Материалы по тегу: nvidia
|
19.03.2024 [01:00], Игорь Осколков
NVIDIA B200, GB200 и GB200 NVL72 — новые ускорители на базе архитектуры BlackwellNVIDIA представила сразу несколько ускорителей на базе новой архитектуры Blackwell, названной в честь американского статистика и математика Дэвида Блэквелла. На смену H100/H200, GH200 и GH200 NVL32 на базе архитектуры Hopper придут B200, GB200 и GB200 NVL72. Все они, как говорит NVIDIA, призваны демократизировать работу с большими языковыми моделями (LLM) с триллионами параметров. В частности, решения на базе Blackwell будут до 25 раз энергоэффективнее и экономичнее в сравнении с Hopper. В разреженных FP4- и FP8-вычислениях производительность B200 достигает 20 и 10 Пфлопс соответственно. Но без толики технического маркетинга не обошлось — показанные результаты достигнуты не только благодаря аппаратным улучшениям, но и программным оптимизациям. Это ни в коей мере не умаляет их важности и полезности, но затрудняет прямое сравнение с конкурирующими решениями. В общем, появление Blackwell стоит рассматривать не как очередное поколение ускорителей, а как расширение всей экосистемы NVIDIA. В Blackwell компания использует тайловую (чиплетную) компоновку — два тайла объединены 2,5D-упаковкой CoWoS-L и на двоих имеют 208 млрд транзисторов, изготовленных по техпроцессу TSMC 4NP. В одно целое со всех точек зрения их объединяет новый интерконнект NV-HBI с пропускной способностью 10 Тбайт/с, а дополняют их восемь стеков HBM3e-памяти ёмкостью до 192 Гбайт с агрегированной пропускной способностью до 8 Тбайт/с. Такой же объём памяти предлагает и Instinct MI300X, но с меньшей ПСП (5,3 Тбайт/с), хотя это скоро изменится. FP8-производительность в разреженных вычислениях у решения AMD составляет 5,23 Пфлопс, но зато компания не забывает и про FP64 в отличие от NVIDIA. 
Источник изображений: NVIDIA Одними из ключевых нововведений, отвечающих за повышение производительности, стали новые Tensor-ядра и второе поколение механизма Transformer Engine, который научился заглядывать внутрь тензоров, ещё более тонко подбирая необходимую точность вычислений, что влияет и на скорость обучения с инференсом, и на максимальный объём модели, умещающейся в памяти ускорителя. 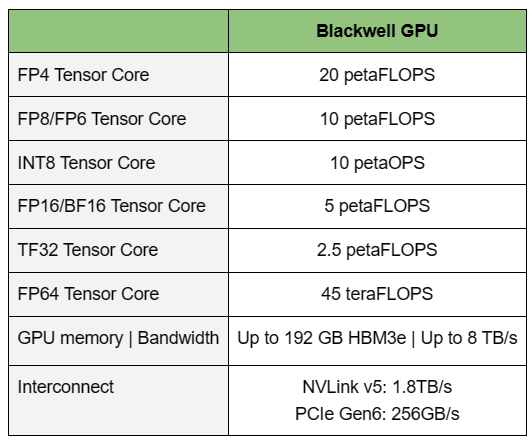 Теперь NVIDIA намекает на то, что обучение можно делать в FP8-формате, а для инференса хватит и FP4. Всё это без потери качества. Но вообще Blackwell поддерживает FP4/FP6/FP8, INT8, BF16/FP16, TF32 и FP64. И только для последнего нет поддержки разреженных вычислений. 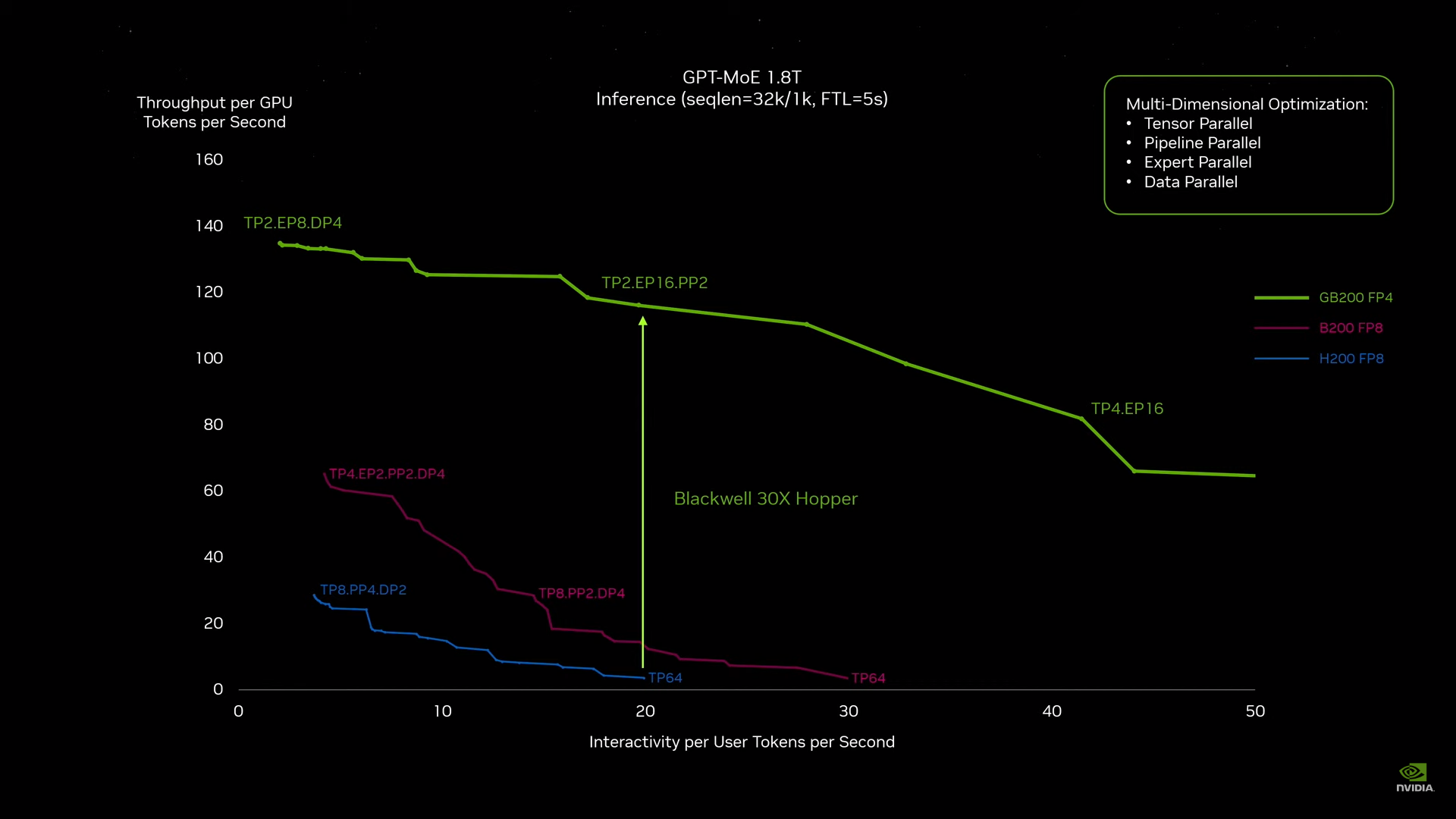 Дополнительно Blackwell обзавёлся движком для декомпрессии (в первую очередь LZ4, Deflate, Snappy) входящих данных со скоростью до 800 Гбайт/с, что тоже должно повысить производительность, т.к. теперь распаковкой будет заниматься не CPU и, соответственно, ускоритель не будет «голодать». Эта функция рассчитана в основном на Apache Spark и другие системы для аналитики больших данных. Также есть по семь движков NVDEC и NVJPEG.  