Лента новостей
|
10.06.2022 [03:30], Игорь Осколков
AMD анонсировала серверные процессоры EPYC Genoa-X, Siena и TurinНа прошедшем этим вечером отчётном мероприятии Financial Analysts Day 2022 компания AMD поделилась планами по дальнейшему развитию серверных процессоров EPYC. Речь шла как об уже анонсированных продуктах, так и о совершенно новых, предназначенных для неосвоенных ранее компанией сегментов. Наиболее значимым, хотя и наименее детальным, стал официальный анонс пятого поколения AMD EPYC под кодовым именем Turin (EPYC 7005), которое должно появиться до конца 2024 года. Они будут основаны на существенно переработанной архитектуре Zen 5 и изготавливаться по смешанному 3- и 4-нм техпроцессу. Обещано три разновидности кристаллов: обычные, с 3D V-Cache и «облачные» (Zen 5c), оптимизированные для повышения плотности размещения. Важно тут то, что таким образом сохранится преемственность между поколениями, что определённо порадует заказчиков. 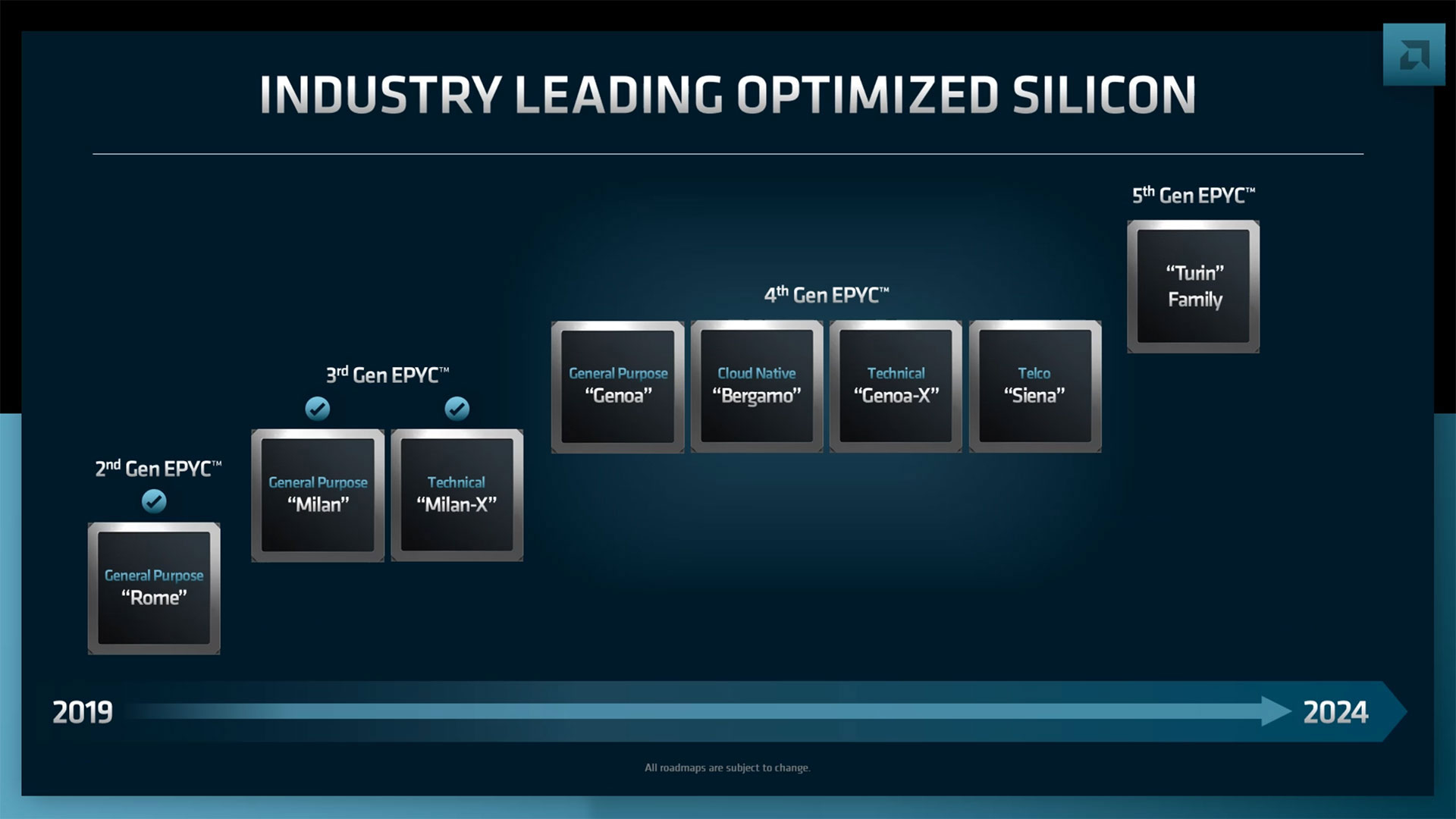
Изображения: AMD (via Tom's Hardware) Но в ближайшее время нас ждёт выход AMD EPYC Genoa, который должен состояться в IV квартале текущего года. Эти 5-нм процессоры получат до 96 ядер Zen 4, 12 каналов DDR5, поддержку PCIe 5.0 и CXL. Причём сейчас уже явно говорится о возможности расширения системной памяти с помощью CXL. Переход на новый техпроцесс и увеличившееся в 1,5 раза количество ядер дали прирост производительности до +75% (в пример приводится тест Java SPECjbb).  Для Genoa потребуется новый сокет SP5 (LGA6096). Он же будет готов принять ещё два варианта процессоров. Первый — это новенький Genoa-X, по названию которого легко догадаться, что это тот же Genoa (тоже до 96 ядер), снабжённый расширенным L3-кешем 3D V-Cache (от 1 Гбайт и более). Как и Milan-X, он будет ориентирован на специфический класс нагрузок, которые выигрывают от увеличения доступного объёма кеша. Это, например, расчётные задачи и СУБД.  Genoa-X появятся в 2023 году. Тогда же стоит ждать и особую серию Bergamo. Эти процессоры, как и было обещано ранее, получат до 128 ядер (и 256 потоков), сохранив совместимость с сокетом SP5. Основаны они будут на 5-нм ядрах Zen 4c, который чем-то напоминают E-ядра в исполнении Intel. Однако набор команд у Zen 4c будет одинаков с Zen 4. Деталей устройства c-ядер AMD снова не раскрыла, но можно предположить, что у них переработана иерархия кешей. Предназначены они для гиперскейлеров, которым важна плотность размещения ресурсов, а не только производительность  В 2023 году появятся и «малые» EPYC’и под кодовым названием Siena. Они оптимизированы с точки зрения энергоэффективности и предлагают до 64 ядер Zen 4. Siena ориентированы на периферийные вычисления и телеком-сегмент. Подробностей о них пока тоже мало. Не исключено, что мы увидим и гибриды наподобие Ice Lake-D, включающие интегрированные «умные» сетевые контроллеры. 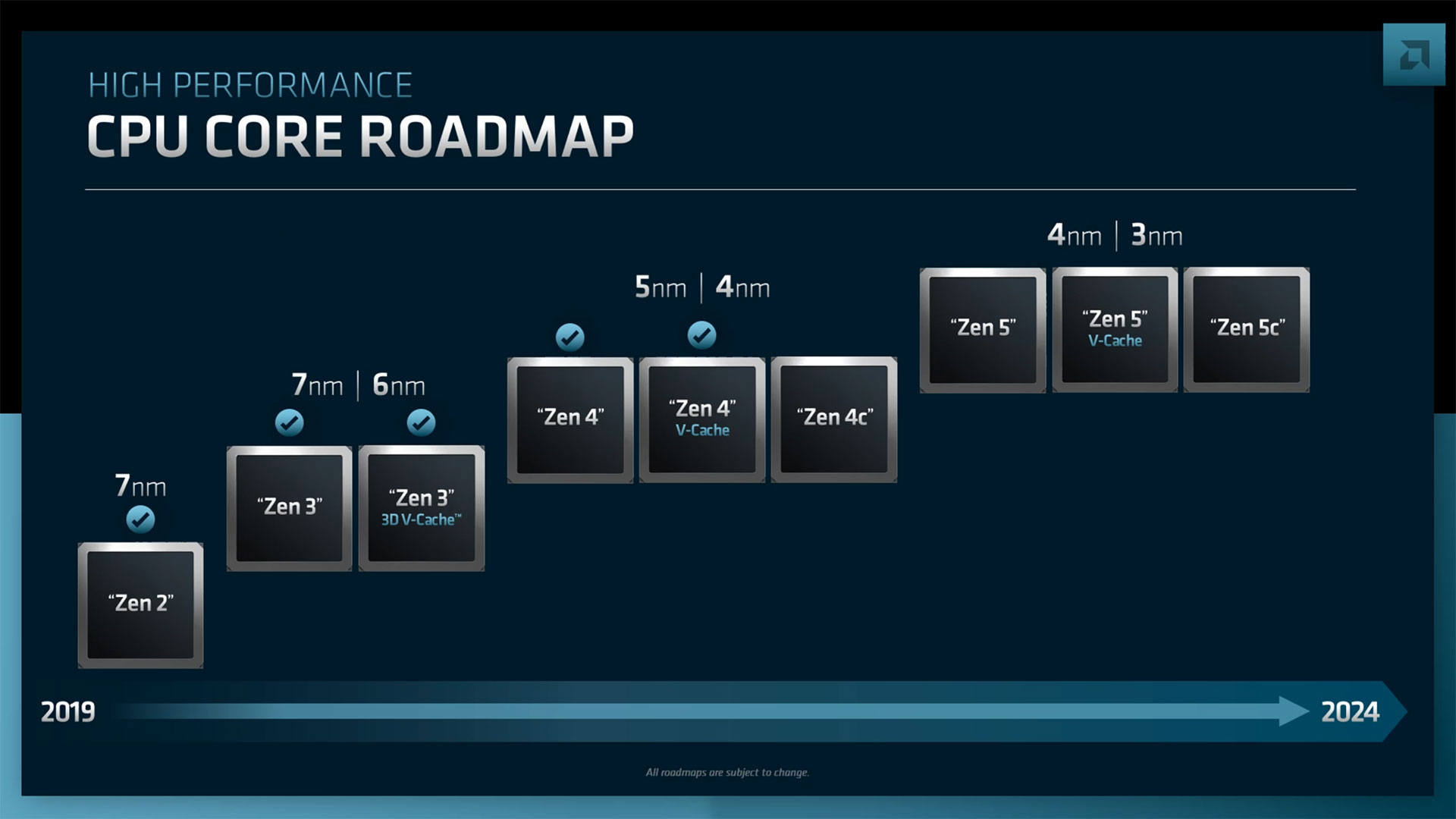 Существенным для всех новинок станет использование архитектуры Zen 4 (4 и 5 нм), которая, помимо ожидаемого прироста производительности, получит новые возможности. Среди них — поддержка AVX-512 (возможно, не самого полного набора) и новых инструкций для ИИ-нагрузок, которыми Intel хвасталась в течение нескольких лет. Но что ещё более важно, Zen 4 получат четвёртое поколение интерконнекта Infinity Architecture, который позволит более плотно связать различные чиплеты, причём и на уровне «кремния» (2.5D- и 3D-упаковка).  А это открывает путь к эффективной компоновке различных функциональных модулей с поддержкой когерентности на уровне всего чипа — AMD подтвердила возможность интеграции FPGA Xilinx и IP-блоков сторонних компаний. Новый интерконнект также совместим с CXL 2.0, что важно для работы с памятью, а будущие версии получат поддержку CXL 3.0 и UCIE. Именно четвёртое поколение Infinity позволило AMD создать свои первые серверные APU Instinct MI300.
