Материалы по тегу: hpc
|
20.01.2026 [21:58], Владимир Мироненко
Tesla возобновит строительство ИИ-суперкомпьютеров DojoГендиректор Tesla (Elon Musk) Илон Маск объявил в соцсети Х о решении компании возобновить работу над Dojo3, третьим поколением суперкомпьютерных систем, о чём сообщает Data Center Dynamics. Команда, занимавшаяся проектом Dojo, была расформирована в прошлом году в связи с тем, что компания отдала предпочтение ИИ-чипам, используемых в бортовых системах электромобилей. Также ранее было объявлено, что компания будет полагаться на чипы внешних партнёров. Вместе с тем компания возвращается к проекту Dojo, поскольку, по словам Маска, достигнуты успехи в разработке чипа AI5, что создало определённый запас прочности. Маск объявил, что однокристальный чип AI5 обеспечит производительность на уровне NVIDIA Hopper, при этом двухкристальный AI5 будет равен по мощности чипу с Blackwell. Он предложил всем заинтересованным в участии в проекте и «работе над созданием самых массово производимых в мире микросхем» отправить сообщение Tesla, указав в трёх пунктах самые сложные технические проблемы, которые они решили. Илон Маск также сообщил, что разработка чипа Tesla AI5 почти завершена, а чип AI6 находится на «ранней стадии» разработки, добавив, что компания также планирует создать чипы AI7, AI8 и AI9. По его словам, нынешний чип Tesla AI4 позволит достичь «уровня безопасности при автономном вождении, намного превышающего человеческий», а AI5 сделает электромобили Tesla «почти идеальными», также значительно улучшив функционирование человекоподобного робота Optimus. «AI6 для Optimus и ЦОД. AI7/Dojo3 будут использовать ИИ для космических вычислений», — написал Маск. В ноябре 2025 года он заявил, что существует «чёткий путь к удвоению производительности по всем показателям для AI6 в течение 10–12 мес. после выпуска AI5», а теперь он намерен сократить срок создания каждого нового поколения ИИ-чипов до 9 мес. Хотя сам миллиардер не стал называть сроки производства чипа AI5, ИИ-чат-бот Grok сообщил пользователям в ответ на запросы, что ограниченное производство AI5 ожидается в 2026 году, а массовое производство запланировано на 2027 год. 
Источник изображения: Tesla В конце прошлого года Маск заявил акционерам Tesla, что компании, вероятно, потребуется построить «гигантскую фабрику» для производства своих ИИ-чипов, чтобы хотя бы частично удовлетворить в них потребности компании. Tesla уже сотрудничает с TSMC и Samsung, которые производят чипы AI5 и AI6 на заводах в Аризоне и Тайване, а также в Южной Корее и Техасе соответственно. На том же собрании акционеров Маск сказал, что, вероятно, стоит обсудить вопрос производства и с Intel. Как отметил Techpowerup, в августе прошлого года появились сообщения о присоединении к компании Маска Intel в качестве ключевого партнёра по упаковке чипов, что ознаменовало отход Tesla от прежней зависимости от TSMC в вопросах производства. Сообщается, что Intel будет управлять сборкой и тестированием, используя свою технологию EMIB. Это лучше подходит для больших блоков Tesla Dojo, объединяющих несколько чипов площадью 654 мм² в одном корпусе. В свою очередь, Samsung будет производить обучающие чипы D3 на своем заводе в Техасе с помощью 2-нм техпроцесса, оставив Intel контроль над процессами упаковки. Такое разделение труда решает проблему ограничений производственных мощностей и предоставляет Tesla большую гибкость в настройке схем межсоединений. Для автомобильных чипов AI5 компании Samsung и TSMC создадут разные версии, хотя Tesla стремится обеспечить одинаковую производительность в обоих случаях. Предполагается, что AI5 будет потреблять 150 Вт, при этом соответствуя по производительности NVIDIA H100, у которого TDP составляет до 700 Вт. Это было достигнуто путём удаления графических подсистем общего назначения и оптимизации архитектуры специально для ИИ-алгоритмов Tesla.
20.01.2026 [10:02], Владимир Мироненко
FP64 у вас ненастоящий: AMD сомневается в эффективности эмуляции научных расчётов на тензорных ядрах NVIDIAВместо создания специализированных чипов для аппаратных FP64-вычислений NVIDIA использует эмуляцию для повышения производительности HPC на ИИ-ускорителях, пишет The Register. Компания отказалась от развития FP64-блоков в поколении Blackwell Ultra, а в новейших ускорителях Rubin пиковая заявленная производительность векторных FP64-вычислений составляет 33 Тфлопс, тогда как у H100, вышедшего четыре года назад, она была равна 34 Тфлопс, а у Blackwell — около 40 Тфлопс. Если включить программную эмуляцию в библиотеках CUDA от NVIDIA, ускоритель, как утверждается, может достичь производительности до 200 Тфлопс в матричных FP64-вычислениях. Впрочем, и Blackwell с эмуляций способен выдать в этом случае до 150 Тфлопс, тогда как у Hopper были «честные» 67 Тфлопс. «В ходе многочисленных исследований с партнёрами и собственных внутренних изысканий мы обнаружили, что точность, достигаемая с помощью эмуляции, как минимум не уступает точности, получаемой от аппаратных тензорных ядер», — сообщил ресурсу The Register Дэн Эрнст (Dan Ernst), старший директор по суперкомпьютерным продуктам NVIDIA. В свою очередь, в AMD считают, что это утверждение справедливо не для всех сценариев. «В некоторых бенчмарках она показывает довольно хорошие результаты, но в реальных физических научных симуляциях это не очевидно», — говорит Николас Малайя (Nicholas Malaya), научный сотрудник AMD. Он выразил мнение, что, хотя эмуляция FP64, безусловно, заслуживает дальнейших исследований и экспериментов, такое решение ещё не готово к широкому применению. AMD и сама изучает возможность программной эмуляции FP64 на Instinct MI355X, чтобы определить области её возможного применения. 
