Лента новостей
|
09.11.2021 [12:33], Алексей Степин
NVIDIA представила платформу Jetson AGX Orin для периферийных ИИ-вычислений, робототехники и автономного транспортаОдним из лидеров в создании высокопроизводительных встраиваемых решений давно является NVIDIA с серией Jetson. На смену уже немолодой платформе Jetson AGX Xavier пришла Jetson AGX Orin, обладающая ускорителем с архитектурой Ampere. Компания не без оснований называет Jetson AGX Orin самой мощной, компактной и энергоэффективной платформой для робототехники, автономного транспорта и встраиваемых решений для работы на периферии — её производительность оценивается в 200 Топс, что более чем в шесть раз выше показателей Xavier. По словам NVIDIA новинка сравнима по скорости работы с GPU-сервером, но при этом умещается на человеческой ладони.  Новая 7-нм SoC состоит из 17 млрд транзисторов. Она включает 12 ядер Cortex-A78AE, одних из самых мощных в арсенале Arm, предназначенных для задач класса mission critical и имеющих продвинутые механизмы защиты от системных сбоев Это немаловажно, к примеру, при применении в беспилотных транспортных средствах и промышленной автоматике. Всё это дополнено 2048 ядрами NVIDIA Ampere. ускорители. Ускорена подсистема памяти (200 Гбайт/с). Серьёзно возросли сетевые возможности — новый чип имеет сразу четыре интерфейса 10 Гбит/с.  Разработчики решений на базе Jetson AGX Orin могут использовать NVIDIA CUDA-X, JetPack SDK и наиболее новые версии утилит NVIDIA. Также на момент анонса уже доступны предварительно натренированные и оптимизированные под новую платформу ИИ-модели из каталога NVIDIA TAO, которые помогут сократить время создания новых решений на базе Orin. Доступность новых плат Jetson AGX запланирована на первый квартал следующего года. Дабы не пропустить этот момент, NVIDIA предлагает зарегистрироваться в соответствующем разделе своего сайта.
09.11.2021 [12:17], Алексей Степин
NVIDIA представила Quantum-2, первый 400G-коммутатор InfiniBand NDRNVIDIA, нынешний владелец Mellanox, представила обновления своих решений InfiniBand NDR: коммутаторы Quantum-2, сетевые адаптеры ConnectX-7 и ускорители DPU BlueField-3. Это весьма своевременный апдейт, поскольку 400GbE-решения набирают популярность, а с приходом PCIe 5.0 в серверный сегмент станут ещё более актуальными. 
NVIDIA Quantum-2 (Здесь и ниже изображения NVIDIA) Первый и самый важный анонс — это платформа Quantum-2. Новый коммутатор не только обеспечивает вдвое более высокую пропускную способность на порт (400 Гбит/с против 200 Гбит/c), но также предоставляет в три раза больше портов, нежели предыдущее поколение. Это сочетание позволяет снизить потребность в коммутаторах в 6 раз при той же суммарной ёмкости сети. При этом новая более мощная инфраструктура также окажется более экономичной и компактной.  Более того, Quantum-2 относится к серии «умных» устройств и содержит в 32 раза больше акселераторов, нежели Quantum HDR первого поколения. В нём также реализована предиктивная аналитика, позволяющая избежать проблем с сетевой инфраструктурой ещё до их возникновения; за это отвечает технология UFM Cyber-AI. Также коммутатор предлагает синхронизацию времени с наносекундной точностью, что важно для распределённых нагрузок.  7-нм чип Quantum-2 содержит 57 млрд транзисторов, то есть он даже сложнее A100 с 54 млрд транзисторов. В стандартной конфигурации чип предоставляет 64 порта InfiniBand 400 Гбит/с, однако может работать и в режиме 128 × 200 Гбит/с. Коммутаторы на базе нового сетевого процессора уже доступны у всех крупных поставщиков серверного оборудования, включая Inspur, Lenovo, HPE и Dell Technologies. Возможно масштабирование вплоть 2048 × 400 Гбит/с или 4096 × 200 Гбит/с. 
NVIDIA ConnectX-7 Конечные устройства для новой инфраструктуры InfiniBand доступны в двух вариантах: это относительно простой сетевой адаптер ConnectX-7 и куда более сложный BlueField-3. В первом случае изменения, в основном, количественные: новый чип, состоящий из 8 млрд транзисторов, позволил вдвое увеличить пропускную способность, равно как и вдвое же ускорить RDMA и GPUDirect. 
NVIDIA BlueField-3 DPU BlueField-3, анонсированный ещё весной этого года, куда сложнее с его 22 млрд транзисторов. Он предоставляет гораздо больше возможностей, чем обычный сетевой адаптер или SmartNIC, и крайне важен для будущего развития инфраструктурных решений NVIDIA. Начало поставок ConnectX-7 намечено на январь, а вот BlueField-3 появится только в мае 2022 года. Оба адаптера совместимы с PCIe 5.0.
08.11.2021 [20:00], Игорь Осколков
AMD анонсировала процессоры EPYC Milan-X с 3D V-Cache: 804 Мбайт кеша и 64 ядра Zen3AMD анонсировала серию своих серверных процессоров под кодовым названием Milan-X. Новинки являются развитием EPYC 7003 (Milan), представленных весной этого года, и рассчитаны в первую очередь на высокопроизводительные вычисления (HPC). Главным же отличием от «обычных» Milan станет резко увеличенный объём кеш-памяти, что позволило AMD снова назвать свои процессоры самими быстрыми в мире. 
AMD EPYC Milan-X с 3D V-Cache (Здесь и ниже изобржаения AMD) Откуда берётся цифра в 804 Мбайт? Математика простая. На каждое ядро Zen3 приходится по 32 Кбайт L1-кеша для инструкций и данных + 512 Кбайт L2-кеша. На восемь ядер в CCX-комплексе приходится 32 Мбайт общего L3-кеша. И вот к ним добавляются ещё 64 Мбайт 3D V-Cache — в максимальной конфигурации на 8 CCX получается суммарно 768 Мбайт 3D V-Cache в дополнение к иерархии нижележащих кешей. Таким образом, конкретно по этому показателю побит рекорд IBM z15, хотя данный CPU ориентирован на совсем другие задачи.   А вот среди x86-64 равных Milan-X сейчас нет. Более того, по словам AMD, реализация 3D V-Cache на текущий момент является уникальной в индустрии. Дополнительный кеш имеет непосредственно подключение к CCX по медным каналами, что позволяет значительно повысить плотность упаковки и энергоэффективность, снизить задержки и улучшить температурный режим. Правда, детальные характеристики V-Cache пока не приводятся.  Что важно, новинки будут совместимы с имеющимися SP3-платформами для Milan, что упростит тестирование и валидацию — для них будет выпущено обновление BIOS. Увы, пока данные по частотам, TDP и цене компания не приводит — выпуск Milan-X запланирован на I квартал 2022 года. Но в сносках к презентации, в частности, упоминаются не только 64-ядерные Milan-X, но и 16-ядерные. Надо полагать, что такие «бутерброды» будут дороже обычных CCX, поскольку здесь цена брака будет выше.   Также заявлена совместимость с имеющимся ПО, но и с разработчиками уже ведётся активная работа по дополнительной оптимизации их решений. Наибольшую выгоду от увеличенного кеша получат нагрузки, для которых критична скорость работы с памятью и задержки доступа. Среди таковых AMD упоминает метод конечных элементов, структурный анализ, вычислительную гидродинамику и автоматизированные системы проектирования электроники (EDA). Для последних на примере Synopsys VCS рост производительности составил 66%.
08.11.2021 [20:00], Игорь Осколков
AMD анонсировала Instinct MI200, самые быстрые в мире ускорители вычислений на базе CDNA 2В прошлом году AMD окончательно развела ускорители для графики и вычислений, представив Instinct MI100, первый продукт на базе архитектуры CDNA, который позволил компании противостоять NVIDIA. Теперь же AMD подготовила новую версию архитектуры CDNA 2 и ускорители MI200 на неё основе. Новинки, согласно внутренним тестам, в ряде задач на голову выше того, что сейчас может предложить NVIDIA. 