09.06.2022 [21:00], Алексей Степин
Серия процессоров Intel Atom P5000 Snow Ridge пополнилась новыми моделямиКорпорация Intel на этой неделе уделила немало внимания серии экономичных процессоров Atom. Помимо новых моделей в серии C5000 Parker Ridge появились и новые чипы в семействе P5000 Snow Ridge. Эта 10-нм SoC-платформа дебютировала в 2020 году, её главное назначение — использование в беспроводном 5G-оборудовании, а главной отличительной особенностью можно назвать развитую сетевую подсистему. Последняя предлагает тесную интеграцию со 100GbE-контроллером Intel Ethernet 800 с поддержкой коммутации и технологии QAT. Изначально в серии было всего четыре модели с номерами серии P5900, количеством ядер Tremont от 8 до 24 и литерой B в названии — от «Base Station». Теперь семейство пополнилось девятью новыми моделями с индексами от P5300 до P5700. Сравнить характеристики всех чипов P5000 можно на сайте Intel, воспользовавшись этой ссылкой. 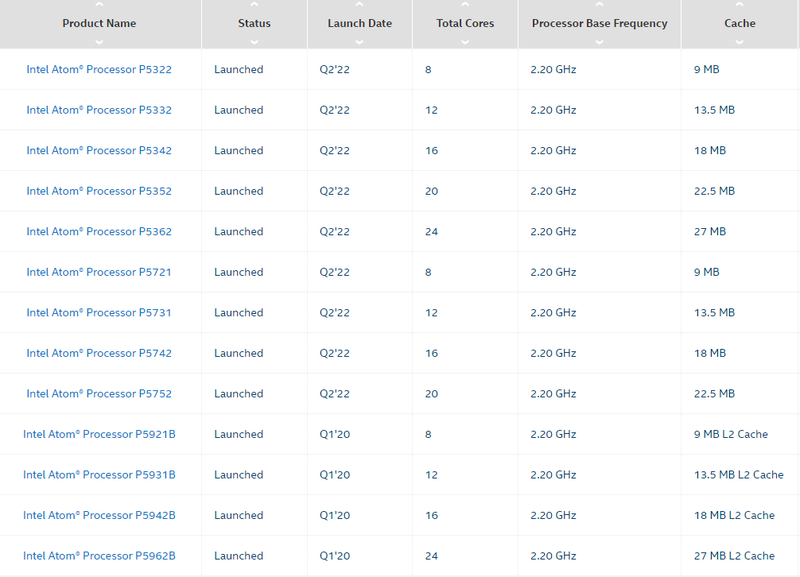
Модельный ряд Intel Atom P5000. Источник: Intel Хотя базовая частота у всех новинок осталась прежней и составляет 2,2 ГГц, объём кеша на кластер из четырёх ядер равен 4,5 Мбайт, а количество линий PCIe составляет 32 шт., есть и отличия. Для новых моделей заявлена поддержка вдвое большего максимального объёма оперативной памяти, 256 Гбайт против 128 Гбайт у чипов с литерой B. Есть и некоторые изменения в подсистеме памяти: младшие версии с номерами P5300 поддерживают либо DDR4-2400, либо 2666, тогда как для P5700 сохранена поддержка DDR4-2933. 
Intel NetSec Accelerator card. Источник: Intel (via ServeTheHome) Теплопакеты достаточно высокие, от 48 до 83 Вт, что отчасти продиктовано наличием продвинутой сетевой подсистемы. Она может быть сконфигурирована в различных режимах, у P5300 это от 8×10GbE до 1×100GbE, P5700 может поддерживать от 8 портов 25GbE с шифрованием, а в режиме 2×100GbE один порт обязательно будет резервным. Сетевой движок QAT третьего поколения сохранился у всех моделей. Режим коммутатора доступен только для P5700. 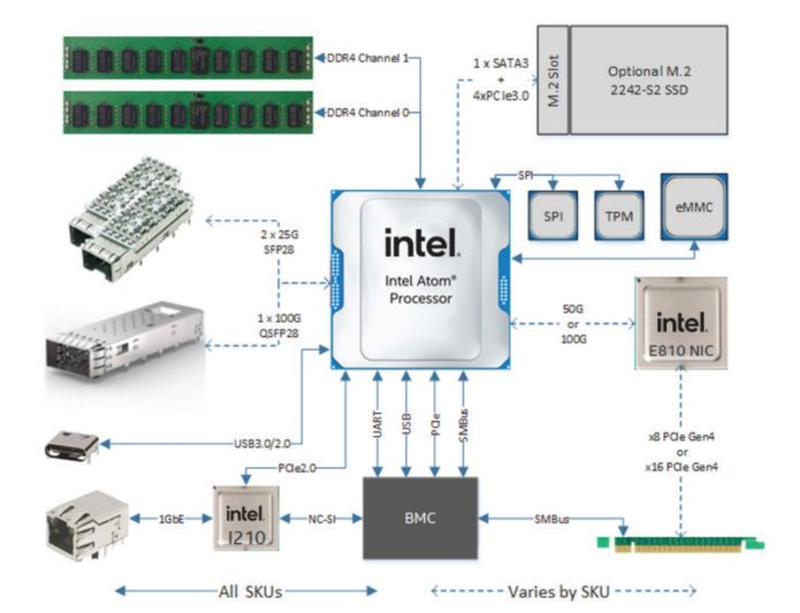
Intel NetSec — полноценная x86-система в виде PCIe-адаптера. Источник: Intel (via ServeTheHome) Новые процессоры Intel Atom P5000 могут служить и основой для современных сетевых ускорителей — компания продемонстрировала плату NetSec Accelerator, спроектированную Silicom и несущую на борту 8-ядерный P5721 или 16-ядерный P5742. Ускоритель имеет либо 2 корзины SFP28 (25GbE), либо корзину QSFP28 (100GbE), свой BMC и опциональный накопитель M.2 2242 в дополнение к 256 Гбайт набортной eMMC. По сути, это полноценная x86-платформа в форм-факторе PCIe-платы. Интерфейс, в зависимости от модели, PCIe 4.0 x8, либо x16, теплопакет у старшего варианта может достигать 115 Вт, поэтому плата использует дополнительное питание. Производительность в дуплексном режиме с полноценным шифрованием в реальном времени — 25 и 50 Гбит/с. Интересно, что новинка не позиционируется как IPU, но и термин DPU компанией не используется.
