Материалы по тегу: hpc
|
25.07.2024 [09:57], Сергей Карасёв
Илон Маск показал ИИ-суперкомпьютер Dojo на основе чипов Tesla D1Глава Tesla Илон Маск (Elon Musk), по сообщению ресурса Tom's Hardware, обнародовал фотографии вычислительного комплекса Dojo, который будет использоваться для разработки инновационных автомобильных технологий, а также для обучения автопилота. Tesla, напомним, начала создание ИИ-суперкомпьютера Dojo в июле 2023 года. Основой системы послужат специализированные чипы собственной разработки Tesla D1. Дата-центр Dojo, расположенный в штаб-квартире Tesla в Остине (Техас, США), по своей конструкции напоминает бункер. В апреле нынешнего года сообщалось, что при строительстве ЦОД компания Маска столкнулась с трудностями, связанными в том числе с доставкой необходимых материалов. Как теперь сообщается, Tesla намерена ввести Dojo в эксплуатацию до конца 2024 года. По производительности этот суперкомпьютер будет сопоставим с кластером из 8 тыс. ускорителей NVIDIA H100. По словам Маска, это «не слишком много, но и не тривиально». Для сравнения: мощнейший ИИ-суперкомпьютер компании xAI, также курируемой Илоном Маском, объединит 100 тыс. карт H100. 
Источник изображений: Илон Маск Отмечается, что чипы Tesla D1 специально ориентированы на машинное обучение и анализ видеоданных. Поэтому систему Dojo планируется использовать прежде всего для совершенствования технологии автономного вождения Tesla путём обработки видеоданных, полученных от автомобилей компании. В свою очередь, «ИИ-гигафабрика» xAI поможет в развитии чат-ботов Grok следующего поколения.  Маск также сообщил, что компания Tesla намерена «удвоить усилия» по разработке и развертыванию Dojo из-за высоких цен на оборудование NVIDIA. Вместе с тем финансовый директор Tesla Вайбхав Танеджа (Vaibhav Taneja) заявил, что, несмотря на снижение капвложений во II квартале 2024 года, компания по-прежнему ожидает, что соответствующие затраты превысят $10 млрд.
30.05.2024 [23:56], Игорь Осколков
NVLink для экономных — AMD, Intel и другие IT-гиганты объединились для создания UALink и противостояния NVIDIAЛетом прошлого года AMD, Arista, Broadcom, Cisco, Eviden/Atos, HPE, Intel, Meta✴ и Microsoft сформировали консорциум Ultra Ethernet (UEC), призванный составить конкуренцию технологии InfiniBand, которая фактически единолично контролируется NVIDIA после покупки Mellanox, и стандартизировать Ethernet-решения для современных ИИ- и HPC-платформ. А теперь AMD, Broadcom, Cisco, Google, HPE, Intel, Meta✴ и Microsoft сформировали альянс Ultra Accelerator Link (UALink), который должен составить конкуренцию NVLink. К UEC за год присоединились ещё полсотни компаний, кроме, конечно, NVIDIA, которая, впрочем, про Ethernet тоже не забывает, хотя периодически получает критику со стороны Broadcom. Единственной альтернативой в деле построения фабрик для более-менее крупных кластеров остаётся Omni-Path Express, развиваемый Cornelis Networks, которая тоже присоединилась к UEC, но доля этой технологии на фоне Ethernet и InfiniBand мизерная. Кроме того, ни одна из этих технологий не может предложить то, что может NVIDIA NVLink — возможность напрямую объединить сотни ускорителей (точнее, их память) сверхбыстрым соединением с низким уровнем задержки. 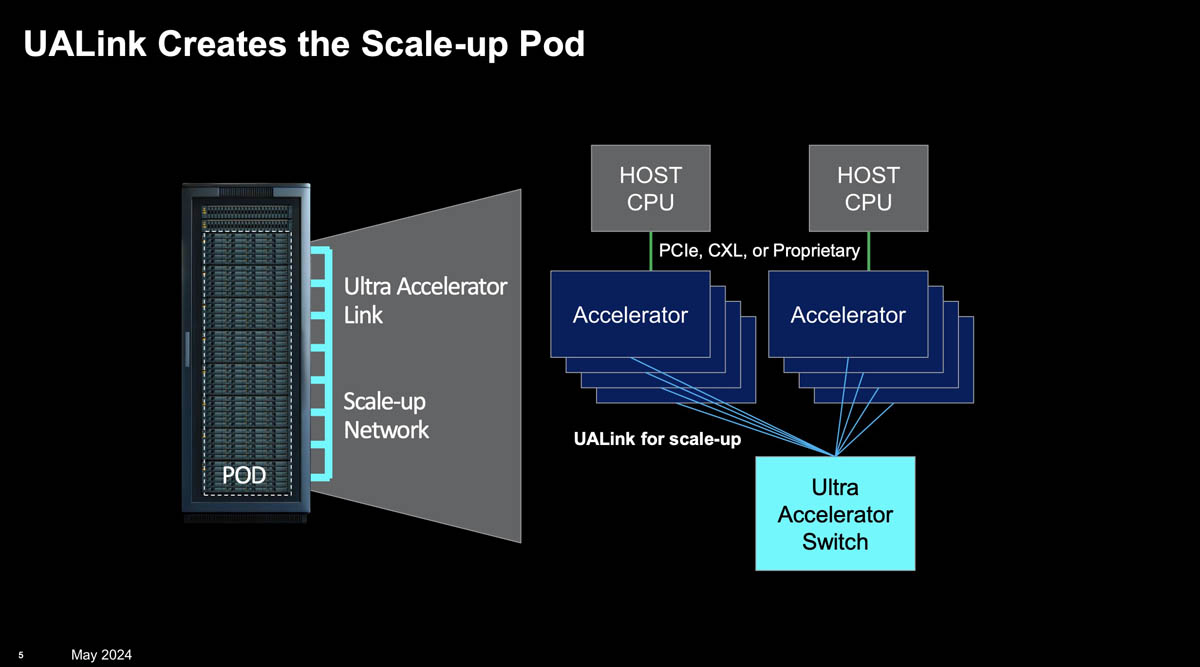
Источник изображений: UALink via ServeTheHome NVLink 4 достиг скорости 900 Гбайт/с на ускоритель и впервые вышел за пределы узла, позволив объединить в домен до 256 ускорителей, что NVIDIA и предложила в рамках DGX SuperPod H100. NVLink 5 удвоил пропускную способность до 1,8 Тбайт/с и теоретически позволит объединить до 576 ускорителей в одном домене. Именно NVLink позволил создать высокоплотные суперускорители GH200 NVL32 и GB200 NVL72. И именно их NVIDIA считает минимальной эффективной единицей кластеров ближайшего будущего, предлагая крупным заказчикам на меньшее даже не размениваться.  Intel в семействе Gaudi использует Ethernet (1,2 Тбайт/с на ускоритель) как для вертикального, так и для горизонтального масштабирования. AMD же полагается на Infinity Fabric (896 Гбайт/с на ускоритель) на базе PCIe и xGMI, которые до недавнего времени за пределы узла не выходили. Однако в конце 2023 года было объявлено, что в 2025 году AMD и Broadcom выпустят коммутатор на базе PCIe 7.0 (стандарт планируют только-только утвердить в этом же году), который будет поддерживать технологию, которая теперь называется AFL (Accelerated Fabric Link) — это и будет выходом Infinity Fabric за пределы узла.  