Материалы по тегу: ускоритель
|
10.11.2022 [01:55], Игорь Осколков
Intel объединила HBM-версии процессоров Xeon Sapphire Rapids и ускорители Xe HPC Ponte Vecchio под брендом MaxВ преддверии SC22 и за день до официального анонса AMD EPYC Genoa компания Intel поделилась некоторыми подробностями об HBM-версии процессоров Xeon Sapphire Rapids и ускорителях Ponte Vecchio, которые теперь входят в серию Intel Max. 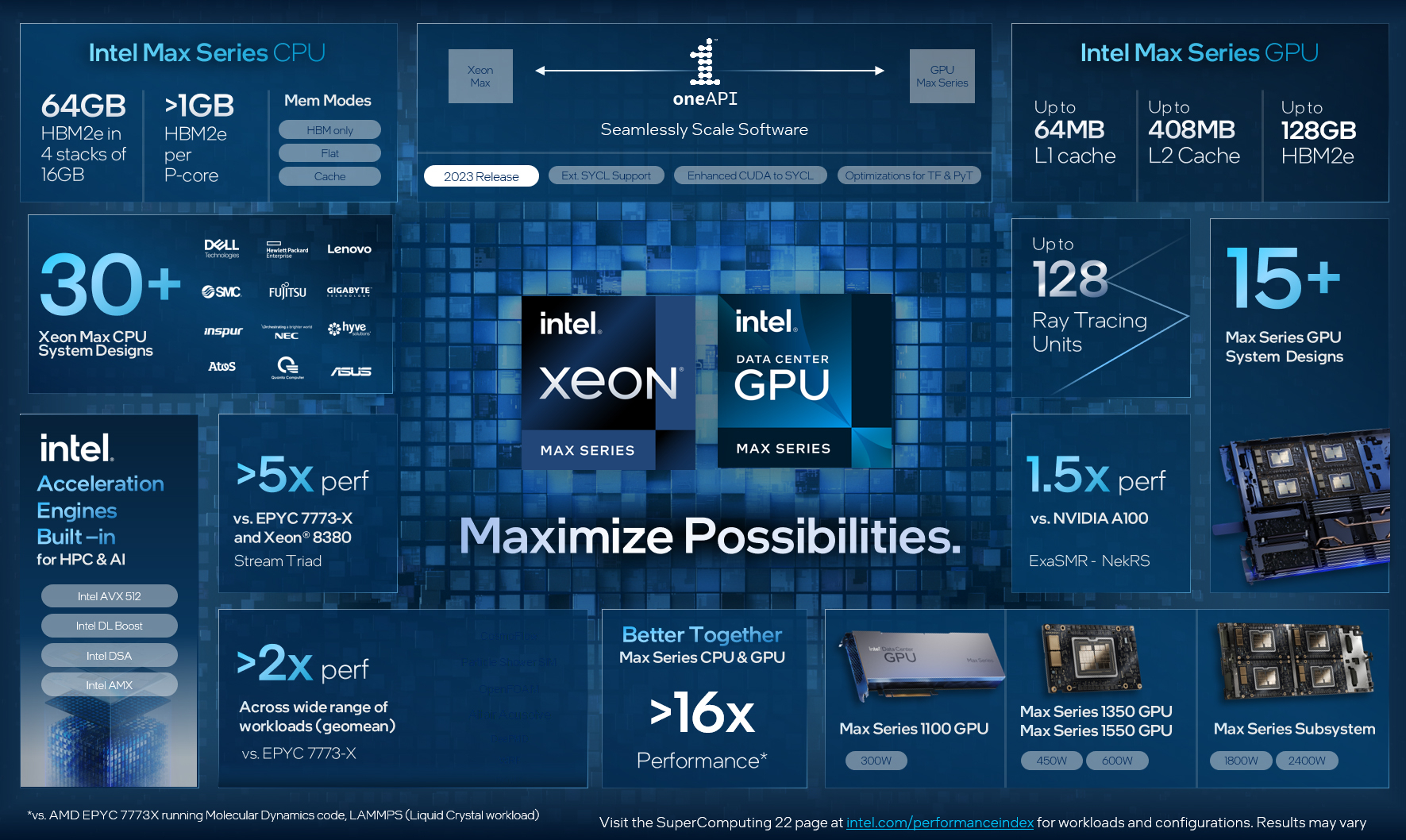
Изображения: Intel Intel Xeon Max предложат до 56 P-ядер, 112,5 Мбайт L3-кеша, 64 Гбайт HBM2e-памяти (четыре стека) с пропускной способностью порядка 1 Тбайт/с, 8 каналов памяти (DDR5-4800 в случае 1DPC, суммарно до 6 Тбайт), а также интерфейсы PCIe 5.0, CXL 1.1, UPI 2.0 и целый ряд различных технологий ускорения для задач HPC и ИИ: AVX-512, DL Boost, AMX, DSA, QAT и т.д. Заявленный уровень TDP составляет 350 Вт.  Первым процессором с набортной HBM-памятью был Arm-чип Fujitsu A64FX (48 ядер, 32 Гбайт HBM2), лёгший в основу суперкомпьютера Fugaku. Intel поднимает планку, давая более 1 Гбайт быстрой памяти на каждое ядро. А поскольку процессор состоит из четырёх отдельных чиплетов, возможно создание четырёх NUMA-доменов с выделенными HBM- и DDR-контроллерами. Но и монолитный режим тоже имеется. А поддержка CXL даёт возможность задействовать RAM-экспандеры. 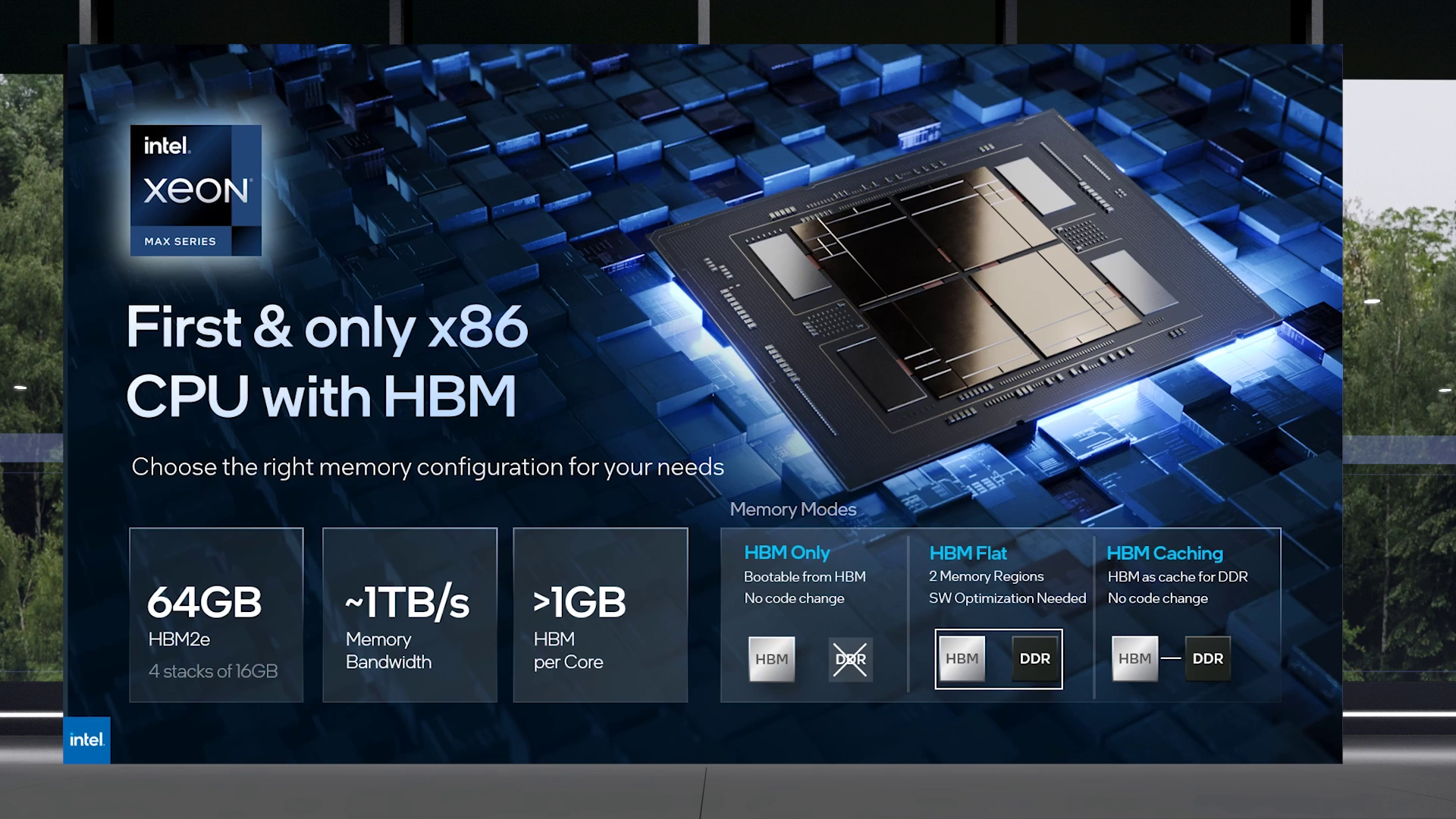 Intel Xeon Max поддерживают 2S-платформы, что суммарно даёт уже 128 Гбайт HBM-памяти, которых вполне хватит для целого ряда задач. Новые процессоры действительно могут обходиться без DIMM. Но есть и два других режима. В первом HBM-память работает в качестве кеша для обычной памяти, и для системы это происходит прозрачно, так что никаких модификаций для ПО (как в случае отсутствия DIMM вообще) не требуется. Во втором режиме HBM и DDR представлены как отдельные пространства, так что тут дорабатывать ПО придётся, зато можно добиться более эффективного использования обоих типов памяти.
В презентации Intel сравнивает новые Xeon Max с AMD EPYC Milan-X – в зависимости от задачи прирост составляет от +20 % до 4,8 раз. Но, во-первых, уже сегодня эти тесты потеряют всякий смысл в связи с презентацией EPYC Genoa (которые, к слову, должны получить AVX-512), а во-вторых, в следующем году AMD обещает представить Genoa-X с 3D V-Cache. Intel же явно не оставляет попытки создать как можно более универсальный процессор.  Что касается Ponte Vecchio, которые теперь называются Max GPU, то практически ничего нового относительно строения и особенностей данных ускорителей Intel не сказала: до 128 ядер Xe (только теперь стало известно об аппаратном ускорении трассировки лучей, что важно для визуализации), 64 Мбайт L1-кеша и аж 408 Мбайт L2-кеша (из них 120 Мбайт приходится на Rambo-кеш в двух стеках), 16 линий Xe Link, 8 HBM2e-контроллеров на 128 Гбайт памяти и пиковая FP64-производительность на уровне 52 Тфлопс. Все эти характеристики относятся к старшей модели Max Series 1550 в OAM-исполнении с TDP в 600 Вт.  Max Series 1350 предложит 112 ядер Xe и 96 Гбайт HBM2e, но и TDP у этой модели составит всего 450 Вт. Для обеих OAM-версий также будут доступны готовые блоки из четырёх ускорителей (по примеру NVIDIA RedStone), объединённых по схеме «каждый с каждым», так что в сумме можно получить 512 Гбайт HBM2e с ПСП в 12,8 Тбайт/с. Ну а самый простой ускоритель в серии называется Max Series 1100. Это 300-Вт PCIe-плата с 56 Xe-ядрами, 48 Гбайт HBM2e и мостиками Xe Link.  Intel утверждает, что ускорители Max до двух раз быстрее NVIDIA A100 в некоторых задачах, но и здесь история повторяется — нет сравнения с более современными H100. Хотя предварительный доступ к этим ускорителям у Intel есть, поскольку именно Sapphire Rapids являются составной частью платформы DGX H100. В целом, Intel прямо говорит, что наибольшей эффективности вычислений позволяет добиться связка CPU и GPU серии Max в сочетании с oneAPI. Всего на базе решений данной серии готовится более 40 продуктов.
