Лента новостей
|
10.12.2021 [12:00], Алексей Степин
Аквариус T50 D224CF: надёжный и масштабируемый сервер для любых задачКомпания «Аквариус» работает на российском рынке с 1989 года, постоянно расширяя ассортимент производимой продукции. При этом она практически не использует оборудование ОЕМ-поставщиков, 94% из всего модельного ряда устройств «Аквариус» составляют системы собственной разработки. В этом году компания сообщила о разработке двадцати новых моделей серверов и преодолела рубеж в 250 тысяч произведенных серверных устройств. Юбилейной стала флагманская модель — Aquarius T50 D224CF.  Это сервер форм-фактора 2U, располагающий серьёзными возможностями: новая модель разработана с прицелом на максимальную гибкость конфигурирования и расширения, поэтому она одинаково хорошо подойдёт как для развёртывания среды виртуализации или работы с объемными базами данных, так и для создания современной высокопроизводительной системы хранения данных. Базируется Аквариус T50 D224CF на хорошо известной и доказавшей свою надёжность платформе Intel® Xeon® Scalable (LGA 3647). Системная плата на базе чипсета Intel® C624 предусматривает установку процессоров Xeon® Scalable с этим разъёмом как первого (Skylake-SP), так и второго (Cascade Lake-SP/Refresh) поколения с теплопакетом вплоть до 205 Вт включительно. 24 слота для модулей памяти позволяют установить до 3 Тбайт оперативной памяти стандарта DDR4, а с использованием модулей Optane DCPMM этот показатель можно довести и до 6 Тбайт. Но по-настоящему интересной данную модель делает её гибкость в конфигурировании. Во-первых, она имеет 24 дисковых корзины формата 2,5″ с поддержкой SAS-3/SATA-3 и NVMe (до 16 накопителей) и опционально может оснащаться ещё 4 такими отсеками на тыльной стороне (но уже без NVMe). А поддержка одновременной работы 16 NVMe SSD делает Aquarius T50 D224CF отличной платформой для создания высокопроизводительной СХД. Во-вторых, новый сервер Аквариус может поставляться в двух конфигурациях в зависимости от адаптеров расширения:
Оба варианта прекрасно работают с любыми картами расширения, включая ускорители, периферийные и сетевые адаптеры стандартов Ethernet, InfiniBand 10/40/100 Гбит/с, а также Fibre Channel. Сервер имеет развитую систему мониторинга и удалённого управления на основе популярного контроллера ASPEED AST2500, поддерживающего стандарты IPMI 2.0 и Redfish 1.1. Контроллер имеет свой выделенный порт 1GbE. 
Стапельная сборка сервера на производственном комплексе «Аквариус», город Шуя, Ивановская область Максимальная конфигурация сервера требует наличие высокоэффективной системы охлаждения, которая в данной модели состоит из 6-ти вентиляторов с ШИМ-управлением, имеющих вибропоглощающие крепления и поддерживающих горячую замену. Дополнительную отказоустойчивость системы охлаждения обеспечивает индикатор отказа. Заменять в горячем режиме можно и ряд других компонентов сервера, за исключением процессоров, что позволяет в случае неисправности сократить время простоя до минимума. За питание отвечает пара (1+1) блоков, которые, в зависимости от конфигурации, могут иметь мощность от 800 до 2000 Ватт. Базовый вариант предполагает питание от стандартной сети, опционально «Аквариус» предлагает питание от сети постоянного тока 48 В, либо высоковольтной сети 380 В. Также доступен встроенный источник бесперебойного питания. Гибкость и масштабируемость данного сервера делают его поистине универсальным решением: Аквариус T50 D224CF может применяться в облачных системах, кластерах HPC, комплексах виртуализации (в том числе для виртуальных рабочих мест, VDI), системах машинного обучения или как сервер веб-приложений. Он может стать частью комплекса ИИ, основой СХД или мощной сетевой инфраструктуры.  Компания-производитель гарантирует совместимость с широчайшим спектром операционных систем и программного обеспечения. В частности, модель сертифицирована для работы с ПО VMware, RedHat, SUSE, Microsoft Windows Server, а также протестирована на совместимость работы с ускорителями вычислений NVIDIA и российскими средствами защиты информации «Соболь» и «Аккорд». Более того, сервер может комплектоваться двумя микросхемами BIOS, предоставляя заказчику возможность переключаться между AMI BIOS и отечественной разработкой NUMA BIOS.  Аквариус T50 D224CF — это современный, высокопроизводительный сервер, который отличается гибкостью конфигурирования и широкоми возможностями расшириения системы. Именно гибкость и масштабируемость делают его действительно универсальной системой для поддержки самого широкого спектра нагрузок и формирования различных IT-систем. Стоимость нового сервера варьируется в зависимости от конфигурации, цена базового варианта стартует от 400 000 рублей. При необходимости можно получить более точную информацию на сайте компании-производителя, либо по телефону +7 (495) 729-51-50.
07.12.2021 [00:36], Алексей Степин
ИИ-ускорители AWS Trainium: 55 млрд транзисторов, 3 ГГц, 512 Гбайт HBM и 840 Тфлопс в FP32GPU давно применяются для ускорений вычислений и в последние годы обросли поддержкой специфических форматов данных, характерных для алгоритмов машинного обучения, попутно практически лишившись собственно графических блоков. Но в ближайшем будущем их по многим параметрам могут превзойти специализированные ИИ-процессоры, к числу которых относится и новая разработка AWS, чип Trainium. На мероприятии AWS Re:Invent компания рассказала о прогрессе в области машинного обучения на примере своих инстансов P3dn (Nvidia V100) и P4 (Nvidia A100). Первый вариант дебютировал в 2018 году, когда модель BERT-Large была примером сложности, и благодаря 256 Гбайт памяти и сети класса 100GbE он продемонстрировал впечатляющие результаты. Однако каждый год сложность моделей машинного обучения растёт почти на порядок, а рост возможностей ИИ-ускорителей от этих темпов явно отстаёт. 
