Материалы по тегу: c
|
24.07.2023 [14:58], Сергей Карасёв
Компания CIQ, поддерживающая Rocky Linux, анонсировала партнёрскую программу для ускорения внедрения НРС и ИИКомпания CIQ официально объявила о запуске партнёрской программы (CIQ Partner Program), ориентированной на объединение поставщиков облачных услуг, интеграторов, реселлеров и OEM-производителей. Основная цель заключается в ускорении внедрения НРС-решений и ИИ. Программа направлена на содействие сотрудничеству и создание развитой отраслевой экосистемы, основанной на инструментах с открытым исходным кодом, таких как Rocky Linux, Apptainer и Warewulf. Объединив усилия с CIQ, партнёры могут открыть новые возможности и получить доступ к ресурсам, которые позволят им предоставлять заказчикам наиболее эффективные решения. На сегодняшний день инициативу CIQ поддержали приблизительно 35 компаний и организаций. В их число входят AWS, Microsoft Azure, Google Cloud, Oracle Cloud, HPE, Dell, Penguin Computing, ALT Systems, Racklive, Zmanda, Graid Technology, Zenlayer и др. Среди ключевых преимуществ партнёрской программы называются: регистрация сделок, обучение специалистов отдела продаж, каталог партнёров, улучшение маркетинговых возможностей, обмен опытом и пр. 
Источник изображения: CIQ Партнёры CIQ имеют возможность использовать передовые инструменты с открытым исходным кодом для решения задач своих клиентов. В целом, как отмечается, инициатива ориентирована на организации, которые готовы сотрудничать, вносить свой вклад и создавать значимые решения в экосистеме с открытым исходным кодом. Нужно отметить, что главой CIQ является Грегори Курцер (Gregory Kurtzer). Он хорошо известен благодаря разработке масштабируемых и простых в управлении безопасных инфраструктурных платформ для HPC. Курцер основал несколько крупных проектов с открытым исходным кодом, таких как CentOS, Warewulf и Perceus, а также Rocky Linux.
23.07.2023 [14:57], Сергей Карасёв
ВМС США обзаведутся 17,7-Пфлопс суперкомпьютером Blueback с ускорителями AMD Instinct MI300AМинистерство обороны США (DoD) объявило о планах по развёртыванию новой суперкомпьютерной системы в рамках Программы модернизации высокопроизводительных вычислений (HPCMP). Комплекс получил название Blueback — в честь американской подводной лодки USS Blueback (SS-581). Сообщается, что Blueback расположится в Центре суперкомпьютерных ресурсов в составе DoD (Navy DSRC), который находится в ведении Командования морской метеорологии и океанографии (CNMOC). Суперкомпьютер заменит три старых вычислительных комплекса в экосистеме HPCMP. Основой Blueback послужит платформа HPE Cray EX4000. Архитектура включает процессоры AMD EPYC Genoa, 128 гибридных ускорителей AMD Instinct MI300A (APU) и 24 ускорителя NVIDIA L40, связанных между собой 200G-интерконнектом Cray Slingshot-11. В состав комплекса войдёт Lustre-хранилище Cray ClusterStor E1000 вместимостью 20 Пбайт, включая 2 Пбайт пространства на базе SSD NVMe. Объём системной памяти — 538 Тбайт. Общее количество вычислительных ядер будет достигать 256 512. 
Источник изображения: Jonathan Holloway / DoD Ожидается, что суперкомпьютер Blueback будет введён в эксплуатацию в 2024 году. Кстати, совсем недавно центр Navy DSRC получил НРС-систему Nautilus производительностью 8,2 Пфлопс. Она содержит 176 128 ядер и 382 Тбайт памяти.
