Материалы по тегу: ии
|
29.06.2024 [12:52], Сергей Карасёв
ИИ-ускоритель InspireSemi Thunderbird объединяет 6144 ядра RISC-V на карте PCIeКомпания InspireSemi объявила о разработке чипа Thunderbird на открытой архитектуре RISC-V для ИИ-нагрузок. Это изделие легло в основу специализированной карты расширения с интерфейсом PCIe, которая, как утверждается, подходит для решения широкого спектра задач. Чип Thunderbird содержит 1536 кастомизированных 64-битных суперскалярных ядер RISC-V, а также высокопроизводительную память SRAM. Говорится о наличии ячеистой сети с малой задержкой для меж- и внутричиповых соединений. Кроме того, предусмотрены блоки ускорения определённых алгоритмов шифрования. 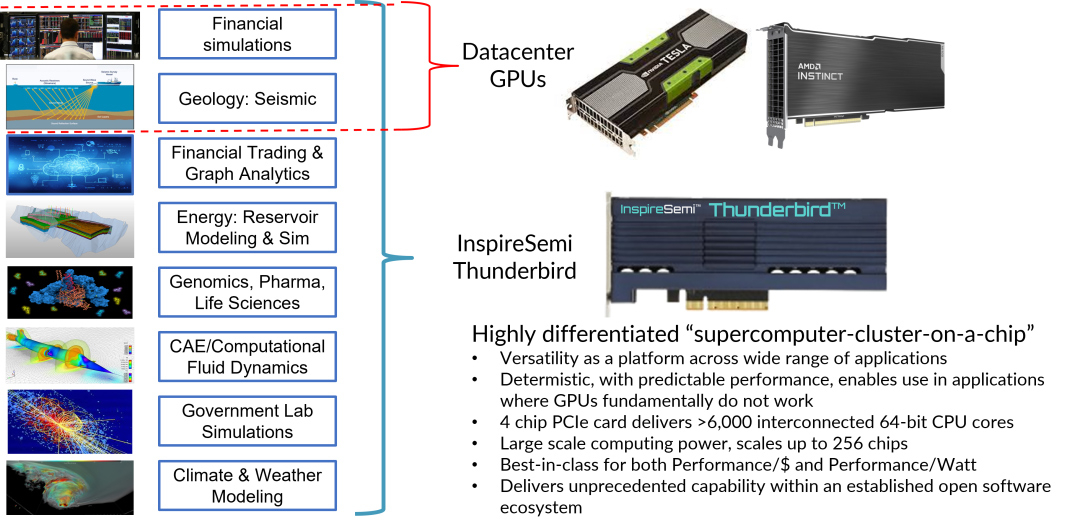
Источник изображения: InspireSemi Идея заключается в том, чтобы объединить универсальность и возможности программирования традиционных CPU с высокой степенью параллелизма GPU. Изделие ориентировано на НРС-приложения, но при этом поддерживает исполнение программ общего назначения. InspireSemi называет новинку «суперкомпьютерным кластером на кристалле». Точно так же назвала свои ИИ-ускорители Esperanto Technologies. Именно её чипы ET-SoC-1, по-видимому, впервые объединили более 1 тыс. ядер RISC-V. Впрочем, сама Esperanto позиционировала их как гибкие и энергоэффективные решения для инференса. В случае Thunderbird четыре могут быть объединены на одной карте PCIe, что в сумме даёт 6144 ядра RISC-V. Более того, заявлена возможность масштабирования до 256 чипов, связанных с помощью высокоскоростных трансиверов. Таким образом, количество ядер может быть доведено до 393 216. Чип обеспечивает производительность до 24 Тфлопс (FP64) при энергетической эффективность 50 Гфлопс/Вт. Для сравнения: NVIDIA A100 обладает быстродействием 19,5 Тфлопс (FP64), а NVIDIA H100 — 67 Тфлопс (FP64). Суперскалярные ядра поддерживают векторные и тензорные операции и форматы данных с плавающей запятой смешанной точности. Однако о совместимости с Linux ничего не говорится. Среди возможных областей применения названы ИИ, НРС, графовый анализ, блокчейн, вычислительная гидродинамика, сложное моделирование в области энергетики, изменений климата и пр.
30.05.2024 [23:56], Игорь Осколков
NVLink для экономных — AMD, Intel и другие IT-гиганты объединились для создания UALink и противостояния NVIDIAЛетом прошлого года AMD, Arista, Broadcom, Cisco, Eviden/Atos, HPE, Intel, Meta✴ и Microsoft сформировали консорциум Ultra Ethernet (UEC), призванный составить конкуренцию технологии InfiniBand, которая фактически единолично контролируется NVIDIA после покупки Mellanox, и стандартизировать Ethernet-решения для современных ИИ- и HPC-платформ. А теперь AMD, Broadcom, Cisco, Google, HPE, Intel, Meta✴ и Microsoft сформировали альянс Ultra Accelerator Link (UALink), который должен составить конкуренцию NVLink. К UEC за год присоединились ещё полсотни компаний, кроме, конечно, NVIDIA, которая, впрочем, про Ethernet тоже не забывает, хотя периодически получает критику со стороны Broadcom. Единственной альтернативой в деле построения фабрик для более-менее крупных кластеров остаётся Omni-Path Express, развиваемый Cornelis Networks, которая тоже присоединилась к UEC, но доля этой технологии на фоне Ethernet и InfiniBand мизерная. Кроме того, ни одна из этих технологий не может предложить то, что может NVIDIA NVLink — возможность напрямую объединить сотни ускорителей (точнее, их память) сверхбыстрым соединением с низким уровнем задержки. 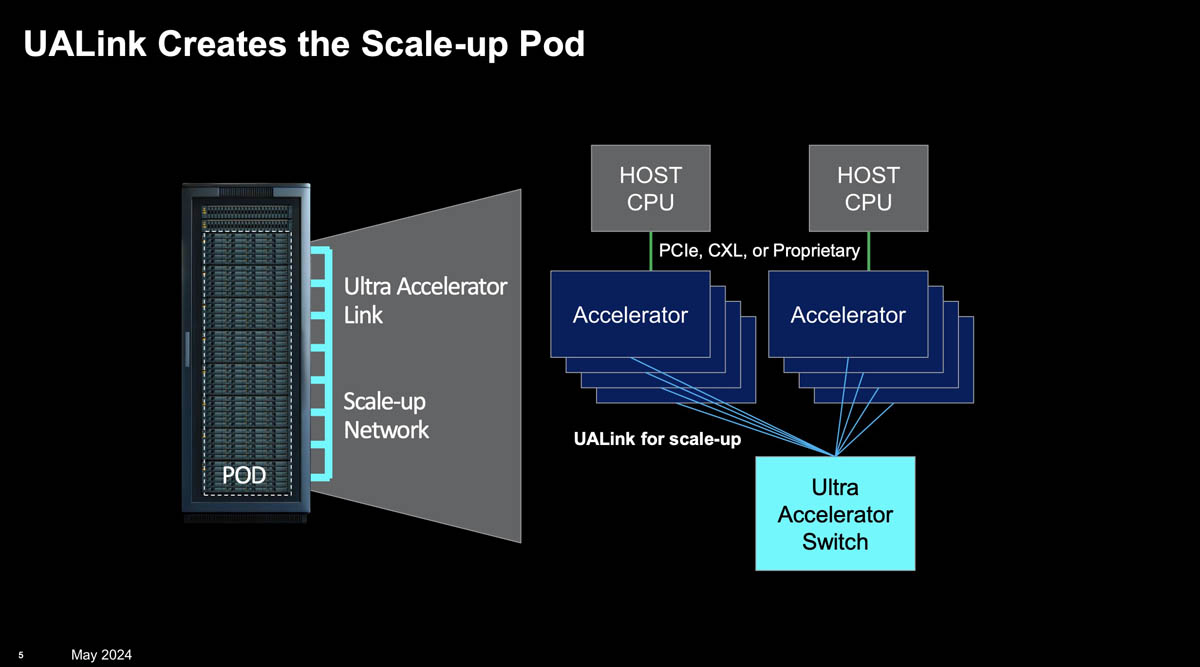
Источник изображений: UALink via ServeTheHome NVLink 4 достиг скорости 900 Гбайт/с на ускоритель и впервые вышел за пределы узла, позволив объединить в домен до 256 ускорителей, что NVIDIA и предложила в рамках DGX SuperPod H100. NVLink 5 удвоил пропускную способность до 1,8 Тбайт/с и теоретически позволит объединить до 576 ускорителей в одном домене. Именно NVLink позволил создать высокоплотные суперускорители GH200 NVL32 и GB200 NVL72. И именно их NVIDIA считает минимальной эффективной единицей кластеров ближайшего будущего, предлагая крупным заказчикам на меньшее даже не размениваться.  Intel в семействе Gaudi использует Ethernet (1,2 Тбайт/с на ускоритель) как для вертикального, так и для горизонтального масштабирования. AMD же полагается на Infinity Fabric (896 Гбайт/с на ускоритель) на базе PCIe и xGMI, которые до недавнего времени за пределы узла не выходили. Однако в конце 2023 года было объявлено, что в 2025 году AMD и Broadcom выпустят коммутатор на базе PCIe 7.0 (стандарт планируют только-только утвердить в этом же году), который будет поддерживать технологию, которая теперь называется AFL (Accelerated Fabric Link) — это и будет выходом Infinity Fabric за пределы узла.  И именно совместными наработками AMD и Broadcom поделятся в рамках UALink. Первую версию нового интерконнекта альянс обещает представить уже в III квартале 2024 года, а в IV квартале — версию 1.1. При этом пока прямо не говорится, будет ли основным транспортом PCIe или Ethernet, и какой протокол будет использоваться для работы с памятью. Но уже обещано, что UALink 1.0 позволит объединить до 1024 ускорителей в одном домене с возможностью прямых load/store-запросов к их памяти. Для дальнейшего масштабирования кластеров по-прежнему предлагается использовать Ultra Ethernet.  При этом UALink, строго говоря, не обещает возможности беспрепятственного общения ускорителей разных вендоров, зато позволяет упростить инфраструктуру и сделать её дешевле благодаря открытости и конкуренции. Хотя было бы приятно увидеть UALink в качестве аппаратной основы и для стандарта UXL, который намерен побороться с NVIDIA CUDA. Что касается CXL, то этот стандарт, тоже использующий PCIe в качестве транспорта, вероятно, останется «привязанным» к CPU и внутриузловым коммуникациям, хотя возможности его гораздо шире.
