Материалы по тегу: c
|
10.09.2025 [12:52], Руслан Авдеев
Microsoft уменьшит зависимость от OpenAI, подключив ИИ Anthropic к Office 365Компания Microsoft намерена снизить зависимость от давнего партнёра в лице OpenAI, прибегнув к помощи стартапа Anthropic. В частности, его технологии будут применяться в приложениях Office 365 для реализации новых функций наряду с решениями OpenAI, сообщает TechCrunch со ссылкой на данные источников The Information. Использование конкурентного ИИ в Word, Excel, Outlook и PowerPoint положит конец монополии OpenAI в этой сфере. Ранее Microsoft фактически зависела от разработчика ChatGPT для обеспечения ИИ-функций в своём офисном пакете. Попытки Microsoft диверсифицировать партнёрство в сфере ИИ происходят на фоне растущих разногласий с OpenAI, реализующей собственные инфраструктурные проекты. Кроме того, компания является потенциальным конкурентом LinkedIn, социальная сеть почти десять лет принадлежит Microsoft. Сделка с Anthropic состоялась на фоне переговоров с OpenAI об обновлении соглашения, которое, вероятно, позволит IT-гиганту получать доступ к новейшим технологиям OpenAI и в будущем, даже после реструктуризации последней в коммерческую компанию. Впрочем, по данным The Information, в Microsoft считают, что новейшие модели Anthropic, включая Claude Sonnet 4, фактически лучше решений OpenAI по ряду параметров, например — при создании презентаций PowerPoint. 
Источник изображения: BoliviaInteligente/unsplash.com Это не первый эпизод расширения ИИ-сотрудничества Microsoft. Хотя модели OpenAI предлагаются «по умолчанию», через GitHub Copilot можно получить доступ и к моделям Grok (xAI) и Claude (Anthropic). Также компания не так давно представила и собственные модели — MAI-Voice-1 и MAI-1-preview. OpenAI може стремится выйти из сферы влияния Microsoft. На прошлой неделе компания запустила платформу для поиска работы, способную конкурировать с LinkedIn, а СМИ сообщают, что OpenAI намерена наладить выпуск собственных ИИ-чипов совместно с Broadcom в 2026 году. Другими словами, компания сможет обучать и запускать ИИ-модели на собственном оборудовании, не полагаясь на ресурсы Microsoft Azure. Впрочем, по словам представителя Microsoft, OpenAI продолжит быть партнёром компании в области передовых ИИ-моделей, и техногигант по-прежнему привержен долгосрочному сотрудничеству.
09.09.2025 [15:46], Сергей Карасёв
d-Matrix представила 400GbE-адаптер JetStream для объединения своих ИИ-ускорителейСтартап d-Matrix анонсировал специализированную IO-карту JetStream, предназначенную для распределения нагрузок ИИ-инференса между серверами в дата-центре. Устройство ориентировано на использование в связке с ускорителями d-Matrix Corsair, архитектура которых основана на модифицированных ячейках SRAM для вычислений в памяти (DIMC). JetStream использует стандарт Ethernet, благодаря чему обладает совместимостью с уже существующими коммутаторами. Новинка выполнена в виде платы расширения с интерфейсом PCIe 5.0 х16. Используются корзины QSFP-DD. Могут быть задействованы два 200GbE-порта со скоростью 200 Гбит/с или один 400GbE-порт. Архитектура серверов d-Matrix для ИИ-инференса предполагает установку ускорителей Corsair с DMX-мостом между каждыми двумя такими картами для обеспечения высокой пропускной способности без использования PCIe. Затем пары ускорителей объединяются посредством коммутатора PCIe. В эталонном дизайне один NIC JetStream обслуживает до четырёх экземпляров Corsair. d-Matrix утверждает, что сетевую задержку в такой конфигурации удалось сократить до 2 мкс. 
