Лента новостей
|
30.03.2022 [22:01], Владимир Мироненко
Российская суперкомпьютерная платформа «РСК Торнадо» объединила отечественные «Эльбрусы» и зарубежные x86-процессорыГруппа компаний РСК на конференции «Параллельные вычислительные технологии (ПаВТ) 2022» сообщила о создании суперкомпьютерной платформы «РСК Торнадо», которая позволяет одновременно использовать в одной системе вычислительные узлы на базе зарубежных x86-процессоров и отечественных чипов «Эльбрус». Возможность использования различных типов микропроцессорных архитектур в одном монтажном шкафу (до 104 серверов в стойке), позволит ускорить темпы импортозамещения в области высокопроизводительных вычислительных систем (HPC), решений для центров обработки данных (ЦОД) и систем хранения данных (СХД). Унифицированная интероперабельная (т.е. обеспечивающая функциональную совместимость разных решений) платформа «РСК Торнадо» предназначена для решения широкого круга задач, в том числе для работы с нагрузками Big Data, HPC и ИИ. 
Суперкомпьютер «Говорун» в ОИЯИ (Фото: Группа компаний РСК) Разработка и создание вычислительных систем на основе «РСК Торнадо» осуществляется на территории России в рамках соглашения с Министерством промышленности и торговли Российской Федерации с целью реализации подпрограммы «Развитие производства вычислительной техники» в составе государственной программы «Развитие электронной и радиоэлектронной промышленности». Программный стек «РСК БазИС» для вышеупомянутой платформы тоже разработан в России. В настоящее время система «РСК БазИС» используется для оркестрации вычислительных мощностей Межведомственного суперкомпьютерного центра (МСЦ) РАН, Санкт-Петербургского политехнического университета (СПбПУ) и Объединенного института ядерных исследований (ОИЯИ), сведённых в единую инфраструктуру для оптимизации вычислительных ресурсов.
26.03.2022 [00:48], Владимир Агапов
Микро-ЦОД вместо котельной — Qarnot предложила отапливать дома б/у серверами«Зелёная» экономика, переход на которую стремится осуществить всё больше стран, требует радикального сокращения вредного воздействия техносферы на окружающую среду. Один из эффективных способов достижения этой задачи связан с включением в полезный оборот побочных продуктов экономической деятельности. В случае дата-центров таким продуктом является тепло. Великобритания, Дания и другие страны направляют тепло от ЦОД в отопительные системы домов, а Норвегия обогревает им омаровые фермы и планирует обязать дата-центры отдавать «мусорное» тепло на общественные нужды. Французская компания Qarnot решила посмотреть на эту задачу под другим углом, разработав в 2017 г. концепцию электрообогревателя для жилых и офисных помещений на процессорах AMD и Intel. В 2018 г. Qarnot продолжила изыскания и выпустила криптообогреватель QC-1. А недавно она порадовала своих заказчиков следующим поколением отопительных устройств QB, которое создано в сотрудничестве с ITRenew. Новые модули используют OCP-серверы, которые ранее работали в дата-центрах гиперскейлеров. Оснащённые водяным охлаждением, они обогревают помещения пользователей и обеспечивают дополнительные мощности для периферийных облачных вычислений. 
Изображение: Qarnot (via DataCenterDynamics) Система отводит 96% тепла, производимого кластером серверов, которое попадает в систему циркуляции воды. IT-часть состоит из процессоров AMD EPYC/Ryzen или Intel Xeon E5 в составе OCP-платформ Leopard, Tioga Pass или Capri с показателем PUE, который, по словам разработчиков, стремится к 1,0. При этом вся система практически бесшумная, поскольку вентиляторы отсутствуют.  В компании заявляют, что с февраля уже развёрнуто 12 000 ядер, и планируется довести их число до 100 000 в течении 2022 года. Среди предыдущих заказчиков систем отопления Qarnot числятся жилищные проекты во Франции и Финляндии, а также банк BNP и клиенты, занимающиеся цифровой обработкой изображений. По словам технического директора Qarnot Клемента Пеллегрини (Clement Pellegrini), QB приносит двойную пользу экологии, используя не только «мусорное» тепло, но и оборудование, которое обычно утилизируется. У ITRenew уже есть очень похожий совместный проект с Blockheating по обогреву теплиц такими же б/у серверами гиперскейлеров.