27.05.2024 [22:20], Алексей Степин
Тридцать на одного: Liqid UltraStack 30 позволяет подключить десятки GPU к одному серверуКомпания Liqid сотрудничает с Dell довольно давно — ещё в прошлом году она смогла добиться размещения 16 ускорителей в своей платформе UltraStack L40S. Но на этом компания не остановилась и представила новую композитную платформу UltraStack 30, в которой смогла довести число одновременно доступных хост-системе ускорителей до 30. Для подключения, конфигурации и управления ресурсами ускорителей Liqid использует комбинацию фирменного программного обеспечения Matrix CDI и интерконнекта Liqid Fabric. В основе последнего лежит PCI Express. Это позволяет динамически конфигурировать аппаратную инфраструктуру с учётом конкретных задач с её возвратом в общий пул ресурсов по завершению работы. Сами «капсулы» с ресурсами подключены к единственному хост-серверу, что упрощает задачу масштабирования, минимизирует потери производительности, повышает энергоэффективность и позволяет добиться наиболее плотной упаковки вычислительных ресурсов, нежели это возможно в классическом варианте с раздельными серверами. А благодаря гибкости конфигурирования буквально «на лету» исключается простой весьма дорогостоящих аппаратных ресурсов. 
Источник здесь и далее: Liqid В случае UltraStack 30 основой по умолчанию является сервер серии Dell PowerEdge R760 с двумя Xeon Gold 6430 и 1 Тбайт оперативной памяти, однако доступен также вариант на базе Dell R7625, оснащённый процессорами AMD EPYC 9354. Опционально можно укомплектовать систему NVMe-хранилищем объёмом 30 Тбайт, в качестве сетевых опций доступны либо пара адаптеров NVIDIA ConnectX-7, либо один DPU NVIDIA Bluefield-3.  За общение с ускорительными модулями отвечает 48-портовой коммутатор PCI Express 4.0 вкупе с фирменными хост-адаптерами Liqid. Технология ioDirect позволяет ускорителям общаться друг с другом и хранилищем данных напрямую, без посредничества CPU. В трёх модулях расширения установлено по 10 ускорителей NVIDIA L40S, каждый несет на борту 48 Гбайт памяти GDDR6. Такая конфигурация теоретически способна развить 7,3 Пфлопс на вычислениях FP16, вдвое больше на FP8, и почти 1,1 Пфлопс на тензорных ядрах в формате TF32. 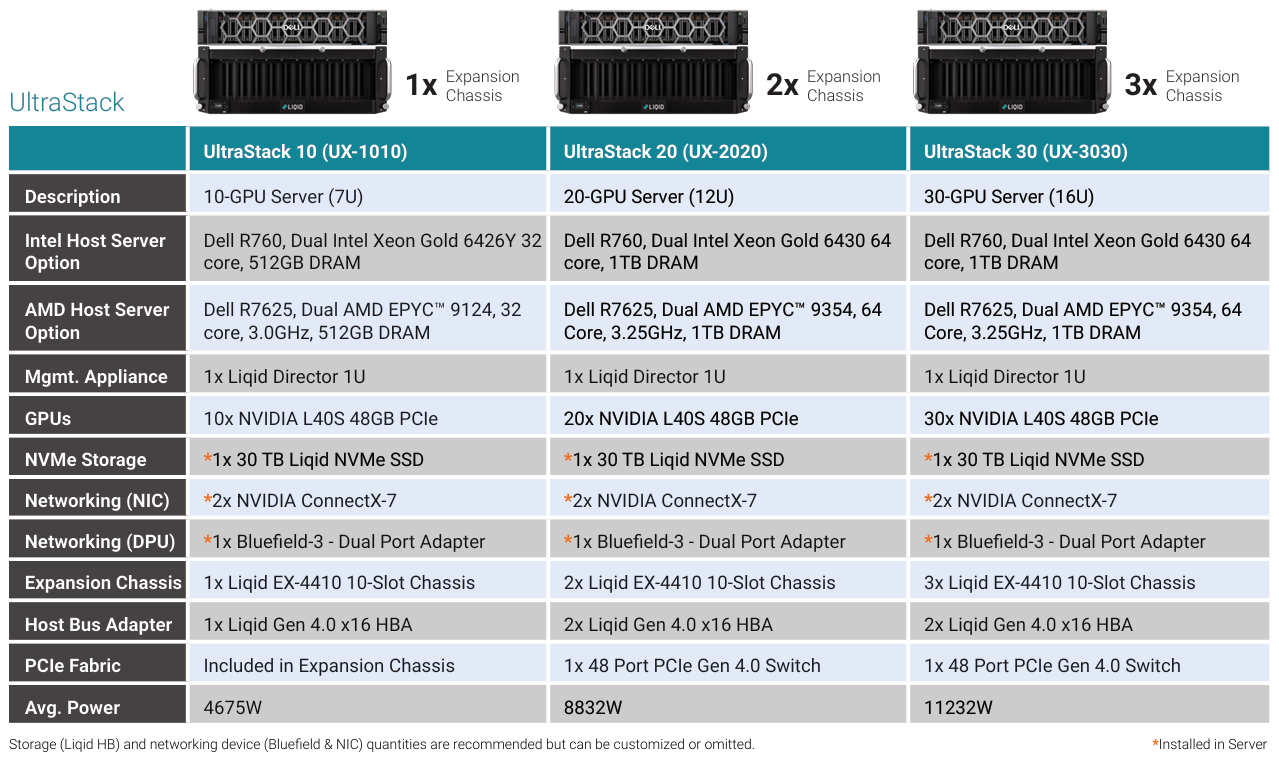 Платформа UltraStack 30 предназначена в первую очередь для быстрого развёртывания достаточно мощной ИИ-инфраструктуры там, где требуется тонкая подстройка и дообучение уже «натасканных» больших моделей. При этом стоит учитывать довольно солидное энергопотребление, составляющее более 11 кВт. Также в арсенале компании есть решения SmartStack на базе модульных систем Dell PowerEdge C-Series, позволяющие подключать к каждому из лезвийных модулей MX760c, MX750с и MX740c до 20 ускорителей. Модульные решения Liqid поддерживают также ускорители других производителей, включая достаточно экзотические, такие как Groq.
26.05.2024 [13:24], Руслан Авдеев
Эрик Шмидт: будущие суперкомпьютеры США и Китая будут окружены пулемётами и колючей проволокой и питаться от АЭС
hardware
hpc
аэс
безопасность
ии
информационная безопасность
китай
суперкомпьютер
сша
цод
энергетика
Бывший генеральный директор Google Эрик Шмидт (Eric Schmidt) прогнозирует, что в обозримом будущем в США и Китае большие суперкомпьютеры будут заниматься ИИ-вычислениями под защитой военных баз. В интервью Noema он подробно рассказал о том, каким видит новые ИИ-проекты, и это будущее вышло довольно мрачным. Шмидт поведал о том, как правительства будут регулировать ИИ и искать возможности контроля ЦОД, работающих над ИИ. Покинув Google, бизнесмен начал очень тесно сотрудничать с военно-промышленным комплексом США. По его словам, рано или поздно в США и Китае появится небольшое число чрезвычайно производительных суперкомпьютеров с возможностью «автономных изобретений» — их производительность будет гораздо выше, чем государства готовы свободно предоставить как своим гражданам, так и соперникам. Каждый такой суперкомпьютер будет соседствовать с военной базой, питаться от атомного источника энергии, а вокруг будет колючая проволока и пулемёты. Разумеется, таких машин будет немного — гораздо больше суперкомпьютеров будут менее производительны и доступ к ним останется более широким. Строго говоря, самые производительные суперкомпьютеры США принадлежат Национальным лабораториям Министерства энергетики США, которые усиленно охраняются и сейчас. Как заявил Шмидт, необходимы и договорённости об уровнях безопасности вычислительных систем по примеру биологических лабораторий. В биологии широко распространена оценка по уровням биологической угрозы для сдерживания её распространения и оценки уровня риска заражения. С суперкомпьютерами имеет смысл применить похожую классификацию. 
Источник изображения: Joel Rivera-Camacho/unsplash.com Шмидт был председателем Комиссии национальной безопасности США по ИИ и работал в Совете по оборонным инновациям. Также он активно инвестировал в оборонные стартапы. В то же время Шмидт сохранил влияние и в Alphabet и до сих пор владеет акциями компании стоимостью в миллиарды долларов. Военные и разведывательные службы США пока с осторожностью относятся к большим языковым моделям (LLM) и генеративному ИИ вообще из-за распространённости «галлюцинаций» в таких системах, ведущих к весьма правдоподобным на первый взгляд неверным выводам. Кроме того, остро стоит вопрос сохранения секретной информации в таких системах. Ранее в этом году Microsoft подтвердила внедрение изолированной от интернета генеративной ИИ-модели для спецслужб США после модернизации одного из своих ИИ-ЦОД в Айове. При этом представитель Microsoft два года назад предрекал, что нынешнее поколение экзафлопсных суперкомпьютеров будет последним и со временем все переберутся в облака.
