Материалы по тегу: 24
|
20.11.2024 [10:56], Сергей Карасёв
Microsoft представила инстансы Azure HBv5 на основе уникальных чипов AMD EPYC 9V64H с памятью HBM3Компания Microsoft на ежегодной конференции Ignite для разработчиков, IT-специалистов и партнёров анонсировала облачные инстансы Azure HBv5 для HPC-задач, которые предъявляют наиболее высокие требования к пропускной способности памяти. Новые виртуальные машины оптимизированы для таких приложений, как вычислительная гидродинамика, автомобильное и аэрокосмическое моделирование, прогнозирование погоды, исследования в области энергетики, автоматизированное проектирование и пр. Особенность Azure HBv5 заключается в использовании уникальных процессоров AMD EPYC 9V64H (поколения Genoa). Эти чипы насчитывают 88 вычислительных ядер Zen4, тактовая частота которых достигает 4 ГГц. Ближайшим родственником является изделие EPYC 9634, которое содержит 84 ядра (168 потоков) и функционирует на частоте до 3,7 ГГц. По данным ресурса ComputerBase.de, чип EPYC 9V64H также фигурирует под именем Instinct MI300C: по сути, это процессор EPYC, дополненный памятью HBM3. При этом клиентам предоставляется возможность кастомизации характеристик. Отметим, что ранее x86-процессоры с набортной памятью HBM2e были доступны в серии Intel Max (Xeon поколения Sapphire Rapids). Каждый инстанс Azure HBv5 объединяет четыре процессора EPYC 9V64H, что в сумме даёт 352 ядра. Система предоставляет доступ к 450 Гбайт памяти HBM3, пропускная способность которой достигает 6,9 Тбайт/с. Задействован интерконнект NVIDIA Quantum-2 InfiniBand со скоростью передачи данных до 200 Гбит/с в расчёте на CPU. 
Источник изображений: Microsoft Применены сетевые адаптеры Azure Boost NIC второго поколения, благодаря которым пропускная способность сети Azure Accelerated Networking находится на уровне 160 Гбит/с. Для локального хранилища на основе NVMe SSD заявлена скорость чтения информации до 50 Гбайт/с и скорость записи до 30 Гбайт/с. 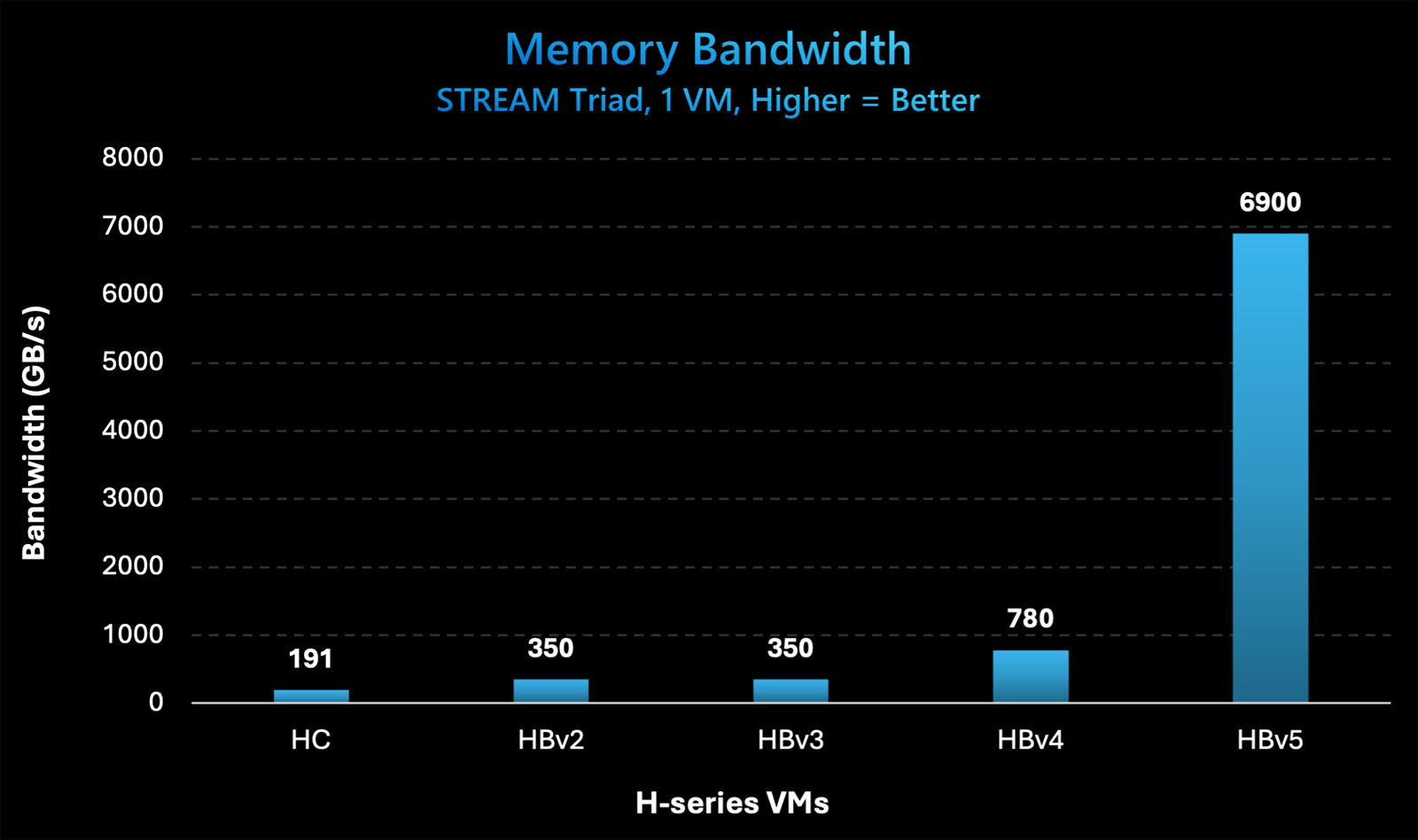 Отмечается, что по показателю пропускной способности памяти виртуальные машины Azure HBv5 примерно в 8 раз превосходят новейшие альтернативы bare-metal и cloud, в 20 раз опережают инстансы Azure HBv3 и Azure HBv2 (на базе EPYC Milan-X и EPYC Rome) и в 35 раз обходят HPC-серверы возрастом 4–5 лет, жизненный цикл которых приближается к завершению. Машины Azure HBv5 станут доступны в I половине 2025 года.
