Материалы по тегу: pc
|
22.03.2023 [22:02], Алексей Степин
AMD и NVIDIA победили: NEC останавливает разработку уникальных векторных процессоров SX-AuroraЯпонская компания NEC была одной из немногих, отстаивавших собственный уникальный путь в сфере развития вычислительных технологий со своими векторными процессорами SX-Aurora. Хотя данное направление до недавних пор активно развивалось, компания, похоже, не выдержала давления со стороны NVIDIA и AMD и объявила о прекращении разработок новых решений в серии Aurora. Работы над усовершенствованием векторной архитектуры NEC продолжались до конца прошлого года, когда компания объявила о подготовке новых вычислительных узлов SX-Aurora TSUBASA C401-8 на базе ускорителей с 16 блоками Vector Engine 3.0 и 96 Гбайт интегрированной памяти HBM2. И хотя в августе этого года в Научном центре Университета Тохоку будет запущен новый суперкомпьютер на их основе, новых разработок в этой сфере не будет. 
Вычислительный модуль SX-Aurora TSUBASA C401-8. Источник изображений здесь и далее: NEC Как отметил Сатоши Мацуока (Satoshi Matsuoka), глава крупнейшего в Японии суперкомпьютерного центра RIKEN, где был создан суперкомпьютер Fugaku, NEC неслучайно объявила об отказе от разработки нового поколения процессоров SX-Aurora. Хотя в целях компании значилось 10-кратное повышение энергоэффективности, теперь NEC считает, что эта цель может быть достигнута с использованием стандартных коммерческих ускорителей. Главной причиной называется появление решений AMD и NVIDIA, на голову превосходящих все наработки NEC. В частности, упоминается AMD Instinct MI300. При этом отмечено, что это решение «похоронило» бы даже новое поколение SX-Aurora, когда речь заходит о ПСП. Целью NEC был показатель 2+ Тбайт/с, в то время как новинка AMD, располагая памятью HBM3 с 8192-бит шиной, может обеспечить 6,8 Тбайт/с. 
Планы NEC по развитию VE-архитектуры. Похоже, им уже не суждено сбыться Также «естественным врагом» SX-Aurora является NVIDIA Grace Hopper с его мощной процессорной частью и развитой инфраструктурой NVLink, демонстрирующий к тому же выдающуюся энергоэффективность. Примечательно, что оба продукта от AMD и NVIDIA являются APU, то есть гибридными чипами, объединяющими ускорители и CPU собственной разработки, а также быструю память. Финансовый кризис 2009 года ударил по разработкам NEC в области процессоростроения сильно, но ситуацию тогда спасла общая незрелость рынка GPGPU и технологии HBM. Сейчас на это надеяться нельзя, да и ситуация с точки зрения программной экосистемы в мире HPC говорит не в пользу NEC. По всей видимости, прямо на наших глазах ещё одна уникальная вычислительная архитектура становится достоянием истории.  При этом в Японии пока что сохраняется ещё одна уникальная отечественная архитектура — PEZY-SC. Arm-процессоры Fujitsu A64FX, ставшие основой Fugaku, тоже достаточно уникальны, однако их наследники в лице MONAKA переориентированы на более массовый сегмент. Таким образом, собственные массовые HPC-решения сейчас есть только у Китая, которому новейшие американские и британские ускорители достанутся в кастрированном виде.
21.03.2023 [20:45], Владимир Мироненко
NVIDIA запустила облачный сервис DGX Cloud — доступ к ИИ-супервычислениям прямо в браузереNVIDIA запустила сервис ИИ-супервычислений DGX Cloud, предоставляющий предприятиям доступ к инфраструктуре и программному обеспечению, необходимым для обучения передовых моделей для генеративного ИИ и других приложений. DGX Cloud предлагает выделенные ИИ-кластеры NVIDIA DGX в сочетании с фирменным набором ПО NVIDIA. С его помощью предприятие сможет получить доступ к облачному ИИ-суперкомпьютеру, используя веб-браузер и без надобности в приобретении, развёртывании и управлении собственной HPC-инфраструктурой. Правда, удовольствие это всё равно не из дешёвых — стоимость инстансов DGX Cloud начинается от $36 999/мес., причём деньги получает в первую очередь сама NVIDIA. Для сравнения — полностью укомплектованная система DGX A100 в Microsoft Azure обойдётся примерно в $20 тыс. Облачные кластеры DGX предлагаются предприятиям на условиях ежемесячной аренды, что гарантирует им возможность быстро масштабировать разработку больших рабочих нагрузок. «DGX Cloud предоставляет клиентам мгновенный доступ к супервычислениям NVIDIA AI в облаках глобального масштаба», — сообщил Дженсен Хуанг (Jensen Huang), основатель и генеральный директор NVIDIA. 
Источник изображения: NVIDIA Развёртыванием инфраструктуры DGX Cloud компания NVIDIA будет заниматься в сотрудничестве с ведущими поставщиками облачных услуг. Первым среди них стала платформа Oracle Cloud Infrastructure (OCI), предлагающая суперкластер (SuperCluster) с объединёнными RDMA-сетью (в том числе на базе BlueField-3 и Connect-X7) системами DGX (bare metal), которые дополняет высокопроизводительное локальное и блочное хранилище. Cуперкластер может включать до 32 768 ускорителей, но этот рекорд был поставлен с использованием DGX A100, а вот предложение DGX H100 пока что ограничено. В следующем квартале похожее решение появится в Microsoft Azure, а потом в Google Cloud и у других провайдеров. 
Источник изображения: NVIDIA Первыми пользователями DGX Cloud стали Amgen, одна из ведущих мировых биотехнологических компаний, лидер рынка страховых технологий CCC Intelligent Solutions (CCC) и провайдер цифровых бизнес-платформ ServiceNow. «Мощные вычислительные и многоузловые возможности DGX Cloud позволили нам в 3 раза ускорить обучение белковых LLM с помощью BioNeMo и до 100 раз ускорить анализ после обучения с помощью NVIDIA RAPIDS по сравнению с альтернативными платформами», — сообщил представитель Amgen. Для управления нагрузками в DGX Cloud предлагается NVIDIA Base Command. Также DGX Cloud включает в себя набор инструментов NVIDIA AI Enterprise для создания и запуска моделей, который предоставляет комплексные фреймворки и предварительно обученные модели для ускорения обработки данных и оптимизации разработки и развёртывания ИИ. DGX Cloud предоставляет поддержку экспертов NVIDIA на всех этапах разработки ИИ. Клиенты смогут напрямую работать со специалистами NVIDIA, чтобы оптимизировать свои модели и быстро решать задачи разработки с учётом сценариев отраслевого использования.