19.05.2024 [18:07], Игорь Осколков
Phison представила новый бренд серверных SSD PASCARI и накопители X200 с PCIe 5.0Phison представила собственный бренд SSD корпоративного класса PASCARI, который включает сразу несколько различных серий: X, AI, D, S и B. Новинки представлены в форм-факторах E1.S, E3.S, U.3/U.2, M.2 2280/22110 и SFF 2,5″ и наделены интерфейсами SATA-3 и PCIe 4.0/5.0. Наиболее интересна серия AI (или aiDAPTIVCache), которая фактически является частью программно-аппаратного комплекса aiDAPTIV+. Пока упоминается только один M.2 SSD — AI100E. Это сверхбыстрые и сверхнадёжные 2-Тбайт NVMe-накопители на базе SLC NAND (вероятно, всё же eSLC) с DWPD, равным 100 на протяжении трёх или пяти лет (в материалах указаны разные сроки). Аналогичные накопители, хотя и в более крупном форм-факторе, предлагают Micron и Solidigm, а Kioxia в прошлом году анонсировала накопители на базе XL-Flash второго поколения с MLC NAND. Во всех случаях, по сути, речь идёт об SCM (Storage Class Memory). Наиболее ярким представителем данной категории была почившая серия продуктов Intel Optane. Phison переняла общую идею перестройки иерархии памяти, где SCM является ещё одним слоем между DRAM и массивом SSD, приложив её к задачам обучения ИИ. AI100E являются кеширующими накопителями, расширяющими доступную память. Программная прослойка aiDAPTIVLink общается с ускорителями NVIDIA и SSD с одной стороны и с PyTorch (также есть упоминание TensorFlow) — с другой. 
Источник изображений: Phison aiDAPTIVLink позволяет автоматически и прозрачно переносить на SSD неиспользуемые в текущий момент части обучаемой LLM и по необходимости отправлять их сначала в системную RAM, а потом и в память ускорителя, что и позволяет обходиться меньшим числом ускорителей при тренировке действительно больших моделей. Естественно, никакого чуда здесь не происходит, поскольку время обучения от этого нисколько не сокращается, но с другой стороны, обучение становится в принципе возможным на системах с малым количеством ускорителей или просто с относительно слабыми GPU и относительно небольшим же объёмом системной RAM. 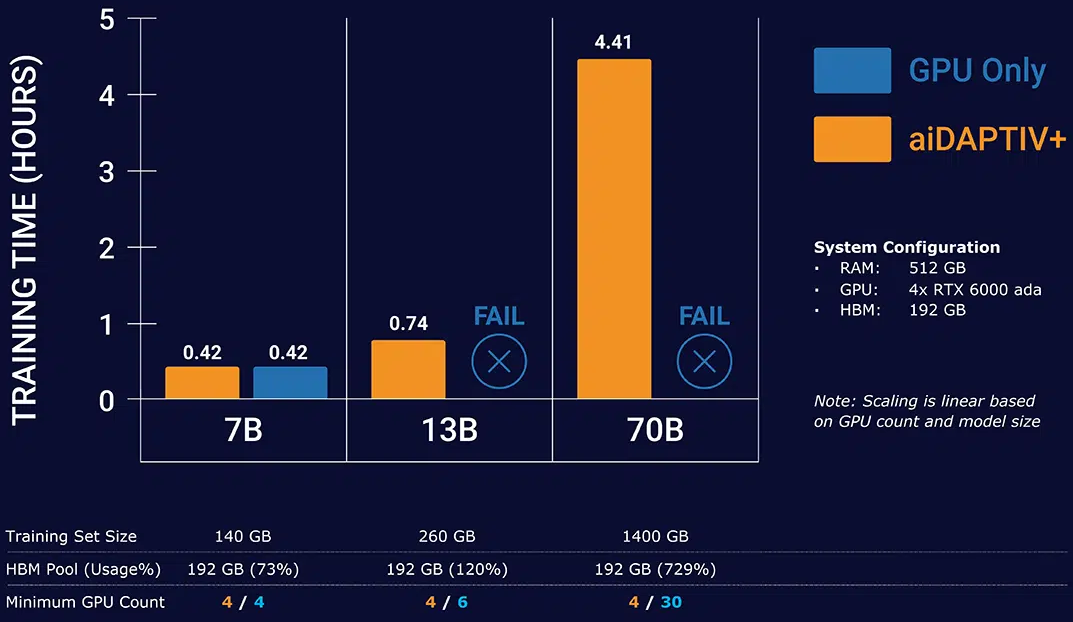 Среди уже поддерживаемых моделей упомянуты некоторые LLM семейств Llama, Mistral, ResNet и т.д. Для них, как заявляется, не нужны никакие модификации для работы с aiDAPTIV+. Также упомянута возможность горизонтального масштабирования при использовании данной технологии. Точные характеристики AI100E компания не приводит, но это и не так существенно, поскольку напрямую продавать эти накопители она не собирается. Вместо этого они будут предлагаться в составе готовых и полностью укомплектованных рабочих станций или серверов. Семейство PASCARI X включает сразу четыре серии накопителей. Так, X200E (DWPD 3) и X200P (DWPD 1) — это двухпортовые накопители на базе TLC NAND с интерфейсом PCIe 5.0 x4, представленные в форм-факторах U.2 и E3.S. Пиковые скорости последовательного чтения и записи составляют 14,8 Гбайт/с и 8,35 Гбайт/с соответственно. На случайных операциях с 4K-блоками производительность чтения достигает 3 млн IOPS, а записи — 900 тыс. IOPS у X200E и 500 тыс. IOPS у X200P. Здесь и далее даны только крайние показатели в рамках серии, а не отдельного накопителя.  Ёмкость X200E составляет 1,6–12,8 Тбайт, но также готовится 25,6-Тбайт U.2-версия. У X200P диапазон ёмкостей простирается от 1,92 Тбайт до 15,36 Тбайт, но опять-таки будет 30,72-Тбайт вариант в U.2-исполнении. Отмечается поддержка MF-QoS (QoS для различных нагрузок), поддержка 64 пространств имён, MTBF на уровне 2,5 млн часов, сквозная защита целостности передаваемых данных, улучшенная защита от потери питания и т.д. У X100E (DWPD 3) и X200P (DWPD 1) среди возможностей дополнительно упомянуты поддержка TCG Opal 2.0, NVMe-MI, шифрования AES-256, безопасной очистки и т.д. От X200 эти накопители отличаются в первую очередь интерфейсом PCIe 4.0 x4 (возможны два порта x2). Выпускаются они только в форм-факторе U.3/U.2. X100E предлагают ёмкость от 1,6 Тбайт до 25,6 Тбайт, а X100P — от 1,92 Тбайт до 30,72 Тбайт. Пиковые скорости последовательного чтения и записи в обоих случаях достигают 7 Гбайт/с. Произвольное чтение 4K-блоками — до 1,7 млн IOPS, а вот запись у X100E упирается в 480 тыс. IOPS, тогда как у X100P и вовсе не превышает 190 тыс. IOPS.  В семейство PASCARI D входит всего одна серия компактных накопителей D100P на базе TLC NAND с интерфейсом PCIe 4.0 x4 (один порт, NVMe 1.4), представленная в форм-факторах M.2 2280 (от 480 Гбайт до 1,92 Тбайт), M.2 22110 (от 480 Гбайт до 3,84 Тбайт) и E1.S (тоже от 480 Гбайт до 1,92 Тбайт). Производительность M.2-вариантов составляет до 6 Гбайт/с и 2 Гбайт/с на последовательных операциях чтения и записи, а на случайных — до 800 тыс. IOPS и 60 тыс. IOPS соответственно. E1.S-версия чуть быстрее в чтении — до 6,8 Гбайт/с. Надёжность — 1 DWPD. Среди особенностей вендор выделяет сквозную защиту целостности данных, LPDC-движок четвёртого поколения, поддержку NVMe-MI и т.п.  PASCARI B включает серию загрузочных накопителей B100P: M.2 2280 (будет и 22110), TLC NAND, PCIe 4.0 x4, 1 DWPD и те же функции, что у D100P. Доступны только накопители ёмкостью 480 Гбайт и 960 Гбайт. Скоростные характеристики относительно скромны. Последовательные чтение и запись не превышают 5 Гбайт/с и 700 Мбайт/с, а произвольные — 450 тыс. IOPS и 30 тыс. IOPS. Также к PASCARI B принадлежит серия BA50P: SATA-накопители в форм-факторах M.2 2280 и SFF 2,5″ на базе TLC NAND с DWPD 1 и ёмкостью 240/480/960 Гбайт. Скорости чтения/записи не превышают 530/500 Мбайт/с при последовательном доступе, и 90/20 тыс. IOPS при случайном доступе 4K-блоками.  Наконец, семейство PASCARI S представлено тремя сериями SFF-накопителей (2,5″) с TLC-памятью и интерфейсом SATA-3, отличающихся в первую очередь опять-таки показателем надёжности: SA50E (3 DWPD), SA50P (1 DWPD) и SA50E (>0,4 DWPD). SA50E имеют ёмкость от 480 Гбайт до 3,84 Тбайт, SA50P — от 480 Гбайт до 7,68 Тбайт, а SA50E — от 1,92 Тбайт до 15,36 Тбайт. Отличаются и максимальные скорости произвольного чтения/записи 4K-блоками: 98/60 тыс., 98/40 тыс. и 97/20 тыс. IOPS соответственно. А вот последовательные чтение и запись естественным образом ограничены самим интерфейсом, т.е. не превышают 530 Мбайт/с и 500 Мбайт/с соответственно. В описании упомянуты сквозная защита целостности данных, LPDC-движок и улучшенная защита от потери питания. Для вообще всех накопителей заявленный диапазон рабочих температур простирается от 0 до 70 °C. А вот срок гарантии не указан, так что показатели DWPD теряют смысл. Кроме того, Phison практически для каждой серии говорит о возможности кастомизации. Например, для X100 предлагаются услуги IMAGIN+.
