Материалы по тегу: nvidia
|
10.07.2024 [10:59], Руслан Авдеев
Венчурный инвестор Andreessen Horowitz (a16z) запасается ИИ-ускорителями, чтобы привлечь ИИ-стартапыВенчурная инвестиционная компания Andreessen Horowitz (a16z) получила тысячи современных ускорителей, включая большое количество NVIDIA H100. The Information сообщает, что компания создаёт собственные запасы для привлечения к сотрудничеству ИИ-стартапов. Компания явно не согласна с позицией венчурного фонда Sequoia Capital и аналитиков Goldman Sachs, которые опасаются, что нынешний бум ИИ — лишь пузырь. Инвестор имеет в управлении активы на $42 млрд. Как сообщают СМИ со ссылкой на источники, знакомыми с делами компании, своим подопечным компания сдаёт в аренду запасённые ускорители. Пока нет сведений, идёт ли речь о наполнении складов или компания только арендует их для передачи в субаренду. В будущем Andreessen Horowitz намерена получить более 20 тыс. ускорителей. Компания рассматривает оборудование как критически важный актив для дальнейшего развития бизнеса. 
Источник изображения: NVIDIA На запросы журналистов Andreessen Horowitz и NVIDIA пока не отвечают. Уже не в первый раз ИИ-ускорители используются не вполне традиционным способом по мере того, как нарастает ажиотаж на рынке ресурсоёмких вычислений, связанных с искусственным интеллектом. Например, в прошлом августе облачный стартап CoreWeave, поддерживаемый NVIDIA, получил в долг $2,3 млрд под залог крупной партии NVIDIA H100 для покупки ещё большего количества ускорителей. В условиях дефицита ускорителей стартапам предлагаются различные варианты решения проблемы. Так, Alibaba Cloud предлагает ИИ-стартапам GPU-мощности в обмен на долю в компании, а AWS готова выделить им миллионы долларов, но в виде кредитов для оплаты ресурсов в своём же облаке. Некоторые стартапы сами готовы поделиться интеллектуальной собственностью в обмен на доступ к ускорителям.
09.07.2024 [23:33], Владимир Мироненко
$10-млрд сделка между Oracle и xAI сорваласьИИ-стартап Илона Маска (Elon Musk) xAI отказался от планов по расширению сотрудничества с Oracle. Как пишет The Wall Street Journal, во вторник миллиардер сообщил в соцсети X, что xAI прекратил переговоры с облачным провайдером о сделке на $10 млрд по поводу расширения аренды вычислительных мощностей, поскольку стартап сам построит «самый мощный кластер для обучения [ИИ-моделей] в мире с большим запасом». Сообщивший ранее о срыве сделки ресурс The Information рассказал, что многолетнее соглашение об аренде у Oracle запланированного к строительству суперкомпьютера на чипах NVIDIA уже было на стадии подписания, но переговоры зашли в тупик из-за того, что Маска не устроили сроки строительства, предложенные Oracle. Oracle же заявила об отсутствии доступа к адекватному источнику энергии для работы ИИ-суперкомпьютера в выбранном xAI регионе. 
Источник изображения: xAI В итоге Маск заявил, что «самый мощный суперкомпьютер в мире» будет построен стартапом в Мемфисе (штат Теннесси, США) и начнёт работу осенью 2025 года. Ранее Маск сообщил, что в течение следующих нескольких месяцев xAI развернёт кластер из 100 тыс. ускорителей NVIDIA H100 с жидкостным охлаждением, а летом следующего года запустит ещё один кластер из 300 тыс. ускорителей NVIDIA B200. Как отметил ресурс Data Center Dynamics, xAI уже арендует у Oracle около 16 тыс. ускорителей NVIDIA, что делает его одним из крупнейших клиентов провайдера облачных услуг. Стартап также использует для работы сервисы AWS и резервные мощности в ЦОД соцсети X (Twitter). Oracle также предоставляет свою ИИ-инфраструктуру Microsoft и OpenAI.
