Лента новостей
|
06.10.2021 [13:07], Сергей Карасёв
«Яндекс», «ЛАНИТ», Gigabyte и ВТБ вложат 1 млрд руб. в российский завод по выпуску серверовВ России неподалёку от Рязани, на территории индустриального парка «Рязанский», началось строительство нового завода по производству серверов. Проект реализуется совместным предприятием, созданным «Яндексом», группой компаний «ЛАНИТ», разработчиком компьютерной техники Gigabyte и банком ВТБ. На заводе будет выпускаться оборудование под торговой маркой Openyard. В частности, планируется организовать производство серверов, систем хранения данных, шлюзов и компонентов умных устройств. Участники проекта на начальном этапе вложат в новую производственную площадку более миллиарда рублей. Пуско-наладочные работы намечены на третий квартал следующего года: их выполнят специалисты Gigabyte. Первый сервер со сборочных линий должен сойти до конца 2022-го. «Первая очередь будет включать производственные линии, лаборатории и тестовые зоны. Здесь будут выполняться все операции, начиная от поверхностного монтажа компонентов и заканчивая испытаниями готовой продукции», — говорится в сообщении. 
Фото: Яндекс Производимые в Рязани серверы будут спроектированы на основе разработок и технологий «Яндекса». Отмечается, что выбор места для строительства завода продиктован хорошей транспортной доступностью, наличием необходимых коммуникаций и близостью учебных заведений, которые готовят профильных специалистов.
04.10.2021 [10:00], Алексей Степин
HPE Synergy 12000 как гимн модульности: новая единая ИТ-инфраструктура для любых задачСинергия — эффект совместного действия двух и более факторов, превышающий простую сумму их действий. Слово это пришло к нам из древнегреческого, где означало «единое дело». Но в обычных ЦОД «старой школы» она проявляется далеко не всегда, и расширение, переконфигурирование или смена задачи может стать долгим, затратным предприятием. К тому же в облачную эпоху каждый час простоя инфраструктуры может обернуться серьёзными убытками. Создавая Synergy, HPE позаботилась о том, чтобы максимально унифицировать новую ЦОД-платформу, способную справиться с любым приложением. В основу легла модульно-лезвийная (blade) компоновка, компания называет её «компонуемой». Такая инфраструктура Synergy — это шаг вперёд от обычных гиперконвергентных систем в сторону большей оптимизации и аппаратных, и программных средств.  Единая структура Synergy одинаково хорошо подойдет для любых типов нагрузок. За счёт использования программно определяемой логики, паттернов автоматизации и единой платформы управления OneView затраты на обслуживание ЦОД на базе новой платформы можно существенно снизить, направив высвободившиеся ресурсы на более важные для компании проекты и задачи. Не возникнет и проблем с совместимостью — все компоненты Synergy изначально созданы в рамках единого форм-фактора и являются взаимозаменяемыми. Имеется также задел на будущее: с появлением новых высокоскоростных технологий (фотоники) платформа не устареет, но может быть легко модернизирована. 
Готовая к работе система HPE Synergy Основные узлы Synergy представляют собой компонуемые модули лезвийного типа Synergy 480 Gen10. Они полностью поддерживают возможность «горячей замены», но самое интересное скрыто внутри: компактная системная плата с двумя Intel Xeon Scalable в окружении 24 слотов DDR4. Поддерживаются все процессоры с теплопакетом до 205 Ватт включительно (до 3,8 ГГц), также поддерживаются модули Optane DCPMM. Имеется специальный слот для дискового контроллера. Само «лезвие» оснащено или двумя SFF-дисками, или четырьмя SSD формата uFF. 