AMD Instinct MI200 в OAM-варианте (Здесь и ниже изображения AMD) Циркулировавшие ранее слухи оказались верны — MI200 являются двухчиповыми решениями с 2.5D-упаковкой кристаллов (GCD) самих ускорителей, четырёх линий Infinity Fabric между ними и восьми стеков памяти HBM2e (8192 бит, 1600 МГц, 128 Гбайт, 3,2 Тбайт/c). В данном случае используется мостик EFB (Elevated Fanout Bridge), который позволяет задействовать стандартные подложки, что удешевляет и упрощает производство и тестирование ускорителей, не потеряв при этом в производительности и, что важнее, без существенного увеличения задержек в обмене данными. 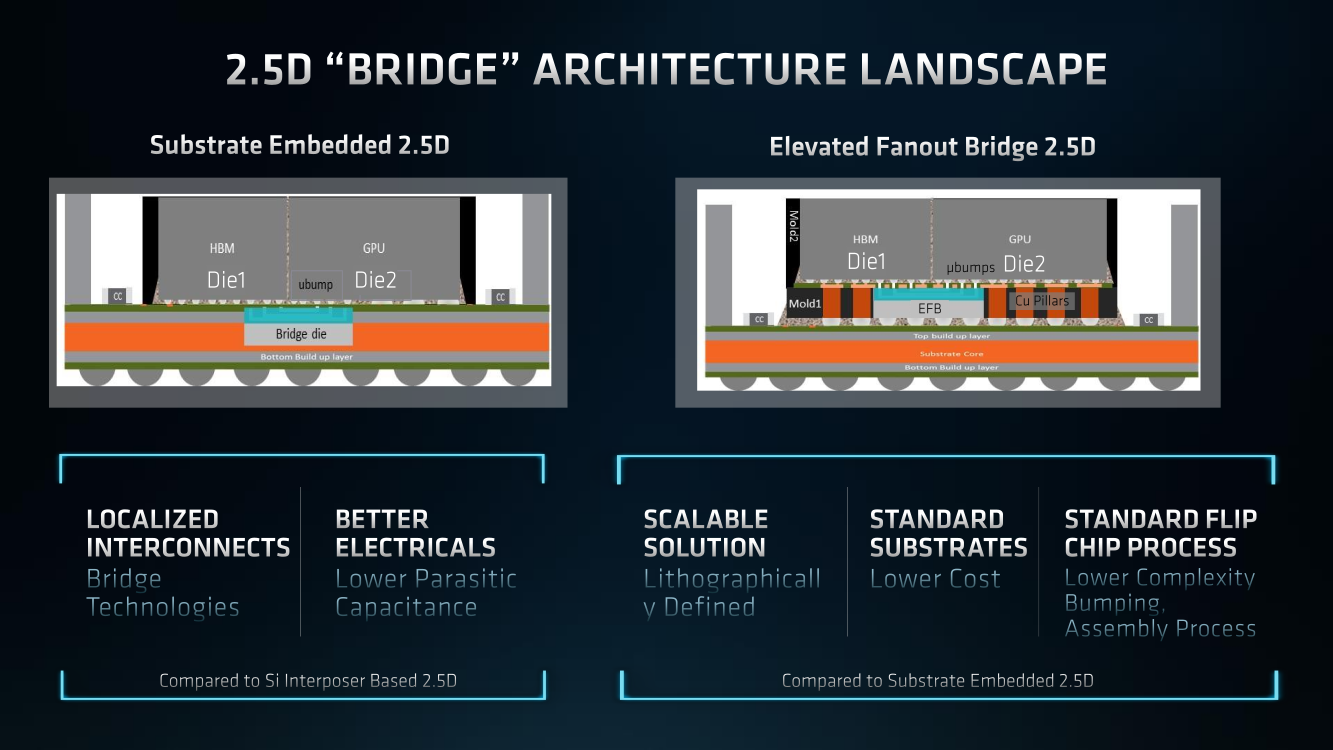 Несмотря на то, что в составе ускорителя два GCD, системе они представляются как единое целое с общей же памятью. Каждый GCD в случае CDNA 2 включает 112 CU (Compute Unit), но в конечных продуктах они задействованы не все. CU разбиты на четыре группы (с индивидуальным планировщиком) с общим L2-кешем объёмом 8 Мбайт и пропускной способностью 6,96 Тбайт/с, который поделён на 32 отдельных блока. А сами блоки имеют индивидуальные подключения к контроллерам памяти в GCD.  Важное отличие CDNA 2 заключается в «подтягивании» производительности векторных FP64- и FP32-вычислений — они исполняются с одинаковой скоростью в отличие от CDNA первого поколения. Кроме того, появилась поддержка сжатых (packed) инструкций для операций FMA/FADD/FMUL для FP32-векторов. Второй крупный апдейт касается матричных вычислений. Для них теперь тоже есть отдельная поддержка FP64, и с той же производительностью, что и для FP32. Новые инструкции рассчитаны на блоки 16×16×4 и 4×4×4.  Поддержка FP16/BF16 в матричных ядрах, конечно, тоже есть, что позволяет задействовать их и для ИИ-задач, а не только HPC. Подспорьем для них в некоторых задачах будут два блока VCN (Video Codec Next) в каждом GCD. Они поддерживают декодирование H.264/AVC, H.265/HEVC, VP9 и JPEG, а также кодирование H.264/H.265, что потенциально позволит более эффективно работать ИИ-алгоритмам с изображениями и/или видео.  Для обмена данными между ускорителями и CPU используется единая шина Infinity Fabric (IF) с поддержкой кеш-когерентности. Всего на ускоритель приходится до восьми внешних линий IF, а суммарная скорость обмена данными может достигать 800 Гбайт/c. В наиболее плотной компоновке из четырёх MI200 и одного EPYC каждый ускоритель имеет по две линии для связи с CPU и со своим соседом. Причём внутренние и внешние IF-линии образуют два двунаправленных кольца между ускорителями. Каждая IF-линия опирается на x16-подключение PCIe 4.0, но в данном случае есть ряд оптимизаций конкретно под HPC-системы HPE Cray.  Дополнительно у каждого ускорителя есть собственный root-комплекс, что позволяет напрямую подключить сетевой адаптер класса 200G. И это явный намёк на возможность непосредственного RDMA-соединения с внешними хранилищами, поскольку в такой схеме на локальные NVMe-накопители линий попросту не остаётся. Более простые топологии уже предполагают использование половины линий IF в качестве обычного PCIe-подключения и задействуют коммутатор(-ы) для связи с CPU и NIC. В этом случае IF-подключение остаётся только между процессорами. Зато в одной системе можно объединить восемь MI200.  Чипы ускорителей MI250X изготовлены по 6-нм техпроцессу FinFet, содержат 58 млрд транзисторов и предлагают 220 CU, включающих 880 ядер для матричных вычислений и 14080 шейдерных ядер второго поколения. У MI250 их 208, 832 и 13312 соответственно. Для обеих моделей уровень TDP составляет 500 или 560 Вт, поэтому поддерживается как воздушное, так и жидкостное охлаждение. В дополнение к OAM-версиям MI250(X) чуть позже появится и более традиционная PCIe-модель MI210.  