Материалы по тегу: стойка
|
10.10.2025 [14:50], Руслан Авдеев
Не для себя стараемся: Microsoft развернула для OpenAI первый в мире ИИ-кластер на базе суперускорителей NVIDIA GB300 NVL72Microsoft представила первый в мире ИИ-кластер, использующий более 4,6 тыс. NVIDIA Blackwell Ultra в составе суперускорителей NVIDIA GB300 NVL72, объединённых интерконнектом Quantum-X800 InfiniBand. Этот кластер — лишь первый из многих. Компания развернёт сотни тысяч ускорителей Blackwell Ultra в ИИ ЦОД по всему миру. Благодаря им Microsoft намерена стать первой, поддерживающей обучение для моделей с сотнями триллионов параметров. Как сообщают в Microsoft, запуск в Microsoft Azure суперкластера NVIDIA GB300 NVL72 стал важным шагом в развитии передовых ИИ-технологий. Разработанная совместно с NVIDIA система представляет собой первый в мире масштабируемый ИИ-кластер на основе GB300, обеспечивающий вычислительные мощности, необходимые OpenAI для обслуживания моделей с триллионами параметров. Речь идёт о новом стандарте ускоренных вычислений, говорят компании. Новые инстансы Azure ND GB300 v6 оптимизированы для рассуждающих моделей, агентных систем и мультимодального генеративного ИИ. Каждая стойка GB300 NVL72 обслуживает 18 виртуальных машин, а сам суперускоритель с производительностью до 1,44 Эфлопс (FP4 Tensor Core) включает:

Источник изображения: Microsoft Создание передовой инфраструктуры требует переосмысления всех уровней системы, включая вычисления, память, системы охлаждения и питания, ЦОД в целом как единой структуры. Новая архитектура стоек обеспечивает высокую пропускную способность инференса при меньших задержках на крупных моделях, это позволяет агентным и мультимодальным ИИ-системам быть более масштабируемыми и эффективными, чем когда-либо, говорит компания. Для масштабирования за пределы стойки используется NVIDIA Quantum-X800 InfiniBand, что гарантирует обучения сверхбольших моделей с применением десятков тысяч ИИ-ускорителей с минимальными накладными расходами на их синхронизацию, что дополнительно повышает производительность. 
Источник изображения: Microsoft Передовые системы охлаждения Azure используют автономные теплообменники, чтобы свести к минимуму расход воды и поддерживать температурную стабильность для высокоплотных кластеров. Также продолжается разработка и внедрение новых моделей распределения питания, обеспечивающих высокую энергетическую плотность и динамический баланс нагрузок. Дополнительную помощь в оптимизации работы оказывает и модернизированное программное обеспечение. Ранее Microsoft обладала эксклюзивными правами на предоставление облачных сервисов компании OpenAI, но в январе 2025 года появилась новость, что ИИ-стартапу разрешили пользоваться и облаками других провайдеров, если у Microsoft не хватит собственных мощностей. Разногласия между компаниями продолжают нарастать. Формально первенство по создание кластера на базе GB300 NVL72 принадлежит CoreWeave, имеющей тесные отношения с NVIDIA и обслуживающей OpenAI — как напрямую, так и при посредничестве Microsoft.
09.09.2025 [17:50], Сергей Карасёв
Бескабельные серверы и стойки Softbank помогут роботам вытеснить людей из ЦОДКорпорация SoftBank объявила о разработке новой стойки для серверов без кабелей. Это поможет в организации обслуживания ЦОД при помощи специализированных роботов. Стойка упрощает выполнение таких задач, как установка и демонтаж модулей, замена компонентов в случае неисправности и проведение автоматизированных проверок. В современных ЦОД большое количество кабелей внутри серверных стоек является серьёзным препятствием для выполнения тех или иных работ с использованием роботов. Из-за плотной кабельной сети затрудняется точное определение и управление целевым оборудованием в стойке, что негативно отражается на возможностях автоматизации обслуживания. Для решения данной проблемы SoftBank разработала серверную стойку с «бескабельной конструкцией». 
Источник изображений: SoftBank Новинка имеет ширину 19″: она выполнена в соответствии со стандартом OCP ORv3 (Open Rack v3). Говорится о совместимости с системами жидкостного охлаждения. Стойка рассчитана на монтаж серверов общего назначения. Питание подаётся по общей шине на задней стороне стойки. В системе охлаждения используется «слепой разъём», упрощающий соединение магистралей СЖО. Для передачи данных служит оптический интерфейс. Таким образом, при установке серверы могут просто задвигаться в стойку без необходимости подключения кабелей.  В настоящее время SoftBank готовится к тестированию стоек в реальных условиях с использованием специализированных роботов для обслуживания. Проект является частью программы SoftBank по внедрению автоматизации в дата-центре для задач ИИ на острове Хоккайдо, открытие которого запланировано на 2026 финансовый год. Нужно отметить, что робототехнические комплексы для выполнения рутинных задач в ЦОД тестируют и многие другие компании. В их число входят Google, Digital Edge, Digital Realty, Scala Data Centers и Oracle. Правда, пока речь идёт в основном о патрулировании и выполнении некоторых простейших с точки зрения человека операций.
01.09.2025 [23:40], Руслан Авдеев
Meta✴ «растянула» суперускорители NVIDIA GB200 NVL36×2 на шесть стоек, чтобы обойтись воздушным охлаждениемДля того, чтобы развернуть в традиционных ЦОД с воздушным охлаждением современные высокоплотные стойки с ИИ-ускорителями, приходится идти на ухищрения. Один из вариантов предложила Meta✴, передаёт Wccftech. Хотя у Meta✴ есть собственный полноценный вариант суперускорителя NVIDIA GB200 NVL72 на базе ORv3-стоек Catalina (до 140 кВт) со встроенными БП и ИБП, компания также разработала также вариант, схожий с конфигурацией NVL36×2, от производства которого NVIDIA отказалась, посчитав его недостаточно эффективным. Ускоритель NVL36×2 задумывался как компромиссный вариант для ЦОД с воздушным охлаждением — одна стойка (плата Bianca, 72 × B200 и 36 × Grace) «растянута» на две. Meta✴ пошла несколько иным путём. Она точно так же использует две стойки, одна конфигурация узлов другая. Если в версии NVIDIA в состав одно узла входят один процессор Grace и два ускорителя B200, то у Meta✴ соотношение CPU к GPU уже 1:1. Все вместе они точно так же образуют один домен с 72 ускорителями, но объём памяти LPDDR5 в два раза больше — 34,6 Тбайт вместо 17,3 Тбайт. Эту пару «обрамляют» четыре стойки — по две с каждый стороны. Для охлаждения CPU и GPU по-прежнему используется СЖО, теплообменники которой находятся в боковых стойках и продуваются холодным воздухом ЦОД. 
