Лента новостей
|
04.03.2022 [20:20], Руслан Авдеев
Опубликован доклад о пожаре в ЦОД OVHcloud: деревянные потолки, отсутствие системы автоматического пожаротушения и единого «электрорубильника»Через год после пожара в дата-центре OVHcloud в Страсбурге, наконец, опубликован официальный отчёт, согласно которому сгоревший объект не соответствовал многим требованиям к безопасности подобного типа помещений. Здание дата-центра SBG2 вспыхнуло 10 марта 2021 года, но пострадал и соседний ЦОД SBG1, который было решено не восстанавливать. По данным местных экспертов, которые приводит DataCenter Dynamics со ссылкой на Le Journal Du Net (JDN), SBG2 не имел автоматической системы пожаротушения, деревянные потолки помещения способны были противостоять огню не более часа, а система вентиляции создавала условия, благодаря которым огонь распространялся гораздо быстрее, чем мог бы. Более того, пожарные встретили в горящем здании электрические дуги протяжённостью более метра, вспыхивавшие на пути в энергоотсек. 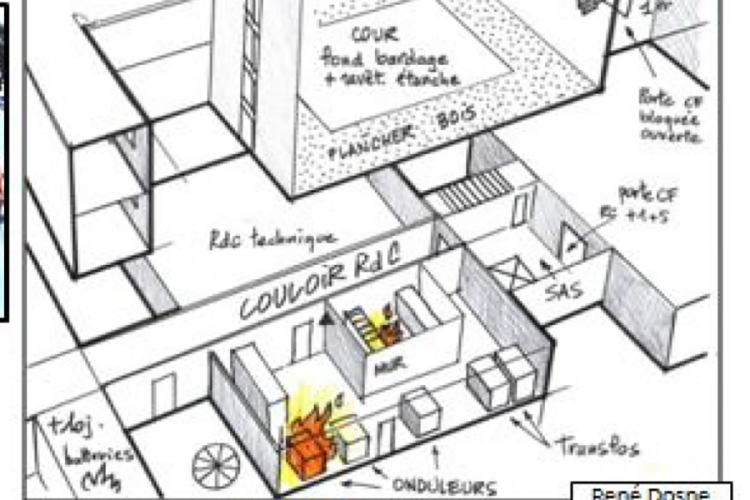
Источник изображения: Bas-Rhin Fire Service (via DataCenter Dynamics) На полное отключение электропитания ушло три часа, поскольку единой точки изоляции от энергосети у ЦОД не было. Так что некоторые клиенты всё ещё пользовались серверами после начала возгорания. После того, как огонь вырвался из энергоотсека, он стал быстро распространяться по помещениям из-за неудачной конструкции системы вентиляции, обеспечивающей приток свежего воздуха для охлаждения серверов. 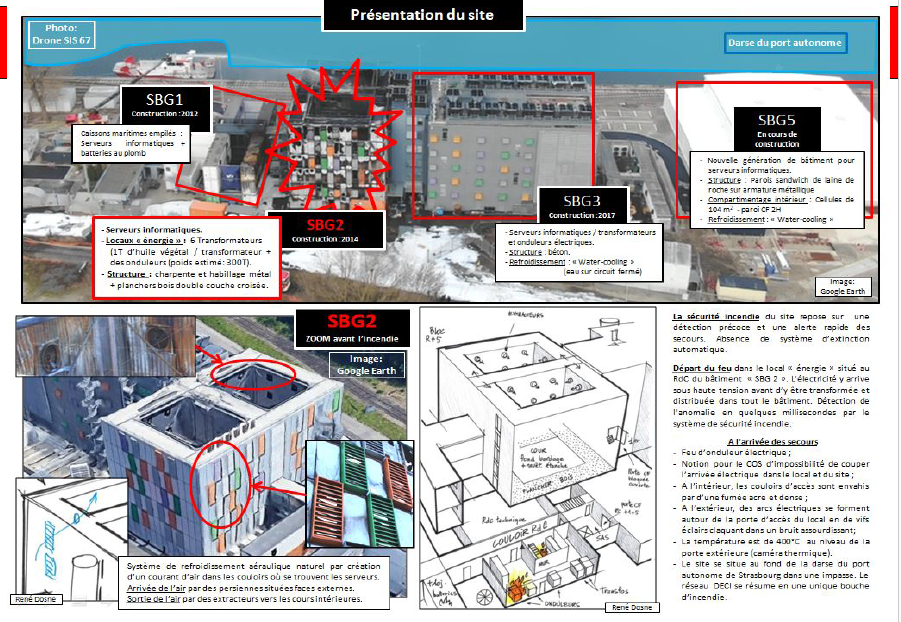
Источник изображения: Bas-Rhin Fire Service (via DataCenter Dynamics) Отчёт может повлиять на грядущие судебные разбирательства и капитализацию компании, которая недавно вышла на биржу — бывшие клиенты подали к OVHcloud коллективный иск, обвиняя её в том, что она не справилась со своими обязанностями и, кроме того, не предоставила адекватную компенсацию пострадавшим. Ранее сообщалось, что к иску присоединились 103 клиента, ещё 4 крупных игрока решили выступить в суде самостоятельно.
03.03.2022 [19:00], Алексей Степин
Intel анонсировала новую версию платформы vPro, в том числе для ChromeOSВместе с расширением двенадцатого поколения процессоров Core (Alder Lake) компания Intel представила и новую версию бизнес-платформы vPro, обеспечивающую улучшенные возможности в области удалённого управления и информационной безопасности. Сама платформа vPro насчитывает уже более 15 лет, но сегодня некогда достаточно простой набор технологий разросся до полноценного портфолио, покрывающего потребности бизнес-клиентов в любых масштабах. 
Изображения: Intel Обновлённое портфолио включает следующие разновидности Intel vPro:
 В рамках новой версии vPro, по словам Intel, представлен полный спектр систем и решений, подходящий для любой задачи любой компании любого размера. Помимо всех тех особенностей, что предлагает архитектура Alder Lake (два вида ядер, DDR5 и т.д.), платформа vPro также включает ряд других программных и аппаратных компонентов:
 На момент анонса партнёрами Intel представлено более 150 различных дизайнов вычислительных платформ, во всех форм-факторах. Все они должны быть доступны уже в этом году. Не забыта и сфера IoT, где процессоры Intel двенадцатого поколения в сочетании с vPro обеспечат высокую производительность и удобство удалённого управления. Новинки этого типа отлично впишутся в современную розничную торговлю, образование медицину, производственные и банковские процессы, экосистемы «умных городов» и т.д.  С точки зрения Cisco, одного из крупнейших производителей сетевого оборудования, в новой платформе очень важна поддержка Wi-Fi 6E, не просто обеспечивающая настоящий «гигабит по воздуху», но и позволяющая без проблем подключать больше беспроводных устройств к точкам доступа, большую надёжность, и предсказуемость поведения Wi-Fi в сценариях класса mission critical. Компания считает очень удачным сочетание систем Intel с поддержкой Wi-Fi 6E c новыми точками доступа Cisco Catalyst и Meraki.
