Материалы по тегу: ии
|
08.08.2024 [00:48], Сергей Карасёв
NVIDIA задержит выпуск ускорителей GB200, отложит B100/B200, а на замену предложит B200AКомпания NVIDIA, по сообщению ресурса The Information, вынуждена повременить с началом массового выпуска ИИ-ускорителей следующего поколения на архитектуре Blackwell, сохранив высокие темпы производства Hopper. Проблема, как утверждается, связана с технологией упаковки Chip on Wafer on Substrate (CoWoS) от TSMC. Отмечается, что NVIDIA недавно проинформировала Microsoft о задержках, затрагивающих наиболее продвинутые решения семейства Blackwell. Речь, в частности, идёт об изделиях Blackwell B200. Серийное производство этих ускорителей может быть отложено как минимум на три месяца — в лучшем случае до I квартала 2025 года. Это может повлиять на планы Microsoft, Meta✴ и других операторов дата-центров по расширению мощностей для задач ИИ и НРС. По данным исследовательской фирмы SemiAnalysis, задержка связана с физическим дизайном изделий Blackwell. Это первые массовые ускорители, в которых используется технология упаковки TSMC CoWoS-L. Это сложная и высокоточная методика, предусматривающая применение органического интерпозера — лимит возможностей технологии предыдущего поколения CoWoS-S был достигнут в AMD Instinct MI300X. Кремниевый интерпорзер, подходящий для B200, оказался бы слишком хрупок. Однако органический интерпозер имеет не лучшие электрические характеристики, поэтому для связи используются кремниевые мостики. В используемых материалах как раз и кроется основная проблема — из-за разности коэффициента теплового расширения различных компонентов появляются изгибы, которые разрушают контакты и сами чиплеты. При этом точность и аккуратность соединений крайне важна для работы внутреннего интерконнекта NV-HBI, который объединяет два вычислительных тайла на скорости 10 Тбайт/с. Поэтому сейчас NVIDIA с TSMC заняты переработкой мостиков и, по слухам, нескольких слоёв металлизации самих тайлов.  Вместе с тем у TSMC наблюдается нехватка мощностей по упаковке CoWoS. Компания в течение последних двух лет наращивала мощности CoWoS-S, в основном для удовлетворения потребностей NVIDIA, но теперь последняя переводит свои продукты на CoWoS-L. Поэтому TSMC строит фабрику AP6 под новую технологию упаковки, а также переведёт уже имеющиеся мощности AP3 на CoWoS-L. При этом конкуренты TSMC не могут и вряд ли смогут в ближайшее время предоставить хоть какую-то альтернативную технологию упаковки, которая подойдёт NVIDIA. Таким образом, как сообщается, NVIDIA предстоит определиться с тем, как использовать доступные производственные мощности TSMC. По мнению SemiAnalysis, компания почти полностью сосредоточена на стоечных суперускорителях GB200 NVL36/72, которые достанутся гиперскейлерам и небольшому числу других игроков, тогда как HGX-решения B100 и B200 «сейчас фактически отменяются», хотя малые партии последних всё же должны попасть на рынок. Однако у NVIDIA есть и запасной план. План заключается в выпуске упрощённых монолитных чипов B200A на базе одного кристалла B102, который также станет основой для ускорителя B20, ориентированного на Китай. B200A получит всего четыре стека HBM3e (144 Гбайт, 4 Тбайт/с), а его TDP составит 700 или 1000 Вт. Важным преимуществом в данном случае является возможность использования упаковки CoWoS-S. Чипы B200A как раз и попадут в массовые HGX-системы вместо изначально планировавшихся B100/B200.  На смену B200A придут B200A Ultra, у которых производительность повысится, но вот апгрейда памяти не будет. Они тоже попадут в HGX-платформы, но главное не это. На их основе NVIDIA предложит компромиссные суперускорители MGX GB200A Ultra NVL36. Они получат восемь 2U-узлов, в каждом из которых будет по одному процессору Grace и четыре 700-Вт B200A Ultra. Ускорители по-прежнему будут полноценно объединены шиной NVLink5 (одночиповые 1U-коммутаторы), но вот внутри узла всё общение с CPU будет завязано на PCIe-коммутаторы в двух адаптерах ConnectX-8. Главным преимуществом GX GB200A Ultra NVL36 станет воздушное охлаждение из-за относительно невысокой мощности — всего 40 кВт на стойку. Это немало, но всё равно позволит разместить новинки во многих ЦОД без их кардинального переоборудования пусть и ценой потери плотности размещения (например, пропуская ряды). По мнению SemiAnalysis, эти суперускорители в случае нехватки «полноценных» GB200 NVL72/36 будут покупать и гиперскейлеры.
