Материалы по тегу: io
|
29.12.2023 [18:10], Руслан Авдеев
Reliance создаст индийскую языковую модель Bharat GPT и развернёт ИИ-экосистему Jio 2.0Глава индийской Reliance Jio Акаш Амбани (Akash Ambani) раскрыл планы компании на ближайшее будущее. По данным DigiTimes, компания намерена расширять работу над генеративными ИИ-решениями и, что не менее важно, обновить мобильную экосистему Jio, представив вариант 2.0, включающий продукты и сервисы на основе искусственного интеллекта. Как свидетельствует опрос, проведённый Automation Anywhere, 63 % индийских компаний инвестируют в ИИ и технологии машинного обучения для автоматизации собственных бизнес-процессов уже в ближайшие 12 месяцев. Рост инвестиций в ИИ-сектор составил 85 % год к году, а 33 % этих компаний полагаются на ИИ как на драйвер будущего роста. 
Источник изображения: geralt/pixabay.com По информации индийских и зарубежных СМИ, на мероприятии IIT Bombay TechFest, проводившемся Индийским технологическим институтом Бомбея (IIT Bombay), компанией было объявлено о совместной разработке с институтом ИИ-проекта Bharat GPT. Преимущество Reliance Jio в её многопрофильности — это не просто телеком-оператор, но и поставщик потокового медиаконтента, оператор площадок для электронной коммерции и т.п. Сообщается, что Reliance планирует запустить ИИ-сервисы во всех сферах своей деятельности, включая медиа- и коммуникационные проекты, и даже внедрять их на предлагаемых компанией устройствах. Более того, по данным Амбани компания разрабатывает собственную ОС для смарт-телевизоров и уже обдумывает механизмы её внедрения. Более подробной информации об экосистеме Jio 2.0 бизнесмен не предоставил. Впрочем, о создании большой языковой модели и масштабной ИИ-инфраструктуры компанией Reliance совместно с NVIDIA сообщалось ещё в сентябре. По прогнозам экспертов EY India, генеративный ИИ, вероятно, совокупно добавит $1,2–1,5 трлн в ВВП страны в следующие семь лет. При этом в краткосрочной перспективе развитие отрасли, вероятно, столкнётся с проблемами из-за дефицита кадров.
07.12.2023 [16:54], Сергей Карасёв
GigaIO создаст уникальное ИИ-облако с тысячами ускорителей AMD Instinct MI300XКомпания GigaIO объявила о заключении соглашения по созданию инфраструктуры для специализированного ИИ-облака TensorNODE, которое создаётся провайдером TensorWave. В составе платформы будут применяться ускорители AMD Instinct MI300X, оснащённые 192 Гбайт памяти HBM3. Основой TensorNODE послужат мини-кластеры SuperNODE, дебютировавшие летом уходящего года. Особенность этого решения заключается в том, что оно позволяет связать воедино 32 и даже 64 ускорителя посредством распределённого интерконнекта на базе PCI Express. TensorWave будет использовать FabreX для формирования пулов памяти петабайтного масштаба. На первом этапе в начале 2024 года платформа TensorNODE объединит до 5760 ускорителей Instinct MI300X в одном домене. Таким образом, при решении сложных задач можно будет получить доступ более чем к 1 Пбайт памяти с любого узла. Это, как отмечается, позволит обрабатывать даже самые ресурсоёмкие нагрузки в рекордно короткие сроки. 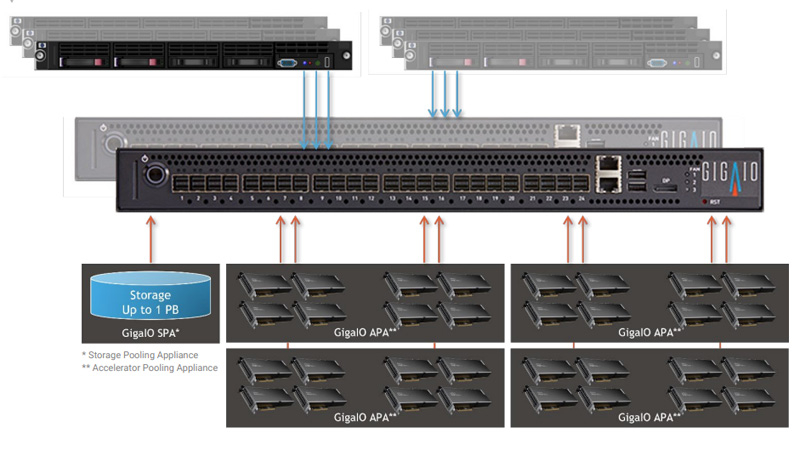
Источник изображения: GigaIO В течение следующего года планируется развернуть несколько систем TensorNODE. Архитектура GigaIO обеспечит улучшенную гибкость по сравнению с традиционными решениями: инфраструктуру можно будет оптимизировать «на лету» для удовлетворения как текущих, так и будущих потребностей в области ИИ и больших языковых моделей (LLM). Отмечается, что TensorNODE полностью базируется на ключевых компонентах AMD. Помимо ускорителей Instinct MI300X, это процессоры EPYC Genoa. Облако TensorWave обеспечит снижение энергозатрат и общей стоимости владения благодаря исключению из конфигурации избыточных серверов и связанного с ними сетевого оборудования.
