Материалы по тегу: io
|
05.05.2025 [13:28], Сергей Карасёв
GigaIO и d-Matrix предоставят инференс-платформу для масштабных ИИ-развёртыванийКомпании GigaIO и d-Matrix объявили о стратегическом партнёрстве с целью создания «самого масштабируемого в мире» решения для инференса, ориентированного на крупные предприятия, которые разворачивают ИИ в большом масштабе. Ожидается, что новая платформа поможет устранить узкие места в плане производительности и упростить внедрение крупных ИИ-систем. В рамках сотрудничества осуществлена интеграция ИИ-ускорителей d-Matrix Corsair в состав НРС-платформы GigaIO SuperNODE. Архитектура Corsair основана на модифицированных ячейках SRAM для вычислений в памяти (DIMC), работающих на скорости около 150 Тбайт/с. По заявлениям d-Matrix, ускоритель обеспечивает непревзойдённую производительность и эффективность инференса для генеративного ИИ. Устройство выполнено в виде карты расширения с интерфейсом PCIe 5.0 х16. Быстродействие достигает 2,4 Пфлопс с (8-бит вычисления). Изделие имеет двухслотовое исполнение, а показатель TDP равен 600 Вт. В свою очередь, SuperNODE использует фирменную архитектуру FabreX на базе PCIe, которая позволяет объединять различные компоненты, включая GPU, FPGA и пулы памяти. По сравнению с обычными серверными кластерами SuperNODE обеспечивает более эффективное использование ресурсов. 
Источник изображения: d-Matrix Новая модификация SuperNODE поддерживает десятки ускорителей Corsair в одном узле. Производительность составляет до 30 тыс. токенов в секунду при времени обработки 2 мс на токен для таких моделей, как Llama3 70B. По сравнению с решениями на базе GPU обещаны трёхкратное повышение энергоэффективности и в три раза более высокое быстродействие при сопоставимой стоимости владения. «Наша система избавляет от необходимости создания сложных многоузловых конфигураций и упрощает развёртывание, позволяя предприятиям быстро адаптироваться к меняющимся рабочим нагрузкам ИИ, при этом значительно улучшая совокупную стоимость владения и операционную эффективность», — говорит Alan Benjamin (Алан Бенджамин), генеральный директор GigaIO.
28.04.2025 [14:48], Сергей Карасёв
ИИ-суперкомпьютер в чемодане — GigaIO Gryf обеспечит производительность до 30 ТфлопсКомпания GigaIO объявила о доступности системы Gryf — так называемого ИИ-суперкомпьютера в чемодане, разработанного в сотрудничестве с SourceCode. Это сравнительно компактное устройство, как утверждается, обеспечивает производительность ЦОД-класса для периферийных развёртываний. Первая информация о Gryf появилась около года назад. Устройство выполнено в корпусе с габаритами 228,6 × 355,6 × 622,3 мм, а масса составляет примерно 25 кг. Система может эксплуатироваться при температурах от +10 до +32 °C. Конструкция предусматривает использование модулей Sled четырёх типов: это вычислительный узел Compute Sled, блок ускорителя Accelerator Sled, узел хранения Storage Sled и сетевой блок Network Sled. Доступны различные конфигурации, но суммарное количество модулей Sled в составе Gryf не превышает шести. Плюс к этому в любой комплектации устанавливается модуль питания с двумя блоками мощностью 2500 Вт. Узел Compute Sled содержит процессор AMD EPYC 7003 Milan с 16, 32 или 64 ядрами, до 512 Гбайт DDR4, системный SSD формата M.2 (NVMe) вместимостью 512 Гбайт и два порта 100GbE QSFP56. Блок Storage Sled объединяет восемь накопителей NVMe SSD E1.L суммарной вместимостью до 492 Тбайт. Модуль Network Sled предоставляет два порта QSFP28 100GbE и шесть портов SFP28 25GbE. За ИИ-производительность отвечает модуль Accelerator Sled, который может нести на борту ускоритель NVIDIA L40S (48 Гбайт), H100 NVL (94 Гбайт) или H200 NVL (141 Гбайт). В максимальной конфигурации быстродействие в режиме FP64 достигает 30 Тфлопс (3,34 Пфлопс FP8), а пропускная способность памяти — 4,8 Тбайт/с. 