18.05.2024 [20:00], Алексей Степин
256 ядер и 12 каналов DDR5: Ampere обновила серверные Arm-процессоры AmpereOne и перевела их на 3-нм техпроцессВесной прошлого года компания Ampere Computing анонсировала наследников серии процессоров Altra и Altra Max — чипы AmpereOne с более высокими показателями производительности, энергоэффективности и масштабируемости. На момент анонса AmpereOne получили до 192 ядер, восемь каналов DDR5 и 128 линий PCIe 5.0. Кроме того, эти чипы могут работать и в двухсокетных платформах. Позднее AmpereOne стали доступны у нескольких облачных провайдеров, а главным бенефециаром их появления стала Oracle, когда-то инвестировавшая в Ampere Computing значительные средства. Компания перевела все свои облачные сервисы на процессоры Ampere и даже портировала на них свою флагманскую СУБД. В общем, повторила путь AWS и Alibaba Cloud с процессорами Graviton и Yitian соответственно. Но если последние являются облачным эксклюзивом, то чипы Ampere хоть и ориентированы в первую очередь на гиперскейлеров, более-менее доступны и небольшим компаниям. Поэтому в процессорной гонке останавливаться нельзя, так что на днях Ampere объявила об обновлении модельного ряда AmpereOne, запланированного к выпуску в 2025 году. Новые модели будут использовать продвинутый техпроцесс TSMC N3. 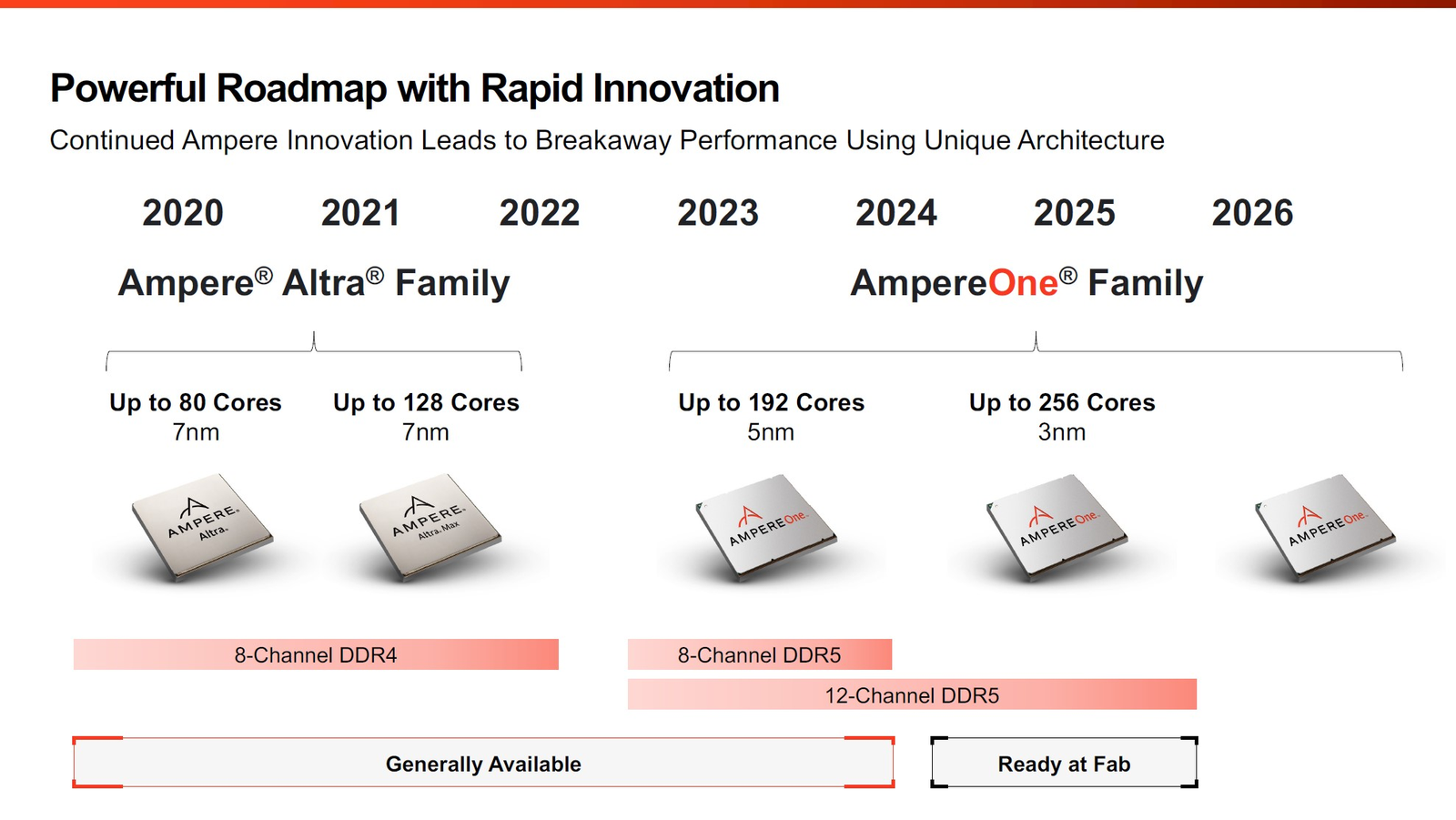
Источник здесь и далее: Ampere Computing via ServeTheHome Согласно опубликованным планам, семейство AmpereOne какое-то время будет существовать в двух ипостасях: изначальном варианте 2023 года с 8-канальным контроллером памяти и 192 ядрами в пределе, производящемся с использованием 5-нм техпроцесса, и новом 3-нм, уже готовом к массовому производству. Ожидается, что 192-ядерный вариант с 12 каналами DDR5 станет доступен в конце этого года. 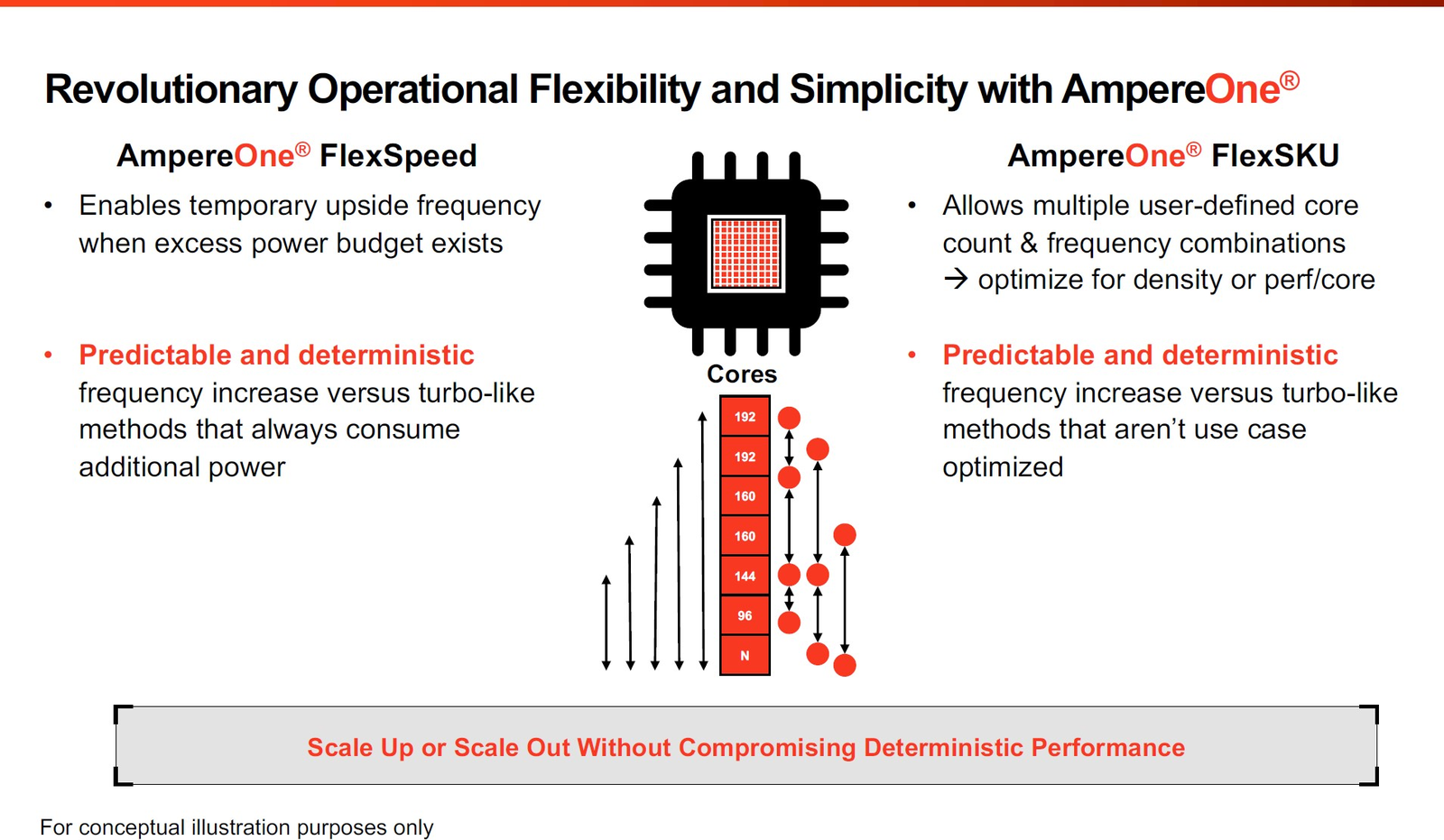
Фирменные технологии Ampere серии Flex позволят гибко управлять характеристиками платформы 3-нм вариант AmpereOne получит до 256 ядер и 12 каналов DDR5, однако отличать его будет не только это. К примеру, в нём дебютируют технологии FlexSpeed и FlexSKU, позволяющие на лету, без перезагрузок или выключения системы оперировать различными параметрами процессора — тактовой частотой, теплопакетом и даже количеством активных ядер. При этом FlexSpeed обеспечит детерминированный прирост производительности в отличие от x86-64, говорит компания. 