Материалы по тегу: pc
|
19.08.2021 [16:00], Игорь Осколков
Intel анонсировала ускорители Xe HPC Ponte Vecchio: 100+ млрд транзисторов, микс 5/7/10-нм техпроцессов Intel и TSMC и FP32-производительность 45+ ТфлопсКак и было обещано несколько лет назад, основным «строительным блоком» для графики и ускорителей Intel станут ядра Xe, которые можно будет гибко объединять и сочетать с другими аппаратными блоками для получения заданной производительности и функциональности. Компания уже анонсировала первые «настоящие» дискретные GPU серии Arc, а на Intel Architecture Day она поделилась подробностями о серверных ускорителях Xe HPC и Ponte Vecchio.  Основой Xe HPC является вычислительное ядро Xe Core, которое включает по восемь векторных и матричных движков для данных шириной 512 и 4096 бит соответственно. Они делят между собой L1-кеш объёмом 512 Кбайт, с которым можно общаться на скорости 512 байт/такт.  Заявленная производительность для векторного движка (бывший EU), ориентированного на «классические» вычисления, составляет 256 операций/такт для FP32 и FP64 или 512 — для FP16. Матричный движок нужен скорее для ИИ-нагрузок, поскольку работает только с данными TF32, FP16, BF16 и INT8 — 2048, 4096, 4096 и 8192 операций/такт соответственно. Данный движок работает с инструкциями XMX (Xe Matrix eXtensions), которые в чём-то схожи с AMX в Intel Xeon Sapphire Rapids.  Отдельные ядра объединяются в «слайсы» (slice) — по 16 Xe-Core в каждом, которые дополнены 16 блоков аппаратной трассировки лучей. Именно слайс является базовым функциональным блоком. Он изготавливается на TSMC по 5-нм техпроцессу в рамках инициативы Intel IDM 2.0. Слайсы объединяются в стеки — по 4 шт. в каждом.  Стек включает также базовую (Base) «подложку» (или тайл), четыре контроллерами памяти HBM2e (сама память вынесена в отдельные тайлы), общим L2-кешем объёмом 144 Мбайт, один медиа-движок с аппаратными кодеками, а также тайл Xe Link и контроллер PCIe 5. Base-тайл изготовлен по техпроцессу Intel 7 и использует EMIB для объединения всех блоков. 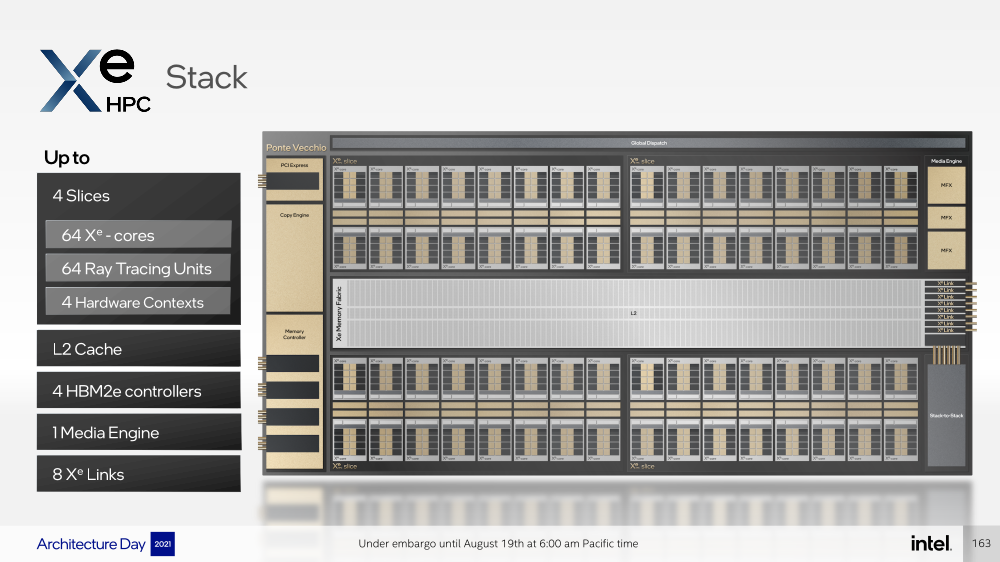 Тайлы Xe Link, изготавливаемые по 7-нм техпроцессу TSMC, включают 8 интерфейсов для стеков/ускорителей вкупе с 8-портовыми коммутатором и используют SerDes-блоки класса 90G. Всё это позволяет объединить до 8 стеков по схеме каждый-с-каждым, что, в целом, напоминает подход NVIDIA, хотя у последней NVSwitch всё же (пока) является внешним компонентом. 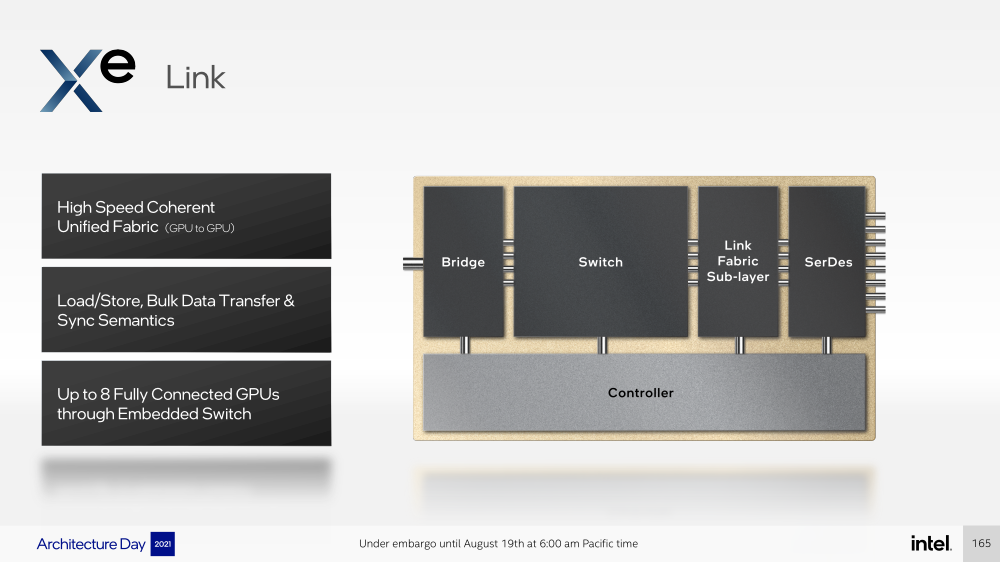  В самом ускорителе в зависимости от конфигурации стеков может быть один или два. В случае Ponte Vecchio их как раз два, и Intel приводит некоторые данные о его производительности: более 45 Тфлопс в FP32-вычислениях, более 5 Тбайт/с пропускной способности внутренней фабрики памяти и более 2 Тбайт/с — для внешних подключений. Для сравнения, у NVIDIA A100 заявленная FP32-производительность равняется 19,5 Тфлопс, а AMD Instinct MI100 — 23,1 Тфлопс. 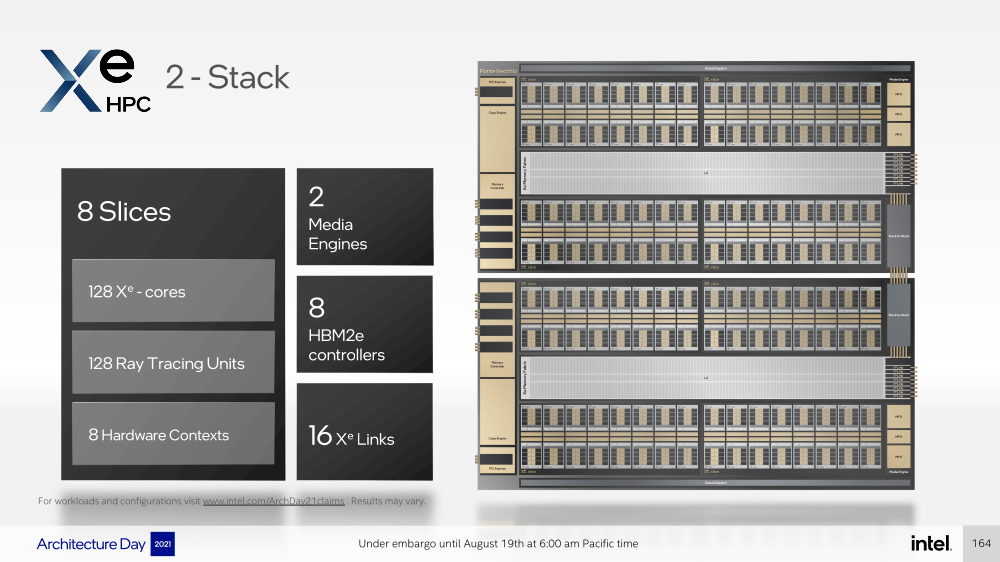 Также Intel показала результаты бенчмарка ResNet-50 в обучении и инференсе: 3400 и 43000 изображений в секунду соответственно. Эти результаты являются предварительными, поскольку получены не на финальной версии «кремния». Но надо учитывать, что Ponte Vecchio есть ещё одно преимущество — отдельный Rambo-тайл с дополнительным сверхбыстрым кешем, который, вероятно, можно рассматривать в качестве L3-кеша.  