23.07.2023 [13:40], Руслан Авдеев
В США введут добровольную маркировку Cyber Trust Mark для безопасных устройств Интернета вещей и умного домаФедеральная комиссия по связи (FCC) США совместно с Национальным институтом стандартов и технологий (NIST) представили национальную маркировку для безопасных устройств Интернета вещей. По данным портала CNX-Software, т.н. U.S. Cyber Trust Mark позволит покупателям выбирать компоненты для Интернета вещей и/или умного дома, соответствующие высоким стандартам безопасности. Проблема низкого уровня защищённости IoT носит критический характер, поскольку такая электроника часто отвечает за важнейшие элементы инфраструктуры — удалённое и/или автоматизированное управление электропитанием, водоснабжением, системами безопасности. Неоднократно поднимался вопрос нежелательности поставки таких устройств с логинами и паролями по умолчанию, ставились вопросы об уязвимостях в инструментах разработчиков, незащищённой передаче данных и прочих проблемах. При этом никаких достоверных данных о безопасности конкретного подключаемого модуля у пользователей обычно нет. Ожидается, что введение Cyber Trust Mark поможет исправить ситуацию хотя бы в США. Проверка и маркировка устройств для производителей будет добровольной. В проекте участвуют техногиганты вроде Amazon, Google, Samsung, Logitech, LG Electronics и даже розничная сеть Best Buy. Поддержку выразили некоторые представители полупроводниковой отрасли, например, Infineon Technologies. 
Источник изображения: FCC Так, покупателю гарантируется, что уровень безопасности маркированных устройств соответствует стандартам, заданным руководством NISTIR 8425 для разработчиков и интеграторов IoT-решений. Более того, поскольку у такой электроники часто меняется прошивка, маркировка будет дополняться QR-кодом для проверки обновлений ПО. Устройства с U.S Cyber Trust Mark будут вноситься в специальный реестр электроники, соответствующей американским стандартам кибербезопасности, в котором можно будет также проверить актуальность информации. До того, как товары с подобной маркировкой появятся в магазинах, пройдёт ещё некоторое время. Инициативу должны поддержать голосованием в Федеральной комиссии по связи, после чего она пройдёт стадию публичного рассмотрения — только после этого маркировку начнут применять на упаковке и товарах в конце 2024 года.
22.07.2023 [14:57], Сергей Карасёв
Tesla начала создание ИИ-суперкомпьютера Dojo стоимостью $1 млрдКомпания Tesla, по сообщению The Register, до конца 2024 года потратит более $1 млрд на создание мощного вычислительного комплекса Dojo, который поможет в разработке инновационных технологий для роботизированных автомобилей. В основу Dojo лягут специализированные чипы собственной разработки — Tesla D1. 25 таких ускорителей в виде массива 5 × 5 объединяются в рамках одного узла, который в Tesla называют «системой на пластине» (System On Wafer). Как отмечает The Verge, компания Tesla намерена совместить в одном шасси шесть таких «систем на пластине», тогда как одна стойка будет включать два шасси. В такой конфигурации производительность на стойку превысит 100 Пфлопс (BF16/CFP8). Таким образом, система из десяти шкафов позволит преодолеть экзафлопсный барьер. Более того, уже к концу следующего года, по словам главы Tesla Илона Маска, производительность может быть доведена до 100 Эфлопс. 
Источник изображения: Tesla В своём отчете за II квартал 2023 года Tesla обозначила «четыре основных технологических столпа», необходимых для решения проблемы автономности транспортных средств: это чрезвычайно большой набор реальных данных, обучение нейронных сетей, аппаратные компоненты и ПО. «Мы разрабатываем каждый из этих столпов собственными силами. В этом месяце мы делаем ещё один шаг к более быстрому и дешёвому обучению нейронной сети с началом производства нашего суперкомпьютера Dojo», — говорится в заявлении компании.