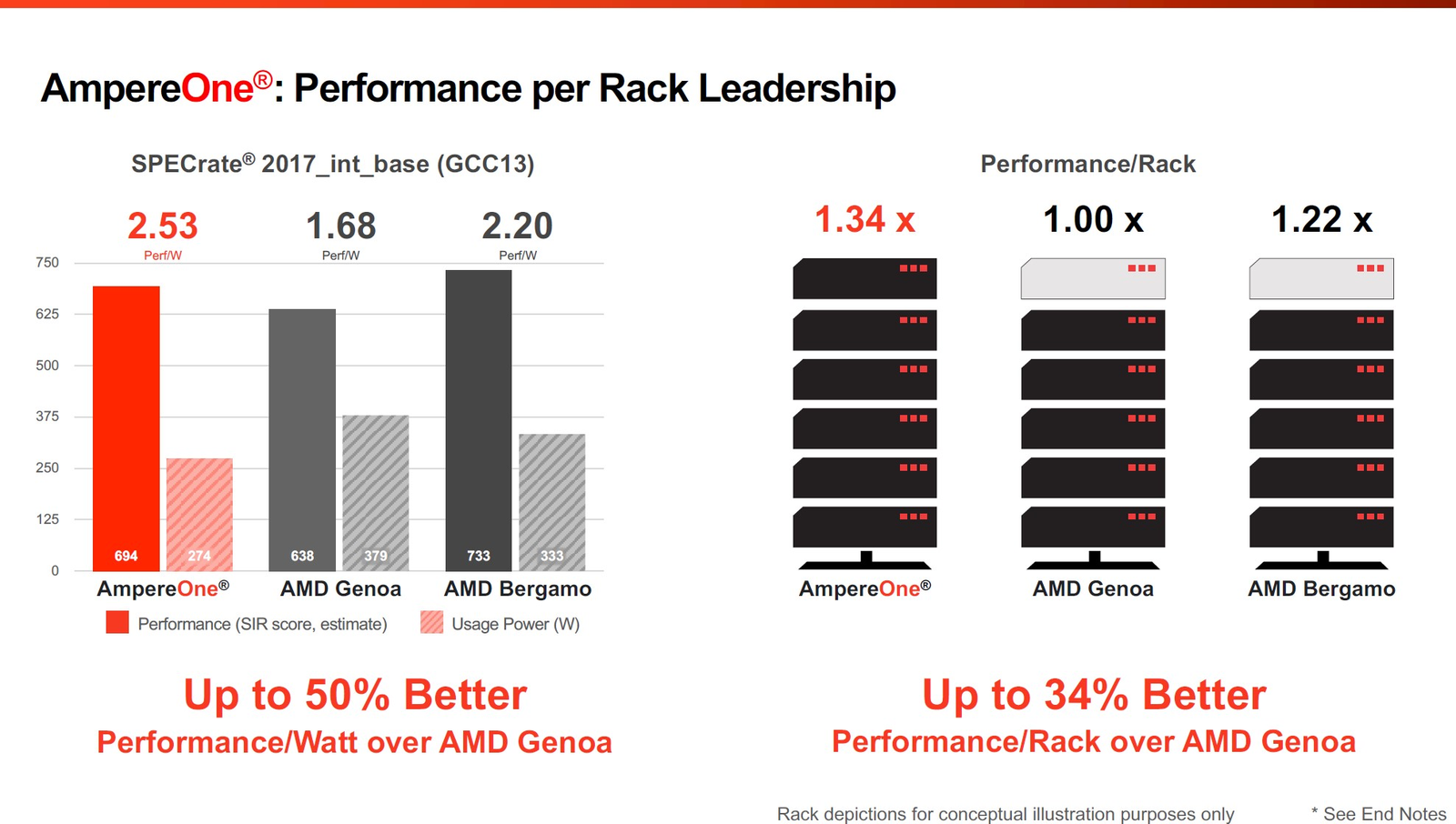 Ampere утверждает, что новые AmpereOne превзойдут в удельной производительности на Вт AMD EPYC Bergamo и обеспечат более высокую производительность в пересчёте на стойку, нежели AMD EPYC Genoa. Особенное внимание компания уделяет энергоэффективности AmpereOne, которая заключается не только в экономии электроэнергии, но и драгоценного места в ЦОД. Проще говоря, компания упирает на повышение плотности размещения вычислительных мощностей. 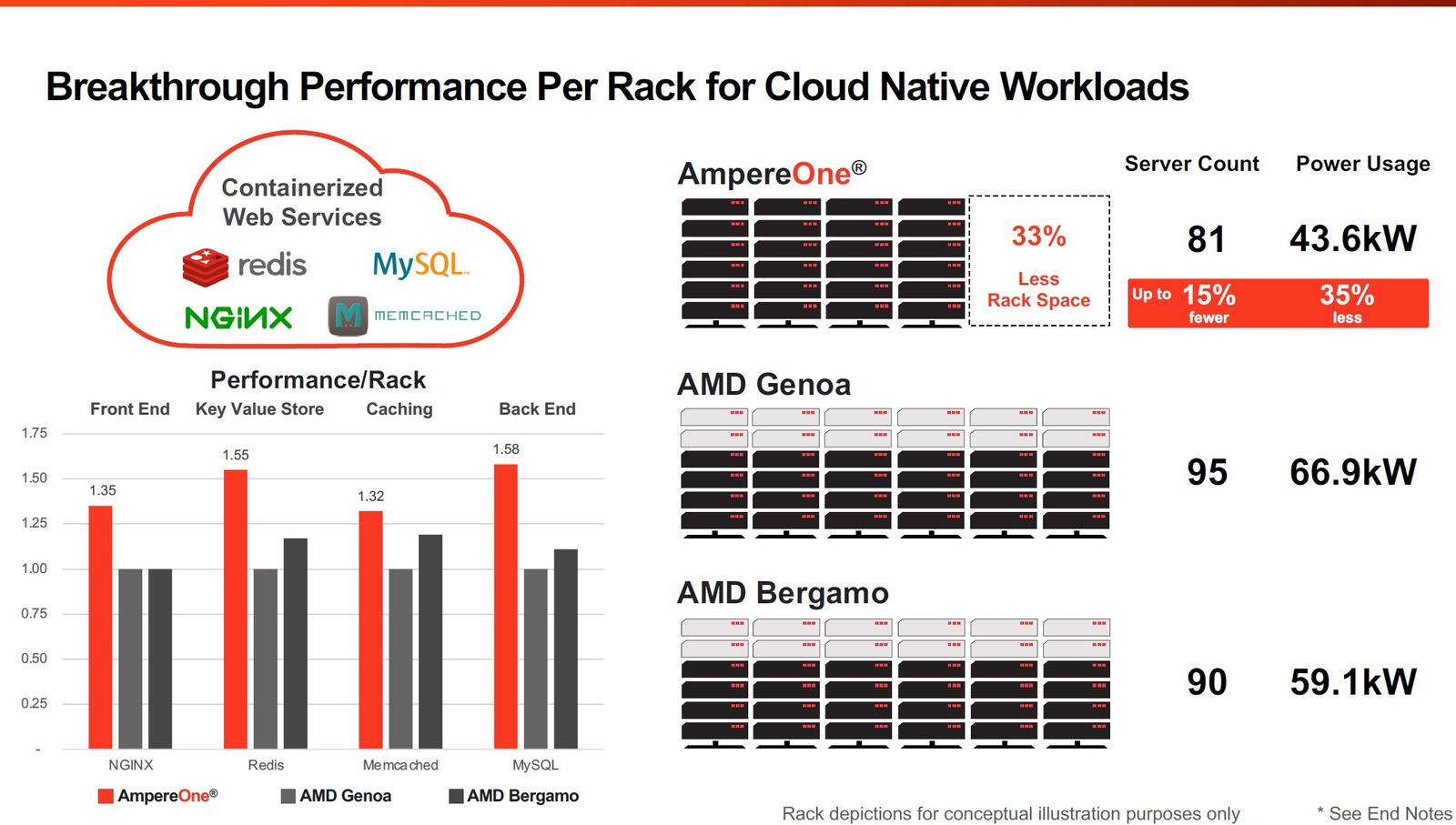 Заодно Ampere в который раз говорит, что в инференс-сценариях её процессоры сопоставимы с некоторыми ускорителями, в частности, NVIDIA A10, но при этом существенно дешевле и экономичнее. В пересчёте на токены при производительности порядка 80 токенов в секунду платформа Ampere обходится на 28% дешевле и в то же время потребляет меньше энергии на целых 67%! 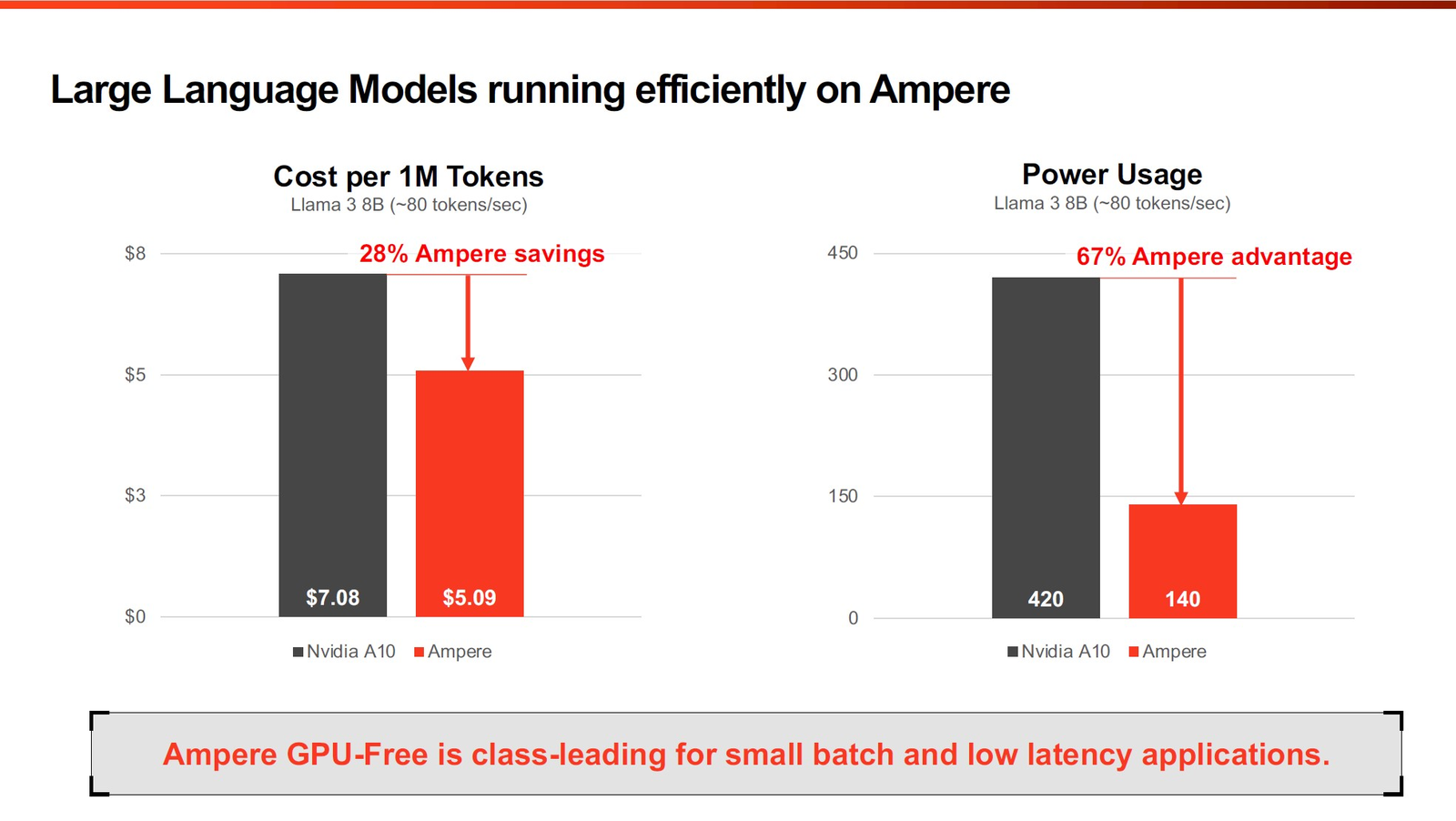 Более того, Ampere заключила союз с Qualcomm для выпуска серверной платформы, сочетающей AmpereOne в качестве процессоров общего назначения и ИИ-ускорителей Qualcomm Cloud AI 100 Ultra. Если сами процессоры успешно работают с LLM сравнительно небольшой сложности (до 7 млрд параметров), то новая платформа позволит запускать и сети с 70 млрд параметров. Кроме того, есть и готовое решение с VPU Quadra T1U.  Увидит ли свет в будущем гибридный процессор Ampere Computing с UCIe-чиплетами, будет зависеть от решений, принятых группой AI Platform Alliance, возглавленной Ampere Computing ещё осенью прошлого года. Но это вполне реальный сценарий: блоки ускорения специфических для ИИ-задач вычислений активно внедряются не только в серверных решениях, подобных Intel Xeon Sapphire/Emerald Rapids — сопроцессоры NPU уже дебютировали в потребительских и промышленных CPU Intel и AMD. При этом Ampere Computing, вероятно, придётся несколько поменять политику дальнейшего развития, поскольку основными конкурентами для неё являются не только 128-ядерные AMD EPYC Bergamo и готовящиеся 144- и 288-ядерные Intel Xeon Sierrra Forest, но и Arm-процессоры Google Axion и Microsoft Cobalt 100, которые изначально создавались гиперскейлерами под свои нужды, а потому наверняка лучше оптимизированы под их задачи и, вероятнее всего, к тому же дешевле, чем продукты Ampere.