05.07.2024 [09:18], Владимир Мироненко
Потрать доллар — получи семь: ИИ-арифметика от NVIDIANVIDIA заявила, что инвестиции в покупку её ускорителей весьма выгодны, передаёт ресурс HPCwire. По словам NVIDIA, компании, строящие огромные ЦОД, получат большую прибыль в течение четырёх-пяти лет их эксплуатации. Заказчики готовы платить миллиарды долларов, чтобы не отстать в ИИ-гонке. «Каждый доллар, вложенный провайдером облачных услуг в ускорители, вернётся пятью долларами через четыре года», — заявил Иэн Бак (Ian Buck), вице-президент HPC-подразделения NVIDIA на конференции BofA Securities 2024 Global Technology Conference. Он отметил, что использование ускорителей для инференса несёт ещё больше выгоды, позволяя получить уже семь долларов за тот же период. Как сообщается, инференс ИИ-моделей Llama, Mistral и Gemma становится всё масштабнее. Для удобства NVIDIA упаковывает открытые ИИ-модели в оптимизированные и готовые к запуску контейнеры NIM. Компания отметила, что её новейшие ускорители Blackwell оптимизированы для инференса. Они, в частности, поддерживают типы данных FP4/FP6, что повышает энергоэффективность оборудования при выполнении рабочих нагрузок ИИ с низкой интенсивностью. 
Источник изображений: NVIDIA Провайдеры облачных услуг планируют строительство ЦОД на пару лет вперёд и хотят иметь представление о том, какими будут ускорители в обозримом будущем. Бак отметил, что провайдерам важно знать, как будут выглядеть ЦОД с серверами на базе чипов Blackwell и чем они будут отличаться от дата-центров на Hopper. Скоро на смену Blackwell придут ускорители Rubin. Их выпуск начнётся в 2026 году, так что гиперскейлерам уже можно готовиться к обновлению дата-центров. Как ожидается, чипы Blackwell, первые партии которых будут поставлены к концу года, будут в дефиците. «С каждым новым технологическим переходом возникает… сочетание проблем спроса и предложения», — отметил Бак. По его словам, операторы ЦОД постепенно отказываются от инфраструктуры на базе CPU, освобождая место под большее количество ускорителей. Ускорители Hopper пока остаются в ЦОД и всё ещё будут основными «рабочими лошадками» для ИИ, но вот решения на базе архитектур Ampere и Volta уже перепродаются.  Microsoft и Google сделали ставку на ИИ и сейчас работают над более функциональными большими языковыми моделями, причём Microsoft (и OpenAI) в значительной степени полагается на ускорители NVIDIA, тогда как Google опирается на TPU собственной разработки для использования в своей ИИ-инфраструктуре. Пока что самая крупная модель насчитывает порядка 1,8 трлн параметров, но по словам Бака, это только начало. В дальнейшем появятся модели с триллионами параметров, вокруг которой будут построены более мелкие и более специализированные модели. Так, свежая GPT-модель (вероятно, речь о GPT-4o) включает 16 отдельных нейросетей. NVIDIA уже адаптирует свои ускорители к архитектуре Mixture of Experts (MoE, набор экспертов), где процесс обработки запроса пользователя делится между несколькими специализированными «экспертными» нейросетями. GB200 NVL72, по словам Бака, идеально подходит для MoE благодаря множеству ускорителей связанных быстрым интерконнектом, каждый из которых может обрабатывать часть запроса и быстро делится ответом с другими.
03.07.2024 [08:32], Владимир Мироненко
Крупный европейский криптомайнер Northern Data обдумывает вывод на биржу подразделений ЦОД и ИИКомпания Northern Data, деятельность которой связана с майнингом криптовалюты, предоставлением услуг высокопроизводительных вычислений (HPC) и ИИ, обдумывает возможность проведения IPO подразделений Taiga и Ardent, предоставляющих услуги облачных вычислений и ЦОД соответственно, пишет Bloomberg. По данным источников Bloomberg, IPO может состояться на площадке Nasdaq. В настоящее время компания ведёт переговоры с банками для проведения публичного размещения акций. По оценкам банков, капитализация этих подразделений может составить $10–$16 млрд. Как и многие компании, занимающиеся майнингом криптовалют, Northern Data рассматривает HPC и ИИ как прибыльное дополнение к своей основной деятельности. В прошлом году Northern Data разделила свой бизнес на три подразделения — Arden, Taiga и Peak Mining, сосредоточив в последнем все операции по майнингу криптовалют. Согласно информации на сайте компании, у неё имеется 11 дата-центров. Peak Mining, американское подразделение компании по майнингу биткоинов, строит и разрабатывает дата-центры суммарной ёмкостью почти 700 МВт, что в случае реализации всех планов сделает его одним из крупнейших майнеров криптовалюты в США. Taiga уже владеет 24,5 тыс. ускорителей NVIDIA, включая H100, A100 и A6000. Они в основном находятся в трёх ЦОД в Швеции и Норвегии и на 100 % запитаны от «зелёных» источников энергии. В понедельник компания объявила, что первой в Европе приобрела 2 тыс. ускорителей NVIDIA H200, дополненных DPU BlueField-3 и ConnectX-7. Они будут размещены в одном из европейских ЦОД с PUE менее 1,2. Запуск первого кластера намечен на IV квартал, а его производительность составит порядка 32 Пфлопс (точность вычислений не указана). Пиковая теоретическая FP64-производительность такого количества ускорителей H200 составляет 68 Пфлопс. 
