Материалы по тегу: nvidia
|
26.04.2023 [19:50], Сергей Карасёв
Meta✴ вынужденно пересмотрела архитектуру своих ЦОД из-за отказа от выпуска собственных ИИ-чипов в пользу ускорителей NVIDIAКомпания Meta✴, по сообщению Reuters, была вынуждена пересмотреть конфигурацию своих дата-центров из-за отставания от конкурентов в плане развития ИИ-платформ. Компания, в частности, решила отказаться от дальнейшего внедрения инференс-чипов собственной разработки. Отмечается, что до прошлого года Meta✴ применяла архитектуру, в которой традиционные CPU соседствуют с кастомизированными решениями. Однако выяснилось, что такой подход менее эффективен по сравнению с применением ускорителей (GPU). При этом ранее компания отказалась от ИИ-ускорителей Qualcomm, указав на недоработки ПО, которые, судя по всему, были устранены только недавно. А с Esperanto, вероятно, отношения у Meta✴ пока не сложились. Впрочем, теперь компании интересен генеративный ИИ, а не только рекомендательные системы, что накладывает иные требования к оборудованию. 
Источник изображения: Meta✴ В течение почти всего 2022 года Meta✴ активно инвестировала в развите инфраструктуры, однако в конце года стало известно, что она приостановила строительство целого ряда ЦОД, а затем пересмотрела расходы на дата-центры. Компания решила кардинально переосмыслить архитектуру своих ЦОД, сделав ставку на СЖО. Как теперь выясняется, связано это с тем, что Meta✴ отказалась от собственных ИИ-чипов в пользу ускорителей NVIDIA: объём заказов последних исчисляется «миллиардами долларов». Соответствующую платформу Grand Teton компания показала в конце прошлого года. 
Источник изображения: Meta✴ Но ускорители потребляют больше энергии и выделяют больше тепла, нежели CPU или узкоспециализированные ASIC. Кроме того, ускорители должны физически находиться довольно близко друг к другу, хотя с интерконнектом компания тоже уже экспериментирует. Всё это влияет на архитектуру ЦОД. Тем не менее, Meta✴ всё же разрабатывает некий секретный чип, который сгодится и для обучения ИИ-моделей, и для инференса. Ожидается, что это решение увидит свет в 2025 году. Пока что для обучения ИИ компания намерена использовать собственный ИИ-суперкомпьютер RSC и облачные кластеры Microsoft Azure. Похожий путь избрала Microsoft, решившая создать свой ИИ-чип, не отказываясь пока от ускорителей NVIDIA. The Information добавляет, что вице-президент Microsoft по разработке «кремния» Жан Буфархат (Jean Boufarhat) присоединится к Meta✴. Он возглавит команду Facebook✴ Agile Silicon Team (FAST), чтобы помочь компании в реализации проектов по созданию чипов. Ранее Meta✴ переманила из Intel руководителя разработки сетевых решений для дата-центров. У Google и Amazon уже есть свои ИИ-чипы для обучения и инференса.
22.03.2023 [20:32], Алексей Степин
Экспортный китайский вариант NVIDIA H100 получил модельный номер H800В связи с санкционными ограничениями некоторые разновидности сложных микроэлектронных чипов запрещено экспортировать в Китайскую Народную Республику. Однако производители находят выход. В частности, компания NVIDIA анонсировала экспортный вариант ускорителя H100, не нарушающий никаких санкций. Модельный номер у такого варианта изменён на H800. Введённые правительством США в 2022 году санкции сделали «невыездными» два наиболее продвинутых продукта NVIDIA: A100 и H100. Такие процессоры сегодня являются основой наиболее динамично развивающейся вычислительной отрасли — нейросетевой. Именно на кластерах из таких ускорителей «натаскивают» мощные нейросети вроде ChatGPT и подобных. 
Ускоритель Hopper H100 в SXM-исполнении. Источник изображений здесь и далее: NVIDIA Ещё осенью прошлого года NVIDIA анонсировала A800 — экспортный вариант A100, не попадающий под ограничения за счёт некоторого снижения пропускной способности NVLink, с 600 до 400 Гбайт/с. Сейчас пришло время архитектуры Hopper, которая запущена в массовое производство. По аналогии с флагманом Ampere модернизированный чип получил модельный номер H800. Ограничения в нём реализованы схожим образом: как известно, NVLink в H100 имеет производительность 900 Гбайт/с в базовом SXM-варианте. 
H100 также существует в PCIe-варианте Версия H800 использует примерно половину этого потенциала, что, впрочем, не делает её в Китае менее популярной: новинка уже используется китайскими облачными гигантами, такими, как Alibaba, Baidu и Tencent. Есть ли у H800 другие отличия от H100, не говорится — NVIDIA пока отказывается предоставлять такую информацию. Достоверно известно лишь то, что они полностью соответствуют всем санкционным ограничениям. Интересно, появится ли в будущем вариант H800 NVL на базе NVIDIA H100 NVL.
22.03.2023 [00:09], Алексей Степин
NVIDIA показала сдвоенный серверный суперпроцессор Grace SuperchipПроект NVIDIA Grace весьма амбициозен: компания всерьёз намерена ворваться с его помощью на рынок высокопроизводительных серверных процессоров, где всё ещё доминируют решения Intel и AMD. Об этом чипе было объявлено ещё на конференции GTC 2022, а на GTC 2023 глава компании, наконец, показал его вживую. В рамках продолжающегося роста плотности упаковки вычислительных мощностей в современных ЦОД на первый план выдвинулась не голая производительность, а соотношение производительности к уровню энергопотребления и тепловыделения. По сочетанию этих параметров x86 далеко не оптимальна, и тут у NVIDIA есть все шансы. С анонсом Grace Superchip NVIDIA провозглашает (впрочем, уже не в первый раз) смерть «закона Мура» — пришло время оптимизации и отказа от устаревших, по мнению компании, вычислительных архитектур. 
