Материалы по тегу: hpc
|
23.05.2023 [15:26], Сергей Карасёв
Intel рассказала о суперкомпьютере Aurora производительностью более 2 ЭфлопсКорпорация Intel в ходе конференции ISC 2023, как сообщает AnandTech, поделилась информацией о проекте Aurora по созданию суперкомпьютера с производительностью экзафлопсного уровня. Эта система создаётся для Аргоннской национальной лаборатории Министерства энергетики США. Изначально анонс HPC-комплекса Aurora состоялся ещё в 2015 году с предполагаемым запуском в 2018-м: ожидалось, что машина обеспечит быстродействие на уровне 180 Пфлопс. Однако реализация проекта значительно затянулась, а технические параметры платформы неоднократно менялись. Пока что развёрнуты тестовый кластер Sunspot. Как теперь сообщается, в конечной конфигурации Aurora объединит 10 624 узла, каждый из которых будет включать два процессора Xeon Max и шесть ускорителей Ponte Vecchio. Таким образом, общее количество CPU будет достигать 21 248, число GPU — 63 744. Быстродействие FP64, как и было заявлено ранее, превысит 2 Эфлопс. 
Источник изображений: Intel (via AnandTech) Каждый процессор оперирует 64 Гбайт памяти HBM, ускоритель — 128 Гбайт. В сумме это даёт соответственно 1,36 Пбайт и 8,16 Пбайт памяти HBM с пиковой пропускной способностью 30,5 Пбайт/с и 208,9 Пбайт/с. В дополнение система сможет использовать 10,9 Пбайт памяти DDR5 с пропускной способностью до 5,95 Пбайт/с. Вместимость подсистемы хранения данных составит 230 Пбайт со скоростью работы до 31 Тбайт/с.  На сегодняшний день Intel поставила более 10 тыс. «лезвий» для Aurora, а это означает, что практически все узлы готовы к окончательному монтажу. Ввод суперкомпьютера в эксплуатацию намечен на текущий год. Для НРС-платформы готовится специализированная научная модель генеративного ИИ — Generative AI for Science, насчитывающая около 1 трлн параметров. Применять Aurora планируется для решения наиболее ресурсоёмких задач в различных областях.