Источник изображения: Hilda Trinidad / Unsplash Хотя чипы всё чаще используют типы данных с более низкой точностью, FP64 остаётся золотым стандартом для научных вычислений, и на то есть веские причины — FP64 не имеет себе равных по динамическому диапазону. Современные же LLM обучаются с использованием FP8-вычислений, а компактные типы данных MXFP8/MXFP4 или NVFP4 позволяют получить достаточный для ИИ диапазон значений. Это хорошее решение для нечёткой математики больших языковых моделей, но это не замена FP64 для HPC. ИИ-нагрузки обладают высокой устойчивостью к ошибкам, а HPC-задачи требуют высокой точности. AMD указала на то, что эмуляция FP64 у NVIDIA не совсем соответствует стандарту IEEE. Алгоритмы NVIDIA не учитывают такие понятия, как положительные и отрицательные нули, ошибки NaN (Not a Number) и ошибки infinite number (бесконечное число). Из-за этого небольшие ошибки в промежуточных вычислениях, используемых для эмуляции более высокой точности, могут привести к искажениям, способным повлиять на точность конечного результата, пояснил Малайя. По его словам, целесообразность использования эмуляции FP64 зависит от конкретного приложения. Эмуляция FP64 лучше всего работает для хорошо обусловленных проблем, где малые изменения «на входе» приводят к малым же изменениям в конечном результате. Ярким примером такой задачи является бенчмарк Linpack (HPL). «Но если вы посмотрите на материаловедение, коды для расчёта процессов горения, системы ленточых матриц и т.п., то увидите, что это гораздо менее обусловленные системы, и внезапно всё начинает давать сбои», — сказал он. 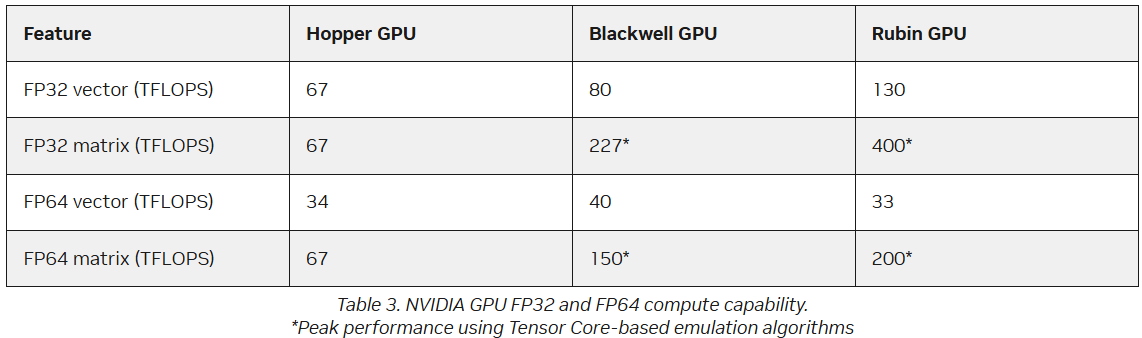
Источник изображения: NVIDIA Точность можно повысить, увеличив количество используемых операций, однако после определённого предела никаких преимуществ от эмуляции уже не будет. Вдобавок все эти операции требуют память. «У нас есть данные, которые показывают, что алгоритму Озаки требуется примерно вдвое больше памяти для эмуляции матриц FP64», — сказал Малайя. Поэтому компания готовит специализированные ускорители MI430X c повышенной FP64/FP32-производительностью, но, как опасаются учёные, она может оказаться не слишком в них заинтересована, поскольку ИИ-ускорители приносят больше денег. Эрнст утверждает, что для большинства специалистов в области HPC неполное соответствие стандарту IEEE не представляет большой проблемы. Всё во многом зависит от конкретного приложения. Тем не менее, NVIDIA разработала дополнительные алгоритмы для обнаружения и смягчения указанных выше ошибок и неэффективных операций эмуляции. Эрнст также признал, что использование памяти при эмуляции может быть несколько выше, но подчеркнул, что эти накладные расходы относятся к расчётам, а не к самому приложению — в большинстве случаев речь идёт о матрицах размером не более нескольких Гбайт. Впрочем, всё это не меняет того, что эмуляция полезна только для подмножества HPC-задач, которые полагаются на операции умножения плотных матриц (DGEMM). По словам Малайи, для 60–70 % рабочих нагрузок HPC эмуляция дает незначительные преимущества или ничего не меняет. «По нашим оценкам, подавляющее большинство реальных рабочих нагрузок HPC полагаются на векторное умножение (FMA), а не на DGEMM», — сказал он, отметив, что это действительно нишевый сегмент, хотя и не крошечная доля рынка. Для рабочих нагрузок, интенсивно использующих векторы, таких как вычислительная гидродинамика (CFD), ускорители Rubin по-прежнему будут полагаться на медленные векторные FP64-блоки.
