Материалы по тегу: hpc
|
17.01.2024 [08:08], Владимир Мироненко
300 кВт на стойку: Aligned представила СЖО DeltaFlow~ для своих дата-центровКомпания Aligned представила новую систему жидкостного охлаждения DeltaFlow~, которая позволяет увеличить плотность размщения вычислительных мощностей 300 кВт на стойку, сообщил ресур Datacenter Dynamics. DeltaFlow~ — это готовое решение, поддерживающее текущие и будущие технологии жидкостного охлаждения, включая прямое охлаждение direct-to-chip с CDU, охлаждение с использованием теплообменника на задней дверце (Rear-door Heat Exchanger, RDHx) и иммерсионное охлаждение. Решение опирается на систему с замкнутым контуром без использования наружного воздуха или воды. По словам Alidned, новая СЖО позволяет клиентам по-максимуму использовать современные чипы и ускорителя, сокращая время выхода на рынок, затраты и риски. 
Фото: Aligned DeltaFlow~ также интегрируется с технологией воздушного охлаждения Delta3 (Delta Cube) без изменений в подаче электроэнергии или существующей температуры в машинных залах. Delta3 вместо традиционного холодного коридора использует вентиляторы и теплообменники, расположенные непосредственно за стойками и подключённые к водяному контуру, уходящему к чиллерам. Delta3 позволяет добиться плотности до 50 кВт на стойку. Aligned стала одной из последних компаний, анонсировавшей платформу для оборудования высокой плотности, основанное на жидкостном охлаждении. Ранее в этом месяце Stack представила решение с использованием погружного охлаждения, которое позволяет поддерживать мощность 300 кВт или выше на стойку. Летом прошлого года CyrusOne анонсировала новую архитектуру ЦОД для ИИ-нагрузок, где тоже используется погружное охлаждение и тоже можно получить 300 кВт на стойку. Тогда же Digital Realty запустила услугу колокации с поддержкой размещений до 70 кВт на стойку, а в декабре Equinix объявила о планах по расширению поддержки передовых технологий СЖО в значительной части своих ЦОД, хотя и не указала предельную плотность. DataBank также переработала конструкцию машинных залов для поддержки размещений высокой плотностью с использованием жидкостного охлаждения.
23.12.2023 [02:11], Владимир Мироненко
В Испании официально запустили 314-Пфлопс суперкомпьютер MareNostrum 5, который вскоре объединится с двумя квантовыми компьютерами21 декабря в Суперкомпьютерном центре Барселоны — Centro Nacional de Supercomputación (BSC-CNS) — в торжественной обстановке официально запустили европейский суперкомпьютер MareNostrum 5 производительностью 314 Пфлопс. В церемонии, посвящённой машине, созданной в рамках проекта European High Performance Computing Joint Undertaking (EuroHPC JU), принял участие председатель правительства Испании. MareNostrum 5 представляет собой крупнейшую инвестицию, когда-либо сделанную Европой в научную инфраструктуру Испании — суммарно €202 млн, из которых €151,4 млн ушло на приобретение суперкомпьютера. Финансирование было проведено EuroHPC JU через Фонд ЕС «Соединение Европы» и программу исследований и инноваций «Горизонт 2020», а также государствами-участниками: Испанией (через Министерство науки, инноваций и университетов и правительство Каталонии), Турцией и Португалией. С запуском MareNostrum 5 заметно укрепились позиции BSC в качестве одного из ведущих суперкомпьютерных центров мира с более чем 900 сотрудниками, занимающимися исследования в области информатики, наук о жизни и о Земле, а также вычислительных систем для науки и техники. Обладая максимальной общей производительностью 314 Пфлопс, MareNostrum 5 присоединяется к двум другим системам EuroHPC: Lumi (Финляндия) и Leonardo (Италия), тоже являющихся суперкомпьютерами предэкзафлопсного класса, единственными системами такого уровня в Европе. 
