Материалы по тегу: hpc
|
15.11.2022 [19:08], Сергей Карасёв
Cerebras построила ИИ-суперкомпьютер Andromeda с 13,5 млн ядерКомпания Cerebras Systems сообщила о запуске уникального вычислительного комплекса Andromeda для выполнения «тяжёлых» ИИ-нагрузок. В основу Andromeda положен кластер из 16 блоков Cerebras CS-2, объединённых 96,8-Тбит/с фабрикой. Каждый из них содержит чип WSE-2, насчитывающий 850 тыс. ядер. Таким образом, общее число ядер достигает 13,5 млн. Кроме того, непосредственно в состав каждого чипа входят 40 Гбайт сверхбыстрой памяти. Система уже доступна коммерческим заказчикам, а также различным научным организациям. 
Источник изображения: Cerebras Systems Суперкомпьютер также использует 284 односокетных сервера с процессорами AMD EPYC 7713. Суммарное количество вычислительных ядер общего назначения составляет 18 176. Каждый из этих серверов несёт на борту 128 Гбайт оперативной памяти, NVMe-накопитель вместимостью 1,92 Тбайт и две сетевые карты 100GbE. Эти узлы отвечают за предварительную обработку информации. 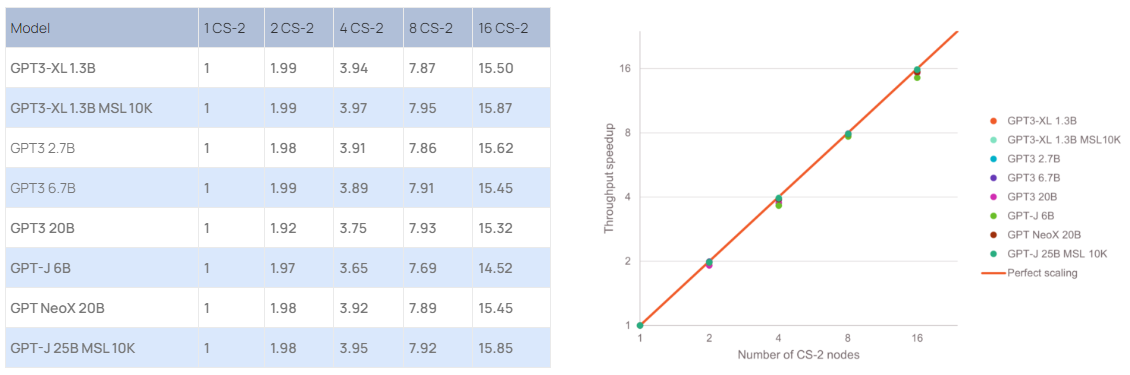
Источник: Cerebras Systems По заявлениям Cerebras, производительность системы превышает 1 Эфлопс на т.н. разреженных вычислениях и достигает 120 Пфлопс при обычных FP16-вычислениях. Это первый в мире суперкомпьютер, который обеспечивает практически идеальное линейное масштабирование при работе с GPT-моделями, в частности, GPT-3, GPT-J и GPT-NeoX. Иначе говоря, при каждом удвоении числа комплексов CS-2 время обучения моделей сокращается почти в два раза.  Суперкомпьютер смонтирован в дата-центре Colovore в Санта-Кларе (Калифорния, США). Стоимость системы составила приблизительно $30 млн, а на её развёртывание потребовалось всего три дня. Использовать ресурсы Andromeda могут одновременно несколько клиентов.
10.11.2022 [17:15], Владимир Мироненко
HPE анонсировала недорогие, энергоэффективные и компактные суперкомпьютеры Cray EX2500 и Cray XD2000/6500Hewlett Packard Enterprise анонсировала суперкомпьютеры HPE Cray EX и HPE Cray XD, которые отличаются более доступной ценой, меньшей занимаемой площадью и большей энергоэффективностью по сравнению с прошлыми решениями компании. Новинки используют современные технологии в области вычислений, интерконнекта, хранилищ, питания и охлаждения, а также ПО. 
Изображение: HPE Суперкомпьютеры HPE обеспечивают высокую производительность и масштабируемость для выполнения ресурсоёмких рабочих нагрузок с интенсивным использованием данных, в том числе задач ИИ и машинного обучения. Новинки, по словам компании, позволят ускорить вывода продуктов и сервисов на рынок. Решения HPE Cray EX уже используются в качестве основы для больших машин, включая экзафлопсные системы, но теперь компания предоставляет возможность более широкому кругу организаций задействовать супервычисления для удовлетворения их потребностей в соответствии с возможностями их ЦОД и бюджетом. В семейство HPE Cray вошли следующие системы:
Все три системы задействуют те же технологии, что и их старшие собратья: интерконнект HPE Slingshot, хранилище Cray Clusterstor E1000 и пакет ПО HPE Cray Programming Environment и т.д. Система HPE Cray EX2500 поддерживает процессоры AMD EPYC Genoa и Intel Xeon Sapphire Rapids, а также ускорители AMD Instinct MI250X. Модель HPE Cray XD6500 поддерживает чипы Sapphire Rapids и ускорители NVIDIA H100, а для XD2000 заявлена поддержка AMD Instinct MI210. 
Изображение: Intel В качестве примеров выгод от использования анонсированных суперкомпьютеров в разных отраслях компания назвала:
12.10.2022 [22:54], Сергей Карасёв
NEC готовит новые векторные ускорители серии SX-Aurora TSUBASAКомпания NEC Corporation сообщила о подготовке нового узла в серии SX-Aurora TSUBASA — модели C401-8, рассчитанной на центры обработки данных, на базе которых осуществляется сложное моделирование, выполняются научные расчёты и другие ресурсоёмкие задачи. Основой новинки станут неназванные пока векторные ускорители — судя по всему, это обещанные ранее Vector Engine 3.0 (VE30). Новинки получили 16 векторных блоков с частотой 1,7 ГГц, тогда как прошлое поколение имело до 10 блоков с частотой 1,6 ГГц. Также появился L3-кеш. Пропускная способность HBM-памяти увеличилась в 1,6 раза — с 1,53 до 2,45 Тбайт/с, а её объём вырос вдвое — с 48 до 96 Гбайт. Итоговая производительность в FP64-вычислениях, как утверждается, выросла приблизительно в 2,5 раза по сравнению с предшественниками и превысила 5 Пфлопс. При этом по энергоэффективности готовящийся ускоритель, по словам NEC, в два раза превосходит традиционные изделия. 