Источник изображения: GigaIO Архитектура новинки обеспечивает возможность масштабирования путём объединения в единый комплекс до пяти экземпляров Gryf: в общей сложности можно совместить до 30 модулей Sled в той или иной конфигурации. Заказы на Gryf уже поступили со стороны Министерства обороны США, американских разведывательных структур и пр.
24.03.2025 [11:59], Руслан Авдеев
OpenAI и Meta✴ ведут переговоры с индийской Reliance Jio о сотрудничестве в сфере ИИMeta✴ и OpenAI по отдельности ведут переговоры с индийской Reliance Industries о потенциальном сотрудничестве для расширения ИИ-сервисов, сообщает The Information. Так, OpenAI хотела бы при помощи Reliance Jio расширить использование ChatGPT в Индии — об этом изданию сообщили два независимых источника, знакомых с вопросом. Более того, OpenAI обсуждала с сотрудниками сокращение стоимости подписок на платный вариант ChatGPT с $20/мес. до всего нескольких долларов. Пока неизвестно, велись ли разговоры об этом в ходе переговоров с Reliance. С последней, как утверждается, обсуждали продажу ИИ-моделей OpenAI корпоративным клиентам (через API). Также индийская компания заинтересована в локальном хостинге моделей OpenAI, чтобы данные местных клиентов будут храниться в пределах Индии. По имеющимся данным, с OpenAI и Meta✴ велись переговоры о запуске ИИ-моделей компаний в 3-ГВт ЦОД, который Reliance пока только планирует построить. Утверждается, что это будет «крупнейший дата-центр в мире» — его возведут в Джамнагаре (штат Гуджарат). Стоит отметить, что Reliance Industries является одним из крупнейших конгломератов Индии, имеющих интересы как в нефтегазовой отрасли, так и в IT и смежных отраслях, а также в сфере «зелёной» энергетики. 
Источник изображения: Shivam Mistry/unsplash.com Индия в целом считается очень перспективной страной для развития инвестиций в ИИ. Например, в конце прошлого года глава NVIDIA Дженсен Хуанг (Jensen Huang) заявил, что страна должна стать одним из лидеров в области ИИ и создать собственную инфраструктуру. Тогда сообщалось, что Индия на государственном уровне обсуждает с NVIDIA совместную разработку чипов для ИИ-проектов, адаптированных к местным задачам. Также страна осваивает связанные с ИИ технологии — например, она затратит $1,2 млрд на суверенный ИИ-суперкомпьютер с 10 тыс. ускорителей и собственные LLM, а также готова покупать много ускорителей, включая ослабленные варианты, которые не достались Китаю после ужесточения американских санкций. И это далеко не все проекты, находящиеся сейчас на стадии разработки и реализации.
06.03.2025 [13:45], Сергей Карасёв
1,5 Пбайт в 2U и 120 Гбайт/с: PEAK:AIO представила обновлённое All-Flash хранилище AI Data ServerБританский стартап PEAK:AIO анонсировал обновлённую платформу хранения данных AI Data Server, предназначенную для поддержания ресурсоёмких нагрузок ИИ. Сервер в форм-факторе 2U на основе SSD производства Solidigm обеспечивает 1,5 Пбайт «сырой» вместимости. PEAK:AIO утверждает, что благодаря новому программному стеку NVMe устраняются «узкие места Linux», что обеспечивает высокую производительность для приложений ИИ с интенсивным использованием данных. AI Data Server — это программно-определяемое хранилище на стороннем оборудовании. В частности, применяется сервер Dell PowerEdge R7625, оборудованный сетевыми адаптерами NVIDIA ConnectX-7. Заявленная пропускная способность достигает 120 Гбайт/с. Система комплектуется накопителями Solidigm D5-P5336 вместимостью 61,44 Тбайт. Эти изделия выполнены на 192-слойных чипах флеш-памяти QLC 3D NAND и оснащены интерфейсом PCIe 4.0 x4 (NVMe 2.0). Скорость последовательного чтения/записи достигает 7000/3000 Мбайт/с, показатель IOPS при произвольном чтении — 1 005 000. Сервер комплектуется 24 накопителями, что в сумме обеспечивает около 1,5 Пбайт ёмкости. 