Источник изображений: Meta✴ via Wccftech Это далеко не самая эффективная с точки зрения занимаемой площади конструкция, но в случае гиперскейлеров оплата в арендуемых дата-центрах нередко идёт за потребляемую энергию, а не пространство. В случае невозможности быстро переделать собственные ЦОД или получить площадку, поддерживающую высокоплотную энергоёмкую компоновоку стоек и готовую к использованию СЖО, это не самый плохой вариант. В конце 2022 года Meta✴ приостановила строительство около дюжины дата-центров для пересмотра их архитектуры и внедрения поддержки ИИ-стоек и СЖО. Первые ЦОД Meta✴, построенные по новому проекту, должны заработать в 2026 году, передаёт DataCenter Dynamics. 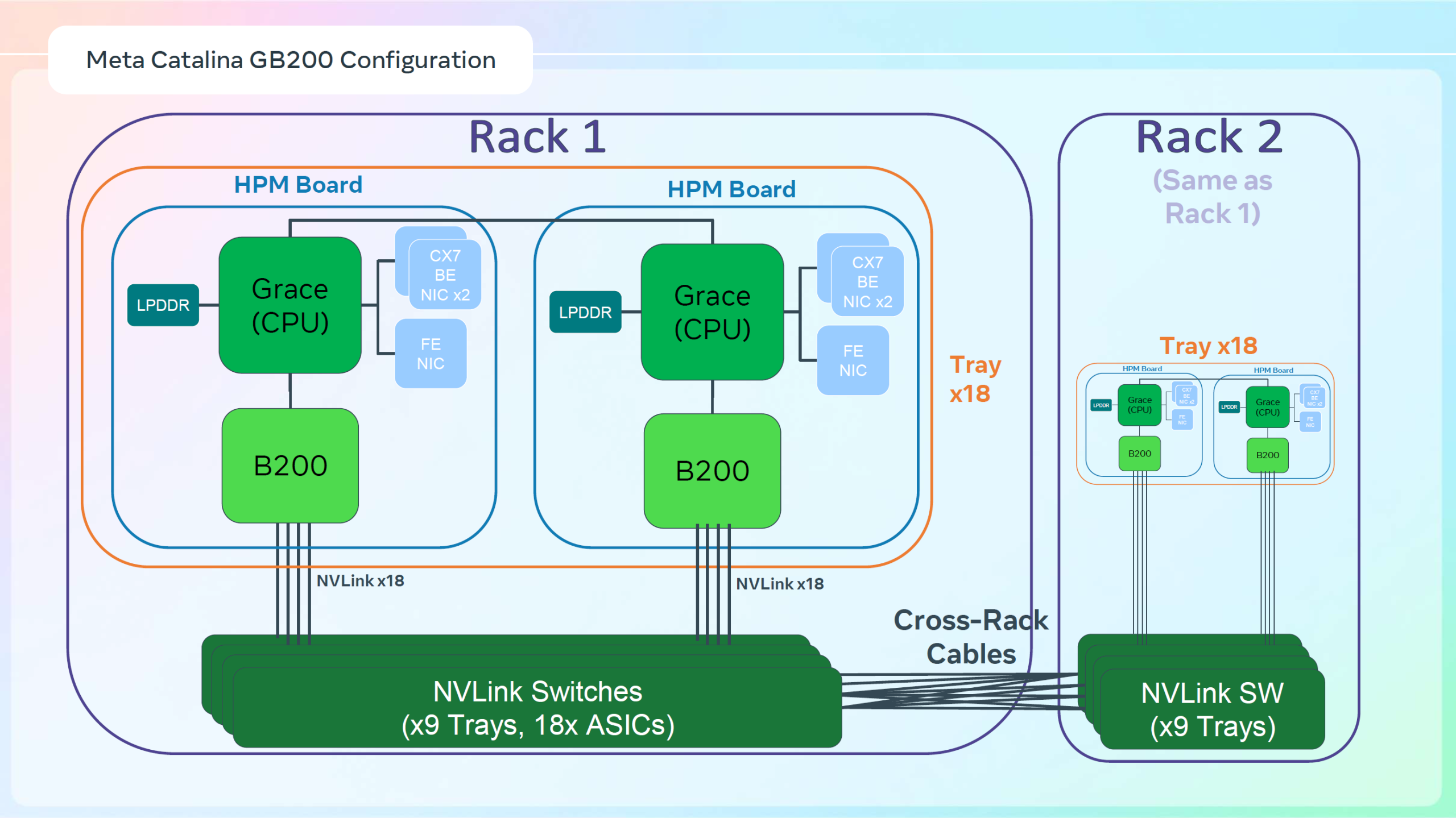 На сегодня у Meta✴ около 30 действующих или строящихся кампусов ЦОД, большей частью на территории США. Планируются ещё несколько кампусов, включая гигаваттные. Также компания выступает крупным арендатором дата-центров, а сейчас в пылу гонки ИИ и вовсе переключилась на быстровозводимые тенты вместо капитальных зданий, лишённые резервного питания и традиционных систем охлаждения. 