Источник изображений: d-Matrix По заявлениям d-Matrix, карты JetStream могут применяться в существующих ЦОД без необходимости замены дорогостоящих инфраструктурных компонентов. В связке с ИИ-ускорителями Corsair и ПО d-Matrix Aviator решения JetStream способны справляться с ИИ-моделями, насчитывающими более 100 млрд параметров. При этом, как утверждает разработчик, обеспечивается в 10 раз более высокая производительность, в три раза лучшая экономическая эффективность и втрое большая энергоэффективность по сравнению с решениями на базе GPU. 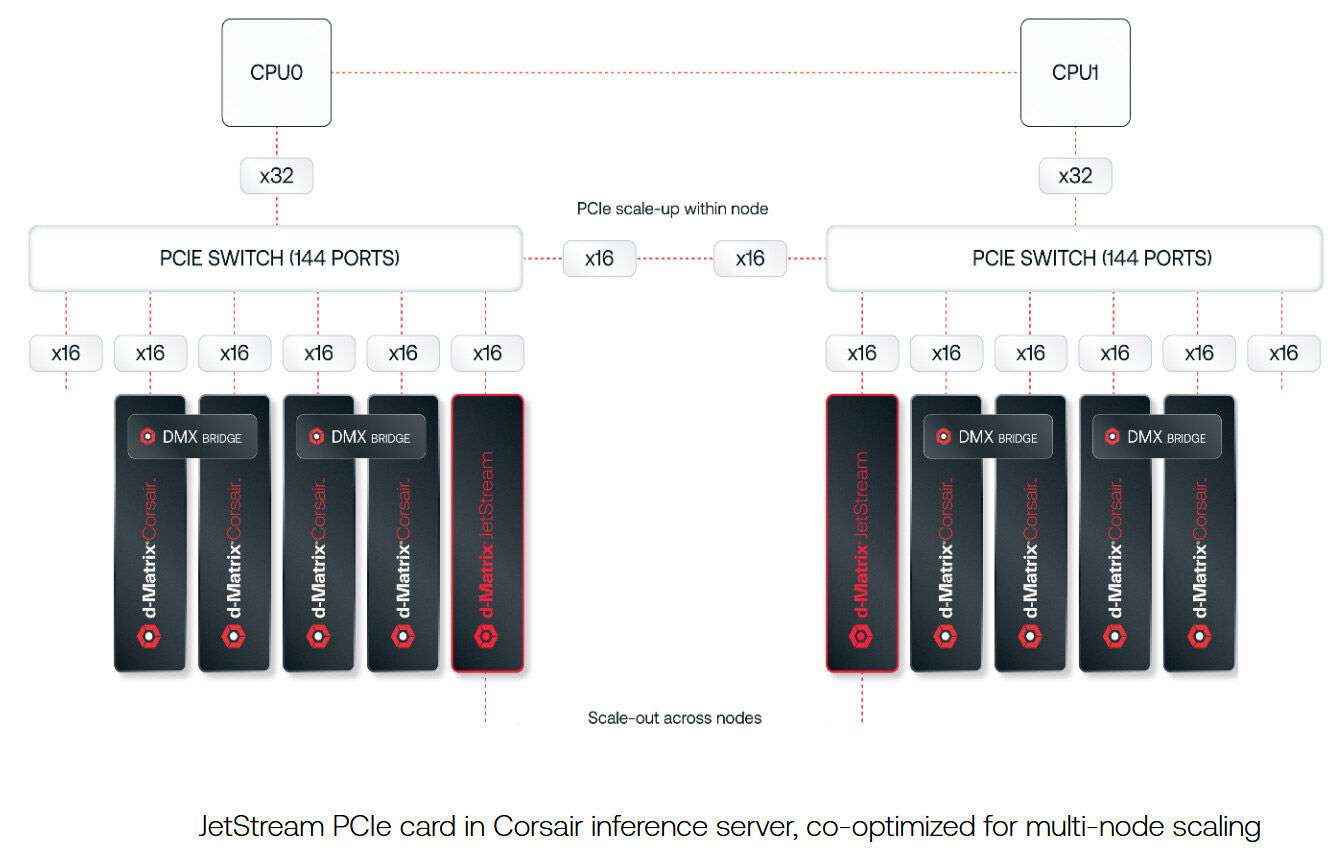 Энергопотребление JetStream составляет около 150 Вт. Адаптер оснащён системой охлаждения с радиатором и тепловыми трубками, которые охватывают зону QSFP-DD. Пробные поставки новинки уже начались, а массовое производство запланировано на конец текущего года.
