Материалы по тегу: hpc
|
20.08.2024 [23:30], Руслан Авдеев
Суперкомпьютер с лабораторией: Пентагон создаёт новый комплекс защиты США от биологических угрозНовейший проект Министерства обороны США объединит суперкомпьютер и т.н. лабораторию быстрого реагирования (RRL, Rapid Response Laboratory). The Register сообщает, что проект призван укрепить биологическую защиту Соединённых Штатов. Расположенная на территории Ливерморской национальной лаборатории им. Э. Лоуренса (Lawrence Livermore National Laboratory, LLNL) в Калифорнии, машина строится при сотрудничестве с Национальным агентством ядерной безопасности США (National Nuclear Security Agency, NNSA) и будет основана на той же архитектуре, что и грядущий экзафлопсный суперкомпьютер El Capitan на базе ускорителей AMD Instinct MI300A. Спецификации аппаратного обеспечения и ПО не раскрываются. Машина будет использоваться как военными, так и гражданскими специалистами для крупномасштабных симуляций, ИИ-моделирования, классификации угроз, а при сотрудничестве с новой биологической лабораторией — для ускорения разработки контрмер. Некоторые из них, как ожидается, будут чрезвычайно важными, поскольку решения можно будет находить в течение дней, если не часов. Впрочем, новые вычислительные мощности военные биологи намерены использовать на регулярной основе. Конечно, как отмечает The Register, инструменты для разработки средств борьбы могут использоваться и для создания биологического оружия, хотя в самом Пентагоне о подобном применении суперкомпьютера не упоминают. 
Источник изображения: Lawrence Livermore National Laboratory Концепция биологической защиты США представляет собой комплекс мер для борьбы как с естественными, так и рукотворными биологическими угрозами военным и гражданским лицам, природным ресурсам, источникам пищи и воды и т.п., воздействие на которые может негативно сказаться на возможностях воюющей стороны. Поскольку биологические угрозы имеют важное значение для самых разных ведомств, суперкомпьютер будет доступен и прочим правительственным агентствам США, а также союзникам Соединённых Штатов, академическим исследователям и промышленным компаниям. Лаборатория RRL будет находиться буквально в «шаговой доступности» от суперкомпьютера. Она станет дополнением к проекту Пентагона Generative Unconstrained Intelligent Drug Engineering (GUIDE). GUIDE занимается разработкой медицинских и биологических контрмер с использованием машинного обучения для создания анител, структурной биологии, биоинформатики, молекулярного моделирования и т.д. Новый суперкомпьютер позволит Пентагону быстрые и многократные тесты моделируемых вакцин и лекарств. RRL автоматизирована и снабжена роботами и иными инструментами для изучения строения и свойств молекул, для редактирования структуры белков и т.д. По словам экспертов LLNL, лаборатория, подключённая к суперкомпьютеру, позволит изменить всю систему распознавания биологических угроз и ответа на них.
16.08.2024 [14:45], Руслан Авдеев
Эдинбургский университет лоббирует создание первого в Великобритании экзафлопсного суперкомпьютера, от которого новое правительство решило отказатьсяКоманда Эдинбургского университета активно лоббирует выделение учреждению £800 млн ($1,02 млрд) для строительства суперкомпьютера экзафлопсного класса. Ранее новое британское правительство фактически отказалось продолжать реализацию некогда уже одобренного проекта, ссылаясь на дефицит бюджета. Ожидалось, что страна выделит почти миллиард долларов на строительство передового суперкомпьютера, причём изначально речь шла об использовании отечественных компонентов. В октябре 2023 года было объявлено, что именно Эдинбург станет пристанищем первой в Великобритании вычислительной машины экзафлопсного уровня. Суперкомпьютер должен был заработать уже в 2025 году. Университет даже успел потратить £31 млн ($38 млн) на строительство нового крыла Advanced Computing Facility. 