Источник изображений здесь и далее: NVIDIA Процессор NVIDIA Grace воплощает в себе все современные тенденции, начиная с отказа от монолитного кристалла. Сборка Grace Superchip состоит из двух кристаллов, каждый из которых включает в себя 72 ядра Arm Neoverse V2 (Arm v9), поддерживающих векторные расширения SVE2 и оптимизированные для ИИ форматы BF16/INT8. Кристаллы соединены между собой шиной NVLink-C2C, обеспечивающей пропускную способность 900 Гбайт/с.  В сборку интегрированы чипы памяти LPDDR5x общим объёмом до 960 Гбайт, причём каждый кристалл имеет свою шину доступа к памяти с производительностью 500 Гбайт/с. При этом с точки зрения ПО Grace Superchip представляется единым 144-ядерным процессором с ПСП на уровне 1 Тбайт/с. 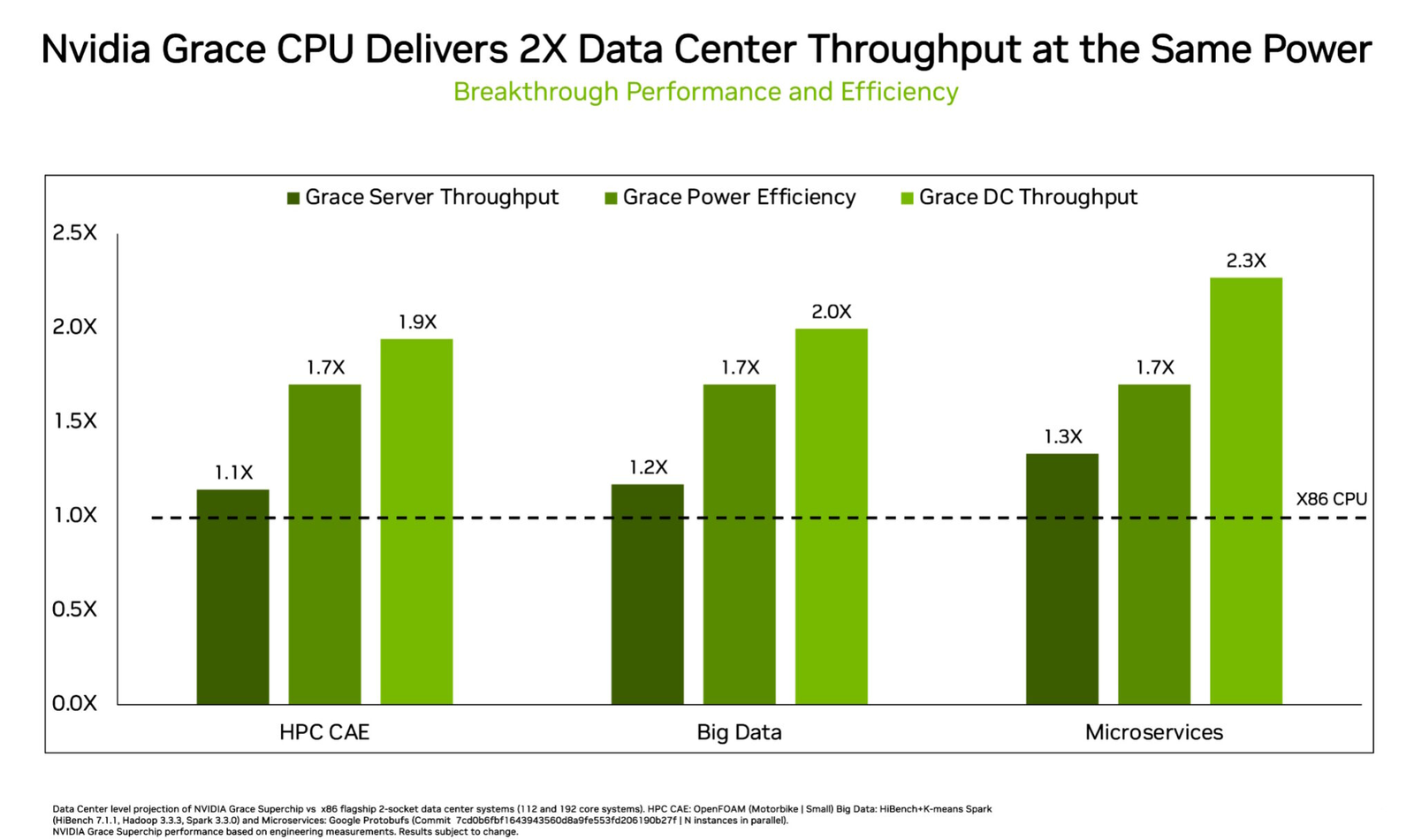 Для достижения схожих параметров в мире x86 требуется двухпроцессорная платформа AMD Genoa, куда более сложная технически и гораздо менее энергоэффективная, но при этом обладающая всеми недостатками NUMA-систем. Достаточно сравнить энергопотребление: 900 Вт против 500 у нового решения NVIDIA. 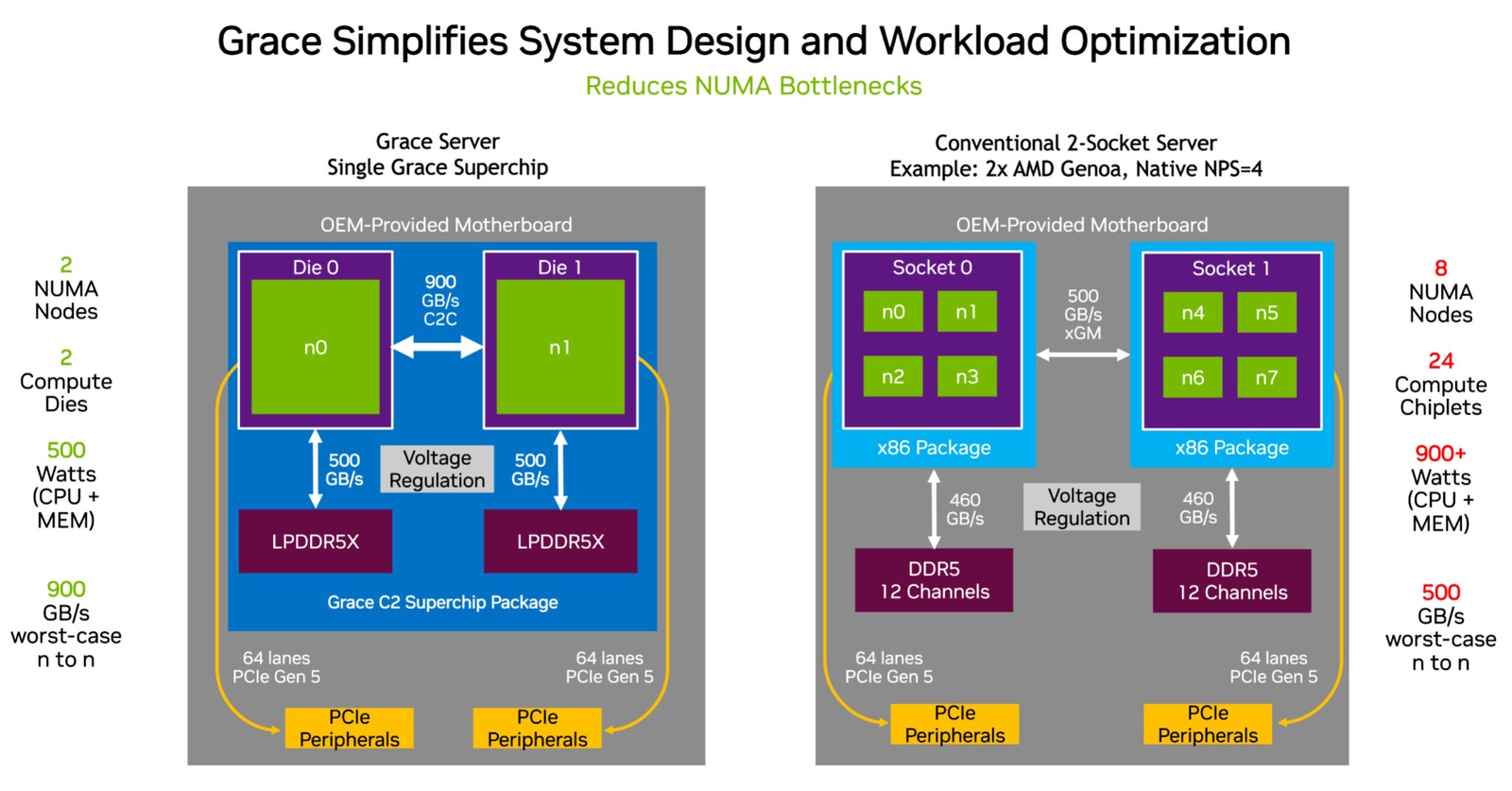 NVIDIA есть чем гордиться: при сопоставимом уровне энергопотребления Grace Superchip превосходит своих конкурентов из мира x86 в 2,3 раза при запуске микросервисов, вдвое опережает их в приложениях с интенсивным обменом данными с памятью и почти вдвое — в задачах симуляции вычислительной гидродинамики. В ряде других научно-технических задач преимущество может быть и более чем двукратным. 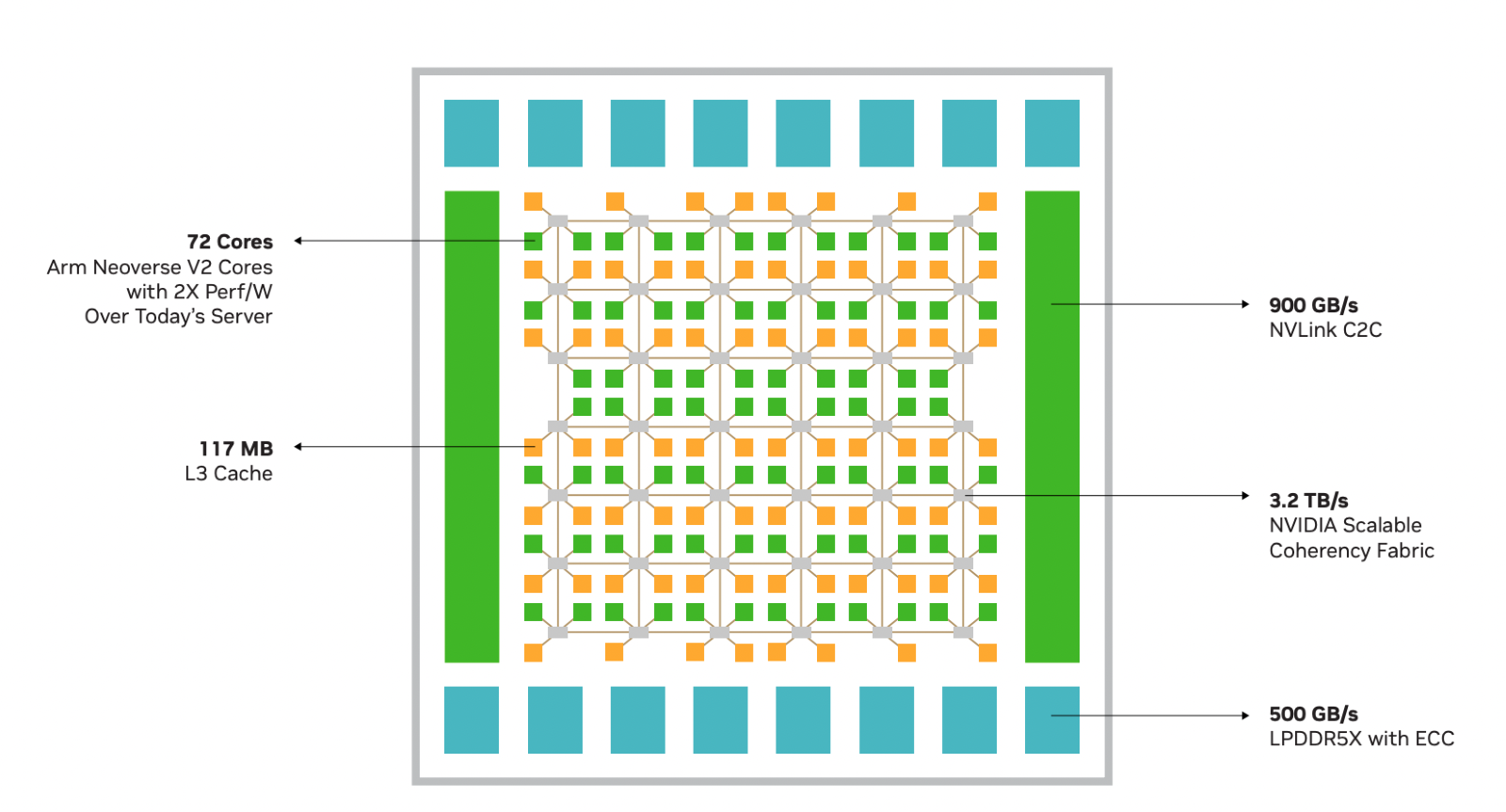 Это достигнуто в том числе благодаря изначальной оптимизации дизайна процессора с упором на максимальную производительность передачи данных. Внутренне Grace организован по принципу меш-сети с распределённой системой кеширования на базе специальных узлов коммутации CSN (Cache Switch Nodes). Называется эта сеть Scalable Coherency Fabric, она имеет пропускную способность 3,2 Тбайт/с, а объём кеша L3 составляет 117 Мбайт на кристалл и 234 Мбайт совокупно.  