Материалы по тегу: дезагрегация
|
20.11.2025 [09:34], Владимир Мироненко
Представлены спецификации CXL 4.0: PCIe 7.0, агрегация портов и поддержка четырёх ретаймеровКонсорциум CXL Consortium объявил о выходе спецификации Compute Express Link (CXL) 4.0, которая более соответствует растущим требованиям рабочих нагрузок в современных ЦОД. По словам Дерека Роде (Derek Rohde), президента CXL Consortium, также занимающего пост главного инженера в NVIDIA, выпуск спецификации CXL 4.0 открывает новую веху в развитии когерентной работы с памятью, удваивая пропускную способность по сравнению с предыдущим поколением и предлагая новые функции. Он отметил, что выпуск отражает стремление компаний-членов консорциума продвигать открытые стандарты, которые способствуют инновациям и открывают всей отрасли возможность масштабироваться для будущих моделей использования. Новый стандарт CXL 4.0 получил поддержку линий с пропускной способности в 128 ГТ/с, что вдвое больше по сравнению с предыдущим, причём без увеличения задержки. Фактически стандарт приведён в соответствие с PCI Express 7.0. Также были сохранены ранее реализованные улучшения протокола CXL 3.0: FLIT-кадры размером 256 байт, FEC и CRC. Сохраняется и полная обратная совместимость со всеми предыдущими версиями — CXL 3.x, 2.0, 1.1 и 1.0. Впрочем, тут есть нюансы. В CXL 4.0 появилась агрегация физических портов (Bundled Ports) в один логический порт, позволяющая одному устройству Type 1/2 одновременно подключаться к нескольким root-портам хоста или коммутатора для увеличения пропускной способности. При этом один из физических портов должен быть полнофункциональным, тогда как остальные порты могут быть оптимизированы исключительно для передачи данных. Агрегированные порты также поддерживают 256-байт FLIT-режим, но как минимум один физический порт должен поддерживать 68-байт режим ради обратной совместимости. 
Источник изображения: CXL Consortium Также спецификация реализует поддержку до четырёх ретаймеров для увеличения дальности передачи сигнала, повышение надёжности (RAS), снижение количества возможных ошибок, а также более детальные и актуальные отчёты о проблемах. Кроме того, появилась функция Post Package Repair (PPR), позволяющая хосту инициировать проверку устройства во время загрузки, т.е. до запуска рабочих нагрузок. Комментируя выход CXL 4.0, Alibaba заявила, что как член-учредитель консорциума CXL, она активно поддерживает экосистему CXL: «Мы рады выпуску CXL 4.0, поддерживающей PCIe 7.0 и объединение портов, что отвечает растущим требованиям к пропускной способности памяти для современных облачных рабочих нагрузок. Кроме того, CXL 4.0 повышает надёжность и удобство обслуживания памяти благодаря расширенным возможностям оповещения об ошибках и резервирования памяти. Мы считаем, что CXL 4.0 представляет собой еще одну важную веху на пути к компонуемым, масштабируемыми надёжным стоечным архитектурам для ЦОД нового поколения».
27.05.2024 [22:20], Алексей Степин
Тридцать на одного: Liqid UltraStack 30 позволяет подключить десятки GPU к одному серверуКомпания Liqid сотрудничает с Dell довольно давно — ещё в прошлом году она смогла добиться размещения 16 ускорителей в своей платформе UltraStack L40S. Но на этом компания не остановилась и представила новую композитную платформу UltraStack 30, в которой смогла довести число одновременно доступных хост-системе ускорителей до 30. Для подключения, конфигурации и управления ресурсами ускорителей Liqid использует комбинацию фирменного программного обеспечения Matrix CDI и интерконнекта Liqid Fabric. В основе последнего лежит PCI Express. Это позволяет динамически конфигурировать аппаратную инфраструктуру с учётом конкретных задач с её возвратом в общий пул ресурсов по завершению работы. Сами «капсулы» с ресурсами подключены к единственному хост-серверу, что упрощает задачу масштабирования, минимизирует потери производительности, повышает энергоэффективность и позволяет добиться наиболее плотной упаковки вычислительных ресурсов, нежели это возможно в классическом варианте с раздельными серверами. А благодаря гибкости конфигурирования буквально «на лету» исключается простой весьма дорогостоящих аппаратных ресурсов. 