07.08.2024 [12:28], Руслан Авдеев
Китайские компании набивают склады HBM-памятью Samsung в ожидании новых американских санкцийКитайские техногиганты, включая игроков вроде Huawei и Baidu, а также стартапы активно запасают HBM-чипы Samsung Electronics. По данным агентства Reuters, это делается в ожидании новых ограничений со стороны США на поставки в КНР чипов, использующих американские технологии. Как сообщают источники издания, компании наращивают закупки соответствующих чипов ещё с начала 2024 года, на долю китайских покупателей придётся порядка 30 % выручки Samsung от продаж HBM в I половине 2024 года. Экстренные меры наглядно демонстрируют нежелание Китая отказываться от технологических амбиций даже на фоне торговых войн с США и их союзниками. Ранее Reuters сообщало, что американские власти намерены представить новые санкционные ограничения ещё до конца текущего месяца. Они призваны ограничить возможности китайской полупроводниковой индустрии. Источники сообщают, что в документах будут заданы и параметры для ограничений на поставки HBM-памяти. Министерство торговли США отказалось от комментариев, но на прошлой неделе заявило, что постоянно обновляет правила экспортного контроля для защиты национальной безопасности США и технологической экосистемы страны. 
Источник изображения: Samsung HBM-чипы считаются критически важными компонентами при разработке передовых ИИ-ускорителей. Возможности выпуска HBM пока доступны только трём производителям: южнокорейским SK Hynix и Samsung, а также американской Micron Technology. По данным информаторов Reuters, в Китае особым спросом пользуется вариант HBM2E, который отстаёт от передового HBM3E. Глобальный бум ИИ-технологий привёл к дефициту наиболее передовых решений. По мнению экспертов, поскольку собственные китайские технологии в этой области ещё не слишком зрелые, спрос китайских компаний и организаций на сторонние HBM-чипы чрезвычайно велик, а Samsung оставалась единственной опцией, поскольку производственные мощности других производителей уже забронированы американскими ИИ-компаниями. Хотя объёмы и стоимость запасённых Китаем HBM-чипов оценить нелегко, известно, что они используются компаниями самого разного профиля, а Huawei, например, применяет Samsung HBM2E для выпуска передовых ИИ-ускорителей Ascend. Впрочем, Huawei и CXMT уже сфокусировали внимание на разработке чипов HBM2 — они на три поколения отстают от HBM3E. Тем не менее, американские санкции могут помешать новым китайским проектам. Более того, от них может больше пострадать Samsung, чем её ключевые соперники, которые меньше связаны с китайским рынком. Micron не продаёт HBM-чипы в Китай с прошлого года, а SK Hynix, чьими ключевыми клиентами являются компании вроде NVIDIA, специализируются на более современных решениях.
06.08.2024 [16:17], Руслан Авдеев
LLM с доставкой на дом: в продаже появились жёсткие диски с комплектом открытых ИИ-моделейТо ли в шутку, то ли всерьёз компания Torrance Computer Supply (TCS) начала продажи накопителей с предзаписанными большими язковыми моделями. Доступны как HDD ёмкостью 14 Тбайт, так и карта памяти вместимостью 1 Тбайт. HDD-вариант базируется на недорогом 14-Тбайт LFF-накопителе MDD (MDD16TSATA25672E): SATA-3, 7200 RPM, кеш 256 Мбайт. Это один из самых доступных жёстких дисков такой ёмкости, поскольку MDD занимается восстановлением б/у накопителей и продажей складских остатков крупных вендоров под своим брендом. В комплекте с жёстким диском поставляется кейс Orico и адаптер USB 3.0 с внешним питанием (12 В, 24 Вт). 