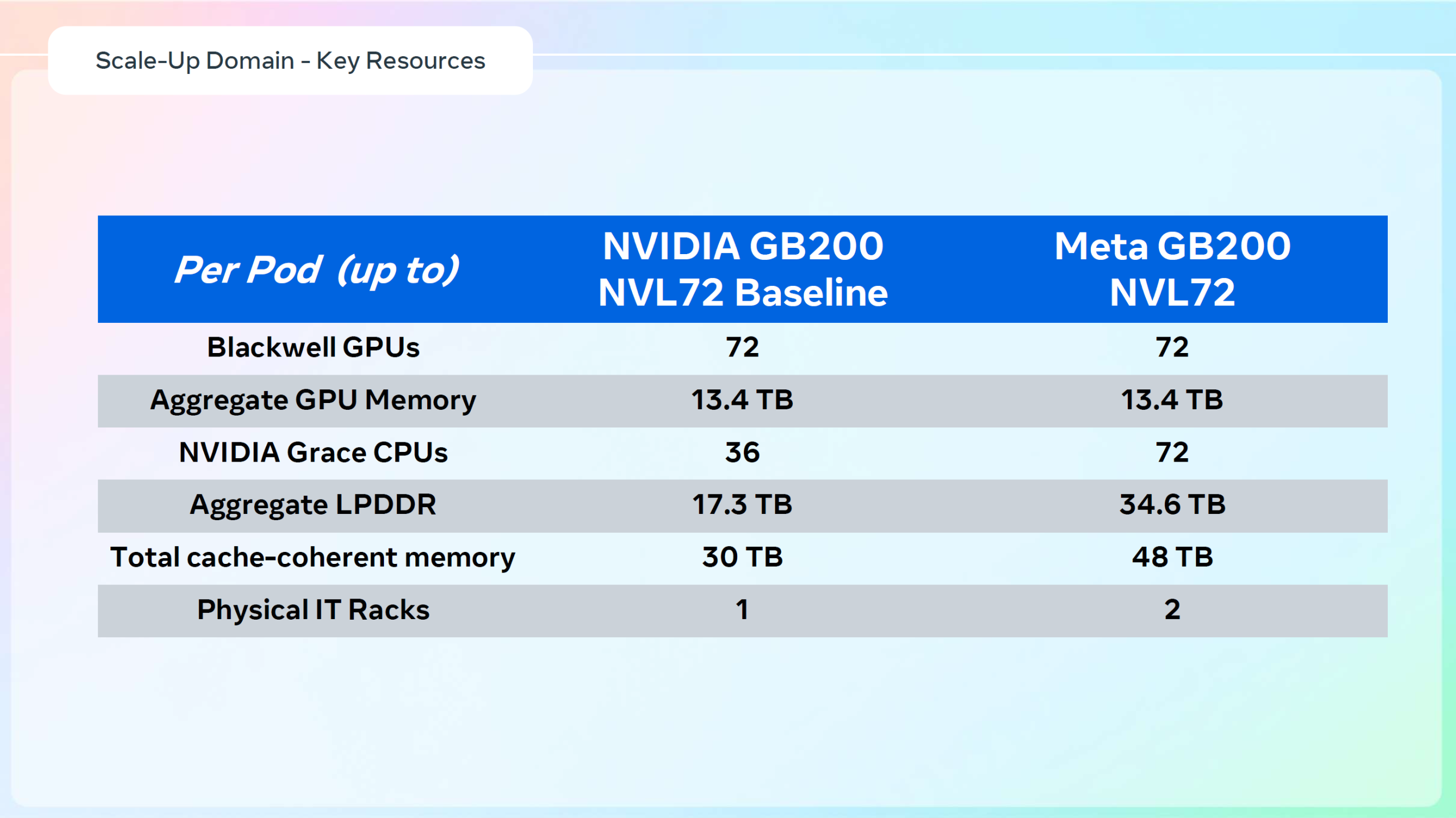 Собственные версии GB200 NVL72 есть у Google, Microsoft и AWS. Причём все они отличаются от эталонного варианта, который среди крупных игроков, похоже, использует только Oracle. Так, AWS решила разработать собственную СЖО, в том числе из-за того, что ей жизненно необходимо использовать собственные DPU Nitro. Google ради собственного OCS-интерконнекта «пристроила» к суперускорителю ещё одну стойку с собственным оборудованием. Microsoft же аналогично Meta✴ добавила ещё одну стойку с теплообменниками и вентиляторами. 
08.08.2025 [10:05], Руслан Авдеев
Масштабирование штабелированием: Air2O предложила высокоплотные модули с горизонтальными 42U-стойкамиРазработчик систем охлаждения Air2O предложил необычные модули High Thermal Density Air-Cooled Rack Assembly с двумя горизонтально расположенными 42U-стойками, которые, по словам компании, позволят заметно увеличить плотность размещения вычислительных мощностей, сообщает Datacenter Dynamics. К стойкам с двух сторон прилегают теплообменники, а между стойками находится воздушный коридор с собственными вытяжными вентиляторами высотой 2,8 м. Таким образом, воздух охлаждается до попадания в стойку и после выхода из него, что, по словам, Air2O, упрощает его повторное использование. По данным компании, новые модули обеспечивают энергетическую плотность до 320 кВт при фрикулинге и до 600 кВт при прямом жидкостном охлаждении. В версии с СЖО место одного из теплообменников занимает CDU. 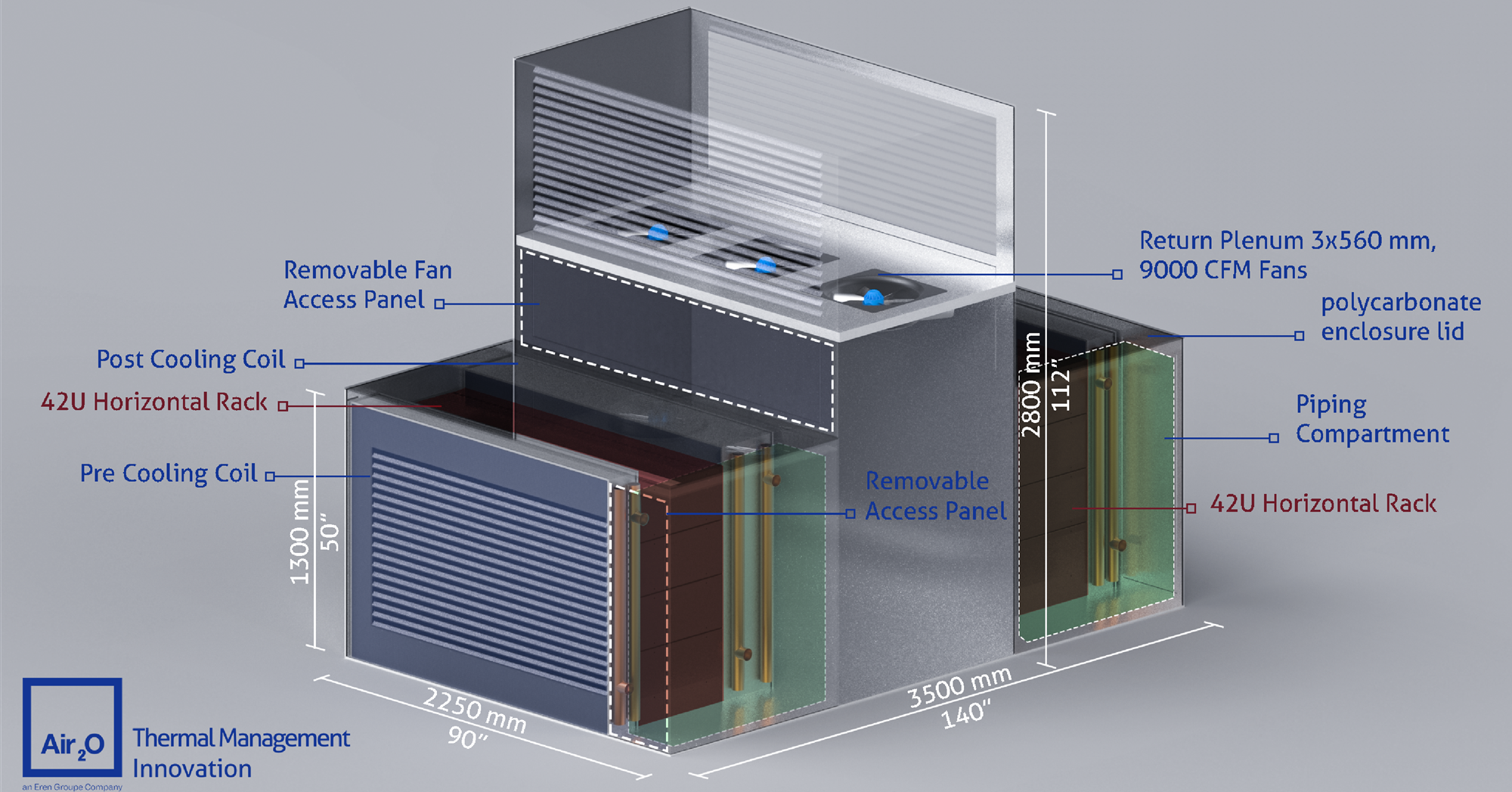