Источник здесь и далее: Liqid В случае UltraStack 30 основой по умолчанию является сервер серии Dell PowerEdge R760 с двумя Xeon Gold 6430 и 1 Тбайт оперативной памяти, однако доступен также вариант на базе Dell R7625, оснащённый процессорами AMD EPYC 9354. Опционально можно укомплектовать систему NVMe-хранилищем объёмом 30 Тбайт, в качестве сетевых опций доступны либо пара адаптеров NVIDIA ConnectX-7, либо один DPU NVIDIA Bluefield-3.  За общение с ускорительными модулями отвечает 48-портовой коммутатор PCI Express 4.0 вкупе с фирменными хост-адаптерами Liqid. Технология ioDirect позволяет ускорителям общаться друг с другом и хранилищем данных напрямую, без посредничества CPU. В трёх модулях расширения установлено по 10 ускорителей NVIDIA L40S, каждый несет на борту 48 Гбайт памяти GDDR6. Такая конфигурация теоретически способна развить 7,3 Пфлопс на вычислениях FP16, вдвое больше на FP8, и почти 1,1 Пфлопс на тензорных ядрах в формате TF32. 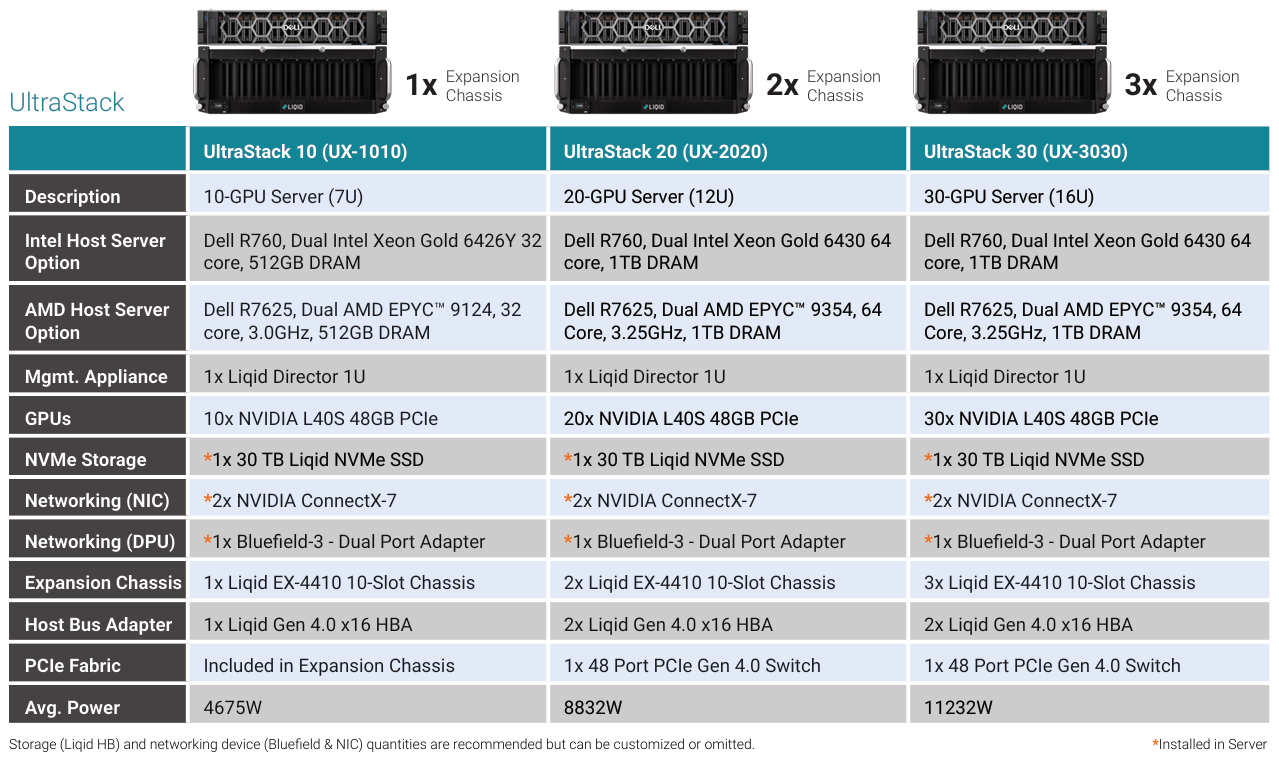 Платформа UltraStack 30 предназначена в первую очередь для быстрого развёртывания достаточно мощной ИИ-инфраструктуры там, где требуется тонкая подстройка и дообучение уже «натасканных» больших моделей. При этом стоит учитывать довольно солидное энергопотребление, составляющее более 11 кВт. Также в арсенале компании есть решения SmartStack на базе модульных систем Dell PowerEdge C-Series, позволяющие подключать к каждому из лезвийных модулей MX760c, MX750с и MX740c до 20 ускорителей. Модульные решения Liqid поддерживают также ускорители других производителей, включая достаточно экзотические, такие как Groq.