Наконец, NVIDIA упоминает ещё две новых возможности Blackwell: шифрование данных в памяти и RAS-функции. В первом случае речь идёт о защите конфиденциальности обрабатываемых данных, что важно в целом ряде областей. Причём формирование TEE-анклава возможно в рамках группы из 128 ускорителей. MIG-доменов по-прежнему семь. В случае RAS говорится о телеметрии и предиктивной аналитике (естественно, на базе ИИ), которые помогут заранее выявить возможные сбои и снизить время простоя. Это важно, поскольку многие модели могут обучаться неделями и месяцами, так что потеря даже относительно небольшого куска данных крайне неприятна и финансово затратна.  Однако всё эти инновации не имеют смысла без возможности масштабирования, поэтому NVIDIA оснастила Blackwell не только интерфейсом PCIe 6.0 (32 линии), который играет всё меньшую роль, но и пятым поколением интерконнекта NVLink. NVLink 5 по сравнению с NVLink 4 удвоил пропускную способность до 1,8 Тбайт/с (по 900 Гбайт/с в каждую сторону), а соответствующий коммутатор NVSwitch 7.2T позволяет объединить до 576 ускорителей в одном домене. SHARP-движки с поддержкой FP8 дополнительно помогут ускорить обработку моделей, избавив ускорители от части работ по предобработке и трансформации данных. Чип коммутатора тоже изготавливается по техпроцессу TSMC N4P и содержит 50 млрд транзисторов.  Для дальнейшего масштабирования и формирования кластеров из 10 тыс. ускорителей и более, вплоть до 100 тыс. ускорителей на уровне ЦОД, NVIDIA предлагает 800G-коммутаторы Quantum-X800 InfiniBand XDR и Spectrum-X800 Ethernet, имеющие соответственно 144 и 64 порта. Узлам же полагаются DPU ConnectX-8 SuperNIC и BlueField-3. Правда, последний предлагает только 400G-порты в отличие от первого. От InfiniBand компания отказываться не собирается.  С базовыми кирпичиками разобрались, пора переходить к конструированию продуктов. Первым идёт HGX B100, в основе которой всё та же базовая плата с восемью ускорителями Blackwell, точно так же провязанных между собой NVLink 5 с агрегированной скоростью 14,4 Тбайт/с. Для связи с внешним миром предлагается пара интерфейсов PCIe 6.0 x16. HGX B100 предназначена для простой замены HGX H100, поэтому ускорители имеют TDP не более 700 Вт, что ограничивает пиковую производительность в разреженных FP4- и FP8/FP6/INT8-вычислениях до 14 и 7 Пфлопс соответственно, а для всей системы — 112 и 56 Пфлопс соответственно. 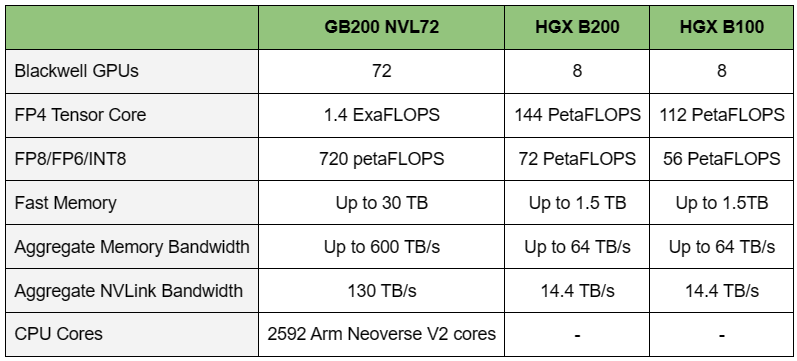 У HGX B200 показатель TDP ограничен уже 1 кВт, причём возможность воздушного охлаждения по-прежнему сохраняется. Производительность одного B200 в разреженных FP4- и FP8/FP6/INT8-вычислениях достигает уже 18 и 9 Пфлопс, а для всей системы — 144 и 72 Пфлопс соответственно. DGX B200 повторяет HGX B200 в плане производительности и является готовой системой от NVIDIA, тоже с воздушным охлаждением. В системе используются два чипа Intel Xeon Emerald Rapids. По словам NVIDIA, DGX B200 до 15 раз быстрее в задачах инференса «триллионных» моделей по сравнению с DGX-узлами прошлого поколения. 800G-интерконнект Ethernet/InfiniBand этим трём платформам не достался, только 400G.  Основным же строительным блоком сама компания явно считает гибридный суперчип GB200, объединяющий уже имеющийся у неё Arm-процессор Grace сразу с двумя ускорителями Blackwell B200. CPU-часть включает 72 ядра Neoverse V2 (по 64 Кбайт L1-кеша для данных и инструкций, L2-кеш 1 Мбайт), 144 Мбайт L3-кеша и до 480 Гбайт LPDDR5x-памяти с ПСП до 512 Гбайт/с. С двумя B200 процессор связан 900-Гбайт/с шиной NVLink-C2C — по 450 Гбайт/с на каждый ускоритель. Между собой B200 напрямую подключены уже по полноценной 1,8-Тбайт/с шине NVLink 5.  