Для сравнения — у NVIDIA A100 объём и пропускная способность памяти (тоже HBM2e) составляют до 80 Гбайт и 2 Тбайт/с соответственно. Шина же NVLink 3.0 имеет пропускную способность 600 Гбайт/c, а коммутатор NVSwitch для связи между восемью ускорителями — 1,8 Тбайт/с. Потребление SXM3-версии составляет 400 Вт. Стоит также отметить, что первая версия A100 появилась ещё весной 2020 года, и скоро ожидается анонс следующего поколения ускорителей на базе архитектуры Hopper. На носу и выход ускорителей Intel Xe Ponte Vecchio.  И если про первые мы пока ничего толком не знаем, то вторые, похоже, уже проиграли MI250X в «голой» производительности как минимум по одной позиции (FP32). AMD говорит, что создавала Instinct MI200 как серию универсальных ускорителей, пригодных и для «классических» HPC-задач, и для ИИ. Отсюда и практически пятикратная разница в пиковой FP64-производительности с NVIDIA A100. 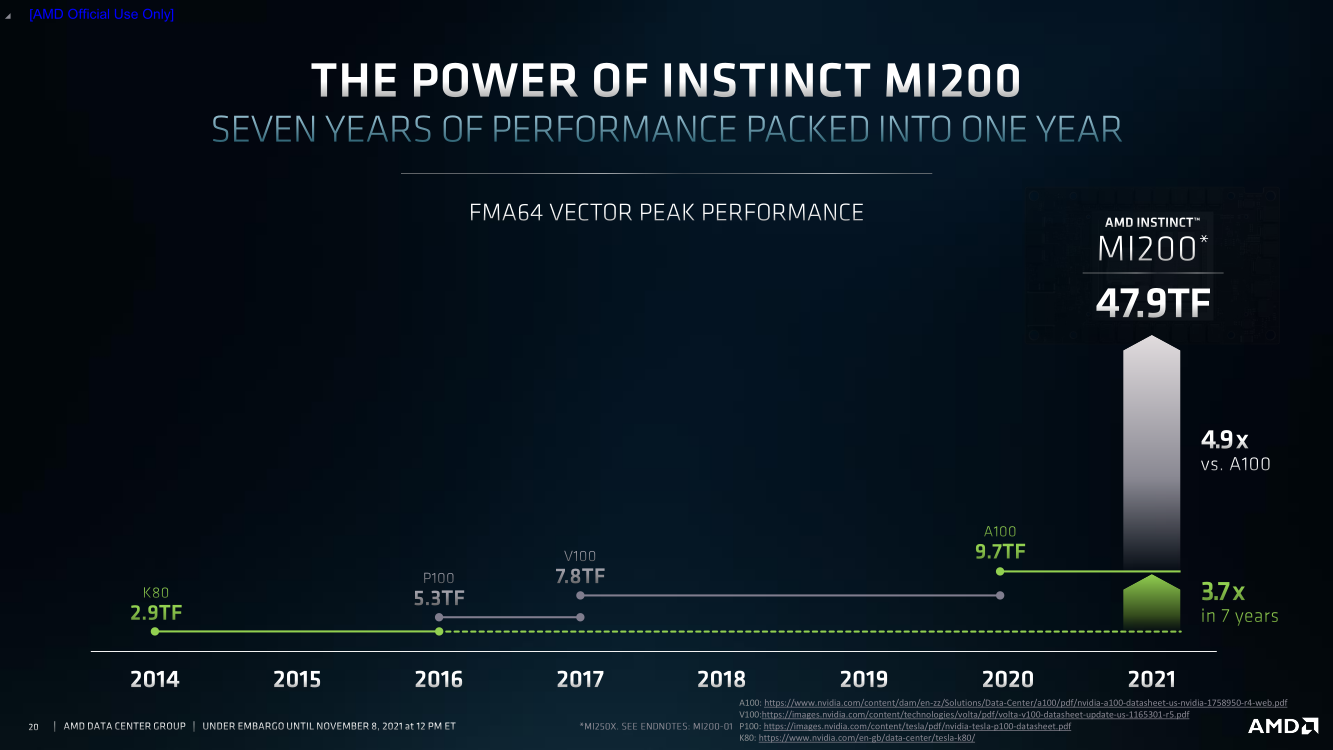 Но вот с нейронками всё не так однозначно. Предпочтительным форматом для обучения у NVIDIA является собственный TF32, поддержка которого есть в Tensor-ядрах Ampere. Ядра для матричных вычислений в CDNA2 про него ничего не знают, поэтому сравнить производительность в лоб нельзя. Разница в BF16/FP16 между MI250X и A100 уже не так велика, так что AMD говорит о приросте в 1,2 раза для обучения со смешанной точностью. 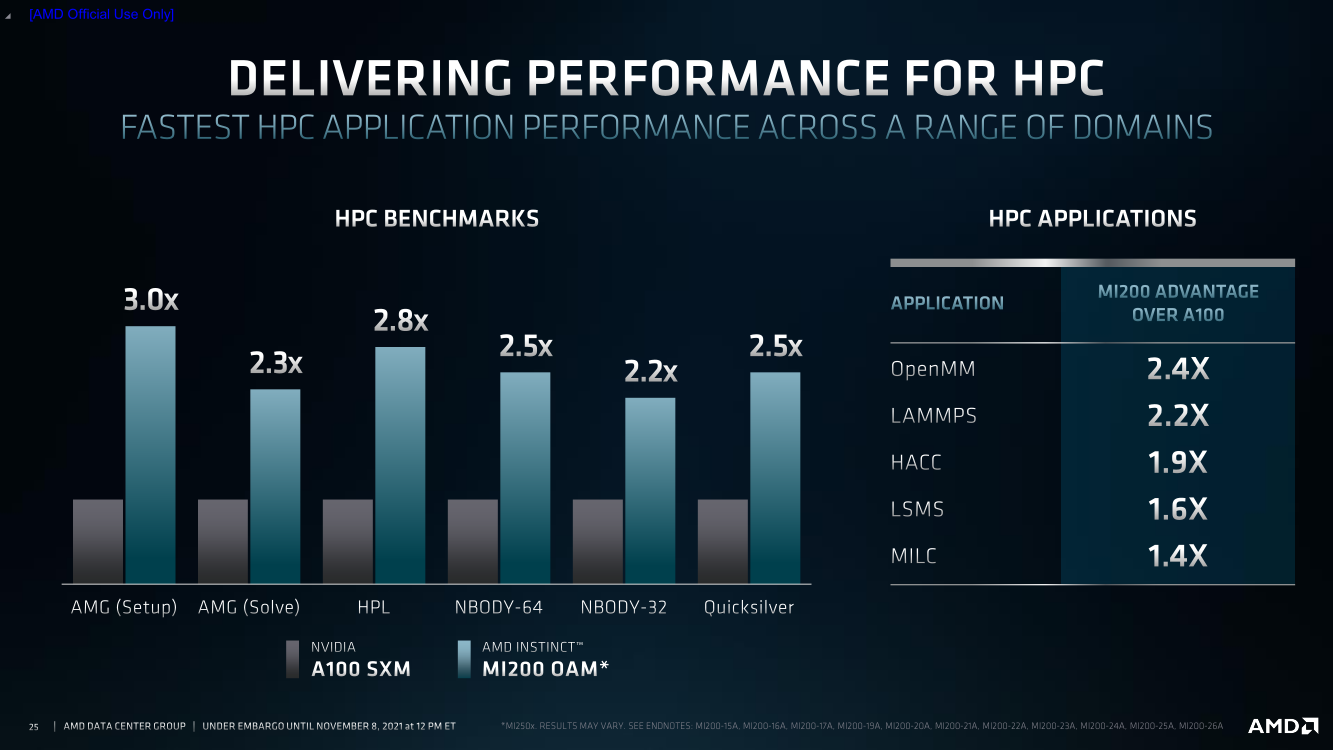 Данные по INT8 и INT4 в презентацию не вынесены, что неудивительно. Пиковый показатель для обоих форматов у MI250X составляет 383 Топс, тогда как тензорные ядра NVIDIA A100 выдают 624 и 1248 Топс соответственно. В данном случае больший объём памяти сыграл бы на руку MI200 в задачах инференса для крупных моделей. Наконец, у A100 есть ещё одно преимущество — поддержка MIG (Multi-Instance GPU), которая позволяет более эффективно задействовать имеющиеся ресурсы, особенно в облачных системах.  Вместе с Instinct MI200 была анонсирована и новая версия открытой (open source) платформы ROCm 5.0, которая обзавелась поддержкой и различными оптимизациями не только для этих ускорителей, но и, например, Radeon Pro W6800. В этом релизе компания уделит особое внимание расширению программной экосистемы и адаптации большего числа приложений. Кроме того, будет развиваться и новый портал Infinity Hub, где будет представлено больше готовых к использованию контейнеров с популярным ПО с рекомендациями по настройке и запуску.  AMD Instinct MI200 появятся в I квартале 2022 года. Новинки, в первую очередь MI210, будут доступны у крупных OEM/ODM-производителей: ASUS, Atos (X410-A5 2U1N2S), Dell Technologies, Gigabyte (G262-ZO0), HPE, Lenovo и Supermicro. Ускорители Instinct MI250X пока остаются эксклюзивом для систем HPE Cray Ex. Именно они вместе с «избранными» процессорами AMD EPYC (без уточнения, будут ли это Milan-X) станут основой для самого мощного в США суперкомпьютера Frontier.  Окончательный ввод в эксплуатацию этого комплекса запланирован на будущий год. Ожидается, что его пиковая производительность превысит 1,5 Эфлопс. При этом он должен стать самой энергоэффективной системой подобного класса. А адаптация ПО под него позволит несколько потеснить NVIDIA CUDA в некоторых областях. И это для AMD сейчас, пожалуй, гораздо важнее, чем победа по флопсам.
