Материалы по тегу: к
|
13.10.2025 [00:30], Владимир Мироненко
Вложи $5 млн — получи $75 млн: NVIDIA похвасталась новыми рекордами в комплексном бенчмарке InferenceMAX v1
b200
gb200
hardware
nvidia
open source
semianalysis
бенчмарк
ии
инференс
рекорд
финансы
энергоэффективность
NVIDIA сообщила о результатах, показанных суперускорителем GB200 NVL72, в новом независимом ИИ-бенчмарке InferenceMAX v1 от SemiAnalysis. InferenceMAX оценивает реальные затраты на ИИ-вычисления, определяя совокупную стоимость владения (TCO) в долларах на миллион токенов для различных сценариев, включая покупку и владение GPU в сравнении с их арендой. InferenceMAX опирается на инференс популярных моделей на ведущих платформах, измеряя его производительность для широкого спектра вариантов использования, а результаты может перепроверить любой желающий, говорят авторы бенчмарка. Суперускоритель GB200 NVL72 победил во всех категориях бенчмарка InferenceMAX v1. Чипы NVIDIA Blackwell показали наилучшую окупаемость инвестиций — вложение в размере $5 млн приносят $75 млн дохода от токенов DeepSeek R1, обеспечивая 15-кратную окупаемость (год назад NVIDIA обещала ROI на уровне 700 %). Также ускорители поколения Blackwell отличаются самой низкой совокупной стоимостью владения. например, оптимизация ПО NVIDIA B200 позволила добиться стоимости всего в два цента на миллион токенов на OpenAI gpt-oss-120b, обеспечив пятикратное снижение стоимости одного токена всего за два месяца. NVIDIA B200 первенствовал и по пропускной способности и интерактивности, обеспечив 60 тыс. токенов в секунду на ускоритель и 1 тыс. токенов в секунду на пользователя в gpt-oss с новейшим стеком