Лента новостей
|
01.09.2021 [23:58], Андрей Галадей
Ветераны индустрии основали стартап Ventana для создания чиплетных серверных процессоров RISC-VСтартап Ventana Micro Systems, похоже, намерен перевернуть рынок серверов. Компания заявила о разработке высокопроизводительных процессоров на архитектуре RISC-V для центров обработки данных. Первые образцы фирменных CPU будут переданы клиентам во второй половине следующего года, а поставки начнутся в первой половине 2023 года. При этом процессоры получат чиплетную компоновку — различные модули и кристаллы на общей подложке. Основные процессорные ядра разработает сама Ventana, а вот остальные чиплеты будут создаваться под нужды определённых заказчиков. CPU-блоки будут иметь до 16 ядер, которые, как обещается, окажутся быстрее любых других реализаций RV64. Использование RISC-V позволит разрабатывать сверхмощные решения в рекордные сроки и без значительного бюджета. Ядра будут «выпекаться» на TSMC по 5-нм нормам, но для остальных блоков могут использовать другие техпроцессы и фабрики. Ventana будет следить за процессом их создания и упаковывать до полудюжины блоков в одну SoC. Для соединения ядер, кеша и других компонентов будет использоваться фирменная кеш-когерентная шина, которая обеспечит задержку порядка 8 нс и скорость передачи данных 16 Гбит/с на одну линию. Основными заказчиками, как ожидается, станут гиперскейлеры и крупные IT-игроки, которым часто требуется специализированное «железо» для ЦОД, 5G и т.д. Сегодня Ventana объявила о привлечении $38 млн в рамках раунда B. Общий же объём инвестиций составил $53 млн. Компания была основана в 2018 году. Однако это не совсем обычный стартап — и сами основатели, и команда являются настоящими ветеранами индустрии. Все они имеют многолетний опыт работы в Arm, AMD, Intel, Samsung, Xilinx и целом ряде других крупных компаний в области микроэлектроники. Часть из них уже имела собственные стартапы, которые были поглощены IT-гигантами.
31.08.2021 [20:34], Игорь Осколков
Western Digital анонсировала «концептуально новые» жёсткие диски с технологией OptiNAND: 20+ Тбайт без SMRWestern Digital анонсировала технологию OptiNAND, которая, по её словам, полностью меняет архитектуру жёстких дисков и вместе с ePMR открывает путь к созданию накопителей ёмкостью более 20 Тбайт (от 2,2 Тбайт на пластину) даже при использовании CMR — вплоть до 50 Тбайт во второй половине этого десятилетия. OptiNAND предполагает интеграцию индустриального UFS-накопителя серии iNAND непосредственно в HDD. Но это не просто ещё один вариант NAND-кеша. Увеличение ёмкости одной пластины происходит благодаря повышению плотности размещения дорожек, что, правда, на современном этапе развития жёстких дисков требует различных ухищрений: заполнение корпуса гелием, использование продвинутых актуаторов, применение новых материалов, требующих энергетической поддержки записи (MAMR, HAMR и т.д.). Вместе с тем механическая часть накопителей не столь «тонка» и подвержена различным колебаниям, которые могут повлиять на запись и считывание столь плотно упакованных дорожек.  При производстве жёстких дисков делается калибровка и учёт этих ошибок в позиционировании головки (RRO, repeatable run out), а данные (речь идёт о гигабайтах) обычно записываются непосредственно на пластины, откуда и считываются во время работы накопителя. В случае OptiNAND эти мета✴-данные попадают во флеш-память, позволяя высвободить место. Правда, пока не уточняется, насколько это значимо на фоне общей ёмкости пластины.  Второй важный тип мета✴-данных, который теперь попадает в iNAND, — это информация о произведённых операциях записи. При повышении плотности размещения риск того, что запись на одну дорожку повлияет на данные в соседней, резко увеличивается. Поэтому, опираясь на данные о прошлых записях, жёсткий диск периодически перезаписывает данные соседних дорожек для повышения сохранности информации.  В старых накопителях одна такая операция приходилась примерно на 10 тыс. записей, в современных — на менее, чем на 10 записей. Причём учёт ведётся именно на уровне дорожек. iNAND же позволяет повысить точность отслеживания записей до секторов, что, в свою очередь, позволяет разнести операции перезаписи в пространстве и времени, снизив общую нагрузку на накопитель и повысив плотность размещения дорожек без ущерба для производительности, поскольку надо тратить меньше времени на «самообслуживание». 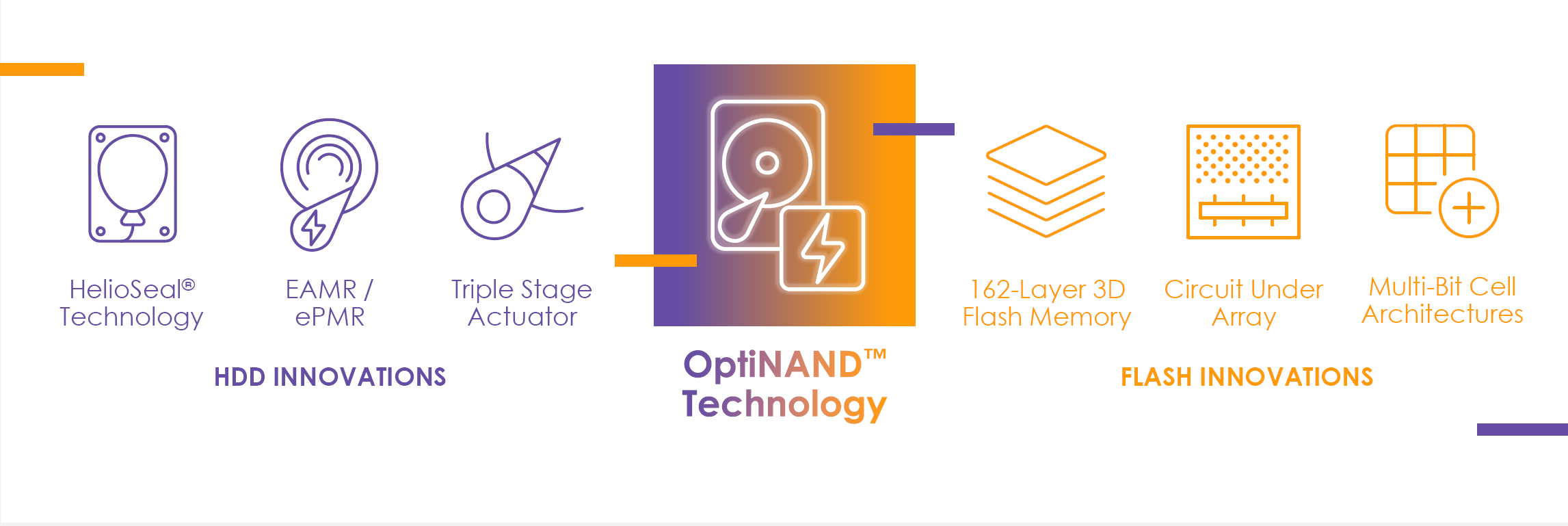 Наконец, быстрая и ёмкая UFS (вплоть до 3.1) позволяет сохранить в 50 раз больше данных и мета✴-данных из DRAM в сравнении с жёсткими дисками без OptiNAND в случае аварийного отключения накопителя и в целом повысить его производительность, причём в независимости от того, включено ли кеширование записи или нет. Кроме того, новый слой памяти позволяет лучше оптимизировать прошивку под конкретные задачи — будут использоваться 162-слойные TLC-чипы от Kioxia, которые можно настроить в том числе на работу в режиме SLC. Western Digital планирует использовать OptiNAND в большинстве серий своих жёстких дисков, предназначенных для облаков и гиперскейлеров, корпоративных нужд (Gold), систем видеонаблюдения (Purple) и NAS (Red). Первые образцы 20-Тбайт накопителей (CMR + ePMR) с OptiNAND уже тестируются избранными клиентами компании. А вот о потребительских решениях пока ничего сказано не было.
31.08.2021 [00:56], Владимир Мироненко
Судебная тяжба 18-летней давности между IBM и SCO закончена, но противостояние по поводу прав на Linux продолжаетсяПохоже, что затянувшийся судебный спор между компаниями Santa Cruz Operation (SCO) и IBM по поводу прав на код ядра Linux может закончиться в ближайшее время. Суд США по делам о банкротстве округа Делавэр объявил, что TSG Group, которая представляет интересы должников обанкротившейся SCO, урегулировала все оставшиеся претензии с IBM. «В соответствии с Мировым соглашением стороны договорились разрешить все споры между собой по выплате Доверительному управляющему [TLD] от имени IBM в размере $14 250 000», — указано в постановлении суда. В свою очередь, TLD отказывается от всех прав и интересов по всем судебным искам, находящимся на рассмотрении или которые могут быть предъявлены в будущем против IBM и Red Hat, а также по любым обвинениям в том, что Linux нарушает интеллектуальную собственность SCO Unix или Unixware. Как пояснил представитель TLD, даже если бы SCO удалось доказать суду присяжных, что около 20 лет назад действительно были нарушены права и была нечестная конкуренция, размер ущерба всё было бы нельзя определить. И выплаты, вероятно, были бы значительно меньше, чем при мировом соглашении. 
Источник изображения: SCO Впрочем, речь идёт о завершении лишь части судебного противостояния, длящегося 18 лет. Дело в том, что Xinuos, которая купила продукты SCO Unix и её интеллектуальную собственность в 2011 году, подала в суд на IBM и Red Hat в связи с «незаконным копированием программного кода Xinuos для своих серверных операционных систем». Хотя во время сделки она обещала, что не намерена вести какие-либо судебные разбирательства, связанные с активами группы SCO. Во-первых, Xinuos утверждает, что IBM украла её интеллектуальную собственность, которую использовала для создания и продажи продукта, чтобы конкурировать с самой Xinuos. Во-вторых, по её мнению, IBM и Red Hat незаконно договорились разделить соответствующий рынок и использовать свои растущие силы на рынке для преследования конкурентов и подавления инноваций. И, наконец, в-третьих, по версии Xinuos, IBM приобрела Red Hat, чтобы укрепить положение на рынке и использовать незаконную схему на постоянной основе.
28.08.2021 [00:16], Владимир Агапов