Сервер на базе NVIDIA Grace не только может потреблять меньше энергии, но и будет существенно проще конструктивно, поскольку модуль Grace Superchip содержит не только процессорные ядра и память, но также и регуляторы напряжения. От платформы на базе нового процессора требуется только PCIe 5.0 — у нового чипа есть два набора по 64 линии. Причём линии с поддержкой CXL 2.0, так что проблем с расширением доступного объёма памяти новинка испытывать не будет.  Даже компактные серверы высотой 1U смогут вместить две сборки Grace Superchip, что даст 288 ядер и почти 2 Тбайт оперативной памяти — труднодостижимый в таких габаритах показтель для более традиционных конструктивов процессоров и системных плат. Сравнительно невысокий теплопакет позволит таким решениям обходиться традиционным воздушным охлаждением.  При этом есть и вариант Grace Hopper, сочетающий в одном модуле кристалл Grace и новейший GPU H100, причём параметрами PCI Express последний ограничен не будет благодаря NVLink-C2C. NVIDIA уже начала первичные поставки Grace, а начало полномасштабного производства ожидается во второй половине года. Новыми процессорами заинтересовались крупные производители оборудования, включая ASUS, Atos, GIGABYTE, HPE, QCT, Supermicro, Wistron и ZT Systems.  Лос-Аламосская национальная лаборатория объявила, что использует NVIDIA Grace в новом суперкомпьютере Venado, который поможет учёным в исследованиях новых материалов и возобновляемых источников энергии. Ряд крупных европейских и азиатских ЦОД также рассматривает перспективы применения новых процессоров NVIDIA. В частности, одной из систем на базе Grace станет кластер Alps в Швейцарском национальном компьютерном центре.
21.03.2023 [20:45], Владимир Мироненко