Источник изображений: BSC Eviden (Atos) была выбрана в качестве основного поставщика, но в создании машины приняли участие Lenovo, IBM, Intel и NVIDIA, а также Partec. Как отмечено в пресс-релизе, уникальная архитектура MareNostrum 5 была создана для того, чтобы предоставить исследователям лучшие из доступных технологий. Это гетерогенная машина, сочетающая в себе две отдельные системы: раздел общего назначения (GPP), предназначенный для классических вычислений, и GPU-раздел (ACC), ориентированный на ИИ. Обе системы по отдельности входят в первую двадцатку TOP500, занимая 19-е и 8-е места соответственно. Раздел общего назначения (GPP) является крупнейшим в мире x86-кластером на базе Intel Xeon Sapphire Rapids. Эта часть суперкомпьютера имеет пиковую производительность 45,9 Пфлопс. Система, произведённая Lenovo, специально разработана для решения сложных научных задач с разделением ресурсов, что обеспечивает большую гибкость и повышает эффективность системы, поскольку разные пользователи или проекты могут использовать её одновременно. GPP имеет 6408 стандарных узлов следующей конфигурации:
Дополнительно система имеет 72 узла с двумя 56-ядерными Xeon Max (1,7 ГГц) и набортной памятью HBM2e объёмом 128 Гбайт.  GPU-раздел (ACC) производства Eviden является третьим по мощности в Европе и восьмым в мире по версии TOP500, с пиковой производительностью 260 Пфлопс. Он основан на 4480 ускорителях NVIDIA H100. Раздел имеет 1120 узлов, каждый из которых включает:
Общая ёмкость хранилища MareNostrum 5 составляет 650 Пбайт, из которых, 402 Пбайт приходятся на LTO, 248 Пбайт — на HDD, а остальное — на NVMe SSD. Задействована ФС IBM Spectrum Scale. Машина использует интерконнект InfiniBand NDR200, объединяющий более 8000 узлов. Можно заметить, что NVIDIA предоставила BSC не совсем стандартные решения. В будущем ожидается появление ещё одного GPP-раздела на базе NVIDIA Grace, а вот расширение ACC узлами с Xeon Emerald Rapids и Rialto Bridge не состоится. 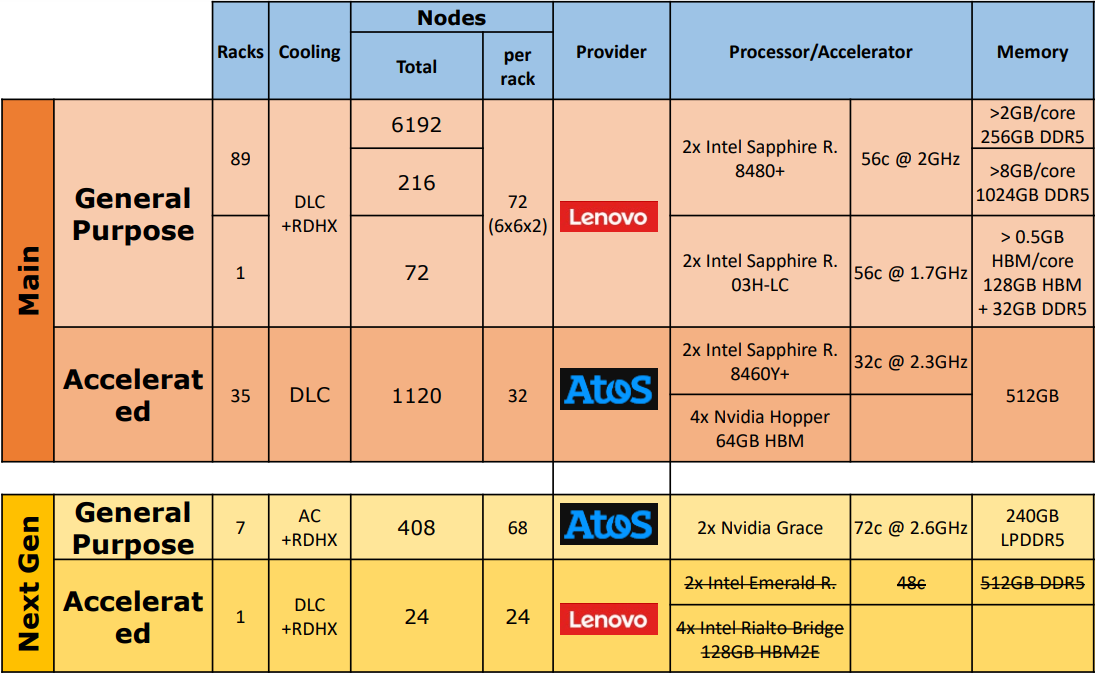 Благодаря увеличенной вычислительной мощности MareNostrum 5 позволяет решать всё более сложные задачи. Например, климатические модели получат более высокое разрешение, что сделает прогнозы гораздо более точными и надёжными. Также появится возможность решать гораздо более сложные проблемы в области ИИ и Big Data. Отдельное внимание уделено поддержке европейских медицинских исследований в области создания новых лекарств, разработки вакцин и моделирования распространения вирусов. Суперкомпьютер также станет важнейшим инструментом для материаловедения и инженерии, включая проектирование и оптимизацию самолётов, развитие более безопасной, экологически чистой и эффективной авиации. Аналогичным образом, машина будет использоваться для моделирования процессов энергогенерации, включая ядерный синтез. В ближайшие месяцы MareNostrum 5 объединится с двумя квантовыми компьютерами: первой системой испанской суперкомпьютерной сети (RES), которая является частью инициативы Quantum Spain, и одним из первых европейских квантовых компьютеров EuroHPC JU. Оба квантовых компьютера будут одними из первых, которых запустили в Южной Европе.