Кластер суперчипов Cerebras WSE-2 позволит тренировать ИИ-модели, сопоставимые по масштабу с человеческим мозгомВ последние годы сложность ИИ-моделей удваивается в среднем каждые два месяца, и пока что эта тенденция сохраняется. Всего три года назад Google обучила «скромную» модель BERT с 340 млн параметров за 9 Пфлоп-дней. В 2020 году на обучение модели Micrsofot MSFT-1T с 1 трлн параметров понадобилось уже порядка 25-30 тыс. Пфлоп-дней. Процессорам и GPU общего назначения всё труднее управиться с такими задачами, поэтому разработкой специализированных ускорителей занимается целый ряд компаний: Google, Groq, Graphcore, SambaNova, Enflame и др.  Особо выделятся компания Cerebras, избравшая особый путь масштабирования вычислительной мощности. Вместо того, чтобы печатать десятки чипов на большой пластине кремния, вырезать их из пластины, а затем соединять друг с другом — компания разработала в 2019 г. гигантский чип Wafer-Scale Engine 1 (WSE-1), занимающий практически всю пластину. 400 тыс. ядер, выполненных по 16-нм техпроцессу, потребляют 15 кВт, но в ряде задач они оказываются в сотни раз быстрее 450-кВт суперкомпьютера на базе ускорителей NVIDIA.  В этом году компания выпустила второе поколение этих чипов — WSE-2, в котором благодаря переходу на 7-нм техпроцесс удалось повысить число тензорных ядер до 850 тыс., а объём L2-кеша довести до 40 Гбайт, что примерно в 1000 раз больше чем у любого GPU. Естественно, такой подход к производству понижает выход годных пластин и резко повышает себестоимость изделий, но Cerebras в сотрудничестве с TSMC удалось частично снизить остроту этой проблемы за счёт заложенной в конструкцию WSE избыточности. 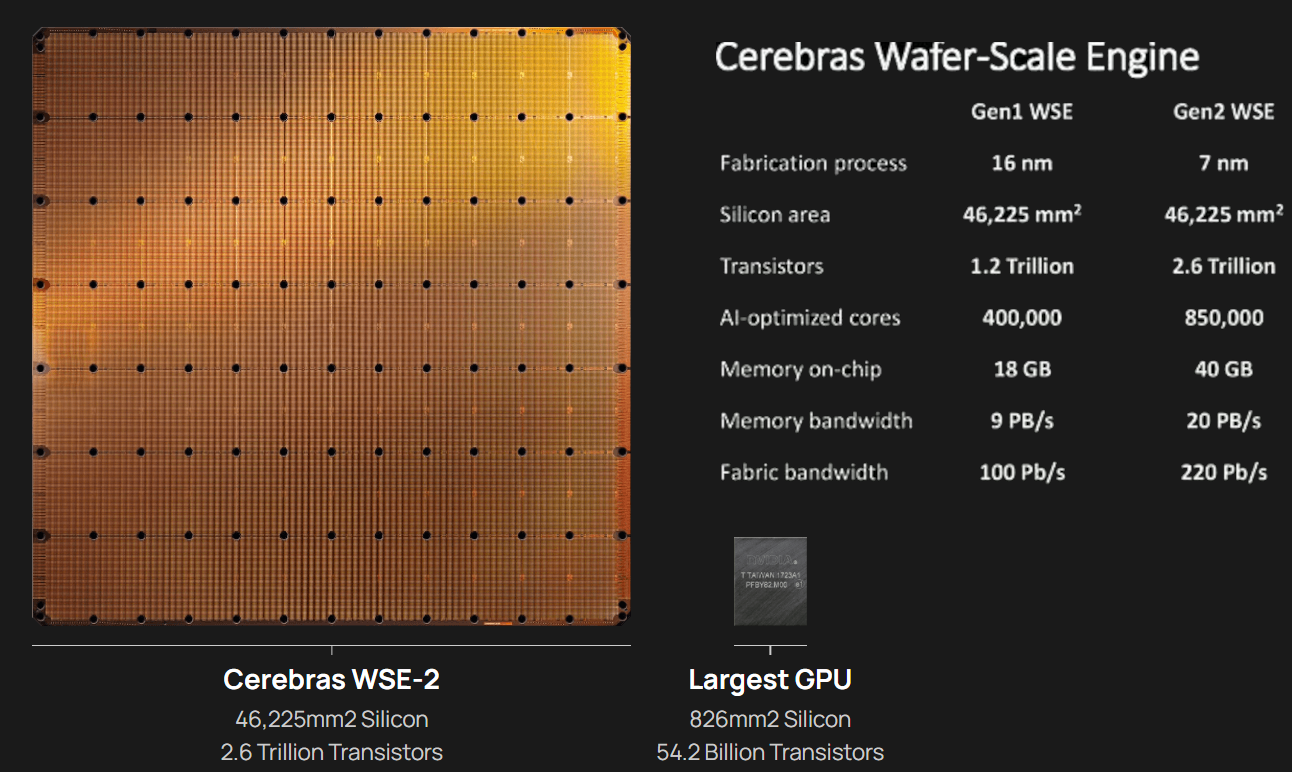 Благодаря идентичности всех ядер, даже при неисправности некоторых их них, изделие в целом сохраняет работоспособность. Тем не менее, себестоимость одной 7-нм 300-мм пластины составляет несколько тысяч долларов, в то время как стоимость чипа WSE оценивается в $2 млн. Зато система CS-1, построенная на таком процессоре, занимает всего треть стойки, имея при этом производительность минимум на порядок превышающую самые производительные GPU. Одна из причин такой разницы — это большой объём быстрой набортной памяти и скорость обмена данными между ядрами.  Тем не менее, теперь далеко не каждая модель способна «поместиться» в один чип WSE, поэтому, по словам генерального директора Cerebras Эндрю Фельдмана (Andrew Feldman), сейчас в фокусе внимания компании — построение эффективных систем, составленных из многих чипов WSE. Скорость роста сложности моделей превышает возможности увеличения вычислительной мощности путём добавления новых ядер и памяти на пластину, поскольку это приводит к чрезмерному удорожанию и так недешёвой системы.  Инженеры компании рассматривают дезагрегацию как единственный способ обеспечить необходимый уровень производительности и масштабируемости. Такой подход подразумевает разделение памяти и вычислительных блоков для того, чтобы иметь возможность масштабировать их независимо друг от друга — параметры модели помещаются в отдельное хранилище, а сама модель может быть разнесена на несколько вычислительных узлов CS, объединённых в кластер. 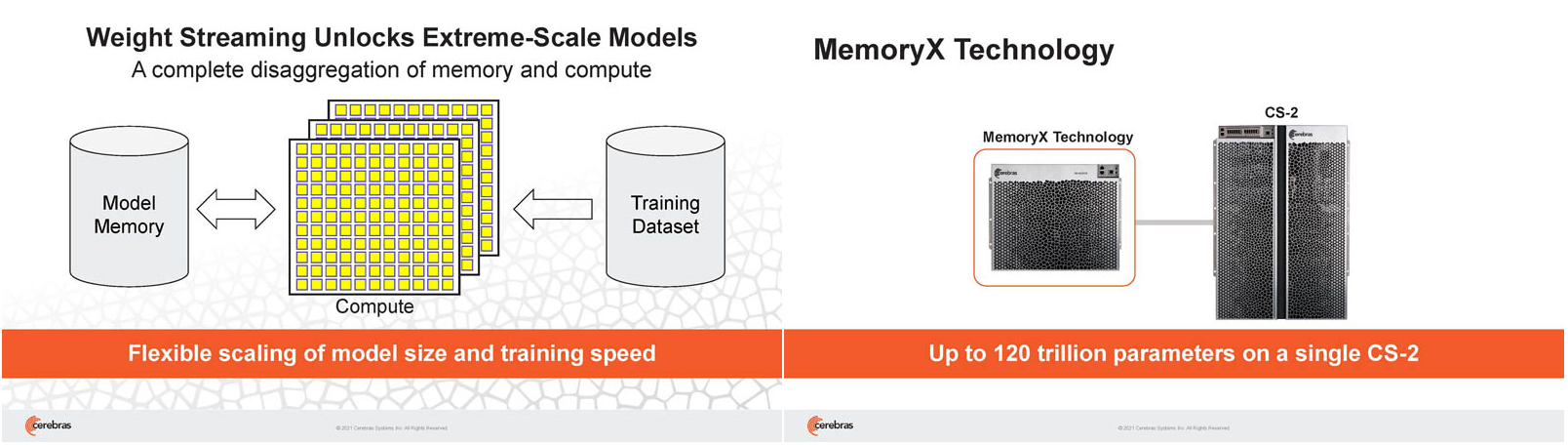 На Hot Chips 33 компания представила особое хранилище под названием MemoryX, сочетающее DRAM и флеш-память суммарной емкостью 2,4 Пбайт, которое позволяет хранить до 120 трлн параметров. Это, по оценкам компании, делает возможным построение моделей близких по масштабу к человеческому мозгу, обладающему порядка 80 млрд. нейронов и 100 трлн. связей между ними. К слову, флеш-память размером с целую 300-мм пластину разрабатывает ещё и Kioxia.  Для обеспечения масштабирования как на уровне WSE, так и уровне CS-кластера, Cerebras разработала технологию потоковой передачи весовых коэффициентов Weight Streaming. С помощью неё слой активации сверхкрупных моделей (которые скоро станут нормой) может храниться на WSE, а поток параметров поступает извне. Дезагрегация вычислений и хранения параметров устраняет проблемы задержки и узости пропускной способности памяти, с которыми сталкиваются большие кластеры процессоров. 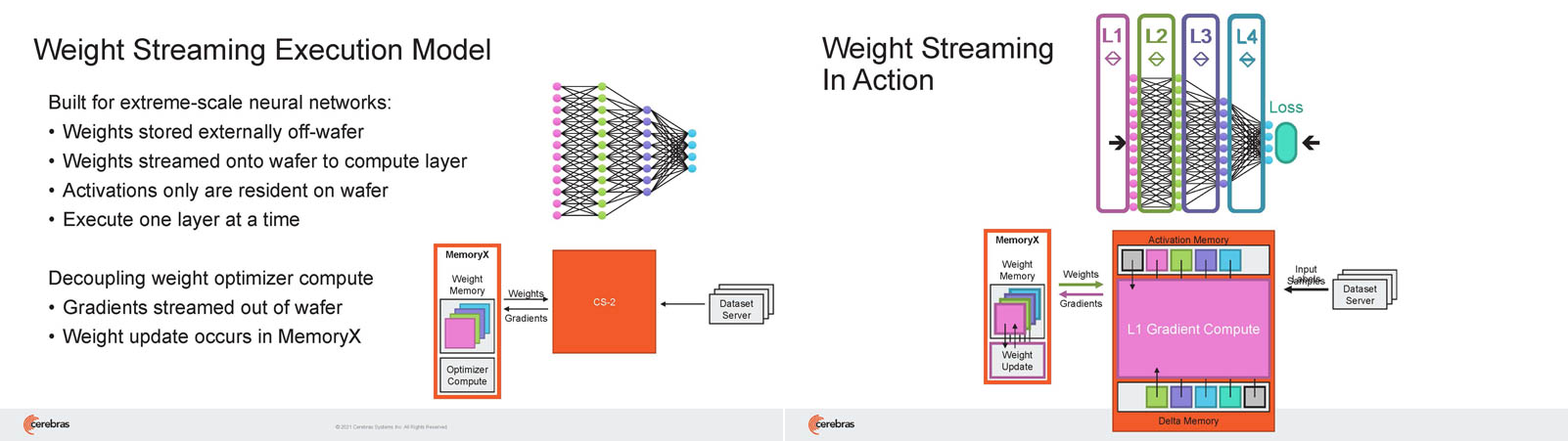 Это открывает широкие возможности независимого масштабирования размера и скорости кластера, позволяя хранить триллионы весов WSE-2 в MemoryX и использовать от 1 до 192 CS-2 без изменения ПО. В традиционных системах по мере добавления в кластер большего количества вычислительных узлов каждый из них вносит всё меньший вклад в решение задачи. Cerebras разработала интерконнект SwarmX, позволяющий подключать до 163 млн вычислительных ядер, сохраняя при этом линейность прироста производительности. 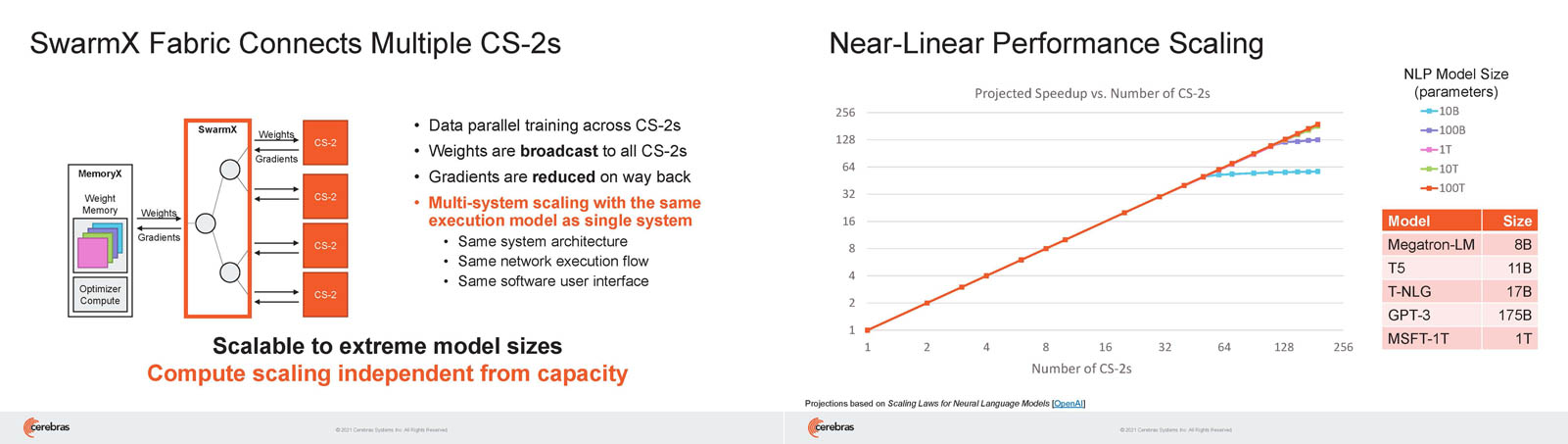 Также, компания уделила внимание разрежённости, то есть исключения части незначимых для конечного результата весов. Исследования показали, что должная оптимизации модели позволяет достичь 10-кратного увеличения производительности при сохранении точности вычислений. В CS-2 доступна технология динамического изменения разрежённости Selectable Sparsity, позволяющая пользователям выбирать необходимый уровень «ужатия» модели для сокращение времени вычислений.  «Крупные сети, такие как GPT-3, уже изменили отрасль машинной обработки естественного языка, сделав возможным то, что раньше было невозможно и представить. Индустрия перешла к моделям с 1 трлн параметров, а мы расширяем эту границу на два порядка, создавая нейронные сети со 120 трлн параметров, сравнимую по масштабу с мозгом» — отметил Фельдман.
26.08.2021 [13:00], Илья Коваль
Huawei OceanProtect X8000 и X9000 — быстрые, ёмкие и надёжные All-Flash СХД для резервного копированияПерефразируя старую поговорку: люди делятся на тех, кто ещё не делает бэкапы, на тех, кто уже делает, и на тех, кто делает их правильно. Хотя, казалось бы, с начала пандемии первая категория должна стремительно уменьшаться, это происходит не везде, несмотря на совершенно неприличные для современной IT-индустрии — как по активности злоумышленников, так и по беспомощности жертв — атаки на бизнес любого размера. Впрочем, даже в тех индустриях, где резервное копирование делать привыкли, есть области с особыми требованиями. Это в первую очередь финансовые институты, энергетика, телекоммуникации, управление производством, ретейл и т.д. Во всех этих областях минута простоя обходится более чем $1 млн, а в случае финансовых учреждений эта цифра достигает почти $6,5 млн. 
Huawei OceanProtect X8000 и X9000 По оценкам экспертов, отсутствие катастрофоустойчивости, важнейшим элементом которой является именно резервное копирование, в более чем половине случае приводит к банкротству в течение 2-3 лет после первого падения IT-систем. А причин такого падения масса — от природных бедствий и человеческого фактора до неумышленного (сбой оборудования) или умышленного (атака) вмешательства в работу систем.  Вместе с тем в последние годы поменялись и сами данные, и требования к работе с ними. Никого уже не удивляет необходимость поддержки надёжности в семь «девяток», резкий рост объёмов «горячих» и «тёплых» данных и постепенный переход от петабайтных хранилищ к экзабайтным, а также изменение самой сути хранимой и обрабатываемой информации — структурированные данные становятся всё менее заметными на фоне растущих как снежный ком неструктурированных. 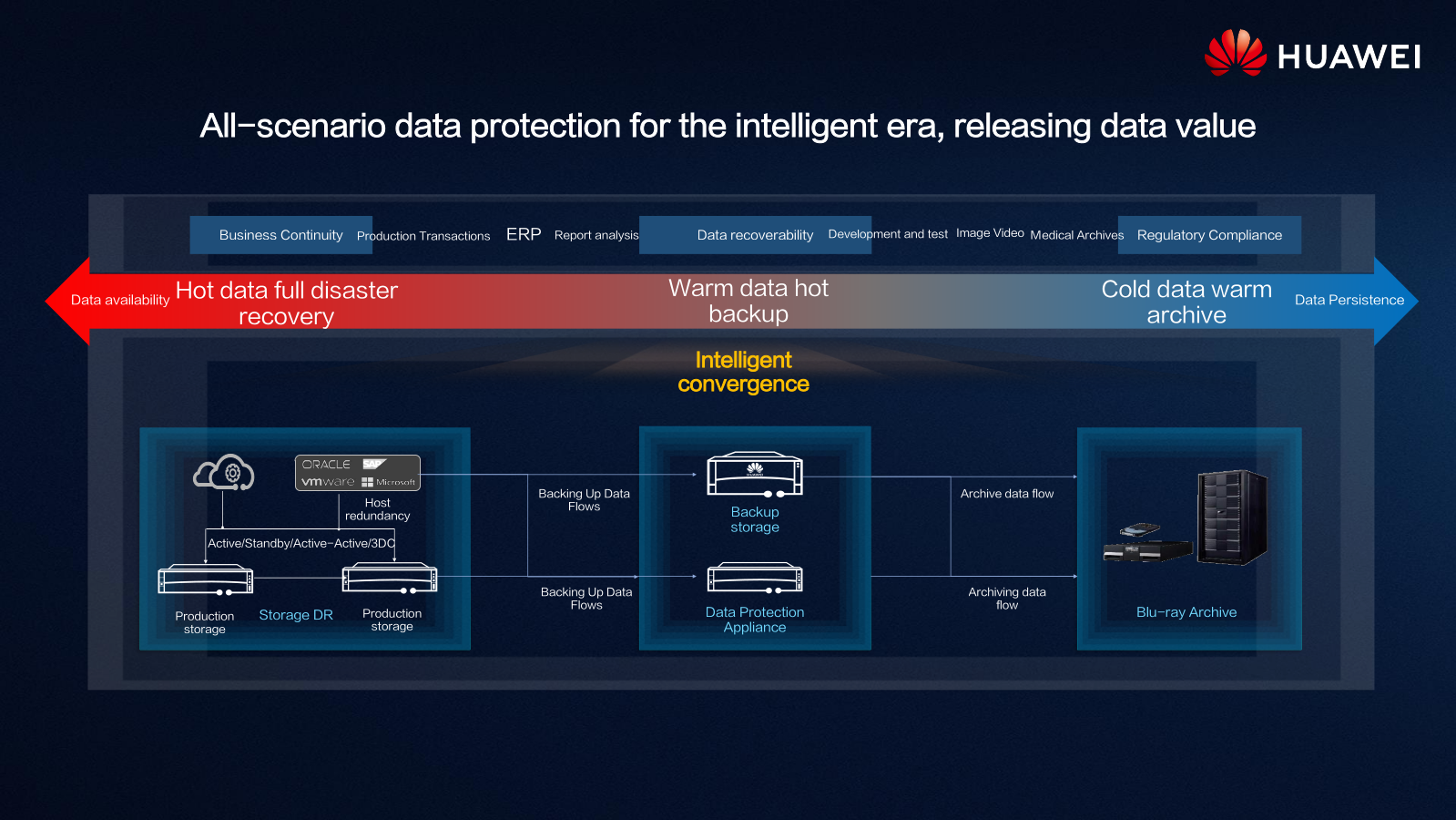 Всё это кардинальным образом меняет требования и к «боевым» СХД, и в особенности к системам резервного копирования. Без бэкапа «тёплых» данных кое-где уже не обойтись, но такие СХД должны обладать уникальным набором характеристик: достаточно высокое быстродействие, причём не только на получение, но и на отдачу данных; повышенная надёжность; универсальность, то есть работа и с SAN, и с NAS; масштабируемость по ёмкости и производительности. 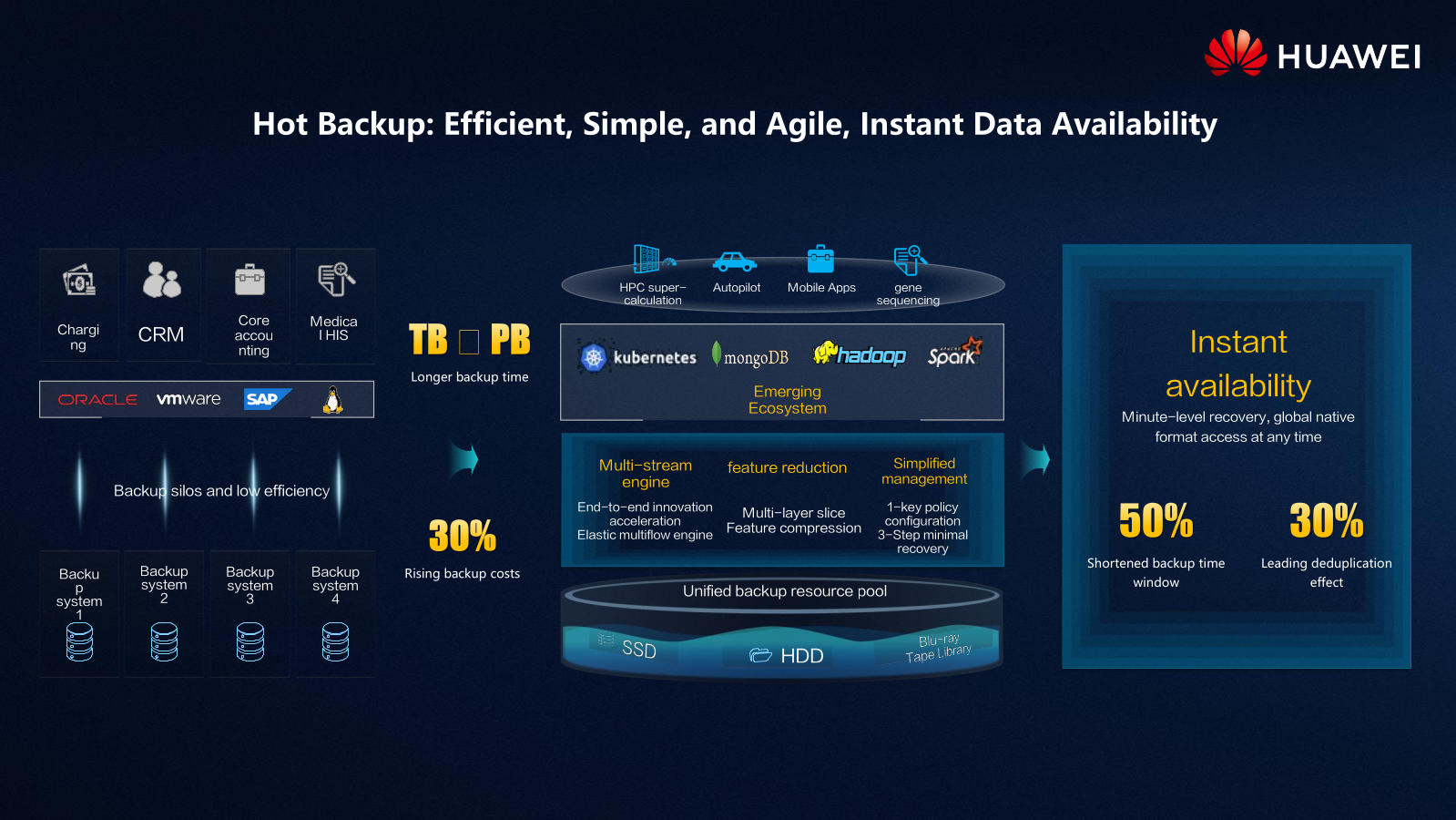 Ровно те же требования предъявляются и к основным СХД, однако для задач бэкапа нужно соблюсти ещё два очень важных условия. Во-первых, доступное пространство должно значительно превышать ёмкость резервируемых СХД, чего, не раздувая размеры системы, можно добиться лишь правильным использованием дедупликации и компрессии, которые при этом должны происходить на лету и минимально влиять на производительность. Во-вторых, такая система должны быть выгоднее, чем просто установка дубля основной СХД. 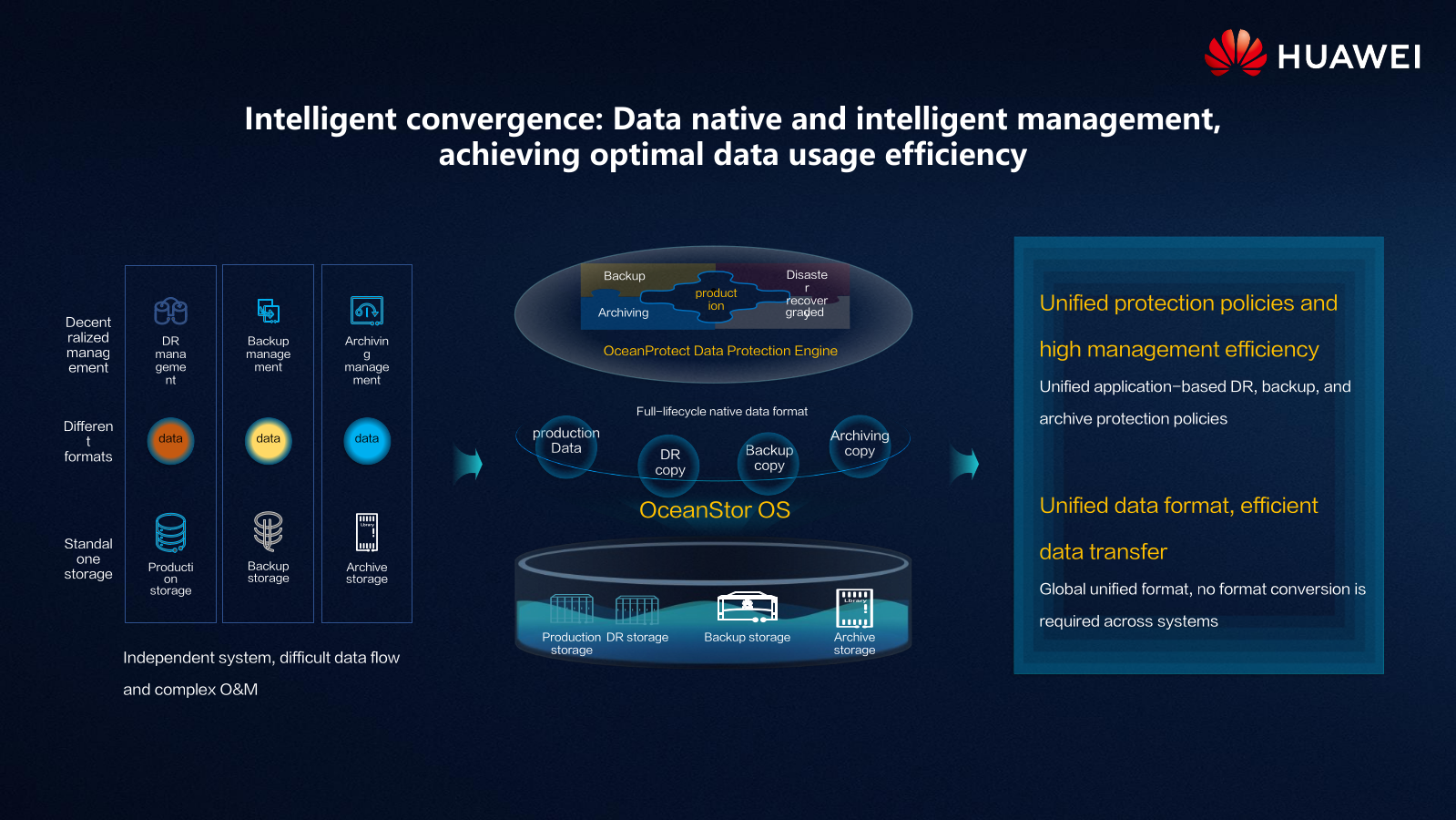 И у Huawei есть именно такое уникальное решение. Весной компания анонсировала новую серию СХД с говорящим названием OceanProtect. Наиболее интересными в ней являются модели X9000 и X8000, относящиеся к высокому и среднему сегменту соответственно. «Хитрость» в том, что основой для них является всё та же современная OceanStor Dorado, которую лишили части некритичных для задач резервного копирования функций и оснастили исключительно SAS SSD.