16.05.2023 [09:23], Сергей Карасёв
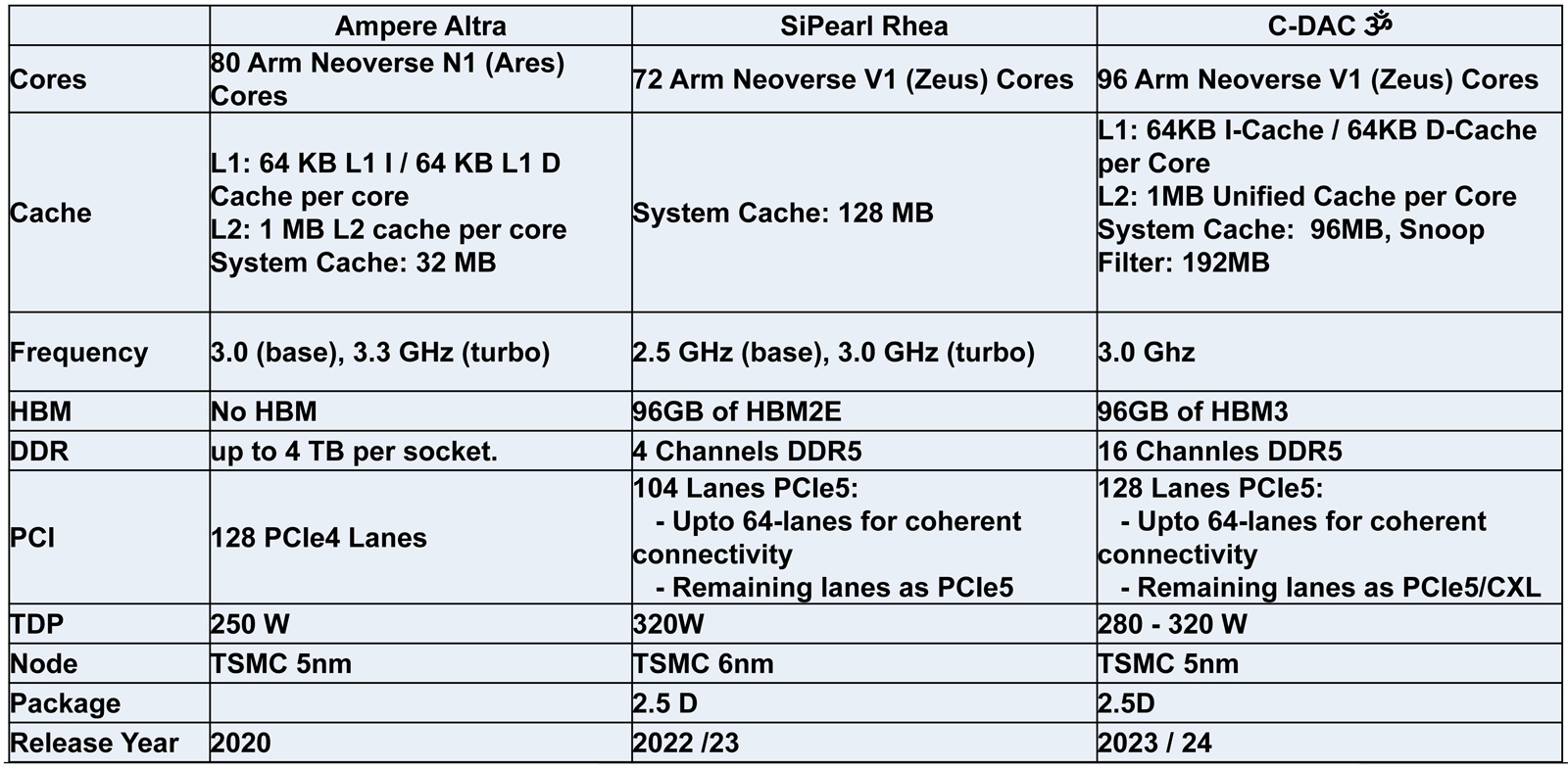
Индия представила свой первый серверный процессор AUM: 96 ядер и 96 Гбайт памяти HBM3Центр развития передовых вычислений (C-DAC) Департамента электроники и информационных технологий Министерства коммуникаций и информационных технологий Индии представил первый в стране процессор для серверов и НРС-систем. Изделие под названием AUM выйдет на коммерческий рынок в текущем или следующем году. Решение имеет чиплетную компоновку на базе двух модулей A48Z, каждый из которых насчитывает 48 вычислительных ядер Zeus с архитектурой Arm. Таким образом, суммарное количество ядер достигает 96. Тактовая частота составляет 3,0 ГГц (до 3,5 ГГц в турбо-режиме); показатель TDP варьируется от 280 до 320 Вт. 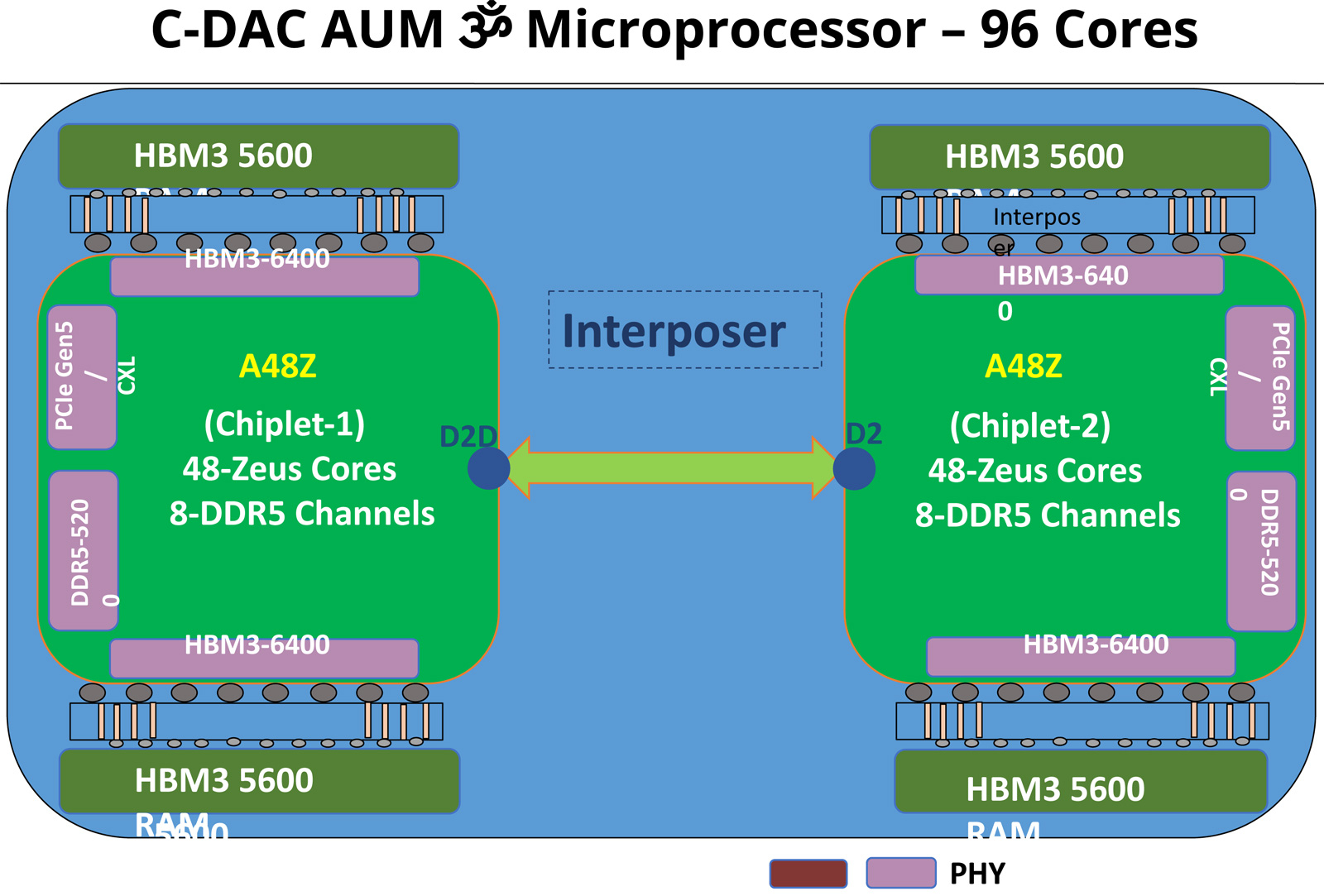
Источник изображений: C-DACC-DAC Новинка будет изготавливаться на предприятии TSMC по 5-нм технологии. Чип содержит 96 Мбайт кеша L2 и 96 Мбайт системного кеша. Изделие получило 96 Гбайт памяти HBM3 и 8-канальный контроллер DDR5-5200; кроме того, имеется доступ к 64 Гбайт памяти HBM3-5600. Таким образом, задействована трёхуровневая подсистема памяти. Упомянуты до 128 линий PCIe 5.0 с поддержкой CXL. 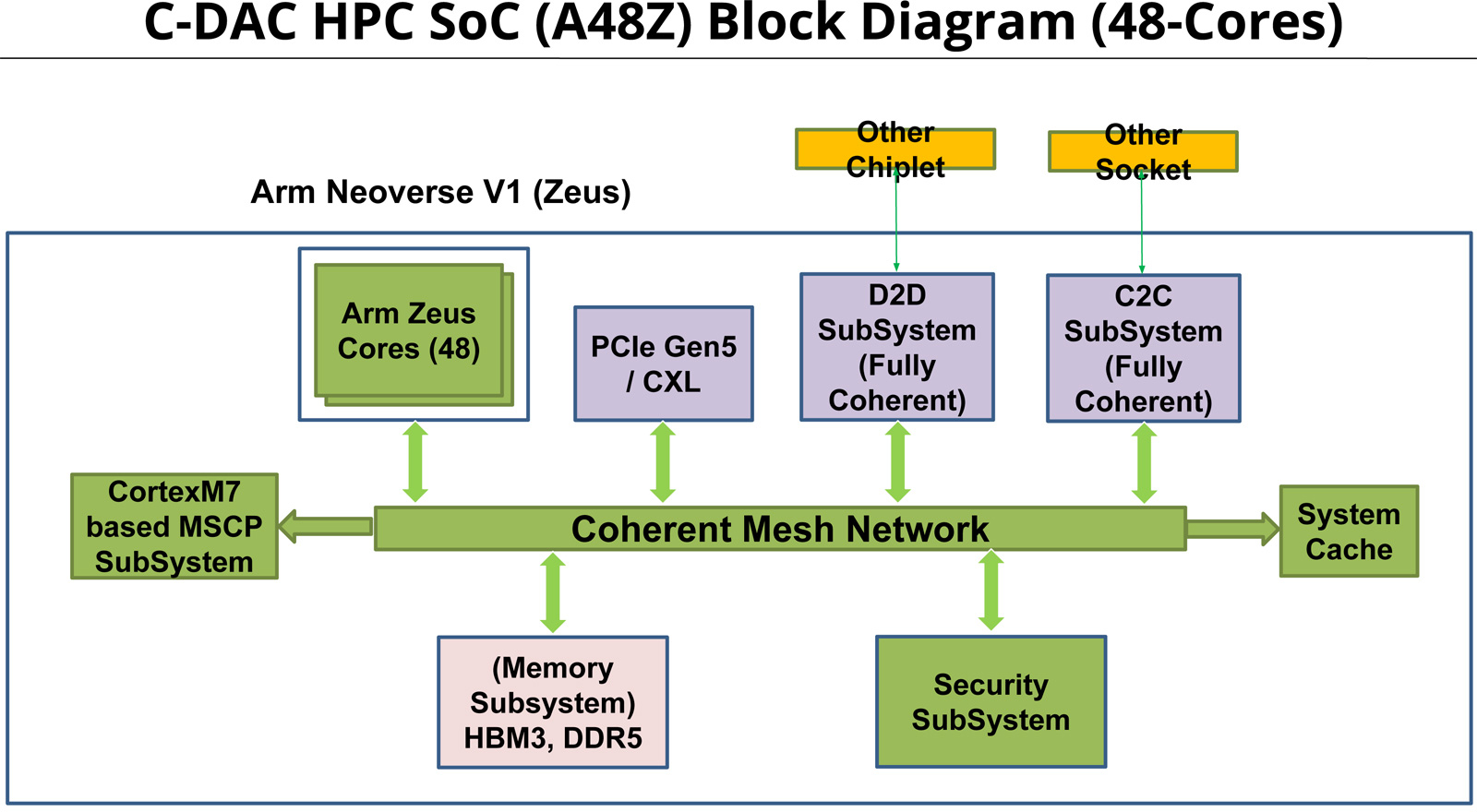 Процессор AUM может применяться в двухсокетных серверах. Заявленная производительность превышает 4,6 Тфлопс в расчёте на разъём. Реализованы различные средства обеспечения безопасности, в том числе функция Secure Boot и криптографические алгоритмы. 
22.04.2023 [00:15], Алексей Степин