NVIDIA TensorRT-LLM. NVIDIA сообщила, что постоянно повышает производительность путём оптимизации аппаратного и программного стека. Первоначальная производительность gpt-oss-120b на системе NVIDIA DGX Blackwell B200 с библиотекой NVIDIA TensorRT LLM уже была лидирующей на рынке, но команды NVIDIA и сообщество разработчиков значительно оптимизировали TensorRT LLM для ускорения исполнения открытых больших языковых моделей (LLM). 
Источник изображений: NVIDIA Компания отметила, что выпуск TensorRT LLM v1.0 стал значительным прорывом в повышении скорости инференса LLM благодаря распараллеливанию и оптимизации IO-операций. А у недавно вышедшей модели gpt-oss-120b-Eagle3-v2 используется спекулятивное декодирование — интеллектуальный метод, позволяющий предсказывать несколько токенов одновременно. Это уменьшает задержку и обеспечивает получение ещё более быстрых результатов — пропускная способность выросла втрое, до 100 токенов в секунду на пользователя (TPS/пользователь), а общая производительность на ускоритель выросла с 6 до 30 тыс. токенов. 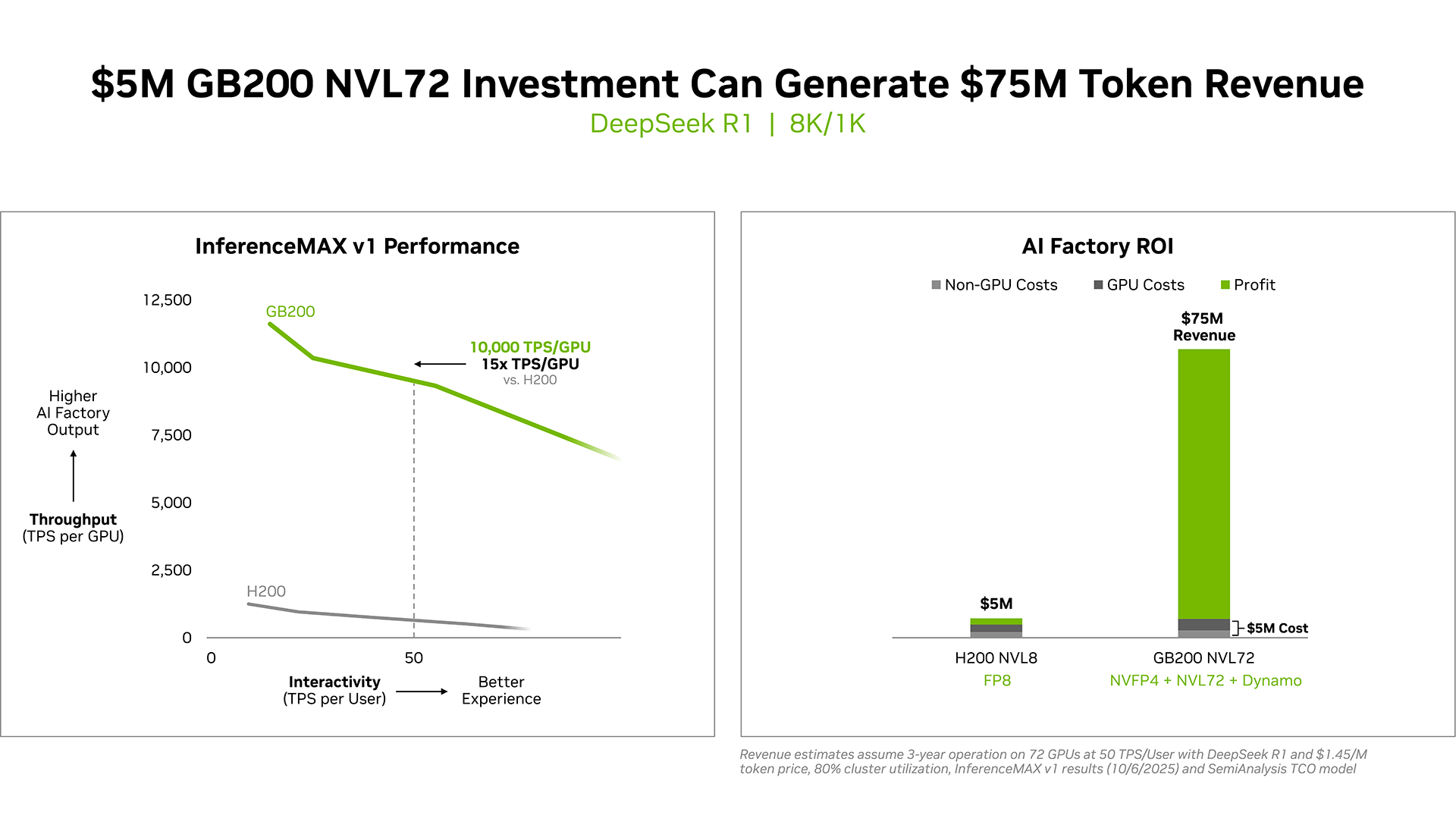 Для моделей с «плотной» архитектурой (Dense AI), таких как Llama 3.3 70b, которые требуют значительных вычислительных ресурсов из-за большого количества параметров и одновременного использования всех параметров в процессе инференса, NVIDIA Blackwell B200 достиг нового рубежа производительности в бенчмарке InferenceMAX v1, отметила NVIDIA. Суперускоритель показал более 10 тыс. токенов/с (TPS) на GPU при 50 TPS на пользователя, т.е. вчетверо более высокую пропускную способность на GPU по сравнению с NVIDIA H200. 