И именно совместными наработками AMD и Broadcom поделятся в рамках UALink. Первую версию нового интерконнекта альянс обещает представить уже в III квартале 2024 года, а в IV квартале — версию 1.1. При этом пока прямо не говорится, будет ли основным транспортом PCIe или Ethernet, и какой протокол будет использоваться для работы с памятью. Но уже обещано, что UALink 1.0 позволит объединить до 1024 ускорителей в одном домене с возможностью прямых load/store-запросов к их памяти. Для дальнейшего масштабирования кластеров по-прежнему предлагается использовать Ultra Ethernet.  При этом UALink, строго говоря, не обещает возможности беспрепятственного общения ускорителей разных вендоров, зато позволяет упростить инфраструктуру и сделать её дешевле благодаря открытости и конкуренции. Хотя было бы приятно увидеть UALink в качестве аппаратной основы и для стандарта UXL, который намерен побороться с NVIDIA CUDA. Что касается CXL, то этот стандарт, тоже использующий PCIe в качестве транспорта, вероятно, останется «привязанным» к CPU и внутриузловым коммуникациям, хотя возможности его гораздо шире.
27.05.2024 [22:20], Алексей Степин
Тридцать на одного: Liqid UltraStack 30 позволяет подключить десятки GPU к одному серверуКомпания Liqid сотрудничает с Dell довольно давно — ещё в прошлом году она смогла добиться размещения 16 ускорителей в своей платформе UltraStack L40S. Но на этом компания не остановилась и представила новую композитную платформу UltraStack 30, в которой смогла довести число одновременно доступных хост-системе ускорителей до 30. Для подключения, конфигурации и управления ресурсами ускорителей Liqid использует комбинацию фирменного программного обеспечения Matrix CDI и интерконнекта Liqid Fabric. В основе последнего лежит PCI Express. Это позволяет динамически конфигурировать аппаратную инфраструктуру с учётом конкретных задач с её возвратом в общий пул ресурсов по завершению работы. Сами «капсулы» с ресурсами подключены к единственному хост-серверу, что упрощает задачу масштабирования, минимизирует потери производительности, повышает энергоэффективность и позволяет добиться наиболее плотной упаковки вычислительных ресурсов, нежели это возможно в классическом варианте с раздельными серверами. А благодаря гибкости конфигурирования буквально «на лету» исключается простой весьма дорогостоящих аппаратных ресурсов. 
Источник здесь и далее: Liqid В случае UltraStack 30 основой по умолчанию является сервер серии Dell PowerEdge R760 с двумя Xeon Gold 6430 и 1 Тбайт оперативной памяти, однако доступен также вариант на базе Dell R7625, оснащённый процессорами AMD EPYC 9354. Опционально можно укомплектовать систему NVMe-хранилищем объёмом 30 Тбайт, в качестве сетевых опций доступны либо пара адаптеров NVIDIA ConnectX-7, либо один DPU NVIDIA Bluefield-3.  За общение с ускорительными модулями отвечает 48-портовой коммутатор PCI Express 4.0 вкупе с фирменными хост-адаптерами Liqid. Технология ioDirect позволяет ускорителям общаться друг с другом и хранилищем данных напрямую, без посредничества CPU. В трёх модулях расширения установлено по 10 ускорителей NVIDIA L40S, каждый несет на борту 48 Гбайт памяти GDDR6. Такая конфигурация теоретически способна развить 7,3 Пфлопс на вычислениях FP16, вдвое больше на FP8, и почти 1,1 Пфлопс на тензорных ядрах в формате TF32. 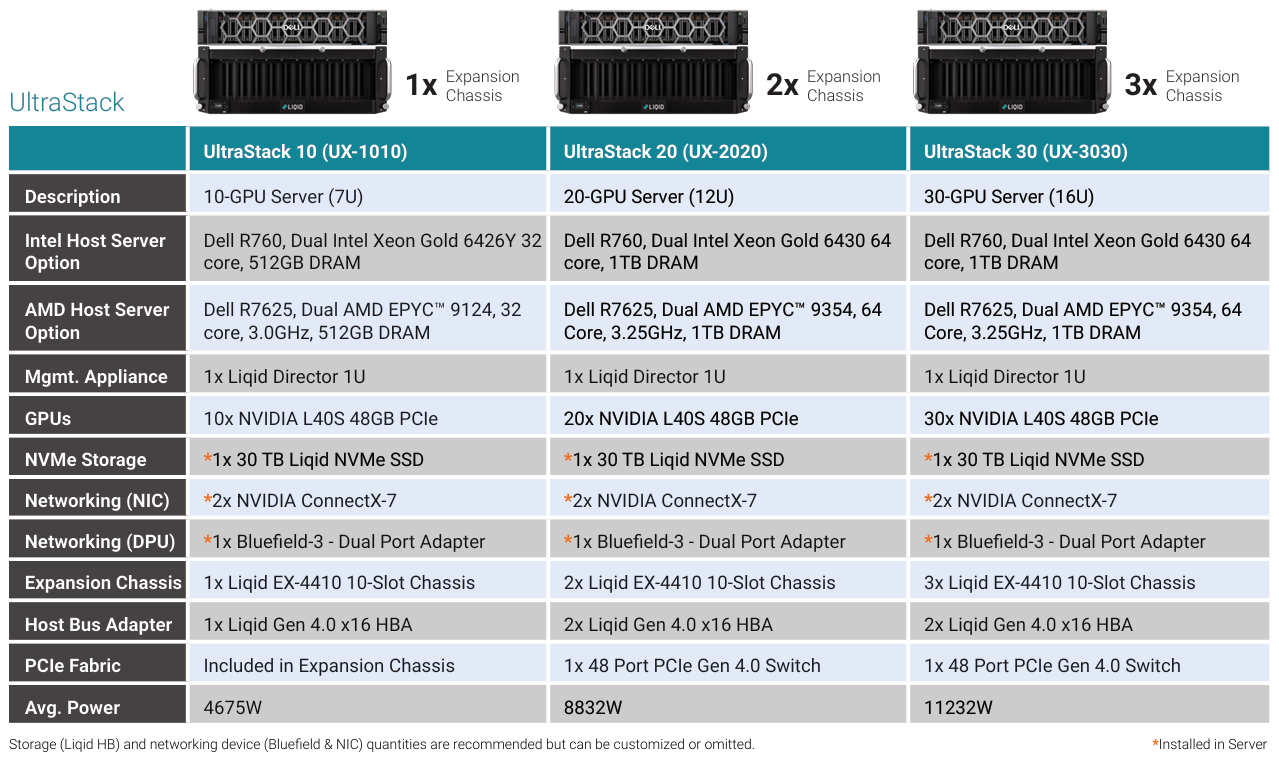 Платформа UltraStack 30 предназначена в первую очередь для быстрого развёртывания достаточно мощной ИИ-инфраструктуры там, где требуется тонкая подстройка и дообучение уже «натасканных» больших моделей. При этом стоит учитывать довольно солидное энергопотребление, составляющее более 11 кВт. Также в арсенале компании есть решения SmartStack на базе модульных систем Dell PowerEdge C-Series, позволяющие подключать к каждому из лезвийных модулей MX760c, MX750с и MX740c до 20 ускорителей. Модульные решения Liqid поддерживают также ускорители других производителей, включая достаточно экзотические, такие как Groq.
