Материалы по тегу: компьютер
|
17.06.2024 [08:53], Руслан Авдеев
Cerebras и Dell предложат заказчикам современные ИИ-платформыРазработчик ИИ-суперчипов Cerebras Systems анонсировал сотрудничество с Dell. Вместе компании займутся созданием передовых вычислительных инфраструктур для генеративного ИИ. В рамках сотрудничества будут создаваться масштабируемые решения для ИИ-суперкомпьютеров Cerebras с платформами Dell на базе процессоров AMD EPYC Genoa. Источник изображения: Cerebras По словам участников проекта, новые технологические решения дадут возможность обучать модели, на порядки более крупные, чем те, что есть на данный момент. В частности, будут задействованы системы Dell PowerEdge R6615 на базе AMD EPYC 9354P, которые предоставят потоковый доступ к 82 Тбайт памяти — для обучения моделей практически любого размера. Совместные платформы Cerebras и Dell будут включать ИИ-системы и суперкомпьютеры. Также будет предложена тренировка ИИ-моделей и иные сервисы поддержки машинного обучения. Как утверждают в самой Cerebras, сотрудничество с Dell станет поворотной точкой, открывающие каналы глобальной дистрибуции. Компании предоставят ИИ-оборудование, ПО и экспертизу, что позволит заказчикам упростить и ускорить внедрении современных ИИ-технологий, попутно снизив TCO. В марте Cerebras представила новейшие суперчипы Cerebras WSE-3, а в мае появилась новость, что совместно с Core42 из ОАЭ компания создаст суперкомпьютер Condor Galaxy 3 (CG-3) со 172,8 млн ИИ-ядер.
16.06.2024 [16:25], Сергей Карасёв
Холодный приём: новый национальный суперкомпьютер Норвегии разместят в руднике и охладят водой из фьордаВласти Норвегии, по сообщению ресурса HPC Wire, подписали контракт стоимостью Kr225 млн ($21 млн) с корпорацией HPE, предусматривающий создание нового национального суперкомпьютера A2 (постоянное имя системе дадут позже). Он станет самым мощным в истории страны и значительно ускорит исследования и разработки в различных областях, в том числе в сфере ИИ. За закупку и эксплуатацию НРС-систем в Норвегии отвечает государственная компания Sigma2 AS. Вычислительные услуги предоставляются в сотрудничестве с университетами Бергена, Осло, Тромсё, а также Норвежским университетом естественных и технических наук (NTNU) в рамках проекта NRIS. В основу нового суперкомпьютера ляжет платформа HPE Cray EX4000. Известно, что в состав комплекса войдут 76 узлов с четырьмя гибридными суперчипами NVIDIA GH200 (всего 304 ускорителя), 252 узла с двумя 128-ядерными AMD EPYC Turin (64 512 ядер) и 5,3-Пбайт хранилище HPE Cray ClusterStor E1000. Узлы объединит интерконнект HPE Slingshot. Ожидаемая производительность системы составит порядка 10 Пфлопс. 
Источник изображения: Sigma2 Монтаж системы планируется выполнить в течение весны–лета 2025 года. Машина расположится в дата-центре Лефдаль (Lefdal Mine Datacenter, LMD), развёрнутом на базе бывшего рудника. Этот объект имеет большую площадь и предоставляет гибкие возможности в плане масштабирования. Новый суперкомпьютер HPE станет первой национальной высокопроизводительной системой, установленной в этом ЦОД. 
Источник изображения: Sigma2 Несмотря на то, что готовящийся комплекс будет значительно мощнее высокопроизводительных вычислительных систем Sigma2 предыдущего поколения, его энергопотребление окажется меньше примерно на 30 %. Для охлаждения будет использоваться холодная вода из близлежащего фьорда. Нагретая вода затем может быть направлена на нужды местных предприятий, в том числе, например, рыбных ферм. Ожидается, что суперкомпьютер сможет удовлетворить потребности Норвегии в НРС-ресурсах в течение следующих пяти лет. Он будет доступен исследователям по всей стране. В дальнейшем суперкомпьютер может дополнительно получить 119 808 CPU-ядер и/или 224 ускорителя. В целом же Норвегия рассчитывает, что современные ЦОД станут для страны «новой нефтью».
15.06.2024 [18:04], Владимир Мироненко
ASUS осваивает строительство суперкомпьютеров, ЦОД и комплексных ИИ-системПроизводитель потребительской электроники ASUS уже давно работает на рынке серверов и ЦОД. Пока он занимает на нём не очень большую долю, но как сообщил ресурсу The Register старший вице-президент ASUS Джеки Сюй (Jackie Hsu), высокопроизводительных вычислений (HPC) и серверов стал для компании «областью большого роста». Сюй рассказал, что ASUS участвовала в строительстве на Тайване суперкомпьютера Taiwania 2 производительностью 9 Пфлопс, занявшего в рейтинге TOP500 двадцатую позицию после дебюта в 2018 году. А в прошлом году ASUS выиграла тендер на участие в создании суперкомпьютера Taiwania 4. Сюй сообщил, что ASUS построила ЦОД для Taiwania 4. Причём PUE новой площадки составляет 1,17, что является неплохим показателем для любого подобного объекта, а тем более для Тайваня, отличающегося климатом с высокими температурой и влажностью. 