11.11.2023 [23:59], Алексей Степин
СуперДупер: GigaIO SuperDuperNODE позволяет объединить посредством PCIe сразу 64 ускорителяКомпания GigaIO, чьей главной разработкой является система распределённого интерконнекта на базе PCI Express под названием FabreX, поставила новый рекорд — в новой платформе разработчикам удалось удвоить количество одновременно подключаемых PCIe-устройств, увеличив его с 32 до 64. О разработках GigaIO мы рассказывали читателям неоднократно. Во многом они действительно уникальны, поскольку созданная компанией композитная инфраструктура позволяет подключать к одному или нескольким серверам существенно больше различных ускорителей, нежели это возможно в классическом варианте, но при этом сохраняет высокий уровень утилизации этих ускорителей. 
GigaIO SuperNODE. Источник изображений здесь и далее: GigaIO В начале года компания уже демонстрировала систему с 16 ускорителями NVIDIA A100, а летом GigaIO представила мини-кластер SuperNODE. В различных конфигурациях система могла содержать 32 ускорителя AMD Instinct MI210 или 24 ускорителя NVIDIA A100, дополненных СХД ёмкостью 1 Пбайт. При этом система в силу особенностей FabreX не требовала какой-либо специфической настройки перед работой. 
FabreX позволяет физически объединить все типы ресурсов на базе существующего стека технологий PCI Express На этой неделе GigaIO анонсировала новый вариант своей HPC-системы, получившей незамысловатое название SuperDuperNODE. В ней она смогла удвоить количество ускорителей с 32 до 64. Как и прежде, система предназначена, в первую очередь, для использования в сценариях генеративного ИИ, но также интересна она и с точки зрения ряда HPC-задач, в частности, вычислительной гидродинамики (CFD). Система SuperNODE смогла завершить самую сложную в мире CFD-симуляцию всего за 33 часа. В ней имитировался полёт 62-метрового авиалайнера Конкорд. Хотя протяжённость модели составляет всего 1 сек, она очень сложна, поскольку требуется обсчёт поведения 40 млрд ячеек объёмом 12,4 мм3 на протяжении 67268 временных отрезков. 29 часов у системы ушло на обсчёт полёта, и ещё 4 часа было затрачено на рендеринг 3000 4К-изображений. С учётом отличной масштабируемости при использовании SuperDuperNODE время расчёта удалось сократить практически вдвое. Как уже упоминалось, FabreX позволяет малой кровью наращивать число ускорителей и иных мощных PCIe-устройств на процессорный узел при практически идеальном масштабировании. Обновлённая платформа не подвела и в этот раз: в тесте HPL-MxP пиковый показатель утилизации составил 99,7 % от теоретического максимума, а в тестах HPL и HPCG — 95,2 % и 88 % соответственно. Компания-разработчик сообщает о том, что программное обеспечение FabreX обрело завершённый вид и без каких-либо проблем обеспечивает переключение режимов SuperNODE между Beast (система видна как один большой узел), Swarm (множество узлов для множества нагрузок) и Freestyle Mode (каждой нагрузке выделен свой узел с заданным количеством ускорителей). Начало поставок SuperDuperNODE запланировано на конец года. Партнёрами, как и в случае с SuperNODE, выступят Dell и Supermicro.
