Материалы по тегу: h200
|
24.11.2025 [12:23], Руслан Авдеев
США рассматривают продажу в Китай ИИ-ускорителей NVIDIA H200Администрация США рассматривает возможность дать «зелёный свет» продажам ИИ-чипов NVIDIA H200 в КНР — по данным источников, некоторая двухсторонняя «разрядка» способствует обсуждению продаж передовых американских технологий в Китай, сообщает Reuters. Впрочем, H200 вряд ли можно назвать «новейшими» — в ходу уже совсем другие решения. В Белом Доме отказались комментировать ситуацию, но заявили, что американская администрация стремится «обеспечению американского технологического лидерства и защите национальной безопасности». Ранее глава NVIDIA Дженсен Хуанг (Jensen Huang) предупреждал, что именно запреты на продажу передовых решений могут угрожать технологическому лидерству США в мире. Теперь в NVIDIA не прокомментировали ситуацию прямо, но заявили, что текущие правила не позволяют продавать в Китае конкурентоспособные чипы, оставляя этот рынок на откуп быстро развивающимся иностранным конкурентам. Данные источников косвенно свидетельствуют о смягчении подхода США к отношениям с Китаем после того, как китайский Лидер Си Цзиньпин (Xi Jinping) в прошлом месяце заключил «перемирие» в технологической и торговой войнах. Антикитайские политики в Вашингтоне обеспокоены тем, что поставки более передовых чипов в Китай могут помочь Пекину «перезагрузить» военную машину, именно поэтому прошлая администрация в своё время ужесточила экспортный контроль в отношении Поднебесной. 
Источник изображения: NVIDIA Столкнувшись с ограничениями Пекина на экспорт редкоземельных металлов, критически важных для производства многих высокотехнологичных продуктов, в этом году США пригрозили ввести новые технологические ограничения, но в итоге отказались от них в большинстве случаев. Чипы H200 представили два года назад, они получили более быструю и ёмкую память в сравнении с оригинальными H100, что позволяет быстрее обрабатывать данные ИИ-серверами. По имеющимся оценкам, модели H200 вдвое производительнее, чем варианты H20, разрешённые для экспорта в Китай Трампом после короткого тотального запрета. В отношении ближневосточных стран, которым тоже долго не разрешали закупать ускоритли из-за опасений, что они в итоге достанутся Китаю, послабления были объявлены на днях. В частности, Министерство торговли США уже одобрило поставку в страну эквивалент до 70 тыс. чипов NVIDIA Blackwell компаниям Humain и G42 из Саудовской Аравии и ОАЭ соответственно.
20.11.2025 [11:37], Сергей Карасёв
Представлен самый мощный суперкомпьютер на Ближнем Востоке — 122,8-Пфлопс система Shaheen IIIУниверситет науки и технологий имени короля Абдаллы (KAUST) в Саудовской Аравии объявил о запуске вычислительного комплекса Shaheen III. На сегодняшний день, как утверждается, это самый мощный суперкомпьютер на Ближнем Востоке: его FP64-производительность достигает 122,8 Пфлопс. Применять Shaheen III планируется для решения широкого спектра ресурсоёмких задач. Среди них названа разработка нового поколения малых и больших языковых моделей (LLM), ориентированных на арабский регион. Кроме того, суперкомпьютер поможет в создании цифрового двойника всего Аравийского полуострова — интегрированной среды моделирования, объединяющей атмосферные, океанические и земные процессы. Эта виртуальная модель будет способствовать решению комплексных проблем, таких как управление разливами нефти и оптимизация морских перевозок. В числе других задач названы оптимизация сельскохозяйственной деятельности и управления водными ресурсами, поиск передовых материалов, диагностика редких заболеваний, улучшение качества медицинской визуализации, разработка перспективных лекарственных препаратов и пр. 
Источник изображения: KAUST Система создана компанией HPE на платформе Cray EX с прямым жидкостным охлаждением (DLC). В общей сложности задействованы 2800 гибридных суперчипов NVIDIA GH200 Grace Hopper с 72-ядерным Arm-процессором NVIDIA Grace и ускорителем NVIDIA H100 с 96 Гбайт памяти HBM3. Общее количество используемых ядер составляет 574 464. Применён интерконнект Slingshot-11. В качестве программной платформы используется HPE Cray OS. В ноябрьском рейтинге самых мощных суперкомпьютеров мира TOP500 система Shaheen III занимает 18-ю позицию. Её теоретическое пиковое быстродействие заявлено на уровне 155,21 Пфлопс. Энергопотребление — 1,98 МВт.