21.07.2023 [15:35], Сергей Карасёв
NVIDIA, подвинься: Cerebras представила 4-Эфлопс ИИ-суперкомпьютер Condor Galaxy 1 и намерена построить ещё восемь таких жеКомпания Cerebras Systems анонсировала суперкомпьютер Condor Galaxy 1 (CG-1), предназначенный для решения ресурсоёмких задач с применением ИИ. Это одна из первых действительно крупных машин на базе уникальных чипов Cerebras. В проекте стоимостью $100 млн приняла участие холдинговая группа G42 из ОАЭ, которая занимается технологиями ИИ и облачными вычислениями. G42 является основным заказчиком комплекса. В текущем виде комплекс CG-1, расположенный в Санта-Кларе (Калифорния, США), объединяет 32 системы Cerebras CS-2 и обеспечивает производительность на уровне 2 Эфлопс (FP16). В IV квартале ткущего года будут добавлены ещё 32 системы Cerebras CS-2, что позволит довести быстродействие до 4 Эфлопс (FP16). Ожидаемый уровень энергопотребления составит порядка 1,5 МВт или более. 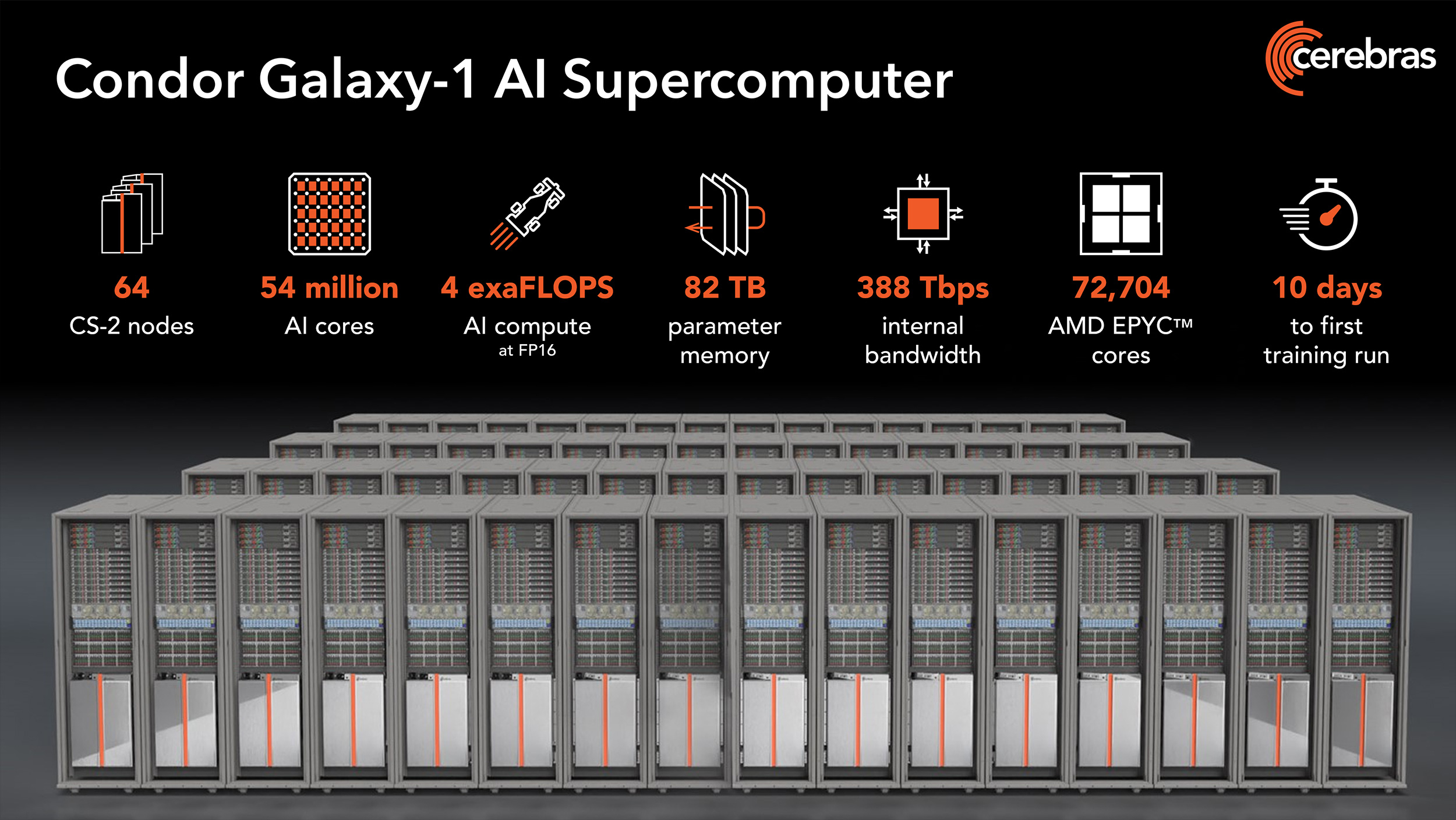
Источник изображений: Cerebras (via ServeTheHome) В системах Cerebras CS-2 применяются гигантские чипы Wafer-Scale Engine 2 (WSE-2), насчитывающие 2,6 трлн транзисторов. Такие чипы имеют 850 тыс. тензорных ядер и несут на борту 40 Гбайт памяти SRAM. Системы выполнены в формате 15 RU и укомплектованы шестью блоками питания мощностью 4 кВт каждый. Задействована технология жидкостного охлаждения. Отдельно отмечается, что программный стек позволит без проблем и существенных модификаций кода работать с ИИ-моделями.  После ввода в строй второй очереди комплекс CG-1 суммарно получит 54,4 млн ИИ-ядер, 2,56 Тбайт SRAM и внутренний интерконнект со скоростью 388 Тбит/с. Их дополнят 72 704 ядра AMD EPYC Milan и 82 Тбайт памяти для хранения параметров. По словам создателей, мощностей суперкомпьютера хватит для обучения модели с 600 млрд параметров и на очередях длиной до 50 тыс. токенов. При этом производительность масштабируется практически линейно.  Cerebras и G42 будут предоставлять доступ к CG-1 по облачной схеме, что позволит заказчикам использовать ресурсы ИИ-суперкомпьютера без необходимости управлять моделями или распределять их по узлам и ускорителям. CG-1 — первый из трёх ИИ-суперкомпьютеров нового поколения. В I полугодии 2024 года будут построены комплексы CG-2 и CG-3, полностью аналогичные CG-1, которые будут объединены в распределённый ИИ-кластер. А к концу следующего года у Cerebras будет уже девять систем CG.  Для Cerebras это означает, что компания более не является стартапом, поскольку в её решения заказчики поверили и без участия в индустриальных тестах вроде MLPerf. Кроме того, теперь компания является не просто очередным производителем «железа», а предоставляет услуги, которые и помогут ей заработать в будущем.
20.07.2023 [23:30], Игорь Осколков