Пока что приоритетным для Intel проектом является 2-Эфлопс суперкомпьютер Aurora, для которого пока что создан тестовый кластер Sunspot со 128 узлами, содержащими ускорители Max. Следующим ускорителем Intel станет Rialto Bridge, который появится в 2024 году. Также компания готовит гибридные (XPU) чипы Falcon Shores, сочетающие CPU, ускорители и быструю память. Аналогичный подход применяют AMD и NVIDIA.
09.11.2022 [14:50], Владимир Мироненко
Производители специально ухудшают характеристики чипов для китайских серверов, чтобы избежать санкций СШАВ связи с вводом Соединёнными Штатами новых экспортных ограничений на поставки в Китай, производители стали намеренно снижать производительность чипов, чтобы соответствовать требованиям экспортного контроля США и избежать проблем с получением специальных лицензий. Как отметил ресурс The Register, у систем, построенных на чипах NVIDIA, изготовленных на производственных мощностях TSMC для поставок в Китай, характеристики хуже по сравнению с теми, что были ранее. В частности, китайский производитель серверов Inspur указал на использование вместо ускорителя NVIDIA A100 чипа A800, разработанного NVIDIA специально для Китая в соответствии с экспортными ограничениями. Китайские производители H3C и Omnisky тоже представили решения на базе A800. Данный ускоритель, по словам NVIDIA, начала производиться в III квартале этого года. У A800 скорость передачи данных составляет 400 Гбайт/с, тогда как у A100 этот показатель равен 600 Гбайт/с, причём обойти эти ограничения, по словам NVIDIA, невозможно. Речь, судя по всему, идёт о характеристиках интерконнекта NVLink, которые прямо влияют на производительность кластеров из двух и более ускорителей в машинном обучении и других задачах. Изменения касаются 40- и 80-Гбайт вариантов с интерфейсами PCIe и SXM. 
Источник изображения: Inspur Между тем ускорители, находящиеся в разработке и выпускаемые TSMC по контракту с Alibaba и стартапом Biren Technology, тоже, как сообщается, имеют пониженную скорость передачи данных. Это позволит выпускать данные чипы на заводе TSMC, не опасаясь санкций США. До этого TSMC приостановила выпуск 7-нм чипов ускорителей Biren BR100 как раз из-за возможных санкций со стороны Вашингтона.
12.10.2022 [22:54], Сергей Карасёв
NEC готовит новые векторные ускорители серии SX-Aurora TSUBASAКомпания NEC Corporation сообщила о подготовке нового узла в серии SX-Aurora TSUBASA — модели C401-8, рассчитанной на центры обработки данных, на базе которых осуществляется сложное моделирование, выполняются научные расчёты и другие ресурсоёмкие задачи. Основой новинки станут неназванные пока векторные ускорители — судя по всему, это обещанные ранее Vector Engine 3.0 (VE30). Новинки получили 16 векторных блоков с частотой 1,7 ГГц, тогда как прошлое поколение имело до 10 блоков с частотой 1,6 ГГц. Также появился L3-кеш. Пропускная способность HBM-памяти увеличилась в 1,6 раза — с 1,53 до 2,45 Тбайт/с, а её объём вырос вдвое — с 48 до 96 Гбайт. Итоговая производительность в FP64-вычислениях, как утверждается, выросла приблизительно в 2,5 раза по сравнению с предшественниками и превысила 5 Пфлопс. При этом по энергоэффективности готовящийся ускоритель, по словам NEC, в два раза превосходит традиционные изделия. 
Источник изображения: NEC В августе 2023 года суперкомпьютер на базе SX-Aurora TSUBASA C401-8 начнёт использоваться в Научном центре Университета Тохоку в Японии. В общей сложности будут задействованы 4032 векторных ускорителя NEC, а быстродействие составит до 21 Пфлопс. Использовать комплекс планируется для масштабных научных исследований. Месяцем позже заработает ещё одна HPC-система на базе C401-8, которую получит метеослужба Германии.
04.10.2022 [22:57], Алексей Степин
Intel Labs представила нейроморфный ускоритель Kapoho Point — 8 млн электронных нейронов на 10-см платеКомпания Intel уже не первый год развивает направление нейроморфных процессоров — чипов, имитирующих поведение нейронов головного мозга. Уже во втором поколении, Loihi II, процессор получил 128 «ядер», эквивалентных 1 млн «цифровых нейронов», однако долгое время этот чип оставался доступен лишь избранным разработчикам Intel Neuromorphic Research Community через облако. Но ситуация меняется, пусть и спустя пять лет после анонса первого нейроморфного чипа: компания объявила о выпуске платы Kapoho Point, оснащённой сразу восемью процессорами Loihi II. Напомним, что они производятся с использованием техпроцесса Intel 4 и состоят из 2,3 млрд транзисторов, образующих асинхронную mesh-сеть из 128 нейроморфных ядер, модель работы которых задаётся на уровне микрокода. 
Источник изображений: Intel Labs Площадь кристалла нейроморфоного процессора Intel второго поколения составляет всего 31 мм2. Судя по всему, активного охлаждения Loihi II не требует: даже в первой реализации в виде PCIe-платы Oheo Gulch кулером оснащалась только управляющая ПЛИС, но не сам нейроморфный чип. В своём интервью ресурсу AnandTech Майк Дэвис (Mike Davies), глава проекта, отметил, что в реальных сценариях, выполняемых в человеческом масштабе времени, речь идёт о цифре порядка 100 милливатт, хотя в более быстром масштабе чип, естественно, может потреблять и больше. 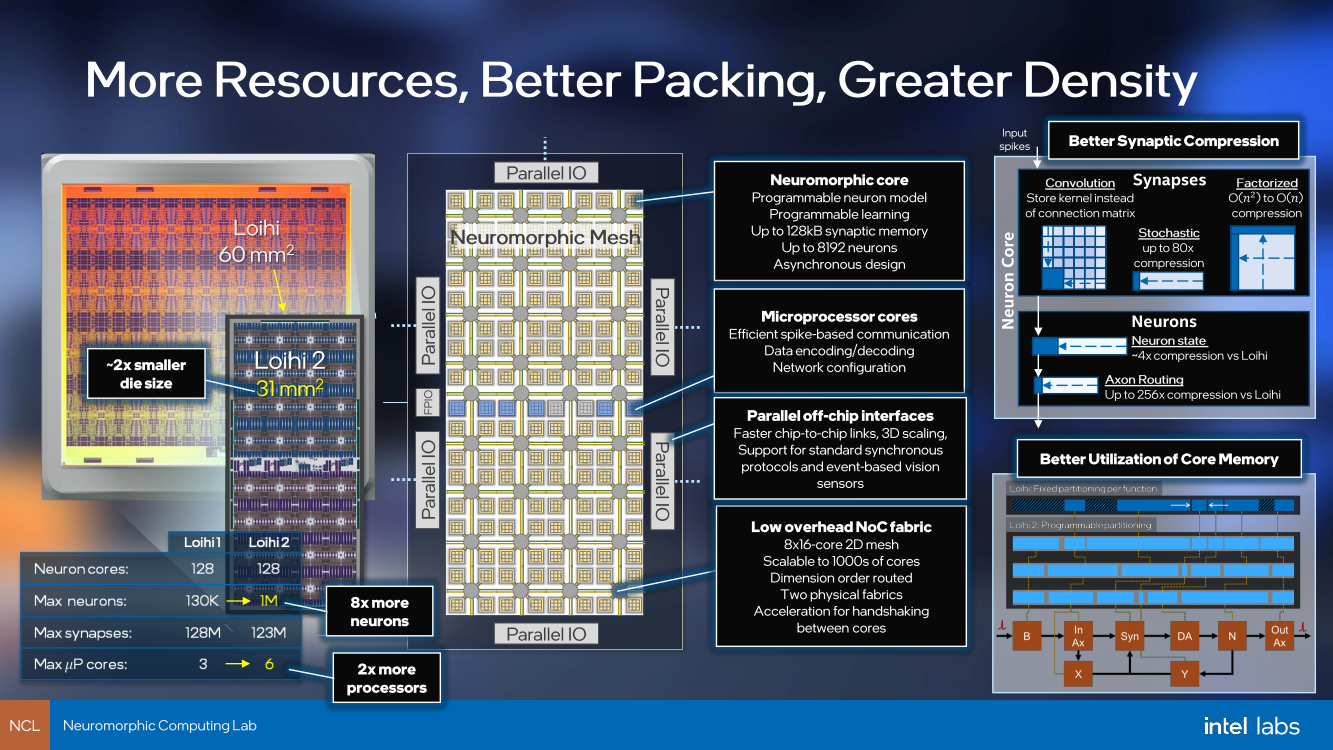
Архитектура и особенности строения Loihi II. По нажатию открывается полноразмерная версия Новый модуль, по словам компании, способен эмулировать до 1 млрд синапсов, а в задачах оптимизации с большим количеством переменных (до 8 миллионов, эквивалентно количеству «нейронов»), где нейроморфная архитектура Intel очень сильна, он может опережать традиционные процессоры в 1000 раз. Каждое ядро имеет свой небольшой пул быстрой памяти объёмом 192 Кбайт. Шесть выделенных ядер отвечают за управление нейросетью Loihi II; также в составе чипа имеются аппаратные ускорители кодирования-декодирования данных. Новинка изначально создана модульной: благодаря интерфейсному разъёму несколько плат Kapoho Point можно устанавливать одна над другой. Поддерживаются «бутерброды» толщиной до 8 плат, в деле опробован, однако, вдвое более тонкий вариант, но даже четыре Kapoho Point дают 32 миллиона нейронов в совокупности. Для коммуникации с внешним миром используется интерфейс Ethernet: в чипе реализована поддержка скоростей от 1 (1000BASE-KX) до 10 Гбит/с (10GBase-KR). Размеры каждой платы невелики, всего 4×4 дюйма (102×102 мм). 
Платы Kapoho Point позволяют легко расширять нейросеть на базе Loihi II В отличие от первого поколения Loihi, доступ к которому можно было получить лишь виртуально, через облако, системы на базе Kapoho Point уже доставлены избранным клиентам Intel, и речь идёт о реальном «железе». В число первых клиентов входит Исследовательская лаборатория ВВС США (Air Force Research Laboratory, AFRL), для задач которой такие достоинства Loihi II, как компактность и экономичность являются решающими. 