24.03.2022 [00:23], Владимир Мироненко
IBM подала в суд на LzLabs, предлагающую дешёвую облачную альтернативу её мейнфреймамIBM подала в Окружной суд в Уэйко (штат Техас) на разработчика ПО LzLabs, заявив, что созданная им платформа Software Defined Mainframe (SDM, программно определяемый мейнфрейм) нарушает её патенты. В судебном иске корпорация утверждает, что платформа LzLabs, позволяющая выполнять приложения для мейнфреймов на стандартном оборудовании в облаке, базируется на ПО, основанном на проприетарной технологии IBM. IBM также обвинила LzLabs в том, что та делает ложные заявления о своих продуктах. Кроме того, в иске сообщается, что люди, стоящие за LzLabs, и раньше нарушали патенты IBM. Среди руководителей LzLabs оказался бывший гендиректор стартапа Neon Enterprise Software, который создал ПО zPrime, предлагающее похожую на SDM функциональность. Более того, компания сама подала в 2009 году иск к IBM, обвиняя последнюю в принуждении заказчиков пользоваться дорогими мейнфреймами. В ответном иске IBM обвинили компания в нарушении патентов, и в 2011 году продукт zPrime прекратил существования. 
Изображение: IBM По счастливой случайности в том же году появилась швейцарская компания LzLabs. В 2016 году она представила платформу, которая позволяла выполнять традиционные рабочие нагрузки мейнфреймов, написанные на Cobol или PL/1, на стандартных x86-серверах под управлением Linux как локально, так и в облаке. Впоследствии компания добавила поддержку контейнеров. У LzLabs есть успешные проекты — так, Swisscom перенесла на облачный вариант SDM «все критически важные бизнес-приложения» без перекомпилирования. IBM утверждает, что LzLabs, используя транслятор CPU-инструкций, нарушила два патента на решения, воплощенные в этих инструкциях. Ещё два нарушения связаны с повышением эффективности эмуляции и трансляции. Последний, пятый патент, о нарушении которого сообщила IBM, касается автоматический замены вызываемых приложений на их аналоги для x86-платформ. В своём иске IBM добивается судебного запрета на использование LzLabs интеллектуальной собственности и коммерческих секретов IBM. У IBM есть собственная платформа для разработки, тестирования, демонстрации и изучения приложений мейнфреймов IBM Z Development and Test Environment (ZD&T) на x86-системах, в том числе облачных. А недавно компания представила сервис Wazi aaS для IBM Cloud. В обоих случаях IBM прямо запрещает использовать эти решения для выполнения любых реальных нагрузок, в особенности критически важных.
23.03.2022 [01:10], Алексей Степин
Анонсирован ускоритель AMD Instinct MI210: половинка MI250 в форм-факторе PCIe-картыAMD продолжает активно осваивать рынок ускорителей и ИИ-сопроцессоров. Вслед за сверхмощными Instinct MI250 и MI250X, анонсированными ещё осенью прошлого года, «красные» представили новинку — ускоритель Instinct MI210. Это менее мощная, одночиповая версия ускорителя с архитектурой CDNA 2, дополняющая семейство MI200 и имеющая более универсальный форм-фактор PCIe-карты. Если Instinct MI250/250X существует только как OAM-модуль, то новый Instinct MI210 имеет вид обычной платы расширения с разъёмом PCI Express 4.0. Это неудивительно, ведь MI250 физически невозможно уложить в тепловые и энергетические рамки, обеспечиваемые таким форм-фактором, поскольку два чипа Aldebaran требуют 560 Вт против привычных для PCIe-плат 300 Вт. Для питания MI210 используется как слот PCIe, так и 8-контактный разъём EPS12V.  