Вся эта немаленькая конструкция шириной в половину стойки имеет TDP до 2,7 кВт. 1U-узел с парой чипов GB200, каждый из которых может отъедать до 1,2 кВт, уже требует жидкостное охлаждение. FP4- и FP8/FP6/INT8-производительность (речь всё ещё о разреженных вычислениях) GB200 достигает 40 и 20 Пфлопс. И именно эти цифры NVIDIA нередко использует для сравнения новинок со старыми решениями.  18 узлов с парой GB200 (суммарно 72 шт.) и 9 узлов с парой коммутаторов NVSwitch 7.2T, которые провязывают все ускорители по схеме каждый-с-каждым (агрегированно 130 Тбайт/с, более 3 км соединений), формируют 120-кВт суперускоритель GB200 NVL72 размером со стойку (Oberon), оснащённый СЖО и единой DC-шиной питания. Всё это даёт до 1,44 Эфлопс в FP4-вычислениях и до 720 Пфлопс в FP8, а также до 13,5 Тбайт HBM3e с агрегированной ПСП до 576 Тбайт/с. Ну а общий объём памяти составляет порядка 30 Тбайт. GB200 NVL72 одновременно является и узлом DGX GB200. Восемь DGX GB200 формируют DGX SuperPOD. Впрочем, будет доступен и SuperPOD попроще, на базе DGX B200.  Ускорители B200 появятся в этом году и будут стоить в диапазоне $30–$40 тыс., что ненамного больше начальной цены Hopper в диапазоне $25–$40 тыс. Глава NVIDIA уже предупредил, что Blackwell сразу будут в дефиците. Вероятно, получить доступ к ним проще всего будет в облаках Amazon, Google, Microsoft и Oracle.
23.12.2023 [02:11], Владимир Мироненко
В Испании официально запустили 314-Пфлопс суперкомпьютер MareNostrum 5, который вскоре объединится с двумя квантовыми компьютерами21 декабря в Суперкомпьютерном центре Барселоны — Centro Nacional de Supercomputación (BSC-CNS) — в торжественной обстановке официально запустили европейский суперкомпьютер MareNostrum 5 производительностью 314 Пфлопс. В церемонии, посвящённой машине, созданной в рамках проекта European High Performance Computing Joint Undertaking (EuroHPC JU), принял участие председатель правительства Испании. MareNostrum 5 представляет собой крупнейшую инвестицию, когда-либо сделанную Европой в научную инфраструктуру Испании — суммарно €202 млн, из которых €151,4 млн ушло на приобретение суперкомпьютера. Финансирование было проведено EuroHPC JU через Фонд ЕС «Соединение Европы» и программу исследований и инноваций «Горизонт 2020», а также государствами-участниками: Испанией (через Министерство науки, инноваций и университетов и правительство Каталонии), Турцией и Португалией. С запуском MareNostrum 5 заметно укрепились позиции BSC в качестве одного из ведущих суперкомпьютерных центров мира с более чем 900 сотрудниками, занимающимися исследования в области информатики, наук о жизни и о Земле, а также вычислительных систем для науки и техники. Обладая максимальной общей производительностью 314 Пфлопс, MareNostrum 5 присоединяется к двум другим системам EuroHPC: Lumi (Финляндия) и Leonardo (Италия), тоже являющихся суперкомпьютерами предэкзафлопсного класса, единственными системами такого уровня в Европе. 