Возможности SDK Lava Одновременно с анонсом Kapoho Point компания Intel обновила и фреймворк Lava. В отлчиие от SDK первого поколения Nx новая открытая программная платформа разработки сделана аппаратно-независимой, что позволит разрабатывать нейро-приложения не только на платформе, оснащённой чипами Loihi II.
21.09.2022 [19:32], Алексей Степин
NVIDIA представила ускорители L40 и новую Omniverse-платформу OVX на их основеНа конференции GTC 2022 NVIDIA анонсировала второе поколение систем для симуляции и запуска «цифровых двойников» OVX. Это вовсе не развлечение: использование точных моделей реальных физических объектов, пространств и устройств потенциально весьма выгодно, поскольку симуляция городского квартала для обучения автопилотов или фабрики для оценки взаимодействия роботов с живыми работниками априори будет стоить намного меньше, нежели проведение натурных испытаний. Зачастую такие симуляции используют тензорные и матричные вычисления, поэтому основой новой платформы OVX стали новые ускорители NVIDIA L40 с архитектурой Ada Lovelace, располагающие ядрами трассировки лучей третьего поколения и тензорными ядрами четвёртого поколения. Они поддерживают как классический трассировку лучей (ray tracing), так и трассировку путей (path tracing), что важно для корректной симуляции поведения различных материалов. 
NVIDIA L40. Здесь и далее источник изображений: NVIDIA Физически L40 представляют собой двухслотовую FHFL-плату расширения PCIe с пассивным охлаждением — теплопакет новинки ограничен рамками 300 Вт. Объём оперативной памяти GDDR6 составляет 48 Гбайт, вдвое больше, нежели у игровых GeForce RTX 4090, и, в отличие от последних, поддерживается совместная работа двух карт в режиме NVLink, что может оказаться полезным в симуляциях с большим объёмом данных. Для вывода изображения служат четыре порта DP 1.4a. 
NVIDIA OVX Server Каждый сервер NVIDIA OVX будет содержать 8 ускорителей L40 и три сетевых адаптера ConnectX-7 с портами класса 200GbE и поддержкой шифрования сетевого трафика на лету. От 4 до 16 таких серверов составят OVX POD, а 32 или более —кластер SuperPOD. Такие кластеры станут домом для новой облачной платформы NVIDIA Omniverse Cloud, услуги которой компания планирует предоставлять робототехникам, создателям автономных транспортных средств, «умной инфраструктуры» и вообще всем, кому нужна точная симуляция сложных объектов и систем с качественной визуализацией результатов.
16.09.2022 [22:58], Алексей Степин
SambaNova Systems представила второе поколение ИИ-систем DataScale — SN30 с 5 Гбайт SRAM и 8 Тбайт DRAMСтартап SambaNova, решивший бросить вызов NVIDIA, представил второе поколение систем машинного обучения — DataScale SN30. В основе лежит собственная разработка компании, ускоритель Cardinal SN30, для обозначения которого SambaNova использует термин Reconfigurable Data Flow Unit (RDU). На новинку уже обратили внимание такие организации, как Аргоннская национальная лаборатория (ANL) и Ливерморская национальная лаборатория им. Э. Лоуренса (LLNL). Cardinal SN30 состоит из 86 млрд транзисторов и производится с использованием 7-нм техпроцесса TSMC. Главной его особенностью является возможность реконфигурации: создатели уподобляют этот процессор сложным FPGA. Последним он уступает в степени гибкости, поскольку не может менять конфигурацию на уровне отдельных логических вентилей, зато выигрывает в скорости перепрограммирования и уровне энергопотребления. За это отвечает фирменный программный стек. 
Источник: HPCwire Большой упор SambaNova сделала на объёме локальной памяти, поскольку современные модели машинного обучения имеют тенденцию к гигантомании. Только SRAM-кеша у Cardinal SN30 640 Мбайт, а объём DRAM составляет 1 Тбайт. По своим параметрам SN30 вдвое превосходит чип первого поколения, SN10, но имеет такую же тайловую архитектуру с программным управлением. 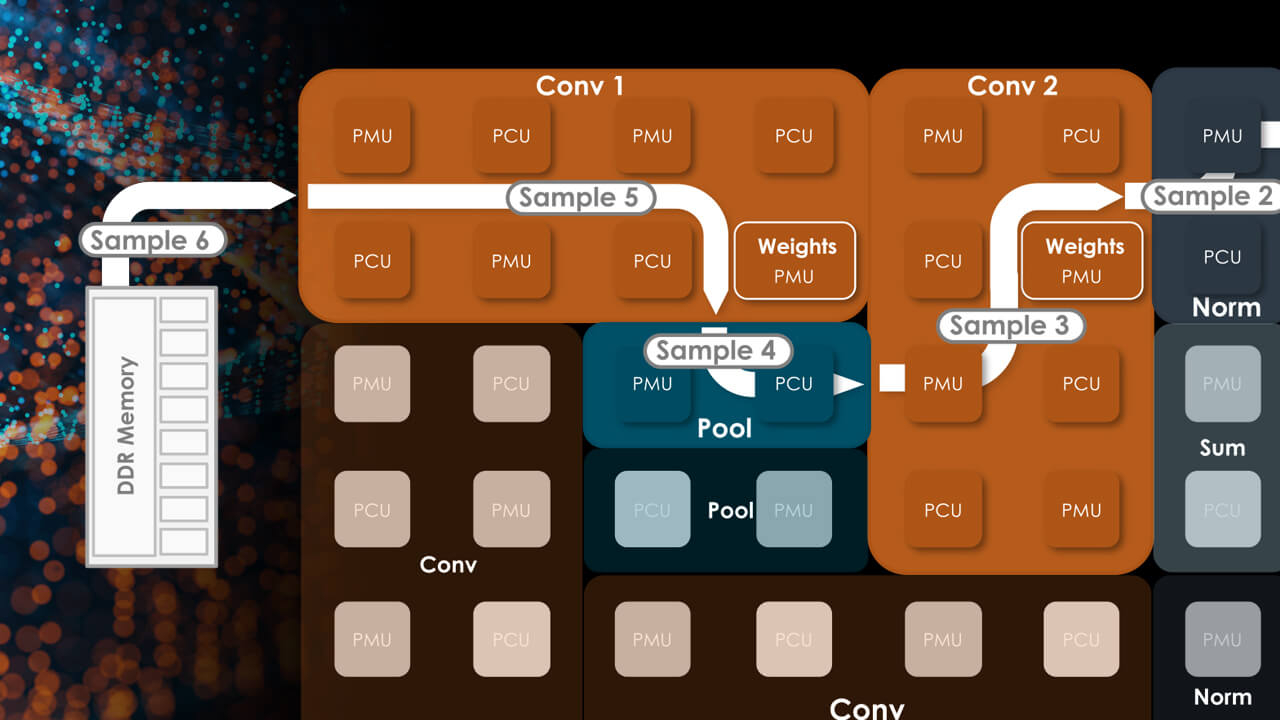
Здесь и далее источник изображений: SambaNova Каждый тайл содержит блоки PCU, отвечающие за вычисления, блоки PMU, содержащие SRAM и обслуживающую логику, а также mesh-интерконнект, обслуживаемый блоками коммутаторов. Такой подход к построению процессора весьма напоминает Tesla D1, у которых вычислительные блоки похожим образом чередуются с блоками быстрой SRAM-памяти. Отдельно ускорители компания не поставляет, минимальная конфигурация готовой 42U-системы DataScale включает в себя 8 чипов SN30.  Комплектация может включать в себя от одного до трёх узлов SN30. Воспользоваться возможностями DataScale можно и в виде услуги, поскольку новинка легко интегрируется в облачные среды и полностью поддерживает платформу Kubernetes. Полный список провайдеров ещё уточняется, на сегодняшний момент партнерами SambaNova являются Aicadium, Cirrascale и ORock.  Высокая производительность в режиме BF16 является главным достоинством новинки — по словам вице-президента SambaNova, каждый чип развивает 688 Тфлопс. Это более чем вдвое выше показателя A100, составляющего 312 Тфлопс. По словам компании, DataScale SN30 вшестеро производительнее NVIDIA DGX A100 (40 Гбайт) и эффективнее всего проявляет себя при обучении сверхбольших моделей вроде GPT-3 с её 13 млрд параметров. Однако нельзя не отметить, что, во-первых, сравнение идёт со старым продуктом NVIDIA, которая вот-вот представит DGX H100, а во-вторых, SambaNova не упоминает в явном виде энергопотребление одного узла SN30.