Поскольку ускоритель на борту новинки только один, она вдвое уступает MI250/250X по всем параметрам, но всё равно обеспечивает весьма неплохую производительность во всех форматах вычислений. Стоит отметить, что функциональные возможности MI210 не уменьшились. Осталась, например, поддержка Infinity Fabric 3.0 — соответствующие разъёмы расположены в верхней части карты, и она поддерживает работу в кластерном режиме из двух или четырёх ускорителей. 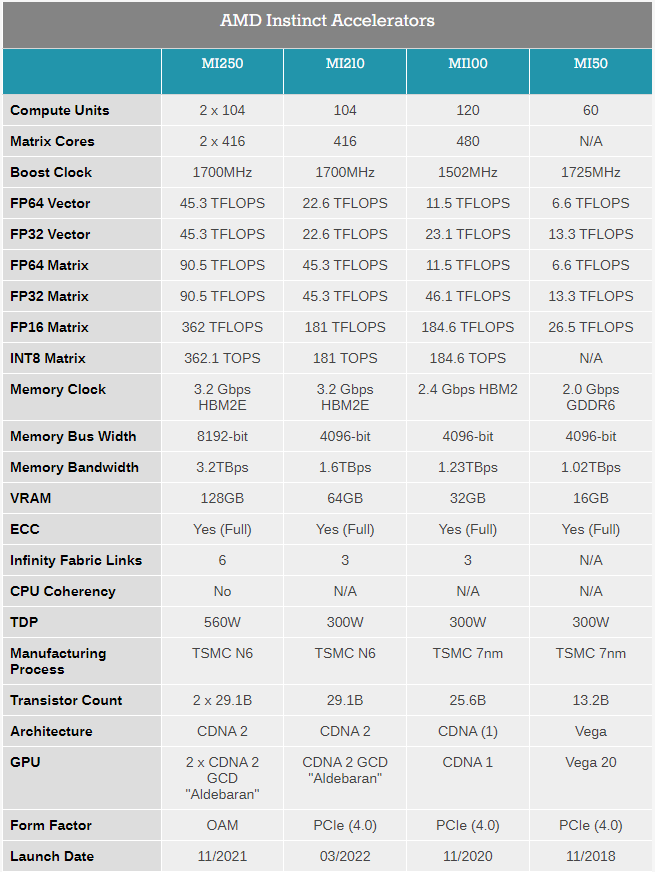
Таблица опубликована AnandTech В MI210 используется более простой вариант Aldebaran с одним кристаллом. Что интересно, по количеству вычислительных блоков этот вариант уступает более старому MI100 (104 CU против 120, 416 матричных ядер против 480). Однако последний использует первую итерацию архитектуры CDNA и работает на меньшей частоте — 1500 против 1700 МГц у новинки. В некоторых форматах вычислений MI100 может быть быстрее, но разница крайне незначительна. 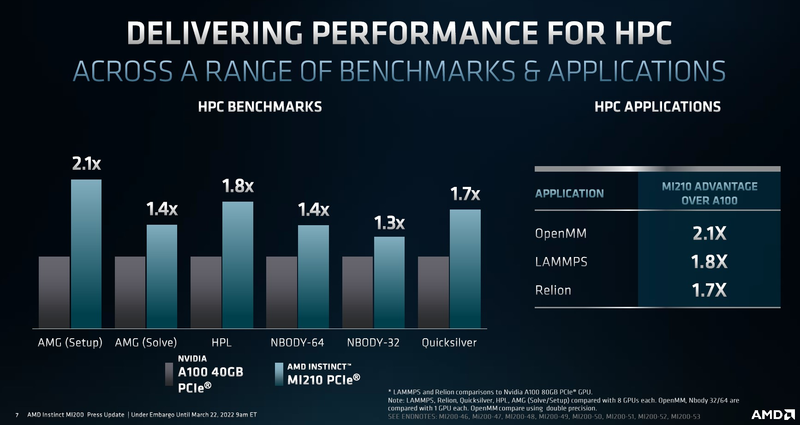
Производительность AMD Instinct MI210 в сравнении с NVIDIA A100 40GB PCIe CDNA2 позволяет использовать уникальные форматы данных, вроде packed FP32, однако это требует поддержки со стороны разработчиков, что несколько затруднит создание универсального ПО, способного полностью задействовать возможности MI210. Но в первую очередь, это ускоритель, не «зажимающий» FP64-производительность: свыше 22 Тфлопс в векторных операциях и 45 Тфлопс — в матричных. Сервер с одним или несколькими MI210 может использоваться в качестве универсальной платформы разработки ПО для суперкомпьютеров на базе более мощных ускорителей AMD Instinct MI250/250X. Новинка уже доступна у традиционных партнёров AMD по выпуску серверов, включая ASUS, Dell, HPE, Supermicro и Lenovo, которые также предлагают более мощные решения на базе MI250/250X.
22.03.2022 [18:48], Игорь Осколков
NVIDIA анонсировала 144-ядерные Arm-процессоры Grace и гибрид Grace HopperГлавным событием GTC 2022 стал анонс новых ускорителей H100 (Hopper), которые станут доступны в III квартале 2022 года. Вслед за ними в первой половине 2023 года появятся давно обещанные CPU Grace и гибридная система Grace Hopper, сочетающие, как понятно из названия, процессоры Grace (ARMv9) и ускорители Hopper. Как и было сказано ранее, для связи всех компонентов между собой будет использоваться mesh-сеть на базе всё той же шины NVLink 4.0 (900 Гбайт/с) с кеш-когерентностью. А сочетание LPDDR5X (с ECC, конечно) и HBM даст суммарный объём памяти до 600 Гбайт с общей полосой пропускания порядка 2 Тбайт/с. Для Grace Hopper компания подготовит полный стек ПО, благо портированием на Arm она начала заниматься ещё 3 года назад. 