09.06.2022 [16:37], Сергей Карасёв
Intel представила первые процессоры серии Atom C5000 Parker RidgeКорпорация Intel анонсировала первые шесть процессоров семейства Atom C5000 (Parker Ridge), предназначенных для применения в серверном и сетевом оборудовании. Дебютировали изделия с обозначениями C5325, C5320, C5315, C5310, C5125 и C5115, которые изготавливаются по 10-нм техпроцессу. В зависимости от модификации чипы содержат четыре или восемь ядер (Tremont). Технология многопоточности не поддерживается. Тактовая частота модели C5310 составляет 1,6 ГГц. Версии C5325, C5320 и C5315 функционируют на частоте 2,4 ГГц, а C5125 и C5115 — 2,8 ГГц. Поддерживается работа с двухканальной оперативной памятью DDR4, частота которой может составлять 2400 или 2933 МГц (см. характеристики отдельных моделей в таблице ниже). Максимально поддерживаемый объём ОЗУ у всех решений равен 256 Гбайт. Все изделия наделены 9 Мбайт кеша второго уровня. Показатель TDP варьируется от 32 до 50 Вт. Это, как отмечает ресурс ServeTheHome, заметивший появление новинок в базе Intel, довольно много для изделий такого класса. 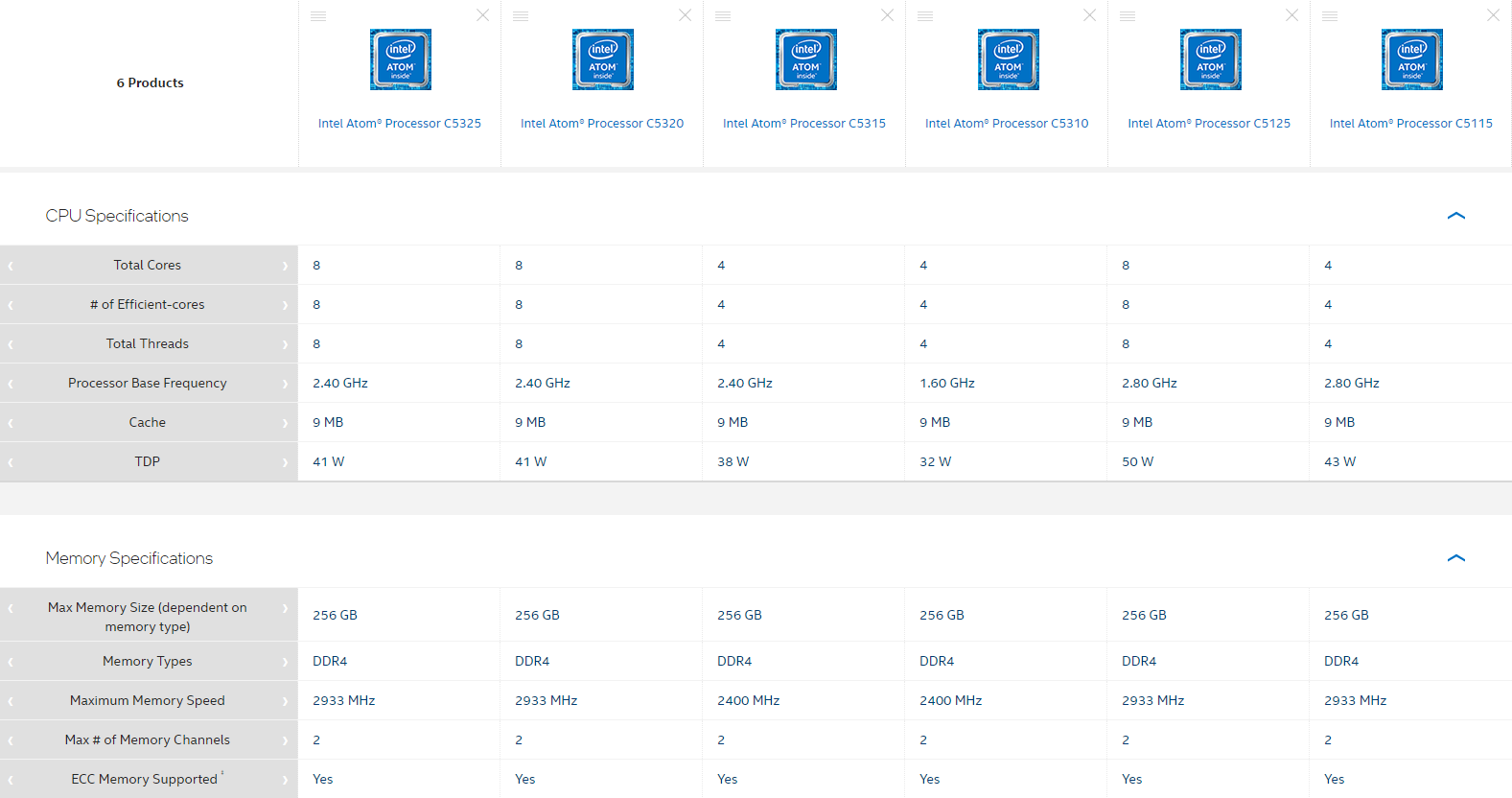
Источник: Intel Процессоры различаются количеством поддерживаемых линий PCIe — 12, 16 или 32. Чипы позволяют задействовать 12 или 16 портов SATA и восемь USB-портов в конфигурации 4 × USB 2.0 и 4 × USB 3.0. Все процессоры поддерживают технологию Intel QuickAssist (QAT) второго поколения (шифрование 20 Гбит/с), средства виртуализации Virtualization Technology (VT-x), инструкции AES, технологии Intel Trusted Execution и Enhanced Intel SpeedStep. Отличительной же чертой серии являются встроенные сетевые интерфейсы (до 8 шт., до 50GbE), которые есть в четырёх из шести представленных моделей.
01.06.2022 [01:18], Владимир Мироненко
Ведущий специалист NERSC перешёл в Microsoft, заявив, что строящиеся экзафлопсные суперкомпьютеры будут последними в своём родеГленн Локвуд (Glenn K. Lockwood), ведущий специалист Национального научного вычислительного центра энергетических исследований (NERSC) при Министерстве энергетики США перешёл на работу в Microsoft. Он является архитектором высокопроизводительных масштабируемых систем хранения данных для суперкомпьютеров. Локвуд, в частности, руководил развёртыванием первого в мире 35-Пбайт All-Flash хранилища с ФС Lustre для суперкомпьютера Perlmutter. В своём блоге Локвуд объяснил, почему он ушёл из NERSC в Microsoft. По его словам, лидирующие HPC-системы балансируют на грани выживания, в то время как HPC-системы среднего клсса практически полностью обесцениваются поставщиками облачных услуг. При текущих тенденциях стоимость строительства нового дата-центра и обширной инфраструктуры питания и охлаждения для каждого нового мощного суперкомпьютера очень скоро станет непомерно высокой, говорит Локвуд. Он высказал мнение, что ЦОД мощностью 50–60 МВт, строящиеся сейчас для экзафлопсных суперкомпьютеров, будут последними в своём роде. 