Источник изображения: Adam Wilson/unsplash.com Однако в начале августа 2024 года британское правительство объявило, что не будет выделять £1,3 млрд ($1,66 млрд) на ранее одобренные технологические и ИИ-проекты. На тот момент представитель Министерства науки, инноваций и технологий (Department for Science, Innovation, and Technology) заявил, что властям приходится принимать «трудные и необходимые» решения. По данным СМИ, вице-канцлер Эдинбургского университета сэр Питер Мэтисон (Peter Mathieson) пытается лично лоббировать среди министров выделение средств на обещанный суперкомпьютер. В письме сотрудникам университета он отметил, что диалог с Министерством науки, инноваций и технологий продолжится и будет взаимодействовать с академическими и промышленными кругами для возобновления инвестиций. По словам учёного, университет десятки лет был лидером в HPC-сфере Великобритании и до сих пор остаётся центром реализации суперкомпьютерных и ИИ-проектов. Если средства всё-таки удастся выбить у британских чиновников и система заработает, она будет в 50 раз производительнее нынешней системы ARCHER2. Тем временем в материковой Европе ведётся активная работа над собственными проектами. В частности, начались работы по строительству суперкомпьютера экзафлопсного уровня класса Jupiter на Arm-чипах и ускорителях NVIDIA. Впрочем, весной этого года Великобритания вновь присоединилась к EuroHPC, так что со временем страна сможет поучаствовать в европейских HPC-проектах.
15.08.2024 [12:19], Руслан Авдеев
Исландский проект IceCloud представил частное облако под ключ с питанием от ГеоТЭС и ГЭСКонсорциум компаний запустил пилотный проект облачного сервиса IceCloud на базе исландского ЦОД с необычными возможностями. The Register сообщает, что дата-центр будет полностью снабжаться возобновляемой энергией для того, чтобы его клиенты смогли достичь своих экологических, социальных и управленческих обязательств (ESG). Проект IceCloud Integrated Services представляет собой частное облако с широкими возможностями настройки для того, чтобы предложить клиентам экономичную масштабируемую платформу, в том числе для ИИ и прочих ресурсоёмких задачах. В консорциум на равных правах входят британский поставщик ЦОД-инфраструктур Vesper Technologies (Vespertec), разработчик облачного ПО Sardina Systems и оператор Borealis Datacenter из Исландии. Vespertec занимается созданием кастомных серверов, хранилищ и сетевых решений, в том числе стандарта OCP. Sardina отвечает за облачную платформу Fish OS. Это дистрибутив OpenStack для частных облачных сервисов, интегрированный с Kubernetes и сервисом хранения данных Ceph. Предполагается, что облачная платформа не будет имитировать AWS и Azure. Решение ориентировано на корпоративных клиентов с задачами, требующими высокой производительности, малого времени отклика и высокого уровня доступности. 
Источник изображения: Robert Lukeman/unsplash.com Таких предложений на рынке уже немало, но IceCloud на базе ЦОД Borealis Datacenter позволит клиентам использовать исключительно возобновляемую энергию и экономить на охлаждении благодаря прохладному местному климату. Выполнение компаниями-клиентами ESG-обязательств, а также снижение на 50 % энергопотребления вне периодов часов пиковых нагрузок и снижение потребления на 38 % в целом ведёт к существенному снижению стоимости эксплуатации облака, говорят авторы проекта. 
Источник изображения: Vespertec До заключения контракта на обслуживание в облаке IceCloud с клиентом ведутся переговоры для выяснения его потребностей в программном и аппаратном обеспечении и пр. После этого клиенту делается индивидуальное пакетное предложение. Перед окончательным принятием решения клиент может протестировать сервис и, если его всё устраивает, он получит персонального менеджера. Эксперты подтверждают, что размещение ЦОД на севере имеет три ключевых преимущества. Низкие температуры окружающей среды позволяют экономить на охлаждении, обеспечивая низкий индекс PUE. Сам регион богат возобновляемой энергией и, наконец, в Исландии не так тесно в сравнении с популярными европейскими локациями ЦОД во Франкфурте, Лондоне, Амстердаме, Париже и Дублине.
15.08.2024 [01:10], Владимир Мироненко
900 серверов, 1,5 ПФлопс и 15 Пбайт: шесть суперкомпьютерных центров России объединились в научный HPC-консорциумШесть специализированных центров коллективного пользования (ЦКП) сформировали консорциум «Распределённая научная суперкомпьютерная инфраструктура», чтобы осуществлять координацию совместных действий по комплексному развитию и поддержке суперкомпьютерных центров и специализированных центров данных для решения актуальных научных, научно-технических и социально-экономических задач, сообщил Telegram-канал Министерства науки и высшего образования РФ. В консорциум вошли ХФИЦ ДВО РАН (г. Хабаровск), Институт автоматики и процессов управления ДВО РАН (г. Владивосток), Институт динамики систем и теории управления им. В.М. Матросова СО РАН (г. Иркутск), Институт вычислительной математики и математической геофизики СО РАН (г. Новосибирск), Институт математики и механики им. Н.Н. Красовского УрО РАН (г. Екатеринбург) и Институт космических исследований РАН (г. Москва). 