21.03.2023 [19:15], Сергей Карасёв
NVIDIA представила систему DGX Quantum для гибридных квантово-классических вычисленийКомпания NVIDIA в партнёрстве с Quantum Machines анонсировала DGX Quantum — первую систему, объединяющую GPU и квантовые вычисления. Решение использует новую открытую программную платформу CUDA Quantum. Утверждается, что система предоставляет революционно архитектуру для исследователей, работающими с гибридными вычислениями с низкой задержкой. NVIDIA DGX Quantum объединяет средства ускоренных вычислений на базе Grace Hopper (Arm-процессор + ускоритель H100), модели программирования с открытым исходным кодом CUDA Quantum и передовую квантовую управляющую платформу Quantum Machines OPX+. Такая комбинация позволяет создавать ресурсоёмкие приложения, сочетающие квантовые вычисления с современными классическими вычислениями. При этом в числе прочего обеспечивается работа гибридных алгоритмов и коррекция ошибок. 
Источник изображения: NVIDIA Представленное решение предполагает соединение Grace Hopper и Quantum Machines OPX+ посредством интерфейса PCIe. Это обеспечивает задержку менее микросекунды между ускорителем и блоками квантовой обработки (QPU). Отмечается, что OPX+ — это универсальная система квантового управления. Таким образом, можно максимизировать производительность QPU и предоставить разработчикам новые возможности при использовании квантовых алгоритмов. Системы Grace Hopper и OPX+ можно масштабировать в соответствии с потребностями — от QPU с несколькими кубитами до суперкомпьютера с квантовым ускорением. 
Источник изображения: NVIDIA О намерении интегрировать CUDA Quantum в свои платформы уже заявили компании по производству квантового оборудования Anyon Systems, Atom Computing, IonQ, ORCA Computing, Oxford Quantum Circuits и QuEra, разработчики ПО Agnostiq и QMware, а также некоторые суперкомпьютерные центры.
07.02.2023 [19:37], Руслан Авдеев
Регулирование оборота «вечных» PFAS-химикатов и отказ 3M от их выпуска могут значительно повлиять на будущее погружных СЖОПерфторалкильные и полифторалкильные вещества (PFAS, «вечные химикаты»), вероятно, представляют угрозу для здоровья людей, хотя их вредоносность по многим параметрам пока не получила документальных подтверждений. Тем не менее, как сообщает портал HPC Wire, PFAS привлекают всё больше внимания регуляторов, а принятые против них в ЕС меры грозят всей полупроводниковой индустрии. Теперь этими веществами заинтересовались и американские регуляторы, включая Агентство по охране окружающей среды США (EPA), что может привести к изменению перспектив развития HPC-индустрии. Дело в том, что PFAS используются в двухфазных системах погружного охлаждения. В частности, речь идёт о жидкостях Novec и Fluorinert компании 3M, также применяемых при выпуске полупроводников и в других сферах. В конце 2022 года 3M заявила, что намерена полностью отказаться от их производства уже к 2025 году и уже остановила крупнейший завод по их выпуску в Бельгии. Действия регуляторов и отказ 3M от производства может привести к серьёзным изменениям в HPC-индустрии, поскольку поставит под угрозу бесперебойность поставок необходимых компонентов и материалов. 
Источник изображения: 3M Но есть и другие факторы. Так, крупные международные производители СЖО будут ориентироваться на страны с наиболее жёсткими регуляторными нормами, даже если на других рынках условия более благоприятны. А крупные заказчики вроде Google и Microsoft, декларирующие достижение определённых целей по защите окружающей среды, могут отказаться от PFAS просто из-за репутационных рисков, даже если PFAS будут вполне легальны. По мнению экспертов Motivair, ужесточение контроля за PFAS может представлять угрозу широкомасштабному распространению технологий двухфазного погружного охлаждения. Впрочем, далеко не все уверены, что новые ограничения могут изменить тренды на рынке HPC, поскольку многие игроки здесь применяют, по их словам, эффективные и безопасные системы на основе других технологий СЖО и химикатов. Как сообщает DataCenter Dynamics, по данным производителя иммерсионных СЖО LiquidStack, большее влияние ограничения на использование PFAS могут оказать на полупроводниковую отрасль, где подобные вещества широко применяются в процессе производства. В компании утверждают, что имеется немало альтернатив жидкостям 3M, хотя как минимум некоторые из них тоже являются PFAS.
29.11.2022 [17:12], Алексей Степин
AWS представила Arm-процессор Graviton3E, оптимизированный для задач ИИ и HPCОдин из крупнейших облачных провайдеров, компания Amazon Web Services объявила о доступности новых инстансов EC2 на базе процессора Graviton3E. Новый чип — наследник анонсированного в конце 2021 года Graviton3, 5-нм 64-ядерного процессора на дизайне Arm Neoverse V1 (Zeus) с поддержкой DDR5 и PCI Express 5.0. Graviton3 использует набор команд Armv8.4 c расширениями Neon (4×128 бит) и SVE (2×256 бит) и поддерживает работу с популярными в сфере машинного обучения форматами данных INT8 и BF16. В сравнении c Graviton2 процессор быстрее на 25-60 % при сохранении аналогичного уровня тепловыделения. Дизайн серверов AWS предусматривает наличие трёх процессоров на узел высотой 1U. 