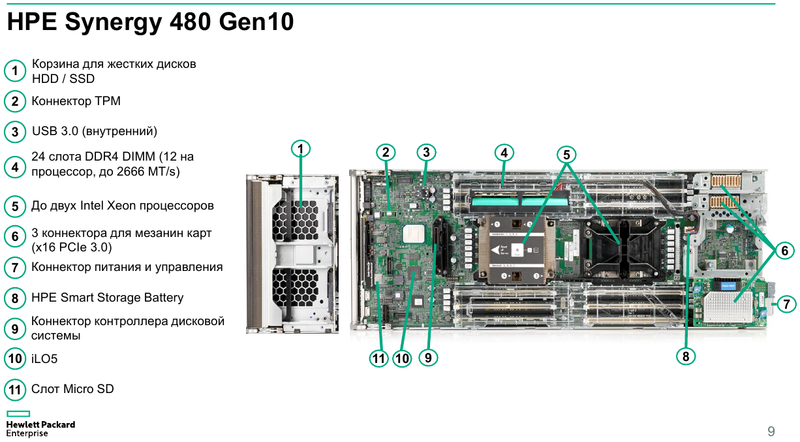 Также к узлу можно подключать до трёх мезаниновых карт расширения с интерфейсом PCI Express x16, правда, только версии 3.0. Эти карты предельно компактны. Так, основой для сетевой инфраструктуры может служить адаптер Synergy 6810C, поддерживающий стандарты Ethernet со скоростями 25 и 50 Гбит/с. Он базируется на технологиях Mellanox и поддерживает RoCEv2. 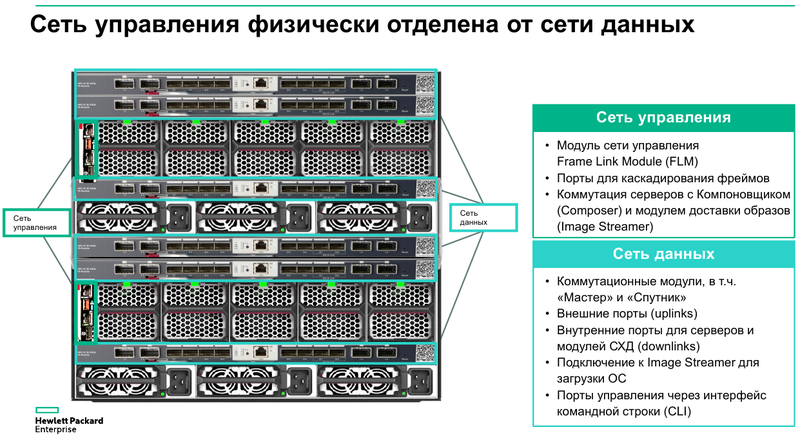 В конструкции изначально предусмотрена резервная батарея (BBU) для сохранения дисковых кешей, тогда как обычный RAID-контроллер не во всякой комплектации имеет BBU. Из прочего отметим наличие системы удалённого мониторинга и управления HPE iLO5 и продвинутую реализацию подключения к системе: за управление данными и питанием отвечает выделенный чип-контроллер.  Есть в вариантах Synergy 480 Gen10 и модуль двойной ширины, предназначенный специально для установки графических или вычислительных ускорителей. Несмотря на скромные габариты, он может принять в себя шесть ускорителей в формате Multi MXM, либо две мощные видеокарты в классическом исполнении. Ещё более производительны модули HPE Synergy 660 Gen10. Они вдвое выше Synergy 480, так что внутри может размещаться уже восемь uFF-накопителей, либо четыре SFF и четыре M.2. Процессорных разъёмов четыре, а количество слотов памяти равно 48. Мезонинов тоже вдвое больше, то есть шесть. 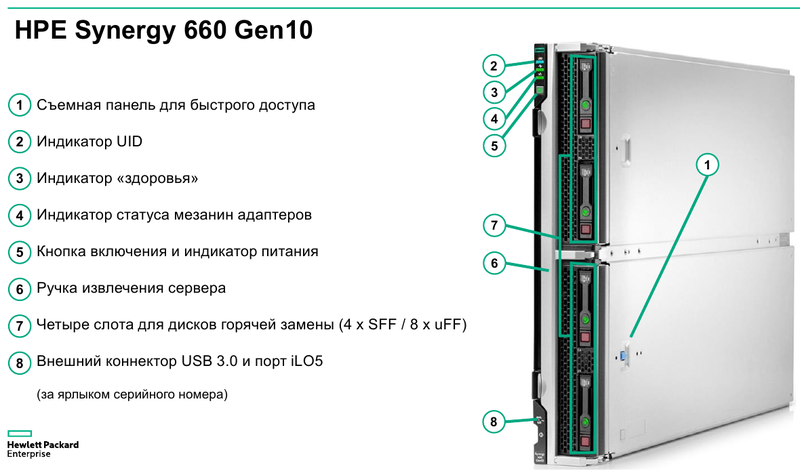 Для высокоплотного хранения данных предлагается использовать модуль Synergy D3940. В нём размещается до 40 накопителей общим объёмом 612 Тбайт, причём поддерживается любое сочетание дисков SAS и SATA. Реализованы операции как на файловом уровне, так и на блочном и даже объектном. Предусмотрено два адаптера ввода/вывода, которые при необходимости быстро заменяются. Сами накопители физически отделены от RAID-контроллеров и связаны с ними независимыми модулями коммутации. Модуль коммутации поддерживает 48 портов SAS, обслуживает до 40 SSD на модуль с производительностью до 50 тыс. IOPS на каждый SSD. Компания хорошо понимает, что за счёт совместимости с оборудованием других производителей охват рынка будет шире, поэтому Synergy легко интегрируется с системами хранения данных, разработанными вне стен HPE. Поддерживаются решения Fibre Channel, FC over Ethernet и iSCSI таких компаний, как Hitachi Data Systems, Net App, IBM и даже извечного конкурента HPE — Dell EMC. На программном уровне обеспечена совместимость с виртуальными SAN Scality, VMWare, Ceph и Microsoft. 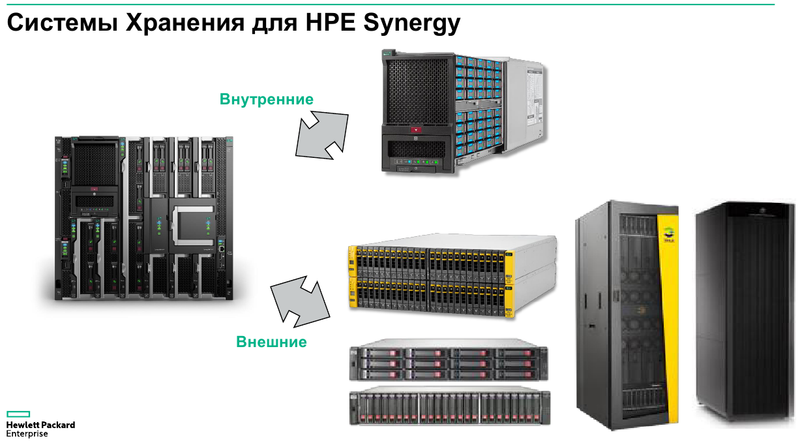 Для связи с SAN и LAN предлагаются различные коммутационные модули с портами вплоть до FC32 и 100GbE. Все эти модули объединяются в рамках 10U-шасси HPE Synergy 12000: до 12 вычислительных, 6 коммутационных и 5 модулей хранения данных. Новое шасси во всём лучше HPE Blade System c7000 прошлого поколения. Оно мощнее, лучше охлаждается, имеет более эффективную систему питания, а общая коммутационная плата для узлов поддерживает суммарную скорость передачи данных до 16 Тбит/с и изначально готова к переходу на использование высокоскоростной фотоники.  Шасси позволяет сформировать шасси с оптимальным набором компонентов, и HPE предлагает типовые варианты конфигураций в зависимости от задачи: базы данных, виртуальные машины, платформы аналитики, максимально ёмкие СХД или платформа для вычислений на графических ускорителях. Все компоненты предельно унифицированы, все базовые функции являются программно-определяемыми и унифицированными. Даже кабели придётся подключить только во время установки. После этого систему можно «нарезать» на отдельные фабрики с нужным набором дискового пространства, числа ядер CPU и GPU, объёмом памяти и сетевых подключений.  