Mika Baumeister / Unsplash Согласно описанию, на жёсткий диск записаны актуальные версии более двух десятков открытых больших языковых моделей (LLM), включая различные варианты Llama, Mistral, Nemotron и др. Предлагаются версии от нескольких миллиардов до почти полутриллиона параметров максимальным объёмом до 820 Гбайт. Продавцы уверяют, что постоянно меняют набор в зависимости от изменений рынка и технологий. Покупка обойдётся в $229, но если накопитель вернуть, то можно получить $125 на дальнейшие покупки в этом же магазине. На том же сайте предлагается и комплект LLM «для бедных» — желающие могут приобрести флэш-карту SanDisk 1TB Ultra microSDXC UHS-I на 1 Тбайт с адаптером в комплекте. Этот вариант стоит всего $119 и поставляется как минимум с тремя ИИ-моделями: Llama3.1 на 8, 70 и 405 млрд параметров. Практическая ценность данных предложений сомнительна, поскольку никто не мешает скачать те же самые модели и записать их на свой накопитель. Впрочем, некоторые компании предлагают услуги по оффлайн-транспортировке данных, но в этом случае речь идёт о на порядок больших объёмах.
06.08.2024 [15:36], Руслан Авдеев
ИИ стимулирует траты и рост прибылей техногигантов, но окупаемость вложений всё ещё остаётся под вопросомКрупные технологические компании не скрывают намерения продолжать активно вкладываться в разработку и эксплуатацию ИИ-систем. Как свидетельствует блог IEEE Communication Society (ComSoc), они готовы идти на это даже с учётом того, что инвесторы уже обеспокоены тем, что гигантские вложения могут окупиться нескоро. Впрочем, признаков того, что бум ИИ-технологий продолжится, всё ещё немало. В прошлом квартале капитальные затраты Apple, Amazon, Meta✴, Microsoft и Alphabet в общей сложности составили $59 млрд, на 63 % больше год к году и на 161 % больше чем четыре года назад. В значительной части средства ушли на постройку дата-центров и их оснащение новыми системами для ИИ. Из крупнейших компаний не особенно много потратила лишь Apple, и то потому, что компания не строит собственных передовых ИИ-систем и, в отличие от прочих, не является традиционным облачным провайдером. 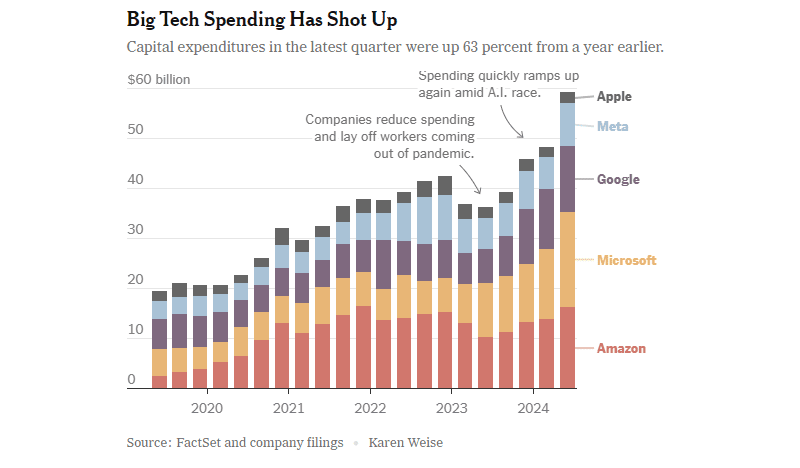
Источник изображения: New York Times В начале года Meta✴ заявила, что потратит в 2024 году более $30 млрд на новую технологическую инфраструктуру. В апреле она подняла прогноз трат до $35 млрд, а в минувшую среду — уже до $37 млрд, и это минимум. По словам главы компании Марка Цукерберга (Mark Zuckerberg), компания будет тратить больше уже в следующем году, он заявил, что лучше будет строить «слишком быстро, чем слишком поздно» — IT-гигант не позволит конкурентам обогнать его в гонке ИИ. Цукерберг считает, что ИИ может использоваться для совершенствования всех продуктов компании буквально в любых аспектах. Новый этап развития генеративных ИИ-систем чрезвычайно дорог, но финансовая отдача от них пока не слишком впечатляет. В последние месяцы некоторые экспертные и инвестиционные компании, включая Goldman Sachs и Sequoia Capital, поставили под вопрос вероятность того, что затраты на ИИ вообще смогут когда-либо окупиться. При этом некоторые считают, что пока непонятно, окажет ли ИИ на общество хотя бы приблизительно то же значение, что и появление интернета и мобильных телефонов. Единого взгляда на проблему нет. Если одни говорят, что ИИ лишь отнимет рабочие места с помощью дорогих технологий (что не всегда случалось в ходе других научно-технических революций), то другие уверены, что количество рабочих мест только увеличится и новые сотрудники требуются уже сейчас — изменится только характер работы. В частности, в Amazon с оптимизмом смотрят в будущее, покупая новую землю, чипы и оборудование, а также строя новые ЦОД и ожидая рост выручки в следующем десятилетии. 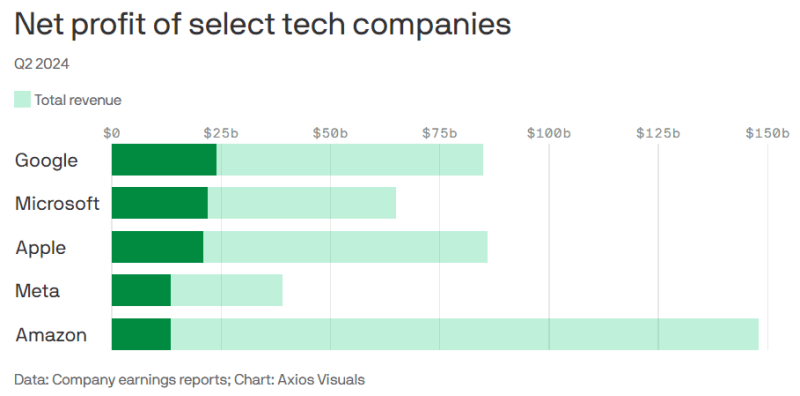
