Материалы по тегу: интерконнект
|
09.06.2026 [18:18], Владимир Мироненко
Oriole Networks и AMD успешно запустили ИИ-сеть на фотонных технологиях, но пока в лабораторных условияхБританский стартап Oriole Networks сообщил о запуске первой в мире масштабируемой ИИ-сети, основанной исключительно на фотонных технологиях, в лаборатории Scaling Inference Lab, финансируемой агентством ARIA. Система сочетает в себе сетевую платформу PRISM от Oriole с ускорителями AMD Instinct и процессорами AMD EPYC. Это первое применение технологии компании, более широкое распространение которой в отрасли запланировано на 2027 год. PRISM — это оптическая сетевая платформа (OCS) для ИИ-кластеров. PRISM полностью исключает необходимость в традиционных коммутаторах в ЦОД, заменяя их оптическими цепями с наносекундной коммутацией, что снижает энергопотребление ядра сети на 81 %. Благодаря возможности прямой передачи фотонов от чипа к чипу, время простоя GPU снижается с нынешних 60 % до менее чем 1 %. По словам компании, такой подход позволяет минимизировать потребность в охлаждении, тем самым резко сокращая потребление воды. Что также важно, PRISM не привязана к какому-либо одному производителю чипов, обеспечивая возможность достижения производительности на уровне всей системы без необходимости использования проприетарных стеков. Лаборатория Scaling Inference Lab представляет собой испытательный полигон стоимостью £50 млн ($68 млн), финансируемый правительством Великобритании через Агентство перспективных исследований и изобретений (ARIA) для решения проблем, связанных с узкими местами в крупномасштабной обработке ИИ-данных. ARIA было создано на основании парламентского акта и финансируется Министерством науки, инноваций и технологий Великобритании (DSIT). Лаборатория Scaling Inference Lab размещается на платформе CommonAI и предназначена для тестирования и оптимизации ИИ-систем в реальных условиях. 
Источник изображения: Oriole Networks Oriole сотрудничает с AMD более года. Компания, основанная в 2023 году на базе подразделения Университетского колледжа Лондона (University College London), заявила, что её технология прошла путь от исследований до производства всего за три года. «Год назад мы доказывали физику; сегодня мы доказываем бизнес. Наше сотрудничество с AMD перешло от концепции к внедрению системы на порядок большего размера, и данные подтверждают, что это уже приводит к быстрому росту производительности», — сообщил Джеймс Риган (James Regan), генеральный директор Oriole. Как отметил ресурс TNW, развёртывание сети на фотонных технологиях компанией Oriole реально, но оно ещё не работает в масштабе кластеров уровня Google, которая уже несколько лет использует оптические коммутаторы Apollo. Запуск в 2027 году определит, сможет ли PRISM пережить переход от лабораторных условий к производственным площадкам компаний. Именно на этом переходе терпят неудачу большинство стартапов, занимающихся разработкой оборудования. По данным SiliconANGLE, на сегодняшний день Oriole привлекла около $35 млн инвестиций, в последнем раунде — $22 млн. В число её инвесторов входят Plural UK Management, UCL Technology Fund, Clean Growth Fund, XTX Ventures и Dorilton Ventures.
03.06.2026 [15:09], Руслан Авдеев
Ayar Labs присоединилась к экосистеме NVIDIA NVLink Fusion с собственной CPO-технологиейAyar Labs присоединилась к экосистеме NVIDIA NVLink Fusion. Технология Co-Packaged Optics (CPO), предлагаемая компанией, позиционируется как решение для подключения будущих стоечных ИИ-систем на основе масштабируемой гетерогенной вычислительной архитектуры NVIDIA, сообщает Converge! Digest. Новый шаг объединяет технологию оптических интерконнектов Ayar Labs с оптическими и SerDes-технологиями NVIDIA. Это позволит крупным компаниям и разработчикам ИИ-систем интегрировать оптические соединения в ИИ-инфраструктуру на базе NVLink Fusion. ИИ-кластерам нового поколения необходимо обеспечить эффективную передачу огромных объёмов информации по мере увеличения гетерогенности систем и количества используемых ускорителей. Обычные интерконнекты практически достигли предела в контексте плотности пропускной способности, дальности действия, задержек и энергопотребления. Ayar Labs пытается преодолеть эти ограничения, интегрируя оптические модули с вычислительными. Это позволит нарастить как пропускную способность, так и дальность действия, одновременно снизив потребление электроэнергии. 
Источник изображения: Ayar Labs В рамках партнёрства с NVIDIA компания Ayar Labs намерена сотрудничать с клиентами и партнёрами по экосистеме, чтобы поддержать развёртывание своих CPO-решений в архитектурах на основе NVLink Fusion. Такая платформа позволяет интегрировать специализированные процессоры и ИИ-ускорители в стоечные системы NVIDIA, сохраняя совместимость с более широкой экосистемой NVLink. Благодаря оптической связи архитекторы систем получат ещё один вариант для проектирования крупных ИИ-фабрик. Объявление последовало за раундом финансирования серии E, в котором Ayar Labs, с 2015 года занимающаяся оптическими IO-технологиями для ИИ и HPC, привлекла $500 млн. В раунде приняла участие и компания NVIDIA. По словам Converge!, речь идёт о новой вехе для рынка CPO-технологий, поскольку этот шаг Ayar Labs приближает массовое внедрение таких решений в ИИ-инфраструктуру. Технология CPO годами рассматривалась как преемник подключаемых оптических модулей с высоким энергопотреблением и медных интерконнектов, и именно сегодня кластеры ИИ-ускорителей достигли такой производительности, что CPO становится всё более привлекательным вариантом для ИИ-систем. Решение NVIDIA включить Ayar Labs в экосистему NVLink Fusion свидетельствует о признании в отрасли ИИ того факта, что будущие системы могут потребовать использования оптики не только между стойками, но и внутри них. NVIDIA NVLink Fusion позволяет создавать кастомные ИИ-платформы со сторонними чипами и другими компонентами. Ранее NVIDIA заключила соглашения в отношении NVLink с Arm, AWS, Fujitsu, Intel, Marvell, MediaTek и SiFive.