Источник изображения: AMD Что касается менее мощных систем, таких как Perlmutter, то необходимость в них постепенно сокращается по мере того, как облако набирает обороты. «Вы можете установить полную систему [HPE] Cray EX, идентичную той, что вы можете найти в NERSC или OLCF, в Azure <…> и интегрировать её с богатыми инфраструктурными возможностями облака», — говорит Локвуд. Кроме того, облака действительно гораздо быстрее внедряют новинки. Так, процессоры AMD EPYC MilanX и ускорители Instinct MI200 появились в инфраструктуре Microsoft Azure намного раньше, чем в HPC-центрах. «Я не утверждаю, что знаю будущее, и многое из того, что я изложил, является в лучшем случае гипотетическим», — заявил Гленн Локвуд, отметив, что приверженность Министерства энергетики США к независимым HPC-системам сохранится по меньшей мере ещё десятилетие. Локвуд стал очередным специалистом, покинувшем традиционный HPC-сектор и ушедшим в Microsoft. В 2020 году в Microsoft перешёл технический директор Cray Стив Скотт (Steve Scott). Год спустя к Microsoft присоединился соруководитель программы Cray PathForward доктор Дэн Эрнст (Dan Ernst).
30.05.2022 [10:00], Игорь Осколков
Июньский TOP500: есть экзафлопс!59-я редакция TOP500, публичного рейтинга самых производительных суперкомпьютеров мира, стала наиболее знаменательной за последние 14 лет, поскольку официально был преодолён экзафлопсный барьер. Путь от петафлопса оказался долгим — первой петафлопсной системой стал суперкомпьютер IBM Roadrunner, и произошло это аж в 2008 году. Но минимальным порогом для попадания в TOP500 эта отметка стала только в 2019 году. Как и было обещано, официально и публично отметку в 1 Эфлопс в бенчмарке HPL на FP64-вычислениях первым преодолел суперкомпьютер Frontier — его устоявшаяся производительность составила 1,102 Эфлопс при теоретическом пике в 1,686 Эфлопс. Система на платформе HPE Cray EX235a использует оптимизированные 64-ядерные процессоры AMD EPYC Milan (2 ГГц), ускорители AMD Instinct MI250X и фирменный интерконнект Slingshot 11-го поколения. Система имеет суммарно 8 730 112 ядер, потребляет 21,1 МВт и выдаёт 52,23 Гфлопс/Вт, что делает её второй по энергоэффективности в мире. 
Суперкомпьютер Frontier (Фото: AMD) Впрочем, первое место в Green500 по данному показателю всё равно занимает тестовый кластер в составе всё того же Frontier: 120 832 ядра, 19,2 Пфлопс, 309 кВт, 62,68 Гфлопс/Вт. Третье и четвёртое места достались европейским машинам LUMI и Adastra, новичкам TOP500, которые по «железу» идентичны Frontier, но значительно меньше. Да и разница в Гфлопс/Вт между ними минимальна. Скопом они сместили предыдущего лидера — экзотичную японскую систему MN-3 от Preferred Networks. Японская система Fugaku, лидер по производительности в течение двух последних лет, сместилась на второе место TOP500. Третье место у финской системы LUMI с показателем производительности 151,9 Пфлопс — обратите внимание, насколько велик разрыв в первой тройке машин. Наконец, в Топ-10 последнее место занял новичок Adastra (46,1 Пфлопс), который расположен во Франции. 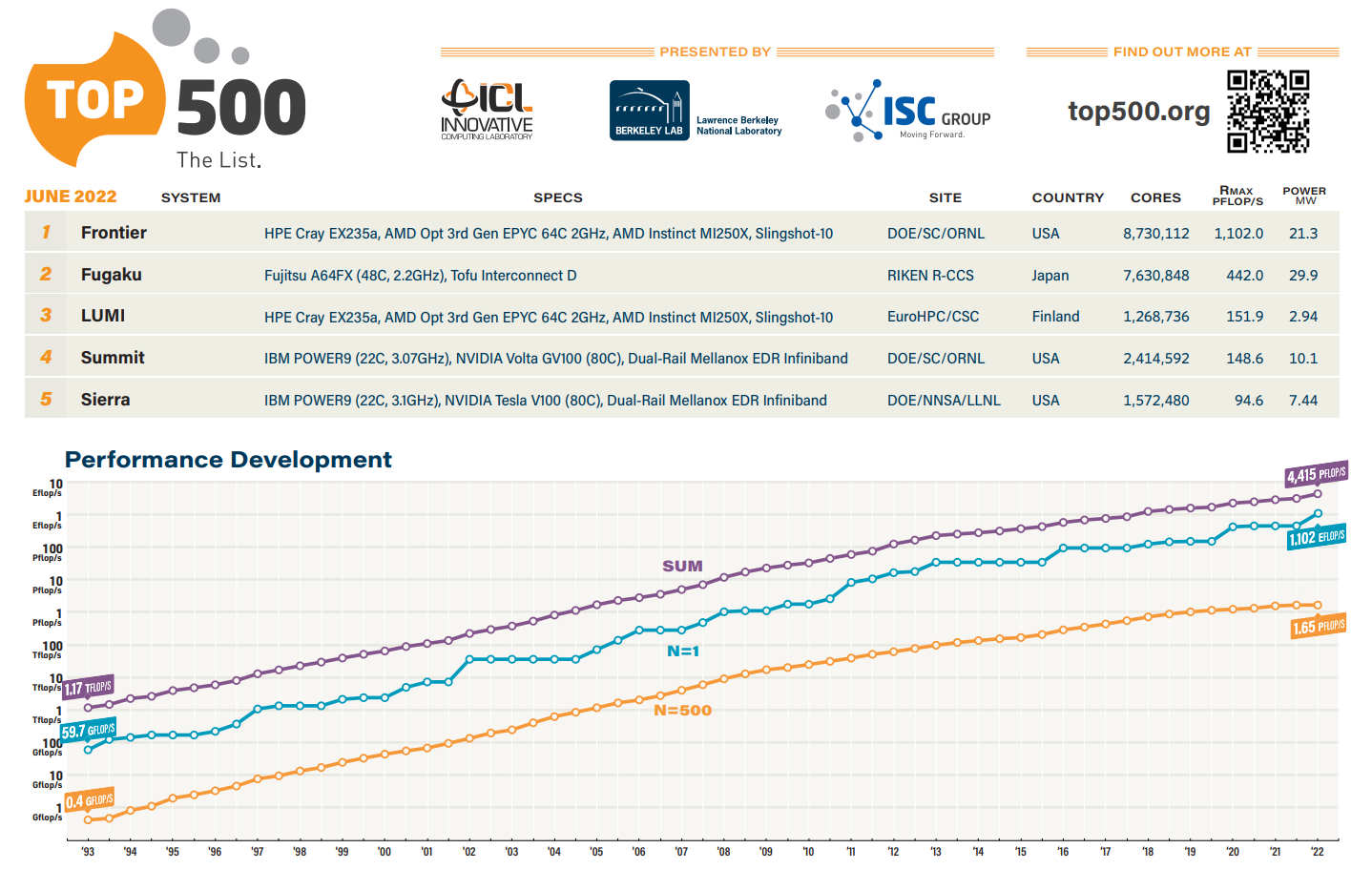
Источник: TOP500 В бенчмарке HPCG всё ещё лидирует Fugaku (16 Пфлопс), но, судя по всему, только потому, что для Frontier данных пока нет. Ну и потому, что результат суперкомпьютера LUMI, который почти на порядок медленнее Frontier, в HPCG составляет 1,94 Пфлопс. Наконец, в HPL-AI Frontier также отобрал первенство у Fugaku — 6,86 Эфлопс в вычислениях смешанной точности против 2 Эфлопс. В общем, у Frontier полная победа по всем фронтам, и эту машину можно назвать не только самой быстрой в мире, но первой по-настоящему экзафлопсной системой. Если, конечно, не учитывать неофициальные результаты OceanLight и Tianhe-3 из Поднебесной, которые в TOP500 никто не заявил. Число китайских систем в нынешнем рейтинге осталось прежним (173 шт.), тогда как США «ужались» со 150 до 127 шт. Российских систем в списке всё так же семь. Лидерами по числу поставленных систем остаются Lenovo, HPE и Inspur, а по их суммарной производительности — HPE, Fujitsu и Lenovo. С другой стороны, массовых изменений и не было — в нынешнем списке всего около сорока новых систем. 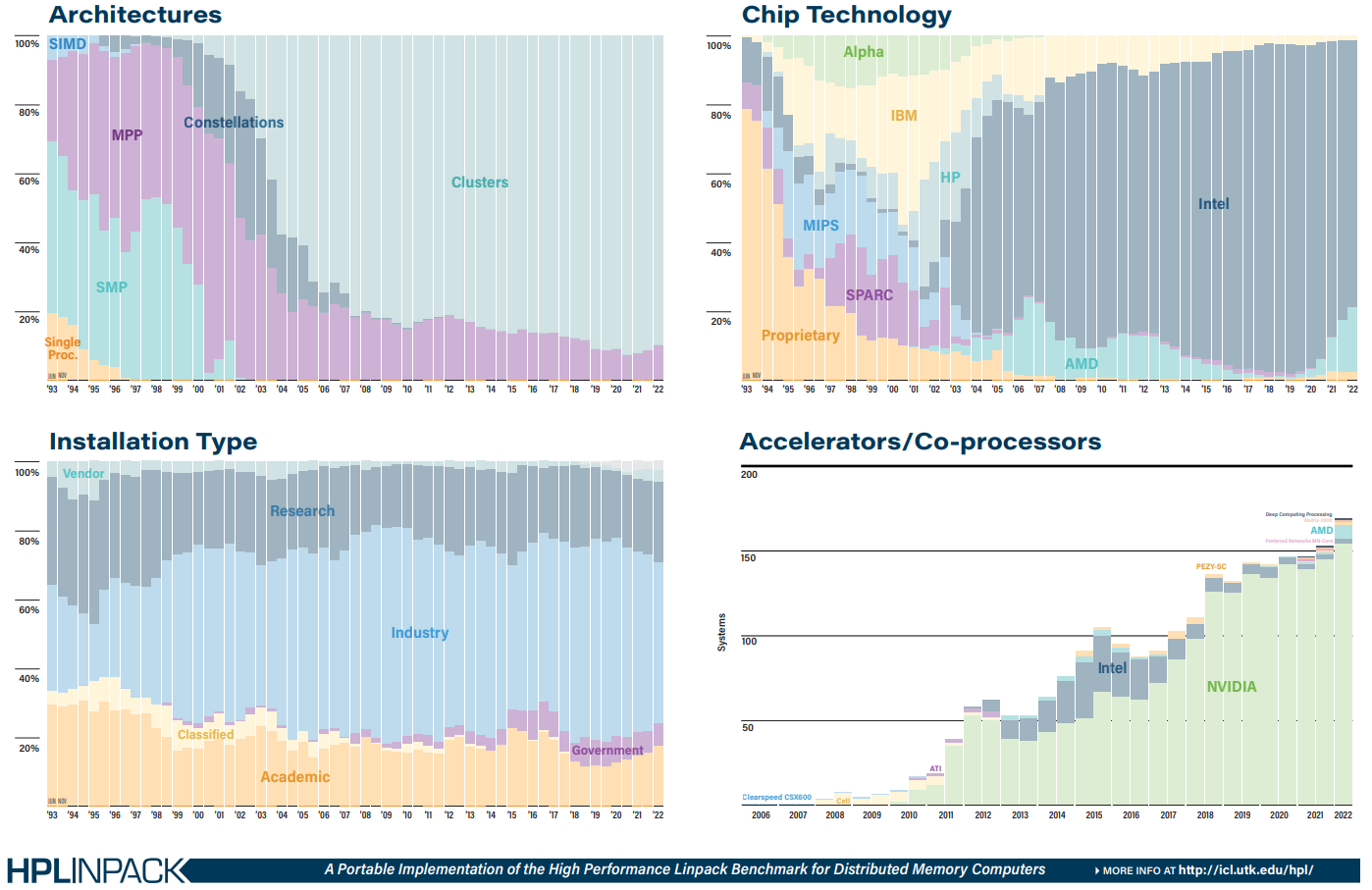