29.10.2021 [02:28], Игорь Осколков
Intel объявила о совместной работе с Google над IPU Mount Evans и анонсировала IPDKIntel в рамках мероприятия Innovation раскрыла имя партнёра по разработке IPU Mount Evans — им оказалась компания Google. Впрочем, это не означает, что новинки будут доступны только ей и окажутся оптимизированы только под её задачи. IPU хоть и ориентированы в первую очередь на гиперскейлеров (среди возможных заказчиков называют и Facebook✴), но, по мнению Intel, будут интересны и менее крупным игрокам. Более того, было, наконец, прямо сказано, что ведётся работа и над Project Monterey от VMware. 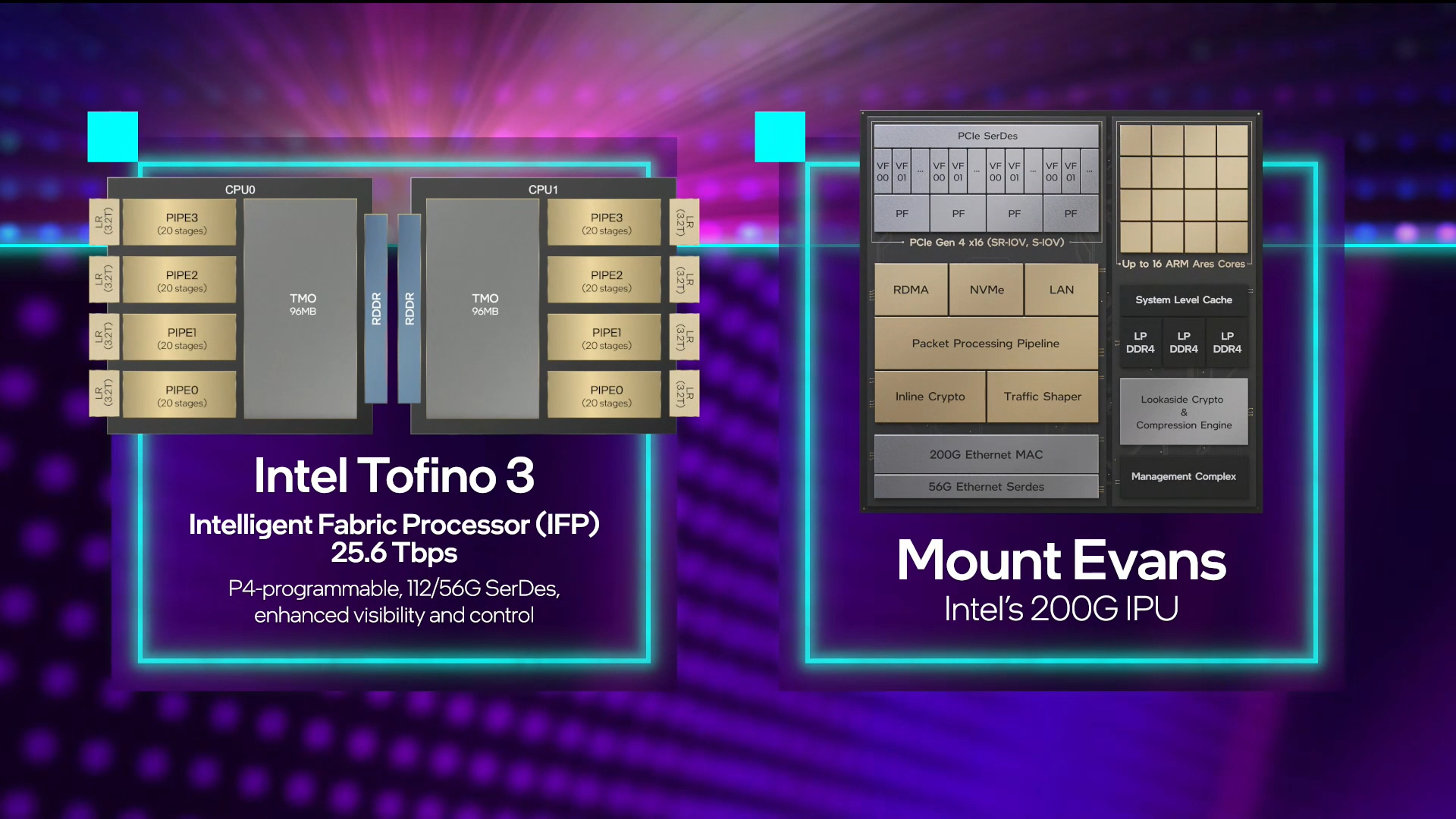 Как пояснил Гвидо Аппенцеллер (Guido Appenzeller), технический директор подразделения Data Platforms Group Intel, название IPU (Infrastructure Processing Unit) было выбрано в противовес всё ещё относительно новому, но более привычному термину DPU (Data Processing Unit) именно потому, что IPU охватывает более широкий спектр задач по работе именно с инфраструктурой, а не только c данными.  Справедливости ради отметим, что и сами DPU, поначалу чаще ориентированные именно на ускорение работы с СХД и устранению узких мест в передаче данных, уже расширили свою функциональность и практически являются IPU именно в терминологии Intel — этот класс сопроцессоров независим от хост-системы и занимается обслуживанием инфраструктуры, включая работу с сетью и хранилищем, изоляцию и телеметрию, управление нагрузками и т.д.  