26.05.2024 [13:24], Руслан Авдеев
Эрик Шмидт: будущие суперкомпьютеры США и Китая будут окружены пулемётами и колючей проволокой и питаться от АЭС
hardware
hpc
аэс
безопасность
ии
информационная безопасность
китай
суперкомпьютер
сша
цод
энергетика
Бывший генеральный директор Google Эрик Шмидт (Eric Schmidt) прогнозирует, что в обозримом будущем в США и Китае большие суперкомпьютеры будут заниматься ИИ-вычислениями под защитой военных баз. В интервью Noema он подробно рассказал о том, каким видит новые ИИ-проекты, и это будущее вышло довольно мрачным. Шмидт поведал о том, как правительства будут регулировать ИИ и искать возможности контроля ЦОД, работающих над ИИ. Покинув Google, бизнесмен начал очень тесно сотрудничать с военно-промышленным комплексом США. По его словам, рано или поздно в США и Китае появится небольшое число чрезвычайно производительных суперкомпьютеров с возможностью «автономных изобретений» — их производительность будет гораздо выше, чем государства готовы свободно предоставить как своим гражданам, так и соперникам. Каждый такой суперкомпьютер будет соседствовать с военной базой, питаться от атомного источника энергии, а вокруг будет колючая проволока и пулемёты. Разумеется, таких машин будет немного — гораздо больше суперкомпьютеров будут менее производительны и доступ к ним останется более широким. Строго говоря, самые производительные суперкомпьютеры США принадлежат Национальным лабораториям Министерства энергетики США, которые усиленно охраняются и сейчас. Как заявил Шмидт, необходимы и договорённости об уровнях безопасности вычислительных систем по примеру биологических лабораторий. В биологии широко распространена оценка по уровням биологической угрозы для сдерживания её распространения и оценки уровня риска заражения. С суперкомпьютерами имеет смысл применить похожую классификацию. 
Источник изображения: Joel Rivera-Camacho/unsplash.com Шмидт был председателем Комиссии национальной безопасности США по ИИ и работал в Совете по оборонным инновациям. Также он активно инвестировал в оборонные стартапы. В то же время Шмидт сохранил влияние и в Alphabet и до сих пор владеет акциями компании стоимостью в миллиарды долларов. Военные и разведывательные службы США пока с осторожностью относятся к большим языковым моделям (LLM) и генеративному ИИ вообще из-за распространённости «галлюцинаций» в таких системах, ведущих к весьма правдоподобным на первый взгляд неверным выводам. Кроме того, остро стоит вопрос сохранения секретной информации в таких системах. Ранее в этом году Microsoft подтвердила внедрение изолированной от интернета генеративной ИИ-модели для спецслужб США после модернизации одного из своих ИИ-ЦОД в Айове. При этом представитель Microsoft два года назад предрекал, что нынешнее поколение экзафлопсных суперкомпьютеров будет последним и со временем все переберутся в облака.
16.05.2024 [01:05], Игорь Осколков
И для ИИ, и для HPC: первые европейские серверные Arm-процессоры SiPearl Rhea1 получат HBM-памятьКомпания SiPearl уточнила спецификации разрабатываемых ею серверных Arm-процессоров Rhea1, которые будут использоваться, в частности, в составе первого европейского экзафлопсного суперкомпьютера JUPITER, хотя основными чипами в этой системе будут всё же гибридные ускорители NVIDIA GH200. Заодно SiPearl снова сдвинула сроки выхода Rhea1 — изначально первые образцы планировалось представить ещё в 2022 году, а теперь компания говорит уже о 2025-м. При этом существенно дизайн процессоров не поменялся. Они получат 80 ядер Arm Neoverse V1 (Zeus), представленных ещё весной 2020 года. Каждому ядру полагается два SIMD-блока SVE-256, которые поддерживают, в частности, работу с BF16. Объём LLC составляет 160 Мбайт. В качестве внутренней шины используется Neoverse CMN-700. Для связи с внешним миром имеются 104 линии PCIe 5.0: шесть x16 + две x4. О поддержке многочиповых конфигураций прямо ничего не говорится. 