В целом, Ponte Vecchio — это один из самых сложны чипов на сегодняшний день. Он объединяет с помощью EMIB и Foveros 47 тайлов, изготовленных по пяти разным техпроцессам, а общий транзисторный бюджет превышает 100 млрд. Данные ускорители будут доступны в форм-факторе OAM и виде готовых плат с четырьмя ускорителями на борту (на ум опять же приходит NVIDIA HGX). И именно такие платы в паре с двумя процессорами Sapphire Rapids войдут в состав узлов суперкомпьютера Aurora. Ещё одной машиной, использующей связку новых CPU и ускорителей Intel станет SuperMUC-NG (Phase 2).  Официальный выход Ponte Vecchio запланирован на 2022 год, но и выход следующих поколений ускорителей AMD и NVIDIA, с которыми и надо будет сравнивать новинки, тоже не за горами. Пока что Intel занята не менее важным делом — развитием программной экосистемы, основой которой станет oneAPI, набор универсальных инструментов разработки приложений для гетерогенных (CPU, GPU, IPU, FPGA и т.д.) приложений, который совместим с оборудованием AMD и NVIDIA.
16.07.2021 [17:31], Алексей Степин
Японский облачный суперкомпьютер ABCI подвергся модернизацииПопулярность идей машинного обучения и искусственного интеллекта приводит к тому, что многие страны и организации планируют обзавестись HPC-системами, специально предназначенными для этого класса задач. В частности, Токийский университет совместно с Fujitsu модернизировал существующую систему ABCI (AI Bridging Cloud Infrastructure), снабдив её новейшими процессорами Intel Xeon и ускорителями NVIDIA. Как правило, когда речь заходит о суперкомпьютерах Fujitsu, вспоминаются уникальные наработки компании в сфере HPC — процессоры A64FX, но ABCI имеет более традиционную гетерогенную архитектуру. Изначально этот облачный суперкомпьютер включал в себя вычислительные узлы на базе Xeon Gold и ускорителей NVIDIA V100, объединённых 200-Гбит/с интерконнектом. В качестве файловой системы применена разработка IBM — Spectrum Scale. Это одна систем, специально созданных для решения задач искусственного интеллекта, при этом доступная независимым исследователям и коммерческим компаниям. 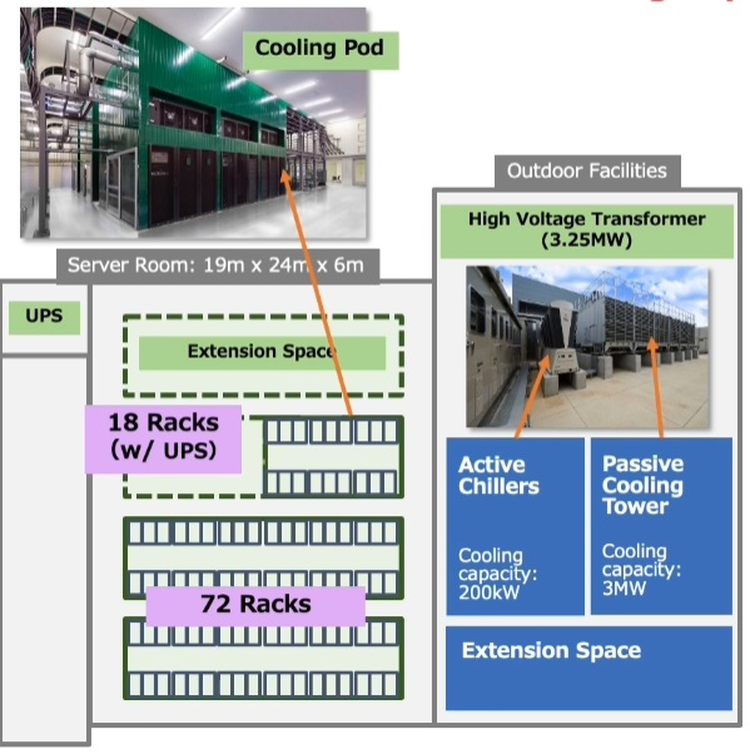 Так, 86% пользователей ABCI не входят в состав Японского национального института передовых технических наук (AIST); их число составляет примерно 2500. Но система явно нуждалась в модернизации. Как отметил глава AIST, с 2019 года загруженность ABCI выросла вчетверо, и сейчас на ней запущено 360 проектов, 60% из которых от внешних заказчиков. Сценарии использования самые разнообразные, от распознавания видео до обработки естественных языков и поиска новых лекарств. 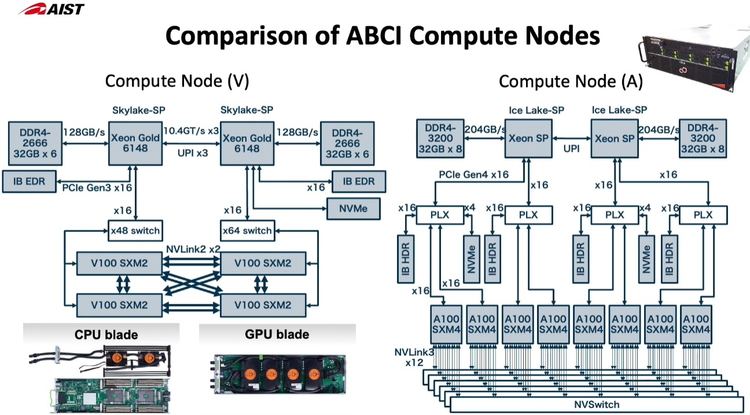
Новые узлы ABCI 2.0 заметно отличаются по архитектуре от старых Как и в большей части систем, ориентированных на машинное обучение, упор при модернизации ABCI был сделан на вычислительную производительность в специфических форматах, включая FP32 и BF16. Изначально в состав ABCI входило 1088 узлов, каждый с четырьмя ускорителями V100 формата SXM2 и двумя процессорами Xeon Gold 6148. После модернизации к ним добавилось 120 узлов на базе пары Xeon Ice Lake-SP и восьми ускорителей A100 формата SXM4. Здесь вместо InfiniBand EDR используется уже InfiniBand HDR. 
