Материалы по тегу: суперкомпьютер
|
16.07.2021 [17:31], Алексей Степин
Японский облачный суперкомпьютер ABCI подвергся модернизацииПопулярность идей машинного обучения и искусственного интеллекта приводит к тому, что многие страны и организации планируют обзавестись HPC-системами, специально предназначенными для этого класса задач. В частности, Токийский университет совместно с Fujitsu модернизировал существующую систему ABCI (AI Bridging Cloud Infrastructure), снабдив её новейшими процессорами Intel Xeon и ускорителями NVIDIA. Как правило, когда речь заходит о суперкомпьютерах Fujitsu, вспоминаются уникальные наработки компании в сфере HPC — процессоры A64FX, но ABCI имеет более традиционную гетерогенную архитектуру. Изначально этот облачный суперкомпьютер включал в себя вычислительные узлы на базе Xeon Gold и ускорителей NVIDIA V100, объединённых 200-Гбит/с интерконнектом. В качестве файловой системы применена разработка IBM — Spectrum Scale. Это одна систем, специально созданных для решения задач искусственного интеллекта, при этом доступная независимым исследователям и коммерческим компаниям. 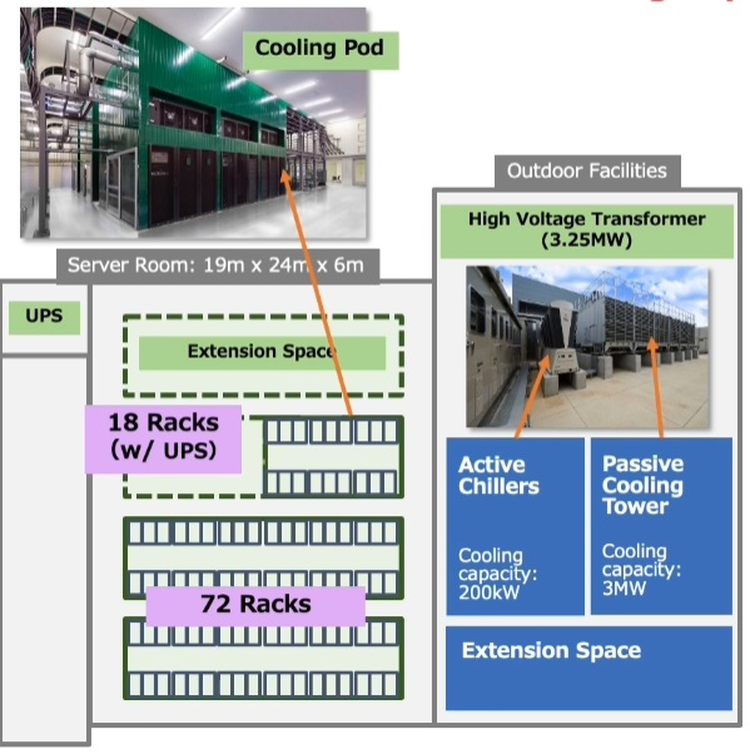 Так, 86% пользователей ABCI не входят в состав Японского национального института передовых технических наук (AIST); их число составляет примерно 2500. Но система явно нуждалась в модернизации. Как отметил глава AIST, с 2019 года загруженность ABCI выросла вчетверо, и сейчас на ней запущено 360 проектов, 60% из которых от внешних заказчиков. Сценарии использования самые разнообразные, от распознавания видео до обработки естественных языков и поиска новых лекарств. 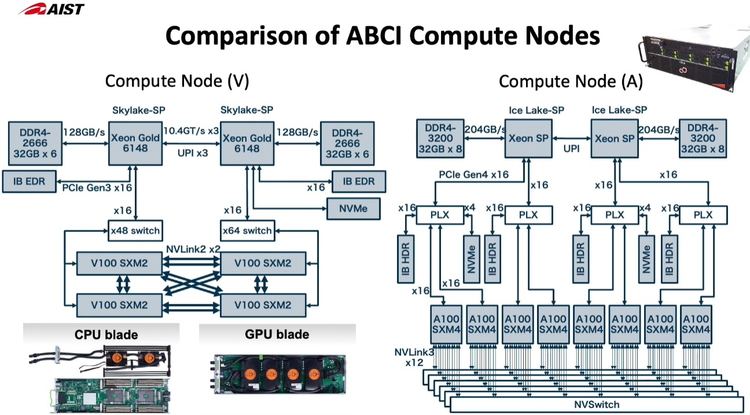
Новые узлы ABCI 2.0 заметно отличаются по архитектуре от старых Как и в большей части систем, ориентированных на машинное обучение, упор при модернизации ABCI был сделан на вычислительную производительность в специфических форматах, включая FP32 и BF16. Изначально в состав ABCI входило 1088 узлов, каждый с четырьмя ускорителями V100 формата SXM2 и двумя процессорами Xeon Gold 6148. После модернизации к ним добавилось 120 узлов на базе пары Xeon Ice Lake-SP и восьми ускорителей A100 формата SXM4. Здесь вместо InfiniBand EDR используется уже InfiniBand HDR. 
