Материалы по тегу: ии
|
15.08.2024 [14:57], Руслан Авдеев
Выходцы из Google DeepMind запустили ИИ-облако FoundryНа рынке ИИ-облаков появился очередной провайдер. The Register сообщает, что стартап Foundry Cloud Platform (FCP) объявил о доступности своей платформы, но пока только для избранных. Компания основана в 2022 году бывшим экспертом Google DeepMind Джаредом Куинси Дэвисом (Jared Quincy Davis) и ей придётся конкурировать с Lambda Labs и CoreWeave, которые уже получили миллиарды инвестиций. Стартап намерен сделать клиентам более интересное предложение, чем просто аренда ИИ-ускорителей в облаке. Так, клиент, зарезервировавший 1000 ускорителей на X часов, получит именно столько ресурсов, сколько заказал. Задача на самом деле не очень простая, поскольку временные отказы вычислительного оборудования возникают довольно часто, а время простоя всё равно оплачивается. В Foudry намерены решить проблему, поддерживая в готовности пул зарезервированных узлов на случай возникновения сбоев основного оборудования. 
Источник изображения: Foundry Cloud Platform При этом резервные мощности будут использоваться даже во время «дежурства» для выполнения более мелких задач, соответствующие ресурсы будут предлагаться клиентам по ценам в 12–20 раз ниже рыночных. При этом пользователь таких spot-инстансов должен быть готов к тому, что их в любой момент могут отобрать. При этом состояние текущей нагрузки будет сохранено, чтобы её можно было перезапустить. А если прямо сейчас мощный инстанс не нужен, то его можно «перепродать» другим пользователям. Также можно задать порог стоимости покупаемых ресурсов, чтобы воспользоваться ими, когда цена на них упадёт ниже заданной. Foundry вообще делает упор именно на гибкость и доступность вычислений, ведь далеко не всем задачам нужны самый быстрые ускорители или самый быстрый отклик. Компания умышленно дистанцируется от традиционных контрактов сроком на год и более. Уже сейчас минимальный срок разовой аренды составляет всего три часа, что для индустрии совершенно нетипично. 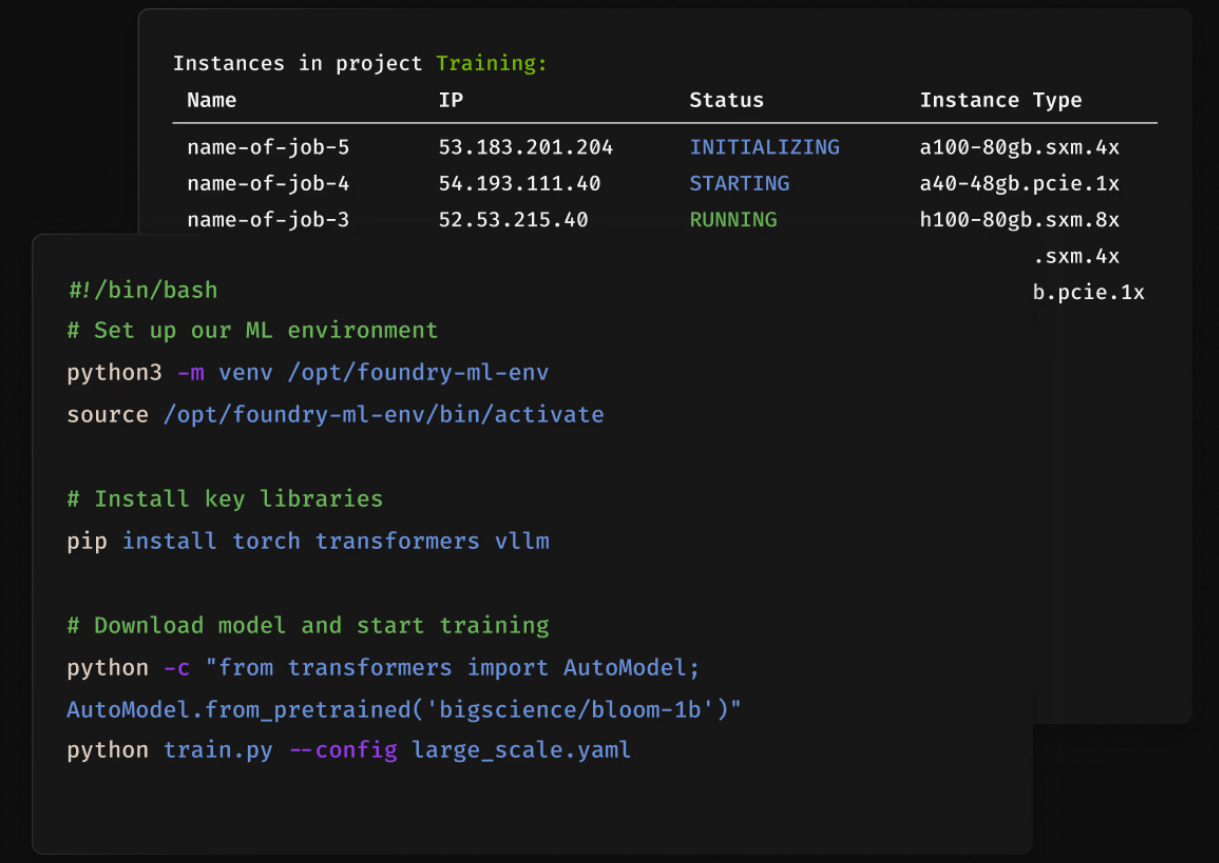