Источник изображения: PEAK:AIO Платформа AI Data Server может использоваться для решения различных задач в специфичных областях, таких как здравоохранение, исследования и периферийные приложения ИИ. Подобные нагрузки требуют наличия высокопроизводительного хранилища, но зачастую доступ к инфраструктуре ЦОД у организаций из указанных отраслей ограничен. Система AI Data Server позволяет устранить данный пробел: она может масштабироваться от единичных узлов до кластеров, рассчитанных на огромные озера данных ИИ.
17.12.2024 [15:30], Руслан Авдеев
Российские компании с большой неохотой отказываются от Microsoft VisioОколо 83 % пользователей, регулярно создающих графики и блок-схемы в России, пользуются Microsoft Visio. По словам участников рынка, опрошенных «Коммерсантом», не помогает даже наличие российских аналогов — некоторые компании не готовы тратиться на переоснащение новым ПО и переобучение сотрудников. Как сообщает издание со ссылкой на статистику «ГрафТеха», разрабатывающего сходное по функциональности ПО, на конец ноября текущего года Microsoft Visio использовали в России более 500 тыс. из 600 тыс. потенциальных пользователей. А до 2022 году Visio использовали все 600 тыс. В «ГрафТехе» отмечают, что таким редактором пользуются преимущественно те компании, которые переходят на российские решения поэтапно: в первую очередь меняют оборудование, потом ИБ-решения и лишь потом ПО. Отечественные аналоги Visio имеются, в том числе бесплатные, но их функциональность не во всём совпадает с решением Microsoft. И хотя многим расширенные функции могут быть и не нужны, компании всё равно закупают Visio посредством параллельного импорта, а то и вовсе пользуются пиратскими версиями, говорят эксперты. Одной из причин называется нежелание перестраивать устоявшиеся бизнес-процессы, завязанные не столько на Visio, сколько на программную экосистему Microsoft. 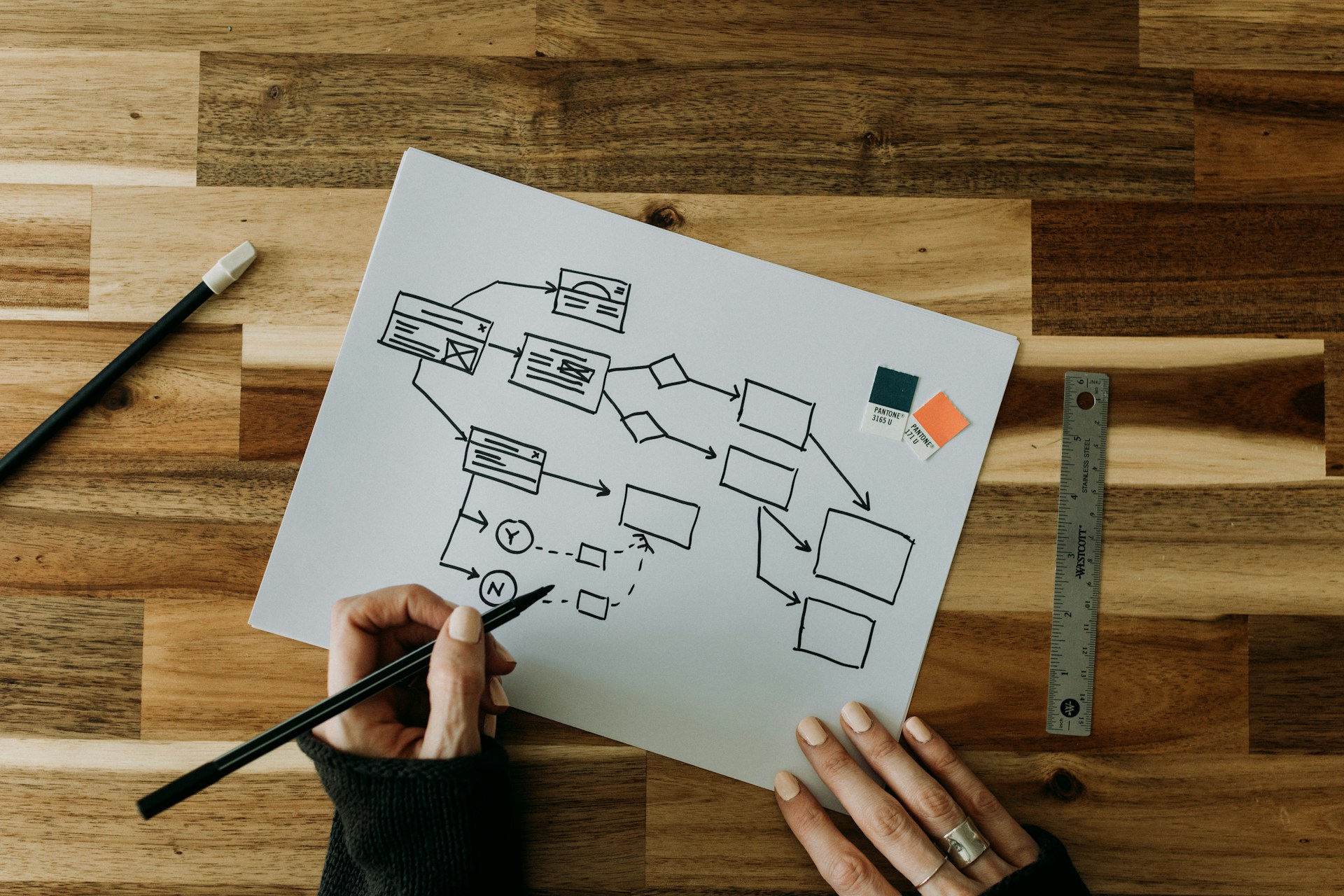
Источник изображения: Kelly Sikkema / Unsplash Некоторые эксперты подчёркивают, что бизнес-процессы придётся существенно перестраивать. Старая схема обычно предусматривала создание графика в Visio с последующей вставкой в Word и отправкой с помощью Microsoft Outlook. Хотя у некоторых компаний сохранились лицензионные версии ПО на собственных