Источник изображения: ЦКП «Центр данных ДВО РАН» Инфраструктура консорциума включает 900 серверов c суммарной пиковой производительностью 1,5 ПФлопс и системами хранения научных данных ёмкостью более 15 Пбайт. С её помощью можно обеспечивать работу распределённых специализированных информационных систем сбора, хранения и обработки научных данных, находящихся в различных регионах страны, говорится в сообщении. На данный момент участники консорциума предоставляют доступ к компьютерным ресурсам и оказывают квалифицированную поддержку для 240 организаций России.
08.08.2024 [17:50], Руслан Авдеев
Виртуальный суперкомпьютер Fugaku теперь можно запустить в облаке AWSЯпонская научная группа RIKEN Center for Computational Science представила виртуальную версию принадлежащего ей Arm-суперкомпьютера, которую можно развернуть в облаке AWS. По данным The Register, суперкомпьютер считался самым производительным в мире в 2020 году, пока его не потеснила первая экзафлопсная машина Frontier двумя годами позже. 
Источник изображения: RIKEN Центр намерен упростить желающим использование системы Fugaku, поэтому в RIKEN и решили создать виртуального двойника, способного работать в облаке или даже на суперкомпьютерах, принадлежащих другим компаниям. Представители центра сообщили, что построить машину из 160 тыс. узлов недостаточно, ведь необходимы ещё и программные решения. Другими словами, в облаке полностью воспроизвели программную HPC-экосистему Fugaku, которая включает массу оптимизированных для Arm пакетов и специализированного ПО. Первая версия Virtual Fugaku доступна в виде Singularity-образа. Она предназначена для запуска на Arm-процессорах Amazon Graviton3E, которые оптимизированы для задач HPC/ИИ. Как и процессоры Fujitsu A64FX, используемые в Fugaku, они предлагают инструкции Scalable Vector Extension (SVE). Основная ОС — RHEL 8.10. ПО собрано с использованием GCC 14.1 и библиотеки OpenMPI, которая поддерживает EFA. В Amazon крайне довольны выбором AWS в качестве базовой платформы для Virtual Fugaku. 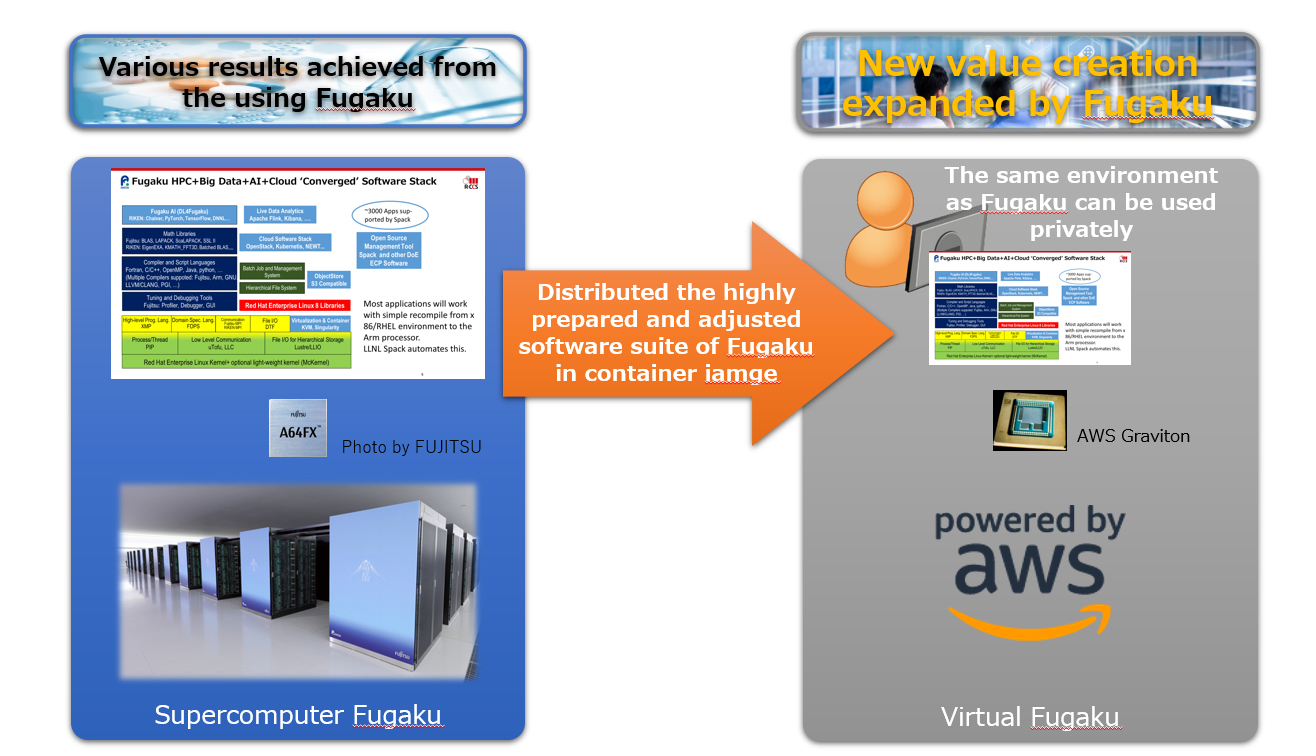
Источник изображения: RIKEN В будущем возможно портирование Virtual Fugaku и на другие архитектуры, но на какие бы платформы его ни перенесли, в RIKEN надеются, что инстансы «продолжат дело» своего родителя. Исследователи заявили, что результаты использования Fugaku, включая разработки, связанные с контролем заболеваний, созданием новых материалов и лекарств, хорошо известны. В ходе эксплуатации