Источник изображения: ASUS Также ASUS участвовала в ряде проектов в области ИИ, включая разработку собственной большой языковой модели (LLM) Formosa Foundation со 176 млрд параметров. Модель была обучена на наборах данных на местном языке для генерации текста с традиционной китайской семантикой.  Благодаря накопленному опыту ASUS начала предлагать услуги на рынке ИИ. Компания уже заключила несколько контрактов, в рамках которых она проектирует и создаёт мощные системы для работы с ИИ, предлагая большую часть программного и аппаратного стека, необходимого для обработки ИИ-нагрузок. Гендиректор NVIDIA Дженсен Хуанг (Jensen Huang) назвал ASUS в числе компаний, с кем NVIDIA будет сотрудничать в работе над созданием так называемых фабрик ИИ.  На Computex 2024 компания представила новые серии серверов ASUS RS700-E12 и RS720-E12 с процессорами Intel Xeon 6, разработанные специально для обработки высокопроизводительных рабочих нагрузок, а также серверы хранения семейства VS320D, предназначенные для использования в составе инфраструктур SAN для работы с базами данных, системами виртуализации и пр. Также ASUS представила ИИ-систему ESC AI POD на базе суперускорителей NVIDIA GB200 NVL72.
14.06.2024 [14:05], Сергей Карасёв
Срок эксплуатации суперкомпьютеров растёт, несмотря на прекращение поддержки оборудованияНаучные учреждения и организации, по сообщению HPC Wire, увеличивают период эксплуатации установленных суперкомпьютеров, несмотря на то что их поставщики прекращают поддержку соответствующего оборудования. В результате, срок службы НРС-комплексов может достигать уже 10 лет. Типичный жизненный цикл суперкомпьютера составляет около пяти–шести лет. После этого требуется замена в связи с моральным устареванием, а также в свете появления более производительных и энергоэффективных компонентов. Кроме того, по прошествии примерно пяти лет дальнейшее обслуживание оборудования обычно становится слишком дорогим. 
Источник изображения: RIKEN Однако японский Институт физико-химических исследований (RIKEN) намерен эксплуатировать существующую систему Fugaku в течение десяти лет. Этот вычислительный комплекс на базе Arm-процессоров Fujitsu A64FX в 2020 году стал самым производительным суперкомпьютером в мире. В текущем рейтинге ТОР500 система занимает четвёртое место с быстродействием приблизительно 442 Пфлопс. Таким образом, Fugaku продолжит активно использоваться вплоть до 2030 года, когда ожидается появление суперкомпьютера FugakuNEXT. Сатоши Мацуока (Satoshi Matsuoka), директор японского Центра вычислительных наук RIKEN, отметил, что зачастую НРС-системы всё ещё годны для эксплуатации спустя пять лет после запуска. Но организациям приходится устанавливать новые комплексы, поскольку производители попросту прекращают поддержку имеющихся платформ. Мацуока подчёркивает, что подобная практика должна быть прекращена. Ливерморская национальная лаборатория им. Э. Лоуренса (LLNL) Министерства энергетики США также заявляет о том, что некоторые её НРС-системы служат в течение 7–10 лет. Большое значение для продления срока службы суперкомпьютеров имеет оптимизация ПО. Отмечается, что средний возраст систем в списке ТОР500 по состоянию на июнь 2024 года составляет около 35 месяцев, что является рекордным показателем. Для сравнения: в период с 1995 по 2011 год это значение варьировалось в среднем от 5 до 10 месяцев. В целом, суперкомпьютеры эксплуатируются дольше, поскольку создание новых систем обходится очень дорого. А некоторые эксперты полагают, что нынешнее поколение сверхкрупных машин и вовсе будет последним в своём роде.
26.05.2024 [13:24], Руслан Авдеев
Эрик Шмидт: будущие суперкомпьютеры США и Китая будут окружены пулемётами и колючей проволокой и питаться от АЭС
hardware
hpc
аэс
безопасность
ии
информационная безопасность
китай
суперкомпьютер
сша
цод
энергетика
Бывший генеральный директор Google Эрик Шмидт (Eric Schmidt) прогнозирует, что в обозримом будущем в США и Китае большие суперкомпьютеры будут заниматься ИИ-вычислениями под защитой военных баз. В интервью Noema он подробно рассказал о том, каким видит новые ИИ-проекты, и это будущее вышло довольно мрачным. Шмидт поведал о том, как правительства будут регулировать ИИ и искать возможности контроля ЦОД, работающих над ИИ. Покинув Google, бизнесмен начал очень тесно сотрудничать с военно-промышленным комплексом США. По его словам, рано или поздно в США и Китае появится небольшое число чрезвычайно производительных суперкомпьютеров с возможностью «автономных изобретений» — их производительность будет гораздо выше, чем государства готовы свободно предоставить как своим гражданам, так и соперникам. Каждый такой суперкомпьютер будет соседствовать с военной базой, питаться от атомного источника энергии, а вокруг будет колючая проволока и пулемёты. Разумеется, таких машин будет немного — гораздо больше суперкомпьютеров будут менее производительны и доступ к ним останется более широким. Строго говоря, самые производительные суперкомпьютеры США принадлежат Национальным лабораториям Министерства энергетики США, которые усиленно охраняются и сейчас. Как заявил Шмидт, необходимы и договорённости об уровнях безопасности вычислительных систем по примеру биологических лабораторий. В биологии широко распространена оценка по уровням биологической угрозы для сдерживания её распространения и оценки уровня риска заражения. С суперкомпьютерами имеет смысл применить похожую классификацию. 