Сложность моделей машинного обучения будет расти всё быстрее Когда в прошлом году был представлен вариант P4d, его вычислительная мощность выросла в четыре раза, а объём памяти и вовсе на четверть, в то время как знаменитая модель GPT-3 превзошла по сложности BERT-Large в 500 раз. А теперь и 175 млрд параметров последней — уже ничто по сравнению с 10 трлн в новых моделях. Приходится наращивать и объём локальной памяти (у Trainium имеется 512 Гбайт HBM с суммарной пропускной способностью 13,1 Тбайт/с), и активнее использовать распределённое обучение.  Для последнего подхода узким местом стала сетевая подсистема, и при разработке стека Elastic Fabric Adapter (EFA) компания это учла, наделив новые инстансы Trn1 подключением со скоростью 800 Гбит/с (вдвое больше, чем у P4d) и с ультранизкими задержками, причём доступен и более оптимизированный вариант Trn1n, у которого пропускная способность вдвое выше и достигает 1,6 Тбит/с. Для связи между самими чипами внутри инстанса используется интерконнект NeuroLink со скоростью 768 Гбайт/с. 
Прогресс подсистем сети и памяти в ИИ-инстансах AWS Но дело не только в возможности обучить GPT-3 менее чем за две недели: важно и количество используемых для этого ресурсов. В случае P3d это потребовало бы 600 инстансов, работающих одновременно, и даже переход к архитектуре Ampere снизил бы это количество до 200. А вот обучение на базе чипов Trainium требует всего 130 инстансов Trn1. Благодаря оптимизациям, затраты на «общение» у новых инстансов составляют всего 7% против 14% у Ampere и целых 49% у Volta. 
Меньше инстансов, выше эффективность при равном времени обучения — вот что даст Trainium Trainium опирается на систолический массив (Google использовала тот же подход для своих TPU), т.е. состоит из множества очень тесно связанных вычислительных блоков, которые независимо обрабатывают получаемые от соседей данные и передают результат следующему соседу. Этот подход, в частности, избавляет от многочисленных обращений к регистрам и памяти, что характерно для «классических» GPU, но лишает подобные ускорители гибкости.  В Trainium, по словам AWS, гибкость сохранена — ускоритель имеет 16 полностью программируемых (на С/С++) обработчиков. Есть и у него и другие оптимизации. Например, аппаратное ускорение стохастического округления, которое на сверхбольших моделях становится слишком «дорогим» из-за накладных расходов, хотя и позволяет повысить эффективность обучения со смешанной точностью. Всё это позволяет получить до 3,4 Пфлопс на вычислениях малой точности и до 840 Тфлопс в FP32-расчётах. 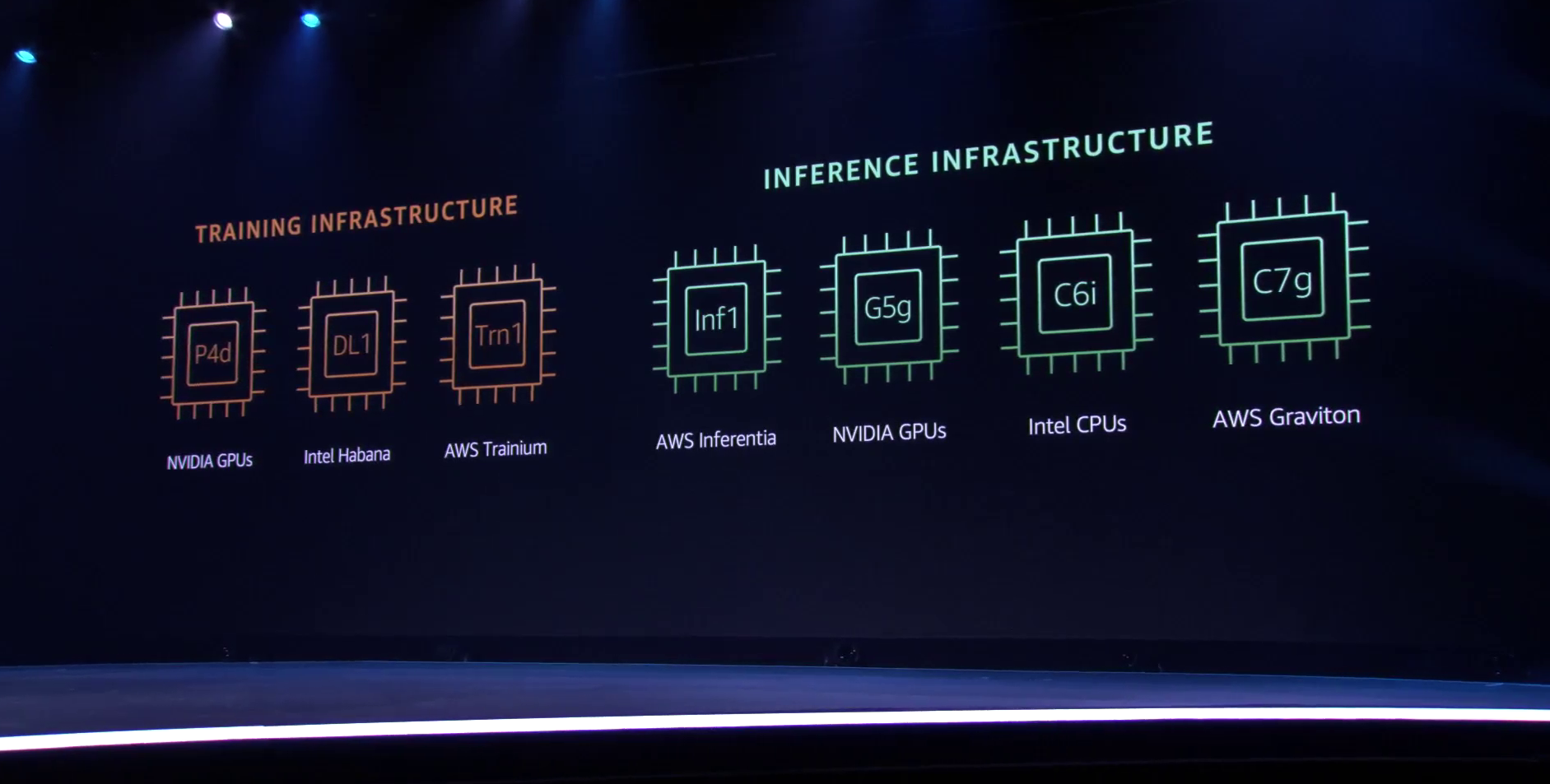 AWS постаралась сделать переход к Trainium максимально безболезненным для разработчиков, поскольку SDK AWS Neuron поддерживает популярные фреймворки машинного обучения. Впрочем, насильно загонять заказчиков на инстансы Trn1 компания не собирается и будет и далее предоставлять на выбор другие ускорители поскольку переход, например, с экосистемы CUDA может быть затруднён. Однако в вопросах машинного обучения для собственных нужд Amazon теперь полностью независима — у неё есть и современный CPU Graviton3, и инфереренс-ускоритель Inferentia.