серверах, обновления они вряд ли получат в обозримом будущем. В «ГрафТехе» отмечают устойчивый тренд на импортозамещение: в 2025 и 2026 гг. доля Microsoft Visio должна снизиться на 19 и 12 % соответственно, а в 2027 — еще на 13 %. В компании считают, что важна совместимость с российскими операционными системами и соответствие новым стандартам информационной безопасности. Обязательное требование по миграции на российское ПО для многих отраслей сместили на 2030 год, поэтому закупку аналогов Visio многие опрошенные «ГрафТехом» закладывают на 2027-2028 гг. В списке ожиданий при закупке новых программных продуктов для создания блок-схем — кроссплатформенность, массовая установка и активация лицензий, качественная персонализированная техподдержка, а также ожидания найти более удобное и современное решение. Покупатели рассчитывают и получить конфигурацию продукта, позволяющую использовать его на терминальных серверах. Главным же является возможность полноценного переноса данных из Visio в другие программы. Большую часть уходящего года компания занималась разработкой конвертера, позволяющего без потерь переносить наработки из Microsoft Visio в «Автограф», предлагаемый самим «ГрафТехом».
19.05.2024 [20:33], Владимир Мироненко
WekaIO стала «единорогом» с рыночной стоимостью $1,6 млрдКомпания WekaIO (WEKA), разработчик платформы хранения данных WEKA Data Platform, объявила о завершении раунда финансирования серии Е, в ходе которого она привлекла $140 млн инвестиций и получила статус «единорога», поскольку её рыночная стоимость по итогам раунда оценивается в $1,6 млрд. Общий объём инвестиций в компанию на данный момент составляет $375 млн. Как сообщает WEKA, раунд прошёл с превышением подписки (объём предлагаемых инвестиций превысил ожидания) с продажей акций на первичном и вторичном рынках. Раунд возглавила уже ранее инвестировавшая в компанию Valor Equity Partners. По условиям сделки основатель, гендиректор и директор по инвестициям Valor Антонио Грасиас (Antonio Gracias) войдёт в совет директоров WEKA. Также в раунде участвовали другие существующие инвесторы, включая Generation Investment Management, NVIDIA, Atreides Management, 10D, Hitachi Ventures, Ibex Investors, Key1 Capital, Lumir Ventures, MoreTech Ventures и Qualcomm Ventures. 