Источник изображения: SiPearl Очень похоже на то, что SiPearl от референсов Arm особо и не отдалялась, поскольку Rhea1 хоть и получит четыре стека памяти HBM, но это будет HBM2e от Samsung. При этом для DDR5 отведено всего четыре канала с поддержкой 2DPC, а сам процессор ожидаемо может быть поделён на четыре NUMA-домена. И в такой конфигурации к общей эффективности работы с памятью могут быть вопросы. Именно наличие HBM позволяет говорить SiPearl о возможности обслуживать и HPC-, и ИИ-нагрузки (инференс). 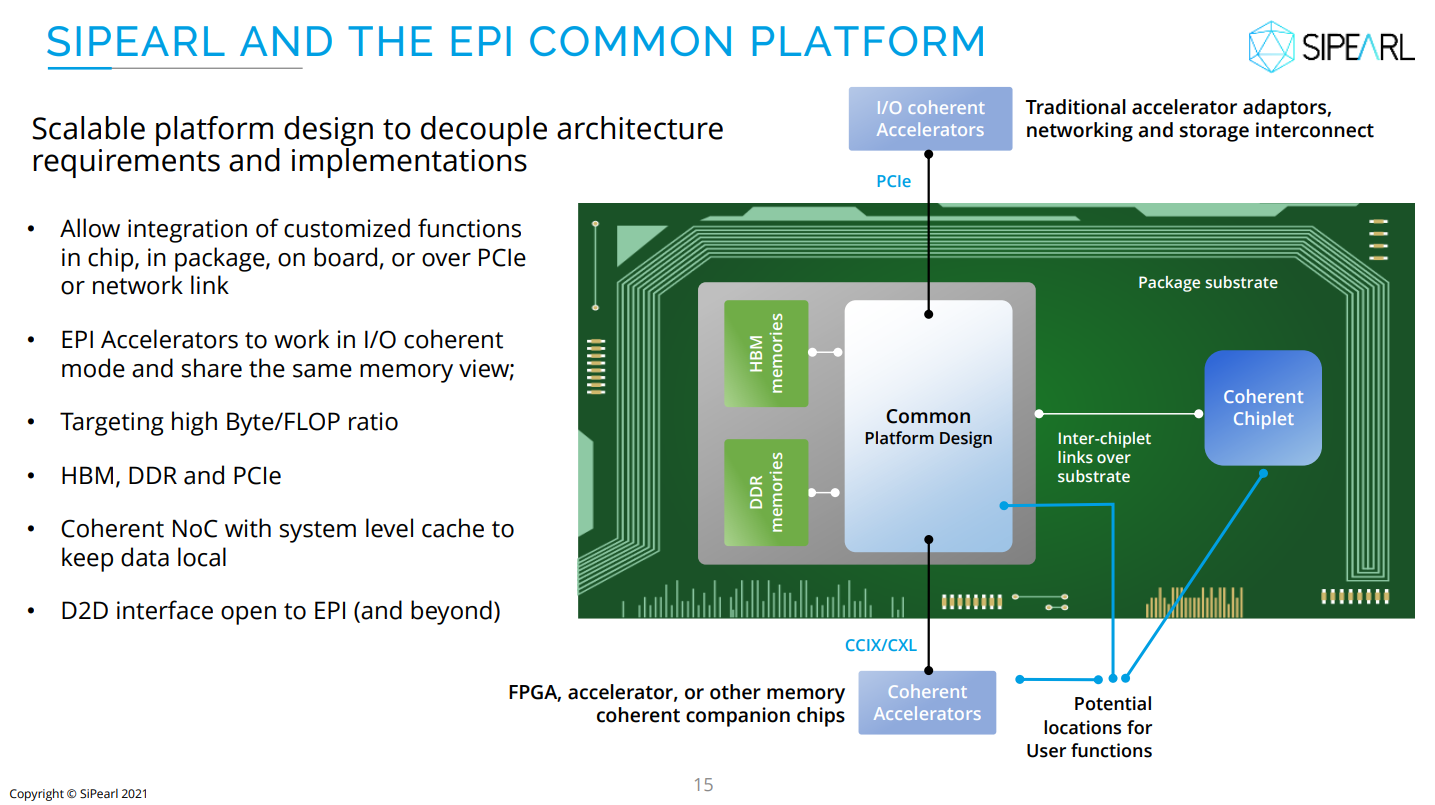
Источник изображения: SiPearl На примере Intel Xeon Max (Sapphire Rapids c 64 Гбайт HBM2e) видно, что наличие сверхбыстрой памяти на борту даёт прирост производительности в означенных задачах, хотя и не всегда. Однако это другая архитектура, другой набор инструкций (AMX), другая же подсистема памяти и вообще пока что единичный случай. С Fujitsu A64FX сравнения тоже не выйдет — это кастомный, дорогой и сложный процессор, который, впрочем, доказал эффективность и в HPC-, и даже в ИИ-нагрузках (с оговорками). В MONAKA, следующем поколении процессоров, Fujitsu вернётся к более традиционному дизайну. 