специалисты получили богатый опыт обращения с суперкомпьютером и намерены поделиться им с обществом. В RIKEN даже рассматривают Virtual Fugaku как стандартную платформу для использования программных HPC-решений — если суперкомпьютерные центры по всему миру примут этот формат, пользователи оценят богатство библиотеки ПО. Впрочем, некоторые эксперты считают, что такая концепция не вполне жизнеспособна — HPC-задачи часто связаны с использованием оборудования, оптимизированного под конкретные цели, поэтому маловероятно, что одна программная платформа подойдёт всем заинтересованным сторонам.
03.08.2024 [21:10], Владимир Мироненко
В Великобритании отложили планы по строительству экзафлопсного суперкомпьютера — нет денегНовый состав правительства Великобритании, сформированный в июле, отменил решение предыдущей администрации о выделении £1,3 млрд на финансирование технологических и ИИ-проектов, включая строительство в Центре передовых вычислений Эдинбургского университета (ACF) экзафлопсного суперкомпьютера при поддержке национального центра AI Research Resource (AIRR), который должен был быть запущен в эксплуатацию в 2025 году. Об этом сообщил ресурс DatacenterDynamics (DCD). В прошлом году правительство консерваторов выделило £800 млн на экзафлопсный суперкомпьютер и £500 млн на дополнительное финансирование AIRR. Однако нынешнее лейбористское правительство заявило, что в планах расходов предыдущего правительства не было выделено нового финансирования для этой программы, и поэтому проекты не будут продолжены. 
Источник изображения: EPCC В Центре передовых вычислений Эдинбургского университета (ACF) уже есть суперкомпьютер, и после объявления в октябре 2023 года о предстоящем строительстве нового, им был израсходован £31 млн на строительство дополнительного помещения в здании для центра Edinburgh Parallel Computing Centre (EPCC). Что дальше будет с этим проектом пока неясно. Отвечая на просьбу DCD прокомментировать ситуацию, представитель Департамента науки, инноваций и технологий Великобритании (DSIT) заявил, что в правительстве по-прежнему привержены созданию технологической инфраструктуры, но приходится принимать сложные решения для восстановления экономической стабильности и реализации национальной миссии по росту экономики. Следует отметить, что в прошлом месяце правительство Великобритании объявило о планах инвестировать £100 млн в пять новых центров квантовых исследований в Глазго, Эдинбурге, Бирмингеме, Оксфорде и Лондоне.