Изображения: AWS Новый процессор Graviton3E представляет собой дальнейшее развитие Graviton3. Чип оптимизирован с учётом потребностей рынка высокопроизводительных вычислений и основное внимание в его архитектуре уделено повышению производительности на операциях с плавающей запятой и вычислениях с использованием векторной математики. AWS, к сожалению, пока не раскрывает деталей относительно архитектуры Graviton3E, но прирост производительности на векторных операциях относительно обычного Graviton3 может достигать 35 %. Помимо классического теста HPL новый процессор хорошо проявляет себя в тестах, имитирующих медико-биологические и финансовые задачи.  Сценарии нагрузок, характерные для HPC, как правило, активно оперируют перемещением крупных объемов данных. Чтобы оптимизировать этот процесс, в новых инстансах AWS использует сеть на базе Elastic Fabric с новыми адаптерами Elastic Network Adapter (ENA). Такая сеть оперирует т. н. Scalable Reliable Datagram (SRD) вместо всем привычных TCP-пакетов. SRD позволяет организовать повторную отправку пакетов за микросекунды вместо миллисекунд в классическом Ethernet. Сердцем же новых инстансов AWS стало пятое поколение аппаратных гипервизоров Nitro 5. В сравнении с предыдущим поколением, Nitro 5 обладает вдвое более высокой вычислительной производительностью, на 50 % повышенной пропускной способностью памяти, а также позволяет обрабатывать на 60 % больше сетевых пакетов при сниженной на 30 % латентности. 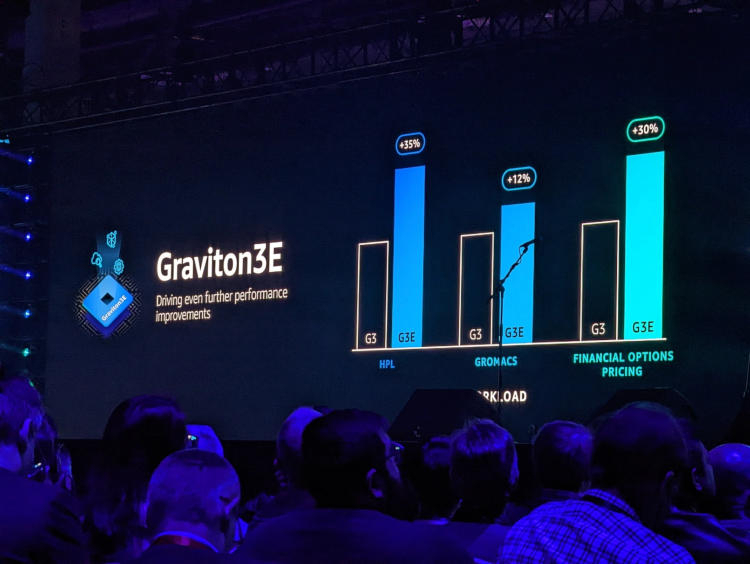
Здесь и далее источник изображений: AWS Инстансы Hpc7g с процессорами Graviton3E получат внутреннюю сеть с пропускной способностью 200 Гбит/с и станут доступны в различных конфигурациях вплоть до 64 vCPU и 128 ГиБ памяти. Аналогичные параметры имеют инстансы C7gn, предназначенные для задач с интенсивным сетевым трафиком: виртуальных маршрутизаторов, сетевых экранов, балансировщиков нагрузки и т.п. Также компания анонсировала инстансы R7iz, в которых используются процессоры Intel Xeon Scalable четвёртого поколения (Sapphire Rapids) с постоянной частотой всех ядер 3,9 ГГц. Они могут иметь конфигурацию до 128 vCPU с 1 ТиБ памяти.
29.11.2022 [12:20], Сергей Карасёв
В Италии официально запущен суперкомпьютер Leonardo — четвёртая по мощности HPC-система в миреСовместная инициатива по высокопроизводительным вычислениям в Европе EuroHPC JU и некоммерческий консорциум CINECA, состоящий из 69 итальянских университетов и 21 национальных исследовательских центров, провели церемонию запуска суперкомпьютера Leonardo. В основу комплекса положены платформы Atos BullSequana X2610 и X2135. Система Leonardo состоит из двух секций — общего назначения и с ускорителями вычислений (Booster). Когда строительство системы будет завершено, первая будет включать 1536 узлов, каждый из которых содержит два процессора Intel Xeon Sapphire Rapids с 56 ядрами и TDP в 350 Вт, 512 Гбайт оперативной памяти DDR5-4800, интерконнект NVIDIA InfiniBand HDR100 и NVMe-накопитель на 8 Тбайт. 
Источник изображения: HPCwire Секция Booster объединяет 3456 узлов, каждый из которых содержит один чип Intel Xeon 8358 с 32 ядрами, 512 Гбайт ОЗУ стандарта DDR4-3200, четыре кастомных ускорителя NVIDIA A100 с 64 Гбайт HBM2-памяти, а также два адаптера NVIDIA InfiniBand HDR100. Кроме того, в состав комплекса входят 18 узлов для визуализации: 6,4 Тбайт NVMe SSD и два ускорителя NVIDIA RTX 8000 (48 Гбайт) в каждом. Вычислительный комплекс объединён фабрикой с топологией Dragonfly+. 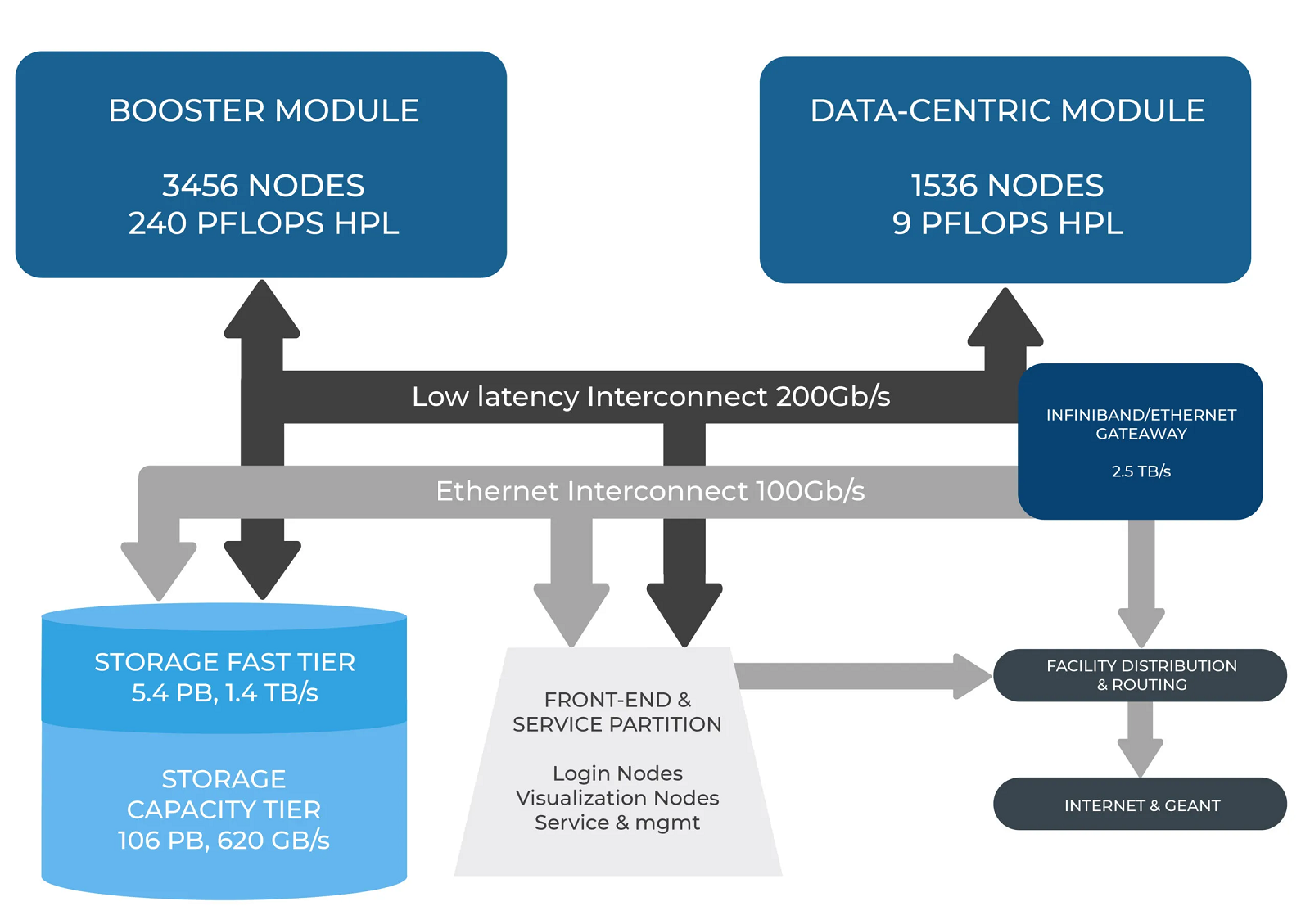