Источник изображения: WekaIO Согласно пресс-релизу, привлечённые средства увеличат денежные резервы компании, ускорят масштабирование бизнеса и позволят расширить разработку продуктов, а также предоставят ликвидность сотрудникам WEKA. Компания отметила, что переживает период стремительного роста — более 300 крупнейших в мире ИИ-проектов используют платформу WEKA Data Platform. «Недавнее ускорение внедрения генеративного ИИ и всё более частое использование компаниями облаков спровоцировали резкий рост спроса, что привело к беспрецедентному количеству сделок с восьмизначным ARR (годовой регулярный доход) — впечатляющий результат, если учесть, что WEKA — это бизнес в области ПО», — отметил финансовый директор компании. Он заявил, что сейчас подходящее время для укрепления денежных резервов компании, это позволило инвесторам увеличить свои позиции в ней, одновременно сведя к минимуму размывание акций сотрудников Как сообщается, платформа WEKA Data Platform может быть развёрнута в любом месте. Она обеспечивает беспрецедентную скорость, простоту, масштабируемость и устойчивость для GPU-вычислений, ИИ и других ресурсоёмких рабочих нагрузок. Согласно данным маркетплейса AWS, WEKA Data Platform идеально подходит для ресурсоёмких рабочих нагрузок, таких как ИИ и машинное обучение, финансовое моделирование, медико-биологические исследования, рендеринг, Big Data.
10.05.2024 [11:32], Сергей Карасёв
Суперкомпьютер в стойке GigaIO SuperNODE обзавёлся поддержкой AMD Instinct MI300XКомпания GigaIO анонсировала новую модификацию системы SuperNODE для рабочих нагрузок генеративного ИИ и приложений НРС. Суперкомпьютер в стойке теперь может комплектоваться ускорителями AMD Instinct MI300X, благодаря чему значительно повышается производительность при работе с большими языковыми моделями (LLM). Решение SuperNODE, напомним, использует фирменную архитектуру FabreX на базе PCI Express, которая позволяет объединять различные компоненты, включая GPU, FPGA и пулы памяти. По сравнению с обычными серверными кластерами SuperNODE даёт возможность более эффективно использовать ресурсы. Изначально для SuperNODE предлагались конфигурации с 32 ускорителями AMD Instinct MI210 или 24 ускорителями NVIDIA A100. Новая версия допускает использование 32 изделий Instinct MI300X. Утверждается, что архитектура FabreX в сочетании с технологией интерконнекта AMD Infinity Fabric наделяет систему SuperNODE «лучшими в отрасли» возможностями в плане задержек при передаче данных, пропускной способности и управления перегрузками. Это позволяет эффективно справляться с обучением LLM с большим количеством параметров. 
Источник изображения: GigaIO Отмечается, что SuperNODE значительно упрощает процесс развёртывания и управления инфраструктурой ИИ. Традиционные конфигурации обычно включают в себя сложную сеть и необходимость синхронизации нескольких серверов, что создаёт определённые технических сложности и приводит к дополнительным временным затратам. Конструкция SuperNODE с 32 мощными ускорителями в рамках одной системы позволяет решить указанные проблемы.
08.05.2024 [13:24], Сергей Карасёв
ИИ-суперкомпьютер в чемодане — GigaIO представила платформу GryfКомпания GigaIO совместно с SourceCode анонсировала вычислительную систему Gryf. Это, как утверждается, первый в мире суперкомпьютер для ИИ-нагрузок, выполненный в виде чемодана на колёсиках. Изделие имеет габариты 228,6 × 355,6 × 622,3 мм и весит около 25 кг. Применяется фирменная система интерконнекта FabreX на базе PCI Express. Конфигурация Gryf предусматривает использование модулей (Sled) четырёх типов: это вычислительный узел (Compute Sled), блок ускорителя (Accelerator Sled), узел хранения (Storage Sled) и сетевой блок (Network Sled). Они могут компоноваться в различных сочетаниях, но общее количество модулей в рамках одного экземпляра Gryf не превышает шести. В состав Compute Sled входят процессор AMD EPYC 7313 Milan (16C/32T; 3,0–3,7 ГГц; 155 Вт), 256 Гбайт DDR4-3200, системный накопитель NVMe M.2 SSD вместимостью 256 Гбайт и два 100GbE-порта QSFP56/QSFP28. Может применяться ОС Linux Rocky 8/9 или Ubuntu 20/24. В свою очередь, Accelerator Sled содержит ускоритель NVIDIA L40S (48 Гбайт). Модуль Storage Sled объединяет восемь накопителей NVMe E1.L SSD суммарной вместимостью 246 Гбайт. 