Источник изображения: Axios Прибыли и выручка крупных компаний продолжат расти, но обеспечат ли большие затраты хорошую окупаемость инвестиций в долгосрочной перспективе? Пока косвенным показателем является отчётность за II квартал 2024 года:
06.08.2024 [09:01], Руслан Авдеев
ИИ ЦОД понадобятся гигантские системы резервного питанияИИ-системам требуются огромные объёмы электроэнергии, что резко повышает требования к системам резервного питания ЦОД на случай сбоев, пишет EE Times. По данным СМИ, глобальный спрос со стороны критических IT-инфраструктур вырастет с 49 ГВт в 2023 году до 96 ГВт к 2026 году, на ИИ придётся порядка 40 ГВт. При этом ёмкость ИИ ЦОД, как ожидается, будет составлять 100 МВт. А общее потребление дата-центров может вырасти до более 1000 ТВт∙ч в 2026 году. Для ИИ ЦОД требуется доступность на уровне 99,99999 %, так что им нужно полномасштабное резервное энергоснабжение. Для этого обычно используются дизельные или газовые генераторы мощностью 1–2 МВт. Для защиты крупного ЦОД нужны десятки таких машин, готовых к пуску. Критически важной является скорость переключения на резервный источник питания — на старт генератора обычно требуется до нескольких минут, так что всё это время питание должно осуществляться от аккумуляторов. Кроме того, нужно распределительное устройство, а также система мониторинга и автоматизации, которая сделает для IT-нагрузки переход с одного источника на другой незаметным. 
Источник изображения: Saif71.com / Unsplash Однако рост ёмкости ЦОД резко усложняет и удорожает создание систем резервного питания. Генератор мегаваттного класса весит около 5 т (без топлива), занимает не так уж мало места (добавьте сюда топливный бак объём от 1 м3) и стоит порядка $1–$2 млн без учёта доставки и установки. При этом аккумуляторная система — это ещё один отдельный комплекс с собственными проблемами установки. Так что не исключено, что недавно запущенный ИИ-кластер xAI, который пока что вынужден питаться как раз от генераторов, даже после подключения к энергосети оставит эти генераторы на площадке.
05.08.2024 [14:40], Андрей Крупин
Служба каталогов ALD Pro получила сертификат ФСТЭК России по 4-му уровню доверия
active directory
astra linux
software
импортозамещение
информационная безопасность
сделано в россии
сертификация
фстэк россии
«Группа Астра» сообщила о получении сертификата Федеральной службы по техническому и экспортному контролю на систему централизованного управления доменом ALD Pro. Программный комплекс ALD Pro предназначен для автоматизации и централизованного управления рабочими станциями, иерархией подразделений и групповыми политиками, а также прикладными сервисами для IT-инфраструктур организаций различного масштаба. Продукт может использоваться в качестве замены Microsoft Active Directory и учитывает интересы администраторов и пользователей компаний, переходящих на отечественный софт. ALD Pro включён в дорожную карту «Новое общесистемное программное обеспечение»; решению присвоен статус «особо важного продукта» в рамках программы Минцифры России. Выданный ФСТЭК России сертификат подтверждает соответствие ALD Pro требованиям по безопасности информации, устанавливающим уровни доверия к средствам технической защиты информации и средствам обеспечения безопасности информационных технологий. Продукт соответствует 4-му уровню доверия и располагает набором декларируемых в технических условиях функциональных возможностей. 