02.08.2022 [16:00], Алексей Степин
Опубликованы спецификации Compute Express Link 3.0Мало-помалу стандарт Compute Express Link пробивает себе путь на рынок: хотя процессоров с поддержкой ещё нет, многие из элементов инфраструктуры для нового интерконнекта и базирующихся на нём концепций уже готово — в частности, регулярно демонстрируются новые контроллеры и модули памяти. Но развивается и сам стандарт. В версии 1.1, спецификации на которую были опубликованы ещё в 2019 году, были только заложены основы. Но уже в версии 2.0 CXL получил массу нововведений, позволяющих говорить не просто о новой шине, но о целой концепции и смене подхода к архитектуре серверов. А сейчас консорциум, ответственный за разработку стандарта, опубликовал свежие спецификации версии 3.0, ещё более расширяющие возможности CXL. 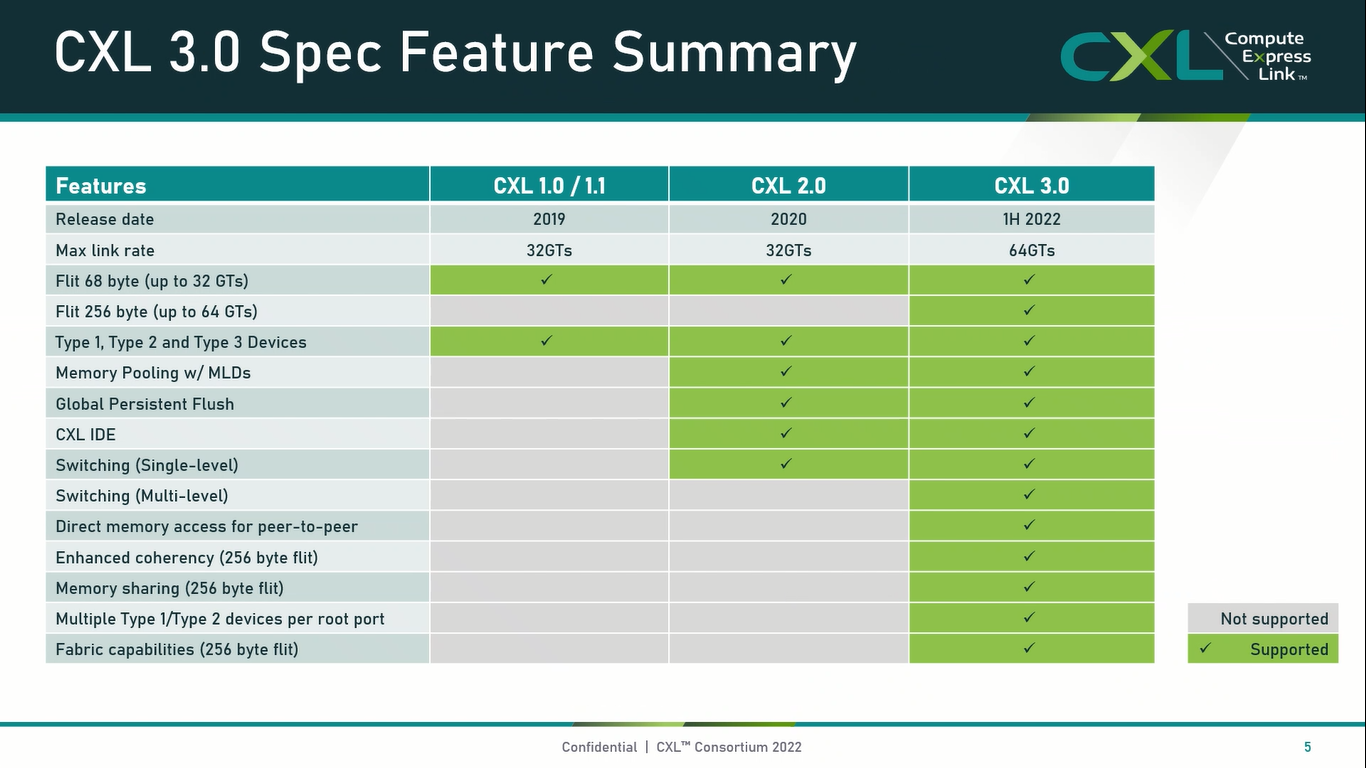
Источник: CXL Consortium И не только расширяющие: в версии 3.0 новый стандарт получил поддержку скорости 64 ГТ/с, при этом без повышения задержки. Что неудивительно, поскольку в основе лежит стандарт PCIe 6.0. Но основные усилия разработчиков были сконцентрированы на дальнейшем развитии идей дезагрегации ресурсов и создания компонуемой инфраструктуры. 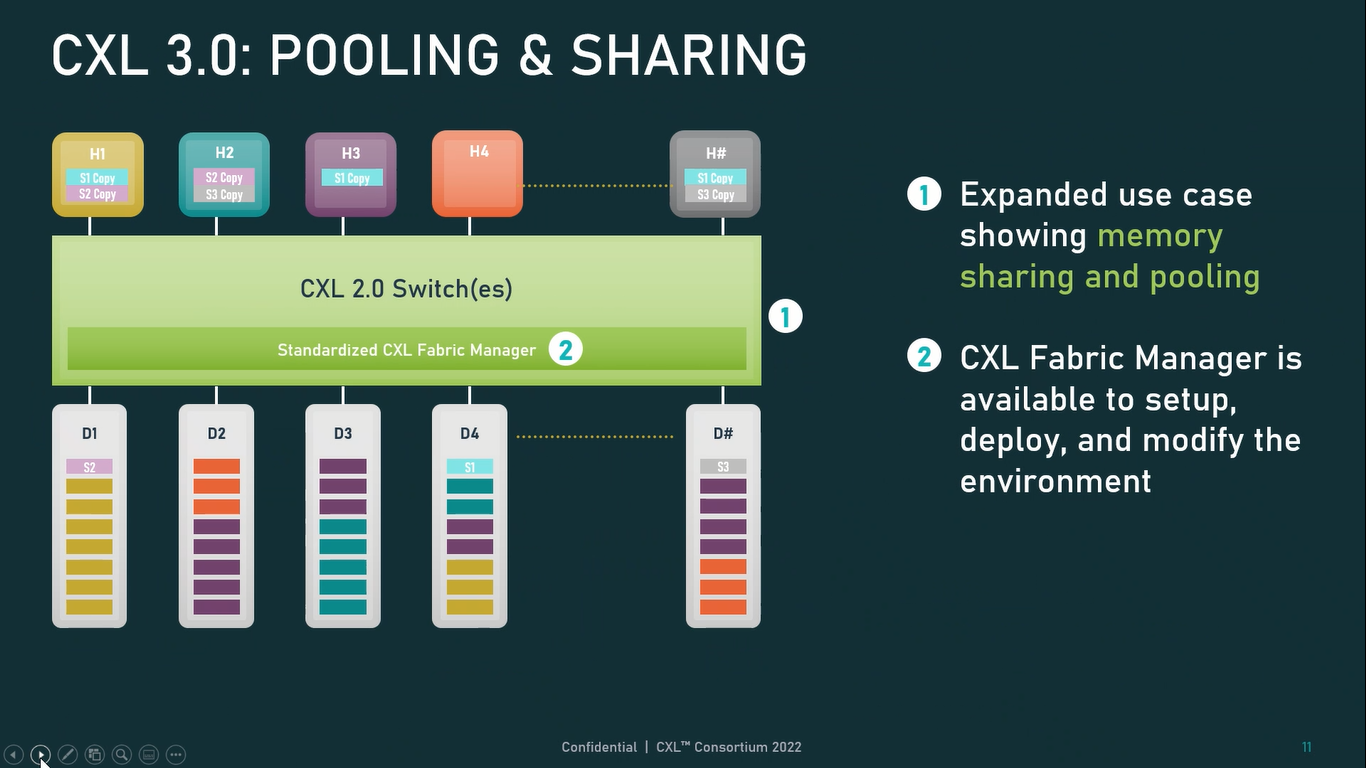 Сама фабрика CXL 3.0 теперь допускает создание и подключение «многоголовых» (multi-headed) устройств, расширены возможности по управлению фабрикой, улучшена поддержка пулов памяти, введены