NVIDIA Grace (Изображения: NVIDIA) Двухчиповый процессор Grace Superchip для ИИ- и HPC-нагрузок имеет 144 ядра, результат которых в SPECrate2017_int_base составляет 740, что, по словам компании, в полтора раза выше, чему у пары AMD EPYC, использующихся в DGX A100. И это, честно говоря, не такой уж и впечатляющий результат.  Но NVIDIA утверждает, что новые CPU вдвое лучше по отношению производительности к энергопотреблению, чем «традиционные серверы» — использование LPDDR5X позволяет добиться пропускной способности памяти в 1 Тбайт/с, а вся сборка CPU+RAM будет потреблять менее 500 Вт. 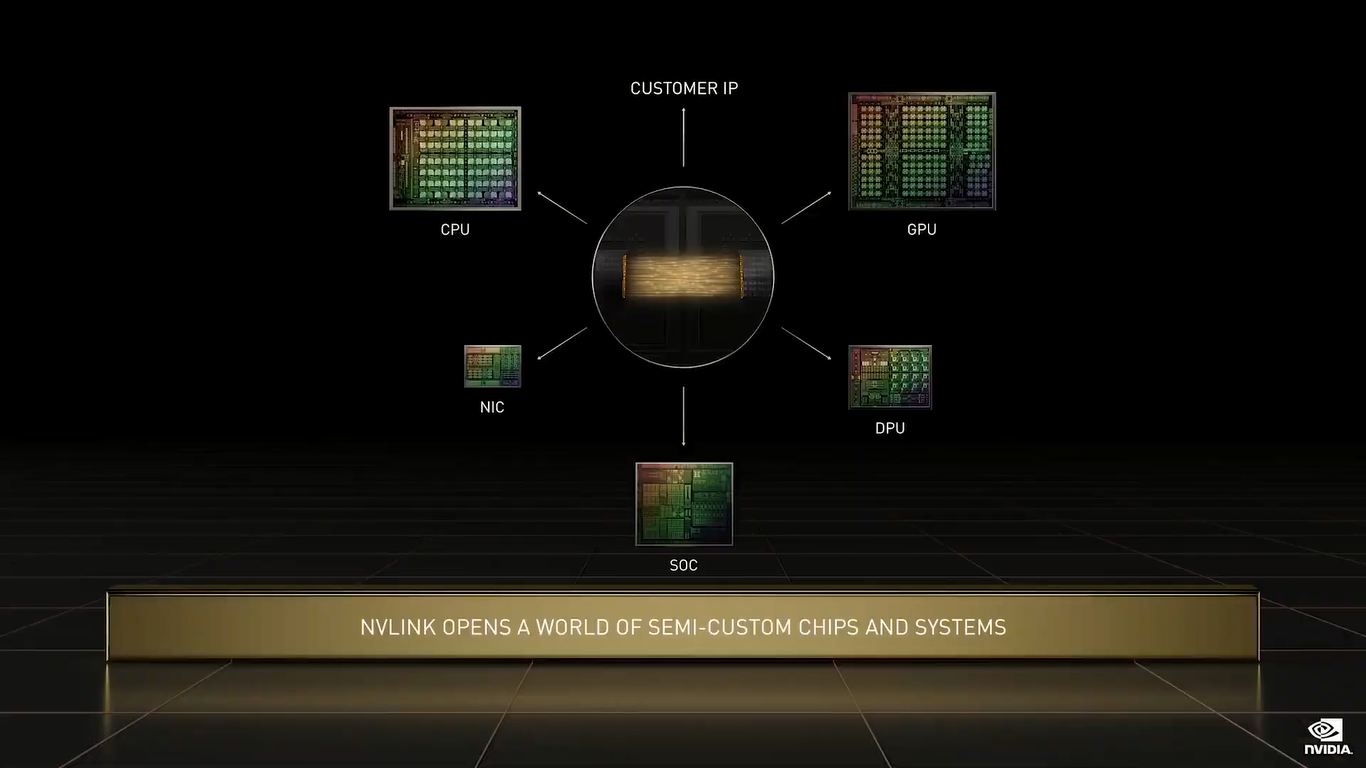 Чипы (или чиплеты, если хотите) в Grace Superchip тоже объединены посредством NVLink, только в данном случае этот интерконнект называется NVLink-C2C (Chip-to-Chip). И его NVIDIA предлагает использовать другим компаниям для создания кастомных сборок, объединяющих необходимые кристаллы, да и сама готова масштабировать и адаптировать свои решения под нужды заказчика. 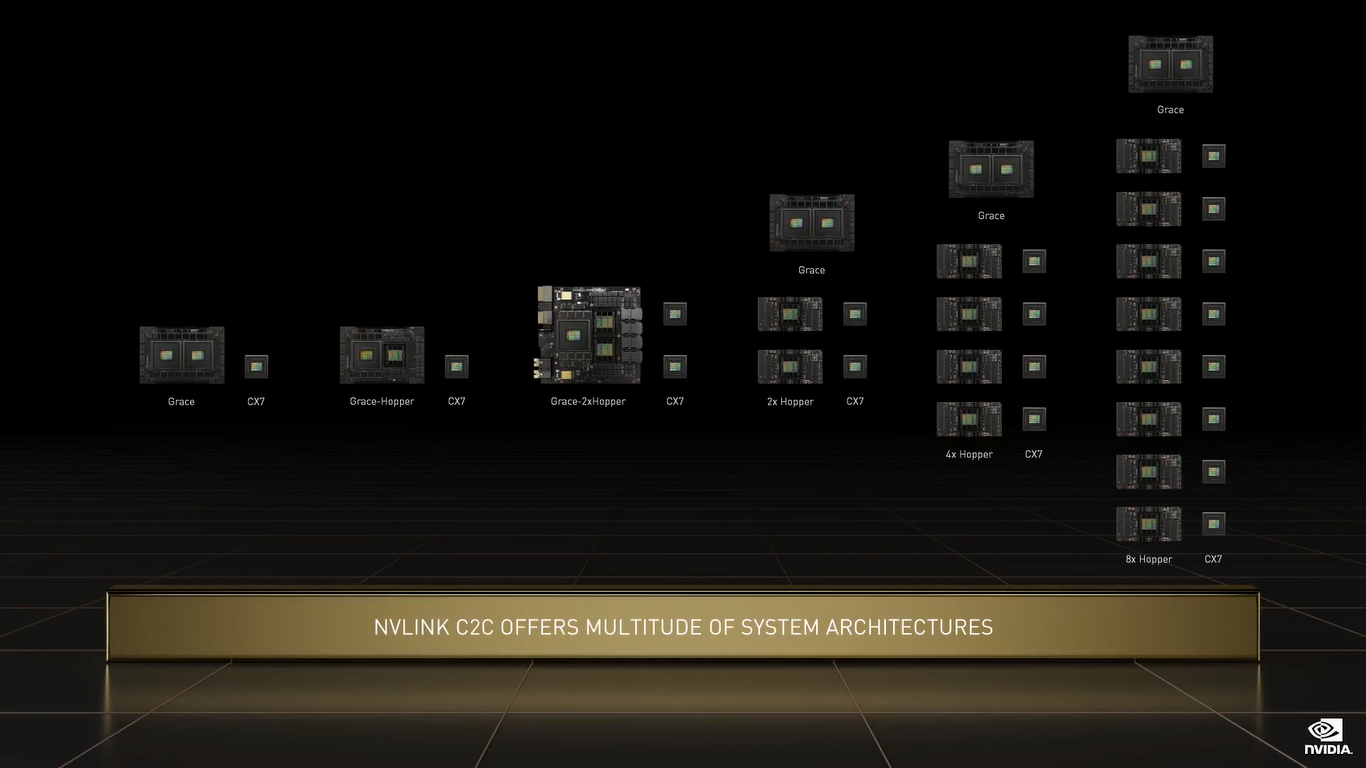 По словам NVIDIA, NVLink-C2C в 25 раз энергоэффективнее PCIe 5.0, а для его реализации нужна в 90 раз меньшая площадь кремния. Шина предлагает высокую скорость (да-да, всё те же 900 Гбайт/с), низкий уровень задержек, поддержку атомарных операций и совместимость с Arm AMBA CHI, CXL и UCIe.
22.03.2022 [18:40], Игорь Осколков