NVIDIA запустила облачный сервис DGX Cloud — доступ к ИИ-супервычислениям прямо в браузереNVIDIA запустила сервис ИИ-супервычислений DGX Cloud, предоставляющий предприятиям доступ к инфраструктуре и программному обеспечению, необходимым для обучения передовых моделей для генеративного ИИ и других приложений. DGX Cloud предлагает выделенные ИИ-кластеры NVIDIA DGX в сочетании с фирменным набором ПО NVIDIA. С его помощью предприятие сможет получить доступ к облачному ИИ-суперкомпьютеру, используя веб-браузер и без надобности в приобретении, развёртывании и управлении собственной HPC-инфраструктурой. Правда, удовольствие это всё равно не из дешёвых — стоимость инстансов DGX Cloud начинается от $36 999/мес., причём деньги получает в первую очередь сама NVIDIA. Для сравнения — полностью укомплектованная система DGX A100 в Microsoft Azure обойдётся примерно в $20 тыс. Облачные кластеры DGX предлагаются предприятиям на условиях ежемесячной аренды, что гарантирует им возможность быстро масштабировать разработку больших рабочих нагрузок. «DGX Cloud предоставляет клиентам мгновенный доступ к супервычислениям NVIDIA AI в облаках глобального масштаба», — сообщил Дженсен Хуанг (Jensen Huang), основатель и генеральный директор NVIDIA. 
Источник изображения: NVIDIA Развёртыванием инфраструктуры DGX Cloud компания NVIDIA будет заниматься в сотрудничестве с ведущими поставщиками облачных услуг. Первым среди них стала платформа Oracle Cloud Infrastructure (OCI), предлагающая суперкластер (SuperCluster) с объединёнными RDMA-сетью (в том числе на базе BlueField-3 и Connect-X7) системами DGX (bare metal), которые дополняет высокопроизводительное локальное и блочное хранилище. Cуперкластер может включать до 32 768 ускорителей, но этот рекорд был поставлен с использованием DGX A100, а вот предложение DGX H100 пока что ограничено. В следующем квартале похожее решение появится в Microsoft Azure, а потом в Google Cloud и у других провайдеров. 