Источник изображения: Foundry Cloud Platform Foundry предлагает ускорители NVIDIA H100, A100, A40 и A5000 с 3,2-Тбит/с InfiniBand-фабрикой, размещённые в ЦОД уровня Tier III/IV. Облако соответствует уровню защиты SOC2 Type II и предлагает HIPAA-совместимые опции. При этом пока не ясны объёмы кластеров, предлагаемых Foundry. Возможно, именно поэтому компания сейчас очень тщательно отбирает клиентов. Другими словами, стартапу ещё рано тягаться с CoreWeave или Lambda, даже при наличии передовых и нестандартных технических решений. Преимуществом для таких «новых облаков» стала относительная простота получения необходимого финансирования для создания больших кластеров ИИ-ускорителей. Помимо привлечения средств в ходе традиционных раундов инвестирования, компании стали занимать новые средства под залог самих ускорителей. В своё время CoreWeave удалось таким способом получить $7,5 млрд. Пока многие компании ещё не выяснили, как оценить финансовую отдачу от внедрения ИИ. Тем не менее, поставщики инфраструктуры этот вопрос, похоже, уже решили. Ранее портал The Next Platform подсчитал, что кластер из 16 тыс. H100 обойдётся примерно в $1,5 млрд и принесёт $5,27 млрд в течение четырёх лет, если ИИ-бум не пойдёт на спад.
15.08.2024 [12:19], Руслан Авдеев
Исландский проект IceCloud представил частное облако под ключ с питанием от ГеоТЭС и ГЭСКонсорциум компаний запустил пилотный проект облачного сервиса IceCloud на базе исландского ЦОД с необычными возможностями. The Register сообщает, что дата-центр будет полностью снабжаться возобновляемой энергией для того, чтобы его клиенты смогли достичь своих экологических, социальных и управленческих обязательств (ESG). Проект IceCloud Integrated Services представляет собой частное облако с широкими возможностями настройки для того, чтобы предложить клиентам экономичную масштабируемую платформу, в том числе для ИИ и прочих ресурсоёмких задачах. В консорциум на равных правах входят британский поставщик ЦОД-инфраструктур Vesper Technologies (Vespertec), разработчик облачного ПО Sardina Systems и оператор Borealis Datacenter из Исландии. Vespertec занимается созданием кастомных серверов, хранилищ и сетевых решений, в том числе стандарта OCP. Sardina отвечает за облачную платформу Fish OS. Это дистрибутив OpenStack для частных облачных сервисов, интегрированный с Kubernetes и сервисом хранения данных Ceph. Предполагается, что облачная платформа не будет имитировать AWS и Azure. Решение ориентировано на корпоративных клиентов с задачами, требующими высокой производительности, малого времени отклика и высокого уровня доступности. 