Источник изображения: EPI Пожалуй, единственный похожий на Rhea1 чип — это индийский 5-нм C-DAC AUM, который тоже базируется на Neoverse V1, но предлагает уже 96 ядер (48+48, два чиплета), восемь каналов DDR5 и до 96 Гбайт HBM3 в четырёх стеках, а также поддержку двухсокетных конфигураций. AWS Graviton3E, который тоже ориентирован на HPC/ИИ-нагрузки, вообще обходится 64 ядрами Zeus и восемью каналами DDR5. Наконец, NVIDIA Grace и Grace Hopper в процессорной части тоже как-то обходятся интегрированной LPDRR5x, да и ядра у них уже Neoverse V2 (Demeter), и своя шина для масштабирования имеется. 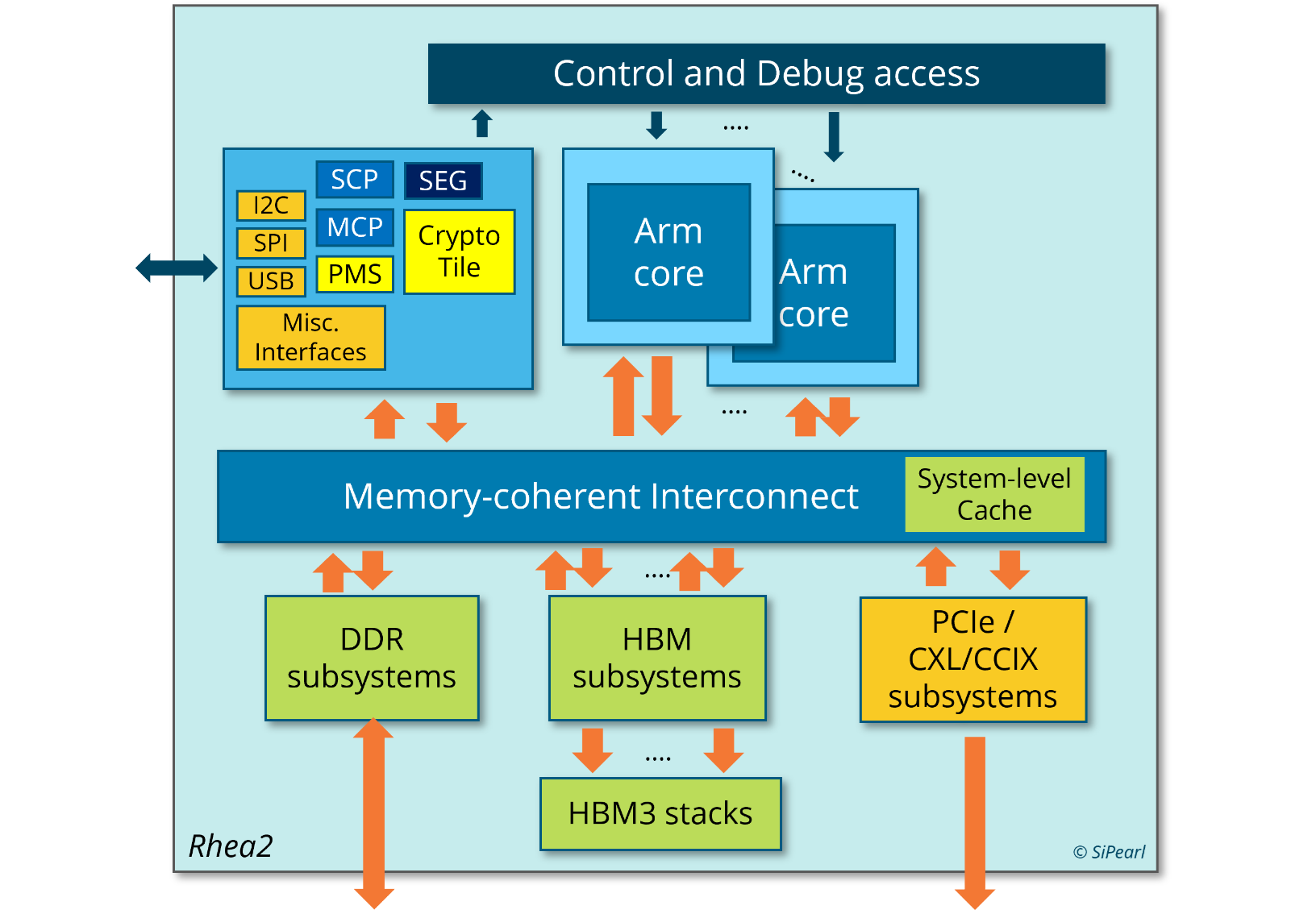
Источник изображения: EPI В любом случае в 2025 году Rhea1 будет выглядеть несколько устаревшим чипом. Но в этом же году SiPearl собирается представить более современные чипы Rhea2 и обещает, что их разработка будет не столь долгой как Rhea1. Компанию им должны составить европейские ускорители EPAC, тоже подзадержавшиеся. А пока Европа будет обходиться преимущественно американскими HPC-технологиями, от которых стремится рано или поздно избавиться.
15.05.2024 [14:18], Руслан Авдеев
PUE у вас неправильный: NVIDIA призывает пересмотреть методы оценки энергоэффективности ЦОД и суперкомпьютеровОператорам дата-центров и суперкомпьютеров не хватает инструментов для корректного измерения энергоэффективности их оборудования и оценки прогресса на пути к экоустойчивым вычислениям. Как утверждает NVIDIA, нужна новая система оценки показателей при использовании оборудования в реальных задачах. Для оценки эффективности ЦОД существует как минимум около трёх десятков стандартов, некоторые уделяют внимание весьма специфическим критериям вроде расхода воды или уровню безопасности. Сегодня чаще всего используется показатель PUE (power usage effectiveness), т.е. отношение энергопотребления всего объекта к потреблению собственно IT-инфраструктуры. В последние годы многие операторы достигли практически идеальных значений PUE, поскольку, например, на преобразование энергии и охлаждение нужно совсем мало энергии. В эпоху роста облачных сервисов оценка PUE показала довольно высокую эффективность, но в эру ИИ-вычислений этот индекс уже не вполне соответствует запросам отрасли ЦОД — оборудование заметно изменилось. NVIDIA справедливо отмечает, что PUE не учитывает эффективность инфраструктуры в реальных нагрузках. С таким же успехом можно измерять расход автомобилем бензина без учёта того, как далеко он может проехать без дозаправки. При этом среднемировой показатель PUE дата-центров остаётся неизменным уже несколько лет, а улучшать его всё дороже. 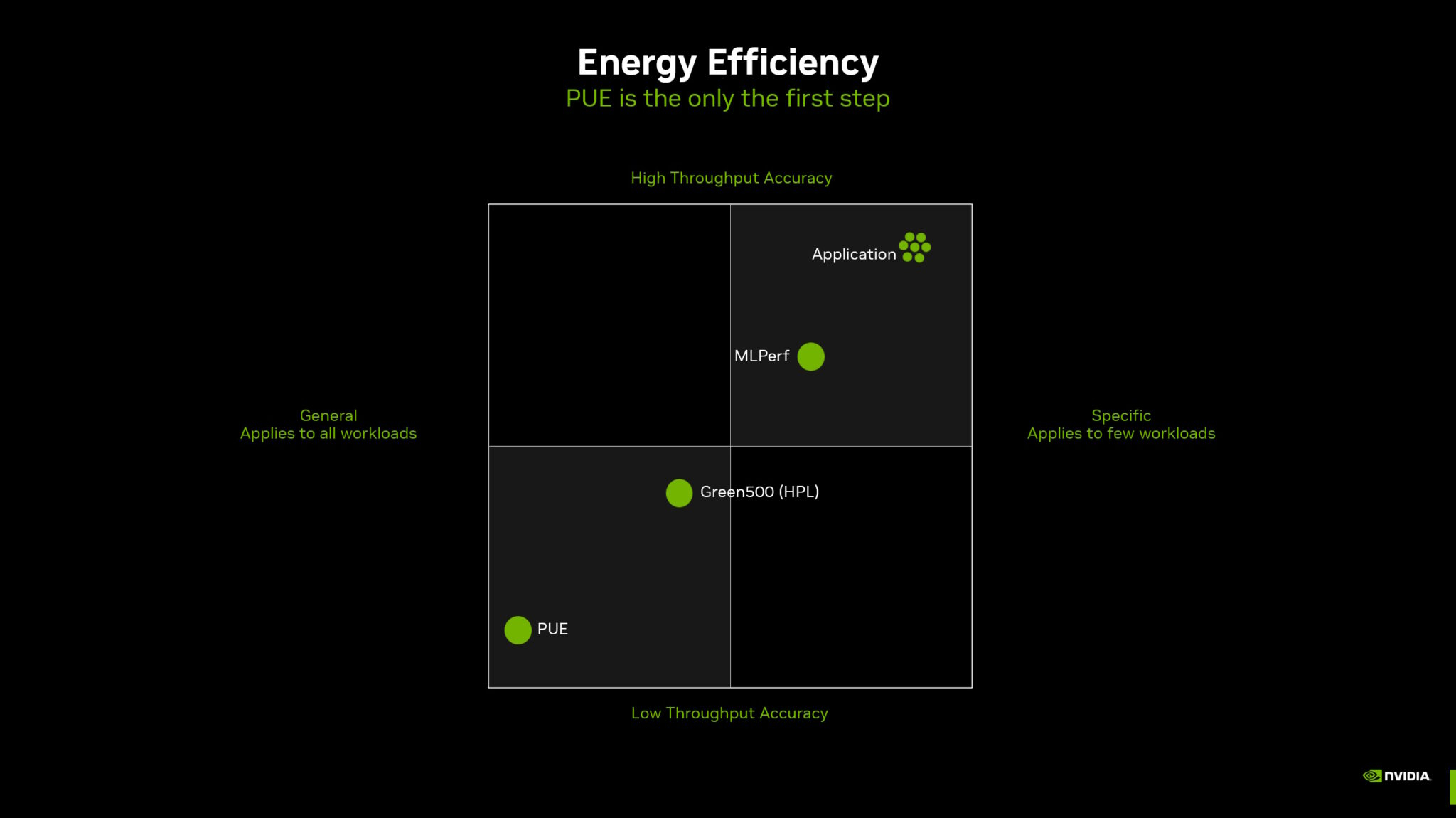