19.11.2024 [23:28], Алексей Степин
HPE обновила HPC-портфолио: узлы Cray EX, СХД E2000, ИИ-серверы ProLiant XD и 400G-интерконнект Slingshot
400gbe
amd
epyc
gb200
h200
habana
hardware
hpc
hpe
intel
mi300
nvidia
sc24
turin
ии
интерконнект
суперкомпьютер
схд
Компания HPE анонсировала обновление модельного ряда HPC-систем HPE Cray Supercomputing EX, а также представила новые модели серверов из серии Proliant. По словам компании, новые HPC-решения предназначены в первую очередь для научно-исследовательских институтов, работающих над решением ресурсоёмких задач. 
Источник изображений: HPE Обновление касается всех компонентов HPE Cray Supercomputing EX. Открывают список новые процессорные модули HPE Cray Supercomputing EX4252 Gen 2 Compute Blade. В их основе лежит пятое поколение серверных процессоров AMD EPYС Turin, которое на сегодняшний день является самым высокоплотным x86-решениями. Новые модули позволят разместить до 98304 ядер в одном шкафу. Отчасти это также заслуга фирменной системы прямого жидкостного охлаждения. Она охватывает все части суперкомпьютера, включая СХД и сетевые коммутаторы. Начало поставок узлов намечено на весну 2025 года. 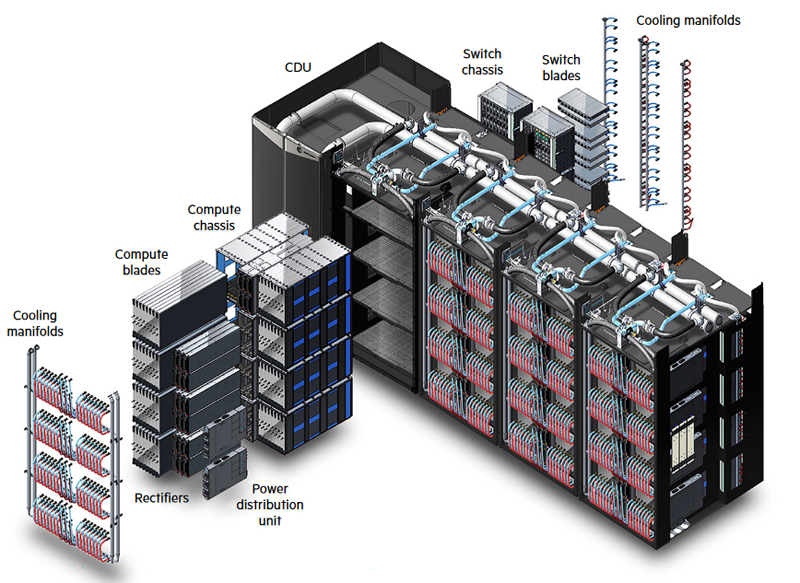 Процессорные «лезвия» дополнены новыми GPU-модулями HPE Cray Supercomputing EX154n Accelerator Blade, позволяющими разместить в одном шкафу до 224 ускорителей NVIDIA Blackwell. Речь идёт о новейших сборках NVIDIA GB200 NVL4 Superchip. Этот компонент появится на рынке позднее — HPE говорит о конце 2025 года. Обновление коснулось и управляющего ПО HPE Cray Supercomputing User Services Software, получившего новые возможности для пользовательской оптимизации вычислений, в том числе путём управления энергопотреблением. Апдейт получит и фирменный интерконнект HPE Slingshot, который «дорастёт» до 400 Гбит/с, т.е. станет вдвое быстрее нынешнего поколения Slingshot. Пропускная способность коммутаторов составит 51,2 Тбит/c. В новом поколении будут реализованы функции автоматического устранения сетевых заторов и адаптивноой маршрутизации с минимальной латентностью. Дебютирует HPE Slingshot interconnect 400 осенью 2024 года.  Ещё одна новинка — СХД HPE Cray Supercomputing Storage Systems E2000, специально разработанная для применения в суперкомпьютерах HPE Cray. В сравнении с предыдущим поколением, новая система должна обеспечить более чем двукратный прирост производительности: с 85 и 65 Гбайт/с до 190 и 140 Гбайт/с при чтении и записи соответственно. В основе новой СХД будет использована ФС Lustre. Появится Supercomputing Storage Systems E2000 уже в начале 2025 года.  Что касается новинок из серии Proliant, то они, в отличие от вышеупомянутых решений HPE Cray, нацелены на рынок обычных ИИ-систем. 5U-сервер HPE ProLiant Compute XD680 с воздушным охлаждением представляет собой решение с оптимальным соотношением производительности к цене, рассчитанное как на обучение ИИ-моделей и их тюнинг, так и на инференс. Он оснащён восемью ускорителями Intel Gaudi3 и двумя процессорами Intel Xeon Emerald Rapids. Новинка поступит на рынок в декабре текущего года.  Более производительный HPE ProLiant Compute XD685 всё так же выполнен в корпусе высотой 5U, но рассчитан на жидкостное охлаждение. Он будет оснащаться восемью ускорителями NVIDIA H200 в формате SXM, либо более новыми решениями Blackwell, но последняя конфигурация будет доступна не ранее 2025 года, когда ускорители поступят на рынок. Уже доступен ранее анонсированный вариант с восемью ускорителями AMD Instinict MI325X и процессорами AMD EPYC Turin.