02.06.2026 [09:03], Владимир Мироненко
Как карта ляжет, как сеть укажет: AWS внедряет в своих ЦОД квазислучайную сетевую архитектуру RNGAWS опубликовала техническое описание сетевой архитектуры ЦОД, которую она без особой огласки внедряет с конца 2024 года. Эта архитектура основана на трёх десятилетиях разработки математической теории, которая, как считалось, не подходит для коммерческого использования. Архитектура на базе отказоустойчивых сетевых графов (Resilient Network Graphs, RNG) уже стала стандартной для большинства новых ЦОД AWS по всему миру и позволит сэкономить миллиарды долларов. Как утверждают в Amazon, традиционная топология Fat-Tree с многоуровневой структурой, используемая в ЦОД на протяжении десятилетий, является неэффективной. Когда данные передаются только по ограниченному числу сетевых путей, в случае перегрузки увеличивается задержка, даже при большой общей пропускной способности. К тому же, эта архитектура хрупка: потеря одного маршрутизатора верхнего уровня может разорвать связь для больших сегментов сети под ним. Кроме того, она требует сложной кабельной разводки. 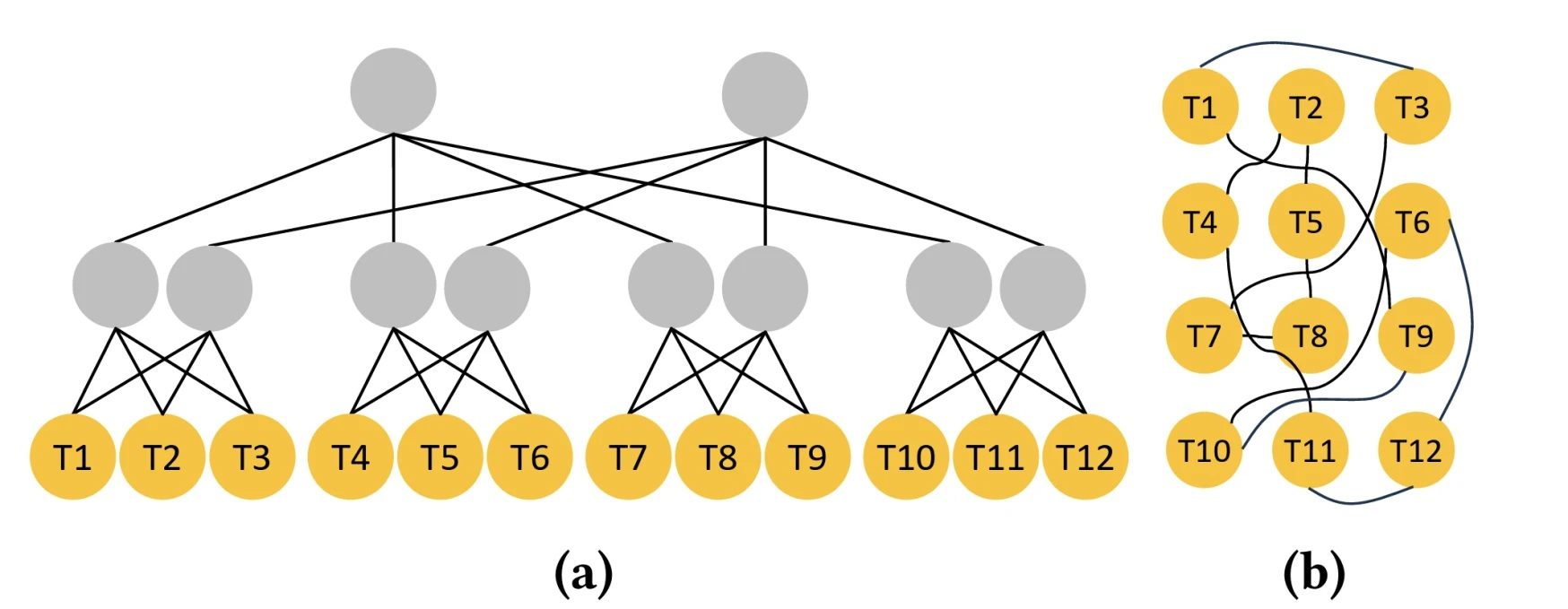
Источник изображений: Amazon Как отметил ресурс SiliconANGLE, существует множество способов решения этой проблемы, но большинство из них дорогостоящи или сложны в реализации. В качестве альтернативы Amazon предложила архитектуру RNG. Она увеличивает количество путей, по которым данные могут передаваться между узлами, что повышает пропускную способность, а также сокращает количество сетевых устройств вдвое и повышает надёжность соединения. Если сетевой путь, используемый узлом, испытывает технические проблемы, система может просто перенаправить трафик на один из множества других доступных ей путей. Но это не всё. Инженеры AWS разработали то, что они называют квазислучайной топологией. Некоторые сегменты в ЦОД проложены и подключены по определённой схеме, в то время как другие объединяются случайным образом. Именно эта случайность делает сети RNG более гибкими, чем Fat-Tree. Для поиска среди большого количества доступных сетевых путей оптимального маршрута для заданной рабочей нагрузки используется собственный распределённый протокол маршрутизации Spraypoint.  Протокол работает в два этапа. Сначала исходный маршрутизатор распределяет свой исходящий трафик случайным образом между всеми своими ближайшими соседями. Затем для каждого пакета использует классический алгоритм поиска кратчайшего пути для достижения промежуточной точки — маршрутизатора, который был предварительно назначен для передачи трафика к определённому пункту назначения. Промежуточные точки перенаправляют пакеты в ряд «концентрических колец» вокруг пункта назначения, при этом каждое кольцо передает трафик внутрь к следующему, пока он не достигнет цели. Согласно данным Amazon, это сочетание случайного начального распределения и структурированной сходимости Spraypoint даёт почти вдвое больше независимых путей между любыми двумя маршрутизаторами, чем стандартные методы поиска кратчайшего пути, и при этом сохраняет низкую вычислительную сложность и требует мало памяти, в отличие от истинно «плоской» сети, где все маршрутизаторы попарно объединены друг с другом действительно случайно образом. 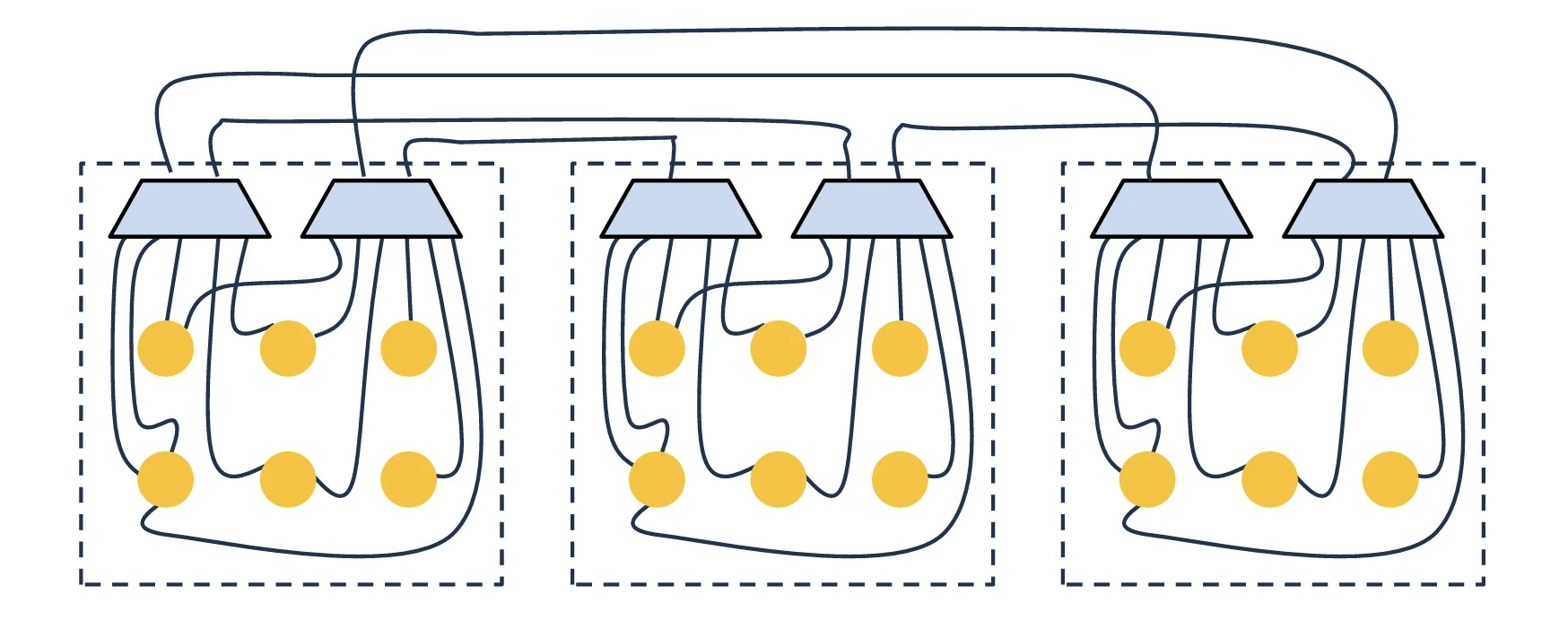 Дополнительная диверсификация маршрутов означает, что участки с перегрузкой в одной части сети могут быть автоматически обойдены без явных решений о перемаршрутизации. «По сути, сделав сеть “плоской”, мы устранили узкие места, которые возникают в традиционных сетевых решениях, — сообщил Мэтт Редер (Matt Rehder), вице-президент AWS Network Engineering, в интервью WIRED. — Мы считаем, что мы единственные, кто сделал это в таком масштабе». Вместе с тем, случайность конфигураций оптоволоконных кабелей RNG затрудняет эффективное управление ими. AWS разработала пассивное сетевое устройство ShuffleBox, которое физически соединяет различные оптоволоконные кабели. Каждый ShuffleBox имеет порты, обращённые к маршрутизаторам, и соединяется с другими ShuffleBox с другой. Внутренние оптические каналы, перемешанные по определённой схеме, и случайные соединения между ShuffleBox формирует общую топологию сети, которая является квазислучайной на макроуровне, без необходимости прокладки отдельных кабелей по всему этажу ЦОД. При установке новой стойки её маршрутизатор просто подключается к ближайшему ShuffleBox.  