Ловкость роборук: TopoOpt от Meta✴ и MIT поможет ускорить и удешевить обучение ИИТехнологии искусственного интеллекта (ИИ) сегодня бурно развиваются и требуют всё более серьёзных вычислительных мощностей. Но наряду с наращиванием этих мощностей растут требования и к сетевой подсистеме, поэтому крупные компании и исследовательские организации ищут всё новые способы оптимизации инфраструктуры. Компания Meta✴ в сотрудничестве с Массачусетским технологическим институтом (MIT) и рядом прочих исследовательских организаций опубликовала данные любопытного эксперимента, в котором ИИ-кластер мог менять топологию своего интерконнекта с помощью механической «роборуки». Система получила название TopoOpt, поскольку вычислительные узлы в ней использовали полностью оптическую сеть с оптической же патч-панелью. Эта сеть объединяла 12 вычислительных узлов ASUS ESC4000A-E10, каждый из которых был оснащён ускорителем NVIDIA A100, сетевыми адаптерами HPE и Mellanox ConnectX-5 (100 Гбит/с) с оптическими трансиверами. 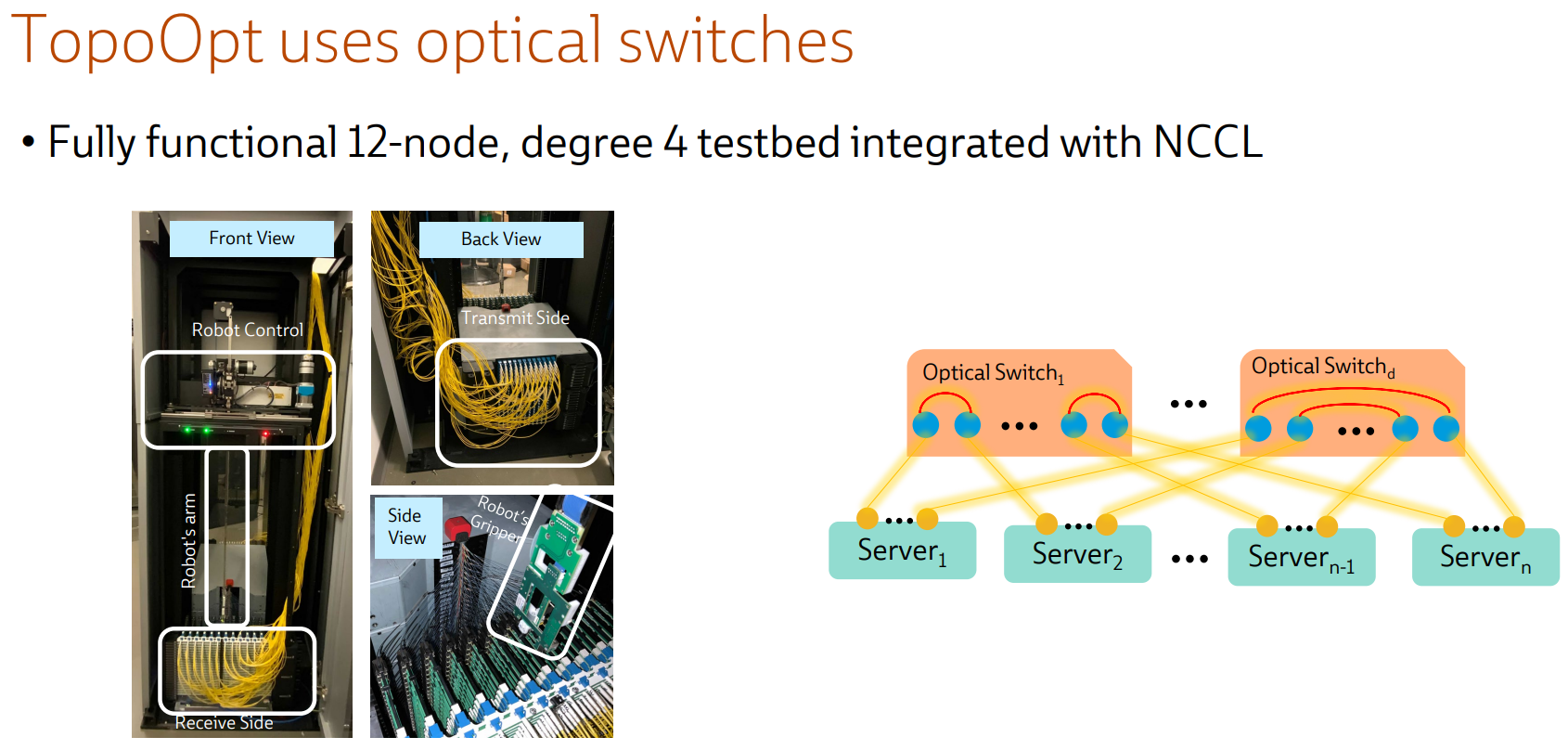
Источник здесь и далее: USENIX Наиболее интересное устройство в эксперименте — оптическая патч-панель Telescent, оснащённая механическим манипулятором, способным производить перекоммутацию на лету. Эта «роборука» работала под управлением специализированного ПО, целью которого ставилось нахождение оптимальной сетевой топологии и сегментации сети применительно к различным задачам машинного обучения. 
Система с перекоммутируемой оптической сетью не требует энергоёмких высокоскоростных коммутаторов и обеспечивает ряд других преимуществ Такая роботизированная патч-панель не столь расторопна, как оптические коммутаторы Google с микрозеркальной механикой, но стоит впятеро дешевле и имеет больше портов. Опубликованные экспериментальные данные уверенно свидетельствуют