Источник изображения: NEC В августе 2023 года суперкомпьютер на базе SX-Aurora TSUBASA C401-8 начнёт использоваться в Научном центре Университета Тохоку в Японии. В общей сложности будут задействованы 4032 векторных ускорителя NEC, а быстродействие составит до 21 Пфлопс. Использовать комплекс планируется для масштабных научных исследований. Месяцем позже заработает ещё одна HPC-система на базе C401-8, которую получит метеослужба Германии.
05.09.2022 [23:00], Алексей Степин
Tesla рассказала подробности о чипах D1 собственной разработки, которые станут основой 20-Эфлопс ИИ-суперкомпьютера DojoКомпания Tesla уже анонсировала собственный, созданный в лабораториях компании процессор D1, который станет основой ИИ-суперкомпьютера Dojo. Нужна такая система, чтобы создать для ИИ-водителя виртуальный полигон, в деталях воссоздающий реальные ситуации на дорогах. Естественно, такой симулятор требует огромных вычислительных мощностей: в нашем мире дорожная обстановка очень сложна, изменчива и включает множество факторов и переменных. До недавнего времени о Dojo и D1 было известно не так много, но на конференции Hot Chips 34 было раскрыто много интересного об архитектуре, устройстве и возможностях данного решения Tesla. Презентацию провел Эмиль Талпес (Emil Talpes), ранее 17 лет проработавший в AMD над проектированием серверных процессоров. Он, как и ряд других видных разработчиков, работает сейчас в Tesla над созданием и совершенствованием аппаратного обеспечения компании. 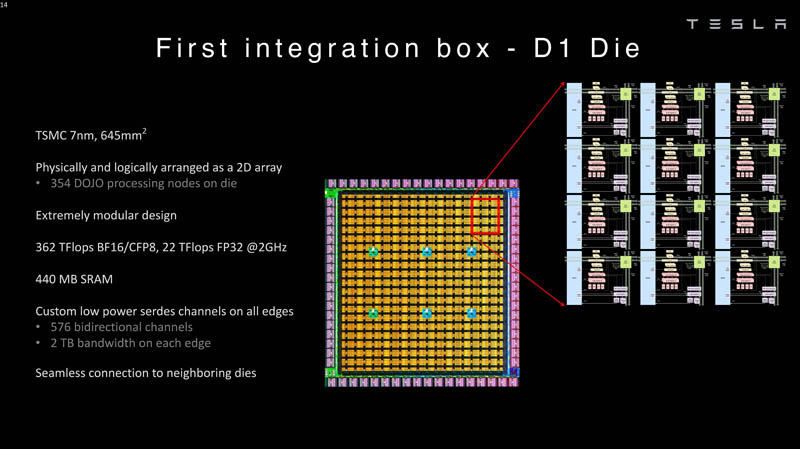
Изображения: Tesla (via ServeTheHome) Главной идеей D1 стала масштабируемость, поэтому в начале разработки нового чипа создатели активно пересмотрели роль таких традиционных концепций, как когерентность, виртуальная память и т.д. — далеко не все механизмы масштабируются лучшим образом, когда речь идёт о построении действительно большой вычислительной системы. Вместо этого предпочтение было отдано распределённой сети хранения на базе SRAM, для которой был создан интерконнект, на порядок опережающий существующие реализации в системах распределённых вычислений. 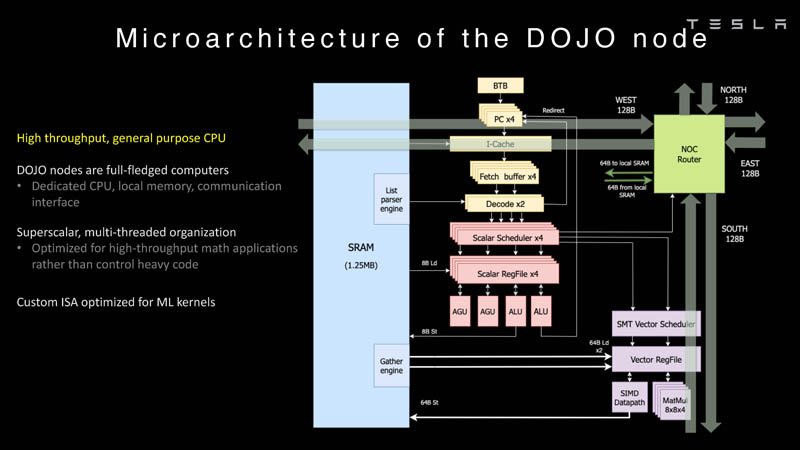 Основой процессора Tesla стало ядро целочисленных вычислений, базирующееся на некоторых инструкциях из набора RISC-V, но дополненное большим количеством фирменных инструкций, оптимизированных с учётом требований, предъявляемых ядрами машинного обучения, используемыми компанией. Блок векторной математики был создан практически с нуля, по словам разработчиков. 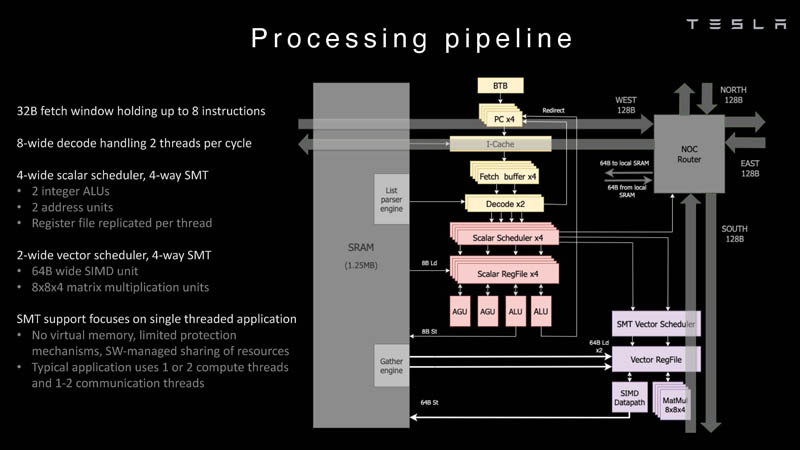 Набор инструкций Dojo включает в себя скалярные, матричные и SIMD-инструкции, а также специфические примитивы для перемещения данных из локальной памяти в удалённую, равно как и семафоры с барьерами — последние требуются для согласования работы c памятью во всей системе. Что касается специфических инструкций для машинного обучения, то они реализованы в Dojo аппаратно. 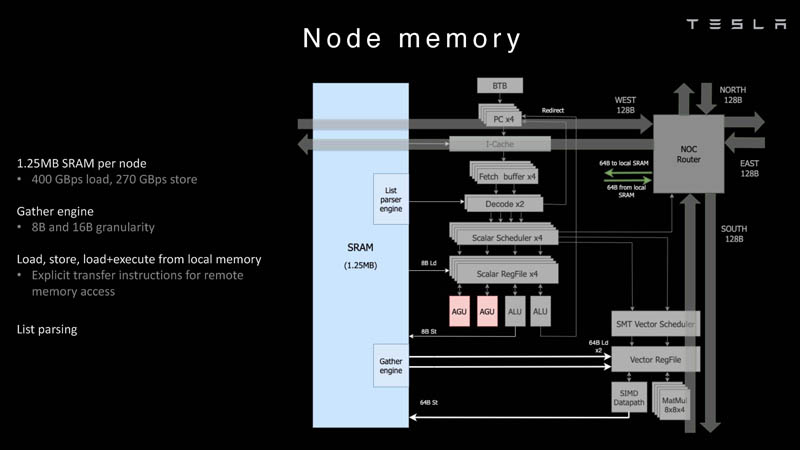 Первенец в серии, чип D1, не является ускорителем как таковым — компания считает его высокопроизводительным процессором общего назначения, не нуждающимся в специфических ускорителях. Каждый вычислительный блок Dojo представлен одним ядром D1 с локальной памятью и интерфейсами ввода/вывода. Это 64-бит ядро суперскалярно. 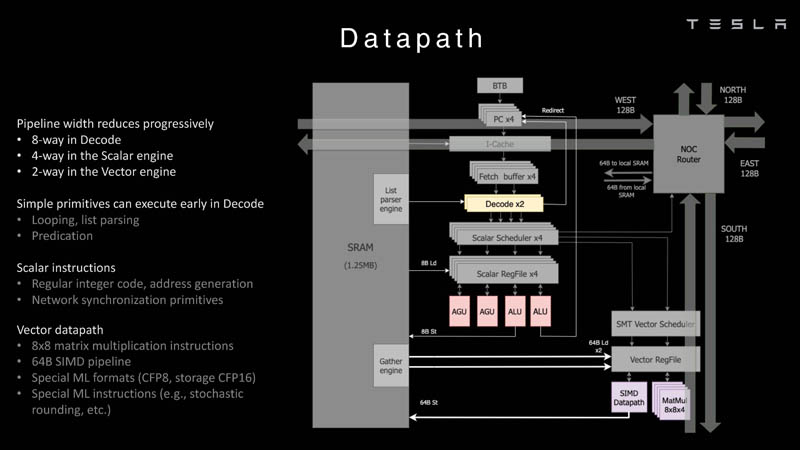 Более того, в ядре реализована поддержка многопоточности (SMT4), которая призвана увеличить производительность на такт (а не изолировать разные задачи друг от друга), поэтому виртуальную память данная реализация SMT не поддерживает, а механизмы защиты довольно ограничены в функциональности. За управление ресурсами Dojo отвечает специализированный программный стек и фирменное ПО. 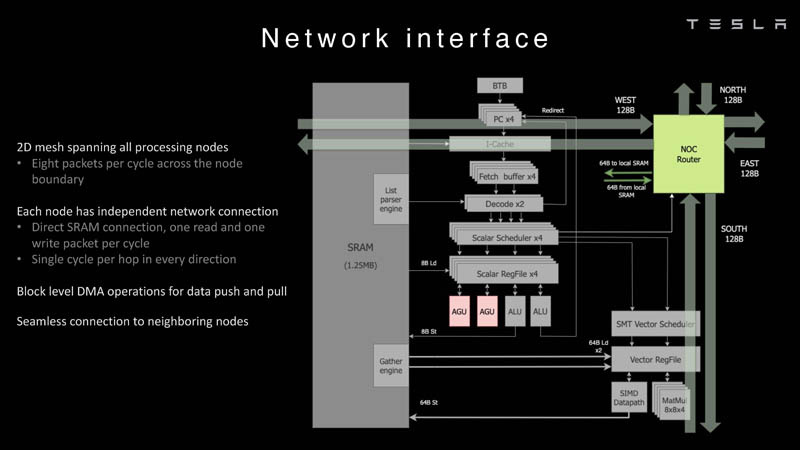 64-бит ядро имеет 32-байт окно выборки (fetch window), которое может содержать до 8 инструкций, что соответствует ширине декодера. Он, в свою очередь, может обрабатывать два потока за такт. Результат поступает в планировщики, которые отправляют его в блок целочисленных вычислений (два ALU) или в векторный блок (SIMD шириной 64 байт + перемножение матриц 8×8×4). 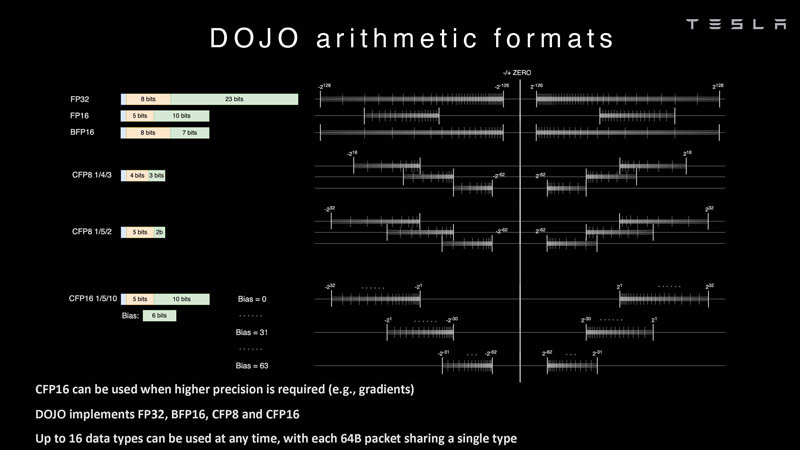 У каждого ядра D1 есть SRAM объёмом 1,25 Мбайт. Эта память — не кеш, но способна загружать данные на скорости 400 Гбайт/с и сохранять на скорости 270 Гбайт/с, причём, как уже было сказано, в чипе реализованы специальные инструкции, позволяющие работать с данными в других ядрах Dojo. Для этого в блоке SRAM есть свои механизмы, так что работа с удалённой памятью не требуют дополнительных операций.  