Материалы по тегу: pc
|
25.10.2023 [11:49], Сергей Карасёв
Экзафлопсный суперкомпьютер Frontier назван лучшим изобретением 2023 года по версии TimeЕжегодно американский журнал Time публикует список из лучших изобретений человечества в самых разных сферах. В нынешнем году в рейтинг вошли 200 продуктов и технологий, которые сгруппированы более чем в 35 категорий. Это, в частности, ПО, связь, виртуальная и дополненная реальность, ИИ, потребительская электроника, чистая энергии, здравоохранение, безопасность, робототехника и многое другое. Одним из направлений являются экспериментальные системы и устройства. В данной категории победителем назван вычислительный комплекс Frontier — самый мощный суперкомпьютер 2023 года. Исследователи уже используют его для самых разных целей: от изучения чёрных дыр до моделирования климата. «Специалисты сравнивают это с эквивалентом высадки на Луну с точки зрения инженерных достижений. Это больше, чем чудо. Это статистическая невозможность», — сказал Ник Дюбе (Nic Dubé), руководитель проекта в HPE. 
Источник изображения: ORNL Система Frontier, созданная специалистами HPE, установлена в Национальной лаборатории Окриджа (ORNL) Министерства энергетики США. Она занимает первое место в рейтинге TOP500 с производительностью 1,194 Эфлопс. В составе системы применяются процессоры AMD EPYC Milan, ускорители Instinct MI250X и интерконнект Cray Slingshot. В общей сложности задействованы 8 699 904 вычислительных ядра. Теоретическое пиковое быстродействие достигает 1,680 Эфлопс.
21.10.2023 [16:09], Сергей Карасёв
В Аргоннской национальной лаборатории запущена ИИ-система GroqАргоннская национальная лаборатория Министерства энергетики США сообщила о запуске вычислительного кластера, использующего специализированные ИИ-решения Groq. Ресурсы системы предоставляются исследователям на базе тестовой площадки ALCF (Argonne Leadership Computing Facility). Groq является разработчиком чипов GroqChip, спроектированных с прицелом на решение задач ИИ и машинного обучения. Эти изделия, наделённые 230 Мбайт памяти SRAM, обеспечивают производительность до 750 TOPS INT8 и до 188 Тфлопс FP16. 
Источник изображения: Аргоннская национальная лаборатория Процессоры GroqChip являются основой ускорителей GroqCard с интерфейсом PCIe 4.0 x16. Восемь таких карт входят в состав сервера GroqNode формата 4U. Наконец, до восьми серверов GroqNode используются в кластерах GroqRack. И именно такие узлы являются основой новой ИИ-платформы ALCF. Заявленная производительность каждого узла достигает 48 POPS (INT8) или 12 Пфлопс (FP16). Экосистема программного и аппаратного обеспечения Groq предназначена для ускорения решения сложных ИИ-задач, в частности, инференса. Исследователи будут применять НРС-платформу при реализации ресурсоёмких научных проектов в таких областях, как визуализация, термоядерная энергия, материаловедение, создание лекарственных препаратов нового поколения и пр. Отмечается, что уникальная архитектура Groq и универсальный компилятор обеспечат повышенную производительность для широкого спектра ИИ-моделей. В рамках сотрудничества Аргоннская национальная лаборатория и Groq работают над лекарствами от коронавируса, спровоцировавшего пандемию COVID-19: говорится, что время получения результатов сократилось с дней до минут. Создавая модели вируса и помогая исследователям быстро сравнивать их с базой данных, содержащей миллиарды молекул препаратов, модели ИИ позволяют идентифицировать перспективные соединения, которые будут использоваться в клинических терапевтических испытаниях.
01.08.2023 [10:02], Сергей Карасёв
Esperanto готовит универсальный чип ET-SoC-2 на базе RISC-V для задач НРС и ИИСтартап Esperanto Technologies, по сообщению ресурса HPC Wire, готовит новый чип с архитектурой RISC-V, ориентированный на системы высокопроизводительных вычислений (НРС) и задачи ИИ. Изделие получит обозначение ET-SoC-2. Нынешний чип ET-SoC-1 объединяет 1088 энергоэффективных ядер ET-Minion и четыре высокопроизводительных ядра ET-Maxion. Решение предназначено для инференса рекомендательных систем, в том числе на периферии. Чип ET-SoC-2 будет включать в себя новые высокопроизводительные ядра CPU на базе RISC-V с векторными расширениями. Точные данные о производительности не раскрываются, но говорится, что изделие обеспечит быстродействие с двойной точностью более 10 Тфлопс. Архитектура ET-SoC-2 предполагает совместную работу сотен и тысяч чипов для организации платформ НРС. При этом Esperanto делает упор на энергетической эффективности своих решений. 
Источник изображения: Esperanto Technologies По словам Дейва Дитцеля (Dave Ditzel), генерального директора Esperanto, чипы RISC-V смогут взять на себя функции и CPU, и GPU при обработке ресурсоёмких приложений, в частности, машинного обучения. Процессоры RISC-V отстают по производительности от чипов x86 и Arm, хотя разрыв постепенно сокращается. Дитцель сказал, что стойки с чипами ET-SoC-1 могут обеспечить производительность в петафлопсы. Однако проблема с внедрением RISC-V заключается в слабо развитой экосистеме ПО.