Источник изображения: aldpro.ru Решение подходит не только для информационных систем общего пользования (ИСОП) II класса, но также для государственных информационных систем (ГИС), информационных систем персональных данных (ИСПДн) и автоматизированных систем управления техническими процессами (АСУ ТП) до 1-го класса защищённости включительно. Кроме того, программный комплекс можно применять на значимых объектах критической информационной инфраструктуры, в том числе 1-ой категории. «Сегодня заказчики активно переходят с зарубежных решений на отечественные. Мы понимаем, что внедряемый софт должен быть не только функциональным, но и надёжным, и получение сертификата ФСТЭК России — это документальное подтверждение безопасности ALD Pro. Защищённость всегда была и будет одним из ключевых приоритетов нашей команды, нам важно предоставлять клиентам стабильные и качественные решения», — говорится в сообщении «Группы Астра».
05.08.2024 [12:48], Руслан Авдеев
NVIDIA купила Run:ai, чтобы «похоронить» наработки стартапа, подозревает Минюст СШАПо данным Silicon Angle, американское Министерство юстиции взялось за сделку NVIDIA по покупке стартапа Run:ai, занимающегося разработкой софта для управления рабочими нагрузками ИИ. ПО позволяет более эффективно использовать вычислительные ресурсы при работе с ИИ-приложениями, что может оказаться помехой для бизнеса NVIDIA. Информация о расследовании появилась у СМИ на прошлой неделе. Пару месяцев назад источники уже сообщали, что министерство расследует доминирующее положение NVIDIA на рынке ИИ-чипов. По данным источников сделку будут рассматривать независимо от предыдущего расследования. 
Источник изображения: Romain Dancre/unsplash.com NVIDIA купила стартап из Тель-Авива Run:ai (зарегистрированный как Runai Labs Ltd) в начале года за $700 млн. Ранее он уже привлёк от инвесторов порядка $118 млн. Предлагаемая им платформа позволяет расширить функциональность кластеров ускорителей и повысить их уровень утилизации. В Run:ai позволяет запускать на одном и том же ускорителе несколько задач. Также платформа позволит избегать конфликтов памяти, а также присущих ИИ-вычислениям ошибок. Выполнение рабочих нагрузок может быть ускорено другими методами. Например, для обучения языковой модели разработчики разбивают её на части, каждую из которых тренируют на отдельном ускорителе. Фрагменты регулярно обмениваются данными в ходе обучения, но работа настроена благодаря Run:ai таким образом, что обмен данными происходит быстрее, а сеансы обучения выходят короче. Другими словами, реализация ИИ-проектов может быть ускорена без добавления новых вычислительных ресурсов. Верно и обратное, задачи можно завершать с той же скоростью с использованием меньшего числа ускорителей. Как раз последний вариант привлёк внимание Министерства юстиции. Платформа, способная снизить количество необходимых ускорителей, может привести к тому, что некоторые клиенты станут покупать меньше продуктов NVIDIA. Чиновники подозревают IT-гиганта в том, что он намерен просто «похоронить» технологию, угрожающую её основному бизнесу. 
Источник изображения: Run:ai Изучаются и другие аспекты деятельности компании. Например, в министерстве желают знать, не ставит ли NVIDIA условием для доступа к своим ускорителям покупку клиентами других своих продуктов или не ставит ли она условием обязательство не покупать оборудование у конкурентов. В NVIDIA утверждают, что лидируют на рынке совершенно заслуженно, соблюдая все законы, а продукты компании открыты и доступны любым бизнесам — клиенты могут сами принять решение, которое подходит им лучше всего. В прошлом месяце появлялась информация о том, что выдвинуть обвинения против NVIDIA намерен антимонопольный регулятор Франции. Вероятно, в поле зрения попадает набор инструментов CUDA для разработки ПО, используемого с ускорителями и видеокартами компании. Чиновников беспокоит и вложения NVIDIA в облачные компании, ориентирующиеся на ИИ, вроде CoreWeave, массово внедряющие ускорители компании в своей инфраструктуре. Предполагается, что инвестор сможет повлиять на предпочтения партнёров при покупке ускорителей и ПО.
