIDIA, обеспечивая исключительную эффективность в масштабах ЦОД». 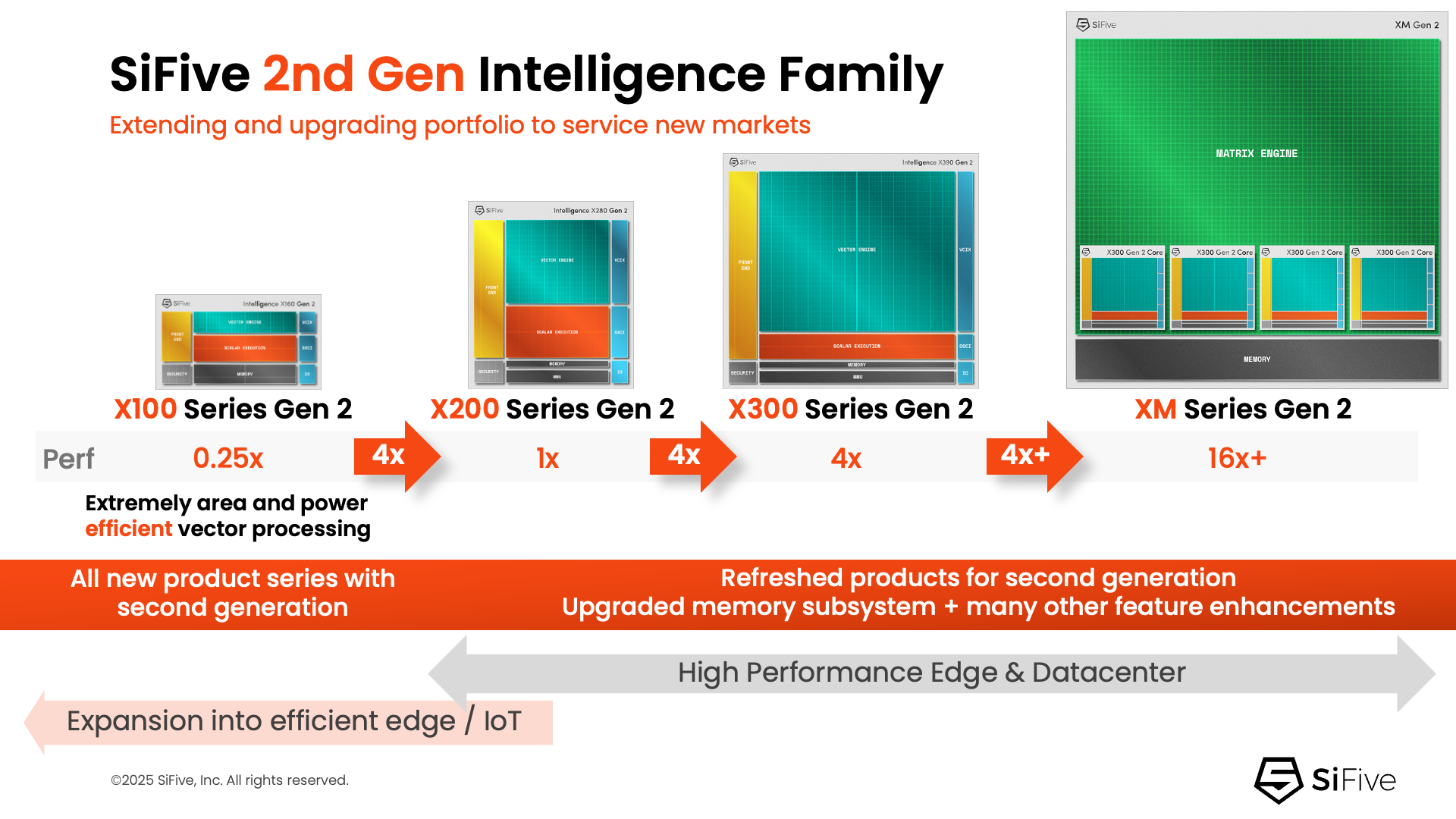
Источник изображения: SiFive Пресс-релиз SiFive не содержит каких-либо конкретных планов по продуктам, кроме сообщения о добавления поддержки NVLink к «высокопроизводительным решениям для ЦОД» SiFive. Предположительно, речь идёт о чипах платформы Vera Rubin или более поздних, т.е. о NVLink 6. Для SiFive — как поставщика IP-блоков RISC-V CPU — интерес заключается в использовании интерконнекта NVLink-C2C, который обеспечивает высокоскоростную, полностью кеш-когерентную связь между CPU и GPU, и это предпочтительный способ подключения к ускорителям NVIDIA в высокоинтегрированных системах. В рамках экосистемы NVLink Fusion NVIDIA предлагает NVLink-C2C в качестве лицензируемого IP-ядра, что упростит интеграцию шины в будущие чипы SiFive. Для SiFive это может стать конкурентным преимуществом. Кроме того, NVIDIA объявила о поддержке RISC-V — на эту архитектуру портируют CUDA и драйверы, что со временем откроет для компании новые рынки.
07.01.2026 [16:47], Владимир Мироненко
В попытке догнать Broadcom: Marvell купила за $540 млн XConn, разработчика коммутаторов PCIe и CXLПосле объявления о заключении окончательного соглашения о приобретении XConn Technologies, поставщика передовых коммутаторов PCIe и CXL, акции Marvell Technology пошли в гору — их цена выросла на 4 %, сообщил ресурс SiliconANGLE. Сумма сделки составляет около $540 млн. Примерно 60 % будет выплачено наличными и 40 % — акциями Marvell, при этом стоимость последних будет определяться на основе средневзвешенной цены за 20 дней. По словам Marvell, приобретение позволит ей расширить портфель коммутационных решений продуктами XConn PCIe и CXL, а также укрепить команду по разработке решений UALink высококвалифицированными инженерами XConn с глубокими знаниями в области высокопроизводительной коммутации. Коммутация необходима для соединения большого количества ИИ-микросхем в гигантские кластеры для запуска мощных больших языковых моделей. Компания XConn, основанная в 2020 году и финансируемая частными инвесторами, выпустила в марте 2024 года первый в отрасли коммутатор Apollo с поддержкой CXL 2.0 и PCIe 5.0, обеспечивающий 256 линий. Его выпускает TSMC с использованием техпроцессов N16 и N5, сообщил ресурс Data Center Dynamics. Затем она выпустила в марте 2025 года гибридный коммутатор Apollo 2, объединяющий CXL 3.1 и PCIe 6.2 на одном чипе в конфигурациях от 64 до 260 линий. 