05.09.2022 [23:00], Алексей Степин
Tesla рассказала подробности о чипах D1 собственной разработки, которые станут основой 20-Эфлопс ИИ-суперкомпьютера DojoКомпания Tesla уже анонсировала собственный, созданный в лабораториях компании процессор D1, который станет основой ИИ-суперкомпьютера Dojo. Нужна такая система, чтобы создать для ИИ-водителя виртуальный полигон, в деталях воссоздающий реальные ситуации на дорогах. Естественно, такой симулятор требует огромных вычислительных мощностей: в нашем мире дорожная обстановка очень сложна, изменчива и включает множество факторов и переменных. До недавнего времени о Dojo и D1 было известно не так много, но на конференции Hot Chips 34 было раскрыто много интересного об архитектуре, устройстве и возможностях данного решения Tesla. Презентацию провел Эмиль Талпес (Emil Talpes), ранее 17 лет проработавший в AMD над проектированием серверных процессоров. Он, как и ряд других видных разработчиков, работает сейчас в Tesla над созданием и совершенствованием аппаратного обеспечения компании. 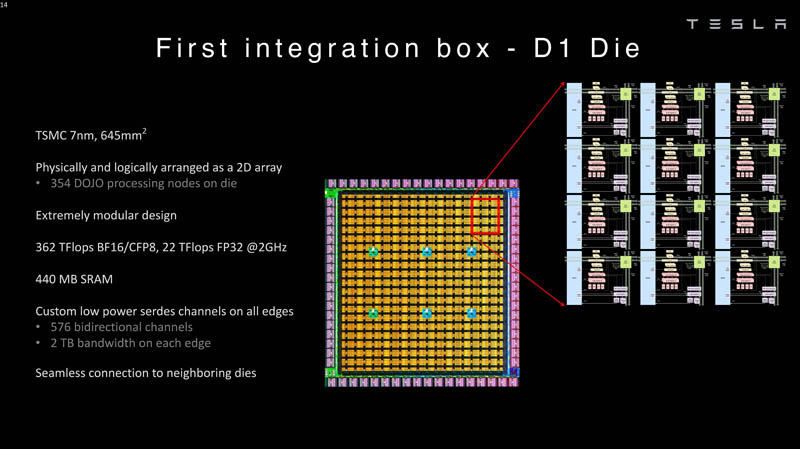
Изображения: Tesla (via ServeTheHome) Главной идеей D1 стала масштабируемость, поэтому в начале разработки нового чипа создатели активно пересмотрели роль таких традиционных концепций, как когерентность, виртуальная память и т.д. — далеко не все механизмы масштабируются лучшим образом, когда речь идёт о построении действительно большой вычислительной системы. Вместо этого предпочтение было отдано распределённой сети хранения на базе SRAM, для которой был создан интерконнект, на порядок опережающий существующие реализации в системах распределённых вычислений. 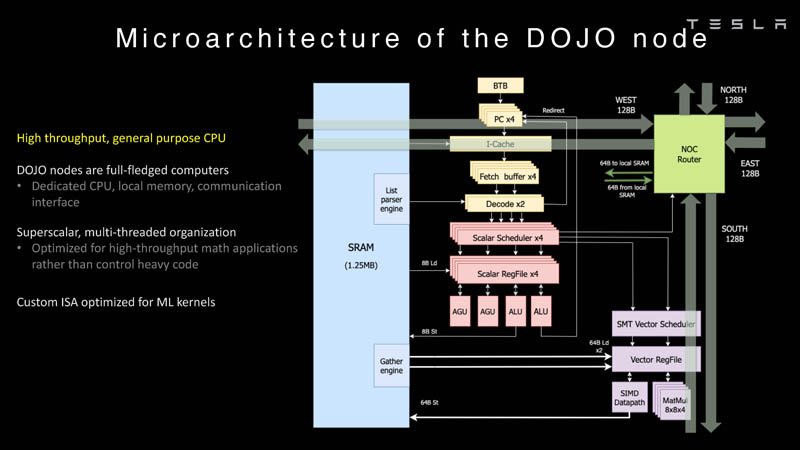 Основой процессора Tesla стало ядро целочисленных вычислений, базирующееся на некоторых инструкциях из набора RISC-V, но дополненное большим количеством фирменных инструкций, оптимизированных с учётом требований, предъявляемых ядрами машинного обучения, используемыми компанией. Блок векторной математики был создан практически с нуля, по словам разработчиков. 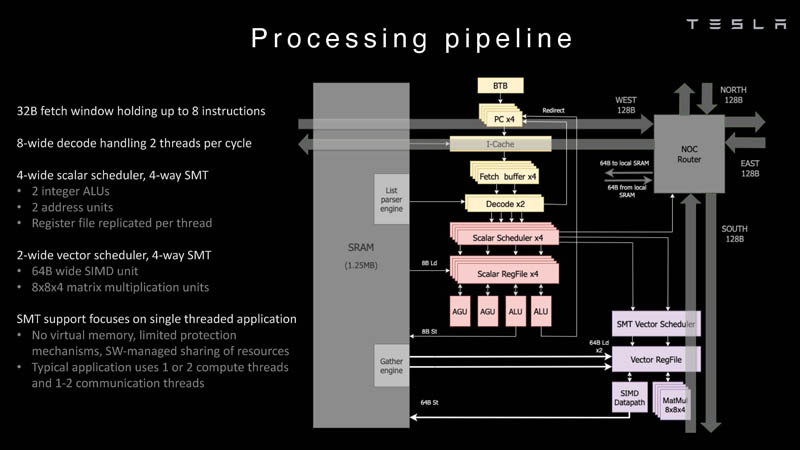 Набор инструкций Dojo включает в себя скалярные, матричные и SIMD-инструкции, а также специфические примитивы для перемещения данных из локальной памяти в удалённую, равно как и семафоры с барьерами — последние требуются для согласования работы c памятью во всей системе. Что касается специфических инструкций для машинного обучения, то они реализованы в Dojo аппаратно. 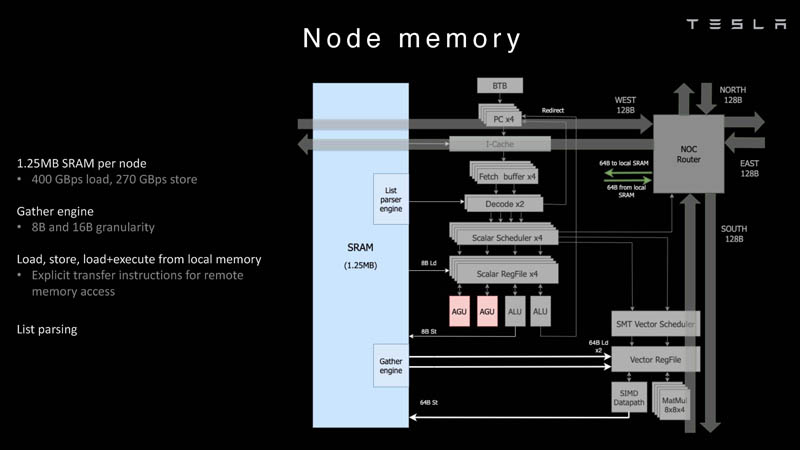 Первенец в серии, чип D1, не является ускорителем как таковым — компания считает его высокопроизводительным процессором общего назначения, не нуждающимся в специфических ускорителях. Каждый вычислительный блок Dojo представлен одним ядром D1 с локальной памятью и интерфейсами ввода/вывода. Это 64-бит ядро суперскалярно. 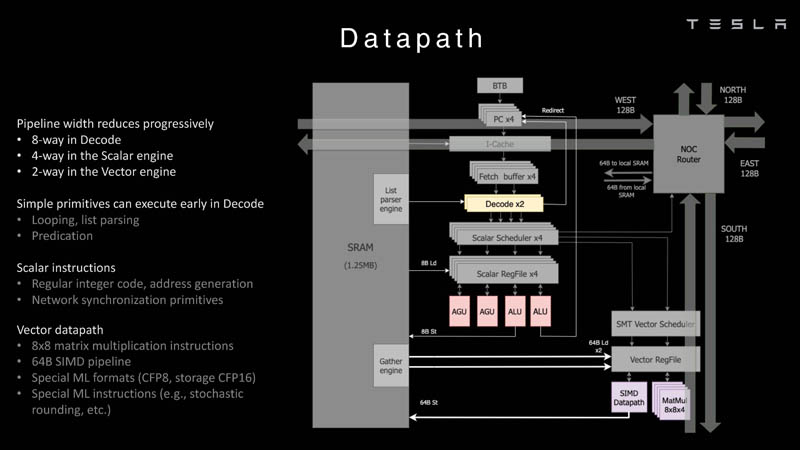 Более того, в ядре реализована поддержка многопоточности (SMT4), которая призвана увеличить производительность на такт (а не изолировать разные задачи друг от друга), поэтому виртуальную память данная реализация SMT не поддерживает, а механизмы защиты довольно ограничены в функциональности. За управление ресурсами Dojo отвечает специализированный программный стек и фирменное ПО. 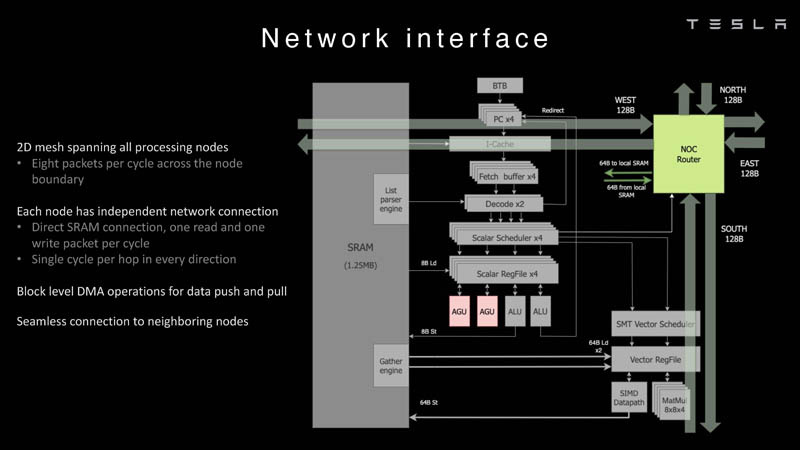 64-бит ядро имеет 32-байт окно выборки (fetch window), которое может содержать до 8 инструкций, что соответствует ширине декодера. Он, в свою очередь, может обрабатывать два потока за такт. Результат поступает в планировщики, которые отправляют его в блок целочисленных вычислений (два ALU) или в векторный блок (SIMD шириной 64 байт + перемножение матриц 8×8×4). 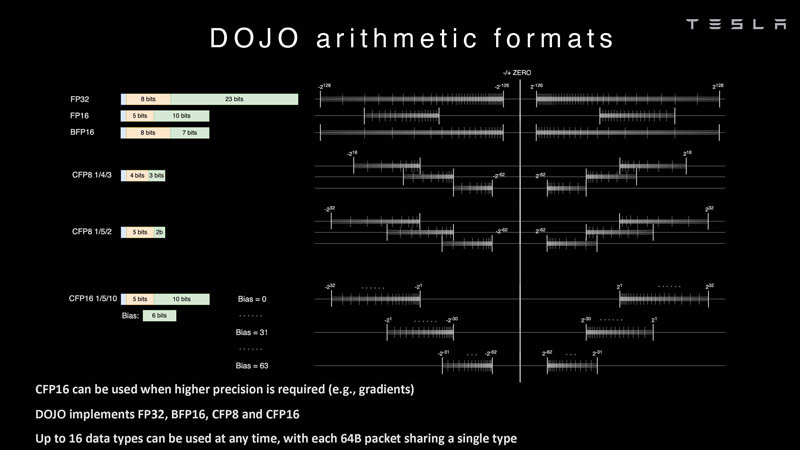 У каждого ядра D1 есть SRAM объёмом 1,25 Мбайт. Эта память — не кеш, но способна загружать данные на скорости 400 Гбайт/с и сохранять на скорости 270 Гбайт/с, причём, как уже было сказано, в чипе реализованы специальные инструкции, позволяющие работать с данными в других ядрах Dojo. Для этого в блоке SRAM есть свои механизмы, так что работа с удалённой памятью не требуют дополнительных операций.  Что касается поддерживаемых форматов данных, то скалярный блок поддерживает целочисленные форматы разрядностью от 8 до 64 бит, а векторный и матричный блоки — широкий набор форматов с плавающей запятой, в том числе для вычислений смешанной точности: FP32, BF16, CFP16 и CFP8. Разработчики D1 пришли к использованию целого набора конфигурируемых 8- и 16-бит представлений данных — компилятор Dojo может динамически изменять значения мантиссы и экспоненты, так что система может использовать до 16 различных векторных форматов, лишь бы в рамках одного 64-байт блока данных он не менялся.  