NVIDIA анонсировала 4-нм ускорители Hopper H100 и самый быстрый в мире ИИ-суперкомпьютер EOS на базе DGX H100На GTC 2022 компания NVIDIA анонсировала ускорители H100 на базе новой архитектуры Hopper. Однако NVIDIA уже давно говорит о себе как создателе платформ, а не отдельных устройств, так что вместе с H100 были представлены серверные Arm-процессоры Grace, в том числе гибридные, а также сетевые решения и обновления наборов ПО. 
NVIDIA H100 (Изображения: NVIDIA) NVIDIA H100 использует мультичиповую 2.5D-компоновку CoWoS и содержит порядка 80 млрд транзисторов. Но нет, это не самый крупный чип компании на сегодняшний день. Кристаллы новинки изготавливаются по техпроцессу TSMC N4, а сопровождают их — впервые в мире, по словам NVIDIA — сборки памяти HBM3 суммарным объёмом 80 Гбайт. Объём памяти по сравнению с A100 не вырос, зато в полтора раза увеличилась её скорость — до рекордных 3 Тбайт/с. 
NVIDIA H100 (SXM) Подробности об архитектуре Hopper будут представлены чуть позже. Пока что NVIDIA поделилась некоторыми сведениями об особенностях новых чипов. Помимо прироста производительности от трёх (для FP64/FP16/TF32) до шести (FP8) раз в сравнении с A100 в Hopper появилась поддержка формата FP8 и движок Transformer Engine. Именно они важны для достижения высокой производительности, поскольку само по себе четвёртое поколение ядер Tensor Core стало втрое быстрее предыдущего (на всех форматах). 