Источник изображения: Marvell Когда-то Marvell считалась одной из самых перспективных компаний после NVIDIA, и многие эксперты полагали, что она станет одним из главных бенефициаров бума ИИ. Однако она по-прежнему уступает по темпам развития NVIDIA, а заодно и своему основному конкуренту Broadcom, который разрабатывает чипы как минимум для четырёх гиперскейлеров. Покупка XConn призвана исправить ситуацию, дополняя недавнее приобретение Celestial AI. По словам Marvell, приобретение XConn добавит проверенные коммутационные продукты PCIe и CXL, IP-решения и инженерные кадры для расширения команды по масштабируемым коммутаторам UALink. «В сочетании с предстоящим приобретением Celestial AI мы будем иметь все возможности для предоставления клиентам производительности, гибкости и архитектурного выбора, необходимых им по мере роста размеров и сложности ИИ-систем», — отметил он. 
Источник изображения: XConn Сделка позволит Marvell расширить свой общий целевой рынок (Total Addressable Market, TAM) за счёт освоения растущих возможностей коммутаторов PCIe и CXL. PCIe-коммутаторы становятся критически важным строительным блоком для ИИ-инфраструктуры. В то же время CXL необходим для дезагрегации памяти в современных ЦОД. Сочетание контроллеров памяти Marvell CXL с коммутаторами XConn CXL позволит создать самый обширный в отрасли портфель коммутаторов для поддержки ресурсоёмких ИИ-задач. На данный момент у XConn насчитывается более чем 20 клиентов. Marvell ожидает, что продукты XConn CXL и PCIe начнут приносить доход во II половине 2027 финансового года. Также ожидается, что в результате сделки Marvell получит около $100 млн дополнительного дохода в 2028 финансовом году.
30.12.2025 [15:20], Руслан Авдеев
Радиоволна вместо меди и стекла: пластиковые волноводы обещают революцию в мире интерконнектов ИИ ЦОДPoint2 Technology и AttoTude работают над ARC-кабелями, способными стать альтернативой оптоволоконным и электрическим интерконнектам. Это позволит увеличить пропускную способность, повысить плотность размещения ускорителей и удешевить строительство ИИ ЦОД, сообщает IEEE Spectrum. Внутри ИИ-стоек для объединения узлов обычно используются относительно короткие медные кабели, а сеть внутри и между ЦОД традиционно использует оптоволокно. Необходимость увеличить скорость передачи данных от ускорителя к ускорителю нередко ограничивается физическими свойствами меди. Для обеспечения терабитных скоростей медные интерконнекты должны становиться всё толще и короче. В условиях, когда NVIDIA рассчитывает в восемь раз увеличить максимальное число чипов в вычислительной системе с 72 до 576 к 2027 году, использование меди станет большой проблемой. Медь весьма эффективна, в первую очередь экономически, при использовании на небольших дистанциях. На очень высоких частотах, характерных для современных чипов, сигнал в проводнике из-за скин-эффекта передаётся преимущественно в поверхностном слое. Для борьбы с этим явлением либо увеличивают количество проводников, либо покрывают их, например, серебром, либо попросту увеличивают размеры. Всё это не позволяет в конечном итоге создать компактные и недорогие системы. Сейчас всё большую популярность набирают активные электрические кабели (AEC), включающие ретаймеры, которые усиливают и «очищают» сигнал. Например, 800G-кабели Credo, которые полюбились гиперскейлерам (и не только) имеют длину до 7 м и весят порядка 800 г. 
Задача со звёздочкой: вычислить массу кабелей Credo (фиолетового цвета) / Источник изображения: X/@elonmusk Тем не менее в будущем даже AEC «упрутся в потолок» из-за законов физики. Тем временем Point2 Technology и AttoTude предлагают промежуточное решение — недорогое и надёжное как медь, с возможностью использования узких и длинных кабелей, соответствующих потребностям ИИ-систем будущего. В 2025 году Point2 намеревалась начать производство чипов для кабелей с пропускной способностью 1,6 Тбит/с, состоящих из восьми тонких полимерных волноводов, каждый из них может передавать данные со скоростью 448 Гбит/с с использованием