26.09.2025 [10:33], Руслан Авдеев
Media Stream AI построит в Манчестере 2-МВт ИИ ЦОД с охлаждением водой из местного каналаБританская медиакомпания Media Stream AI (MSAI) намерена открыть в Солфорде (Salford, Большой Манчестер) дата-центр в популярном «творческом» районе Media City. Объект мощностью 2 МВт будет использовать для охлаждения воду из канала Рочдейл (Rochdale), сообщает Datacenter Dynamics. Система охлаждения будет состоять из замкнутого контура с теплообменниками и драйкулеров. При поддержке Lenovo объект стоимостью £50 млн ($67,3 млн) сможет обеспечить плотность стоек на уровне 30–60 кВт при PUE менее 1,2. На площадке планируется разместить 1,1 тыс. ускорителей NVIDIA H200 в составе серверов Lenovo ThinkSystem с СЖО Neptune. В будущем возможно расширение до 2,3 тыс. ускорителей. Объект должен заработать в I квартале 2026 года. Компания намерена создать там же собственную виртуальную продакшн-студию и робототехническую лабораторию. Media Stream AI рассчитывает предоставлять ИИ-сервисы медиакомпаниям и работникам творческих профессий. На сайте стартапа объявлено, что он намерен предоставить доступ к ускорителям NVIDIA L4, A10G, A4000, A5000, A100, H100 и L40. Также компания намерена развернуть к концу 2026 года площадки в Германии и Франции. Более того, MSAI заключила соглашение с властями Ямайки о строительстве и эксплуатации первого на острове ИИ ЦОД. 
Источник изображения: Jonny Gios/unsplash.com Прецеденты использования похожих систем охлаждения есть. Например, Digital Realty использует для охлаждения ЦОД во Франции и Великобритании проточную речную воду. Green Mountain намерена развернуть систему охлаждения речной водой на своём новом объекте в Германии. Речное охлаждение также используют Denv-R во Франции и Nautilus в Калифорнии. Наконец, сеть европейских супермаркетов Lidl объявила, что один из её ЦОД в Германии тоже использует охлаждение речной водой, а норвежский оператор дата-центров Polar утверждает, что для охлаждения одного из своих ЦОД намерен использовать близлежащую реку. Участвуют в подобных проектах и гиперскейлеры. Площадка Google в Финляндии использует для охлаждения и морскую воду.
06.09.2025 [13:42], Сергей Карасёв
Состоялся официальный запуск первого в Европе экзафлопсного суперкомпьютера JUPITERВ Юлихском исследовательском центре (FZJ) в Германии официально введён в эксплуатацию суперкомпьютер JUPITER (Joint Undertaking Pioneer for Innovative and Transformative Exascale Research) — первый в Европе вычислительный комплекс экзафлопсного класса. Система будет использоваться в том числе для исследований в области климата, нейробиологии и квантового моделирования. Контракт на создание JUPITER подписан между Европейским совместным предприятием по развитию высокопроизводительных вычислений (EuroHPC JU) и консорциумом, в который входят Eviden (Atos) и ParTec. Суперкомпьютер состоит из блока Booster для решения ресурсоёмких задач и универсального блока cCuster. В основу Booster положена платформа BullSequana XH3000 с прямым жидкостным охлаждением. Используются около 6000 вычислительных узлов с гибридными ускорителями NVIDIA Quad GH200 и интерконнектом InfiniBand NDR200 (4×200G на узел, DragonFly+). В общей сложности задействованы почти 24 тыс. суперчипов NVIDIA GH200 (Grace Hopper). В июньском рейтинге TOP500 блок JUPITER Booster располагался на четвёртом месте: на тот момент его FP64-производительность составляла 793,4 Пфлопс. Теперь показатель преодолел рубеж в 1 Эфлопс. При этом ИИ-производительность, как ожидается, будет находиться на уровне 90 Эфлопс. 