27.02.2022 [01:01], Владимир Мироненко
Облако ждёт: к 2030 году Fujitsu откажется от мейнфреймов и UNIX-системFujitsu подтвердила, что выпуску её мейнфреймов и серверных систем c Unix подходит конец. Согласно новым планам компании, она прекратит производство и продажу мейнфреймов к 2030 году, а выпуск серверных систем UNIX — к концу 2029 года. Сопровождение обоих продуктов продлится в течение ещё пяти лет и закончится в 2035 году и в 2034 году соответственно. Как надеется компания, к тому времени пользователи подобных систем окончательно перейдут в облако. 
Источник изображений: Fujitsu Тем не менее, Fujitsu по-прежнему планирует выпустить в 2024 году новую модель в серии мейнфреймов GS21. Также планируется обновление семейства UNIX-серверов Fujitsu SPARC M12 в конце этого года и в 2026 году. Впрочем, это пока предварительные планы. Компания уже составила график перехода с мейнфреймов и UNIX-серверов в облако в рамках нового бизнес-бренда Fujitsu Uvance. Теперь у пользователей мейнфреймов Fujitsu есть чётко обозначенный срок, к которому они должны перенести свои приложения на другую платформу или воспользоваться возможностью создать их с нуля в рамках более современной инфраструктуры.  Сомнительной альтернативой может быть уход на платформу IBM z. Филип Доусон (Philip Dawson), вице-президент Gartner Research сообщил The Register, что отказ от UNIX пройдёт менее болезненно, так как рабочие нагрузки могут быть относительно легко перенесены на Linux: «По сути, Linux заменил UNIX. Но такой замены нет для мейнфреймов. Когда аппаратное обеспечение исчезнет, что вы будете делать с приложениями?». Фактически Fujitsu в наследство достались две разные серии мейнфреймов от Amdahl Corporation (GS21) и Siemens (BS2000), если не считать старые решения ICL.
24.02.2022 [22:53], Владимир Мироненко
Инфраструктурное подразделение Lenovo впервые получило квартальную прибыльLenovo сообщила итоги III квартала 2021/2022 года, закончившегося 31 декабря. Компания завершила квартал с рекордной выручкой в размере $20,1 млрд, увеличив прибыль по сравнению с аналогичным периодом предыдущего финансового года на 62 % до рекордных $640 млн. Следует отметить, что серверное подразделение впервые принесло компании прибыль за квартал. Lenovo объяснила выход подразделения на прибыльность позитивной реакцией покупателей на продукты, ориентированные на новых облачных игроков. 
Источник изображения: Lenovo Долгое время приобретённый ею в 2014 году бизнес IBM по выпуску x86-серверов был убыточен. Пытаясь исправить положение, компания провела реорганизацию, в результате которой было создано специальное подразделение по выпуску продуктов для ЦОД, но это не помогло. Поэтому в феврале 2021 года Lenovo провела ещё одну реорганизацию, передав производство продукции для ЦОД в группу инфраструктурных решений Infrastructure Solutions Group (ISG). В итоге в отчётном квартале эта группа получила выручку в размере $1,93 млрд, превысившую прошлогодний результат на 19 %, и заработала $16,9 млн прибыли. 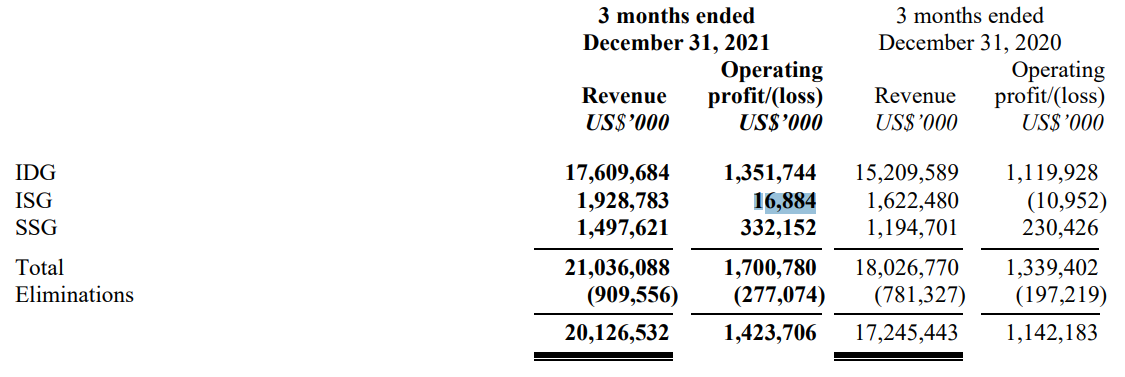 Кроме того, выросли продажи серверов, ПО и услуг для организаций всех размеров. По словам компании, у ISG хорошие перспективы, так как из-за дефицита полупроводников накопились заказы, которые ожидают выполнения. Но даже с выходом на прибыльность ISG остается второстепенным игроком на рынке продуктов для ЦОД. Например, выручка инфраструктурного подразделения Dell в 2021 финансовом году составила $32,5 млрд, а выручка HPE от продаж оборудования для ЦОД превысила $23 млрд.
24.02.2022 [19:00], Алексей Степин
Intel анонсировала процессоры Xeon D-1700 и D-2700: Ice Lake-SP + 100GbEКонцепция периферийных вычислений сравнительно молода и до недавнего времени зачастую её реализации были вынуждены обходиться стандартными процессорами, разработанными для применения в серверах, или даже в обычных ПК и ноутбуках. Intel, достаточно давно имеющая в своём арсенале серию процессоров Xeon D, обновила модельный ряд этих CPU, которые теперь специально предназначены для использования на периферии. 