Что касается поддерживаемых форматов данных, то скалярный блок поддерживает целочисленные форматы разрядностью от 8 до 64 бит, а векторный и матричный блоки — широкий набор форматов с плавающей запятой, в том числе для вычислений смешанной точности: FP32, BF16, CFP16 и CFP8. Разработчики D1 пришли к использованию целого набора конфигурируемых 8- и 16-бит представлений данных — компилятор Dojo может динамически изменять значения мантиссы и экспоненты, так что система может использовать до 16 различных векторных форматов, лишь бы в рамках одного 64-байт блока данных он не менялся.  Как уже упоминалось, топология D1 использует меш-структуру, в которой каждые 12 ядер объединены в логический блок. Чип D1 целиком представляет собой массив размером 18×20 ядер, однако доступны лишь 354 ядра из 360 присутствующих на кристалле. Сам кристалл площадью 645 мм2 производится на мощностях TSMC с использованием 7-нм техпроцесса. Тактовая частота составляет 2 ГГц, общий объём памяти SRAM — 440 Мбайт.  Процессор D1 развивает 362 Тфлопс в режиме BF16/CFP8, в режиме FP32 этот показатель снижается до 22 Тфлопс. Режим FP64 векторными блоками D1 не поддерживается, поэтому для многих традиционных HPC-нагрузок данный процессор не подойдёт. Но Tesla создавала D1 для внутреннего использования, поэтому совместимость её не очень волнует. Впрочем, в новых поколениях, D2 или D3, такая поддержка может появиться, если это будет отвечать целям компании. 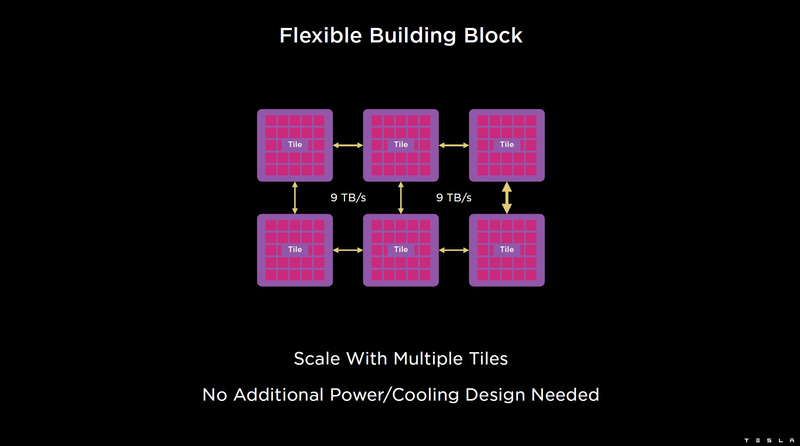 Каждый кристалл D1 имеет 576-битный внешний интерфейс SerDes с совокупной производительностью по всем четырём сторонам, составляющей 18 Тбайт/с, так что узким местом при соединении D1 он явно не станет. Этот интерфейс объединяет кристаллы в единую матрицу 5х5, такая матрица из 25 кристаллов D1 носит название Dojo training tile. 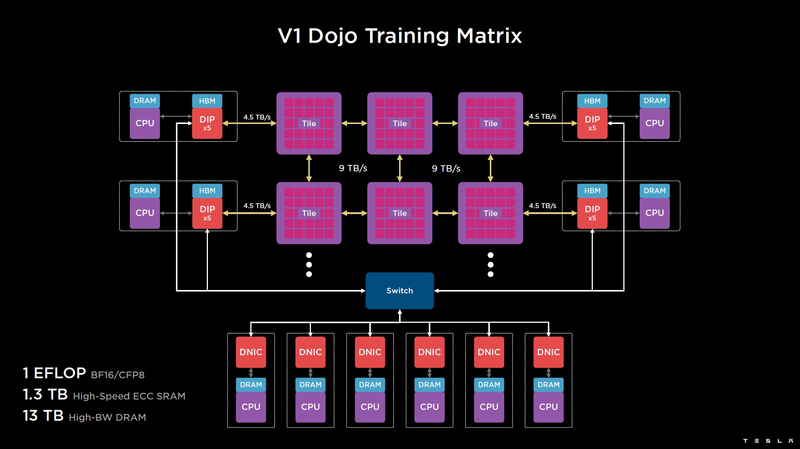 Этот тайл выполнен как законченный термоэлектромеханический модуль, имеющий внешний интерфейс с пропускной способностью 4,5 Тбайт/с на каждую сторону, совокупно располагающий 11 Гбайт памяти SRAM, а также собственную систему питания мощностью 15 кВт. Вычислительная мощность одного тайла Dojo составляет 9 Пфлопс в формате BF16/CFP8. При таком уровне энергопотребления охлаждение у Dojo может быть только жидкостное.  Тайлы могут объединяться в ещё более производительные матрицы, но как именно физически организован суперкомпьютер Tesla, не вполне ясно. Для связи с внешним миром используются блоки DIP — Dojo Interface Processors. Это интерфейсные процессоры, посредством которых тайлы общаются с хост-системами и на долю которых отведены управляющие функции, хранение массивов данных и т.п. Каждый DIP не просто выполняет IO-функции, но и содержит 32 Гбайт памяти HBM (не уточняется, HBM2e или HBM3). 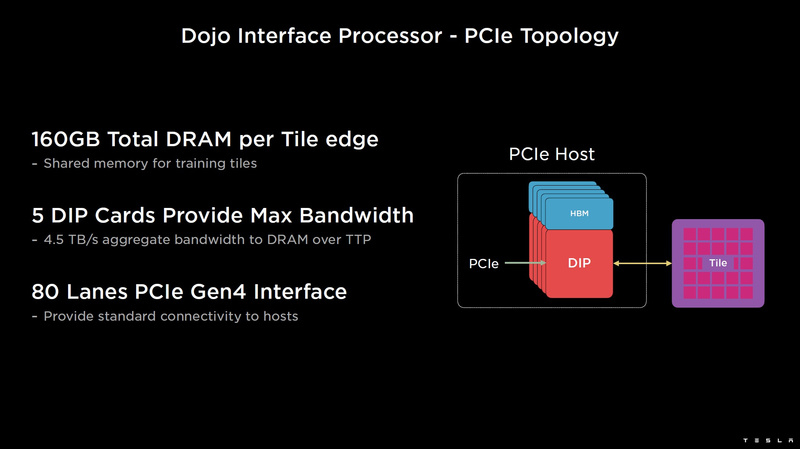 DIP использует полностью свой транспортный протокол (Tesla Transport Protocol, TTP), разработанный в Tesla и обеспечивающий пропускную способность 900 Гбайт/с, а поверх Ethernet — 50 Гбайт/с. Внешний интерфейс у карточек — PCI Express 4.0, и каждая интерфейсная карта несёт пару DIP. С каждой стороны каждого ряда тайлов установлено по 5 DIP, что даёт скорость до 4,5 Тбайт/с от HBM-стеков к тайлу.  В случаях, когда во всей системе обращение от тайла к тайлу требует слишком много переходов (до 30 в случае обращения от края до края), система может воспользоваться DIP, объединённых снаружи 400GbE-сетью по топологии fat tree, сократив таким образом, количество переходов до максимум четырёх. Пропускная способность в этом случае страдает, но выигрывает латентность, что в некоторых сценариях важнее. 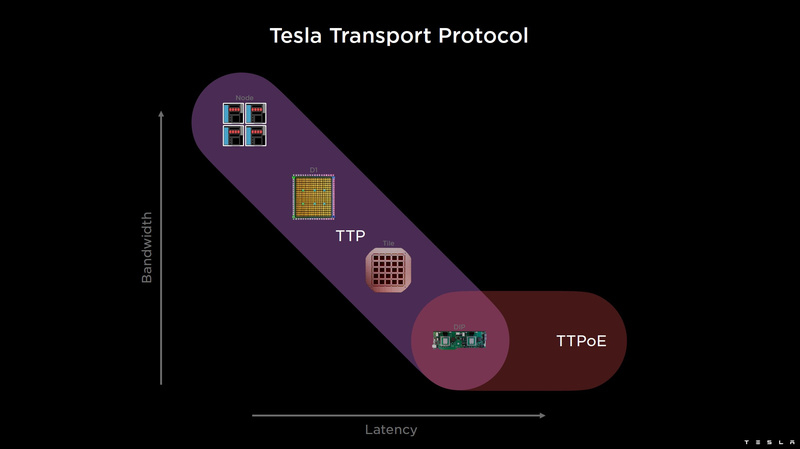 В базовой версии суперкомпьютер Dojo V1 выдаёт 1 Эфлопс в режиме BF16/CFP8 и может загружать непосредственно в SRAM модели объёмом до 1,3 Тбайт, ещё 13 Тбайт данных можно хранить в HBM-сборках DIP. Следует отметить, что пространство SRAM во всей системе Dojo использует единую плоскую адресацию. Полномасштабная версия Dojo будет иметь производительность до 20 Эфлопс. Сколько сил потребуется компании, чтобы запустить такого монстра, а главное, снабдить его рабочим и приносящим пользу ПО, неизвестно — но явно немало. Известно, что система совместима с PyTorch. В настоящее время Tesla уже получает готовые чипы D1 от TSMC. А пока что компания обходится самым большим в мире по числу установленных ускорителей NVIDIA ИИ-суперкомпьютером.
26.08.2022 [12:45], Алексей Степин
Интерконнект NVIDIA NVLink 4 открывает новые горизонты для ИИ и HPCПотребность в действительно быстром интерконнекте для ускорителей возникла давно, поскольку имеющиеся шины зачастую становились узким местом, не позволяя «прокормить» данными вычислительные блоки. Ответом NVIDIA на эту проблему стало создание шины NVLink — и компания продолжает активно развивать данную технологию. На конференции Hot Chips 34 было продемонстрировано уже четвёртое поколение, наряду с новым поколением коммутаторов NVSwitch. 