06.09.2025 [13:42], Сергей Карасёв
Состоялся официальный запуск первого в Европе экзафлопсного суперкомпьютера JUPITERВ Юлихском исследовательском центре (FZJ) в Германии официально введён в эксплуатацию суперкомпьютер JUPITER (Joint Undertaking Pioneer for Innovative and Transformative Exascale Research) — первый в Европе вычислительный комплекс экзафлопсного класса. Система будет использоваться в том числе для исследований в области климата, нейробиологии и квантового моделирования. Контракт на создание JUPITER подписан между Европейским совместным предприятием по развитию высокопроизводительных вычислений (EuroHPC JU) и консорциумом, в который входят Eviden (Atos) и ParTec. Суперкомпьютер состоит из блока Booster для решения ресурсоёмких задач и универсального блока cCuster. В основу Booster положена платформа BullSequana XH3000 с прямым жидкостным охлаждением. Используются около 6000 вычислительных узлов с гибридными ускорителями NVIDIA Quad GH200 и интерконнектом InfiniBand NDR200 (4×200G на узел, DragonFly+). В общей сложности задействованы почти 24 тыс. суперчипов NVIDIA GH200 (Grace Hopper). В июньском рейтинге TOP500 блок JUPITER Booster располагался на четвёртом месте: на тот момент его FP64-производительность составляла 793,4 Пфлопс. Теперь показатель преодолел рубеж в 1 Эфлопс. При этом ИИ-производительность, как ожидается, будет находиться на уровне 90 Эфлопс. 
Источник изображений: Forschungszentrum Jülich / Sascha Kreklau «С запуском первого в Европе эксафлопсного суперкомпьютера мы открываем новую главу в развитии науки, искусственного интеллекта и инноваций. JUPITER укрепляет цифровой суверенитет Европы и ускоряет научные исследования», — отмечает Екатерина Захариева (Ekaterina Zaharieva), еврокомиссар по стартапам, исследованиям и инновациям.  JUPITER планируется использовать для прогнозирования погоды и моделирования изменений климата, работы с европейскими большими языковыми моделями (LLM) и генеративным ИИ, разработки лекарственных препаратов и картирования человеческого мозга, моделирования молекулярной динамики и пр. Ожидается, что JUPITER сможет побить мировой рекорд по скорости обработки кубитов в квантовых вычислениях.  Между тем продолжается создание блока cCuster. В его состав войдут энергоэффективные высокопроизводительные Arm-процессоры SiPearl Rhea1. Эти чипы содержат 80 ядер Neoverse V1 (Zeus), 64 Гбайт HBM2e и четыре интерфейса DDR5. Модуль cCuster будет оснащён двумя такими процессорами на каждый вычислительный узел, 512 Гбайт DDR5 (в отдельных узлах 1 Тбайт) и одним NDR200-подключением. Общее количество узлов составит около 1300. Ожидаемая FP64-производительность — 5 Пфлопс.  Хранилище суперкомпьютера включает быструю СХД ExaFLASH и ёмкую ExaSTORE. ExaFLASH включает 20 All-Flash СХД IBM Storage Scale 6000: 21 Пбайт («сырая» 29 Пбайт), запись до 2 Тбайт/с, чтение до 3 Тбайт/с. В ExaSTORE под хранение будет выделена «сырая» ёмкость 300 Пбайт, а для резервного копирования и архивов будет использоваться ленточная библиотека ёмкостью 700 Пбайт. 
Узел Booster По оценкам, суммарные расходы на JUPITER и его эксплуатацию в течение шести лет достигнут примерно €500 млн. Половину от этой суммы предоставит EuroHPC, а остальную часть покроют Федеральное министерство образования и научных исследований Германии (BMBF) и Министерство культуры и науки земли Северный Рейн-Вестфалия (MKW NRW). Машина размещена в модульном ЦОД, что упростит дальнейшую модернизацию. Нужно отметить, что на сегодняшний день только три суперкомпьютера в мире официально преодолели планку в 1 Эфлопс. Это машины El Capitan, Frontier и Aurora: все они установлены в лабораториях Министерства энергетики США (DoE). Впрочем, Китай о своих HPC-комплексах публично практически не говорит уже несколько лет, так что реальный список экзафлопсных систем гораздо больше.