На уровне фабрик HPE позаботилась о резервировании и физическом разделении сетей управления и данных. Есть отдельное подключение к серверу образов для загрузки операционных систем и отдельные порты управления. Сетевые коммутаторы могут быть типов «Мастер» или «Спутник». Первый отвечает за весь сетевой трафик и обладает минимальными задержками, а второй является повторителем сигнала и содержит ретаймеры; задержка в передаче сетевого пакета не превышает 8 нс. Поддерживаются порты со скоростью 10 и 20 Гбит/с. 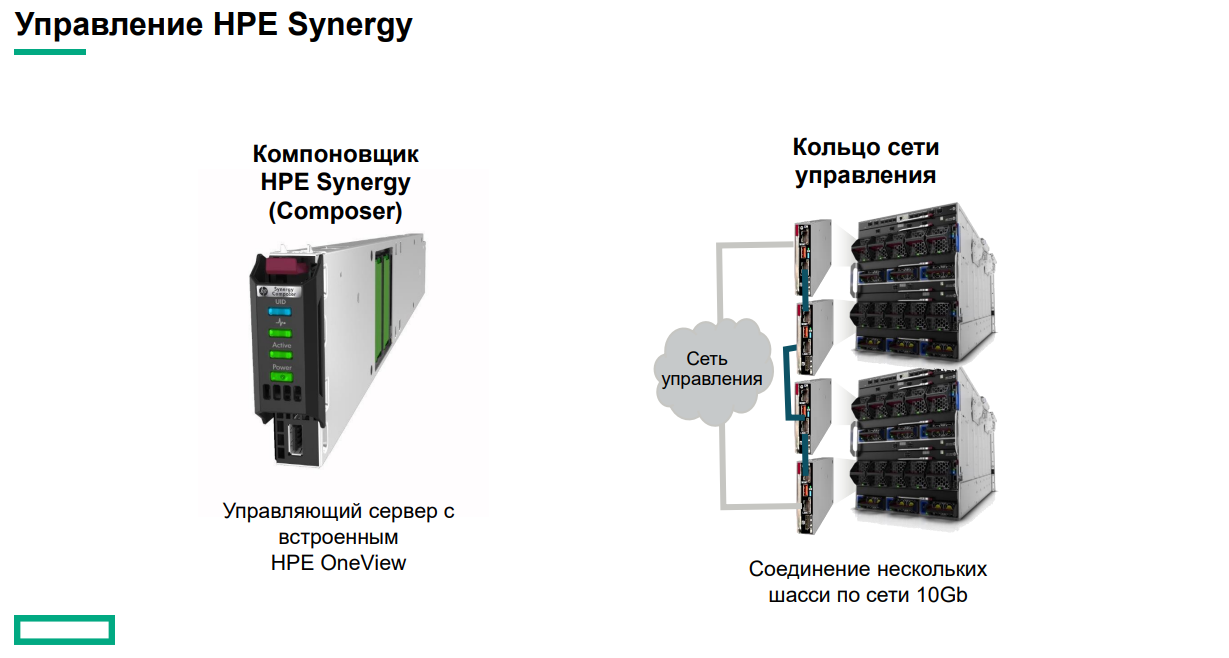 Дирижёром всего этого оркестра является модуль компоновщика (composer). Он базируется на фирменном управляющем ПО HPE OneView. При необходимости настроить систему на месте в дело вступает модуль сети управления (frame link module), который имеет разъём Display Port для монитора и порт USB. Если обычная процедура ввода в строй нового сервера содержит множество пунктов, от установки его в стойку до настроек BIOS и установки ОС, то в Synergy достаточно установить новый модуль в шасси и применить нужный серверный профиль из шаблона. Остальное система сделает сама. 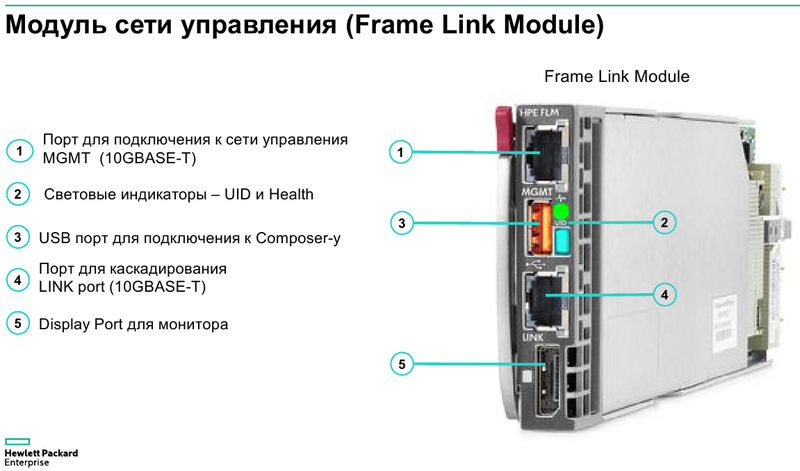 Компоновщик поддерживает форматы виртуализации Hyper-V и ESXi, а фирменное ядро OneView работает с аппаратными и сетевыми компонентами, но наружу информация предоставляется посредством стандартного API RESTful. Предусмотрено управление как с помощью веб-интерфейса, так и с помощью различного ПО — CHEF, Microsoft PowerShell или System Center; имеется также и фирменное приложение HPE OneView для VMWare. 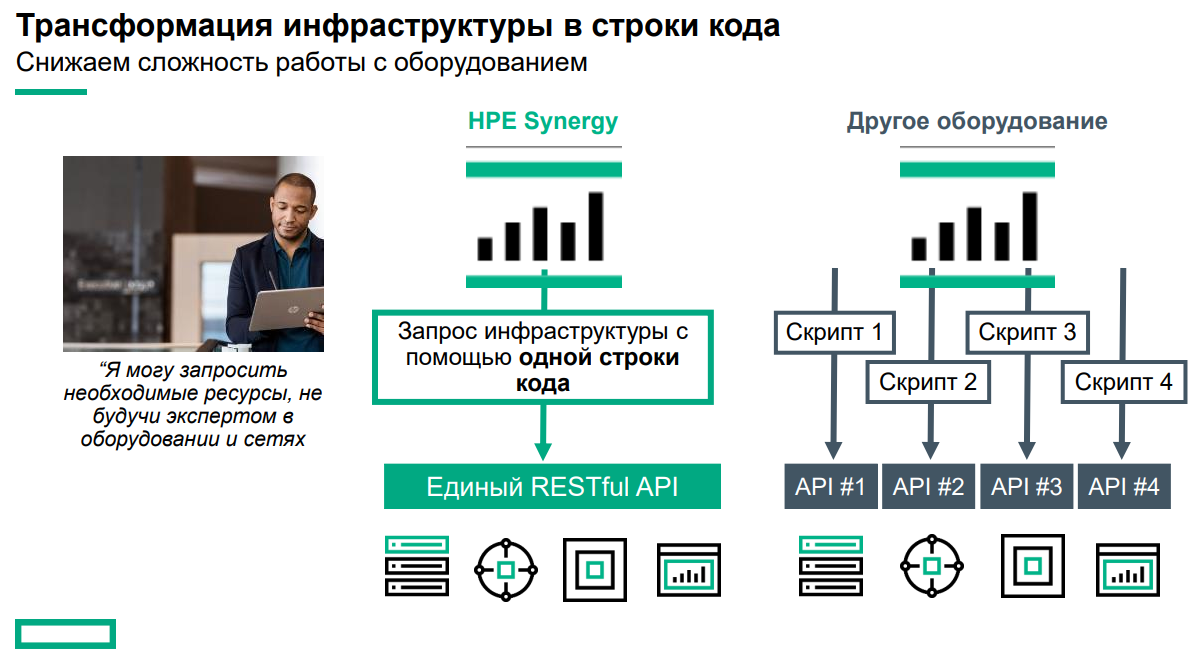 Таким образом, перед нами действительно уникальная, инновационная технология. HPE Synergy образует совершенно новый класс систем, по-настоящему универсальных на всех уровнях построения и конфигурации. Образуемая этим «конструктором» инфраструктура подходит для выполнения любого класса задач, причём разворачивается она по меркам мира ИТ практически мгновенно, буквально одной строкой кода, и сразу в нужных заказчику масштабах, в том числе облачных.  Простои практически исключены, все элементы унифицированы и легко заменяются, управление аппаратными серверами в облаке так же просто, как и традиционными виртуальными машинами. Использование HPE Synergy или модернизация ИТ-экосистемы этой новинкой означает сокращение как финансовых затрат, так и трудовых ресурсов, а единый API позволяет провести такую модернизацию постепенно, но в кратчайшие сроки за счёт совместимости с оборудованием СХД других поставщиков.  Кому подойдёт HPE Synergy? Всем, но особенно крупным компаниям, специализирующимся на ресурсоёмких ИТ-задачах любого класса, включая телеком, CAD/CAM, VDI, 3D-моделирование, а также медицину. Более того, именно медикам новинка подойдёт особенно хорошо. Об этом хорошо рассказывает нижеприведённое видео: Сценариев развёртывания Synergy может быть множество, вот лишь некоторые из них: 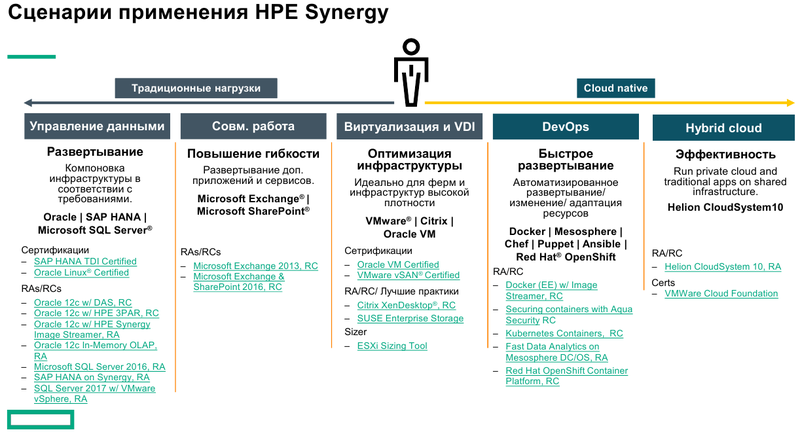 Сама HPE называет десять причин для выбора Synergy. Они просты и понятны:
 При этом заказать Synergy весьма просто: компания готова как к немедленной отправке оплаченного оборудования со склада, так и к компоновке под заказ. В России поставкой систем HPE Synergy занимается компания OCS, авторизованный партнёр Hewlett Packard Enterprise с опытом работы более 25 лет. Системы могут поставляться во все регионы страны, партнёрам предоставляются дополнительные удобные сервисы. Также отметим, что 12 октября в 10:00 по московскому времени состоится веб-семинар, посвящённый новой модульной платформе HPE. Записаться на него можно здесь.