Изображения: NVIDIA Возможность использования коммутаторов для NVLink появилась не сразу, изначально использовалось соединение блоков ускорителей по схеме «точка-точка». Но дальнейшее наращивание числа ускорителей по этой схеме стало невозможным, и тогда NVIDIA разработала коммутаторы NVSwitch. Они появились вместе с V100 и предлагали до 50 Гбайт/с на порт. Нынешнее же, третье поколение NVSwitch и четвёртое поколение NVLink сделали важный шаг вперёд — теперь они позволяют вынести NVLink-подключения за пределы узла. 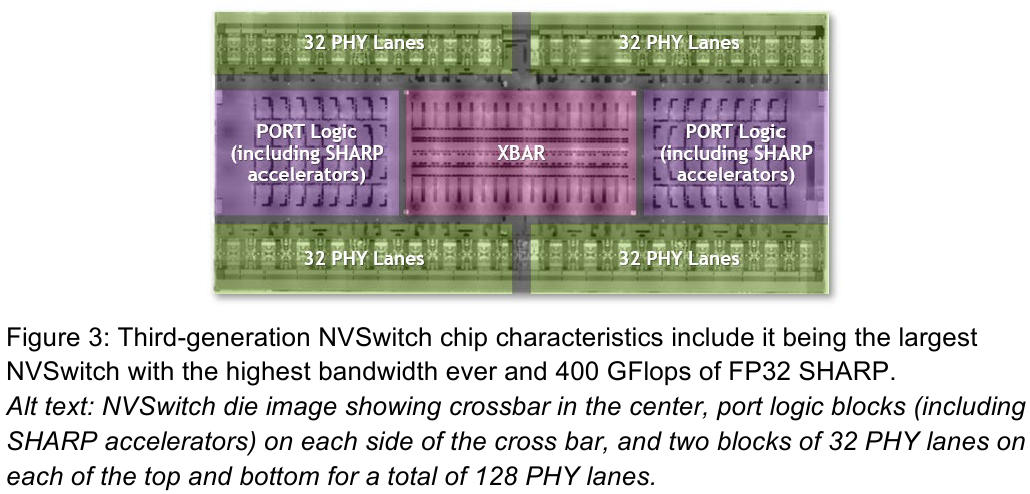 Так, совокупная пропускная способность одного чипа NVSwitch теперь составляет 3,2 Тбайт/с в обе стороны в 64 портах NVLink 4 (x2). Это, конечно, отразилось и на сложности самого «кремния»: 25,1 млрд транзисторов (больше чем у V100), техпроцесс TSMC 4N и площадь 294мм2. Скорость одной линии NVLink 4 осталась равной 50 Гбайт/с, но новые ускорители H100 имеют по 18 линий NVLink, что даёт впечатляющие 900 Гбайт/с. В DGX H100 есть сразу четыре NVSwitch-коммутатора, которые объединяют восемь ускорителей по схеме каждый-с-каждым и дополнительно отдают ещё 72 NVLink-линии (3,6 Тбайт/с). 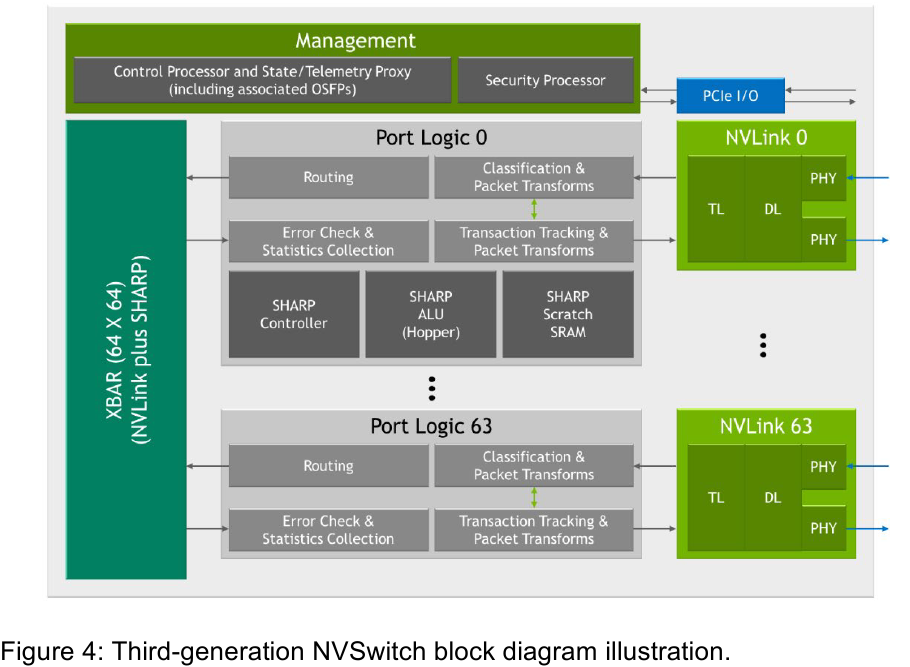 При этом у DGX H100 сохраняются прежние 400G-адаптеры Ethernet/InfiniBand (ConnectX-7), по одному на каждый ускоритель, и пара DPU BlueField-3, тоже класса 400G. Несколько упрощает физическую инфраструктуру то, что для внешних NVLink-подключений используются OSFP-модули, каждый из которых обслуживает 4 линии NVLink. Любопытно, что электрически интерфейсы совместимы с имеющейся 400G-экосистемой (оптической и медной), но вот прошивки для модулей нужны будут кастомные. 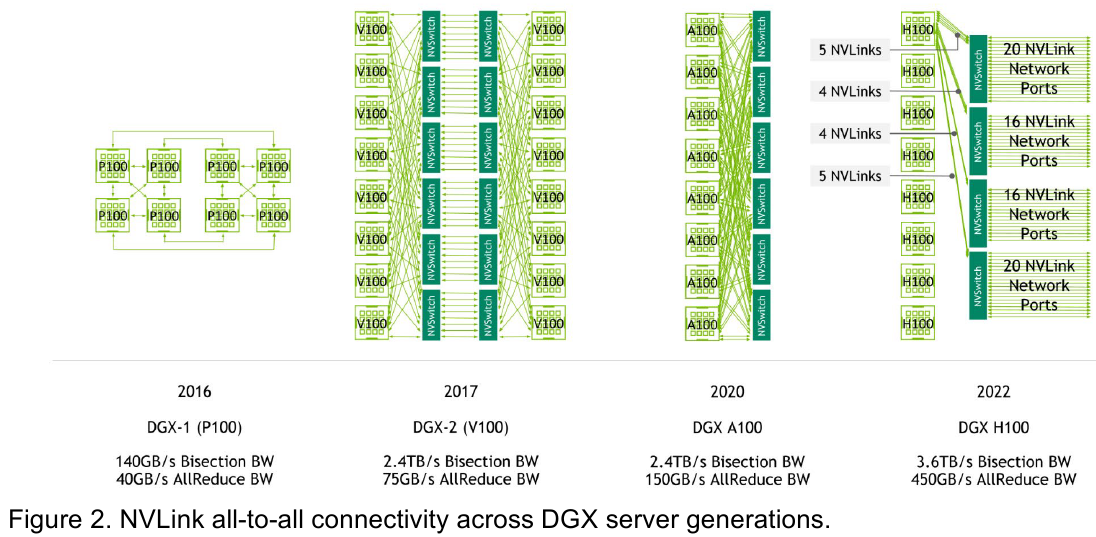 Подключаются узлы DGX H100 к 1U-коммутатору NVLink Switch, включающему два чипа NVSwitch третьего поколения: 32 OSFP-корзины, 128 портов NVLink 4 и агрегированная пропускная способность 6,4 Тбайт/с. В составе DGX SuperPOD есть 18 коммутаторов NVLink Switch и 256 ускорителей H100 (32 узла DGX). Таким образом, можно связать ускорители и узлы 900-Гбайт/с каналом. Как конкретно, остаётся на усмотрение пользователя, но сама NVLink-сеть поддерживает динамическую реконфигурацию на лету. 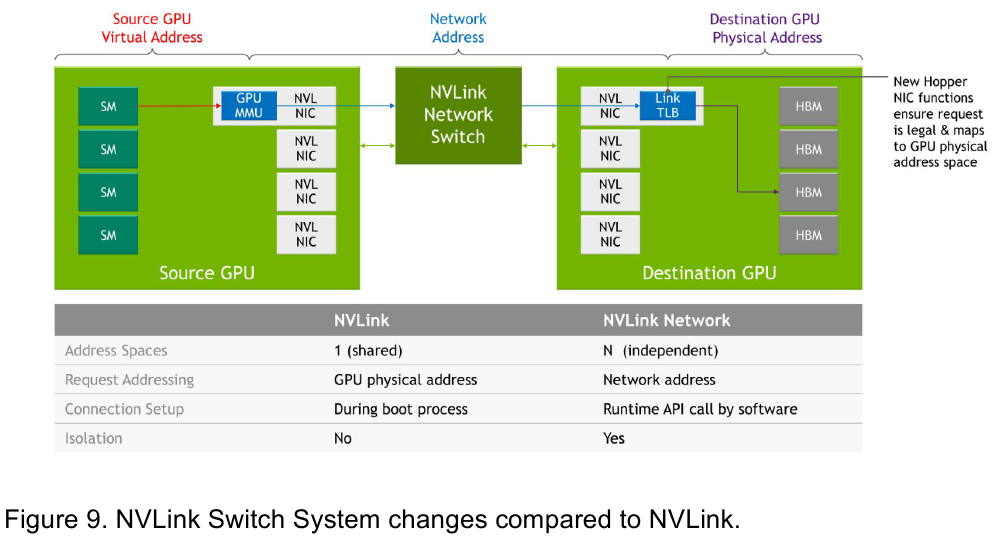 Ещё одна особенность нового поколения NVLink — продвинутые аппаратные SHARP-движки, которые избавляют CPU/GPU от части работ по подготовке и предобработки данных и избавляющие саму сеть от ненужных передач. Кроме того, в NVLink-сети реализованы разделение и изоляция, брандмауэр, шифрование, глубокая телеметрия и т.д. В целом, новое поколение NVLink получило полуторакратный прирост в скорости обмена данными, а в отношении дополнительных сетевых функций он стал трёхкратным. Всё это позволит освоить новые класса HPC- и ИИ-нагрузок, однако надо полагать, что удовольствие это будет недешёвым.
22.08.2022 [20:55], Алексей Степин
Китайский ускоритель Birentech BR100 готов бросить вызов NVIDIA A100Как известно, Китай первым в мире успешно ввёл в эксплуатацию суперкомпьютеры экзафлопсного класса, но современная HPC-система практически немыслима без ускорителей. Однако и здесь китайские разработчики подготовили прорыв: на конференции Hot Chips 34 компания Birentech рассказала о чипе BR100, решении, которое может бросить вызов как AMD, так и NVIDIA. Новинка базируется на архитектуре собственной разработки под кодовым названием Bi Liren. Это первый китайский ускоритель общего назначения, использующий чиплетную компоновку и поддерживающий PCI Express 5.0/CXL. Новые ускорители будут сопровождаться полноценной программной поддержкой, начиная с драйверов и библиотек и заканчивая популярными фреймворками, такими, как TensorFlow и PyTorch. 