Источник изображения: Joel Rivera-Camacho/unsplash.com Шмидт был председателем Комиссии национальной безопасности США по ИИ и работал в Совете по оборонным инновациям. Также он активно инвестировал в оборонные стартапы. В то же время Шмидт сохранил влияние и в Alphabet и до сих пор владеет акциями компании стоимостью в миллиарды долларов. Военные и разведывательные службы США пока с осторожностью относятся к большим языковым моделям (LLM) и генеративному ИИ вообще из-за распространённости «галлюцинаций» в таких системах, ведущих к весьма правдоподобным на первый взгляд неверным выводам. Кроме того, остро стоит вопрос сохранения секретной информации в таких системах. Ранее в этом году Microsoft подтвердила внедрение изолированной от интернета генеративной ИИ-модели для спецслужб США после модернизации одного из своих ИИ-ЦОД в Айове. При этом представитель Microsoft два года назад предрекал, что нынешнее поколение экзафлопсных суперкомпьютеров будет последним и со временем все переберутся в облака.
15.05.2024 [14:18], Руслан Авдеев
PUE у вас неправильный: NVIDIA призывает пересмотреть методы оценки энергоэффективности ЦОД и суперкомпьютеровОператорам дата-центров и суперкомпьютеров не хватает инструментов для корректного измерения энергоэффективности их оборудования и оценки прогресса на пути к экоустойчивым вычислениям. Как утверждает NVIDIA, нужна новая система оценки показателей при использовании оборудования в реальных задачах. Для оценки эффективности ЦОД существует как минимум около трёх десятков стандартов, некоторые уделяют внимание весьма специфическим критериям вроде расхода воды или уровню безопасности. Сегодня чаще всего используется показатель PUE (power usage effectiveness), т.е. отношение энергопотребления всего объекта к потреблению собственно IT-инфраструктуры. В последние годы многие операторы достигли практически идеальных значений PUE, поскольку, например, на преобразование энергии и охлаждение нужно совсем мало энергии. В эпоху роста облачных сервисов оценка PUE показала довольно высокую эффективность, но в эру ИИ-вычислений этот индекс уже не вполне соответствует запросам отрасли ЦОД — оборудование заметно изменилось. NVIDIA справедливо отмечает, что PUE не учитывает эффективность инфраструктуры в реальных нагрузках. С таким же успехом можно измерять расход автомобилем бензина без учёта того, как далеко он может проехать без дозаправки. При этом среднемировой показатель PUE дата-центров остаётся неизменным уже несколько лет, а улучшать его всё дороже. 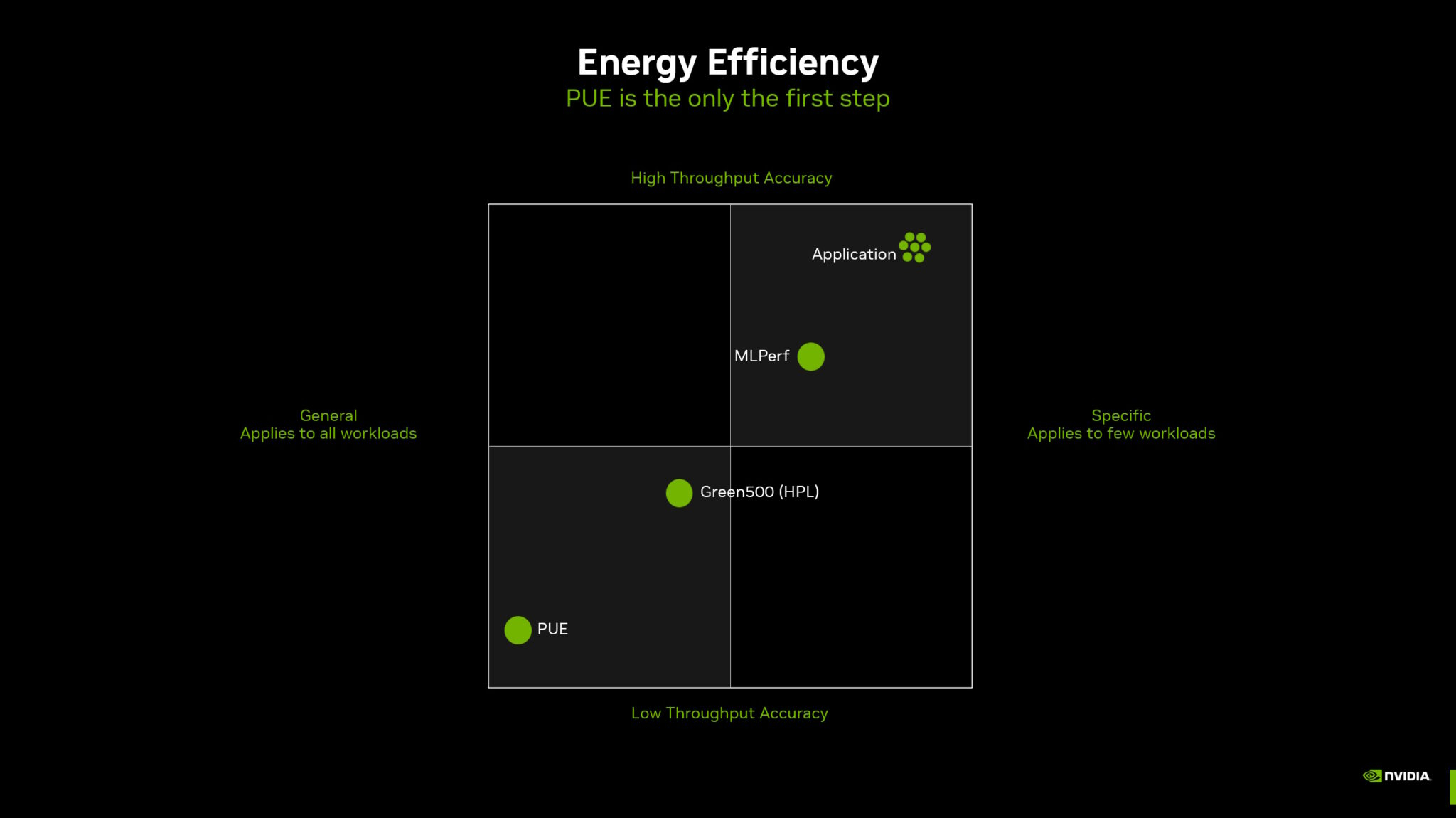