19.11.2024 [17:30], Сергей Карасёв
1,742 Эфлопс: El Capitan стал самым мощным в мире суперкомпьютером рейтинга TOP500Ливерморская национальная лаборатория им. Э. Лоуренса (LLNL) Министерства энергетики США (DOE), Администрация по национальной ядерной безопасности США (NNSA), компании AMD и HPE официально представили El Capitan — самый производительный в мире суперкомпьютер. Эта машина возглавила ноябрьский рейтинг мощнейших вычислительных систем TOP500. Комплекс El Capitan создан специалистами HPE Cray. Суперкомпьютер обладает FP64-быстродействием 1,742 Эфлопс в тесте Linpack (HPL), тогда как пиковый теоретический показатель достигает 2,746 Эфлопс. Прежний лидер TOP500 — система Frontier — с производительностью 1,353 Эфлопс теперь находится на втором месте рейтинга. Машина Aurora, так и не прибавившая в производительности, хотя и заявленная когда-то как 2-Эфлопс система, занимает теперь третье место. В основу El Capitan легла платформа HPE Cray Shasta. Используется гибридная архитектура AMD с APU Instinct MI300A: изделие содержит 24 ядра Zen 4 общего назначения, блоки CDNA 3 и 128 Гбайт памяти HBM3. В общей сложности в составе суперкомпьютера объединены 11 136 узлов, каждый из которых несёт на борту четыре экземпляра Instinct MI300A. Применён интерконнект HPE Slingshot-11 с пропускной способностью 200 Гбит/с. Система включает узлы Rabbit, которые формируют дезагрегированное NVMe-хранилище с прямым PCIe-подключением к вычислительным узлам. 
Источник изображений: LLNL Суммарное количество ядер CPU и GPU в составе El Capitan достигает 11 039 616, объём памяти — 5,4375 Пбайт. За отвод тепла отвечает система прямого жидкостного охлаждения HPE. Заявленная энергетическая эффективность составляет 58,89 Гфлопс/Вт: с таким показателем машина оказалась на 18-м месте в списке «зелёных» суперкомпьютеров GREEN500, но с учётом масштаба и общего энергопотребления 29,58 МВт — это хороший показатель. Система охлаждения HPC-объекта использует 28 тыс. т воды. Отмечается, что El Capitan станет главным вычислительным ресурсом для Tri-lab — группы, в которую вместе с LLNL входят Сандийские национальные лаборатории (SNL) и Лос-Аламосская национальная лаборатория (LANL). Использовать мощности нового суперкомпьютера планируется для обеспечения национальной безопасности и решения сложных задач, связанных с ядерным оружием. В частности, El Capitan обеспечит беспрецедентные возможности моделирования и имитации, необходимые для Программы управления ядерными запасами NNSA. Кроме того, НРС-комплекс поможет в модернизации и создании нового оружия, такого как боеголовки W87-1 и W93, которые в настоящее время находятся на стадии разработки.  Отмечается также, что на 10-й позиции в рейтинге TOP500 оказался суперкомпьютер Tuolumne, также построенный в рамках проекта LLNL и NNSA. Фактически Tuolumne — это младший брат El Capitan: машина использует ту же архитектуру на базе Instinct MI300A, но обладает примерно на порядок меньшей FP64-производительностью 208,10 Пфлопс с пиковым значением 288,88 Пфлопс. Применять мощности Tuolumne планируется для «несекретных» задач, таких как исследования в области энергетической безопасности, изменений климата, вычислительной биологии, разработки лекарственных препаратов следующего поколения и пр. Стоит отметить, что Frontier — не единственная система, которая уступила пальму первенства более новым НРС-комплексам в ноябрьском рейтинге TOP500. Та же участь постигла самый мощный суперкомпьютер Европы LUMI, который опустился с пятого на восьмое место. На пятой позиции оказалась совершенно новая система HPC6, расположенная в центре нефтегазовой компании Eni в Феррера-Эрбоньоне (Италия). Её производительность достигает 477,9 Пфлопс при пиковом показателе 606,97 Пфлопс.