19.01.2026 [14:16], Руслан Авдеев
100+ кВт на стойку с СЖО: Vertiv обновила модульную инфраструктуру MegaMod HDX для ИИ и HPCVertiv анонсировала новые конфигурации MegaMod HDX. Это модульное силовое и охлаждающее решение, разработанное для вычислительных сред высокой плотности. Новые конфигурации обеспечивают гибкую адаптацию к растущим требованиям к питанию и охлаждению, занимают меньше места, требуют меньше времени на развёртывание и обеспечивают воспроизводимость благодаря заранее собранным на заводе конструкциям, прошедшим интеграцию и тестирование компонентов. Vertiv MegaMod HDX сочетает прямое жидкостное охлаждение чипов и воздушное охлаждение — это помогает справиться с интенсивными ИИ-нагрузками, поддерживая модульные среды для ИИ и передовые кластеры ускорителей. Базовый модуль стандартной высоты поддерживает до 13 стоек и мощность до 1,25 МВт. Комбинированное решение отличается большей высотой и поддерживает уже до 144 стоек и мощность до 10 МВт. Оба варианта обеспечивают плотность от 50 кВт до 100+ кВт на стойку с возможностью оптимизации системы охлаждения под актуальные запросы и с возможностью масштабирования. 
Источник изображения: Vertiv Новые решения используют распределённую силовую архитектуру с резервированием. Для СЖО предусмотрен буфер, который обеспечит поддержку стабильной работы кластеров ускорителей во время техобслуживания. Обе конфигурации основаны на этом обширном портфолио, включающем, например, ИБП Vertiv Liebert APM2, блок распределения жидкости Vertiv CoolChip CDU, а также шинопровод Vertiv PowerBar и систему мониторинга инфраструктуры Vertiv Unify. Также Vertiv предлагает инфраструктуру IT-стоек, разработанную для беспрепятственной интеграции и поддержки IT-систем. В том числе речь идёт о стойках Vertiv и OCP-совместимых стойках, теплообменниках задней двери Vertiv CoolLoop RDHx, PDU и DC-системах Vertiv PowerDirect и т.п. Летом 2025 года сообщалось, что выручка Vertiv выросла на 35 % на фоне «беспрецедентного роста ЦОД», но новые тарифы, введённые США, не дают бизнесу развиваться активнее.
12.01.2026 [13:16], Сергей Карасёв
Supermicro представила SuperBlade-сервер на базе Intel Xeon 6900 с СЖОКомпания Supermicro анонсировала сервер SBI-622BA-1NE12-LCC семейства SuperBlade, предназначенный для построения вычислительных платформ высокой плотности. Устройство будет предлагаться в вариантах с воздушным и прямым жидкостным охлаждением: в первом случае в шасси типоразмера 6U могут быть размещены пять узлов, во втором — десять. Каждый узел SuperBlade поддерживает установку двух процессоров Intel Xeon 6900 поколения Granite Rapids, насчитывающих до 128 производительных P-ядер. Показатель TDP может достигать 500 Вт. Доступны 24 слота для модулей оперативной памяти DDR5-6400/8800 суммарным объёмом до 3 Тбайт. Предусмотрены два посадочных места для накопителей E1.S. Опционально могут быть также установлены два NVMe SSD формата M.2 2280 или M.2 22110. Реализованы три слота PCIe 5.0 x16 для карт формата FHHL, HHHL/LP и OCP 3.0. В оснащение входят контроллер Aspeed AST2600 и адаптер Intel E810-XXVAM2, на базе которого реализованы два сетевых порта 25GbE. 
Источник изображения: Supermicro Шасси, в которое монтируются серверные узлы SBI-622BA-1NE12-LCC, оснащено модулями управления и Ethernet-коммутаторами с резервированием. Питание обеспечивают восемь блоков с сертификатом 80 Plus Titanium. Диапазон рабочих температур — от +10 до +35 °C. По заявлениям Supermicro, передовой дизайн шасси 6U обеспечивает сокращение количества кабелей на 93 % и экономию пространства на 50 % по сравнению с серверами в форм-факторе 1U с сопоставимой конфигурацией. Новинка ориентирована на решение НРС-задач в таких областях, как производство, финансы, научные исследования, энергетика, моделирование климата и пр.