13.11.2023 [17:00], Игорь Осколков
NVIDIA анонсировала ускорители H200 и «фантастическую четвёрку» Quad GH200NVIDIA анонсировала ускорители H200 на базе всё той же архитектуры Hopper, что и их предшественники H100, представленные более полутора лет назад. Новый H200, по словам компании, первый в мире ускоритель, использующий память HBM3e. Вытеснит ли он H100 или останется промежуточным звеном эволюции решений NVIDIA, покажет время — H200 станет доступен во II квартале следующего года, но также в 2024-м должно появиться новое поколение ускорителей B100, которые будут производительнее H100 и H200. 
HGX H200 (Источник здесь и далее: NVIDIA) H200 получил 141 Гбайт памяти HBM3e с суммарной пропускной способностью 4,8 Тбайт/с. У H100 было 80 Гбайт HBM3, а ПСП составляла 3,35 Тбайт/с. Гибридные ускорители GH200, в состав которых входит H200, получат до 480 Гбайт LPDDR5x (512 Гбайт/с) и 144 Гбайт HBM3e (4,9 Тбайт/с). Впрочем, с GH200 есть некоторая неразбериха, поскольку в одном месте NVIDIA говорит о 141 Гбайт, а в другом — о 144 Гбайт HBM3e. Обновлённая версия GH200 станет массово доступна после выхода H200, а пока что NVIDIA будет поставлять оригинальный 96-Гбайт вариант с HBM3. Напомним, что грядущие конкурирующие AMD Instinct MI300X получат 192 Гбайт памяти HBM3 с ПСП 5,2 Тбайт/с.  На момент написания материала NVIDIA не раскрыла полные характеристики H200, но судя по всему, вычислительная часть H200 осталась такой же или почти такой же, как у H100. NVIDIA приводит FP8-производительность HGX-платформы с восемью ускорителями (есть и вариант с четырьмя), которая составляет 32 Пфлопс. То есть на каждый H200 приходится 4 Пфлопс, ровно столько же выдавал и H100. Тем не менее, польза от более быстрой и ёмкой памяти есть — в задачах инференса можно получить прирост в 1,6–1,9 раза.  При этом платы HGX H200 полностью совместимы с уже имеющимися на рынке платформами HGX H100 как механически, так и с точки зрения питания и теплоотвода. Это позволит очень быстро обновить предложения партнёрам компании: ASRock Rack, ASUS, Dell, Eviden, GIGABYTE, HPE, Lenovo, QCT, Supermicro, Wistron и Wiwynn. H200 также станут доступны в облаках. Первыми их получат AWS, Google Cloud Platform, Oracle Cloud, CoreWeave, Lambda и Vultr. Примечательно, что в списке нет Microsoft Azure, которая, похоже, уже страдает от недостатка H100.  