Источник изображений: NVIDIA Что касается энергопотребления, разное оборудование при одинаковых затратах может давать самые разные результаты. Другими словами, если современные ускорители потребляют больше энергии, это не значит, что они менее эффективны, поскольку они дают несопоставимо лучший результат в сравнении со старыми решениями. NVIDIA неоднократно приводила подобные сравнения и между своими GPU с обычными CPU, а теперь предлагает распространить этот подход на ЦОД целиком, что справедливо, учитывая стремление NVIDIA сделать минимальной единицей развёртывания целую стойку. 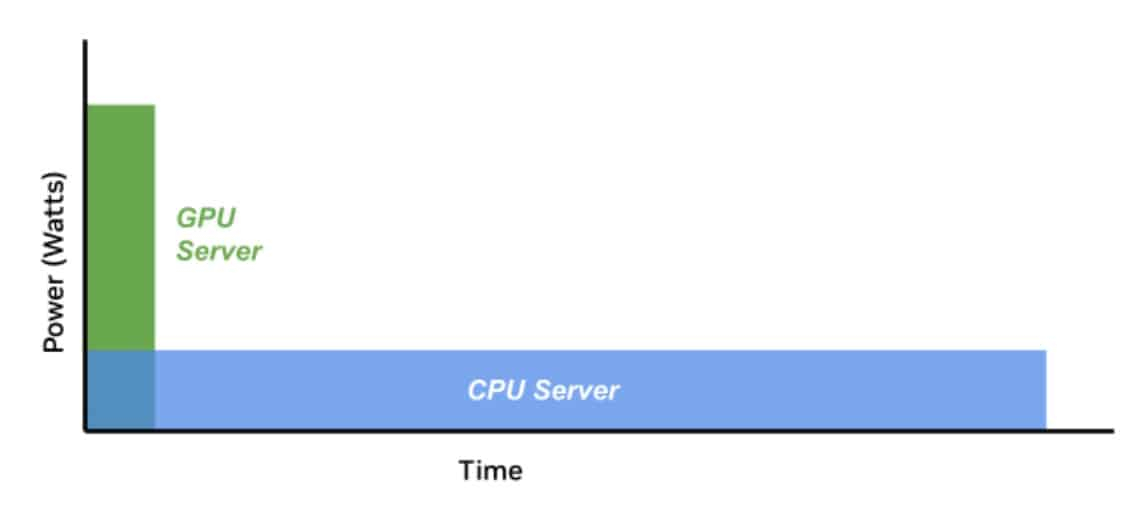 Как считают в NVIDIA, оценивать качество ЦОД можно только с учётом того, сколько энергии тратится для получения результата. Так, ЦОД для ИИ могут полагаться на MLPerf-бенчмарки, суперкомпьютеры для научных исследований могут требовать измерения других показателей, а коммерческие дата-центры для стриминговых сервисов — третьих. В идеале бенчмарки должны измерять прогресс в ускоренных вычислениях с использованием специализированных сопроцессоров, ПО и методик. Например, в параллельных вычислениях GPU намного энергоэффективнее обычных процессоров Отмечается, что с 2003 года производительность ускорителей выросла приблизительно в 7 тыс. раз, а соотношение цены и производительности стало в 5,6 тыс. раз лучше. А с учётом того, что современные ЦОД достигли PUE на уровне приблизительно 1,2, подобная метрика практически исчерпала себя, теперь стоит ориентироваться на другие показатели, релевантные актуальным проблемам. Хотя напрямую сравнить некоторые аспекты невозможно, сегментировав деятельность ЦОД на типы рабочих нагрузок, возможно, удалось бы получить некоторые результаты. В частности, операторам ЦОД нужен пакет бенчмарков, измеряющих показатели при самых распространённых рабочих ИИ-нагрузках. Например, неплохой метрикой может стать Дж/токен. Впрочем, NVIDIA грех жаловаться на недостойные оценки — в последнем рейтинге Green500 именно её системы заняли лидерские позиции.