31.07.2024 [11:21], Сергей Карасёв
Vertiv представила модульные дата-центры высокой плотности для ИИ-нагрузокКомпания Vertiv представила модульную платформу MegaMod CoolChip, предназначенную для построения дата-центров высокой плотности для задач ИИ. Утверждается, что данное решение позволяет сократить время развёртывания вычислительных мощностей примерно в два раза по сравнению с традиционным строительством. Отмечается, что стремительное развитие генеративного ИИ, машинного обучения и НРС-приложений приводит к необходимости изменения обычной концепции ЦОД. Из-за большого количества мощных ускорителей требуется внедрение более эффективных систем охлаждения. В случае MegaMod CoolChip реализуется гибридный подход с воздушным и жидкостным охлаждением. Инфраструктура MegaMod CoolChip может включать в себя блоки распределения охлаждающей жидкости Vertiv XDU, стойки с поддержкой СЖО Vertiv Liquid-cooled Rack, решения Vertiv Air Cooling, стоечные блоки распределения питания Vertiv rPDU и пр. Модульная архитектура MegaMod CoolChip предусматривает возможность установки до 12 стоек в ряд. Мощность каждой из них может превышать 100 кВт. 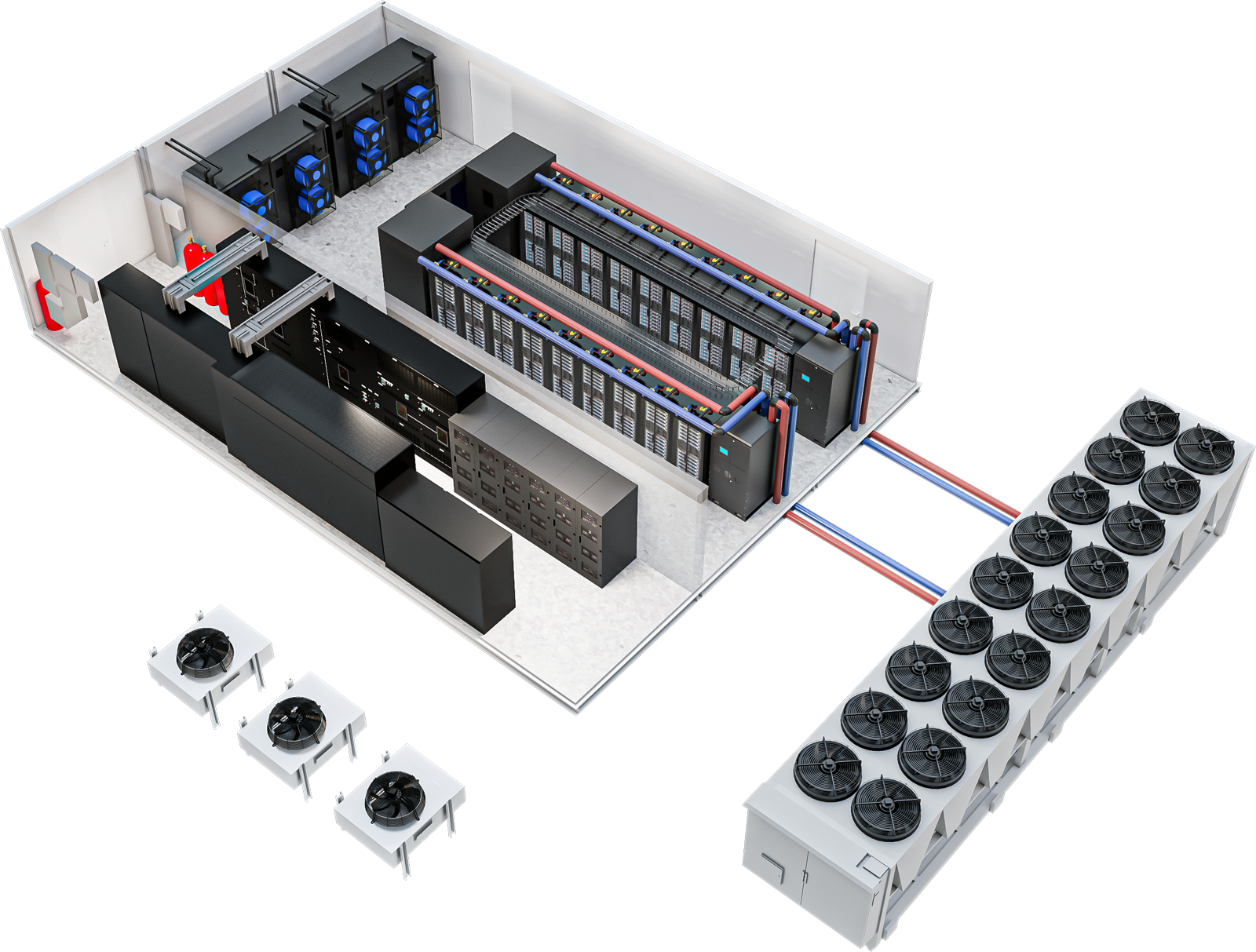
Источник изображения: Vertiv MegaMod CoolChip поставляется в виде отдельных блоков, которые монтируются непосредственно на месте размещения дата-центра. Возможны различные варианты организации воздушно-жидкостного охлаждения. Для СЖО используется технология однофазного прямого жидкостного охлаждения Direct-To-Chip. Возможно резервирование охлаждающих систем по схеме N+1.