Изображения: Intel Анонс выглядит очень своевременно, поскольку по оценкам Intel, к 2025 году более 50% всех данных будет обрабатываться вне традиционных ЦОД. Новые серии процессоров Xeon D-1700 и D-2700 обладают рядом свойств, востребованных именно на периферии — особенно на периферии нового поколения. 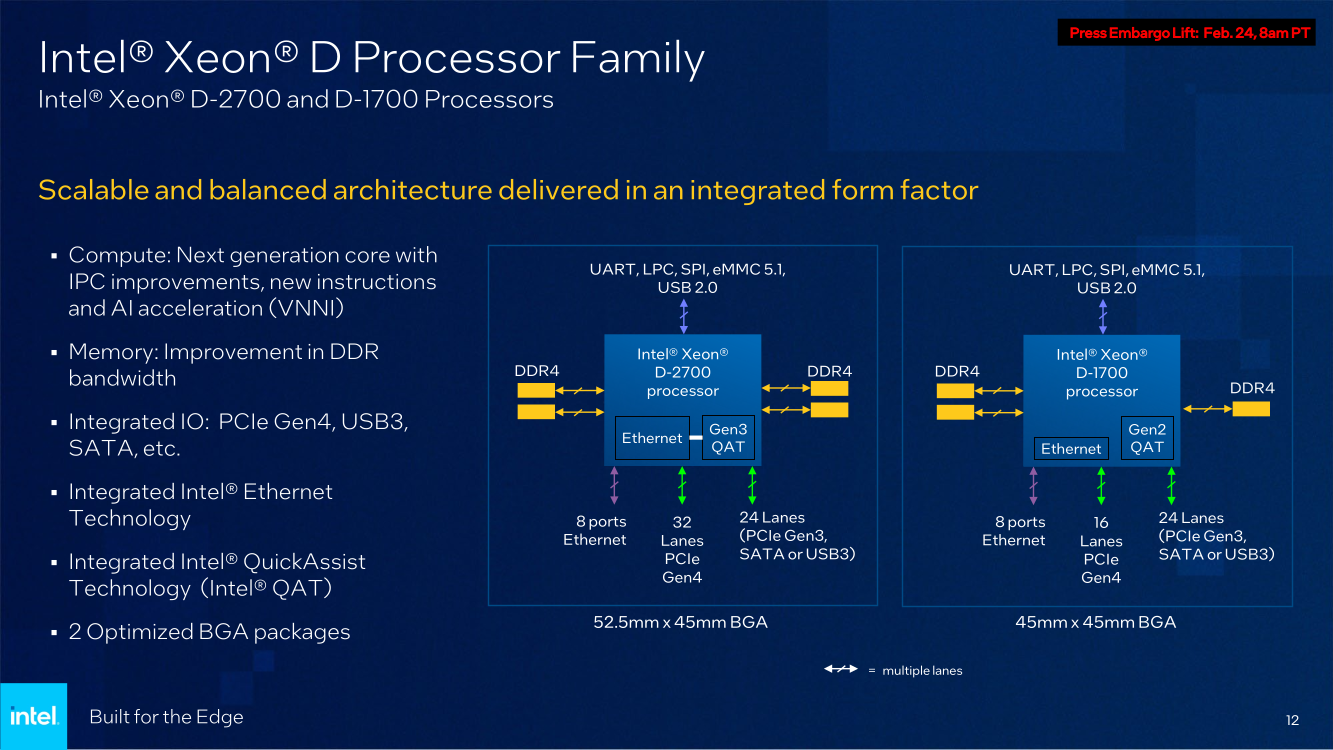 Новинки имеют следующие особенности:
Последний пункт ранее был реализован в процессорах серий Atom x6000E, Xeon W-1100E и некоторых процессорах Core 11-го поколения. Вкратце это технология, позволяющая координировать вычисления с точностью менее 200 мкс в режиме TCC за счёт точной синхронизации таймингов внутри платформы. И здесь у Xeon D, как у высокоинтегрированной SoC, есть преимущество в реализации подобного класса точности. Помогает этому и наличие специального планировщика для общего кеша L3, позволяющего добиться более консистентного доступа к кешу и памяти. 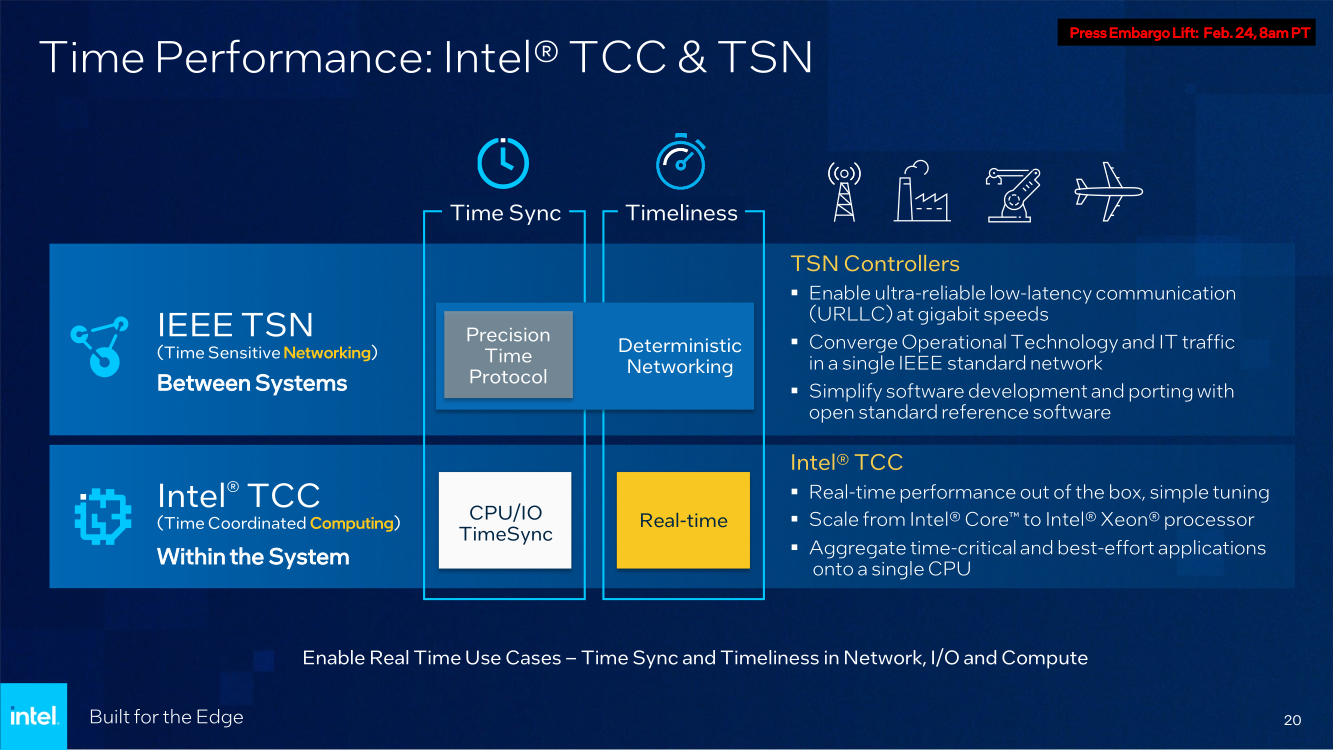 Это незаменимая возможность для систем, обслуживающих сверхточные промышленные процессы, тем более что Intel предлагает хорошо документированный набор API и средств разработки для извлечения из режима TCC всех возможностей. Важной также выглядит наличие поддержки пакета технологий Intel QuickAssist (QAT) для ускорения задач (де-)шифрования и (де-)компрессии. 