У Intel достаточно богатый опыт работы по сетевому направлению с гиперскейлерами. По словам Аппенцеллера, семь из восьми крупнейших компаний этого класса используют решения Intel во всей или хотя бы в некоторых частях своей инфраструктуры. Так, Microsoft, Baidu и JD полагаются на SmartNIC на базе FPGA. Партнёрство же с Google будет выгодно для обеих компаний. Intel получит заказы, а Google, наконец, обретёт то, что давно есть у Amazon — аналог Nitro. На масштабе в миллионы серверов это очень важно. 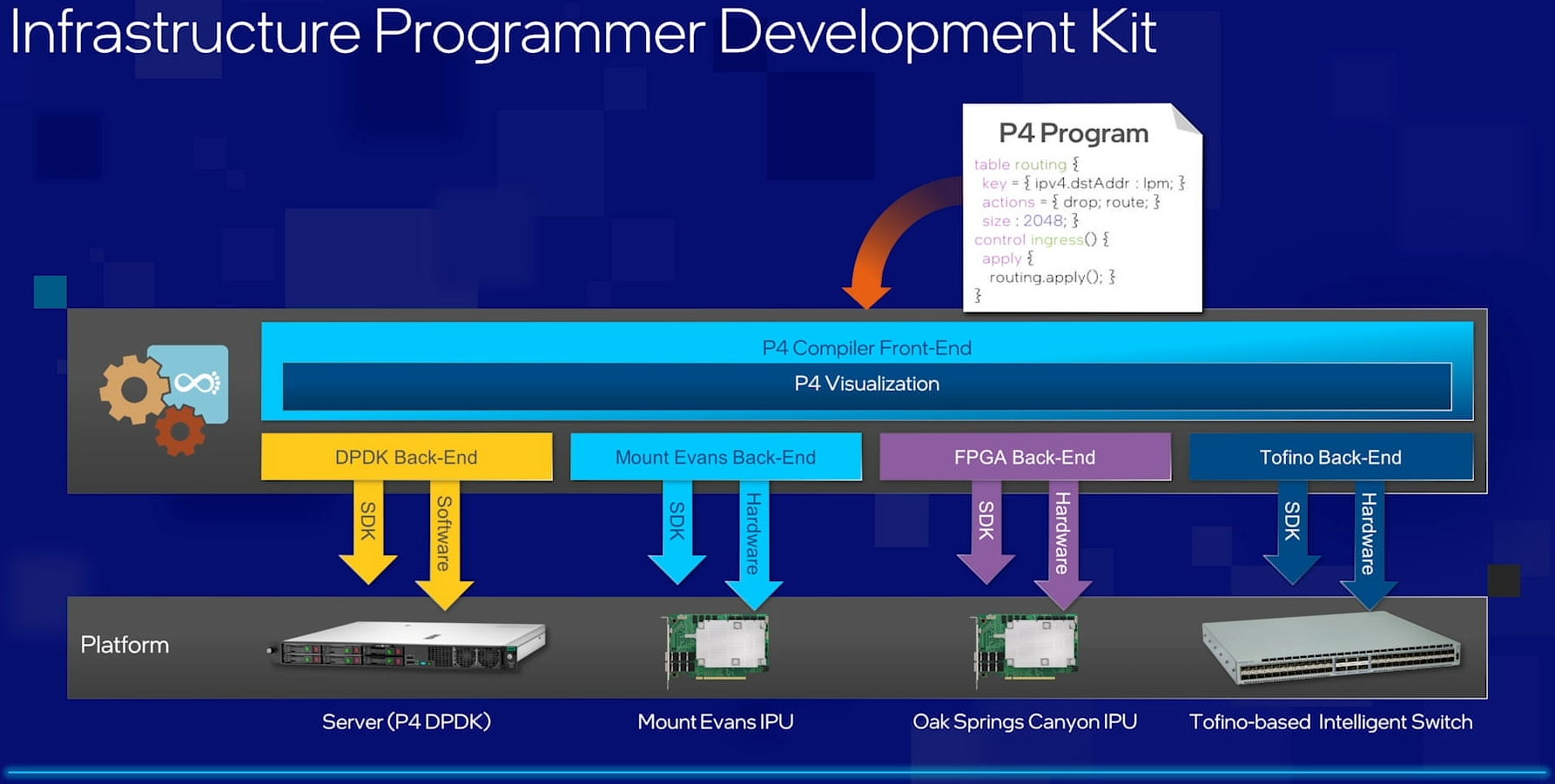 Однако IPU (как аппаратные устройства) — только часть общей картины. Для полноты не хватает как минимум ещё двух компонентов: программного стека и сопутствующей инфраструктуру. Tofino-3 — анонсированный ранее чип или, как его называет сама Intel, Intelligent Fabric Processor — не только поддерживает коммутацию на скорости 25,6 Тбит/с с параллельным сбором телеметрии, но и является полностью P4-программируемым. А это позволяет организовать сквозные мониторинг, управление и оптимизацию трафика для конкретных задач. 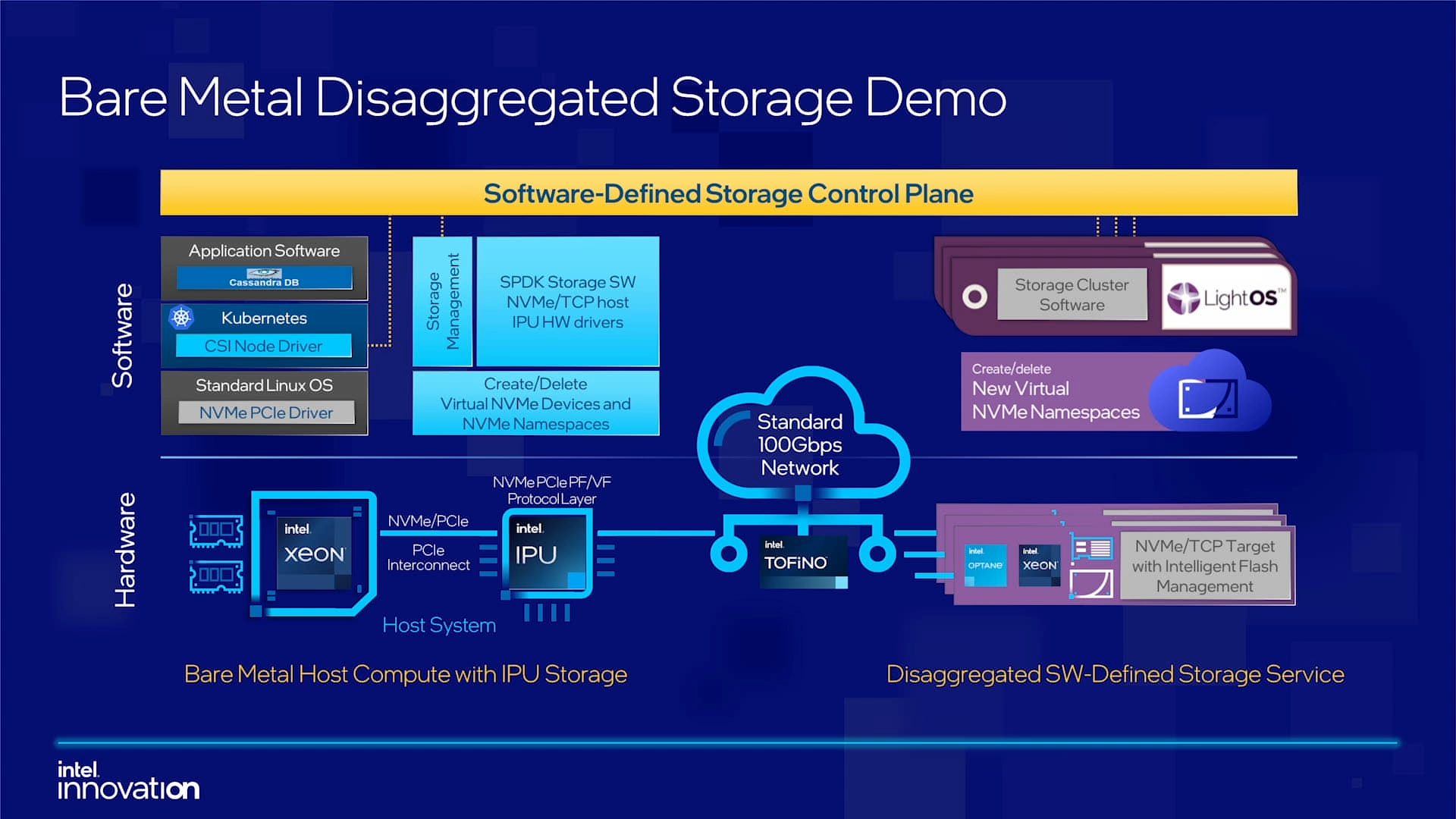 Или, иными словам, IPU и подходящие коммутаторы позволяют сделать всю инфраструктуру практически полностью программно определяемой, но с аппаратной разгрузкой части функций и близкой к bare metal итоговой производительностью. Правда, в качестве демо Intel опять же приводит «классические» примеры с СХД и Open vSwitch, а также сценарии глубокого мониторинга производительности и быстрого поиска проблемных мест в сети. Но этим потенциальные возможности не ограничиваются. 