NVIDIA H100 CNX (PCIe) TF32 останется форматом по умолчанию при работе с TensorFlow и PyTorch, но для ускорения тренировки ИИ-моделей NVIDIA предлагает использовать смешанные FP8/FP16-вычисления, с которыми Tensor-ядра справляются эффективно. Хитрость в том, что Transformer Engine на основе эвристик позволяет динамически переключаться между ними при работе, например, с каждым отдельным слоем сети, позволяя таким образом добиться повышения скорости обучения без ущерба для итогового качества модели. На больших моделях, а именно для таких H100 и создавалась, сочетание Transformer Engine с другими особенностями ускорителей (память и интерконнект) позволяет получить девятикратный прирост в скорости обучения по сравнению с A100. Но Transformer Engine может быть полезен и для инференса — готовые FP8-модели не придётся самостоятельно конвертировать в INT8, движок это сделает на лету, что позволяет повысить пропускную способность от 16 до 30 раз (в зависимости от желаемого уровня задержки). 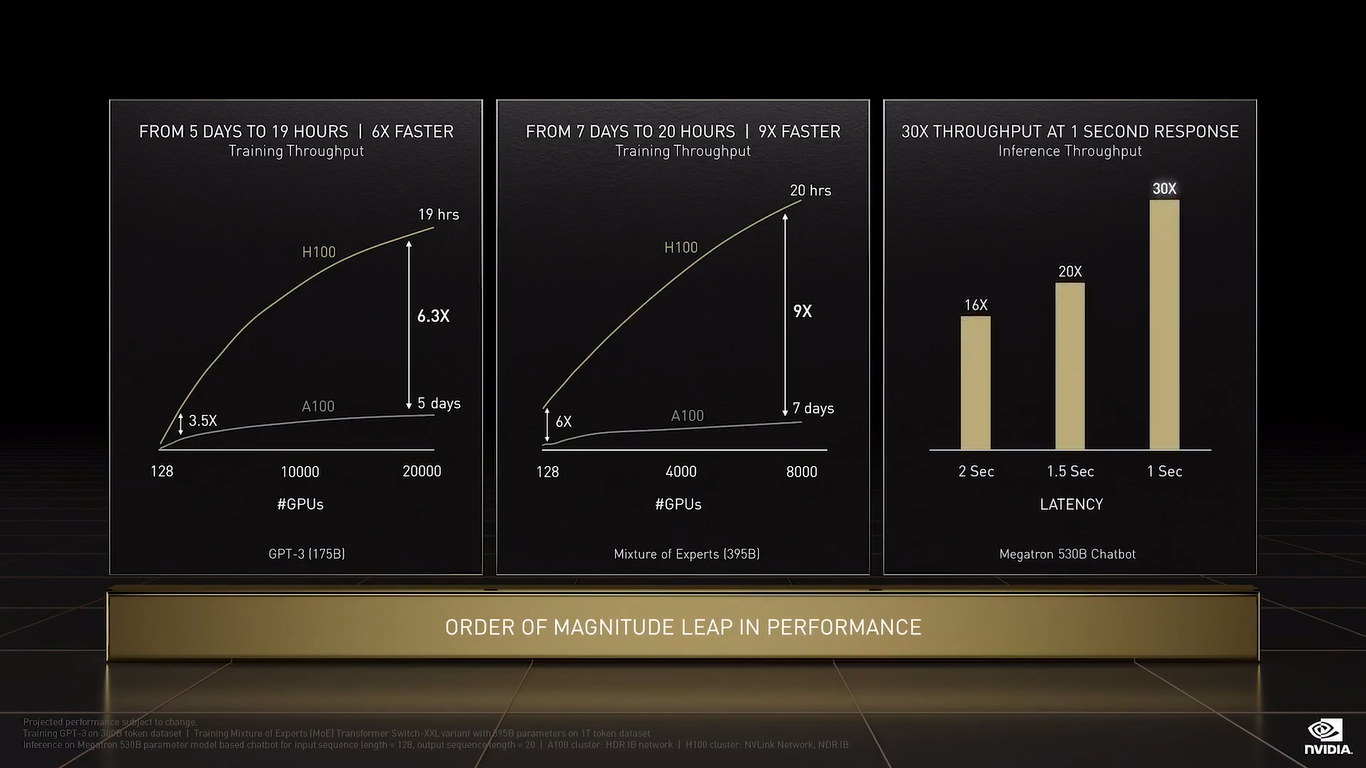 Другое любопытное нововведение — специальные DPX-инструкции для динамического программирования, которые позволят ускорить выполнение некоторых алгоритмов до 40 раз в задачах, связанных с поиском пути, геномикой, квантовыми системами и при работе с большими объёмами данных. Кроме того, H100 получили дальнейшее развитие виртуализации. В новых ускорителях всё так же поддерживается MIG на 7 инстансов, но уже второго поколения, которое привнесло больший уровень изоляции благодаря IO-виртуализации, выделенным видеоблокам и т.д.  Так что MIG становится ещё более предпочтительным вариантом для облачных развёртываний. Непосредственно к MIG примыкает и технология конфиденциальных вычислений, которая по словам компании впервые стала доступна не только на CPU. Программно-аппаратное решение позволяет создавать изолированные ВМ, к которым нет доступа у ОС, гипервизора и других ВМ. Поддерживается сквозное шифрование при передаче данных от CPU к ускорителю и обратно, а также между ускорителями.  Память внутри GPU также может быть изолирована, а сам ускоритель оснащается неким аппаратным брандмауэром, который отслеживает трафик на шинах и блокирует несанкционированный доступ даже при наличии у злоумышленника физического доступа к машине. Это опять-таки позволит без опаски использовать H100 в облаке или в рамках колокейшн-размещения для обработки чувствительных данных, в том числе для задач федеративного обучения.  NVIDIA HGX H100 Но главная инновация — это существенное развитие интерконнекта по всем фронтам. Суммарная пропускная способность внешних интерфейсов чипа H100 составляет 4,9 Тбайт/с. Да, у H100 появилась поддержка PCIe 5.0, тоже впервые в мире, как утверждает NVIDIA. Однако ускорители получили не только новую шину NVLink 4.0, которая стала в полтора раза быстрее (900 Гбайт/с), но и совершенно новый коммутатор NVSwitch, который позволяет напрямую объединить между собой до 256 ускорителей! Пропускная способность «умной» фабрики составляет до 70,4 Тбайт/с.  