Источник: CINECA Для хранения данных служит двухуровневая система. Производительный блок (5,4 Пбайт, 1400 Гбайт/с) содержит 31 модуль DDN Exascaler ES400NVX2, каждый из которых укомплектован 24 NVMe SSD вместимостью 7,68 Тбайт и четырьмя адаптерами InfiniBand HDR. Второй уровень большой ёмкости (106 Пбайт, чтение/запись 744/620 Гбайт/с) состоит из 31 массива DDN EXAScaler SFA799X с 82 SAS HDD (7200 PRM) на 18 Тбайт и четырьмя адаптерами InfiniBand HDR. Каждый из массивов включает два JBOD-модуля с 82 дисками на 18 Тбайт. Для хранения метаданных используются 4 модуля DDN EXAScaler SFA400NVX: 24 × 7,68 Тбайт NVMe + 4 × InfiniBand HDR. 
Изображение: CINECA В настоящее время Leonardo обеспечивает производительность более 174 Пфлопс. Ожидается, что суперкомпьютер будет полностью запущен в первой половине 2023 года, а его пиковое быстродействие составит 250 Пфлопс. Уже сейчас система занимает четвёртое место в последнем рейтинге самых мощных суперкомпьютеров мира TOP500. В Европе Leonardo является второй по мощности системой после LUMI. Leonardo оборудован системой жидкостного охлаждения для повышения энергоэффективности. Кроме того, предусмотрена возможность регулировки энергопотребления для обеспечения баланса между расходом электричества и производительностью. Суперкомпьютер ориентирован на решение высокоинтенсивных вычислительных задач, таких как обработка данных, ИИ и машинное обучение. Половина вычислительных ресурсов Leonardo будет предоставлена пользователям EuroHPC.
15.11.2022 [19:08], Сергей Карасёв
Cerebras построила ИИ-суперкомпьютер Andromeda с 13,5 млн ядерКомпания Cerebras Systems сообщила о запуске уникального вычислительного комплекса Andromeda для выполнения «тяжёлых» ИИ-нагрузок. В основу Andromeda положен кластер из 16 блоков Cerebras CS-2, объединённых 96,8-Тбит/с фабрикой. Каждый из них содержит чип WSE-2, насчитывающий 850 тыс. ядер. Таким образом, общее число ядер достигает 13,5 млн. Кроме того, непосредственно в состав каждого чипа входят 40 Гбайт сверхбыстрой памяти. Система уже доступна коммерческим заказчикам, а также различным научным организациям. 
Источник изображения: Cerebras Systems Суперкомпьютер также использует 284 односокетных сервера с процессорами AMD EPYC 7713. Суммарное количество вычислительных ядер общего назначения составляет 18 176. Каждый из этих серверов несёт на борту 128 Гбайт оперативной памяти, NVMe-накопитель вместимостью 1,92 Тбайт и две сетевые карты 100GbE. Эти узлы отвечают за предварительную обработку информации. 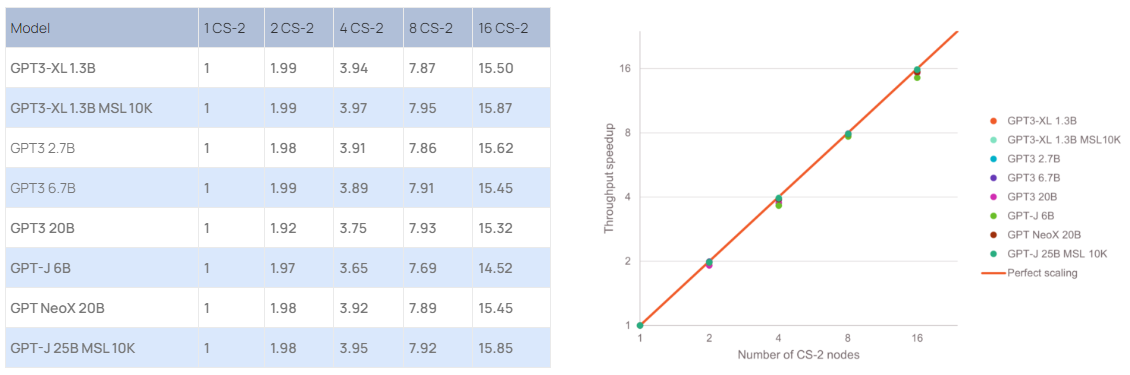
Источник: Cerebras Systems По заявлениям Cerebras, производительность системы превышает 1 Эфлопс на т.н. разреженных вычислениях и достигает 120 Пфлопс при обычных FP16-вычислениях. Это первый в мире суперкомпьютер, который обеспечивает практически идеальное линейное масштабирование при работе с GPT-моделями, в частности, GPT-3, GPT-J и GPT-NeoX. Иначе говоря, при каждом удвоении числа комплексов CS-2 время обучения моделей сокращается почти в два раза.  Суперкомпьютер смонтирован в дата-центре Colovore в Санта-Кларе (Калифорния, США). Стоимость системы составила приблизительно $30 млн, а на её развёртывание потребовалось всего три дня. Использовать ресурсы Andromeda могут одновременно несколько клиентов.