Источник изображений: Forschungszentrum Jülich / Sascha Kreklau «С запуском первого в Европе эксафлопсного суперкомпьютера мы открываем новую главу в развитии науки, искусственного интеллекта и инноваций. JUPITER укрепляет цифровой суверенитет Европы и ускоряет научные исследования», — отмечает Екатерина Захариева (Ekaterina Zaharieva), еврокомиссар по стартапам, исследованиям и инновациям.  JUPITER планируется использовать для прогнозирования погоды и моделирования изменений климата, работы с европейскими большими языковыми моделями (LLM) и генеративным ИИ, разработки лекарственных препаратов и картирования человеческого мозга, моделирования молекулярной динамики и пр. Ожидается, что JUPITER сможет побить мировой рекорд по скорости обработки кубитов в квантовых вычислениях.  Между тем продолжается создание блока cCuster. В его состав войдут энергоэффективные высокопроизводительные Arm-процессоры SiPearl Rhea1. Эти чипы содержат 80 ядер Neoverse V1 (Zeus), 64 Гбайт HBM2e и четыре интерфейса DDR5. Модуль cCuster будет оснащён двумя такими процессорами на каждый вычислительный узел, 512 Гбайт DDR5 (в отдельных узлах 1 Тбайт) и одним NDR200-подключением. Общее количество узлов составит около 1300. Ожидаемая FP64-производительность — 5 Пфлопс.  Хранилище суперкомпьютера включает быструю СХД ExaFLASH и ёмкую ExaSTORE. ExaFLASH включает 20 All-Flash СХД IBM Storage Scale 6000: 21 Пбайт («сырая» 29 Пбайт), запись до 2 Тбайт/с, чтение до 3 Тбайт/с. В ExaSTORE под хранение будет выделена «сырая» ёмкость 300 Пбайт, а для резервного копирования и архивов будет использоваться ленточная библиотека ёмкостью 700 Пбайт. 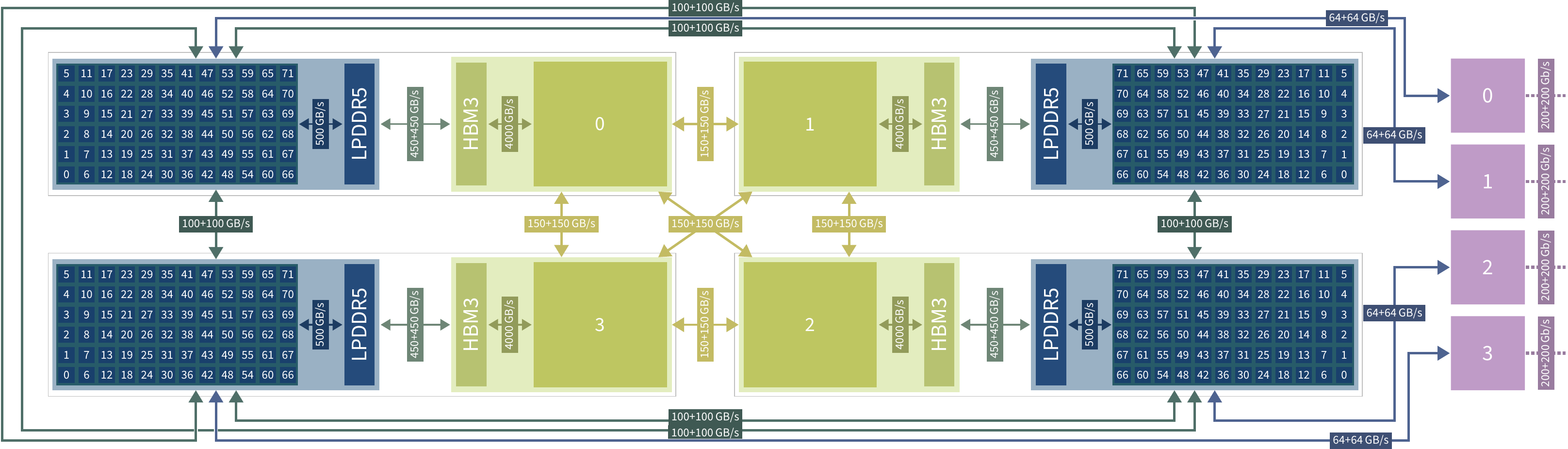
Узел Booster По оценкам, суммарные расходы на JUPITER и его эксплуатацию в течение шести лет достигнут примерно €500 млн. Половину от этой суммы предоставит EuroHPC, а остальную часть покроют Федеральное министерство образования и научных исследований Германии (BMBF) и Министерство культуры и науки земли Северный Рейн-Вестфалия (MKW NRW). Машина размещена в модульном ЦОД, что упростит дальнейшую модернизацию. Нужно отметить, что на сегодняшний день только три суперкомпьютера в мире официально преодолели планку в 1 Эфлопс. Это машины El Capitan, Frontier и Aurora: все они установлены в лабораториях Министерства энергетики США (DoE). Впрочем, Китай о своих HPC-комплексах публично практически не говорит уже несколько лет, так что реальный список экзафлопсных систем гораздо больше.