Источник изображений: NVIDIA Что касается энергопотребления, разное оборудование при одинаковых затратах может давать самые разные результаты. Другими словами, если современные ускорители потребляют больше энергии, это не значит, что они менее эффективны, поскольку они дают несопоставимо лучший результат в сравнении со старыми решениями. NVIDIA неоднократно приводила подобные сравнения и между своими GPU с обычными CPU, а теперь предлагает распространить этот подход на ЦОД целиком, что справедливо, учитывая стремление NVIDIA сделать минимальной единицей развёртывания целую стойку. 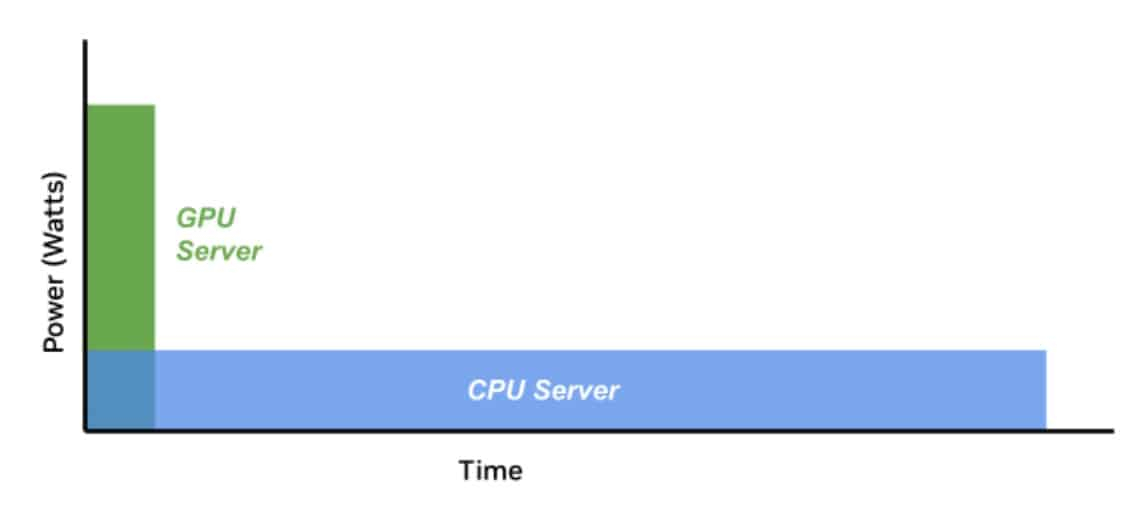 Как считают в NVIDIA, оценивать качество ЦОД можно только с учётом того, сколько энергии тратится для получения результата. Так, ЦОД для ИИ могут полагаться на MLPerf-бенчмарки, суперкомпьютеры для научных исследований могут требовать измерения других показателей, а коммерческие дата-центры для стриминговых сервисов — третьих. В идеале бенчмарки должны измерять прогресс в ускоренных вычислениях с использованием специализированных сопроцессоров, ПО и методик. Например, в параллельных вычислениях GPU намного энергоэффективнее обычных процессоров Отмечается, что с 2003 года производительность ускорителей выросла приблизительно в 7 тыс. раз, а соотношение цены и производительности стало в 5,6 тыс. раз лучше. А с учётом того, что современные ЦОД достигли PUE на уровне приблизительно 1,2, подобная метрика практически исчерпала себя, теперь стоит ориентироваться на другие показатели, релевантные актуальным проблемам. Хотя напрямую сравнить некоторые аспекты невозможно, сегментировав деятельность ЦОД на типы рабочих нагрузок, возможно, удалось бы получить некоторые результаты. В частности, операторам ЦОД нужен пакет бенчмарков, измеряющих показатели при самых распространённых рабочих ИИ-нагрузках. Например, неплохой метрикой может стать Дж/токен. Впрочем, NVIDIA грех жаловаться на недостойные оценки — в последнем рейтинге Green500 именно её системы заняли лидерские позиции.