19.11.2024 [11:47], Сергей Карасёв
Esperanto и NEC займутся созданием HPC-решений на базе RISC-VСтартап Esperanto Technologies и корпорация NEC объявили о заключении соглашения о сотрудничестве в области НРС. Речь идёт о создании программных и аппаратных решений следующего поколения, использующих открытую архитектуру RISC-V. Напомним, Esperanto разрабатывает высокопроизводительные RISC-V-чипы для задач НРС и ИИ. Первым продуктом компании стало изделие ET-SoC-1, которое объединяет 1088 энергоэффективных ядер ET-Minion и четыре высокопроизводительных ядра ET-Maxion. Решение предназначено для инференса рекомендательных систем, в том числе на периферии. В августе 2023 года стало известно о подготовке чипа ET-SoC-2 с высокопроизводительными ядрами RISC-V с векторными расширениями. В рамках соглашения о сотрудничестве, как отмечается, будут объединены опыт и экспертизы NEC в области проектирования суперкомпьютеров и создания специализированного софта для HPC-задач с технологиями Esperanto в сфере высокопроизводительных энергоэффективных чипов на основе набора инструкций RISC-V. При этом упоминаются достижения NEC по направлению векторных процессоров: японская компания проектировала уникальные изделия SX-Aurora, но их разработка была остановлена в 2023 году. 
Источник изображения: Esperanto «Используя глубокий опыт и экспертные знания NEC в области HPC, а также открытый набор инструкций RISC-V в сочетании с вычислительной технологией Esperanto, мы сможем разрабатывать масштабируемые и эффективные решения для ИИ и высокопроизводительных вычислений», — отметил Арт Свифт (Art Swift), президент и генеральный директор Esperanto.
18.11.2024 [21:30], Сергей Карасёв
Счетверённые H200 NVL и 5,5-кВт GB200 NVL4: NVIDIA представила новые ИИ-ускорителиКомпания NVIDIA анонсировала ускоритель H200 NVL, выполненный в виде двухслотовой карты расширения PCIe. Изделие, как утверждается, ориентировано на гибко конфигурируемые корпоративные системы с воздушным охлаждением для задач ИИ и НРС. Как и SXM-вариант NVIDIA H200, представленный ускоритель получил 141 Гбайт памяти HBM3e с пропускной способностью 4,8 Тбайт/с. При этом максимальный показатель TDP снижен с 700 до 600 Вт. Четыре карты могут быть объединены интерконнкетом NVIDIA NVLink с пропускной способностью до 900 Гбайт/с в расчёте на GPU. При этом к хост-системе ускорители подключаются посредством PCIe 5.0 x16. В один сервер можно установить две такие связки, что в сумме даст восемь ускорителей H200 NVL и 1126 Гбайт памяти HBM3e, что весьма существенно для рабочих нагрузок инференса. Заявленная производительность FP8 у карты H200 NVL достигает 3,34 Пфлопс против примерно 4 Пфлопс у SXM-версии. Быстродействие FP32 и FP64 равно соответственно 60 и 30 Тфлопс. Производительность INT8 — до 3,34 Пфлопс. Вместе с картами в комплект входит лицензия на программную платформа NVIDIA AI Enterprise. 
Источник изображения: NVIDIA Кроме того, NVIDIA анонсировала ускорители GB200 NVL4 с жидкостным охлаждением. Они включает два суперчипа Grace-Backwell, что даёт два 72-ядерных процессора Grace и четыре ускорителя B100. Объём памяти LPDDR5X ECC составляет 960 Гбайт, памяти HBM3e — 768 Гбайт. Задействован интерконнект NVlink-C2C с пропускной способностью до 900 Гбайт/с, при этом всем шесть чипов CPU-GPU находятся в одном домене. 
Источник изображения: NVIDIA Система GB200 NVL4 наделена двумя коннекторами M.2 22110/2280 для SSD с интерфейсом PCIe 5.0, восемью слотами для NVMe-накопителей E1.S (PCIe 5.0), шестью интерфейсами для карт FHFL PCIe 5.0 x16, портом USB, сетевым разъёмом RJ45 (IPMI) и интерфейсом Mini-DisplayPort. Устройство выполнено в форм-факторе 2U с размерами 440 × 88 × 900 мм, а его масса составляет 45 кг. TDP настраиваемый — от 2,75 кВт до 5,5 кВт.
18.11.2024 [13:38], Руслан Авдеев
Foxlink запустила мощнейший на Тайване суперкомпьютер для малого и среднего бизнесаFoxlink Group (Cheng Uei Precision Industry) открыла крупнейший на Тайване суперкомпьютерный центр Ubilink (Ubilink.AI). По данным DigiTimes, центр предназначен для обслуживания предприятий малого и среднего бизнеса (SME), которые не могут позволить себе собственных вычислительных мощностей. Хотя основной деятельностью Foxlink является производство разъёмов, компания расширяет бизнес, осваивая решения для управления электропитанием и коммуникаций, а также выпуск энергетических модулей. Центр Ubilink создан дочерней Shinfox Energy совместно с Asustek Computer и японской Ubitus, занимающейся предоставлением облачных услуг. В Ubitus сообщили, что инфраструктура Ubilink включает 128 серверов Asus, 1024 ускорителя NVIDIA H100 и интерконнект NVIDIA Quantum-2 InfiniBand. Конфигурация обеспечивает до 45,82 Пфлопс (FP64) — система занимает 31-е место в рейтинге TOP500. В будущем станут применять и более современные B100 и B200 — когда те будут доступны. Ожидается, что в 2025 году суммарно будет установлено 10 240 ускорителей H100, B100 и B200. Представители местных властей уже заявили, что Ubilink существенно улучшит позиции Тайваня на рынке ИИ-вычислений, на котором территория сегодня занимает 26-е место. В Asustek добавляют, что достигнутая производительность в 45,82 Пфлопс заметно превышает плановые 40 Пфлопс. Кроме того, центр имеет PUE на уровне 1,2 — ранее ожидалось, что удастся добиться энергоэффективности лишь на уровне 1,38. Благодаря использованию опыта Shinfox Energy в области возобновляемой энергетики, Ubilink стал первым в Азии суперкомпьютерным центром, использующим «зелёные» источники энергии — клиенты могут воспользоваться вычислениями без существенного ущерба окружающей среде. 