Источник изображения: Robert Lukeman/unsplash.com Таких предложений на рынке уже немало, но IceCloud на базе ЦОД Borealis Datacenter позволит клиентам использовать исключительно возобновляемую энергию и экономить на охлаждении благодаря прохладному местному климату. Выполнение компаниями-клиентами ESG-обязательств, а также снижение на 50 % энергопотребления вне периодов часов пиковых нагрузок и снижение потребления на 38 % в целом ведёт к существенному снижению стоимости эксплуатации облака, говорят авторы проекта. 
Источник изображения: Vespertec До заключения контракта на обслуживание в облаке IceCloud с клиентом ведутся переговоры для выяснения его потребностей в программном и аппаратном обеспечении и пр. После этого клиенту делается индивидуальное пакетное предложение. Перед окончательным принятием решения клиент может протестировать сервис и, если его всё устраивает, он получит персонального менеджера. Эксперты подтверждают, что размещение ЦОД на севере имеет три ключевых преимущества. Низкие температуры окружающей среды позволяют экономить на охлаждении, обеспечивая низкий индекс PUE. Сам регион богат возобновляемой энергией и, наконец, в Исландии не так тесно в сравнении с популярными европейскими локациями ЦОД во Франкфурте, Лондоне, Амстердаме, Париже и Дублине.
14.08.2024 [17:13], Владимир Мироненко
Google предупредила об отключении облачного сервиса BigQuery в России 9 сентябряПользователи облачного сервиса BigQuery в России получили уведомление Google о предстоящем прекращении его работы в стране с 9 сентября, сообщил Telegram-канал ГК Softline (ПАО «Софтлайн»). Отмечается, что отключение коснётся только BigQuery, в то время как Google Workspace (включает электронную почту, сервисы Docs, Sheets, Slides, Drive и т.д.) и другие сервисы Google Cloud пока продолжат работу и дальше. BigQuery — полностью управляемая платформа для хранения и анализа больших массивов данных с поддержкой ИИ, рассчитанная на многодвижковую, многоформатную и мультиоблачную среду. Её запустили около 10 лет назад. Сейчас пользователи имеют возможность создания и запуска моделей ML для своих данных в BigQuery. Также можно использовать новейшие модели Gemini, чтобы извлекать информацию из всех типов данных и выполнять с помощью генеративного ИИ такие задачи как резюмирование текста, генерация текста, векторный поиск и т.д. 
Источник изображения: Google Весной 2024 года Microsoft также начала отключать российских корпоративных пользователей от ряда облачных продуктов. Аналогичные меры ожидались и от AWS, а также других крупных зарубежных облачных провайдеров. Позавчера Google также объявила о закрытии платформы AdSense для пользователей из РФ.
13.08.2024 [20:33], Владимир Мироненко
Huawei готовит к выпуску ИИ-ускоритель Ascend 910C, конкурента NVIDIA H100Huawei Technologies вскоре представит новый ИИ-ускоритель Ascend 910C, сопоставимый по производительности с NVIDIA H100, сообщила газета The Wall Street Journal со ссылкой на информированные источники. По их словам, китайские интернет-компании и операторы в последние недели тестировали этот чип и в настоящее время ByteDance (материнская компания TikTok), поисковик Baidu и государственный оператор связи China Mobile ведут переговоры по поводу его поставок. Судя по озвученным цифрам, заказы могут превысить 70 тыс. шт. на общую сумму около $2 млрд. Huawei намерена начать поставки уже в октябре, сообщили источники, но компания не стала комментировать эти сообщения. Huawei была включена в «чёрный» список Entity List Министерства торговли США в 2019 году, что лишило её возможности производить закупки передовых чипов и оборудования для их выпуска, а также размещать заказы на производство микросхем за пределами Поднебесной. Однако благодаря многомиллиардной государственной поддержке компания стала национальным лидером во многих областях, включая ИИ, и ключевой частью усилий Пекина по «удалению» американских технологий, отметила WSJ. При этом Китай наращивает поддержку отечественного производства полупроводников и в мае выделил $48 млрд в рамках третьего транша национального инвестиционного фонда для этой отрасли. 