19.12.2025 [15:20], Владимир Мироненко
США объявили о заключении партнёрских отношений с 24 ведущими IT-компаниями в рамках «Миссии Генезис»В четверг в Белом доме США состоялся круглый стол с участием представителей администрации президента США и 24 ведущих технологических компаний страны, в ходе которого было объявлено о заключении Министерством энергетики США (DoE) партнёрских соглашений с компаниями с целью продвижения «Миссии Генезис» (Genesis Mission) — национальной инициативы для ускорения научных открытий, повышения национальной безопасности и стимулирования инноваций в энергетике с помощью ИИ. Об этом сообщил Bloomberg. Президент подписал указ о запуске «Миссии Генезис» 24 ноября 2025 года, поставив задачу удвоить производительность и повысить влияние американских исследований в течение десяти лет, предоставляя учёным и инженерам инструменты для разработки, обучения и эксплуатации ИИ-систем следующего поколения с большей скоростью, эффективностью и надёжностью. В мероприятии в четверг приняли участие министр энергетики Крис Райт (Chris Wright), заместитель министра энергетики по науке и директор миссии Genesis д-р Дарио Гил (Darío Gil) и директор Управления научно-технической политики Белого дома (OSTP) Майкл Крациос (Michael Kratsios). В число 24 организаций, подписавших меморандумы о взаимопонимании, входят такие крупные технологические компании, как Microsoft, Google, AWS, IBM, NVIDIA, Intel, AMD и OpenAI. Также к инициативе присоединились Anthropic, Accenture, Armada, Cerebras, CoreWeave, Dell, DrivenData, Groq, HPE, Oracle, Periodic Labs, Palantir, Project Prometheus, Radical AI, xAI и XPRIZE. 
Источник изображения: CoreWeave «Сегодняшнее объявление о 24 новых исследовательских партнёрствах — это только начало, поскольку мы выполняем указ президента Трампа по вовлечению всего научного сообщества, включая компании, университеты, некоммерческие организации и федеральные агентства, в “Миссию Генезис”», — сказал Крациос. Он добавил, что «Миссия Генезис» поможет американским учёным и исследователям автоматизировать разработку экспериментов, ускорить моделирование и создать прогностические модели, которые приведут к прорывам в энергетике, производстве, разработке лекарств и многом другом. Компания NVIDIA объявила на своём сайте о присоединении к инициативе и планах увеличить инвестиции в ИИ-инфраструктуру и научные исследования и разработки. Также компания сообщила, что в рамках партнёрства с DoE уже «добивается прорывных результатов в ключевых областях». В частности, упомянуты:
Другие компании, присоединившиеся к «Миссии Генезис», тоже выступили с заявлениями. Например, Google сообщила, что DeepMind предоставит учёным всех 17 национальных лабораторий DoE программу ускоренного доступа к передовым моделям ИИ для науки и агентным инструментам, начиная с AI co-scientist в Google Cloud. AI co-scientist — это многоагентный виртуальный научный сотрудник, построенный на платформе Gemini. Он разработан для того, чтобы помочь учёным синтезировать огромные объёмы информации для ускорения разработки научных и биомедицинских открытий. В начале 2026 года компания планирует расширить программу ускоренного доступа для национальных лабораторий, включив в нее AlphaEvolve — программный агент на базе Gemini для разработки сложных алгоритмов, AlphaGenome — ИИ-модель, помогающую учёным лучше понимать ДНК, ускоряя исследования в области геномной биологии и улучшая понимание заболеваний, и WeatherNext — современное семейство моделей прогнозирования погоды. Министерство энергетики и все национальные лаборатории также получат доступ к Gemini for Government. В свою очередь, AWS отметила, что прошлом месяце объявила об инвестициях в размере до $50 млрд в инфраструктуру ИИ и суперкомпьютеров, специально созданную для государственных учреждений США. Инвестиции добавят почти 1,3 ГВт мощности в её регионах Top Secret, Secret и GovCloud. По словам компании, этого достаточно для одновременного запуска тысяч моделей и симуляций ИИ, а также обработки научных данных за десятилетия в режиме реального времени. «Эта инфраструктура обеспечит доступ к вычислительным мощностям по запросу, что позволит государственным заказчикам запускать сложные ИИ-задачи и обрабатывать огромные массивы данных для критически важных приложений — от разработки автономных систем и энергетических инноваций до обработки геномных данных, — подчеркнула Amazon. Компания сообщила, что через Amazon Bedrock организации смогут получить доступ к базовым моделям, таким как Amazon Nova — новейшее семейство современных, экономически эффективных моделей, предлагающих многомодальное понимание, разработку пользовательских моделей и возможности агентного управления, — наряду с моделями от ведущих компаний, таких как Anthropic. Это обеспечит исследователям гибкость в выборе подходящей модели для каждой научной задачи, от анализа сложных геномных данных до создания синтетических обучающих наборов данных для автономных систем.