05.09.2025 [11:39], Сергей Карасёв
AMD готовит суперускоритель Mega Pod с 256 ускорителями Instinct MI500Компания AMD, по сообщению ресурса Tom's Hardware, готовит платформу MI500 Scale Up MegaPod для наиболее ресурсоёмких нагрузок ИИ. Эта система, как ожидается, выйдет в 2027 году и составит конкуренцию стоечным решениям NVIDIA следующего поколения. Известно, что в основу MI500 Scale Up MegaPod лягут 64 процессора EPYC поколения Verano и 256 ускорителей серии Instinct MI500. Для сравнения: платформа AMD Helios, выход которой запланирован на 2026 год, сможет объединять до 72 ускорителей Instinct MI400, тогда как в состав системы NVIDIA NVL576 на основе стойки Kyber войдут 144 ускорителя поколения Rubin Ultra. В конструктивном плане MI500 Scale Up MegaPod, согласно имеющейся информации, будет представлять собой платформу с тремя серверными стойками. В боковых разместятся по 32 вычислительных лотка с одним процессором EPYC Verona и четырьмя ИИ-ускорителями Instinct MI500, тогда как центральная стойка получит 18 лотков, предназначенных для коммутаторов UALink. В целом, в состав системы войдут 64 узла, насчитывающих в общей сложности 256 ускорителей. 
Источник изображения: AMD По сравнению с NVIDIA NVL576 со 144 ускорителями новая платформа AMD обеспечит примерно на 78 % больше карт в расчёте на систему. Однако пока не ясно, сможет ли AMD MI500 Scale Up MegaPod превзойти решение NVIDIA по производительности: NVL576, как ожидается, получит 147 Тбайт памяти HBM4, тогда как быстродействие этой системы будет достигать 14 400 Пфлопс на операциях FP4. Отмечается также, что для AMD MI500 Scale Up MegaPod предусмотрено использование исключительно жидкостного охлаждения — как для вычислительных, так и для сетевых узлов. Предполагается, что система поступит в продажу в конце 2027 года — примерно в то же время, когда, вероятно, дебютирует NVIDIA NVL576.
01.09.2025 [12:05], Сергей Карасёв
Giga Computing представила блейд-серверы B-series на платформах AMD и IntelКомпания Giga Computing, подразделение Gigabyte, объявила о выходе на рынок блейд-серверов, оптимизированных для корпоративных, периферийных и облачных рабочих нагрузок. Первыми системами данного класса стали устройства B343-C40 на аппаратной платформе AMD и B343-X40 с процессорами Intel. Все новинки выполнены в форм-факторе 3U с 10-узловой конфигурацией. Серверы B343-C40 могут комплектоваться чипами EPYC 4005 Grado или Ryzen 9000 с показателем TDP до 170 Вт (один CPU на узел). Доступны четыре слота для модулей оперативной памяти DDR5-5600/3600 в расчете на узел. Каждый из узлов также предлагает слот M.2 2280/22110 для SSD с интерфейсом PCIe 3.0 x1, два посадочных места для SFF-накопителей NVMe/SATA, один разъём для карты расширения FHHL с интерфейсом PCIe 5.0 x16 и три слота OCP NIC 3.0 (PCIe 4.0 x4). В семейство B343-C40 вошли три модификации — B343-C40-AAJ1, B343-C40-AAJ2 и B343-C40-AAJ3, у которых каждый из узлов располагает соответственно двумя портами 1GbE (контроллер Intel I350-AM2), 10GbE (Broadcom BCM57416) и 25GbE (Broadcom BCM57502). Кроме того, во всех случаях предусмотрен выделенный сетевой порт управления 1GbE и контроллер ASPEED AST2600 (на узел). За питание системы в целом отвечают четыре блока мощностью 2000 Вт с сертификатом 80 PLUS Titanium. Диапазон рабочих температур — от +10 до +30 °C. Применяется воздушное охлаждение. 
Источник изображения: Gigabyte В свою очередь, у сервера B343-X40 каждый из узлов может оснащаться одним процессором Xeon 6300 с TDP до 95 Вт. Реализованы четыре слота для модулей DDR5-4400/4000/3600 и два порта 1GbE на основе контроллера Intel I350-AM2 (в расчёте на узел). В остальном технические характеристики аналогичны AMD-версиям. При этом в систему установлены два блока питания мощностью 3200 Вт с сертификатом 80 PLUS Titanium.