04.12.2021 [03:42], Игорь Осколков
Процессор Amazon Graviton3: 64 ядра Arm, 5-нм техпроцесс, чиплетная компоновка и DDR5 с PCIe 5.0Анонсированный на днях Arm-процессор Graviton3, создававшийся специально для нужд Amazon и AWS, неожиданно оказался по ряду параметров на голову выше ещё даже не вышедших EPYC и Xeon следующего поколения. И это не самый хороший сигнал для AMD, Intel, Qualcomm и прочих производителей. 
Amazon Graviton3. Фото: Ian Colle Graviton3 — первый массовый (самой Amazon и рядом избранных клиентов он используется уже не один месяц) серверный процессор с поддержкой DDR5 и PCIe 5.0. CPU выполнен по 5-нм техпроцессу TSMC и содержит примерно 55 млрд транзисторов. Для удешевления он использует BGA-корпусировку и чиплетную компоновку из семи отдельных кристаллов — два PCIe-контроллера и четыре двухканальных контроллера DDR5 вынесены за пределы собственно CPU. 
Узел EC2 C7g. Здесь и ниже изображения Amazon AWS Более того, их упаковка использует передовые решения с каналами длиной менее 55 мкм, что вдвое меньше, чем у других серверных CPU. Уменьшение длины проводников положительно сказывается на энергоэффективности, которая очень важна для любого гиперскейлера. Этим же объясняется и относительно небольшое по современным меркам число ядер (всего 64) и их частота (2,6 ГГц). Всё это позволило добиться энергопотребления примерно в 100 Вт. 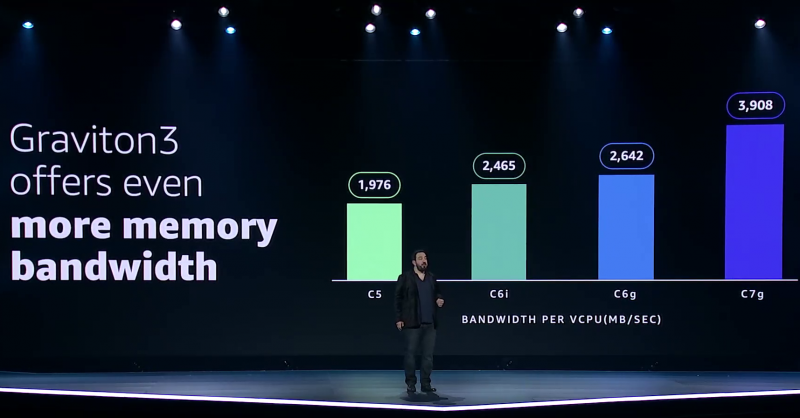 Есть и ещё один важный плюс в сохранении числа ядер — переход на DDR5-4800 позволил не только достичь пиковой суммарной пропускной способности памяти в 300 Гбайт/с на чип, но и повысить реальную скорость работы с памятью каждого vCPU (фактически ядра) в полтора раза по сравнению с прошлым поколением. Та же ситуация и с PCIe 5.0 — для достижения той же пропускной способности, что ранее, нужно вдвое меньше линий.  