о том, что топология «толстого дерева» (fat tree), использующая несколько слоёв коммутаторов, не оптимальна и даже избыточна для ряда нейросетевых задач. К тому же перекоммутируемая оптическая сеть без традиционных высокоскоростных коммутаторов требует меньше оборудования, а значит, может быть не только быстрее сети fat tree в ряде ИИ-задач, но и существенно дешевле в развёртывании и поддержании в рабочем состоянии — как минимум за счёт отсутствия затрат на питание множества коммутаторов.
07.04.2023 [20:36], Сергей Карасёв
Google заявила, что её ИИ-кластеры на базе TPU v4 и оптических коммутаторов эффективнее кластеров на базе NVIDIA A100 и InfiniBandКомпания Google обнародовала новую информацию о своей облачной суперкомпьютерной платформе Cloud TPU v4, предназначенной для решения задач ИИ и машинного обучения с высокой эффективностью. Система может использоваться в том числе для работы с крупномасштабными языковыми моделями (LLM). Один кластер Cloud TPU Pod содержит 4096 чипов TPUv4, соединённых между собой через оптические коммутаторы (OCS). По словам Google, решение OCS быстрее, дешевле и потребляют меньше энергии по сравнению с InfiniBand. Google также утверждает, что в составе её платформы на OCS приходится менее 5 % от общей стоимости. Причём данная технология даёт возможность динамически менять топологию для улучшения масштабируемости, доступности, безопасности и производительности. Отмечается, что платформа Cloud TPU v4 в 1,2–1,7 раза производительнее и расходует в 1,3–1,9 раза меньше энергии, чем платформы на базе NVIDIA A100 в системах аналогичного размера. Правда, пока компания не сравнивала TPU v4 с более новыми ускорителями NVIDIA H100 из-за их ограниченной доступности и 4-нм архитектуры (по сравнению с 7-нм у TPU v4). 