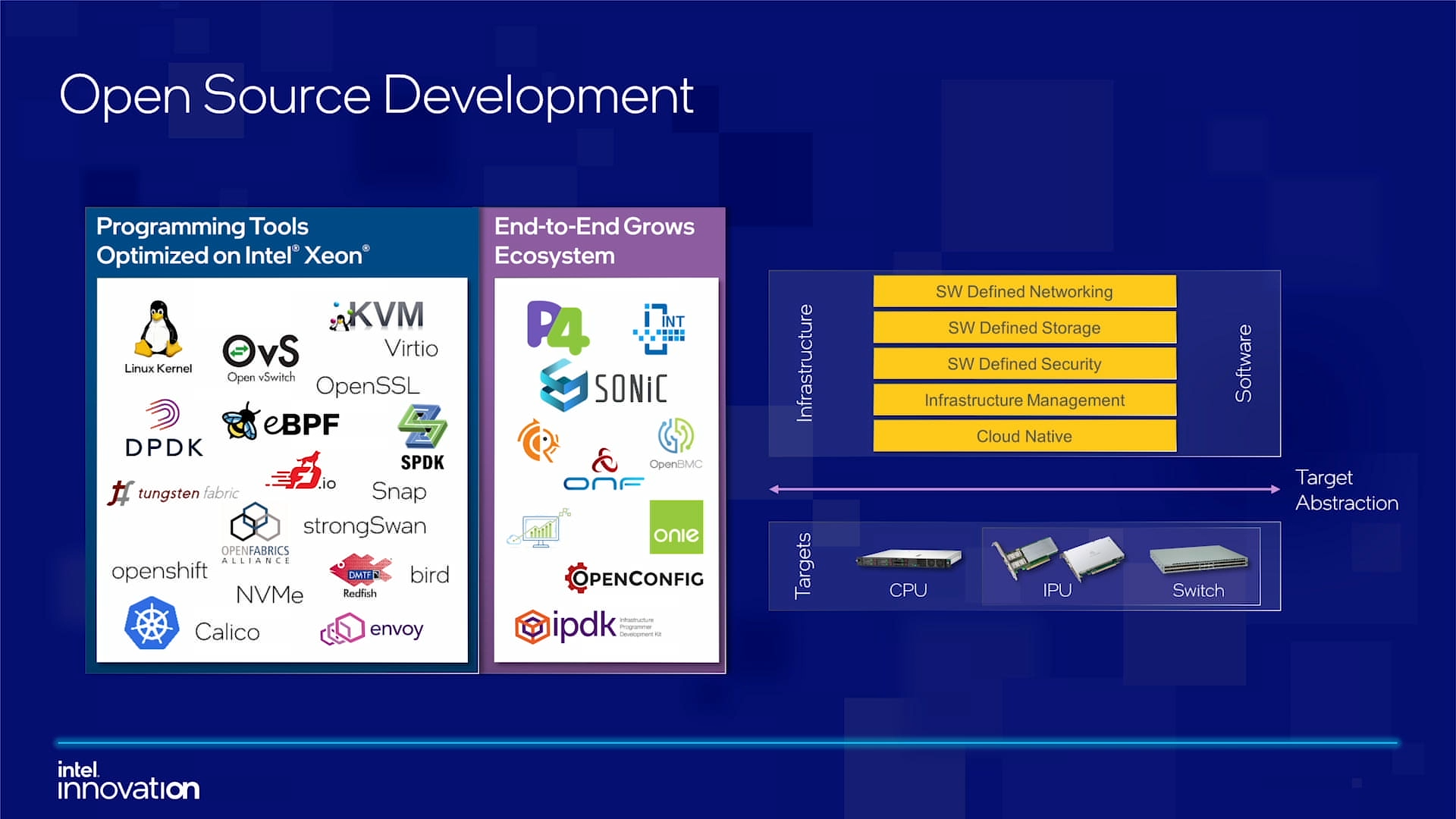 Более того, со стороны ПО и средств разработки жёсткой привязки именно к «железу» Intel нет. Компания представила open source фреймворк IPDK (Infrastructure Programmer Development Kit) для упрощения переноса и, что важно, оптимизации наиболее тяжёлых или нетривиально реализуемых функций ПО на SmartNIC (с FPGA или иной программируемой логикой), IPU/DPU, коммутаторы или CPU. IPDK дополняет уже имеющиеся решения вроде DPDK, SPDK и т.д. возможностями работы с P4.
28.10.2021 [17:02], Алексей Степин
Rockport Networks представила интерконнект с пассивным оптическим коммутаторомПроизводительность любого современного суперкомпьютера или кластера во многом зависит от интерконнекта, объединяющего вычислительные узлы в единое целое, и практически обязательным компонентом такой сети является коммутатор. Однако последнее не аксиома: компания Rockport Networks представила своё видение HPC-систем, не требующее использования традиционных коммутирующих устройств. Проблема межсоединений существовала в мире суперкомпьютеров всегда, даже в те времена, когда сам процессор был набором более простых микросхем, порой расположенных на разных платах. В любом случае узлы требовалось соединять между собой, и эта подсистема иногда бывала неоправданно сложной и проблемной. Переход на стандартные сети Ethernet, Infiniband и их аналоги многое упростил — появилась возможность собирать суперкомпьютеры по принципу конструктора из стандартных элементов. 