частот 90 и 225 ГГц. Решение AttoTude практически такое же, только использует частоты терагерцового диапазона. Обе компании утверждают, что их технологии превосходят медь по «дальнобойности» — сигнал легко передаётся на расстояние 10–20 м без значимых потерь, чего будет вполне достаточно для объединения будущих стоек. Point2 утверждает, что её решение в сравнение с оптическими интерконнектами потребляет втрое меньше электроэнергии, втрое дешевле и обеспечивает на три порядка меньшие задержки при передаче. По словам сторонников технологии, надёжность и лёгкость производства волноводов, сравнимая с лёгкостью выпуска оптоволокна, означает, что она способна не только заменить оптические интерконнекты между ускорителями, но и частично вытеснить медь с печатных плат. 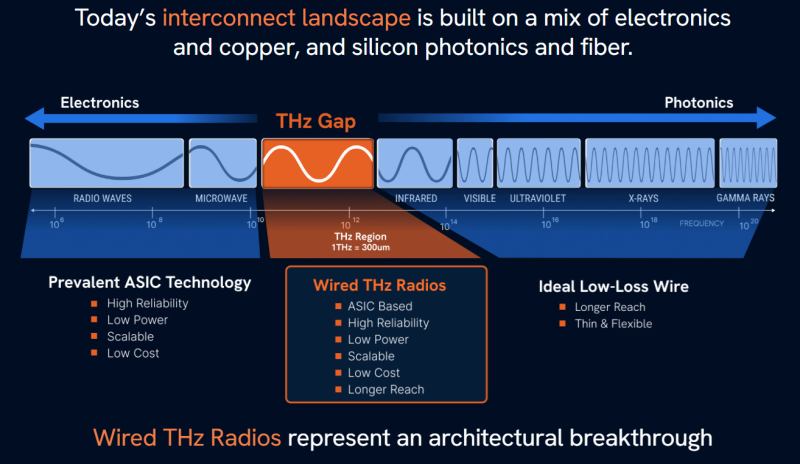
Источник изображения: AttoTude Основатель AttoTude Дэйв Уэлч (Dave Welch), участвовавший в создании Infinera, десятилетиями занимался фотонными системами и хорошо знает их слабые и сильные места. В частности, по данным NVIDIA, на «оптику» уже уходит около 10 % энергопотребления ИИ ЦОД. Системы на базе фотоники в принципе очень чувствительны к температурам, требуют высокой точности производства (на уровне микрометров) и в целом не особенно надёжны. В результате Уэлч заинтересовался не оптическим, а радиодиапазоном от 300 ГГц до 3 ТГц. Решение AttoTude используют волноводы толщиной около 200 мкм с диэлектрическим сердечником, которые уже показывают затухание на уровне 0,3 дБ/м, что в разы меньше, чем у медного 224G-кабеля. У AttoTude уже есть все основные компоненты, включая интерфейс для подключения к ускорителям, терагерцовый генератор, мультиплексор, антенны и собственно волноводы. Главная задача сейчас — объединить всё в компактный модуль, который можно будет легко подключать к ускорителям, как уже действующие решения. Компания уже продемонстрировала передачу данных на скорости 224 Гбит/с на частоте 970 ГГц на расстояние 4 м. 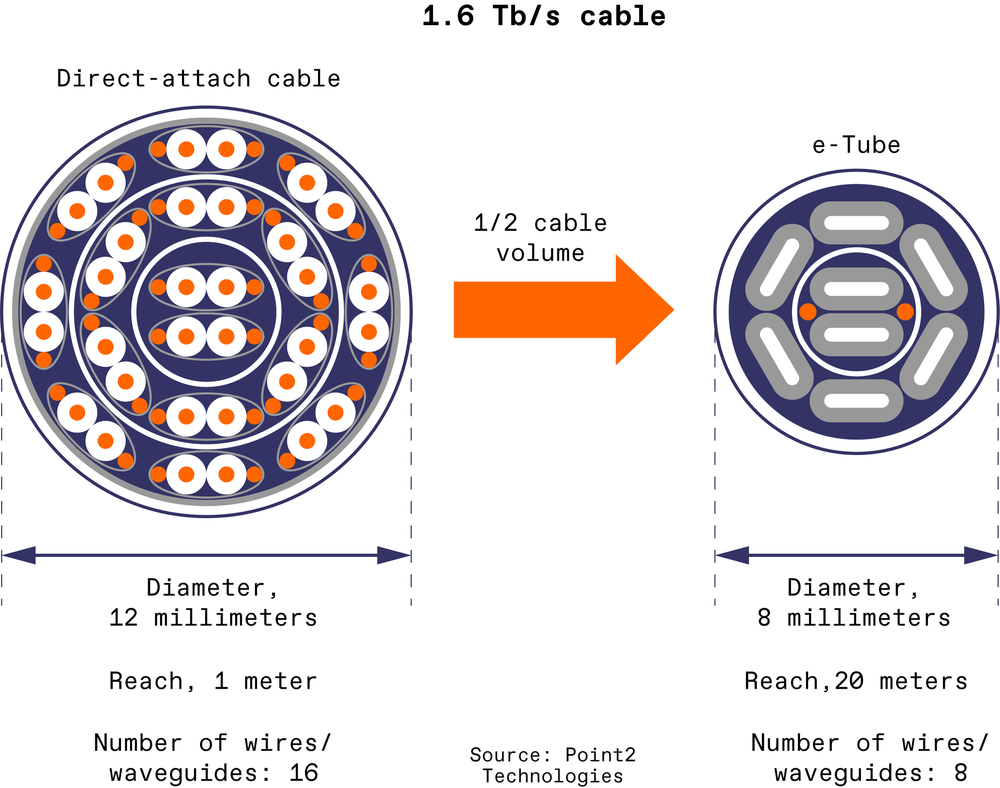
Источник изображения: Point2 Technologies via IEEE Spectrum Point2, созданная девять лет назад ветеранами Marvell, NVIDIA и Samsung, привлекла $55 млн инвестиций, в основном от Molex, занимающейся кабелями и коннекторами. Последняя уже продемонстрировала, что можно выпускать кабели Point2 без изменения своих производственных линий, а теперь партнёром стартапа стала и Foxconn Interconnect Technology. Такая поддержка может оказаться решающей при попытке привлечь гиперскейлеров в качестве клиентов. На каждом конце кабеля Point2 e-Tube, точно так же имеются генератор, антенны и чип для преобразования цифровых сигналов в радиоволны. Волновод состоит из диэлектрического ядра с металлическим покрытием. Для достижения скорости 1,6 Тбит/с требуется восемь волноводов, каждый из которых работает на собственной частоте и с собственными параметрами. Такой кабель значительно тоньше и легче AEC. По словам вице-президента компании Дэвида Куо (David Kuo), одним из ключевых преимуществ технологии Point2 является возможность выпуска чипов по дешёвому и доступному техпроцессу 28 нм. 
Источник изображения: Point2 Technologies via IEEE Spectrum Оба стартапа параллельно занимаются вопросами интеграции своих решений непосредственно в вычислительные чипы. Интегрированная фотоника (CPO) уже появилась в коммутаторах Broadcom и NVIDIA, но до прямой интеграции аналогичных интерфейсов в ускорители и другие чипы дело всё никак не дойдёт. NVIDIA и Broadcom, работающие по отдельности, вынуждены проделывать массу работы для того, чтобы наладить выпуск надёжных систем, работающих в одном корпусе с дорогими ускорителями. Одна из проблем — подключение оптоволокна к волноводу на фотонном чипе с точностью на уровне микрометров. В частности, инфракрасный лазер необходимо разместить точно напротив ядра оптоволокна, толщина которого составляет всего 10 мкм. Для сравнения, миллиметровые и терагерцовые сигналы имеют значительно большие длины волн, поэтому подобной точности при подключении радиоволновода не требуется.