30.09.2021 [16:15], Сергей Карасёв
128-ядерный Arm-процессор Ampere Altra Max оказался на треть дешевле флагманских Xeon и EPYCРесурс Phoronix раскрыл стоимость многоядерных процессоров Ampere Altra Max, предназначенных для использования в высокопроизводительных серверах. Наблюдатели отмечают, что эти изделия, насчитывающие до 128 вычислительных ядер, предлагаются по цене ниже флагманских серверных чипов Intel Xeon и AMD EPYC. Arm-процессоры Ampere Altra Max M128-30 с частотой 3,0 ГГц изготавливаются по 7-нм технологии и предлагают 128 линий PCIe 4.0 и восемь каналов оперативной памяти DDR4-3200. Тесты Phoronix показывают, что в целом ряде задач чипы Ampere Altra Max M128-30 могут вполне конкурировать со старшими моделями Intel Xeon Ice Lake и AMD EPYC Milan. 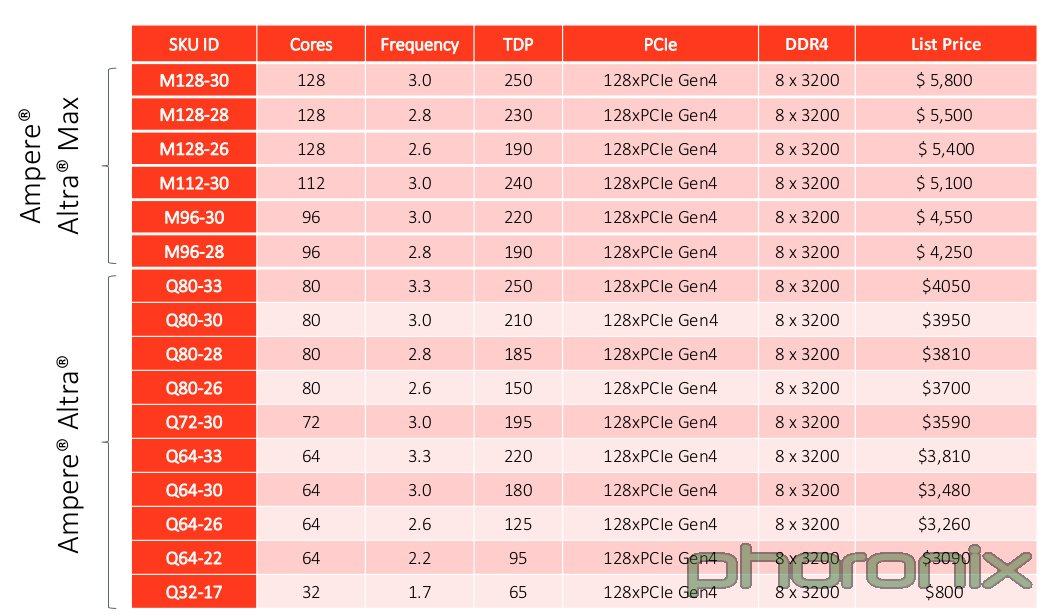
Источник: Phoronix Итак, сообщается, что цена Ampere Altra Max M128-30 составляет $5800. Для сравнения: чип Intel Xeon Platinum 8380 сейчас предлагается за $8099, тогда как AMD EPYC 7763 стоит $8600. Процессор Ampere Altra Q80-30 с 80 вычислительными ядрами можно приобрести по цене $3950, а самая младшая 32-ядерная модель Ampere Altra Q32-17 стоит всего $800. Правда, надо учитывать, что всё это рекомендованные цены, а у AMD с Intel намного больше возможностей по их снижению для конечных заказчиков.
25.09.2021 [17:29], Руслан Авдеев
На Аляске появился быстрый беспроводной интернет на базе Facebook✴ TerragraphСложный рельеф и суровый климат Аляски создают серьёзные трудности при обеспечении пользователей стабильным быстрым интернетом-соединением. С распространением пандемии и переходом многих жителей на удалённую работу потребность в устойчивых соединениях только выросла. На помощь местным жителям пришёл провайдер Alaska Communications с беспроводной технологией Terragraph, разработанной Facebook✴ Connectivity. Провайдер использует оборудование компании Cambium Networks, получившего лицензию от Facebook✴ на использование Terragraph в своих решениях. Технология использует спектр 60 ГГц и позволяет наладить быструю связь значительно дешевле, чем обходится прокладка под землёй кабельных соединений. Многие интернет-провайдеры штата уже убедились, что в местных суровых условиях прокладывать кабели конечным потребителям не только дорого, но и долго. Если же возникает обрыв, установить его местонахождение и устранить поломку очень сложно, особенно зимой. Cambium Networks предоставляет беспроводные решения на основе Terragraph — от Пинанга в Малайзии до Пуэрто-Рико. 
tech.fb.com Facebook✴ Connectivity разработала Terragraph, намереваясь расширить доступность стабильного беспроводного интернет-соединения в регионах с плохим или отсутствующим соединением. Лицензии на технологию выдаются партнёрам по всему миру — производители оборудования и провайдеры могут сосредоточить усилия на её внедрении вместо проведения собственных разработок. Первая фаза развёртывания на Аляске планируется с использованием клиентских узлов cnWave 60 ГГц производства Cambium Networks, обеспечивающих скорость передачи данных до 1 Гбит/с для 6500 локаций. «Доступный, надёжный высокоскоростной интернет сегодня отсутствует на рынке Аляски. Поэтому мы здесь — для того, чтобы обеспечить местным жителям связь с тем, что наиболее важно для них», — говорит вице-президент по маркетингу Alaska Communications Бет Барнс (Beth Barnes). Вместо использования кабельных соединений, Terragraph полагается на ячеистую mesh-топологию, в которой клиентские беспроводные узлы размером с книгу размещаются на уже существующих объектах вроде крыш или телефонных столбов. Отдельные узлы не только обеспечивают интернетом конкретные дома, но и передают сигнал другим аналогичным узлам, находящимся в зоне досягаемости. Структура mesh-сетей предусматривает многочисленные альтернативные пути соединения между узлами, поэтому связь в сети остаётся стабильной почти в любых условиях. Для сравнения, обрыв связи на «последней миле» кабельного соединения требует обязательного ремонта, иначе доступ к Интернету прервётся. 
tech.fb.com Местные жители уже начали пользоваться преимуществами Terragraph. Даже тем, кому по роду деятельности приходится пересылать очень большие файлы, теперь доступны по-настоящему быстрые соединения. По данным некоторых пользователей, скорость соединения выросла почти в 100 раз в сравнении с проводными решениями, применявшимися прежде: на отправку файла чуть более 10 Гбайт уходит около 10 минут. Из-за низкой плотности населения на Аляске связь имеет ещё большее значение, чем в густонаселённых регионах. Например, Аляска в 2,5 раза больше Техаса или в 77 раз больше Нью-Джерси, при этом здесь приходится приблизительно по одному человеку на 2,5 км2. Если трудно предоставить высокоскоростное интернет-соединение даже населению городов вроде Анкориджа, то ещё труднее обеспечить связь за пределами городов. При этом в период пандемии критически важно оставаться на связи. До конца текущего года Terragraph намерены использовать в 6500 локациях по всему штату, а скоро в Alaska Communications планируется обеспечить и более широкое распространение технологии. В следующие несколько лет сервис появится в новых районах вблизи Анкориджа, а также Фэрбенксе, Джуно, на Кенайском полуострове.
22.09.2021 [21:16], Алексей Степин
Выпущена тестовая партия европейских высокопроизводительных RISC-V процессоров EPI EPAC1.0Наличие собственных высокопроизводительных процессоров и сопровождающей их технической инфраструктуры — в современном мире вопрос стратегического значения для любой силы, претендующей на первые роли. Консорциум European Processor Initiative (EPI), в течение долгого времени работавший над созданием мощных процессоров для нужд Евросоюза, наконец-то, получил первые весомые плоды. О проекте EPI мы неоднократно рассказывали читателям в 2019 и 2020 годах. В частности, в 2020 году к консорциуму по разработке мощных европейских процессоров для систем экза-класса присоединилась SiPearl. Но сегодня достигнута первая серьёзная веха: EPI, насчитывающий на данный момент 28 членов из 10 европейских стран, наконец-то получил первую партию тестовых образцов процессоров EPAC1.0. 