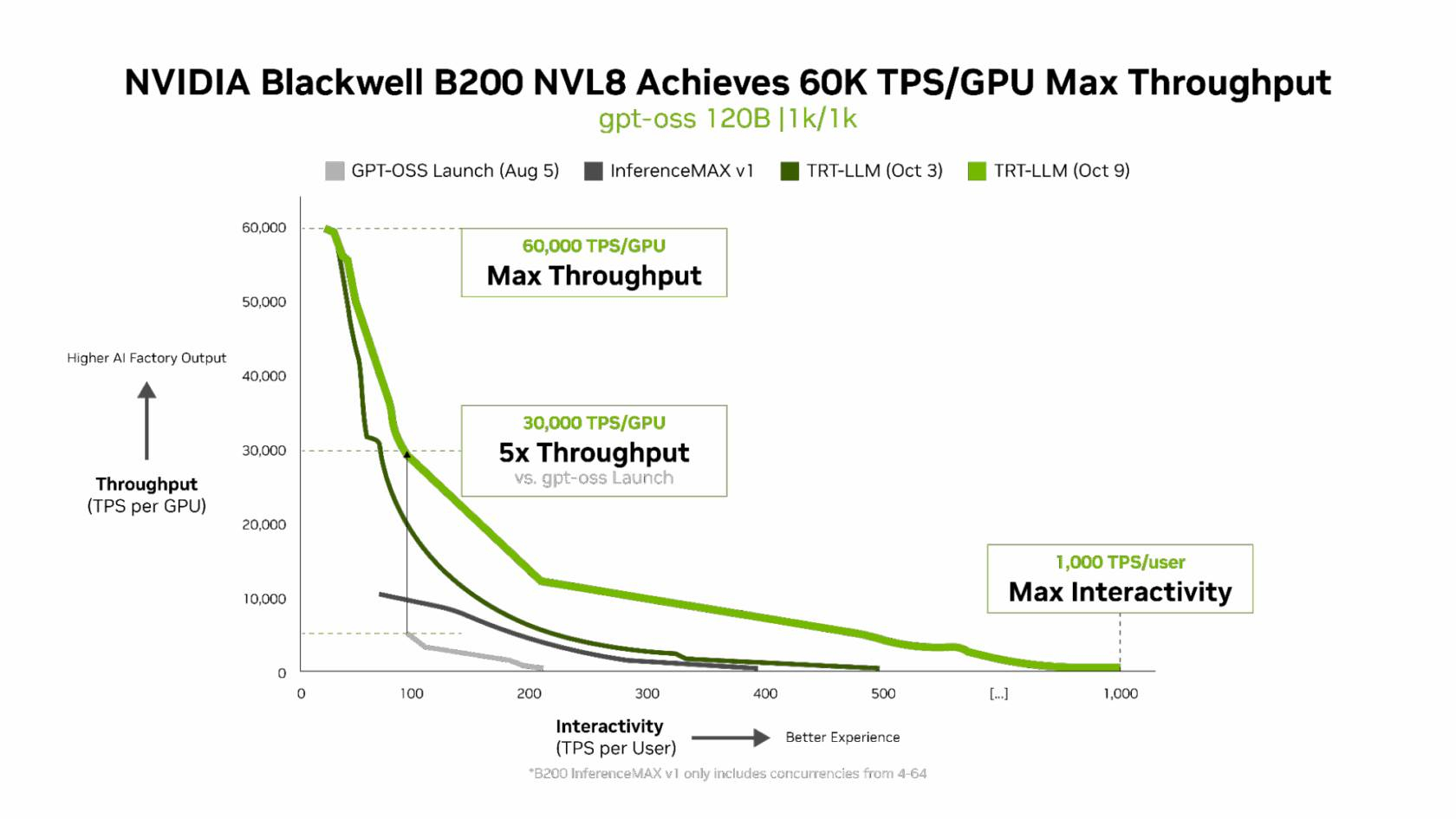 NVIDIA подчеркнула, что такие показатели, как количество токенов на Вт, стоимость на миллион токенов и TPS/пользователь не уступают по важности пропускной способности. Фактически, для ИИ-фабрик с ограниченной мощностью ускорители с архитектурой Blackwell обеспечивают до 10 раз лучшую производительность на МВт по сравнению с предыдущим поколением и позволяют получать более высокий доход от токенов. 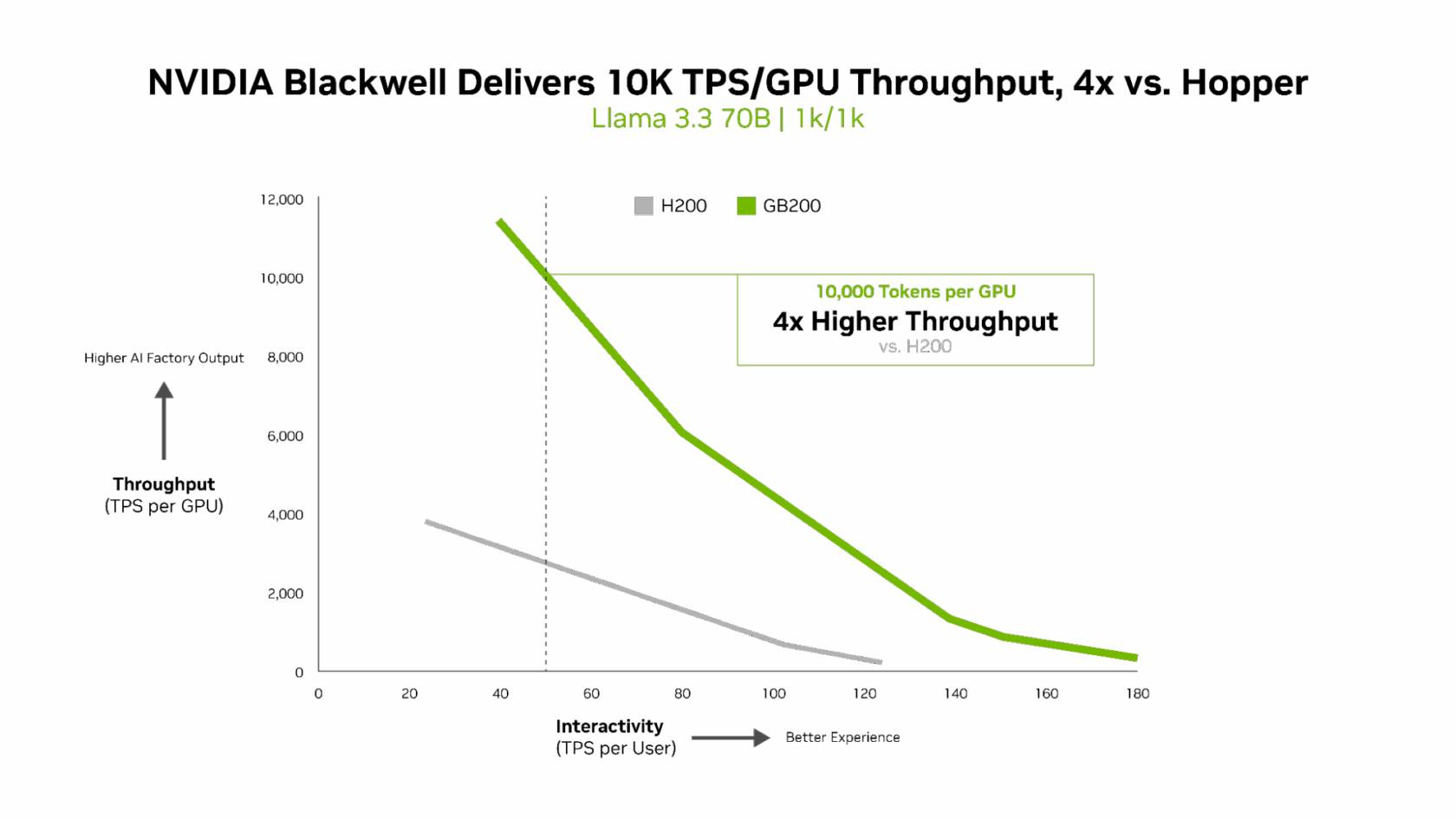 Компания отметила, что стоимость обработки одного токена (Cost per Token) имеет решающее значение для оценки эффективности ИИ-модели и напрямую влияет на эксплуатационные расходы. NVIDIA утверждает, что в целом архитектура NVIDIA Blackwell позволила снизить стоимость обработки миллиона токенов в 15 раз по сравнению с предыдущим поколением. 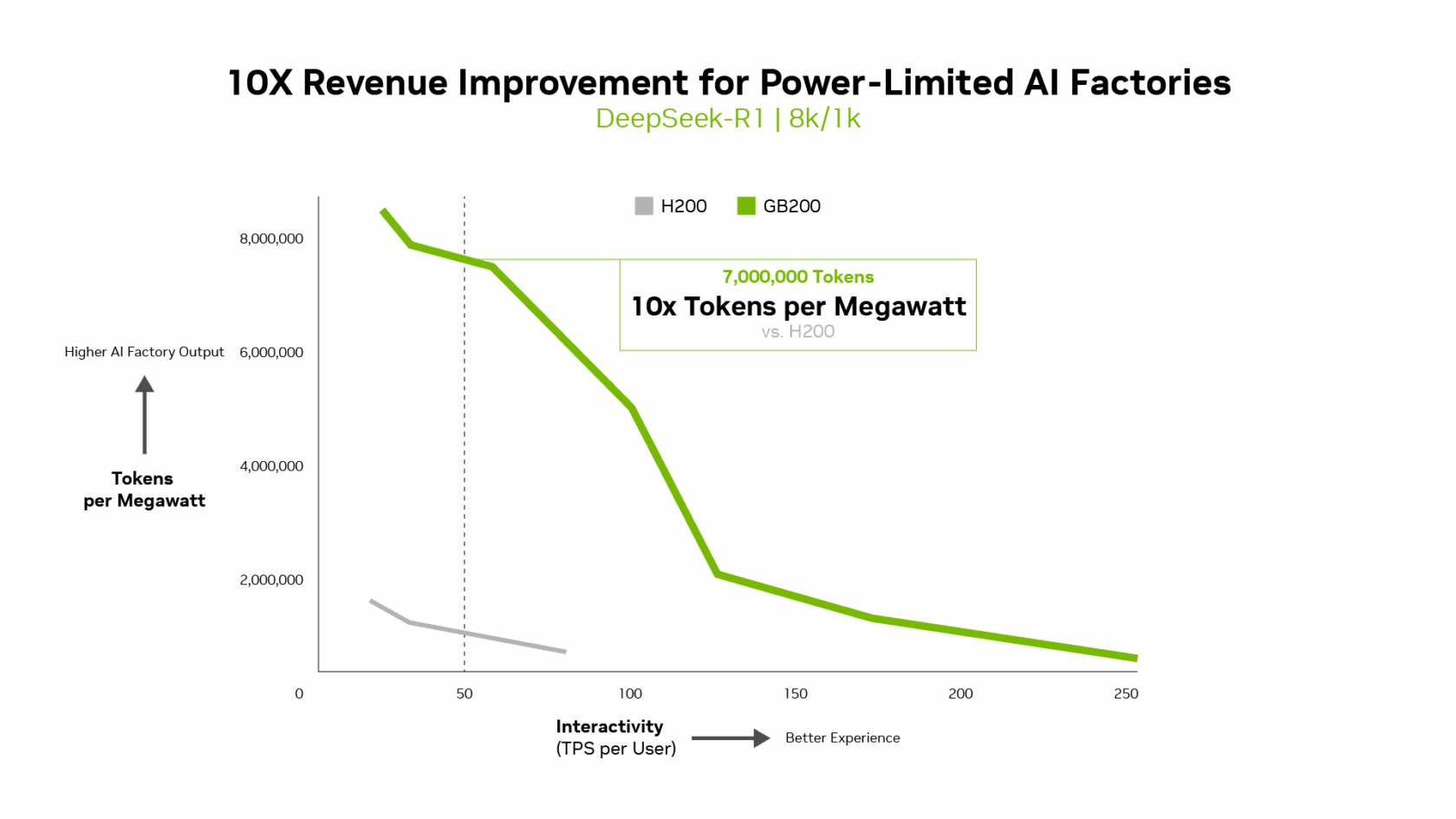 В InferenceMAX используется метод оценки эффективности Pareto front, определяющий наилучшее (компромиссное) сочетание различных факторов для оценки производительности ускорителя. Это показывает, насколько Blackwell лучше конкурентов справляется с балансом стоимости, энергоэффективности, пропускной способности и скорости отклика. Системы, оптимизированные только для одной метрики, могут демонстрировать пиковую производительность «в вакууме», но такая «экономика» не масштабируется в производственных средах. 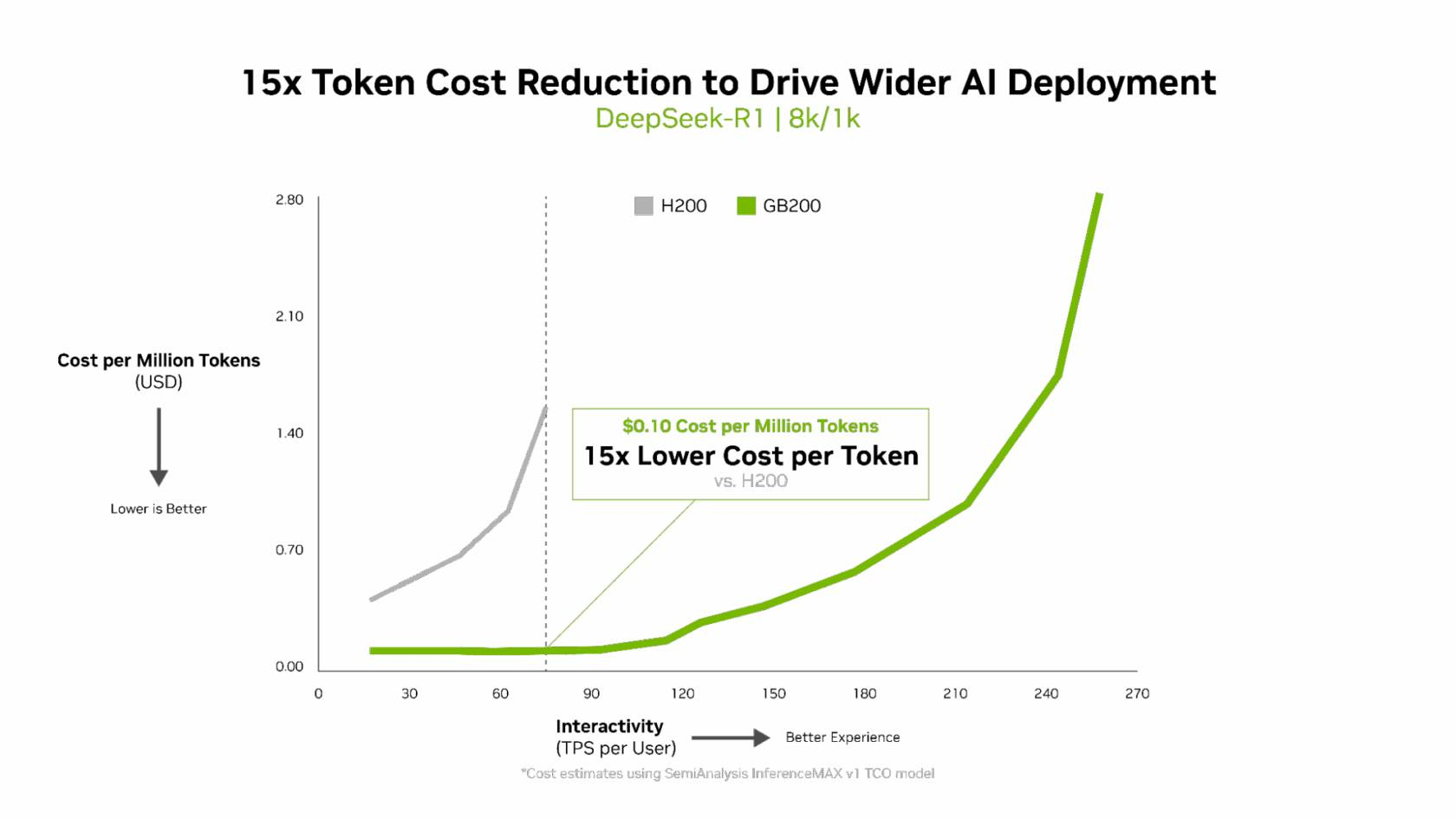 Компания отметила, что ИИ переходит от экспериментальных пилотных проектов к ИИ-фабрикам — инфраструктуре, которая производит интеллектуальные решения, преобразуя данные в токены и решения в режиме реального времени. Фреймворк NVIDIA Think SMART помогает предприятиям ориентироваться в