Источник изображения: NVIDIA Первыми пользователями DGX Cloud стали Amgen, одна из ведущих мировых биотехнологических компаний, лидер рынка страховых технологий CCC Intelligent Solutions (CCC) и провайдер цифровых бизнес-платформ ServiceNow. «Мощные вычислительные и многоузловые возможности DGX Cloud позволили нам в 3 раза ускорить обучение белковых LLM с помощью BioNeMo и до 100 раз ускорить анализ после обучения с помощью NVIDIA RAPIDS по сравнению с альтернативными платформами», — сообщил представитель Amgen. Для управления нагрузками в DGX Cloud предлагается NVIDIA Base Command. Также DGX Cloud включает в себя набор инструментов NVIDIA AI Enterprise для создания и запуска моделей, который предоставляет комплексные фреймворки и предварительно обученные модели для ускорения обработки данных и оптимизации разработки и развёртывания ИИ. DGX Cloud предоставляет поддержку экспертов NVIDIA на всех этапах разработки ИИ. Клиенты смогут напрямую работать со специалистами NVIDIA, чтобы оптимизировать свои модели и быстро решать задачи разработки с учётом сценариев отраслевого использования.
21.03.2023 [19:45], Игорь Осколков
Толстый и тонкий: NVIDIA представила самый маленький и самый большой ИИ-ускорители L4 и H100 NVLНа весенней конференции GTC 2023 компания NVIDIA представила два новых ИИ-ускорителя, ориентированных на инференес: неприличной большой H100 NVL, фактически являющийся парой обновлённых ускорителей H100 в формате PCIe-карты, и крошечный L4, идущий на смену T4. 
Изображения: NVIDIA NVIDIA H100 NVL действительно выглядит как пара H100, соединённых мостиками NVLink. Более того, с точки зрения ОС они выглядят как пара независимых ускорителей, однако ПО воспринимает их как единое целое, а обмен данными между двумя картам идёт в первую очередь по мостикам NVLink (600 Гбайт/с). Новинка создана в первую очередь для исполнения больших языковых ИИ-моделей, в том числе семейства GPT, а не для их обучения. 
NVIDIA H100 NVL Однако аппаратно это всё же не просто пара обычных H100 PCIe. По уровню заявленной производительности NVL-вариант вдвое быстрее одиночного ускорителя H100 SXM, а не PCIe — 3958 и 7916 Тфлопс в разреженных (в обычных показатели вдвое меньше) FP16- и FP8-вычислениях на тензорных ядрах соответственно, что в 2,6 раз больше, чем у H100 PCIe. Кроме того, NVL-вариант получил сразу 188 Гбайт HBM3-памяти с суммарной пропускной способностью 7,8 Тбайт/с. 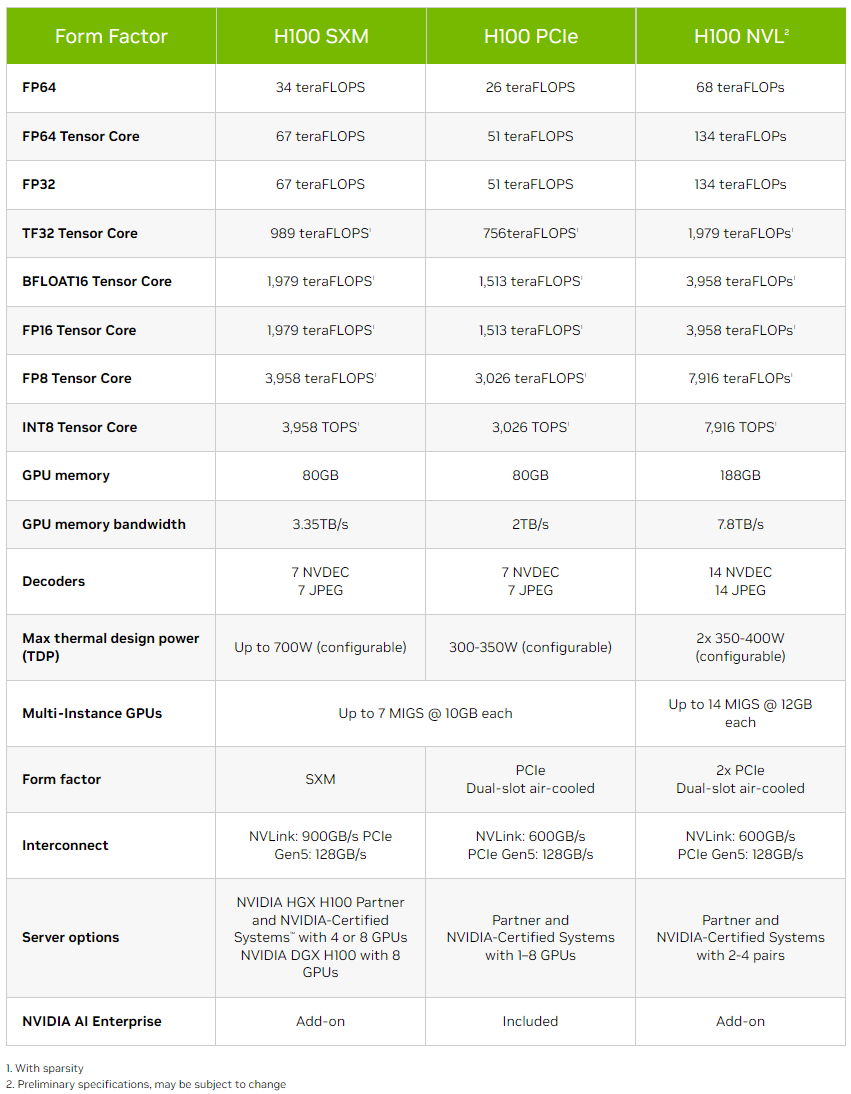 NVIDIA утверждает, что форм-фактор H100 NVL позволит задействовать новинку большему числу пользователей, хотя четыре слота и TDP до 800 Вт подойдут далеко не каждой платформе. NVIDIA H100 NVL станет доступна во второй половине текущего года. А вот ещё одну новинку, NVIDIA L4 на базе Ada, в ближайшее время можно будет опробовать в облаке Google Cloud Platform, которое первым получило этот ускоритель. Кроме того, он же будет доступен в рамках платформы NVIDIA Launchpad, да и ключевые OEM-производители тоже взяли его на вооружение. 