09.09.2023 [11:27], Сергей Карасёв
NVIDIA и Reliance создадут большую языковую модель для Индии и развернут ИИ-инфраструктуру мощностью до 2 ГВтКомпании NVIDIA и Reliance Industries сообщили о заключении соглашения о сотрудничестве, которое предусматривает разработку большой языковой модели для Индии. Она будет обучена на различных языках страны и адаптирована для приложений генеративного ИИ. Кроме того, будет построена отдельная ИИ-инфраструктура мощностью до 2000 МВт. Внедрением системы займутся специалисты компании Jio. Партнёры намерены развернуть аппаратную ИИ-инфраструктуру, которая по производительности более чем на порядок превзойдёт самый мощный суперкомпьютер Индии. Для этого планируется задействовать суперчипы NVIDIA GH200 Grace Hopper, а также облачный сервис DGX Cloud. Говорится, что платформа NVIDIA станет основой ИИ-вычислений для Reliance Jio Infocomm, телекоммуникационного подразделения Reliance Industries. В рамках партнёрства Reliance будет создавать приложения и услуги на основе ИИ для примерно 450 млн клиентов Jio, а также предоставит энергоэффективную ИИ-инфраструктуру учёным, разработчикам и стартапам по всей Индии. 
Источник изображения: Reliance Industries Применять ИИ планируется в самых разных отраслях — в сельском хозяйстве, медицине, климатологии и пр. В частности, приложения нового типа помогут предсказывать циклонические штормы, а также улучшат экспертную диагностику симптомов тех или иных заболеваний. Похожий проект реализуется и с Tata Group.
18.07.2023 [22:45], Сергей Карасёв
Суперкомпьютер в стойке: GigaIO SuperNODE позволяет объединить 32 ускорителя AMD Instinct MI210Компания GigaIO анонсировала HPC-систему SuperNODE, предназначенную для решения ресурсоёмких задач в области генеративного ИИ. SuperNODE позволяет связать воедино до 32 ускорителей посредством компонуемой платформы GigaIO FabreX. Архитектура FabreX на базе PCI Express, по словам создателей, намного лучше InfiniBand и NVIDIA NVLink по уровню задержки и позволяет объединять различные компоненты — GPU, FPGA, пулы памяти и пр. SuperNODE даёт возможность более эффективно использовать ресурсы, нежели в случае традиционного подхода с ускорителями в составе нескольких серверов. В частности для SuperNODE доступны конфигурации с 32 ускорителями AMD Instinct MI210 или 24 ускорителями NVIDIA A100 с хранилищем ёмкостью до 1 Пбайт. При этом платформа компактна, энергоэффективна (до 7 кВт) и не требует дополнительной настройки перед работой. 