10.11.2022 [17:15], Владимир Мироненко
HPE анонсировала недорогие, энергоэффективные и компактные суперкомпьютеры Cray EX2500 и Cray XD2000/6500Hewlett Packard Enterprise анонсировала суперкомпьютеры HPE Cray EX и HPE Cray XD, которые отличаются более доступной ценой, меньшей занимаемой площадью и большей энергоэффективностью по сравнению с прошлыми решениями компании. Новинки используют современные технологии в области вычислений, интерконнекта, хранилищ, питания и охлаждения, а также ПО. 
Изображение: HPE Суперкомпьютеры HPE обеспечивают высокую производительность и масштабируемость для выполнения ресурсоёмких рабочих нагрузок с интенсивным использованием данных, в том числе задач ИИ и машинного обучения. Новинки, по словам компании, позволят ускорить вывода продуктов и сервисов на рынок. Решения HPE Cray EX уже используются в качестве основы для больших машин, включая экзафлопсные системы, но теперь компания предоставляет возможность более широкому кругу организаций задействовать супервычисления для удовлетворения их потребностей в соответствии с возможностями их ЦОД и бюджетом. В семейство HPE Cray вошли следующие системы:
Все три системы задействуют те же технологии, что и их старшие собратья: интерконнект HPE Slingshot, хранилище Cray Clusterstor E1000 и пакет ПО HPE Cray Programming Environment и т.д. Система HPE Cray EX2500 поддерживает процессоры AMD EPYC Genoa и Intel Xeon Sapphire Rapids, а также ускорители AMD Instinct MI250X. Модель HPE Cray XD6500 поддерживает чипы Sapphire Rapids и ускорители NVIDIA H100, а для XD2000 заявлена поддержка AMD Instinct MI210. 
Изображение: Intel В качестве примеров выгод от использования анонсированных суперкомпьютеров в разных отраслях компания назвала:
12.10.2022 [22:54], Сергей Карасёв
NEC готовит новые векторные ускорители серии SX-Aurora TSUBASAКомпания NEC Corporation сообщила о подготовке нового узла в серии SX-Aurora TSUBASA — модели C401-8, рассчитанной на центры обработки данных, на базе которых осуществляется сложное моделирование, выполняются научные расчёты и другие ресурсоёмкие задачи. Основой новинки станут неназванные пока векторные ускорители — судя по всему, это обещанные ранее Vector Engine 3.0 (VE30). Новинки получили 16 векторных блоков с частотой 1,7 ГГц, тогда как прошлое поколение имело до 10 блоков с частотой 1,6 ГГц. Также появился L3-кеш. Пропускная способность HBM-памяти увеличилась в 1,6 раза — с 1,53 до 2,45 Тбайт/с, а её объём вырос вдвое — с 48 до 96 Гбайт. Итоговая производительность в FP64-вычислениях, как утверждается, выросла приблизительно в 2,5 раза по сравнению с предшественниками и превысила 5 Пфлопс. При этом по энергоэффективности готовящийся ускоритель, по словам NEC, в два раза превосходит традиционные изделия. 