Источник изображения: huaweicentral.com Из-за санкций США китайским клиентам NVIDIA приходится довольствоваться ИИ-ускорителем H20, разработанным специально для Китая с учётом экспортных ограничений Министерства торговли США, в то время как американские клиенты NVIDIA, такие, как OpenAI, Amazon и Google, вскоре получат доступ к гораздо более производительным чипам, включая GB200. NVIDIA также готовит для Китая чип B20, хотя есть опасения, что и он может попасть под новые ограничения США. По оценкам аналитиков SemiAnalysis, 910C может быть даже лучше, чем B20, и если Huawei сможет наладить выпуск нового чипа, а NVIDIA по-прежнему не сможет продавать китайским клиентам передовые ускорители, то у последней все шансы быстро потерять долю рынка в стране. Согласно подсчётам SemiAnalysis, в 2025 году Huawei может произвести 1,3–1,4 млн ускорителей 910C, если не столкнётся с дополнительными ограничениями США. Аналитики ожидают, что NVIDIA продаст более 1 млн H20 в Китае в этом году на сумму около $12 млрд, т.е. в штучном выражении примерно вдове больше, чем Huawei 910B. По словам источников, в последние недели Huawei начала накапливать запасы HBM-чипов, используемых в ИИ-ускорителях, в связи с опасениями ввода США новых экспортных ограничений. На прошедшей в июне конференции, посвящённой полупроводниковой промышленности, представитель руководства Huawei сообщил, что почти половина больших языковых моделей (LLM), созданных в Китае, была обучена с помощью ускорителей компании. Он также отметил, что в этих задачах 910B превосходит по производительности NVIDIA A100.
13.08.2024 [13:33], Руслан Авдеев
SK Telecom и Nokia с помощью ИИ превратят коммерческие оптоволоконные сети в гигантские сенсорыSK Telecom (SKT) и Nokia договорились о разработке «чувствительных» оптоволоконных сетей. Технология будет использовать ИИ для мониторинга окружающей среды вокруг кабелей. На первом этапе компании намерены собрать с использованием машинного обучения данные с коммерческой сети SKT. Систему планируется использовать для распознавания землетрясений, климатических изменений и прочих ситуаций, например, инцидентов на близлежащих стройках. К концу года планируется внедрение технологии на территории всей Южной Кореи. Прохождение сигнала по оптоволокну может меняться под влиянием различных факторов, включая перепады температуры, вибрации и т.д. На основе технологии, предусматривающей применение ИИ, SKT и Nokia намерены добиться более стабильной работы оптоволоконных сетей, изучая воздействие погодных условий и даже близлежащих строительных объектов на кабели. При этом никакой модификации самих кабелей не требуется, так что систему мониторинга можно быстро развернуть на существующей инфраструктуре. 
Источник изображения: ulleo/pixabay.com Идея использования ВОЛС в качестве сенсоров далеко не нова. Такие системы нередко используются в охранных целях, правда, в этом случае речи о передачи данных обычно не идёт. Но операторы пытаются найти новые применения своим сетям. В ноябре появилась новость об использовании кабелей в Японии для оценки снежного покрова, Güralp проложила в водах близ Италии кабель SMART для мониторинга сейсмической активности, а SMART-кабель TAM TAM между Новой Каледонией и Вануату предупредит о землетрясениях и цунами.
10.08.2024 [23:28], Руслан Авдеев
ЦОД с газопроводом: энергокомпании США обсуждают с операторами дата-центров поставки голубого топливаАмериканские энергокомпании US Energy Transfer и Williams Cos. обсуждают с операторами дата-центров возможность строительства трубопроводов для поставки газа непосредственно на территорию кампусов для питания электростанций. По данным Datacenter Dynamics, бум ИИ ведёт к росту спроса на энергию и многие видят в получении энергии на месте возможное решение проблемы. По словам представителя Energy Transfer, общавшегося с отраслевыми экспертами, компания обсуждает возможности с ЦОД разных масштабов. Многие из них весьма положительно относятся к самой идее генерировать электричество на месте. Сейчас компания расширяет уже существующие электростанции и изучает возможность подключения к газовым магистралям новых. Williams Cos. также отмечает рост спроса и, как сообщают в компании, пытаются найти решение в ответ на многочисленные запросы. В частности речь идёт о юго-восточной части США и центре атлантического побережья страны. В число регионов попал и штат Вирджиния, на территории которого расположено огромное количество ЦОД, уже страдающих от дефицита электроэнергии. 