Источник изображений: GigaIO Поскольку приложения с большими языковыми моделями требуют огромных вычислительных мощностей, технологии, которые сокращают количество необходимых обменов данными между узлом и ускорителем, имеют решающее значение для обеспечения необходимой скорости выполнения операций при снижении общих затрат на формирование инфраструктуры. Что немаловажно, платформ, по словам разработчиков, демонстрирует хорошую масштабируемость производительности при увеличении числа ускорителей. 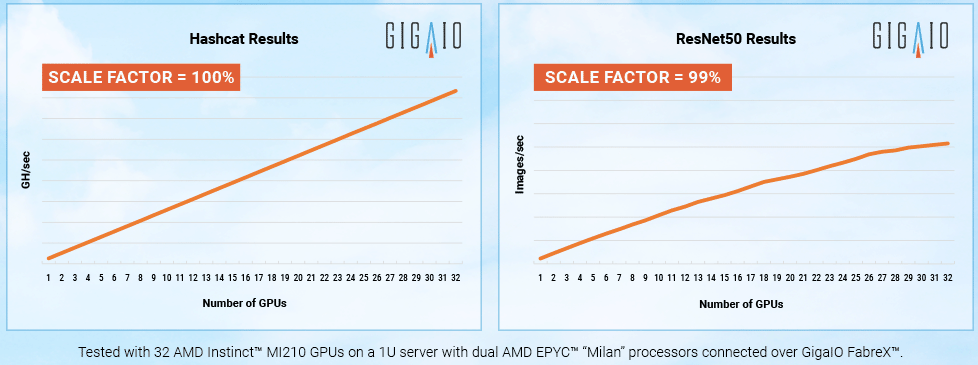 «Система SuperNODE, созданная GigaIO и работающая на ускорителях AMD Instinct, обеспечивает привлекательную совокупную стоимость владения как для традиционных рабочих нагрузок HPC, так и для задач генеративного ИИ», — сказал Эндрю Дикманн (Andrew Dieckmann), корпоративный вице-президент и генеральный менеджер по дата-центрам AMD. Стоит отметить, что у AMD нет прямого аналога NVIDIA NVLink, так что для объединение ускорителей в большие пулы с высокой скоростью подключения возможно как раз с использованием SuperNODE.
10.05.2023 [12:57], Сергей Карасёв
Внедрение облачных приложений стимулирует рост рынка ПО для малого и среднего бизнесаКомпания Technavio обнародовала прогноз по глобальному рынку ПО для малого и среднего бизнеса. По мнению аналитиков, в ближайшие годы развитию соответствующего сегмента будет способствовать внедрение облачных приложений в различных отраслях. Отмечается, что растущий спрос на облачные бизнес-решения, такие как ERP, связан прежде всего с более низкими первоначальными затратами и ускоренным развёртыванием. Облачные продукты предоставляют и ряд других преимуществ, в частности, согласованность операций в организации, высокий уровень доступности, отсутствие необходимости в специалистах поддержки, своевременное обновление и снижение расходов на локальное оборудование. 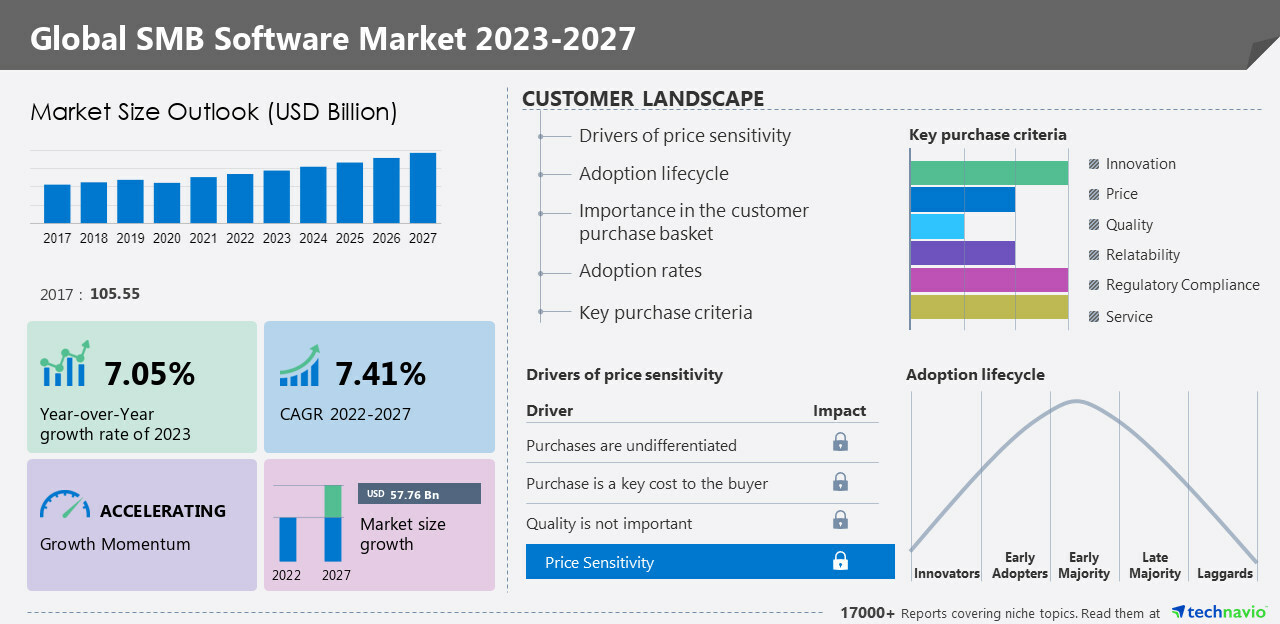