Стойка с новыми вычислительными узлами ABCI 2.0 Согласно предварительным ожиданиям, производительность обновлённого суперкомпьютера должна вырасти практически в два раза на задачах вроде ResNet50, в остальных случаях заявлен прирост производительности от полутора до трёх раз. На вычислениях половинной точности речь идёт о цифре свыше 850 Пфлопс, что вплотную приближает ABCI к системам экза-класса. Разработчики также надеются повысить энергоэффективность системы путём применения специфических ускорителей, включая ASIC, но пока речь идёт о связке Intel + NVIDIA. ABCI и сейчас можно назвать экономичной системой — при максимальной общей мощности комплекса 3,25 МВт сам суперкомпьютер при полной нагрузке потребляет лишь 2,3 МВт. Поскольку система ориентирована на предоставление вычислительных услуг сторонним заказчикам, модернизировано и системное ПО, в котором упор сместился в сторону контейнеризации.
29.06.2021 [17:49], Алексей Степин
Cornelis Networks подняла упавшее знамя Intel Omni-PathОт собственной технологии интерконнекта Omni-Path (OPA) компания Intel довольно неожиданно отказалась летом 2019 года, хотя на тот момент OPA-решения составляли достойную конкуренцию InfiniBand EDR, Ethernet и проприетарным интерконнектам как по скорости, так и по уровню задержки и поддержки необходимых для высокопроизводительных вычислений (HPC) функций. В конце прошлого года все наработки по OPA перешли к компании Cornelis Networks, образованной выходцами из Intel. В арсенале Intel были процессоры Xeon и Xeon Phi со встроенным интерфейсом Omni-Path, PCIe-адаптеры, коммутаторы и сопутствующее ПО. Казалось бы, у технологии большое будущее, однако второе поколение шины OPA, поддерживающее скорость 200 Гбит/с, так и не было выпущено, а компания сосредоточилась на Ethernet. При этом NVIDIA уже анонсировала InfiniBand NDR (400 Гбит/c), да и 200GbE-решениями сейчас никого не удивить.  Однако идеи, заложенные в Omni-Path, не умерли, и упавшее знамя нашлось, кому подхватить. Cornelis Networks быстро принялась за дело — через месяц после представления компании уже были представлены новые машины с Omni-Path, причём как на базе Intel, так и на базе AMD. А на ISC 2021 Cornelis Networks анонсировала полный спектр собственных решений под брендом Omni-Path Express, реализующих все основные достоинства технологии.  Конечно, процессоров с разъёмом Omni-Path мы по понятным причинам уже не увидим, но компания предлагает низкопрофильные хост-адаптеры с пропускной способностью до 25 Гбайт/с (100 Гбит/с в каждом направлении). Они поддерживают открытый фреймворк Open Fabrics Interface (OFI) и предлагают коррекцию ошибок с нулевой латентностью. В качестве разъёма используется популярный в индустрии QSFP28.  Также представлен ряд коммутаторов. В серии CN-100SWE есть модели с поддержкой горячей замены, которые имеют 48 портов и общую пропускную способность до 1,2 Тбайт/с при латентности, не превышающей 110 нс. Поддерживается организация виртуальных линий Omni-Path Express и фреймы большого размера, от 2 до 10 Кбайт. При этом коммутаторы компактны и занимают всего 1 слот в стандартной стойке.  Директор CN-100SWE предназначен для крупных кластерных систем. Он является модульным и может занимать от 7U до 20U, реализуя при этом от 288 до 1152 портов Omni-Path Express со скоростью 100 Гбит/с на порт. Латентность при этом не превышает 340 нс. Для сравнения, сети на базе Ethernet, как правило, оперируют значениями в десятки миллисекунд в лучшем случае.  Технологиями Cornelis Networks уже заинтересовался крупный российский поставщик HPC-систем, группа компаний РСК, которая и ранее поставляла кластеры и суперкомпьютеры с Omni-Path, в том числе с коммутаторами, снабжёнными фирменной СЖО. РСК получила наивысший партнёрский статус Elite+ у Cornelis и уже готова интегрировать Omni-Path Express в системы «РСК Торнадо» на базе третьего поколения процессоров Xeon Scalable.
28.06.2021 [13:22], Алексей Степин
Обновление NVIDIA HGX: PCIe-вариант A100 с 80 Гбайт HBM2e, InfiniBand NDR и Magnum IO с GPUDirect StorageНа суперкомпьютерной выставке-конференции ISC 2021 компания NVIDIA представила обновление платформы HGX A100 для OEM-поставщиков, которая теперь включает PCIe-ускорители NVIDIA c 80 Гбайт памяти, InfiniBand NDR и поддержку Magnum IO с GPUDirect Storage. В основе новинки лежат наиболее продвинутые на сегодняшний день технологии, имеющиеся в распоряжении NVIDIA. В первую очередь, это, конечно, ускорители на базе архитектуры Ampere, оснащённые процессорами A100 с производительностью почти 10 Тфлопс в режиме FP64 и 624 Топс в режиме тензорных вычислений INT8.  HGX A100 предлагает 300-Вт версию ускорителей с PCIe 4.0 x16 и удвоенным объёмом памяти HBM2e (80 Гбайт). Увеличена и пропускная способность (ПСП), в новой версии ускорителя она достигла 2 Тбайт/с. И если по объёму и ПСП новинки догнали SXM-версию A100, то в отношении интерконнекта они всё равно отстают, так как позволяют напрямую объединить посредством NVLink только два ускорителя.  В качестве сетевой среды в новой платформе NVIDIA применена технология InfiniBand NDR со скоростью 400 Гбит/с. Можно сказать, что InfiniBand догнала Ethernet, хотя не столь давно её потолком были 200 Гбит/с, а в плане латентности IB по-прежнему нет равных. Сетевые коммутаторы NVIDIA Quantum 2 поддерживают до 64 портов InfiniBand NDR и вдвое больше для скорости 200 Гбит/с, а также имеют модульную архитектуру, позволяющую при необходимости нарастить количество портов NDR до 2048. Пропускная способность при этом может достигать 1,64 Пбит/с.  Технология NVIDIA SHARP In-Network Computing позволяет компании заявлять о 32-крантом превосходстве над системами предыдущего поколения именно в области сложных задач машинного интеллекта для индустрии и науки. Естественно, все преимущества машинной аналитики используются и внутри самого продукта — технология UFM Cyber-AI позволяет новой платформе исправлять большинство проблем с сетью на лету, что минимизирует время простоя.  Отличным дополнением к новым сетевым возможностями является технология GPUDirect Storage, которая позволяет NVMe-накопителям общаться напрямую с GPU, минуя остальные компоненты системы. В качестве программной прослойки для обслуживания СХД новая платформа получила систему Magnum IO с поддержкой вышеупомянутой технологии, обладающую низкой задержкой ввода-вывода и по максимуму способной использовать InfiniBand NDR. 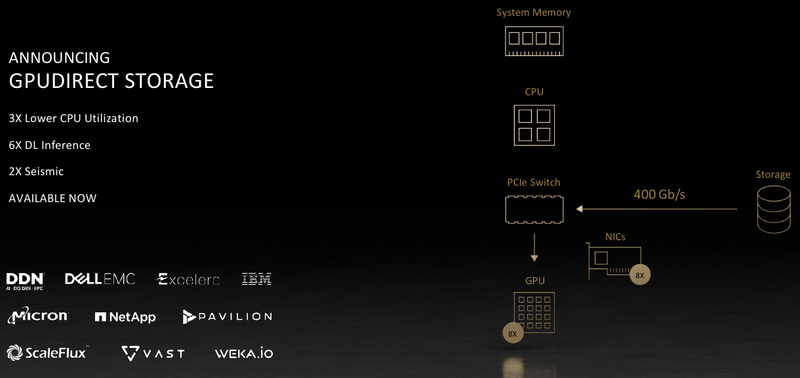 Три новых ключевых технологии NVIDIA помогут супервычислениям стать ещё более «супер», а суперкомпьютерам следующего поколения — ещё более «умными» и производительными. Достигнуты договорённости с такими крупными компаниями, как Atos, Dell Technologies, HPE, Lenovo, Microsoft Azure и NetApp. Решения NVIDIA используются как в индустрии — в качестве примера можно привести промышленный суперкомпьютер Tesla Automotive, так и в ряде других областей.  В частности, фармакологическая компания Recursion использует наработки NVIDIA в области машинного обучения для поиска новых лекарств, а национальный научно-исследовательский центр энергетики (NERSC) применяет ускорители A100 в суперкомпьютере Perlmutter при разработке новых источников энергии. И в дальнейшем NVIDIA продолжит своё наступление на рынок HPC, благо, она может предложить заказчикам как законченные аппаратные решения, так и облачные сервисы, также использующие новейшие технологии компании.