08.12.2025 [14:20], Владимир Мироненко
$2 млрд инвестиций NVIDIA в Synopsys несут риски для UALinkОбъявление NVIDIA о расширении сотрудничества с Synopsys, разработчиком ПО для проектирования чипов и членом совета директоров UALink, и инвестициях в размере $2 млрд в совместные инициативы, последовавшее после недавнего решения производителя ИИ-ускорителей инвестировать $5 млрд в Intel, вызвали опасения по поводу его возможного влияния на разработку UALink — альтернативы собственному интерконнекту NVLink. Как отметил Network World, Synopsys входит в совет директоров консорциума Ultra Accelerator Link (UALink) — отраслевой коалиции из более чем 80 компаний, включая AMD, Intel, Google, Microsoft и Meta✴, которая работает над созданием открытой альтернативы технологии NVIDIA NVLink для объединения ИИ-ускорителей в один домен. NVIDIA инвестировала $2 млрд в обыкновенные акции Synopsys ($414,79/ед.), получив долю в разработчике ПО и планируя в рамках партнёрства объединить преимущества своих технологий с ведущими на рынке инженерными решениями Synopsys. В сентябре NVIDIA инвестировала $5 млрд в Intel, объявив о сотрудничестве с целью разработки чипов для ЦОД и ПК с использованием NVLink Fusion. За несколько месяцев до этого Intel взяла на себя обязательство совместно разрабатывать конкурирующий стандарт UAlink. Arm тоже присоединилась к консорциуму UAlink, участвуя при этом и в экосистеме NVLink Fusion. 
Источник изображения: NVIDIA Moor Insights & Strategy считает, что с помощью инвестиций NVIDIA укрепляет свою экосистему на фоне вызовов AMD, будь то CPU, GPU или сетевые решения. Вместе с тем аналитики признают, что это «действительно усиливает давление на UALink» — финансовая «доля» NVIDIA в консорциуме UALink может повлиять на разработку открытого стандарта, специально созданного для конкуренции с технологиями самой NVIDIA и предоставления предприятиям более широкого выбора компонентов. Компании считают такие открытые стандарты критически важными для предотвращения привязки к одному поставщику и поддержания конкурентоспособных цен. В апреле консорциум ратифицировал спецификацию UALink 200G 1.0, определяющую открытый стандарт для объединения в один кластер до 1024 ИИ-ускорителей со скоростью 200 Гбит/с на линию. Это прямой конкурент NVLink, хотя и не такой производительный. При этом Synopsys играет ключевую роль в работе консорциума. Она не только вошла в совет директоров UALink, но и анонсировала первые в отрасли компоненты для проектирования UALink, позволяющие создавать ускорители, совместимые с UALink. 
Источник изображения: Synopsys Gartner признаёт наличие напряжённости: «Сделка между NVIDIA и Synopsys действительно вызывает вопросы о будущем UALink, поскольку Synopsys является ключевым партнёром консорциума и владеет критически важными IP на UALink, который конкурирует с проприетарным NVLink». По оценкам Greyhound Research, Synopsys играет ведущую роль в UALink, поэтому вхождение NVIDIA в структуру акционеров Synopsys может повлиять на заинтересованность последней в работе консорциума. UALink действует благодаря коммерческому согласованию, общим приоритетам НИОКР и близости планов развития участников. Даже потенциальная возможность влияния NVIDIA может подорвать доверие среди членов UALink. «Партнёры по консорциуму должны быть готовы к тому, что будущие версии UALink могут быть сформированы таким образом, что это либо замедлит их развитие, либо будет смещено в сторону компромиссов в дизайне для минимизации конкурентного давления на NVLink», — предупреждает Greyhound Research, призывая консорциум «срочно усилить управление, повысить прозрачность в отношении вклада Synopsys и рассмотреть механизмы защиты, если хочет сохранить доверие». 
Источник изображения: Synopsys Объявляя о партнёрстве, NVIDIA и Synopsys подчеркнули, что сотрудничество будет сосредоточено на инженерных инструментах на базе ИИ, а не на интерконнектах. В частности, библиотеки NVIDIA CUDA-X будут интегрированы в приложения Synopsys для проектирования микросхем, молекулярного моделирования и электромагнитного анализа. В пресс-релизе по поводу сотрудничества не было никакого упоминания NVLink или интерконнектов. «Поэтому это больше похоже на партнёрство в сфере ПО, чем в сфере интеллектуальной собственности», — пишет Moor Insights & Strategy. Генеральный директор Synopsys Сассин Гази (Sassine Ghazi), подчеркнул, что партнёрство никак не связано с циклическим финансированием. «Мы не намерены и не берём на себя обязательство использовать эти $2 млрд на покупку GPU NVIDIA», — сказал он, добавив, что к партнёрству могут присоединиться другие производители микросхем. Это означает, что компании могут продолжать сотрудничество в рамках более широкой экосистемы, то есть Synopsys продолжит работать с другими поставщиками, конкурирующими с NVIDIA, будь то AMD, Broadcom или один из гиперскейлеров. В ответ на просьбу Network World прокомментировать возможное влияние партнёрства на её приоритеты, Synopsys заявила, что это не меняет её стратегию. В свою очередь, NVIDIA не ответила вопрос ресурса о том, как эти инвестиции могут повлиять на деятельность Synopsys в рамках UALink или на независимость консорциума. Впрочем, аналитики сходятся во мнении, что для консорциума это партнёрство вряд ли можно считать чем-то позитивным. UALink важен для будущих ИИ-платформ AMD. HPE, которая одной из первых поддержала решение AMD Helios AI, будет использовать реализацию UALink over Ethernet (UALoE).