Для удешевления используются готовые IP-блоки сторонних компаний и, судя по всему, ядра тоже несильно отличаются от референсов Arm. А вот какие именно, узнаем не сразу, поскольку Amazon явно не указала, будут ли это Neoverse V1 (Zeus) или N2 (Perseus). Вероятно, это всё же V1 (ARMv8.5-A), поскольку по описанию Graviton3 похожи именно на эту архитектуру. Новые ядра стали значительно «шире» прежних — они забирают 8 инструкций, декодируют от 5 до 8 из них и отправляют на исполнение сразу 15 инструкций. Соответственно и число исполнительных блоков по сравнению с Neoverse-N1 (Graviton2) практически удвоилось. 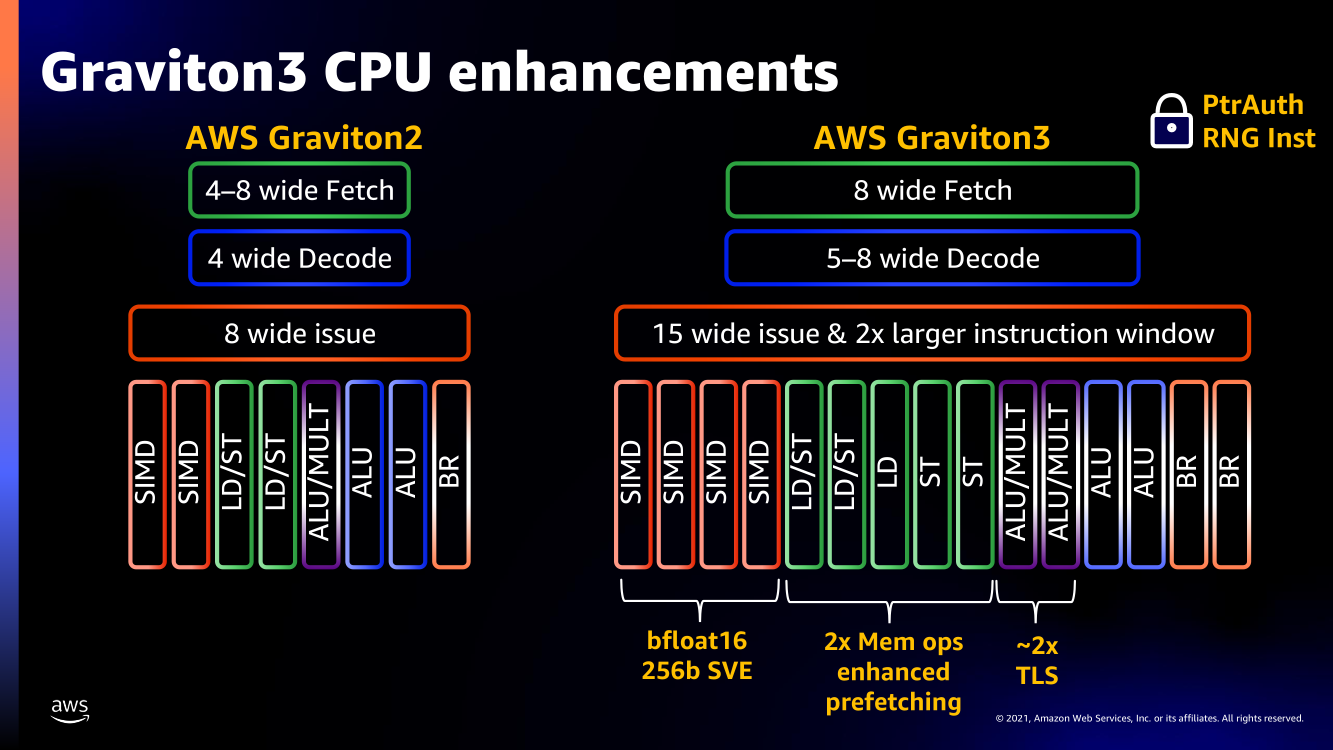  Кроме того, они обзавелись поддержкой 256-бит векторных инструкций SVE, что повысило не только скорость выполнения «классических» FP-операций (например, для задач медиакодирования и шифрования), но и благодаря поддержке bfloat16 позволило утверждать Amazon, что новые чипы годятся и для инференса. Среди упомянутых ранее мер защиты есть, например, принудительное шифрование оперативной памяти, изолированные кеши для каждого vCPU (ядра), аппаратная защита стека. 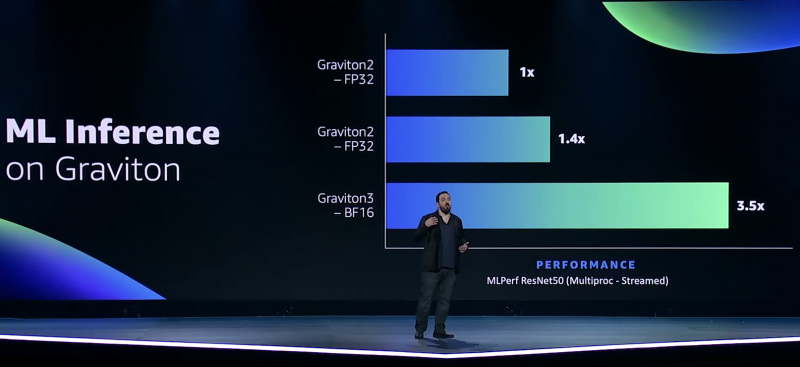
В подписи второго столбца явная опечатка В целом, средний прирост производительности Graviton3 по сравнению с Graviton2 составил 25 %, но в некоторых задачах он достигает 60 %. И всё это при сохранении того же уровня энергопотребления и тепловыделения. Всё это позволило уместить в одном 1U-узле с воздушным охлаждением сразу три процессора Graviton3. И они разительно отличаются от грядущих 128-ядерных процессоров Altra Max и EPYC Bergamo, которые Ampere и AMD позиционируют как решения для гиперскейлеров. Зато в чём-то похожи на Yitian 710 от Alibaba Cloud. 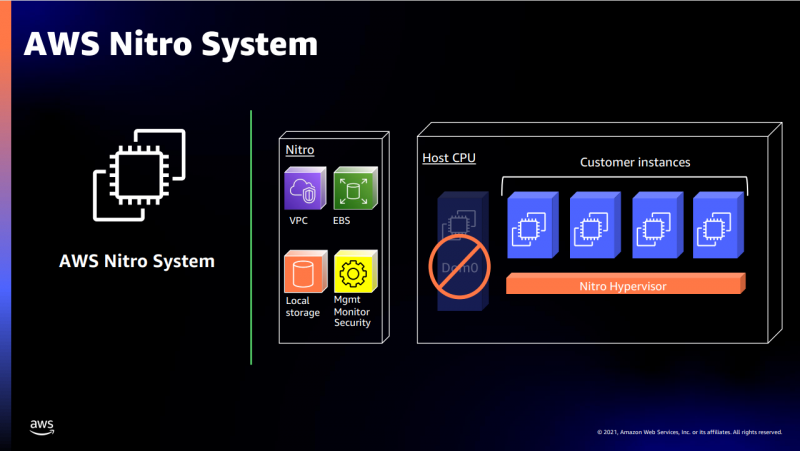 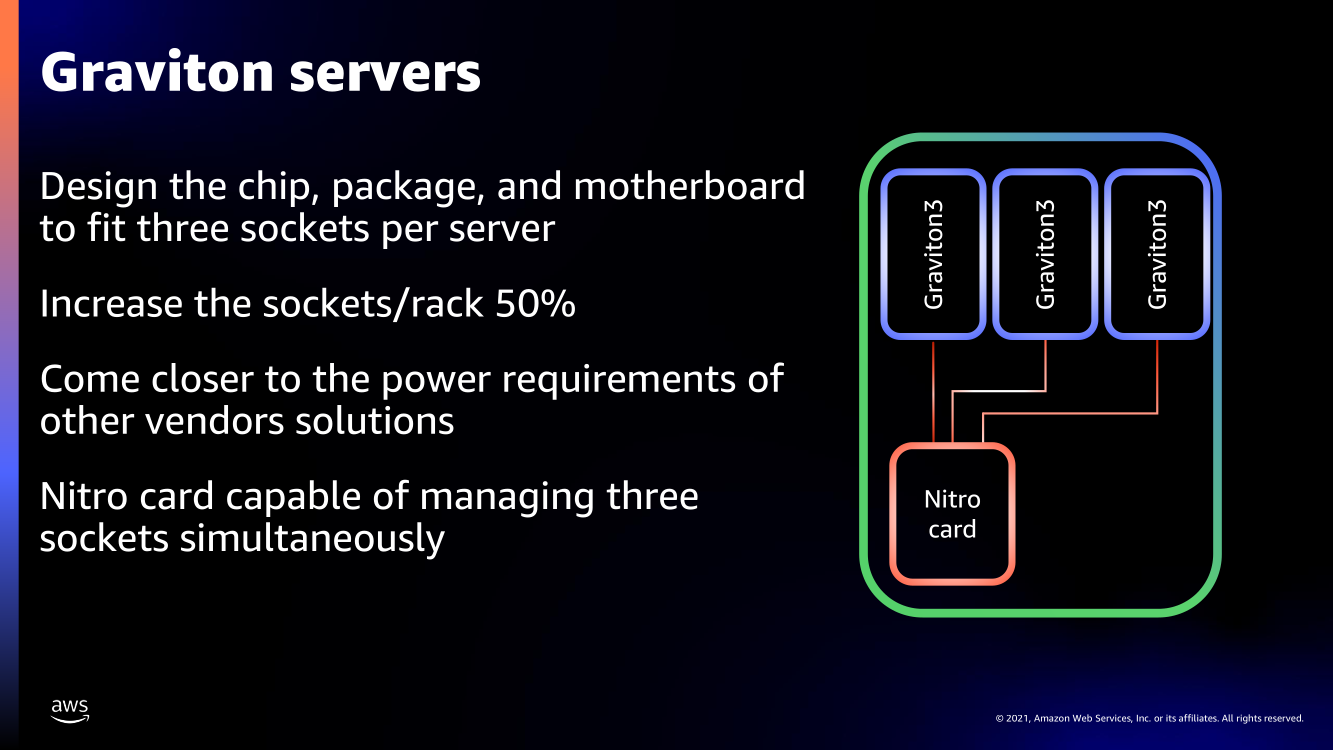 Но CPU — это лишь часть платформы, фундамент для которой несколько лет назад заложило появление чипов Nitro. Их сейчас стоило бы назвать DPU/IPU, хотя на момент их появления такого понятия, можно сказать, и не было. Nitro берёт на себя все задачи по обслуживанию гипервизора, обеспечению безопасности, работе с хранилищем и сетью и т.д., высвобождая, с одной стороны, все ресурсы CPU, памяти и SSD для обработки задачи клиента, а с другой — позволяя практически полностью дезагрегировать всю инфраструктуру. 