Стойка с новыми вычислительными узлами ABCI 2.0 Согласно предварительным ожиданиям, производительность обновлённого суперкомпьютера должна вырасти практически в два раза на задачах вроде ResNet50, в остальных случаях заявлен прирост производительности от полутора до трёх раз. На вычислениях половинной точности речь идёт о цифре свыше 850 Пфлопс, что вплотную приближает ABCI к системам экза-класса. Разработчики также надеются повысить энергоэффективность системы путём применения специфических ускорителей, включая ASIC, но пока речь идёт о связке Intel + NVIDIA. ABCI и сейчас можно назвать экономичной системой — при максимальной общей мощности комплекса 3,25 МВт сам суперкомпьютер при полной нагрузке потребляет лишь 2,3 МВт. Поскольку система ориентирована на предоставление вычислительных услуг сторонним заказчикам, модернизировано и системное ПО, в котором упор сместился в сторону контейнеризации.
28.05.2021 [00:33], Владимир Мироненко
Perlmutter стал самым мощным ИИ-суперкомпьютером в мире: 6 тыс. NVIDIA A100 и 3,8 ЭфлопсВ Национальном вычислительном центре энергетических исследований США (NERSC) Национальной лаборатории им. Лоуренса в Беркли состоялась торжественная церемония, посвящённая официальному запуску суперкомпьютера Perlmutter, также известного как NERSC-9, созданного HPE в партнёрстве с NVIDIA и AMD. Это самый мощный в мире ИИ-суперкомпьютер, базирующийся на 6159 ускорителях NVIDIA A100 и примерно 1500 процессорах AMD EPYC Milan. Его пиковая производительность в вычислениях смешанной точности составляет 3,8 Эфлопс или почти 60 Пфлопс в FP64-вычислениях. Perlmutter основан на платформе HPE Cray EX с прямым жидкостным охлаждением и интерконнектом Slingshot. В состав системы входят как GPU-узлы, так и узлы с процессорами. Для хранения данных используется файловая система Lustre объёмом 35 Пбайт скорость обмена данными более 5 Тбайт/с, которая развёрнута на All-Flash СХД HPE ClusterStor E1000 (тоже, к слову, на базе AMD EPYC). 
Perlmutter (Phase 1). Фото: NERSC Установка Perlmutter разбита на два этапа. На сегодняшней презентации было объявлено о завершении первого (Phase 1) этапа, который начался в ноябре прошлого года. В его рамках было установлено 1,5 тыс. вычислительных узлов, каждый из которых имеет четыре ускорителя NVIDIA A100, один процессор AMD EPYC Milan и 256 Гбайт памяти. На втором этапе (Phase 2) в конце 2021 года будут добавлены 3 тыс. CPU-узлов c двумя AMD EPYC Milan и 512 Гбайт памяти., а также ещё ещё 20 узлов доступа и четыре узла с большим объёмом памяти. 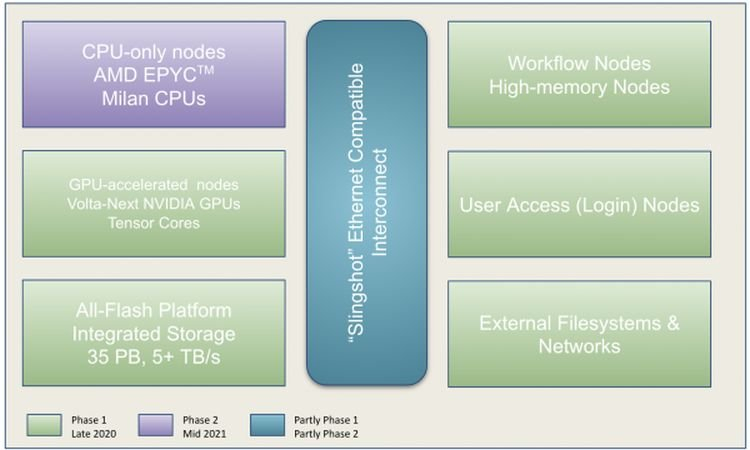
NERSC Также на первом этапе были развёрнуты служебные узлы, включая 20 узлов доступа пользователей, на которых можно подготавливать контейнеры с приложениями для последующего запуска на суперкомпьютере и использовать Kubernetes для оркестровки. Среда разработки будет включать NVDIA HPC SDK в дополнение к наборам компиляторов CCE (Cray Compiling Environment), GCC и LLVM для поддержки различных средств параллельного программирования, таких как MPI, OpenMP, CUDA и OpenACC для C, C ++ и Fortran. 
Фото: DESI Сообщается, что для Perlmutter готовится более двух десятков заявок на вычисления в области астрофизики, прогнозирования изменений климата и в других сферах. Одной из задач для новой системы станет создание трёхмерной карты видимой Вселенной на основе данных от DESI (Dark Energy Spectroscopic Instrument). Ещё одно направление, для которого задействуют суперкомпьютер, посвящено материаловедению, изучению атомных взаимодействий, которые могут указать путь к созданию более эффективных батарей и биотоплива.