28.08.2025 [09:28], Владимир Мироненко
ASUS Cloud увеличит вычислительные мощности Тайваня на 50 %, построив 250-Пфлопс ИИ-суперкомпьютерASUS Cloud в партнёрстве с Taiwan AI Cloud (Taiwan Web Service Corp) и Национальным центром высокопроизводительных вычислений Тайваня (National Center for High-performance Computing, NCHC) в Тайнане (Тайвань) построит суперкомпьютер на ускорителях NVIDIA. Об этом сообщил гендиректор ASUS Cloud и Taiwan AI Cloud Питер Ву (Peter Wu, на фото ниже) в интервью газете South China Morning Post (SCMP). Питер Ву рассказал, что суперкомпьютер с начальной производительностью 80 Пфлопс (точность не уточняется) будет работать на 1700 ускорителях NVIDIA H200. Его запуск запланирован на декабрь, а со временем производительность новой системы вырастет до 250 Пфлопс. Ранее сообщалось, что NVIDIA также поставит два суперускорителя GB200 NVL72 и узлы HGX B300 для данной машины. По словам Ву, после запуска суперкомпьютера общая вычислительную мощность HPC-систем Тайваня вырастет минимум на 50 %. В феврале 2025 года Национальный совет по науке и технологиям Тайваня (NSTC) объявил о планах по увеличению общей вычислительной мощности систем страны примерно до 1200 Пфлопс к 2029 году с имеющихся 160 Пфлопс. 
Источник изображения: ASUS Как отметил DataCenter Dynamics, ASUS ранее сотрудничала с NVIDIA в развёртывании суперкомпьютеров на Тайване, включая 9-Плфопс машину Taiwania 2. В 2022 году ASUS и NVIDIA построили на Тайване суперкомпьютер для медицинских исследований. Taiwan AI Cloud уже реализовала аналогичные нынешнему проекты по созданию ИИ-инфраструктуры в других странах. Среди них — ЦОД в Сингапуре, а также объект во Вьетнаме с 200 ускорителями NVIDIA, который строят для государственного оператора Viettel. Этот проект стартовал в начале 2025 года после того, как правительство США одобрило поставку чипов NVIDIA. Ву отметил рост популярности агентного ИИ. Министерство цифровых технологий острова (MODA) «рекомендовало нам предоставить открытую архитектуру с фреймворком агентного ИИ», чтобы помочь местным компаниям использовать или модернизировать свои существующие приложения, сказал он. Говоря о материковом Китае, Питер Ву заявил, что компании будет «непросто» реализовывать там аналогичные проекты «из-за ситуации с поставками GPU». Китайский подход, заключающийся в «стекировании и кластеризации» малопроизводительных чипов для достижения производительности, аналогичной системам с передовыми ИИ-ускорителями, может быть осуществим с точки зрения инференса. Ву отметил, что запуск DeepSeek «рассуждающей» модели R1 в январе спровоцировал рост спроса на инференс, поскольку эта модель превосходно справляется с такими задачами. «Если рабочая нагрузка аналогична [инференсу], будет легче внедрить альтернативную технологическую схему с существующими [чипами]», — сказал Ву, добавив, что разработчики «могут столкнуться с проблемами в выборе GPU», если проект предполагает обучение или тонкую настройку ИИ-систем. Говоря о будущем, Ву сообщил, что ожидает дальнейшего развития трёх сегментов ИИ в будущем: вычислительной геномики, квантовых вычислений и так называемых цифровых двойников. «Приложение-убийца [для цифровых двойников] может появиться в сфере ухода за пожилыми людьми, помогая им получать лекарства, еду или принимать душ», — прогнозирует Ву.