Источник изображения: Northern Data В свою очередь Ardent занимается дизайном и строительством высокоплотных ЦОД, ориентированных на HPC- и ИИ-нагрузки. Компания использует СЖО, а заявленный уровень PUE не превышает 1,15. При этом Ardent обещает 100 % доступность своих площадок. Как сообщается, Northern Data в ноябре получила кредитное финансирование на сумму €575 млн от компании Tether Group, занимающейся стейблкоинами, а в январе завершила приобретение у Tether компании Damoon за €400 млн, рассчитавшись с помощью облигаций, конвертируемых в акции, выпущенные Northern Data AG. В результате Tether стала основным инвестором Northern Data. Полученные средства Northern Data использует для закупок самых востребованных чипов NVIDIA. Благодаря этому к концу лета компанией будет развёрнуто около 20 тыс. NVIDIA H100.
30.06.2024 [14:28], Сергей Карасёв
В Австралии запущен ИИ-суперкомпьютер Virga [Обновлено]Государственное объединение научных и прикладных исследований Австралии (CSIRO) сообщило о вводе в эксплуатацию высокопроизводительного вычислительного комплекса Virga. Система, предназначенная для ИИ-задач, ускорит научные открытия, а также поможет развитию промышленности и экономики страны. Суперкомпьютер располагается в дата-центре Hume компании CDC в Канберре. Его созданием занималась компания Dell: в основу положены серверы PowerEdge XE9640, оснащённые двумя процессорами Intel Xeon Sapphire Rapids 8452Y (36C/72T, 2,0/3,2 ГГц, 300 Вт), до 512 Гбайт RAM и четырьмя 61,44-Тбайт NVMe SSD. Задействованы ИИ-ускорители NVIDIA H100 с 96 Гбайт памяти HBM3 — всего 448 шт. Система занимает 14 стоек, а в качестве интерконнекта используется Infiniband NDR. Dell заключила контракт на создание Virga в 2023 году: сумма изначально составляла $9,65 млн, однако фактическое строительство комплекса обошлось в $10,85 млн. Новый суперкомпьютер придёт на смену НРС-системе CSIRO предыдущего поколения под названием Bracewell, но унаследует от неё BeeGFS-хранилище, также построенное на оборудовании Dell. В нынешнем рейтинге TOP500 машина занимает 72 место с пиковой и практической FP64-производительностью 18,46 Пфлопс и 14,94 Пфлопс соответственно. Комплекс Virga получил своё имя в честь метеорологического эффекта «вирга» — это дождь, который испаряется, не достигая земли: видеть его можно в виде полос, выходящих из-под облаков. Систему Virga планируется использовать для таких задач, как прогнозирование пожаров, разработка вакцин нового поколения, проектирование гибких солнечных панелей, анализ медицинских изображений и пр. 
Источник изображения: CSIRO Пока подробные технические характеристики Virga и показатели быстродействия не раскрываются. Отмечается лишь, что в составе комплекса применена гибридная система прямого жидкостного охлаждения. Говорится также, что CDC оперирует двумя кампусами дата-центров Hume. Площадка Hume Campus One объединяет три ЦОД и имеет мощность 21 МВт, тогда как в состав Hume Campus Two входят два объекта суммарной мощностью 51 МВт.
27.06.2024 [12:58], Сергей Карасёв
В Японии запущен суперкомпьютер TSUBAME4.0 с ускорителями NVIDIA H100 для ИИ-задачГлобальный научно-информационный вычислительный центр (GSIC) Токийского технологического института (Tokyo Tech) в Японии объявил о вводе в эксплуатацию вычислительного комплекса TSUBAME4.0, созданного компанией HPE. Новый суперкомпьютер будет применяться в том числе для задач ИИ. В основу машины легли 240 узлов HPE Cray XD665. Каждый из них несёт на борту два процессора AMD EPYC Genoa и четыре ускорителя NVIDIA H100 SXM5 (94 Гбайт HBM2e). Объём оперативной памяти DDR5-4800 составляет 768 Гбайт. Задействован интерконнект Infiniband NDR200. Вместимость локального накопителя NVMe SSD — 1,92 Тбайт. В состав НРС-комплекса входит подсистема хранения данных HPE Cray ClusterStor E1000. Сегмент на основе HDD имеет ёмкость 44,2 Пбайт — это в 2,8 раза больше по сравнению с суперкомпьютером предыдущего поколения TSUBAME 3.0. Кроме того, имеется SSD-раздел ёмкостью 327 Тбайт. Пиковая производительность TSUBAME4.0 достигает 66,8 Пфлопс (FP64), что в 5,5 больше по отношению к системе третьего поколения. Быстродействие на операциях половинной точности (FP16) поднялось в 20 раз по сравнению с TSUBAME3.0 — до 952 Пфлопс. 