21.07.2023 [15:35], Сергей Карасёв
NVIDIA, подвинься: Cerebras представила 4-Эфлопс ИИ-суперкомпьютер Condor Galaxy 1 и намерена построить ещё восемь таких жеКомпания Cerebras Systems анонсировала суперкомпьютер Condor Galaxy 1 (CG-1), предназначенный для решения ресурсоёмких задач с применением ИИ. Это одна из первых действительно крупных машин на базе уникальных чипов Cerebras. В проекте стоимостью $100 млн приняла участие холдинговая группа G42 из ОАЭ, которая занимается технологиями ИИ и облачными вычислениями. G42 является основным заказчиком комплекса. В текущем виде комплекс CG-1, расположенный в Санта-Кларе (Калифорния, США), объединяет 32 системы Cerebras CS-2 и обеспечивает производительность на уровне 2 Эфлопс (FP16). В IV квартале ткущего года будут добавлены ещё 32 системы Cerebras CS-2, что позволит довести быстродействие до 4 Эфлопс (FP16). Ожидаемый уровень энергопотребления составит порядка 1,5 МВт или более. 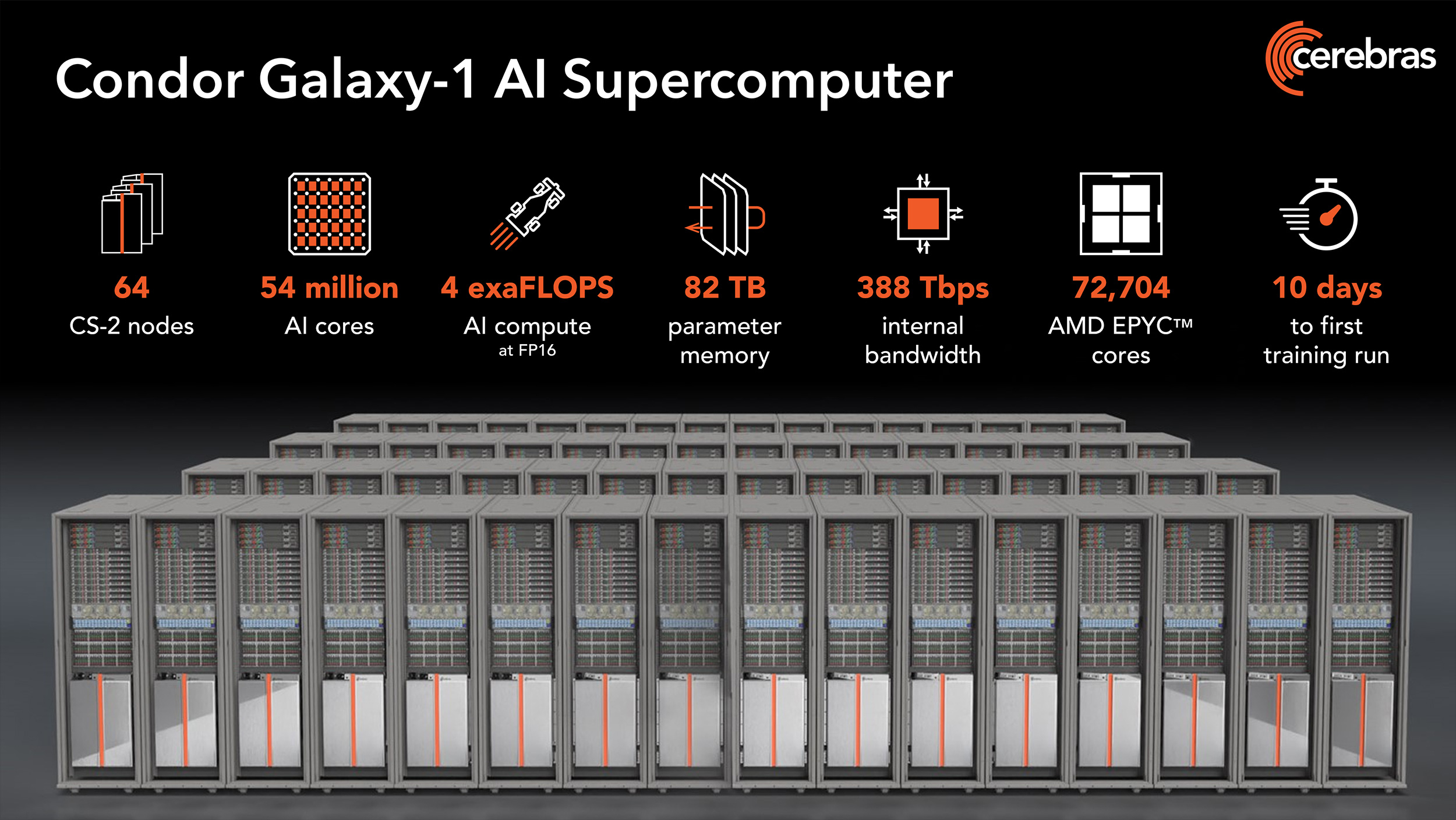
Источник изображений: Cerebras (via ServeTheHome) В системах Cerebras CS-2 применяются гигантские чипы Wafer-Scale Engine 2 (WSE-2), насчитывающие 2,6 трлн транзисторов. Такие чипы имеют 850 тыс. тензорных ядер и несут на борту 40 Гбайт памяти SRAM. Системы выполнены в формате 15 RU и укомплектованы шестью блоками питания мощностью 4 кВт каждый. Задействована технология жидкостного охлаждения. Отдельно отмечается, что программный стек позволит без проблем и существенных модификаций кода работать с ИИ-моделями.  После ввода в строй второй очереди комплекс CG-1 суммарно получит 54,4 млн ИИ-ядер, 2,56 Тбайт SRAM и внутренний интерконнект со скоростью 388 Тбит/с. Их дополнят 72 704 ядра AMD EPYC Milan и 82 Тбайт памяти для хранения параметров. По словам создателей, мощностей суперкомпьютера хватит для обучения модели с 600 млрд параметров и на очередях длиной до 50 тыс. токенов. При этом производительность масштабируется практически линейно.  Cerebras и G42 будут предоставлять доступ к CG-1 по облачной схеме, что позволит заказчикам использовать ресурсы ИИ-суперкомпьютера без необходимости управлять моделями или распределять их по узлам и ускорителям. CG-1 — первый из трёх ИИ-суперкомпьютеров нового поколения. В I полугодии 2024 года будут построены комплексы CG-2 и CG-3, полностью аналогичные CG-1, которые будут объединены в распределённый ИИ-кластер. А к концу следующего года у Cerebras будет уже девять систем CG.  Для Cerebras это означает, что компания более не является стартапом, поскольку в её решения заказчики поверили и без участия в индустриальных тестах вроде MLPerf. Кроме того, теперь компания является не просто очередным производителем «железа», а предоставляет услуги, которые и помогут ей заработать в будущем.