17.05.2021 [18:26], Сергей Карасёв
Иран запустил Simurgh, свой самый мощный суперкомпьютерВ Иране введён в эксплуатацию самый мощный в стране вычислительный комплекс: система получила название Simurgh — в честь фантастического существа в иранской мифологии, царя всех птиц. Суперкомпьютер разработан специалистами Технологического университета имени Амира Кабира (Amirkabir University of Technology). Смонтирована система в Иранском исследовательском центре высокопроизводительных вычислений (IHPCRC). В настоящее время быстродействие комплекса составляет 0,56 Пфлопс. В дальнейшем мощность суперкомпьютера планируется довести до 1 Пфлопс — на доработку системы потребуется около двух месяцев. Конфигурация суперкомпьютера не раскрывается, а появление его в публичных рейтингах производительности вряд ли стоит ожидать. 
Суперкомпьютер Simurgh. Фото: Maryam Kamyab / MEHR Новый суперкомпьютер, по словам представителей власти, по мощности приблизительно в 100 раз превосходит системы высокопроизводительных вычислений, до сих пор применявшиеся в Иране. Система будет использоваться для задач в области генетики, Big Data, ИИ, интернета вещей и так далее. Часть мощностей будет выделена для облачных систем. 
Суперкомпьютер Simurgh. Фото: Maryam Kamyab / MEHR Интернет-источники отмечают, что Simurgh, по всей видимости, построен с использованием комплектующих, приобретённых на «чёрном» рынке, поскольку официально Иран не может закупать многие современные технологии из-за санкций — несколько лет назад ZTE получила крупный штраф из-за нелегальных поставок оборудования в страну. Тем не менее, Ирану периодически удаётся получить необходимые компоненты: в начале века был построен кластер из Pentium III/IV, а в 2007 году был построен суперкомпьютер на базе AMD Opteron.
15.04.2021 [01:31], Владимир Мироненко
TSMC остановит выпуск Arm-процессоров Phytium — судьба китайского экзафлопсного суперкомпьютера Tianhe-3 под вопросомТайваньская компания Taiwan Semiconductor Manufacturing Company (TSMC) приостановила поставку чипов по новым заказам китайской компании Phytium, которая на прошлой неделе была добавлена властями США в «чёрный» список Министерства торговли. Внесение компаний в этот перечень означает запрет для американских компаний на работу с ними и предоставление продуктов или услуг без получения соответствующих лицензий. Иностранные компании, такие как TSMC, теоретически могут продолжать работать с компаниями из «чёрного списка», но США могут оказывать на них давление через их американских поставщиков. Например, когда США занесли Huawei в «чёрный» список, TSMC была вынуждена отказаться от сотрудничества с ней, поскольку многие ключевые технологии, лежащие в основе её производственных процессов, были разработаны американскими фирмами. Пока неясно, оказывалось ли сейчас подобное давление на TSMC, и были ли ею прекращены поставки остальным шести суперкомпьютерным китайским фирмам из «чёрного» списка. Как сообщает South China Morning Post, TSMC выполнит заказы, размещённые Phytium до внесения в «чёрный список», но больше поставлять ей чипы не будет. 
Прототип Tianhe-3. Фото: Xinhua Предполагается, что Phytium стоит за развёртыванием систем высокопроизводительных вычислений для китайского военно-промышленного комплекса, использующего её разработки при создании гиперзвуковых ракет. Компания сотрудничает с Оборонным научно-техническим университетом Народно-освободительной армии Китая (NUDT), который ранее создал суперкомпьютеры Tianhe-1 и Tianhe-2, в своё время занимавшие первые строчки рейтинга TOP500. Tianhe-3, один из трёх проектов китайских суперкомпьютеров экзафлопсного класса, должен был быть закончен в прошлом году, однако осенью было объявлено, что из-за пандемии коронавируса сроки сдвигаются. Летом 2020 года в распоряжении исследователей уже был прототип новой машины, имевший теоретическую производительность 3,146 Пфлопс. Он включал 512 плат с тремя процессорами Phytium MT2000+ и 128 плат с четырьмя Phytium FT2000+. Точные параметры этих 7-нм Arm-чипов не приводятся, но в одной из свежих научных публикаций упоминается, что на каждый 64-ядерный FT2000+ в прототипе Tianhe-3 приходилось 64 Гбайт RAM. А каждый MT2000+ можно поделить на четыре NUMA-узла с 32 ядрами и 16 Гбайт RAM, то есть, судя по описанию, это 128-ядерный чип, о котором ранее ничего не было известно. Теперь же судьба этих CPU и суперкомпьютера Tianhe-3 и вовсе под вопросом.