05.08.2024 [10:34], Руслан Авдеев
Microsoft начала активно внедрять прямое жидкостное охлаждение в своих ЦОД и приступила к прикладному изучению микрогидродинамикиКомпания Microsoft стала активно применять прямое жидкостное охлаждение чипов в серверах своих ЦОД. Datacenter Dynamics сообщает, что IT-гигант приступил и к изучению более передовой технологии, основанной на принципах микрогидродинамики. Как свидетельствует недавний пост в блоге компании, посвящённый использованию воды и применяемым СЖО разных поколений, сейчас разрабатывается новая архитектура дата-центров, оптимизированных для прямого жидкостного охлаждения чипов. Это требует переосмысления конструкции серверов и серверных стоек для внедрения новых методов терморегуляции и управления энергией. Компания уже использует sidekick-СЖО в действующих ЦОД. Впервые они были представлены во время анонса процессоров Cobalt и ИИ-ускорителей Maya. Последние будут развёрнуты в кастомных стойках и кластерах Ares. Серверы для них шире 19″ и даже OCP-стоек и нуждаются именно в жидкостном охлаждении — других конфигураций не предусмотрено. Каждый сервер получит по четыре ускорителя Maya, а стойка будет вмещать восемь серверов. А рядом с ней будет ещё одна стойка с компонентами охлаждения. Аналогичный дизайн использует Meta✴, которая также была вынуждена пересмотреть архитектуру своих ЦОД из-за ИИ. 
Источник изображений: Microsoft Не менее интересны и разработки в сфере микрогидродинамики. Этот подход предусматривает размещение микроканалов для подачи жидкости буквально внутри самих чипов, что обеспечивает ещё более высокую эффективность охлаждения. В компании утверждают, что все эти разработки оптимизированы для поддержки ИИ-нагрузок в ЦОД и в то же время дружественны к экологии. Благодаря инновациям можно значительно снизить потребление чистой воды, одновременно обеспечивая повышенную ёмкость серверных стоек, благодаря чему возрастает польза от каждого задействованного квадратного метра.  Microsoft намерена стать «водно-положительной» к 2030 году. В ESG-докладе 2023 года компания заявила, что использовала в 2022 году 6,4 млн м3, преимущественно для своих ЦОД. В докладе 2024 года показатель увеличился уже до 7,8 млн м3 в 2023 году. Проблемы с потреблением воды вообще характерны для IT-гиганта и его партнёров. Запись в блоге Microsoft также свидетельствует о том, что компания расширила использование восстановленной и переработанной воды на площадках в Техасе, Вашингтоне, в Калифорнии и Сингапуре. В Нидерландах, Ирландии и Швеции компания собирает дождевую воду и намерена расширить эту практику на Канаду, Великобританию, Финляндию, Италию, Южную Африку и Австрию. В Нидерландах, правда, всё оказалось не так хорошо, как обещала компания. Как заявляют Microsoft, с первого поколения собственных дата-центров в начале 2000-х годов до текущего поколения в 2020-х, использование воды на кВт·ч снизилось более чем на 80 %. Ранее компания сотрудничала с разработчиком систем двухфазного погружного жидкостного охлаждения LiquidStack, который поддерживается одним из поставщиков Microsoft — Wiwynn. В прошлом году LiquidStack представила однофазную систему иммерсионного охлаждения для ИИ-систем, а также запустила в США производство СЖО, но для кого именно она их выпускает, не уточняется.