Как уже упоминалось, топология D1 использует меш-структуру, в которой каждые 12 ядер объединены в логический блок. Чип D1 целиком представляет собой массив размером 18×20 ядер, однако доступны лишь 354 ядра из 360 присутствующих на кристалле. Сам кристалл площадью 645 мм2 производится на мощностях TSMC с использованием 7-нм техпроцесса. Тактовая частота составляет 2 ГГц, общий объём памяти SRAM — 440 Мбайт.  Процессор D1 развивает 362 Тфлопс в режиме BF16/CFP8, в режиме FP32 этот показатель снижается до 22 Тфлопс. Режим FP64 векторными блоками D1 не поддерживается, поэтому для многих традиционных HPC-нагрузок данный процессор не подойдёт. Но Tesla создавала D1 для внутреннего использования, поэтому совместимость её не очень волнует. Впрочем, в новых поколениях, D2 или D3, такая поддержка может появиться, если это будет отвечать целям компании. 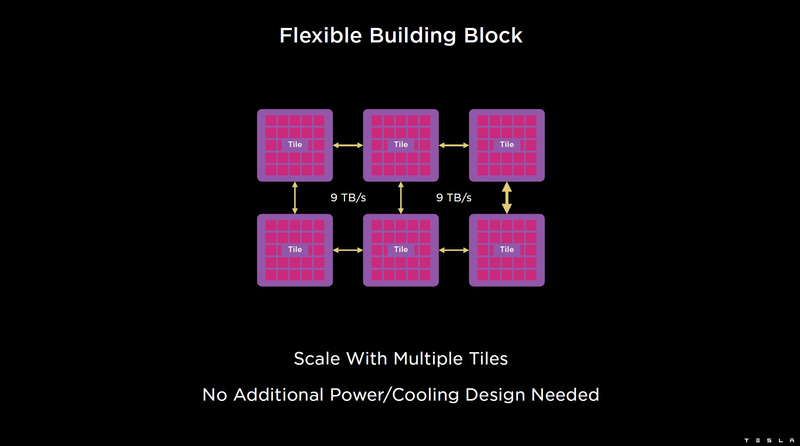 Каждый кристалл D1 имеет 576-битный внешний интерфейс SerDes с совокупной производительностью по всем четырём сторонам, составляющей 18 Тбайт/с, так что узким местом при соединении D1 он явно не станет. Этот интерфейс объединяет кристаллы в единую матрицу 5х5, такая матрица из 25 кристаллов D1 носит название Dojo training tile. 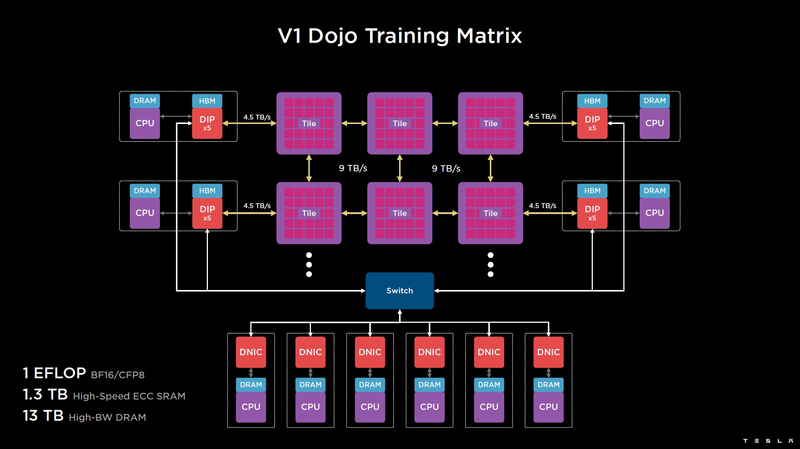 Этот тайл выполнен как законченный термоэлектромеханический модуль, имеющий внешний интерфейс с пропускной способностью 4,5 Тбайт/с на каждую сторону, совокупно располагающий 11 Гбайт памяти SRAM, а также собственную систему питания мощностью 15 кВт. Вычислительная мощность одного тайла Dojo составляет 9 Пфлопс в формате BF16/CFP8. При таком уровне энергопотребления охлаждение у Dojo может быть только жидкостное.  Тайлы могут объединяться в ещё более производительные матрицы, но как именно физически организован суперкомпьютер Tesla, не вполне ясно. Для связи с внешним миром используются блоки DIP — Dojo Interface Processors. Это интерфейсные процессоры, посредством которых тайлы общаются с хост-системами и на долю которых отведены управляющие функции, хранение массивов данных и т.п. Каждый DIP не просто выполняет IO-функции, но и содержит 32 Гбайт памяти HBM (не уточняется, HBM2e или HBM3). 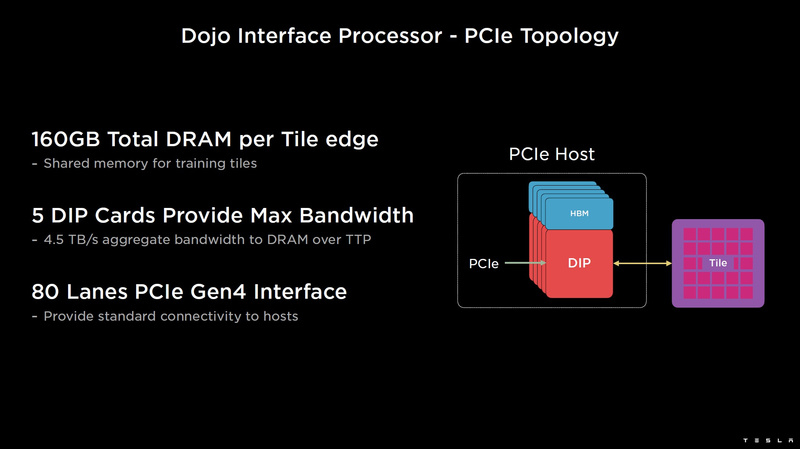 DIP использует полностью свой транспортный протокол (Tesla Transport Protocol, TTP), разработанный в Tesla и обеспечивающий пропускную способность 900 Гбайт/с, а поверх Ethernet — 50 Гбайт/с. Внешний интерфейс у карточек — PCI Express 4.0, и каждая интерфейсная карта несёт пару DIP. С каждой стороны каждого ряда тайлов установлено по 5 DIP, что даёт скорость до 4,5 Тбайт/с от HBM-стеков к тайлу.  В случаях, когда во всей системе обращение от тайла к тайлу требует слишком много переходов (до 30 в случае обращения от края до края), система может воспользоваться DIP, объединённых снаружи 400GbE-сетью по топологии fat tree, сократив таким образом, количество переходов до максимум четырёх. Пропускная способность в этом случае страдает, но выигрывает латентность, что в некоторых сценариях важнее. 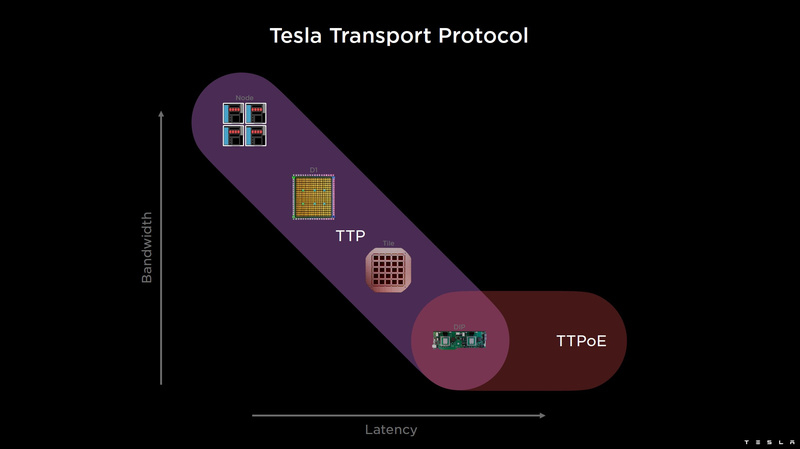 В базовой версии суперкомпьютер Dojo V1 выдаёт 1 Эфлопс в режиме BF16/CFP8 и может загружать непосредственно в SRAM модели объёмом до 1,3 Тбайт, ещё 13 Тбайт данных можно хранить в HBM-сборках DIP. Следует отметить, что пространство SRAM во всей системе Dojo использует единую плоскую адресацию. Полномасштабная версия Dojo будет иметь производительность до 20 Эфлопс. Сколько сил потребуется компании, чтобы запустить такого монстра, а главное, снабдить его рабочим и приносящим пользу ПО, неизвестно — но явно немало. Известно, что система совместима с PyTorch. В настоящее время Tesla уже получает готовые чипы D1 от TSMC. А пока что компания обходится самым большим в мире по числу установленных ускорителей NVIDIA ИИ-суперкомпьютером.
24.08.2022 [22:42], Владимир Мироненко
Untether AI представила ИИ-ускоритель speedAI240 — 1,5 тыс. ядер RISC-V и 238 Мбайт SRAM со скоростью 1 Пбайт/сКомпания Untether AI анонсировала ИИ-архитектуру следующего поколения speedAI (кодовое название «Boqueria»), ориентированную на инференс-нагрузки. При энергоэффективности 30 Тфлопс/Вт и производительности до 2 Пфлопс на чип speedAI устанавливает новый стандарт энергоэффективности и плотности вычислений, говорит компания.  Поскольку at-memory вычисления в ряде задач значительно энергоэффективнее традиционных архитектур, они могут обеспечить более высокую производительность при одинаковых затратах энергии. Первое поколение устройств runAI в 2020 году Untether AI достигла энергоэффективности на уровне 8 Тфлопс/Вт для INT8-вычислений. Новая архитектура speedAI обеспечивает уже 30 Тфлопс/Вт. .jpg)