NVIDIA L4 Сама NVIDIA называет L4 поистине универсальным серверным ускорителем начального уровня. Он вчетверо производительнее NVIDIA T4 с точки зрения графики и в 2,7 раз — с точки зрения инференса. Маркетинговые упражнения компании при сравнении L4 с CPU оставим в стороне, но отметим, что новинка получила новые аппаратные ускорители (де-)кодирования видео и возможность обработки 130 AV1-потоков 720p30 для мобильных устройств. С L4 возможны различные сценарии обработки видео, включая замену фона, AR/VR, транскрипцию аудио и т.д. При этом ускорителю не требуется дополнительное питание, а сам он выполнен в виде HHHL-карты. 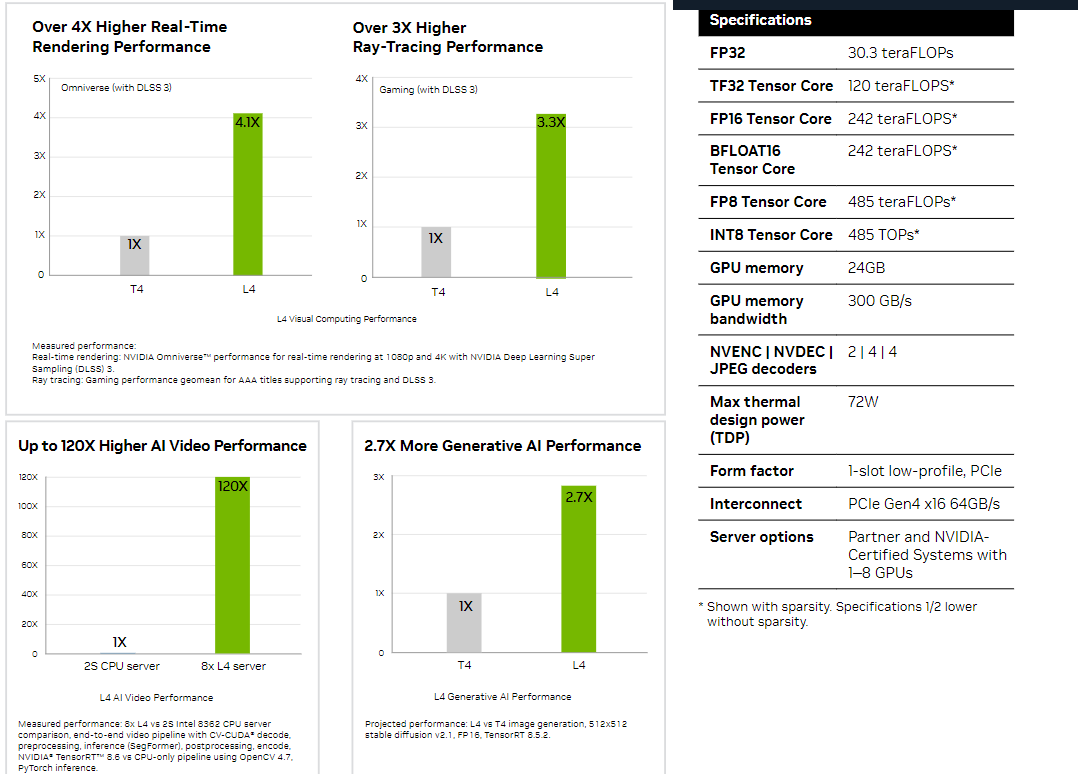
21.03.2023 [19:15], Сергей Карасёв
NVIDIA представила систему DGX Quantum для гибридных квантово-классических вычисленийКомпания NVIDIA в партнёрстве с Quantum Machines анонсировала DGX Quantum — первую систему, объединяющую GPU и квантовые вычисления. Решение использует новую открытую программную платформу CUDA Quantum. Утверждается, что система предоставляет революционно архитектуру для исследователей, работающими с гибридными вычислениями с низкой задержкой. NVIDIA DGX Quantum объединяет средства ускоренных вычислений на базе Grace Hopper (Arm-процессор + ускоритель H100), модели программирования с открытым исходным кодом CUDA Quantum и передовую квантовую управляющую платформу Quantum Machines OPX+. Такая комбинация позволяет создавать ресурсоёмкие приложения, сочетающие квантовые вычисления с современными классическими вычислениями. При этом в числе прочего обеспечивается работа гибридных алгоритмов и коррекция ошибок. 
Источник изображения: NVIDIA Представленное решение предполагает соединение Grace Hopper и Quantum Machines OPX+ посредством интерфейса PCIe. Это обеспечивает задержку менее микросекунды между ускорителем и блоками квантовой обработки (QPU). Отмечается, что OPX+ — это универсальная система квантового управления. Таким образом, можно максимизировать производительность QPU и предоставить разработчикам новые возможности при использовании квантовых алгоритмов. Системы Grace Hopper и OPX+ можно масштабировать в соответствии с потребностями — от QPU с несколькими кубитами до суперкомпьютера с квантовым ускорением. 