16.05.2024 [01:05], Игорь Осколков
И для ИИ, и для HPC: первые европейские серверные Arm-процессоры SiPearl Rhea1 получат HBM-памятьКомпания SiPearl уточнила спецификации разрабатываемых ею серверных Arm-процессоров Rhea1, которые будут использоваться, в частности, в составе первого европейского экзафлопсного суперкомпьютера JUPITER, хотя основными чипами в этой системе будут всё же гибридные ускорители NVIDIA GH200. Заодно SiPearl снова сдвинула сроки выхода Rhea1 — изначально первые образцы планировалось представить ещё в 2022 году, а теперь компания говорит уже о 2025-м. При этом существенно дизайн процессоров не поменялся. Они получат 80 ядер Arm Neoverse V1 (Zeus), представленных ещё весной 2020 года. Каждому ядру полагается два SIMD-блока SVE-256, которые поддерживают, в частности, работу с BF16. Объём LLC составляет 160 Мбайт. В качестве внутренней шины используется Neoverse CMN-700. Для связи с внешним миром имеются 104 линии PCIe 5.0: шесть x16 + две x4. О поддержке многочиповых конфигураций прямо ничего не говорится. 
Источник изображения: SiPearl Очень похоже на то, что SiPearl от референсов Arm особо и не отдалялась, поскольку Rhea1 хоть и получит четыре стека памяти HBM, но это будет HBM2e от Samsung. При этом для DDR5 отведено всего четыре канала с поддержкой 2DPC, а сам процессор ожидаемо может быть поделён на четыре NUMA-домена. И в такой конфигурации к общей эффективности работы с памятью могут быть вопросы. Именно наличие HBM позволяет говорить SiPearl о возможности обслуживать и HPC-, и ИИ-нагрузки (инференс). 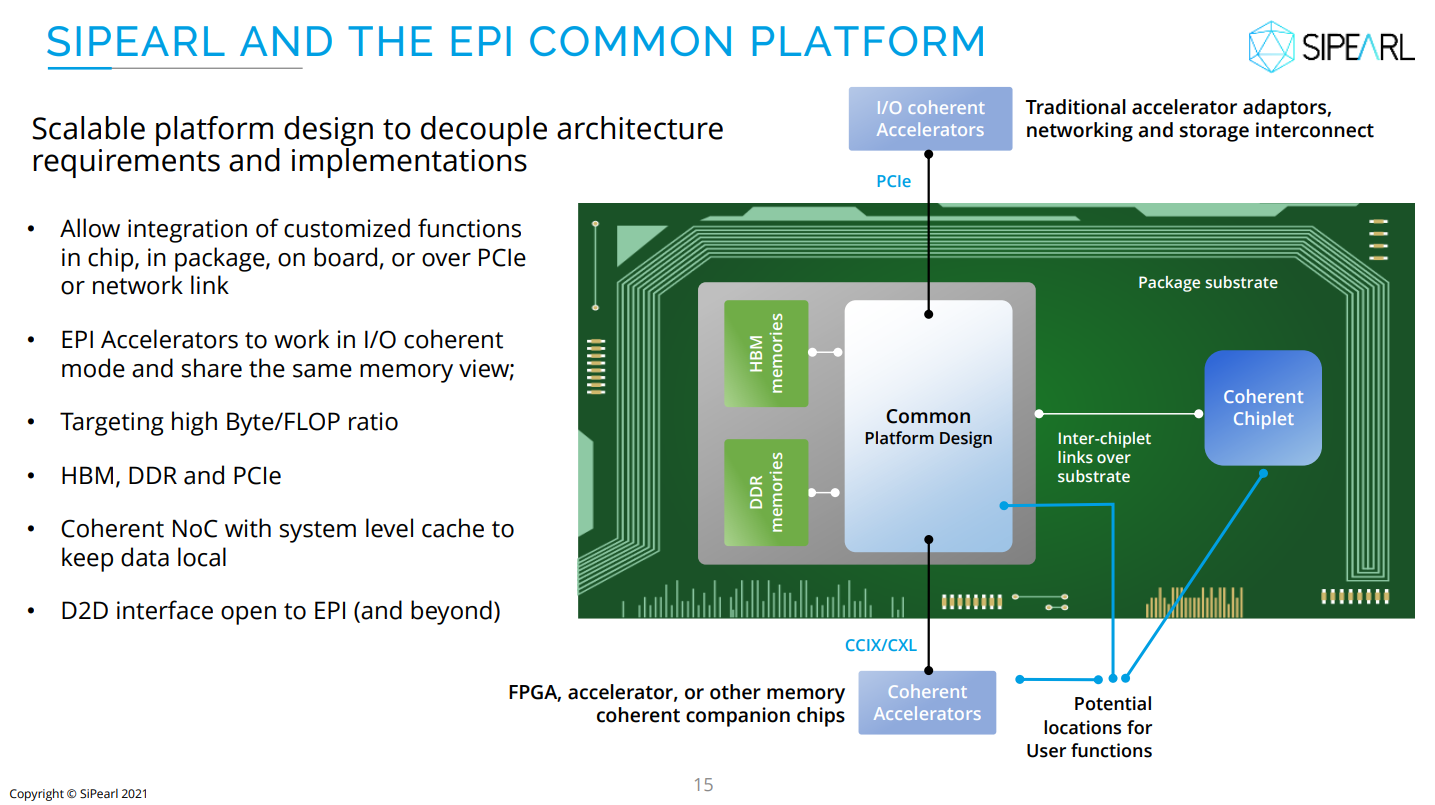
Источник изображения: SiPearl На примере Intel Xeon Max (Sapphire Rapids c 64 Гбайт HBM2e) видно, что наличие сверхбыстрой памяти на борту даёт прирост производительности в означенных задачах, хотя и не всегда. Однако это другая архитектура, другой набор инструкций (AMX), другая же подсистема памяти и вообще пока что единичный случай. С Fujitsu A64FX сравнения тоже не выйдет — это кастомный, дорогой и сложный процессор, который, впрочем, доказал эффективность и в HPC-, и даже в ИИ-нагрузках (с оговорками). В MONAKA, следующем поколении процессоров, Fujitsu вернётся к более традиционному дизайну. 