И, конечно, добавили ряд специфичных для работы с бэкапом оптимизаций. Например, в OceanProtect наряду с RAID-5/6 доступен и фирменный массив RAID-TP, сохраняющий работоспособность при потере до трёх накопителей сразу. Однако в данном случае данные агрегируются в длинные непрерывные блоки в кеше, сливаются воедино и записываются с использованием RoW (redirect-on-write) целыми страйпами. 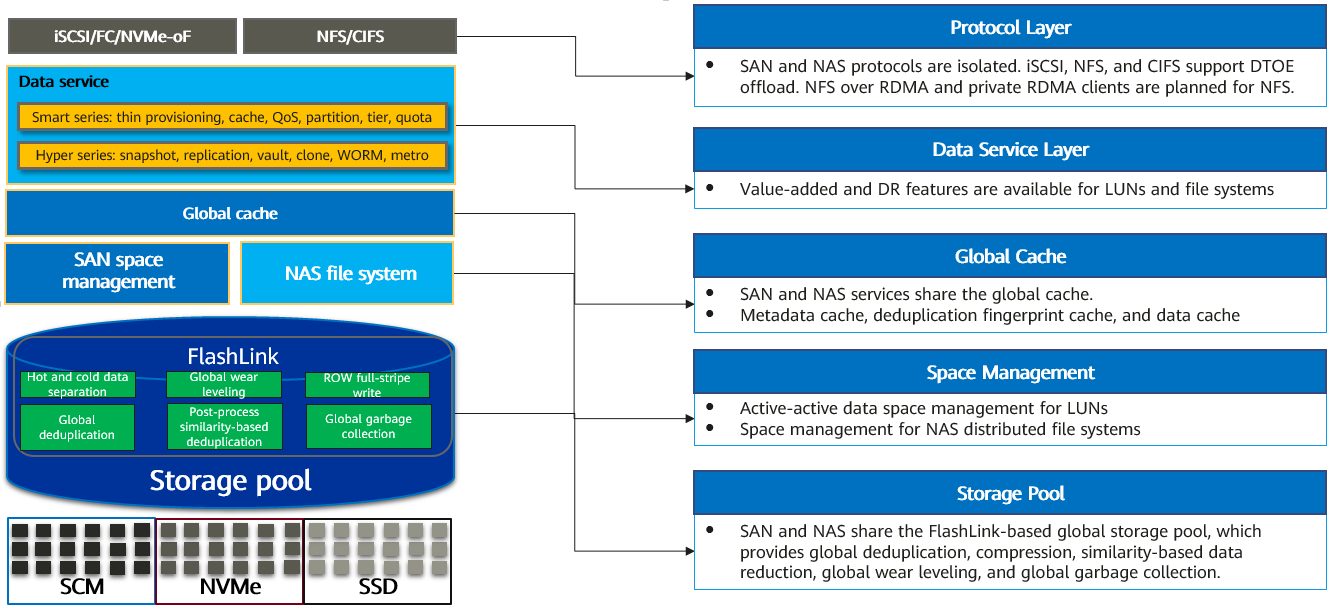 Такой подход отчасти связан с используемыми в OceanProtect алгоритмами дедупликации и компрессии, которые вместе позволяют достичь коэффициента сжатия вплоть до 55:1. Для этого используется несколько техник. В частности, мета✴-данные выявляются и отделяются от остальных, подвергаясь только компрессии. Для основных же данных используется динамически подстраиваемая системой дедупликация с сегментами переменной длины. После неё данные снова анализируются и делятся на те, которые хорошо подвергаются компрессии и для которых используются стандартные алгоритмы сжатия, и на те, которые просто так сжать не удастся. 
Контроллер Huawei OceanProtect X9000 Для последних применяется фирменный алгоритм сжатия, который, к слову, является детищем российского подразделения исследований и разработок компании — Huawei регулярно проводит конкурс по созданию именно таких алгоритмов среди отечественных вузов, так что некоторые наработки попадают в столь заметные продукты. Сжатые данные побайтно выравниваются для компактности и отправляются на запись. Таким образом достигается и эффективное использование дискового пространства, и снижение нагрузки на накопители. 
Контроллер Huawei OceanProtect X8000 Повышение надёжности СХД достигается несколькими механизмами на различных уровнях. Так, непосредственно внутри SSD из чипов памяти формируются массивы RAID 4. Сами SSD представляются системе не как «монолиты», а в виде групп RAID 2.0+ из блоков фиксированного размера. Это позволяет не только повысить надёжность без потери производительности, но и сбалансировать нагрузку, выровнять износ и значительно сократить время на пересборку массивов. 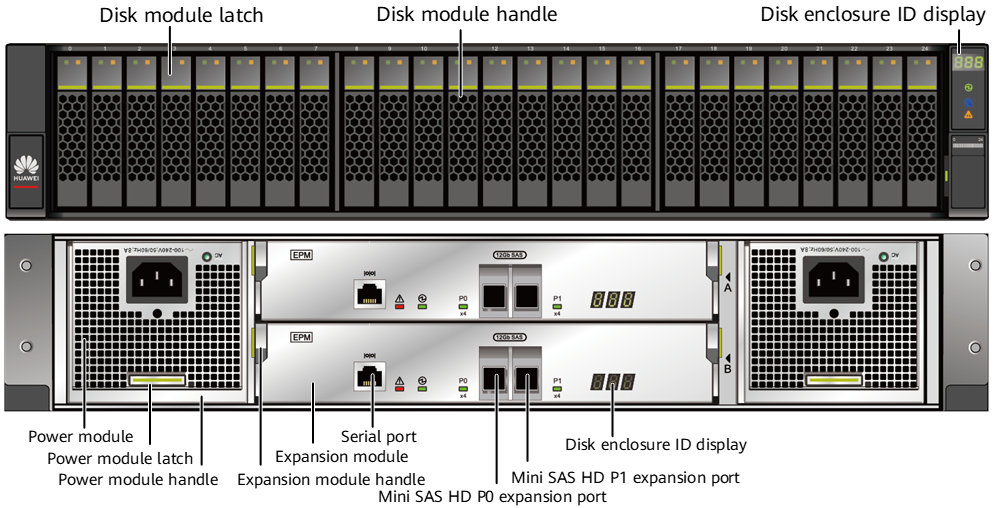
Дисковая полка Huawei OceanProtect X8000/X9000 Для подключения дисковых полок используются 4-портовые (Mini-SAS) интерфейсные модули SAS-3, для контроллеров — 25/100GbE с RDMA, а для хостов — модули FC8/16/32 и 10/25/40/100GbE с RDMA. Ethernet-контроллеры поддерживают разгрузку стека TCP/IP, избавляя CPU от лишней нагрузки. Посадочных мест для модулей достаточно для того, чтобы объединить контроллеры с резервированием подключения без использования внешнего коммутатора. Для SAN доступна поддержка Fibre Channel и iSCSI, а для NAS — NFSv3/4.1, SMB/CIFS 2.0/3.0 и NDMP. 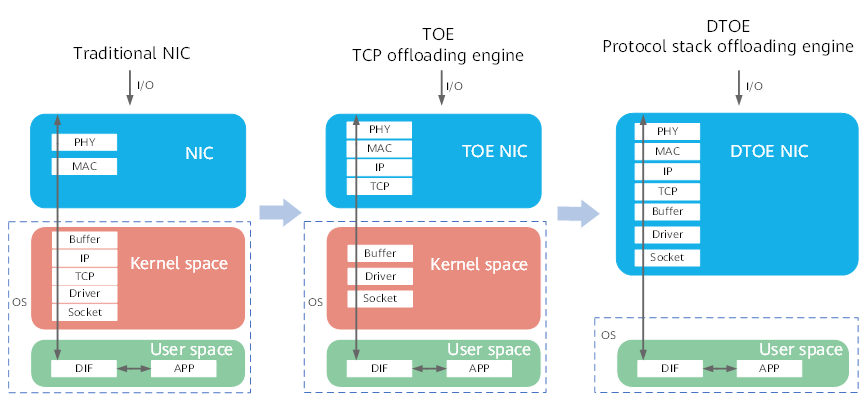 Дисковый бэкенд и IO-фронтенд подключаются к контроллерам по схеме «каждый-с-каждым» с дополнительным резервированием, да и сами контроллеры провязаны между собой по той же схеме. Таким образом формируется полноценная mesh-сеть из всех компонентов и линков. Это даёт всё те же отказоустойчивость, производительность и сбалансированность. Ну и поддержку горячей замены или обновления (что программного, что аппаратного) практически любого из компонентов системы без её остановки. 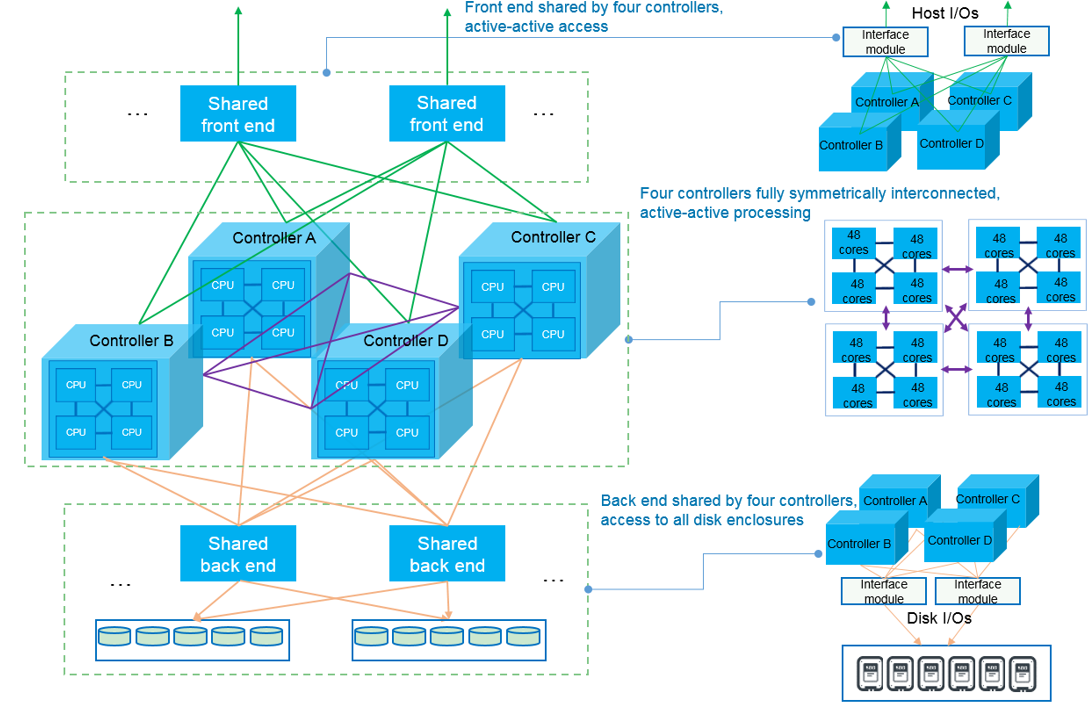 На программном уровне доступны различные варианты репликации и работы со снапшотами, «умные» квоты и классы обслуживания (по скорости, IOPS и задержке), расширенная система мониторинга, прогнозная аналитика по состоянию системы в целом и отдельных её компонентов, в том числе по производительности и ёмкости. Для задач безопасности доступно шифрование на уровне дисков, безопасное затирание данных по международным стандартам, а также аппаратный RoT, формирующий цепочку доверия для всего ПО. 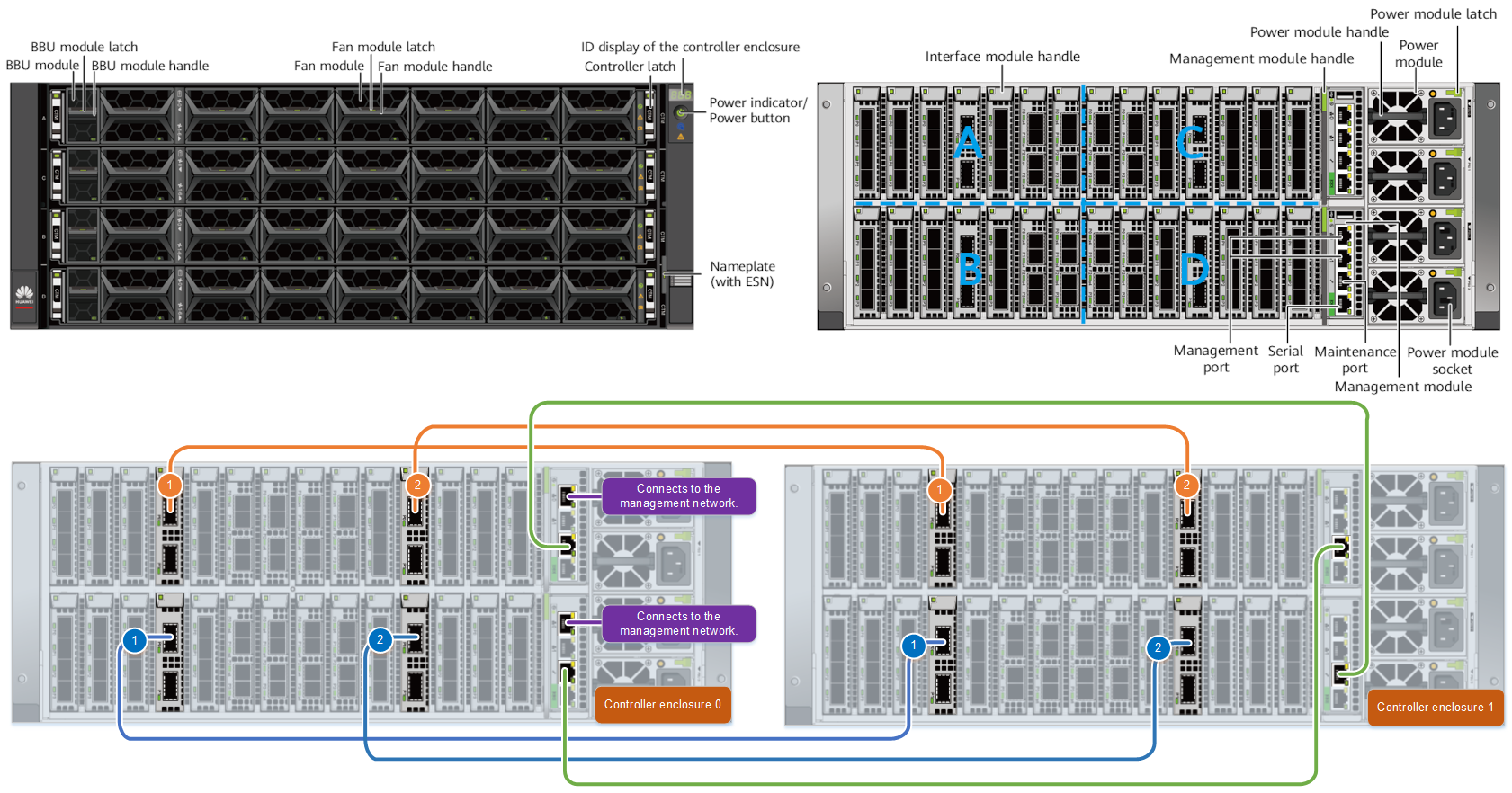