29.05.2023 [07:30], Сергей Карасёв
NVIDIA представила 1-Эфлопс ИИ-суперкомпьютер DGX GH200: 256 суперчипов Grace Hopper и 144 Тбайт памятиКомпания NVIDIA анонсировала вычислительную платформу нового типа DGX GH200 AI Supercomputer для генеративного ИИ, обработки огромных массивов данных и рекомендательных систем. HPC-платформа станет доступна корпоративным заказчикам и организациям в конце 2023 года. Платформа представляет собой готовый ПАК и включает, в частности, наборы ПО NVIDIA AI Enterprise и Base Command. Для платформы предусмотрено использование 256 суперчипов NVIDIA GH200 Grace Hopper, объединённых при помощи NVLink Switch System. Каждый суперчип содержит в одном модуле Arm-процессор NVIDIA Grace и ускоритель NVIDIA H100. Задействован интерконнект NVLink-C2C (Chip-to-Chip), который, как заявляет NVIDIA, значительно быстрее и энергоэффективнее, нежели PCIe 5.0. В результате, скорость обмена данными между CPU и GPU возрастает семикратно, а затраты энергии сокращаются примерно в пять раз. Пропускная способность достигает 900 Гбайт/с. 
Источник изображений: NVIDIA Технология NVLink Switch позволяет всем ускорителям в составе системы функционировать в качестве единого целого. Таким образом обеспечивается производительность на уровне 1 Эфлопс (~ 9 Пфлопс FP64), а суммарный объём памяти достигает 144 Тбайт — это почти в 500 раз больше, чем в одной системе NVIDIA DGX A100. Архитектура DGX GH200 AI Supercomputer позволяет добиться 10-кратного увеличения общей пропускной способности по сравнению с HPC-платформой предыдущего поколения.  Ожидается, что Google Cloud, Meta✴ и Microsoft одними из первых получат доступ к суперкомпьютеру DGX GH200, чтобы оценить его возможности для генеративных рабочих нагрузок ИИ. В перспективе собственные проекты на базе DGX GH200 смогут реализовывать крупнейшие провайдеры облачных услуг и гиперскейлеры. Для собственных нужд NVIDIA до конца 2023 года построит суперкомпьютер Helios, который посредством Quantum-2 InfiniBand объединит сразу четыре DGX GH200.
29.05.2023 [07:30], Сергей Карасёв
NVIDIA представила модульную архитектуру MGX для создания ИИ-систем на базе CPU, GPU и DPUКомпания NVIDIA на выставке Computex 2023 представила архитектуру MGX, которая открывает перед разработчиками серверного оборудования новые возможности для построения HPC-систем, платформ для ИИ и метавселенных. Утверждается, что MGX закладывает основу для быстрого создания более 100 вариантов серверов при относительно небольших затратах. Концепция MGX предусматривает, что разработчики на первом этапе проектирования выбирают базовую системную архитектуру для своего шасси. Далее добавляются CPU, GPU и DPU в той или иной конфигурации для решения определённых задач. Таким образом, на базе MGX может быть построена серверная система для уникальных рабочих нагрузок в области наук о данных, больших языковых моделей (LLM), периферийных вычислений, обработки графики и видеоматериалов и пр. Говорится также, что благодаря гибридной конфигурации на одной машине могут выполняться задачи разных типов, например, и обучение ИИ-моделей, и поддержание работы ИИ-сервисов. 
Источник изображений: NVIDIA Одними из первых системы на архитектуре MGX выведут на рынок компании Supermicro и QCT. Первая предложит решение ARS-221GL-NR с NVIDIA Grace, а вторая — сервер S74G-2U на базе NVIDIA GH200 Grace Hopper. Эти платформы дебютируют в августе нынешнего года. Позднее появятся MGX-платформы ASRock Rack, ASUS, Gigabyte, Pegatron и других производителей.  Архитектура MGX совместима с нынешним и будущим оборудованием NVIDIA, включая H100, L40, L4, Grace, GH200 Grace Hopper, BlueField-3 DPU и ConnectX-7. Поддерживаются различные форм-факторы систем: 1U, 2U и 4U. Возможно применение воздушного и жидкостного охлаждения.
23.05.2023 [15:26], Сергей Карасёв
Intel рассказала о суперкомпьютере Aurora производительностью более 2 ЭфлопсКорпорация Intel в ходе конференции ISC 2023, как сообщает AnandTech, поделилась информацией о проекте Aurora по созданию суперкомпьютера с производительностью экзафлопсного уровня. Эта система создаётся для Аргоннской национальной лаборатории Министерства энергетики США. Изначально анонс HPC-комплекса Aurora состоялся ещё в 2015 году с предполагаемым запуском в 2018-м: ожидалось, что машина обеспечит быстродействие на уровне 180 Пфлопс. Однако реализация проекта значительно затянулась, а технические параметры платформы неоднократно менялись. Пока что развёрнуты тестовый кластер Sunspot. Как теперь сообщается, в конечной конфигурации Aurora объединит 10 624 узла, каждый из которых будет включать два процессора Xeon Max и шесть ускорителей Ponte Vecchio. Таким образом, общее количество CPU будет достигать 21 248, число GPU — 63 744. Быстродействие FP64, как и было заявлено ранее, превысит 2 Эфлопс. 