Источник изображений: European Processor Initiative (EPI) По предварительным данным, первичные тесты новых чипов прошли успешно. Процессоры EPAC имеют гибридную архитектуру: в качестве базовых вычислительных ядер общего назначения в них используются ядра Avispado с архитектурой RISC-V, разработанные компанией SemiDynamics. Они объединены в микро-тайлы по четыре ядра и дополнены блоком векторных вычислений (VPU), созданным совместно Барселонским Суперкомпьютерным Центром (Испания) и Университетом Загреба (Хорватия). 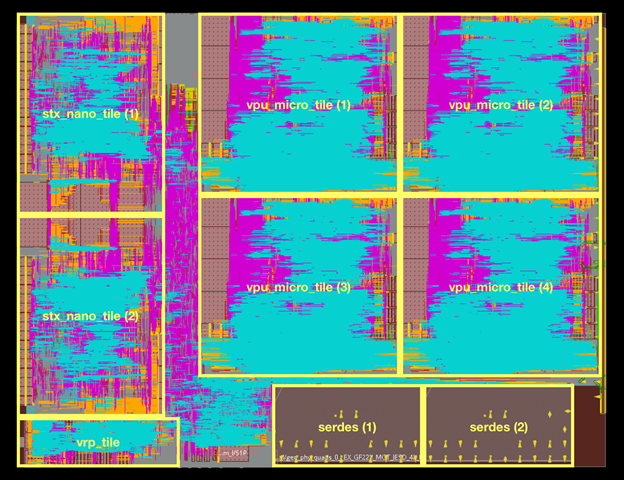
Строение кристалла EPAC1.0 Каждый такой тайл содержит блоки Home Node (интерконнект) с кешем L2, обеспечивающие когерентную работу подсистем памяти. Имеется в составе EPAC1.0 и описанный нами ранее тензорно-стенсильный ускоритель STX, к созданию которого приложил руку небезызвестный Институт Фраунгофера (Fraunhofer IIS). Дополняет картину блок вычислений с изменяемой точностью (VRP), за его создание отвечала французская лаборатория CEA-LIST. Все ускорители в составе нового процессора связаны высокоскоростной сетью, использующей SerDes-блоки от EXTOLL.  Первые 143 экземпляра EPAC произведены на мощностях GlobalFoundries с использованием 22-нм техпроцесса FDX22 и имеют площадь ядра 27 мм2. Используется упаковка FCBGA 22x22. Тактовая частота невысока, она составляет всего 1 ГГц. Отчасти это следствие использования не самого тонкого техпроцесса, а отчасти обусловлено тестовым статусом первых процессоров. Но новорожденный CPU жизнеспособен: он успешно запустил первые написанные для него программы, в числе прочего, ответив традиционным «42» на главный вопрос жизни и вселенной. Ожидается, что следующее поколение EPAC будет производиться с использованием 12-нм техпроцесса и получит чиплетную компоновку.
14.09.2021 [10:10], Руслан Авдеев
Итальянская IT-фирма построит дата-центр в древней шахте на СардинииКомпания Dauvea из города Кальяри на Сардинии превратит древнюю шахту на близлежащем небольшом острове Сант'Антиоко в новый дата-центр. Проект назван Digital Metalla или Digital Mine — «цифровая шахта». Впервые его анонсировали в январе, и по данным местной прессы, компания начинает строительные работы в этом месяце. Dauvea пока не обнародовала спецификации, но уже сообщила, что проект будет «энергоэффективным зелёным дата-центром». По данным основателя компании Сальваторе Пульвиренти (Salvatore Pulvirenti), в Осло (Норвегия) превратили в дата-центр бывший склад боеприпасов. Итальянская компания тоже намерена дать новую жизнь местным объектам на долгосрочную перспективу, создавать рабочие места, обеспечивать решения для новых трендов в цифровом мире, внедрять «настоящие инновации». 
Источник изображения: Yosuke Ota / Unsplash Основанная в 2017 году Dauvea обеспечивает разнообразные IT-сервисы, включая проекты по обеспечению кибербезопасности и предоставление клиентам облачных хранилищ. Ранее Пульвиренти работал директором по информационным технологиям в итальянской телекоммуникационной компании Tiscali, а также занимал различные руководящие должности в Telecom Italia и сардинской исследовательской организации CRS4. Metalla — имя археологического памятника, расположенного на территории бывшего финикийского города Сульчи (Сульчис) на небольшом острове, расположенном к юго-востоку от самой Сардинии, в непосредственной близости от главного острова. На этой территории тысячи лет добывались свинцовые, серебряные, цинковые руды и уголь, а также другие минералы, шахты начали закрываться здесь только в 90-х годах прошлого века. Ранее подавалась заявка на включение территории в список Всемирного наследия ЮНЕСКО.
09.09.2021 [14:49], Владимир Мироненко
Lenovo представила TruScale, обновлённое портфолио решений всё-как-сервисКомпания Lenovo представила на ежегодном мероприятии Tech World решение «всё-как-услуга» (XaaS) — сервис Lenovo TruScale. С его помощью Lenovo объединила все свои предложения «как-услуга» в единое целое. Сервис выходит далеко за рамки исключительно инфраструктурных решений, позволяя создать комплексное — от мобильных устройств до облака — и индивидуализированное предложение для конкретного заказчика в рамках единой подписки.  «Lenovo TruScale воплощает в себе трансформацию компании в новой реальности — удовлетворение растущего глобального спроса на более продвинутые технологии в условиях новой эры гибридного режима работы и обучения», — отмечено в пресс-релизе компании. Lenovo TruScale представляет собой гибкую платформу «всё как услуга», позволяющую компаниям сохранять конкурентоспособность и предлагающую изменяемую облачную модель с возможностью выбора подходящих условий оплаты обслуживания, оборудования и необходимого перечня услуг. 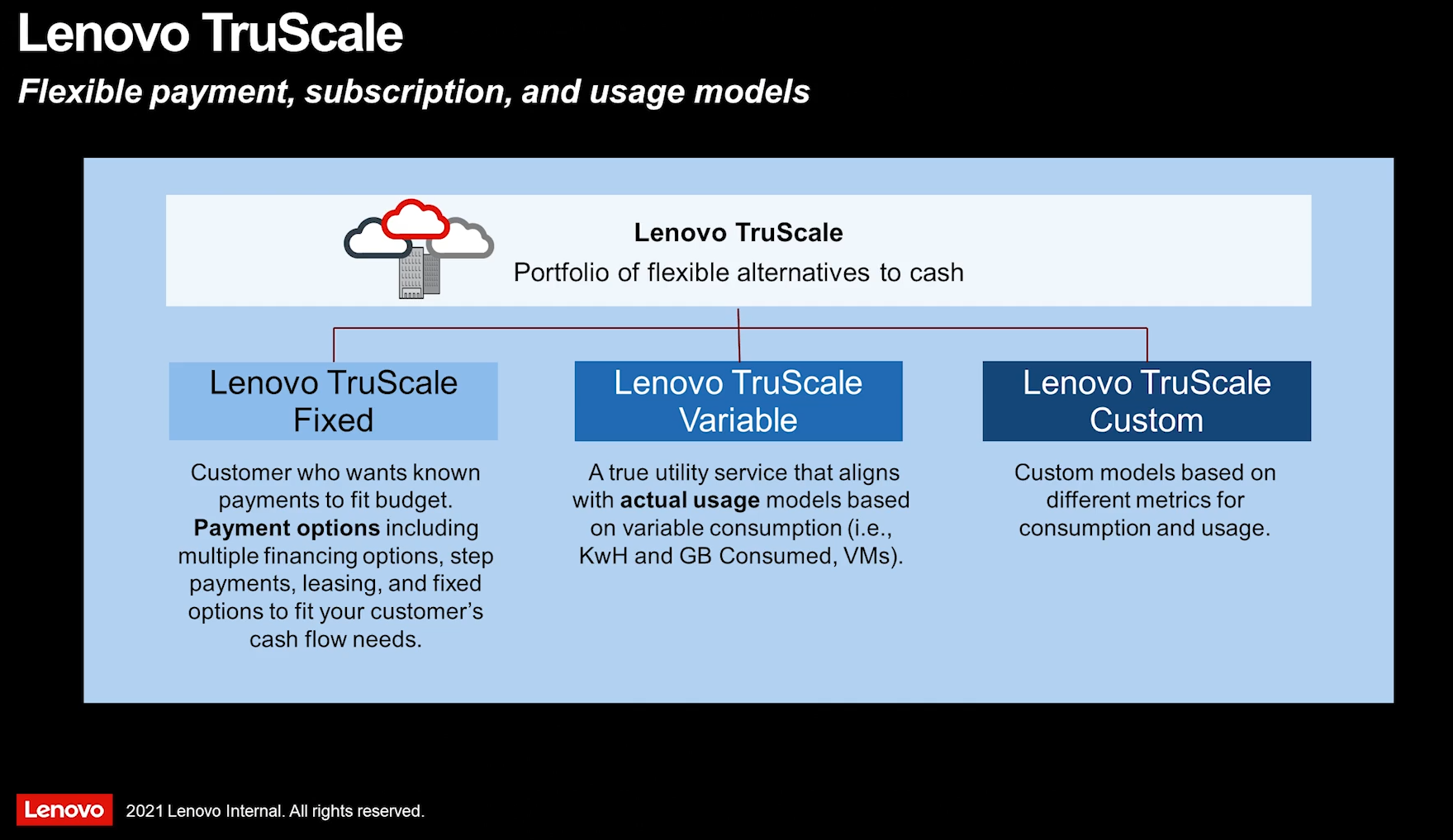 Согласно исследованиям Gartner, IDC и Lenovo Market Intelligence, скорость роста рынка предложений по модели «как-услуга» вчетверо выше по сравнению с общим рынком ИТ-услуг. Аналитики прогнозируют, что через три года на такую модель придётся 12% расходов на корпоративные x86-серверы и более половины затрат на новые корпоративные СХД. В целом, если верить отчётам компаний, программы вроде Dell APEX, HPE Greenlake или Cisco Plus действительно являются достаточно привлекательными для клиентов.  Поскольку Lenovo в рамках TruScale отходит от исключительно инфраструктурных решений, компания отдельно подчеркнула наличие нового предложения устройство-как-услуга (DaaS), которое охватывает оборудование для конечных пользователей вместе с lifecycle-услугами, поддержкой и подходящим финансированием для снижения общей стоимости. В рамках новой платформы компания сотрудничает с ведущими партнёрами по инфраструктуре: Deloitte, VMWare и Intel, а также партнёрами по безопасности DaaS Absolute Software и SentinelOne.  На мероприятии Lenovo Tech World 21 компания более подробно рассказала о ряде новых (и обновлённых) продуктов в составе TruScale: «кремний-по-запросу» от Intel (динамическое изменения числа доступных ядер CPU), STaaS-решения Infinite Storage, VDI для мобильных и десктопных клиентов на базе продуктов Nutanix и т.д. В развитии TruScale Lenovo, как и прежде, будет во многом полагаться на канальных партнёров.