Huawei OceanProtect X9000 Всё вышесказанное относится к обеим моделям, X8000 и X900. Но различия между ними, конечно, есть. У OceanProtect X9000 в отдельном 4U-шасси находятся четыре контроллера Active-Active, каждый из которых может иметь до четырёх CPU и до 1 Тбайт памяти для кеширования. Система сохраняет работоспособность при выходе из строя трёх из четырёх контроллеров. На шасси приходится 28 интерфейсных модулей и четыре БП, которые являются общими для всех. Можно объединить два шасси, то есть получить восемь контроллеров, связанных между собой 100GbE-подключениями. 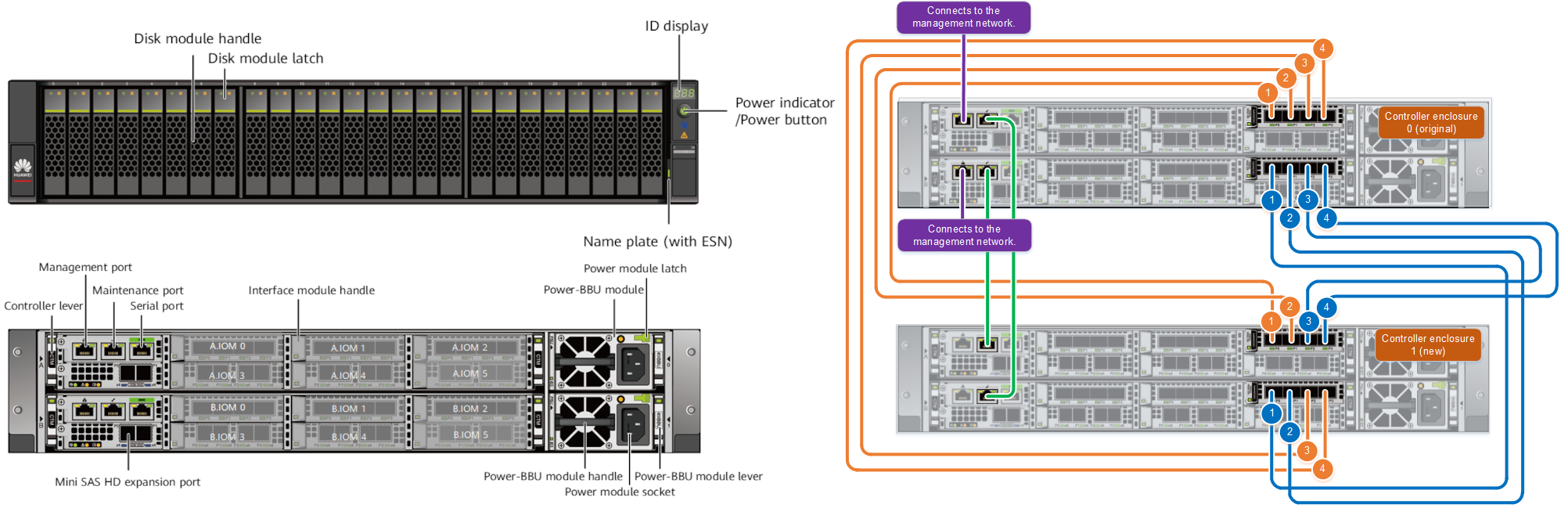
Huawei OceanProtect X8000 OceanProtect X8000 объединяет в 2U-шасси два контроллера Active-Active, 25 накопителей SAS-3 и два БП. Каждый контроллер имеет до 2 CPU, до 512 Гбайт памяти для кеширования и шесть интерфейсных модулей. Можно объединить два шасси (четыре контроллера) посредством 25GbE-подключений. Дисковые полки одинаковые для обеих моделей — 2U-шасси на 25 накопителей с четырьмя портами Mini-SAS и двумя БП. Пока что доступны только накопители объёмом 3,84 и 7,68 Тбайт, но в будущем появятся и более ёмкие модели.  В серии OceanProtect есть и СХД попроще. Так, модель A8000 похожа на X8000, но имеет более скромные показатели производительности и предлагает только 10/25GbE-интерфейсы. А линейка Huawei DPA использует уже SATA-накопители и 1/10GbE-подключения. В будущем появится и серия оптических библиотек OceanArchive для «холодных» данных. Таким образом, продукты компании покроют все ключевые задачи в этом сегменте. Huawei ожидает, что рынок СХД для резервного копирования вырастет к 2025 году до $14,7 млрд и рассчитывает «отъесть» от него примерно половину.
26.08.2021 [03:07], Алексей Степин
Получены первые образцы 1000-ядерного суперкомпьютера-на-чипе Esperanto ET-SoC-1Рекомендательные системы, активно используемые социальными сетями, рекламными платформами и т.д. имеют специфические особенности. От них требуется высокая скорость отклика, но вместе с тем их ИИ-модели весьма объёмны, порядка 100 Гбайт или более. А для их эффективной работы нужен ещё и довольно большой кеш. Для инференса чаще всего используется либо CPU (много памяти, но относительно низкая скорость) или GPU (высокая скорость, но мало памяти), но они не слишком эффективны для этой задачи. При этом существуют ещё и физические ограничения со стороны гиперскейлеров: в сервере не так много полноценных PCIe-слотов и свободного места + есть жёсткие ограничения по энергопотреблению и охлаждению (чаще всего воздушному). Всё это было учтено компанией Esperanto, чьей специализацией является разработка чипов на базе архитектуры RISC-V. На днях она получила первые образцы ИИ-ускорителя ET-SoC-1, который она сама называет суперкомпьютером-на-чипе (Supercomputer-on-Chip).  Новинка предназначена для инференса рекомендательных систем, в том числе на периферии, где на первый план выходит экономичность. Компания поставила для себя непростую задачу — весь комплекс ускорителей с памятью и служебной обвязкой должен потреблять не более 120 Вт. Для решения этой задачи пришлось применить немало ухищрений. Самое первое и очевидное — создание относительно небольшого, но универсального чипа, который можно было бы объединять с другими такими же чипами с линейным ростом производительности.  Для достижения высокой степени параллелизма основой такого чипа должны стать небольшие, но энергоэффективные ядра. Именно поэтому выбор пал на 64-бит ядра RISC-V, поскольку они «просты» не только с точки зрения ISA, но и по транзисторному бюджету. Чип ET-SoC-1 сочетает в себе два типа ядер RISC-V: классических «больших» ядер (ET-Maxion) с внеочередным выполнением у него всего 4, зато «малых» ядер (ET-Minion) с поддержкой тензорных и векторных вычислений — целых 1088. 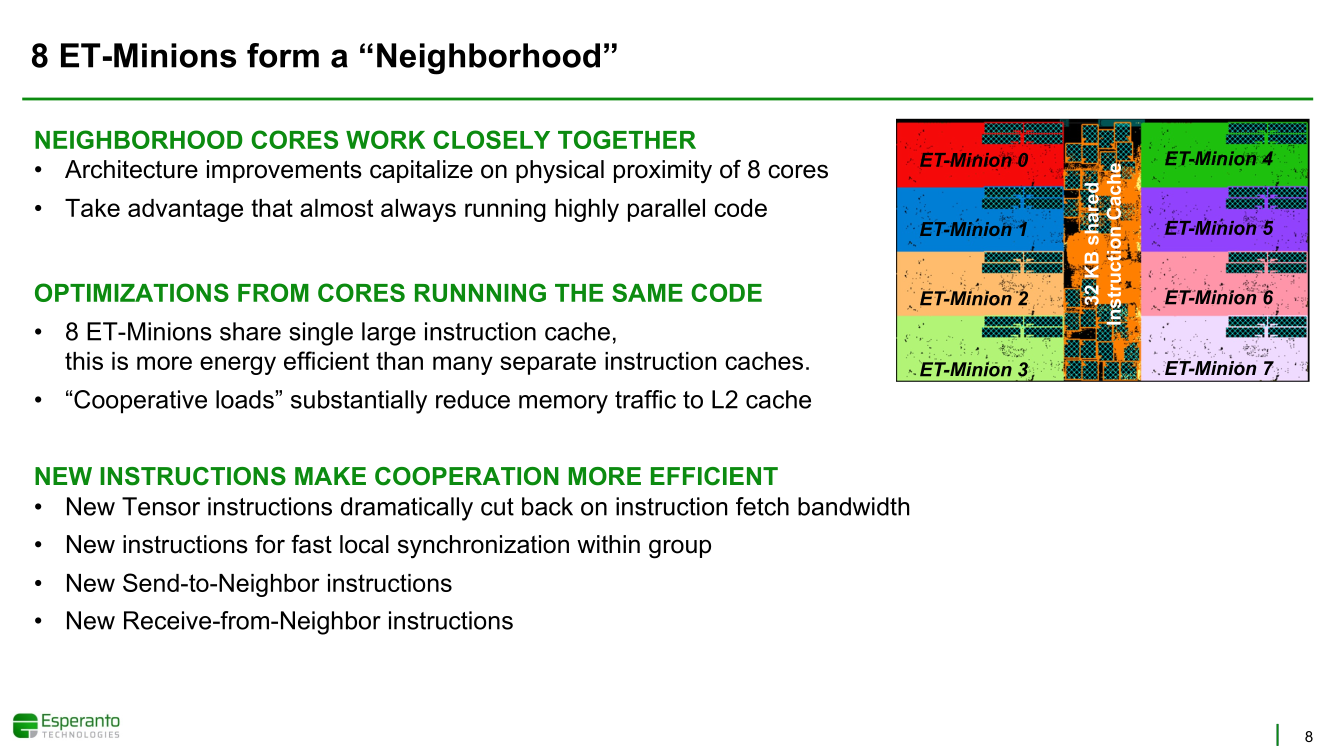 На комплекс ядер ET-Maxion возлагаются задачи общего назначения и в ИИ-вычислениях он напрямую не участвует, зато позволяет быть ET-SoC-1 полностью автономным, так как прямо на нём можно запустить Linux. Помогает ему в этом ещё один служебный RISC-V процессор для периферии. А вот ядра ET-Minion довольно простые: внеочередного исполнения инструкций в них нет, зато есть поддержка SMT2 и целый набор новых инструкций для INT- и FP-операций с векторами и тензорами. 