Technavio полагает, что в период с 2022 по 2027 гг. величина CAGR (среднегодовой темп роста в сложных процентах) на рынке ПО для малого и среднего бизнеса составит около 7,41 %. В результате, к концу рассматриваемого периода прирост в денежном выражении окажется на уровне $57,76 млрд. Среди ключевых игроков отрасли названы Accenture, Acumatica, Cisco Systems, Epicor Software, IBM, Microsoft, Newgen Software Technologies, Sage Group, SAP, Oracle и др. По оценкам, на Северную Америку придется 34 % роста мирового рынка в течение прогнозируемого периода. Доминирование региона обусловлено наличием развитой IT-инфраструктуры. Расширению отрасли в целом, по мнению экспертов, будет способствовать рост востребованности ПО для малого и среднего бизнеса. Среди ключевых тенденций на ближайшие годы Technavio выделяет увеличение количества сделок по слияниям и поглощениям в сегменте бизнес-софта. Сдерживающими факторами станут недостаточная осведомлённость о ПО для малого и среднего бизнеса в развивающихся странах, неэффективное управление и вопросы обеспечения безопасности.
28.04.2022 [22:54], Алексей Степин
Chelsio представила седьмое поколение сетевых чипов Terminator: 400GbE и PCIe 5.0 x16Компания Chelsio Communications анонсировала седьмое поколение своих сетевых процессоров Terminator с поддержкой 400GbE. От предшественников T7 отличает более развитая вычислительная часть общего назначения, включающая в себя до 8 ядер Arm Cortex-A72, так что их уже можно назвать DPU. Всего представлено пять вариантов 5 чипов (T7, N7, D7, S74 и S72), которые различаются между собой набором движков и ускорителей. Референсная платформа T7 будет доступна в мае, первых же адаптеров на базе новых DPU следует ожидать в III квартале 2022 года. Для задач сжатия, дедупликации или криптографии есть отдельные сопроцессоры. Никуда не делся и привычный для серии Unified Wire встроенный L2-коммутатор. Для подключения к хосту T7 теперь использует шину PCIe 5.0 x16, причём он же содержит и root-комплекс. Более того, имеется и набортный коммутатор+мост PCIe 4.0, и NVMe-интерфейс, и даже поддержка