Источник изображений: BSC Eviden (Atos) была выбрана в качестве основного поставщика, но в создании машины приняли участие Lenovo, IBM, Intel и NVIDIA, а также Partec. Как отмечено в пресс-релизе, уникальная архитектура MareNostrum 5 была создана для того, чтобы предоставить исследователям лучшие из доступных технологий. Это гетерогенная машина, сочетающая в себе две отдельные системы: раздел общего назначения (GPP), предназначенный для классических вычислений, и GPU-раздел (ACC), ориентированный на ИИ. Обе системы по отдельности входят в первую двадцатку TOP500, занимая 19-е и 8-е места соответственно. Раздел общего назначения (GPP) является крупнейшим в мире x86-кластером на базе Intel Xeon Sapphire Rapids. Эта часть суперкомпьютера имеет пиковую производительность 45,9 Пфлопс. Система, произведённая Lenovo, специально разработана для решения сложных научных задач с разделением ресурсов, что обеспечивает большую гибкость и повышает эффективность системы, поскольку разные пользователи или проекты могут использовать её одновременно. GPP имеет 6408 стандарных узлов следующей конфигурации:
Дополнительно система имеет 72 узла с двумя 56-ядерными Xeon Max (1,7 ГГц) и набортной памятью HBM2e объёмом 128 Гбайт.  GPU-раздел (ACC) производства Eviden является третьим по мощности в Европе и восьмым в мире по версии TOP500, с пиковой производительностью 260 Пфлопс. Он основан на 4480 ускорителях NVIDIA H100. Раздел имеет 1120 узлов, каждый из которых включает:
Общая ёмкость хранилища MareNostrum 5 составляет 650 Пбайт, из которых, 402 Пбайт приходятся на LTO, 248 Пбайт — на HDD, а остальное — на NVMe SSD. Задействована ФС IBM Spectrum Scale. Машина использует интерконнект InfiniBand NDR200, объединяющий более 8000 узлов. Можно заметить, что NVIDIA предоставила BSC не совсем стандартные решения. В будущем ожидается появление ещё одного GPP-раздела на базе NVIDIA Grace, а вот расширение ACC узлами с Xeon Emerald Rapids и Rialto Bridge не состоится. 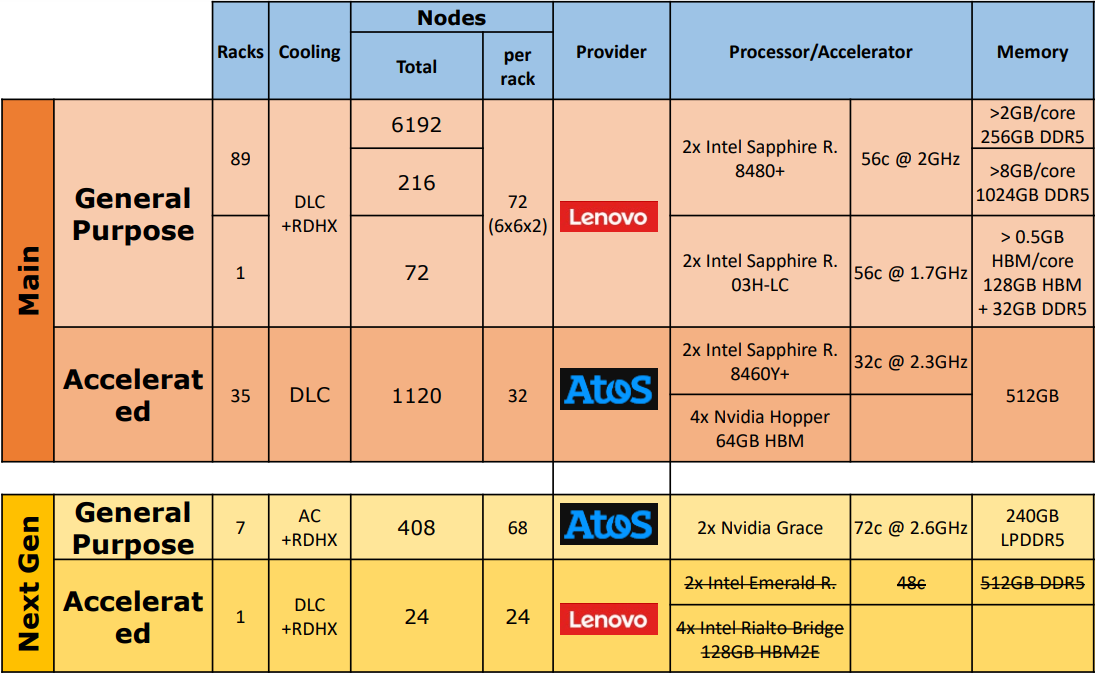 Благодаря увеличенной вычислительной мощности MareNostrum 5 позволяет решать всё более сложные задачи. Например, климатические модели получат более высокое разрешение, что сделает прогнозы гораздо более точными и надёжными. Также появится возможность решать гораздо более сложные проблемы в области ИИ и Big Data. Отдельное внимание уделено поддержке европейских медицинских исследований в области создания новых лекарств, разработки вакцин и моделирования распространения вирусов. Суперкомпьютер также станет важнейшим инструментом для материаловедения и инженерии, включая проектирование и оптимизацию самолётов, развитие более безопасной, экологически чистой и эффективной авиации. Аналогичным образом, машина будет использоваться для моделирования процессов энергогенерации, включая ядерный синтез. В ближайшие месяцы MareNostrum 5 объединится с двумя квантовыми компьютерами: первой системой испанской суперкомпьютерной сети (RES), которая является частью инициативы Quantum Spain, и одним из первых европейских квантовых компьютеров EuroHPC JU. Оба квантовых компьютера будут одними из первых, которых запустили в Южной Европе.