GH200 уже доступны избранным в облаках Lamba Labs и Vultr, а в начале 2024 года они появятся у CoreWeave. До конца этого года поставки серверов с GH200 начнут ASRock Rack, ASUS, GIGABYTE и Ingrasys. В скором времени эти чипы также появятся в сервисе NVIDIA Launchpad, а вот про доступность там H200 компания пока ничего не говорит.  Одновременно NVIDIA представила и базовый «строительный блок» для суперкомпьютеров ближайшего будущего — плату Quad GH200 с четырьмя чипами GH200, где все ускорители связаны друг с другом посредством NVLink по схеме каждый-с-каждым. Суммарно плата несёт более 2 Тбайт памяти, 288 Arm-ядер и имеет FP8-производительность 16 Пфлопс. На базе Quad GH200 созданы узлы HPE Cray EX254n и Eviden Bull Sequana XH3000. До конца 2024 года суммарная ИИ-производительность систем с GH200, по оценкам NVIDIA, достигнет 200 Эфлопс.
25.10.2023 [11:49], Сергей Карасёв
Экзафлопсный суперкомпьютер Frontier назван лучшим изобретением 2023 года по версии TimeЕжегодно американский журнал Time публикует список из лучших изобретений человечества в самых разных сферах. В нынешнем году в рейтинг вошли 200 продуктов и технологий, которые сгруппированы более чем в 35 категорий. Это, в частности, ПО, связь, виртуальная и дополненная реальность, ИИ, потребительская электроника, чистая энергии, здравоохранение, безопасность, робототехника и многое другое. Одним из направлений являются экспериментальные системы и устройства. В данной категории победителем назван вычислительный комплекс Frontier — самый мощный суперкомпьютер 2023 года. Исследователи уже используют его для самых разных целей: от изучения чёрных дыр до моделирования климата. «Специалисты сравнивают это с эквивалентом высадки на Луну с точки зрения инженерных достижений. Это больше, чем чудо. Это статистическая невозможность», — сказал Ник Дюбе (Nic Dubé), руководитель проекта в HPE. 
Источник изображения: ORNL Система Frontier, созданная специалистами HPE, установлена в Национальной лаборатории Окриджа (ORNL) Министерства энергетики США. Она занимает первое место в рейтинге TOP500 с производительностью 1,194 Эфлопс. В составе системы применяются процессоры AMD EPYC Milan, ускорители Instinct MI250X и интерконнект Cray Slingshot. В общей сложности задействованы 8 699 904 вычислительных ядра. Теоретическое пиковое быстродействие достигает 1,680 Эфлопс.
21.10.2023 [16:09], Сергей Карасёв
В Аргоннской национальной лаборатории запущена ИИ-система GroqАргоннская национальная лаборатория Министерства энергетики США сообщила о запуске вычислительного кластера, использующего специализированные ИИ-решения Groq. Ресурсы системы предоставляются исследователям на базе тестовой площадки ALCF (Argonne Leadership Computing Facility). Groq является разработчиком чипов GroqChip, спроектированных с прицелом на решение задач ИИ и машинного обучения. Эти изделия, наделённые 230 Мбайт памяти SRAM, обеспечивают производительность до 750 TOPS INT8 и до 188 Тфлопс FP16. 