этом переходе, демонстрируя, как полнофункциональная платформа инференса обеспечивает измеримую окупаемость инвестиций. Обещая 15-кратную окупаемость инвестиций и непрерывный рост производительности за счёт ПО, NVIDIA не просто лидирует в текущей гонке ИИ-технологий, но и задаёт правила для следующего этапа, где экономика будет определять победителей рынка, пишет The Tech Buzz. Для предприятий, делающих ставку на конкурирующие платформы в своих стратегиях по развёртыванию ИИ, результаты таких бенчмарков должны побудить к пересмотру выбора ИИ-инфраструктуры.
06.10.2025 [14:00], Сергей Карасёв
HP представила компактный «ИИ-суперкомпьютер» ZGX Nano G1n AI Station на основе NVIDIA GB10Компания HP анонсировала рабочую станцию ZGX Nano G1n AI Station небольшого форм-фактора, предназначенную для работы с ИИ, включая «тонкую» настройку языковых моделей, инференс и агентные приложения. Основой новинки служит суперчип NVIDIA GB10 Grace Blackwell. В целом решение практически не отличается от систем на базе GB10 других вендоров. Устройство заключено в корпус с габаритами 150 × 150 × 51 мм, а масса составляет 1,25 кг. В состав чипа GB10 входят 20-ядерный процессор Grace (10 × Arm Cortex-X925 и 10 × Arm Cortex-A725) и ускоритель Blackwell. Имеется 128 Гбайт унифицированной системной памяти LPDDR5x, пропускная способность которой достигает 273 Гбайт/с. Компьютер может быть оборудован SSD типоразмера M.2 вместимостью 1 или 4 Тбайт (NVMe OPAL). В оснащение входят сетевой контроллер 10GbE (Realtek RTL8127), адаптер NVIDIA ConnectX-7 200GbE, беспроводной модуль MediaTek MT7925 с поддержкой Wi-Fi 7 (2×2) / Bluetooth 5.4. В тыльной части корпуса располагаются разъём USB Type-C для подачи питания, три порта USB Type-C (20 Гбит/с), гнездо RJ45 (10GbE), два порта QSFP и интерфейс HDMI 2.1a. 