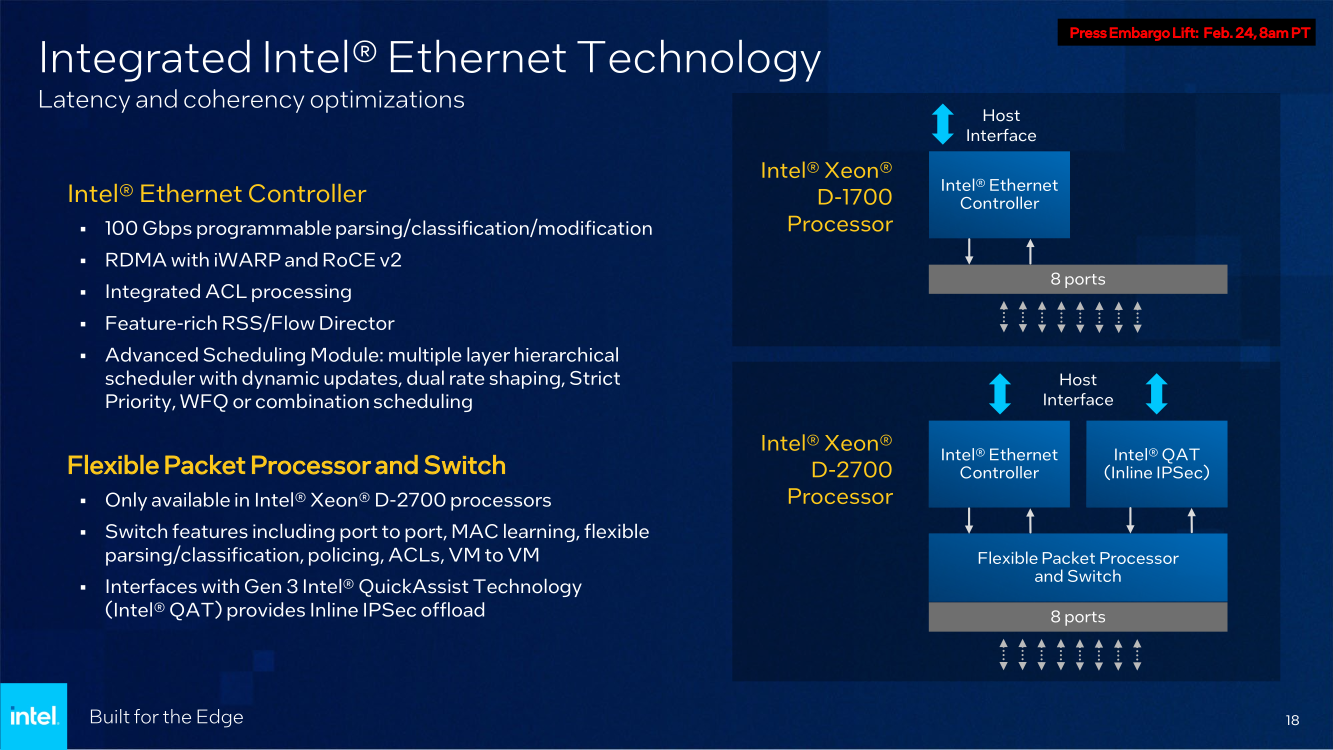 Третье поколение QAT, доступное, правда, только в Xeon D-2700, в отличие от второго (и это случай D-1700), связано в новых SoC непосредственно с контроллером Ethernet и встроенным программируемым коммутатором. В частности, поддерживается, и IPSec-шифрование на лету (inline) на полной скорости, и классификация (QoS) трафика. Также реализована поддержка новых алгоритмов, таких, как Chacha20-Poly1305 и SM3/4, имеется собственный движок для публичных ключей, улучшены алгоритмы компрессии. 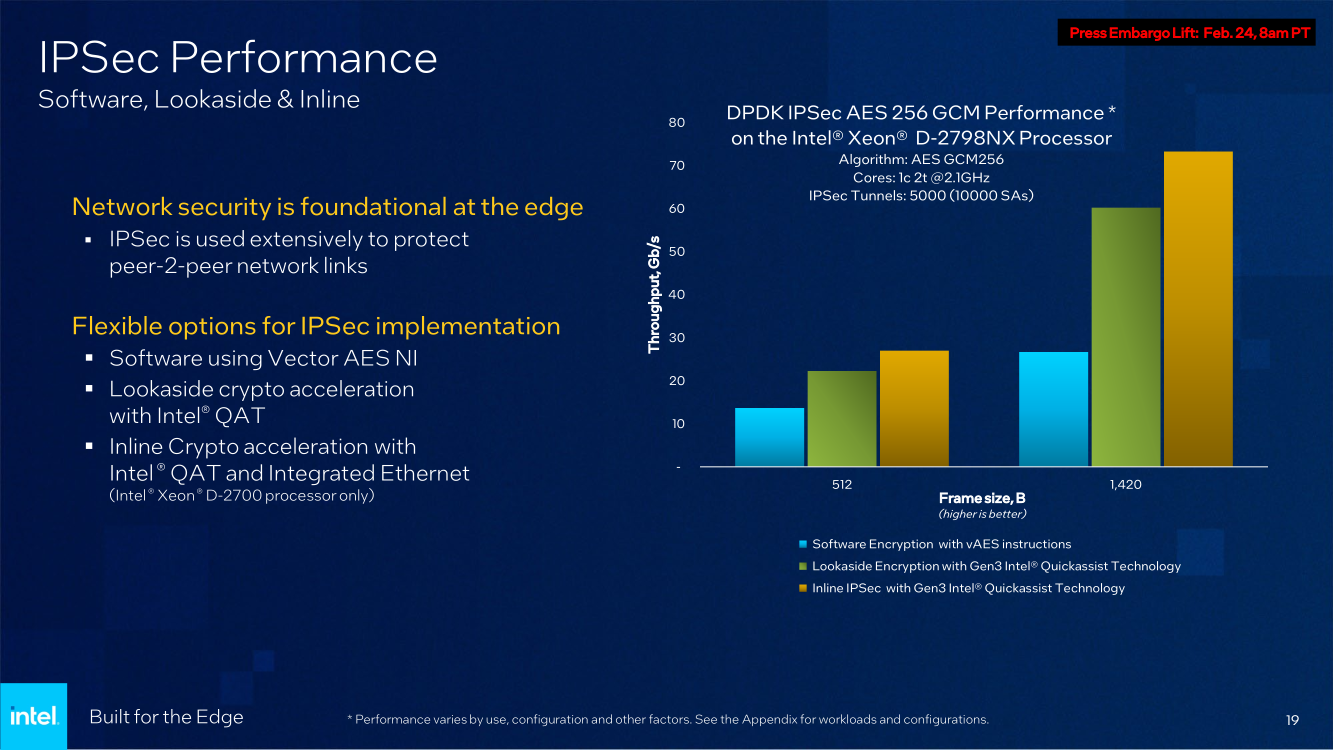 Но QAT может работать и совместно с CPU (lookaside-разгрузка), а можно и вовсе обойтись без него, воспользовавшись AES-NI. Поддержке безопасности помогает и полноценная поддержка защищённых вычислительных анклавов SGX, существенно ограничивающая векторы атак как со стороны ОС и программного обеспечения, так и со стороны гипервизора виртуальных машин. Это важно, поскольку на периферии уровень угрозы обычно выше, чем в контролируемом окружении в ЦОД, но для использования SGX требуется модификация ПО.  