продвинутые режимы когерентности, а также появилась поддержка многоуровневой коммутации. При этом CXL 3.0 сохранил обратную совместимость со всеми предыдущими версиями — 2.0, 1.1 и даже 1.0. В этом случае часть имеющихся функций попросту не будет активирована. 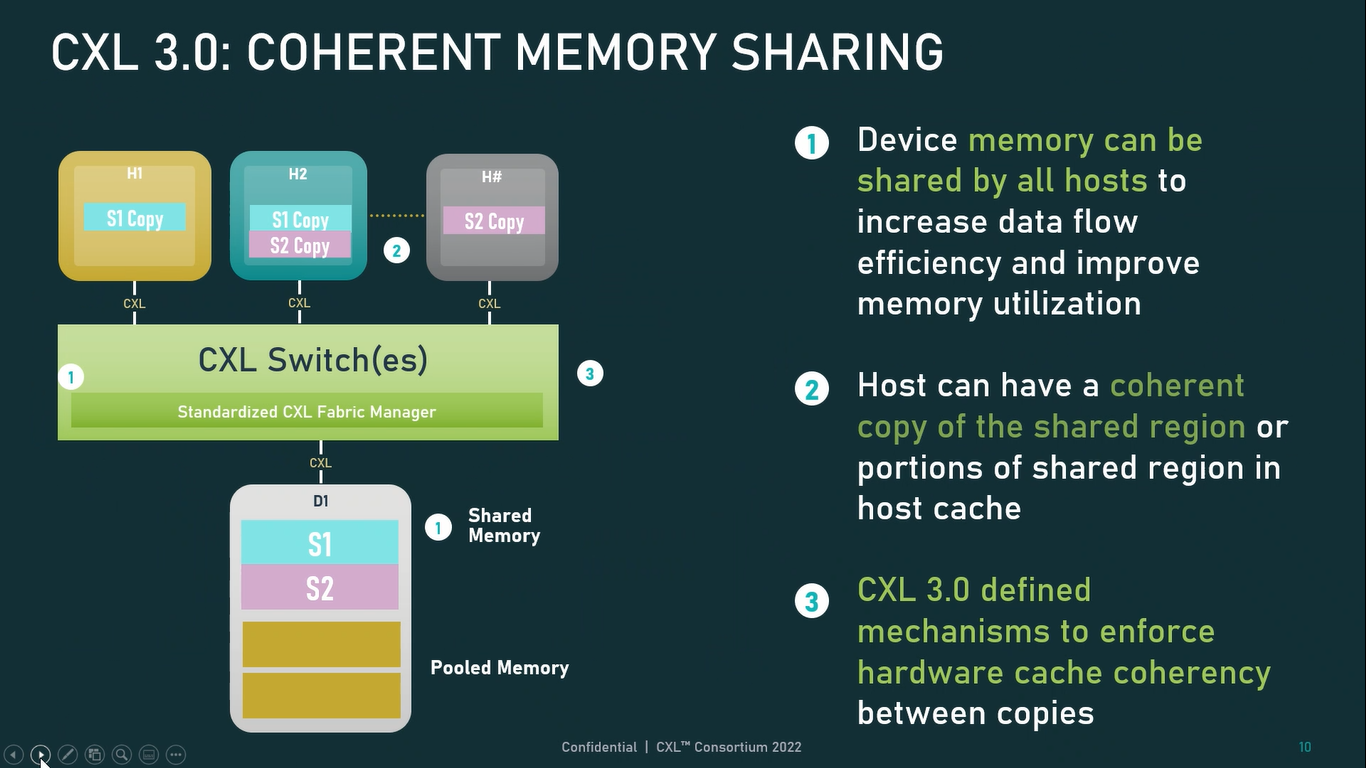 Одно из ключевых новшеств — многоуровневая коммутация. Теперь топология фабрики CXL 3.0 может быть практически любой, от линейной до каскадной с группами коммутаторов, подключенных к коммутаторам более высокого уровня. При этом каждый корневой порт процессора поддерживает одновременное подключение через коммутатор устройств различных типов в любой комбинации. 