05.08.2024 [08:16], Сергей Карасёв
Новые кластеры Supermicro SuperCluster с ускорителями NVIDIA L40S ориентированы на платформу Omniverse
emerald rapids
hardware
intel
l40
nvidia
omniverse
sapphire rapids
supermicro
xeon
ии
кластер
сервер
Компания Supermicro расширила семейство высокопроизводительных вычислительных систем SuperCluster, предназначенных для обработки ресурсоёмких приложений ИИ/HPC. Представленные решения оптимизированы для платформы NVIDIA Omniverse, которая позволяет моделировать крупномасштабные виртуальные миры в промышленности и создавать цифровых двойников. Системы SuperCluster for NVIDIA Omniverse могут строиться на базе серверов SYS-421GE-TNRT или SYS-421GE-TNRT3 с поддержкой соответственно восьми и четырёх ускорителей NVIDIA L40S. Обе модели соответствуют типоразмеру 4U и допускают установку двух процессоров Intel Xeon Emerald Rapids или Sapphire Rapids в исполнении Socket E (LGA-4677) с показателем TDP до 350 Вт (до 385 Вт при использовании СЖО). Каждый из узлов в составе новых систем SuperCluster несёт на борту 1 Тбайт оперативной памяти DDR5-4800, два NVMe SSD вместимостью 3,8 Тбайт каждый и загрузочный SSD NVMe M.2 на 1,9 Тбайт. В оснащение включены четыре карты NVIDIA BlueField-3 (B3140H SuperNIC) или NVIDIA ConnectX-7 (400G NIC), а также одна карта NVIDIA BlueField-3 DPU Dual-Port 200G. Установлены четыре блока питания с сертификатом Titanium мощностью 2700 Вт каждый. В максимальной конфигурации система SuperCluster for NVIDIA Omniverse объединяет пять стоек типоразмера 48U. В общей сложности задействованы 32 узла Supermicro SYS-421GE-TNRT или SYS-421GE-TNRT3, что в сумме даёт 256 или 128 ускорителей NVIDIA L40S. 
Источник изображения: Supermicro Кроме того, в состав такого комплекса входят три узла управления Supermicro SYS-121H-TNR Hyper System, три коммутатора NVIDIA Spectrum SN5600 Ethernet 400G с 64 портами, ещё два коммутатора NVIDIA Spectrum SN5600 Ethernet 400G с 64 портами для хранения/управления, два коммутатора управления NVIDIA Spectrum SN2201 Ethernet 1G с 48 портами. При необходимости конфигурацию SuperCluster for NVIDIA Omniverse можно оптимизировать под задачи заказчика, изменяя масштаб вплоть до одной стойки. В этом случае применяются четыре узла Supermicro SYS-421GE-TNRT или SYS-421GE-TNRT3.
04.08.2024 [15:25], Сергей Карасёв
В Google Cloud появился выделенный ИИ-кластер для стартапов Y CombinatorОблачная платформа Google Cloud, по сообщению TechCrunch, развернула выделенный субсидируемый кластер для ИИ-стартапов, которые поддерживаются венчурным фондом Y Combinator. Предполагается, что данная инициатива поможет Google привлечь в своё облако перспективные компании, которым в будущем могут понадобиться значительные вычислительные ресурсы. Отмечается, что для ИИ-стартапов на ранней стадии одной из самых распространённых проблем является ограниченная доступность вычислительных мощностей. Крупные предприятия обладают достаточными финансами для заключения многолетних соглашений с поставщиками облачных услуг на доступ к НРС/ИИ-сервисам. Однако у небольших фирм с этим возникают сложности. Ожидается, что Google Cloud поможет в решении данной проблемы. Google предоставит выделенный кластер с приоритетным доступом для стартапов Y Combinator. Платформа базируется на ускорителях NVIDIA и тензорных процессорах (TPU) самой Google. Каждый участник программы получит кредиты на сумму $350 тыс. для использования облачных сервисов Google в течение двух лет. Кроме того, Google предоставит стартапам кредиты в размере $12 тыс. на расширенную поддержку и бесплатную годовую подписку Google Workspace Business Plus. Молодые компании также смогут консультироваться с экспертами Google в области ИИ. 
Источник изображения: Google Оказав поддержку ИИ-стартапам, Google в дальнейшем сможет рассчитывать на заключение с ними долгосрочных контрактов на обслуживание. Говорится, что за последние 18 лет примерно 5 % стартапов Y Combinator стали единорогами с оценкой $1 млрд и более. Такие компании могут принести облачной платформе Google значительную выручку в случае заключения соглашения о сотрудничестве. С другой стороны, фонд Y Combinator сможет привлечь больше перспективных ИИ-проектов, предлагая вычислительные ресурсы Google вместе со своей поддержкой. Аналогичные программы есть и у других игроков. Так, венчурный инвестор Andreessen Horowitz (a16z) тоже запасается ИИ-ускорителями, чтобы стать более привлекательным для ИИ-стартапов. AWS предлагает ИИ-стартапам доступ к облаку и сервисам, а Alibaba Cloud готова предоставить ресурсы в обмен на долю в стартапе. Сама Google на днях наняла основателей стартапа Character.AI и лицензировал его модели. Стартапу, по-видимому, не хватило средств на ИИ-ускорители для дальнейшего развития. |
|