Источник изображения: Аргоннская национальная лаборатория Процессоры GroqChip являются основой ускорителей GroqCard с интерфейсом PCIe 4.0 x16. Восемь таких карт входят в состав сервера GroqNode формата 4U. Наконец, до восьми серверов GroqNode используются в кластерах GroqRack. И именно такие узлы являются основой новой ИИ-платформы ALCF. Заявленная производительность каждого узла достигает 48 POPS (INT8) или 12 Пфлопс (FP16). Экосистема программного и аппаратного обеспечения Groq предназначена для ускорения решения сложных ИИ-задач, в частности, инференса. Исследователи будут применять НРС-платформу при реализации ресурсоёмких научных проектов в таких областях, как визуализация, термоядерная энергия, материаловедение, создание лекарственных препаратов нового поколения и пр. Отмечается, что уникальная архитектура Groq и универсальный компилятор обеспечат повышенную производительность для широкого спектра ИИ-моделей. В рамках сотрудничества Аргоннская национальная лаборатория и Groq работают над лекарствами от коронавируса, спровоцировавшего пандемию COVID-19: говорится, что время получения результатов сократилось с дней до минут. Создавая модели вируса и помогая исследователям быстро сравнивать их с базой данных, содержащей миллиарды молекул препаратов, модели ИИ позволяют идентифицировать перспективные соединения, которые будут использоваться в клинических терапевтических испытаниях.
01.08.2023 [10:02], Сергей Карасёв
Esperanto готовит универсальный чип ET-SoC-2 на базе RISC-V для задач НРС и ИИСтартап Esperanto Technologies, по сообщению ресурса HPC Wire, готовит новый чип с архитектурой RISC-V, ориентированный на системы высокопроизводительных вычислений (НРС) и задачи ИИ. Изделие получит обозначение ET-SoC-2. Нынешний чип ET-SoC-1 объединяет 1088 энергоэффективных ядер ET-Minion и четыре высокопроизводительных ядра ET-Maxion. Решение предназначено для инференса рекомендательных систем, в том числе на периферии. Чип ET-SoC-2 будет включать в себя новые высокопроизводительные ядра CPU на базе RISC-V с векторными расширениями. Точные данные о производительности не раскрываются, но говорится, что изделие обеспечит быстродействие с двойной точностью более 10 Тфлопс. Архитектура ET-SoC-2 предполагает совместную работу сотен и тысяч чипов для организации платформ НРС. При этом Esperanto делает упор на энергетической эффективности своих решений. 
Источник изображения: Esperanto Technologies По словам Дейва Дитцеля (Dave Ditzel), генерального директора Esperanto, чипы RISC-V смогут взять на себя функции и CPU, и GPU при обработке ресурсоёмких приложений, в частности, машинного обучения. Процессоры RISC-V отстают по производительности от чипов x86 и Arm, хотя разрыв постепенно сокращается. Дитцель сказал, что стойки с чипами ET-SoC-1 могут обеспечить производительность в петафлопсы. Однако проблема с внедрением RISC-V заключается в слабо развитой экосистеме ПО.