18.12.2025 [09:25], Сергей Карасёв
CERN накопила экзабайт данных от Большого адронного коллайдераЕвропейская организация по ядерным исследованиям (CERN) сообщила о том, что в её системе хранения данных накоплен 1 Эбайт (1 млн Тбайт) экспериментальной информации, поступившей от Большого адронного коллайдера (БАК) — крупнейшего в мире ускорителя частиц протяжённостью около 27 км, расположенного под землёй на границе Швейцарии и Франции. БАК каждую секунду сталкивает миллиарды протонов, в результате чего генерируются колоссальные потоки информации. Для её предварительной обработки используется высокоселективная система фильтрации (так называемый триггер), которая отсеивает львиную долю данных, собранных детекторами. Оставшаяся часть сведений, представляющих наибольшую ценность, поступает в хранилище CERN для последующего анализа. 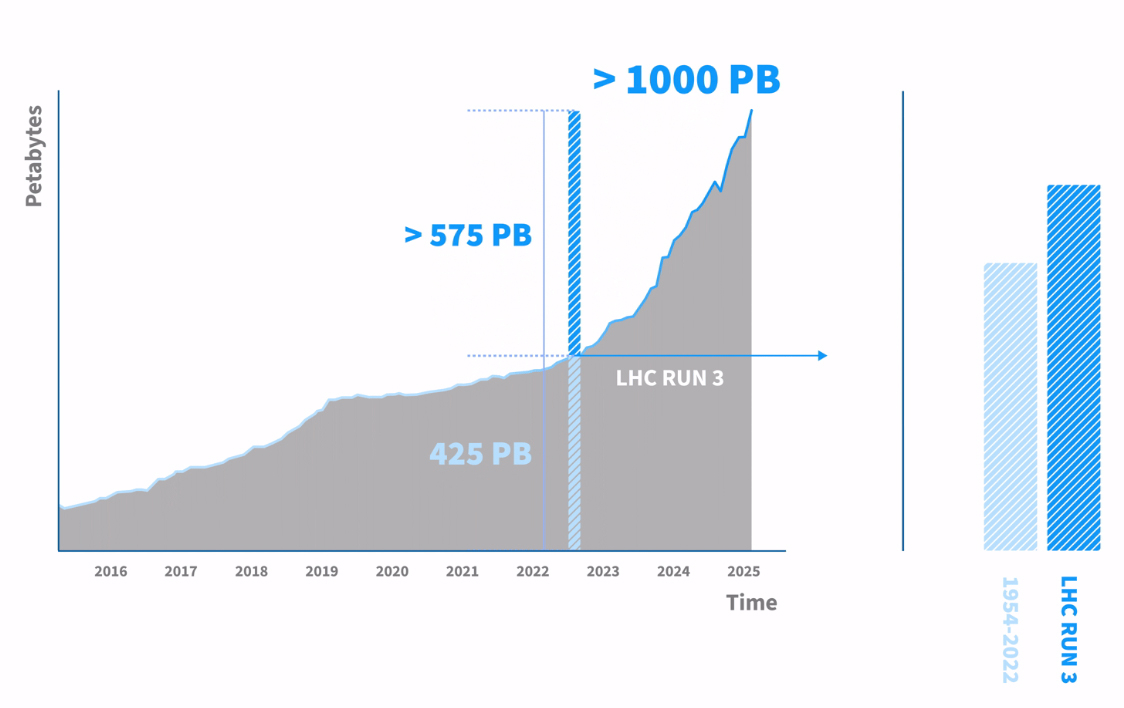
Источник изображения: CERN «Мы достигли рубежа в 1 Эбайт, что является важной вехой проекта, но на этом всё не заканчивается. Это всего лишь 10 % от того, что нам предстоит хранить и обрабатывать в последующие 10 лет», — говорит Якуб Мосцицки (Jakub Mościcki), руководитель группы хранения и управления данными в CERN. Накопление научных сведений имеет огромное значение для проекта БАК, поскольку анализ может проводиться спустя долгое время после сбора показателей — иногда через десятилетия после проведения экспериментов. Основная часть информации записывается на магнитные ленты, что обусловлено экономичностью, безопасностью и надёжностью накопителей этого типа. Для хранения 1 Эбайт данных задействованы около 60 тыс. ленточных картриджей. В настоящее время в CERN ведутся работы по модернизации Большого адронного коллайдера для использования в режиме высокой светимости (High Luminosity LHC). Такие эксперименты планируется начать в середине 2030 года: при этом ускоритель будет генерировать в 10 раз больше информации, чем в текущем виде. Соответственно на порядок возрастёт нагрузка на СХД.