Источник: WCCFTech Сложность BR100 внушает уважение: новый чип состоит из 77 млрд транзисторов, скомпонованных воедино с использованием 7-нм техпроцесса и технологии TSMC 2.5D CoWoS. Площадь чипа составляет 1074 мм2, правда, не очень понятно, идёт ли речь исключительно о кристалле, т.н. «вычислительном тайле», или о сборке в целом, поскольку в состав BR100 входит 64 Гбайт памяти HBM2e. 
Источник: WCCFTech Среди особенностей можно отметить наличие быстрого кеша объёмом 300 Мбайт (256 Мбайт L2) — для сравнения, у NVIDIA A100 он составляет всего 40 Мбайт, и даже у новейшего H100 он увеличен лишь до 50 Мбайт. Что касается ПСП, то она составляет 1,64 Тбайт/с. 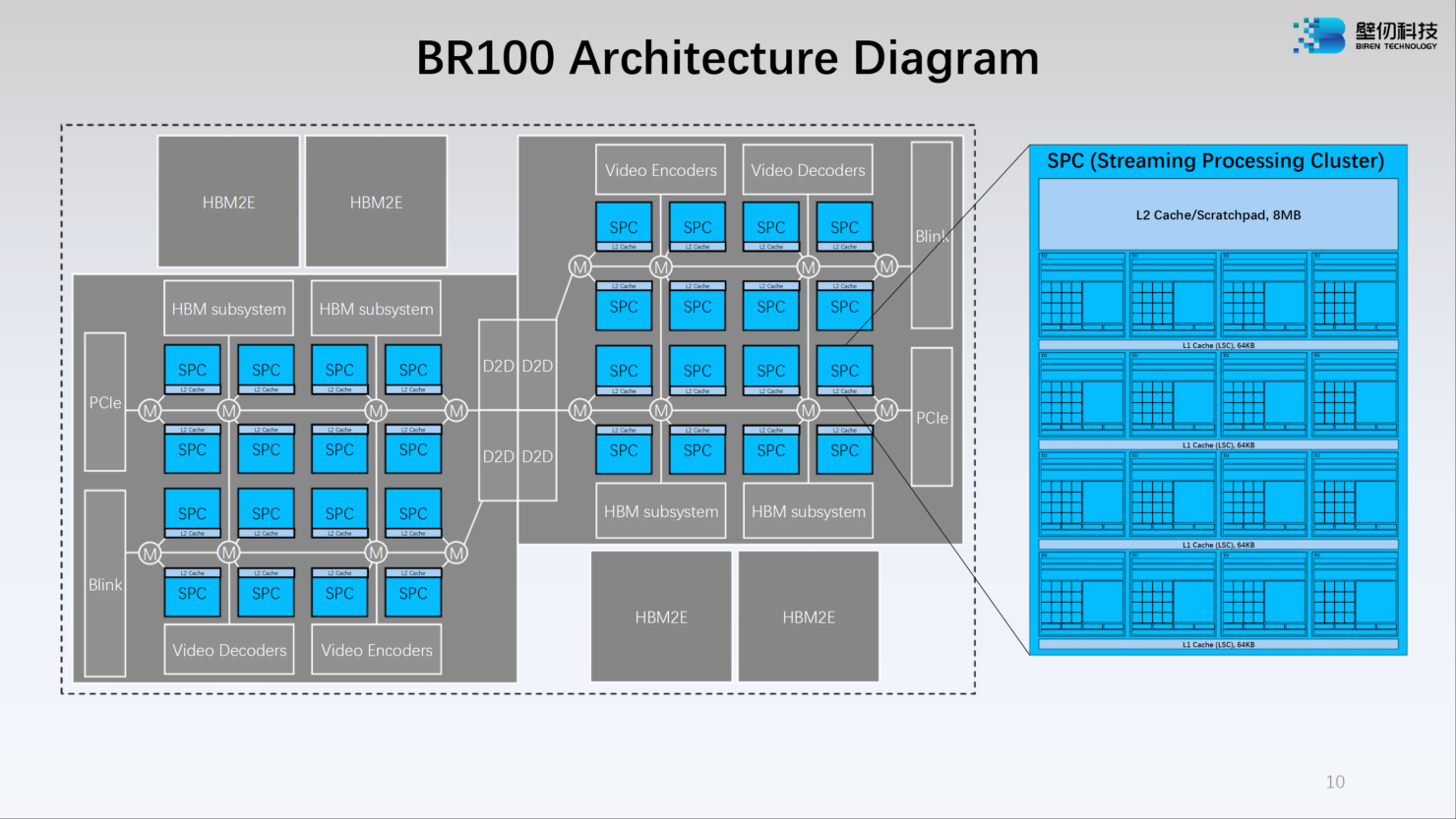
Источник: WCCFTech Модульная компоновка BR100 включает в себя два вычислительных тайла и четыре сборки HBM2e. Между собой кристаллы соединены интерконнектом с пропускной способностью 896 Гбайт/с, а для дальнейшего масштабирования в составе нового ускорителя предусмотрен фирменный интерконнект BLink (8 линий) с производительностью 2,3 Тбайт/с. 
Источник: WCCFTech Каждый из двух кристаллов несёт в себе по 16 потоковых вычислительных кластеров (SPC), а каждый такой кластер, в свою очередь, содержит 16 исполнительных блоков (EU). Каждый блок EU содержит 16 потоковых ядер V-Core и одно тензорное ядро T-Core, так что всего в составе BR100 имеется 8192 классических ядра и 512 тензорных. Каждый SPC имеет свой кеш L2 объёмом 8 Мбайт, суммарно 256 Мбайт на всю сборку BR100. 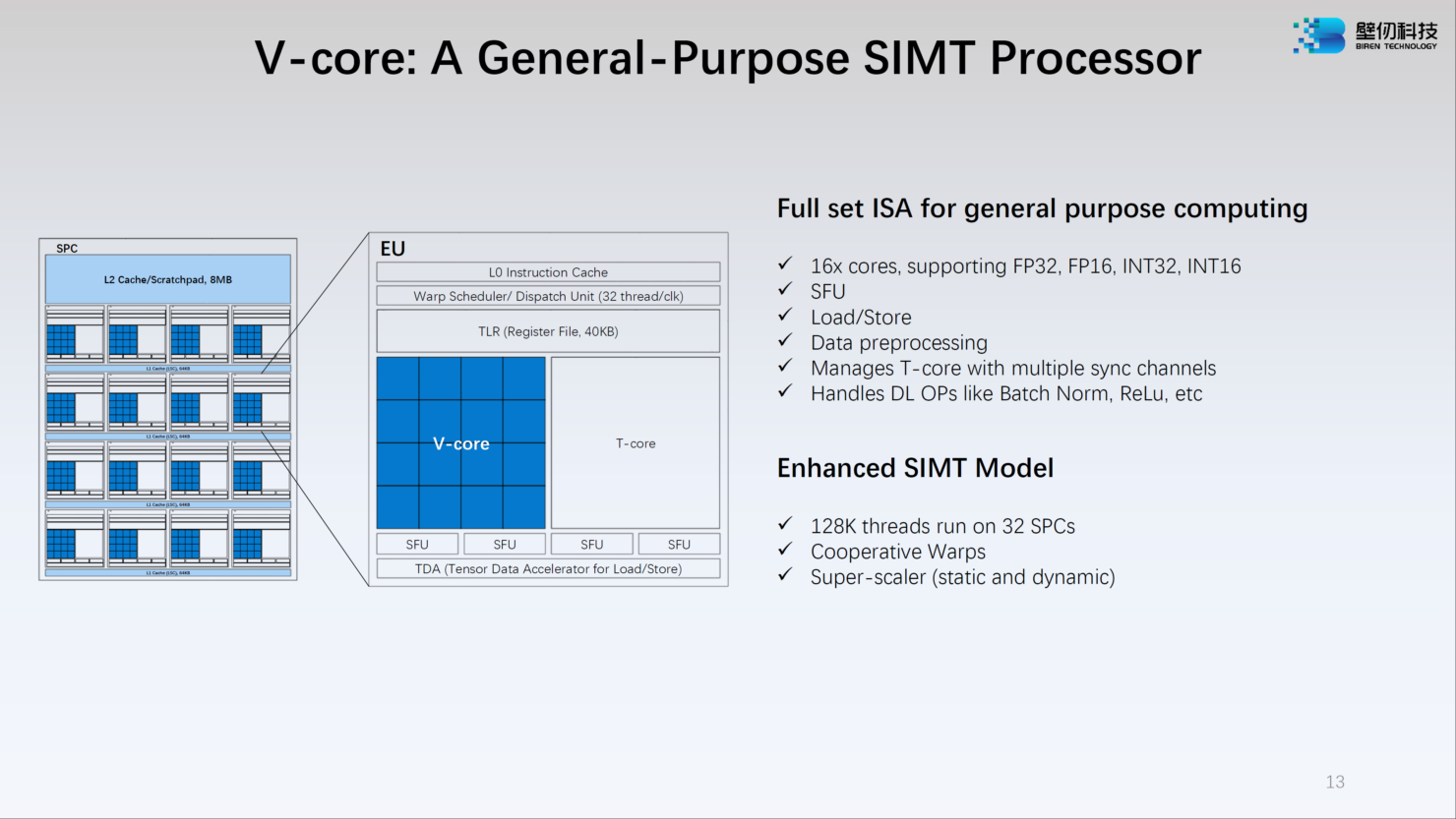
Источник: WCCFTech Ядро V-Core имеет архитектуру SIMT (Single Instructions, Multiple Thread) и поддерживает вычисления в форматах INT16/32, FP16 и FP32. Тензорные ядра T-Core предназначены для выполнения операций типа MMA, свёртки и прочих, характерных для современных задач машинного обучения. Предельное количество потоков у BR100 в суперскалярном режиме — 128 тысяч. 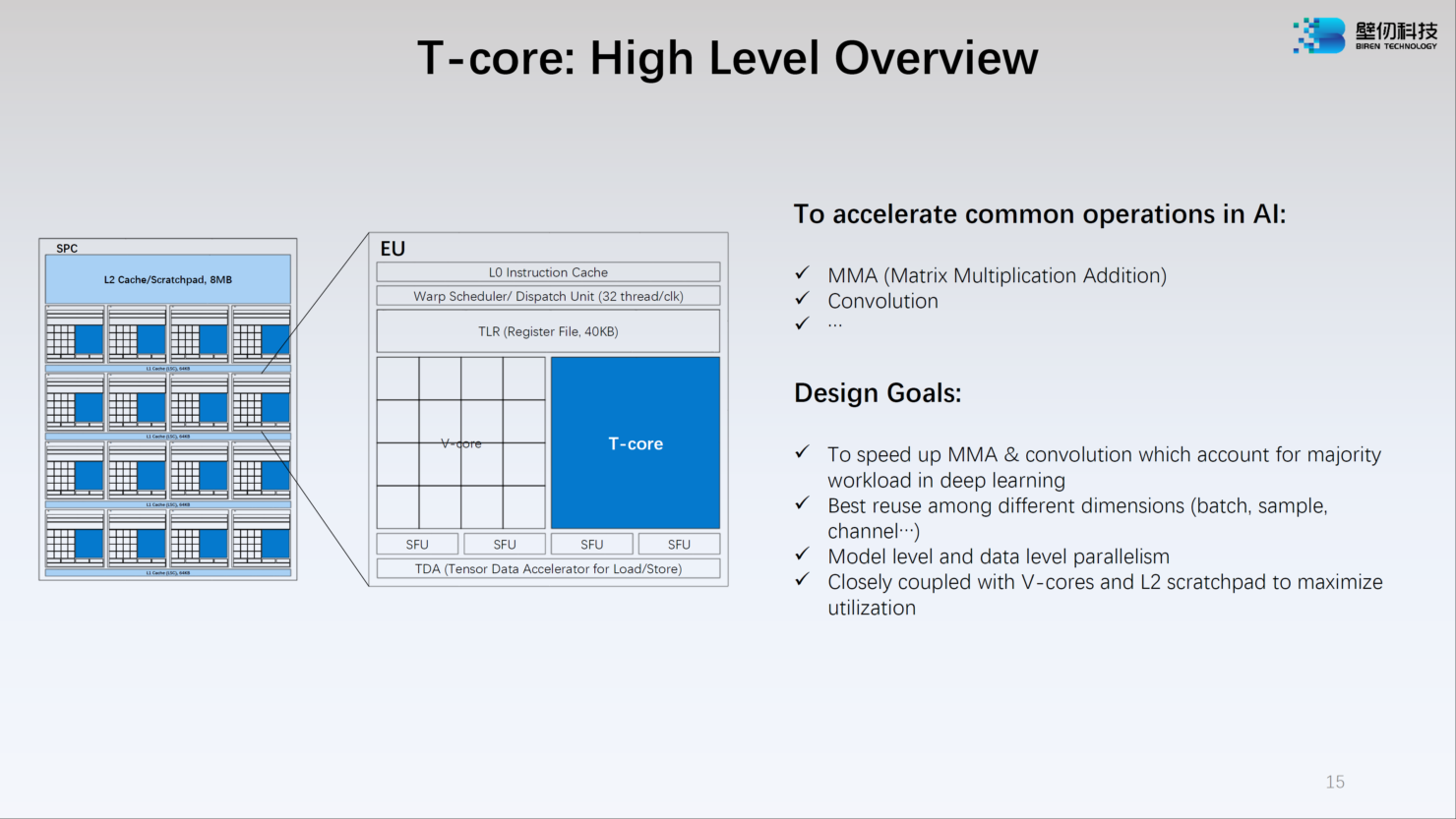