21.07.2023 [15:35], Сергей Карасёв
NVIDIA, подвинься: Cerebras представила 4-Эфлопс ИИ-суперкомпьютер Condor Galaxy 1 и намерена построить ещё восемь таких жеКомпания Cerebras Systems анонсировала суперкомпьютер Condor Galaxy 1 (CG-1), предназначенный для решения ресурсоёмких задач с применением ИИ. Это одна из первых действительно крупных машин на базе уникальных чипов Cerebras. В проекте стоимостью $100 млн приняла участие холдинговая группа G42 из ОАЭ, которая занимается технологиями ИИ и облачными вычислениями. G42 является основным заказчиком комплекса. В текущем виде комплекс CG-1, расположенный в Санта-Кларе (Калифорния, США), объединяет 32 системы Cerebras CS-2 и обеспечивает производительность на уровне 2 Эфлопс (FP16). В IV квартале ткущего года будут добавлены ещё 32 системы Cerebras CS-2, что позволит довести быстродействие до 4 Эфлопс (FP16). Ожидаемый уровень энергопотребления составит порядка 1,5 МВт или более. 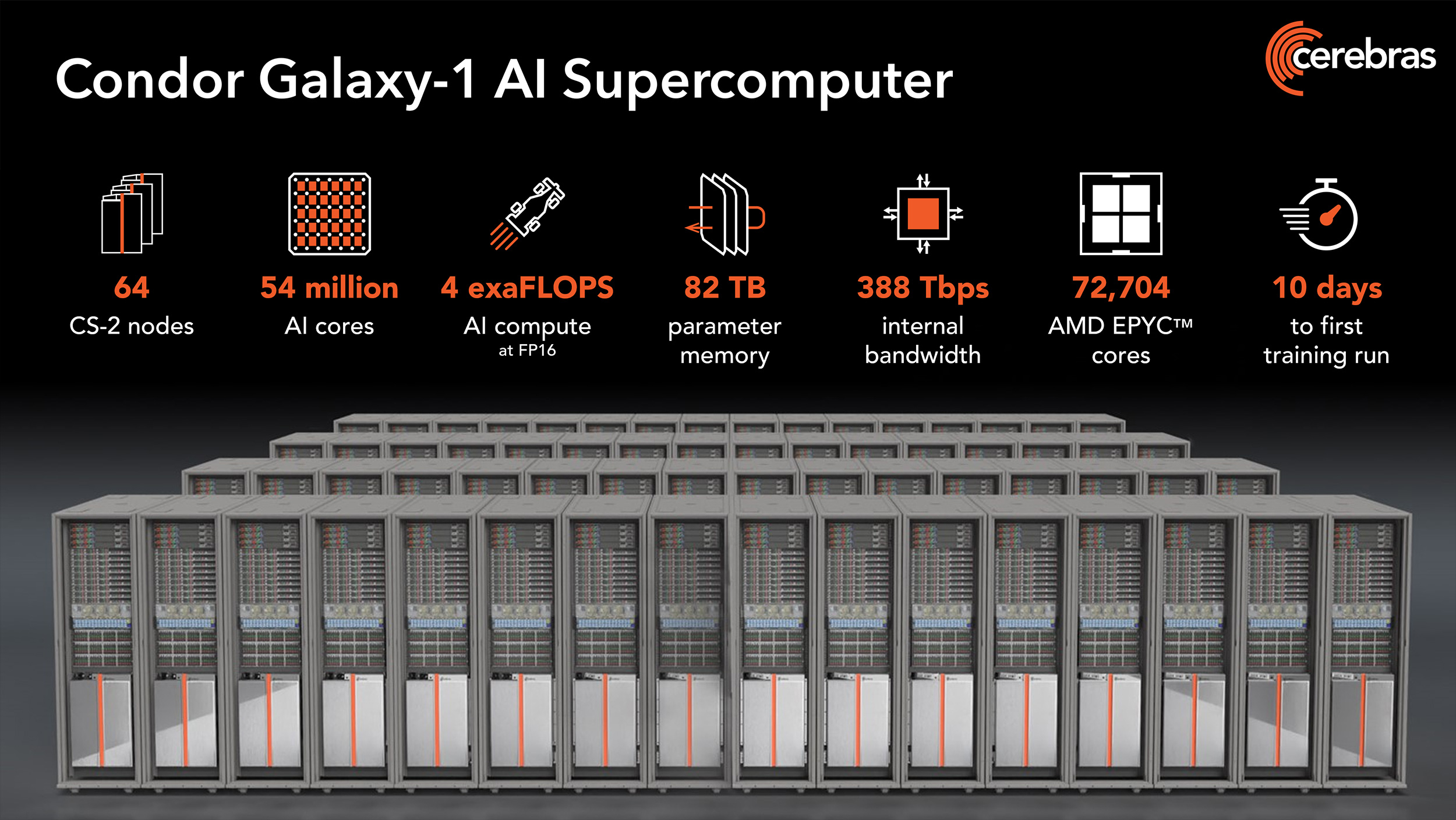
Источник изображений: Cerebras (via ServeTheHome) В системах Cerebras CS-2 применяются гигантские чипы Wafer-Scale Engine 2 (WSE-2), насчитывающие 2,6 трлн транзисторов. Такие чипы имеют 850 тыс. тензорных ядер и несут на борту 40 Гбайт памяти SRAM. Системы выполнены в формате 15 RU и укомплектованы шестью блоками питания мощностью 4 кВт каждый. Задействована технология жидкостного охлаждения. Отдельно отмечается, что программный стек позволит без проблем и существенных модификаций кода работать с ИИ-моделями.  После ввода в строй второй очереди комплекс CG-1 суммарно получит 54,4 млн ИИ-ядер, 2,56 Тбайт SRAM и внутренний интерконнект со скоростью 388 Тбит/с. Их дополнят 72 704 ядра AMD EPYC Milan и 82 Тбайт памяти для хранения параметров. По словам создателей, мощностей суперкомпьютера хватит для обучения модели с 600 млрд параметров и на очередях длиной до 50 тыс. токенов. При этом производительность масштабируется практически линейно.  Cerebras и G42 будут предоставлять доступ к CG-1 по облачной схеме, что позволит заказчикам использовать ресурсы ИИ-суперкомпьютера без необходимости управлять моделями или распределять их по узлам и ускорителям. CG-1 — первый из трёх ИИ-суперкомпьютеров нового поколения. В I полугодии 2024 года будут построены комплексы CG-2 и CG-3, полностью аналогичные CG-1, которые будут объединены в распределённый ИИ-кластер. А к концу следующего года у Cerebras будет уже девять систем CG.  Для Cerebras это означает, что компания более не является стартапом, поскольку в её решения заказчики поверили и без участия в индустриальных тестах вроде MLPerf. Кроме того, теперь компания является не просто очередным производителем «железа», а предоставляет услуги, которые и помогут ей заработать в будущем.