16.12.2025 [01:05], Владимир Мироненко
NVIDIA купила разработчика Slurm, пообещав не забрасывать open source решениеNVIDIA объявила о приобретении SchedMD — ведущего разработчика открытой системы оркестрации Slurm для высокопроизводительных вычислений (HPC) и ИИ. Финансовые условия сделки не разглашаются. Созданная SchedMD система Slurm обеспечивает планирование и управление большими вычислительными задачами в ЦОД, позволяя уменьшить количество ошибок, ускорить вывод продукции на рынок и снизить затраты. Как сообщает NVIDIA, сделка поможет укрепить экосистему ПО с открытым исходным кодом и стимулировать инновации в области ИИ для исследователей, разработчиков и предприятий. Компания отметила, что рабочие нагрузки HPC и ИИ включают сложные вычисления с выполнением параллельных задач на кластерах, для чего требуется организация очередей, планирование и распределение вычислительных ресурсов. По мере увеличения размеров и мощности кластеров HPC и ИИ задача эффективного использования ресурсов становится критически важной. 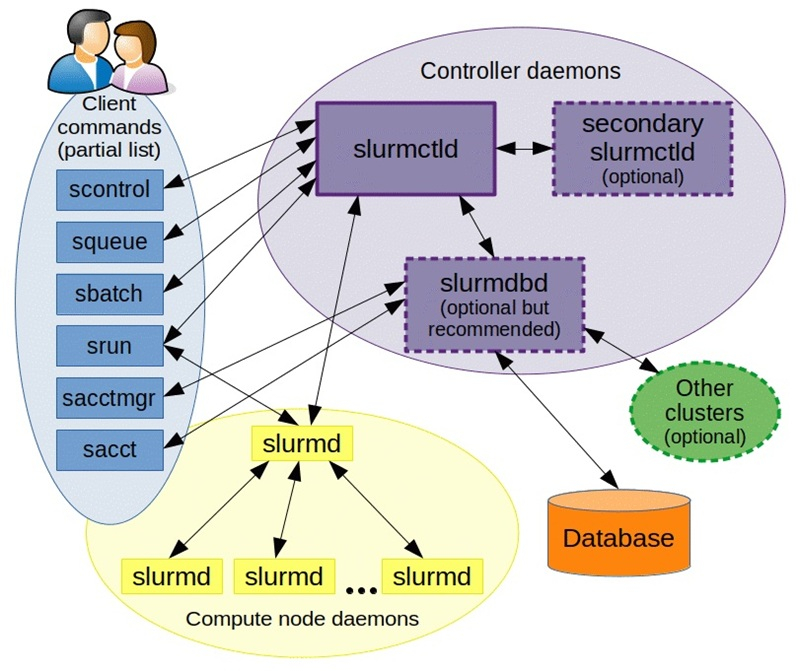
Источник изображения: SchedMD SchedMD была основана в 2010 году разработчиками ПО Slurm Моррисом «Мо» Джеттом (Morris «Moe» Jette) и Дэнни Оублом (Danny Auble) в Ливерморе (Livermore, штат Калифорния). В настоящее время персонал компании насчитывает 40 человек. Сейчас Slurm — ведущий менеджер рабочих нагрузок и планировщик заданий по масштабируемости, пропускной способности и управлению сложными политиками, который используется более чем в половине из десяти и ста лучших систем в списке TOP500 суперкомпьютеров. NVIDIA сообщила, что сотрудничает с SchedMD более десяти лет и продолжит инвестировать в разработку Slurm, чтобы сохранить его поизиции как ведущего планировщика с открытым исходным кодом для HPC и ИИ. NVIDIA обеспечит доступ SchedMD к новым системам, чтобы клиенты могли запускать гетерогенные кластеры с использованием последних инноваций Slurm. Также NVIDIA пообещала и далее поддерживать open source ПО, вкладываться в разработку Slurm и обучение. NVIDIA делает ставку на технологии с открытым исходным кодом и наращивает инвестиции в ИИ-экосистему, чтобы противостоять растущей конкуренции, отметил ресурс Reuters. В конце прошлого года NVIDIA завершила приобретение стартапа Run:ai, разрабатывающего ПО для управления рабочими нагрузками ИИ и оркестрации на базе Kubernetes. А в 2022 году она купила фирму Bright Computing, ещё одного известного разработчика инструментов оркестрации и управления кластерами.
10.12.2025 [09:24], Владимир Мироненко
Евросоюз опять захотел занять 20 % рынка полупроводников, но Китай и США уже «улетели в стратосферу»Реализация планов Европейского союза по ускорению движения к технологическому суверенитету вступает во вторую, критически важную фазу, пишет ресурс EE Times. «Европейский закон о чипах» (European Chips Act), принятый в апреле 2023 года с целью ускорения развития новых технологий и увеличения доли Европы на мировом рынке чипов до 20 % к 2030 году с нынешних 10 %, позволил мобилизовать капитал — общие обязательства по инвестициям достигли почти €69 млрд. «Закон ЕС о чипах 2.0», который находится в разработке, должен внести существенные изменения в политику ЕС и сместить акцент с производственных обязательств на обеспечение разработки следующего поколения вычислительной архитектуры и развитии кадрового потенциала. Цели ЕС также включают укрепление внутренних цепочек поставок полупроводников в Европе и стимулирование инвестиций в микросхемы для нагрузок ИИ и HPC, пишет ioplus.nl. Стратегический поворот в стратегии ЕС находит свою интеллектуальную опору в HiPEAC Vision 2025 — долгосрочной программе европейской сети HiPEAC (High Performance, Edge and Cloud computing), утверждающей, что будущая значимость Европы зависит не только от производства «кремния», но и от освоения парадигмы распределённых, устойчивых вычислений, которая сегодня требуется для развития ИИ-технологий. 