22.11.2023 [11:18], Сергей Карасёв
NVIDIA представила сетевой ускоритель SuperNIC для ИИ-нагрузокКомпания NVIDIA анонсировала аппаратное решение SuperNIC — это сетевой ускоритель нового типа, предназначенный для масштабных рабочих нагрузок ИИ в системах на базе Ethernet. Устройство обеспечивает скорость передачи данных до 400 Гбит/с с использованием RDMA (RoCE). Новинка выполнена на основе DPU BlueField-3: это часть сетевой 400G/800G-платформы Spectrum-X, которая предусматривает использование коммутаторов на базе ASIC NVIDIA Spectrum-4 (51,2 Тбит/с). Отмечается, что сообща BlueField-3 SuperNIC и Spectrum-4 составляют основу вычислительной системы, специально разработанной для ускорения ИИ-нагрузок. При этом платформа Spectrum-X обеспечивает высокую эффективность сети, превосходя по производительности традиционные среды Ethernet. По заявления NVIDIA, DPU предоставляет множество расширенных функций, таких как высокая пропускная способность, подключение с небольшой задержкой и пр. 
Источник изображения: NVIDIA Среди ключевых особенностей SuperNIC называются: высокоскоростное переупорядочение пакетов; расширенный контроль перегрузок с использованием данных в реальном времени и специализированных сетевых алгоритмов; возможность программирования ввода-вывода (I/O); энергоэффективный низкопрофильный дизайн; полная оптимизация для ИИ (включая вычисления, сети, хранилище, системное ПО, коммуникационные библиотеки). В одной системе могут быть задействованы до восьми SuperNIC, что позволяет добиться соотношения 1:1 с GPU. А это даёт возможность максимизировать производительность при выполнении сложных задач ИИ.
13.11.2023 [17:00], Игорь Осколков
NVIDIA анонсировала ускорители H200 и «фантастическую четвёрку» Quad GH200NVIDIA анонсировала ускорители H200 на базе всё той же архитектуры Hopper, что и их предшественники H100, представленные более полутора лет назад. Новый H200, по словам компании, первый в мире ускоритель, использующий память HBM3e. Вытеснит ли он H100 или останется промежуточным звеном эволюции решений NVIDIA, покажет время — H200 станет доступен во II квартале следующего года, но также в 2024-м должно появиться новое поколение ускорителей B100, которые будут производительнее H100 и H200. 