Источник изображений: Air2O Масштабировать модули предполагается путём штабелирования. Air2O заявляет, что способна разместить до 120 соответствующих модулей общей мощностью до 40 МВт в помещении 16 × 25 × 20 м (400 м2), тогда как традиционный ЦОД такой же мощности может занимать более 25 тыс. м2. Каким образом предполагается обслуживать оборудование в таких стойках, компания, к сожалению, не уточняет. Также нет данных, построила ли компания хоть один такой модуль. 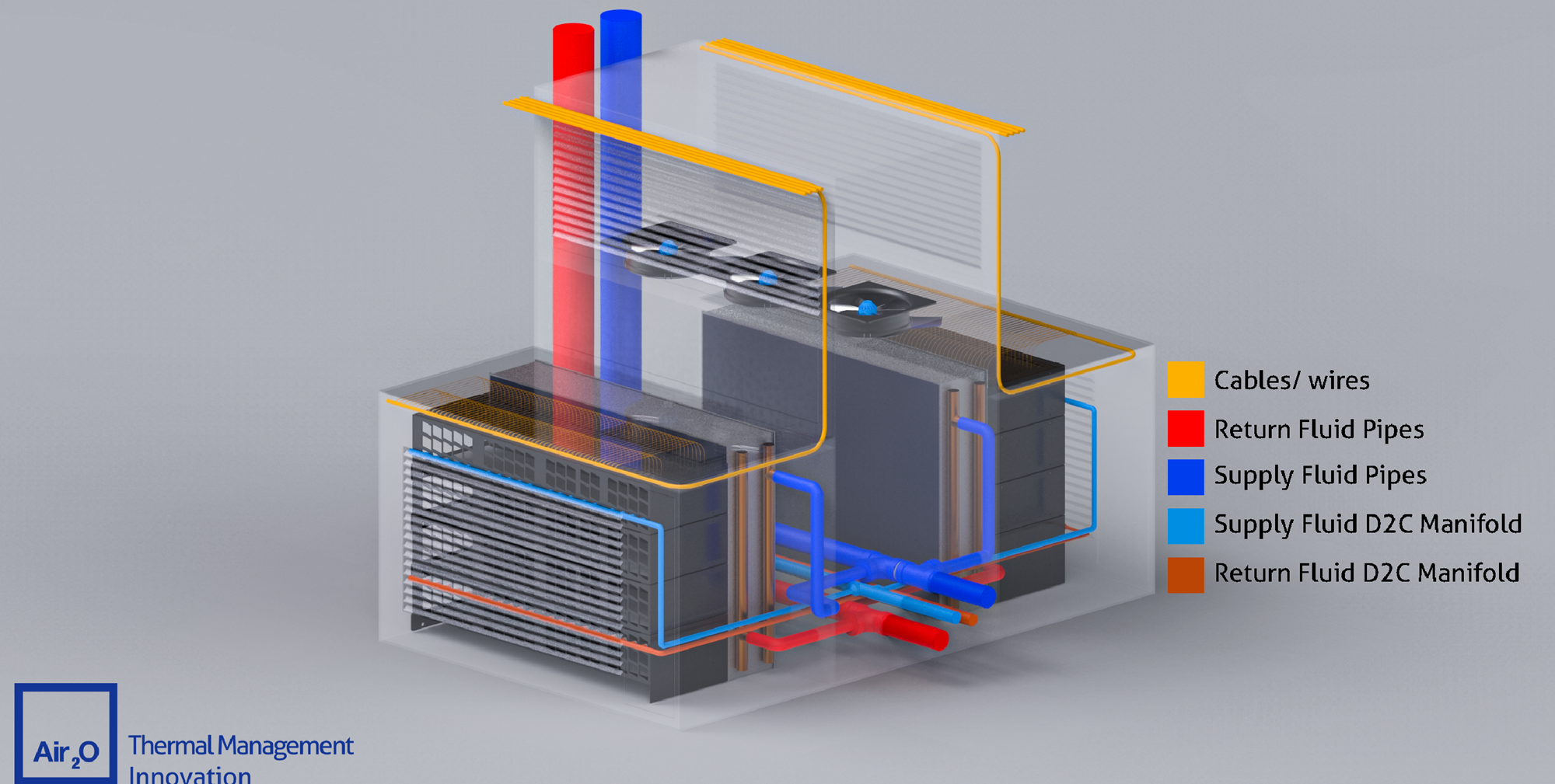 По словам компании, стандартные 19″ стойки, разработанные AT&T более ста лет назад и используемые в большинстве дата-центров, устарели и никогда не предназначались для оборудования с высокой плотностью тепловой энергии. Подчёркивается, что оборудование современных ЦОД не должно выглядеть, как оснащение телефонной станции столетней давности.  Со стойками экспериментируют не только специализированные компании, но и гиперскейлеры. Например, в конце 2024 года Microsoft и Meta✴ представили дизайн ИИ-стойки с раздельными шкафами для питания и IT-оборудования, а в мае 2025 года Google показала мегаваттные стойки с питанием 400 В и СЖО для ИИ-платформ будущего. А NVIDIA предлагает перейти уже к 800 В.