28.08.2025 [09:28], Владимир Мироненко
ASUS Cloud увеличит вычислительные мощности Тайваня на 50 %, построив 250-Пфлопс ИИ-суперкомпьютерASUS Cloud в партнёрстве с Taiwan AI Cloud (Taiwan Web Service Corp) и Национальным центром высокопроизводительных вычислений Тайваня (National Center for High-performance Computing, NCHC) в Тайнане (Тайвань) построит суперкомпьютер на ускорителях NVIDIA. Об этом сообщил гендиректор ASUS Cloud и Taiwan AI Cloud Питер Ву (Peter Wu, на фото ниже) в интервью газете South China Morning Post (SCMP). Питер Ву рассказал, что суперкомпьютер с начальной производительностью 80 Пфлопс (точность не уточняется) будет работать на 1700 ускорителях NVIDIA H200. Его запуск запланирован на декабрь, а со временем производительность новой системы вырастет до 250 Пфлопс. Ранее сообщалось, что NVIDIA также поставит два суперускорителя GB200 NVL72 и узлы HGX B300 для данной машины. По словам Ву, после запуска суперкомпьютера общая вычислительную мощность HPC-систем Тайваня вырастет минимум на 50 %. В феврале 2025 года Национальный совет по науке и технологиям Тайваня (NSTC) объявил о планах по увеличению общей вычислительной мощности систем страны примерно до 1200 Пфлопс к 2029 году с имеющихся 160 Пфлопс. 
Источник изображения: ASUS Как отметил DataCenter Dynamics, ASUS ранее сотрудничала с NVIDIA в развёртывании суперкомпьютеров на Тайване, включая 9-Плфопс машину Taiwania 2. В 2022 году ASUS и NVIDIA построили на Тайване суперкомпьютер для медицинских исследований. Taiwan AI Cloud уже реализовала аналогичные нынешнему проекты по созданию ИИ-инфраструктуры в других странах. Среди них — ЦОД в Сингапуре, а также объект во Вьетнаме с 200 ускорителями NVIDIA, который строят для государственного оператора Viettel. Этот проект стартовал в начале 2025 года после того, как правительство США одобрило поставку чипов NVIDIA. Ву отметил рост популярности агентного ИИ. Министерство цифровых технологий острова (MODA) «рекомендовало нам предоставить открытую архитектуру с фреймворком агентного ИИ», чтобы помочь местным компаниям использовать или модернизировать свои существующие приложения, сказал он. Говоря о материковом Китае, Питер Ву заявил, что компании будет «непросто» реализовывать там аналогичные проекты «из-за ситуации с поставками GPU». Китайский подход, заключающийся в «стекировании и кластеризации» малопроизводительных чипов для достижения производительности, аналогичной системам с передовыми ИИ-ускорителями, может быть осуществим с точки зрения инференса. Ву отметил, что запуск DeepSeek «рассуждающей» модели R1 в январе спровоцировал рост спроса на инференс, поскольку эта модель превосходно справляется с такими задачами. «Если рабочая нагрузка аналогична [инференсу], будет легче внедрить альтернативную технологическую схему с существующими [чипами]», — сказал Ву, добавив, что разработчики «могут столкнуться с проблемами в выборе GPU», если проект предполагает обучение или тонкую настройку ИИ-систем. Говоря о будущем, Ву сообщил, что ожидает дальнейшего развития трёх сегментов ИИ в будущем: вычислительной геномики, квантовых вычислений и так называемых цифровых двойников. «Приложение-убийца [для цифровых двойников] может появиться в сфере ухода за пожилыми людьми, помогая им получать лекарства, еду или принимать душ», — прогнозирует Ву.
21.07.2025 [16:42], Сергей Карасёв
Запущен самый мощный в Великобритании ИИ-суперкомпьютер — комплекс Isambard-AIВ Великобритании официально введён в эксплуатацию суперкомпьютер Isambard-AI: это самый мощный в стране вычислительный комплекс, ориентированный на задачи ИИ. В июньском рейтинге TOP500 машина занимает 11-е место, а в списке наиболее энергоэффективных систем Green500 — четвёртую позицию. Суперкомпьютер назван в честь британского инженера Изамбарда Кингдома Брюнеля (Isambard Kingdom Brunel), внёсшего значимый вклад в Промышленную революцию. Проект реализован при участии компаний NVIDIA и HPE, Бристольского университета (University of Bristol) и других организаций. Создание Isambard-AI обошлось примерно в £225 млн ($302 млн). В основу комплекса положена платформа HPE Cray EX с интерконнектом Slingshot 11. Задействованы 5448 суперчипов NVIDIA GH200 Grace Hopper, которые объединяют 72-ядерный Arm-процессор NVIDIA Grace и ускоритель NVIDIA H200. Применена СХД Cray ClusterStor E1000 вместимостью 25 Пбайт. Питание полностью обеспечивается от источников энергии с нулевыми выбросами углерода. Избыточное тепло может использоваться для обогрева близлежащих зданий. Развёрнута система прямого жидкостного охлаждения HPE. 