Источник изображения: UBITUS Предполагается, что Ubilink компенсирует отсутствие мощностей для местных малых и средних компаний, не имеющих доступа к значительным вычислительным ресурсам. Предлагая доступные вычислительные мощности, центр позволяет таким бизнесам расширить свои портфели предложений и конкурировать даже на мировом уровне. Суперкомпьютер уже востребован местными разработчиками чипов, компаний, занимающихся их упаковкой и тестированием, биотехнологическими бизнесами, а также исследовательскими институтами различной направленности. Из-за высокого спроса Foxlink уже рассматривает вторую и третью фазы расширения проекта.
15.11.2024 [10:31], Сергей Карасёв
Eviden представила интерконнект BullSequana eXascale третьего поколения для ИИ-системКомпания Eviden (дочерняя структура Atos) анонсировала BullSequana eXascale Interconnect (BXI v3) — интерконнект третьего поколения, специально разработанный для рабочих нагрузок ИИ и HPC. Технология станет доступа на рынке во II половине 2025 года. Отмечается, что существующие высокоскоростные сетевые решения недостаточно эффективны, поскольку не устраняют критическое узкое место, известное как «сетевая стена». По заявлениям Eviden, зачастую при крупномасштабном обучении ИИ компании наращивают количество ускорителей, однако на самом деле ограничивающим фактором является интерконнект. Хотя поставщики сетевых решений продолжают удваивать пропускную способность каждые несколько лет, этого недостаточно для решения проблемы. В результате, до 70 % времени GPU простаивают, ожидая получения данных из-за задержек, утверждает Eviden. Технология BXI v3 призвана устранить этот недостаток. 
Источник изображений: Eviden Новый интерконнект использует стандарт Ethernet в качестве базового протокола связи. При этом реализованы функции, которые обычно характерны для масштабируемых сетей высокого класса, таких как Infiniband. Отмечается, что BXI v3 обеспечивает низкие задержки (менее 200 нс от порта к порту), высокую пропускную способность, упорядоченную (in order) доставку пакетов, расширенное управление перегрузками и масштабируемость. Технология BXI v3 ляжет в основу интеллектуального сетевого адаптера (Smart NIC) нового поколения, который поможет снизить влияние задержек сети на GPU и CPU. При использовании такого решения ускоритель ИИ выгружает данные на сетевой адаптер и сразу же переходит к другим задачам, что устраняет неэффективность, связанную с простоями. Подчёркивается, что протокол BXI v3 интегрируется непосредственно в Smart NIC, благодаря чему оборудование работает сразу после установки, а в приложения не требуется вносить какие-либо изменения.  Кроме того, новая технология предоставляет ряд дополнительных функций, ориентированных на повышение производительности путём оптимизации системных операций и обработки данных. В частности, BXI v3 обеспечивает прозрачную трансляцию виртуальных адресов в физические, что позволяет приложениям напрямую отправлять запросы в SmartNIC с использованием виртуальных адресов без необходимости системных вызовов. Такой подход повышает эффективность, обеспечивая бесперебойное управление памятью при сохранении высокой производительности. Технология BXI v3 также позволяет регистрировать до 32 млн приёмных буферов, которые SmartNIC выбирает с помощью ключей сопоставления на основе атрибутов сообщения. Благодаря этому уменьшается нагрузка на CPU, что повышает общую эффективность системы. Кроме того, сетевой адаптер способен выполнять математические атомарные операции, что дополнительно высвобождает ресурсы CPU. Впрочем, деталей пока мало, зато говорится об участии в консорциуме Ultra Ethernet (UEC) и партнёрстве с AMD.
22.06.2024 [15:01], Сергей Карасёв
Samsung случайно упомянула о разработке RISC-V чипа для ИИ-задачВ ходе конференции ISC 2024 компания Samsung, по сообщению HPC Wire, намекнула на разработку некоего чипа на открытой архитектуре RISC-V. Предполагается, что это изделие будет использоваться при решении задач, связанных с ИИ и НРС. На одном из продемонстрированных южнокорейским производителем слайдов упоминается изделие CPU/ИИ-ускоритель на базе RISC-V («RISC-V CPU/AI accelerator from Samsung»). О чём именно идёт речь, сказать трудно. Возможно, Samsung проектирует процессор RISC-V с нейромодулем для ускорения ИИ-операций. С другой стороны, это может быть самостоятельный чип, предназначенный для работы в связке с ИИ-ускорителем. Например, Google уже использует RISC-V процессоры SiFive вместе со своим TPU. 