08.09.2021 [19:31], Алексей Степин
Fujifilm и HPE представили ленточные картриджи LTO-9 ёмкостью 45 ТбайтЛенточные накопители и библиотеки остаются одним из самых популярных вариантов для «холодного» хранения больших объёмов данных, и новые технологии в этой сфере продолжают активно развиваться. Компании Fujifilm и HPE объявили о выпуске ленточных картриджей LTO-9 Ultrium, эффективная ёмкость которых достигает 45 Тбайт. Правда, эта цифра относится к режиму со сжатием данных, «чистая» же ёмкость LTO-9 составляет 18 Тбайт. Для сравнения, картриджи LTO-8 могут хранить до 12 и 30 Тбайт несжатых и сжатых данных соответственно, Хотя налицо паритет с традиционными HDD, темпы прироста ёмкости LTO замедлились: так, при переходе от седьмого поколения к восьмому «чистый» объём вырос вдвое (с 6 до 12 Тбайт), а сейчас мы видим лишь 50% прирост. Тем не менее, в будущем планируется вернуться к удвоению ёмкости в каждом новом поколении. Скорость передачи данных LTO-9 в сравнении c LTO-8 выросла, но ненамного: с 360/750 Мбайт/с до 440/1000 Мбайт/с в режимах без сжатия и со сжатием соответственно.  В новых картриджах Fujifilm используется лента на основе феррита бария (BaFe), покрытие формируется с использованием фирменной технологии NANOCUBIC. Компания заявляет о 50 годах стабильного хранения данных с использованием новой ленты. HPE пока что ограничилась коротким сообщением о выходе RW- и WORM-картриджей. Quantum анонсировала приводы LTO-9, а IBM объявила о совместимости ПО Spectrum Archive с новым стандартом. Наконец, Spectra Logic сообщила о поддержке нового стандарта в своих ленточных библиотеках.  Ленточные накопители, пожалуй, являются своеобразными патриархами в мире систем хранения данных — магнитная лента использовалась ещё в первых компьютерах IBM. Однако даже сегодня именно они могут похвастаться одной из самых больших ёмкостей в пересчёте на единицу носителя, а кроме того, имеют и ряд других достоинств, например, повышенную надёжность хранения данных за счёт «пассивного» характера хранения записанной информации. 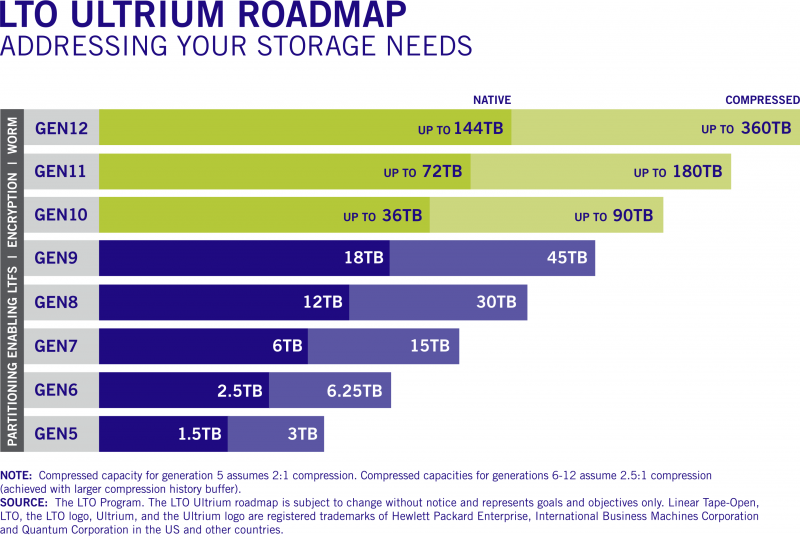
В будущем темпы роста ёмкостей картриджей LTO будут восстановлены Также ленточные библиотеки могут похвастаться меньшей стоимостью владения, нежели HDD-фермы или облачные хранилища. Среди областей применения ленточных накопителей и библиотек называется сценарий защиты данных от «шифровальщиков» и вымогательства, поскольку при необходимости уцелевшую копию можно просто восстановить с картриджа. Однако при современных объёмах данных даже скорость 3,6 Тбайт/час может оказаться недостаточно быстрой. 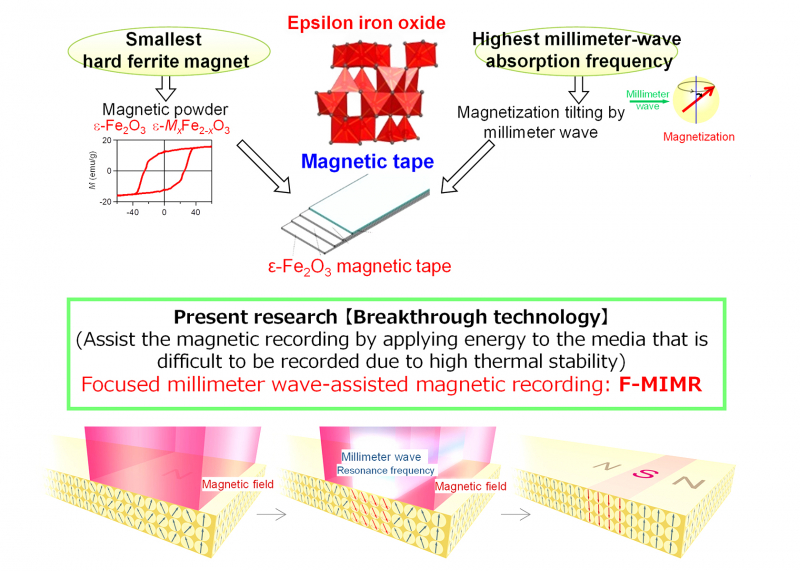
Петабайтные ёмкости потребуют перехода от феррита бария к эпсилон-ферриту железа (ɛ-Fe2O3) Тем не менее, развитие LTO не останавливается. В экспериментальных устройствах ещё в конце 2020 года была достигнута ёмкость 580 Тбайт, а уже 2021 году было объявлено уже о разработке лент и накопителей, способных хранить до 2,5 Пбайт сжатых данных. Так что говорить о смерти ленточных накопителей не приходится, хотя пандемия и повлияла отрицательно на объёмы продаж оборудования LTO.