26.08.2025 [22:13], Руслан Авдеев
IBM и AMD займутся разработкой новых вычислительных архитектур на стыке квантовых и классических подходовAMD и IBM анонсировали разработку нового поколения вычислительных архитектур, в основе которых лежат квантовые компьютеры и HPC-системы. Речь идёт о т.н. «квантово-центричных супервычислениях», сообщает пресс-служба AMD. Команды намерены продемонстрировать первые результаты до конца текущего года. Компании сотрудничают над разработкой масштабируемых, open source платформ, способствующих переосмыслению будущего вычислений с использованием лидерства IBM в сфере квантовых компьютеров и ПО для них, а также ведущей роли AMD в сфере HPC и ИИ-ускорителей. По словам главы IBM Арвинда Кришны (Arvind Krishna), квантовые вычисления со временем позволят «симулировать» реальный мир и представлять информацию принципиально новым способом. Комбинация технологий IBM и AMD позволят построить мощную гибридную модель, оставляющую позади традиционные вычисления. В новой архитектуре квантовые компьютеры будут работать в тандеме с HPC-кластерами и ИИ-инфраструктурой с использованием CPU, ИИ-ускорителей и прочих вычислительных модулей. При таком гибридном подходе различные части задачи решаются оптимальным для них типом оборудования. Например, в будущем квантовые компьютеры смогут моделировать поведение атомов и молекул, а классические ИИ-суперкомпьютеры — анализировать большие массивы данных. Вместе эти технологии смогут решать реальные задачи в беспрецедентном масштабе и с беспрецедентной скоростью, говорят компании. 
Источник изображения: Yue WU/unsplash.com Компании изучают способы интеграции CPU, FPGA и ИИ-ускорителей AMD с квантовыми компьютерами IBM для совместного ускорения выполнения принципиально новых алгоритмов. Ключевым планом сотрудничества является разработка систем коррекции ошибок, что является важнейшим шагом на пути к созданию отказоустойчивых квантовых компьютеров, которые IBM планирует выпустить к 2030 году. Также компании планируют изучить, как именно open source решения вроде Qiskit могли бы выступить катализаторами развития и внедрения новых алгоритмов, использующих квантово-центричные супервычисления. IBM уже начала работать в направлении интеграции квантовых и традиционных систем. Недавно она заключила соглашение с японским НИИ RIKEN о подключении своего модульного квантового компьютера IBM Quantum System Two к одному из самых быстрых суперкомпьютеров мира Fugaku. Суперкомпьютеры Frontier в Ок-Риджской национальной лаборатории (ORNL) и El Capitan в Ливерморской национальной лаборатории (LLNL) полагаются на CPU и ускорители AMD. Другими словами, на чипах AMD работают два из быстрейших суперкомпьютеров из мирового рейтинга TOP500.
22.08.2025 [13:30], Алексей Разин
NVIDIA поможет японцам создать один из мощнейших суперкомпьютеров мира FugakuNEXTВ начале этого десятилетия созданный в Японии суперкомпьютер Fugaku пару лет удерживался на верхней строчке в рейтинге мощнейших систем мира TOP500, он и сейчас занимает в нём седьмое место. В попытке технологического реванша японский исследовательский институт RIKEN доверился компании NVIDIA, которая поможет Fujitsu создать суперкомпьютер Fugaku NEXT. Помимо Arm-процессоров Fujitsu MONAKA-X, в основу нового японского суперкомпьютера лягут и ускорители NVIDIA, хотя изначально планировалось обойтись без них. NVIDIA будет принимать непосредственное участие в интеграции своих компонентов в суперкомпьютерную систему, создаваемую японскими партнёрами. По меньшей мере, скоростные интерфейсы, которыми располагает NVIDIA, пригодятся для обеспечения быстрого канала передачи информации между CPU и ускорителями. Сама NVIDIA обтекаемо говорит, что для этого можно задействовать шину NVLink Fusion. С ускорителями AMD, по-видимому, эти процессоры будут общаться более традиционно, т.е. по шине PCIe. 