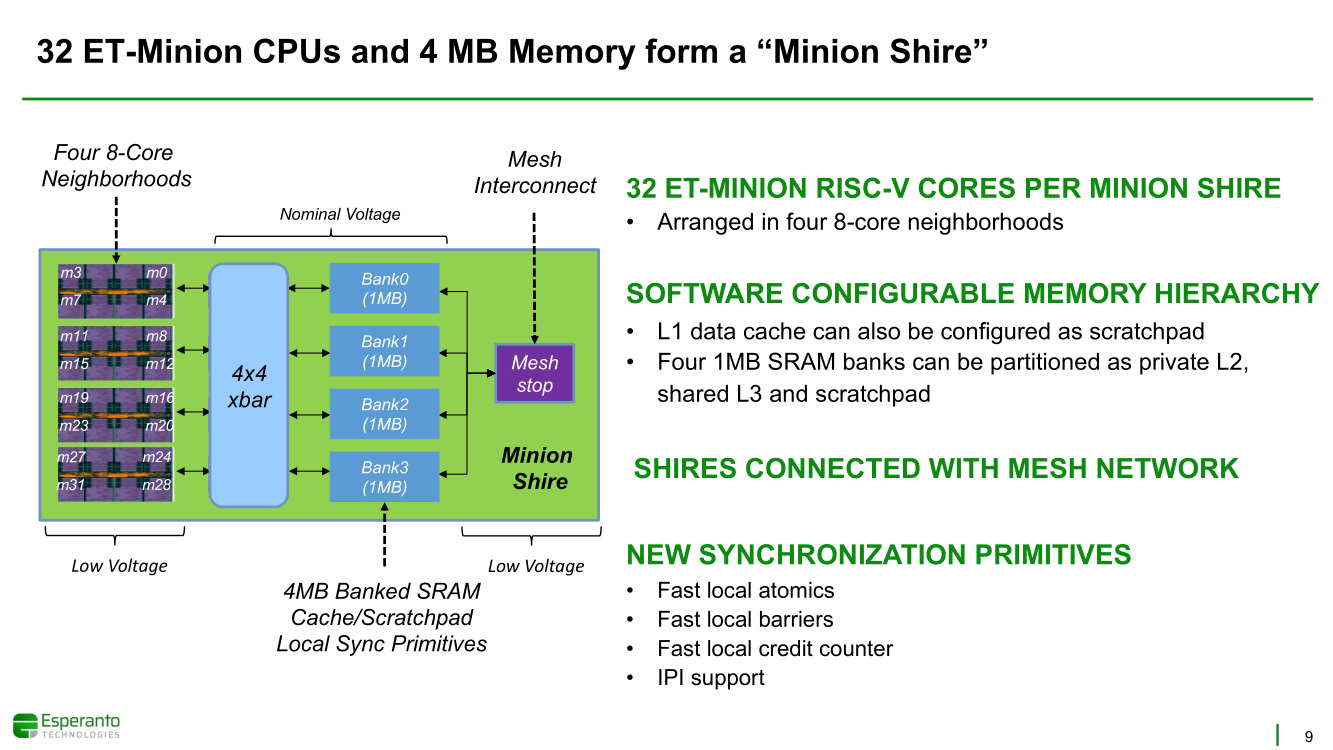 За каждый такт ядро ET-Minion способно выполнять 128 INT8-операций с сохранением INT32-результата, 16 FP32-операций или 32 — FP16. «Длинные» тензорные операции могут непрерывно исполняться в течение 512 циклов (до 64 тыс. операций), при этом целочисленные блоки в это время отключаются для экономии питания. Система кешей устроена несколько непривычным образом. На ядро приходится 4 банка памяти, которые можно использовать как L1-кеш для данных и как быструю универсальную память (scratchpad). 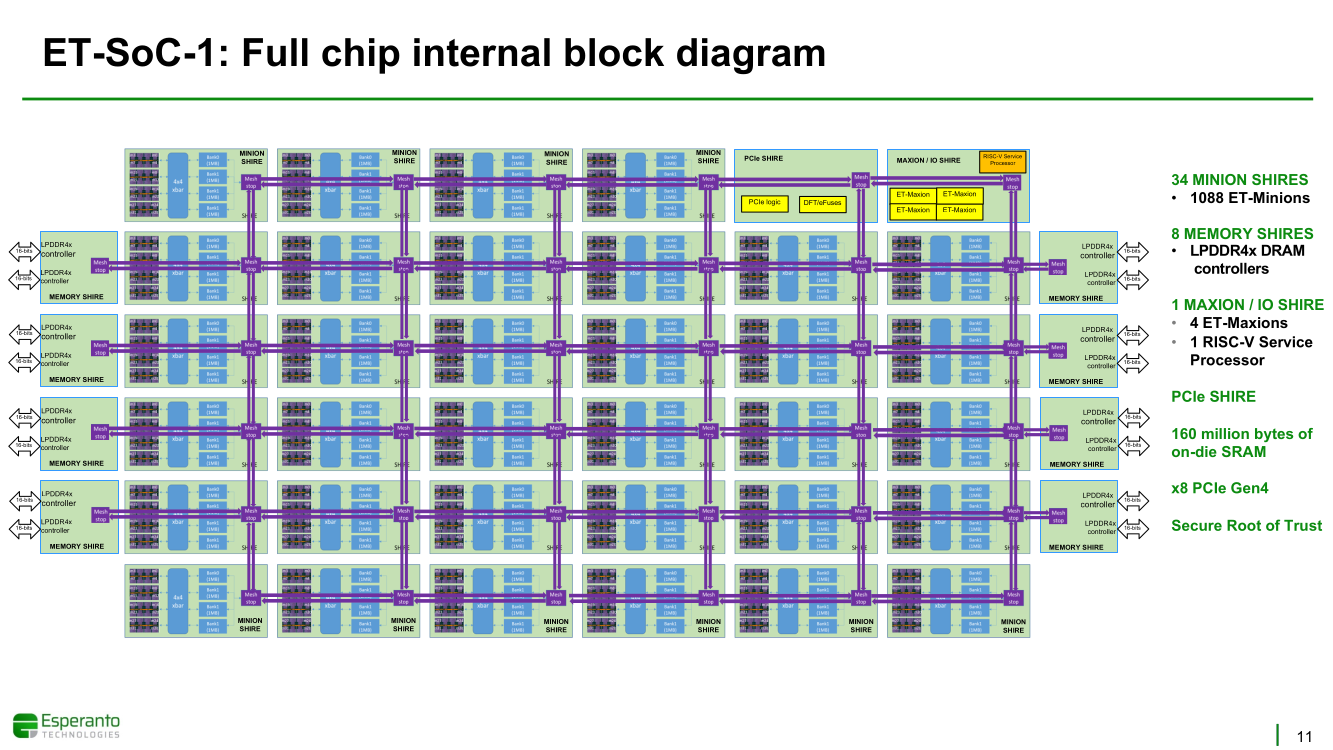 Восемь ядер ET-Minion формируют «квартал» вокруг общего для них кеша инструкций, так как на таких задачах велика вероятность того, что инструкции для всех ядер действительно будут одни и те же. Кроме того, это энергоэффективнее, чем восемь индивидуальных кешей, и позволяет получать и отправлять данные большими блоками, снижая нагрузку на L2-кеш. Восемь «кварталов» формируют «микрорайон» с коммутатором и четырьмя банками SRAM объёмом по 1 Мбайт, которые можно использовать как приватный L2-кеш, как часть общего L3-кеша или как scratchpad. 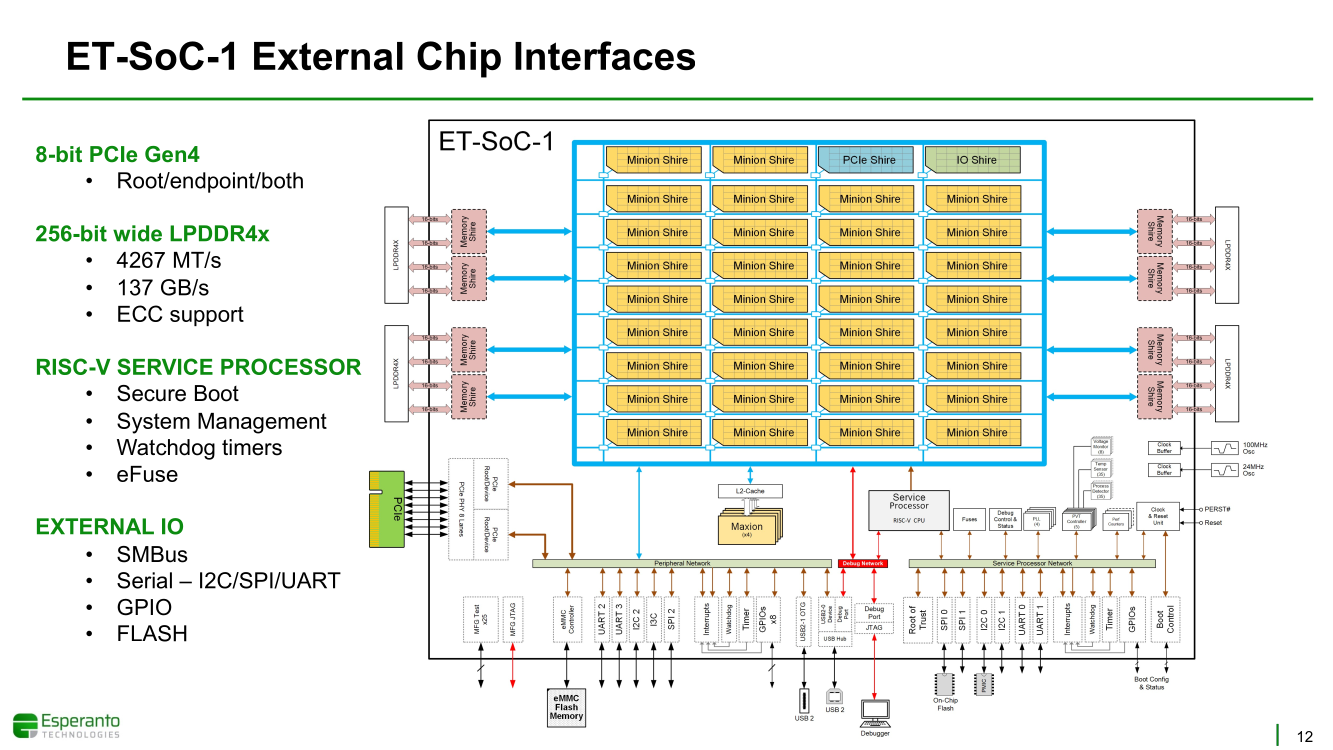 Посредством mesh-сети «микрорайоны» общаются между собой и с другими блоками: ET-Maxion, восемь двухканальных контроллеров памяти, два root-комплекса PCIe 4.0 x8, аппаратный RoT. Суммарно на чип приходится порядка 160 Мбайт SRAM. Контроллеры оперативной памяти поддерживают модули LPDDR4x-4267 ECC (256 бит, до 137 Гбайт/с). Тактовая частота ET-Minion варьируется в пределах от 500 МГц до 1,5 ГГц, а ET-Maxion — от 500 МГц до 2 ГГц. 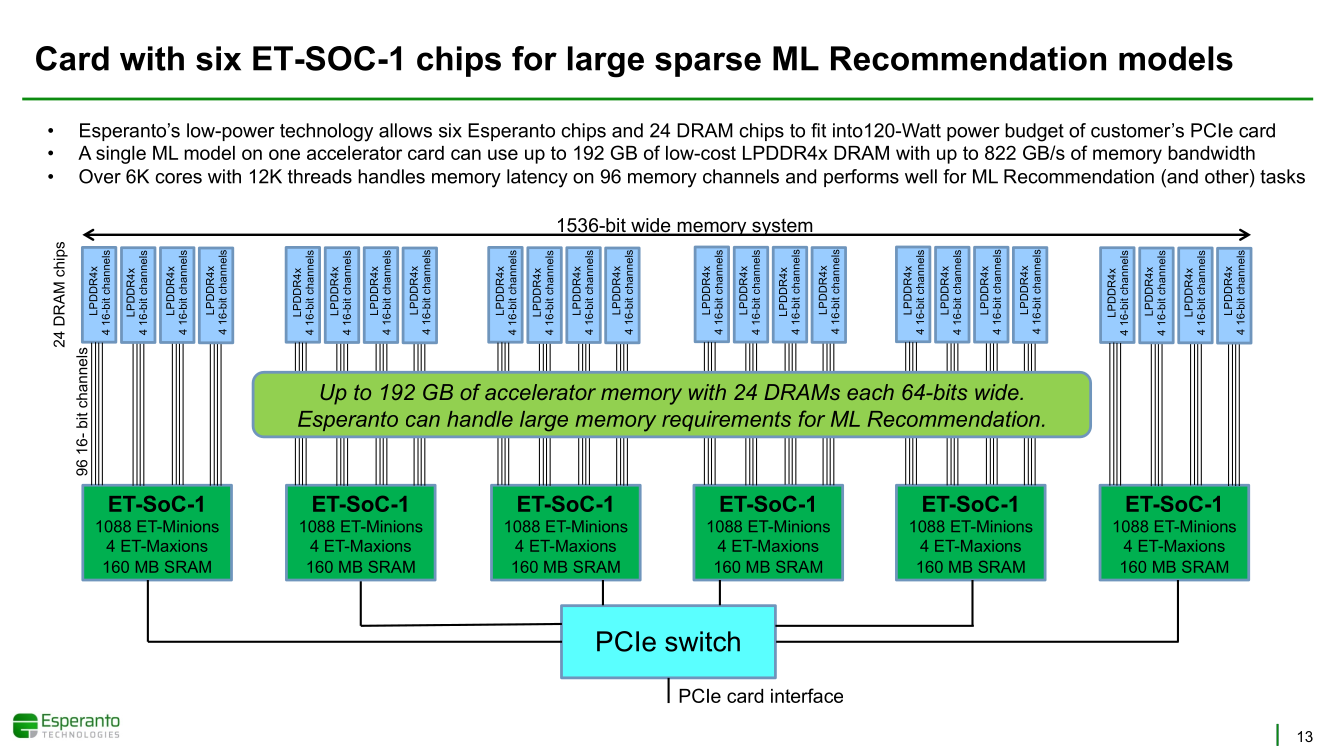 В рамках OCP-блока Glacier Point V2 компания объединила на одной плате шесть ET-SoC-1 (всего 6558 ядер RISC-V), снабдив их 192 Гбайт памяти (822 Гбайт/с) — это больше, нежели у NVIDIA A100 (80 Гбайт). Такая связка развивает более 800 Топс, требуя всего 120 Вт. В среднем же она составляет 100 ‒ 200 Топс на один чип с потреблением менее 20 Вт. Это позволяет создать компактный M.2-модуль или же наоборот масштабировать систему далее. Шасси Yosemite v2 может вместить 64 чипа, а стойка — уже 384 чипа. 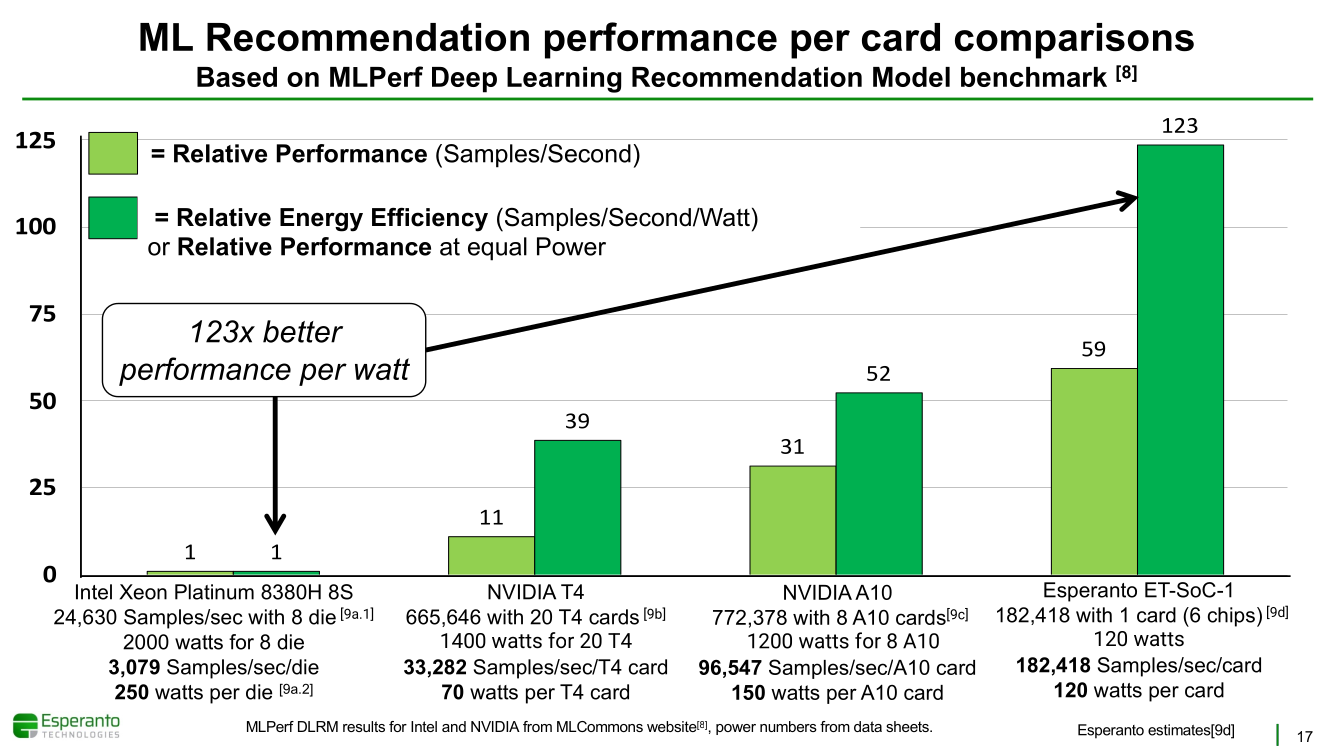 В тесте MLPerf для рекомендательных систем производительность указанной выше связки из шести чипов в пересчёте на Ватт оказалась в 123 раза выше, чем у Intel Xeon Platinum 8380H (250 Вт), и в два-три раза выше, чем у NVIDIA A10 (150 Вт) и T4 (70 Вт). В «неудобном» для чипа тесте ResNet-50 разница с CPU и ускорителем Habana Goya уже не так велика, а вот с решениями NVIDIA, напротив, более заметна. 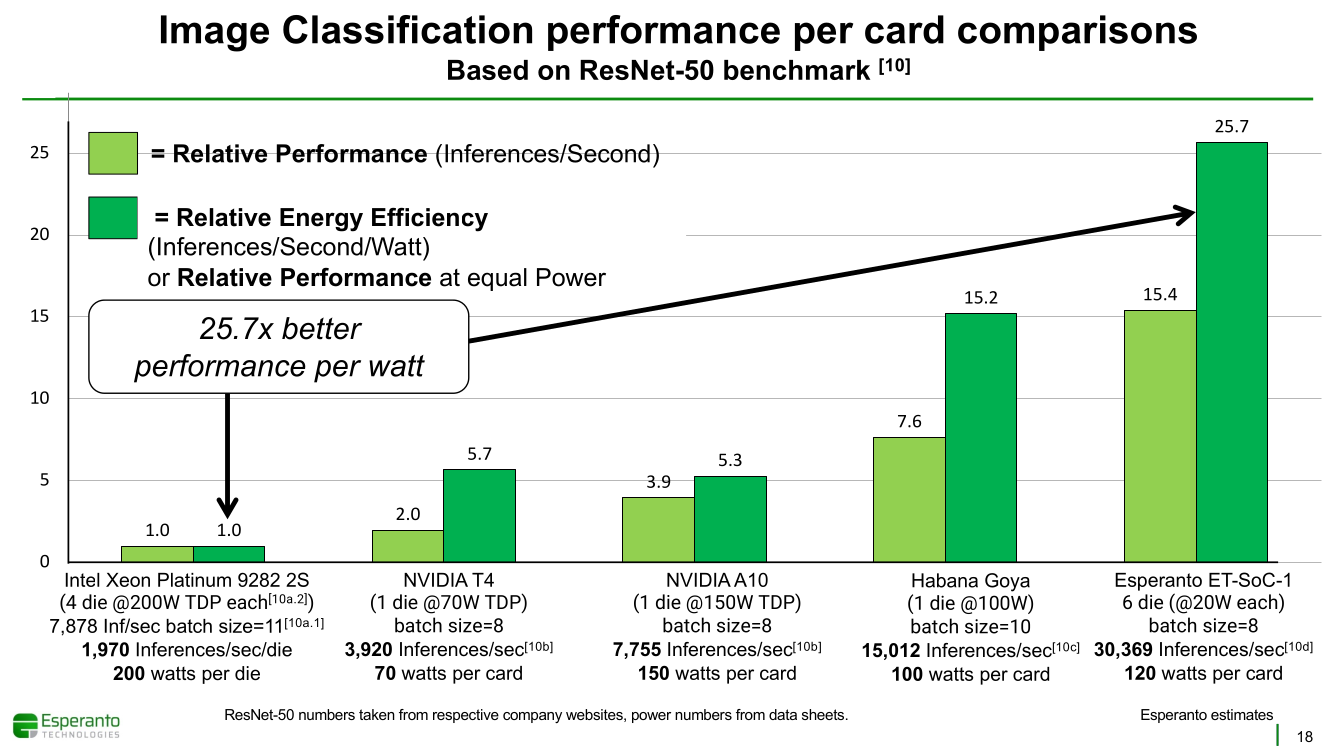 При этом о поддержке со стороны ПО разработчики также подумали: чипы Esperanto могут работать с широко распространёнными фреймворками PyTorch, TensorFlow, MXNet и Caffe2, а также принимать готовые ONNX-модели. Есть и SDK для C++, а также драйверы для x86-хостов.  Опытные образцы изготовлены на TSMC по 7-нм техпроцессу. Кристалл площадью 570 мм2 содержит 24 млрд транзисторов. Чип имеет упаковку BGA2494 размерами 45 × 45 мм2. Энергопотребление (а вместе с ним и производительность) настраивается в диапазоне от 10 до 60+ Ватт. Потенциальным заказчикам тестовые чипы станут доступны до конца года. Компания также готова адаптировать ET-SoC-1 под другие техпроцессы и фабрики, но демо на базе OCP-платформы и сравнение с Cooper Lake — это недвусмысленный намёк для Facebook✴, что Esperanto будет рада видеть её в числе первых клиентов.
24.08.2021 [04:11], Алексей Степин
IBM представила процессоры Telum: 8 ядер, 5+ ГГц, L2-кеш 256 Мбайт и ИИ-ускорительФинансовые организации, системы бронирования и прочие операторы бизнес-критичных задач любят «большие машины» IBM за надёжность. Недаром литера z в названии систем означает Zero Downtime — нулевое время простоя. На конференции Hot Chips 33 компания представила новое поколение z-процессоров, впервые в истории получившее собственное имя Telum (дротик в переводе с латыни). «Оружейное» название выбрано неспроста: в новой архитектуре IBM внедрила и новые, ранее не использовавшиеся в System z решения, предназначенные, в частности, для борьбы с фродом. 