03.12.2025 [16:37], Руслан Авдеев
Вперёд в светлое будущее: Marvell купила за $3,25 млрд разработчика фотонного интерконнекта Celestial AIMarvell Technology объявила о заключении окончательного соглашения, предусматривающего покупку компании Celestial AI — пионера в области создания оптических интерконнектов, работающих над технологией Photonic Fabric. Последняя специально разработана для масштабируемых интерконнектов, позволяющих объединять тысячи ИИ-ускорителей и стоек. Это ускорит реализацию стратегии Marvell, связанной с обеспечением подключений в ИИ ЦОД нового поколения и облаках, сообщает HPC Wire. ИИ-системы нового поколения используют многостоечные конструкции, объединяющие сотни XPU. Они требуют интерконнектов с высокой пропускной способностью, сверхнизкой задержкой и возможностью подключения любых устройств. Подобная архитектура позволяет XPU напрямую обращаться к памяти любого другого XPU. Правда, для этого требуются специализированные коммутаторы и протоколы, разработанные для эффективного масштабирования. Оптические интерконнекты показали себя наиболее эффективным решением, а новое приобретение позволит Marvell возглавить технологический переход. С учётом лидерства Marvell в технологиях горизонтального и распределённого масштабирования, компания рассчитывает, что её новая линейка продуктов обеспечит статус поставщика наиболее полных, комплексных решений для дата-центров следующего поколения с сетями с высокой пропускной способностью, низким энергопотреблением и малой задержкой. 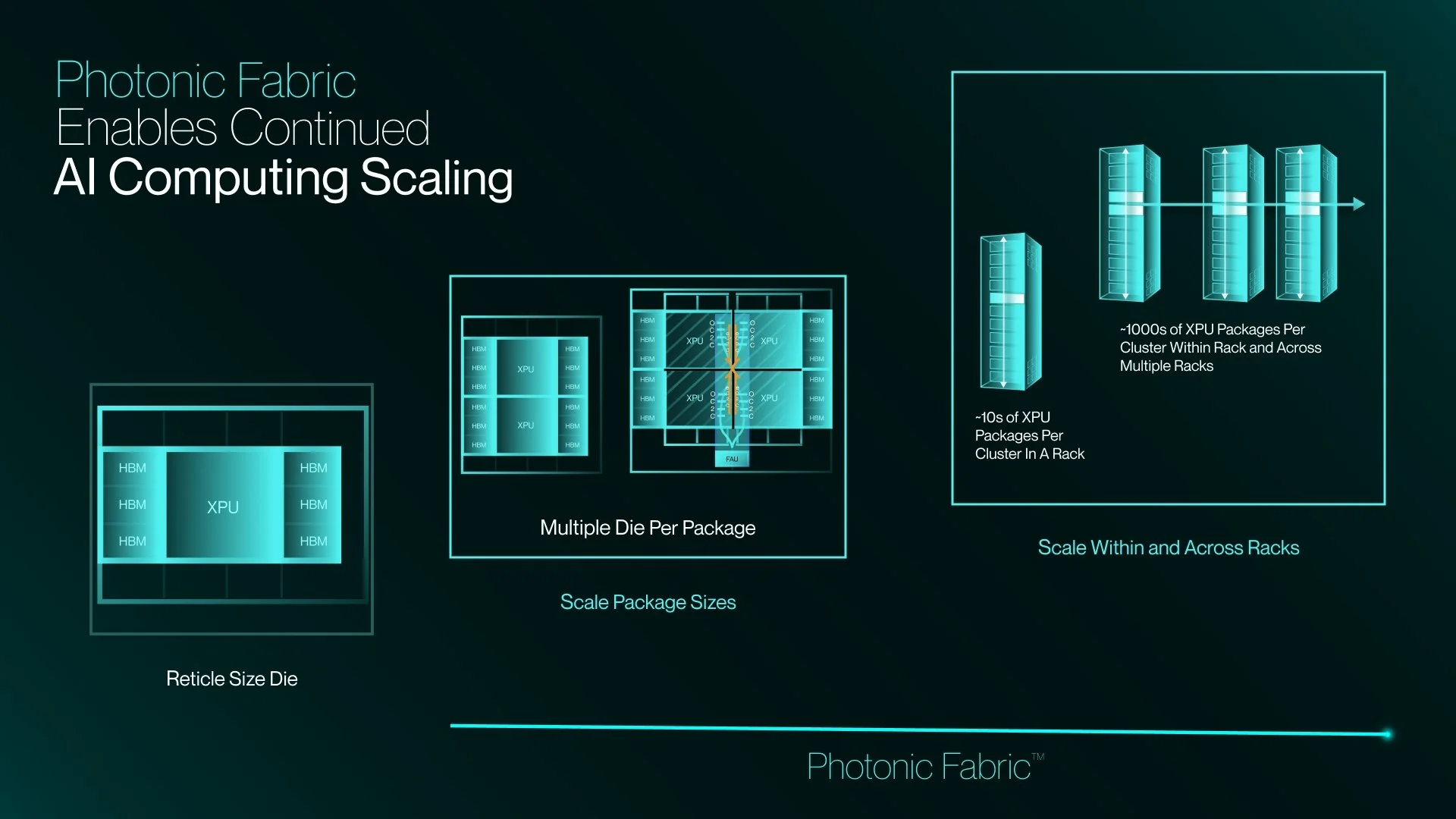
Источник изображений: Celestial AI Компания подчёркивает, что инфраструктура ИИ трансформируется с беспрецедентной скоростью, поэтому будущее за решениями, обеспечивающими высочайшую пропускную способность, энергоэффективность и дальность связи. Комбинация UALink и технологий Celestial AI, позволит клиентам создавать ИИ-системы, способные преодолевать ограничения медных соединений. Это позволит переопределить стандарты архитектуры ИИ ЦОД. В AWS заявляют, что Celestial AI добилась впечатляющего прогресса в разработке оптических интерконнектов и подчеркнули, что объединение с Marvell поможет ускорить инновации в области оптического масштабирования для ИИ нового поколения. Стоит отметить, что сама Amazon владеет небольшой долей акций Marvell. 