Что примечательно, команда, разработавшая RNG, не предлагает эту сетевую концепцию в контексте генеративного ИИ. Речь идёт о повышении эффективности повседневной архитектуры ЦОД компании. «RNG отлично подходит для наших основных задач, но шаблоны передачи обучающих данных для ИИ гораздо более скоординированы и централизованно управляются», — говорит Редер. По данным Amazon, по сравнению с архитектурами типа Fat-Tree, RNG использует на 69 % меньше маршрутизаторов и обеспечивает до 33 % большую пропускную способность, сокращает энергопотребление сети на 40 % и снижает затраты на инфраструктуру на 9–45 %. Первая сеть RNG была запущена в конце 2024 года в Ирландии и начала обрабатывать реальный трафик, сообщил ресурс PPC Land. Развёртывание послужило проверкой: инженеры AWS сравнили реальную производительность с математическими прогнозами, выявили недостатки в работе и применили оптимизации в двух последующих развёртываниях. По данным SiliconANGLE, технология уже используется в ряде ЦОД в Ирландии, Германии и Испании. Компания заявила, что большинство её новых ЦОД использует RNG.
30.05.2026 [14:25], Сергей Карасёв
Lightmatter представила лазерную сетевую карту Guide DR для CPO-платформКомпания Lightmatter, специализирующаяся на фотонных вычислениях и интерконнекте, анонсировала сетевую карту Guide DR на основе лазера (Laser Network Interface Card, LNIC), предназначенную для масштабирования инфраструктур нового поколения с технологией CPO (Co-Packaged Optics — интегрированная оптика). Новинка спроектирована специально для организации оптического интерконнекта с высокой пропускной способностью, в том числе на базе собственного решения Lightmatter Passage L200. Карта ориентирована прежде всего на дата-центры, поддерживающие ресурсоёмкие приложения ИИ с интенсивным обменом данными. Guide DR соответствует стандарту OCP NIC 3.0. Разработчик утверждает, что это изделие обеспечивает повышение плотности оптической мощности в четыре раза по сравнению с обычными модулями малого форм-фактора ELSFP (External Laser Small Form Factor Pluggable). Совокупная пропускная способность CPO или NPO достигает 51,2 Тбит/с. 
Источник изображения: Lightmatter Для новинки предусмотрено применение жидкостного охлаждения. При этом четыре карты Guide DR могут быть объединены в одном коммутационном блоке типоразмера 1U, что обеспечит суммарную скорость передачи данных до 204,8 Тбит/с. В целом, как отмечается, Guide DR позволяет решить проблему недостаточной масштабируемости оптики путём переноса источника света с внешней части коммутационного оборудования внутрь корпуса. Среди преимуществ предложенного решения названы модульная конструкция, высокая надёжность и производительность. Пробные поставки Guide DR LNIC компания Lightmatter планирует организовать в IV квартале нынешнего года.
28.05.2026 [09:13], Руслан Авдеев
ИИ осветят путь: Goldman Sachs прогнозирует резкий рост рынка оптических сетейПо прогнозам Goldman Sachs, рынок оптических сетевых решений для ИИ-инфраструктуры увеличится до $154 млрд на фоне роста спроса со стороны облачных гиперскейлеров и ИИ-кластеров, сообщает блог IEEE ComSoc. Техногиганты стремятся эффективно объединить как можно больше чипов, что приведёт к росту рынка волоконно-оптических соединений в ИИ ЦОД в девять раз. В Goldman Sachs отмечают, что показатели ИИ-систем теперь зависят не только от производительности GPU и HBM, но и от того, насколько быстро данные передаются между чипами и стойками. Аналитики подчёркивают, что именно оптические сетевые решения «разблокируют» вычислительные мощности, с чем уже не особенно эффективно справляются медные интерконнекты. В докладе рынок делится на решения для вертикального (scale-up) и горизонтального (scale-out) масштабирования. Примечательно, что на первые, как ожидается, придётся около $106 млрд из $154 млрд, т.е. 69 % рынка. Рынок оптических интерфейсов CPO составит порядка $91 млрд (59 %), т.е. большая часть затрат пойдёт на сети внутри ИИ-кластеров. По прогнозам Goldman Sachs, при переходе от систем NVIDIA GB300 NVL72 к Rubin Ultra NVL576 рост долларового содержания на вычислительную единицу вырастет в 16 раз в сегменте scale-out и в 45 раз — в сегменте scale-up. Рост связан с увеличением спроса на подключаемые оптические модули, оптические «движки», медные кабели и др. Рынок подключаемых оптических модулей и оптических «движков» вырастет в 13 раз при переходе от scale-out (как в случае GB300 NVL72/Oberon) к scale-up (Rubin Ultra NVL576/Kyber) в расчёте на вычислительную единицу. 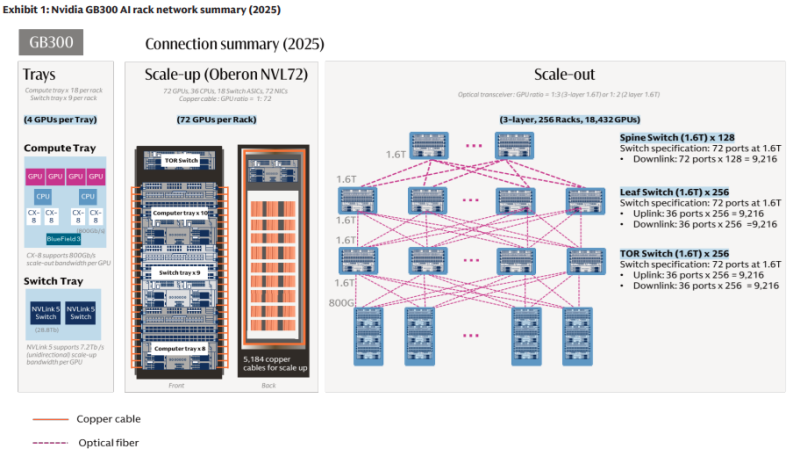