28.05.2021 [00:33], Владимир Мироненко
Perlmutter стал самым мощным ИИ-суперкомпьютером в мире: 6 тыс. NVIDIA A100 и 3,8 ЭфлопсВ Национальном вычислительном центре энергетических исследований США (NERSC) Национальной лаборатории им. Лоуренса в Беркли состоялась торжественная церемония, посвящённая официальному запуску суперкомпьютера Perlmutter, также известного как NERSC-9, созданного HPE в партнёрстве с NVIDIA и AMD. Это самый мощный в мире ИИ-суперкомпьютер, базирующийся на 6159 ускорителях NVIDIA A100 и примерно 1500 процессорах AMD EPYC Milan. Его пиковая производительность в вычислениях смешанной точности составляет 3,8 Эфлопс или почти 60 Пфлопс в FP64-вычислениях. Perlmutter основан на платформе HPE Cray EX с прямым жидкостным охлаждением и интерконнектом Slingshot. В состав системы входят как GPU-узлы, так и узлы с процессорами. Для хранения данных используется файловая система Lustre объёмом 35 Пбайт скорость обмена данными более 5 Тбайт/с, которая развёрнута на All-Flash СХД HPE ClusterStor E1000 (тоже, к слову, на базе AMD EPYC). 
Perlmutter (Phase 1). Фото: NERSC Установка Perlmutter разбита на два этапа. На сегодняшней презентации было объявлено о завершении первого (Phase 1) этапа, который начался в ноябре прошлого года. В его рамках было установлено 1,5 тыс. вычислительных узлов, каждый из которых имеет четыре ускорителя NVIDIA A100, один процессор AMD EPYC Milan и 256 Гбайт памяти. На втором этапе (Phase 2) в конце 2021 года будут добавлены 3 тыс. CPU-узлов c двумя AMD EPYC Milan и 512 Гбайт памяти., а также ещё ещё 20 узлов доступа и четыре узла с большим объёмом памяти. 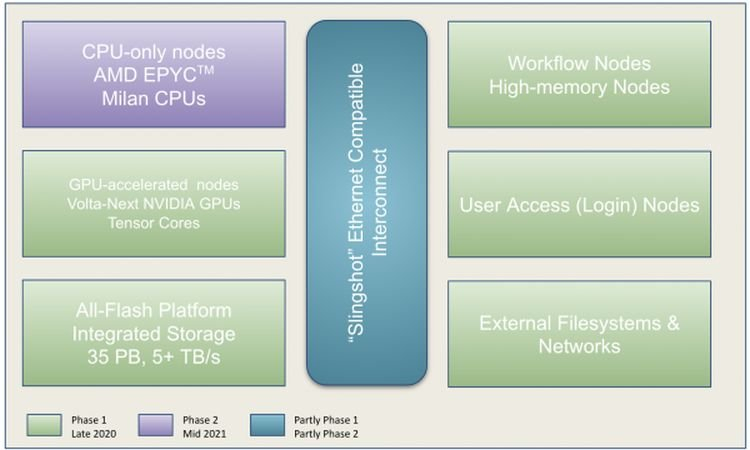
NERSC Также на первом этапе были развёрнуты служебные узлы, включая 20 узлов доступа пользователей, на которых можно подготавливать контейнеры с приложениями для последующего запуска на суперкомпьютере и использовать Kubernetes для оркестровки. Среда разработки будет включать NVDIA HPC SDK в дополнение к наборам компиляторов CCE (Cray Compiling Environment), GCC и LLVM для поддержки различных средств параллельного программирования, таких как MPI, OpenMP, CUDA и OpenACC для C, C ++ и Fortran. 
Фото: DESI Сообщается, что для Perlmutter готовится более двух десятков заявок на вычисления в области астрофизики, прогнозирования изменений климата и в других сферах. Одной из задач для новой системы станет создание трёхмерной карты видимой Вселенной на основе данных от DESI (Dark Energy Spectroscopic Instrument). Ещё одно направление, для которого задействуют суперкомпьютер, посвящено материаловедению, изучению атомных взаимодействий, которые могут указать путь к созданию более эффективных батарей и биотоплива.
17.05.2021 [18:26], Сергей Карасёв
Иран запустил Simurgh, свой самый мощный суперкомпьютерВ Иране введён в эксплуатацию самый мощный в стране вычислительный комплекс: система получила название Simurgh — в честь фантастического существа в иранской мифологии, царя всех птиц. Суперкомпьютер разработан специалистами Технологического университета имени Амира Кабира (Amirkabir University of Technology). Смонтирована система в Иранском исследовательском центре высокопроизводительных вычислений (IHPCRC). В настоящее время быстродействие комплекса составляет 0,56 Пфлопс. В дальнейшем мощность суперкомпьютера планируется довести до 1 Пфлопс — на доработку системы потребуется около двух месяцев. Конфигурация суперкомпьютера не раскрывается, а появление его в публичных рейтингах производительности вряд ли стоит ожидать. 
Суперкомпьютер Simurgh. Фото: Maryam Kamyab / MEHR Новый суперкомпьютер, по словам представителей власти, по мощности приблизительно в 100 раз превосходит системы высокопроизводительных вычислений, до сих пор применявшиеся в Иране. Система будет использоваться для задач в области генетики, Big Data, ИИ, интернета вещей и так далее. Часть мощностей будет выделена для облачных систем. 
Суперкомпьютер Simurgh. Фото: Maryam Kamyab / MEHR Интернет-источники отмечают, что Simurgh, по всей видимости, построен с использованием комплектующих, приобретённых на «чёрном» рынке, поскольку официально Иран не может закупать многие современные технологии из-за санкций — несколько лет назад ZTE получила крупный штраф из-за нелегальных поставок оборудования в страну. Тем не менее, Ирану периодически удаётся получить необходимые компоненты: в начале века был построен кластер из Pentium III/IV, а в 2007 году был построен суперкомпьютер на базе AMD Opteron.