08.09.2021 [19:00], Алексей Степин
Intel представила процессоры Xeon E-2300: Rocket Lake-E для серверов и рабочих станций начального уровняВ современном мире нагрузки на процессор год от года становятся всё сложнее и объёмнее, и не только крупные ЦОД нуждаются в архитектурных новшествах и новых наборах инструкций — малому бизнесу также требуются чипы нового поколения. Корпорация Intel ответила на это выпуском новых процессоров Xeon серии E-2300 и соответствующей платформы для них. Новинки стали быстрее и получили долгожданную поддержку PCI Express 4.0. Платформа Xeon E-2x00 не обновлялась достаточно давно: процессоры серии E-2200 были представлены ещё в 2019 году. На тот момент это был действительно прорыв в сегменте чипов Intel начального уровня — они впервые получили до 8 ядер Coffee Lake-S, а поддерживаемый объём памяти вырос с 64 до 128 Гбайт. Однако на сегодня таких возможностей уже может оказаться недостаточно: у E-2200 нет AVX-512 с VNNI, шина PCIe ограничена версией 3.0, а графическое ядро HD Graphics P630 и по меркам 2019 года быстрым назвать было нельзя. 
Источник изображений: Intel 10 новых процессоров Xeon E-2300, анонсированных Intel сегодня, должны заполнить пустующую нишу младших бизнес-решений. Нововведений в новой платформе не так уж мало, как может показаться на первый взгляд, ведь максимальное количество процессорных ядер у Xeon E-2300 по-прежнему восемь. Однако их максимальная частота выросла до 5,1 ГГц. Изменился процессорный разъём, теперь это LGA1200. 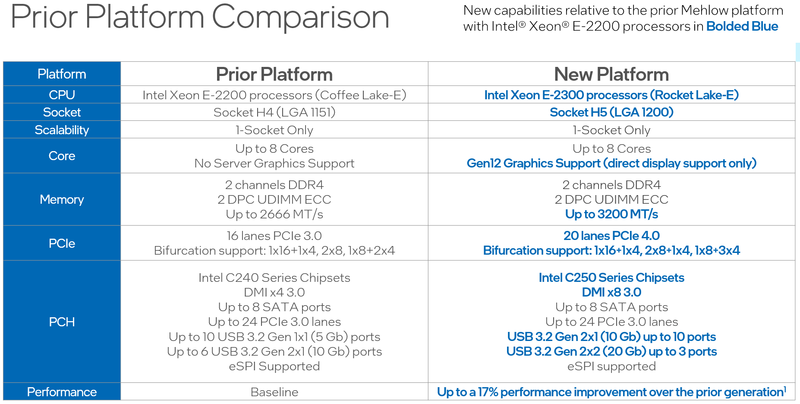 Ядра 11-го поколения Rocket Lake-E (Cypress Cove) по-прежнему используют 14-нм техпроцесс, но оптимизированная микроархитектура позволила Xeon E-2300 быть быстрее соответствующих моделей предыдущего поколения на 17%, и это без учёта качественных нововведений — теперь у них есть AVX-512 с поддержкой инструкций VNNI, ускоряющих работу нейросетей. Нововведения касаются и вопросов информационной безопасности, в которой малый бизнес нуждается не меньше крупного. Как и «большие» Xeon на базе Ice Lake-SP, процессоры Xeon E-2300 получили «взрослую» поддержку защищённых анклавов SGX объёмом до 512 Мбайт, что существенно выше максимально доступных для прошлого поколения Xeon E 64 Мбайт. Максимальный объём памяти остался прежним, но скорость подросла — до 128 Гбайт DDR4-3200 ECC UDIMM в двух каналах (2DPC).  Весьма важно также появление нового графического ядра с архитектурой Xe-LP. Конечно, высокой 3D-производительности от него ждать не стоит, но даже в этом оно на шаг впереди устаревшей архитектуры. К этому стоит добавить поддержку HDMI 2.0b и DP 1.4a, аппаратное декодирование 12-бит HEVC и VP9 и 10-бит AV1, а также кодирование в 8-бит AVC и 10-бит HEVC и VP9. 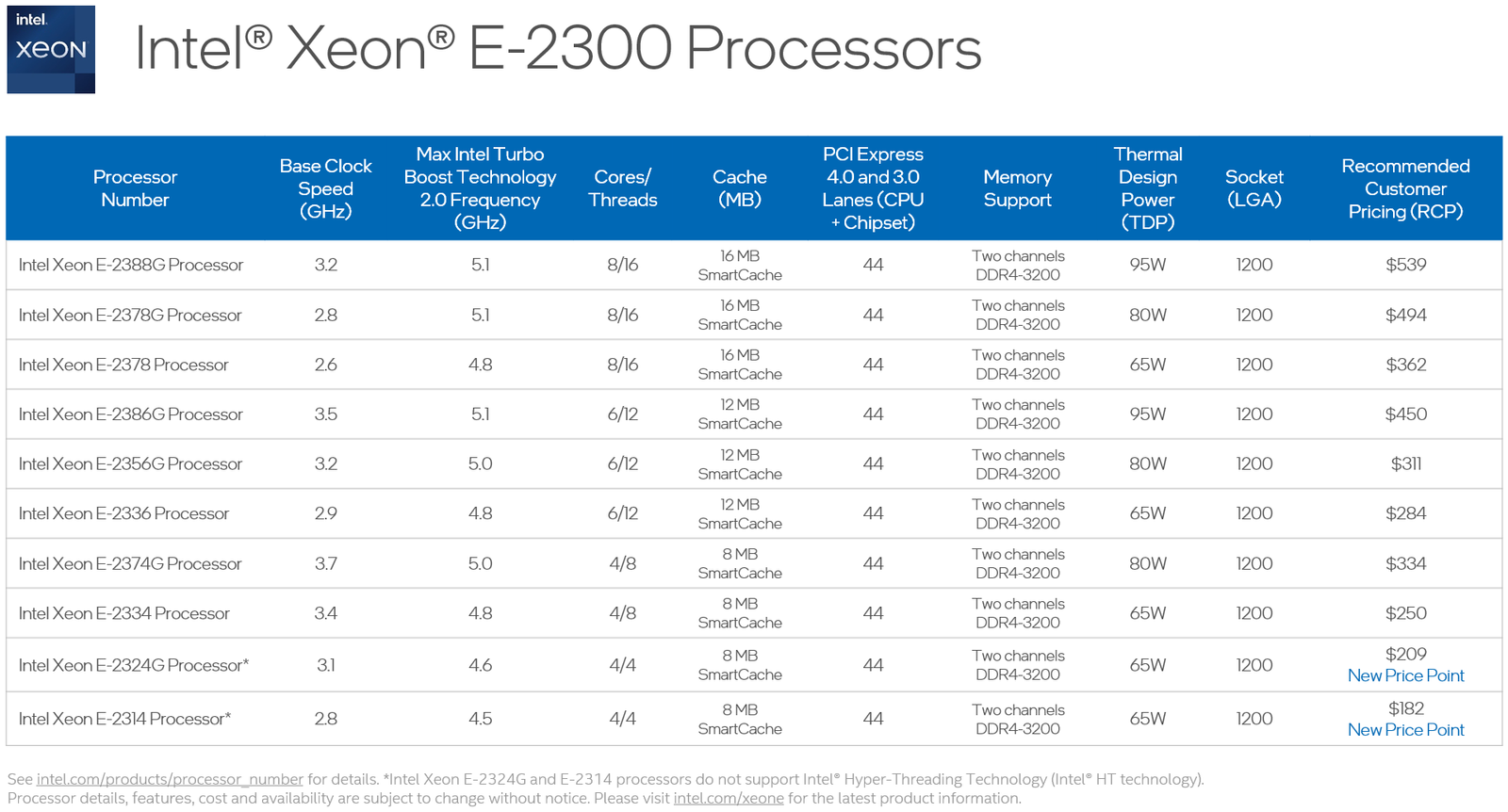 Поддержка PCIe 4.0 пришла и на платформу Xeon E — новые процессоры могут предложить 20 линий PCIe 4.0, причём с поддержкой бифуркации. Ещё 24 линии PCIe 3.0 включает чипсет серии C250. В нём же имеется поддержка 8 портов SATA-3 и USB 3.2 Gen 2x2 — до трёх портов со скоростью 20 Гбит/с. Сетевая часть может быть реализована как на базе недорогих чипов i210, так и более производительных i225 (2,5 Гбит/с) или x550 (10 Гбит/с).  В новой серии, как уже было сказано, представлено 10 процессоров, стоимостью от $182 до $539 и теплопакетами от 65 до 95 Вт. Лишь две младшие модели в списке не имеют поддержки Hyper-Threading. Все Xeon E-2300 располагают встроенным движком Manageability Engine 15 и поддержкой Intel Server Platform Services 6, облегчающей развёртывание и удалённое управление. Свои решения на базе новой платформы представят все ведущие производители серверного оборудования.