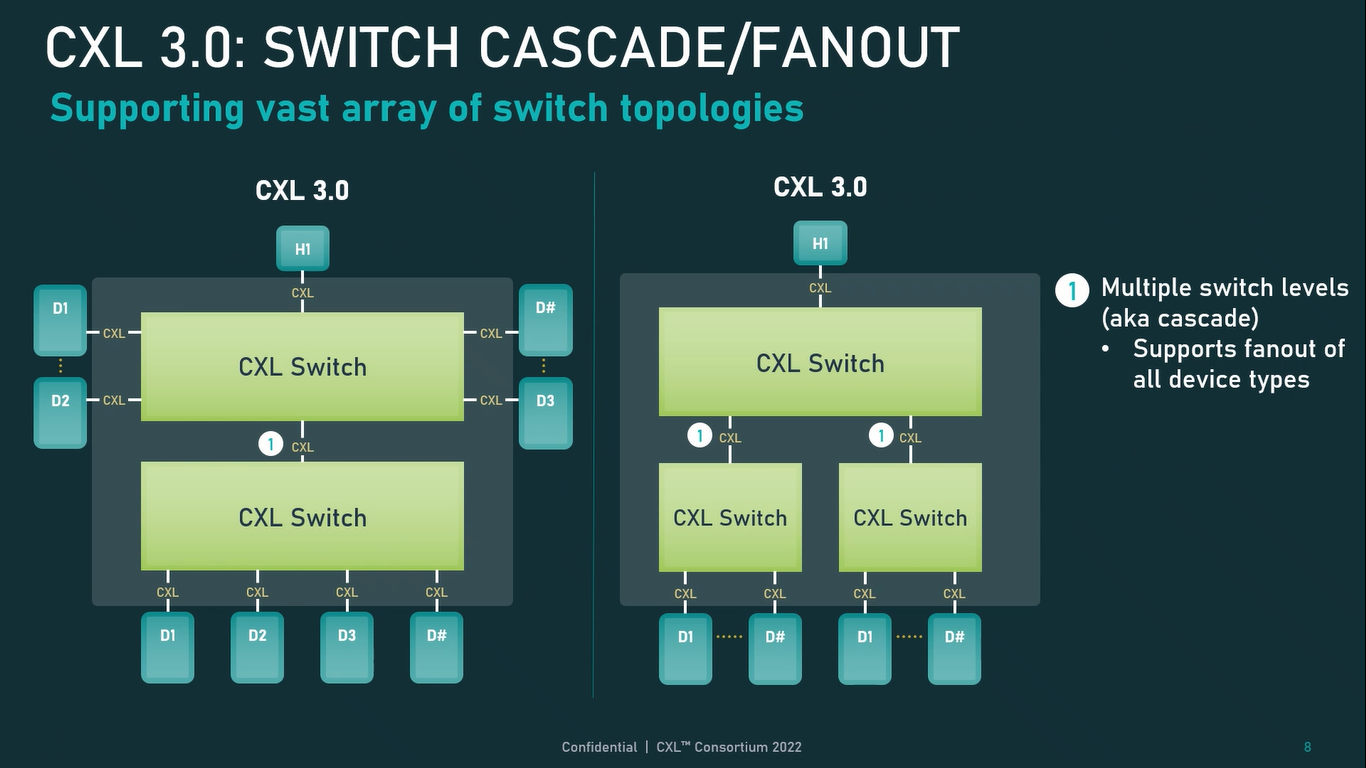 Ещё одним интересным нововведением стала поддержка прямого доступа к памяти типа peer-to-peer (P2P). Проще говоря, несколько ускорителей, расположенных, к примеру, в соседних стойках, смогут напрямую общаться друг с другом, не затрагивая хост-процессоры. Во всех случаях обеспечивается защита доступа и безопасность коммуникаций. Кроме того, есть возможность разделить память каждого устройства на 16 независимых сегментов. 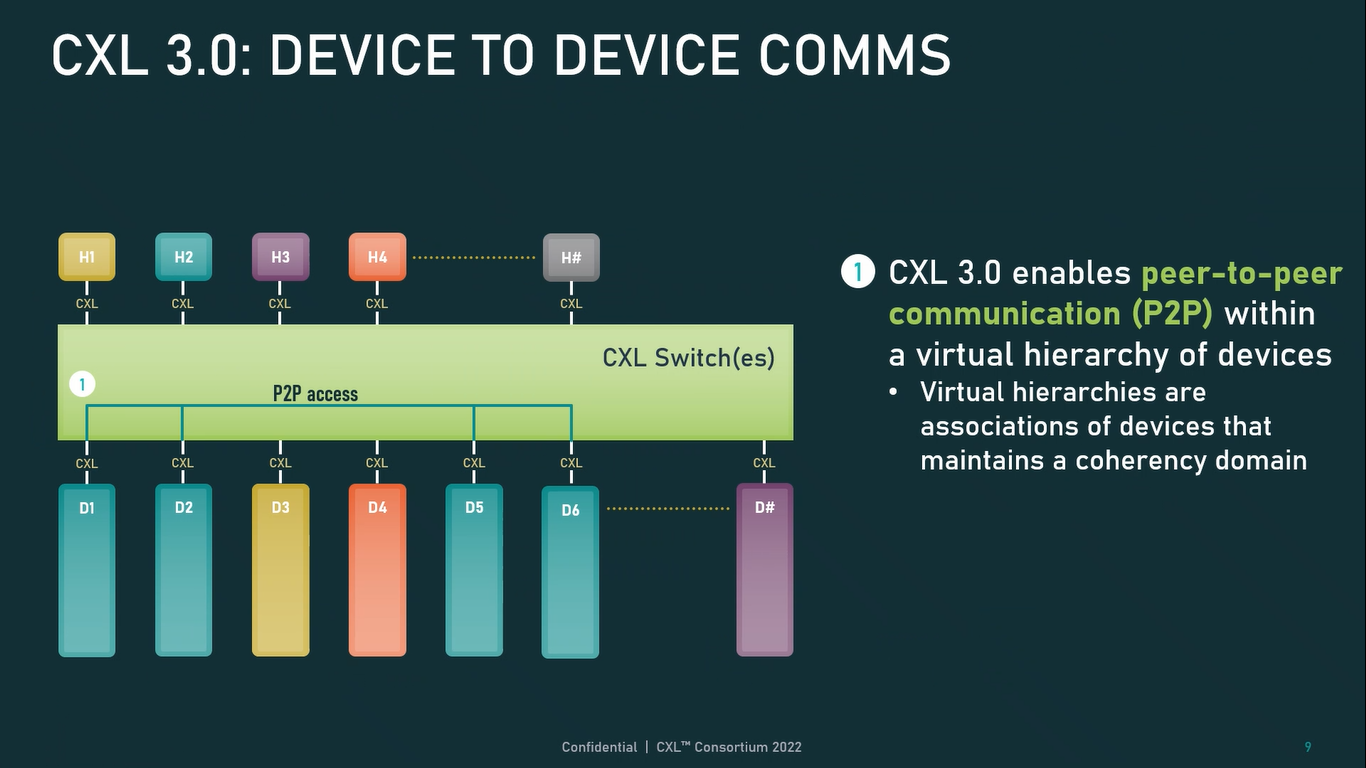 При этом поддерживается иерархическая организация групп, внутри которых обеспечивается когерентность содержимого памяти и кешей (предусмотрена инвалидация). Теперь помимо эксклюзивного доступа к памяти из пула доступен и общий доступ сразу нескольких хостов к одному