Источник изображения: Quinten de Graaf/unsplash.com Местный поставщик электричества Dominion Energy в докладе за 2023 год сообщил, что принадлежащая ему распределяющая компания Virginia Power продавала 24 % всего поставляемого здесь электричества именно дата-центрам в минувшем году, в 2022 году рост составлял 21 %. Компания объявила, что потребление индивидуальных объектов выросло с приблизительно 30 МВт до 60–90 МВт, а аппетиты кампусов могут составлять от 300 МВт до нескольких гигаватт. В январе 2024 года PJM Interconnection отметила, что ожидает роста энергопотребления в зонах своей ответственности почти на 40 % в следующие 15 лет, одним из ключевых драйверов роста должны стать дата-центры. С увеличением ограничений для сетей электропередач выработка энергии на месте может стать единственным средством получения одобрения на строительство новых ЦОД. Нечто подобное уже происходит и в Ирландии. В результате фактического моратория на строительство дата-центров в районе Дублин, некоторые ЦОД выразили намерение подключиться к газовым магистралям вместо попыток присоединения к энергосети. С тех пор Ирландия уже начала реализовывать политику частного энергоснабжения, позволяя компаниям строить собственную энерготранспортную инфраструктуру во избежание проблем с энергоснабжением в других сферах, использующих сети общего пользования.
10.08.2024 [22:58], Сергей Карасёв
CoreWeave активно нанимает топ-менеджеров Google, Oracle и AWS для развития ИИ ЦОДКомпания CoreWeave, предоставляющая облачные услуги для ИИ-задач, по сообщению Datacenter Dynamics, приняла на работу сразу нескольких топ-менеджеров, которые ранее занимали различные руководящие должности в Google, Oracle и AWS. Ожидается, что они помогут CoreWeave в развитии направления дата-центров. В частности, CoreWeave назначила старшим вице-президентом по проектированию Чена Голдберга (Chen Goldberg). До этого он в течение восьми лет работал в Google, в том числе в качестве генерального директора и вице-президента по развитию Kubernetes и направления бессерверных вычислений. Кроме того, в CoreWeave в качестве главного операционного директора пришёл Сачин Джайн (Sachin Jain). Ранее он трудился в Oracle, отвечая за инфраструктуру ИИ, снабжение ЦОД и управление группами IaaS в рамках облачной платформы Oracle Cloud Infrastructure (OCI). Кроме того, в течение примерно четырёх лет Джайн занимал пост вице-президента Google Cloud, руководя планированием мощностей и оптимизацией ресурсов. 
Источник изображения: CoreWeave В середине марта 2024 года CoreWeave назначила нового финансового директора: им стал Нитин Агравал (Nitin Agrawal), до этого занимавший должность вице-президента по финансам в Google Cloud. А позднее CoreWeave объявила о том, что на пост её продуктового директора назначен Четан Капур (Chetan Kapoor), ранее исполнявший обязанности директора по управлению продуктами в подразделении AWS EC2. CoreWeave активно развивает бизнес, в том числе в сфере дата-центров. В мае нынешнего года компания сообщила о намерении вложить £1 млрд в ИИ ЦОД в Великобритании. Ещё $2,2 млрд будет инвестировано в аналогичные проекты в материковой Европе. За последние два года CoreWeave привлекла приблизительно $12 млрд, в том числе в виде долгового финансирования. Средства направляются на развитие ЦОД и закупку необходимого оборудования.
10.08.2024 [12:01], Руслан Авдеев
Cisco второй раз за год уволит тысячи сотрудников и сосредоточится на ИИ и кибербезопасностиКомпания Cisco сократит тысячи сотрудников в ходе второго раунда увольнений. По данным Reuters, это связано с тем, что компания намерена сместить фокус внимания на области с высокими темпами роста, включая кибербезопасность и системы искусственного интеллекта (ИИ). Если в феврале Cisco уволила порядка 4 тыс. человек, то теперь, не исключено, под сокращение попадёт несколько больше. Вероятнее всего, компания объявит о непростых кадровых решениях уже в будущую среду в ходе очередного квартального отчёта. В своё время Reuters сообщила о февральских увольнениях ещё до того, как об этом объявила сама компания, поэтому её источники могут считаться довольно надёжными. При этом в июле 2023 года штат Cisco составлял 84,9 тыс человек. 