22.06.2020 [18:20], Игорь Осколков
ARM-суперкомпьютер Fugaku поднялся на вершину рейтингов TOP500, HPCG и HPL-AIКонечно же, речь идёт о японском суперкомпьютере Fugaku на базе ARM-процессоров A64FX, который досрочно начал трудиться весной этого года. Эта машина стала самым мощным суперкомпьютером в мире сразу в трёх рейтингах: классическом TOP500, современном HPCG и специализированном HPL-AI.  Суперкомпьютер состоит из 158976 узлов, которые имеют почти 7,3 млн процессорных ядер, обеспечивающих реальную производительность на уровне 415,5 Пфлопс, то есть Fugaku почти в два с половиной раза быстрее лидера предыдущего рейтинга, машины Summit. Правда, оказалось, что с точки зрения энергоэффективности новая ARM-система мало чем отличается от связки обычного процессора и GPU, которой пользуется большая часть суперкомпьютеров. Так что на первое место в Green500 она не попала. 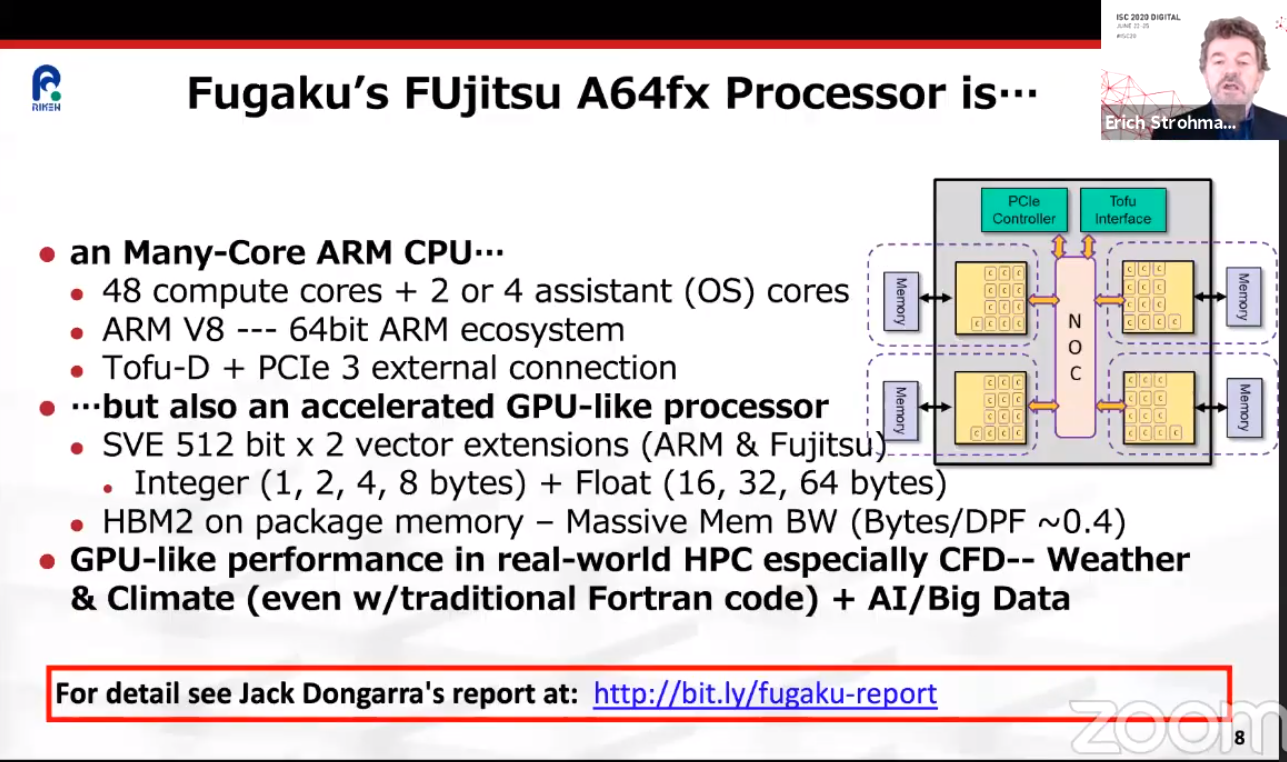  Однако на стороне Fugaku универсальность — понижение точности вычислений вдвое приводит к удвоение производительности. Так что машина имеет впечатляющую теоретическую пиковую скорость вычислений 4,3 Эопс на INT8 и не менее впечатляющие 537 Пфлопс на FP64. Это помогло занять её первое место в бенчмарке HPL-AI, которые использует вычисления разной точности. А общая архитектура процессора, включающего набортную память HBM2, и системы, использующей интерконнект Tofu, способствовали лидерству в бенчмарке HPCG, который оценивает эффективность машины в целом. 