15.04.2021 [01:31], Владимир Мироненко
TSMC остановит выпуск Arm-процессоров Phytium — судьба китайского экзафлопсного суперкомпьютера Tianhe-3 под вопросомТайваньская компания Taiwan Semiconductor Manufacturing Company (TSMC) приостановила поставку чипов по новым заказам китайской компании Phytium, которая на прошлой неделе была добавлена властями США в «чёрный» список Министерства торговли. Внесение компаний в этот перечень означает запрет для американских компаний на работу с ними и предоставление продуктов или услуг без получения соответствующих лицензий. Иностранные компании, такие как TSMC, теоретически могут продолжать работать с компаниями из «чёрного списка», но США могут оказывать на них давление через их американских поставщиков. Например, когда США занесли Huawei в «чёрный» список, TSMC была вынуждена отказаться от сотрудничества с ней, поскольку многие ключевые технологии, лежащие в основе её производственных процессов, были разработаны американскими фирмами. Пока неясно, оказывалось ли сейчас подобное давление на TSMC, и были ли ею прекращены поставки остальным шести суперкомпьютерным китайским фирмам из «чёрного» списка. Как сообщает South China Morning Post, TSMC выполнит заказы, размещённые Phytium до внесения в «чёрный список», но больше поставлять ей чипы не будет. 
Прототип Tianhe-3. Фото: Xinhua Предполагается, что Phytium стоит за развёртыванием систем высокопроизводительных вычислений для китайского военно-промышленного комплекса, использующего её разработки при создании гиперзвуковых ракет. Компания сотрудничает с Оборонным научно-техническим университетом Народно-освободительной армии Китая (NUDT), который ранее создал суперкомпьютеры Tianhe-1 и Tianhe-2, в своё время занимавшие первые строчки рейтинга TOP500. Tianhe-3, один из трёх проектов китайских суперкомпьютеров экзафлопсного класса, должен был быть закончен в прошлом году, однако осенью было объявлено, что из-за пандемии коронавируса сроки сдвигаются. Летом 2020 года в распоряжении исследователей уже был прототип новой машины, имевший теоретическую производительность 3,146 Пфлопс. Он включал 512 плат с тремя процессорами Phytium MT2000+ и 128 плат с четырьмя Phytium FT2000+. Точные параметры этих 7-нм Arm-чипов не приводятся, но в одной из свежих научных публикаций упоминается, что на каждый 64-ядерный FT2000+ в прототипе Tianhe-3 приходилось 64 Гбайт RAM. А каждый MT2000+ можно поделить на четыре NUMA-узла с 32 ядрами и 16 Гбайт RAM, то есть, судя по описанию, это 128-ядерный чип, о котором ранее ничего не было известно. Теперь же судьба этих CPU и суперкомпьютера Tianhe-3 и вовсе под вопросом.
12.04.2021 [19:26], Игорь Осколков
NVIDIA анонсировала серверные Arm-процессоры Grace и будущие суперкомпьютеры на их базеВ рамках GTC’21 NVIDIA анонсировала Arm-процессоры Grace серверного класса, которые станут компаньонами будущих ускорителей компании. Это не означает полный отказ от x86-64, но это позволит компании предложить клиентам более глубоко оптимизированные, а, значит, и более быстрые решения. NVIDIA говорит, что новый CPU позволит на порядок повысить производительность систем на его основе в ИИ и HPC-задачах в сравнении с современными решениями. Процессор назван в честь Грейс Хоппер (Grace Hopper), одного из пионеров информатики и создательницы целого ряда основополагающих концепций и инструментов программирования. И это имя нам уже встречалось в контексте NVIDIA — в конце 2019 года компания зарегистрировала торговую марку Hopper для MCM-решений.  