29.07.2024 [08:11], Сергей Карасёв
Инсбрукский университет запустил гибридный квантово-классический суперкомпьютерИнсбрукский университет имени Леопольда и Франца (UIBK) в Австрии объявил о том, что его НРС-комплекс LEO5 интегрирован с квантовый системой IBEX Q1 компании AQT. Таким образом, сформирован гибридный квантово-классический суперкомпьютер, который, как утверждается, открывает совершенно новые возможности для решения сложных научных и промышленных задач и создания вычислительных платформ следующего поколения. Машина LEO5, запущенная в 2023 году, объединяет 63 узла, каждый из которых содержит два процессора Intel Xeon 8358 (Ice Lake-SP) с 32 ядрами. Применён интерконнект Infiniband HDR100. В состав 36 узлов входят ускорители NVIDIA — A30, A40 или A100. Производительность достигает 300 Тфлопс на операциях FP64 и 740 Тфлопс на операциях FP32. 
Источник изображения: UIBK В свою очередь, лазерная квантовая система IBEX Q1, разработанная специалистами AQT (дочерняя структура UIBK), не требует для работы экстремального охлаждения. Утверждается, что она может функционировать при комнатной температуре, а энергопотребление составляет менее 2 кВт. Квантовое оборудование размещено в двух кастомизированных стойках. Проект по созданию гибридного суперкомпьютера реализован в рамках инициативы HPQC (High-Performance integrated Quantum Computing), финансируемой австрийским Агентством по продвижению и стимулированию прикладных исследований, технологий и инноваций (FFG). Новая платформа, как отмечается, создаёт основу для будущих гетерогенных инфраструктур, ориентированных на решение сложных задач. «Успешная интеграция квантового компьютера в высокопроизводительную вычислительную среду знаменует собой важную веху для австрийских и европейских исследований и развития технологий в целом», — говорит Генриетта Эгерт (Henrietta Egerth), управляющий директор FFG.
27.07.2024 [23:44], Алексей Степин
Не так просто и не так быстро: учёные исследовали особенности работы памяти и NVLink C2C в NVIDIA Grace HopperГибридный ускоритель NVIDIA Grace Hopper объединяет CPU- и GPU-модули, которые связаны интерконнектом NVLink C2C. Но, как передаёт HPCWire, в строении и работе суперчипа есть некоторые нюансы, о которых рассказали шведские исследователи. Им удалось замерить производительность подсистем памяти Grace Hopper и интерконнекта NVLink в реальных сценариях, дабы