09.06.2020 [19:49], Юрий Поздеев
Суперкомпьютер Neocortex: 800 тыс. ядер Cerebras для ИИПиттсбургский суперкомпьютерный центр (PSC) получит $5 млн от Национального научного фонда на создание суперкомпьютера нового типа Neocortex, который объединяет ИИ-серверы Cerebras CS-1 и HPE SuperDome Flex в единую систему с общей памятью. Планируется, что решение будет введено в эксплуатацию до конца 2020 года.  Каждый сервер Cerebras CS-1 имеет процессор Cerebras Wafer Scale Engine (WSE), который содержит 400 000 ядер, оптимизированных для работы с ИИ (46 225 мм2, 1,2 трлн транзисторов). В паре с ними работает HPE SuperDome Flex, который используется для предварительной обработки информации и постобработки после Cerebras. SuperDome Flex представлен в максимальной комплектации, то есть с 32 процессорами Intel Xeon, 24 Тбайт оперативной памяти, 205 Тбайт флеш-памяти и 24 интерфейсными картами.  Каждый сервер Cerebras CS-1 подключается к SuperDome Flex через 12 каналов со скоростью 100 Гбит/с каждый. Процессор WSE способен обрабатывать 9 Пбайт данных в секунду, что, по подсчетам Nystrom, эквивалентно примерно миллиону фильмов в HD-качестве. Характеристики решения действительно впечатляют! 
Neocortex назван в честь области мозга, отвечающей за функции высокого порядка, включая когнитивные способности, сновидения и формирование речи Архитектура решения строилась таким образом, чтобы не пришлось разбивать вычислительные блоки на множество узлов — это позволило снизить задержки в обработке информации и ускорить обучение моделей ИИ. Cerebras CS-1 разрабатывался специально для ИИ, поэтому он имеет преимущества перед серверами с графическими ускорителями, которые хорошо справляются с матричными операциями, но имеют многие конструктивные ограничения.  По заявлениям Neocortex, сервер CS-1 будет на несколько порядков мощнее системы PSC Bridges-AI. Один сервер Neocortex CS-1 будет эквивалентен примерно 800-1500 серверов с традиционной архитектурой с использованием графических ускорителей. Задачи, в которых Neocortex покажет себя максимально эффективно относятся к классу нейронных сетей DCIGN (deep convolutional inverse graphics networks) и RNN (recurrent neural networks). Если говорить простыми словами, то это более точное прогнозирование погоды, анализ геномов, поиск новых материалов и разработка новых лекарств. 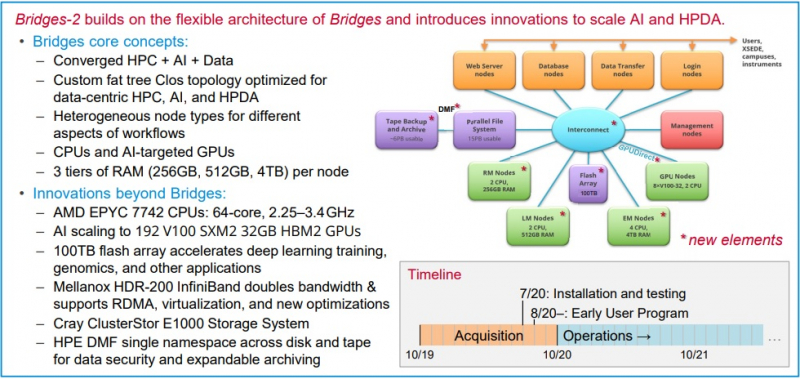 PSC, помимо Neocortex, запускает еще и новое поколение системы Bridges-2, которое будет развернуто осенью 2020 года. Таким образом, до конца этого года будут введены в эксплуатацию два мощных суперкомпьютера для ИИ. Neocortex и Bridges-2 будут поддерживать самые популярные фреймворки машинного обучения, что позволит создать гибкую и мощную экосистему для ИИ, анализа данных, моделирования и симуляции. До 90% машинного времени Neocortex будет выделяться через XSEDE (Extreme Science and Engineering Discovery Environment), финансируемую NSF организацию, которая координирует совместное использование передовых цифровых услуг, включая суперкомпьютеры и ресурсы для визуализации и анализа данных, с исследователями на национальном уровне.