Источник: WCCFTech Компания-разработчик приводит некоторые цифры производительности для BR100: это 256 Тфлопс в режиме FP32, вдвое больше в режиме TF32+, 1024 Тфлопс в формате BF16 и целых 2048 Топс в режиме INT8. Это серьёзная заявка: с такими показателями BR100 должен опережать NVIDIA A100. Заявлено превосходство от 2,5х до 2,8х в зависимости от задачи и сценария. 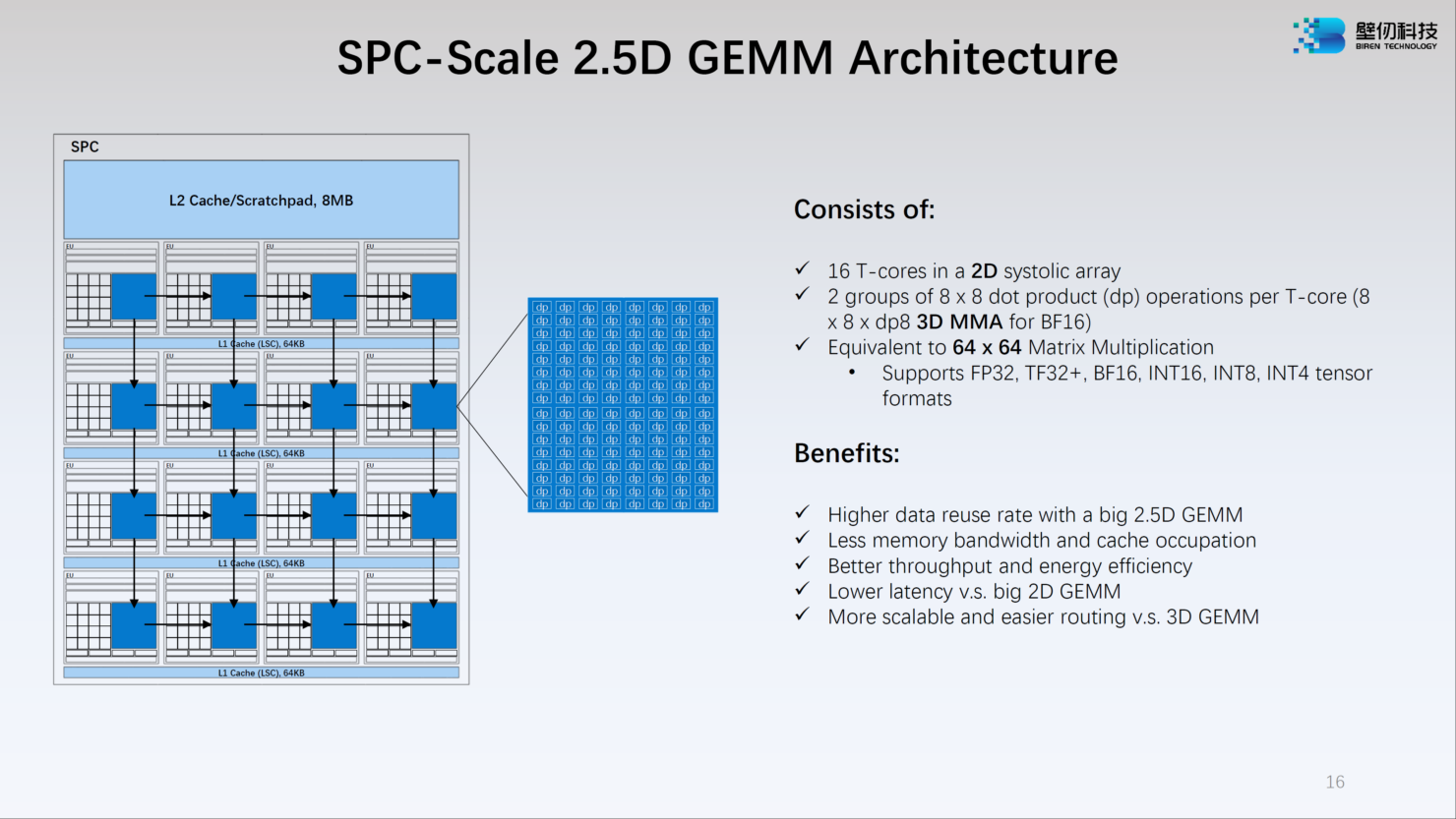
Источник: WCCFTech Любопытно, что BR100 несильно уступает NVIDIA H100 по количеству транзисторов (77 против 80 млрд), но, естественно, использование более грубого 7-нм техпроцесса против N4 у последней разработки NVIDIA означает и большее тепловыделение. Этот параметр у BR100 составляет 550 Вт в то время, как PCIe-вариант H100 укладывается в стандартные 350 Вт. 
Источник: WCCFTech Это не единственная новинка: в арсенале Birentech заявлен и менее мощный чип BR104. Он вдвое медленнее старшей модели по всем показателям и несёт 32 Гбайт памяти против 64, но в отличие от BR100, использует монолитный, а не чиплетный дизайн. На его основе будут выпущены ускорители в формате PCIe с TDP в районе 300 Вт, тогда как старшая версия будет доступна только в виде OAM-модуля.
20.08.2022 [22:30], Алексей Степин
NVIDIA поделилась некоторыми деталями о строении Arm-процессоров Grace и гибридных чипов Grace HopperНа GTC 2022 весной этого года NVIDIA впервые заявила о себе, как о производителе мощных серверных процессоров. Речь идёт о чипах Grace и гибридных сборках Grace Hopper, сочетающих в себе ядра Arm v9 и ускорители на базе архитектуры Hopper, поставки которых должны начаться в первой половине следующего года. Многие разработчики суперкомпьютеров уже заинтересовались новинками. В преддверии конференции Hot Chips 34 компания раскрыла ряд подробностей о чипах. Grace производятся с использованием техпроцесса TSMC 4N — это специально оптимизированный для решений NVIDIA вариант N4, входящий в серию 5-нм процессов тайваньского производителя. Каждый кристалл процессорной части Grace содержит 72 ядра Arm v9 с поддержкой масштабируемых векторных расширений SVE2 и расширений виртуализации с поддержкой S-EL2. Как сообщалось ранее, NVIDIA выбрала для новой платформы ядра Arm Neoverse. 