HGX H200 (Источник здесь и далее: NVIDIA) H200 получил 141 Гбайт памяти HBM3e с суммарной пропускной способностью 4,8 Тбайт/с. У H100 было 80 Гбайт HBM3, а ПСП составляла 3,35 Тбайт/с. Гибридные ускорители GH200, в состав которых входит H200, получат до 480 Гбайт LPDDR5x (512 Гбайт/с) и 144 Гбайт HBM3e (4,9 Тбайт/с). Впрочем, с GH200 есть некоторая неразбериха, поскольку в одном месте NVIDIA говорит о 141 Гбайт, а в другом — о 144 Гбайт HBM3e. Обновлённая версия GH200 станет массово доступна после выхода H200, а пока что NVIDIA будет поставлять оригинальный 96-Гбайт вариант с HBM3. Напомним, что грядущие конкурирующие AMD Instinct MI300X получат 192 Гбайт памяти HBM3 с ПСП 5,2 Тбайт/с.  На момент написания материала NVIDIA не раскрыла полные характеристики H200, но судя по всему, вычислительная часть H200 осталась такой же или почти такой же, как у H100. NVIDIA приводит FP8-производительность HGX-платформы с восемью ускорителями (есть и вариант с четырьмя), которая составляет 32 Пфлопс. То есть на каждый H200 приходится 4 Пфлопс, ровно столько же выдавал и H100. Тем не менее, польза от более быстрой и ёмкой памяти есть — в задачах инференса можно получить прирост в 1,6–1,9 раза.  При этом платы HGX H200 полностью совместимы с уже имеющимися на рынке платформами HGX H100 как механически, так и с точки зрения питания и теплоотвода. Это позволит очень быстро обновить предложения партнёрам компании: ASRock Rack, ASUS, Dell, Eviden, GIGABYTE, HPE, Lenovo, QCT, Supermicro, Wistron и Wiwynn. H200 также станут доступны в облаках. Первыми их получат AWS, Google Cloud Platform, Oracle Cloud, CoreWeave, Lambda и Vultr. Примечательно, что в списке нет Microsoft Azure, которая, похоже, уже страдает от недостатка H100.  GH200 уже доступны избранным в облаках Lamba Labs и Vultr, а в начале 2024 года они появятся у CoreWeave. До конца этого года поставки серверов с GH200 начнут ASRock Rack, ASUS, GIGABYTE и Ingrasys. В скором времени эти чипы также появятся в сервисе NVIDIA Launchpad, а вот про доступность там H200 компания пока ничего не говорит.  Одновременно NVIDIA представила и базовый «строительный блок» для суперкомпьютеров ближайшего будущего — плату Quad GH200 с четырьмя чипами GH200, где все ускорители связаны друг с другом посредством NVLink по схеме каждый-с-каждым. Суммарно плата несёт более 2 Тбайт памяти, 288 Arm-ядер и имеет FP8-производительность 16 Пфлопс. На базе Quad GH200 созданы узлы HPE Cray EX254n и Eviden Bull Sequana XH3000. До конца 2024 года суммарная ИИ-производительность систем с GH200, по оценкам NVIDIA, достигнет 200 Эфлопс.
09.11.2023 [16:15], Сергей Карасёв
NVIDIA готовит для Китая три новых ускорителя взамен подпавших под санкции: H20, L20 и L2Компания NVIDIA, по сообщению Reuters, планирует выпустить три новых ИИ-ускорителя, модифицированных специально для Китая с учётом дополнительных санкций со стороны США. Изделия фигурируют под обозначениями HGX H20 (SXM), L20 (PCIe) и L2 (PCIe), а их официальная презентация состоится не раньше 16 ноября. Напомним, в середине октября 2023 года США ввели новые ограничения на поставку передовых чипов NVIDIA в Китай: они затронули решения A800 и H800 — модифицированные версии A100 и H100, созданные специально для рынка КНР с учетом ранее действовавших американских ограничений. После этого NVIDIA пришлось искать новые регионы сбыта для «урезанных» ускорителей, предназначавшихся для Поднебесной. Как теперь сообщается, NVIDIA снова нашла возможность поставлять ускорители на китайский рынок, который потенциально может обеспечить значительную выручку. Решения H20, L20 и L2 не подпадают ни под одно из действующих экспортных ограничений. Обратной стороной медали является то, что производительность у них серьёзно снижена (см. характеристики в таблице выше), передаёт SemiAnalysis. 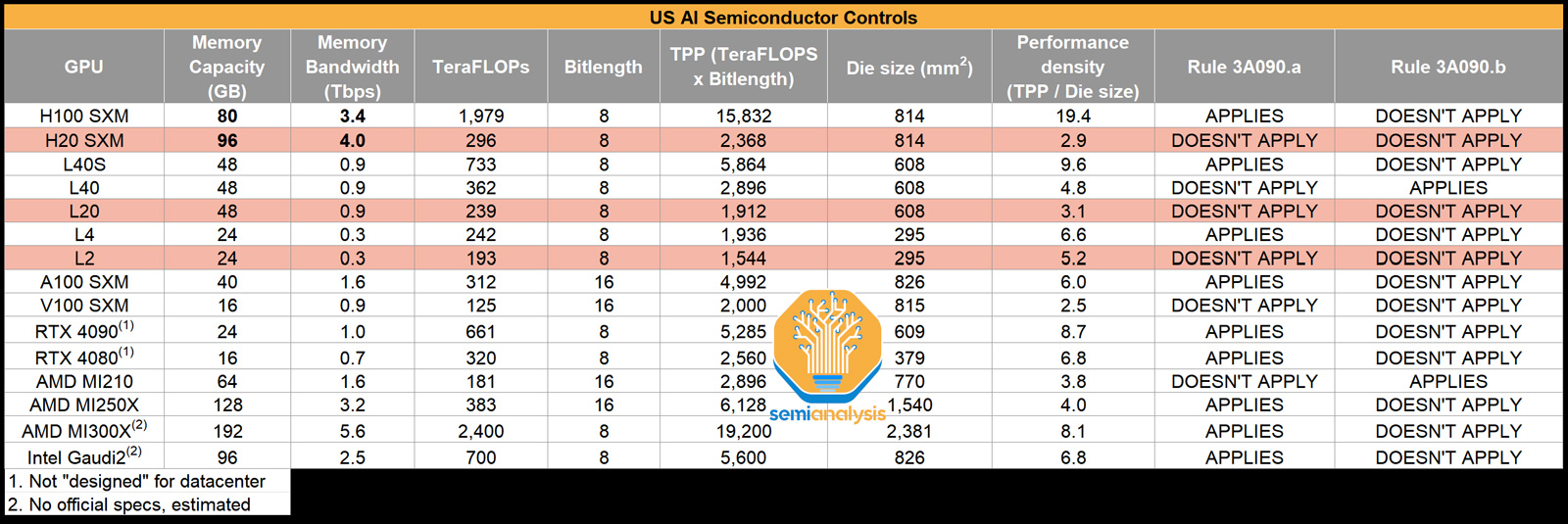
Источник: SemiAnalysis Отмечается, что у NVIDIA уже готовы образцы новых ускорителей для китайского рынка, а их массовое производство будет организовано в течение следующего месяца. Сама компания какие-либо комментарии по поводу обнародованной в интернете информации не даёт.