19.11.2019 [00:29], Андрей Созинов
Ноябрьский TOP500: больше китайских систем и меньше американских, и первая система на AMD EPYC RomeУже традиционно в рамках конференции SC была опубликована свежая версия TOP500, рейтинга пятисот самых производительных суперкомпьютеров в мире.  В новой версии списка стало больше систем из Китая, и в то же время сократилось количество систем, расположенных в США. Значительно увеличилась общая производительность всех систем, однако десятка лидеров рейтинга изменений не претерпела. 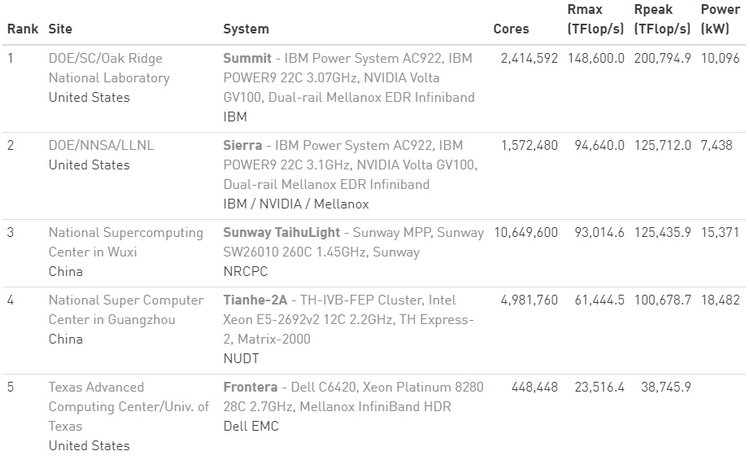 За последние шесть месяцев число китайских суперкомпьютеров в рейтинге TOP500 увеличилась с 219 до 228, и в итоге их доля составила 45,6 %. В то же время количество американских суперкомпьютеров достигло минимума в 117 систем, что составляет 23,4 %. Однако общая производительность систем из США выше — 37,1 % от общей, в то время как доля Китая здесь составляет 32,2 %. Суммарная производительность всех пятисот самых мощных суперкомпьютеров в мире составляет 1,65 Экзафлопс. Российских машин в рейтинге три. На 29 месте TOP500 теперь находится суперкомпьютер Кристофари, принадлежащий Сбербанку. 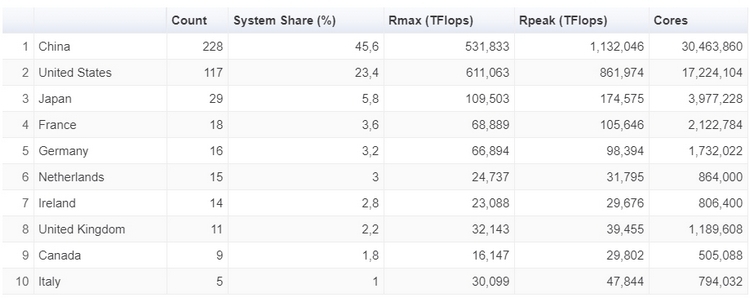 Количество систем, использующих ускорители вычислений и сопроцессоры также возросло, со 134 до 145. Большинство из них использует продукты на базе NVIDIA Volta, a также Pascal и Kepler. Что касается центральных процессоров, то здесь безоговорочным лидером остаётся Intel — 94,8 % систем из TOP500 построены на её чипах.  И здесь же хотелось бы отметить, что в свежем рейтинге TOP500 появилась первая система на процессорах AMD EPYC Rome. Это французский суперкомпьютер Joliot-Curie, построенный на платформе AtoS BullSequana XH2000, которая включает 64-ядерные процессоры AMD EPYC 7H12. Данный суперкомпьютер обладает производительностью 9,4 Пфлопс, он разместился на 59 строке рейтинга TOP500. Значительно увеличилась и минимальная производительность систем рейтинга TOP500. Теперь пятисотая система в рейтинге обладает производительностью в 1,142 Петафлопс. Полгода назад эта система располагалась на 399 месте. А чтобы претендовать на сотое место в рейтинге, системе теперь необходимо обладать производительностью более чем в 2,57 Пфлопс. 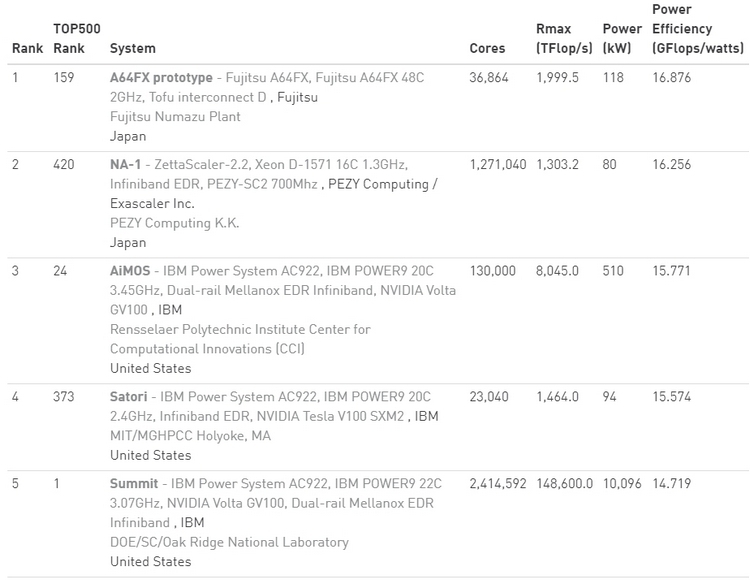 Рейтинг наиболее энергоэффективных систем — Green500 — возглавила японская система от Fujitsu. Это прототип суперкомпьютера на базе процессоров A64FX, который обеспечивает производительность в 16,9 Гфлопс на 1 ватт энергии. В общем рейтинге TOP500 данная система занимает 159 строку с общей производительностью в 2 Пфлопс. Интересно, что система обладает всего лишь 36 864 ядрами и не использует ускорители, что делает её результаты ещё более впечатляющими. Кстати, среднее количество ядер на систему из списка TOP500 также увеличилось — с 118 213 до 126 308.