Изображение: Google Благодаря ключевым инновациям в области интерконнекта и специализированных ускорителей (DSA, Domain Specific Accelerator) платформа Google Cloud TPU v4 обеспечивает почти 10-кратный прирост в масштабировании производительности по сравнению с TPU v3. Это также позволяет повысить энергоэффективность примерно в 2–3 раза по сравнению с современными DSA ML и сократить углеродный след примерно в 20 раз по сравнению с обычными дата-центрами.
22.03.2023 [22:02], Алексей Степин
AMD и NVIDIA победили: NEC останавливает разработку уникальных векторных процессоров SX-AuroraЯпонская компания NEC была одной из немногих, отстаивавших собственный уникальный путь в сфере развития вычислительных технологий со своими векторными процессорами SX-Aurora. Хотя данное направление до недавних пор активно развивалось, компания, похоже, не выдержала давления со стороны NVIDIA и AMD и объявила о прекращении разработок новых решений в серии Aurora. Работы над усовершенствованием векторной архитектуры NEC продолжались до конца прошлого года, когда компания объявила о подготовке новых вычислительных узлов SX-Aurora TSUBASA C401-8 на базе ускорителей с 16 блоками Vector Engine 3.0 и 96 Гбайт интегрированной памяти HBM2. И хотя в августе этого года в Научном центре Университета Тохоку будет запущен новый суперкомпьютер на их основе, новых разработок в этой сфере не будет. 
Вычислительный модуль SX-Aurora TSUBASA C401-8. Источник изображений здесь и далее: NEC Как отметил Сатоши Мацуока (Satoshi Matsuoka), глава крупнейшего в Японии суперкомпьютерного центра RIKEN, где был создан суперкомпьютер Fugaku, NEC неслучайно объявила об отказе от разработки нового поколения процессоров SX-Aurora. Хотя в целях компании значилось 10-кратное повышение энергоэффективности, теперь NEC считает, что эта цель может быть достигнута с использованием стандартных коммерческих ускорителей. Главной причиной называется появление решений AMD и NVIDIA, на голову превосходящих все наработки NEC. В частности, упоминается AMD Instinct MI300. При этом отмечено, что это решение «похоронило» бы даже новое поколение SX-Aurora, когда речь заходит о ПСП. Целью NEC был показатель 2+ Тбайт/с, в то время как новинка AMD, располагая памятью HBM3 с 8192-бит шиной, может обеспечить 6,8 Тбайт/с. 
Планы NEC по развитию VE-архитектуры. Похоже, им уже не суждено сбыться Также «естественным врагом» SX-Aurora является NVIDIA Grace Hopper с его мощной процессорной частью и развитой инфраструктурой NVLink, демонстрирующий к тому же выдающуюся энергоэффективность. Примечательно, что оба продукта от AMD и NVIDIA являются APU, то есть гибридными чипами, объединяющими ускорители и CPU собственной разработки, а также быструю память. Финансовый кризис 2009 года ударил по разработкам NEC в области процессоростроения сильно, но ситуацию тогда спасла общая незрелость рынка GPGPU и технологии HBM. Сейчас на это надеяться нельзя, да и ситуация с точки зрения программной экосистемы в мире HPC говорит не в пользу NEC. По всей видимости, прямо на наших глазах ещё одна уникальная вычислительная архитектура становится достоянием истории.  При этом в Японии пока что сохраняется ещё одна уникальная отечественная архитектура — PEZY-SC. Arm-процессоры Fujitsu A64FX, ставшие основой Fugaku, тоже достаточно уникальны, однако их наследники в лице MONAKA переориентированы на более массовый сегмент. Таким образом, собственные массовые HPC-решения сейчас есть только у Китая, которому новейшие американские и британские ускорители достанутся в кастрированном виде.
21.03.2023 [20:45], Владимир Мироненко
NVIDIA запустила облачный сервис DGX Cloud — доступ к ИИ-супервычислениям прямо в браузереNVIDIA запустила сервис ИИ-супервычислений DGX Cloud, предоставляющий предприятиям доступ к инфраструктуре и программному обеспечению, необходимым для обучения передовых моделей для генеративного ИИ и других приложений. DGX Cloud предлагает выделенные ИИ-кластеры NVIDIA DGX в сочетании с фирменным набором ПО NVIDIA. С его помощью предприятие сможет получить доступ к облачному ИИ-суперкомпьютеру, используя веб-браузер и без надобности в приобретении, развёртывании и управлении собственной HPC-инфраструктурой. Правда, удовольствие это всё равно не из дешёвых — стоимость инстансов DGX Cloud начинается от $36 999/мес., причём деньги получает в первую очередь сама NVIDIA. Для сравнения — полностью укомплектованная система DGX A100 в Microsoft Azure обойдётся примерно в $20 тыс. Облачные кластеры DGX предлагаются предприятиям на условиях ежемесячной аренды, что гарантирует им возможность быстро масштабировать разработку больших рабочих нагрузок. «DGX Cloud предоставляет клиентам мгновенный доступ к супервычислениям NVIDIA AI в облаках глобального масштаба», — сообщил Дженсен Хуанг (Jensen Huang), основатель и генеральный директор NVIDIA. 
Источник изображения: NVIDIA Развёртыванием инфраструктуры DGX Cloud компания NVIDIA будет заниматься в сотрудничестве с ведущими поставщиками облачных услуг. Первым среди них стала платформа Oracle Cloud Infrastructure (OCI), предлагающая суперкластер (SuperCluster) с объединёнными RDMA-сетью (в том числе на базе BlueField-3 и Connect-X7) системами DGX (bare metal), которые дополняет высокопроизводительное локальное и блочное хранилище. Cуперкластер может включать до 32 768 ускорителей, но этот рекорд был поставлен с использованием DGX A100, а вот предложение DGX H100 пока что ограничено. В следующем квартале похожее решение появится в Microsoft Azure, а потом в Google Cloud и у других провайдеров. 