блоку памяти, причём с аппаратной поддержкой когерентности. Организация пулов теперь не отдаётся на откуп стороннему ПО, а осуществляется посредством стандартизированного менеджера фабрики. 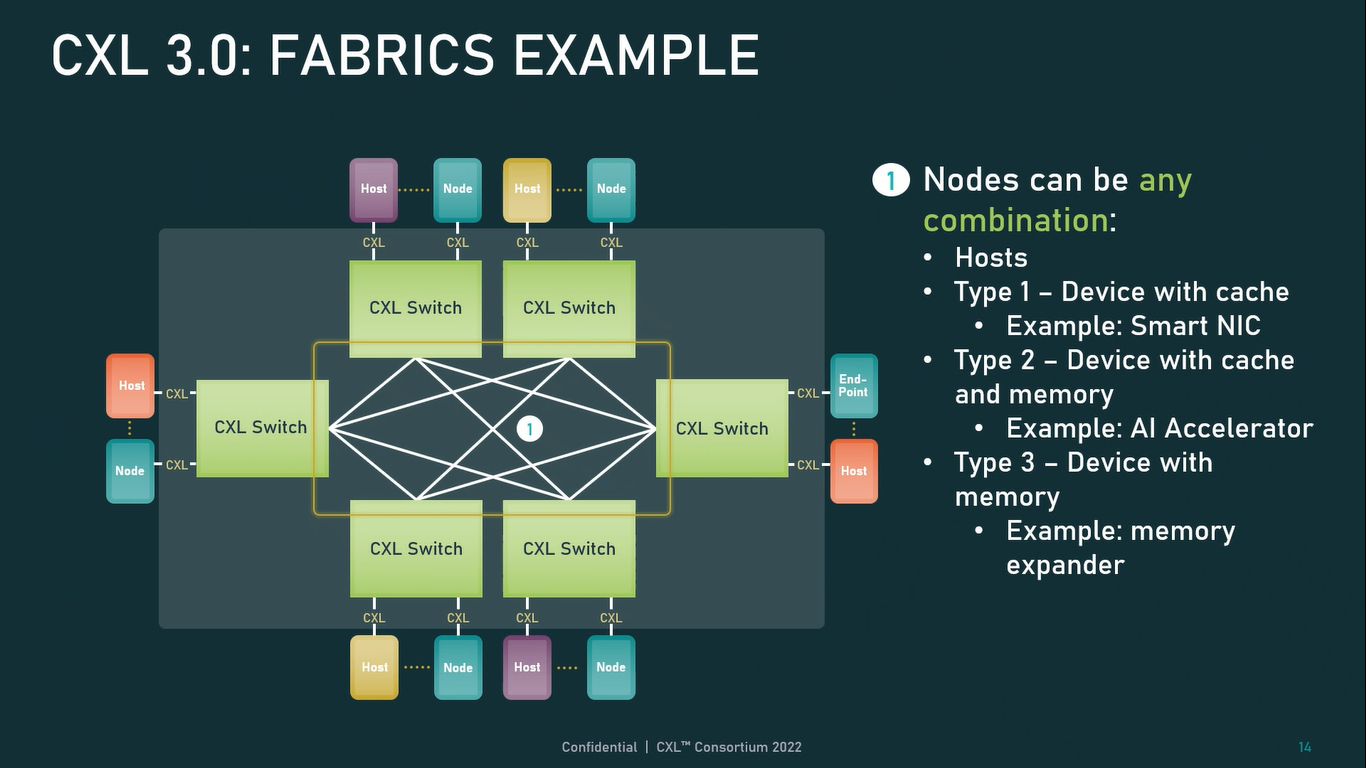 Сочетание новых возможностей выводит идею разделения памяти и вычислительных ресурсов на новый уровень: теперь возможно построение систем, где единый пул подключенной к фабрике CXL 3.0 памяти (Global Fabric Attached Memory, GFAM) действительно существует отдельно от вычислительных модулей. При этом возможность адресовать до 4096 точек подключения скорее упрётся в физические лимиты фабрики. 