Источник изображения: HP На устройстве применяется программная платформа NVIDIA DGX OS на базе Ubuntu, оптимизированная специально для задач ИИ. Заявленная производительность достигает 1000 TOPS на операциях FP4. Возможна работа с ИИ-моделями, насчитывающими до 200 млрд параметров. Кроме того, два экземпляра ZGX Nano G1n AI Station могут быть объединены в одну систему, что позволит использовать ИИ-модели, оперирующие 405 млрд параметров. Продажи компактного ИИ-суперкомпьютера начнутся текущей осенью.
03.10.2025 [13:05], Сергей Карасёв
РСК и HTS предложат передовые СЖО для дата-центровРоссийская компания «РСК Технологии» (группа РСК) и дистрибьютор оборудования для прецизионного кондиционирования воздуха и холодоснабжения HTS в ходе саммита Ассоциации участников отрасли ЦОД в Нижнем Новгороде объявили о заключении стратегического соглашения о сотрудничестве. В рамках партнёрства HTS займётся поставками и комплексным сопровождением модулей охлаждения (CDU) РСК на территории России и стран СНГ. Речь идёт о решениях следующего поколения, которые, как утверждается, смогут превзойти существующие иностранные аналоги по энергоэффективности, гибкости и масштабируемости. В частности, РСК предложит изделия, поддерживающие прямое жидкостное охлаждение горячей водой. Применение таких систем позволит достигать высоких показателей эффективности использования электроэнергии (PUE). Продукты РСК ориентированы на инфраструктуры ЦОД нового уровня, рассчитанные на решение задач ИИ, НРС и периферийные вычисления. 