Источник изображения: Samsung / HPC Wire Отмечается, что слайд был показан на сессии ISC 2024, посвящённой инициативе UXL Foundation (Unified Acceleration Foundation). Целью данного проекта является создание универсального открытого ПО, которое позволит разработчикам ИИ-решений отказаться от CUDA и использовать ускорители других производителей. В состав UXL входят Intel, Qualcomm, Samsung, Arm и Google. На слайде также упоминается модель параллельного программирования в контексте вычислений в памяти. Данная концепция позволяет повысить производительность, в том числе при обучении ИИ-моделей. Ранее Samsung и AMD представили экспериментальный ИИ-суперкомпьютер, скрестив «вычислительную» память HBM-PIM и ускорители Instinct MI100. Кроме того, Samsung работает над похожей концепцией PNM (processing-near-memory), которая будет использоваться в модулях памяти CXL. Samsung также работает над собственными ИИ-ускорителями Mach-1, которые уже заказала ведущая южнокорейская интернет-компания Naver. По заявлениям Samsung, изделие Mach-1 позволяет выполнять инференс больших языковых моделей (LLM) даже с маломощной памятью. Таким образом, есть вероятность, что новый RISC-V-процессор Samsung сможет работать в связке с ИИ-ускорителями компании для максимизации производительности.
21.05.2024 [16:36], Руслан Авдеев
Core42 и Cerebras построят в Техасе ИИ-суперкомпьютер с 173 млн ядерБазирующаяся в ОАЭ компания Core42 занялась строительством ИИ-суперкомпьютера, в эксплуатацию объект должны ввести до конца текущего года. HPC Wire сообщает, что компьютер Condor Galaxy 3 (CG-3) получит 192 узла с 5-нм мегачипами Cerebras WSE-3 и 172,8 млн ИИ-ядер. WSE-3 в 50 раз крупнее актуальных ИИ-ускорителей NVIDIA и, конечно, гораздо производительнее. По данным Core42, развёртывание CG-3 в Далласе (Техас) начнётся в июне и завершится в сентябре–октябре. Core42 уже считается значимым игроком на рынке ЦОД, HPC- и ИИ-систем. Машины G42 уже попадали в TOP500 — это системы Artemis (NVIDIA) и POD3 (Huawei). Последняя покинула рейтинг в 2023 году. Суперкомпьютер CG-3, как теперь сообщается, получит 192 узла CS-3. Каждый узел с чипом WSE-3 обеспечивает до 125 Пфлопс (FP16 с разрежением), так что общая производительность Condor Galaxy 3 составит 24 Эфлопс. Всего же Cerebras намеревается построить девять суперкомпьютеров семейства Condor Galaxy. Машины GC-1 и GC-2 на базе чипов WSE-2 также созданы при участии G42. 
Источник изображения: Cerebras Core42 появилась в 2023 году в результате слияния G42 Cloud и G42 Inception AI. Родительская компания G42, основанная в 2018 году, также сотрудничает с NVIDIA, AMD, OpenAI и другими компаниями. G42 не так давно попала под пристальное внимание американских властей. Её подозревали в том, что она помогала Китаю получать доступ к новейшим ускорителям NVIDIA и другому ИИ-оборудованию американских компаний. В результате, как считается, она была вынуждена отказать от сотрудничества с Huawei. Также сообщалось, что G42 заключила с американским правительством взаимовыгодное секретное соглашение — компания обязалась лишить КНР доступа к ускорителям, а в ответ ей самой разрешали сохранить доступ к продукции NVIDIA. Не исключено, что были оговорены и иные пункты. По некоторым данным, именно в то же время, когда было заключено соглашение с руководством США, Microsoft инвестировала в G42 около $1,5 млрд.
13.05.2024 [17:39], Игорь Осколков
В TOP500 дебютировали первые суперкомпьютеры на базе суперчипов NVIDIA Grace Hopper и AMD Instinct MI300AОчередной рейтинг TOP500 теперь включает сразу две экзафлопсных системы. Суперкомпьютер Frontier, занимающий в рейтинге первое место с весны 2022 года, так и остался лидером, чуть прибавив в производительности за последние полгода — 1,206 Эфлопс на практике и 1,715 Эфлопс в теории. Aurora, дебютировавшая в ноябрьском TOP500, стала практически вдвое производительнее в бенчмарках и едва-едва преодолела экзафлопсный барьер (1,012 Эфлопс). Пиковая теоретическая FP64-производительность Aurora составляет 1,98 Эфлопс, однако формально система всё ещё не принята, а текущий результат был получен на 87 % доступных узлов (9234 шт). Всего же машина включает 166 стоек, 10624 узлов, 21248 процессоров Intel Xeon Max (Sapphire Rapids с HBM) и 63744 ускорителя Intel Data Center GPU Max. При этом энергопотребление её составляет почти 38,7 МВт против 22,7 МВт у Frontier. 