08.09.2021 [17:40], Владимир Мироненко
IBM представила серверы E1080: 16 CPU POWER10, 240 ядер, 1920 потоков, 64 Тбайт RAM и 224 PCIe-слота в одной системеIBM объявила о выходе нового поколения серверов IBM POWER E1080 на базе 7-нм чипа POWER10. Это первая коммерческая система на новых процессорах IBM, представленных на прошлогодней конференции Hot Chips и использующих архитектуру POWER v3.1. IBM POWER E1080 предназначен для удовлетворения спроса на надёжные гибридные облачные среды. E1080 представляет собой четырёхсокетный сервер с процессорами POWER10. На текущий момент компания предлагает CPU c 10, 12 или 15 ядрами (ещё одно «запасное» ядро отключено), тогда как у POWER9 число ядер не превышало 12. На каждое ядро приходится 2 Мбайт L2-кеша и 8 Мбайт — L3 (до 120 Мбайт общего кеша на CPU). Для систем на базе E1080 поддерживается масштабирование до четырёх узлов, то есть можно получить 16 процессоров, 240 ядер, 1920 потоков, 64 Тбайт RAM и 224 PCIe-слота. 
IBM POWER E1080 Отличительной чертой новинок является поддержка SMT8, то есть обработка до 120 потоков на процессор. По сравнению с POWER9 производительность новых CPU выросла на 20% на поток и на 30% на ядро, а в пересчёте на Вт она выросла трёхкратно. А четыре 512-бит матричных движка и восемь 128-бит SIMD-блоков повысили скорость INT8-операций в 20 и более раз. 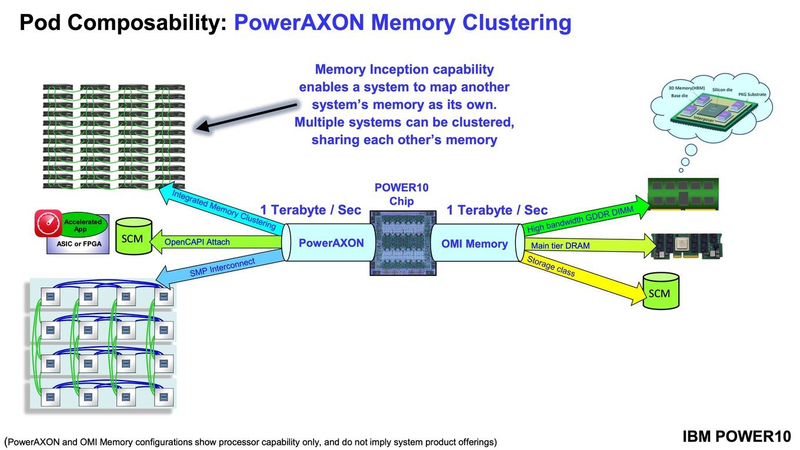 Память тоже новая — буферизированная OMI DDR4 DDIMM, которая, по словам компании, отличается повышенной надёжностью и отказоустойчивостью в сравнении с традиционными DDIMM. На один сервер приходится 64 слота с поддержкой до 16 Тбайт RAM с поддержкой технологии прозрачного шифрования памяти (Transparent Secure Memory Encryption, TSME), которая в 2,5 раза быстрее по сравнению с IBM POWER9. Заявленная пропускная способность составляет 409 Гбайт/с на ядро. 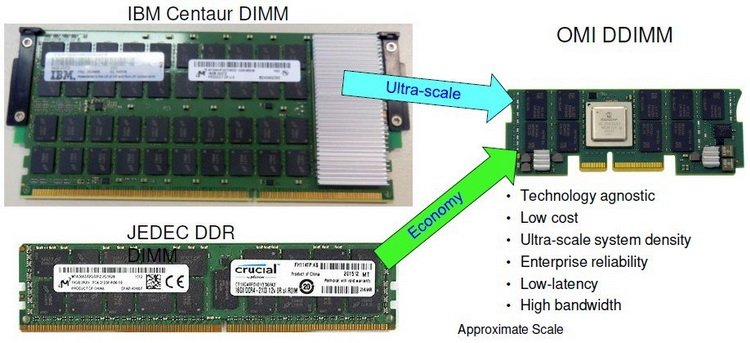 И для OMI, и для OpenCAPI используется шина PowerAXON (1 Тбайт/с), которая позволяет подключать к системе различные типы памяти (можно адресовать до 2048 Тбайт в рамках одного кластера), накопители, ускорители и т.д. Также в самой системе доступно четыре слота для NVMe SSD и 8 слотов PCIe 5.0. К E1080 можно подключить до четырёх полок расширения с 12 слотами PCIe 5.0 в каждой.  По данным IBM, благодаря E1080 установлен «мировой рекорд производительности: это первая система, достигшая 955 000 SAPS (SAP Application Performance Standard, в стандартном тесте приложений SAP SD в восьмипроцессорной системе — значительно больше, чем у альтернативной архитектуры x86, 2x на сокет (и) до 4 раз больше возможностей на ядро с E1080 (по сравнению с Intel)».  IBM заявила, что повышение производительности на ядро и увеличение количества ядер в системе означает значительное сокращение занимаемой серверами площади и энергопотребления. В тематическом исследовании неназванного клиента компания сообщила, что 126 серверов на чипах Intel, обслуживающих СУБД Oracle, были заменены тремя E980 на базе POWER9 и, по прогнозам, их можно будет заменить на два E1080. В результате потребляемая мощность упадёт со 102 до 20 кВт, а количество требуемых лицензий сократится с 891 (для системы Intel) до 263 (для E1080).  Новинка имеет в 4,1 раза более высокую по сравнению с x86-серверами пропускную способность контейнеризированных приложений OpenShift, а также целостность архитектуры и гибкость в гибридной облачной среде для повышения универсальности и снижения расходов без рефакторинга приложений. А по сравнению с IBM POWER E980v рост производительности и масштабируемости составил до 50% с одновременным снижением энергопотребления.  Кроме того, E1080 предлагает новые функции RAS для расширенного восстановления, самовосстановления и диагностики, а также усовершенствования для гибридного облака, включая первый в индустрии поминутный контроль использования ПО Red Hat, в том числе OpenShift и Red Hat Enterprise Linux. У IBM POWER E1080 также имеется возможность мгновенного масштабирования с помощью POWER Private Cloud with Dynamic Capacity, что позволит платить только за использованные ресурсы. Среди прочих преимуществ своего решения IBM отмечает наличие надёжной экосистемы независимых поставщиков ПО, бизнес-партнёров и поддержки для E1080. Кроме того, IBM анонсировала многоуровневый сервис POWER Expert Care, призванный обеспечить защиту от продвинутых киберугроз, а также согласованное функционирование аппаратного и программного обеспечения и более высокую эксплуатационную готовность систем. |
|