Пассивный оптический коммутатор SHFL Тем не менее, проблема масштабирования (в том числе и на физическом уровне кабельной инфраструктуры), повышения скорости и снижения задержек никуда не делась. У DARPA даже есть особый проект FastNIC, нацеленный на 100-кратное ускорение сетевых интерфейсов, чтобы в конечном итоге сгладить разницу в скорости обмена данными внутри узлов и между ними.  Сам по себе высокоскоростной коммутатор для HPC-систем — устройство непростое, требующее использования недешёвого и сложного кремния, и вкупе с остальными компонентами интерконнекта может составлять заметную долю от стоимости всего кластера в целом. При этом коммутаторы могут вносить задержки, по определению являясь местами избыточной концентрации данных, а также требуют дополнительных мощностей подсистем питания и охлаждения.  Подход, продвигаемый компанией Rockport Networks, свободен от этих недостатков и изначально нацелен на минимизацию точек избыточности и возможных коллизий. А достигнуто это благодаря архитектуре, в которой концепция традиционного сетевого коммутатора отсутствует изначально. Вместо этого имеется специальный модуль SHFL, в котором топология сети задаётся оптически, а все логические задачи берут на себя специализированные сетевые адаптеры, работающие под управлением фирменной ОС rNOS и имеющие на борту сконфигурированную нужным образом ПЛИС. 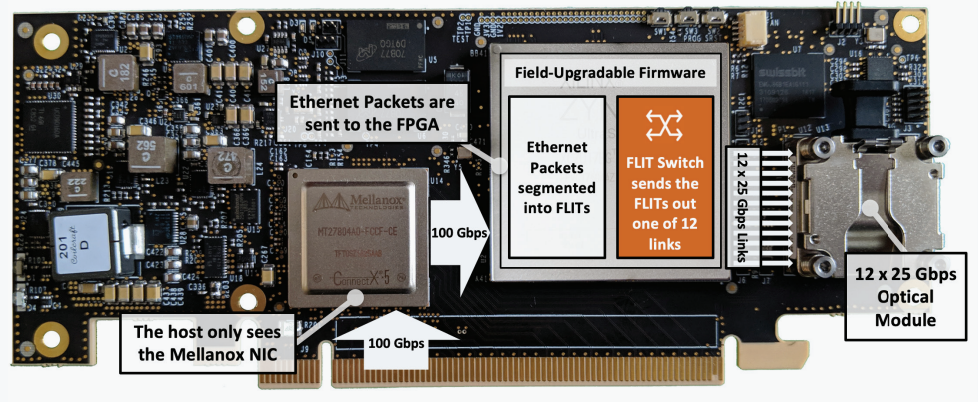 Модуль SHFL даже не требует отдельного электропитания, а вот адаптеры Rockport NC1225 его хотя и требуют, но умещаются в конструктив низкопрофильного адаптера с разъёмом PCIe x16 и потребляют всего 36 Вт. Правда, в настоящий момент речь идёт только о PCIe 3.0, поэтому полнодуплексного подключения на скорости 200 Гбит/с пока нет. Тем не менее, Техасский центр передовых вычислений (TACC) посчитал, что этого уже достаточно и стал одним из первых заказчиков — 396 узлов суперкомпьютера Frontera используют решение Rockport.  Использование не совсем традиционной оптической сети, впрочем, накладывает свои особенности: вместо популярных *SFP-корзин используются разъёмы MTP/MPO-24, а каждый кабель даёт для подключения 12 отдельных волокон, что при скорости 25 Гбит/с на волокно позволит достичь совокупной пропускной способности 300 Гбит/с. ОС и приложениям адаптер «представляется» как чип Mellanox ConnectX-5, который и входит в его состав, а потому не требует каких-то особых драйверов или модулей ядра. 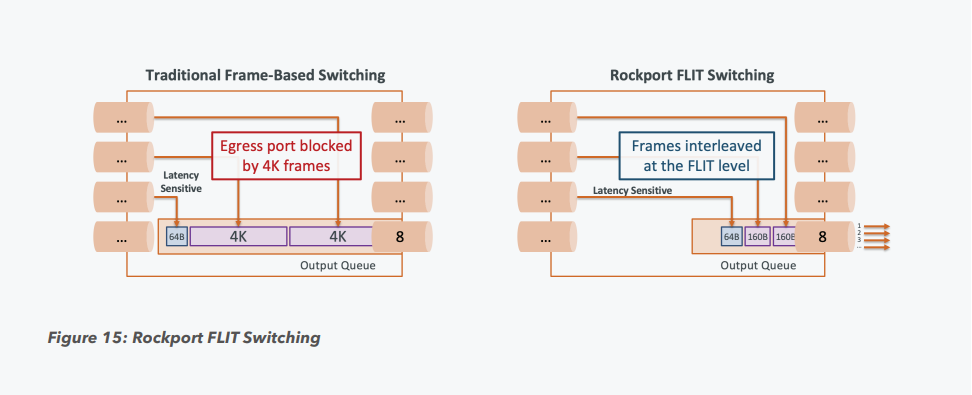 Rockport фактически занимается транспортировкой Ethernet и реализует уровень OSI 1/1.5, однако традиционной коммутации как таковой нет — адаптеры самостоятельно определяют конфигурацию сети и оптимальные маршруты передачи сигнала по отдельным волокнам с возможностью восстановления связности на лету при каких-либо проблемах. Весь трафик разбивается на маленькие кусочки (FLIT'ы) и отправляется по виртуальным каналам (VC) с чередованием, что позволяет легко управлять приоритизацией (в том числе на L2/L3) и снизить задержки.  SHFL имеет 24 разъёма для адаптеров и ещё 9 для объединения с другими SHFL и Ethernet-шлюзами для подключения к основной сети ЦОД (в ней сеть Rockport видна как обычная L2). Таким образом, в составе кластера каждый узел может быть подключён как минимум к 12 другим узлам на скорости 25 Гбит/с. Однако топологию можно менять по своему усмотрению. Компания-разработчик заявляет о преимуществе своего интерконнекта на классических HPC-задачах, могущем достигать почти 30% при сравнении c InfiniBand класса 100G и даже 200G. Кроме того, для Rockport требуется на 72% меньше кабелей.
26.10.2021 [22:45], Игорь Осколков
Получена первая партия российских серверных Arm-процессоров Baikal-S: 48 ядер, 6 каналов DDR4-3200 и 80 линий PCIe 4.0Компания «Байкал Электроникс» сообщила о получении первой партии инженерных образцов серверных Arm-процессоров Baikal-S объёмом 400 шт. Следующую партию компания ожидает получить в первом квартале следующего года, а первые массовые поставки (партия более 10 тыс. шт.) должны начаться до конца третьего квартала. Инженерные платы для разработчиков, созданы «Гаоди рус» (Dannie Group) и выпущены компанией «Рутек». Baikal-S, изготавливаемый по 16-нм техпроцессу на TSMC, имеет 48 ядер Arm Cortex-A75 на базе достаточно свежей 64-бит архитектуры ARMv8.2-A, которая была анонсирована в 2017 году. Частота составляет до 2,2 ГГц, а уровень TDP равен 120 Вт. Заявленный диапазон рабочих температур простирается от 0 до +70 °C. Производительность в HPL составляет 385 Гфлопс, а рейтинг в SPEC CPU2006 INT — до 600. Ориентировочная цена одного процессора ожидается на уровне $3 тыс.  L1-кеш имеет объём по 64 Кбайт для данных и инструкций, а L2 — 512 Кбайт на ядро. Любопытно, что в дополнение к L3-кешу (по 2 Мбайт на кластер) есть ещё и L4-кеш на 32 Мбайт. Контроллер памяти имеет шесть каналов DDR4-3200 ECC и обслуживает до 128 Гбайт на канал (суммарно 768 Гбайт на сокет). Кроме того, каждый процессор имеет 80 линий PCIe 4.0, из которых 48 линий делятся тремя интерфейсами CCIX x16. Также есть пара 1GbE-интерфейсов. 
Источник: CNews При этом новинка поддерживает аппаратную виртуализацию, Arm TrustZone и позволяет создавать четырёхсокетные платформы. Всё это делает её привлекательным решением не только для традиционных серверов и СХД, но и для и HCI- и HPC-систем. С экосистемой ПО проблемы вряд ли будут. Во-первых, для «малого» Байкал-М уже сейчас есть отечественные ОС и другие продукты. Во-вторых, серверные платформы Arm в мире развивают сразу несколько игроков, да и сама Arm стимулирует процесс разработки и портирования ПО. Кроме того, «Байкал Электроникс» имеет тесные связи с ГК Astra Linux.