Узел с Nitro SSD Впрочем, Amazon пошла ещё дальше — теперь она самостоятельно закупает NAND-чипы и производит SSD, тоже под управлением Nitro. То есть у компании под контролем практически полный стек современных аппаратных решений: CPU, DPU, SSD, ИИ-ускорители для обучения (Trainium) и инференса (Inferentia). Она активно переносит на него собственные сервисы и предлагает их клиентам. И именно это и должно обеспокоить крупных вендоров, поскольку их решения вряд ли позволят добиться такого же уровня TCO, а гиперскейлеров, желающих перейти на аналогичную модель, немало.  UPD 06.12.21: презентация новых процессоров стала доступна публично, поэтому в материал добавлены некоторые иллюстрации, а в галерее ниже приведены результаты тестов производительности.
02.12.2021 [22:18], Илья Коваль
ByteDance взялась за облака — уставной капитал Volcano Engine вырос на два порядкаВ ноябре ByteDance, известная своим сервисом TikTok, объявила о реорганизации, направленной на создание шести подразделений. Среди них есть и облачная платформа Volcano Engine, которая будет предоставлять бизнес-услуги. Об одной из них — рекомендательной системе — компания рассказала ещё летом. Сегодня же был анонсирован ряд новых облачных сервисов. ByteDance уже давно планировала освоить новые рыночные ниши для увеличения своих доходов, и дочерняя компания Volcano Engine может стать хорошим источником прибыли, поскольку китайский облачный рынок является не только вторым по величине в мире, но и весьма быстрорастущим (+50% ежегодно). Компания намерена стать четвёртым по величине облачным провайдером в Китае после Alibaba Cloud, Tencent Cloud и Huawei Cloud. 