13.06.2025 [02:20], Владимир Мироненко
AMD готовит ИИ-стойки Helios AI двойной ширины с Instinct MI400, AMD EPYC Venice и 800GbE DPU Pensando Vulcano
amd
dpu
epyc
hardware
instinct
mi400
pensando systems
ualink
ultra ethernet
venice
ии
стойка
ускоритель
Вместе с анонсом ускорителей MI350X и MI355X также рассказала о планах на ближайшее будущее, включая выпуск ускорителей серий MI400 (Altair) в 2026 году и MI500 (Altair+) в 2027 году, а также решений UALink, Ultra Ethernet, DPU Pensando и стоечных архитектур, которые послужат основой ИИ-кластеров. Так, AMD анонсировала новую архитектуру Helios AI с стойками двойной ширины, которая объединит процессоры AMD EPYC Venice с ядрами Zen 6, ускорители Instinct MI400 и DPU Vulcano. Благодаря приобретению ZT Systems компания смогла существенно ускорить разработку и интеграцию решений уровня стойки — Helios AI появятся уже в 2026 году. Как сообщает DataCenter Dynamics, Эндрю Дикманн (Andrew Dieckmann), корпоративный вице-президент и генеральный менеджер AMD по ЦОД рассказал перед мероприятием, что решение об увеличении ширины стойки было принято в сотрудничестве с «ключевыми партнёрами» AMD, поскольку предложение должно соответствовать «правильной точке проектирования между сложностью, надёжностью и предоставлением преимуществ производительности». По словам AMD, это позволит объединить тысячи чипов таким образом, чтобы их можно было использовать как единую систему «стоечного масштаба». «Впервые мы спроектировали каждую часть стойки как единую систему», — заявила генеральный директор AMD Лиза Су (Lisa Su) на мероприятии, пишет CNBC. 
Источник изображений: AMD Дикманн заявил, что Helios предложит на 50 % больше пропускной способности памяти и на 50 % больше горизонтальной пропускной способности (по сравнению с NVIDIA Vera Rubin), поэтому «компромисс [за счёт увеличения ширины стойки] был признан приемлемым, поскольку крупные ЦОД, как правило, ограничены не квадратными метрами, а мегаваттами». 