Источник изображений: Intel (via AnandTech) Каждый процессор оперирует 64 Гбайт памяти HBM, ускоритель — 128 Гбайт. В сумме это даёт соответственно 1,36 Пбайт и 8,16 Пбайт памяти HBM с пиковой пропускной способностью 30,5 Пбайт/с и 208,9 Пбайт/с. В дополнение система сможет использовать 10,9 Пбайт памяти DDR5 с пропускной способностью до 5,95 Пбайт/с. Вместимость подсистемы хранения данных составит 230 Пбайт со скоростью работы до 31 Тбайт/с.  На сегодняшний день Intel поставила более 10 тыс. «лезвий» для Aurora, а это означает, что практически все узлы готовы к окончательному монтажу. Ввод суперкомпьютера в эксплуатацию намечен на текущий год. Для НРС-платформы готовится специализированная научная модель генеративного ИИ — Generative AI for Science, насчитывающая около 1 трлн параметров. Применять Aurora планируется для решения наиболее ресурсоёмких задач в различных областях.
16.05.2023 [09:23], Сергей Карасёв
Индия представила свой первый серверный процессор AUM: 96 ядер и 96 Гбайт памяти HBM3Центр развития передовых вычислений (C-DAC) Департамента электроники и информационных технологий Министерства коммуникаций и информационных технологий Индии представил первый в стране процессор для серверов и НРС-систем. Изделие под названием AUM выйдет на коммерческий рынок в текущем или следующем