Источник: TOP500 Однако нельзя не отметить явный прогресс AMD — да, чуть больше трёх четвертей машин из списка используют процессоры Intel, но AMD удалось за полгода отъесть около 4 %. При этом AMD EPYC Milan присутствует в более чем трёх десятках систем, а доля Intel Xeon Ice Lake-SP вдвое меньше, хотя эти процессоры появились практически одновременно. Ускорители ожидаемо стали использовать больше — они применяются в 170 системах (было 150). Подавляющее большинство приходится на решения NVIDIA разных поколений, но и для новых Instinct MI250X нашлось место в восьми машинах. Ну а в области интерконнекта Infiniband потихоньку догоняет Ethernet: 226 машин против 196 + ещё 40 с Omni-Path + редкие проприетарные решения.
26.05.2022 [11:53], Владимир Мироненко
Материнская компания розничной сети Lidl запустила конкурента AWS в ГерманииSchwarz Group, материнская компания европейской сети розничных продовольственных магазинов Lidl, официально объявила о доступности сервисов своего облачного подразделения StackIT для сторонних клиентов. О планах Schwarz Group по оказанию облачных услуг сторонним ретейлерам стало известно в 2020 году после приобретения ею компании Camao IDC, специализирующейся на разработке программного обеспечения. Сообщается, что Schwarz Group начала работу над облачным сервисом в 2018 году и запустила его для собственных нужд примерно в 2019 году. В ноябре 2021 года Schwarz Group приобрела контрольный пакет акций израильской фирмы по кибербезопасности XM Cyber. До нынешнего дня StackIT предоставляла услуги компаниям Schwarz Group, включая сети супермаркетов Lidl и гипермаркетов Kaufland, компанию по производству продуктов питания Schwarz Produktion и компанию по переработке вторичных отходов PreZero. 
Источник изображения: Schwartz Group / StackIT Помимо услуги колокейшна, StackIT предлагает ряд облачных и инфраструктурных сервисов, включая хранение данных, базы данных, вычислительные инстансы и многое другое. Компания предлагает услуги на базе объекта в австрийском Остермитинге, известного как DC10, и ЦОД в Эльхофене (Германия), известного как DC08. «Благодаря StackIT впервые становится доступным облачное решение, которое на 100 % “Сделано в Германии” и ориентировано на высокие требования и потребности в безопасности предприятий и организаций государственного сектора», — отметил директор по данным Schwarz Digital Рольф Шуман (Rolf Schumann).
24.05.2022 [14:09], Андрей Крупин
Selectel приступила к строительству в Москве нового 20-МВт дата-центра на 2 тыс. стоекКомпания Selectel, являющаяся специализированным поставщиком IT-решений на базе собственной сети дата-центров в Москве, Санкт-Петербурге и Ленинградской области, планирует ввести в эксплуатацию ещё один вычислительный комплекс. Новый центр обработки данных под названием «Юрловский» будет развёрнут в Москве и рассчитан на 2 тыс. серверных стоек. Дата-центр проектируется в соответствии с уровнем надёжности Tier IV. Основная ёмкость центра обработки данных будет задействована для предоставления облачных сервисов Infrastructure as a Service (IaaS). Особенностью ЦОД станет самый большой единый машинный зал в России площадью 4500 м2, в котором компания планирует разместить до 80 тыс. серверов. Общая подведённая мощность объекта составит 20 МВт, средняя мощность на стойку — 8 кВт. Selectel уже получила технические условия на подключение к ближайшему питающему центру с верхним уровнем напряжения 500 кВ, который расположен в 700 м от кампуса. Подключение будет выполнено по второй категории надёжности, то есть будет проложено две линии от независимых ячеек на подстанции, а между ними на стороне подстанции будет организован автоматический ввод резерва. 
Фото: Selectel Дата-центр «Юрловский» будет построен с применением технологии охлаждения без использования фреоновых систем, что позволит минимизировать воздействие на окружающую среду. ЦОД будет охлаждаться наружным воздухом (технология фрикулинга), а в качестве доохлаждения будут использоваться адиабатические маты. Предполагается, что эти и другие меры позволят Selectel экономить электроэнергию и занимать меньше полезной площади машинного зала. Среднегодовой коэффициент эффективности использования энергии (Power Usage Effectiveness, PUE) будет в диапазоне от 1,1 до 1,15. Таким образом, «Юрловский» станет самым «зелёным» дата-центром Selectel. 