сравнить полученные результаты с характеристиками, заявленными NVIDIA. Напомним, для интерконнекта изначально заявлена скорость 900 Гбайт/с, что в семь раз превышает возможности PCIe 5.0. Память HBM3 в составе GPU-части имеет ПСП до 4 Тбайт/с, а вариант с HBM3e предлагает уже до 4,9 Тбайт/с. Процессорная часть (Grace) использует LPDDR5x с ПСП до 512 Гбайт/с. В руках исследователей оказалась базовая версия Grace Hopper с 480 Гбайт LPDDR5X и 96 Гбайт HBM3. Система работала под управлением Red Hat Enterprise Linux 9.3 и использовала CUDA 12.4. В бенчмарке STREAM исследователям удалось получить следующие показатели ПСП: 486 Гбайт/с для CPU и 3,4 Тбайт/с для GPU, что близко к заявленным характеристиками. Однако результат скорость NVLink-C2C составила всего 375 Гбайт/с в направлении host-to-device и лишь 297 Гбайт/с в обратном направлении. Совокупно выходит 672 Гбайт/с, что далеко от заявленных 900 Гбайт/с (75 % от теоретического максимума). 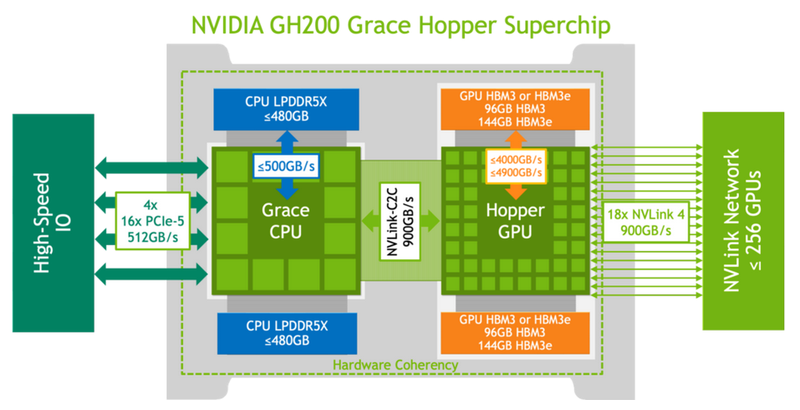
Источник: NVIDIA Grace Hopper в силу своей конструкции предлагает два вида таблицы для страниц памяти: общесистемную (по умолчанию страницы размером 4 Кбайт или 64 Кбайт), которая охватывает CPU и GPU, и эксклюзивную для GPU-части (2 Мбайт). При этом скорость инициализации зависит от того, откуда приходит запрос. Если инициализация памяти происходит на стороне CPU, то данные по умолчанию помещаются в LPDDR5x, к которой у GPU-части есть прямой доступ посредством NVLink C2C (без миграции), а таблица памяти видна и GPU, и CPU. 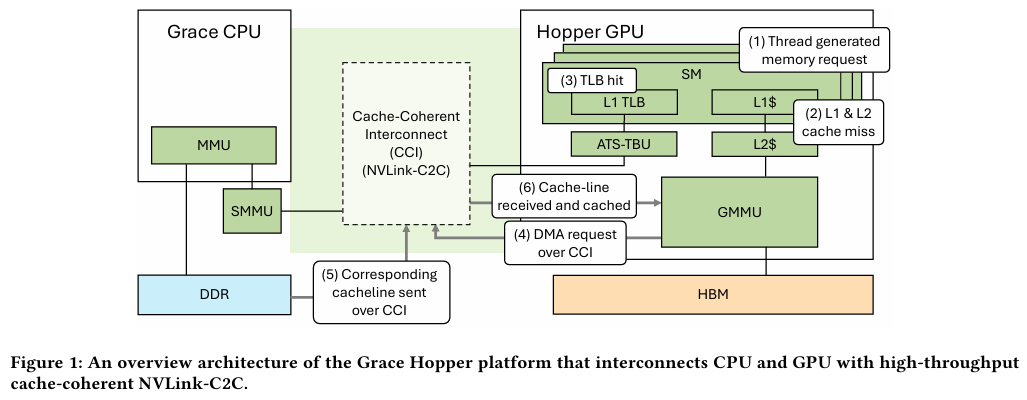
Источник: arxiv.org Если же памятью управляет не ОС, а CUDA, то инициализацию можно сразу организовать на стороне GPU, что обычно гораздо быстрее, а данные поместить в HBM. При этом предоставляется единое виртуальное адресное пространство, но таблиц памяти две, для CPU и GPU, а сам механизм обмена данными между ними подразумевает миграцию страниц. Впрочем, несмотря на наличие NVLink C2C, идеальной остаётся ситуация, когда GPU-нагрузке хватает HBM, а CPU-нагрузкам достаточно LPDDR5x. 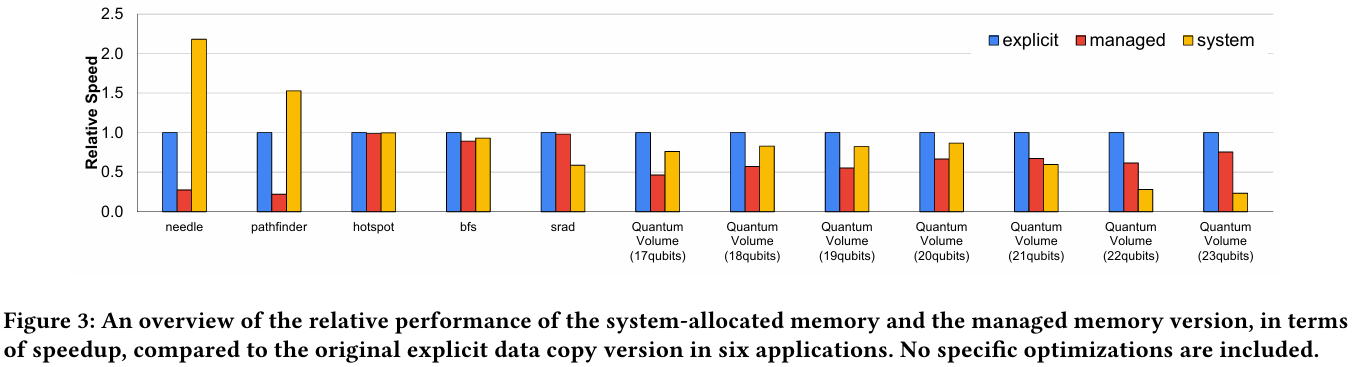