20.07.2023 [23:30], Игорь Осколков
AMD, Broadcom, Cisco, Intel и другие вендоры создадут интерконнект Ultra Ethernet для HPC и ИИAMD, Arista, Broadcom, Cisco, Eviden (Atos), HPE, Intel, Meta✴ и Microsoft в рамках Linux Foundation сформировали новый консорциум Ultra Ethernet Consortium, который намерен создать на базе Ethernet новый масштабируемый и эффективный с точки зрения стоимости коммуникационный стек, ориентированный на высокопроизводительные вычисления (HPC) и ИИ. Иными словами, речь идёт о создании спецификаций интерконнекта нового поколения на базе Ethernet для современных кластеров, облаков и иных платформ. UEC сформировал четыре рабочих группы, ответственных за физический, канальный и транспортный уровни, а также за уровень ПО. Целью же является создание современного сетевого стека, который учитывает потребности HPC- и ИИ-нагрузок, включая новые методы борьбы с заторами в сети, высокий уровень утилизации канала (в том числе 800G/1.6T), многопутевую и гарантированную доставку, сквозную телеметрию, консистентность и низкий уровень задержек, автоматизацию, безопасность и защищённость, масштабируемость, стабильность, надёжность, снижение TCO и так далее. 
Источник: Ultra Ethernet Consortium Фактически отдельные вендоры уже наделили рядом перечисленных свойств свои продукты, однако унификация и объединение усилий, как считается, должны пойти на пользу всем. Всем, кроме, по-видимому, NVIDIA, которой в списке основателей UEC нет (как и Marvell, к слову). NVIDIA после поглощения Mellanox фактически стала монополистом на рынке InfiniBand, который она активно продвигает, не забывая, впрочем, и о своём проприетарном интерконнекте NVLink, который в последней своей версии выбрался за пределы узла. Справедливости ради — про Ethernet компании тоже не забывает. В обзоре UEC аккуратно критикуется и InfiniBand, и его адаптация в виде RoCE. Авторы указывают на правильность и успешность идеи RDMA, но жалуются на не слишком высокую практичность и удобство современных реализаций. И именно поэтому они первым делом предлагают внедрить новый транспортный протокол Ultra Ethernet Transport (UET), который и позволит реализовать интерконнект будущего, а заодно ещё раз доказать эффективность и гибкость технологии Ethernet, которой в этом году исполнилось 50 лет. Впрочем, это только один из кирпичиков UEC. Примечательно, что первые продукты на базе новых спецификаций обещали показать уже в 2024 году.