Источник изображения: ByteDance В середине ноября уставной капитал Volcano Engine был увеличен на два порядка, с ¥10 млн до ¥1 млрд (примерно $156 млн). Также компания переманила ряд специалистов из JD.com и китайского подразделения AWS. Кроме того, сама ByteDance отказалась от услуг Alibaba Cloud за пределами Китая, занялась строительством собственных дата-центров и поглотила ряд компаний, включая Caiyun Technology. Список всех услуг и продуктов Volcano Engine сейчас включает уже более 70 пунктов. Среди них есть инстансы, bare-metal и GPU-серверы, собственный Linux-дистрибутив, блочное и объектное хранилище, поддержка контейнеров (репозитории + Kubernetes), управляемые СУБД (MySQL + Redis), средства коллективной разработки, CDN, SMS и телефония, услуги по управлению и анализу данных (в том числе BigData), защита от DDoS и WAF. Также есть целая пачка готовых решений для обработки и стриминга медиаконтента, включая задачи AR/VR и CV, и с десяток готовых ИИ-решений в различных областях. Есть даже собственная платформа для периферийных вычислений. В общем, набор очень приличный. Для привлечения новых пользователей Volcano Engine предлагает скидки и бесплатные пакеты услуг, но только для новых проектов на платформе, подавших заявку и прошедших отбор.
26.11.2021 [19:20], Руслан Авдеев
2021 год снова может стать рекордным по числу и объёму сделок на рынке ЦОДОдни из крупнейших в США операторов дата-центров — компании CyrusOne и CoreSite будут приобретены за рекордные суммы $15 и $10 млрд. Это крупнейшие сделки на рынке ЦОД в этом году, а по состоянию на середину ноября общее число закрытых сделок в отрасли намного превысило показатели прошлого года. Хотя их суммарная стоимость пока не достигла объёмов 2020 года, именно покупка CoreSite, если она будет официально завершена до конца года, кардинально изменит ситуацию — только благодаря ей общая сумма сделок превысит показатели прошлого года на 16%. Если учитывать более мелкие сделки, которые планируется закрыть до конца года, процент будет ещё выше. Таким образом, 2021 год снова станет рекордным для мирового рынка дата-центров. CyrusOne и CoreSite являются соответственно третьим и четвёртым по размеру операторами ЦОД в США, а в начале этого года состоялась смена хозяев у компаний, занимающих пятое и шестое места — QTS и Cyxtera. CoreSite и QTS почти полностью ориентированы на рынок США, тогда как CyrusOne и Cyxtera активно действуют и на международном рынке. Тем не менее, CyrusOne, Cyxtera и CoreSite входят и в мировой Топ-10. 
Источник изображения: Synergy Research Group CoreSite была приобретена American Tower, впервые делающей столь масштабные инвестиции в ЦОД. CyrusOne совместно купили инвестиционные фонды KKR и Global Investment Partners. До этого наиболее значимыми были сделки Blackstone и QTS ($10 млрд), Digital Realty и Interxion ($8,4 млрд), Digital Realty и DuPont Fabros ($7,6 млрд), Jiangsu Shagang Group и Global Switch ($8+ млрд с рассрочкой на три года). Более мелкие сделки также провели Equinix, EQT, Digital Bridge (Colony), CyrusOne, GDS, Macquarie и Mapletree. Интерес к приобретению как дата-центров, так и сетевой инфраструктуры не ослабевает. На днях появились новости о возможном выкупе оператора Global Switch Holdings Ltd. компаниями Blackstone, KKR, DigitalBridge, Equinix и Digital Realty. Оператор владеет 13 ЦОД в Европе, Австралии и Азии. Сумма сделки может составить до $11 млрд. Одновременно KKR захотел приобрести TIM/Telecom Italia за $12 млрд, но сделка ещё не заключена, т.к. крупнейшие акционеры считают предложенную сумму заниженной. По словам главного аналитика Synergy Research Group Джона Динсдейла (John Dinsdale), по мере роста спроса на облака уровень необходимых инвестиций превысил возможности даже крупных операторов, поэтому в этот бизнес входят сторонние инвесторы. Четыре из шести ведущих в США операторов ЦОД в последнее время сменили собственников, а крупнейшие компании Equinix и Digital всё чаще вынуждены прибегать к сотрудничеству со сторонними инвесторами, причём за последние 1,5 года инвесторы были активнее операторов.
23.11.2021 [02:10], Владимир Мироненко
Microsoft, Caterpillar и Ballard протестируют 1,5-МВт генератор на водородных топливных элементахMicrosoft объединила усилия с Caterpillar и Ballard Power Systems для тестирования резервных генераторов на водородных топливных элементах в своём дата-центре в Куинси (штат Вашингтон). Проект рассчитан на три года и нацелен на изучение возможности использования водородных топливных элементов в масштабе ЦОД. Проект частично финансируется Министерством энергетики США (DOE) в рамках инициативы H2@Scale. Caterpillar станет генеральным подрядчиком, обеспечивающим общую интеграцию всех систем, работу силовой электроники и средств управления. Ballard предоставит водородный электрогенератор на топливных элементах ClearGen-II мощностью 1,5 МВт, а Национальная лаборатория возобновляемых источников энергии (NREL) выполнит анализ его безопасности, экологичности и технико-экономических аспектов эксплуатации. 
Источник изображения: Microsoft Для успешной реализации проекта необходимо решить ряд проблем. Чтобы топливные элементы обеспечивали мощность 3 МВт в течение 48 часов, требуется около 68 м3 жидкого водорода, для хранения которого требуется намного больше места, чем для дизельного топлива. Для избегания утечек требуются специальные трубопроводы, а сам водород надо хранить при температуре ниже -253 °C. Ранее Microsoft успешно испытала водородные топливные ячейки мощностью 250 кВт от Power Innovations.