Источник изображения: Goldman Sachs Рынок подключаемых оптических модулей в сегменте scale-out вырастет в 10 раз на вычислительную единицу при переходе с GB300 NVL72 на Rubin Ultra NVL576, даже при проникновении CPO на уровне 29 %. Количество оптических модулей (в эквиваленте 1.6TbE) в одной вычислительной единице увеличится с 216 шт. в GB300 NVL72 до приблизительно 2,5 тыс. в Rubin Ultra NVL576. Банк прогнозирует, что долларовое содержание на вычислительную единицу в сегментах scale-up и scale-out увеличится в 20 раз с $315 тыс. в GB300 NVL72 до $9,4 млн в Rubin Ultra NVL576. При этом прогнозируется, что за полный жизненный цикл продукта будет поставлено 48 тыс. стоек GB300 NVL72 и 16,5 тыс. систем Rubin Ultra NVL576. Совокупный адресуемый рынок (TAM) для вертикальных и горизонтальных решений вырастет в 9 раз, с $15 млрд в случае с GB300 NVL72 (преимущественно в 2026 году) до $154 млрд для Rubin Ultra NVL576 (в основном в 2028 году). 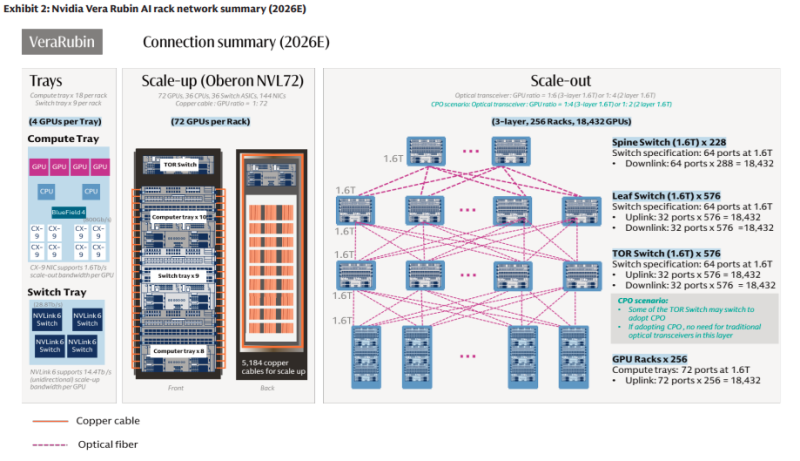
Источник изображения: Goldman Sachs Одним из ключевых выводов является то, что ИИ-кластеры становятся всё более насыщенными на разных уровнях стека оптическими системами, а не только на уровне подключения между стойками. Более всего от ситуации выиграют поставщики, способные снизить энергопотребление, повысить плотность и упростить упаковку для сверхскоростных интерконнектов. Чаще всего в числе основных бенефициаров упоминаются Coherent, Lumentum и Fabrinet, занятых в индустрии производства оптических компонентов и модулей, которое растёт вместе со спросом на ИИ-интерконнекты. Наилучшие перспективы у производителей специализированных оптических решений, а не у игроков более широкого профиля, включая Ciena, Nokia/Infinera, Cisco/Acacia, ADVA или Calix. В целом в Goldman Sachs считают, что оптические решения более не являются вспомогательным элементом инфраструктуры и становятся ключевым фактором для масштабирования инвестиций в ИИ. В результате инвесторы всё активнее интересуются производителями оптических компонентов, кремниевой фотоники, трансиверов и смежных технологий упаковки и пр. Ключевой вывод — по мере развития ИИ-кластеров сетевая инфраструктура становится одним из главных потенциальных ограничений, а оптика — наиболее вероятным решением этой проблемы.
15.05.2026 [08:38], Сергей Карасёв
Сетевой протокол Multipath Reliable Connection (MRC) улучшит производительность и надёжность ИИ-кластеровOpenAI в партнёрстве с AMD, Broadcom, Intel, Microsoft и NVIDIA анонсировала технологию Multipath Reliable Connection (MRC) — сетевой протокол, призванный повысить производительность и отказоустойчивость масштабных GPU-кластеров, ориентированных на ресурсоёмкие задачи ИИ. MRC уже используется во всех крупных кластерах OpenAI c NVIDIA GB200, в том числе в первом ЦОД Stargate, а также в ЦОД Microsoft по проекту Fairwater. Отмечается, что при обучении больших языковых моделей (LLM) каждый этап предполагает огромное количество пересылок данных между узлами в кластере. При этом единственная задержка при подобных транзакциях может повлиять на весь процесс, потенциально провоцируя простои тысяч ИИ-ускорителей. Такие прерывания приводят к снижению эффективности использования имеющихся вычислительных мощностей и к увеличению временных затрат. Наиболее распространёнными причинами задержек и нестабильности при передаче данных являются перегрузка сети, сбои в работе каналов связи и коммутационных устройств. Причём по мере увеличения масштабов кластеров проблемы усугубляются: неполадки возникают всё чаще, а их устранение становится более затруднительным. Протокол MRC, как утверждается, устраняет ряд ключевых недостатков сетей Ethernet применительно к инфраструктурам ИИ. В частности, вводятся такие механизмы, как адаптивная многопутевая передача данных, многоканальные перекрёстные Ethernet-фабрики, «распыление» пакетов, быстрое восстановление после сбоев и пр. MRC коренным образом меняет способ передачи трафика по сети. 