04.10.2023 [14:59], Сергей Карасёв
Без гиперскейлеров: NVIDIA хочет арендовать ЦОД для облачного сервиса DGX CloudКомпания NVIDIA, по сообщению ресурса The Information, ведёт переговоры об аренде площадей у одного из операторов ЦОД, но о ком именно идёт речь, не сообщается. Предполагается, что площадка будет использоваться для поддержания работы собственного облачного сервиса DGX Cloud, предназначенного для обучения передовых моделей для генеративного ИИ. О доступности облака DGX Cloud компания NVIDIA объявила в июле нынешнего года. Тогда сообщалось, что соответствующая вычислительная инфраструктура достанется в первую очередь США и Великобритании. Стоимость доступа к DGX Cloud начинается с $36 999 в месяц. Говорилось, что NVIDIA намерена продвигать DGX Cloud в партнёрстве с ведущими гиперскейлерами. Первым сервис появился в облаке Oracle Cloud Infrastructure (OCI), на очереди Microsoft Azure, Google Cloud Platform и другие. Большая часть выручки в этом случае достаётся именно NVIDIA, а не облакам. 
Источник изображения: NVIDIA Теперь же, судя по всему, NVIDIA решила частично отказаться от услуг облачных провайдеров и развернуть DGX Cloud на арендованных ЦОД-площадях. Впрочем, как отмечается, переговоры всё ещё находятся на начальной стадии, а поэтому говорить о том, что NVIDIA сама превратится в гиперскейлера, преждевременно. При этом компания неоднократно упрекали в том, что в последнее время она более благосклонна к небольшим и специализированным облачным провайдерам, которые не пытаются создавать собственные ИИ-ускорители, могущие составить прямую конкуренцию продуктам NVIDIA.
09.08.2023 [18:00], Алексей Степин
NVIDIA анонсировала L40S — новый универсальный ускоритель на базе Ada LovelaceКорпорация NVIDIA обновила серию укорителей L40, представленных осенью прошлого года в рамках платформы OVX. Новинка под названием NVIDIA L40S позиционируется как универсальный ускоритель в форм-факторе двухслотовой FHFL-карты расширения с интерфейсом PCIe 4.0 x16, пригодный для решения практически любых задач. Во многом L40S повторяет L40 — она также базируется на архитектуре Ada Lovelace, оснащена графическим процессором AD102, дополненным 48 Гбайт памяти GDDR6 ECC (384 бит, 864 Гбайт/с). В составе ускорителя работают 18176 ядер CUDA, 142 RT-ядра третьего поколения и 568 тензорных ядер четвёртого поколения. То есть в этом отличий от L40 нет. Но значение TDP у новинки выше на 50 Вт и составляет 350 Вт, она все ещё имеет пассивное охлаждение. 
Источник изображений здесь и далее: NVIDIA При этом L40S умудряется быть практически вдвое быстрее L40 во всех форматах вычислений с использованием тензорных ядер, а вот без Tensor Core её FP32-производительность выросла минимально — с 90,5 до 91,6 Тфлопс. Поддержкой NVLink-мостика новинка так и не обзавелась. L40S оснащён четырьмя портами DP 1.4a с поддержкой NVIDIA Mosaic и Quadro Sync. Также доступны профили vGPU для vDWS, GRID vApps/vPC, vCS. Имеется поддержка Secure Boot с Root of Trust и соответствие стандарту NEBS Level 3.  Таким образом, новинка подходит не только в качестве ускорителя для обучения ИИ-моделей или инференс-систем, но и в качестве основы для систем рендеринга 3D-графики, визуализации или создания и запуска приложений для мета✴-вселенных. NVIDIA отмечает, что в ИИ-задачах L40S опережает A100 в 1,2–1,7 раза, а наличие трёх движков NVENC/NVDEC с поддержкой AV1 позволяет использовать новый ускоритель в качестве эффективной платформы транскодирования видео.
31.05.2023 [14:23], Сергей Карасёв
Supermicro представила MGX-сервер ARS-221GL-NR с суперчипами NVIDIA GraceКомпания Supermicro официально анонсировала сервер ARS-221GL-NR, построенный на новейшей модульной архитектуре NVIDIA MGX. Решение ориентировано на корпоративных заказчиков, реализующих проекты в области НРС, ИИ, метавселенных и пр. Сервер выполнен в форм-факторе 2U с габаритами 438,4 × 900 × 88 мм. Применена материнская плата Super G1SMH для процессоров NVIDIA Grace CPU Superchip, насчитывающих 144 ядра Arm. Возможна установка до четырёх ускорителей NVIDIA H100. 