году. Решение имеет чиплетную компоновку на базе двух модулей A48Z, каждый из которых насчитывает 48 вычислительных ядер Zeus с архитектурой Arm. Таким образом, суммарное количество ядер достигает 96. Тактовая частота составляет 3,0 ГГц (до 3,5 ГГц в турбо-режиме); показатель TDP варьируется от 280 до 320 Вт. 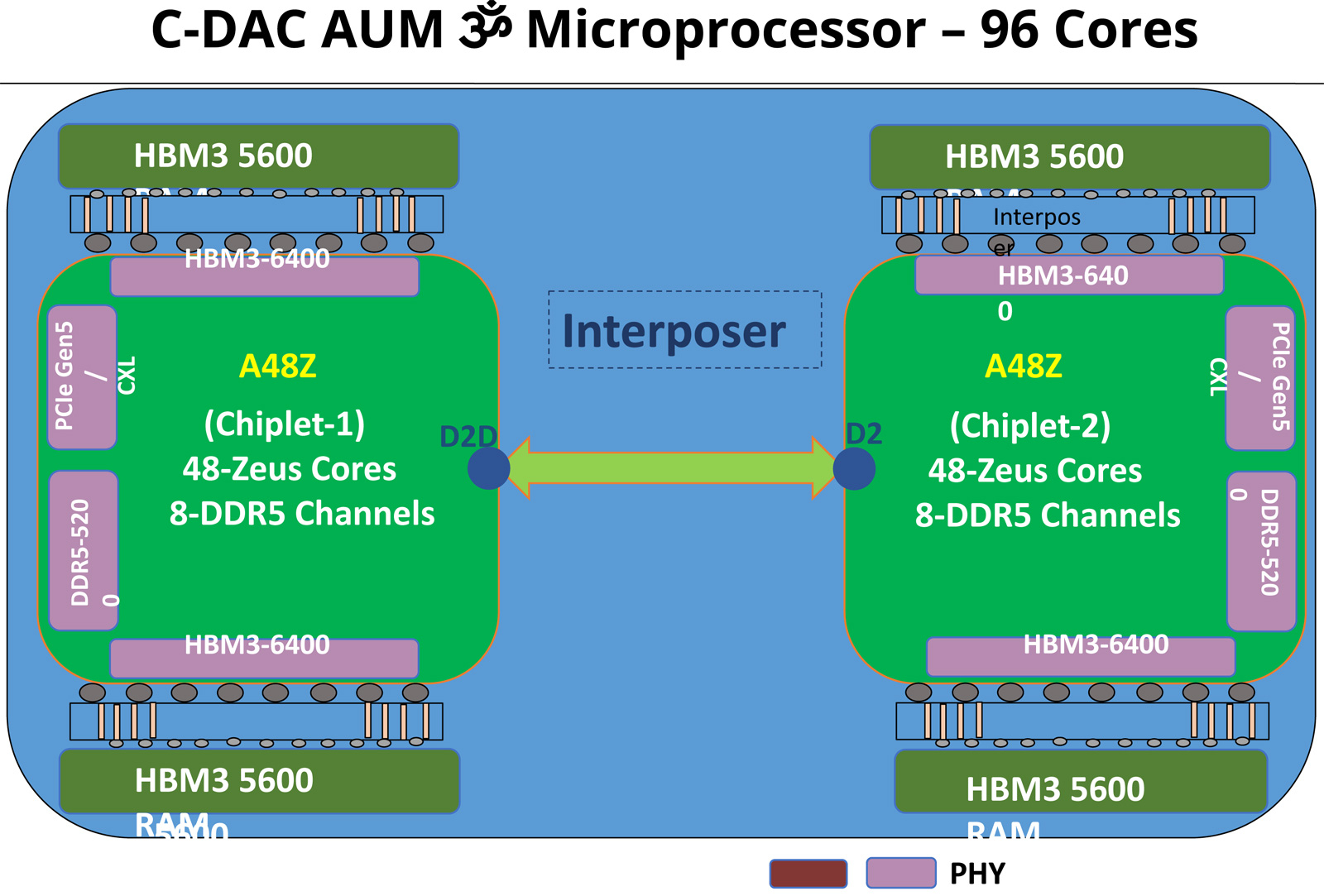
Источник изображений: C-DACC-DAC Новинка будет изготавливаться на предприятии TSMC по 5-нм технологии. Чип содержит 96 Мбайт кеша L2 и 96 Мбайт системного кеша. Изделие получило 96 Гбайт памяти HBM3 и 8-канальный контроллер DDR5-5200; кроме того, имеется доступ к 64 Гбайт памяти HBM3-5600. Таким образом, задействована трёхуровневая подсистема памяти. Упомянуты до 128 линий PCIe 5.0 с поддержкой CXL. 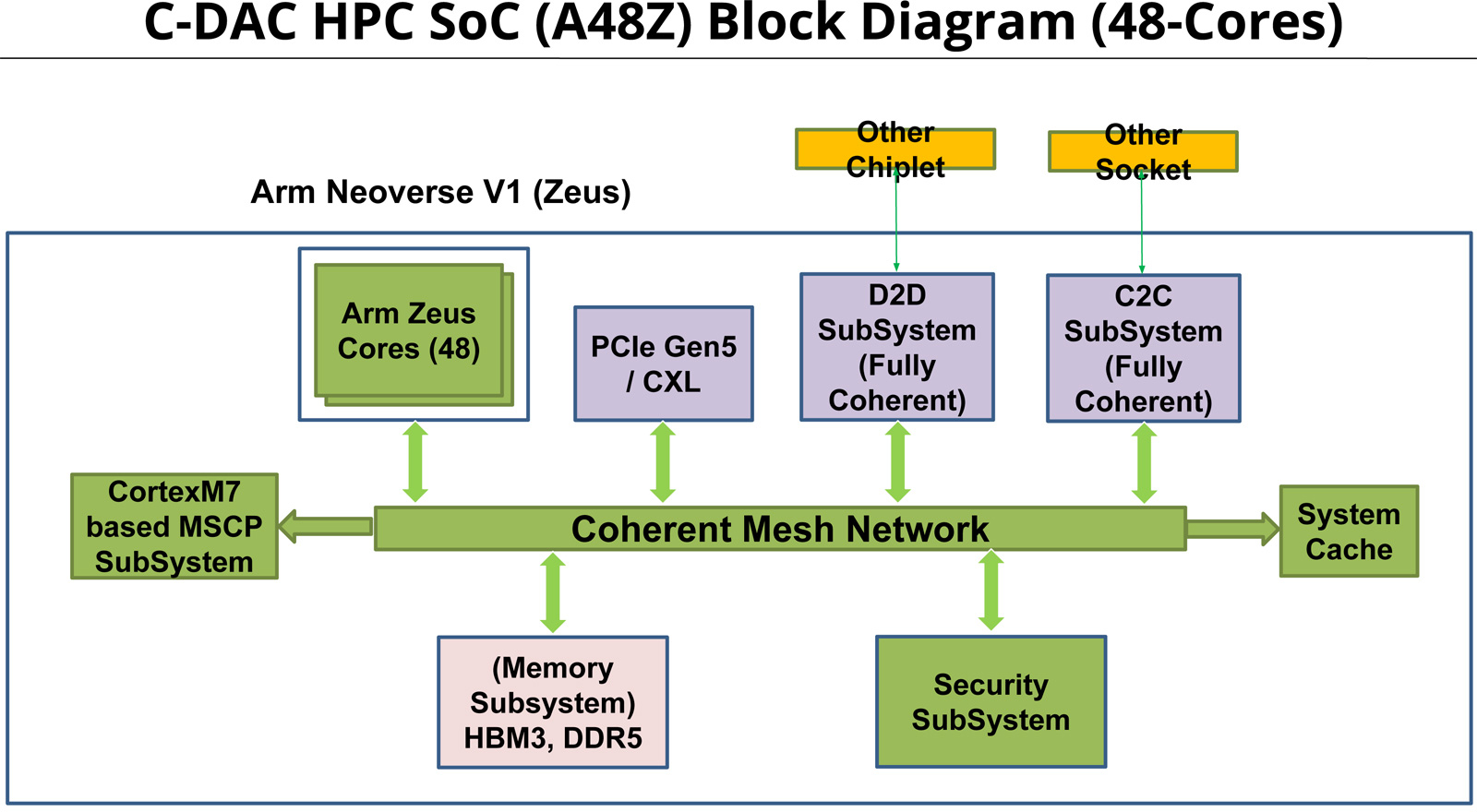 Процессор AUM может применяться в двухсокетных серверах. Заявленная производительность превышает 4,6 Тфлопс в расчёте на разъём. Реализованы различные средства обеспечения безопасности, в том числе функция Secure Boot и криптографические алгоритмы. 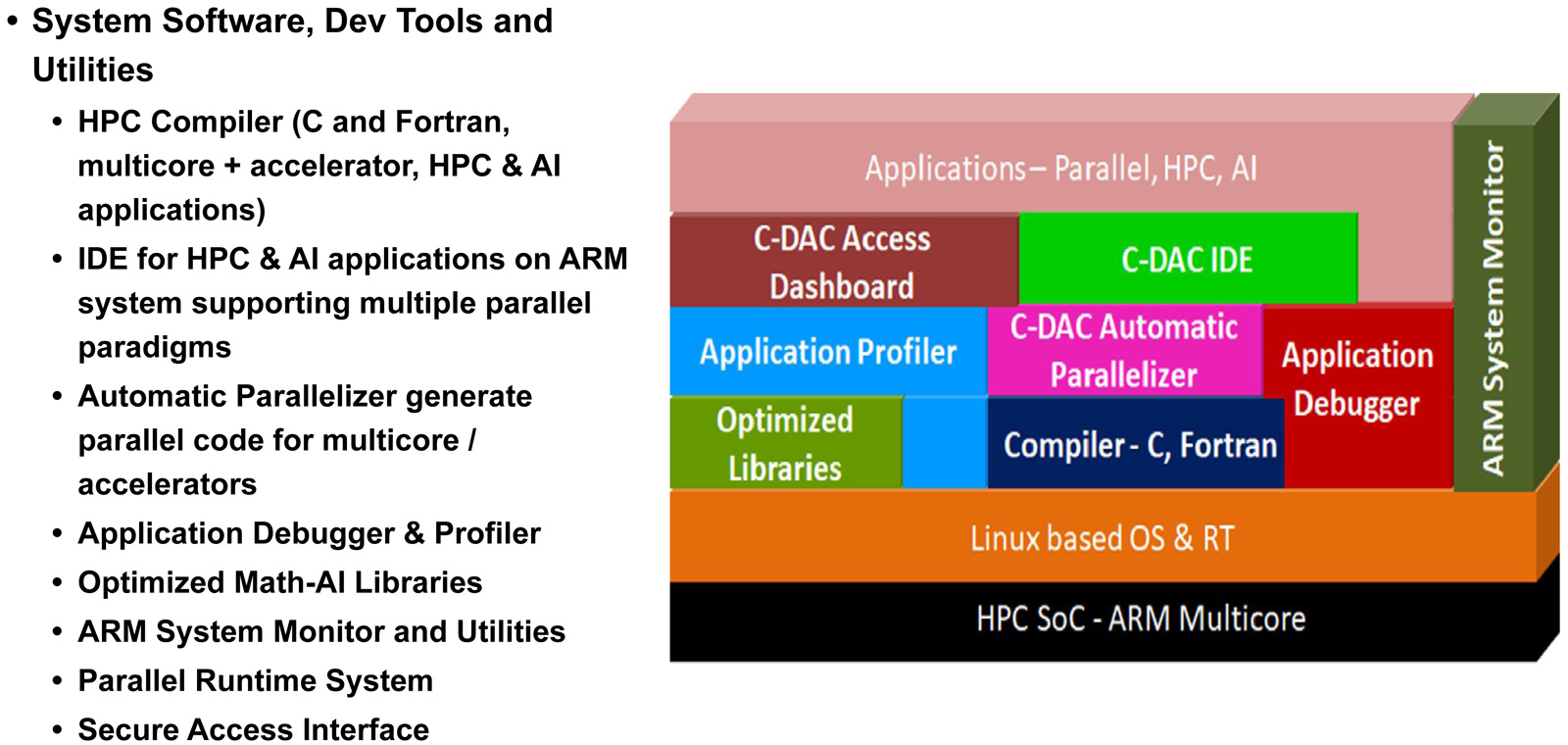
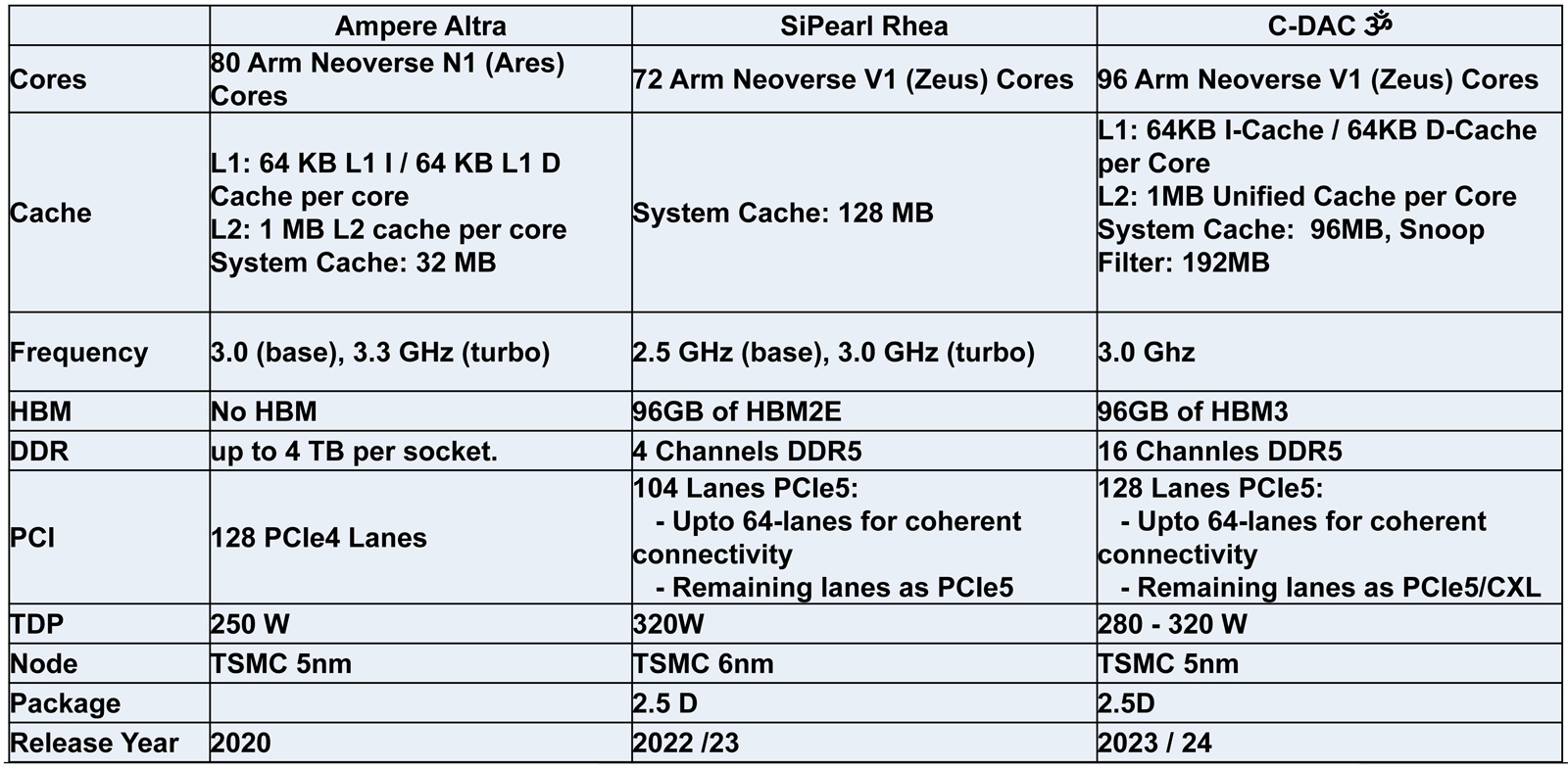
22.04.2023 [00:15], Алексей Степин