16.11.2021 [03:33], Игорь Осколков
TOP500: уж ноябрь на дворе, а экзафлопса не видатьПоследняя версия публичного рейтинга самых производительных в мире суперкомпьютеров TOP500 так и осталась без экзафлопсных машин. Китай не захотел включать в него две системы такого класса и пошёл обходным путём, номинировав работы своих учёных на премию Гордона Белла — в соответствующих научных работах даны неполные характеристики машин и показатели их производительности. Поэтому лидером списка остаётся обновлённая японская система Fugaku, 7,6 млн ядер которой выдают 442 Пфлопс. И она всё ещё втрое быстрее своего ближайшего конкурента Summit. Первые результаты сборки Frontier в список попасть не успели. Всего в ноябрьском рейтинге есть порядка 70 новых систем, но, как и прежде, больше половины из них — однотипные системы Lenovo, массово устанавливаемые в Китае. На Китай вообще приходится более трети (34,6%) систем в списке. На втором месте находятся США (29,8%), а на третьем — Япония (6,4%). По суммарной производительности Топ-3 тот же, но порядок иной: США (32,5%), Япония (20,7%), Китай (17,5%). В число лидеров также входят Германия, Франция, Нидерланды, Канада, Великобритания, Южная Корея и Россия. У РФ теперь есть сразу семь машин в списке с суммарной производительностью 73,715 Пфлопс. Для сравнения — Perlmutter (5 место) после апгрейда выдаёт 70,87 Пфлопс, а у Южной Кореи тоже есть семь машин, но с чуть более высокой суммарной производительностью в 82,177 Пфлопс. 
Суперкомпьютер Chervonenkis (Фото: Яндекс) К уже имевшимся в TOP500 российским системам MTS GROM (294 место), Lomonosov-2 (Ломоносов-2, 241 место) и Christofari (Кристофари, 72 место) добавились Christofari Neo (Кристофари Нео, 43 место), а также сразу три системы Яндекса: Ляпунов (Lyapunov, 40 место), Галушкин (Galushkin, 36 место) и Червоненкис (Chervonenkis, 19 место). Примечательно, что все российские системы этого года используют AMD EPYC Rome и NVIDIA A100, а также интерконнект Infininiband. Машины для МТС и Сбера сделала сама NVIDIA (это всё DGX), а вот у Яндекса путь особый. Ляпунов (12,81 Пфлопс) создан китайским Национальным университетом оборонных технологий (National University of Defense Technology, NUDT) и Inspur на базе серверов NF5488A5 (AMD EPYC 7662@2 ГГц + A100 40 Гбайт). Червоненкис (21,53 Пфлопс) и Галушкин (16,02 Пфлопс) разработаны IPE, NVIDIA и Tyan. В этих системах используются EPYC 7702 (тоже 64-ядерные с базовой частотой 2 ГГц) и более новые A100 (80 Гбайт). Среди прочих новых систем TOP500 особо выделяется Voyager-EUS2, которая замыкает Топ-10. Это ещё система на базе обновлённых инстансов Microsoft Azure ND A100 v4 с 80-Гбайт версией A100. Однако ещё одной облачной машиной уже никого не удивить, в отличие от совершенно неожиданного возврата японской PEZY, пропавшей с радаров после скандала 2017 года. Новая ZettaScaler3.0 занимает 453 место и базируется на AMD EPYC 7702P и фирменных ускорителях PEZY-SC3. 
Изображение: OGAWA, Tadashi (twitter.com/ogawa_tter) В целом, последний год был удачным и для AMD, и для NVIDIA. Первая почти втрое нарастила число систем на базе EPYC — их теперь в списке 74 (или почти треть новых участников списка), если учитывать Naples/Hygon (таких систем 3). Если же смотреть более детально именно на CPU, то тут лидером всё равно остаётся Intel, хотя она и потеряла несколько процентных пунктов за последние полгода — всего 408 машин используют её процессоры. Правда, новейших Ice Lake-SP среди них всего 10, тогда как у EPYC Milan уже 17. Без акселераторов обходятся 350 суперкомпьютеров списка, зато из 150 оставшихся 143 используют различные поколения ускорителей NVIDIA. Удивительно, но ни одной системы с ускорителями AMD Instinct в ноябрьском рейтинге нет. Остальные акселераторы представлены в единичном экземпляре. И это либо устаревшие системы, либо экзотика из Китая и Японии. Последняя в лице MN-3 всё ещё лидирует по энергоэффективности в Green500. Систем с Infiniband в списке 178, с Ethernet — 242. Как обычно, по производительности систем лидирует именно IB — 44,5% против 22,4% у Ethernet. Это, к слову, несколько отличается от показателей HPC-индустрии в целом, где в количественном выражении у них практически равные доли. На Omni-Path пришлось 40 систем в TOP500, и столько же на проприетарные интерконнекты. Тут интересно разве что появление второй машины с Atos BXI V2. 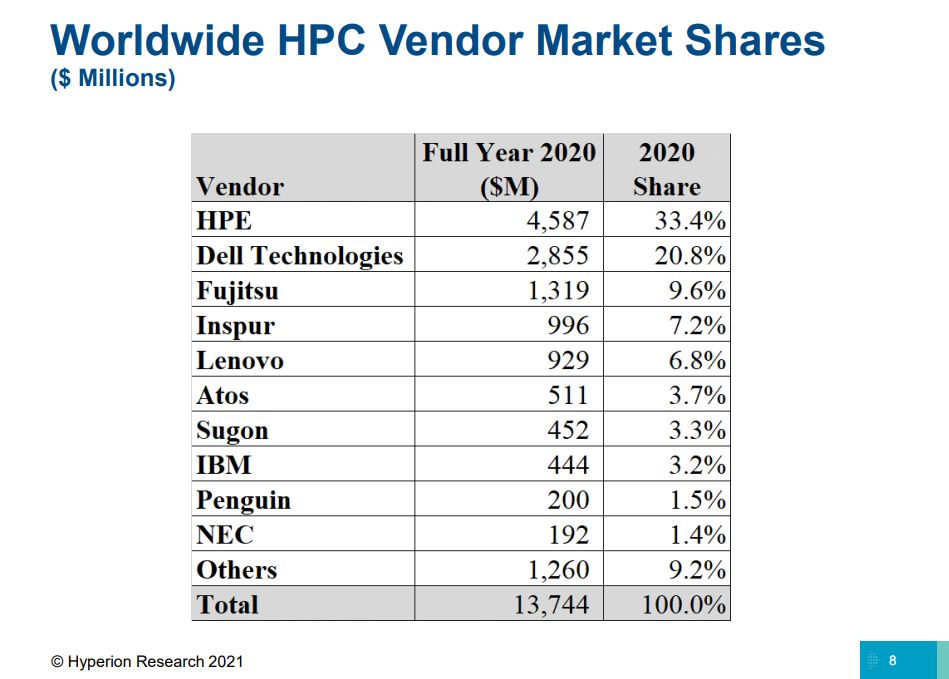 Среди производителей по количеству машин лидируют Lenovo (180 шт., это в основном уже упомянутые типовые развёртывания в Китае), HPE (84 шт., сюда же входит наследие Cray и SGI) и Inspur (50 шт.). По производительности картина иная, в Топ-3 входят HPE, Fujitsu (во многом благодаря Fugaku) и Lenovo. По HPC-рынку в целом, согласно данным Hyperion Research, в денежном выражении тройка лидеров включает HPE, Dell и Fujitsu (да, опять «виноват» Fugaku).