Источник изображений: OpenAI Традиционные платформы RoCE обычно привязывают поток данных к одному сетевому пути, что может снижать эффективность при возникновении неполадок. MRC же распределяет пакеты из одной серии одновременно по сотням путей и нескольким физическим сетевым каналам. В пакетах содержатся сведения об их конечном назначении, что позволяет ускорителям размещать данные в нужной последовательности, даже если пакеты поступают не по порядку. MRC хранит информацию о состоянии множества используемых путей: если обнаруживается перегрузка какого-либо из них, выбирается альтернативный маршрут, что позволяет оперативно перераспределить нагрузку по всей сети. 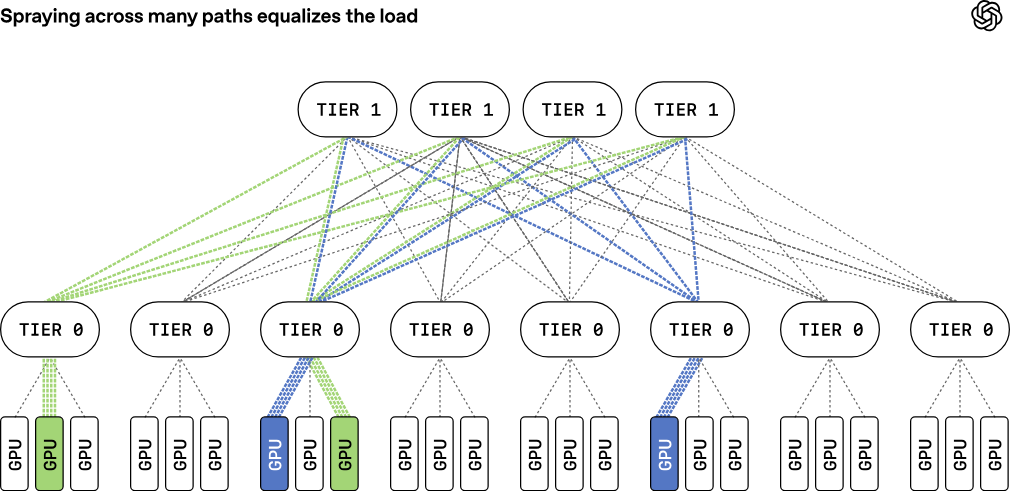 Ещё одной важной особенностью MRC является многоуровневая архитектура, которая изменяет саму физическую концепцию построения интерконнекта. Так, например, сетевой интерфейс 800GbE может быть разделён на 100GbE-каналы, связанные с восемью различными коммутаторами отдельными каналами. В результате можно построить восемь отдельных параллельных сетей. Такой подход оказывает значительное влияние на структуру кластера. В частности, коммутатор c 64 портами 800GbE можно использовать в конфигурации на 512 × 100GbE. И это позволяет построить сеть, объединяющую около 131 тыс. GPU, используя всего два уровня коммутации, против традиционных трёх- или четырёхуровневых топологий. 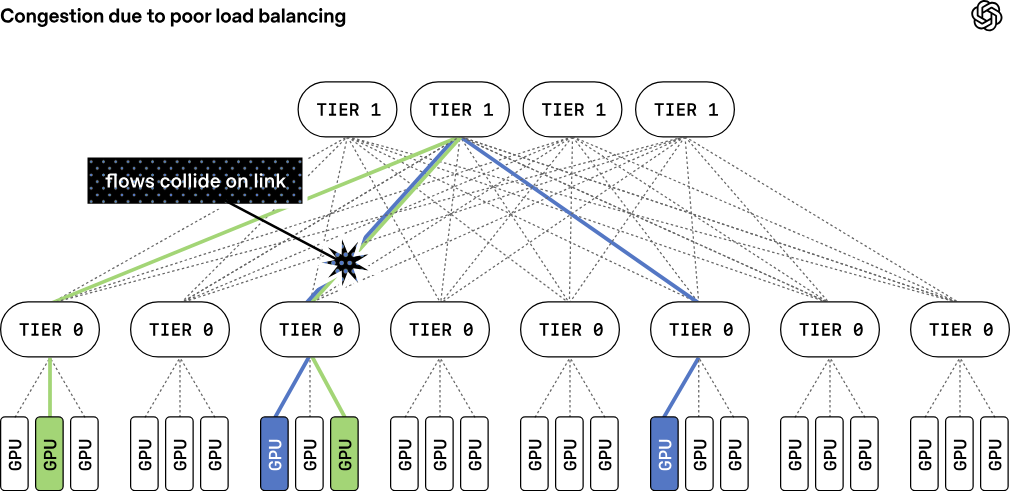 В протоколе MRC также используется новый способ обработки перегрузок и потери пакетов в сетях Ethernet. Обычно применяется технология PFC (Priority Flow Control) — управление потоками на основе приоритетов: этот механизм предполагает приостановку передачи данных для конкретных классов трафика, а не для всего порта целиком. В случае MRC задействован иной подход, основанный на выборочных подтверждениях, явных запросах на повторную передачу и обрезке пакетов. Так, когда коммутатор сталкивается с перегрузкой, он может отрезать полезную нагрузку и переслать в пункт назначения только заголовок пакета, что позволяет получателю быстро идентифицировать отсутствующие данные и запросить повторную передачу. Утверждается, что это даёт возможность восстанавливаться после сбоев и перегрузок в течение микросекунд, что на порядки быстрее по сравнению с обычными архитектурами. 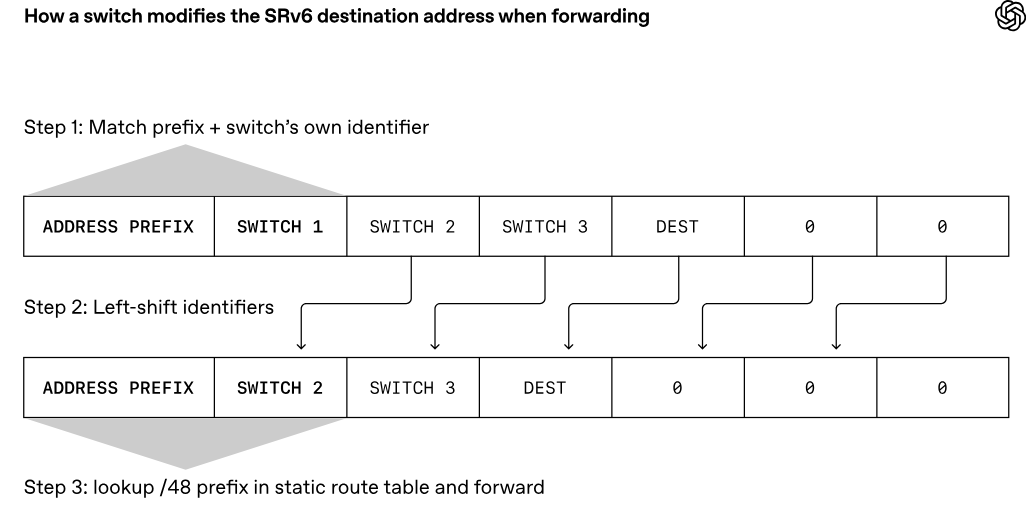 С внедрением MRC сокращается необходимость в динамической маршрутизации. Если пакеты теряются на каком-либо пути, система на основе MRC просто перестаёт использовать этот путь. Вместо динамической маршрутизации применяется так называемая сегментная маршрутизация IPv6 (IPv6 Segment Routing, SRv6), которая позволяет отправителю напрямую задать путь прохождения пакета, прописав последовательность идентификаторов коммутаторов. При пересылке данных коммутатор проверяет наличие собственного идентификатора. Если он присутствует, он удаляет из пакета свой идентификатор и ищет следующий за ним идентификатор в статической таблице маршрутизации, которая указывает, куда необходимо отправить пакет данных. 