Источник изображения: EPI Пожалуй, единственный похожий на Rhea1 чип — это индийский 5-нм C-DAC AUM, который тоже базируется на Neoverse V1, но предлагает уже 96 ядер (48+48, два чиплета), восемь каналов DDR5 и до 96 Гбайт HBM3 в четырёх стеках, а также поддержку двухсокетных конфигураций. AWS Graviton3E, который тоже ориентирован на HPC/ИИ-нагрузки, вообще обходится 64 ядрами Zeus и восемью каналами DDR5. Наконец, NVIDIA Grace и Grace Hopper в процессорной части тоже как-то обходятся интегрированной LPDRR5x, да и ядра у них уже Neoverse V2 (Demeter), и своя шина для масштабирования имеется. 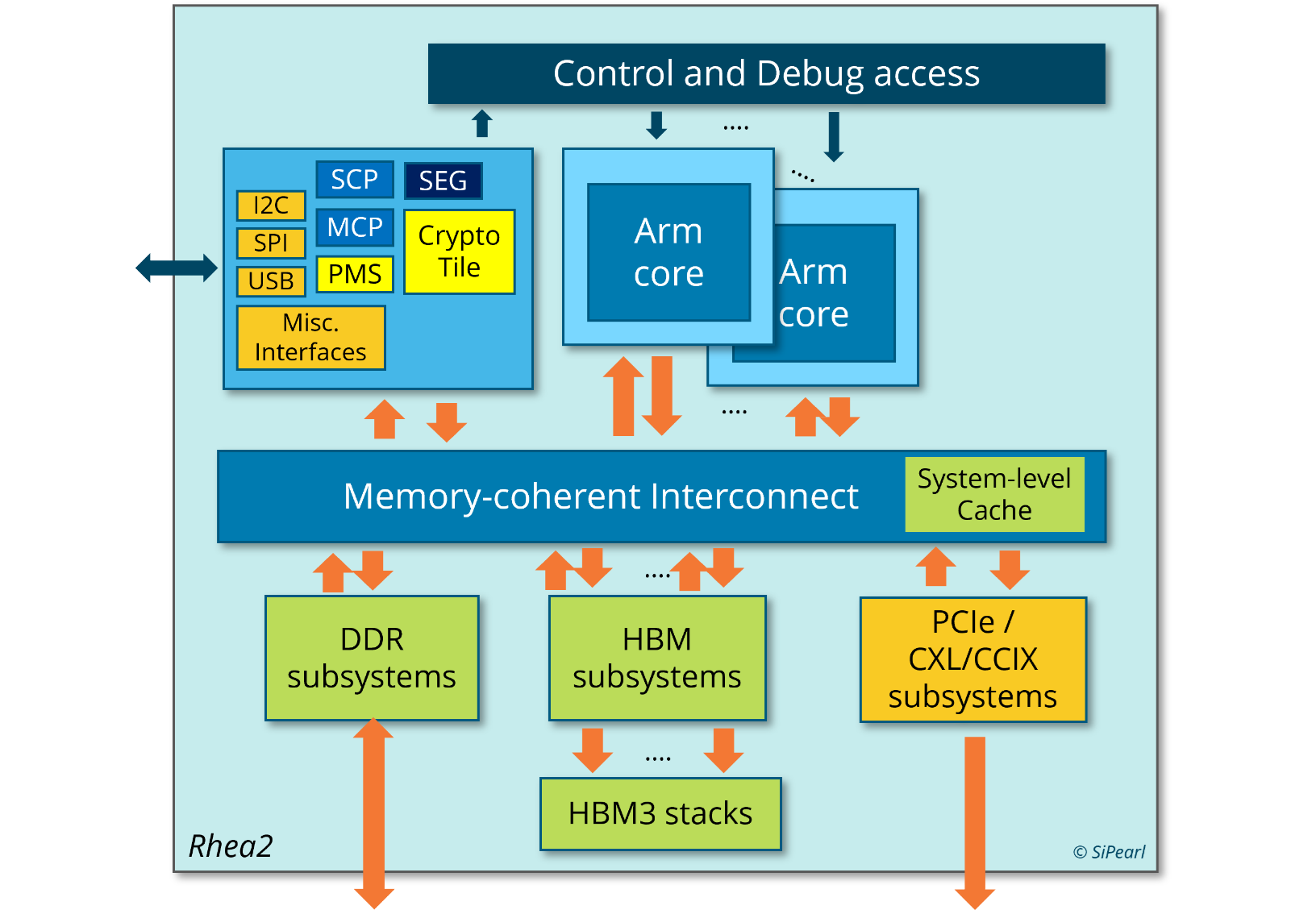
Источник изображения: EPI В любом случае в 2025 году Rhea1 будет выглядеть несколько устаревшим чипом. Но в этом же году SiPearl собирается представить более современные чипы Rhea2 и обещает, что их разработка будет не столь долгой как Rhea1. Компанию им должны составить европейские ускорители EPAC, тоже подзадержавшиеся. А пока Европа будет обходиться преимущественно американскими HPC-технологиями, от которых стремится рано или поздно избавиться.
15.05.2024 [14:18], Руслан Авдеев
PUE у вас неправильный: NVIDIA призывает пересмотреть методы оценки энергоэффективности ЦОД и суперкомпьютеровОператорам дата-центров и суперкомпьютеров не хватает инструментов для корректного измерения энергоэффективности их оборудования и оценки прогресса на пути к экоустойчивым вычислениям. Как утверждает NVIDIA, нужна новая система оценки показателей при использовании оборудования в реальных задачах. Для оценки эффективности ЦОД существует как минимум около трёх десятков стандартов, некоторые уделяют внимание весьма специфическим критериям вроде расхода воды или уровню безопасности. Сегодня чаще всего используется показатель PUE (power usage effectiveness), т.е. отношение энергопотребления всего объекта к потреблению собственно IT-инфраструктуры. В последние годы многие операторы достигли практически идеальных значений PUE, поскольку, например, на преобразование энергии и охлаждение нужно совсем мало энергии. В эпоху роста облачных сервисов оценка PUE показала довольно высокую эффективность, но в эру ИИ-вычислений этот индекс уже не вполне соответствует запросам отрасли ЦОД — оборудование заметно изменилось. NVIDIA справедливо отмечает, что PUE не учитывает эффективность инфраструктуры в реальных нагрузках. С таким же успехом можно измерять расход автомобилем бензина без учёта того, как далеко он может проехать без дозаправки. При этом среднемировой показатель PUE дата-центров остаётся неизменным уже несколько лет, а улучшать его всё дороже. 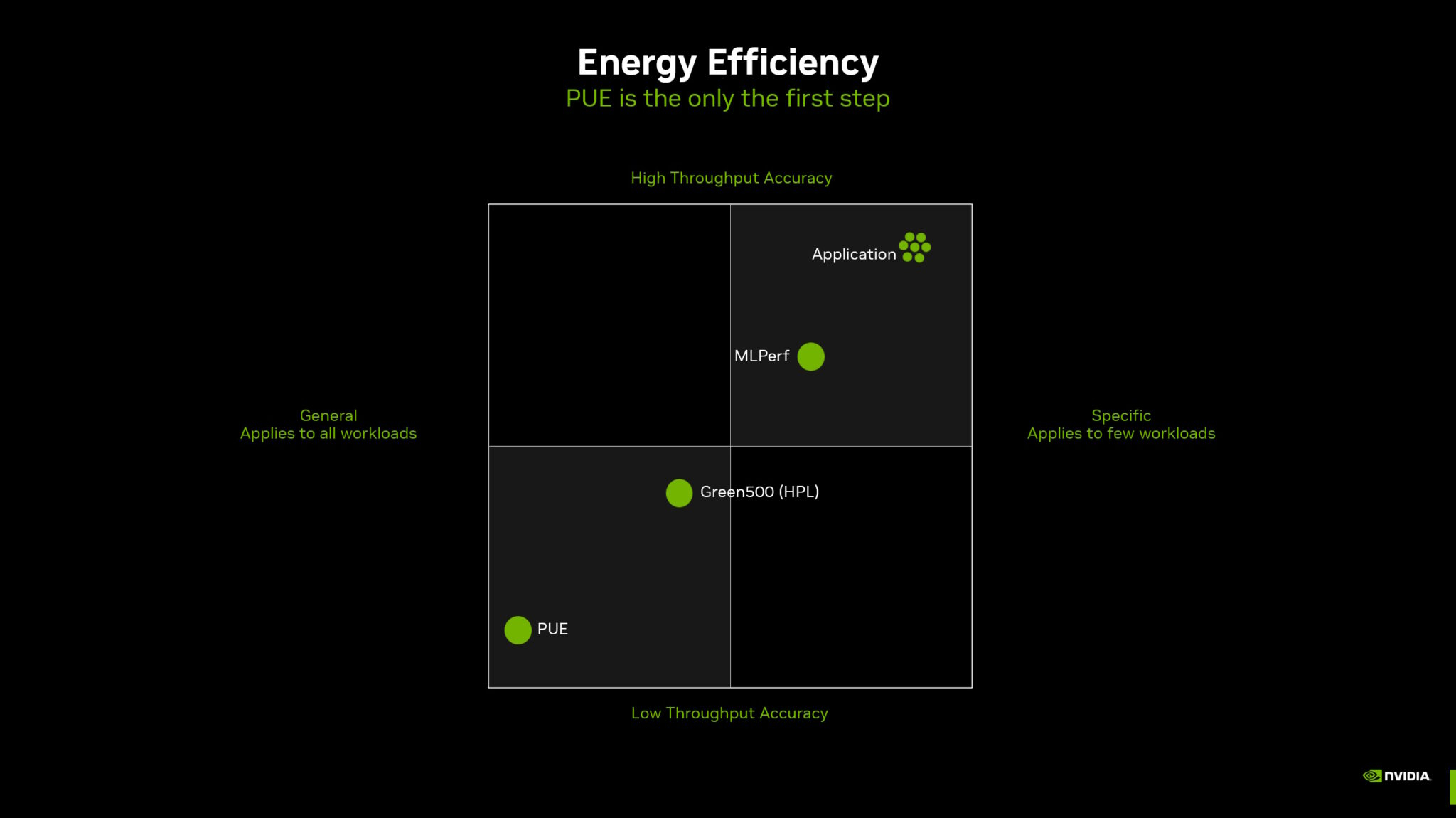
Источник изображений: NVIDIA Что касается энергопотребления, разное оборудование при одинаковых затратах может давать самые разные результаты. Другими словами, если современные ускорители потребляют больше энергии, это не значит, что они менее эффективны, поскольку они дают несопоставимо лучший результат в сравнении со старыми решениями. NVIDIA неоднократно приводила подобные сравнения и между своими GPU с обычными CPU, а теперь предлагает распространить этот подход на ЦОД целиком, что справедливо, учитывая стремление NVIDIA сделать минимальной единицей развёртывания целую стойку. 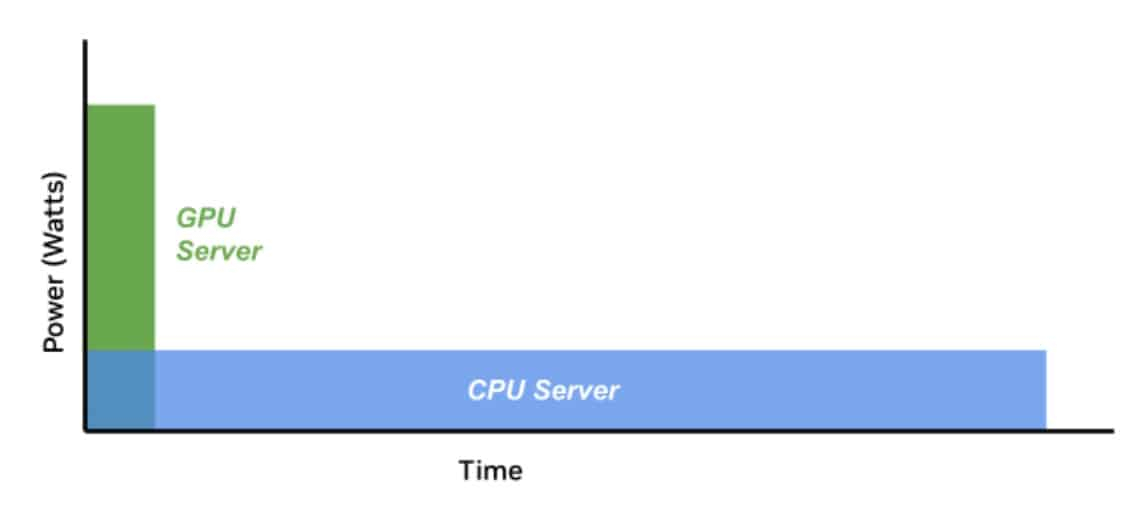 Как считают в NVIDIA, оценивать качество ЦОД можно только с учётом того, сколько энергии тратится для получения результата. Так, ЦОД для ИИ могут полагаться на MLPerf-бенчмарки, суперкомпьютеры для научных исследований могут требовать измерения других показателей, а коммерческие дата-центры для стриминговых сервисов — третьих. В идеале бенчмарки должны измерять прогресс в ускоренных вычислениях с использованием специализированных сопроцессоров, ПО и методик. Например, в параллельных вычислениях GPU намного энергоэффективнее обычных процессоров Отмечается, что с 2003 года производительность ускорителей выросла приблизительно в 7 тыс. раз, а соотношение цены и производительности стало в 5,6 тыс. раз лучше. А с учётом того, что современные ЦОД достигли PUE на уровне приблизительно 1,2, подобная метрика практически исчерпала себя, теперь стоит ориентироваться на другие показатели, релевантные актуальным проблемам. Хотя напрямую сравнить некоторые аспекты невозможно, сегментировав деятельность ЦОД на типы рабочих нагрузок, возможно, удалось бы получить некоторые результаты. В частности, операторам ЦОД нужен пакет бенчмарков, измеряющих показатели при самых распространённых рабочих ИИ-нагрузках. Например, неплохой метрикой может стать Дж/токен. Впрочем, NVIDIA грех жаловаться на недостойные оценки — в последнем рейтинге Green500 именно её системы заняли лидерские позиции.