Источник изображения: NVIDIA Первыми пользователями DGX Cloud стали Amgen, одна из ведущих мировых биотехнологических компаний, лидер рынка страховых технологий CCC Intelligent Solutions (CCC) и провайдер цифровых бизнес-платформ ServiceNow. «Мощные вычислительные и многоузловые возможности DGX Cloud позволили нам в 3 раза ускорить обучение белковых LLM с помощью BioNeMo и до 100 раз ускорить анализ после обучения с помощью NVIDIA RAPIDS по сравнению с альтернативными платформами», — сообщил представитель Amgen. Для управления нагрузками в DGX Cloud предлагается NVIDIA Base Command. Также DGX Cloud включает в себя набор инструментов NVIDIA AI Enterprise для создания и запуска моделей, который предоставляет комплексные фреймворки и предварительно обученные модели для ускорения обработки данных и оптимизации разработки и развёртывания ИИ. DGX Cloud предоставляет поддержку экспертов NVIDIA на всех этапах разработки ИИ. Клиенты смогут напрямую работать со специалистами NVIDIA, чтобы оптимизировать свои модели и быстро решать задачи разработки с учётом сценариев отраслевого использования.
21.03.2023 [19:15], Сергей Карасёв
NVIDIA представила систему DGX Quantum для гибридных квантово-классических вычисленийКомпания NVIDIA в партнёрстве с Quantum Machines анонсировала DGX Quantum — первую систему, объединяющую GPU и квантовые вычисления. Решение использует новую открытую программную платформу CUDA Quantum. Утверждается, что система предоставляет революционно архитектуру для исследователей, работающими с гибридными вычислениями с низкой задержкой. NVIDIA DGX Quantum объединяет средства ускоренных вычислений на базе Grace Hopper (Arm-процессор + ускоритель H100), модели программирования с открытым исходным кодом CUDA Quantum и передовую квантовую управляющую платформу Quantum Machines OPX+. Такая комбинация позволяет создавать ресурсоёмкие приложения, сочетающие квантовые вычисления с современными классическими вычислениями. При этом в числе прочего обеспечивается работа гибридных алгоритмов и коррекция ошибок. 
Источник изображения: NVIDIA Представленное решение предполагает соединение Grace Hopper и Quantum Machines OPX+ посредством интерфейса PCIe. Это обеспечивает задержку менее микросекунды между ускорителем и блоками квантовой обработки (QPU). Отмечается, что OPX+ — это универсальная система квантового управления. Таким образом, можно максимизировать производительность QPU и предоставить разработчикам новые возможности при использовании квантовых алгоритмов. Системы Grace Hopper и OPX+ можно масштабировать в соответствии с потребностями — от QPU с несколькими кубитами до суперкомпьютера с квантовым ускорением. 
Источник изображения: NVIDIA О намерении интегрировать CUDA Quantum в свои платформы уже заявили компании по производству квантового оборудования Anyon Systems, Atom Computing, IonQ, ORCA Computing, Oxford Quantum Circuits и QuEra, разработчики ПО Agnostiq и QMware, а также некоторые суперкомпьютерные центры.
07.02.2023 [19:37], Руслан Авдеев
Регулирование оборота «вечных» PFAS-химикатов и отказ 3M от их выпуска могут значительно повлиять на будущее погружных СЖОПерфторалкильные и полифторалкильные вещества (PFAS, «вечные химикаты»), вероятно, представляют угрозу для здоровья людей, хотя их вредоносность по многим параметрам пока не получила документальных подтверждений. Тем не менее, как сообщает портал HPC Wire, PFAS привлекают всё больше внимания регуляторов, а принятые против них в ЕС меры грозят всей полупроводниковой индустрии. Теперь этими веществами заинтересовались и американские регуляторы, включая Агентство по охране окружающей среды США (EPA), что может привести к изменению перспектив развития HPC-индустрии. Дело в том, что PFAS используются в двухфазных системах погружного охлаждения. В частности, речь идёт о жидкостях Novec и Fluorinert компании 3M, также применяемых при выпуске полупроводников и в других сферах. В конце 2022 года 3M заявила, что намерена полностью отказаться от их производства уже к 2025 году и уже остановила крупнейший завод по их выпуску в Бельгии. Действия регуляторов и отказ 3M от производства может привести к серьёзным изменениям в HPC-индустрии, поскольку поставит под угрозу бесперебойность поставок необходимых компонентов и материалов. 
Источник изображения: 3M Но есть и другие факторы. Так, крупные международные производители СЖО будут ориентироваться на страны с наиболее жёсткими регуляторными нормами, даже если на других рынках условия более благоприятны. А крупные заказчики вроде Google и Microsoft, декларирующие достижение определённых целей по защите окружающей среды, могут отказаться от PFAS просто из-за репутационных рисков, даже если PFAS будут вполне легальны. По мнению экспертов Motivair, ужесточение контроля за PFAS может представлять угрозу широкомасштабному распространению технологий двухфазного погружного охлаждения. Впрочем, далеко не все уверены, что новые ограничения могут изменить тренды на рынке HPC, поскольку многие игроки здесь применяют, по их словам, эффективные и безопасные системы на основе других технологий СЖО и химикатов. Как сообщает DataCenter Dynamics, по данным производителя иммерсионных СЖО LiquidStack, большее влияние ограничения на использование PFAS могут оказать на полупроводниковую отрасль, где подобные вещества широко применяются в процессе производства. В компании утверждают, что имеется немало альтернатив жидкостям 3M, хотя как минимум некоторые из них тоже являются PFAS.