Источник изображения: NEC В августе 2023 года суперкомпьютер на базе SX-Aurora TSUBASA C401-8 начнёт использоваться в Научном центре Университета Тохоку в Японии. В общей сложности будут задействованы 4032 векторных ускорителя NEC, а быстродействие составит до 21 Пфлопс. Использовать комплекс планируется для масштабных научных исследований. Месяцем позже заработает ещё одна HPC-система на базе C401-8, которую получит метеослужба Германии.
05.09.2022 [23:00], Алексей Степин
Tesla рассказала подробности о чипах D1 собственной разработки, которые станут основой 20-Эфлопс ИИ-суперкомпьютера DojoКомпания Tesla уже анонсировала собственный, созданный в лабораториях компании процессор D1, который станет основой ИИ-суперкомпьютера Dojo. Нужна такая система, чтобы создать для ИИ-водителя виртуальный полигон, в деталях воссоздающий реальные ситуации на дорогах. Естественно, такой симулятор требует огромных вычислительных мощностей: в нашем мире дорожная обстановка очень сложна, изменчива и включает множество факторов и переменных. До недавнего времени о Dojo и D1 было известно не так много, но на конференции Hot Chips 34 было раскрыто много интересного об архитектуре, устройстве и возможностях данного решения Tesla. Презентацию провел Эмиль Талпес (Emil Talpes), ранее 17 лет проработавший в AMD над проектированием серверных процессоров. Он, как и ряд других видных разработчиков, работает сейчас в Tesla над созданием и совершенствованием аппаратного обеспечения компании. 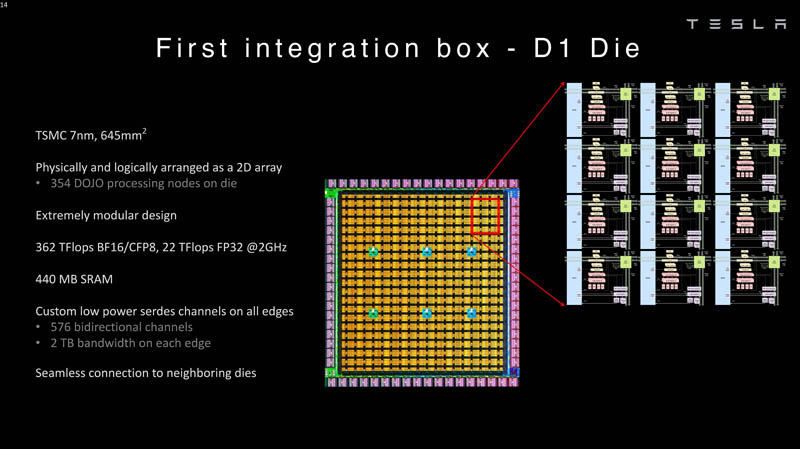
Изображения: Tesla (via ServeTheHome) Главной идеей D1 стала масштабируемость, поэтому в начале разработки нового чипа создатели активно пересмотрели роль таких традиционных концепций, как когерентность, виртуальная память и т.д. — далеко не все механизмы масштабируются лучшим образом, когда речь идёт о построении действительно большой вычислительной системы. Вместо этого предпочтение было отдано распределённой сети хранения на базе SRAM, для которой был создан интерконнект, на порядок опережающий существующие реализации в системах распределённых вычислений. 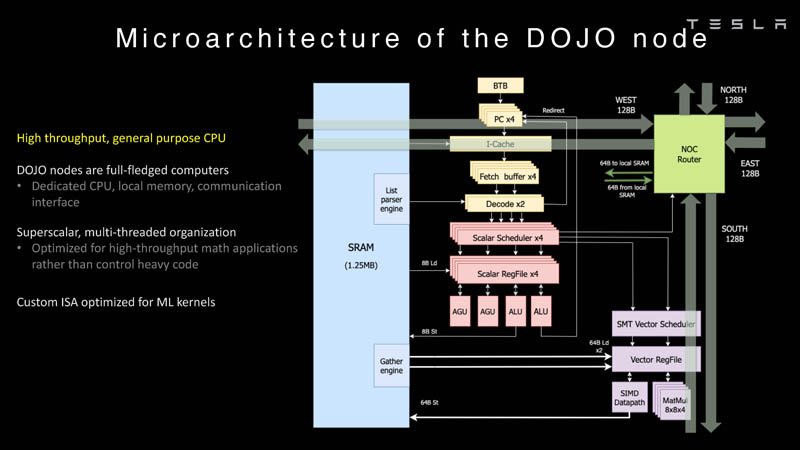 Основой процессора Tesla стало ядро целочисленных вычислений, базирующееся на некоторых инструкциях из набора RISC-V, но дополненное большим количеством фирменных инструкций, оптимизированных с учётом требований, предъявляемых ядрами машинного обучения, используемыми компанией. Блок векторной математики был создан практически с нуля, по словам разработчиков. 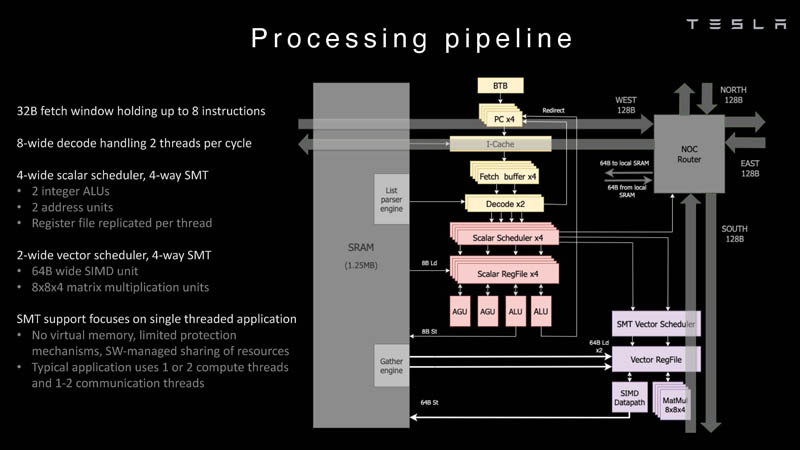 Набор инструкций Dojo включает в себя скалярные, матричные и SIMD-инструкции, а также специфические примитивы для перемещения данных из локальной памяти в удалённую, равно как и семафоры с барьерами — последние требуются для согласования работы c памятью во всей системе. Что касается специфических инструкций для машинного обучения, то они реализованы в Dojo аппаратно. 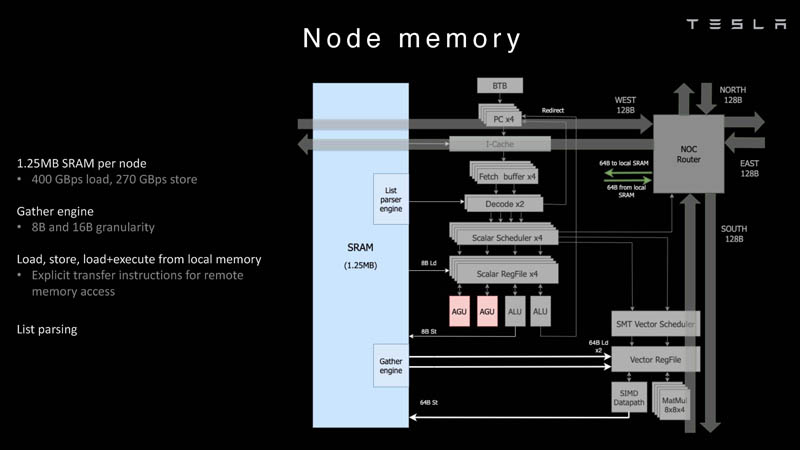 Первенец в серии, чип D1, не является ускорителем как таковым — компания считает его высокопроизводительным процессором общего назначения, не нуждающимся в специфических ускорителях. Каждый вычислительный блок Dojo представлен одним ядром D1 с локальной памятью и интерфейсами ввода/вывода. Это 64-бит ядро суперскалярно. 