Источник изображения: Tokyo Tech На сегодняшний день TSUBAME4.0 является вторым по производительности суперкомпьютером в Японии после Fugaku. Эта система в нынешнем рейтинге TOP500 занимает четвёртое место с показателем 442 Пфлопс. Лидером в мировом масштабе является американский комплекс Frontier — 1,21 Эфлопс.
27.06.2024 [11:08], Сергей Карасёв
Встраиваемая система AAEON Boxer-8658AI получила модуль NVIDIA Jetson Orin NX и восемь 1GbE-портов с PoEКомпания AAEON представила встраиваемую систему Boxer-8658AI, предназначенную для использования прежде всего в транспортной сфере. Устройство выполнено на аппаратной платформе NVIDIA Jetson Orin NX в соответствии со стандартом MIL-STD-810G, что означает защиту от вибрации, ударов и других воздействий. В зависимости от модификации система комплектуется модулем Orin NX 8GB или Orin NX 16GB с шестью и восемью ядрами Arm Cortex-A78AE соответственно. Отмечается, что производительность Boxer-8658AI на операциях ИИ достигает 100 TOPS. Объём памяти LPDDR5 — 8 и 16 Гбайт. Есть посадочное место для SFF-накопителя с интерфейсом SATA-3 и коннектор M.2 2280 для SSD (NVMe). 
Источник изображений: AAEON Устройство заключено в корпус с габаритами 210 × 164,2 × 76 мм (без монтажных планок), а масса составляет около 3 кг. Доступны восемь сетевых портов 1GbE RJ-45 с поддержкой PoE/PSE (802.3af/at, до 120 Вт) и ещё два разъёма 1GbE RJ-45 без РоЕ. Предусмотрены коннектор M.2 2230 E Key для комбинированного адаптера Wi-Fi/Bluetooth и разъём M.2 3052 B Key для модема 4G (плюс два слота для SIM-карт).  В число доступных интерфейсов входят HDMI 2.0, USB 3.2 Gen2 Type-A (×4), DB-9 (CANBus FD), DB-15 (RS232/422/485), линейный аудиовыход, порт Micro-USB и трёхконтактный разъём для подачи питания (9–36 В). Диапазон рабочих температур простирается от -15 до +60 °C. Говорится о совместимости с программными платформами на ядре Linux.
15.05.2024 [14:18], Руслан Авдеев