В целом, «ядерная» часть новых Xeon-D — это всё та же архитектура Ice Lake-SP. Так что Intel в очередной раз напомнила про поддержку DL Boost/VNNI для работы с форматами пониженной точности и возможности эффективного выполнения инференс-нагрузок — новинки почти в 2,5 раза превосходят Xeon D-1600. Есть и прочие стандартные для платформы функции вроде PFR или SST. Из важных дополнений можно отметить поддержку Intel Slim BootLoader. 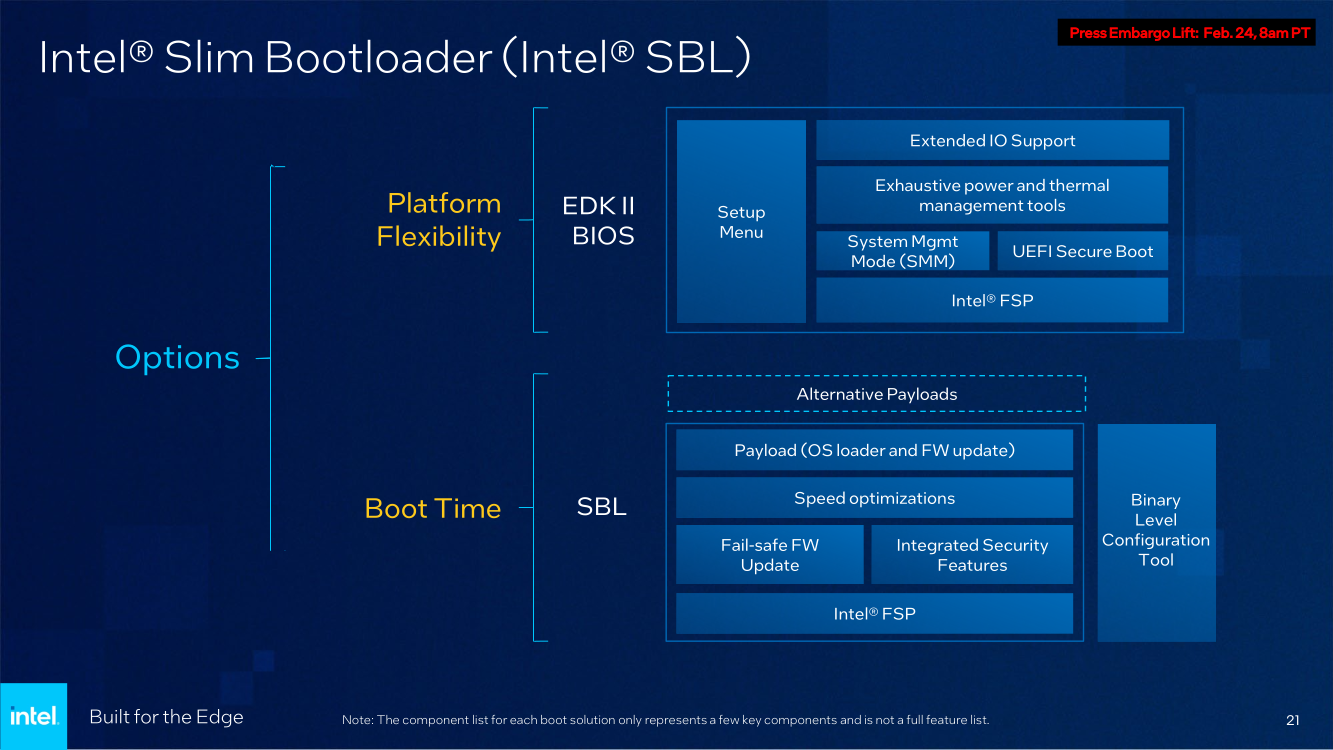 Масштабируемость у новой платформы простирается от 2 до 10 (D-1700) или 20 (D-2700) ядер, а TDP составляет 25–90 и 65–129 Вт соответственно. В зависимости от модели поддерживается работа в расширенном диапазоне температур (до -40 °C). У обоих вариантов упаковка BGA, но с чуть отличными размерами — 45 × 45 мм против 45 × 52,5 мм. На этом различия не заканчиваются. У младших Xeon D-1700 поддержка памяти ограничена тремя каналами DDR4-2933, а вот у D-2700 четыре полноценных канала DDR4-3200. 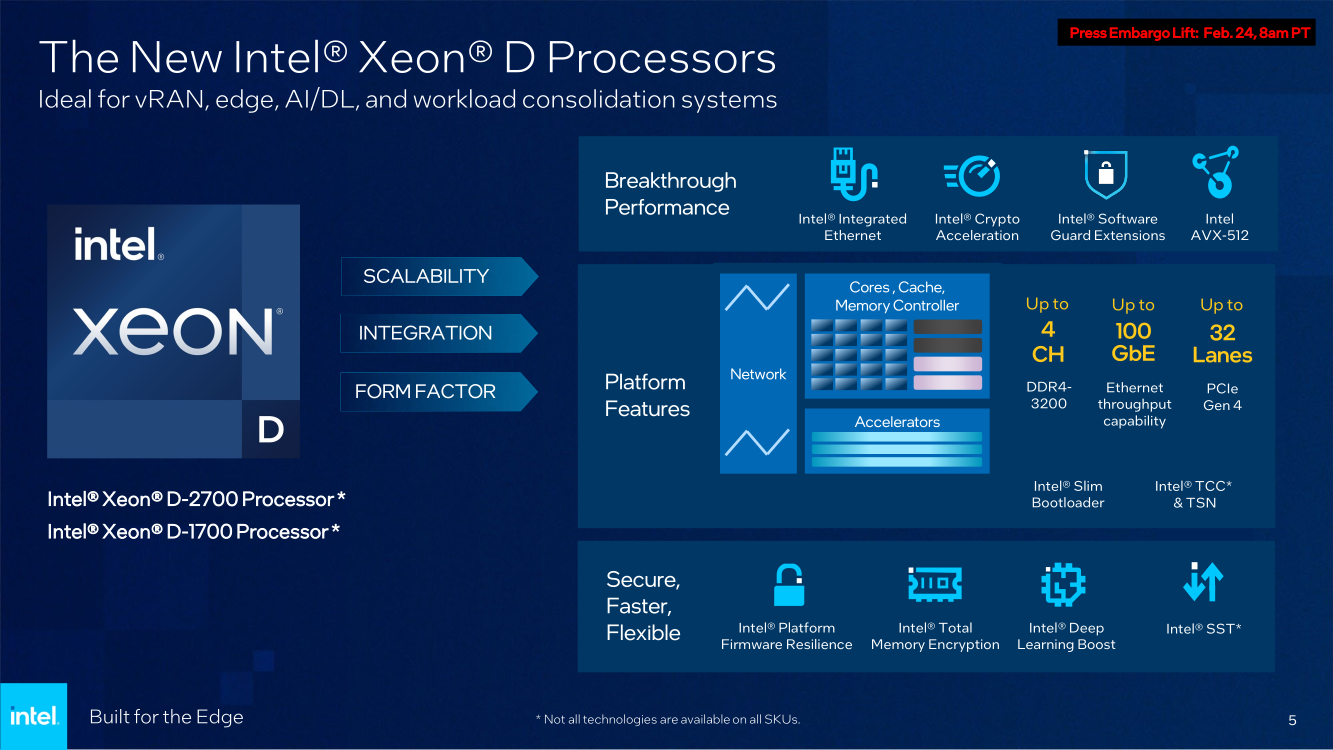 Однако возможности работы с Optane PMem обе модели лишены, несмотря на то, что контроллер памяти их поддерживать должен. Представитель Intel отметил, что если будет спрос со стороны заказчиков, то возможен выпуск вариантов CPU с поддержкой PMem. Дело в том, что прошлые поколения Xeon-D использовались и для создания СХД, а наличие 100GbE-контроллера с RDMA делает новинки не менее интересными для этого сегмента. 