Источник изображения: NVIDIA О намерении интегрировать CUDA Quantum в свои платформы уже заявили компании по производству квантового оборудования Anyon Systems, Atom Computing, IonQ, ORCA Computing, Oxford Quantum Circuits и QuEra, разработчики ПО Agnostiq и QMware, а также некоторые суперкомпьютерные центры.
20.01.2023 [15:28], Алексей Степин
NVIDIA Grace Superchip получит 144 Arm-ядра, 960 Гбайт набортной памяти LPDDR5x и 128 линий PCIe 5.0, а TDP составит 500 ВтGrace можно назвать одним из самых амбициозных проектов NVIDIA. О намерении ворваться на рынок мощных серверных процессоров компания объявила ещё на GTC 2022, но до недавних пор о чипах Grace были доступны лишь общие сведения. Однако ситуация меняется. NVIDIA явно располагает рабочим «кремнием», и на днях опубликовала пару деталей о Grace Superchip. Ожидается, что официальный анонс новинки состоится в марте этого года на GTC 2023. Эта сборка включает в себя два 72-ядерных кристалла Grace, использующих ядра Arm Neoverse V2. Данное ядро использует набор инструкций Armv9, а также имеет четыре 128-битных блока векторных расширений SVE2, блоки для работы с матрицами и поддержку BF16/INT8. Объём кеша L1 составляет по 64 Кбайт для инструкций и данных, L2 — 1 Мбайт на ядро, а общий объём L3 на сборку достигает 234 Мбайт. 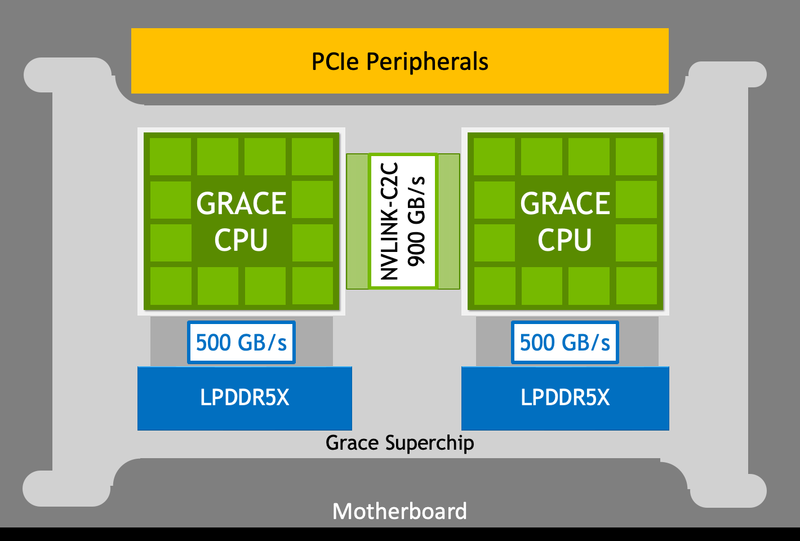
Блок-схема сборки Grace Superchip. Источник изображений здесь и далее: NVIDIA Между собой кристаллы соединены шиной NVLink C2C с пропускной способность 900 Гбайт/с, и работают они как единый 144-ядерный процессор. Но это ещё не всё: каждый из кристаллов соединен со своим банком памяти LPDDR5x ECC шиной с пропускной способностью 500 Гбайт/с (т.е. суммарно на чип получается 1 Тбайт/с). Совокупный объём памяти может достигать 960 Гбайт. 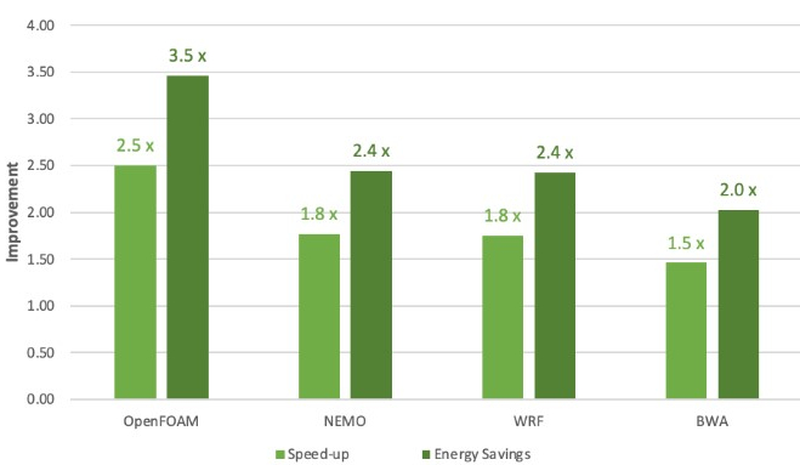
Сравнение производительности и энергоэффективности Grace Superchip с двумя AMD EPYC 7763 (Milan) Сборка Grace Superchip общается с внешним миром посредством восьми комплексов PCIe 5.0 x16 (всего 128 линий, поддерживается бифуркация). Чип при теплопакете 500 Вт (вместе с набортной памятью) способен развивать 7,1 Тфлопс на вычислениях двойной точности. С учетом интегрированной памяти это делает Grace Superchip интересной альтернативой AMD Genoa. 
Программная экосистема платформы NVIDIA Grace. По клику открывается полноразмерная версия. Помимо данных о производительности в режиме FP64 компания уже опубликовала результаты тестов новинки в HPC-нагрузках, где сравнила своё детище с двухсокетной системой на базе AMD EPYC 7763. Выигрыш в производительности составляет от 1,5x до 2,5x, но что не менее важно — Grace Superchip намного эффективнее энергетически, здесь преимущество может достигать 3,5x. В условиях высокоплотных ЦОД или HPC-кластеров это может стать решающим.