Фото: Selectel В инфраструктуре дата-центра «Юрловский» будет задействована схема резервирования 6/5N — для каждой части на 1000 стоек будет выделено пять рабочих кластеров и один резервный. Фактически работать будут все шесть, но один можно в любой момент отключить. Кроме того, такой подход позволяет добиться физической изоляции резервируемых кластеров друг от друга. А автоматизации бесперебойной подачи питания и непрерывное охлаждение обеспечат возможность проводить любые профилактические и ремонтные работы без приостановки оказания услуг. Для поддержания связности новый ЦОД будет подключен несколькими независимым ВОЛС к MSK-IX (M9) и ЦОД «Берзарина», который уже имеется независимые подключения к нескольким IX. Вопрос с закупкой оборудования компания намерена решать в конце текущего года, поскольку в текущей ситуации прогнозировать что-либо затруднительно. На текущем этапе Selectel занимается проектированием и выполняет общестроительные работы. Ввод объекта в коммерческую эксплуатацию запланирован на 2023 год, однако сроки могут быть скорректированы в зависимости от ситуации на рынке. Инвестиции в проект оцениваются в миллиарды рублей.
24.05.2022 [07:00], Игорь Осколков
NVIDIA представила референсные платформы CGX, OVX и HGX на базе собственных Arm-процессоров GraceНа весенней конференции GTC 2022 NVIDIA поделилась подробностями о грядущих серверных Arm-процессорах Grace Superchip и гибридах Grace Hopper Superchip, а на Computex 2022 представила первые референсные платформы на базе этих чипов для OEM-производителей и объявила о расширении программы NVIDIA Certified. Последнее, впрочем, не означает отказ от x86-систем, поскольку программа будет просто расширена. Да и портирование стороннего и собственного ПО займёт некоторое время. Первые несколько десятков моделей серверов от ASUS, Foxconn, GIGABYTE, QCT, Supermicro и Wiwynn появятся в первой половине 2023 года. Представлены они будут в трёх категориях, причём все, за исключением одной, базируются на «сдвоенных» процессорах Grace Superchip, насчитывающих до 144 ядер. 
Источник: NVIDIA Системы серии OVX, представленной ранее, всё так же будут предназначены для цифровых двойников и Omniverse — NVIDIA продолжает наставить на том, что любое современное производство или промышленное предприятие должно быть интеллектуальным. Arm-версия OVA получит неназванные ускорители NVIDIA и DPU Bluefield-3. Новая платформа NVIDIA CGX очень похожа на OVX — она тоже получит DPU Bluefield-3 и до четырёх ускорителей NVIDIA A16. CGX создана специального для облачных гейминга и работы с графикой. А вот новое поколение платформы NVIDIA HGX гораздо интереснее. Оно заметно отличается от предыдущих, которые в основном представляли собой различные комбинации базовых плат NVIDIA с четырьмя или восемью ускорителями, вокруг которых OEM-партнёры строили системы в меру своих умений и фантазий. Нынешняя инкарнация NVIDIA HGX всё же несколько более комплексная, поскольку сейчас предлагается два варианта узлов, специально спроектированных для высокоплотных систем и явно ориентированных на высокопроизводительные вычисления (HPC). 
Источник: NVIDIA Первый вариант — это 1U-лезвие (до 84 шт. в стандартной стойке), которое включает один процессор Grace Superchip, до 1 Тбайт LPDDR5x-памяти с пропускной способностью (ПСП) до 1 Тбайт/с и DPU BlueField-3. Иные варианты сетевого подключения оставлены на усмотрение конечного производителя. Заявленный уровень TDP составляет 500 Вт, так что на выбор доступны системы с воздушным и жидкостным охлаждением. Второй вариант базируется на гибридных чипах Grace Hopper Superchip, объединяющих в себе посредством шины NVLink-C2C процессорную часть с 512 Гбайт LPDDR5x-памяти и ускоритель NVIDIA H100 c 80 Гбайт HBM3-памяти (ПСП до 3,5 Тбайт/с). Помимо DPU BlueField-3 опционально доступен и интерконнект NVLink 4.0, но и здесь вендору оставлена свобода выбора. Уровень TDP для данной платформы составляет 1 кВт, но вот обойтись одним только воздушным охлаждением (а такой вариант есть) при полном заполнении стойки всеми 42-мя 2U-лезвиями будет трудно.
16.05.2022 [23:41], Алексей Степин
Intel: UCIe объединит разнородные чиплеты внутри одной упаковки и за её пределамиШина PCI Express давно стала стандартом де-факто: она не требует много контактов, её производительность в пересчёте на линию уже достигла ≈4 Гбайт/с (32 ГТ/с) в версии PCIe 5.0, а использование стека CXL сделает PCI Express поистине универсальной. Но для соединения чиплетов или межпроцессорной коммуникации эта шина в текущем её виде подходит не лучшим образом. Но использование проприетарных технологий существенно ограничивает потенциал чиплетных решений, и для преодоления этого ограничения в марте этого года 10-ю крупными компаниями-разработчиками, включая AMD, Qualcomm, TSMC, Arm и Samsung, был основан новый стандарт Universal Chiplet Interconnect Express (UCIe). 
Изображение: UCIe Consortium Уже первая реализация UCIe должна превзойти PCI Express во многих аспектах: если линия PCIe 5.0 представляет собой четыре физических контакта с пропускной способностью 32 ГТ/с, то UCIe позволит передавать по единственному контакту до 12 Гбит/с, а затем планка будет повышена до 16 Гбит/с. При этом энергопотребление у UCIe ниже, а эффективность — выше. На равном с PCIe расстоянии новый стандарт может быть вчетверо производительнее при том же количестве проводников. В перспективе эта цифра может быть увеличена до 10–20 раз, то есть, узким местом между чиплетами UCIe явно не станет. Более того, новый интерконнект не только изначально совместим с CXL, но и гораздо лучше приспособлен к задачам дезагрегации. Иными словами, быстрая связь напрямую между чиплетами возможна не только в одной упаковке или внутри узла, но и за его пределами. 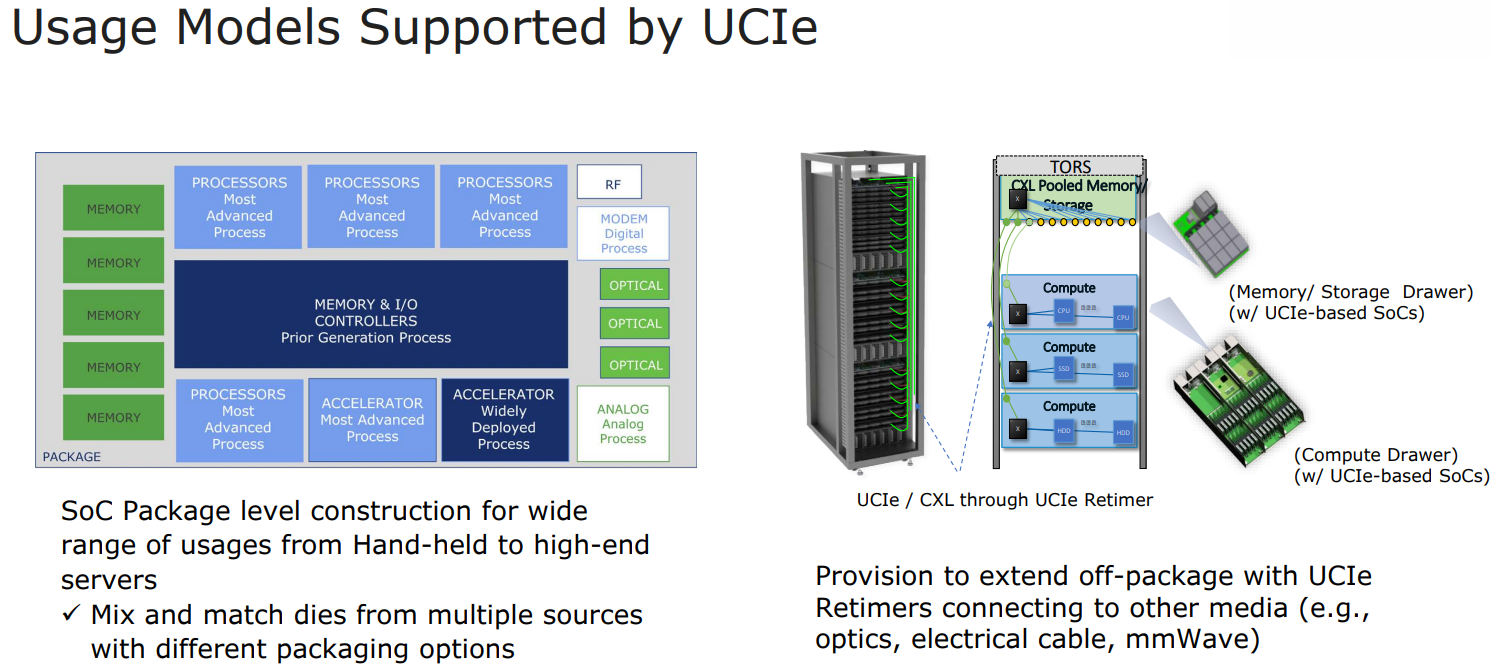
Изображение: UCIe Consortium Весьма заинтересована в новом стандарте Intel, которая планирует использовать UCIe таким образом, что в процессорах нового поколения ядра x86 смогут соседствовать с Arm или RISC-V. При этом планируется обеспечить совместимость UCIe с технологиями упаковки Intel EMIB и TSMC CoWoS, заодно добавив поддержку других шин, в том числе Arm AMBA, а также возможность легкой конвертации в проприетарные протоколы других разработчиков. В настоящее время Intel уже есть несколько примеров использования UCIe. Так, в одном из вариантов с помощью новой шины к процессорным ядрам подключаются ускорители и блок управления, а упаковка EMIB используется для подключения чипа к дезагрегированной памяти DDR5 и линиям PCI Express.