Сама NVIDIA предлагает как новые системы DGX H100 (8 × H100, 2 × BlueField-3, 8 × ConnectX-7), так и SuperPOD-сборку из 32-х DGX, как раз с использованием NVLink и NVSwitch. Партнёры предложат HGX-платформы на 4 или 8 ускорителей. Для дальнейшего масштабирования SuperPOD и связи с внешним миром используются 400G-коммутаторы Quantum-2 (InfiniBand NDR). Сейчас NVIDIA занимается созданием своего следующего суперкомпьютера EOS, который будет состоять из 576 DGX H100 и получит FP64-производительность на уровне 275 Пфлопс, а FP16 — 9 Эфлопс.  Компания надеется, что EOS станет самой быстрой ИИ-машиной в мире. Появится она чуть позже, как и сами ускорители, выход которых запланирован на III квартал 2022 года. NVIDIA представит сразу три версии. Две из них стандартные, в форм-факторах SXM4 (700 Вт) и PCIe-карты (350 Вт). А вот третья — это конвергентный ускоритель H100 CNX со встроенными DPU Connect-X7 класса 400G (подключение PCIe 5.0 к самому ускорителю) и интерфейсом PCIe 4.0 для хоста. Компанию ей составят 400G/800G-коммутаторы Spectrum-4.
11.03.2022 [20:59], Алексей Степин
Ростелеком и Мегафон отлучили от лондонской точки обмена интернет-трафиком LINXЛондонская точка обмена интернет-трафиком LINX (London Internet Exchange Network), объединяющая сети более 950 различных операторов, хотя и не является коммерческой компанией, тем не менее, как сообщают зарубежные источники, тоже оказалась вынуждена применить санкции — совет директоров LINX принял решение отключить две крупные телекоммуникационные компании: Мегафон (AS 1133) и Ростелеком (AS 12389). В приводимом источником письме из внутренней рассылки для клиентов LINX говорится, что решение вступило в силу сразу после принятия и что LINX продолжит проверку в отношении других российских клиентов, которые могут быть связаны с владельцами двух вышеназванных компаний. Пока неясно, как это скажется на функционировании сетей, принадлежащих Ростелеком и Мегафону, но предполагается, что эффект будет более мягким, чем отключение от магистральных сетей Cogent и Lumen. Среди других крупных российских клиентов LINX есть, к примеру, Вымпелком, МТС и ТрансТелеКом. 
Источник: Twitter/woodyatpch Публичного подтверждения LINX о принятых мерах пока получено не было. Сейчас LINX является одним из крупнейших в Европе сетевым хабом с пиковым на текущий момент трафиком 6,89 Тбит/с. Напомним, что в 2017 году LINX стала участником скандала, приняв инициативу, позволяющую руководителям организации не сообщать клиентам об установке следящего оборудования несмотря на то, что законы ряда стран компаний-участников LINX запрещают массовую слежку за пользователями всемирной сети. UPD: «Мегафон» и «Ростелеком» подтвердили отключение от LINX, но уточнили, что обмен трафиком с этой точкой и так был невелик, поэтому отключение не скажется на абонентах.