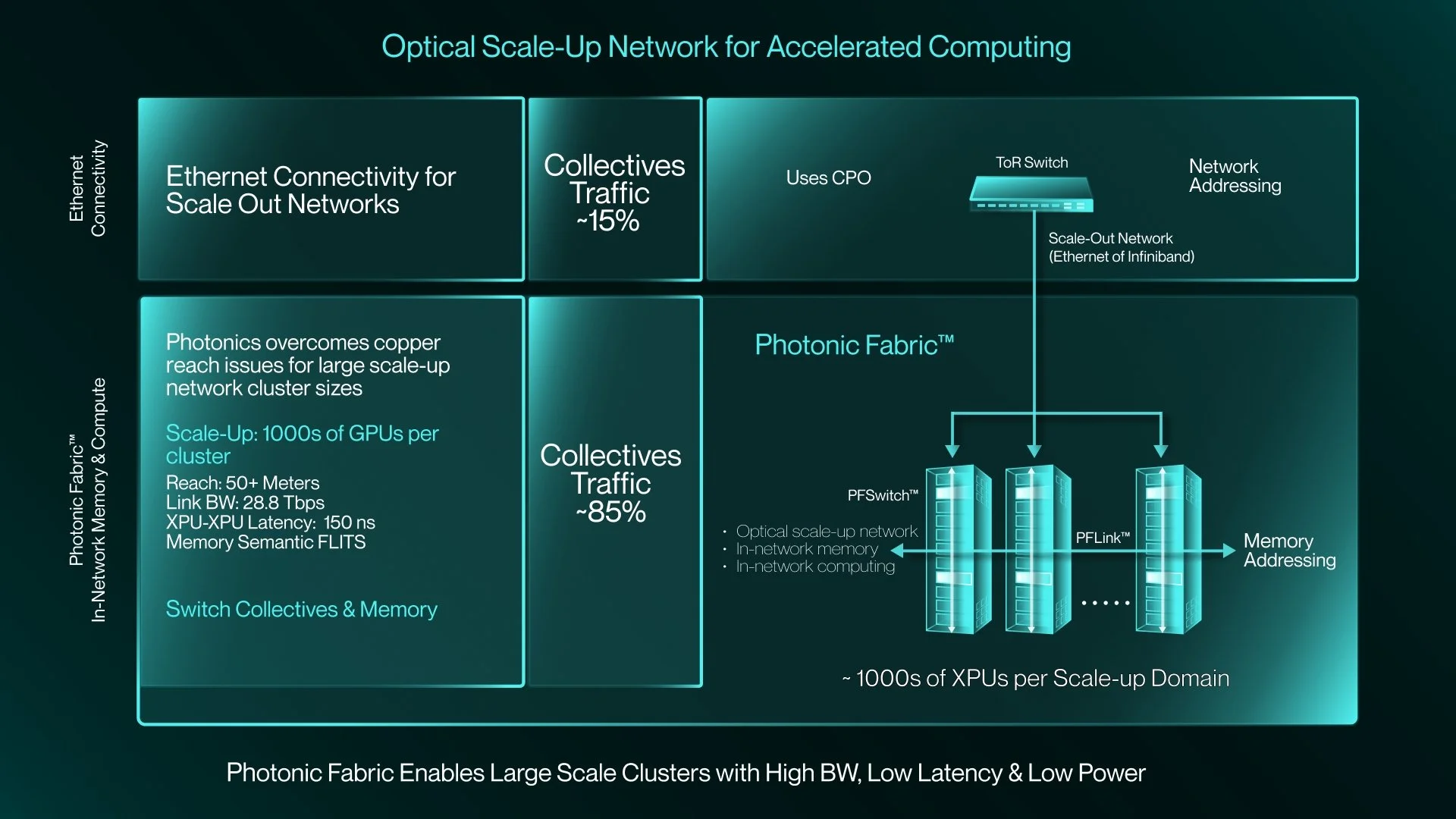 По мере роста требований к пропускной способности и дальности передачи данных каждый узел в дата-центре должен перейти с меди на оптику. На уровне стоек и соединений между ЦОД это уже произошло, следующий этап — переход на оптические соединения в самих стойках. Платформа Celestial AI Photonic Fabric специально разрабатывалась для нового этапа развития. Она позволяет масштабировать крупные ИИ-кластеры как внутри стоек, так и между ними. Энергоэффективность при этом более чем вдвое выше, чем у медных интерконнектов, также обеспечивается большая дальность передачи данных и более высокая пропускная способность. При этом, в сравнении с альтернативными оптическими технологиями, решение Celestial AI обеспечивает чрезвычайно низкое энергопотребление, сверхнизкую задержку на уровне наносекунд и превосходную термоустойчивость. Последнее является важным конкурентным преимуществом Photonic Fabric. Решение обеспечивает надёжную работу в экстремальных температурных условиях, создаваемых многокиловаттными XPU. Благодаря этому оптические компоненты можно размещать поверх вычислительных блоков XPU, а не по его краям, что даёт больше пространства для размещения HBM-стеков. 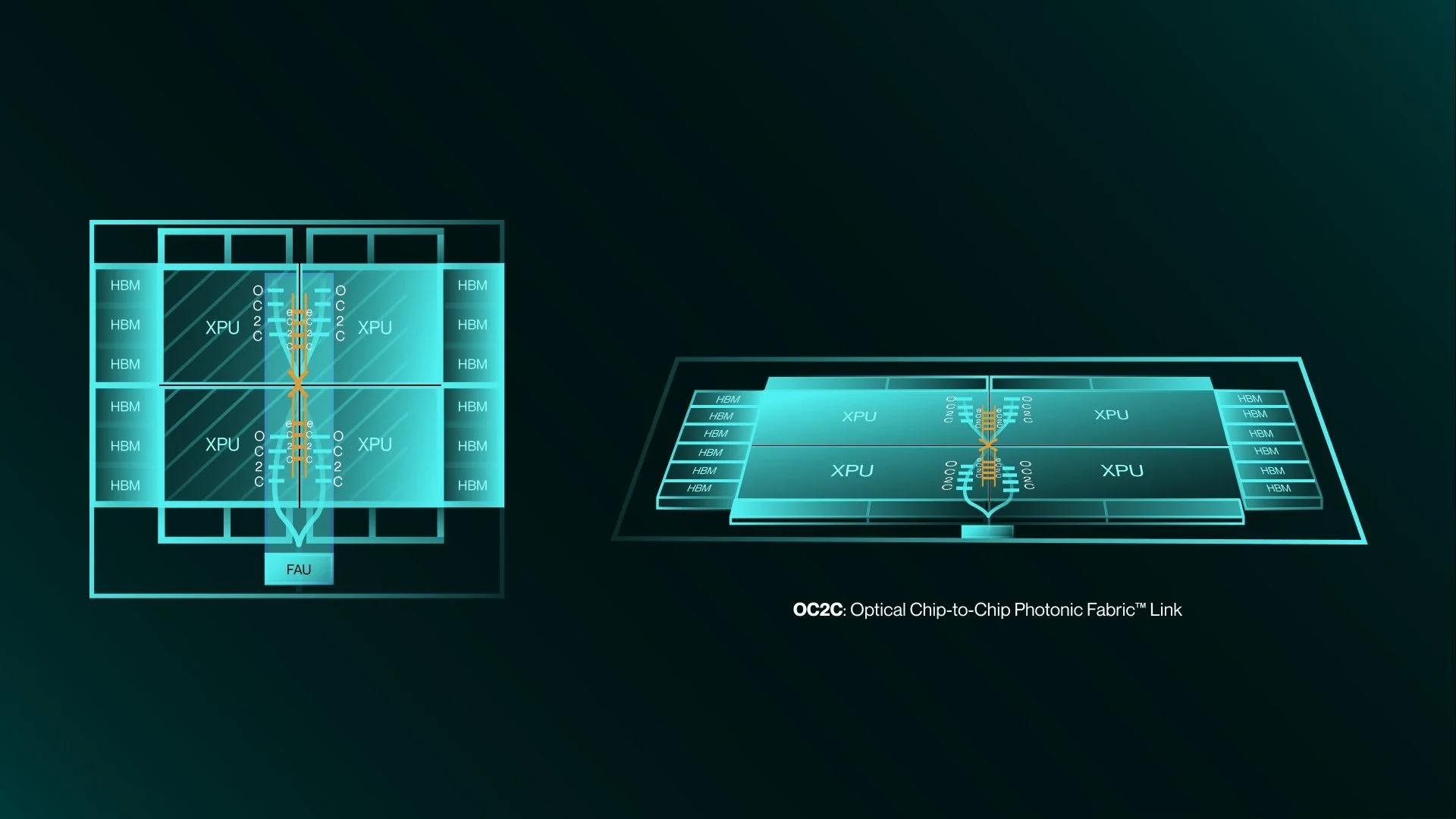 Первым вариантом применения технологии станут полностью оптические интерконнекты для вертикального масштабирования. Чиплет Photonic Fabric включает электрические и оптические компоненты в компактном чипе, обеспечивает скорость передачи данных до 16 Тбит/с (вдвое больше, чем у Ayar Labs TeraPHY). В один XPU можно интегрировать несколько таких чиплетов. При этом таким образом можно объединять и чиплеты внутри чипов, и массивы памяти. Celestial AI уже активно взаимодействует с гиперскейлерами и другими партнёрами. Marvell ожидает, что чиплеты Photonic Fabric станут интегрировать в XPU и коммутаторы, что позволит отрасли обеспечить масштабное коммерческое развёртывание передовых интерконнектов. В компании рассчитывают, что значимый приток выручки от продуктов Celestial AI появится во II половине 2028 финансового года, в IV квартале того же года годовая выручка достигнет $500 млн, а годом позже вырастет до $1 млрд. 