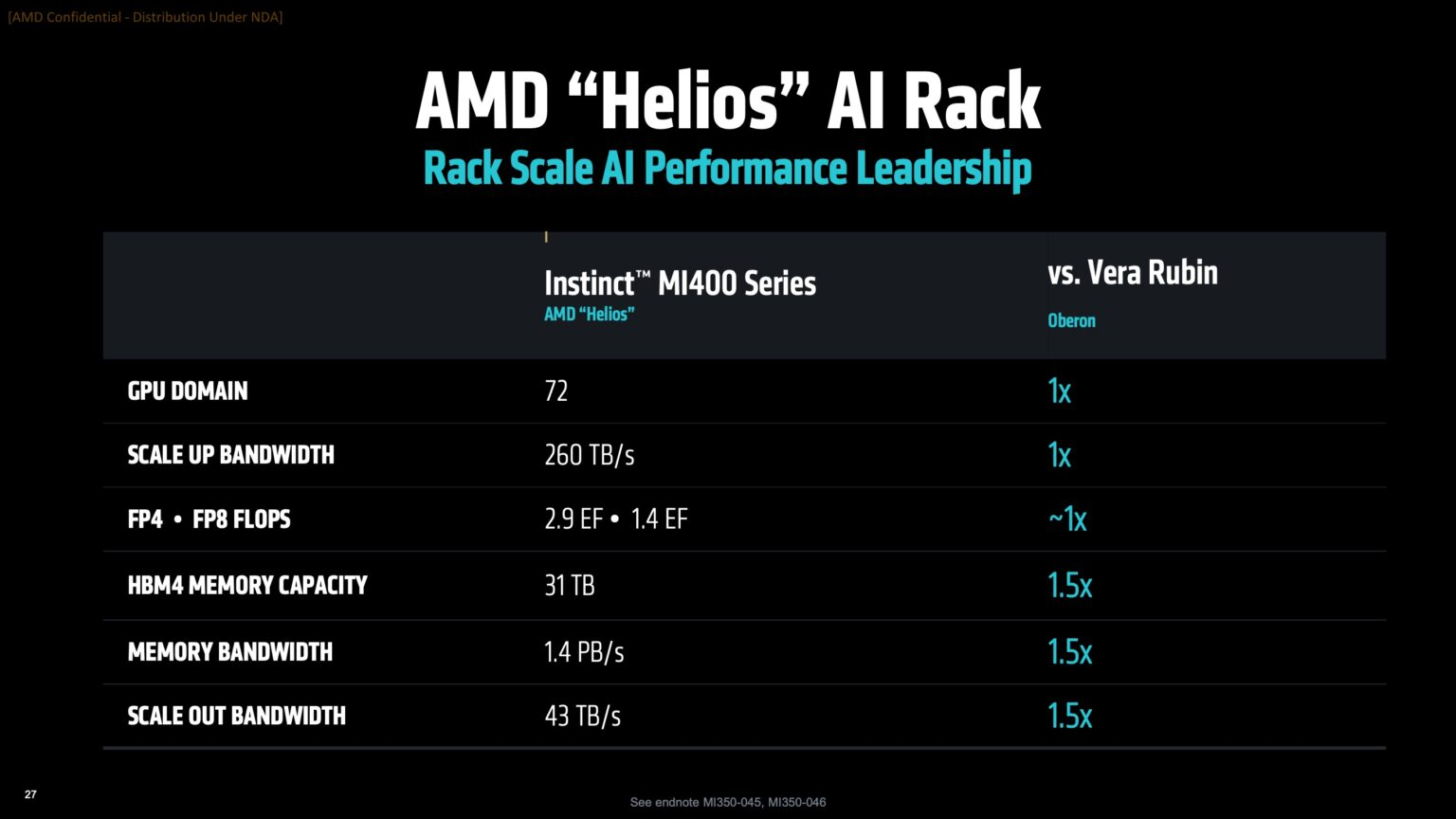 Как указано в блоге компании, «Helios создана для обеспечения вычислительной плотности, пропускной способности памяти, производительности и горизонтального масштабирования, необходимых для самых требовательных рабочих ИИ-нагрузок, в готовом к развёртыванию решении, которое ускоряет время выхода на рынок».  Helios представляет собой сочетание технологий AMD следующего поколения, включая:
 AMD отказалась сообщить стоимость анонсированных чипов, но, по словам Дикманна, ИИ-ускорители компании будут дешевле и в эксплуатации, и в приобретении в сравнении с чипами NVIDIA. «В целом, есть существенная разница в стоимости приобретения, которую мы затем накладываем на наше конкурентное преимущество в производительности, поэтому выходит значительная, исчисляемая двузначными процентами экономия», — сказал он.  AMD ожидает, что общий рынок ИИ-чипов превысит к 2028 году $500 млрд. Компания не указала, на какую долю общего пирога она будет претендовать — по оценкам аналитиков, в настоящее время у NVIDIA более 90 % рынка. Обе компании взяли на себя обязательство выпускать новые ИИ-чипы ежегодно, а не раз в два года, что говорит о том, насколько жёстче стала конкуренция и насколько важны передовые ИИ-технологии для гиперскейлеров. 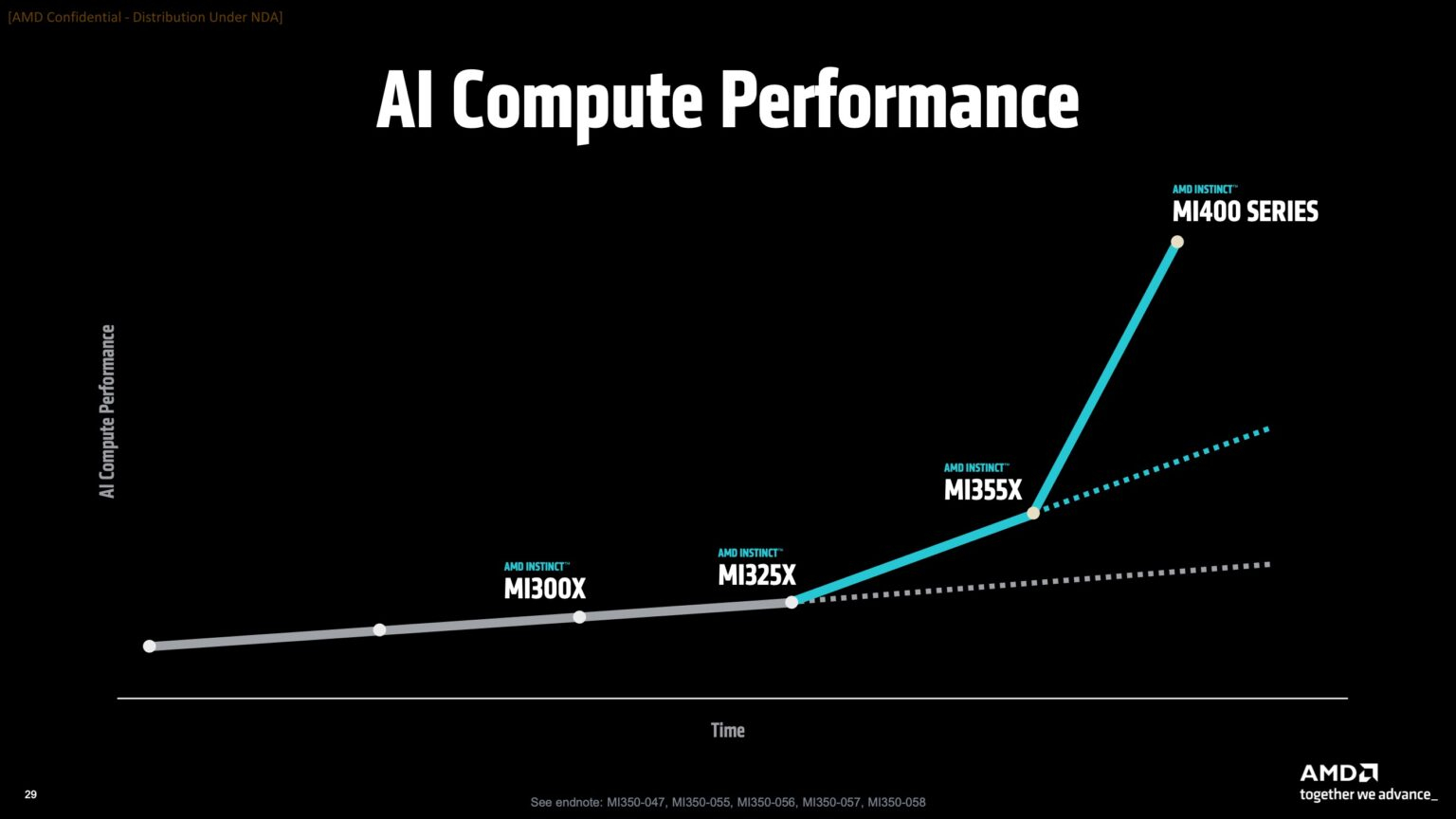 AMD сообщила, что её чипы Instinct используются семью из десяти крупнейших игроков ИИ-рынка, включая OpenAI, Tesla, xAI и Cohere. По словам AMD, Oracle планирует предложить своим клиентам кластеры с более чем 131 тыс. ускорителей MI355X. Meta✴ сообщила, что уже использует AMD-кластеры для инференса Llama и что она планирует купить серверы с чипами AMD следующего поколения. В свою очередь, представитель Microsoft сказал, что компания использует чипы AMD для обслуживания ИИ-функций чат-бота Copilot.