11.03.2022 [18:28], Владимир Мироненко
ENOG, евразийская группа сетевых операторов RIPE NCC, похоже, фактически расформированаЕвразийская группа сетевых операторов (ENOG), основанная RIPE NCC (некоммерческая ассоциация, выполняющая функции регионального Интернет-реестра [RIR]), оказалась фактически расформированной после того, как её руководство покинуло посты. ENOG поддерживает развитие Сети в азербайджанском, армянском, белорусском, русском, украинском и других, преимущественно постсоветских региональных сообществах. Председатель Программного комитета ENOG Артём Гавриченков в своё посте на форуме RIPE указал, что сообщество ENOG практически распалось: «Настоящим я при всем уважении прошу, чтобы Исполнительный совет RIPE официально распустил ENOG и отменил все возможные будущие встречи на неопределённый срок», — написал Гавриченков. Он отметил, что при нормальных обстоятельствах такое решение должно было быть вынесено на голосование, но в существующих условиях, когда ряд членов Программного комитета фактически не может выполнять свои функции в привычном режиме, организовывать голосование по этому поводу нельзя назвать разумным действием. После этого заявления Артём Гавриченков объявил, что покидает пост. 
Источник изображения: ENOG Алексей Семеняка, директор по внешним связям RIPE NCC выразил согласие с тем, что сообщество больше не существует и заявил об уходе с поста заместителя председателя Программного комитета ENOG. Отставки вызвали неоднозначную реакцию сообщества. Один из участников раскритиковал это решение, назвав его эскалацией и добавив, что может быть, целесообразнее было бы передать управление кому-то другому. RIPE отказалась от комментариев по этому поводу. Группа ранее отклонила просьбу украинского правительства помочь отключить Россию, что в основном получило поддержку сообщества. ENOG планировала провести следующую региональную встречу RIPE NCC в июне этого года в Москве. В ENOG входят участники из Ростелекома, Scaleway, СВК-Телеком, Яндекса, DE-CIX, Servers.com, Megalink и т. д.
11.03.2022 [14:14], Владимир Мироненко
CDN-провайдер Akamai прекращает продажи в России и Беларуси, но сохраняет присутствиеAkamai Technologies, поставщик услуг для акселерации онлайн-сервисов, а также платформ доставки контента и приложений, объявил о предпринятых в последние дни мерах для соблюдения всех применяемых санкций. В частности, компания сообщила о приостановке всех продаж в России и Беларуси, а также о прекращении работы с российскими и белорусскими клиентами с государственным участием. Кроме того, компания намерена задействовать фонд Akamai Foundation для оказания гуманитарной помощи пострадавшим. Источник изображения: Akamai Тем не менее, было объявлено об «обдуманном решении сохранить своё присутствие в Сети в России». «Это поддержит наших глобальных клиентов, в том числе многие крупнейшие мировые службы новостей, социальные сети и демократические государственные институты, поскольку они стремятся предоставлять важную и точную информацию во все уголки земного шара, в том числе гражданам России», — пояснила компания. Ранее аналогичное решение принял другой крупный CDN-провайдер — Cloudflare.
08.03.2022 [17:59], Илья Коваль
Магистральный интернет-провайдер Lumen вслед за Cogent ввёл ограничения для российских компанийПровайдер Lumen официально сообщил о том, что со вчерашнего дня прекратил продажу всех своих продуктов и услуг как российским компаниям, так и иностранным компаниям, которые планируют оказывать услуги на территории России. Похожее, но более жёсткое заявление ранее сделал другой крупный магистральный провайдер — Cogent. Также Lumen теперь отклоняет все запросы на оказание услуг от российских организаций, находящихся под санкциями. Компания уже расторгла соглашение об оказании услуг неназванному российскому финансовому учреждению и отказалась от предложения вести работу с неким другим финансовым учреждением в России. Компания отметила, что её бизнес в России и Украине не является для неё существенным, но пообещала принять меры для для защиты сотрудников, активов, заинтересованных сторон и собственной в случае потенциального критического сбоя в работе. Lumen продолжит наблюдение за собственной инфраструктурой и её поддержку, и будет и далее обеспечивать её защиту на всех уровнях. 
Источник изображения: Lumen Lumen (ранее CenturyLink) является одним из крупнейших в мире магистральных операторов, который оперирует более 800 тыс. км линий связи и обеспечивает транзит трафика и связность с глобальной Сетью для многих регионах. Как отмечает DataCenter Dynamics, в России заказчиками Lumen являют Ростелеком, ТТК, а также «большая тройка» мобильных операторов: МТС, МегаФон и VEON (бренд «Билайн»). |
|