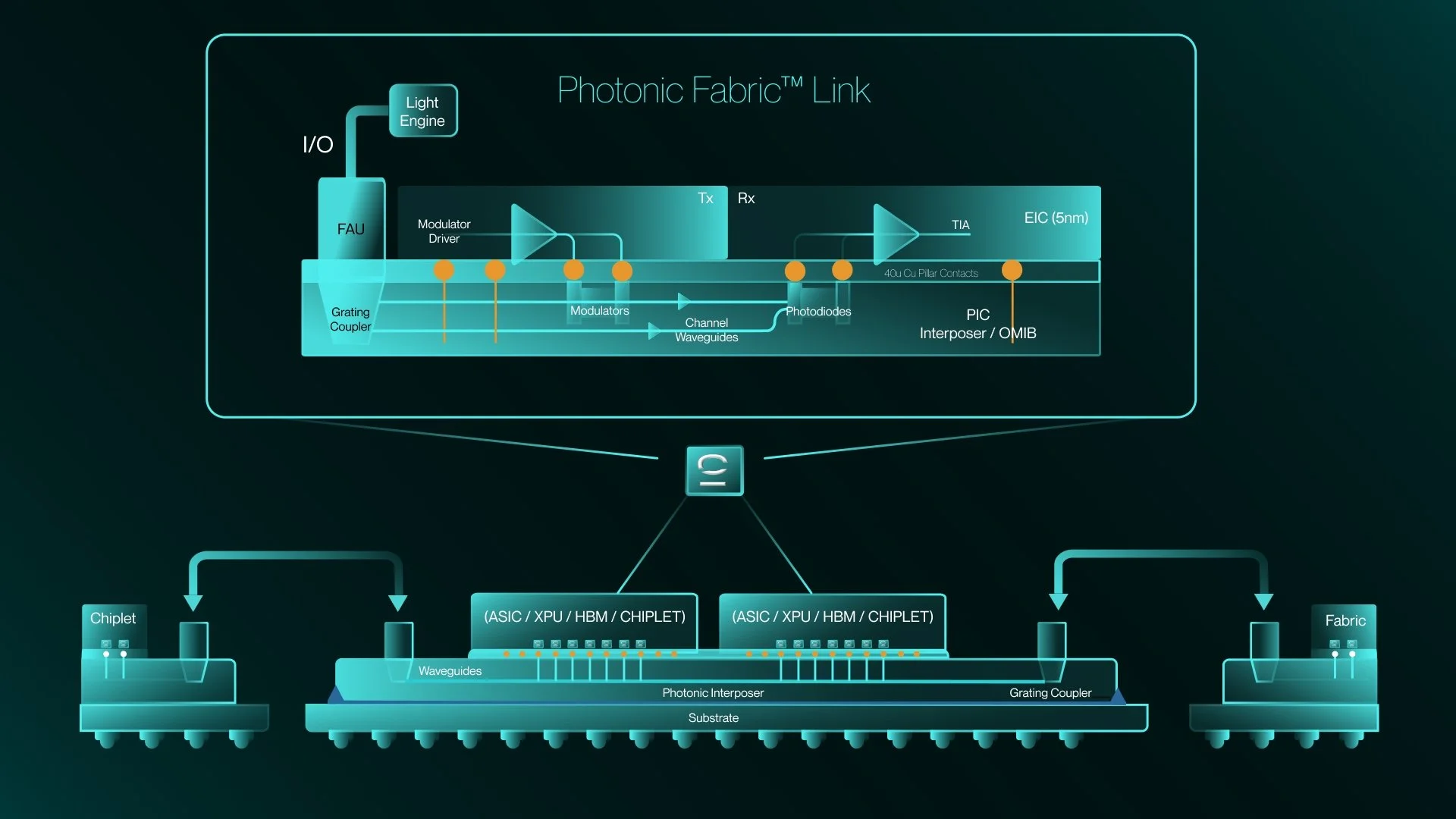 Первоначальная выплата за Celestial AI составит приблизительно $3,25 млрд. $1 млрд будет выплачен деньгами, а оставшуюся сумму — в виде приблизительно 27,2 млн обыкновенных акций Marvell. Кроме того, акционеры Celestial AI дополнительно получат ещё столько же акций Marvell стоимостью до $2,25 млрд при достижении компанией определённых финансовых показателей. Треть бонусов выплатят, если совокупная выручка Celestial AI составит не менее $500 млн к концу 2029 финансового года Marvell (январь 2030-го). Если же выручка превысит $2 млрд, то акционеры получат сразу все бонусы. Как ожидается, сделка будет завершена в I квартале 2026 календарного года при выполнении обычных условий закрытия и получении необходимых разрешений регуляторов. Celestial AI неоднократно успешно привлекала средства на развитие перспективных интерконнектов. В частности, в марте 2024 года она получила от инвесторов $175 млн, а годом позже — $250 млн.
03.12.2025 [01:28], Владимир Мироненко
AWS «сдалась на милость» NVIDIA: анонсированы ИИ-ускорители Trainium4 с шиной NVLink FusionAWS готовит Arm-процессоры Graviton5, которые составят компанию ИИ-ускорителям Trainium4 с интерконнектом NVLink Fusion, фирменными EFA-адаптерам и DPU Nitro 6 с движком Nitro Isolation Engine. Но что более важно, все они будут «упакованы» в стойки стандарта NVIDIA MGX. Amazon и NVIDIA объявили о долгосрочном партнёрстве, в рамках которого ИИ-ускорители Trainium4 получит шину NVIDIA NVLink Fusion шестого поколения (по-видимому, 3,6 Тбайт/с в дуплексе), которая позволит создать стоечную платформу нового поколения, причём, что интересно, на базе архитектуры NVIDIA MGX, которая передана в OCP. Пикантность ситуации в том, что AWS годами практически игнорировала OCP, самостоятельно создавая стойки, их компоненты, включая СЖО, и архитектуру ИИ ЦОД в целом. Даже в нынешнем поколении стоек с GB300 NVL72 отказалась от