Пластина с кристаллами IBM Telum Одни из ключевых заказчиков IBM — крупные финансовые корпорации и банки — давно ждали встроенных ИИ-средств, поскольку их системы должны обрабатывать тысячи и тысячи транзакций в секунду, и делать это максимально надёжно. Одной из целей при разработке Telum было внедрение инференс-вычислений, происходящих в реальном времени прямо в процессе обработки транзакции и без отсылки каких-либо данных за пределы системы.  Поэтому инференс-ускоритель в Telum соединён напрямую с подсистемой кешей и использует все механизмы защиты процессора и памяти z/Architecture. И сам он тоже несёт ряд характерных для z подходов. Так, управляет работой акселератора отдельная «прошивка» (firmware), которую можно менять для оптимизации задач конкретного клиента. Она выполняется на одном из ядер и собственно ускорителе, который общается с данным ядром, и отвечает за обращения к памяти и кешу, безопасность и целостность данных и управление собственно вычислениями. 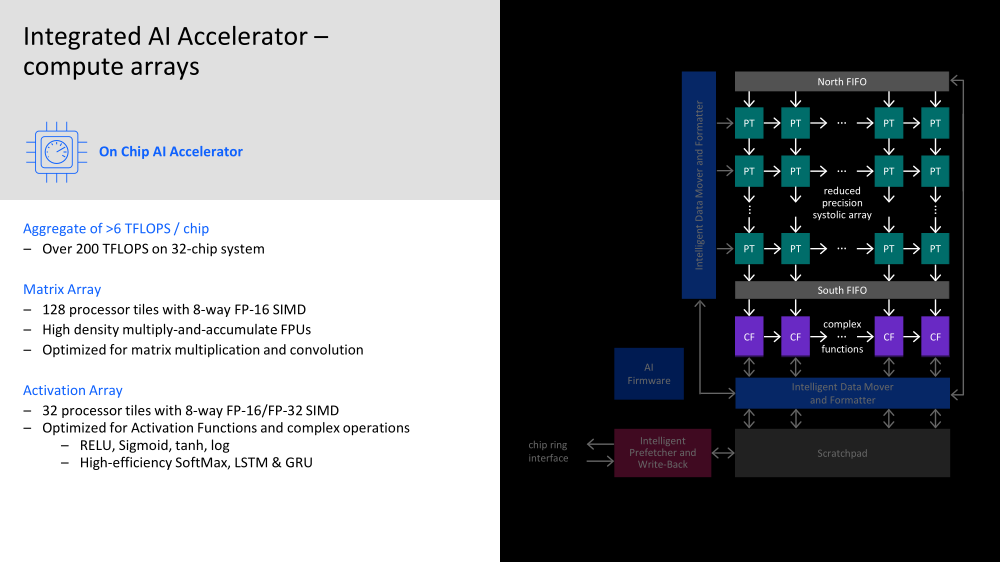 Акселератор включает два вида движков. Первый имеет 128 SIMD-блоков для MAC-операций с FP16-данными и нужен для перемножения и свёртки матриц. У второго всего 32 SIMD-блока, но он может работать с FP16/FP32-данными и оптимизирован для функций активации сети и других, более комплексных задач. Дополняет их блок сверхбыстрой памяти (scratchpad) и «умный» IO-движок, ответственный за перемещение и подготовку данных, который умеет переформатировать их на лету. 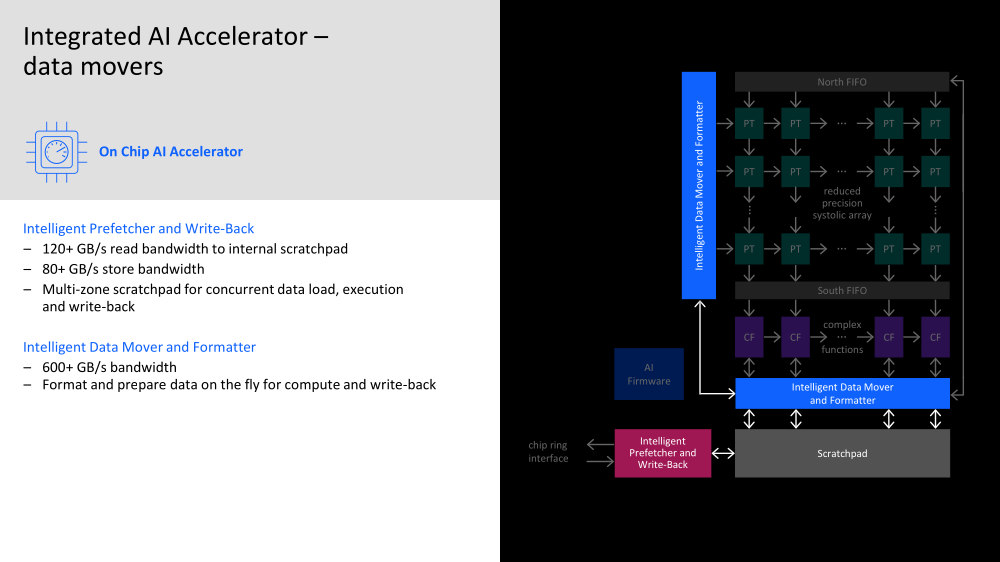 Scratchpad подключён к блоку, который подкачивает данные из L2-кеша и отправляет обратно результаты вычислений. IBM отдельно подчёркивает, что наличие выделенного ИИ-ускорителя позволяет параллельно использовать и обычные SIMD-блоки в ядрах, явно намекая на AVX-512 VNNI. Впрочем, в Sapphire Rapids теперь тоже есть отдельный AMX-блок в ядре, который однако скромнее по функциональности. 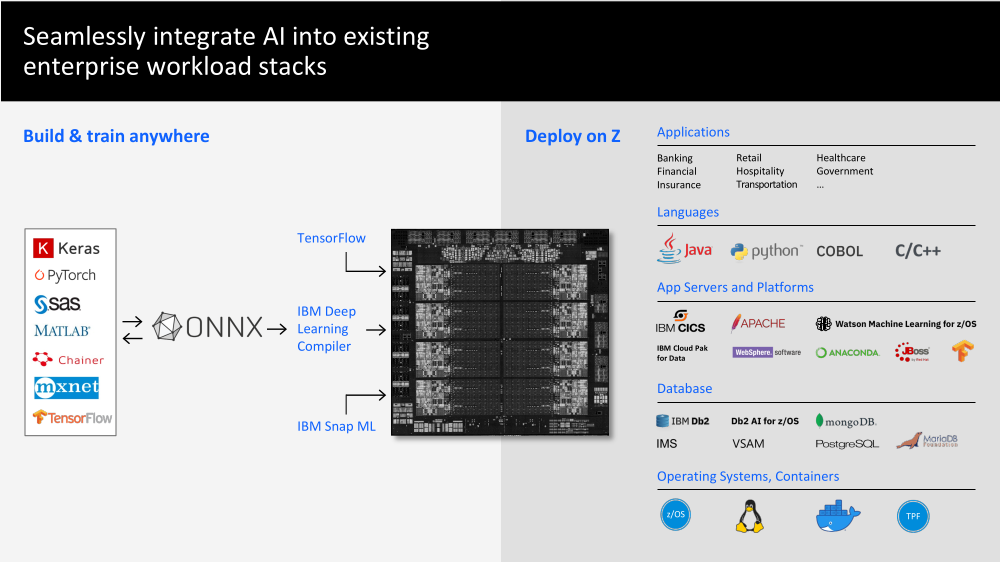 Доступ к ускорителю возможен из пространства пользователя, в том числе в виртуализированном окружении. Для работы с новым ускорителем компания предлагает IBM Deep Learning Compiler, который поможет оптимизировать импортируемые ONNX-модели. Также есть готовая поддержка TensorFlow, IBM Snap ML и целого ряда популярных средств разработки. На процессор приходится один ИИ-ускоритель производительностью более 6 Тфлопс FP16. 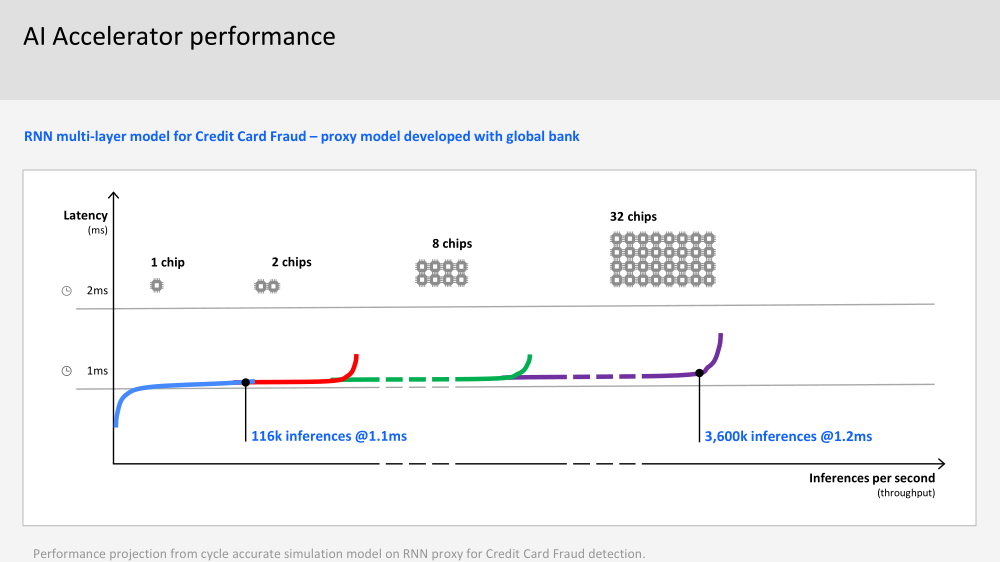 На тестовой RNN-модели для защиты от фрода чип может выполнять 116 тыс. инференс-операций с задержкой в пределах 1,1 мс, а для системы из 32 процессоров этот показатель составляет уже 3,6 млн инференс-операций, а латентность при этом возрастает всего лишь до 1,2 мс. Помимо ИИ-акселератора также имеется общий для всех ядер ускоритель (де-)компрессии (gzip) + у каждого ядра есть ещё и движок для CSMP. Ну и ускорители для сортировки и шифрования тоже никуда не делись.  За надёжность отвечают сотни различных механизмов проверки и перепроверки работоспособности. Так, например, регистры и кеш дублируются, позволяя в случае сбоя ядра сделать его полную перезагрузку и продолжить выполнение задач ровно с того места, где оно прервалось. А для оперативной памяти, которая в обязательном порядке шифруется, используется режим Redundant Array of Memory (RAIM), своего рода RAID-массив, где одна кеш-линия «размазывается» сразу между восемью модулями.  Telum, унаследовав многое от своего предшественника z15, всё же кардинально отличается от него. Процессор содержит восемь ядер с поддержкой «умного» глубокого внеочередного исполнения и SMT2, работающих на частоте более 5 ГГц. Каждому ядру полагается 32 Мбайт L2-кеша, так что на его фоне другие современные CPU выглядят блекло. Но не всё так просто. 
IBM Telum Между собой кеши общаются посредством двунаправленной кольцевой шины с пропускной способностью более 320 Гбайт/с, формируя таким образом виртуальный L3-кеш объёмом 256 Мбайт и со средней задержкой в 12 нс. Каждый чип Telum может содержать один (SCM) или два (DCM) процессора. А в одном узле может быть до четырёх чипов, то есть до восьми CPU, объединённых по схеме каждый-с-каждым с той же скоростью 320 Гбайт/с.  Таким образом, в рамках узла формируется виртуальный L4-кеш объёмом уже 2 Гбайт. Плоская топология кешей, по данным IBM, обеспечивает новым процессорам меньшую латентность в сравнении с z15. Масштабирование возможно до 32 процессоров, но отдельные узлы связаны несколькими подключениями со скоростью «всего» 45 Гбайт/с в каждую сторону.  В целом, IBM говорит о 40% прироста производительности в сравнении с z15 в пересчёте на сокет. Telum содержит 22 млрд транзисторов и имеет TDP на уровне 400 Вт в нормальном режиме работы. Процессор будет производиться на мощностях Samsung с использованием 7-нм техпроцесса EUV. Он станет основной для мейнфреймов IBM z16 и LinuxNOW. Программной платформой всё так же будут как традиционная z/OS, так и Linux.