AMD, Broadcom, Cisco, Intel и другие вендоры создадут интерконнект Ultra Ethernet для HPC и ИИAMD, Arista, Broadcom, Cisco, Eviden (Atos), HPE, Intel, Meta✴ и Microsoft в рамках Linux Foundation сформировали новый консорциум Ultra Ethernet Consortium, который намерен создать на базе Ethernet новый масштабируемый и эффективный с точки зрения стоимости коммуникационный стек, ориентированный на высокопроизводительные вычисления (HPC) и ИИ. Иными словами, речь идёт о создании спецификаций интерконнекта нового поколения на базе Ethernet для современных кластеров, облаков и иных платформ. UEC сформировал четыре рабочих группы, ответственных за физический, канальный и транспортный уровни, а также за уровень ПО. Целью же является создание современного сетевого стека, который учитывает потребности HPC- и ИИ-нагрузок, включая новые методы борьбы с заторами в сети, высокий уровень утилизации канала (в том числе 800G/1.6T), многопутевую и гарантированную доставку, сквозную телеметрию, консистентность и низкий уровень задержек, автоматизацию, безопасность и защищённость, масштабируемость, стабильность, надёжность, снижение TCO и так далее. 
Источник: Ultra Ethernet Consortium Фактически отдельные вендоры уже наделили рядом перечисленных свойств свои продукты, однако унификация и объединение усилий, как считается, должны пойти на пользу всем. Всем, кроме, по-видимому, NVIDIA, которой в списке основателей UEC нет (как и Marvell, к слову). NVIDIA после поглощения Mellanox фактически стала монополистом на рынке InfiniBand, который она активно продвигает, не забывая, впрочем, и о своём проприетарном интерконнекте NVLink, который в последней своей версии выбрался за пределы узла. Справедливости ради — про Ethernet компании тоже не забывает. В обзоре UEC аккуратно критикуется и InfiniBand, и его адаптация в виде RoCE. Авторы указывают на правильность и успешность идеи RDMA, но жалуются на не слишком высокую практичность и удобство современных реализаций. И именно поэтому они первым делом предлагают внедрить новый транспортный протокол Ultra Ethernet Transport (UET), который и позволит реализовать интерконнект будущего, а заодно ещё раз доказать эффективность и гибкость технологии Ethernet, которой в этом году исполнилось 50 лет. Впрочем, это только один из кирпичиков UEC. Примечательно, что первые продукты на базе новых спецификаций обещали показать уже в 2024 году.
20.07.2023 [17:35], Алексей Степин
К2Тех развернула в Новосибирском университете 47-Тфлопс суперкомпьютер с российским интерконнектом «Ангара»
a100
hardware
hpc
ice lake-sp
intel
nvidia
xeon
ангара
к2тех
новосибирск
россия
сделано в россии
суперкомпьютер
Компания K2Tex объявила о создании суперкомпьютерного вычислительного комплекса для центра Центра Национальной технологической инициативы (НТИ) по Новым функциональным материалам на базе Новосибирского государственного университета (НГУ). 