референсного дизайна NVIDIA. NVIDIA же напирает на то, что для гиперскейлерам крайне трудно заниматься кастомными решениями — циклы разработки стоечной архитектуры занимают много времени, поскольку помимо проектирования специализированного ИИ-чипа, гиперскейлеры должны озаботиться вертикальным и горизонтальным масштабированием, интерконнектами, хранилищем, а также самой конструкцией стойки, включая лотки, охлаждение, питание и ПО. 
Источник изображения: NVIDIA Вместе с тем управление цепочкой поставок отличается высокой сложностью, так как требуется обеспечить согласованную работу десятков поставщиков, ответственных за десятки тысяч компонентов. И даже одна задержка поставки или замена одного компонента может поставить под угрозу весь проект. Платформа NVIDIA если не устраняет целиком, то хотя бы смягчает эти проблемы, предлагая готовые стандартизированные решения, которые могут поставлять множество игроков рынка. 
Источник изображения: NVIDIA По словам NVIDIA, в отличие от других подходов к масштабированию сетей, NVLink — проверенная и широко распространённая технология. В сочетании с фирменным ПО NVLink Switch обеспечивает увеличение производительности и дохода от ИИ-инференса до трёх раз, объединяя 72 ускорителя в одном домене. Пользователи, внедрившие NVLink Fusion, могут использовать любую часть платформы — каждый компонент может помочь им быстро масштабироваться для удовлетворения требований интенсивного инференса и обучения моделей агентного ИИ, говорит NVIDIA. 
Источник изображения: AWS Что касается самих ускорителей Trainium4, то в сравнении с Trainium3 они будут вшестеро быстрее в FP4-расчётах, втрое быстрее в FP8-вычислениях, а пропускная способность памяти будет увеличена вчетверо. Впрочем, пока собственные ускорители Amazon не всегда могут составить конкуренцию чипам NVIDIA. Любопытно и то, что в рассказе о Trainium3 компания отметила о переходе от PCIe к UALink в коммутаторах NeuronSwitch для фирменного интерконнекта NeuronLink, объединяющего до 144 чипов Trainium. Однако после крупных инвестиций NVIDIA в Synopsys развитие UALink как открытой альтернативы NVLink теперь под вопросом. |
|