29.11.2022 [17:12], Алексей Степин
AWS представила Arm-процессор Graviton3E, оптимизированный для задач ИИ и HPCОдин из крупнейших облачных провайдеров, компания Amazon Web Services объявила о доступности новых инстансов EC2 на базе процессора Graviton3E. Новый чип — наследник анонсированного в конце 2021 года Graviton3, 5-нм 64-ядерного процессора на дизайне Arm Neoverse V1 (Zeus) с поддержкой DDR5 и PCI Express 5.0. Graviton3 использует набор команд Armv8.4 c расширениями Neon (4×128 бит) и SVE (2×256 бит) и поддерживает работу с популярными в сфере машинного обучения форматами данных INT8 и BF16. В сравнении c Graviton2 процессор быстрее на 25-60 % при сохранении аналогичного уровня тепловыделения. Дизайн серверов AWS предусматривает наличие трёх процессоров на узел высотой 1U. 
Изображения: AWS Новый процессор Graviton3E представляет собой дальнейшее развитие Graviton3. Чип оптимизирован с учётом потребностей рынка высокопроизводительных вычислений и основное внимание в его архитектуре уделено повышению производительности на операциях с плавающей запятой и вычислениях с использованием векторной математики. AWS, к сожалению, пока не раскрывает деталей относительно архитектуры Graviton3E, но прирост производительности на векторных операциях относительно обычного Graviton3 может достигать 35 %. Помимо классического теста HPL новый процессор хорошо проявляет себя в тестах, имитирующих медико-биологические и финансовые задачи.  Сценарии нагрузок, характерные для HPC, как правило, активно оперируют перемещением крупных объемов данных. Чтобы оптимизировать этот процесс, в новых инстансах AWS использует сеть на базе Elastic Fabric с новыми адаптерами Elastic Network Adapter (ENA). Такая сеть оперирует т. н. Scalable Reliable Datagram (SRD) вместо всем привычных TCP-пакетов. SRD позволяет организовать повторную отправку пакетов за микросекунды вместо миллисекунд в классическом Ethernet. Сердцем же новых инстансов AWS стало пятое поколение аппаратных гипервизоров Nitro 5. В сравнении с предыдущим поколением, Nitro 5 обладает вдвое более высокой вычислительной производительностью, на 50 % повышенной пропускной способностью памяти, а также позволяет обрабатывать на 60 % больше сетевых пакетов при сниженной на 30 % латентности. 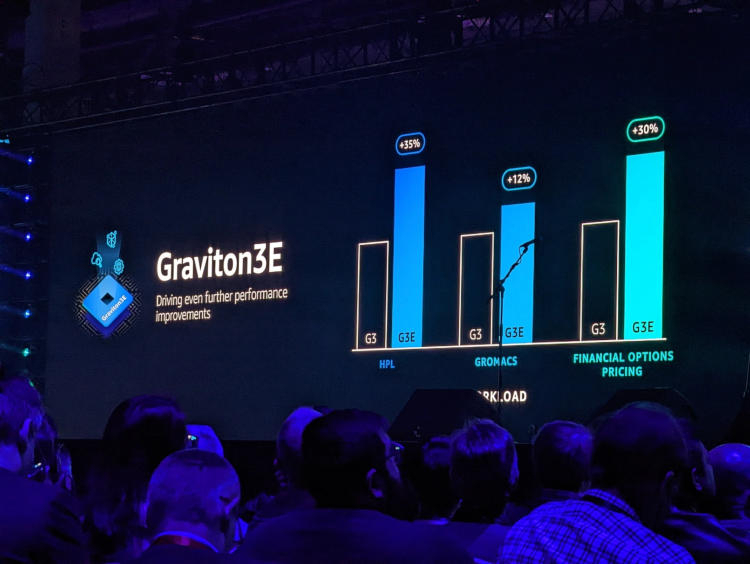
Здесь и далее источник изображений: AWS Инстансы Hpc7g с процессорами Graviton3E получат внутреннюю сеть с пропускной способностью 200 Гбит/с и станут доступны в различных конфигурациях вплоть до 64 vCPU и 128 ГиБ памяти. Аналогичные параметры имеют инстансы C7gn, предназначенные для задач с интенсивным сетевым трафиком: виртуальных маршрутизаторов, сетевых экранов, балансировщиков нагрузки и т.п. Также компания анонсировала инстансы R7iz, в которых используются процессоры Intel Xeon Scalable четвёртого поколения (Sapphire Rapids) с постоянной частотой всех ядер 3,9 ГГц. Они могут иметь конфигурацию до 128 vCPU с 1 ТиБ памяти.
29.11.2022 [12:20], Сергей Карасёв
В Италии официально запущен суперкомпьютер Leonardo — четвёртая по мощности HPC-система в миреСовместная инициатива по высокопроизводительным вычислениям в Европе EuroHPC JU и некоммерческий консорциум CINECA, состоящий из 69 итальянских университетов и 21 национальных исследовательских центров, провели церемонию запуска суперкомпьютера Leonardo. В основу комплекса положены платформы Atos BullSequana X2610 и X2135. Система Leonardo состоит из двух секций — общего назначения и с ускорителями вычислений (Booster). Когда строительство системы будет завершено, первая будет включать 1536 узлов, каждый из которых содержит два процессора Intel Xeon Sapphire Rapids с 56 ядрами и TDP в 350 Вт, 512 Гбайт оперативной памяти DDR5-4800, интерконнект NVIDIA InfiniBand HDR100 и NVMe-накопитель на 8 Тбайт. 