Источник изображений: NVIDIA В тесте Linpack комплекс Isambard-AI демонстрирует FP64-быстродействие на уровне 216,5 Пфлопс, тогда как теоретический пиковый показатель составляет 278,58 Пфлопс. Производительность при решении ИИ-задач достигает 21 Эфлопс (FP8). Как отмечается, Isambard-AI более чем в 10 раз превосходит по скорости второй по быстродействию суперкомпьютер в Великобритании и предоставляет больше вычислительной мощности, чем все остальные НРС-машины страны вместе взятые.  Новый комплекс будет применяться для решения наиболее сложных и ресурсоёмких задач, таких как разработка передовых лекарственных препаратов, моделирование климата, материаловедение, большие языковые модели (LLM) и др. Доступ к ресурсам Isambard-AI регулируется Министерством науки, инноваций и технологий и Департаментом исследований и инноваций Великобритании.
10.07.2025 [17:30], Сергей Карасёв
Bloomberg: Китай строит в пустыне гигантский комплекс ИИ ЦОД для 115 тыс. ускорителей NVIDIA, поставки которых запрещены СШАНа окраине пустыни Гоби в Синьцзяне (автономный район на северо-западе Китая), по сообщению Bloomberg News, ведутся активные работы по строительству кампуса ЦОД для ИИ-задач. Согласно имеющейся информации, в этих дата-центрах будут применяться серверы с ускорителями NVIDIA, поставки которых запрещены в КНР в соответствии с американскими санкциями. Специалисты Bloomberg News проанализировали сведения, содержащиеся в инвестиционных одобрениях, тендерных документах и заявках китайских компаний. Утверждается, что масштабные планы Китая в отношении развития ИИ прямо предусматривают использование «запрещённых» продуктов NVIDIA, а не только местных решений вроде Huawei Ascend. В частности, в IV квартале 2024 года власти Синьцзяна (Xinjiang) и соседней провинции Цинхай (Qinghai) одобрили создание в общей сложности 39 дата-центров, в которых будет задействовано более 115 тыс. ИИ-ускорителей NVIDIA. Причём во всех случаях речь идёт об H100 и H200. Операторы ЦОД в Синьцзяне намерены разместить львиную долю этих ускорителей в одном крупном комплексе, который будет использоваться для обучения передовых ИИ-моделей и других ресурсоёмких нагрузок. Строительные работы организованы в уезде Иу (Yìwū). Сотрудникам Bloomberg News не удалось установить, каким способом китайские компании намерены приобретать изделия NVIDIA, закупки которых запрещены без получения специальных лицензий от правительства США. Местные операторы дата-центров, государственные чиновники и представители центрального правительства в Пекине отказались давать какие-либо комментарии по данному вопросу. Между тем, как отмечается в публикации, стоимость 115 тыс. указанных ИИ-ускорителей может составить миллиарды долларов, исходя из цен на чёрном рынке Китая. 