Источник здесь и далее: Новосибирский государственный университет Новый кластер базируется на отечественных вычислительных узлах, и что немаловажно, объединён интерконнектом российской же разработки — речь идёт о решении «Ангара», созданном АО «НИЦЭВТ». В данном случае используется вариант с пропускной способностью 75 Гбит/с на линк с подключением через неблокирующий коммутатор и модуль синхронизации. С помощью этого же интерконнекта подключено и внешнее NFS-хранилище, состоящее из двух выделенных серверов с дисковой полкой, оснащённой 24 дисками SAS (2,4 Тбайт, 10k RPM). Ёмкость хранилища — не менее 40 Тбайт. Сами вычислительные узлы построены на базе Intel Xeon Scalable Ice Lake-SP: каждый узел содержит по паре 28-ядерных процессоров, 256 Гбайт RAM и пару локальных 480-Гбайт SSD. Отдельный GPU-узел включает пару ускорителей NVIDIA A100 (80GB). Всего в системе 11 узлов, а общее количество доступных для вычислений процессорных ядер составляет 392. Заявленный пиковый уровень производительности достигает 47 Тфлопс (FP64).  Также в системе задействована отечественная платформа виртуализации zVirt, развёрнутая на двух управляющих узлах кластера. На основе zVirt реализованы средства автоматического развёртывания, подсистема входа пользователей, сервис планировщика заданий, средства аутентификации и мониторинга. Новый кластер потребовался для решения стратегических задач, в том числе для разработки новых материалов с заданными свойствами, в частности, композиционных электрохимических покрытий, перспективных магнитных материалов и огнеупорных материалов. Также новый суперкомпьютер будет использоваться в ключевых проектах, связанных с ИИ и машинным обучением. Сюда входит, например, разработка цифровых паспортов для материалов и создание цифровых двойников технологических процессов.
19.07.2023 [22:03], Илья Коваль
Ядер много не бывает: первые тесты AMD EPYC Genoa-X и Bergamo показали почти безоговорочную победу над Intel Xeon Sapphire Rapids и Xeon MaxВ Сети появились первые тесты процессоров AMD EPYC Genoa-X и Bergamo, которые были представлены в конце мая. Первый из них является вариантом Genoa с 3D V-Cache объёмом 768 Мбайт в максимальной конфигурации с 96 ядрами, что в сумме даёт 1152 Мбайт L3-кеша на процессор. Второй же предлагает до 128 ядер Zen4c с пониженной частотой и урезанным кешем и оптимизирован для нужд гиперскейлеров. Так, согласно тестам Phoronix, в HPC- и ИИ-бенчмарках, на которые Genoa-X и ориентирован, 9684X в стандартном режиме в среднем обгоняет и обычные Genoa 9654 с «открученными» лимитами (cTDP 400 Вт), и Milan-X (7773X), и Xeon Sapphire Rapids (8490H), и Xeon Max (9480). Отдельно отмечается прирост производительности в сравнении с Milan-X, при этом разница между чипами составляет менее двух лет. 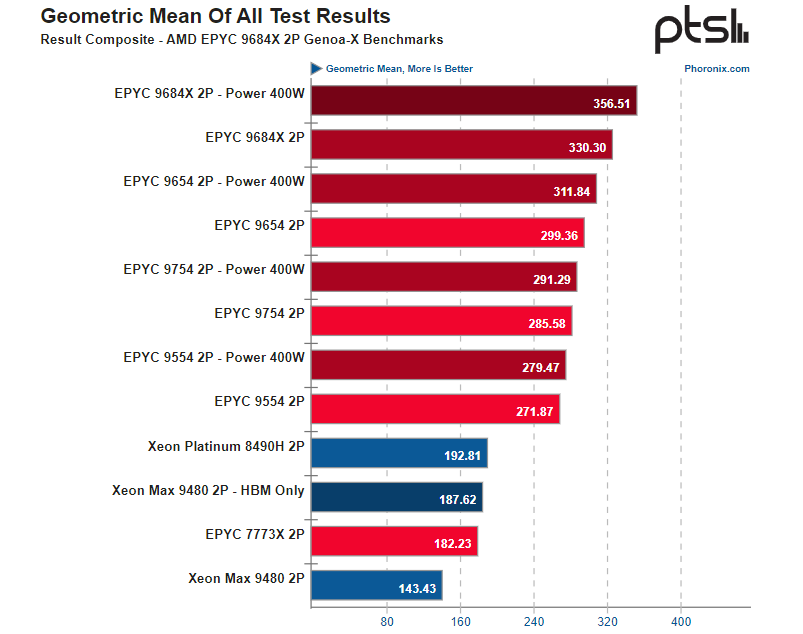