Источник изображений: Fujitsu Кроме того, NVIDIA собирается применить в составе данной системы передовые типы памяти. Применяемые при создании FugakuNEXT решения, по мнению представителей NVIDIA, смогут стать типовыми для всей отрасли в дальнейшем. Подчёркивается, что будущая платформа станет не просто техническим апгрейдом, а инвестицией в будущее страны.  Сама архитектура системы не уточняется, поэтому сложно судить, насколько активно японские разработчики будут использовать ускорители NVIDIA, и к какому поколению они будут относиться. Создатели ставят перед собой амбициозные цели — FugakuNEXT должна стать первой системой «зетта-масштаба». Своего предшественника она должна превзойти более чем в пять раз, обеспечив быстродействие на уровне 600 Эфлопс (FP8). 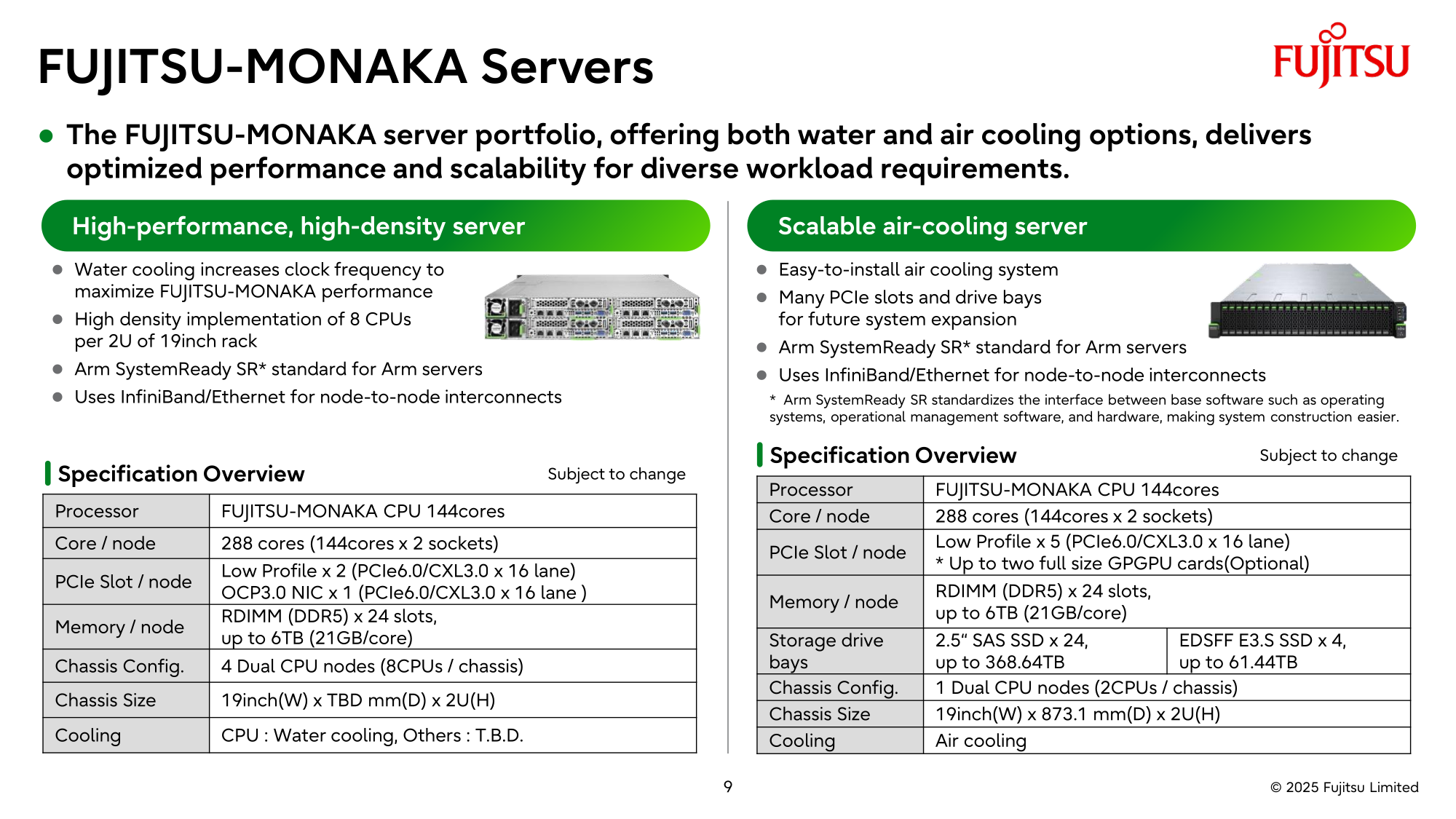 На уровне приложений прирос быстродействия может быть стократным, отмечают создатели. Новый суперкомпьютер сможет применяться для обучения больших языковых моделей. Впрочем, в строй он будет введён лишь к 2030 году, а Fujitsu ещё только предстоит выпустить свои процессоры MONAKA-X для этой системы.