Источник изображения: Hunters Race/unsplash.com После сообщения Reuters об очередных сокращениях акции компании упали в цене приблизительно на 1 %, всего они подешевели за год более чем на 9 %. Сейчас компания страдает от малого спроса и проблем с цепочками поставок для своего основного бизнеса. Это заставляет её диверсифицировать бизнес — например, в марте закрыта сделка по покупке за $28 млрд компании Splunk, занимающейся обеспечением кибербезопасности. Покупка позволит снизить зависимость от «разовых» продаж, стимулируя бизнес, связанный с продажей технологических решений по подпискам. Кроме того, компания пытается интегрировать ИИ в свои продукты и в мае подтвердила намерение добиться в 2025 году продаж ИИ-решений на $1 млрд. В июне компания основала миллиардный фонд для инвестиций в ИИ-стартапы вроде Cohere, Mistral AI и Scale AI. На тот момент компания объявила, что за последние годы приобрела 20 связанных с ИИ компаний. Увольнения — последнее из событий такого рода в технологической индустрии, позволяющая сократить издержки в текущем году, чтобы компенсировать большие инвестиции в ИИ. Всего, по данным портала Layoffs.fyi, с начала года в 393 технокомпаниях уволили более 126 тыс. человек. Ранее в августе Dell объявила о сокращении более 10 % рабочей силы — около 12,5 тыс. человек, в основном из отделов продаж и маркетинга.
09.08.2024 [23:50], Владимир Мироненко
Купить, не покупая: IT-гиганты научились поглощать ИИ-стартапы, не привлекая внимания регуляторовСтартапы в сфере ИИ привлекли миллиарды долларов инвестиций в прошлом году в надежде, что вложения в скором времени окупятся. Однако этого не случилось и сейчас многим из них приходится бороться за выживание, обращаясь за помощью к крупным технологическим компаниям, пишет газета The Wall Street Journal. Так, стартап Character.AI объявил о сделке с Google по использованию его технологии, в рамках которой часть его персонала, а также соучредители Ноам Шазир (Noam Shazeer) и Даниэль Де Фрейтас (Daniel De Freitas) переходят в штат поискового гиганта. Также согласно условиям сделки Google выплатит стартапу лицензионный сбор в размере $2 млрд, что позволит рассчитаться с ранними инвесторами, сообщили люди, знакомые с этим вопросом. По словам источника WSJ, компании обсуждали возможность прямого приобретения, но пришли к выводу, что в этом случае без расследования регуляторов вряд ли обойдётся. 
Источник изображения: Diana Polekhina / Unsplash Новый тип сделки, который фактически является приобретением, хотя формально к таковым не относится, позволяет обойти типичный процесс регулирования в то время, когда регулирующие органы ужесточают контроль деятельности крупных технологических компаний по расширению влияния на рынке генеративного ИИ. Аналогичную сделку заключил в июне стартап Adept AI с компанией Amazon, взявшей на себя обязательство нанять большую часть сотрудников стартапа и заплатить около $330 млн за лицензирование технологии, сообщили информированные источники WSJ. Этого было достаточно, чтобы вместе с оставшимися у Adept AI средствами расплатиться с инвесторами. Хотя сам стартап, который в прошлом году оценивался в $1 млрд, рассчитывал на более блестящее будущее. Adept привлёк чуть более $400 млн инвестиций, но затраты на создание его технологии превзошли ожидания ее основателей, сообщил информатор WSJ. Этой весной стартап обратился к ряду компаний, включая Microsoft и Salesforce, а в итоге заключил сделку с Amazon. Сейчас в Adept осталось около 25 сотрудников, и теперь стартап будет заниматься использованием и продажей существующих технологий без разработки новых. Аналогичную сделку провернула в марте Microsoft, приняв на работу почти всех сотрудников разработчика ИИ Inflection, чтобы открыть новое подразделение потребительского ИИ, и заплатив около $650 млн за лицензирование технологий. Впрочем, эта сделка уже заинтересовала британского регулятора. 