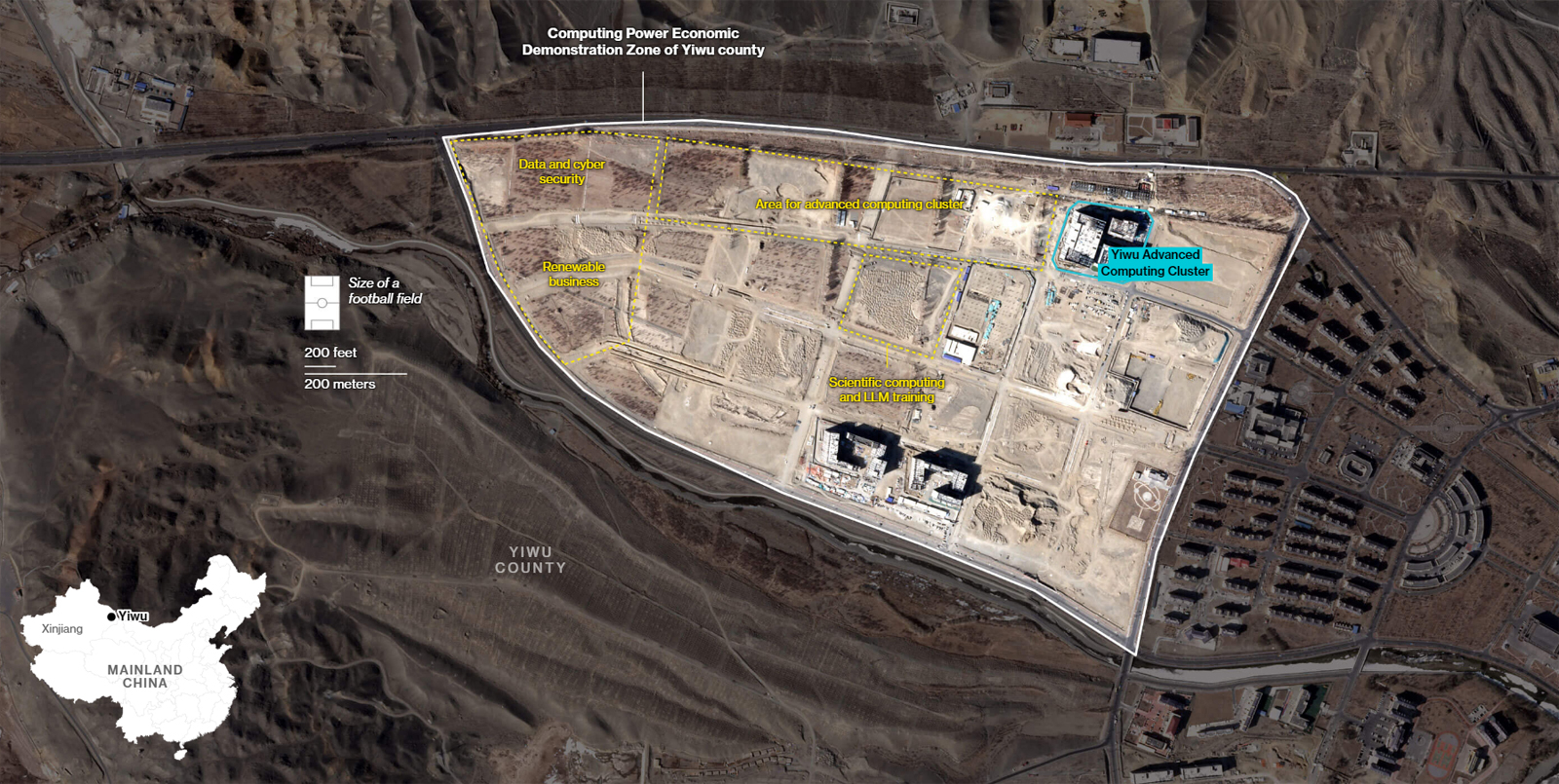
Источник изображения: Bloomberg И всё же строительство комплекса ЦОД продолжается. Синьцзян, и особенно регион Хами (Hāmì), включающий уезд Иу, богаты ветровой и солнечной энергией, а также углём. Это позволит решить вопросы, связанные с энергообеспечением дата-центров. Дополнительными достоинствами выбранного региона являются доступность больших территорий, низкая стоимость земли и прохладный климат в высотных районах. Согласно тендерной документации, полученной Bloomberg, по состоянию на июнь 2025 года по семи проектам ЦОД в Синьцзяне либо начаты строительные работы, либо выиграны тендеры на услуги ИИ-вычислений. В частности, один из крупнейших проектов связан с энергокомпанией Nyocor из Тяньцзиня (Tianjin), которая специализируется на солнечной и ветровой энергетике. Инициатива предусматривает создание дата-центра на базе 625 серверов с ускорителями H100. Nyocor продаёт вычислительные мощности корпорации Infinigence AI — одной из крупнейших организаций в сфере ИИ-инфраструктуры в Китае. В документах по 27 другим проектам ЦОД, одобренным в Синьцзяне и Цинхае в прошлом году, упоминаются в общей сложности более 9 тыс. серверов и около 72 тыс. ускорителей H100/H200. Два высокопоставленных чиновника американской администрации заявили, что по их оценкам, в Китае имеется примерно 25 тыс. запрещенных ИИ-ускорителей NVIDIA: такое количество, как утверждается, не вызывает серьёзного беспокойства. Более того, даже в случае приобретения ещё 115 тыс. карт NVIDIA масштабы соответствующих ИИ-платформ в КНР окажутся несопоставимы с мощью развитой инфраструктурой ИИ в США. Нужно отметить, что за последние годы власти Китая потратили $6,1 млрд на строительство крупных кампусов ЦОД, тогда как ещё $28 млрд вложили частные инвесторы. Площадки дата-центров появились в регионе Внутренняя Монголия, провинциях Нинся, Ганьсу, Гуйчжоу, регионе Пекин-Тяньцзинь-Хэбэй, а также в дельте Янцзы и на других территориях. Однако многие подобные объекты оказались невостребованными из-за переоценённого спроса и архитектурных недоработок.