05.05.2024 [13:56], Сергей Карасёв
Власти США продали на аукционе 5,34-ПФлопс суперкомпьютер Cheyenne из-за растущего числа сбоев и протечек СЖОАдминистрация общих служб США (GSA) реализовала на аукционе НРС-систему под названием Cheyenne, которая была введена в строй в Центре суперкомпьютерных вычислений NCAR-Wyoming (NWSC) штата Вайоминг в 2016 году. Стоимость лота составила $480 085, тогда как затраты на строительство машины оцениваются как минимум в $25 млн. Cheyenne стал одним из последних суперкомпьютеров компании Silicon Graphics International (SGI). Корпорация HPE приобрела эту фирму после того, как Cheyenne был смонтирован, но до фактического запуска системы в эксплуатацию. На момент начала работы производительность комплекса составляла 5,34 Пфлопс, что соответствовало 20 месту в актуальном тогда списке ТОР500. Cheyenne представляет собой кластер SGI ICE XA с 4032 узлами, каждый из которых содержит два процессора Intel Xeon E5-2697v4 Broadwell (18C/36; 2,3 ГГц). Таким образом, суммарное количество ядер достигает 145 152. Применяется оперативная память DDR4-2400 ECC общей ёмкостью 313 Тбайт (4890 модулей на 64 Гбайт). В состав машины изначально входило хранилище данных вместимостью 40 Пбайт. Энергопотребление — приблизительно 1,7 МВт. Задействована система жидкостного охлаждения. 
Источник изображения: GSA Две стойки управления с воздушным охлаждением состоят из 26 серверов типоразмера 1U (20 со 128 Гбайт ОЗУ и ещё 6 с 256 Гбайт ОЗУ), 10 коммутаторов и двух блоков питания. Суперкомпьютер эксплуатировался с 12 января 2017 года по 31 декабря 2023-го, решая задачи в области изменений климата и в других сферах, связанных с науками о Земле. Cheyenne превзошёл свой запланированный срок службы: в заявлении NWSC говорилось, что он будет эксплуатироваться до 2021 года. Однако к концу 2023-го количество сбоев и проблем стало слишком большим. В описании лота говорится, что «примерно 1 % узлов столкнулись с отказами за последние шесть месяцев», в основном из-за модулей памяти. Кроме того, система испытывает ограничения по техническому обслуживанию из-за неисправных быстроразъёмных соединений, вызывающих протечки воды. Таким образом, «учитывая затраты и время простоя, связанные с устранением проблем», дальнейшее использование комплекса признано нецелесообразным, в связи с чем он пущен с молотка. Вместе с тем, как отмечает Tom's Hardware, новый владелец суперкомпьютера может реализовать его основные компоненты на вторичном рынке. Например, стоимость чипов Xeon E5-2697 v4 на eBay составляет около $50, а модулей DDR4-2400 ECC ёмкостью 64 Гбайт — примерно $65. То есть, по самым скромным подсчётам, только эти компоненты могут принести новому владельцу суперкомпьютера приблизительно $700 тыс. без учёта затрат на демонтаж и вывоз машины массой 43 т, а также на тестирование компонентов. Впрочем, массовый выброс на рынок CPU и RAM в таких объёмах приведёт к снижению цен.
13.03.2024 [22:40], Алексей Степин
Больше флопс за те же ватты: Cerebras представила царь-ускоритель WSE-3 и подружилась с QualcommКомпания Cerebras Systems, известная своими разработками в области сверхбольших ИИ-процессоров, рассказала о третьем поколении чипов Wafer Scale Engine. В своё время компания произвела фурор, представив процессор, занимающий всю площадь кремниевой пластины (46225 мм2). В первом поколении WSE речь шла о 1,2 трлн транзисторов при 400 тыс. ядер и 18 Гбайт сверхбыстрой памяти. WSE-2 состоял из 2,6 трлн транзисторов, имел 850 тыс. ядер и 40 Гбайт интегрированной памяти. В WSE-3 разработчики перешли на использование 5-нм техпроцесса TSMC, что позволило разместить на пластине такого же размера уже 4 трлн транзисторов, составляющих 900 тыс. ядер и 44 Гбайт SRAM. Суммарная пропускная способность набортной памяти достигает 21 Пбайт/с, а внутреннего интерконнекта — 214 Пбит/с. 