Источник изображения: Antoine Schibler/unsplash.com Эта переоценка становится неотложной необходимостью в связи с реальностью «Великого перераспределения» (Great Reallocation) США, которые с помощью агрессивной торговой политики и масштабных субсидий способствуют оттоку из Европы в США капиталов и интеллектуальной собственности, создавая сложности для развития промышленной базы Европы. Кроме того, отмечается «стратосферный рост» компаний из США и Китае на фоне отставания европейских в сфере вычислительных технологий. HiPEAC Vision, определяющее курс европейских исследований в области вычислений на следующее десятилетие, основано на концепции «Следующей вычислительной парадигмы» (Next Computing Paradigm, NCP), охватывающей высокопроизводительные экзафлопсные вычисления, облачные ЦОД и встраиваемые устройства. HiPEAC рассматривает этот сдвиг как динамичную совокупность «федеративных и распределённых сервисов». У Европы всё ещё есть сильные стороны, такие как мощный потенциал для разработки «периферийных и локальных устройств», сложных киберфизических систем (cyber-physical systems, CPS) и инструментов промышленной автоматизации. Важнейшим аспектом в NCP краткосрочной перспективе является использование и развитие «распределённого агентного ИИ» с акцентом на локальной обработке данных и федеративности с целью снижения зависимость от централизованных иностранных решений гиперскейлеров для обеспечения безопасности критически важных данных и инфраструктуры. Хотя сейчас Евросоюз готов признать, что отказаться от американских облаков «почти невозможно». При этом и гиперскейлеры признают, что уже не могут гарантировать суверенитет данных в Европе. 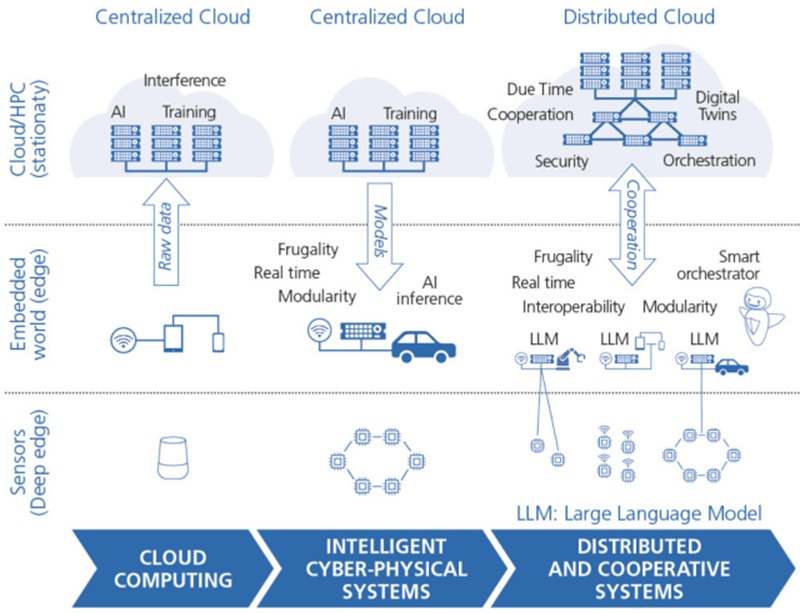
Источник изображения: HiPEAC, Denis Dutoit, CEA/EE Times Хотя «Европейский закон о чипах» позволил привлечь иностранные инвестиции, включая крупные проекты в Германии и Франции, углубленный анализ показывает «структурные ограничения, которые угрожают его долгосрочной эффективности». Также наблюдается перекос в пользу компаний, впервые реализующих инновационные технологии в реальных условиях и в коммерческом масштабе (First-of-a-Kind, FOAK), оставляя без достаточной поддержки более широкую цепочку поставок — проектные организации, производителей оборудования и поставщиков ключевых материалов. Вдобавок заявленная цель увеличить до 20 % долю на мировом рынке полупроводников к 2030 году вызывает в отрасли большие сомнения — отсутствие гарантированного рыночного спроса в Европе остаётся «главным сдерживающим фактором для инвестиций». В связи с этим SEMI Europe выступает за фундаментальное изменение инструментария стимулирования, рекомендуя, чтобы «Закон ЕС о чипах 2.0» обязывал государства-участников блока принять рамочную программу «гармонизированных налоговых льгот для НИОКР и капитальных затрат в области полупроводников», чтобы поддерживать инновации и производство на начальном этапе для дальнейшего укрепления европейской экосистемы с упором на поставщиков материалов и оборудования, проектирование и современную упаковку. Также отмечается, что налоговые льготы обеспечивают «предсказуемость и снижение административных расходов» по сравнению со сложными грантами. Они особенно эффективны для поддержки малых и средних предприятий (МСП) и модернизации существующих объектов. Согласно HiPEAC Vision, инвестиции в экосистему МСП имеют жизненно важное значение, поскольку именно МСП являются движущей силой прорывных инноваций. 