10.05.2022 [22:46], Игорь Осколков
Intel анонсировала ИИ-ускорители Habana Gaudi2 и GrecoНа мероприятии Intel Vision было анонсировано второе поколение ИИ-ускорителей Habana: Gaudi2 для задач глубокого обучения и Greco для инференс-систем. Оба чипа теперь производятся с использованием 7-нм, а не 16-нм техпроцесса, но это далеко не единственное улучшение. Gaudi2 выпускается в форм-факторе OAM и имеет TDP 600 Вт. Это почти вдвое больше 350 Вт, которые были у Gaudi, но второе поколение чипов значительно отличается от первого. Так, объём набортной памяти увеличился втрое, т.е. до 96 Гбайт, и теперь это HBM2e, так что в итоге и пропускная способность выросла с 1 до 2,45 Тбайт/с. Объём SRAM вырос вдвое, до 48 Мбайт. Дополняют память DMA-движки, способные преобразовывать данные в нужную форму на лету. 
Изображения: Intel/Habana В Gaudi2 имеется два основных типа вычислительных блоков: Matrix Multiplication Engine (MME) и Tensor Processor Core (TPC). MME, как видно из названия, предназначен для ускорения перемножения матриц. TPC же являются программируемыми VLIW-блоками для работы с SIMD-операциями. TPC поддерживают все популярные форматы данных: FP32, BF16, FP16, FP8, а также INT32, INT16 и INT8. Есть и аппаратные декодеры HEVC, H.264, VP9 и JPEG.  Особенностью Gaudi2 является возможность параллельной работы MME и TPC. Это, по словам создателей, значительно ускоряет процесс обучения моделей. Фирменное ПО SynapseAI поддерживает интеграцию с TensorFlow и PyTorch, а также предлагает инструменты для переноса и оптимизации готовых моделей и разработки новых, SDK для TPC, утилиты для мониторинга и оркестрации и т.д. Впрочем, до богатства программной экосистемы как у той же NVIDIA пока далеко. 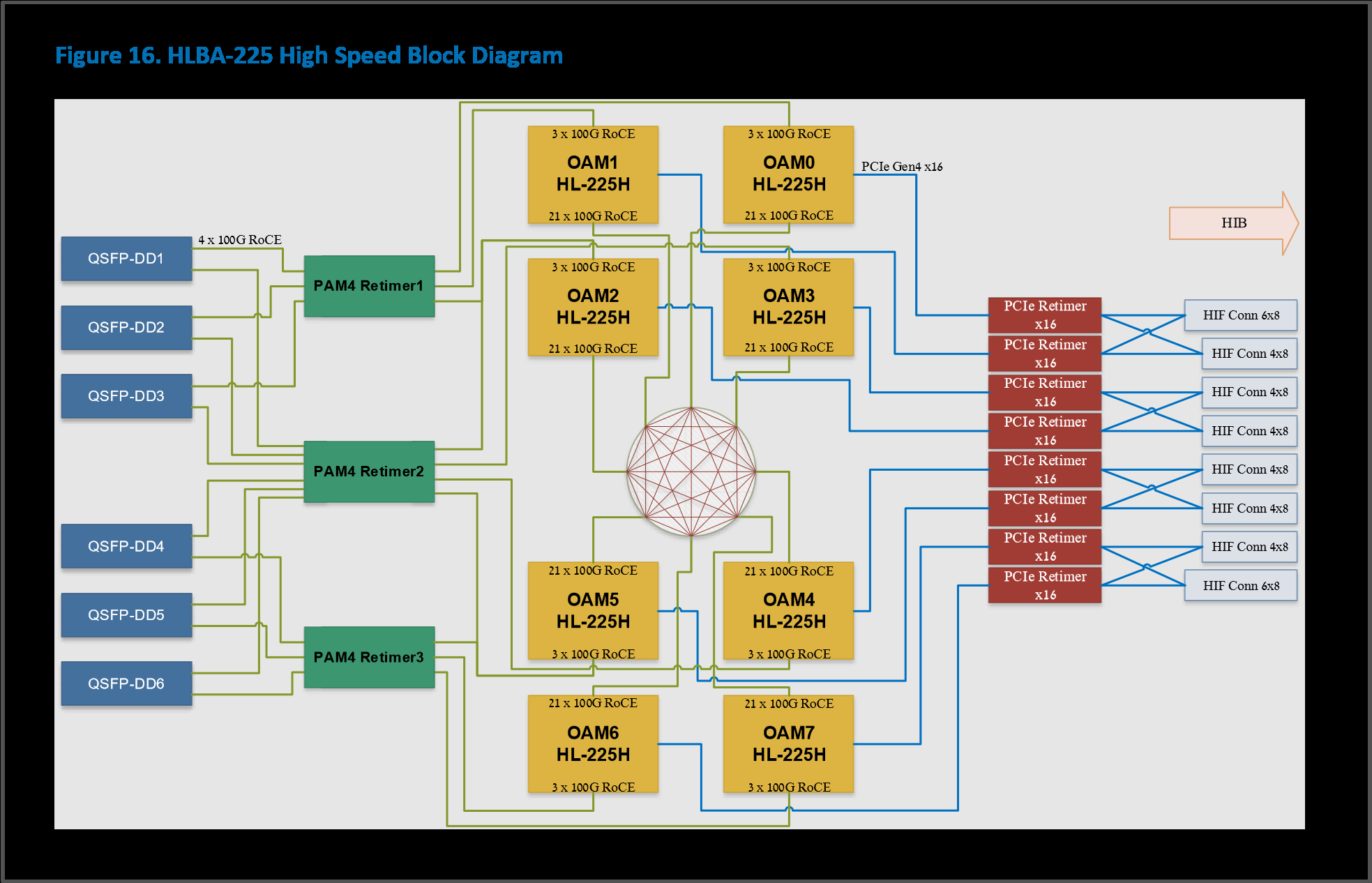 Интерфейсная часть новинок включает PCIe 4.0 x16 и сразу 24 (ранее было только 10) 100GbE-каналов с RDMA ROcE v2, которые используются для связи ускорителей между собой как в пределах одного узла (по 3 канала каждый-с-каждым), так и между узлами. Intel предлагает плату HLBA-225 (OCP UBB) с восемью Gaudi2 на борту и готовую ИИ-платформу, всё так же на базе серверов Supermicro X12, но уже с новыми платами, и СХД DDN AI400X2. 