Ловкость роборук: TopoOpt от Meta✴ и MIT поможет ускорить и удешевить обучение ИИТехнологии искусственного интеллекта (ИИ) сегодня бурно развиваются и требуют всё более серьёзных вычислительных мощностей. Но наряду с наращиванием этих мощностей растут требования и к сетевой подсистеме, поэтому крупные компании и исследовательские организации ищут всё новые способы оптимизации инфраструктуры. Компания Meta✴ в сотрудничестве с Массачусетским технологическим институтом (MIT) и рядом прочих исследовательских организаций опубликовала данные любопытного эксперимента, в котором ИИ-кластер мог менять топологию своего интерконнекта с помощью механической «роборуки». Система получила название TopoOpt, поскольку вычислительные узлы в ней использовали полностью оптическую сеть с оптической же патч-панелью. Эта сеть объединяла 12 вычислительных узлов ASUS ESC4000A-E10, каждый из которых был оснащён ускорителем NVIDIA A100, сетевыми адаптерами HPE и Mellanox ConnectX-5 (100 Гбит/с) с оптическими трансиверами. 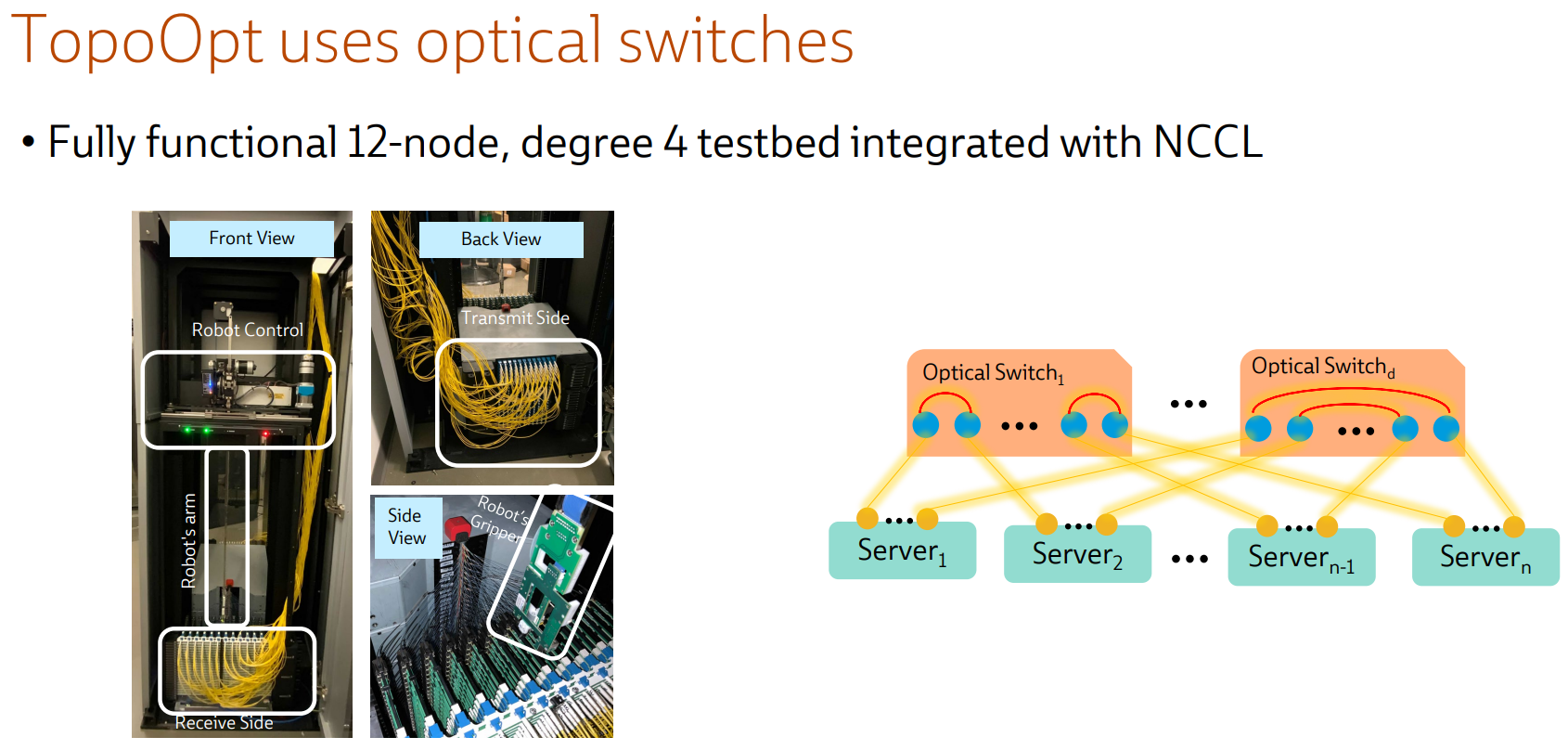
Источник здесь и далее: USENIX Наиболее интересное устройство в эксперименте — оптическая патч-панель Telescent, оснащённая механическим манипулятором, способным производить перекоммутацию на лету. Эта «роборука» работала под управлением специализированного ПО, целью которого ставилось нахождение оптимальной сетевой топологии и сегментации сети применительно к различным задачам машинного обучения. 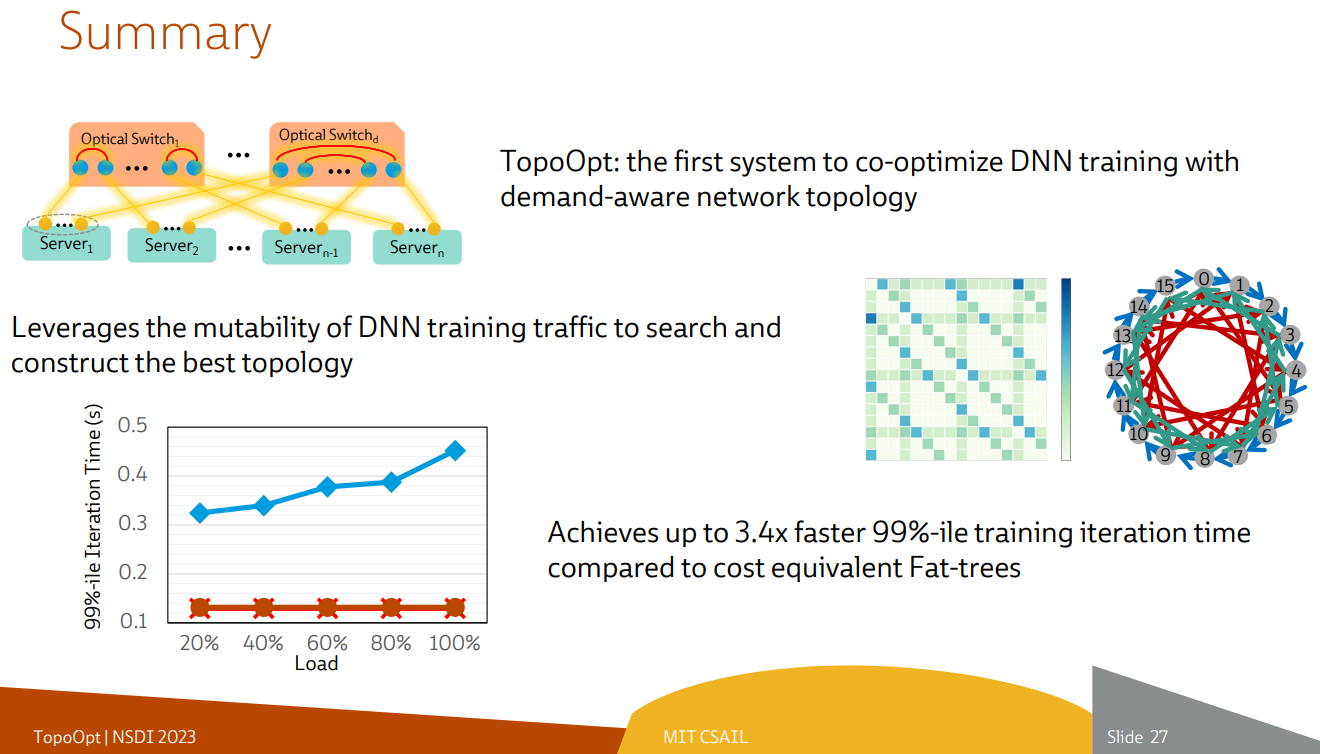