19.09.2019 [21:46], Андрей Созинов
Atos BullSequana XH2000 на процессорах EPYC 7H12 установила ряд мировых рекордовНовая версия суперкомпьютерного узла BullSequana XH2000 компании Atos, построенная на новейших 64-ядерных процессорах AMD EPYC 7H12, смогла установить сразу несколько абсолютных мировых рекордов производительности.  Новинка была протестирована самой Atos в пакете бенчмарков SPECrate 2017, который как раз и предназначен для оценки производительности мощных вычислительных систем. По результатам тестов, новинка претендует на звание рекордсмена среди всех двухпроцессорных систем в четырёх бенчмарках пакета: 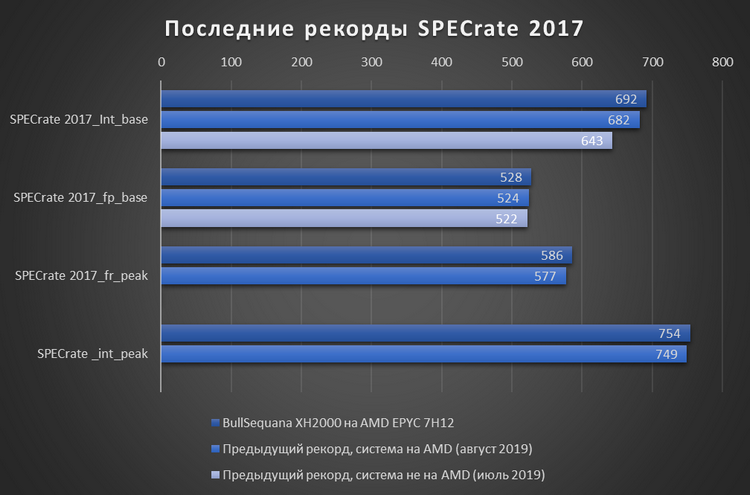 На данный момент представленные Atos результаты тестов проходят проверку комитетом SPEC. Кроме того, Atos заявляет, что система BullSequana XH2000 на базе EPYC 7H12 установила рекорд в бенчмарке HPL Linpack для систем на процессорах AMD. Новинка показала результат в 4,296 Тфлопс, что на 11 % больше результата системы с процессорами AMD EPYC 7742. 
Atos оставляет системы AMD для ряда европейских суперкомпьютеров Прирост производительности обусловлен тем, что средняя рабочая частота процессора EPYC 7H12 выше по сравнению с моделью EPYC 7742. А чтобы справиться с тепловыделением, увеличившимся вместе с частотой, компания Atos использует в BullSequana XH2000 систему жидкостного охлаждения.
02.08.2019 [14:32], Геннадий Детинич
Intel хоронит шину Omni-PathДовольно неожиданно компания Intel отказалась от развития интерконнекта Omni-Path, которую она продвигала в серверных и HPC-платформах сначала для соединения узлов, в том числе для гиперконвергентных систем. Первое поколение шины Omni-Path с пропускной способностью до 100 Гбит/с на порт появилось несколько лет назад. Но ожидаемого второго поколения решений с пропускной способностью до 200 Гбит/с уже не будет. 
Ускорители Intel Xeon Phi с интегрированными контроллером и шиной Omni-Path Информацию о прекращении разработки и выпуска продукции Intel OmniPath Architecture 200 (OPA200) компания подтвердила, например, нашим коллегам с сайта HPCwire. Компания продолжит поддержку и поставку решений с шиной OPA100, но поставок продуктов с архитектурой OPA200 на рынок больше не будет. В принципе, сравнительно слабая поддержка шины Intel OmniPath со стороны клиентов рынка высокопроизводительных систем намекала на нечто подобное. Большей популярностью у строителей суперсистем и не только продолжает пользоваться InfiniBand и её новое HDR-воплощение с той же пропускной способностью до 200 Гбит/с. В свете ликвидации OPA200 становится понятно, почему Intel схватилась с NVIDIA за право поглощения компании Mellanox. Но не вышло: приз ушёл к NVIDIA. «Вообще, половина инсталляций в TOP500 использует Ethernet, но в основном 10/25/40 Гбит/с, и лишь совсем чуть-чуть может похвастаться 100 Гбит/с. InfiniBand установлен почти в 130 машинах, а Omni-Path есть чуть больше чем в 40. Остальное — проприетарные разработки». Что остаётся Intel? У лидера рынка микропроцессоров есть I/O-активы. Компания около 8 лет активно выстраивает направление для развития коммуникаций в ЦОД. За это время она поглотила разработчика коммутационных ASIC компанию Fulcrum Microsystems, подразделение по разработке адаптеров и коммутаторов InfiniBand компании QLogic и коммуникационное подразделение компании Cray. Относительно свежей покупкой Intel стала компания Barefoot Networks, разработчик решений для Ethernet-коммутаторов. Похоже, Intel решила вернуться к классике: InfiniBand (что менее вероятно) и Ethernet (что более вероятно), а о проприетарных шинах в виде той же Omni-Path решила забыть. В конце концов, Ethernet-подразделение компании славится своими продуктами. Новое поколения Intel Ethernet 800 Series способно заменить OPA100.