Источник изображения: Sebastian Herrmann / Unsplash Инвесторы прогнозируют дальнейшие сделки по поглощению ИИ-стартапов, как реальные, так и фиктивные, поскольку сроки окупаемости ИИ-технологий оказались гораздо больше, чем они рассчитывали, и сейчас приходится думать о выживании. Спасение технологическим гигантом лучше, чем закрытие, но это далеко не нарушение статус-кво технологической отрасли, на которое делали ставку инвесторы, отметила WSJ. Вместо этого технологические гиганты ещё больше укрепили своё влияние на рынке ИИ. По словам источников WSJ в ИИ-отрасли, усиление мер администрации США по блокированию технологических слияний и поглощений стало одной из причин необычных сделок с Character, Adept и Inflection. Так называемые сделки acqui-hires, когда крупная компания покупает стартап в основном для найма его сотрудников, для Кремниевой долины не новость. Но найм ключевых сотрудников стартапа и получение его технологий в обмен на лицензионный сбор отличаются от этого типа сделки, позволяя компании получить желаемое без необходимости в одобрении регулятором. Впрочем, по словам источников, Федеральная торговая комиссия США (FTC) изучает как сделку Amazon с Adept, так и сделку Microsoft с Inflection с целью выяснить, не было ли у покупателя умысла избежать с помощью составленного таким образом соглашения одобрения правительства. В Великобритании у регуляторов вызвала вопросы инвестиция Amazon $4 млрд в ИИ-стартап Anthropic.
09.08.2024 [09:32], Руслан Авдеев
ИИ ЦОД за полгода: Supermicro анонсировала DCBBS, методологию быстрого возведения и модернизации дата-центровВ Supermicro рассказали о методологии строительства дата-центров DCBBS, позволяющей создавать небольшие ЦОД за срок от полугода или сокращать время строительства более крупных объектов с трёх до двух лет. Как сообщает The Register, о новом подходе рассказал глава компании Чарльз Лян (Charles Liang) во время последнего финансового отчёта. Глава Supermicro подчеркнул, что выручка только за IV квартал 2024 финансового года превзошла всю выручку за 2022 год. Впрочем, Лян признал, что новую проприетарную технологию прямого жидкостного охлаждения (DLC) оказалось трудно и дорого разработать, не в последнюю очередь из-за дефицита компонентов. Именно это стало причиной того, что компания недополучила $800 млн квартальной выручи, разоачаровала аналитиков и резко потеряла в рыночной стоимости.  Тем не менее глава компании уверен, что инвестиции в дополнительные производственные мощности помогут справиться с этой нехваткой и удвоить число выпускаемых стоек с DLC с 1500 до 3000 в месяц в течение финансового года. По словам Ляна, СЖО Supermicro стоят не больше, чем обычные системы охлаждения, но системы с ним потребляют меньше энергии, т.е. в итоге позволяют экономить средства. Спрос на подобные комплекты увеличится, уверены в компании. 
Источник изображения: Supermicro Анонсированная в ходе отчёта методология Supermicro 4.0 Datacenter Building Block Solutions (DCBBS) позволит значительно ускорить ввод в эксплуатацию ЦОД и оптимизировать их стоимость. Предполагается полная интеграция ИИ-вычислений, серверов, хранилищ, сети, энергетического оборудования и, конечно, СЖО, а также ПО для сквозного управления и услуги по развёртыванию и обслуживанию. Предполагается, что два года будет уходить создание крупных ИИ ЦОД, а для на объекты меньшего масштаба или модернизацию старых ЦОД уйдёт всего 6-12 месяцев. При этом в компании не ожидают, что новые ускорители NVIDIA Blackwell, которые как раз без СЖО обходиться будут с трудом, поспособствуют росту Supermicro в 2025 финансовом году. Финансовые аналитики выразили озабоченность падением маржинальности бизнеса, но Лян подчеркнул, что Supermicro улучшит показатели. Впрочем, планам компании может помешать сама NVIDIA, вынужденно отложившая массовое производство новейших ускорителей. Услуги в рамках DCBBS компания намерена предложить к концу 2024 года. |
|