Система с перекоммутируемой оптической сетью не требует энергоёмких высокоскоростных коммутаторов и обеспечивает ряд других преимуществ Такая роботизированная патч-панель не столь расторопна, как оптические коммутаторы Google с микрозеркальной механикой, но стоит впятеро дешевле и имеет больше портов. Опубликованные экспериментальные данные уверенно свидетельствуют о том, что топология «толстого дерева» (fat tree), использующая несколько слоёв коммутаторов, не оптимальна и даже избыточна для ряда нейросетевых задач. К тому же перекоммутируемая оптическая сеть без традиционных высокоскоростных коммутаторов требует меньше оборудования, а значит, может быть не только быстрее сети fat tree в ряде ИИ-задач, но и существенно дешевле в развёртывании и поддержании в рабочем состоянии — как минимум за счёт отсутствия затрат на питание множества коммутаторов.
07.04.2023 [20:36], Сергей Карасёв
Google заявила, что её ИИ-кластеры на базе TPU v4 и оптических коммутаторов эффективнее кластеров на базе NVIDIA A100 и InfiniBandКомпания Google обнародовала новую информацию о своей облачной суперкомпьютерной платформе Cloud TPU v4, предназначенной для решения задач ИИ и машинного обучения с высокой эффективностью. Система может использоваться в том числе для работы с крупномасштабными