Источник: NVIDIA Процессор Grace также соответствует ряду других спецификаций Arm, в частности, имеет отвечающий стандарту RAS v1.1 контроллер прерываний (Generic Interrupt Controller, GIC) версии v4.1, блок System Memory Management Unit (SMMU) версии v3.1 и средства Memory Partitioning and Monitoring (MPAM). Базовых кристаллов у Grace два, что в сумме даёт 144 ядра — рекордное количество как в мире Arm, так и x86. 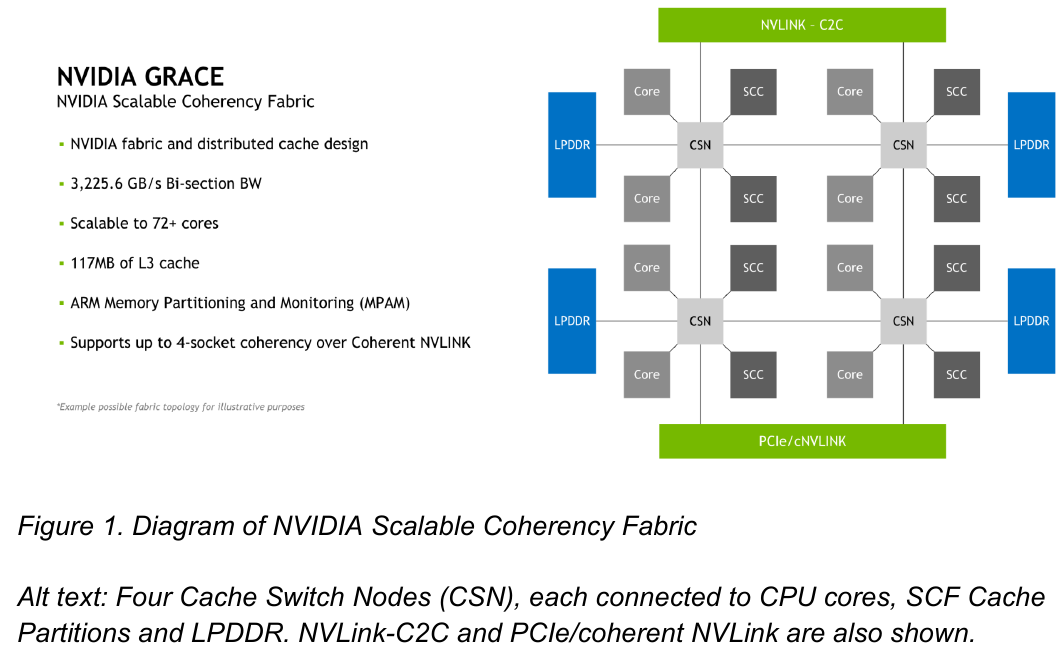
Внутренняя организация кластеров ядр в Grace. Источник: NVIDIA Внутренние блоки Grace соединяются посредством фабрики Scalable Coherency Fabric (SCF), вариации NVIDIA на тему сети CMN-700, применяемой в дизайнах Arm Neoverse. Производительность данного интерконнекта составляет 3,2 Тбайт/с. В случае Grace он предполагает наличие 117 Мбайт кеша L3 и поддерживает когерентность в пределах четырёх сокетов (посредством новой версии NVLink). Но SCF поддерживает масштабирование. Пока что в «железе» она ограничена двумя блоками Grace, а это уже 144 ядра и 234 Мбайт L3-кеша. Ядра и кеш-разделы (SCC) рапределены по внутренней mesh-фабрике SCF. Коммутаторы (CSN) служат интерфейсами для ядер, кеш-разделов и остальными частями системы. Блоки CSN общаются непосредственно друг с другом, а также с контроллерами LPDDR5X и PCIe 5.0/cNVLink/NVLink C2C. 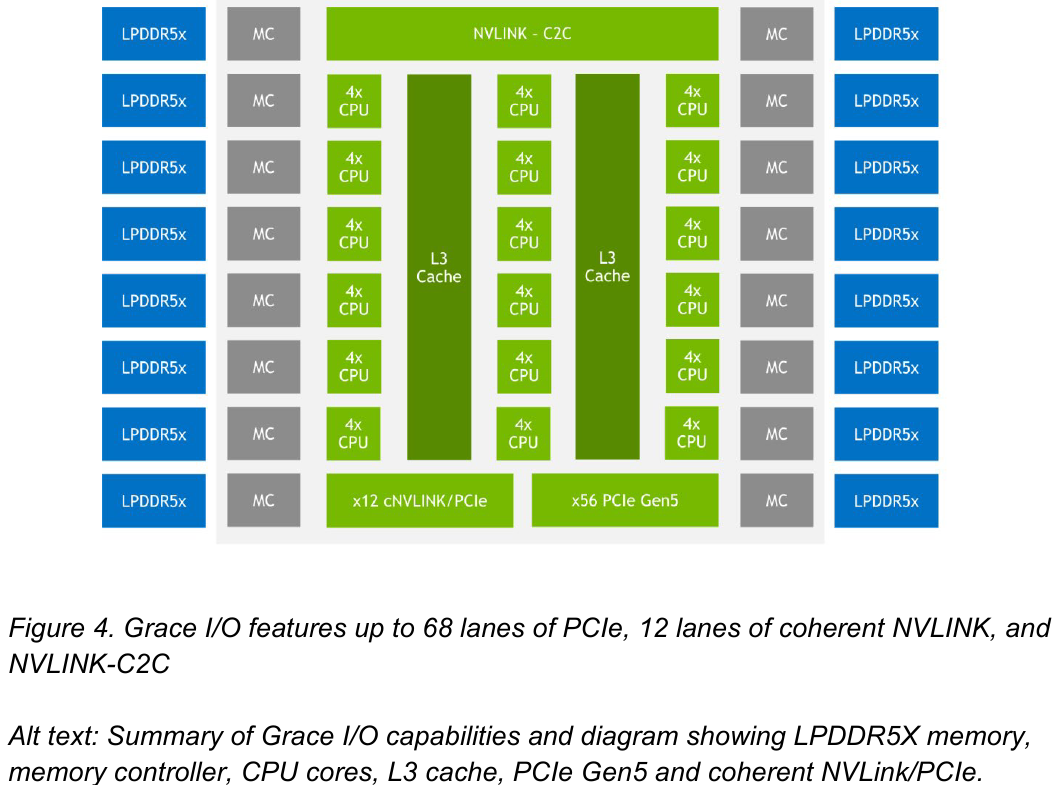
Блок-схема кристалла Grace. Источник: NVIDIA В чипе реализована поддержка PCI Express 5.0. Всего контроллер поддерживает 68 линий, 12 из которых могут также работать в режиме cNVLink (NVLink с когерентностью). x16-интерфейс посредством бифуркации может быть превращен в два x8. Также на приведённой NVIDIA диаграмме можно видеть целых 16 двухканальных контроллеров LPDDR5x. Заявлена ПСП на уровне свыше 1 Тбайт/с для сборки (до 546 Гбайт/с на кристалл CPU). 
Источник: NVIDIA Основной же межчиповой связи NVIDIA видит новую версию NVLink — NVLink-C2C, которая в семь раз быстрее PCIe 5.0 и способна обеспечить двунаправленную скорость передачи данных на уровне до 900 Гбайт/с, будучи при этом в пять раз экономичнее. Удельное потребление у новинки составляет 1,3 пДж/бит, что меньше, нежели у AMD Infinity Fabric с 1,5 пДж/бит. Впрочем, существуют и более экономичные решения, например, UCIe (~0,5 пДж/бит). 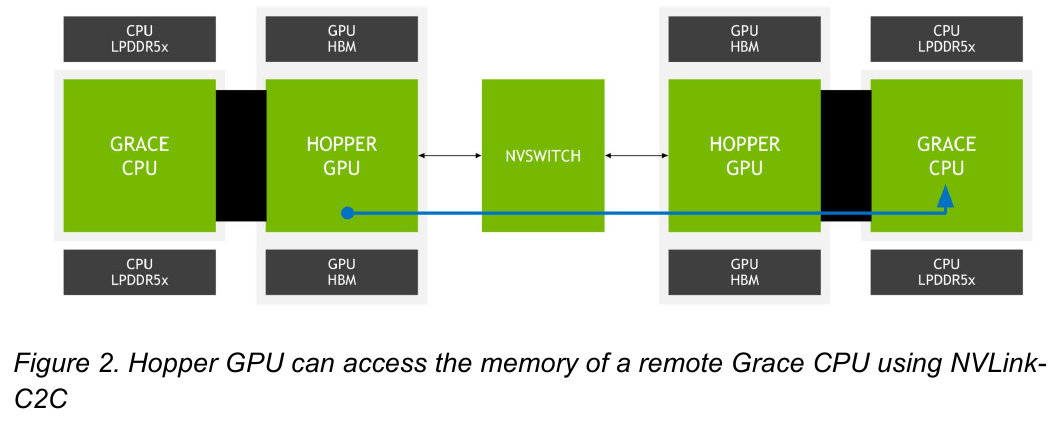
Новый вариант NVLink обеспечит кластер на базе Grace Hopper единым пространством памяти. Источник: NVIDIA NVLink-C2C позволяет реализовать унифицированный «плоский» пул памяти с общим адресным пространством для Grace Hopper. В рамках одного узла возможно свободное обращение к памяти соседей. А вот для объединения нескольких узлов понадобится уже внешний коммутатор NVSwitch. Он будет занимать 1U в высоту, и предоставлять 128 портов NVLink 4 с агрегированной пропускной способностью до 6,4 Тбайт/с в дуплексе. 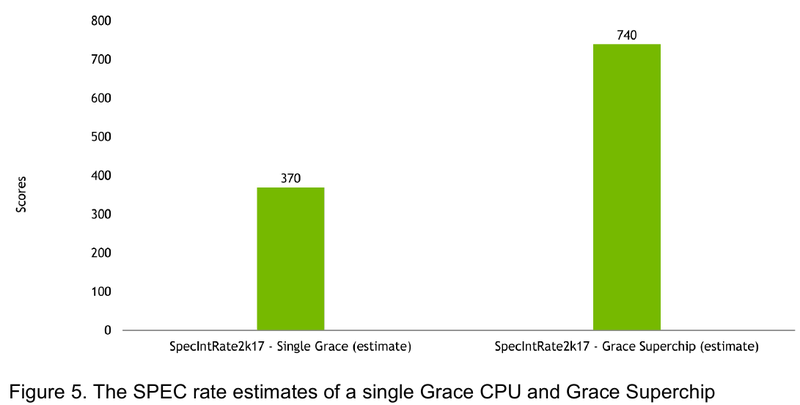
Источник: NVIDIA Производительность Grace также обещает быть рекордно высокой благодаря оптимизированной архитектуре и быстрому интерконнекту. Даже по предварительным цифрам, опубликованным NVIDIA, речь идёт о 370 очках SPECrate2017_int_base для одного кристалла Grace и 740 очках для 144-ядерной сборки из двух кристаллов — и это с использованием обычного компилятора GCC без тонких платформенных оптимизаций. Последняя цифра существенно выше результатов, показанных 128-ядерными Alibaba T-Head Yitian 710, также использующим архитектуру Arm v9, и 64-ядерными AMD EPYC 7773X.