Изображения: Untether AI (via ServeTheHome) 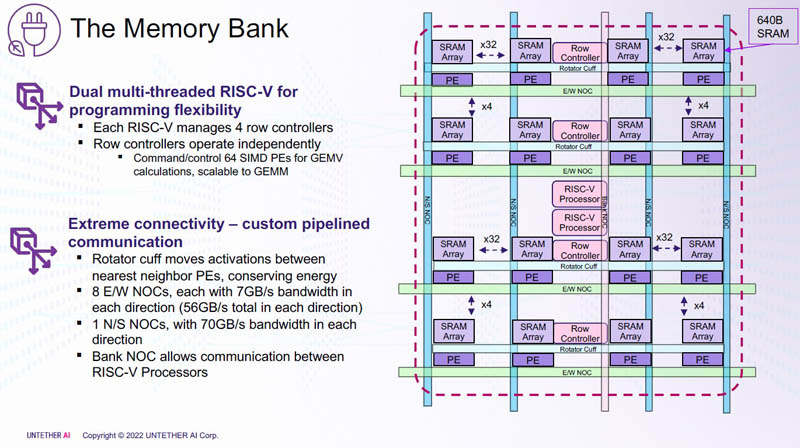 Этого удалось добиться благодаря архитектуре второго поколения, использованию более 1400 оптимизированных 7-нм ядер RISC-V (1,35 ГГц) с кастомными инструкциями, энергоэффективному управлению потоком данных и внедрению поддержки FP8. Вкупе это позволило вчетверо поднять эффективность speedAI по сравнению с runAI. Новинка может быть гибко адаптирована к различным архитектурам нейронных сетей. Концептуально speedAI напоминает ещё один тысячеядерный чип RISC-V — Esperanto ET-SoC-1. 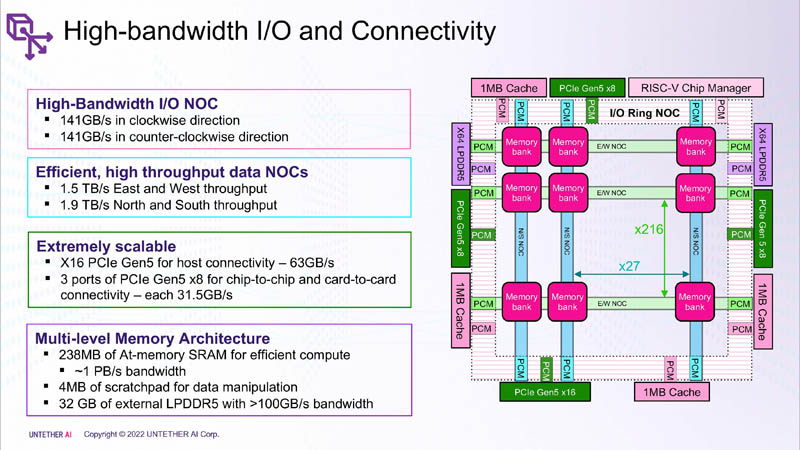 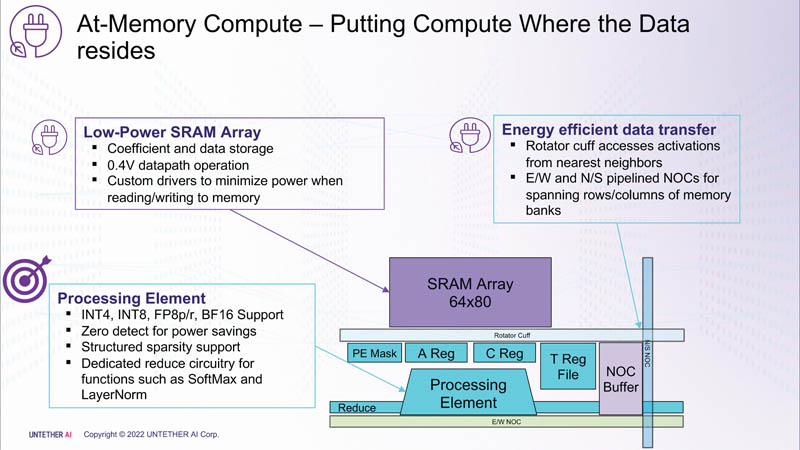 Первый член семейства speedAI — speedAI240 — обеспечивает 2 Пфлопс вычислениях в FP8-вычислениях или 1 Пфлопс для BF16-операций. Благодаря этому обеспечивается самая высокая в отрасли эффективность — например, для модели BERT заявленная производительность составляет 750 запросов в секунду на Вт (qps/w), что, по словам компании, в 15 раз выше, чем у современных GPU. Добиться повышения производительности удалось благодаря тесной интеграции вычислительных элементов и памяти.  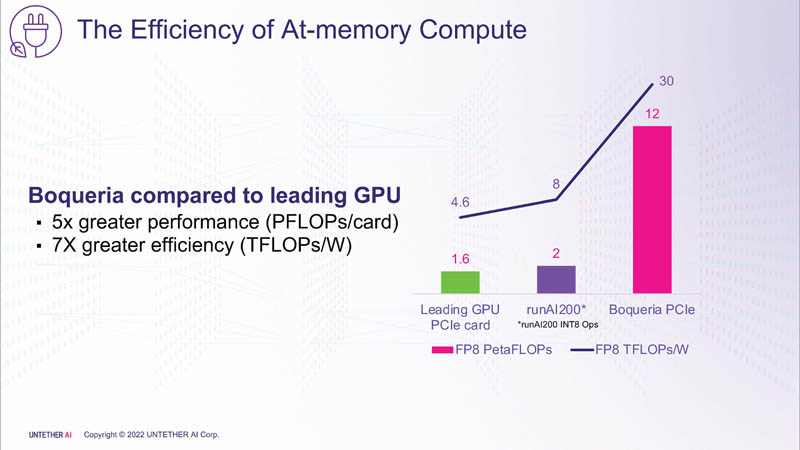 На каждый блок SRAM объёмом 328 Кбайт приходится 512 вычислительных блоков, поддерживающих работу с форматами INT4, INT8, FP8 и BF16. Каждый вычислительный блок имеет два 32-бит (RV32EMC) кастомных ядра RISC-V с поддержкой четырёх потоков и 64 SIMD. Всего есть 729 блоков, так что суммарно чип несёт 238 Мбайт SRAM и 1458 ядер. Блоки провязаны между собой mesh-сетью, к которой также подключены кольцевая IO-шина, несущая четыре 1-Мбайт блока общего кеша, два контроллера LPDRR5 (64 бит) и порты PCIe 5.0: один x16 для подключения к хосту и три x8 для объединения чипов. Суммарная пропускная способность SRAM составляет около 1 Пбайт/с, mesh-сети — от 1,5 до 1,9 Тбайт/с, IO-шины — 141 Гбайт/c в обоих направлениях, а 32 Гбайт DRAM — чуть больше 100 Гбайт/с. PCIe-интерфейсы позволяют объединить до трёх ускорителей, с шестью speedAI240 чипами у каждого. Решения speedAI будут предлагаться как в виде отдельных чипов, так и в составе готовых PCIe-карт и M.2-модулей. Ожидается, что первые поставки избранным клиентам начнутся в первой половине 2023 года.
24.08.2022 [21:16], Алексей Степин
Intel переименовала свои первые серверные ускорители Intel Arctic Sound-M во FlexРанее мы уже рассказывали об ускорителях Intel Arctic Sound-M, о которых впервые стало известно ещё зимой. Это универсальное решение, базирующееся на графической архитектуре Xe-HPG и предназначенное для решения широкого круга задач, от организации виртуальных рабочих мест до применения в системах машинной аналитики. Сегодня Intel официально заявила, что ускорители Arctic Sound-M теперь будут доступны под брендом Flex. В основе по-прежнему лежит микроархитектура DG2 Alchemist, и компания позиционирует Flex как решение, способное ощутимо снизить стоимость владения для серверной инфраструктуры, особенно занятой в задачах транскодирования видеопотоков. 
Источник: Intel Intel заявляет, что Flex 140 в пять раз превосходит NVIDIA A10 в задачах транскодирования видео, вдвое — в сценариях декодирования, и всё это с вдвое меньшим уровнем энергопотребления, а значит, и тепловыделения. Речь идёт о младшем решении в серии с интерфейсом PCIe 4.0 x8, которое имеет два восьмиядерных чипа Xe (1600/1950 МГц) и 12 Гбайт GDDR6-памяти (192 бит, 336 Гбайт/с). Flex 170 оснащён одним чипом, но в 32-ядерном варианте (1950/2050 МГц), и имеет вдвое более высокий теплопакет (150 против 75 Вт), а также 16 Гбайт GDDR6 (256 бит, 576 Гбайт/с) и интерфейс PCIe 4.0 x16. 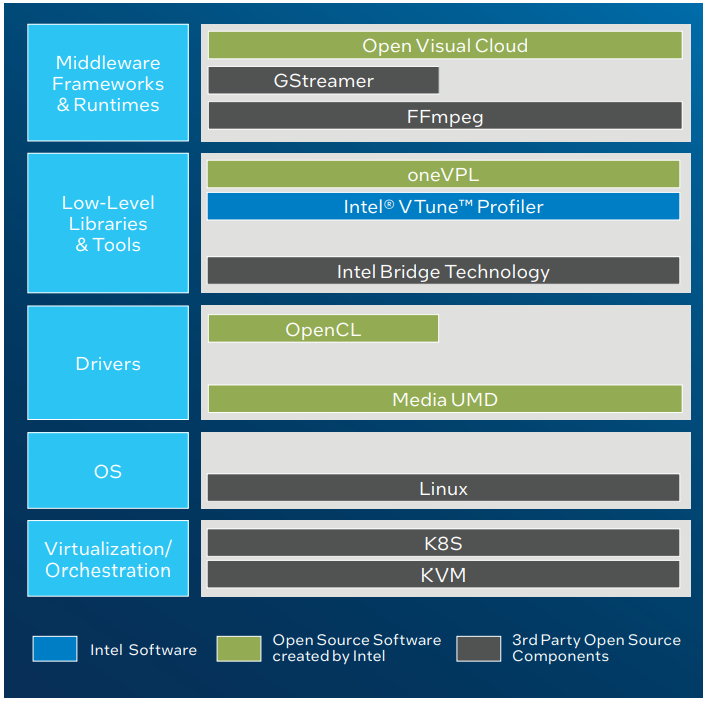
Источник: Intel До 10 ускорителей Flex 140 можно разместить в стандартном 4U-шасси, что позволит одновременно обрабатывать до 360 потоков 1080р60 HEVC. Производительность Flex 140 достаточно высока, чтобы гарантировать задержку не более 1 сек при начале транскодирования видеопотока с параметрами 8K@60 (AV1 или HEVC HDR). Intel активно делает упор на аппаратной поддержке видеостандарта AV1, но ускорители работают и с HEVC, AVC и VP9. 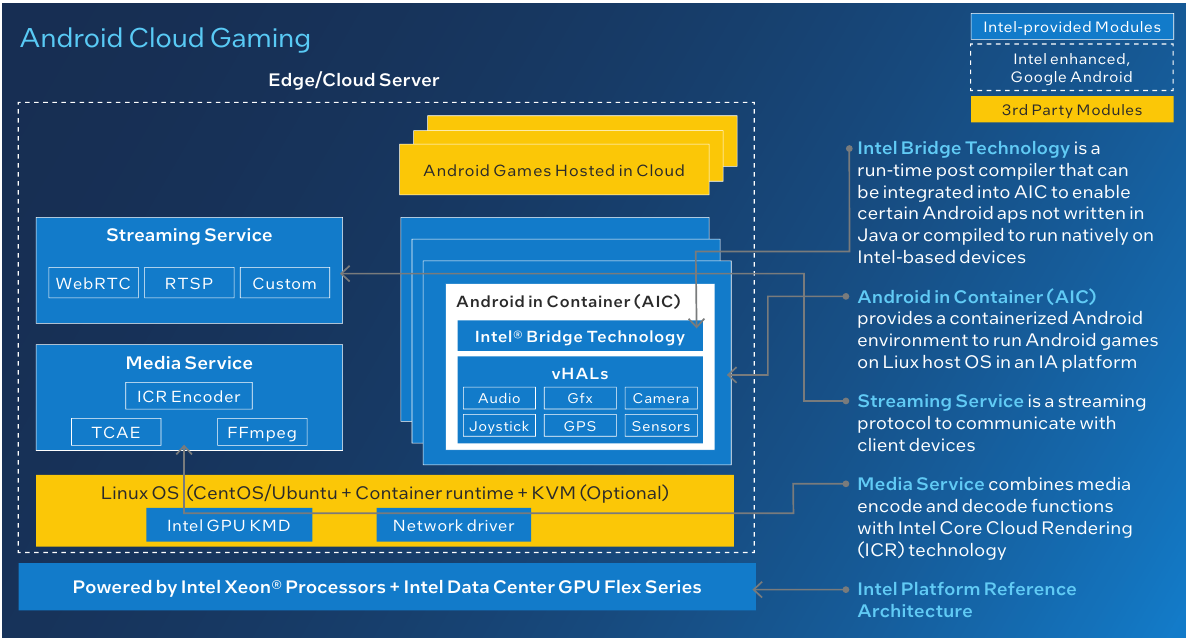
Архитектура облачного Android-гейминга Intel. Источник: Intel Также найдут своё применения ускорители Intel Flex Series и в облачных игровых платформах для Android, где единственная плата Flex 170 сможет обслуживать до 68 сессий в режиме 720p30, а шесть ускорителей Flex 140 будут в состоянии обеспечить до 216 игровых сессий с такими же параметрами. Помимо всего прочего поддерживается и аппаратное ускорение трассировки лучей. Работают новые ускорители под управлением унифицированной платформы oneAPI. 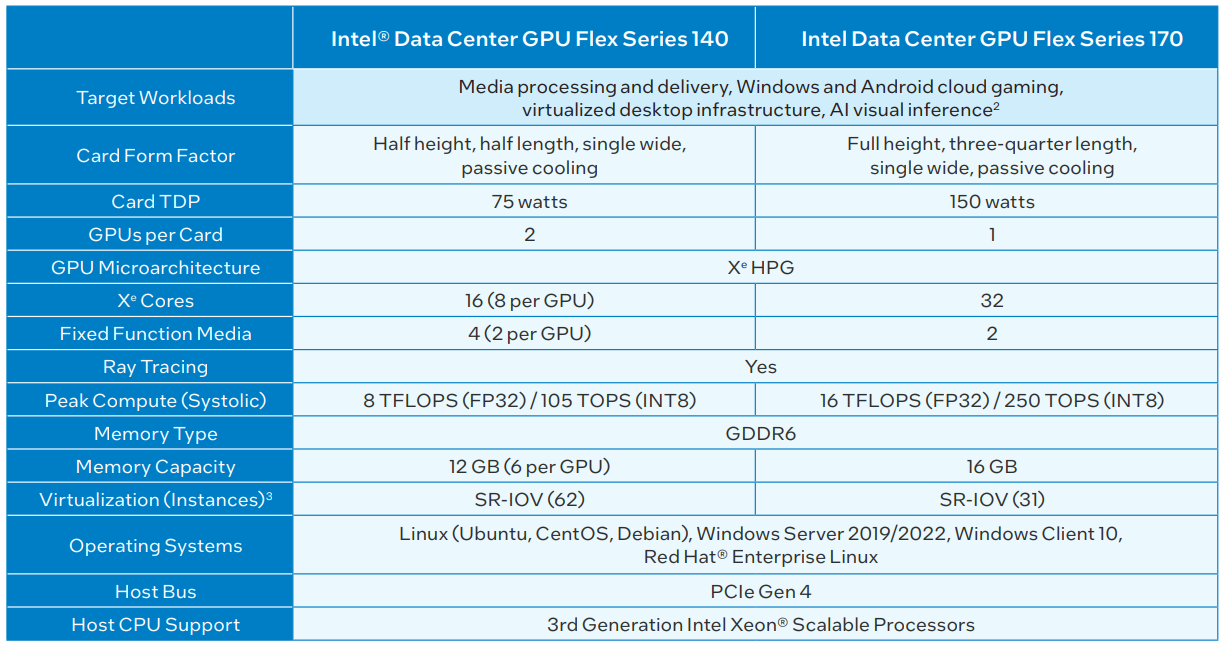 Стоимости новых ускорителей Intel пока не разглашает, но с учётом того, что компания сильно упирает на снижение стоимости владения, цена, судя по всему, будет сравнительно доступной и наверняка более привлекательной, чем у NVIDIA A10. Кроме того, Intel говорит об отсутствии необходимости докупать лицензии, чтобы воспользоваться всеми возможностями ускорителей. Но умалчивает, что производительность старшей модели Flex 170 в INT8-вычислениях совпадает с таковой у A10 (250 Топс), а в FP32-расчётах решение Intel и вовсе проигрывает. К тому же у A10 в полтора раза больше RAM.