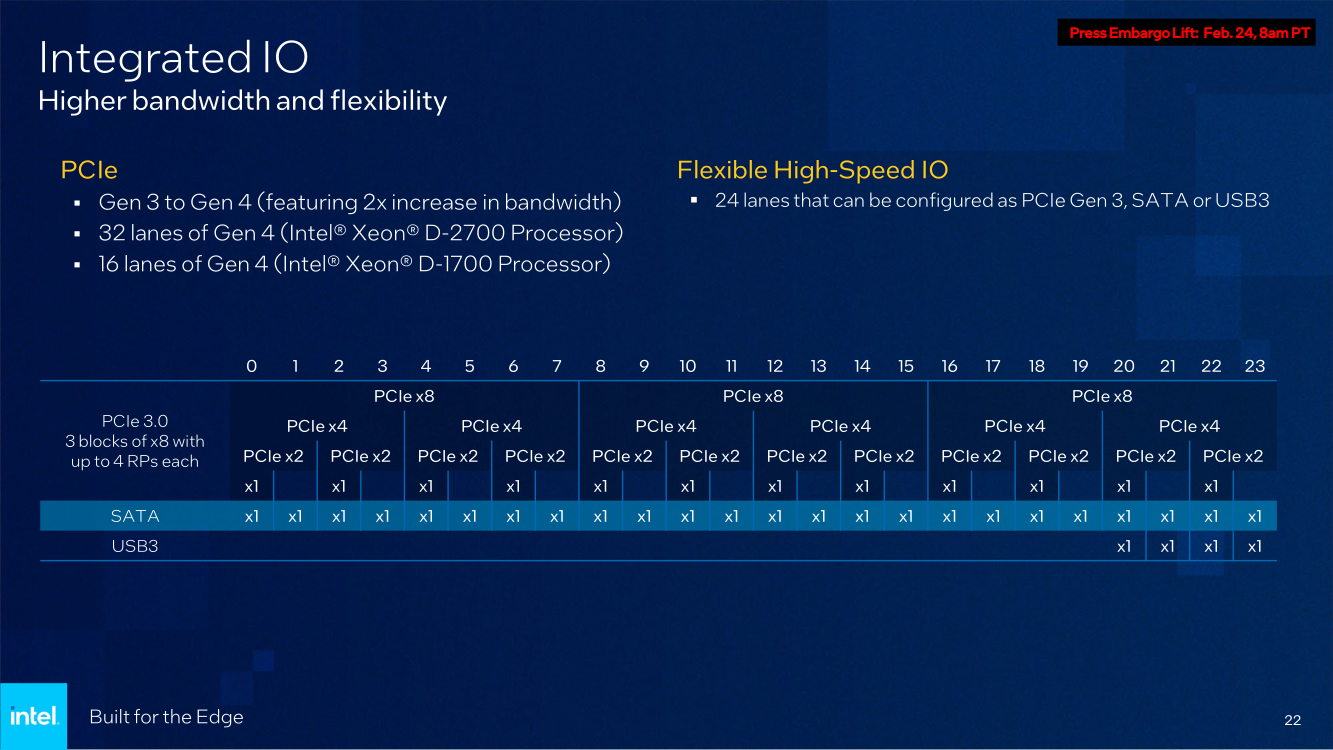 Кроме того, есть и поддержка NTB, да и VROC с VMD вряд ли исчезли. Для подключения периферии у D-2700 доступно 32 линии PCIe 4.0, а у D-1700 — 16. У обоих серий CPU также есть 24 линии HSIO, которые на усмотрение производителя можно использовать для PCIe 3.0, SATA или USB 3.0. Впрочем, пока Intel предлагает использовать всё это разнообразие интерфейсов для подключения ускорителей и различных адаптеров.  Поскольку в качестве одной из основных задач для новых процессоров компания видит их работу в качестве контроллеров программно-определяемых сетей, включая 5G, она разработала для этой цели референсную платформу. В ней предусматривается отдельный модуль COM-HPC с процессором и DIMM-модулями, что позволяет легко модернизировать систему. А базовая плата предусматривает наличие радиотрансиверов, что актуально для сценария vRAN.  Поскольку речь идёт не столько о процессорах, сколько о полноценной платформе, Intel серьезное внимание уделила программной поддержке, причём, в основе лежат решения с открытым программным кодом. Это позволит заказчикам систем на базе новых Xeon D разворачивать новые точки и комплексы периферийных вычислений быстрее и проще. Многие производители серверного аппаратного обеспечения уже готовы представить свои решения на базе Xeon D-1700 и 2700.