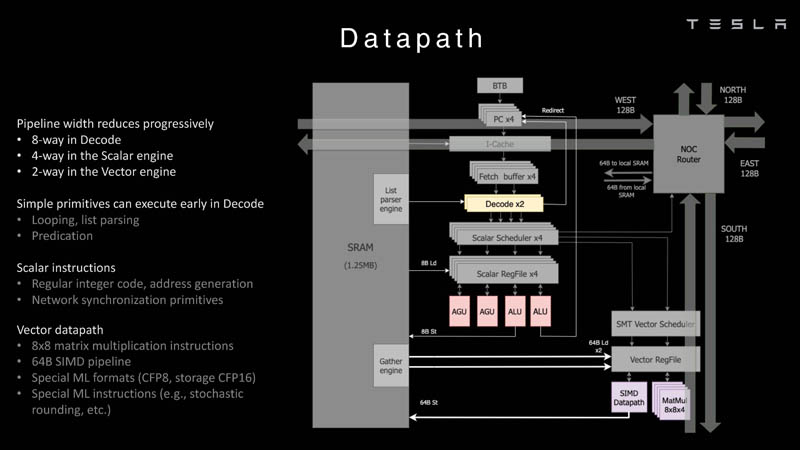 Более того, в ядре реализована поддержка многопоточности (SMT4), которая призвана увеличить производительность на такт (а не изолировать разные задачи друг от друга), поэтому виртуальную память данная реализация SMT не поддерживает, а механизмы защиты довольно ограничены в функциональности. За управление ресурсами Dojo отвечает специализированный программный стек и фирменное ПО. 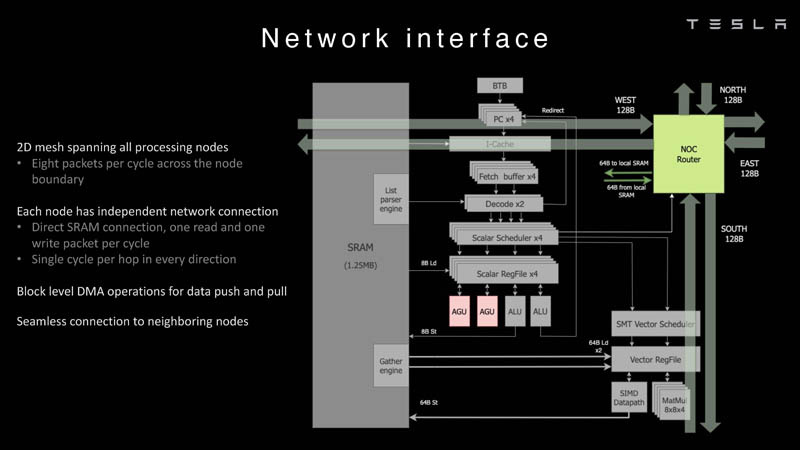 64-бит ядро имеет 32-байт окно выборки (fetch window), которое может содержать до 8 инструкций, что соответствует ширине декодера. Он, в свою очередь, может обрабатывать два потока за такт. Результат поступает в планировщики, которые отправляют его в блок целочисленных вычислений (два ALU) или в векторный блок (SIMD шириной 64 байт + перемножение матриц 8×8×4). 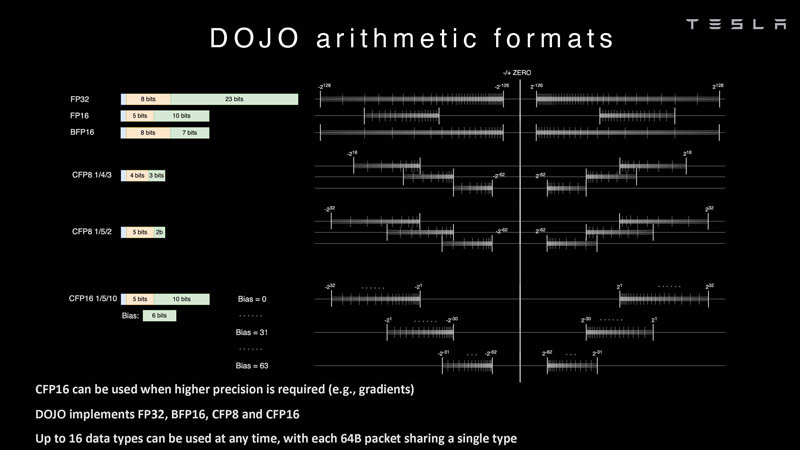 У каждого ядра D1 есть SRAM объёмом 1,25 Мбайт. Эта память — не кеш, но способна загружать данные на скорости 400 Гбайт/с и сохранять на скорости 270 Гбайт/с, причём, как уже было сказано, в чипе реализованы специальные инструкции, позволяющие работать с данными в других ядрах Dojo. Для этого в блоке SRAM есть свои механизмы, так что работа с удалённой памятью не требуют дополнительных операций.  Что касается поддерживаемых форматов данных, то скалярный блок поддерживает целочисленные форматы разрядностью от 8 до 64 бит, а векторный и матричный блоки — широкий набор форматов с плавающей запятой, в том числе для вычислений смешанной точности: FP32, BF16, CFP16 и CFP8. Разработчики D1 пришли к использованию целого набора конфигурируемых 8- и 16-бит представлений данных — компилятор Dojo может динамически изменять значения мантиссы и экспоненты, так что система может использовать до 16 различных векторных форматов, лишь бы в рамках одного 64-байт блока данных он не менялся.  Как уже упоминалось, топология D1 использует меш-структуру, в которой каждые 12 ядер объединены в логический блок. Чип D1 целиком представляет собой массив размером 18×20 ядер, однако доступны лишь 354 ядра из 360 присутствующих на кристалле. Сам кристалл площадью 645 мм2 производится на мощностях TSMC с использованием 7-нм техпроцесса. Тактовая частота составляет 2 ГГц, общий объём памяти SRAM — 440 Мбайт.  Процессор D1 развивает 362 Тфлопс в режиме BF16/CFP8, в режиме FP32 этот показатель снижается до 22 Тфлопс. Режим FP64 векторными блоками D1 не поддерживается, поэтому для многих традиционных HPC-нагрузок данный процессор не подойдёт. Но Tesla создавала D1 для внутреннего использования, поэтому совместимость её не очень волнует. Впрочем, в новых поколениях, D2 или D3, такая поддержка может появиться, если это будет отвечать целям компании. 