19.08.2021 [18:04], Алексей Степин
Intel представила IPU Mount Evans и Oak Springs Canyon, а также ODM-платформу N6000 Arrow CreekВесной Intel анонсировала свои первые DPU (Data Processing Unit), которые она предпочитает называть IPU (Infrastructure Processing Unit), утверждая, что такое именования является более корректным. Впрочем, цели у этого класса устройств, как их не называй, одинаковые — перенос части функций CPU по обслуживанию ряда подсистем на выделенные аппаратные блоки и ускорители. Классическая архитектура серверных систем такова, что при работе с сетью, хранилищем, безопасностью значительная часть нагрузки ложится на плечи центральных процессоров. Это далеко не всегда приемлемо — такая нагрузка может отъедать существенную часть ресурсов CPU, которые могли бы быть использованы более рационально, особенно в современных средах с активным использованием виртуализации, контейнеризации и микросервисов. 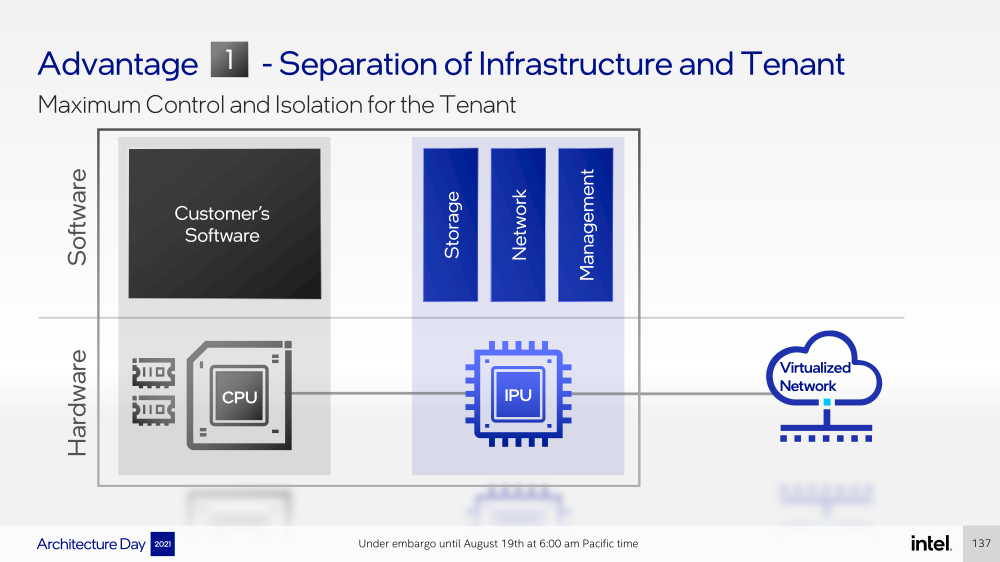 Для решения этой проблемы и были созданы DPU, которые эволюционировали из SmartNIC, бравших на себя «тяжёлые» задачи по обработке трафика и данных. DPU имеют на борту солидный пул вычислительных возможностей, что позволяет на некоторых из них запускать даже гипервизор. Однако Intel IPU имеют свои особенности, отличающие их и от SmartNIC, и от виденных ранее DPU. 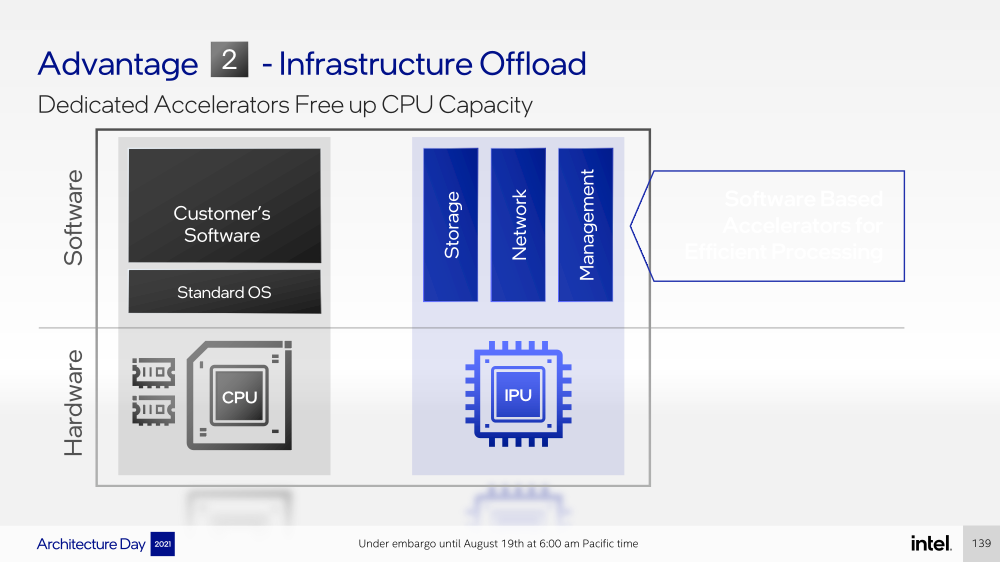 Новый класс сопроцессоров Intel должен взять на себя все заботы по обслуживанию инфраструктуры во всех её проявлениях, будь то работа с сетью, с подсистемами хранения данных или удалённое управление. При этом и DPU, и IPU в отличие от SmartNIC полностью независим от хост-системы. Полное разделение инфраструктуры и гостевых задач обеспечивает дополнительную прослойку безопасности, поскольку аппаратный Root of Trust включён в IPU. 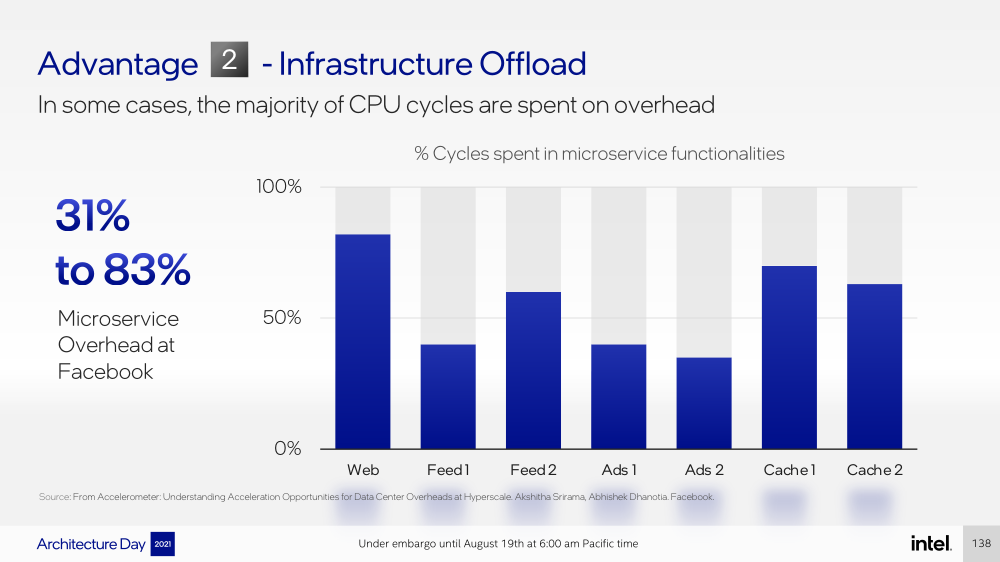 Это не единственное преимущество нового подхода. Компания приводит статистику Facebook✴, из которой видно, что иногда более 50% процессорных тактов серверы тратят на «обслуживание самих себя». Все эти такты могут быть пущены в дело, если за это обслуживание возьмётся IPU. Кроме того, новый класс сетевых ускорителей открывает дорогу к бездисковой серверной инфраструктуре: виртуальные диски создаются и обслуживаются также чипом IPU. 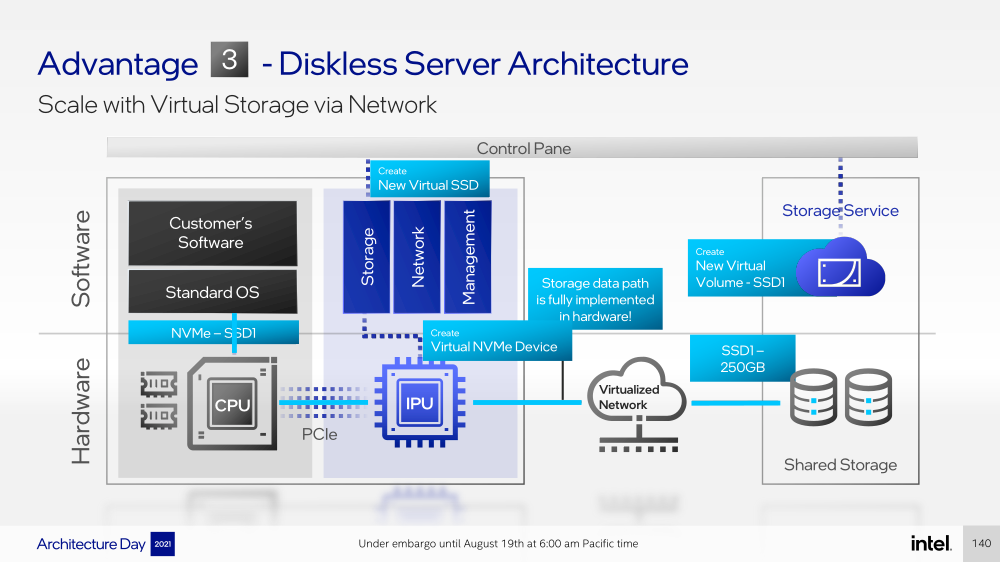 Первый чип в новом семействе IPU, получивший имя Mount Evans, создавался в сотрудничестве с крупными облачными провайдерами. Поэтому в нём широко используется кремний специального назначения (ASIC), обеспечивающий, однако, и нужную степень гибкости, За основу взяты ядра общего назначения Arm Neoverse N1 (до 16 шт.), дополненные тремя банками памяти LPDRR4 и различными ускорителями. 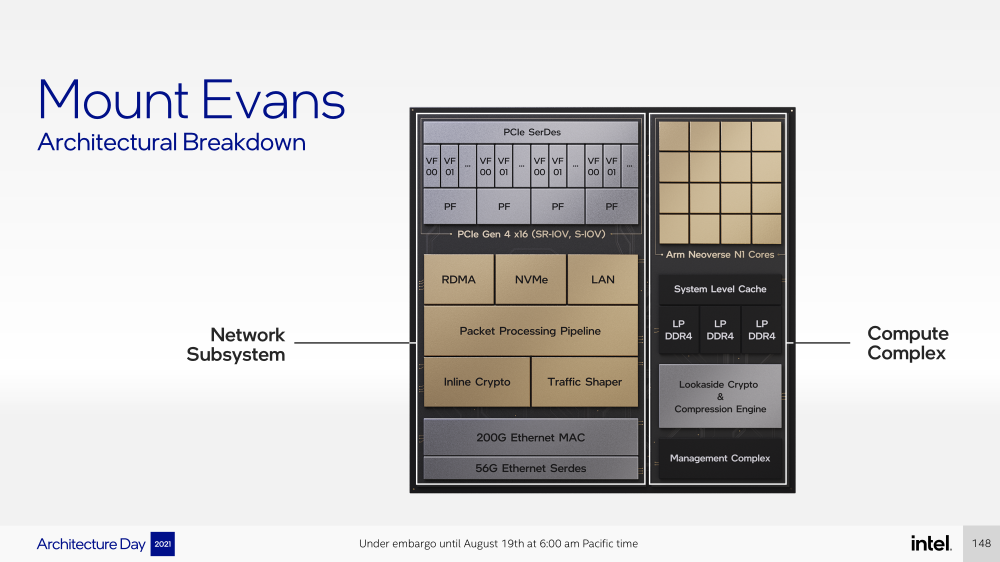 Сетевая часть представлена 200GbE-интерфейсом с выделенным P4-программируемым движком для обработки сетевых пакетов и управления QoS. Дополняет его выделенный IPSec-движок, способный на лету шифровать весь трафик без потери скорости. Естественно, есть поддержка RDMA (RoCEv2) и разгрузки NVMe-oF, причём отличительной чертой является возможность создавать для хоста виртуальные NVMe-накопители — всё благодаря контроллеру, который был позаимствован у Optane SSD.  Дополняют этот комплекс ускорители (де-)компресии и шифрования данных на лету. Они базируются на технологиях Intel QAT и, в частности, предложат поддержку современного алгоритма сжатия Zstandard. Наконец, у IPU будет выделенный блок для независимого внешнего управления. Работать с устройством можно будет посредством привычных SPDK и DPDK. Один IPU Mount Evans может обслуживать до четырёх процессоров. В целом, новинку можно назвать интересной и более доступной альтернативной AWS Nitro.  Также Intel представила платформу Oak Springs Canyon с двумя 100GbE-интерфейсами, которая сочетает процессоры Xeon-D и FPGA семейства Agilex. Каждому чипу которых полагается по 16 Гбайт собственной памяти DDR4. Платформа может использоваться для ускорения Open vSwitch и NVMe-oF с поддержкой RDMA/RocE, имеет аппаратные криптодвижки т.д. Наличие FPGA позволяет выполнять специфичные для конкретного заказчика задачи, но вместе с тем совместимость с x86 существенно упрощает разработку ПО для этой платформы. В дополнение к SPDK и DPDK доступны и инструменты OFS.  Наконец, компания показала и референсную плаформу для разработчиков Intel N6000 Acceleration Development Platform (Arrow Creek). Она несколько отличается от других IPU и относится скорее к SmartNIC, посколько сочетает FPGA Agilex, CPLD Max10 и сетевые контроллеры Intel Ethernet 800 (2 × 100GbE). Дополняет их аппаратный Root of Trust, а также PTP-блок.  Работать с устройством можно также с помощью DPDK и OFS, да и функциональность во многом совпадает с Oak Springs Canyon. Но это всё же платформа для разработки конечных решений ODM-партнёрами Intel, которые могут с её помощью имплементировать какие-то специфические протоколы или функции с ускорением на FPGA, например, SRv6 или Juniper Contrail. IPU могут стать частью высокоинтегрированной ЦОД-платформы Intel, и на этом поле она будет соревноваться в первую очередь с NVIDIA, которая активно продвигает DPU BluefIeld, а вскоре обзаведётся ещё и собственным процессором. Из ближайших интересных анонсов, вероятно, стоит ждать поддержку Project Monterey, о которой уже заявили NVIDIA и Pensando.
19.08.2021 [16:00], Игорь Осколков
Intel представила Xeon Sapphire Rapids: четырёхкристалльная SoC, HBM-память, новые инструкции и ускорителиВ рамках Architecture Day компания Intel рассказала о грядущих серверных процессорах Sapphire Rapids, подтвердив большую часть опубликованной ранее информации и дополнив её некоторыми деталями. Intel позиционирует новинки как решение для более широкого круга задач и рабочих нагрузок, чем прежде, включая и популярные ныне микросервисы, контейнеризацию и виртуализацию. Компания обещает, что CPU будут сбалансированы с точки зрения вычислений, работой с памятью и I/O. Новые процессоры, наконец, получили чиплетную, или тайловую в терминологии Intel, компоновку — в состав SoC входят четыре «ядерных» тайла на техпроцессе Intel 7 (10 нм Enhanced SuperFIN). Каждый тайл объединён с соседом посредством EMIB. Их системные агенты, включающие общий на всех L3-кеш объём до 100+ Мбайт, образуют быструю mesh-сеть с задержкой порядка 4-8 нс в одну сторону. Со стороны процессор будет «казаться» монолитным.  Каждые ядро или поток будут иметь свободный доступ ко всем ресурсам соседних тайлов, включая кеш, память, ускорители и IO-блоки. Потенциально такой подход более выгоден с точки зрения внутреннего обмена данными, чем в случае AMD с общим IO-блоком для всех чиплетов, которых в будущих EPYC будет уже 12. Но как оно будет на самом деле, мы узнаем только в следующем году — выход Sapphire Rapids запланирован на первый квартал 2022-го, а массовое производство будет уже во втором квартале.  Ядра Sapphire Rapids базируются на микроархитектуре Golden Cove, которая стала шире, глубже и «умнее». Она же будет использована в высокопроизводительных ядрах Alder Lake, но в случае серверных процессоров есть некоторые отличия. Например, увеличенный до 2 Мбайт на ядро объём L2-кеша или новый набор инструкций AMX (Advanced Matrix Extension). Последний расширяет ИИ-функциональность CPU и позволяет проводить MAC-операции над матрицами, что характерно для такого рода нагрузок.  Для AMX заведено восемь выделенных 2D-регистров объёмом по 1 Кбайт каждый (шестнадцать 64-байт строк). Отдельный аппаратный блок выполняет MAC-операции над тремя регистрами, причём делаться это может параллельно с исполнением других инструкций в остальной части ядра. Настройкой параметров и содержимого регистров, а также перемещением данных занимается ОС. Пока что в процессорах представлен только MAC-блок, но в будущем могут появиться блоки и для других, более сложных операций. 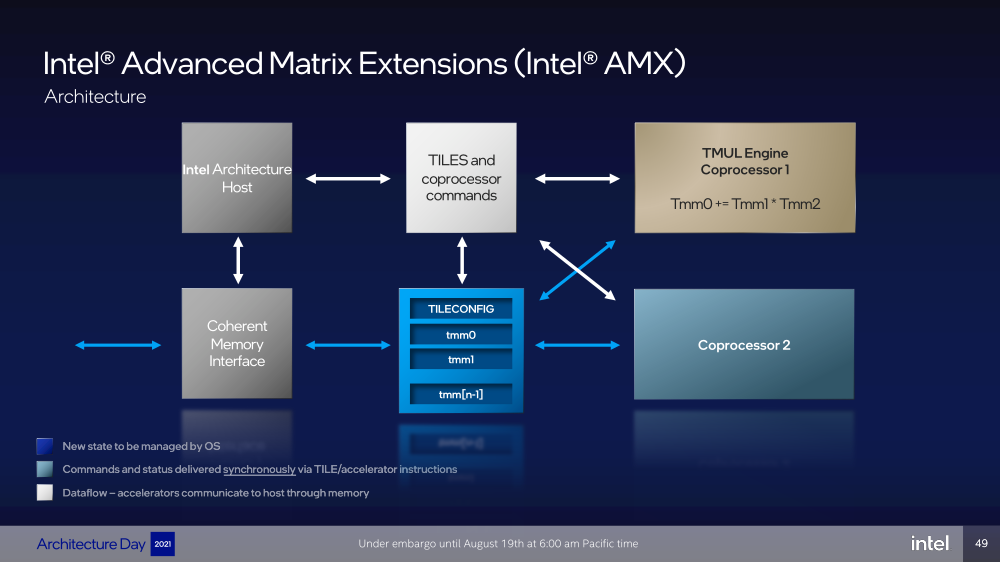 В пике производительность AMX на INT8 составляет 2048 операций на цикл на ядро, что в восемь раз больше, чем при использовании традиционных инструкций AVX-512 (на двух FMA-портах). На BF16 производительность AMX вдвое ниже, но это всё равно существенный прирост по сравнению с прошлым поколением Xeon — Intel всё так же пытается создать универсальные ядра, которые справлялись бы не только с инференсом, но и с обучением ИИ-моделей. Тем не менее, компания говорит, что возможности AMX в CPU будут дополнять GPU, а не напрямую конкурировать с ними.  