Источник изображения: Intel Совсем скоро должен заработать старший брат Frontier — 2-Эфлопс суперкомпьютер El Capitan на базе AMD Instinct MI300. Так что времени у Intel на то, чтобы тоже преодолеть этот барьер, не так уж много. Пока компания оправдывается тем, что, например, в бенчмарке HPCG, который в отличие от HPL более корректно отображает производительность машины в реальных задачах, Aurora показала 5,6 Пфлопс, задействовав лишь 39 % имеющихся узлов. Вот только у Frontier и Fugaku этот показатель составляет 14 и 16 Пфлопс соответственно, причём японскую систему в HPCG уже четыре года никто обогнать не может. 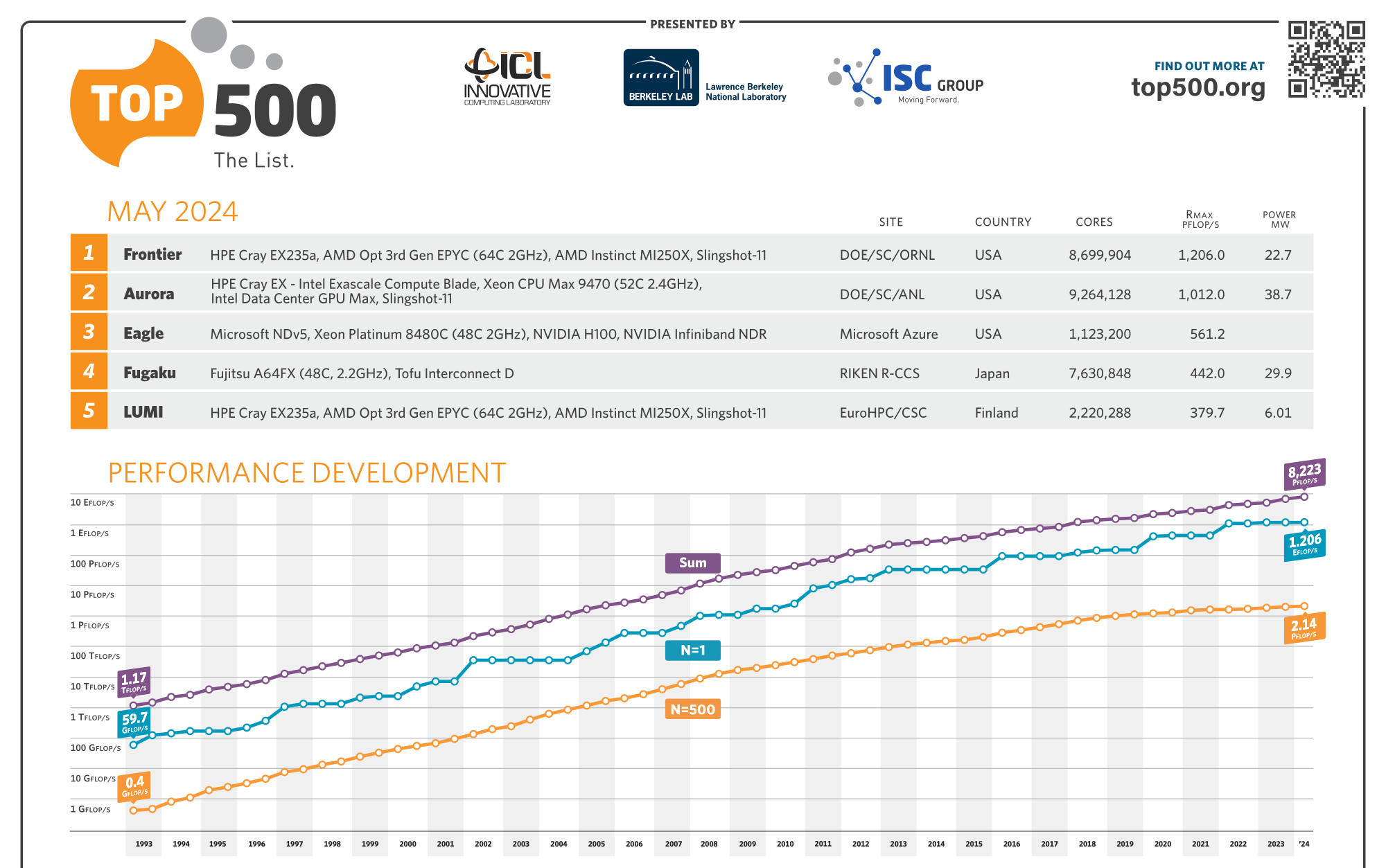
Источник изображения: TOP500 Наконец, Intel сообщила, что Aurora (точнее, 89 % узлов) лидирует в ИИ-бенчмарке HPL-MxP (HPL-AI), где показала 10,6 Эфлопс на вычислениях смешанной точности. Обновлённый рейтинг пока не выложен, но у Frontier в прошлом году результат был 9,95 Эфлопс. Как бы то ни было, Intel заявляет, что Aurora теперь является самым быстрым ИИ-суперкомпьютером для научных задач, который доступен открытом сообществу. NVIDIA, вероятно, поспорит с этим утверждением. 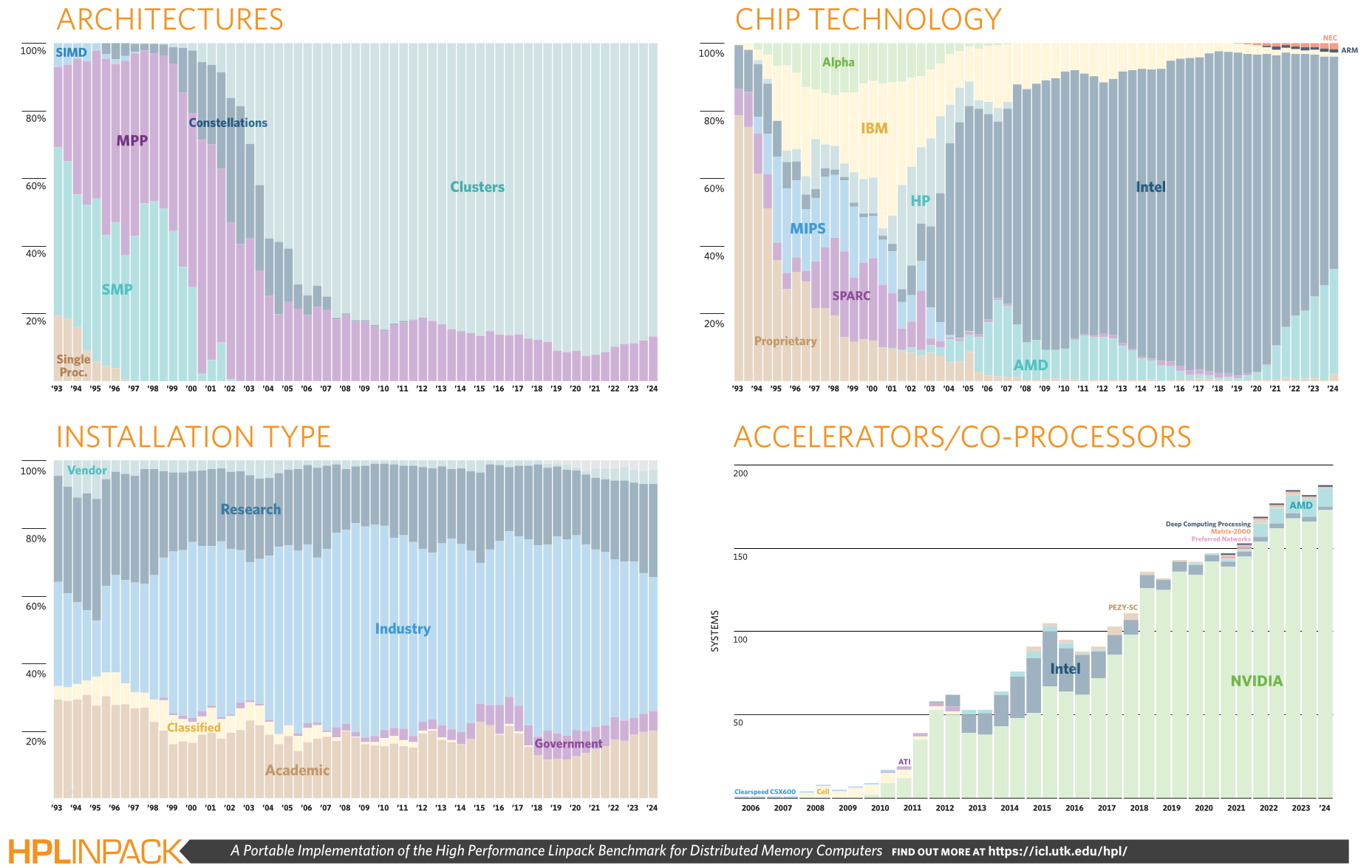
Источник изображения: TOP500 Любопытно, что у Frontier за прошедшие полгода конфигурация не изменилась, только чуть выросло энергопотребление. У системы Microsoft Azure Eagle, которая по-прежнему занимает третье место в TOP500, неожиданно стало вдвое больше ядер, но на производительности это никак не отразилось. MareNostrum 5 ACC чуть похудел в ядрах, но в то же время нарастил производительность. 
Источник изображения: CSCS Ну а главное изменение в десятке лидеров TOP500 — это появление на шестом месте швейцарского суперкомпьютера Alps, анонсированного ещё три года назад. Машина включает 2688 узлов с «фантастической четвёркой» Quad GH200 от NVIDIA, которые выдают 270 Пфлопс в FP64 и потребляют всего 5,19 МВт. На самом деле суперкомпьютер включает