Источник изображений: Cerebras Казалось бы, выигрыш в количестве ядер по сравнению с WSE-2 не так уж велик, однако на этот раз Cerebras сделала упор на архитектуру. Если верить заявлениям разработчиков, WSE-3 практически вдвое быстрее WSE-2 при сопоставимом уровне энергопотребления (15 кВт) и той же цене: 125 Пфлопс против 75 Пфлопс в разреженных FP16-вычислениях. WSE-3 в 62 раза быстрее NVIDIA H100, хотя и сам чип WSE-3 в 57 раз больше. 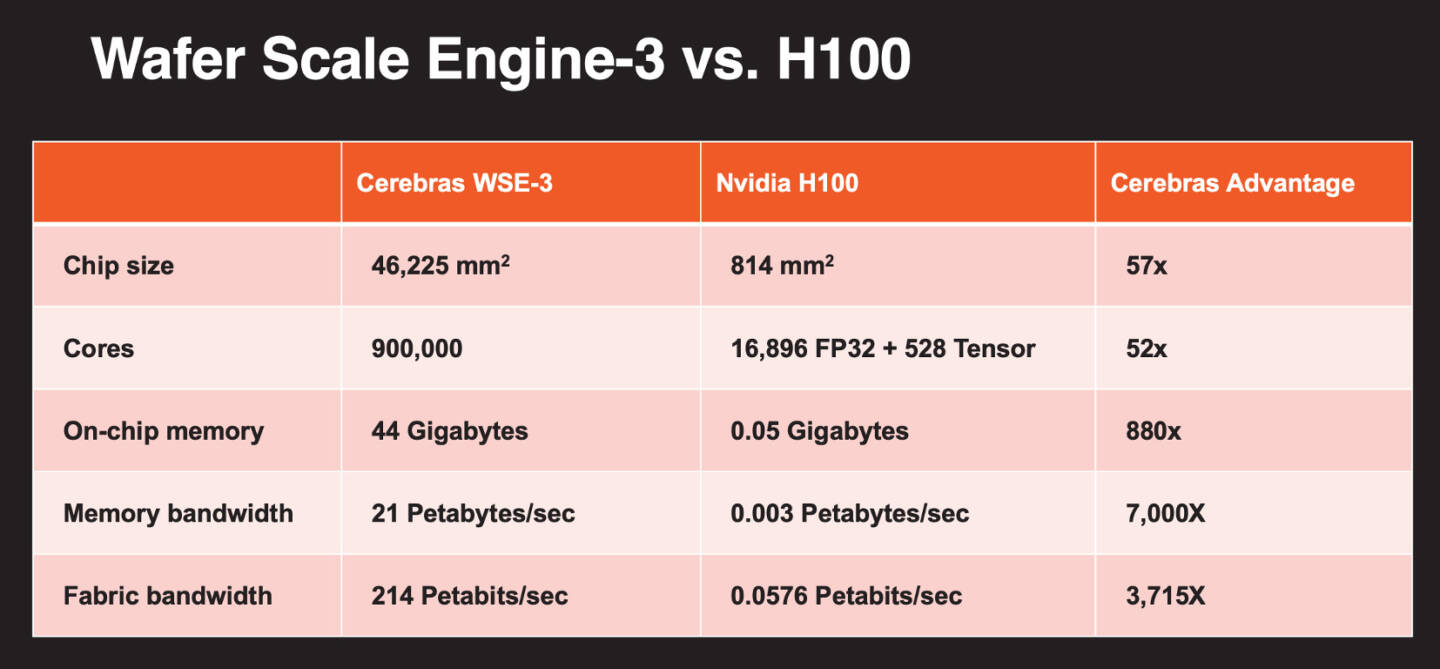 WSE-3 по-прежнему требует специфического окружения. Он станет сердцем новой системы CS-3 (23 кВт), содержащей всю необходимую сопутствующую инфраструктуру, включая СЖО, подсистемы питания, а также сетевого интерконнекта Ethernet. Последний не изменился и состоит из 12 каналов со скоростью 100 Гбит/с. Для подготовки «сырых» данных по-прежнему будет использоваться внешний суперсервер. А для их хранения будут использоваться узлы MemoryX ёмкостью до 1200 Тбайт (1,2 Пбайт). 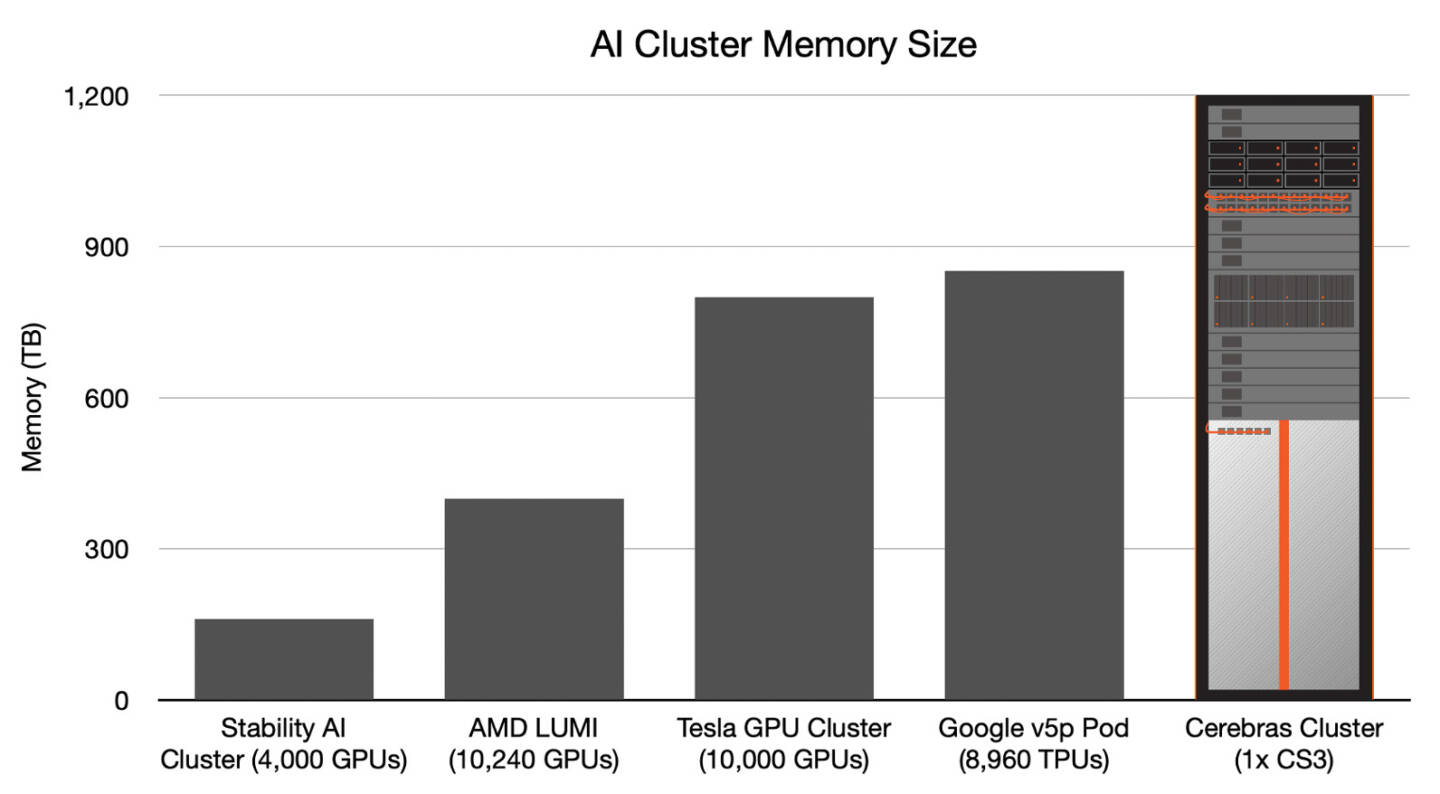 Главной задачей CS-3 станет «натаскивание» сверхбольших языковых моделей, в 10 раз превышающих по количеству параметров GPT-4 и Google Gemini. Cerebras говорит о 24 трлн параметров, причём без необходимости различных ухищрений для эффективного распараллеливания процесса обучения, что требуется в случае с GPU-кластерами. По словам компании, для обучения Megatron 175B на таких кластерах требуется 20 тыс. строка кода Python/C++/CUDA, а в случае WSE-3 потребуется лишь 565 строк на Python.  