Источник изображения: HPCwire Секция Booster объединяет 3456 узлов, каждый из которых содержит один чип Intel Xeon 8358 с 32 ядрами, 512 Гбайт ОЗУ стандарта DDR4-3200, четыре кастомных ускорителя NVIDIA A100 с 64 Гбайт HBM2-памяти, а также два адаптера NVIDIA InfiniBand HDR100. Кроме того, в состав комплекса входят 18 узлов для визуализации: 6,4 Тбайт NVMe SSD и два ускорителя NVIDIA RTX 8000 (48 Гбайт) в каждом. Вычислительный комплекс объединён фабрикой с топологией Dragonfly+. 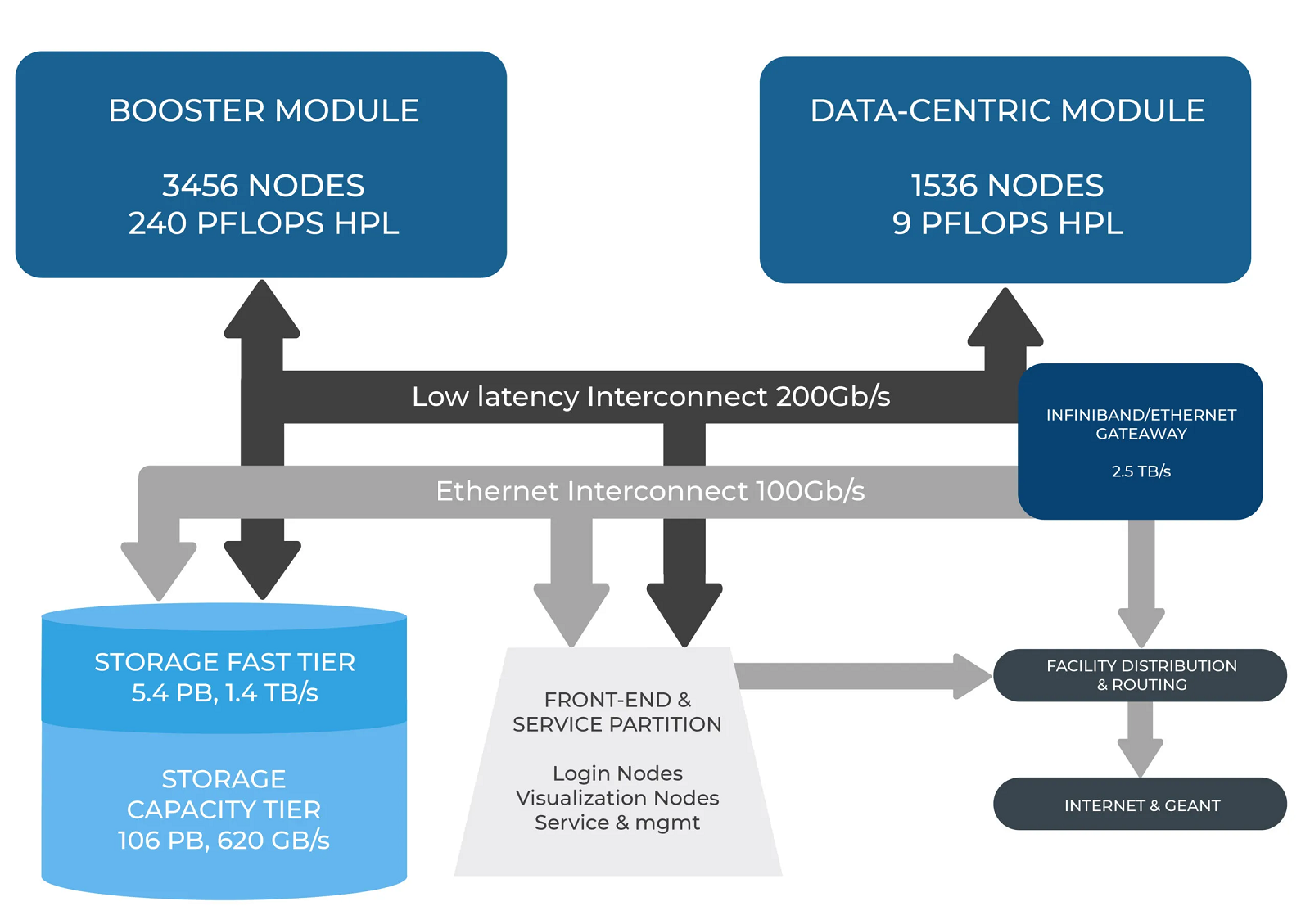
Источник: CINECA Для хранения данных служит двухуровневая система. Производительный блок (5,4 Пбайт, 1400 Гбайт/с) содержит 31 модуль DDN Exascaler ES400NVX2, каждый из которых укомплектован 24 NVMe SSD вместимостью 7,68 Тбайт и четырьмя адаптерами InfiniBand HDR. Второй уровень большой ёмкости (106 Пбайт, чтение/запись 744/620 Гбайт/с) состоит из 31 массива DDN EXAScaler SFA799X с 82 SAS HDD (7200 PRM) на 18 Тбайт и четырьмя адаптерами InfiniBand HDR. Каждый из массивов включает два JBOD-модуля с 82 дисками на 18 Тбайт. Для хранения метаданных используются 4 модуля DDN EXAScaler SFA400NVX: 24 × 7,68 Тбайт NVMe + 4 × InfiniBand HDR. 
Изображение: CINECA В настоящее время Leonardo обеспечивает производительность более 174 Пфлопс. Ожидается, что суперкомпьютер будет полностью запущен в первой половине 2023 года, а его пиковое быстродействие составит 250 Пфлопс. Уже сейчас система занимает четвёртое место в последнем рейтинге самых мощных суперкомпьютеров мира TOP500. В Европе Leonardo является второй по мощности системой после LUMI. Leonardo оборудован системой жидкостного охлаждения для повышения энергоэффективности. Кроме того, предусмотрена возможность регулировки энергопотребления для обеспечения баланса между расходом электричества и производительностью. Суперкомпьютер ориентирован на решение высокоинтенсивных вычислительных задач, таких как обработка данных, ИИ и машинное обучение. Половина вычислительных ресурсов Leonardo будет предоставлена пользователям EuroHPC. |
|