04.06.2025 [17:30], Руслан Авдеев
Неподъёмный груз: ИИ-серверы стали слишком тяжелы для обычных ЦОДОператоры дата-центров столкнулись с неочевидной на первый взгляд проблемой. ИИ-оборудование не только требует больше электроэнергии и более эффективного охлаждения в сравнении с обычными серверами — оно ещё и тяжелее платформ для классических задач, сообщает Datacenter Knowledge. Плотность оборудования в стойках для ИИ-серверов значительно выше стандартной. Это обеспечивает большую мощность, но в то же время в одном пространстве помещается больше металла, что ведёт к увеличению массы, что необходимо учитывать при проектировании ИИ-инфраструктуры. Современная стандартная стойка 42U с набором оборудования весит порядка 680–1150 кг, максимально допустимая масса для многих составляет около 1360 кг. При этом стойка для ИИ-серверов в полной комплектации с системами охлаждения и сетевыми модулями может весить более 1800 кг. Десятки или даже сотни таких стоек в среднем ЦОД гиперскейлера могут серьёзно повлиять на всё устройство помещения. В Dell'Oro Group отмечает, что в машинных залах всё реже используются фальшполы, под которыми часто размещают кабели, элементы системы охлаждения и др., поскольку установка такой конструкции — довольно дорогая задача. В JLL оговаривают, что во многих ЦОД фальшполы всё же используются, поскольку они нужны для кабелей и труб, но их высота может быть уже в районе 30 см, а не традиционных 60 см. Операторы по-прежнему опасаются прокладывать трубы сверху из-за возможных протечек. 
Источник изображения: Dmitry Ant/unsplash.com В новых ЦОД, как сообщают специалисты, снижают не только высоту фальшполов, но и высоту потолков. Более того, многие операторы предпочитают строить одноэтажные дата-центры вместо многоэтажных, чтобы упростить конструкцию и не тратить деньги на укрепление перекрытий ради ИИ-стоек. Высокая плотность размещения оборудования сказывается не только на строительстве новых зданий, но и на модернизации существующих. Строительные компании должны уделять больше ресурсов анализу и проектированию, чтобы гарантировать, что пол выдержит вес аппаратного обеспечения нового типа. На практике далеко не каждый дата-центр можно модернизировать для размещения ИИ-оборудования. При этом растёт интерес операторов ЦОД как раз к уже построенным объектам. В зданиях некоторых фабрик, больниц или торговых центров часто вполне можно разместить инфраструктуру — те же заводы как правило имеют прочные пол, да и подстанции у крупных объектов тоже уже есть. Тем временем на большинстве рынков даже подключение к новой подстанции — вопрос проблемный и зарегулированный. xAI вряд ли случайно выбрала бывший завод Electrolux для размещения своего ИИ-суперкомпьютера Colossus. Но и она вопрос присоединения к энергосети и получения нужных мощностей оперативно не решила. Хотя для ИИ ЦОД могут потребоваться более крепкие полы, но на сроки строительства это не повлияет, говорят эксперты — просто надо использовать бетон другой прочности, сталь другой марки и т.п. Пока ещё никто не отказывался от проекта из-за более дорогих полов. Однако влияние ИИ-оборудования на процесс проектирования дата-центров весьма велико, поскольку такое объекты обычно рассчитаны на 10–20 лет эксплуатации, а перестраивать их появлением нового типа оборудования каждые несколько лет попросту невыгодно.
01.05.2025 [00:45], Руслан Авдеев
Google готовит мегаваттные стойки с питанием 400 В и СЖО для ИИ-платформ будущегоGoogle представил технологию питания 400 В постоянного тока (DC) и систему жидкостного охлаждения пятого поколения Project Deschutes для стоек нового поколения, которы призваны поддержать стремительное развитие ИИ. В течение последних десяти лет компания использует питание 48 В DC, но переход к новому стандарту позволит повысить максимальную мощность на одну стойку со 100 кВт до 1 МВт. Ожидается, что отдельные стойки с ИИ-системами будут потреблять свыше 500 кВт уже к 2030 году. Так, грядущий суперускоритель NVIDIA Rubin Ultra NVL576, который появится в 2027 году, будет «упакован» в стойку нового поколения Kyber и потреблять порядка 600 кВт. Google, надо полагать, разработает собственную модификацию данного ускорителя, адаптированного к её дата-центрам, как уже сделала для GB200 NVL72. Использование 400 В позволяет задействовать цепочку поставок, используемую индустрией электромобилей, что способствует снижению затрат и повышению качества. Совместно с Meta✴ и Microsoft компания Google работает над проектом Mt. Diablo, в рамках которого вырабатываются общие стандарты электрических и механических интерфейсов. Первая версия спецификаций (v0.5) будет доступна для отраслевого обсуждения в мае 2025 года. 
Источник изображения: Google Подсистема питания в Mt. Diablo вынесена в отдельный модуль (sidecar). Это увеличивает полезное пространство в серверных стойках, позволяя целиком отдать их под ускорители, и повышает общую энергоэффективность приблизительно на 3 %, что в масштабах гиперскейлера очень существенно. В перспективе рассматривается переход на прямое распределение высоковольтного постоянного тока внутри ЦОД для ещё большей эффективности и повышения плотности. 
Источник изображения: Google С резким повышением энергопотребления чипов использование СЖО стало неизбежным. В последние семь лет Google развернула СЖО в более 2 тыс. кластеров TPU Pod. Впервые жидкостное охлаждение стало применяться для ИИ-ускорителей TPU v3, появившихся в 2018 году. Компания использует водоблоки, что позволяет практически удвоить плотность размещения вычислительных мощностей в сравнении с воздушным охлаждением. При переходе от TPU v2 к TPU v3 это также позволило вчетверо увеличить размер кластеров. СЖО применяются и для ускорителей Ironwood (TPU v7). CDU-архитектура Project Deschutes, в которой используются резервные теплообменники и насосы, обеспечивает уровень доступности 99,999 %. Пятое поколение Project Deschutes Google планирует передать Open Compute Project (OCP) в 2025 году. Публикация спецификаций, проектных данных и рекомендаций по эксплуатации ускорит массовое внедрение СЖО в индустрии. В компании уверены, что совместные усилия помогут индустрии справиться с будущими вызовами в индустрии ИИ и масштабировать вычислительные мощности и дальше.
22.02.2025 [22:45], Сергей Карасёв
В облаке Google Cloud появились инстансы A4X на базе суперускорителей NVIDIA GB200 NVL72Облачная платформа Google Cloud объявила о запуске виртуальных машин A4 с ускорителями NVIDIA B200 и A4X на основе суперускорителей NVIDIA GB200 NVL72 поколения Blackwell. Эти инстансы ориентированы на ресурсоёмкие приложения ИИ. 