20.08.2025 [11:13], Сергей Карасёв
SSSTC представила SSD серии CA8 — первые на рынке индустриальные M.2-накопители с памятью Kioxia BiCS Flash восьмого поколенияКомпания Solid State Storage Technology Corporation (SSSTC) анонсировала SSD семейства CA8, предназначенные для применения в интеллектуальных устройствах интернета вещей, платформах промышленной автоматизации, периферийных компьютерах, автомобильных системах и пр. По заявлениям SSSTC, изделия CA8 — это первые на рынке индустриальные устройства M.2 2280 с памятью Kioxia BiCS Flash восьмого поколения. Применены 218-слойные флеш-чипы 3D TLC NAND с технологией CBA (CMOS direct Bonded to Array), которая, как утверждается, существенно повышает энергоэффективность, производительность и плотность хранения данных по сравнению с решениями предыдущего поколения. 
Источник изображения: SSSTC В серию CA8 вошли модели вместимостью 512 Гбайт, а также 1, 2 и 4 Тбайт. Для подключения служит интерфейс PCIe 5.0 х4 (NVMe 2.0). Заявленная скорость последовательного чтения информации достигает 14 000 Мбайт/с, скорость последовательной записи — 12 000 Мбайт/с. Величина IOPS (операций ввода/вывода в секунду) составляет до 2 млн при произвольном чтении и 1,6 млн при произвольной записи: это, как подчеркивается, одни из самых высоких значений для индустриальных SSD, доступных на рынке. Диапазон рабочих температур простирается от 0 до +85 °C. Значение MTBF (средняя наработка на отказ) превышает 3 млн часов. Упомянута поддержка AES-256 и TCG Opal. Функция Power Loss Notification (PLN) предотвращает повреждение данных при неожиданных отключениях питания. Накопители способны выдерживать более одной полной перезаписи в сутки (1 DWPD) на протяжении пяти лет.
17.08.2025 [14:15], Сергей Карасёв
Inspur разработала СЖО для мегаваттных стоек с 3-кВт ИИ-ускорителямиКитайская компания Inspur Information представила передовую систему двухфазного жидкостного охлаждения для ИИ-платформ следующего поколения, таких как суперускоритель Metabrain SD200. Решение может использоваться для отвода тепла от серверных стоек мегаваттного класса. Inspur отмечает, что из-за стремительного развития ИИ наблюдается тенденция к повышению плотности вычислений. Это приводит к быстрому увеличению энергопотребления стоек с серверным оборудованием. Различные компании, такие как Aligned, JetCool и CyrusOne, разрабатывают решения для стоек мощностью 300 кВт, тогда как крупные ЦОД-операторы и гиперскейлеры готовятся к появлению мегаваттных установок. В таких условиях возможностей стандартных систем охлаждения становится недостаточно. 
Источник изображения: Inspur Двухфазная СЖО Inspur способна охлаждать кристаллы мощностью более 3000 Вт, тогда как показатель теплосъёма превышает 250 Вт на квадратный 1 см2. Благодаря изоляции хладагента предотвращается коррозия, что сводит к минимуму риск коротких замыканий, снижает износ и отказы компонентов, говорит компания. Ключевыми преимуществами новой СЖО названы надёжность и долговечность, отсутствие утечек, простота эксплуатации, безопасная работа IT-оборудования, а также уменьшение общей стоимости владения по сравнению с другими аналогичными решениями. При разработке системы специалистам Inspur Information удалось преодолеть узкие места управления температурой и давлением фазового перехода, а также решить проблемы дисбаланса потока и перегрева во время скачков нагрузки: утверждается, что в конфигурации с 200 чипами отклонение распределения потока составляет менее 10 %, а разница температур — менее 2 °C. Применяется специально разработанный хладагент низкого давления, который безопасен для окружающей среды. Несмотря на отсутствие риска утечки, рабочее давление системы составляет менее 1 МПа. |
|