Источник: Phoronix Что касается Intel Xeon Max, которые благодаря набортной памяти HBM2e объёмом 64 Гбайт как раз должны составлять конкуренцию Genoa-X в «тяжёлых» задачах, из-за значительного меньшего количества ядер тягаться с EPYC могут далеко не всегда и показывают хорошие результаты в режиме HBM-only (без системной DDR5). Но это касается только задач, которым хватает набортной памяти, и отдельных (пока редких) нагрузок, которые заранее оптимизированы для актуальной платформы Intel и, например, умеют задействовать инструкции AMX для ИИ-вычислений. 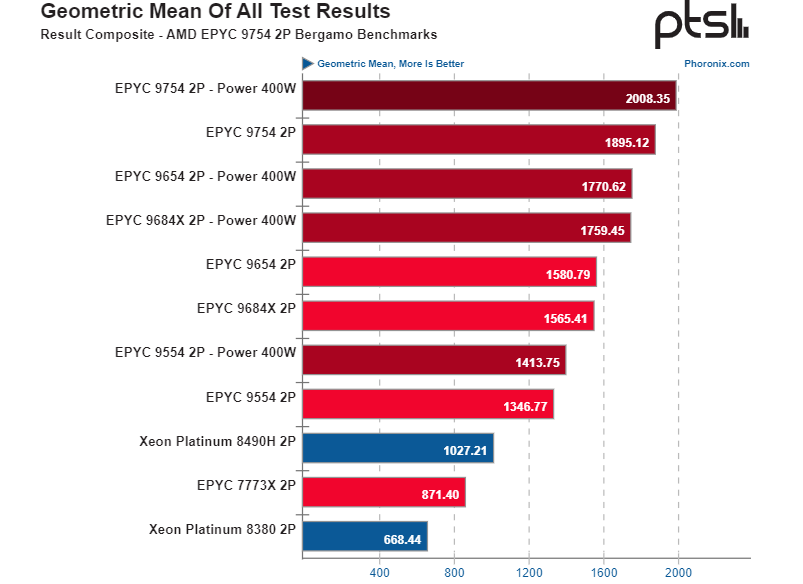
Источник: Phoronix В этих же тестах был ещё один участник — EPYC 9754 (Bergamo). В нетипичных для него нагрузках он всё равно показал достойный результат, всё же 128 ядер — это 128 ядер. В ещё одном тестировании Phoronix он обогнал всех прочих участников, показав прирост на уровне 20 % в сравнении со старшим Genoa(-X) в нагрузках, которые хорошо распараллеливаются. При этом он оказался энергоэффективнее и своих собратьев с ядрами Zen4, и Intel Xeon. Так что этот чип действительно будет интересен облачным провайдерам, но не только им. Это отлично решение для рендера и некоторых расчётных нагрузок. Intel сейчас не в состоянии противопоставить что-либо Bergamo, но гораздо интереснее увидеть сравнение новинок с AmpereOne. Пока что ServeTheHome отмечает значительное превосходство Bergamo над процессорами Ampere Altra Max, которые тоже имеют 128 ядер, но Arm и без SMT.
18.07.2023 [22:45], Сергей Карасёв
Суперкомпьютер в стойке: GigaIO SuperNODE позволяет объединить 32 ускорителя AMD Instinct MI210Компания GigaIO анонсировала HPC-систему SuperNODE, предназначенную для решения ресурсоёмких задач в области генеративного ИИ. SuperNODE позволяет связать воедино до 32 ускорителей посредством компонуемой платформы GigaIO FabreX. Архитектура FabreX на базе PCI Express, по словам создателей, намного лучше InfiniBand и NVIDIA NVLink по уровню задержки и позволяет объединять различные компоненты — GPU, FPGA, пулы памяти и пр. SuperNODE даёт возможность более эффективно использовать ресурсы, нежели в случае традиционного подхода с ускорителями в составе нескольких серверов. В частности для SuperNODE доступны конфигурации с 32 ускорителями AMD Instinct MI210 или 24 ускорителями NVIDIA A100 с хранилищем ёмкостью до 1 Пбайт. При этом платформа компактна, энергоэффективна (до 7 кВт) и не требует дополнительной настройки перед работой. 