Источник изображения: РСК Клиентам будут предлагаться CDU мощностью от десятков кВт до нескольких МВт. Модули РСК объединяют внутренний и внешний контуры, что значительно упрощает и ускоряет развёртывание в существующих дата-центрах. Особенностью решений РСК названо применение уникальных алгоритмов управления, которые позволяют системам охлаждения динамически подстраиваться под текущую нагрузку. Подчёркивается, что партнёрство с HTS гарантирует заказчикам полный комплекс услуг по проектированию, внедрению и сервисному сопровождению систем на территории России и СНГ. «Вместо простой замены иностранного оборудования мы предлагаем клиентам качественный скачок: решения, которые не только соответствуют, но и превосходят зарубежные аналоги по интеллектуальному управлению, адаптивности к нагрузке и общей стоимости владения», — говорит HTS.
02.10.2025 [10:56], Сергей Карасёв
РСК представила внешний JBOG-массив RSC ScaleStream-CГруппа компаний РСК представила на международной конференции «Суперкомпьютерные дни в России», прошедшей в МГУ имени Ломоносова, внешний массив PCIe-коммутации RSC ScaleStream-C (JBOG). Это решение предназначено для установки ускорителей GPU/TPU с целью повышения производительности серверов при работе с различными ресурсоёмкими приложениями, включая задачи ИИ и НРС. Решение RSC ScaleStream-C выполнено в форм-факторе 3U. Допускается установка до десяти карт с интерфейсом PCIe x16 (до 600 Вт), связанных интерконнектом NVLink. При использовании ускорителей на базе GPU применяется гибридное охлаждение, при работе с TPU — воздушное. Питание обеспечивают четыре блока мощностью 2200 Вт каждый. Массив может монтироваться в стандартную 19″ серверную стойку. Задействованы средства управления и мониторинга на базе Redfish, RESTful API, GUI разработки РСК. К системе RSC ScaleStream-C могут быть подсоединены до четырёх серверов посредством внешних кабелей на базе стандарта PCIe 4.0 x16. Ресурсы GPU/TPU могут динамически перераспределяться между подключенными серверами, что, как утверждается, обеспечивает уникальные возможности по созданию оптимальных конфигураций под конкретную нагрузку. Благодаря этому достигается наиболее эффективное использование вычислительных мощностей ИИ-ускорителей, используемых в составе массива. РСК заявляет, что утилизация GPU в некоторых случаях повышается на десятки процентов по сравнению с применением ускорителей в составе традиционных серверных платформах. 
Источник изображения: РСК В целом, RSC ScaleStream-C обеспечивает производительность до 300 ТФлопс (FP64) на массив в случае применения десяти ускорителей NVIDIA H200. При установке карт LinQ HPQ, разработанных российской компании «ХайТэк», быстродействие достигает 960 TOPS на операциях INT8. Среди ключевых сфер применения новинки названы: машинное обучение и ИИ (инференс и работа с большими языковыми моделями), НРС-нагрузки (научные исследования и моделирование), анализ больших данных, виртуализация, криптография и блокчейн (майнинг криптовалют и задачи распределенных реестров).
01.10.2025 [10:46], Сергей Карасёв
Компактный ИИ-компьютер Orange Pi AI Studio оснащён ускорителем Huawei Ascend 310Команда Orange Pi анонсировала компьютер небольшого форм-фактора AI Studio, разработанный для ИИ-приложений. Устройство несёт на борту ускоритель Huawei Ascend 310, а заявленная ИИ-производительность достигает 176 TOPS (по всей видимости, на операциях INT8). Новинка заключена в корпус с габаритами 132,6 × 110,9 × 39 мм. Объём оперативной памяти LPDDR4X-4266 может составлять 48 или 96 Гбайт. Кроме того, предусмотрено 32 Мбайт памяти SPI Flash. Питание подаётся через DC-гнездо (5,5/2,5 мм) от адаптера мощностью 120 Вт. 
Источник изображений: Orange Pi Кроме того, дебютировала модификация компьютера под названием Orange Pi AI Studio Pro. Она фактически представляет собой связку из двух базовых версий устройства. Таким образом, задействованы два ускорителя Huawei Ascend 310, благодаря чему обеспечивается ИИ-быстродействие до 352 TOPS. Объём памяти LPDDR4X-4266 — 96 или 192 Гбайт. Присутствуют два модуля SPI Flash на 32 Мбайт каждый. Мощность блока питания увеличена до 240 Вт. Размеры этого компьютера составляют 207,7 × 132,6 × 40 мм.  Набор разъёмов у обоих устройств сведён к минимуму: доступен лишь единственный порт USB 4.0 Type-C. Говорится о совместимости с Ubuntu 22.04.5 и Linux 5.15.0.126, а в перспективе планируется добавить поддержку Windows и OpenEuler. Модель Orange Pi AI Studio предлагается по цене $955 и $1100 за варианты с 48 и 96 Гбайт памяти соответственно. Версия Orange Pi AI Studio Pro обойдётся в $1909 в комплектации с 96 Гбайт ОЗУ и в $2200 в исполнении со 192 Гбайт памяти.
27.09.2025 [16:18], Сергей Карасёв
Чип с «сосудами»: Microsoft и Corintis вытравили микроканалы для СЖО прямо в кремнииВедущие разработчики ИИ-ускорителей продолжают наращивать мощность своих устройств, что требует применения передовых систем охлаждения. Речь идёт прежде всего о системах прямого жидкостного охлаждения, способных отводить тепло непосредственно от поверхности чипов. Корпорация Microsoft сообщила о разработке совместно со швейцарским стартапом Corintis альтернативной СЖО, которая охлаждает процессоры изнутри. Новая технология базируется на принципах микрогидродинамики (microfluidic). Подход основан на формировании крошечных каналов на обратной стороне кремниевого кристалла: циркулируя через эти канавки, жидкость эффективно отводит тепло от наиболее горячих зон чипа. Для оптимизации расположения каналов, которые по толщине сопоставимы с человеческим волосом, использовался ИИ. Полученный рисунок вытравленных канавок напоминает прожилки на листе дерева или крыло бабочки. 