Компания не готова раскрыть полные технически характеристики новинки, которая станет доступна в начале 2023 года, но приводит некоторые интересные детали. В частности, процессор будет использовать Arm-ядра Neoverse следующего поколения (надо полагать, уже на базе ARMv9), которые позволят получить в SPECrate2017_int_base результат выше 300. Для сравнения — система с парой современных AMD EPYC 7763 в том же бенчмарке показывает результат на уровне 800. Вторая особенность Grace — использование памяти LPDRR5X (с ECC, естественно). В сравнении с DDR4 она будет иметь вдвое большую пропускную способность (ПСП) и в 10 раз меньшее энергопотребление. Число и скорость каналов памяти не уточняются, но говорится о суммарной ПСП в более чем 500 Гбайт/с на процессор. А у того же EPYC 7763 теоретический пик ПСП чуть больше 200 Гбайт/с. Очевидно, что другие процессоры к моменту выхода NVIDIA Grace тоже увеличат и производительность, и пропускную способность памяти. Гораздо более интересный вопрос, сколько линий PCIe 5.0 они смогут предложить. Если допустить, что у них будет 128 линий, то общая скорость для них составит чуть больше 500 Гбайт/с. 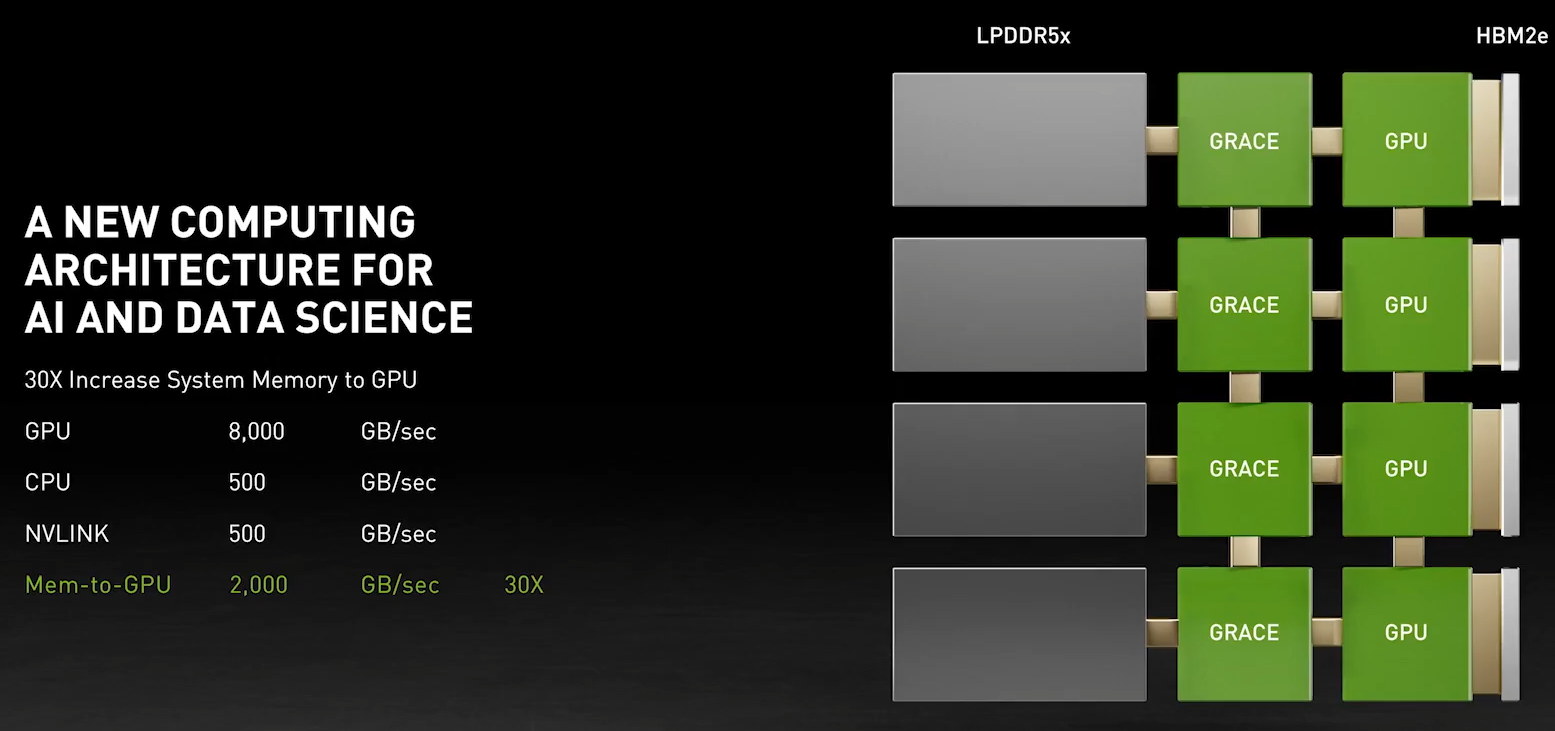 И NVIDIA этого мало — процессоры Grace получат прямое, кеш-когерентное подключение к GPU по NVLInk 4.0 (14x) с суммарной пропускной способностью боле 900 Гбайт/с. GPU тоже, как и прежде, будут общаться напрямую друг с другом по NVLink. Скорость связи между двумя CPU превысит 600 Гбайт/с, а в сборке из четырёх модулей CPU+GPU суммарная скорость обмена данными между системной памятью процессоров и GPU в такой mesh-сети составит 2 Тбайт/с. Но самое интересное тут то, что у памяти CPU (LPDDR5X) и GPU (HBM2e) в такой системе будет единое адресное пространство. Собственно говоря, таким образом компания решает давно назревшую проблему дисбаланса между скоростью обмена данными и доступным объёмом памяти в различных частях вычислительного комплекса. Для сравнения можно посмотреть на архитектуру нынешних DGX A100 или HGX. У каждого ускорителя A100 есть 40 или 80 Гбайт набортной памяти HBM2e (1555 или 2039 Гбайт/с соответственно) и NVLInk-подключение на 600 Гбайт/c, которое идёт к коммутатору NVSwitch, имеющего суммарную пропускную способность 1,8 Тбайт/с. Всего таких коммутаторов шесть, а объединяют они восемь ускорителей. Внутри этой NVLInk-фабрики сохраняется достаточно высокая скорость обмена данными, но как только мы выходим за её пределы, ситуация меняется. 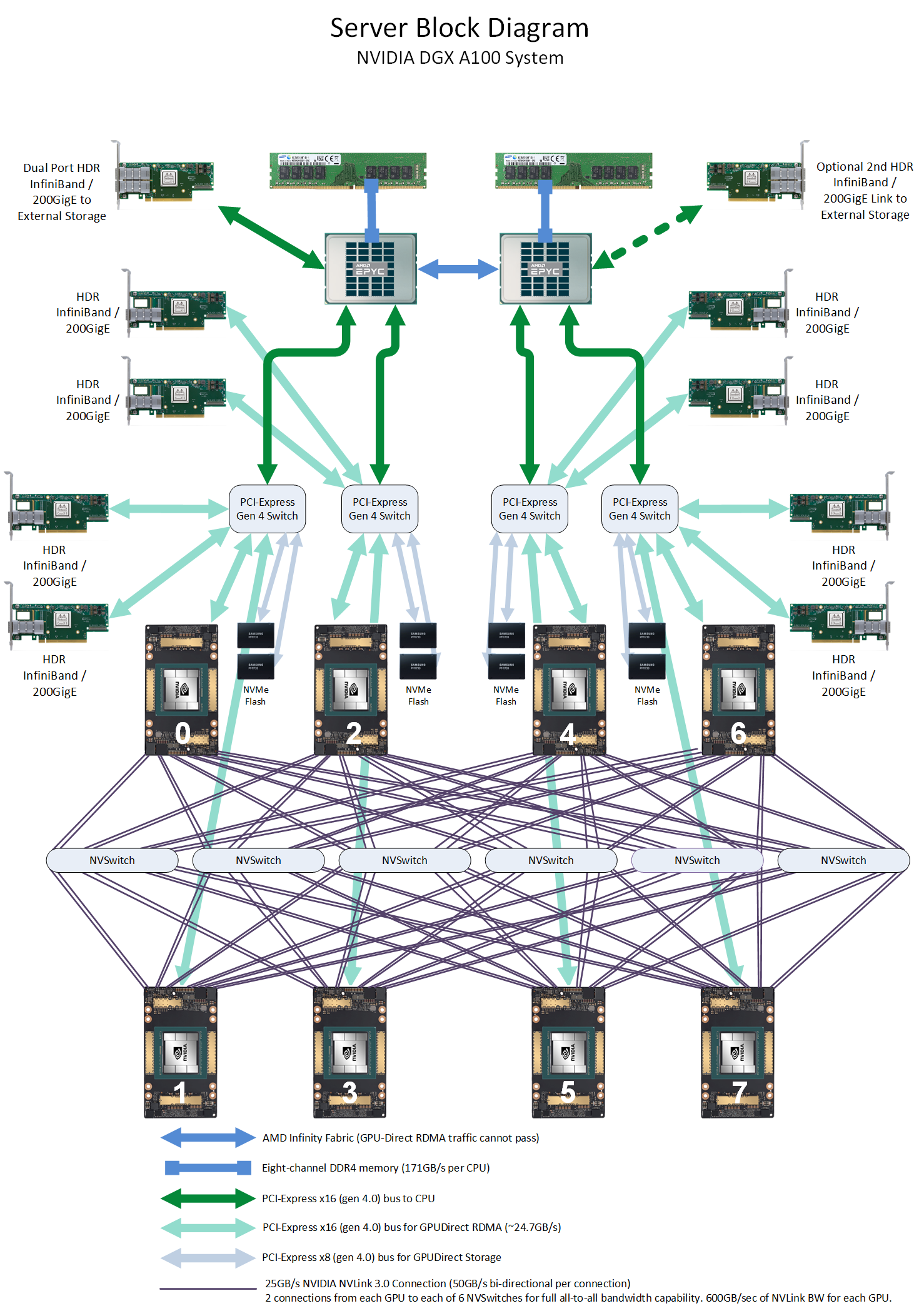
Схема NVIDIA DGX A100. Источник: Microway Каждый ускоритель A100 имеет второй интерфейс — PCIe 4.0 x16 (64 Гбайт/с), который уходит к PCIe-коммутатору, каковых в DGX A100 имеется четыре. Коммутаторы, в свою очередь, объединяют между собой сетевые 200GbE-адаптеры (суммарно в дуплексе до 1,6 Тбайт/с для связи с другими DGX A100), NVMe-накопители и CPU. У каждого CPU может быть довольно много памяти (от 512 Гбайт), но её скорость ограничена упомянутыми выше 200 Гбайт/c.  Узким местом во всей этой схеме является как раз PCIe, поэтому переход исключительно на NVLInk позволит NVIDIA получить большой объём памяти при сохранении приемлемой ПСП, не тратясь лишний раз на дорогую локальную HBM2e у каждого GPU. Впрочем, если компания не переведёт на NVLink и собственные будущие DPU Bluefield-3 (400GbE), которые будут скармливать связке CPU+GPU по, например, GPUDirect Storage данные из внешних NVMe-oF хранилищ и объединять узлы DGX POD, то PCIe 5.0 в составе Grace стоит ждать. Это опять-таки упростит и повысит эффективность масштабирования. 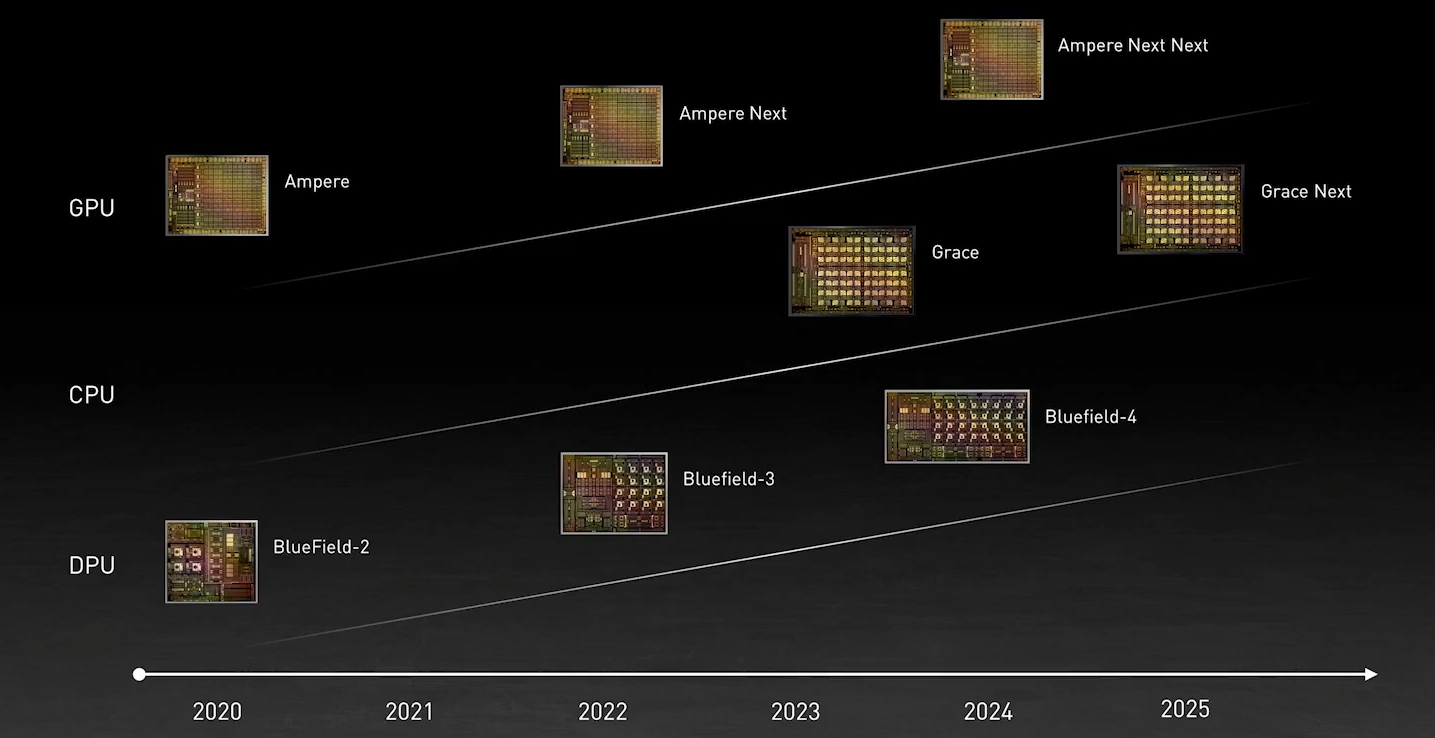 В целом, всё это необходимо из-за быстрого роста объёма ИИ-моделей — в GPT-3 уже 175 млрд параметров, а в течение пары лет можно ожидать модели уже с 0,5-1 трлн параметров. Им потребуются не только новые решения для обучения, но и для инференса. То же касается и физических расчётов — модели становятся всё больше и требовательнее + ИИ здесь тоже активно внедряется. Параллельно с разработкой Grace NVIDIA развивает программную экосистему вокруг Arm и своих решений, готовя почву для будущих систем на их основе.  