Источник: arxiv.org Также исследователи затронули вопрос производительности при использовании страниц памяти разного размера. 4-Кбайт страницы обычно используются процессорной частью с LPDDR5X, а также в тех случаях, когда GPU нужно получить данные от CPU через NVLink-C2C. Но как правило в HPC-нагрузках оптимальнее использовать 64-Кбайт страницы, на управление которыми расходуется меньше ресурсов. Когда же доступ в память хаотичен и непостоянен, страницы размером 4 Кбайт позволяют более тонко управлять ресурсами. В некоторых случаях возможно двукратное преимущество в производительности за счёт отсутствия перемещения неиспользуемых данных в страницах объёмом 64 Кбайт. В опубликованной работе отмечается, что для более глубокого понимания механизмов работы унифицированной памяти у гетерогенных решений, подобных Grace Hopper, потребуются дальнейшие исследования.
27.07.2024 [10:30], Сергей Карасёв
Аргоннская национальная лаборатория намерена создать СХД ёмкостью 400 Пбайт за $20 млнАргоннская национальная лаборатория (ANL) Министерства энергетики США (DOE) обнародовала запрос на создание нового кластера хранения данных для своего парка суперкомпьютеров. Как сообщает ресурс Datacenter Dynamics, реализация проекта может обойтись в $15–$20 млн. Речь идёт о создании СХД, которая обеспечит ёмкость и производительность, необходимые для поддержания работы действующих НРС-комплексов, а также будущих суперкомпьютеров. Отмечается, что на площадке Argonne Leadership Computing Facility (ALCF) развёрнуты несколько высокопроизводительных параллельных файловых систем для обработки данных, генерируемых исследователями и инженерами. Это, в частности две системы Lustre вместимостью 100 Пбайт с пропускной способностью 650 Гбайт/с. Обе они используют интерконнект Infiniband HDR. 
Источник изображения: DOE Новая СХД будет обладать ёмкостью на уровне 400 Пбайт. В число требований входят IOPS-производительность до 240 млн, пиковая пропускная способность в 6 Тбайт/с, совместимость с POSIX и возможность одновременного монтирования до 30 тыс. узлов. Поставщик должен обеспечивать поддержку в течение пяти лет. Предполагается, что платформа будет использоваться суперкомпьютером Aurora, который в нынешнем рейтинге TOP500 занимает второе место с быстродействием 1,012 Эфлопс. Кроме того, доступ к СХД получит НРС-комплекс Polaris: его пиковая производительность составляет около 44 Пфлопс. Проектируемая СХД должна обеспечивать «надёжность и масштабируемость, необходимые для следующего поколения HPC и ИИ». Поставку платформы исполнителю работ необходимо осуществить ко II или к IV кварталу 2025 года, если дополнительные полгода позволят внедрить новые технологии. |
|