05.05.2024 [13:56], Сергей Карасёв
Власти США продали на аукционе 5,34-ПФлопс суперкомпьютер Cheyenne из-за растущего числа сбоев и протечек СЖОАдминистрация общих служб США (GSA) реализовала на аукционе НРС-систему под названием Cheyenne, которая была введена в строй в Центре суперкомпьютерных вычислений NCAR-Wyoming (NWSC) штата Вайоминг в 2016 году. Стоимость лота составила $480 085, тогда как затраты на строительство машины оцениваются как минимум в $25 млн. Cheyenne стал одним из последних суперкомпьютеров компании Silicon Graphics International (SGI). Корпорация HPE приобрела эту фирму после того, как Cheyenne был смонтирован, но до фактического запуска системы в эксплуатацию. На момент начала работы производительность комплекса составляла 5,34 Пфлопс, что соответствовало 20 месту в актуальном тогда списке ТОР500. Cheyenne представляет собой кластер SGI ICE XA с 4032 узлами, каждый из которых содержит два процессора Intel Xeon E5-2697v4 Broadwell (18C/36; 2,3 ГГц). Таким образом, суммарное количество ядер достигает 145 152. Применяется оперативная память DDR4-2400 ECC общей ёмкостью 313 Тбайт (4890 модулей на 64 Гбайт). В состав машины изначально входило хранилище данных вместимостью 40 Пбайт. Энергопотребление — приблизительно 1,7 МВт. Задействована система жидкостного охлаждения. 
Источник изображения: GSA Две стойки управления с воздушным охлаждением состоят из 26 серверов типоразмера 1U (20 со 128 Гбайт ОЗУ и ещё 6 с 256 Гбайт ОЗУ), 10 коммутаторов и двух блоков питания. Суперкомпьютер эксплуатировался с 12 января 2017 года по 31 декабря 2023-го, решая задачи в области изменений климата и в других сферах, связанных с науками о Земле. Cheyenne превзошёл свой запланированный срок службы: в заявлении NWSC говорилось, что он будет эксплуатироваться до 2021 года. Однако к концу 2023-го количество сбоев и проблем стало слишком большим. В описании лота говорится, что «примерно 1 % узлов столкнулись с отказами за последние шесть месяцев», в основном из-за модулей памяти. Кроме того, система испытывает ограничения по техническому обслуживанию из-за неисправных быстроразъёмных соединений, вызывающих протечки воды. Таким образом, «учитывая затраты и время простоя, связанные с устранением проблем», дальнейшее использование комплекса признано нецелесообразным, в связи с чем он пущен с молотка. Вместе с тем, как отмечает Tom's Hardware, новый владелец суперкомпьютера может реализовать его основные компоненты на вторичном рынке. Например, стоимость чипов Xeon E5-2697 v4 на eBay составляет около $50, а модулей DDR4-2400 ECC ёмкостью 64 Гбайт — примерно $65. То есть, по самым скромным подсчётам, только эти компоненты могут принести новому владельцу суперкомпьютера приблизительно $700 тыс. без учёта затрат на демонтаж и вывоз машины массой 43 т, а также на тестирование компонентов. Впрочем, массовый выброс на рынок CPU и RAM в таких объёмах приведёт к снижению цен.
29.03.2024 [21:54], Сергей Карасёв
Eviden увеличит производительность французского суперкомпьютера Jean Zay более чем втроеФранцузское национальное агентство по высокопроизводительным вычислениям (GENCI) и Национальный центр научных исследований (CNRS) заключили соглашение с компанией Eviden (дочерняя структура Atos) о модернизации НРС-комплекса Jean Zay. Ожидается, что производительность этого суперкомпьютера увеличится приблизительно в 3,5 раза. В рамках проекта Eviden оборудует комплекс 1456 ускорителями NVIDIA H100 в дополнение к 416 ускорителям NVIDIA A100 и 1832 ускорителям NVIDIA V100, которые задействованы в настоящее время. Модернизация предполагает использование 14 стоек суперкомпьютерной платформы Eviden BullSequana XH3000. В общей сложности будут задействованы 364 двухпроцессорных узла на базе Intel Xeon Sapphire Rapids с 48 ядрами. Каждый сервер получит 512 Гбайт оперативной памяти и четыре ускорителя NVIDIA H100 SXM5. Говорится об использовании адаптеров NVIDIA ConnectX-7. 
Источник изображения: Eviden Проект также предусматривает комплексное обновление подсистемы хранения данных. Она будет состоять из флеш-массива вместимостью 4,3 Пбайт со скоростями чтения/записи свыше 1 Тбайт/с и дискового массива ёмкостью 39 Пбайт со скоростями чтения/записи более 300 Гбайт/с. Компоненты СХД поставит компания DataDirect Networks (DDN). Для обоих уровней хранения предусмотрено использование файловой системы Lustre. 
Фото: Photothèque CNRS/Cyril Frésillon Ожидается, что модернизация позволит увеличить пиковую производительность Jean Zay с 36,85 до 125,9 Пфлопс. Проект получил финансирование в рамках национальной инвестиционной программы «Франция 2030». Усовершенствованный суперкомпьютер будет использоваться для решения ресурсоёмких задач, в том числе в области ИИ. Отмечается, что Jean Zay — это один из наиболее экологичных суперкомпьютеров в Европе. Отчасти это достигается благодаря использованию генерируемого машиной тепла для обогрева более 1000 зданий в кампусе Париж-Сакле.
28.03.2024 [21:03], Руслан Авдеев
Nautilus запустила линейку инфраструктурных решений EcoCore для модульных ЦОДNautilus Data Technologies запустила новую серию решений для модульных дата-центров на основе разработанных ранее технологий охлаждения. По данным Datacenter Dynamics, новый проект предлагает варианты для ЦОД ёмкостью до 2,5 МВт. По словам Nautilus, EcoCore расширяет эффективность сборных конструкций и упрощает процесс строительства, позволяя интегрировать рабочее пространство с техническими помещениями и размещать MEP-компоненты (электрику, водоснабжение и вентиляцию) на крыше. Конструкция использует четыре CDU-установки для кондиционирования, каждая из которых способна отводить до 833 кВт тепла. Система поддерживает как традиционные варианты охлаждения, так и современные жидкостные. Основной модуль электропитания (PEU) обеспечивает мощность 1250 кВт (415 В, три фазы), но есть и точно такой же резервный (N+1). Новинка будет развёрнута в Start Campus в Синише (Португалия) — впервые за пределами собственных мощностей Nautilus. EcoCore, по словам компании, соответствует запросам Start по организации бесперебойной работы серверов высокой плотности с СЖО. Компании договорились о сотрудничестве в прошлом году и заключили «многомегаваттное» соглашение. Первый модуль EcoCore будет развёрнут в ходе первой фазы строительства кампуса Start. В Nautilus и Start заявляют, что экобезопасные технологии первой задают новый стандарт в индустрии, обеспечивая непревзойдённые эффективность и адаптивность. 