08.05.2024 [12:50], Сергей Карасёв
IBM представила небольшой сервер POWER S1012 для ИИ-вычислений на периферииКорпорация IBM анонсировала компактный сервер POWER S1012 на платформе POWER10, предназначенный для решения ИИ-задач на периферии. Новинка будет предлагаться в двух вариантах исполнения — в корпусе башенного типа и в виде системы формата 2U половинной ширины, что позволит размещать в стандартной стойке два устройства бок о бок. Решение оснащается модулем POWER10 eSCM с одним, четырьмя или восемью ядрами (3,0–3,9 ГГц) и 256 Гбайт памяти. Каждое ядро способно выполнять до восьми потоков инструкций одновременно (SMT8), благодаря чему максимальная конфигурация обеспечивает до 64 потоков. Заявленная пропускная способность памяти — до 102 Гбайт/с. 
Источник изображений: IBM Конфигурация POWER S1012 (Bonnell) может включать два слота PCIe 5.0 x8 или один слот PCIe 4.0 x16, а также дополнительный разъём PCIe 5.0 x8. Допускается установка четырёх накопителей NVMe U.2.  По заявлениям IBM, в плане производительности новинка втрое превосходит сервер POWER S814, поддержка которого закончится буквально на днях. Модификация в формате 2U половинной ширины позволяет сократить пространство для оборудования до 75 % по сравнению со стоечным сервером POWER S1014 (4U). Применение POWER S1012 на периферии даёт возможность выполнять определённые ИИ-задачи непосредственно в точке получения данных, что снижает задержки и уменьшает нагрузку на сетевые каналы.  Сервер POWER S1012 станет доступен у IBM и сертифицированных бизнес-партнёров 14 июня 2024 года. Клиенты смогут выбрать оптимальный для себя период поддержки в диапазоне от трёх до пяти лет. Кроме того, в зависимости от потребностей будут доступны дополнительные варианты обслуживания.
19.04.2024 [13:11], Сергей Карасёв
HPE обвинила китайскую Inspur в нарушении серверных патентов и обходе санкций СШАКорпорация HPE, по сообщению The Register, подала в суд на Inspur Group: крупнейший в Китае и один из крупнейших производителей серверов в мире обвиняется в незаконном использовании ряда запатентованных технологий. Иск направлен в инстанцию Северного округа Калифорнии (США). Истцы заявляют, что Inspur нарушила пять патентов HPE. Речь в них идёт, в частности, о методах и системах для управления массивами хранения, средствах определения энергопотребления в IT-сетях, инструментах эмуляции устройств и пр. Утверждается, что Inspur на протяжении нескольких лет игнорировала неоднократные предложения обсудить лицензирование технологий НРЕ. В судебных документах говорится, что в состав Inspur Group входит ряд дочерних компаний, работающих под разными названиями. В число ответчиков включены Inspur Group, Inspur Electronic Information Industry (IEIT Systems), Aivres Systems (ранее известна как Inspur Systems), Betapex (прежнее название — Inspur Asset Holdings), Inspur USA и KAYTUS Singapore Pte. Сама Inspur Group неоднократно попадала под санкции США. 
Источник изображения: Inspur Одной из причин смены названий некоторых структур, как отмечается в иске, является то, что в марте 2023 года Inspur Group была внесена в санкционный список Министерства торговли США. Компаниям из этого перечня необходимо получить лицензию от американского правительства для ведения бизнеса в США. Вместо этого, как утверждается в жалобе, Inspur Group просто поменяла имена дочерних компаний, чтобы продолжить продавать свое IT-оборудование на американском рынке. Вместе с тем, как считает НРЕ, компания Inspur продолжает продавать продукты, нарушающие патенты, под другими названиями. Например, сервер Aivres 5280M6, по сути, представляет собой переименованную версию Inspur IR5280M6. Оба решения имеют схожие названия, одни и те же изображения и идентичные технические характеристики. В целом, как говорится в иске, Inspur «нарушила многочисленные патенты HPE». Из-за того, что китайский производитель не ответил на предложения о лицензировании технологий, HPE будет отставить права на интеллектуальную собственность в судебном порядке. О выдвигаемых требованиях ничего не сообщается. |
|