25.10.2021 [21:33], Руслан Авдеев
В тихом омуте: дата-центры потребляют сотни миллионов кубометров воды, но сколько именно, не знает никтоВ сентябре текущего года на юго-востоке США случилась сильная засуха. По данным местных регуляторов, ситуация может только усугубиться. Это нахудшая ситуация с водными ресурсами за всю зарегистрированную в регионе историю. На этом фоне гигантские расходы воды дата-центрами является одним из тревожных факторов — хотя бы потому, что никто точно не знает, сколько воды они используют на самом деле.  По словам профессора Армана Шехаби (Arman Shehabi) из Национальной лаборатории им. Лоуренса в Беркли (США), которые приводит Datacenter Dynamics, достоверные сведения о потреблении дата-центрами воды централизованно никем не собираются, а сами компании, если и ведут статистику, не горят желанием показывать её даже властям, ссылаясь на коммерческую тайну. Отрывочные сведения поступают из юридических документов, публикуемых в ходе разбирательств. И хотя дата-центры, как и заводы, потребляют много электричества и воды, от них — в отличие от предприятий, например, текстильной или химической промышленности — власти обычно не требуют регулярных отчётов. По данным Uptime Institute, операторы только половины ЦОД собирают хоть какую-то статистику о расходе воды. Вместе с тем, по экспертным оценкам, ЦОД входят в десятку крупнейших коммерческих потребителей воды в США. И, что важно, зачастую это питьевая вода.  Профессор, в своё время сумевший подсчитать энергопотребление всех ЦОД США (205 ТВт·ч в 2018 году), пытается сделать схожие вычисления расхода воды. При этом важно учесть не только прямое потребление воды кампусами ЦОД, но и ту воду, которая используется ГЭС, воду, израсходованную очистительными предприятиями, а также другие факторы. Как считает профессор, дата-центры потребляют воду из 90% бассейнов США. Предположительно суммарно на дата-центры в 2018 году ушло 513 млн м3. В среднем на один потраченный МВт·ч приходится 7,1 м3 воды, но разница между регионами просто огромная. Оценить меры по восстановлению водного баланса тоже крайне сложно. Многие из подобных проектов не «восстанавливают» воду — вместо этого минимизируются её потери, высаживаются растения, ремонтируются водопроводы, устанавливаются очистные сооружения. Хотя такие действия безусловно полезны, расход воды не компенсируется напрямую. Кроме того, в каждом конкретном регионе возможно конечное число водосберегающих мероприятий, которые можно провести, поэтому дата-центрам помельче не остаётся поля деятельности в соответствующей сфере.  Среди крупных игроков Facebook✴ и Microsoft планируют достичь положительного водного баланса к 2030 году, а Google обещает к концу десятилетия возвращать по 120% от объёма использованной воды. Во всех случаях речь идёт прямом потреблении воды и не уточняется, как именно будет восстанавливаться баланс. Возможна та же ситуация, что и с «зелёной» энергетикой, когда крупные компании потребляют электроэнергию из обычных сетей, используя для компенсации углеродного следа т.н. «зелёный камуфляж». По мнению Шехаби, бизнесу стоит делиться подобными данными хотя бы на анонимной основе. В случае отказа усиливающиеся засухи и рост осведомлённости общества о деятельности дата-центров приведут к тому, что будут приняты законы, обязывающие собирать и раскрывать сведения о потреблении воды в принудительном порядке (и с возможной последующей регуляцией рынка). Профессор считает, что водные ресурсы имеют даже более критическое значение, чем энергетические.
22.10.2021 [20:03], Руслан Авдеев
Для обеспечения работы суперкомпьютера El Capitan потребуется 28 тыс. тонн воды и 35 МВт энергииК моменту ввода в эксплуатацию в 2023 году суперкомпьютер El Capitan на базе AMD EPYC Zen4 и Radeon Instinct, как ожидается, будет иметь самую высокую в мире производительность — более 2 Эфлопс. А это означает, что ему потребуются гигантские мощности для питания и охлаждения. Ливерморская национальная лаборатория (LLNL), в которой и будет работать El Capitan, поделилась подробностями о масштабном проекте, призванном обеспечить HPC-центр необходимой инфраструктурой. В основе плана модернизации лежит проект Exascale Computing Facility Modernization (ECFM) стоимостью около $100 млн. В его рамках будет обновлена уже существующая в LLNL инфраструктура. Для реализации проекта необходимо получить очень много разрешений от местных регуляторов и очень тесно взаимодействовать с местными поставщиками электроэнергии. Тем не менее, LLNL заявляет, что проект «почти готов», по некоторым оценкам — на 93%. Функционировать новая инфраструктура должна с мая 2022 года (с опережением графика).  Сам проект стартовал ещё в 2019 году и, согласно планам, должен быть полностью завершён в июле 2022 года. В его рамках модернизируют территорию центра, введённого в эксплуатацию в 2004 году, общей площадью около 1,4 га. Если раньше центр, в котором работали системы вроде лучшего для 2012 года суперкомпьютера Sequoia (ныне выведенного из эксплуатации), обеспечивал подачу до 45 МВт, то теперь инфраструктура рассчитана уже на 85 МВт. Конечно, даже для El Capitan такие мощности будут избыточны — ожидается, что суперкомпьютер будет потреблять порядка 30-35 МВт. Однако LLNL заранее думает о «жизнеобеспечении» преемника El Capitan. Следующий суперкомпьютер планируется ввести в эксплуатацию до того, как его предшественник будет отключён в 2029 году. Кроме того, для новой системы потребуется установка нескольких 3000-тонных охладителей. Если раньше общая ёмкость системы охлаждения составляла 10 000 т воды, то теперь она вырастет до 28 000 т.
19.10.2021 [19:39], Алексей Степин
Alibaba Cloud представила серверный 128-ядерный Armv9-процессор Yitian 710Эпоха неоспоримого господства x86-64 в серверах, похоже, постепенно всё же подходит к концу. Ampere, AWS, Fujitsu, HiSilicon, Phytium и другие производители Arm-процессоров дают бой x86-64 и выигрывает его, пусть и не во всех областях. Эффективность серверных Arm-решений уже неоспорима, количество ядер уже перевалило за сотню, а теперь ещё один крупный провайдер облачных услуг, китайская компания Alibaba Cloud, анонсировала свой вариант высокопроизводительного CPU на базе Arm. Первые попытки Arm проникнуть на рынок серверов или рабочих станций были робкими и неуверенными, но за последние несколько лет ситуация сильно изменилась: уверенно показывают себя такие интересные чипы, как Ampere Altra, недавно доросшие уже до 128 ядер, Amazon активно предлагает инстансы на базе Graviton2, а Huawei даже открывает первый в России ЦОД на базе своих чипов Kunpeng 920.  Более того, мощные многоядерные Arm-процессоры обрастают собственной инфраструктурой: появляются собственные процессорные разъёмы, системные платы, не уступающие x86-моделям, и даже варианты в виде рабочих станций для разработчиков программного обеспечения, без которого любая платформа мертва. Тем интереснее выглядит анонс Alibaba Cloud. Компания сообщила о выпуске нового процессора, который послужит основой для её облачных. И по ряду характеристик можно видеть, что это весьма передовые решения. Новинка носит название Yitian 710, она имеет собственный процессорный сокет и инфраструктуру сопутствующей «обвязки» (есть и референс-дизайн сервера, Panjiu). Впрочем, интереснее то, что эти процессоры — как и Altra Max — могут иметь до 128 ядер.  Но если текущее поколение Ampere Altra базируется на наборе инструкций Armv8.2 с некоторыми заимствованиями из v8.3 и v8.4, то китайский гигант использует более новый вариант, Armv9. Эта версия архитектуры была анонсирована только весной этого года, она, как минимум, на треть быстрее v8, поддерживает аппаратную ускорение работы контейнеров и виртуальных машин, а также наделена востребованными нынче векторными инструкциями со средствами ускорения машинного обучения (SVE2). 5-нм процессоры Yitian 710 поставляются с июля этого года. Они содержат примерно 60 млрд транзисторов и могут иметь тактовую частоту до 3,2 ГГц, а также включают 128 Мбайт L3-кеша, восьмиканальный контроллер DDR5-4400 и 96 линий PCIe 5.0. TDP равен 250 Вт. Так что это один из самых передовых на сегодня серверных процессоров не только в плане чистой производительности. Сама Alibaba называет свое детище универсальным, одинаково хорошо подходящим для нагрузок общего назначения, развёртывания СХД и ИИ-нагрузок, но, разумеется, приоритет отдаётся задачам, характерным для облачных сред. 
Alibaba Cloud: Yitian 710 превосходит всех ARM-соперников и в своём классе является лучшим Ввиду санкционных трений решение Alibaba Cloud разработать собственный мощный процессор выглядит вполне обоснованно, как и принятое ранее решение о создании собственной ИИ-платформы Hanguang 800. И это не единственные разработки Alibaba Cloud. Компания собирается сделать открытым дизайн не только четырёх чипов XuanTie (RISC-V), но и некоторых будущих ядер. Открыт будет и сопутствующий набор ПО, так что Alibaba Cloud всерьёз намеревается вырастить вокруг своего «кремния» развитую инфраструктуру аппаратного и программного обеспечения. |
|