Источник изображения: Nautilus Nautilus известна прежде всего проектами плавучих ЦОД и системой охлаждения дата-центров речной или морской водой. Пока компания выступает лишь оператором ЦОД-баржи в Стоктоне (Калифорния), но планирует построить и наземный объект в Мэне. Также в работе находятся и другие проекты в США, Франции и Ирландии. Меморандумы о взаимопонимании заключены в Таиланде и на Филиппинах. Впрочем, появление EcoCore, похоже, указывает на желание стать поставщиком решений для других операторов. Принадлежащая инвестиционному фонду Davidson Kempner и британской British Pioneer Point Partners компания Start намерена построить 495-МВт кампус площадью 60 га в Португалии. Компании заявили, что Nautilus поставит охладительные системы и для второй фазы проекта, предусматривающего расширение на 120 МВт. Ранее Start оказалась вовлечена в коррупционный скандал.
22.03.2024 [21:10], Сергей Карасёв
Консорциум Ultra Ethernet пополнился 45 участниками, но NVIDIA среди них так и нетКонсорциум Ultra Ethernet объявил о том, что в его состав вошли 45 новых участников. Таким образом, на сегодняшний день общее количество членов этой организации достигает 55. К участию в Ultra Ethernet приглашаются и другие заинтересованные компании и институты. Напомним, консорциум был создан в июле 2023 года. Его задача заключается в разработке основанной на Ethernet открытой высокопроизводительной архитектуры с полным коммуникационным стеком, отвечающей задачам современных рабочих нагрузок ИИ и НРС. Изначально в состав Ultra Ethernet входили AMD, Arista, Broadcom, Cisco, Eviden (Atos), HPE, Intel, Meta✴ и Microsoft. Позднее к консорциуму присоединилась компания Cornelis Networks, поставщик HPC-интерконнекта на базе Omni-Path. 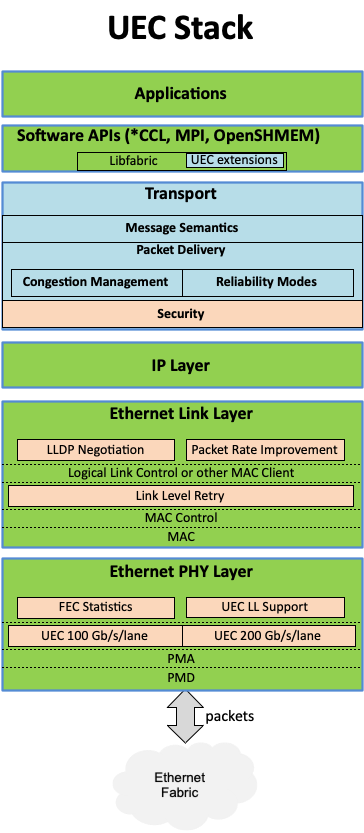
Источник изображения: Ultra Ethernet С ноября 2023-го организация начала принимать новых участников в массовом порядке. С тех пор инициативу поддержали Nokia, Lenovo, Baidu, Dell, Huawei, IBM, Supermicro, Tencent и многие другие компании. Примечательно, что в списке участников так и нет AWS, Google и NVIDIA. Последняя по-прежнему считает InfinBand лучшим интерконнектом для HPC/ИИ-кластеров и является фактически единственным поставщиком данной технологии. Более того, даже Ethernet-решения NVIDIA подвергаются критике со стороны конкурентов. 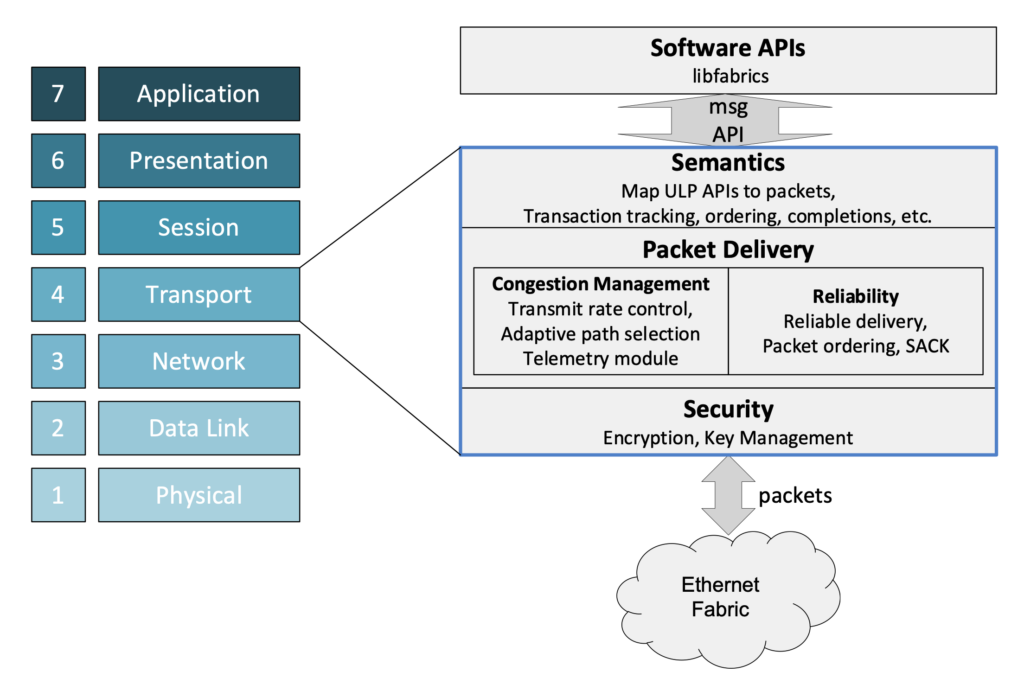
Источник изображения: Ultra Ethernet Для тех, кто заинтересован в работах в рамках проекта, Ultra Ethernet предлагает различные варианты участия через восемь технических групп. В их число, в частности, входят физический, транспортный и программный уровни, хранение, управление, отладка и пр. В настоящее время ведётся активная работа над спецификацией Ultra Ethernet версии 1.0: представить её планируется в III квартале текущего года. Ожидается, что совместная работа десятков IT-компаний в перспективе позволит создать революционные коммуникационные платформы. |
|