08.07.2025 [17:09], Владимир Мироненко
Российский суперкомпьютер «Говорун» получил два узла «РСК Экзастрим ИИ» с NVIDIA H100 и фирменной СЖО
emerald rapids
h100
h200
hpc
intel
nvidia
sapphire rapids
xeon
россия
рск
сделано в россии
сервер
суперкомпьютер
ГК РСК продемонстрировала 2U-узел (912 × 508 × 88 мм) собственной разработки «РСК Экзастрим ИИ» на базе восьми ускорителей NVIDIA H100 с прямым жидкостным охлаждением. Два таких узла были установлены в суперкомпьютере «Говорун» в Дубне. «РСК Экзастрим ИИ» включает:
«РСК Экзастрим ИИ» имеет локальную подсистему хранения «тёплых данных», сетевую подсистему с доступом на основе технологии GPUDirect. Также есть возможность расширения ресурсов путём подключения дополнительных пар ускорителей или системы внешнего хранения данных на базе пула JBOF, подключаемой напрямую. Производительность «РСК Экзастрим ИИ» составляет до 208 Тфлопс (FP64). При установке 21 сервера в шкаф «РСК Экзастрим» пиковая производительность достигает 4,26 Пфлопс (FP64). Сервер отличается высокой энергоэффективностью, сверхвысокой плотностью монтажа и надёжной работой. Он может использоваться для решения ресурсоёмких задач в области машинного обучения и ИИ, создания мощных вычислительных ресурсов облачных провайдеров и в частных облаках и т.д. 
Источник изображений: РСК Два узла «РСК Экзастрим ИИ» были установлены в суперкомпьютере «Говорун» в Лаборатории информационных технологий им М.Г. Мещерякова Объединенного института ядерных исследований (ЛИТ ОИЯИ) в Дубне в рамках нового этапа модернизации, проведенной силами специалистов ГК РСК и лаборатории.  Как сообщается, новые серверы «РСК Экзастрим ИИ» уникальны и были сконструированы и изготовлены для СК «Говорун» с учётом его архитектурных особенностей. При этом пиковая FP64-производительность GPU-компоненты суперкомпьютера «Говорун» выросла на 36 % и достигла 1,4 Пфлопс, пиковая суммарная FP64-производительность суперкомпьютера теперь составляет 2,2 Пфлопс. Характеристики серверов «РСК Экзастрим ИИ», установленных в ОИЯИ:
 В конце 2024 года было проведено расширение СХД суперкомпьютера «Говорун», после чего её ёмкость увеличилась до 10 Пбайт. В СХД вычислительного комплекса ОИЯИ были добавлены два узла хранения данных RSC Tornado AFS ёмкостью 1 Пбайт каждый. Обновленная модификация СХД RSC Tornado AFS включает серверную плату на базе процессоров Intel Xeon Sapphire Rapids, а также коммутатор с интерфейсом PCIe 4.0, что позволило установить по два адаптера интерконнекта с пропускной способностью 200 Гбит/с каждый.  СХД RSC Tornado AFS поддерживает технологию GPUDirect Storage (GDS), которая обеспечивает прямую передачу данных между локальным или удалённым хранилищем и памятью ускорителя. Две СХД, установленные ранее специалистами РСК в суперкомпьютере «Говорун» входят в мировой рейтинг IO500 самых высокопроизводительных системам хранения данных. В суперкомпьютере «Говорун» используются интегрированный программный комплекс «РСК БазИС 4» и модуль «РСК БазИС СХД» (включены в Реестр российского ПО). Микроагентная архитектура «РСК БазИС 4» обеспечивает функционирование объектов системы, позволяя также взаимодействовать с ними. «РСК БазИС» в сочетании с аппаратными платформами РСК позволяет создавать гиперконвергентные решения для HPC и эффективной обработки больших объёмов данных.