14.11.2021 [21:11], Владимир Мироненко
LiquidStack и Microsoft продемонстрировали ИИ-серверы с двухфазным иммерсионным охлаждениемLiquidStack, дочернее предприятие BitFury, специализирующееся на разработке иммерсионных СЖО, и Microsoft продемонстрировали на OCP Global Summit стандартизированное решение с двухфазным погружным жидкостным охлаждением. Демо-серверы Wiwynn, разработанные в соответствии со спецификациями OCP Open Accelerator Infrastructure (OAI), были погружены в бак LiquidStack DataTank 4U, способный отводить порядка 3 кВт/1U (эквивалент 126 кВт на стойку). LiquidStack сообщила, что она впервые оптимизировала серверы OCP OAI для охлаждения путем погружения в жидкость. По словам компании, её двухфазные иммерсионные СЖО DataTank предоставляют наиболее эффективное решение, которое требует немного пространства и потребляет меньше энергии, чем другие системы охлаждения, и вместе с тем повышает плотность размещения компонентов и их производительность. 
Фото: LiquidStack В демо-серверах использовались ИИ-ускорители Intel Habana Gaudi, погружённые в жидкий диэлектрик (от 3M) с низкой температурой кипения, который наиболее эффективно отводит тепло благодаря фазовому переходу. Данное решение должно помочь достижению показателя PUE в пределах от 1,02 до 1,03, поскольку оно практически не потребляет энергию. LiquidStack утверждает, что у её СЖО эффективность теплоотвода примерно в 16 раз выше, чем у типичных систем воздушного охлаждения. 
Фото: LiquidStack По мнению компании, системы высокопроизводительных вычислений (HPC) уже сейчас слишком энергоёмки, чтобы их можно было охлаждать воздухом. Поэтому следует использовать платы, специально предназначенные для жидкостного охлаждения, а не пытаться адаптировать те, что были созданы с расчётом на воздушные системы — при использовании СЖО вычислительная инфраструктура может занимать на 60% меньше места. 
Изображение: Microsoft LiquidStack и Wiwynn являются партнёрами. В апреле Wiwynn инвестировала в LiquidStack $10 млн. Также Wiwynn протестировала серверы с погружным жидкостным охлаждением в центре обработки данных Microsoft Azure в Куинси (штат Вашингтон). Microsoft, как и другие гиперскейлеры, уже некоторое время изучает возможности иммерсионных СЖО.
12.11.2021 [12:12], Сергей Карасёв
Kioxia выпустила NVMe-oF SSD серии EM6 c Ethernet-подключением 25 Гбит/сКомпания Kioxia сообщила о доступности твердотельных накопителей семейства EM6, относящихся к корпоративному классу. Решения предназначены для использования в составе платформ высокопроизводительных вычислений, систем машинного обучения и искусственного интеллекта. 
Источник изображения: Kioxia Устройства серии EM6 выполнены на основе контроллера Marvell 88SN2400 NVMe-oF. Реализована спецификация NVMe 1.4. Доступны один или два интерфейса Ethernet с пропускной способностью 25 Гбит/с. Накопители заключены в корпус формата 2,5" толщиной 15 мм. Предлагаются два варианта вместимости — 3,84 и 7,68 Тбайт, оба с 1 DWPD. 
Источник изображения: Ingrasys Устройства доступны в составе платформы ES2000 EBOF (Ethernet Bunch of Flash) производства Ingrasys (подразделение Foxconn). Данный продукт представляет собой систему хранения данных в 2U-шасси с возможностью установки 24 накопителей NVMe-oF типоразмера 2,5"/U2/E3.S или 48 E1.S. СХД имеет коммутатор Marvell 98EX5630 и предоставляет 12 200GbE-портов QSFP28/56.
10.11.2021 [14:45], Руслан Авдеев
Google инвестирует $1 млрд в биржевую группу CME Exchange и станет её облачным провайдеромКрупнейшая в мире группа биржевых площадок Chicago Mercantile Exchange (CME Exchange) заключила с Google соглашение, согласно которому последняя инвестирует в финансовые сервисы $1 млрд. В обмен техногигант получит не только ценные бумаги, но и выгодный контракт на предоставление облачных сервисов. CME Exchange построила собственные дата-центры в США, а в Европе пользуется услугами Equinix. Пять лет назад году главный ЦОД компании был продан CyrusOne за $130 млн с договором «обратной» аренды на 15 лет — здесь размещается основная торговая платформа CME Globex и другие сервисы. В 2018 году CyrusOne даже построила здесь телекоммуникационную вышку высотой порядка 100 м, на которой клиенты могут разместить свои антенны для организации прямой связи с платформой. Теперь же CME Group планирует переместить всю свою IT-инфраструктуру в облако Google Cloud в несколько этапов. Как ожидается, партнёрство позволит CME Group быстрее предоставлять клиентам новые продукты и сервисы. Google получит конвертируемые привилегированные акции без права голоса и контракт на обслуживание CME Group в течение 10 лет — начиная с 2022 года. |
|