и другие кластеры на базе AMD EPYC, MI300A и MI250X, а также NVIDIA A100. Главное тут не чистая производительность, а энергоэффективность, что для Швейцарии весьма актуально. Собственно говоря, ключевые изменения есть именно в Green500 — первые три места (и половину первой десятки вообще) занимают тестовые системы на базе NVIDIA Grace Hopper. Наиболее энергоэффективной является машина JEDI (JUPITER Exascale Development Instrument), которая является тестовой платформой для первого в Европе экзафлопсного суперкомпьютера Jupiter. Она предлагает 72,733 Гфлопс/Вт, тогда как тестовая платформ Frontier TDS — 62,684 Гфлопс/Вт. Однако насколько хорошим будет масштабирование у новых платформ NVIDIA, покажет время. Например, у малой системы preAlps и полноценной Alps показатели энергоэффективности составляют 64,381 и 51,983 Гфлопс/Вт соответственно. 
Источник изображения: NVIDIA Всего же в TOP500 новых систем на базе Grace Hopper набралось семь штук (просто Grace нет), но их будет гораздо больше. На базе AMD EPYC Genoa построено 16 машин, на базе Intel Xeon Sapphire Rapids — 38. Есть даже один новый суперкомпьютер с Fujitsu A64FX (всего в списке таковых девять) — португальский Deucalion. Систем с AMD Instinct MI300A появилось сразу три, причём все они абсолютно одинаковые: Tuolumne, RZAdams и «кусочек» El Capitan. Они занимают в списке места 46, 47 и 48 и представляют собой фактически одну стойку с производительностью 19,65 Пфлопс (в пике 32,1 Пфлопс). Всего в нынешнем TOP500 есть 49 новых машин, часть из них даже не имеет имён. По количество установленных систем снова лидирует Lenovo (32,4 %), за которой следуют HPE (22,2 %) и Eviden (9,8 %). По суммарной производительности картина тоже прежняя, поскольку HPE опять в лидерах (36,1 %), а за ней идут Eviden (9,6 %) и Lenovo (7,4 %). И по количеству (33,8 %), и по общей мощности (53,6 %) суперкомпьютеров в списке лидируют США. Увы, Китай продолжает игнорировать TOP500. |
|