Источник изображения: GigaIO Наконец, Network Sled предоставляет два разъёма QSFP56 100GbE и шесть 25GbE-портов SFP28. Вся система получает питание от двух блоков мощностью 2500 Вт каждый. Применены шесть вентиляторов охлаждения диаметром 60 мм. Диапазон рабочих температур — от 10 до +32 °C. Одно устройство Gryf обеспечивает производительность до 91,6 Тфлопс FP32, до 733 Тфлопс FP16 и до 1466 Тфлопс FP8. При этом в единый комплекс могут быть связаны до пяти экземпляров Gryf, что позволяет масштабировать быстродействие для выполнения тех или иных задач.
29.03.2024 [13:39], Сергей Карасёв
GigaIO представила оптические кабели PCIe 5.0 для развёртывания масштабных ИИ-кластеровКомпания GigaIO, разрабатывающая систему распределённого интерконнекта на базе PCI Express под названием FabreX, представила первые в отрасли оптические кабели QSFP-DD с поддержкой PCIe 5.0. Отмечается, что оптические кабели обеспечивают ряд преимуществ перед традиционными медными соединениями. Это, в частности, повышенная пропускная способность. Кроме того, длина оптических линий может превышать 3 м, что является ограничением для медных кабелей. Представленные кабели используют конфигурацию PCIe 5.0 x8 с возможностью агрегации 16 линий. Благодаря этим изделиям упрощается развёртывание высокопроизводительных систем GigaIO SuperNODE, которые позволяют связать воедино до 32 ускорителей посредством упомянутой платформы FabreX. 
Фото: LinkedIn/GigaIO Отмечается, что оптические кабели способны обеспечить передачу данных с высокой скоростью на десятки метров. Таким образом, несколько систем SuperNODE или SuperDuperNODE могут быть объединены в единый кластер для решения наиболее ресурсоёмких задач ИИ. Медные соединения обычно ограничивают размер кластеров двумя–тремя стойками. В случае оптических кабелей предоставляется гораздо большая гибкость в плане конфигурации оборудования. В результате системы SuperNODE могут быть развёрнуты даже в тех дата-центрах, в которых существуют жёсткие ограничения по мощности и охлаждению в расчёте на стойку. Оптические кабели QSFP-DD с поддержкой PCIe 5.0 станут доступны предстоящим летом.
24.03.2024 [02:19], Сергей Карасёв
WEKApod для SuperPOD: WekaIO представила платформу хранения данных для ИИ-кластеров NVIDIAКомпания WekaIO, разработчик решений для хранения данных, анонсировала высокопроизводительное All-Flash хранилище WEKApod, оптимизированное для работы с платформой NVIDIA DGX SuperPOD на базе NVIDIA DGX H100. Новинка объединяет специализированное ПО WekaIO и «лучшее в своем классе оборудование». Хранилище WEKApod спроектировано для ресурсоёмких нагрузок ИИ. Базовая конфигурация состоит из восьми 1U-узлов, обеспечивающих суммарную вместимость в 1 Пбайт. Показатель IOPS (операций ввода-вывода в секунду) достигает 18,3 млн. Заявленная пропускная способность при чтении составляет до 720 Гбайт/с, при записи — до 186 Гбайт/с. Утверждается, что восемь узлов WEKApod обеспечивает производительность, необходимую для 128 систем NVIDIA DGX H100. При этом WEKApod может масштабироваться до сотен узлов блоками по четыре узла. Таким образом, можно сформировать систему необходимой вместимости с высокой отказоустойчивостью для обучения больших языковых моделей (LLM), ИИ-приложений, работающих в реальном времени, и пр. 
Источник изображения: WekaIO Отмечается, что архитектура WEKApod обеспечивает снижение энергопотребления благодаря оптимальному использованию пространства, улучшенному охлаждению и средствам энергосбережения в режиме простоя. В результате, достигается потенциальное сокращение углеродного следа до 260 т/Пбайт. WEKApod использует адаптеры NVIDIA ConnectX-7 и NVIDIA Base Command Manager для мониторинга и управления. Каждый из узлов несёт на борту процессор AMD EPYC 9454P (48C/96T; 2,75–3,80 ГГц; 290 Вт) и 384 Гбайт памяти DDR5-4800. Есть посадочные места для 14 накопителей формата E3.S с интерфейсом PCIe 5.0. Производительность в расчёте на узел достигает 90 Гбайт/с при чтении и 23,3 Гбайт/с при записи, а величина IOPS равна 2,3 млн при произвольном чтении и 535 тыс. при произвольной записи. |
|