Источник изображения: Dan DeLong / Microsoft При разработке системы нужно было убедиться, что каналы обеспечивают возможность циркуляции необходимого объема охлаждающей жидкости без засорения, но при этом не ухудшают прочность кристалла из-за своих размеров и расположения. Только за последний год команда Microsoft опробовала четыре разных варианта конструкции. 
Источник изображения: Dan DeLong / Microsoft Для практического использования такой СЖО потребовалась разработка герметичного корпуса для чипов. Кроме того, были опробованы различные методы травления каналов: специалистам пришлось создать пошаговую схему добавления этапа травления в стандартный процесс производства чипов. Наконец, была разработана специальная формула охлаждающей жидкости. 
Источник изображения: Corintis По заявлениям Microsoft, предложенная технология по сравнению с традиционными водоблоками способна повысить эффективность отвода тепла до трёх раз — в зависимости от нагрузки и конфигурации. При этом максимальный рост температуры кремния внутри GPU снижается на 65 %, хотя этот показатель варьируется в зависимости от типа чипа. Плюс к этому повышается энергоэффективность. 
Источник изображения: Corintis В дальнейшем Microsoft намерена изучить возможность внедрения технологии охлаждения нового типа в будущие поколения собственных изделий для дата-центров. Корпорация также сотрудничает с производителями и партнёрами по вопросу использования предложенного решения. Предполагается, что в дальнейшем результаты работы откроют путь к совершенно новым архитектурам микросхем, основанным на 3D-компоновке: в этом случае охлаждающая жидкость сможет протекать через слои в многоярусных чипах. Между тем стартап Corintis, основанный на базе Федеральной политехнической школы Лозанны (EPFL), провёл раунд финансирования Series A, в ходе которого на развитие привлечено $24 млн. Инвестиционную программу возглавил BlueYard Capital при участии Founderful, Acequia Capital, Celsius Industries и XTX Ventures. Таким образом, на сегодняшний день компания получила в общей сложности $33,4 млн. Corintis направит средства на расширение деятельности и дальнейшее развитие новой технологии охлаждения чипов. Будут открыты несколько офисов в США и инженерный центр в Мюнхене.
26.09.2025 [08:59], Сергей Карасёв
Индустриальный компьютер Biostar EdgeComp MU-N150 на базе Intel Twin Lake выполнен в корпусе объёмом 0,6 лКомпания Biostar анонсировала компьютер небольшого форм-фактора EdgeComp MU-N150, ориентированный на использование в коммерческой и индустриальной сферах. Устройство может применяться в системах автоматизации и периферийных вычислений, в различных терминалах и пр. Аппаратной основой служит платформа Intel Twin Lake. Новинка заключена в корпус объёмом примерно 0,6 л с габаритами 117,8 × 114,7 × 49 мм. Устройство весит около 0,75 кг. Установлен чип Intel Processor N150 (четыре ядра; до 3,6 ГГц; 6 Вт) с графическим ускорителем Intel UHD Graphics. Компьютер довольствуется пассивным охлаждением, а ребристая верхняя панель улучшает рассеяние тепла. Диапазон рабочих температур — от 0 до +50 °C. 
Источник изображений: Biostar Поддерживается до 16 Гбайт ОЗУ DDR5-4800 в виде одного модуля SO-DIMM. Есть коннектор M.2 Key M 2242/2280 для SSD с интерфейсом PCIe 3.0 x4 (NVMe) и разъём M.2 Key E 2230 (PCIe 3.0 x1 + USB 2.0) для адаптера Wi-Fi/Bluetooth. На базе контроллера Intel I226V реализованы два сетевых порта 2.5GbE. В оснащение также входит звуковой кодек ALC897.  Во фронтальной части расположены два порта USB 3.2, разъём USB Type-C (DP), последовательный порт (RS232) и 3,5-мм аудиогнездо. Сзади находятся два порта USB 2.0, интерфейсы HDMI 2.0 и DP++1.4 с поддержкой видео с разрешением до 4096 × 2160 пикселей (60 Гц), два гнезда RJ45 для сетевых кабелей и DC-разъём для подачи питание (в комплект поставки входит адаптер мощностью 60 Вт). Возможен вывод изображения одновременно на три дисплея. Заявлена совместимость с Windows 10/11 и Ubuntu.
23.09.2025 [16:21], Сергей Карасёв
РСК и «ХайТэк» представили ПАК с российскими ИИ-ускорителями LinQ HPQГруппа компаний РСК и российский разработчик ИИ-ускорителей «ХайТэк» представили отечественный программно-аппаратный комплекс LinQ HPC для ресурсоёмких ИИ-нагрузок. Производительность этой системы достигает 1920 TOPS на операциях INT8. В основу решения положены два узла LinQ HPS, в состав которых входят десять PCIe-ускорителей LinQ HPQ, разработанных компанией «ХайТэк». В свою очередь, каждый ускоритель несёт на борту четыре фирменных тензорных процессора LinQ H с тактовой частотой 500–812 МГц и памятью DDR4 ECC. По заявлениям «ХайТэк», ИИ-производительность одного чипа LinQ H составляет до 24 TOPS. Таким образом, у карт LinQ HPQ это значение достигает 96 TOPS, а у одного узла LinQ HPS — 960 TOPS. При соединении двух узлов обеспечивается показатель в 1920 TOPS. Задействованы внешний массив PCIe-коммутации RSC ScaleStream-C разработки группы компаний РСК и сервер, входящий в реестр Минпромторга РФ. 