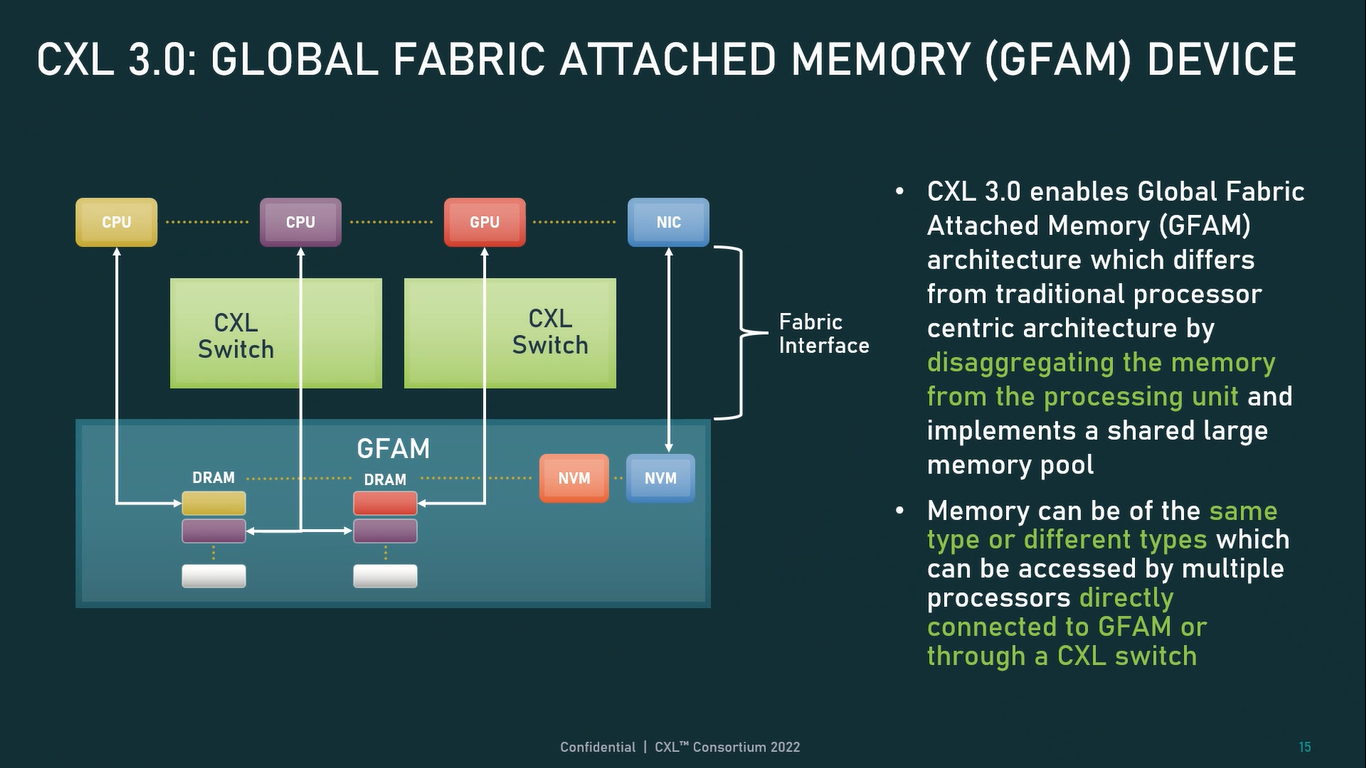 Пул может содержать разные типы памяти — DRAM, NAND, SCM — и подключаться к вычислительным мощностями как напрямую, так и через коммутаторы CXL. Предусмотрен механизм сообщения самими устройствами об их типе, возможностях и прочих характеристиках. Подобная архитектура обещает стать востребованной в мире машинного обучения, в котором наборы данных для нейросетей нового поколения достигают уже поистине гигантских размеров. 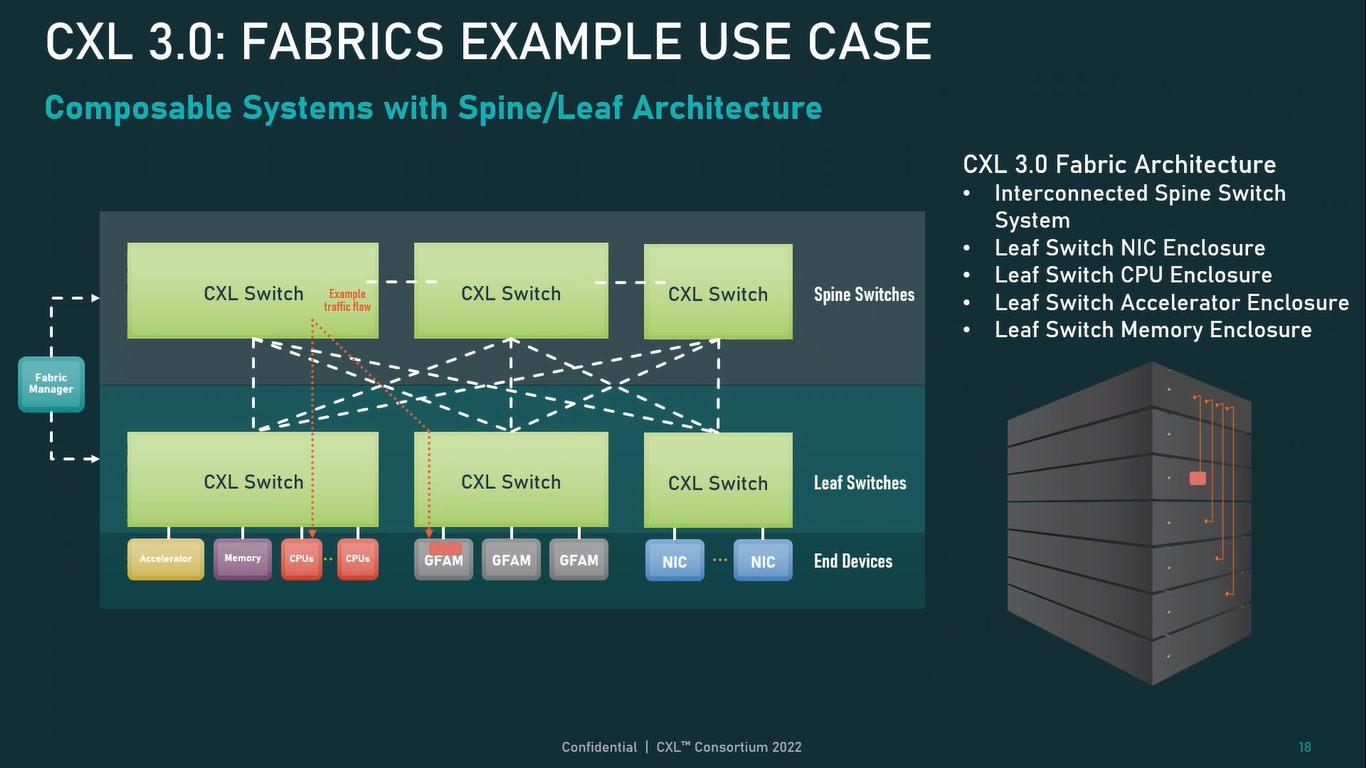 В настоящее время группа CXL уже включает 206 участников, в число которых входят компании Intel, Arm, AMD, IBM, NVIDIA, Huawei, крупные облачные провайдеры, включая Microsoft, Alibaba Group, Google и Meta✴, а также ряд крупных производителей серверного оборудования, в том числе, HPE и Dell EMC. |
|