Одной из такой систем станет суперкомпьютер Alps в Швейцарском национальном компьютерном центре (Swiss National Computing Centre, CSCS), который придёт на смену Piz Daint (12 место в нынешнем рейтинге TOP500). Этот суперкомпьютер серии HPE Cray EX, в частности, сможет в семь раз быстрее обучить модель GPT-3, чем машина NVIDIA Selene (5 место в TOP500). Впрочем, на нём будут выполняться и классические HPC-задачи в области метеорологии, физики, химии, биологии, экономики и так далее. Ввод в эксплуатацию намечен на 2023 год. Тогда же в США появится аналогичная машина от HPE в Лос-Аламосской национальной лаборатории (LANL). Она дополнит систему Crossroads, использующую исключительно процессоры Intel Xeon Sapphire Rapids.
21.12.2020 [18:41], Алексей Степин
128-ядерные супепроцессоры Tachyum Prodigy стали на шаг ближе к реальностиЛетом уходящего года компания Tachyum объявила о том, что собирается отправить Xeon «на свалку истории». Сделать это должен 128-ядерный процессор нового поколения Prodigy. Хотя массово он пока не производится, компания продолжает активно работать над проектом и совсем недавно объявила начало предзаказов на эмуляторы нового процессора, как программные, так и базирующиеся на ПЛИС. Также она продемонстрировала рабочий UEFI для будущих CPU. 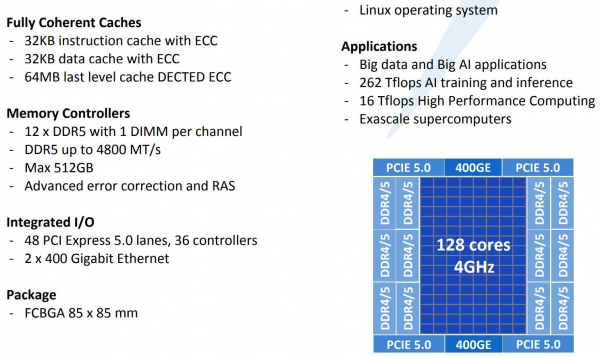 Молодая словацкая компания замахнулась на многое. Её процессор должен получить до 128 ядер, работающих на частоте до 4 ГГц. Чтобы «накормить» его данными, предусмотрен 12-канальный контроллер памяти DDR5. С периферией Prodigy будет общаться посредством 48 линий PCIe 5.0, но также получит и два контроллера Ethernet класса 400G. Характеристики весьма впечатляют.  Разработчики заявляют, что Prodigy найдёт своё место в системах класса Big Data и мощных системах машинного обучения. Если верить Tachyum, производительность разрабатываемого процессора должна достигнуть 16 и 8 Тфлопс на классичесих вычислениях FP32/FP64. В режиме машинного обучения и инференса возможности новой архитектуры выглядят ещё внушительнее, поскольку речь идёт о цифре 262 Тфлопс. 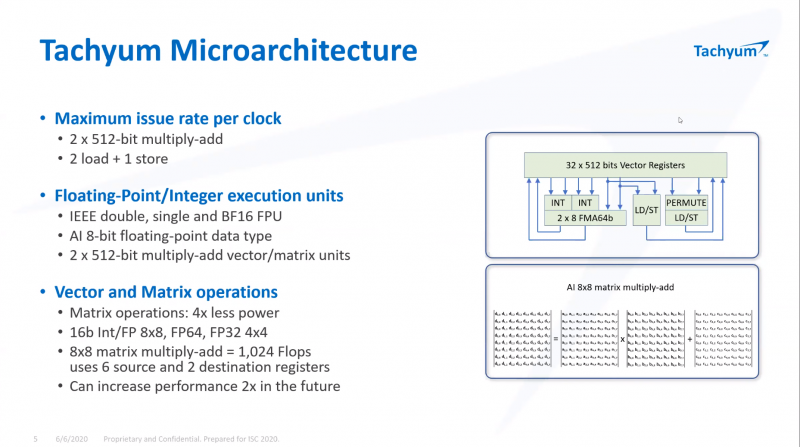 Столь громкие анонсы в истории вычислительной техники часто заканчивались «на бумаге», но Tachyum действительно работает над реализацией Prodigy. Как это обычно бывает, новая процессорная архитектура отрабатывается разработчиками с помощью эмуляции — как чисто программной, так и базирующейся на мощных ПЛИС. Это позволяет понять возможности и особенности поведения архитектуры, пусть и работающей с меньшей производительностью.  В начале декабря Tachyum объявила об открытии предзаказов на ПЛИС-эмулятор Prodigy, позволяющий начать разработку программного обеспечения для будущих систем на базе нового процессора уже сейчас. Поставки должны начаться в первом квартале 2021 года. В середине месяца Tachyum анонсировала и возможность заказа программного эмулятора Prodigy. Главная ценность такого эмулятора — более низкая стоимость в сравнении с вариантом на базе ПЛИС. Любой процессор неработоспособен без сопутствующего системного программного обеспечения — BIOS или, что сейчас встречается намного чаще, UEFI. В начале месяца Tachyum объявила о том, что передаст OEM и ODM-партнёрам UEFI, разработанное для новой архитектуры. При этом ПО будет поставляться не только в бинарном виде, разработчики получат и исходные коды. 