языковыми моделями (LLM). Один кластер Cloud TPU Pod содержит 4096 чипов TPUv4, соединённых между собой через оптические коммутаторы (OCS). По словам Google, решение OCS быстрее, дешевле и потребляют меньше энергии по сравнению с InfiniBand. Google также утверждает, что в составе её платформы на OCS приходится менее 5 % от общей стоимости. Причём данная технология даёт возможность динамически менять топологию для улучшения масштабируемости, доступности, безопасности и производительности. Отмечается, что платформа Cloud TPU v4 в 1,2–1,7 раза производительнее и расходует в 1,3–1,9 раза меньше энергии, чем платформы на базе NVIDIA A100 в системах аналогичного размера. Правда, пока компания не сравнивала TPU v4 с более новыми ускорителями NVIDIA H100 из-за их ограниченной доступности и 4-нм архитектуры (по сравнению с 7-нм у TPU v4). 
Изображение: Google Благодаря ключевым инновациям в области интерконнекта и специализированных ускорителей (DSA, Domain Specific Accelerator) платформа Google Cloud TPU v4 обеспечивает почти 10-кратный прирост в масштабировании производительности по сравнению с TPU v3. Это также позволяет повысить энергоэффективность примерно в 2–3 раза по сравнению с современными DSA ML и сократить углеродный след примерно в 20 раз по сравнению с обычными дата-центрами. |
|