15.08.2022 [15:15], Сергей Карасёв
Капитализация китайского разработчика HPC-чипов Hygon превысила $20 млрдКитайская компания Hygon Information Technology, разработчик процессоров, осуществила первичное публичное размещение акций (IPO) на Шанхайской фондовой бирже. Стоимость ценных бумаг достигла ¥70 (приблизительно $10,34), что на 94 % больше цены начального предложения в ¥36 ($5,32). Hygon Information Technology, тесно связанная с одним из крупных китайских IT-вендоров, была основана в 2014 году. Она специализируется на создании чипов с архитектурой х86, а также ускорителей (DCU). CPU и DCU компании в настоящее время используются только в персональных компьютерах и серверах китайского производства, в которых особое внимание уделяется информационной безопасности и стоимости владения. 
Источник изображения: Hygon В активе компании имеются серверные чипы Hygon Dhyana, клоны первого поколения EPYC. Однако без сопровождения со стороны AMD, разрыв с которой произошёл в 2019 году из-за санкций США, как-либо заметно улучшить их она вряд ли сможет. Впрочем, ранее Hygon и объявляла, что планирует перевести эти чипы на 7-нм техпроцесс Samsung или TSMC. Нужно отметить, что Sugon намеревалась использовать процессоры Hygon Dhyana и ускорители DCU для создания суперкомпьютера экзафлопсного класса, который должен был составить компанию OceanLight и Tianhe-3. Однако в сложившейся ситуации этот проект оказался под угрозой срыва: пока окончательные сроки создания системы не называются. Так или иначе, но процедура размещения акций Hygon на Шанхайской фондовой бирже прошла с большим успехом: капитализация компании оценена в ¥139,6 млрд ($20,7 млрд). При этом выручка по итогам прошлого года составила 2,3 млрд юаней, из которых почти 70 % тратится на исследования и разработки.
10.08.2022 [22:05], Владимир Мироненко
На пути к Aurora: запущен «тренировочный» суперкомпьютер PolarisАргоннская национальная лаборатория (ANL) Министерства энергетики США объявила о доступности суперкомпьютера Polaris, ранний вариант которого занял 14-е место в последней версии списка TOP500. Он будет использоваться для проведения научных исследований и в качестве испытательного стенда для 2-Эфлопс суперкомпьютера Aurora, запуск которой намечен на ближайшие месяцы. Правда, аппаратно Aurora и Polaris отличаются. Созданная HPE система Polaris состоит из 560 узлов Apollo 6500, каждый из которых оснащён процессором AMD EPYC Milan, четырьмя ускорителями NVIDIA A100 (40 Гбайт) и 512 Гбайт DDR4-памяти. Эти узлы объединены в сеть интерконнектом HPE Slingshot 10 (осенью он будет обновлен до Slingshot 11) и подключены к сдвоенному 100-Пбайт Lustre-хранилищу (Grand и Eagle). Заявленная пиковая производительность должна составить 44 Пфлопс. «Polaris примерно в четыре раза быстрее нашего суперкомпьютера Theta, что делает его самым мощным компьютером в Аргонне на сегодняшний день», — отметил Майкл Папка (Michael Papka), директор Argonne Leadership Computing Facility (ALCF). Он добавил, что возможности Polaris позволят пользователям выполнять моделирование, анализ данных и ИИ-задачи с такими масштабом и скоростью, которые были невозможны с предыдущими вычислительными системами. 
Фото: ANL Помимо работы над подготовкой к запуску Aurora, суперкомпьютер Polaris будет обслуживать внутренние потребности лаборатории, например, работу с комплексом Advanced Photon Source (APS) X-ray. «Благодаря тесной интеграции суперкомпьютеров ALCF с APS, CNM и другими экспериментальными установками мы можем помочь ускорить проведение анализа данных и предоставить информацию, которая позволит исследователям управлять своими экспериментами в режиме реального времени», — заявил Майкл Папка.
09.08.2022 [18:09], Игорь Осколков
Китайская компания Biren представила ИИ-ускоритель BR100, который обгоняет по производительности NVIDIA A100Шанхайская компания Biren Technology, основанная в 2019 году и уже получившая более $280 млн инвестиций, официально представила серию ускорителей BR100, которые способные потягаться с актуальными решениями от западных IT-гигантов. Утверждается, что это первое изделие подобного класса, созданное в Поднебесной. Компания уже подписала соглашение о сотрудничестве с ведущим производителем серверов Inspur. Новинка содержит 77 млрд транзисторов, использует чиплетную компоновку, изготавливается по 7-нм техпроцессу на TSMC и имеет 2.5D-упаковку CoWoS. Для сравнения — грядущие NVIDIA H100 имеют такую же упаковку, но включают 80 млрд транзисторов и изготавливаются по более современному техпроцессу TSMC N4. При этом BR100 примерно вдвое производительнее 7-нм NVIDIA A100 и примерно вдвое же медленнее H100. Впрочем, Biren приводит только данные о вычислениях пониженной точности, да и в целом говорит о том, что новинка предназначена в первую очередь для ИИ-нагрузок. 
Изображения: Biren В серию входят два решения: BR100 и BR104. Оба варианта оснащаются интерфейсом PCIe 5.0 x16 с поддержкой CXL. Первый вариант имеет OAM-исполнение с TDP на уровне 550 Вт. Он позволяет объединить до восьми ускорителей на UBB-плате, связав их между собой фирменным интерконнектом BLink (512 Гбайт/с) по схеме каждый-с-каждым. BR100 полагается 300 Мбайт кеш-памяти и 64 Гбайт HBM2e (4096 бит, 1,64 Тбайт/c). 
BR100 Также он способен одновременно кодировать до 64 потоков FullHD@30 HEVC/H.264, а декодировать — до 512. Кроме того, доступно создание до 8 аппаратно изолированных инстансов Secure Virtual Instance (SVI) по аналогии с NVIDIA MIG. Заявленная производительность составляет 256 Тфлопс для FP32-вычислений, 512 Тфлопс для TF32+ (по-видимому, подразумевается некая совместимость с фирменным форматом NVIDIA TF32), 1024 Тфлопс для BF16 и, наконец, 2048 Топс для INT8. 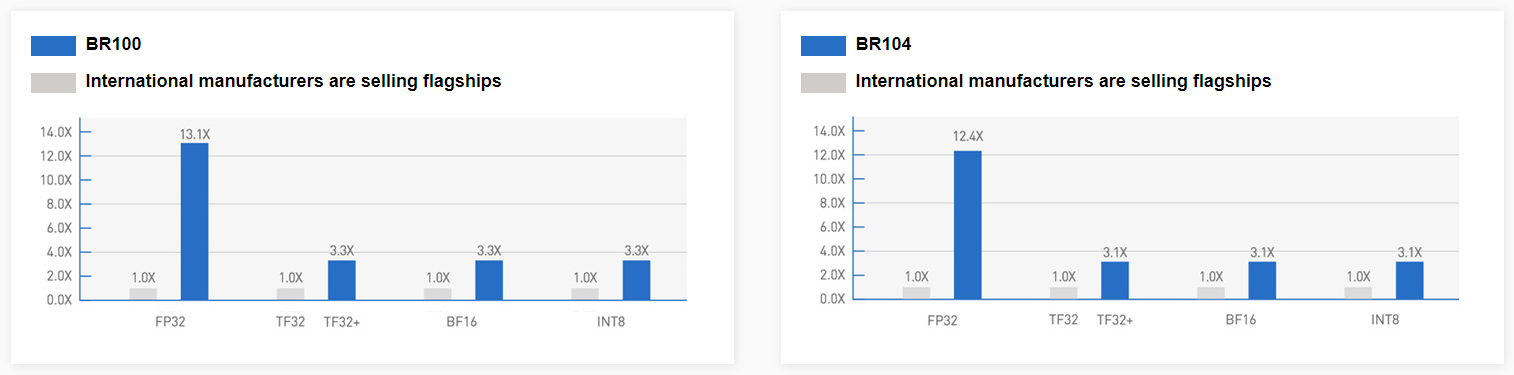 
BR104 BR104 представляет более традиционную FHFL-карту с TDP на уровне 300 Вт. По производительности она ровно вдвое медленнее старшей версии BR100, способна обрабатывать вдвое меньшее количество видеопотоков и предлагает только до 4 SVI-инстансов. BR104 имеет 150 Мбайт кеш-памяти, 32 Гбайт HBM2e (2048 бит, 819 Гбайт/c) и три 192-Гбайт/с интерфейса BLink. Для работы с ускорителями компания предлагает собственную программную платформу BIRENSUPA, совместимую с популярными фреймворками PyTorch, TensorFlow и PaddlePaddle. |
|