23.06.2025 [11:58], Сергей Карасёв
Подземный суперкомпьютер Olivia стал самым мощным в НорвегииВ Норвегии введён в эксплуатацию самый мощный в стране суперкомпьютер — система Olivia, созданная корпорацией HPE. Комплекс расположен в дата-центре Лефдаль (Lefdal Mine Datacenter, LMD) на базе бывшего рудника, а для его охлаждения используется холодная вода из близлежащего фьорда. Машина построена на платформе HPE Cray Supercomputing EX (EX254n). В её состав входят 252 узла, каждый из которых содержит два 128-ядерных процессора AMD EPYC 9745 (Turin). В сумме это даёт 64 512 CPU-ядер. Кроме того, задействован GPU-кластер с 76 узлами, оснащёнными четырьмя гибридными суперчипами NVIDIA GH200: таким образом, в общей сложности применены 304 ускорителя. Используется интерконнект HPE Slingshot 11. За хранение данных отвечает система HPE Cray ClusterStor E1000 вместимостью 5,3 Пбайт. В текущей конфигурации GPU-кластер Olivia обладает производительностью 13,2 Пфлопс (FP64) и пиковым быстродействием 16,8 Пфлопс. При этом энергопотребление составляет 219 кВт. Таким образом, машина демонстрирует производительность в 60,274 Гфлопс/Вт. В июньском рейтинге мощнейших суперкомпьютеров мира TOP500 GPU-комплекс Olivia располагается на 117-й позиции, тогда как в списке самых энергоэффективных суперкомпьютеров GREEN500 он занимает 22-ю строку. CPU-блок Olivia занимает 271-е место в рейтинге с фактической и пиковой FP64-производительностью 4,25 и 4,95 Пфлопс соответственно. 
Источник изображения: Sigma2 Olivia эксплуатируется государственной компанией Sigma2. Применять суперкомпьютер планируется для проведения исследований в различных областях, включая изменения климата, здравоохранение, ИИ и пр. Суперкомпьютер обладает возможностями для дальнейшего расширения. В частности, количество ядер CPU может быть увеличено до 119 808. Кроме того, могут быть добавлены ещё 224 ускорителя.
11.06.2025 [09:11], Владимир Мироненко
AWS резко снизила стоимость EC2-инстансов с ускорителями NVIDIA, но только для старых моделейAWS объявила об очередном снижении тарифов на GPU-инстансы, которое, по словам компании, стало регулярной практикой благодаря активной работе над снижением расходов. Впрочем, в период острого дефицита вычислительных мощностей в последние год-два, когда использование ускорителей даже для внутренних нужд было резко ограничено, компания наверняка заработала достаточно, чтобы неоднократно окупить закупку и обслуживание соответствующего «железа». На прошлой неделе была снижена до 45 % стоимость использования инстансов EC2 на базе ускорителей NVIDIA, включая семейства P4 (P4d и P4de на базе A100) и P5 (P5 и P5en на базе H100 и H200 соответственно). Снижение стоимости тарифов On-Demand и Savings Plan распространяется на все регионы, где доступны эти инстансы. На On-Demand — с 1 июня, на Savings Plan — после 4 июня. Savings Plans предлагает гибкую модель ценообразования с низкими ценами на использование вычислений в обмен на обязательство по постоянному объёму использования (измеряется в $/час) в течение 1 года или 3 лет. AWS предлагает два типа Savings Plans:
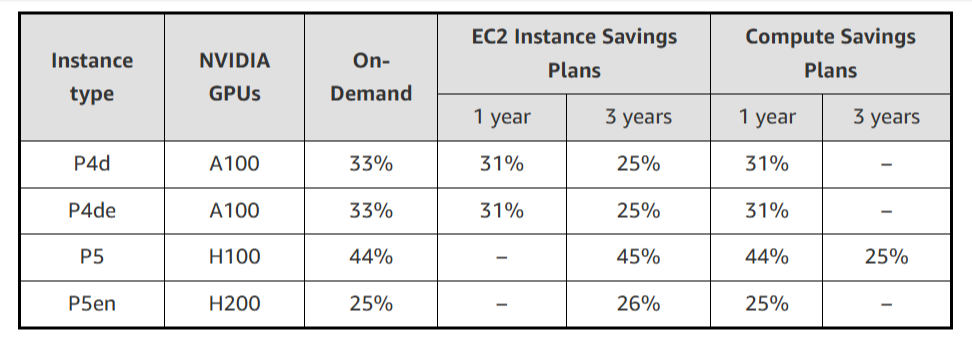
Источник изображения: AWS Чтобы обеспечить повышенную доступность по сниженным ценам, AWS предоставляет масштабируемую ёмкость в рамках тарифа On-Demand для:
Также теперь AWS предлагает инстансы Amazon EC2 P6-B200 в рамках тарифа Savings Plan для поддержки крупномасштабных развёртываний, которые стали доступны 15 мая 2025 года при запуске только через EC2 Capacity Blocks для машинного обучения. Инстансы EC2 P6-B200 на базе ускорителей NVIDIA Blackwell обеспечивают обработку широкого спектра рабочих нагрузок, но особенно хорошо подходят для крупномасштабного распределённого обучения и ИИ-инференса, отметила AWS. |
|