Источник изображения: Julia Fiander / Unsplash Необходимость разработки единой европейской стратегии также связана с агрессивной индустриальной политикой США, пишет EE Times. После принятия программы «Миссия Генезис» (The Genesis Mission) и угрозы введения «100-% пошлины на импортные полупроводники» правительством США ведущие технологические компании направляют миллиарды долларов инвестиций в инфраструктуру США, создавая ощутимый отток капитала из Европы. Так, Nokia уже пообещала инвестировать $4 млрд в США, а Ericsson расширила свой «умный» завод в Техасе, чтобы и далее участвовать в федеральных закупках. Чтобы Европа не стала просто рынком потребления зарубежных технологий, новый закон должен принять философские основы HiPEAC Vision: приоритет экосистемы проектирования и инструментальных средств, считают эксперты. Создание совместного предприятия по разработке чипов (Chips JU) вместо KDT JU направлено на решение этой проблемы путём развитии передовых мощностей проектирования и создании платформы виртуального проектирования (VDP). Этот процесс должен быть ускорен за счёт поддержки важнейших технологий, продвигаемых HiPEAC, таких как чиплеты и открытое аппаратное обеспечение, например, RISC-V, которые снижают барьеры для выхода на рынок и уменьшают зависимость от иностранцев. Ориентируясь в своей стратегии на фокусе на распределённом интеллекте и устойчивом развитии, сформулированном HiPEAC, и внедряя механизмы промышленной поддержки, предлагаемые SEMI Europe, Европа может превратить новый «Закон о чипах» из чрезвычайной меры в последовательную долгосрочную промышленную стратегию. Этот переход закрепляет за Европой статус не только площадки для размещения иностранных заводов, но и суверенного архитектора цифрового будущего.
09.12.2025 [13:05], Сергей Карасёв
Сандийские национальные лаборатории запустили суперкомпьютер Spectra с ускорителями NextSilicon Maverick-2Сандийские национальные лаборатории (SNL) Министерства энергетики США (DOE) объявили о создании суперкомпьютера Spectra с нестандартной архитектурой. В его основу положены изделия Maverick-2 — интеллектуальные вычислительные ускорители (Intelligent Compute Accelerator, ICA), разработанные компанией NextSilicon. Система Spectra спроектирована по программе Vanguard, цель которой заключается в исследовании потенциала передовых компьютерных архитектур применительно к проектам в сфере национальной безопасности. Первой платформой Vanguard стал комплекс Astra, запущенный в 2018 году: на момент анонса это был самый быстрый в мире суперкомпьютер на базе Arm-чипов. Среди других примечательных машин SNL можно отметить Kingfisher на ИИ-чипах Cerebras WSE-3, а также две нейроморфные системы: на базе SpiNNaker2 и на базе Loihi II (Hala Point). 
Источник изображения: SNL Spectra объединяет 64 вычислительных узла, каждый из которых оснащён двумя двухкристальными ОАМ-модулями Maverick-2: эти изделия содержат 64 управляющих ядра RISC-V, 192 Гбайт памяти HBM3E и два интерфейса 100GbE. В общей сложности задействованы 128 экземпляров Maverick-2. Особенностью ускорителей является возможность динамической реконфигурации оборудования на основе данных, получаемых непосредственно во время выполнения задачи. Такой подход позволяет устранять узкие места, присущие традиционным CPU и GPU. Подробнее об архитектуре Maverick-2 можно узнать в нашем материале. За монтаж суперкомпьютера Spectra отвечала компания Penguin Solutions. Она разработала специализированный сервер, поддерживающий до четырёх ОАМ-модулей Maverick-2, хотя в текущей конфигурации используются два. Применены передовая СЖО с отрицательным давлением Chilldyne и платформа Penguin Tundra, что обеспечивает оптимизацию управления температурой и распределения питания, а также возможности масштабирования.
04.12.2025 [15:49], Сергей Карасёв
Лаборатория МФТИ получила российский JBOG-массив RSC ScaleStream-C для решения сложных ИИ-задачЛаборатория машинного обучения в науках о Земле Московского физико-технического института (МФТИ) взяла на вооружение внешний массив PCIe-коммутации RSC ScaleStream-C, разработанный российской группой компаний РСК. Это решение предназначено для выполнения ресурсоёмких задач, связанных с ИИ. RSC ScaleStream-C представляет собой JBOG-платформу в форм-факторе 3U, допускающую установку до десяти карт с интерфейсом PCIe 4.0 x16 (могут применяться карты разной ширины), которая может быть подключена к четырём серверам. Мощности ускорителей могут динамически перераспределяться между серверами. По заявлениям РСК, такой подход позволяет значительно увеличить утилизацию GPU (в некоторых случаях на десятки процентов) по сравнению со стандартными конфигурациями, когда карты устанавливаются непосредственно в серверы. Лаборатория получила массив RSC ScaleStream-C с четырьмя GPU (модель не уточняется). В перспективе могут быть добавлены дополнительные карты. Предполагается, что система поможет ускорить выполнение задач, связанных с базовыми высокоразрешающими ИИ-моделями атмосферы, океана и климата. Ожидается, что применение RSC ScaleStream-C позволит Лаборатории машинного обучения в науках о Земле существенно расширить возможности уже имеющегося оборудования при работе с ИИ-моделями. 
Источник изображения: РСК Основным направлением деятельности Лаборатории является создание ИИ-методов для моделирования атмосферы, океана и климата, а также для обработки данных в фундаментальных и прикладных задачах морской геологии, морской биологии, экологии моря, метеорологии, в области взаимодействия океана и атмосферы, городской микрометеорологии и пр. Специалисты лаборатории занимаются обработкой данных натурных наблюдений и измерений в метеорологии и океанологии, экологическим мониторингом, моделированием природных процессов и другими задачами, для которых требуются значительные вычислительные ресурсы. |
|