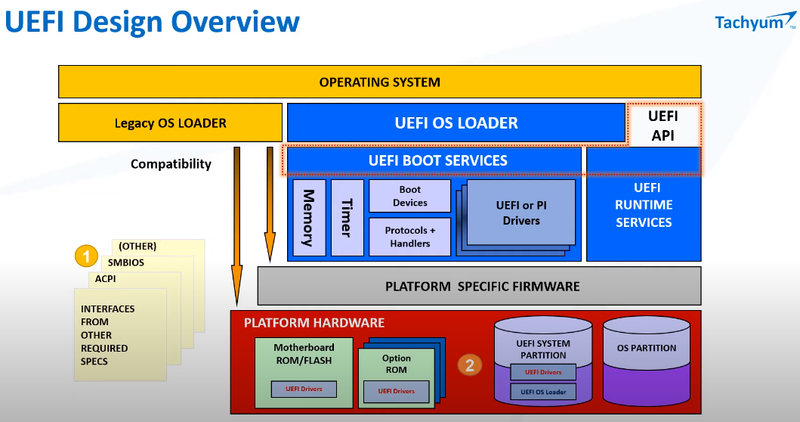 К настоящему времени, таким образом, компания предлагает программные и ПЛИС-эмуляторы нового процессора, и сопутствующее программное обеспечение. К чести Tachym, разработан не только UEFI — имеется и ядро Linux с поддержкой новой архитектуры, набор средств разработки, включая компиляторы (в том числе, для ИИ-задач) и отладчики кода. Успешно продемонстрирована возможность работы на Prodigy бинарного кода, созданного для архитектур x86, ARM и RISC-V. Первые чипы Prodigy должны появиться уже в следующем году. Если запуск будет успешным, Tachym может сильно изменить привычную картину мира в сфере HPC и ИИ, ведь новая архитектура обещает быть производительнее классических Xeon и EPYC при на порядок более низком энергопотреблении, втрое более низкой стоимостью в пересчёте на MIPS, и вчетверо более низкой стоимостью владения. Более того, Prodigy угрожает даже ускорителям, обеспечивая сравнимый или более высокий уровень производительности в задачах, где последние традиционно сильны, например, в системах машинного обучения. Остаётся лишь пожелать Tachyum удачи в столь смелом начинании.
16.11.2020 [17:00], Игорь Осколков
SC20: NVIDIA представила ускоритель A100 с 80 Гбайт HBM2e и настольный «суперкомпьютер» DGX STATIONNVIDIA представила новую версию ускорителя A100 с увеличенным вдвое объёмом HBM2e-памяти: 80 Гбайт вместо 40 Гбайт у исходной A100, представленной полгода назад. Вместе с ростом объёма выросла и пропускная способность — с 1,555 Тбайт/с до 2 Тбайт/с. В остальном характеристики обоих ускорителей совпадают, даже уровень энергопотребления сохранился на уровне 400 Вт. Тем не менее, объём и скорость работы быстрой набортной памяти влияет на производительность ряда приложений, так что им такой апгрейд только на пользу. К тому же MIG-инстансы теперь могут иметь объём до 10 Гбайт. PCIe-варианта ускорителя с удвоенной памятью нет — речь идёт только об SXM3-версии, которая используется в собственных комплексах NVIDIA DGX и HGX-платформах для партнёров. 
NVIDIA A100 80 Гбайт  Последним ориентировочно в первом квартале следующего года будут предоставлены наборы для добавления новых A100 в существующие решения, включая варианты плат на 4 и 8 ускорителей. У самой NVIDIA обновлению подверглись, соответственно, DGX A100 POD и SuperPOD for Enterprise. Недавно анонсированные суперкомпьютеры Cambridge-1 и HiPerGator на базе SuperPOD одними из первых получат новые ускорители с 80 Гбайт памяти. Ожидается, что HGX-решения на базе новой A100 будут доступны от партнёров компании — Atos, Dell Technologies, Fujitsu, GIGABYTE, Hewlett Packard Enterprise, Inspur, Lenovo, Quanta и Supermicro — в первой половине 2021 года.   Но, пожалуй, самый интересный анонс касается новой рабочей станции NVIDIA DGX STATION A100, которую как раз и можно назвать настольным «суперкомпьютером». В ней используются четыре SXM3-ускорителя A100 с не требующей обслуживания жидкостной системой охлаждения и полноценным NVLink-подключением. Будут доступны две версии, со 160 или 320 Гбайт памяти с 40- и 80-Гбайт A100 соответственно. Базируется система на 64-ядерном процессоре AMD EPYC, который можно дополнить 512 Гбайт RAM.   Для ОС доступен 1,92-Тбайт NVMe M.2 SSD, а для хранения данных — до 7,68 Тбайт NVMe U.2 SSD. Сетевое подключение представлено двумя 10GbE-портами и выделенным портом управления. Видеовыходов четыре, все mini Display Port. DGX STATION A100 отлично подходит для малых рабочих групп и предприятий. В том числе благодаря тому, что функция MIG позволяет эффективно разделить ресурсы станции между почти тремя десятками пользователей. В продаже она появится у партнёров компании в феврале следующего года.  Вероятно, все выпускаемые сейчас A100 c увеличенным объёмом памяти идут на более важные проекты. Новинкам предстоит конкурировать с первым ускорителем на базе новой архитектуры CDNA — AMD Instinct MI100. |
|