Источник изображения: Supermicro Система несёт на борту до 480 Гбайт памяти LPDDR5X-4800. В комплектацию может быть включён адаптер 10GbE NVIDIA ConnectX-7 или Bluefield-3 DPU. Предусмотрены 16 отсеков для накопителей E1.S NVMe с возможностью горячей замены.  В общей сложности есть семь слотов расширения PCIe 5.0 x16 FHFL. Упомянут аналоговый интерфейс D-Sub. Питание обеспечивают блоки мощностью 3000 Вт с сертификатом 80 PLUS Titanium. Диапазон рабочих температур — от +10 до +35 °C. Сервер оборудован системой воздушного охлаждения с шестью вентиляторами, рассчитанными на продолжительную работу под высокими нагрузками.  Компания Supermicro также сообщила о намерении применять в своих продуктах Ethernet-платформу NVIDIA Spectrum-X. Она обеспечивает возможность обслуживания до 256 портов 200GbE (или 64 × 800GbE, или 128 × 400GbE) одним коммутатором.
29.05.2023 [07:30], Сергей Карасёв
NVIDIA представила 1-Эфлопс ИИ-суперкомпьютер DGX GH200: 256 суперчипов Grace Hopper и 144 Тбайт памятиКомпания NVIDIA анонсировала вычислительную платформу нового типа DGX GH200 AI Supercomputer для генеративного ИИ, обработки огромных массивов данных и рекомендательных систем. HPC-платформа станет доступна корпоративным заказчикам и организациям в конце 2023 года. Платформа представляет собой готовый ПАК и включает, в частности, наборы ПО NVIDIA AI Enterprise и Base Command. Для платформы предусмотрено использование 256 суперчипов NVIDIA GH200 Grace Hopper, объединённых при помощи NVLink Switch System. Каждый суперчип содержит в одном модуле Arm-процессор NVIDIA Grace и ускоритель NVIDIA H100. Задействован интерконнект NVLink-C2C (Chip-to-Chip), который, как заявляет NVIDIA, значительно быстрее и энергоэффективнее, нежели PCIe 5.0. В результате, скорость обмена данными между CPU и GPU возрастает семикратно, а затраты энергии сокращаются примерно в пять раз. Пропускная способность достигает 900 Гбайт/с. 
Источник изображений: NVIDIA Технология NVLink Switch позволяет всем ускорителям в составе системы функционировать в качестве единого целого. Таким образом обеспечивается производительность на уровне 1 Эфлопс (~ 9 Пфлопс FP64), а суммарный объём памяти достигает 144 Тбайт — это почти в 500 раз больше, чем в одной системе NVIDIA DGX A100. Архитектура DGX GH200 AI Supercomputer позволяет добиться 10-кратного увеличения общей пропускной способности по сравнению с HPC-платформой предыдущего поколения.  Ожидается, что Google Cloud, Meta✴ и Microsoft одними из первых получат доступ к суперкомпьютеру DGX GH200, чтобы оценить его возможности для генеративных рабочих нагрузок ИИ. В перспективе собственные проекты на базе DGX GH200 смогут реализовывать крупнейшие провайдеры облачных услуг и гиперскейлеры. Для собственных нужд NVIDIA до конца 2023 года построит суперкомпьютер Helios, который посредством Quantum-2 InfiniBand объединит сразу четыре DGX GH200.
29.05.2023 [07:30], Сергей Карасёв
NVIDIA представила модульную архитектуру MGX для создания ИИ-систем на базе CPU, GPU и DPUКомпания NVIDIA на выставке Computex 2023 представила архитектуру MGX, которая открывает перед разработчиками серверного оборудования новые возможности для построения HPC-систем, платформ для ИИ и метавселенных. Утверждается, что MGX закладывает основу для быстрого создания более 100 вариантов серверов при относительно небольших затратах. Концепция MGX предусматривает, что разработчики на первом этапе проектирования выбирают базовую системную архитектуру для своего шасси. Далее добавляются CPU, GPU и DPU в той или иной конфигурации для решения определённых задач. Таким образом, на базе MGX может быть построена серверная система для уникальных рабочих нагрузок в области наук о данных, больших языковых моделей (LLM), периферийных вычислений, обработки графики и видеоматериалов и пр. Говорится также, что благодаря гибридной конфигурации на одной машине могут выполняться задачи разных типов, например, и обучение ИИ-моделей, и поддержание работы ИИ-сервисов. 
Источник изображений: NVIDIA Одними из первых системы на архитектуре MGX выведут на рынок компании Supermicro и QCT. Первая предложит решение ARS-221GL-NR с NVIDIA Grace, а вторая — сервер S74G-2U на базе NVIDIA GH200 Grace Hopper. Эти платформы дебютируют в августе нынешнего года. Позднее появятся MGX-платформы ASRock Rack, ASUS, Gigabyte, Pegatron и других производителей.  Архитектура MGX совместима с нынешним и будущим оборудованием NVIDIA, включая H100, L40, L4, Grace, GH200 Grace Hopper, BlueField-3 DPU и ConnectX-7. Поддерживаются различные форм-факторы систем: 1U, 2U и 4U. Возможно применение воздушного и жидкостного охлаждения. |
|