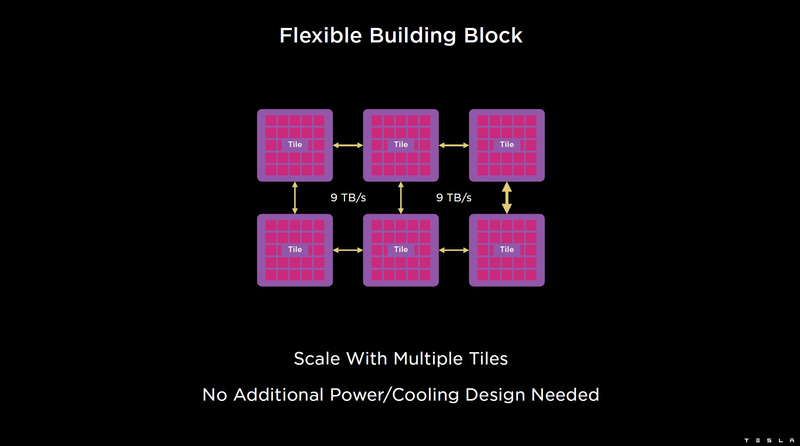 Каждый кристалл D1 имеет 576-битный внешний интерфейс SerDes с совокупной производительностью по всем четырём сторонам, составляющей 18 Тбайт/с, так что узким местом при соединении D1 он явно не станет. Этот интерфейс объединяет кристаллы в единую матрицу 5х5, такая матрица из 25 кристаллов D1 носит название Dojo training tile. 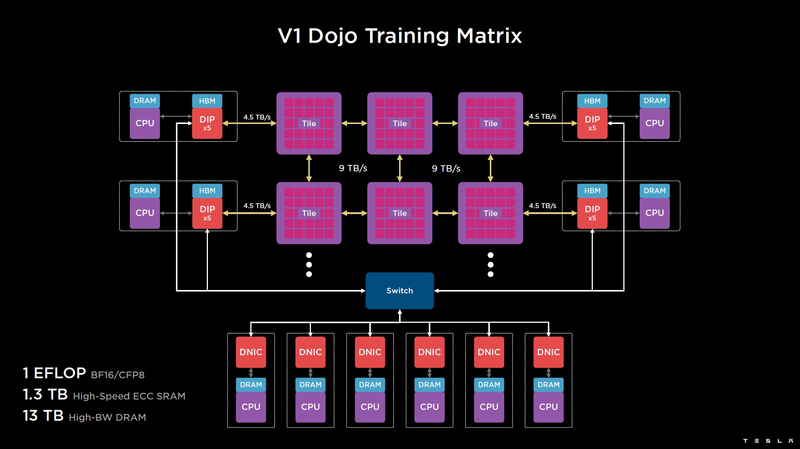 Этот тайл выполнен как законченный термоэлектромеханический модуль, имеющий внешний интерфейс с пропускной способностью 4,5 Тбайт/с на каждую сторону, совокупно располагающий 11 Гбайт памяти SRAM, а также собственную систему питания мощностью 15 кВт. Вычислительная мощность одного тайла Dojo составляет 9 Пфлопс в формате BF16/CFP8. При таком уровне энергопотребления охлаждение у Dojo может быть только жидкостное.  Тайлы могут объединяться в ещё более производительные матрицы, но как именно физически организован суперкомпьютер Tesla, не вполне ясно. Для связи с внешним миром используются блоки DIP — Dojo Interface Processors. Это интерфейсные процессоры, посредством которых тайлы общаются с хост-системами и на долю которых отведены управляющие функции, хранение массивов данных и т.п. Каждый DIP не просто выполняет IO-функции, но и содержит 32 Гбайт памяти HBM (не уточняется, HBM2e или HBM3). 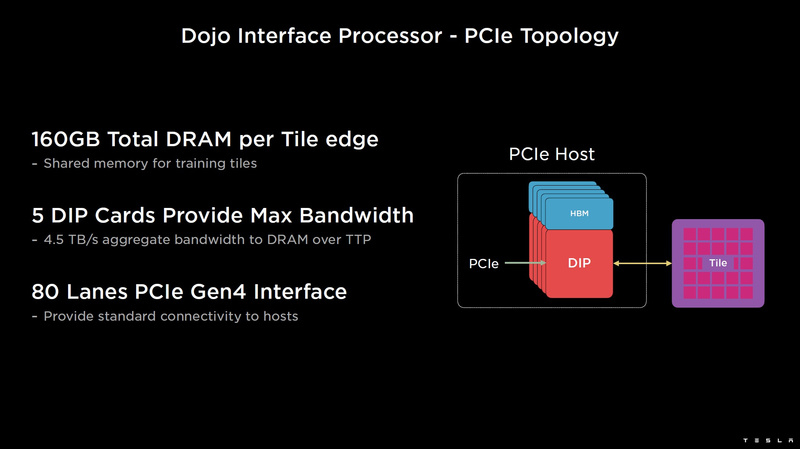 DIP использует полностью свой транспортный протокол (Tesla Transport Protocol, TTP), разработанный в Tesla и обеспечивающий пропускную способность 900 Гбайт/с, а поверх Ethernet — 50 Гбайт/с. Внешний интерфейс у карточек — PCI Express 4.0, и каждая интерфейсная карта несёт пару DIP. С каждой стороны каждого ряда тайлов установлено по 5 DIP, что даёт скорость до 4,5 Тбайт/с от HBM-стеков к тайлу.  В случаях, когда во всей системе обращение от тайла к тайлу требует слишком много переходов (до 30 в случае обращения от края до края), система может воспользоваться DIP, объединённых снаружи 400GbE-сетью по топологии fat tree, сократив таким образом, количество переходов до максимум четырёх. Пропускная способность в этом случае страдает, но выигрывает латентность, что в некоторых сценариях важнее. 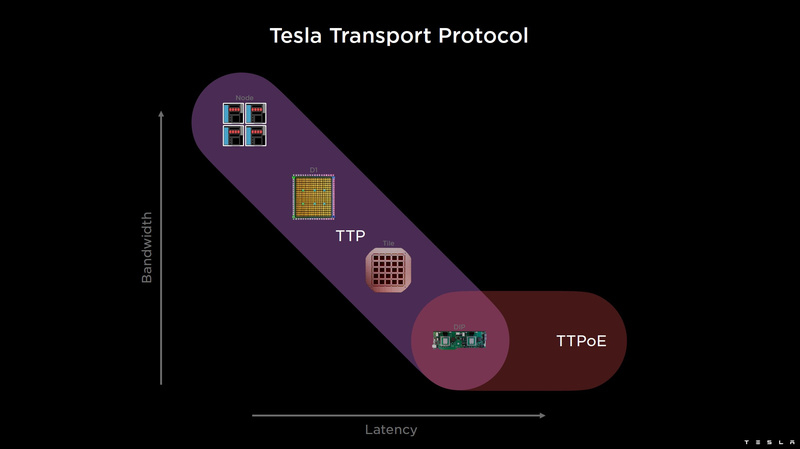 В базовой версии суперкомпьютер Dojo V1 выдаёт 1 Эфлопс в режиме BF16/CFP8 и может загружать непосредственно в SRAM модели объёмом до 1,3 Тбайт, ещё 13 Тбайт данных можно хранить в HBM-сборках DIP. Следует отметить, что пространство SRAM во всей системе Dojo использует единую плоскую адресацию. Полномасштабная версия Dojo будет иметь производительность до 20 Эфлопс. Сколько сил потребуется компании, чтобы запустить такого монстра, а главное, снабдить его рабочим и приносящим пользу ПО, неизвестно — но явно немало. Известно, что система совместима с PyTorch. В настоящее время Tesla уже получает готовые чипы D1 от TSMC. А пока что компания обходится самым большим в мире по числу установленных ускорителей NVIDIA ИИ-суперкомпьютером. |
|