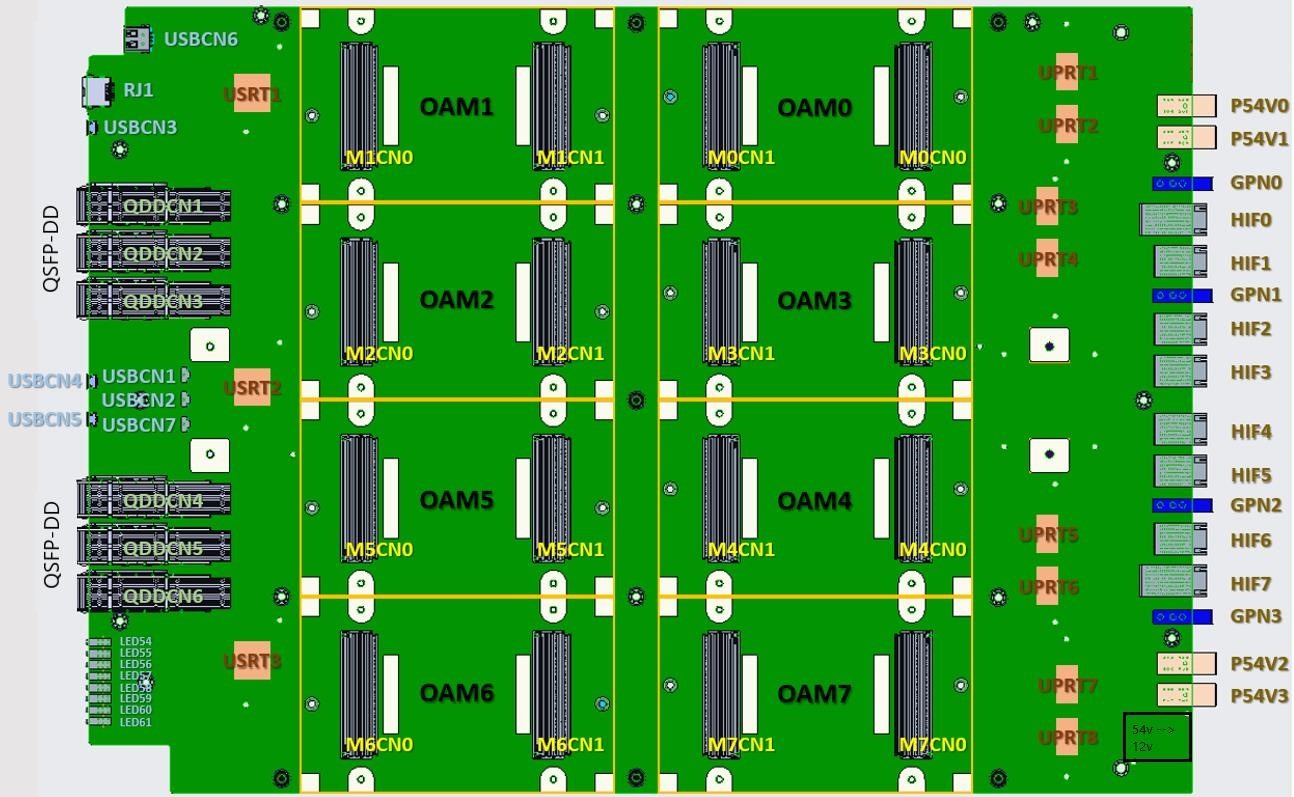 Наконец, самое интересное — сравнение производительности. В ряде популярных нагрузок новинка оказывается быстрее NVIDIA A100 (80 Гбайт) в 1,7–2,8 раз. На первый взгляд результат впечатляющий. Однако A100 далеко не новы. Более того, в III квартале этого года ожидается выход ускорителей H100, которые, по словам NVIDIA, будут в среднем от трёх до шести раз быстрее A100, а благодаря новым функциям прирост в скорости обучения может быть и девятикратным. Ну и в целом H100 являются более универсальными решениями. 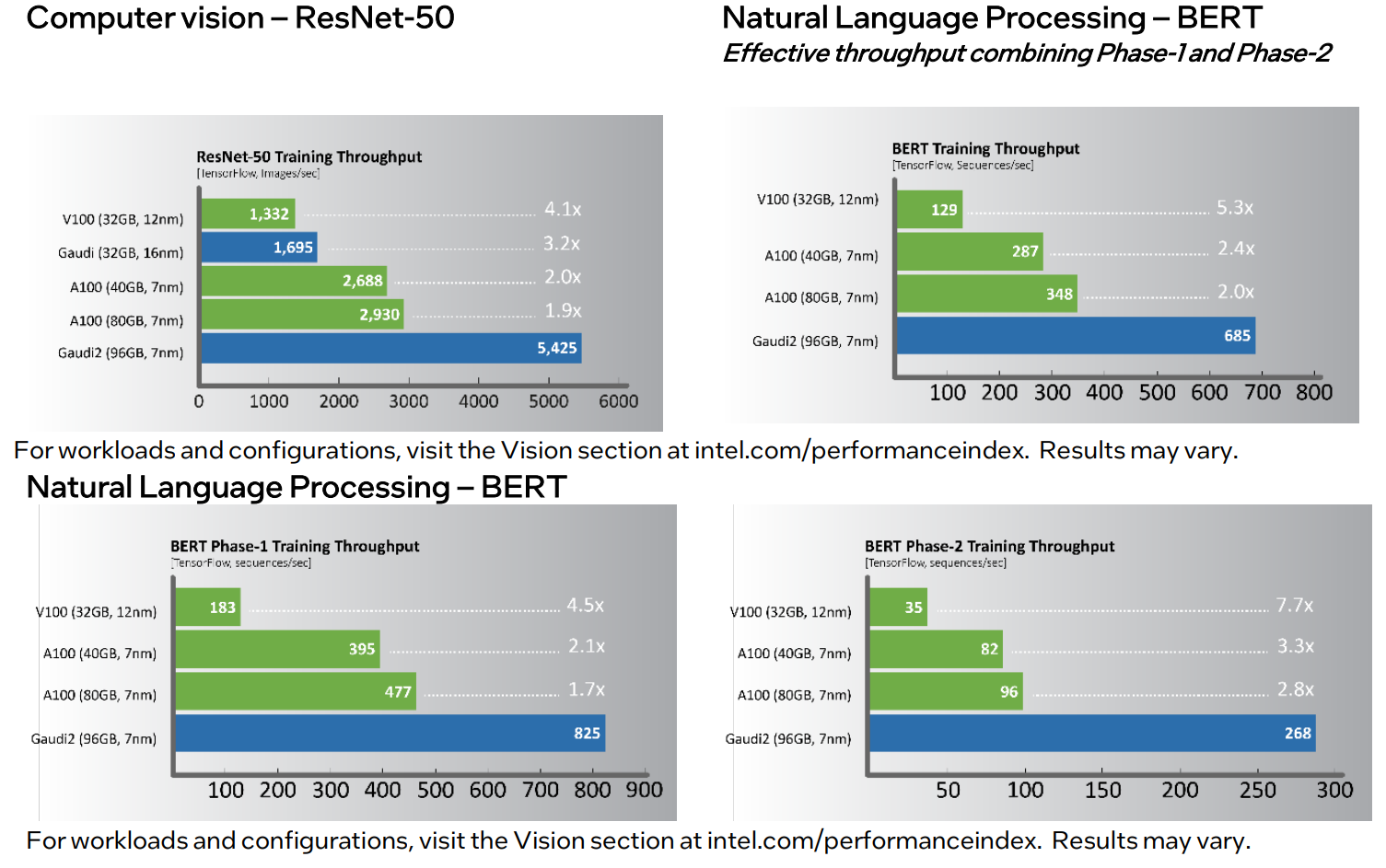 Gaudi2 уже доступны клиентам Habana, а несколько тысяч ускорителей используются самой Intel для дальнейшей оптимизации ПО и разработки чипов Gaudi3. Greco будут доступны во втором полугодии, а их массовое производство намечено на I квартал 2023 года, так что информации о них пока немного. Например, сообщается, что ускорители стали намного менее прожорливыми по сравнению с Goya и снизили TDP с 200 до 75 Вт. Это позволило упаковать их в стандартную HHHL-карту расширения с интерфейсом PCIe 4.0 x8.  Объём набортной памяти всё так же равен 16 Гбайт, но переход от DDR4 к LPDDR5 позволил впятеро повысить пропускную способность — с 40 до 204 Гбайт/с. Зато у самого чипа теперь 128 Мбайт SRAM, а не 40 как у Goya. Он поддерживает форматы BF16, FP16, (U)INT8 и (U)INT4. На борту имеются кодеки HEVC, H.264, JPEG и P-JPEG. Для работы с Greco предлагается тот же стек SynapseAI. Сравнения производительности новинки с другими инференс-решениями компания не предоставила.  Впрочем, оба решения Habana выглядят несколько запоздалыми. В отставании на ИИ-фронте, вероятно, отчасти «виновата» неудачная ставка на решения Nervana — на смену так и не вышедшим ускорителям NNP-T для обучения пришли как раз решения Habana, да и новых инференс-чипов NNP-I ждать не стоит. Тем не менее, судьба Habana даже внутри Intel не выглядит безоблачной, поскольку её решениям придётся конкурировать с серверными ускорителями Xe, а в случае инференс-систем даже с Xeon. |
|