29.05.2023 [07:30], Сергей Карасёв
NVIDIA представила 1-Эфлопс ИИ-суперкомпьютер DGX GH200: 256 суперчипов Grace Hopper и 144 Тбайт памятиКомпания NVIDIA анонсировала вычислительную платформу нового типа DGX GH200 AI Supercomputer для генеративного ИИ, обработки огромных массивов данных и рекомендательных систем. HPC-платформа станет доступна корпоративным заказчикам и организациям в конце 2023 года. Платформа представляет собой готовый ПАК и включает, в частности, наборы ПО NVIDIA AI Enterprise и Base Command. Для платформы предусмотрено использование 256 суперчипов NVIDIA GH200 Grace Hopper, объединённых при помощи NVLink Switch System. Каждый суперчип содержит в одном модуле Arm-процессор NVIDIA Grace и ускоритель NVIDIA H100. Задействован интерконнект NVLink-C2C (Chip-to-Chip), который, как заявляет NVIDIA, значительно быстрее и энергоэффективнее, нежели PCIe 5.0. В результате, скорость обмена данными между CPU и GPU возрастает семикратно, а затраты энергии сокращаются примерно в пять раз. Пропускная способность достигает 900 Гбайт/с. 
Источник изображений: NVIDIA Технология NVLink Switch позволяет всем ускорителям в составе системы функционировать в качестве единого целого. Таким образом обеспечивается производительность на уровне 1 Эфлопс (~ 9 Пфлопс FP64), а суммарный объём памяти достигает 144 Тбайт — это почти в 500 раз больше, чем в одной системе NVIDIA DGX A100. Архитектура DGX GH200 AI Supercomputer позволяет добиться 10-кратного увеличения общей пропускной способности по сравнению с HPC-платформой предыдущего поколения.  Ожидается, что Google Cloud, Meta✴ и Microsoft одними из первых получат доступ к суперкомпьютеру DGX GH200, чтобы оценить его возможности для генеративных рабочих нагрузок ИИ. В перспективе собственные проекты на базе DGX GH200 смогут реализовывать крупнейшие провайдеры облачных услуг и гиперскейлеры. Для собственных нужд NVIDIA до конца 2023 года построит суперкомпьютер Helios, который посредством Quantum-2 InfiniBand объединит сразу четыре DGX GH200.
29.05.2023 [07:30], Сергей Карасёв
NVIDIA представила модульную архитектуру MGX для создания ИИ-систем на базе CPU, GPU и DPUКомпания NVIDIA на выставке Computex 2023 представила архитектуру MGX, которая открывает перед разработчиками серверного оборудования новые возможности для построения HPC-систем, платформ для ИИ и метавселенных. Утверждается, что MGX закладывает основу для быстрого создания более 100 вариантов серверов при относительно небольших затратах. Концепция MGX предусматривает, что разработчики на первом этапе проектирования выбирают базовую системную архитектуру для своего шасси. Далее добавляются CPU, GPU и DPU в той или иной конфигурации для решения определённых задач. Таким образом, на базе MGX может быть построена серверная система для уникальных рабочих нагрузок в области наук о данных, больших языковых моделей (LLM), периферийных вычислений, обработки графики и видеоматериалов и пр. Говорится также, что благодаря гибридной конфигурации на одной машине могут выполняться задачи разных типов, например, и обучение ИИ-моделей, и поддержание работы ИИ-сервисов. 
Источник изображений: NVIDIA Одними из первых системы на архитектуре MGX выведут на рынок компании Supermicro и QCT. Первая предложит решение ARS-221GL-NR с NVIDIA Grace, а вторая — сервер S74G-2U на базе NVIDIA GH200 Grace Hopper. Эти платформы дебютируют в августе нынешнего года. Позднее появятся MGX-платформы ASRock Rack, ASUS, Gigabyte, Pegatron и других производителей.  Архитектура MGX совместима с нынешним и будущим оборудованием NVIDIA, включая H100, L40, L4, Grace, GH200 Grace Hopper, BlueField-3 DPU и ConnectX-7. Поддерживаются различные форм-факторы систем: 1U, 2U и 4U. Возможно применение воздушного и жидкостного охлаждения. |
|