22.08.2022 [20:55], Алексей Степин
Китайский ускоритель Birentech BR100 готов бросить вызов NVIDIA A100Как известно, Китай первым в мире успешно ввёл в эксплуатацию суперкомпьютеры экзафлопсного класса, но современная HPC-система практически немыслима без ускорителей. Однако и здесь китайские разработчики подготовили прорыв: на конференции Hot Chips 34 компания Birentech рассказала о чипе BR100, решении, которое может бросить вызов как AMD, так и NVIDIA. Новинка базируется на архитектуре собственной разработки под кодовым названием Bi Liren. Это первый китайский ускоритель общего назначения, использующий чиплетную компоновку и поддерживающий PCI Express 5.0/CXL. Новые ускорители будут сопровождаться полноценной программной поддержкой, начиная с драйверов и библиотек и заканчивая популярными фреймворками, такими, как TensorFlow и PyTorch. 
Источник: WCCFTech Сложность BR100 внушает уважение: новый чип состоит из 77 млрд транзисторов, скомпонованных воедино с использованием 7-нм техпроцесса и технологии TSMC 2.5D CoWoS. Площадь чипа составляет 1074 мм2, правда, не очень понятно, идёт ли речь исключительно о кристалле, т.н. «вычислительном тайле», или о сборке в целом, поскольку в состав BR100 входит 64 Гбайт памяти HBM2e. 
Источник: WCCFTech Среди особенностей можно отметить наличие быстрого кеша объёмом 300 Мбайт (256 Мбайт L2) — для сравнения, у NVIDIA A100 он составляет всего 40 Мбайт, и даже у новейшего H100 он увеличен лишь до 50 Мбайт. Что касается ПСП, то она составляет 1,64 Тбайт/с. 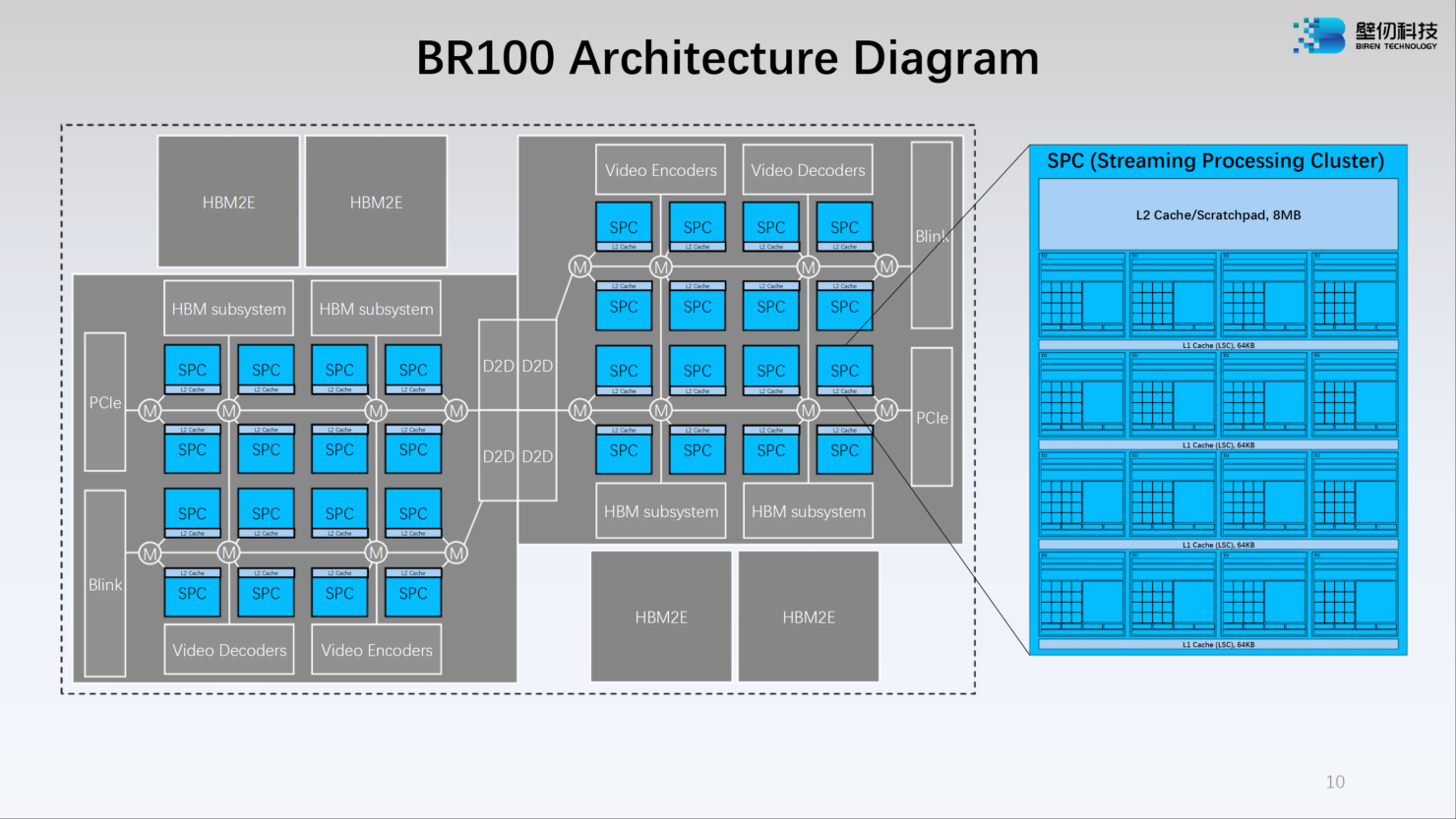
Источник: WCCFTech Модульная компоновка BR100 включает в себя два вычислительных тайла и четыре сборки HBM2e. Между собой кристаллы соединены интерконнектом с пропускной способностью 896 Гбайт/с, а для дальнейшего масштабирования в составе нового ускорителя предусмотрен фирменный интерконнект BLink (8 линий) с производительностью 2,3 Тбайт/с. 