23.02.2022 [16:35], Руслан Авдеев
«Сингулярность» планетарного масштаба: ИИ-инфраструктура Microsoft включает более 100 тыс. GPU, FPGA и ASICMicrosoft неожиданно раскрыла подробности использования своей распределённой службы планирования «планетарного масштаба» Singularity, предназначенной для управления ИИ-нагрузками. В докладе компании целью Singularity названа помощь софтверному гиганту в контроле затрат путём обеспечения высокого коэффициента использования оборудования при выполнении задач, связанных с глубоким обучением. Singularity удаётся добиться этого с помощью нового планировщика, способного обеспечить высокую загрузку ускорителей (в том числе FPGA и ASIC) без роста числа ошибок или снижения производительности. Singularity предлагает прозрачное выделение и эластичное масштабирование выделяемых каждой задаче вычислительных ресурсов. Фактически она играет роль своего рода «умной» прослойки между собственно аппаратным обеспечением и программной платформой для ИИ-нагрузок. 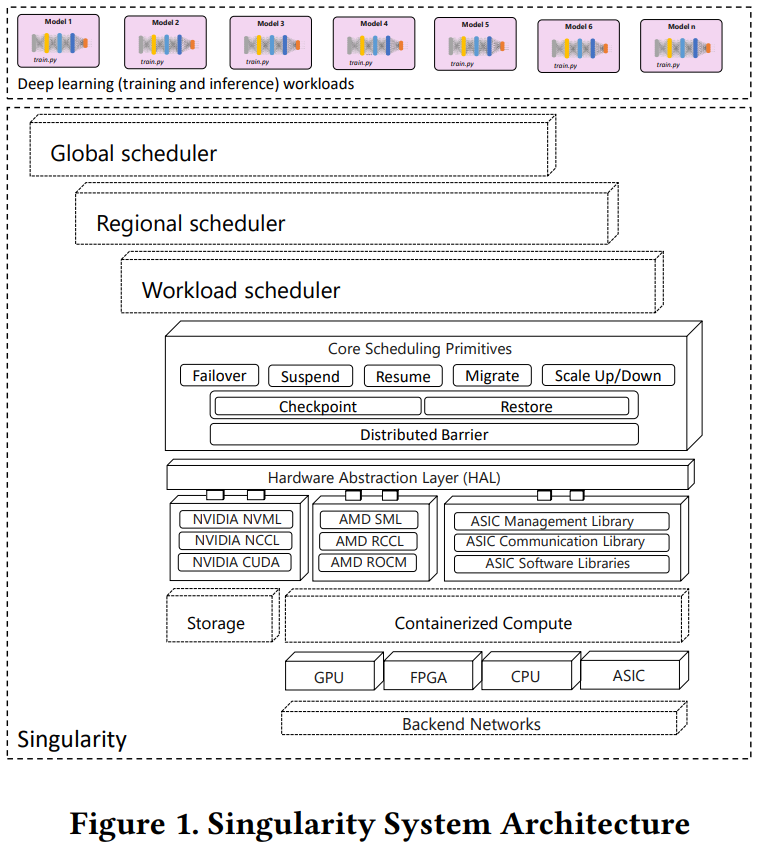
Изображение: Microsoft Singularity позволяет разделять задачи, поручаемые ресурсам ускорителей. Если необходимо масштабирование, система не просто меняет число задействованных устройств, но и управляет распределением и выделением памяти, что крайне важно для ИИ-нагрузок. Правильное планирование позволяет не простаивать без нужды весьма дорогому «железу», благодаря чему и достигается положительный экономический эффект. 
NVIDIA DGX-2 В докладе также прямо говорится, что у Microsoft есть сотни тысяч GPU и других ИИ-ускорителей. В частности, упоминается, что Singularity используется на платформах NVIDIA DGX-2: два Xeon Platinum 8168 (по 20 ядер каждый), восемь ускорителей V100 с NVSwitch, 692 Гбайт RAM и интерконнект InfiniBand. Таким образом, ИИ-парк компании должен включать десятки тысяч узлов, поэтому эффективное управление им очень важно.
16.02.2022 [21:17], Алексей Степин
Atos анонсировала экзафлопсные суперкомпьютеры BullSequana XH3000 — гибридные и «зелёные»Atos представила суперкомпьютерную платформу BullSequana XH3000, которая придёт на смену XH2000 и станет основой для машин экзафлопсного класса, ориентированных на такие требовательные к вычислениям области науки как климатология, фармакология и генетика. Суперкомпьютер имеет гибридную архитектуру и на данный момент является самым мощным и энергоэффективным решением в арсенале Atos. Что немаловажно, новая система разработана в Европе и будет производиться на заводе Atos в городе Анже ( Франция). Начало коммерческих поставок запланировано на IV квартал 2022 года.  Наиболее интересной особенностью BullSequana XH3000, пожалуй, можно назвать действительно беспрецедентный уровень гибридизации архитектур «под одной крышей». В рамках одного кластера могут быть задействованы вычислительные архитектуры AMD, Intel, NVIDIA и даже чипы, разрабатываемые консорциумом EPI, в том числе SiPearl. А в будущем возможна интеграция квантовых систем. Такая гибкость позволяет компании-разработчику говорить о шестикратном превосходстве новинки над решениями предыдущего поколения.  Кроме того, Atos весьма серьёзное внимание уделяет проблеме энергоэффективности и экологичности. В BullSequana XH3000 используется последнее, четвёртое поколение систем жидкостного охлаждения с «прямым контактом», которое минимум на 50% эффективнее предыдущего поколения. К тому же, вся платформа спроектирована таким образом, чтобы весь её жизненный цикл, от добычи материалов и производства до демонтажа и утилизации, был как можно более «зелёным». Новый суперкомпьютер изначально спроектирован как масштабируемое решение — будут доступны конфигурации производительностью от 1 Пфлопс до 1 Эфлопс, а к моменту появления ускорителей следующего поколения появятся и варианты с производительностью 10 Экзафлопс. Также разработчики обращают внимание на крайнюю гибкость BullSequana XH3000 по части интерконнекта — она будет совместима с фирменной фабрикой BXI, Ethernet, а также InfiniBand HDR/NDR.