эмуляции NVMe. Всё это, к примеру, позволяет легко и быстро создать NVMe-oF хранилище или мост NVMe-NVMe для компрессии и шифрования данных на лету. Новинка предлагает ускорение работы RoCEv2 и iWARP, FCoE и NVMe/TCP, iSCSI и iSER, а также RAID5/6. Сетевая часть поддерживает разгрузку Open vSwitch и Virt-IO. 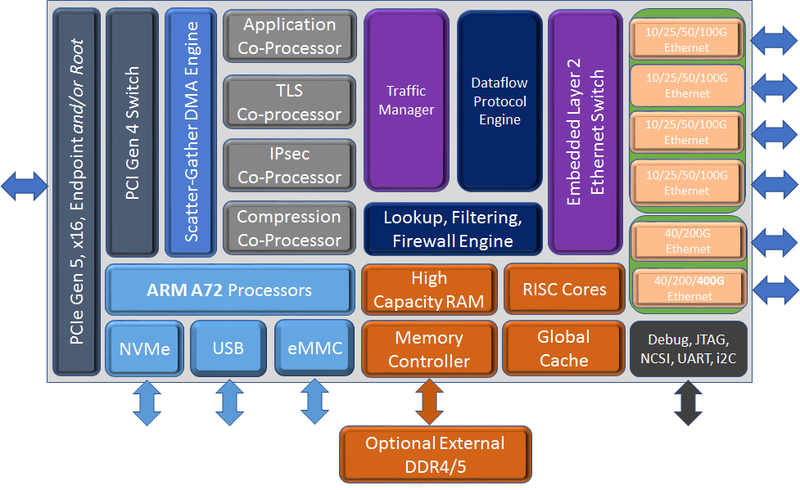
Блок-схема старшего варианта T7 (Изображения: Chelsio Communcations) Впрочем, поддержки P4 тут нет — Chelsio продолжает использовать собственные движки для обработки трафика. Но наработки, сделанные для серий T5 и T6, будет проще перенести на новое поколение чипов. Кроме того, появилась и практически обязательная нынче «глубокая» телеметрия всего проходящего через DPU трафика для повышения управляемости и его защиты. Если и этого окажется мало, то к T7 (и D7) можно напрямую подключить FPGA, а набортную память расширить банками DDR4/5. В пресс-релизе также отмечается, что T7 сможет стать достойной заменой InfiniBand в HРC-системах. 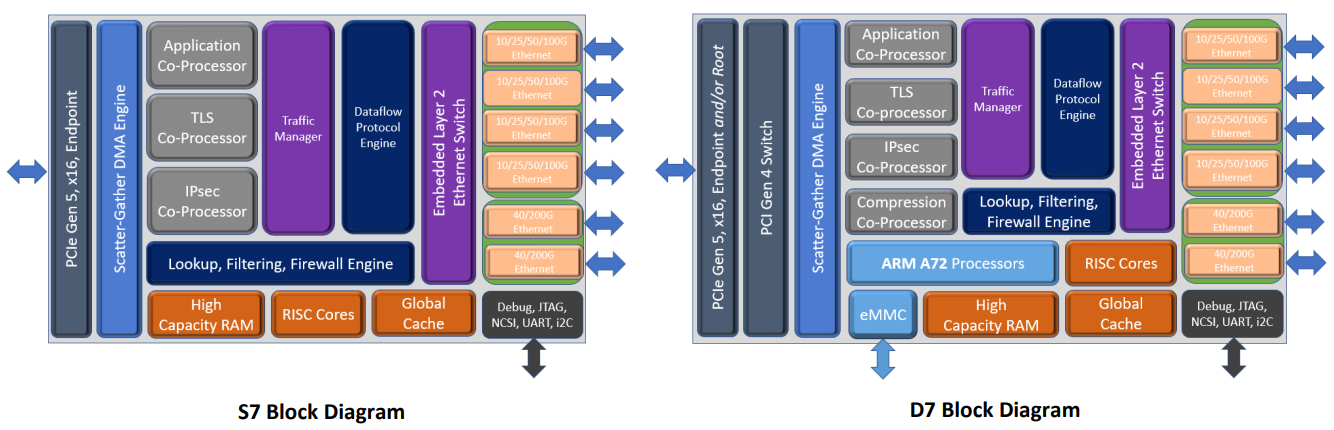 Вариант D7 наиболее близок к T7, но предлагает только 200GbE-подключение, лишён некоторых функций и второстепенных интерфейсов, да и в целом рассчитан на создание СХД. N7, напротив, лишён Arm-ядер и всех функций для работы с хранилищами, нет у него и PCIe-коммутатора и моста. Предлагает он только 200GbE-интерфейсы. Наконец, чипы серии S7 лишены целого ряда второстепенных функций и предоставляют только 100/200GbE-подключение. Они относятся скорее к SmartNIC, поскольку начисто лишены Arm-ядер и некоторых функций. Но зато они и недороги. Кроме того, в седьмом поколении Termintator появилась возможность обойтись без набортной DRAM с сохранением всей функциональности. Так что использование памяти хоста позволит дополнительно снизить стоимость конечных решений, которые будут создавать OEM-производители. Сами чипы производятся с использованием техпроцесса TSMC 12-нм FFC, так что даже у старшей версии чипов типовое энергопотребление не превышает 22 Вт. |
|