CS-3 поддерживает масштабирование вплоть до 2048 систем. Такая конфигурация вкупе с MemoryX сможет обучить модель типа Llama 70B всего за день. Первый суперкомпьютер на базе CS-3 — 8-Эфлопс Condor Galaxy 3 — будет скромнее и получит всего 64 стойки CS-3, которые разместятся в Далласе (США). В совокупности с уже имеющимися кластерами на базе CS-1 и CS-2 вычислительная мощность систем Cerebras должна достигнуть 16 Эфлопс. В сотрудничестве c группой G42 запланировано создание ещё шести систем CS-3, что в сумме позволит довести производительность до 64 Эфлопс.  Condor Galaxy 3 будет отличаться от предшественников ещё одним нововведением: в рамках сотрудничества с Qualcomm Cerebras установит в новом кластере существенное число инференс-ускорителей Qualcomm Cloud AI100 Ultra. Каждый такой ускоритель имеет 64 ядра, 128 Гбайт памяти LPDDR4x, потребляет 140 Вт и развивает 870 Топс на INT8-операциях. Причём програмнный стек полностью интегрирован, что позволит в один клик запустить обученные WSE-3 модели на ускорителях Qualcomm. 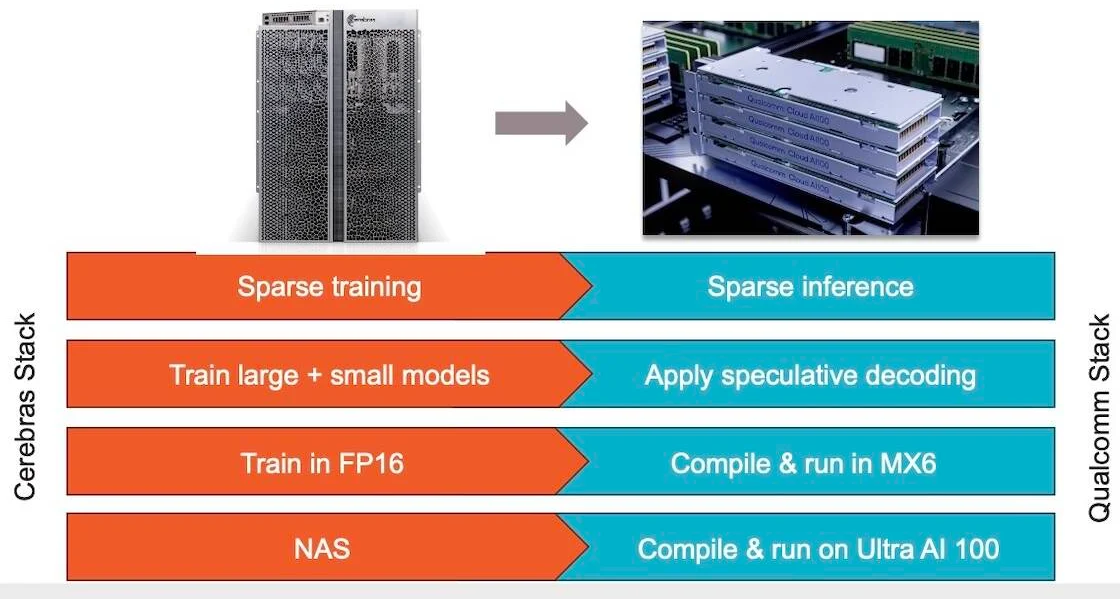 Сотрудничество Cerebras и Qualcomm носит официальный характер, его целью является оптимизация ИИ-моделей для запуска на AI100 Ultra с учетом различных продвинутых техник, таких как разреженные вычисления, спекулятивное исполнение (сочетание малых LLM для получения быстрого результата с проверкой большой LLM), использование «сжатого» формата MxFP6 для весов и других. Благодаря мощностям, предоставляемым WSE-3, цикл разработки, оптимизации и тестирования таких моделей удастся существенно ускорить, что в итоге должно обеспечить десятикратное улучшение удельной производительности новых решений.