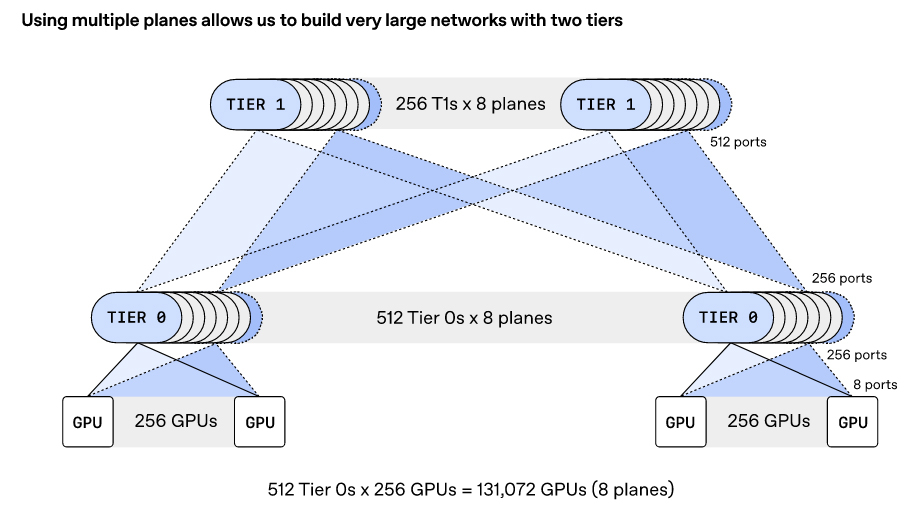 В отличие от динамической маршрутизации, такая статическая таблица формируется при первой настройке коммутатора и в дальнейшем не изменяется. MRC использует SRv6 для передачи пакетов по всем физическим каналам и уровням, а также по множеству путей в каждом из них. Если какой-либо путь становится недоступен, система игнорирует его. При этом коммутаторам не нужно пересчитывать маршруты или выполнять другие действия, кроме как строго следовать статическим маршрутам, заложенным в таблице. 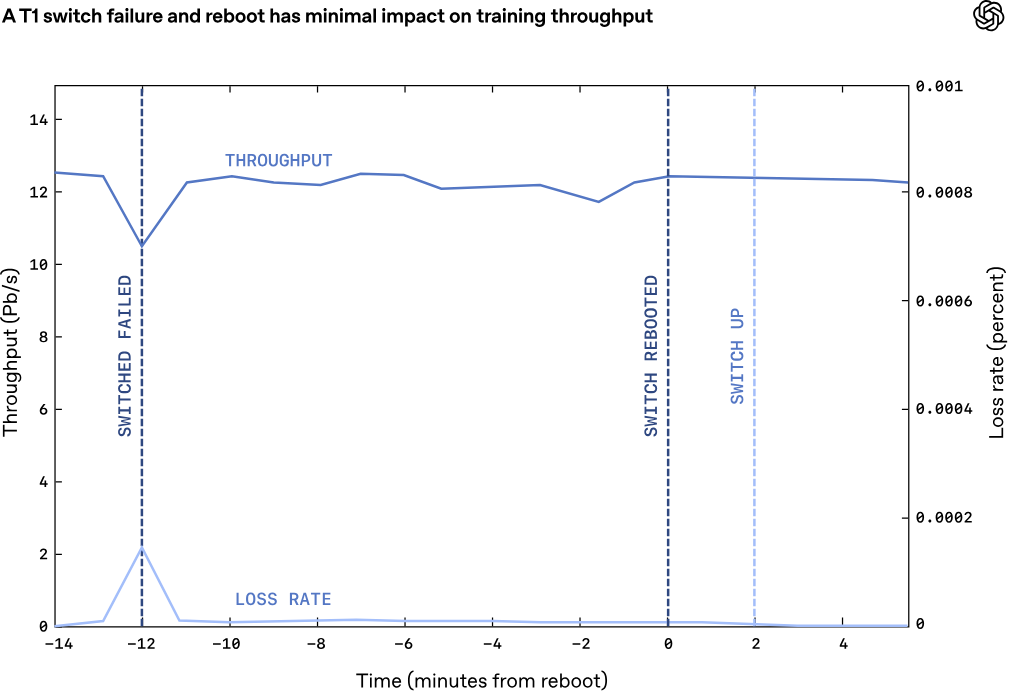 Протокол MRC выпущен в рамках проекта OCP. В целом, как отмечается, MRC обеспечивает три ключевых преимущества перед стандартными Ethernet-сетями для кластеров ИИ. Во-первых, MRC позволяет создавать многоуровневые высокоскоростные инфраструктуры для платформ с более чем 131 072 конечных точек, используя всего два уровня коммутаторов. Во-вторых, адаптивное распределение пакетов обеспечивает эффективную балансировку нагрузки, благодаря чему практически отсутствуют перегрузки в ядре сети. В-третьих, применение SRv6 обеспечивает быстрый обход сбоев и отправку пакетов только по работающим путям.  Компания Broadcom заявила, что её сетевые адаптеры Thor Ultra, а также коммутаторы Tomahawk 5 и Tomahawk 6 изначально поддерживают функциональность MRC. В частности, Thor Ultra позволяет использовать 2, 4 или 8 параллельных сетей на одном порту и распределять трафик одновременно по 128 каналам. При этом Tomahawk 5 обеспечивает коммутационную способность до 51,2 Тбит/с, а Tomahawk 6 — до 102,4 Тбит/с. В свою очередь, NVIDIA отмечает, что протокол MRC, будучи расширением RoCE, совместим с решениями Spectrum-X Ethernet. OpenAI уже использовала MRC при обучении нескольких ИИ-моделей, задействовав коммутаторы Broadcom и NVIDIA. Конкуренцию MRC составляет схожий во многих аспектах Ultra Ethernet.
07.05.2026 [00:55], Владимир Мироненко
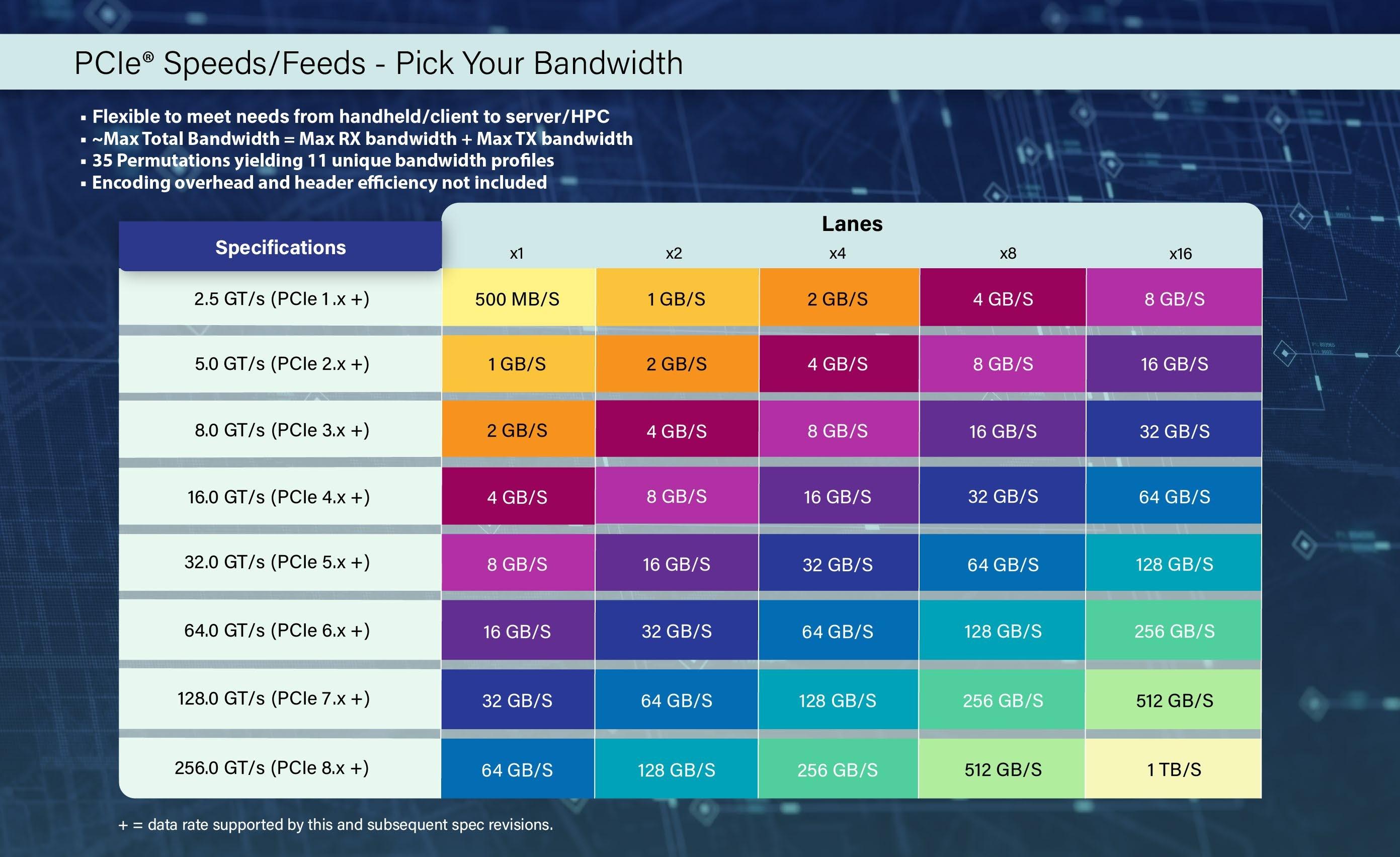
1 Тбайт/с на x16: PCI-SIG раньше срока предоставила спецификации PCI Express 8.0 версии 0.5Некоммерческая организация PCI-SIG объявила о выходе версии 0.5 стандарта PCIe 8.0, которую предоставили отраслевым партнёрам раньше запланированного срока. Это официальный первый вариант спецификации PCIe 8.0, включающий отзывы о прошлогоднем выпуске стандарта 0.3. Как ожидается, стандарт будет полностью готов к 2028 году, что значительно повысит производительность шины PCIe. 