Источник изображения: Google По заявлениям Google, виртуальные машины A4 обеспечивают высокий уровень производительности при работе с ИИ-моделями на различных архитектурах. Инстансы подходят для таких рабочих нагрузок, как обучение и тонкая настройка. В свою очередь, экземпляры A4X специально созданы для обучения и обслуживания самых требовательных и сверхмасштабных задач ИИ, включая большие языковые модели (LLM) с наиболее ёмкими контекстными окнами и «рассуждающие» модели. Суперускорители GB200 NVL72 объединяют в одной стойке 72 чипа B200 и 36 процессоров Grace. Применяются шина NVLink 5 и инфраструктура жидкостного охлаждения Google третьего поколения. Каждая система GB200 NVL72 обеспечивает быстродействие до 1,44 Эфлопс в режиме FP4 и до 720 Пфлопс в режиме FP8. По заявлениям Google, достигается четырёхкратное увеличение производительности при обучении LLM по сравнению с виртуальными машинами A3 на базе ускорителей NVIDIA H100. Инстансы A4X допускают масштабирование до десятков тысяч графических процессоров Blackwell. Говорится об интеграции с сервисами хранения Cloud Storage FUSE, Parallelstore и Hyperdisk ML, что обеспечивает доступ к данным с малой задержкой (менее 1 мс) и высокую пропускную способность. Новые виртуальные машины будут развёрнуты в различных регионах Google Cloud. Нужно отметить, что ранее о запуске общедоступных инстансов на базе NVIDIA GB200 NVL200 объявила компания CoreWeave, предоставляющая облачные услуги для ИИ-задач. Скоро эти суперускорители станут доступны и в облаке Lambda Labs.
28.01.2025 [12:10], Сергей Карасёв
Pegatron поставит суперускорители NVIDIA GB200 NVL72 ИИ-стартапу Lambda LabsСтартап Lambda Labs, по сообщению ресурса Datacenter Dynamics, заключил партнёрское соглашение с серверным подразделением тайваньского ODM-производителя компьютерных комплектующих Pegatron. В рамках договора Pegatron развернёт суперускорители NVIDIA GB200 NVL72 для ИИ-инфраструктуры Lambda Labs. Напомним, фирма Lambda Labs была основана в 2012 году. Она предоставляет услуги облачных ИИ-вычислений с использованием собственных систем, оснащённых ускорителями NVIDIA, а также процессорами AMD и Intel. Кроме того, компания продаёт рабочие станции на базе GPU и предоставляет услуги колокации. Lambda Labs провела несколько раундов финансирования: полученные средства направляются на наращивание вычислительных мощностей и увеличение штата. В июле 2024 года сообщалось, что у суперускорителей с чипами NVIDIA GB200 возникли проблемы с СЖО: из-за дефектных компонентов фиксировались протечки. А в ноябре появилась информация, что стойки NVL72 перегревались, в связи с чем NVIDIA была вынуждена обратиться к поставщикам с просьбой внести ряд изменений в конструкцию стоек. Кроме того, NVIDIA и Schneider Electric занялись разработкой эталонной архитектуры охлаждения для ЦОД на основе GB200 NVL72. 
Источник изображения: Pegatron Впрочем, на текущий момент все проблемы устранены, а NVIDIA и партнёры организовали полномасштабное производство серверов на базе Blackwell. При этом клиенты уже приступили к монтажу суперускорителей GB200 NVL72. Такие системы, в частности, устанавливает стартап xAI Илона Маска (Elon Musk). Как отмечается, стратегическое партнёрство с Lambda Labs позволит Pegatron выйти на стремительно расширяющийся рынок ИИ-серверов. Первая система GB200 NVL72 (производства Supermicro), принадлежащая Lambda, была запущена на прошедших выходных в «водородном» дата-центре EdgeCloudLink.
23.11.2024 [15:57], Сергей Карасёв
Microsoft и Meta✴ представили дизайн ИИ-стойки с раздельными шкафами для питания и IT-оборудованияКорпорация Microsoft в сотрудничестве с Meta✴ представила дизайн серверной стойки нового поколения для дата-центров, ориентированных на задачи ИИ. Спецификации системы, получившей название Mount Diablo, предоставляются участникам проекта Open Compute Project (OCP). Отмечается, что инфраструктура ЦОД постоянно эволюционирует, а наиболее значительное влияние на неё оказывает стремительное внедрение ИИ. Тогда как традиционные стойки с вычислительным оборудованием и средствами хранения данных имеют мощность максимум до 20 кВт, при размещении современных ИИ-ускорителей этот показатель исчисляется сотнями киловатт. В результате при развёртывании дата-центров могут возникать различные сложности. Идея Mt. Diablo заключается в разделении стойки на независимые шкафы для компонентов подсистемы питания и вычислительного оборудования. То есть, речь идёт о дезагрегированной архитектуре, позволяющей гибко регулировать мощность в соответствии с меняющимися требованиями. 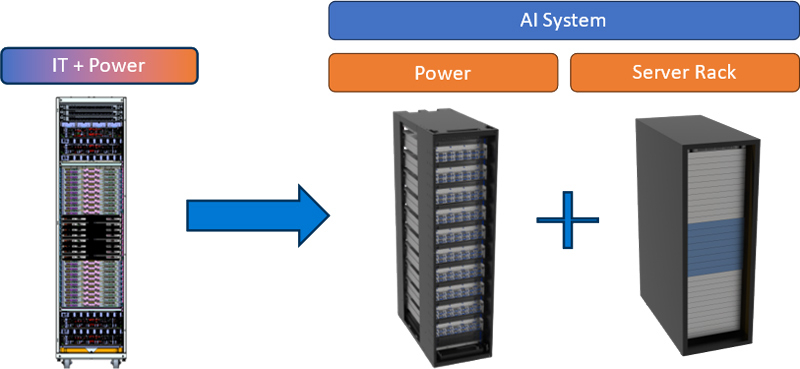
Источник изображения: Microsoft Одним из ключевых преимуществ нового подхода является оптимизация пространства. Утверждается, что в каждой серверной стойке можно размещать на 35 % больше ИИ-ускорителей по сравнению с традиционным дизайном. Ещё одним достоинством названа масштабируемость: конфигурацию стойки питания можно изменять в соответствии с растущими потребностями. Плюс к этому модульная конструкция позволяет реализовывать несколько проектов одновременно. Отмечается, что в современных OCP-системах уже используется единая шина питания постоянного тока с напряжением 48 В. В случае с новым дизайном возможен переход на архитектуру 400 В DC. Это открывает путь для создания более мощных и эффективных систем ИИ. Однако для внедрения стандарта 400 В потребуется общеотраслевая стандартизация. В индивидуальных проектах — например, суперкомпьютерах — для питания узлов уже используется шина DC. |
|