Источник изображений: GigaIO Поскольку приложения с большими языковыми моделями требуют огромных вычислительных мощностей, технологии, которые сокращают количество необходимых обменов данными между узлом и ускорителем, имеют решающее значение для обеспечения необходимой скорости выполнения операций при снижении общих затрат на формирование инфраструктуры. Что немаловажно, платформ, по словам разработчиков, демонстрирует хорошую масштабируемость производительности при увеличении числа ускорителей. 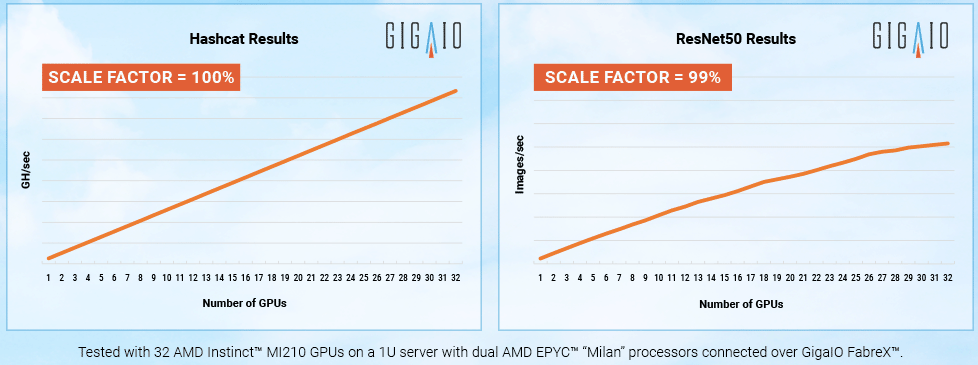 «Система SuperNODE, созданная GigaIO и работающая на ускорителях AMD Instinct, обеспечивает привлекательную совокупную стоимость владения как для традиционных рабочих нагрузок HPC, так и для задач генеративного ИИ», — сказал Эндрю Дикманн (Andrew Dieckmann), корпоративный вице-президент и генеральный менеджер по дата-центрам AMD. Стоит отметить, что у AMD нет прямого аналога NVIDIA NVLink, так что для объединение ускорителей в большие пулы с высокой скоростью подключения возможно как раз с использованием SuperNODE.
13.07.2023 [23:49], Алексей Степин
Младший напарник El Capitan: кластер Tuolumne будет использоваться для открытых исследованийЛиверморская национальная лаборатория (LLNL) вовсю ведёт монтаж суперкомпьютера El Capitan, мощность которого превзойдёт 2 Эфлопс. Дебютирует новая система в середине следующего года. Однако это не единственный суперкомпьютер LLNL. Помимо тестовых кластеров rzVernal, Tioga и Tenay, в строй будет введён и суперкопмьютер Tuolumne производительностью более 200 Пфлопс. El Capitan получит уникальные серверные APU AMD Instinct MI300A, содержащие 24 ядра Zen 4 и массив ускорителей с архитектурой CDNA3, дополненный собственным стеком памяти HBM3 объёмом 128 Гбайт. El Capitan будет использоваться в том числе для секретных и закрытых проектов, но, как сообщают зарубежные источники, кластер Tuolumne на базе той же аппаратной платформы HPE станет открытой платформой, практически самой мощной в своём классе. Сообщается о том, что производительность Tuolumne составит около 15 % от таковой у El Capitan, то есть от 200 до 300 Пфлопс. Хотя это не позволяет отнести Tuolumne к экза-классу, такие цифры позволяют претендовать на вхождении в первую пятёрку рейтинга TOP500. 
Тестовые стойки в ЦОД LLNL Впервые имя Tuolumne было упомянуто в 2021 году, когда речь шла о системе раннего доступа RZNevada, целью которой была тестирование и отработка аппаратного и программного стеков El Capitan. Также известно, что система охлаждения и питания в главном ЦОД LLNL была модернизирована, в результате чего её мощность выросла с 85 до 100 МВт, и часть этих мощностей достанется Tuolumne. Правда, когда суперкомпьютер будет введён в строй, не говорится. |
|