Источник изображений: РСК Система LinQ HPC оперирует в общей сложности 1280 Гбайт многоканальной памяти DDR4 ECC, что позволяет обрабатывать большие объёмы данных и одновременно запускать более 100 моделей. При этом задержка составляет 2,3 мс для ResNet-50 с возможностью снижения до 1,5 мс при оптимизации. Говорится о поддержке TensorFlow 2.x и PyTorch. Заявленное энергопотребление находится на уровне 3000 Вт. Это достигается благодаря интеллектуальному управлению частотами чипов и адаптивному контролю посредством специализированного ПО. Встроенные алгоритмы температурного мониторинга и динамического управления рабочей частотой автоматически оптимизируют параметры, обеспечивая стабильное функционирование комплекса при различных нагрузках. В результате, достигается снижение операционных расходов на электроэнергию и охлаждение.  Ключевым преимуществом LinQ HPC, как отмечают разработчики, является отказ от зарубежных решений, которые могут содержать скрытые уязвимости. В составе платформы не применяется стороняя интеллектуальная собственность. LinQ HPC подходит для решения различных задач, связанных с ИИ. Среди них названы предиктивное обслуживание оборудования, оптимизация энергопотребления, автоматизированный контроль качества производственных процессов, обнаружение мошенничества при финансовых операциях, а также интеллектуальная видеоаналитика в реальном времени, включая распознавание лиц, поведенческий анализ и контроль критически важных объектов. Система также может использоваться для ИИ-инференса и создания рекомендательных сервисов.
21.09.2025 [13:40], Сергей Карасёв
Schneider Electric готовит стойки NVIDIA GB300 NVL72 мощностью 142 кВтКомпания Schneider Electric анонсировала две эталонные платформы, призванные ускорить построение инфраструктур для дата-центров, ориентированных на ресурсоёмкие нагрузки ИИ и НРС. Разработка систем ведётся в партнёрстве с NVIDIA. Один из проектов предусматривает создание референсных стоек для суперускорителей NVIDIA GB300 NVL72. Такие стойки смогут обеспечивать мощность до 142 кВт. Предусмотрено использование жидкостного охлаждения. В одном машинном зале могут быть расположены три кластера GB300 NVL72, насчитывающих в общей сложности до 1152 ускорителей. Отмечается, что в основу решения положены наработки и опыт, полученные в ходе реализации аналогичного проекта для NVIDIA GB200 NVL72. Клиентам будет доступна специальная среда моделирования на базе вычислительной гидродинамики (CFD): могут применяться цифровые двойники для оценки различных конфигураций электропитания и охлаждения с целью оптимизации платформ под определённые нужды. 
Источник изображения: Schneider Electric Второй эталонный проект, как утверждается, представляет собой первую и единственную в отрасли платформу, предполагающую интеграцию систем управления питанием и жидкостным охлаждением, включая решения Motivair (контрольный пакет акций этой фирмы Schneider Electric приобрела в конце 2024 года). Для новой платформы заявлена совместимость с NVIDIA Mission Control — программным обеспечением NVIDIA для контроля производственных процессов и оркестрации работы ИИ-систем, включая управление кластерами и рабочими нагрузками. В таких системах могут применяться суперускорители GB300 NVL72 и GB200 NVL72. Подчёркивается, что новые эталонные решения являются результатом продолжающегося сотрудничества Schneider Electric и NVIDIA, которое направлено на удовлетворение растущих потребностей операторов дата-центров в области ИИ.
19.09.2025 [16:00], Руслан Авдеев
Больше половины британских банков использует ПО, написанное более 60 лет назадБританские банки до сих пор используют программное обеспечение, написанное в 60–70-е годы XX века, причём разобраться в коде могут очень немногие. Согласно исследованию, проведённому в 200 банках Соединённого Королевства, 16 % полагаются на ПО из 1960-х, а почти 40 % — на ПО из 1970-х, сообщает Computer Weekly. Опрос консалтинговой компании Baringa проводился среди топ-менеджеров, специализирующихся на технологиях. 50 % банков признали, что полагаются на ПО, которое понимают лишь один-два сотрудника предпенсионного возраста. Ещё у 31,5 % тоже есть один-два человека, но несколько помоложе. В 38 банках признали, что до сих пор работают с кодом, разрабатывавшимся для перфокарт, а в 15 % случаев код написан для мэйнфреймов размером с комнату. По словам экспертов Baringa, такая ситуация неизбежна в сложных технологических системах. Банки — сложные организации, обслуживающие миллионы клиентов, поэтому невозможно требовать, чтобы они создавали свою информационную инфраструктуру с нуля каждый раз после появления инноваций. 
Источник изображения: Nick Pampoukidis/unsplash.com Тем не менее, вряд ли ситуацию можно считать нормальной. По словам одного из респондентов, одна из сетей банкоматов всё ещё использует Windows NT из 1993 года с множеством патчей. Ещё один заявил, что основы ключевых банковских систем были созданы в 1970-х годах и всё ещё требуют COBOL-разработчиков. По словам одного из топ-менеджеров, немало старых решений продержались столь долго из-за своей простоты и надёжности. Банки постепенно уходят от таких систем, поскольку уходят и люди, их понимающие, а молодые профессионалы не желают учить языки вроде Cobol. В агентстве считают, что использование старого ПО является источником двух угроз для банков. Во-первых, код написан для давно не поддерживаемых систем, с которыми способны справляться лишь некоторые старые эксперты — это серьёзный риск для критической инфраструктуры. Во-вторых, старые технологии редко отличаются гибкостью. Их будет чрезвычайно трудно адаптировать под меняющиеся запросы заказчиков. Адаптация обходится непропорционально дорого, и со временем стоимость только растёт. Впрочем, не всегда новое лучше старого. Не так давно крупнейший в Европе муниципалитет — Бирмингем оказался на грани банкротства после неудачной попытки внедрить вместо ERP-системы SAP решение Oracle. Проблема до сих пор не решена полностью. |
|