Источник изображения: Synopsys PCIe 8.0 должен увеличить пропускную способность в два раза по сравнению с PCIe 7.0, который в свою очередь в два раза превосходит по скорости актуальную версию стандарта — PCIe 6.0. Серверные процессоры AMD и Intel получат поддержку PCIe 6.0, и в планы обеих компаний уже включена реализация в будущем стандарта PCIe 7.0. В свою очередь, PCI-SIG стремится выпустить PCIe 8.0 до того, как отрасли потребуется ещё более высокая пропускная способность, что позволит рынку строить дальнейшие планы развития с учётом требований PCIe. 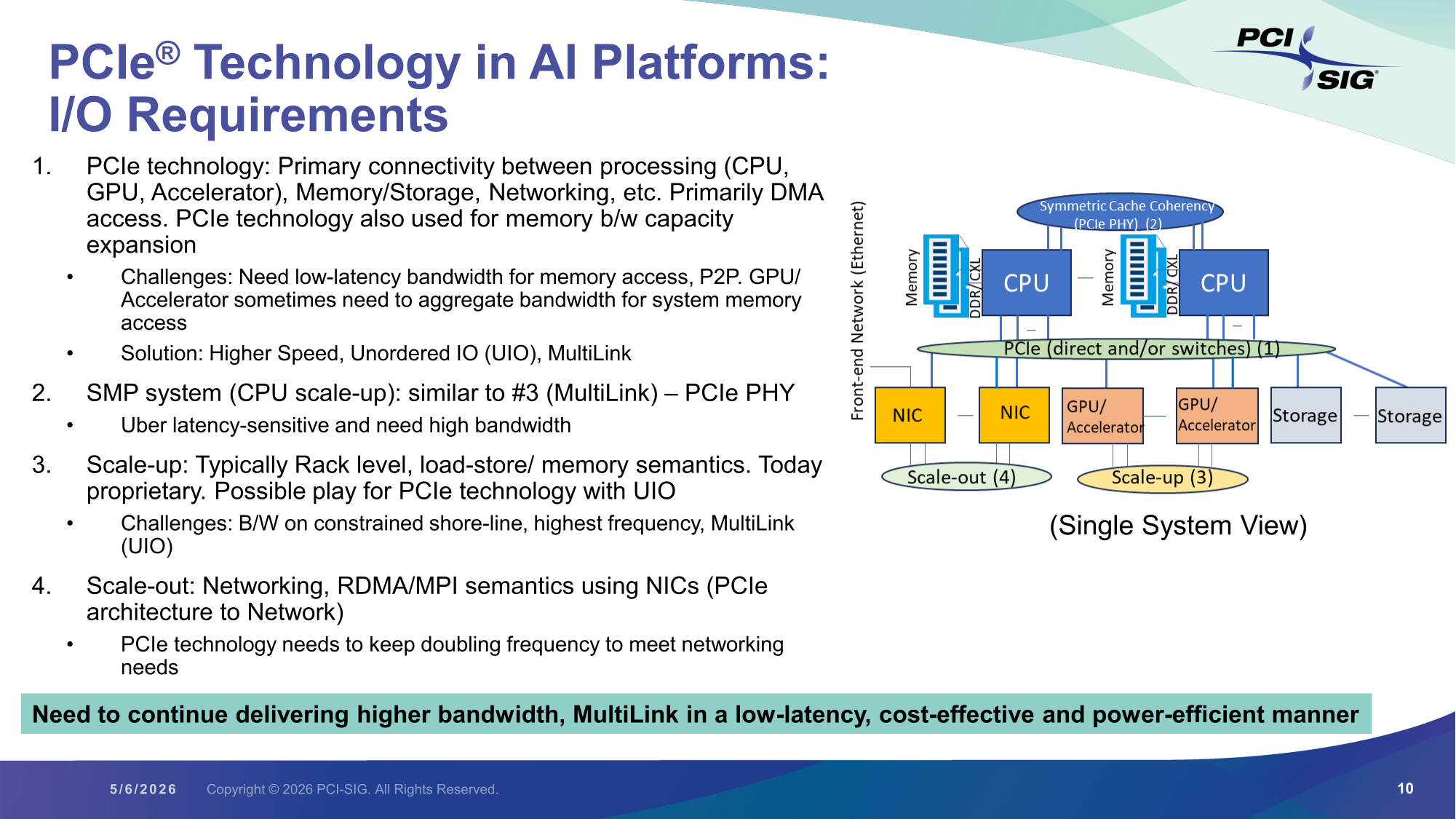
Источник изображения: PCI-SIG Цели спецификации PCIe 8.0:
Источник изображения: PCI-SIG
23.04.2026 [22:49], Владимир Мироненко
Cisco представила прототип универсального квантового коммутатораCisco Systems представила прототип универсального сетевого коммутатора для квантовых систем Cisco Universal Quantum Switch, позволяющий соединять квантовые компьютеры разных производителей, а также квантовые датчики различных типов в единую когерентную сеть, путём перемещения запутанных фотонов с сохранением их квантового состояния. Устройство преобразует все основные режимы квантовой запутанности и кодирования и работает при комнатной температуре, на телекоммуникационных частотах, по стандартному оптоволоконному кабелю, не требует криогенной среды или специальной инфраструктуры. Исследователи и предприятия уже используют квантовые компьютеры в качестве дополнительных сопроцессоров для решения конкретных, математически сложных задач, которые недоступны для классических суперкомпьютеров. Одна из самых актуальных проблем, стоящих перед квантовыми вычислениями, связана с масштабированием. Большинство квантовых систем могут взаимодействовать с другими системами, использующими только тот же режим кодирования. Для того чтобы получить систему на миллионы кубитов, что необходимо для обеспечения научных прорывов, нужно или изыскать возможность создания более крупных и мощных квантовых компьютеров или найти способ соединения вместе нескольких квантовых компьютеров, возможно, от разных вендоров, подобно тому, как классические компьютеры соединяются в ЦОД, чтобы они функционировали как единое целое. 