28.11.2023 [22:20], Игорь Осколков
NVIDIA анонсировала суперускоритель GH200 NVL32 и очередной самый мощный в мире ИИ-суперкомпьютер Project CeibaAWS и NVIDIA анонсировали сразу несколько новых совместно разработанных решений для генеративного ИИ. Основным анонсом формально является появление ИИ-облака DGX Cloud в инфраструктуре AWS, вот только облако это отличается от немногочисленных представленных ранее платформ DGX Cloud тем, что оно первом получило гибридные суперчипах GH200 (Grace Hoppper), причём в необычной конфигурации. 
Изображения: NVIDIA В основе AWS DGX Cloud лежит платформа GH200 NVL32, но это уже не какой-нибудь сдвоенный акселератор вроде H100 NVL, а целая, готовая к развёртыванию стойка, включающая сразу 32 ускорителя GH200, провязанных 900-Гбайт/с интерконнектом NVLink. В состав такого суперускорителя входят 9 коммутаторов NVSwitch и 16 двухчиповых узлов с жидкостным охлаждением. По словам NVIDIA, GH200 NVL32 идеально подходит как для обучения, так и для инференса действительно больших LLM с 1 трлн параметров.  Простым перемножением количества GH200 на характеристики каждого ускорителя получаются впечатляющие показатели: 128 Пфлопс (FP8), 20 Тбайт оперативной памяти, из которых 4,5 Тбайт приходится на HBM3e с суммарной ПСП 157 Тбайтс, и агрегированная скорость NVLink 57,6 Тбайт/с. И всё это с составе одного EC2-инстанса! Да, новая платформа использует фирменные DPU AWS Nitro и EFA-подключение (400 Гбит/с на каждый GH200). Новые инстансы, пока что безымянные, можно объединять в кластеры EC2 UltraClasters.  Одним из таких кластеров станет Project Ceiba, очередной самый мощный в мире ИИ-суперкомпьютер с FP8-производительность 65 Эфлопс, объединяющий сразу 16 384 ускорителя GH200 и имеющий 9,1 Пбайт памяти, а также агрегированную пропускную способность интерконнекта на уровне 410 Тбайт/с (28,8 Тбайт/с NVLink). Он и станет частью облака AWS DGX Cloud, которое будет доступно в начале 2024 года. В скором времени появятся и EC2-инстансы попроще: P5e с NVIDIA H200, G6e с L40S и G6 с L4. 
25.10.2023 [11:49], Сергей Карасёв
Экзафлопсный суперкомпьютер Frontier назван лучшим изобретением 2023 года по версии TimeЕжегодно американский журнал Time публикует список из лучших изобретений человечества в самых разных сферах. В нынешнем году в рейтинг вошли 200 продуктов и технологий, которые сгруппированы более чем в 35 категорий. Это, в частности, ПО, связь, виртуальная и дополненная реальность, ИИ, потребительская электроника, чистая энергии, здравоохранение, безопасность, робототехника и многое другое. Одним из направлений являются экспериментальные системы и устройства. В данной категории победителем назван вычислительный комплекс Frontier — самый мощный суперкомпьютер 2023 года. Исследователи уже используют его для самых разных целей: от изучения чёрных дыр до моделирования климата. «Специалисты сравнивают это с эквивалентом высадки на Луну с точки зрения инженерных достижений. Это больше, чем чудо. Это статистическая невозможность», — сказал Ник Дюбе (Nic Dubé), руководитель проекта в HPE. 
Источник изображения: ORNL Система Frontier, созданная специалистами HPE, установлена в Национальной лаборатории Окриджа (ORNL) Министерства энергетики США. Она занимает первое место в рейтинге TOP500 с производительностью 1,194 Эфлопс. В составе системы применяются процессоры AMD EPYC Milan, ускорители Instinct MI250X и интерконнект Cray Slingshot. В общей сложности задействованы 8 699 904 вычислительных ядра. Теоретическое пиковое быстродействие достигает 1,680 Эфлопс. |
|