16.02.2022 [13:04], Сергей Карасёв
Akamai купила облачного провайдера LinodeКомпания Akamai Technologies, крупный провайдер платформ доставки контента и приложений, сообщила о заключении соглашения о покупке фирмы Linode. Предполагается, что данное приобретение позволит Akamai превратиться в наиболее распределённую вычислительную платформу в мире. Завершить поглощение планируется в текущем квартале после получения необходимых разрешений со стороны регулирующих органов. Частная американская компания Linode была основана ещё в 2003 году. Она специализируется на предоставлении облачных услуг по модели IaaS (инфраструктура как сервис). Штаб-квартира Linode находится в Филадельфии (штат Пенсильвания). Облачные дата-центры компании расположены во многих странах — в США, Канаде, Великобритании, Германии, Японии, Австралии, Сингапуре и Индии. 
Источник изображения: Akamai После покупки Linode компания Akamai намерена развернуть уникальную инфраструктуру для создания, запуска и обеспечения безопасности приложения на всех уровнях — от edge-решений до облачных систем. Сумма сделки оценивается приблизительно в $900 млн. Ожидается, что слияние позволит Akamai увеличить выручку по итогам 2022 финансового года примерно на $100 млн.
15.02.2022 [17:16], Владимир Мироненко
IBM опровергла сообщения о дискриминации сотрудников по возрасту и неправомерном увольнении тысяч человекДиректор по работе с персоналом IBM Никль Ламоро (Nickle LaMoreaux) выступила с опровержением «ложных утверждений о возрастной дискриминации в компании». Это заявление поступило после обнародования в СМИ документов судебного процесса против IBM по иску от супруги бывшего сотрудника IBM Йоргена Лонна, который покончил с собой после увольнения из компании. В иске, поданном в июле прошлого года, сообщается, что Йорген Лонн проработал в IBM около 15 лет, пока его не уволили в 2016 году в возрасте 57 лет. Он занимал в компании пост менеджера по продажам и дистрибуции. Истцом теперь выступает его жена, Дениз Лонн (Denise Lohnn), которая утверждает, что Лонн стал жертвой многолетней дискриминационной схемы в масштабах всей компании, реализуемой высшим руководством IBM для омоложения персонала путём сокращения работников в возрасте и замещения их более молодыми специалистами. В иске цитируется письмо Комиссии по равным возможностям при трудоустройстве (EEOC) от 31 августа 2020 года, в котором отмечается, что в результате многолетнего расследования EEOC обнаружила «спускаемые сверху, от высших чинов IBM, предписания менеджерам применять агрессивный подход с целью значительного сокращения численности пожилых работников, чтобы освободить место для молодых специалистов». Также сообщается, что топ-менеджеры во внутренней переписке называли сотрудников старше 40 лет динозаврами. Ранее сообщалось, что кампания началась ещё в 2014 году, а всего было уволено от 50 до 100 тыс. человек. 
Источник изображения: IBM «Любая дискриминация полностью противоречит нашей культуре и тому, кем мы являемся в IBM, и в нашей компании не было (и нет) систематической возрастной дискриминации», — подчеркнула Ламоро в публичном заявлении, размещённом на веб-сайте компании. Заявление Ламоро подверглось критике со стороны участников Fishbowl, дискуссионного форума сотрудников компании, а также тех, кто участвует в судебном процессе против IBM. «Я не понимаю, как директор по персоналу IBM может делать такие заявления, — сообщил The Register Стивен Кан (Steven Cah) из юридической фирмы Cahn&Parra (Нью-Джерси). — Я сомневаюсь, что она видела гору улик, которые собрали юристы по всей стране». Кан представляет интересы истца Ойгена Шенфельда (Eugen Schenfeld) в деле против IBM о дискриминации по возрасту. Сотни бывших сотрудников IBM в настоящее время судятся с IBM на основании заявлений о дискриминации по возрасту, а пул потенциальных истцов, как сообщается, составляет около 13 000 человек. На вопрос, как IBM описывает урегулированные дела, учитывая заявление Ламоро о том, что компания не допускала дискриминации, представитель IBM ответил: «IBM никогда не признавала ответственности ни в одном из предыдущих расчётов по возрасту». Также отмечено, что медианный возраст сотрудников корпорации в 2020 году составлял 48 лет, как и в 2010 году. Чтобы изменить ход дела в пользу работников, адвокат Лонна обратился к судье с просьбой аннулировать положение арбитражного соглашения IBM, которое предотвращает совмещение существующего группового иска против IBM по возрастной дискриминации и положения о конфиденциальности. Последнее используется IBM для предотвращения обмена доказательствами между разными производствами и позволяет блокировать использование важных и разоблачающих улик в других судебных делах.
15.02.2022 [01:33], Владимир Мироненко
Из-за неисправной IT-системы Horizon были неправомерно осуждены более 700 человек, а некоторые даже получили тюремные срокиВ понедельник, 14 февраля в Лондоне началось публичное расследование по поводу неправомерных приговоров сотням британских почтовых служащих, которые были несправедливо осуждены за кражу, мошенничество или искажение отчётности, хотя истинной причиной оказалась ошибка в IT-системе Horizon, построенной Fujitsu. В период с 2000 по 2014 год пострадало более 700 сотрудников, причём некоторые даже получили тюремные сроки. Система Horizon разворачивалась в местных отделениях почты с 1999 года. Почтовая служба Великобритании в течение многих лет утверждала, что данные Horizon были надёжными, обвиняя менеджеров филиалов в нечестности, когда система ошибочно отражала недостачу. В апреле прошлого года Апелляционный суд отменил неправомерные приговоры 39 сотрудникам. Однако, как оказалось, это лишь верхушка айсберга. Пострадавших из-за неисправности компьютерной системы гораздо больше. 
Изображение: www.royalmail.com Более того, в ходе расследования выяснилось, что государственная почтовая служба знала о ненадёжности Horizon, однако данные из системы всё равно использовались для обвинения почтмейстеров в составлении ложных отчётов и краже денежных средств. По предварительным оценкам, 706 судебных преследований могли быть основаны на данных неисправной компьютерной системы. К настоящему времени приговоры по уголовным делам 72 почтмейстеров были отменены, а другие апелляции находятся на рассмотрении суда. В декабре Министерство по делам бизнеса, энергетики и промышленной стратегии Великобритании выделило почтовой службе £1,013 млрд на покрытие расходов, связанных со скандалом. Министерство выплатит компенсацию тем, чьи уголовные судимости были отменены, а также 2500 почтмейстерам, которые не были привлечены к уголовной ответственности, но которых обязали вернуть деньги почтовой службе в связи с тем, что на счетах возглавляемых ими отделений была выявлена недостача. |
|