К слову, именно Sapphire Rapids должен, наконец, сделать BF16 более массовым, поскольку Cooper Lake, где поддержка этого формата данных впервые появилась в CPU Intel, имеет довольно узкую нишу применения. Из прочих архитектурных обновлений можно отметить поддержку FP16 для AVX-512, инструкции для быстрого сложения (FADD) и более эффективного управления данными в иерархии кешей (CLDEMOTE), целый ряд новых инструкций и прерываний для работы с памятью и TLB для виртуальных машин (ВМ), расширенную телеметрию с микросекундными отсчётами и так далее.  Последние пункты, в целом, нужны для более эффективного и интеллектуального управления ресурсами и QoS для процессов, контейнеров и ВМ — все они так или иначе снижают накладные расходы. Ещё больше ускоряют работу выделенные акселераторы. Пока упомянуты только два. Первый, DSA (Data Streaming Accelerator), ускоряет перемещение и передачу данных как в рамках одного хоста, так и между несколькими хостами. Это полезно при работе с памятью, хранилищем, сетевым трафиком и виртуализацией. 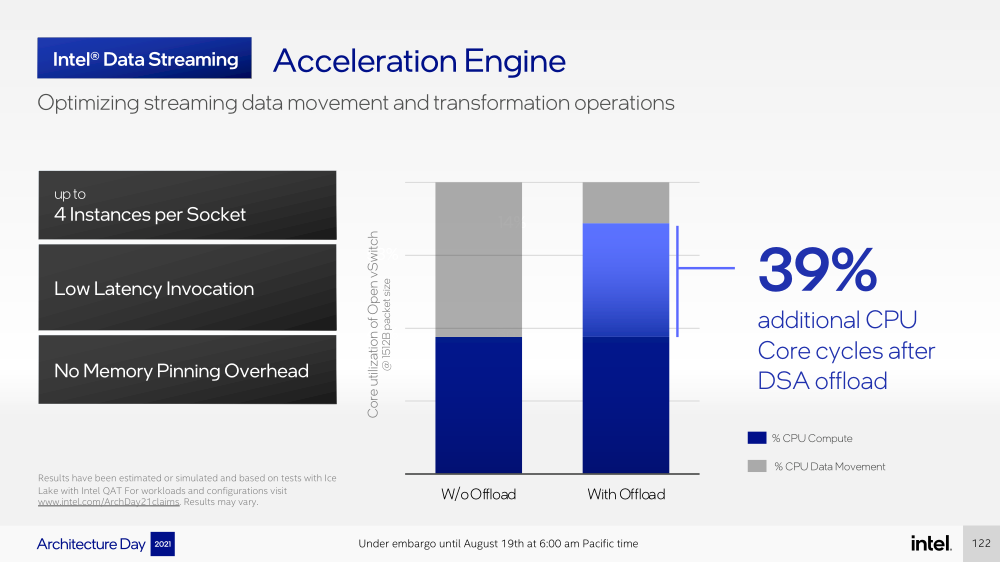 Второй упомянутый ускоритель — это движок QAT (Quick Assist Engine), на который можно возложить операции или сразу цепочки операций (де-)компрессии (до 160 Гбит/с в обе стороны одновременно), хеширования и шифрования (до 400 Гбитс/с) в популярных алгоритмах: AES GCM/XTS, ChaChaPoly, DH, ECC и т.д. Теперь блок QAT стал частью самого процессора, тогда как прежде он был доступен в составе некоторых чипсетов или в виде отдельной карты расширения. Это позволило снизить задержки и увеличить производительность блока. 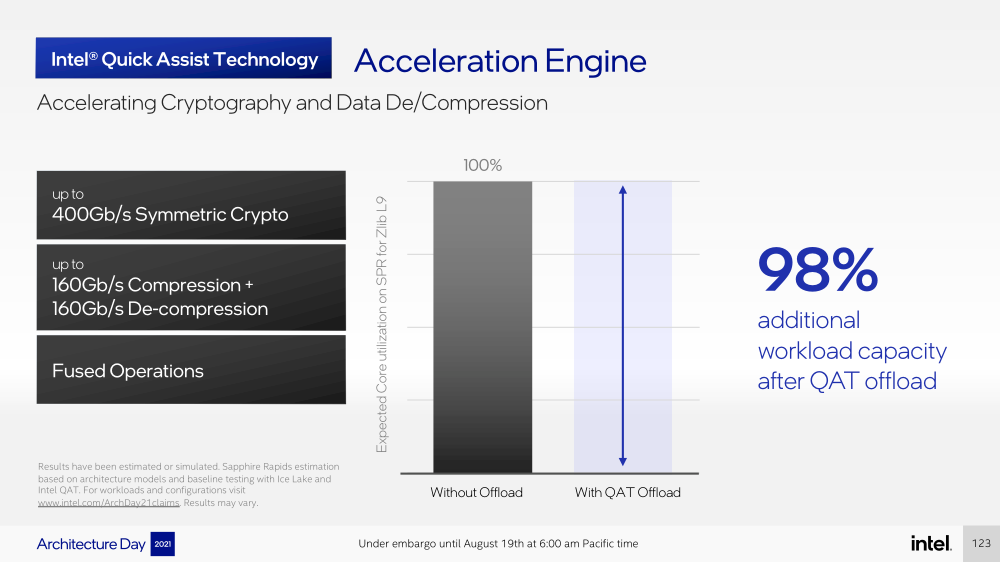 Кроме того, QAT можно будет задействовать, например, для виртуализации или Intel Accelerator Interfacing Architecture (AiA). AiA — это ещё один новый набор инструкций, предназначенный для более эффективной работы с интегрированными и дискретными ускорителями. AiA помогает с управлением, синхронизацией и сигнализацией, что опять таки позволит снизить часть накладных расходов при взаимодействии с ускорителями из пространства пользователя.  Подсистема памяти включает четыре двухканальных контроллера DDR5, по одному на каждый тайл. Надо полагать, что будут доступные четыре же NUMA-домена. Больше деталей, если не считать упомянутой поддержки следующего поколения Intel Optane PMem 300 (Crow Pass), предоставлено не было. Зато было официально подтверждено наличие моделей с набортной HBM, тоже по одному модулю на тайл. HBM может использоваться как в качестве кеша для DRAM, так и независимо. В некоторых случаях можно будет обойтись вообще без DRAM. 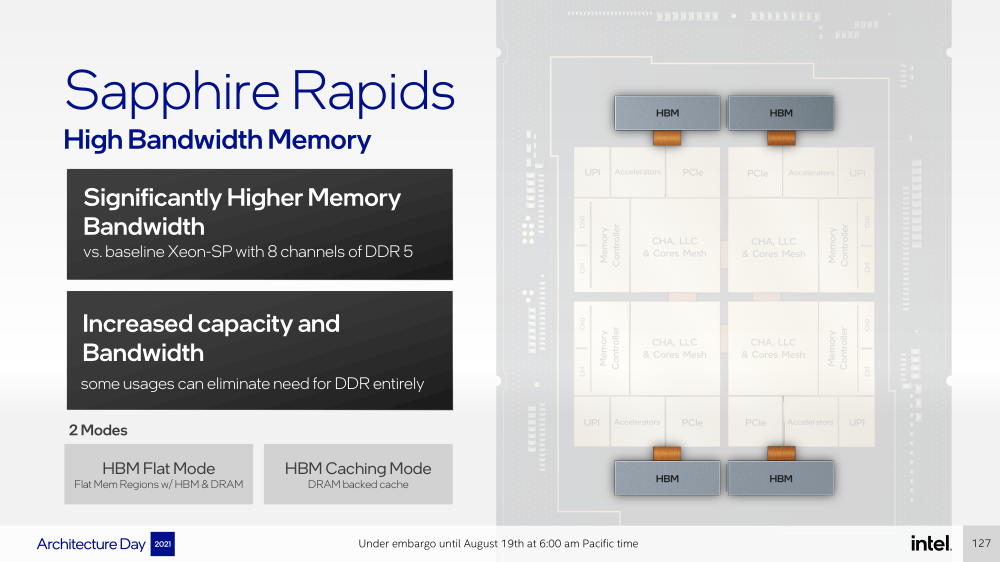 Про PCIe 5.0 и CXL 1.1 (CXL.io, CXL.cache, CXL.memory) добавить нечего, хотя в рамках другого доклада Intel ясно дала понять, что делает ставку на CXL в качестве интерконнекта не только внутри одного узла, но и в перспективе на уровне стойки. Для объединения CPU (бесшовно вплоть до 8S) всё так же будет использоваться шина UPI, но уже второго поколения (16 ГТ/с на линию) — по 24 линии на каждый тайл. 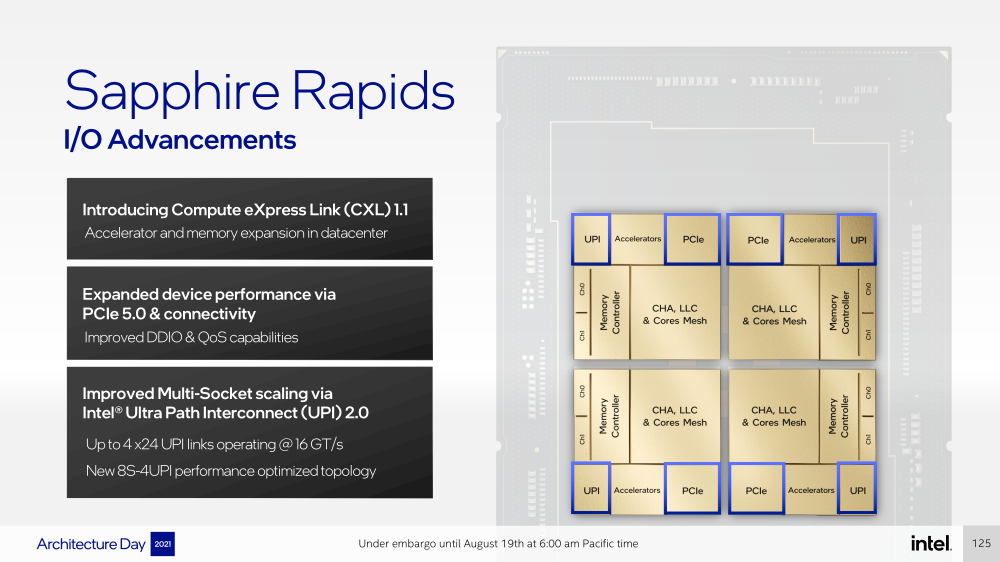 Конкретно для Sapphire Rapids Intel пока не приводит точные данные о росте IPC в сравнении с Ice Lake-SP, ограничиваясь лишь отдельными цифрами в некоторых задачах и областях. Также не был указан и ряд других важных параметров. Однако AMD EPYC Genoa, если верить последним утечкам, даже по чисто количественным характеристикам заметно опережает Sapphire Rapids.
19.08.2021 [16:00], Игорь Осколков
Intel анонсировала ускорители Xe HPC Ponte Vecchio: 100+ млрд транзисторов, микс 5/7/10-нм техпроцессов Intel и TSMC и FP32-производительность 45+ ТфлопсКак и было обещано несколько лет назад, основным «строительным блоком» для графики и ускорителей Intel станут ядра Xe, которые можно будет гибко объединять и сочетать с другими аппаратными блоками для получения заданной производительности и функциональности. Компания уже анонсировала первые «настоящие» дискретные GPU серии Arc, а на Intel Architecture Day она поделилась подробностями о серверных ускорителях Xe HPC и Ponte Vecchio.  Основой Xe HPC является вычислительное ядро Xe Core, которое включает по восемь векторных и матричных движков для данных шириной 512 и 4096 бит соответственно. Они делят между собой L1-кеш объёмом 512 Кбайт, с которым можно общаться на скорости 512 байт/такт.  Заявленная производительность для векторного движка (бывший EU), ориентированного на «классические» вычисления, составляет 256 операций/такт для FP32 и FP64 или 512 — для FP16. Матричный движок нужен скорее для ИИ-нагрузок, поскольку работает только с данными TF32, FP16, BF16 и INT8 — 2048, 4096, 4096 и 8192 операций/такт соответственно. Данный движок работает с инструкциями XMX (Xe Matrix eXtensions), которые в чём-то схожи с AMX в Intel Xeon Sapphire Rapids.  Отдельные ядра объединяются в «слайсы» (slice) — по 16 Xe-Core в каждом, которые дополнены 16 блоков аппаратной трассировки лучей. Именно слайс является базовым функциональным блоком. Он изготавливается на TSMC по 5-нм техпроцессу в рамках инициативы Intel IDM 2.0. Слайсы объединяются в стеки — по 4 шт. в каждом.  Стек включает также базовую (Base) «подложку» (или тайл), четыре контроллерами памяти HBM2e (сама память вынесена в отдельные тайлы), общим L2-кешем объёмом 144 Мбайт, один медиа-движок с аппаратными кодеками, а также тайл Xe Link и контроллер PCIe 5. Base-тайл изготовлен по техпроцессу Intel 7 и использует EMIB для объединения всех блоков. 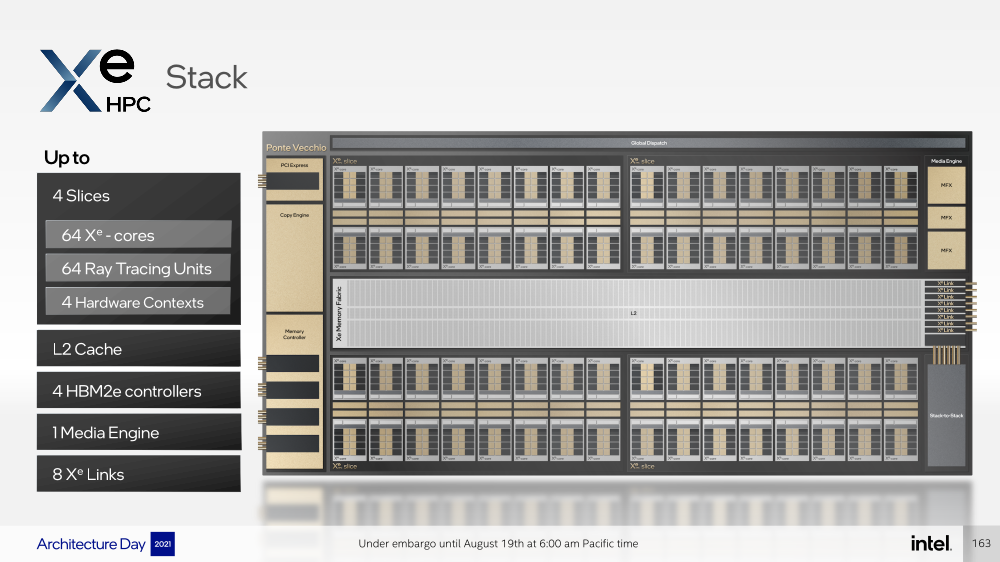 Тайлы Xe Link, изготавливаемые по 7-нм техпроцессу TSMC, включают 8 интерфейсов для стеков/ускорителей вкупе с 8-портовыми коммутатором и используют SerDes-блоки класса 90G. Всё это позволяет объединить до 8 стеков по схеме каждый-с-каждым, что, в целом, напоминает подход NVIDIA, хотя у последней NVSwitch всё же (пока) является внешним компонентом. 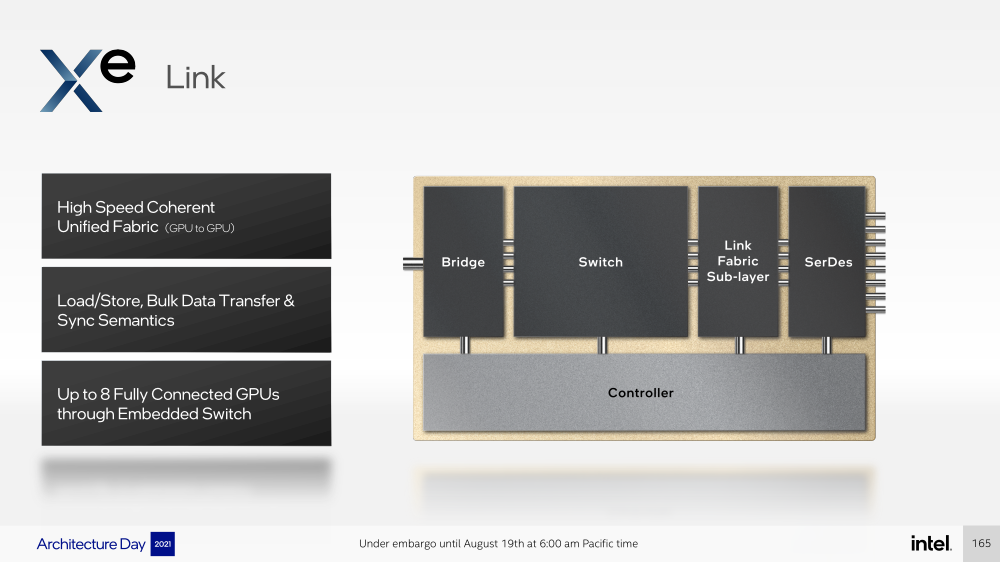  В самом ускорителе в зависимости от конфигурации стеков может быть один или два. В случае Ponte Vecchio их как раз два, и Intel приводит некоторые данные о его производительности: более 45 Тфлопс в FP32-вычислениях, более 5 Тбайт/с пропускной способности внутренней фабрики памяти и более 2 Тбайт/с — для внешних подключений. Для сравнения, у NVIDIA A100 заявленная FP32-производительность равняется 19,5 Тфлопс, а AMD Instinct MI100 — 23,1 Тфлопс. 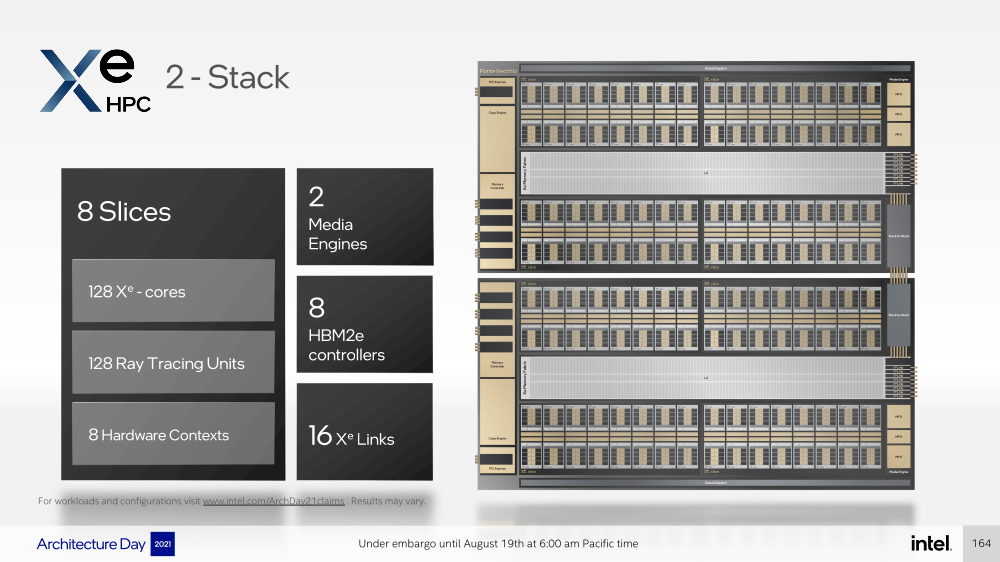 Также Intel показала результаты бенчмарка ResNet-50 в обучении и инференсе: 3400 и 43000 изображений в секунду соответственно. Эти результаты являются предварительными, поскольку получены не на финальной версии «кремния». Но надо учитывать, что Ponte Vecchio есть ещё одно преимущество — отдельный Rambo-тайл с дополнительным сверхбыстрым кешем, который, вероятно, можно рассматривать в качестве L3-кеша.  В целом, Ponte Vecchio — это один из самых сложны чипов на сегодняшний день. Он объединяет с помощью EMIB и Foveros 47 тайлов, изготовленных по пяти разным техпроцессам, а общий транзисторный бюджет превышает 100 млрд. Данные ускорители будут доступны в форм-факторе OAM и виде готовых плат с четырьмя ускорителями на борту (на ум опять же приходит NVIDIA HGX). И именно такие платы в паре с двумя процессорами Sapphire Rapids войдут в состав узлов суперкомпьютера Aurora. Ещё одной машиной, использующей связку новых CPU и ускорителей Intel станет SuperMUC-NG (Phase 2).  Официальный выход Ponte Vecchio запланирован на 2022 год, но и выход следующих поколений ускорителей AMD и NVIDIA, с которыми и надо будет сравнивать новинки, тоже не за горами. Пока что Intel занята не менее важным делом — развитием программной экосистемы, основой которой станет oneAPI, набор универсальных инструментов разработки приложений для гетерогенных (CPU, GPU, IPU, FPGA и т.д.) приложений, который совместим с оборудованием AMD и NVIDIA. |
|
|||||||||||||||||||||||||||||||||||||