Источник: WCCFTech Каждый из двух кристаллов несёт в себе по 16 потоковых вычислительных кластеров (SPC), а каждый такой кластер, в свою очередь, содержит 16 исполнительных блоков (EU). Каждый блок EU содержит 16 потоковых ядер V-Core и одно тензорное ядро T-Core, так что всего в составе BR100 имеется 8192 классических ядра и 512 тензорных. Каждый SPC имеет свой кеш L2 объёмом 8 Мбайт, суммарно 256 Мбайт на всю сборку BR100. 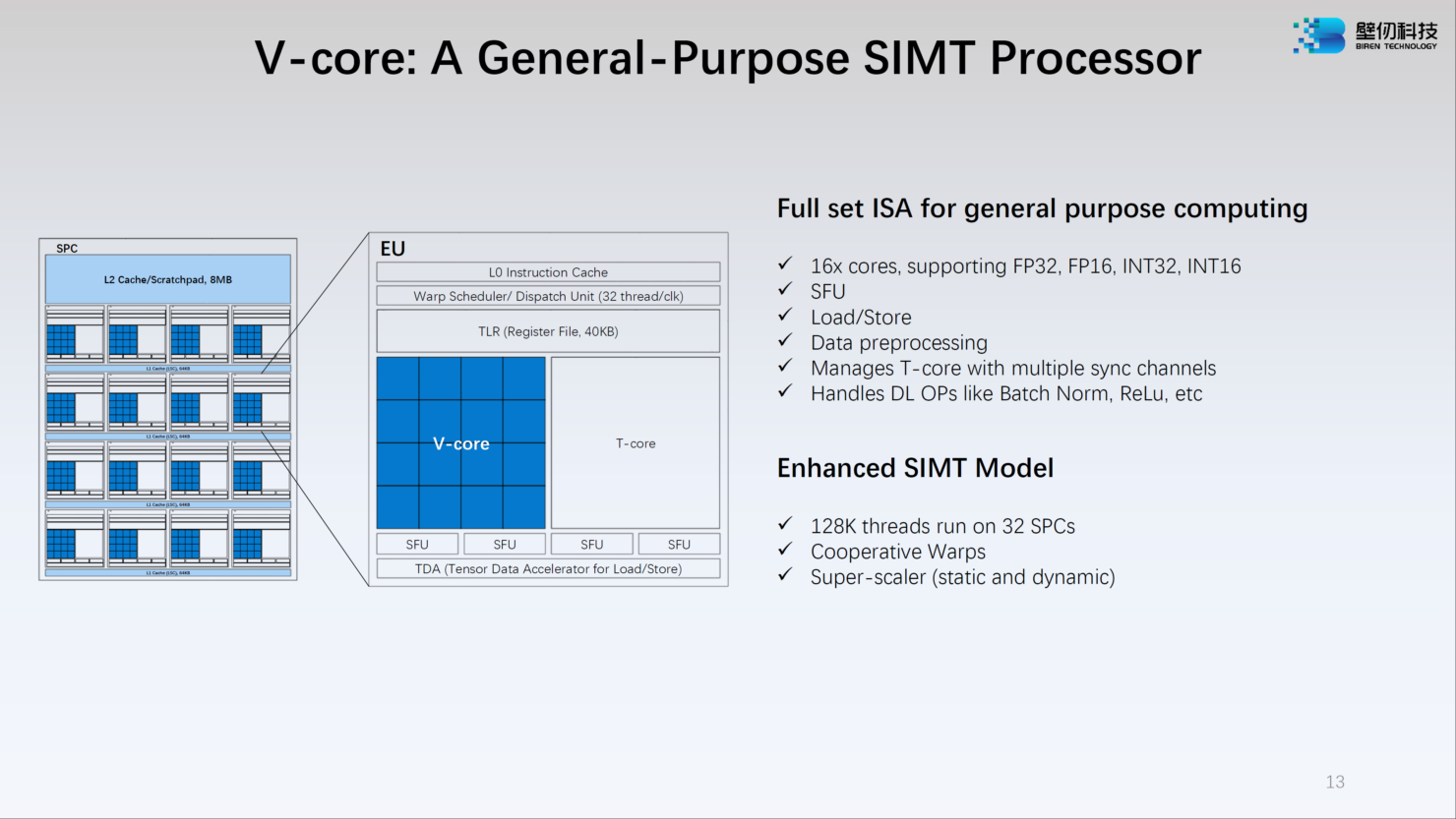
Источник: WCCFTech Ядро V-Core имеет архитектуру SIMT (Single Instructions, Multiple Thread) и поддерживает вычисления в форматах INT16/32, FP16 и FP32. Тензорные ядра T-Core предназначены для выполнения операций типа MMA, свёртки и прочих, характерных для современных задач машинного обучения. Предельное количество потоков у BR100 в суперскалярном режиме — 128 тысяч. 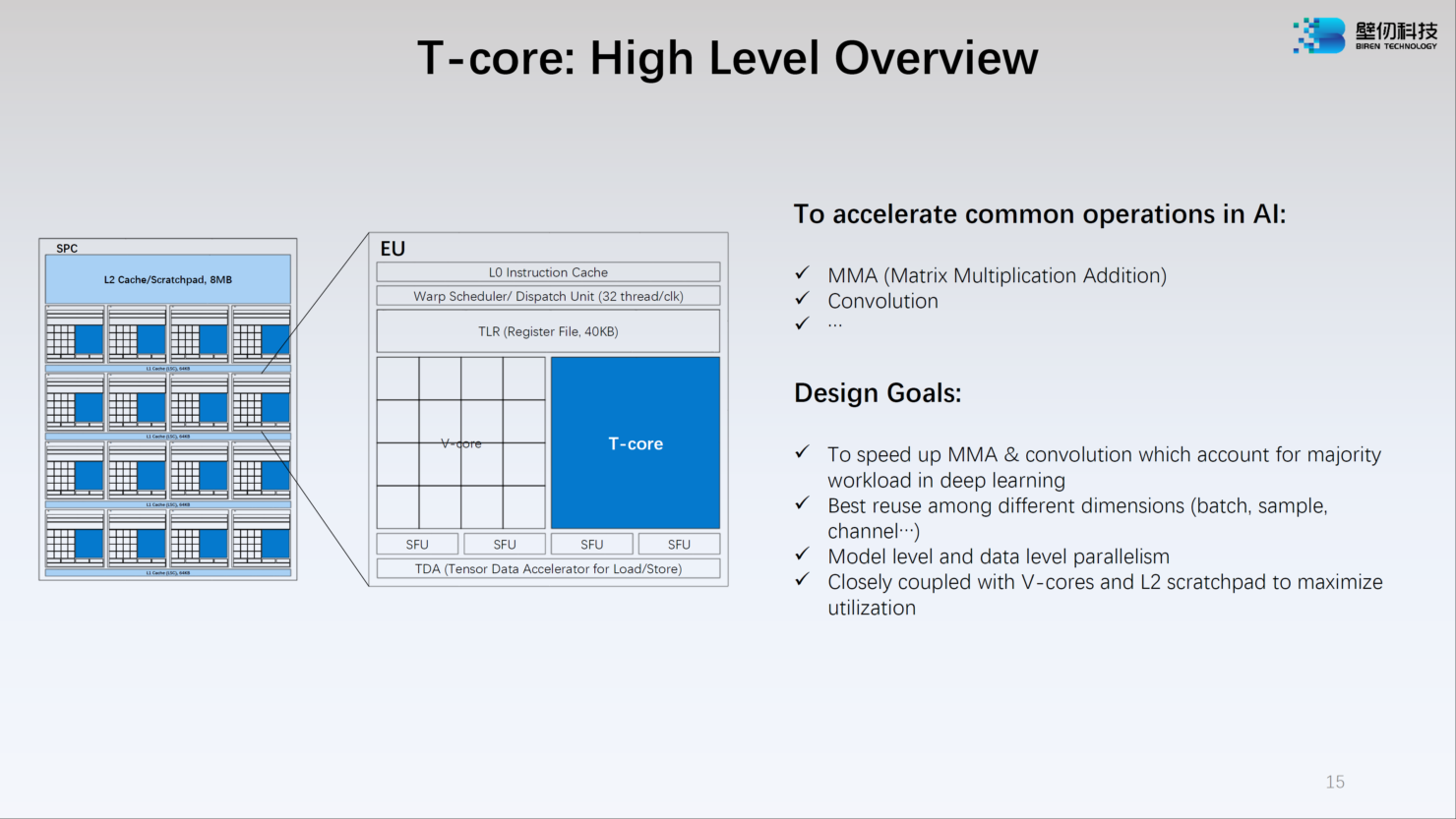
Источник: WCCFTech Компания-разработчик приводит некоторые цифры производительности для BR100: это 256 Тфлопс в режиме FP32, вдвое больше в режиме TF32+, 1024 Тфлопс в формате BF16 и целых 2048 Топс в режиме INT8. Это серьёзная заявка: с такими показателями BR100 должен опережать NVIDIA A100. Заявлено превосходство от 2,5х до 2,8х в зависимости от задачи и сценария. 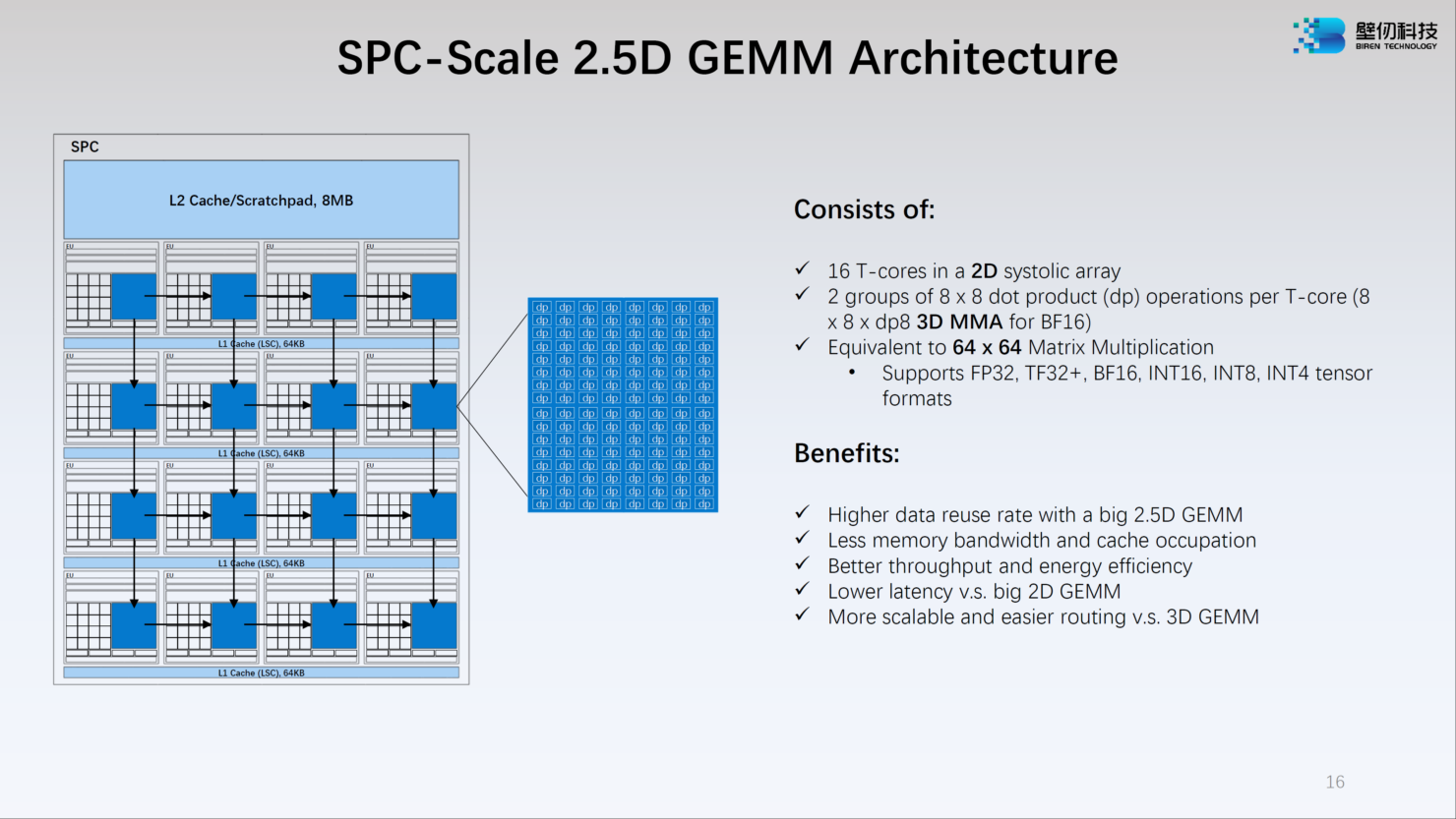
Источник: WCCFTech Любопытно, что BR100 несильно уступает NVIDIA H100 по количеству транзисторов (77 против 80 млрд), но, естественно, использование более грубого 7-нм техпроцесса против N4 у последней разработки NVIDIA означает и большее тепловыделение. Этот параметр у BR100 составляет 550 Вт в то время, как PCIe-вариант H100 укладывается в стандартные 350 Вт. 
Источник: WCCFTech Это не единственная новинка: в арсенале Birentech заявлен и менее мощный чип BR104. Он вдвое медленнее старшей модели по всем показателям и несёт 32 Гбайт памяти против 64, но в отличие от BR100, использует монолитный, а не чиплетный дизайн. На его основе будут выпущены ускорители в формате PCIe с TDP в районе 300 Вт, тогда как старшая версия будет доступна только в виде OAM-модуля. |
|