10.11.2022 [17:15], Владимир Мироненко
HPE анонсировала недорогие, энергоэффективные и компактные суперкомпьютеры Cray EX2500 и Cray XD2000/6500Hewlett Packard Enterprise анонсировала суперкомпьютеры HPE Cray EX и HPE Cray XD, которые отличаются более доступной ценой, меньшей занимаемой площадью и большей энергоэффективностью по сравнению с прошлыми решениями компании. Новинки используют современные технологии в области вычислений, интерконнекта, хранилищ, питания и охлаждения, а также ПО. 
Изображение: HPE Суперкомпьютеры HPE обеспечивают высокую производительность и масштабируемость для выполнения ресурсоёмких рабочих нагрузок с интенсивным использованием данных, в том числе задач ИИ и машинного обучения. Новинки, по словам компании, позволят ускорить вывода продуктов и сервисов на рынок. Решения HPE Cray EX уже используются в качестве основы для больших машин, включая экзафлопсные системы, но теперь компания предоставляет возможность более широкому кругу организаций задействовать супервычисления для удовлетворения их потребностей в соответствии с возможностями их ЦОД и бюджетом. В семейство HPE Cray вошли следующие системы:
Все три системы задействуют те же технологии, что и их старшие собратья: интерконнект HPE Slingshot, хранилище Cray Clusterstor E1000 и пакет ПО HPE Cray Programming Environment и т.д. Система HPE Cray EX2500 поддерживает процессоры AMD EPYC Genoa и Intel Xeon Sapphire Rapids, а также ускорители AMD Instinct MI250X. Модель HPE Cray XD6500 поддерживает чипы Sapphire Rapids и ускорители NVIDIA H100, а для XD2000 заявлена поддержка AMD Instinct MI210. 
Изображение: Intel В качестве примеров выгод от использования анонсированных суперкомпьютеров в разных отраслях компания назвала:
09.11.2022 [14:50], Владимир Мироненко
Производители специально ухудшают характеристики чипов для китайских серверов, чтобы избежать санкций СШАВ связи с вводом Соединёнными Штатами новых экспортных ограничений на поставки в Китай, производители стали намеренно снижать производительность чипов, чтобы соответствовать требованиям экспортного контроля США и избежать проблем с получением специальных лицензий. Как отметил ресурс The Register, у систем, построенных на чипах NVIDIA, изготовленных на производственных мощностях TSMC для поставок в Китай, характеристики хуже по сравнению с теми, что были ранее. В частности, китайский производитель серверов Inspur указал на использование вместо ускорителя NVIDIA A100 чипа A800, разработанного NVIDIA специально для Китая в соответствии с экспортными ограничениями. Китайские производители H3C и Omnisky тоже представили решения на базе A800. Данный ускоритель, по словам NVIDIA, начала производиться в III квартале этого года. У A800 скорость передачи данных составляет 400 Гбайт/с, тогда как у A100 этот показатель равен 600 Гбайт/с, причём обойти эти ограничения, по словам NVIDIA, невозможно. Речь, судя по всему, идёт о характеристиках интерконнекта NVLink, которые прямо влияют на производительность кластеров из двух и более ускорителей в машинном обучении и других задачах. Изменения касаются 40- и 80-Гбайт вариантов с интерфейсами PCIe и SXM. 
Источник изображения: Inspur Между тем ускорители, находящиеся в разработке и выпускаемые TSMC по контракту с Alibaba и стартапом Biren Technology, тоже, как сообщается, имеют пониженную скорость передачи данных. Это позволит выпускать данные чипы на заводе TSMC, не опасаясь санкций США. До этого TSMC приостановила выпуск 7-нм чипов ускорителей Biren BR100 как раз из-за возможных санкций со стороны Вашингтона.
21.09.2022 [19:39], Алексей Степин
NVIDIA представила новые сверхкомпактные модули Jetson Orin NanoКомпания NVIDIA полна решимости занять лидирующие позиции на рынке робототехники: помимо новой платформы IGX, предназначенной для «умной» промышленности и медицины, на конференции GTC 2022 она представила и другие новинки в этой сфере. В частности, анонсированы новые модули в серии Jetson. Если в основу IGX лёг старший вариант, Jetson AGX Orin (Arm Cortex-A78AE + 1792 ядра Ampere + 56 тензорных ядер), то для более простых сценариев, требующих пониженного энергопотребления, он подходит не лучшим образом. Но именно для таких случаев предназначено пополнение серии — Jetson Orin Nano. 
NVIDIA Jetson Orin Nano 8GB (слева) и 4GB. Здесь и далее источник изображений: NVIDIA Архитектурно Orin Nano похож на старшего собрата, но вычислительных ресурсов у него поменьше: 6 ядер Arm Cortex-A78AE и кластер GPC Ampere, состоящий из 1024 ядер CUDA и 32 тензорных ядер. Имеется отдельный процессор управления питанием, широко развиты подсистемы различных шин, от SPI, CAN и I2C до USB 3.2 Gen2, Ethernet и PCIe 3.0. 
Архитектура процессора Orin Nano Доступны новые модули будут в самом начале следующего года по цене от $199, причём изначально компания планирует выпустить два варианта, с 4 и 8 Гбайт оперативной памяти LPDDR5. Старший вариант будет сконфигурирован в рамках теплопакета 7–15 Вт, его пиковая производительность в INT8 составит 40 Топс. Младший вариант с усечённой вдвое конфигурацией GPU будет ограничен 5–10 Вт и 20 Топс. 
Характеристики семейства Jetson Orin Nano Модули Orin Nano совместимы по контактам с Orin NX и имеют тот же форм-фактор, 70 × 45 мм SODIMM, но за счёт использования более продвинутой архитектуры в задачах инференса новинки могут опережать предшественников в 80 раз. Благодаря обновлению фирменного SDK начать разработку приложений под Orin Nano заказчики смогут уже сейчас, пусть и в режиме эмуляции. |
|