Источник изображений: Cisco Cisco выбрала второй путь. Универсальный коммутатор использует запатентованную Cisco систему преобразования, которая преобразует различные режимы кодирования, используемые различными квантовыми технологиями на входе и выходе. Квантовые системы в основном используют четыре основных метода кодирования: поляризационное, временное, частотное и траекторное, и они используют различные схемы запутанности поверх них. Универсальный квантовый коммутатор Cisco разработан для поддержки всех четырёх модальностей и динамически переключается между ними, позволяя системам с различными физическими архитектурами взаимодействовать без изменения их работы. Cisco заявила, что на данный момент система протестирована с поляризацией, которая использует ориентацию фотонов для передачи информации.  Как отметил ресурс SiliconANGLE, преобразование модальностей обеспечивает реальную гетерогенность как для квантовых компьютеров, так и для квантовых датчиков. Квантовый процессор на основе нейтральных атомов может взаимодействовать с квантовым процессором на основе захваченных ионов, который, в свою очередь, может взаимодействовать с фотонным датчиком или сенсором на основе нейтральных атомов через тот же коммутатор. Квантовые ЦОД и сети квантовых датчиков, построенные таким образом, могут развиваться и интегрировать новые технологии по мере их появления, не будучи ограниченными единым стандартом модальности или архитектурой. В настоящее время квантовая индустрия развивается в нескольких направлениях. Производители создают различные типы квантовых систем, и на данный момент неизвестно, какой аппаратный подход и метод кодирования будет преобладать, и какая экосистема станет доминирующей. Поэтому создание универсального коммутатора крайне важно.  Коммутатор Cisco Universal Quantum Switch разработан с учётом реальных условий ЦОД, с целью интеграции в уже существующую инфраструктуру. За пределами ЦОД, по словам Cisco, текущая дальность действия коммутатора составляет до 100 км, хотя утверждается, что со временем расстояние перестанет быть ограничивающим фактором. Компания отметила, что коммутатор является частью масштабной инициативы Cisco Quantum Labs по созданию квантовых сетей, охватывающей все уровни — от чипов и протоколов до приложений. В прошлом году Cisco представила прототип специализированного сетевого квантового чипа для генерации запутанных фотонов, позволяющий масштабировать квантовые системы, объединяя квантовые процессоры в единую инфраструктуру.
20.04.2026 [17:38], Владимир Мироненко
Ещё капельку: XPO-модули повысят плотность сетей в ИИ ЦОД, но CPO всё равно не избежатьЭкосистема XPO (eXtra-dense Pluggable Optics) набирает обороты после презентации на OFC 2026, поскольку производители объединяются вокруг нового формата подключаемых 12,8-Тбит/с модулей, разработанного для ИИ-инфраструктуры, сообщил ресурс Converge Digest. Инициатива, возглавляемая Arista Networks и поддерживаемая растущей группой поставщиков оптических и кремниевых компонентов, ориентирована на следующее поколение ИИ-кластеров, где плотность портов, полоса пропускания и тепловые ограничения будут основными факторами, ограничивающими производительность. Модуль XPO помещает 64 200G-канала (224 Гбит/с PAM4) в то же пространство, что и два модуля OSFP. В 1OU помещается 16 модулей XPO, что даёт 204,8 Тбит/с на юнит или 6,5 Пбит/с на ORv3-стойку. Это примерно вчетверо больше в сравнении 1.6T-модулями OSFP 1,6T, сообщил ресурс The Next Platform. XPO поддерживает интегрированное жидкостное охлаждение (водоблок), позволяет использовать любые типы оптики, а также предлагает значительное повышение отказоустойчивости. XPO поддерживает оптические стандарты SR, DR, FR, LR и ZR/ZR+, а также совместим с LPO. 
Источник изображений: Arista Networks По словам Андреаса Бехтольсхайма (Andreas Bechtolsheim), соучредителя и главного архитектора Arista, в ИИ ЦОД мощностью 400 МВт с 1024 стойками, в каждой из которых размещено по 128 GPU, из расчёта 12,8 Тбит/с на вертикальное масштабирование и 1,6 Тбит/с для горизонтального масштабирования на каждый GPU при использовании коммутаторов с OSFP плотностью 1,6 Пбит/с на стойку потребуется более 1400 стоек. XPO позволит сократить количество стоек на 75 %, попутно сэкономив 44 % площади ЦОД.  Бехтольсхайм отметил, что крупные ИИ ЦОД будут охлаждаться жидкостью, и коммутаторы, используемые в них, также должны изначально поддерживать СЖО. Он допустил, что можно добавить охлаждающие пластины с жидкостным охлаждением на модули OSFP с плоской верхней панелью, но это не улучшит существенно тепловые характеристики. В случае XPO водоблок интегрируется внутрь модуля и способен отводить более 400 Вт как от маломощных, так и высокопроизводительных модулей, таких как 8×1.6T-ZR/ZR+, утверждает Бехтольсхайм.  Еще одно дополнительное преимущество заключается в том, что при жидкостном охлаждении компонентов XPO они работают с температурой на 20–25 °C ниже в ZR-модуле на 12,8 Тбит/с, чем в модуле OSFP-ZR на 1,6 Тбит/с с воздушным охлаждением. Кроме того, модули XPO конструктивно значительно проще, чем модули OSPF, что также повышает надёжность. «Каждая 32-канальная плата имеет только один микроконтроллер и один набор преобразователей напряжения, что на 75 % меньше общих компонентов по сравнению с четырьмя модулями OSPF», — сообщил Бехтольсхайм.  Вместе с тем повышение плотности размещения ведёт и к повышению энергопотребления. По оценкам Arista, 1,6-Пбит/с стойка с OSFP потребляет порядка 32 кВт, тогда как 6,5-Пбит/с XPO-стойка требует уже 128 кВт. Однако XPO-модули рассчитаны на питание 48/50 В DC непосредственно от общей шины всей стойки и уже сами отдают трансиверам 3,3 В, что способствуют упрощению всей конструкции, повышению компактности и снижению энергопотерь.  Arista объявила о заключении многостороннего соглашения (MSA) на поставку XPO, к которому присоединились около 45 ведущих поставщиков оптических модулей, включая Lightmatter, Eoptolink Technology и TeraHop. Ожидается, что серийное производство XPO начнётся в 2027 году. Впрочем, XPO можно рассматривать как временное решение до начала действительно массового внедрения интегрированной оптикой (CPO).
17.04.2026 [14:21], Сергей Карасёв
IonQ разработала фотонный интерконнект для объединения квантовых компьютеровКомпания IonQ, занимающаяся разработкой квантовых платформ, объявила о создании фотонного интерконнекта, предназначенного для объединения квантовых компьютеров в единый вычислительный кластер. Это, как утверждается, основополагающее техническое достижение, которое в перспективе обеспечит возможность масштабирования квантовых систем. В ходе демонстрации IonQ установила связь между двумя удаленными квантовыми компьютерами на основе захваченных ионов. В таких установках в качестве кубитов используются ионы, удерживаемые в вакууме электромагнитными полями. Комплексы данного типа отличаются высокой стабильностью и точностью операций, говорит компания. 
Источник изображения: IonQ Объединив две квантовые системы, IonQ впервые подтвердила возможность генерации, передачи и детектирования фотонов, служащих для обеспечения квантовой запутанности. При этом сохраняется когерентность, необходимая для сложных квантовых операций. Предложенное решение открывает путь для создания квантовых вычислительных кластеров большой мощности, способных выполнять сложнейшие задачи. «Масштабирование квантовых вычислений за пределы возможностей одного чипа имеет большое значение для реализации будущего квантового интернета. Эта демонстрация доказывает, что наша платформа на основе захваченных ионов подходит для формирования систем, предназначенных для решения самых сложных глобальных проблем», — говорит Никколо де Маси (Niccolo de Masi), генеральный директор IonQ. Разработкой технологий для объединения квантовых компьютеров занимаются и другие компании. В частности, стартап CavilinQ намерен создать фотонные каналы связи с усилением на базе резонаторов, которые позволят отдельным квантовым процессорам работать сообща в составе кластеров. На реализацию проекта фирма CavilinQ получила $8,8 млн в ходе посевного раунда финансирования. |
|