22.08.2018 [13:00], Геннадий Детинич
Раскрыты спецификации ARM-процессоров Fujitsu A64FX для суперкомпьютера Post-KПримерно через три года начнётся коммерческая эксплуатация суперкомпьютера Post-K, который компании Fujitsu и RIKEN разрабатывают на смену предыдущей совместной системы суперкомпьютера K (начал работать в 2011 году). Новая система Post-K обещает 100-кратно поднять производительность на уровне приложений. И сделано это будет благодаря переходу Fujitsu на ARM-совместимые ядра и новую архитектуру с масштабируемыми векторными инструкциями (Scalable Vector Extensions).  На прошедшей на днях конференции Hot Chips 30 (2018) компания Fujitsu впервые обнародовала спецификации новых процессоров, которые получили обозначение A64FX. Ни «A», ни «64», ни «FX» не имеют отношение к компании AMD, хотя в названии новых суперпроцессоров Fujitsu что-то немного согревает душу. Это процессоры с поддержкой 64-разрядных команд ARM и векторных инструкций длиной до 512 бит. Каждый процессор Fujitsu A64FX будет нести 48 вычислительных ядер и 4 вспомогательных ядра, разделённые на четыре блока, соединённых внутренней кольцевой шиной. Для связи с другими процессорами Fujitsu использует две линии внешнего интерфейса Tofu с пропускной способностью 28 Гбит/с. Строение процессора и внешний скоростной интерфейс обещают значительное наращивание параллелизма в вычислениях. 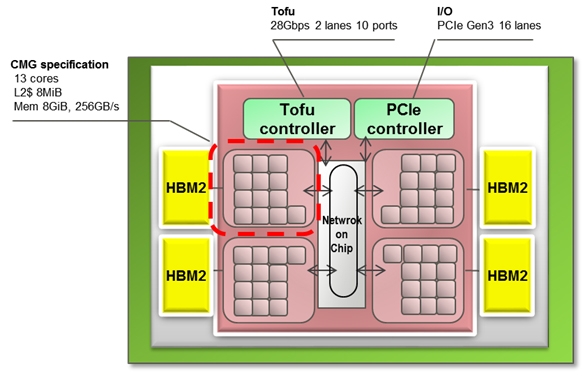
Fujitsu Каждый из 13-ядерных блоков поддержан кеш-памятью L2 объёмом 8 Мбайт. Кроме этого каждый из блоков напрямую обращается к модулю стековой памяти HBM2 объёмом 8 Гбайт. Суммарный объём памяти HBM2 у каждого процессора насчитывает 32 Гбайт, а общая скорость доступа достигает 1024 Гбайт/с. Поскольку память HBM2 можно рассматривать в качестве кеш-памяти третьего уровня, все или большинство операций выполняются в процессоре, что обещает отличный прирост производительности.  Процессор Fujitsu A64FX выпускается с использованием 7-нм техпроцесса, очевидно, что на линиях компании TSMC. Он насчитывает 8,7 млрд транзисторов. Пиковая производительность процессора для операций с двойной точностью достигает 2,7 терафлопс. Процессор без потерь на переход может вычислять операции с одинарной точностью и половинной, соответственно, в два и четыре раза быстрее. Также, за что надо благодарить тему машинного обучения, процессор A64FX оптимизирован для обработки 16- и 8-битных целочисленных значений. 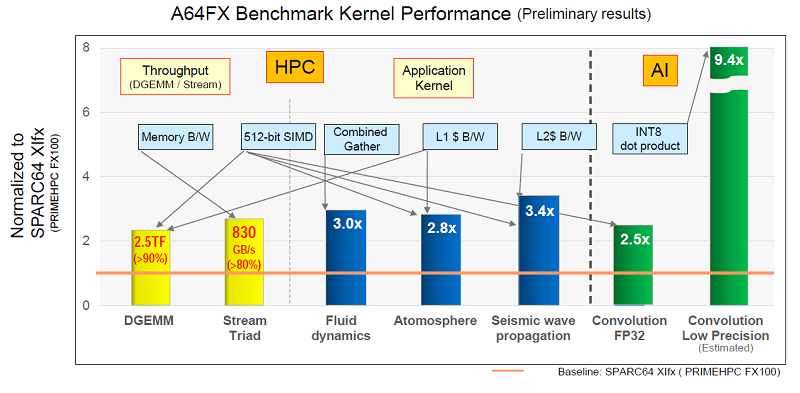 |
|