PUE у вас неправильный: NVIDIA призывает пересмотреть методы оценки энергоэффективности ЦОД и суперкомпьютеровОператорам дата-центров и суперкомпьютеров не хватает инструментов для корректного измерения энергоэффективности их оборудования и оценки прогресса на пути к экоустойчивым вычислениям. Как утверждает NVIDIA, нужна новая система оценки показателей при использовании оборудования в реальных задачах. Для оценки эффективности ЦОД существует как минимум около трёх десятков стандартов, некоторые уделяют внимание весьма специфическим критериям вроде расхода воды или уровню безопасности. Сегодня чаще всего используется показатель PUE (power usage effectiveness), т.е. отношение энергопотребления всего объекта к потреблению собственно IT-инфраструктуры. В последние годы многие операторы достигли практически идеальных значений PUE, поскольку, например, на преобразование энергии и охлаждение нужно совсем мало энергии. В эпоху роста облачных сервисов оценка PUE показала довольно высокую эффективность, но в эру ИИ-вычислений этот индекс уже не вполне соответствует запросам отрасли ЦОД — оборудование заметно изменилось. NVIDIA справедливо отмечает, что PUE не учитывает эффективность инфраструктуры в реальных нагрузках. С таким же успехом можно измерять расход автомобилем бензина без учёта того, как далеко он может проехать без дозаправки. При этом среднемировой показатель PUE дата-центров остаётся неизменным уже несколько лет, а улучшать его всё дороже. 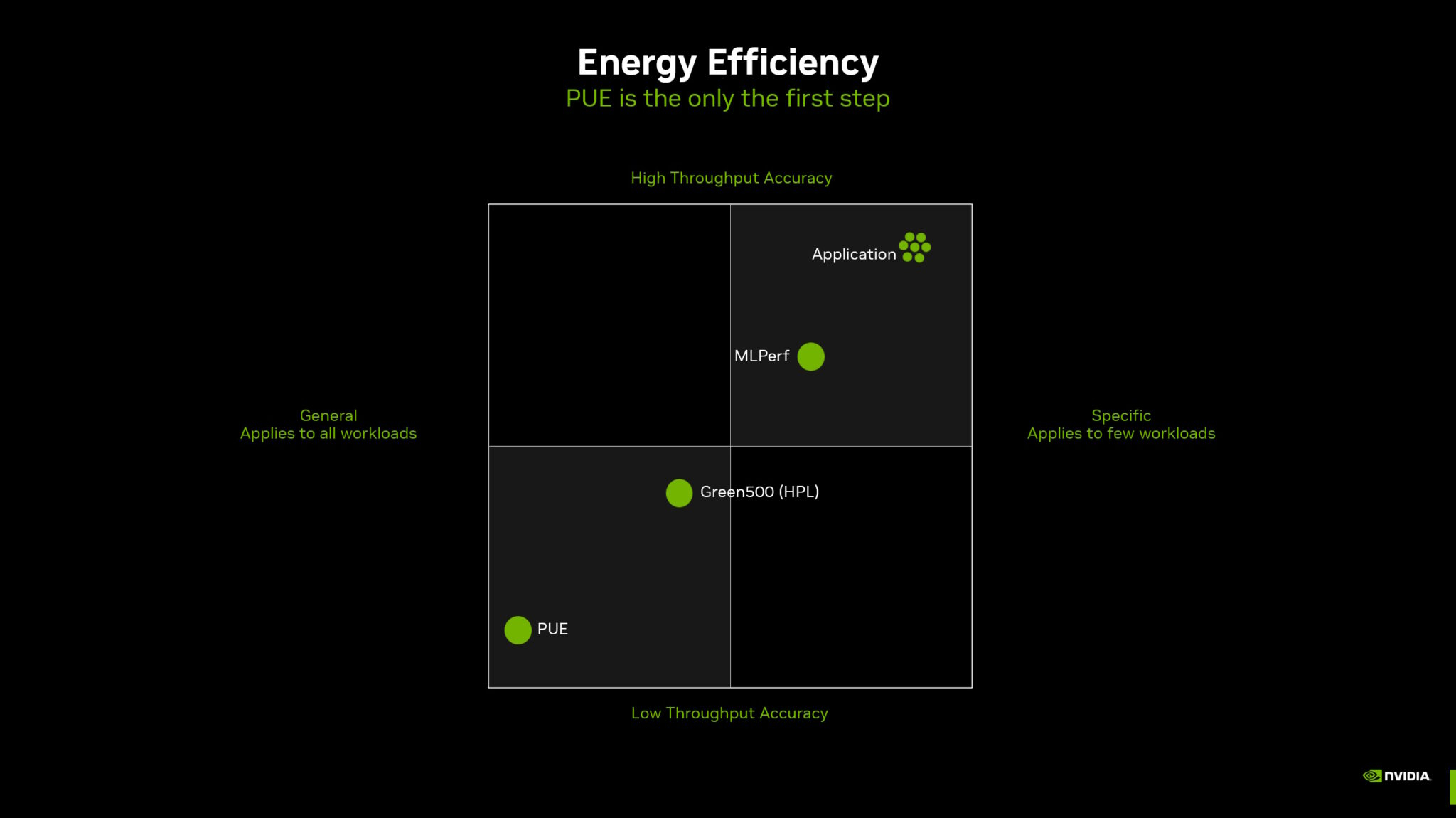
Источник изображений: NVIDIA Что касается энергопотребления, разное оборудование при одинаковых затратах может давать самые разные результаты. Другими словами, если современные ускорители потребляют больше энергии, это не значит, что они менее эффективны, поскольку они дают несопоставимо лучший результат в сравнении со старыми решениями. NVIDIA неоднократно приводила подобные сравнения и между своими GPU с обычными CPU, а теперь предлагает распространить этот подход на ЦОД целиком, что справедливо, учитывая стремление NVIDIA сделать минимальной единицей развёртывания целую стойку. 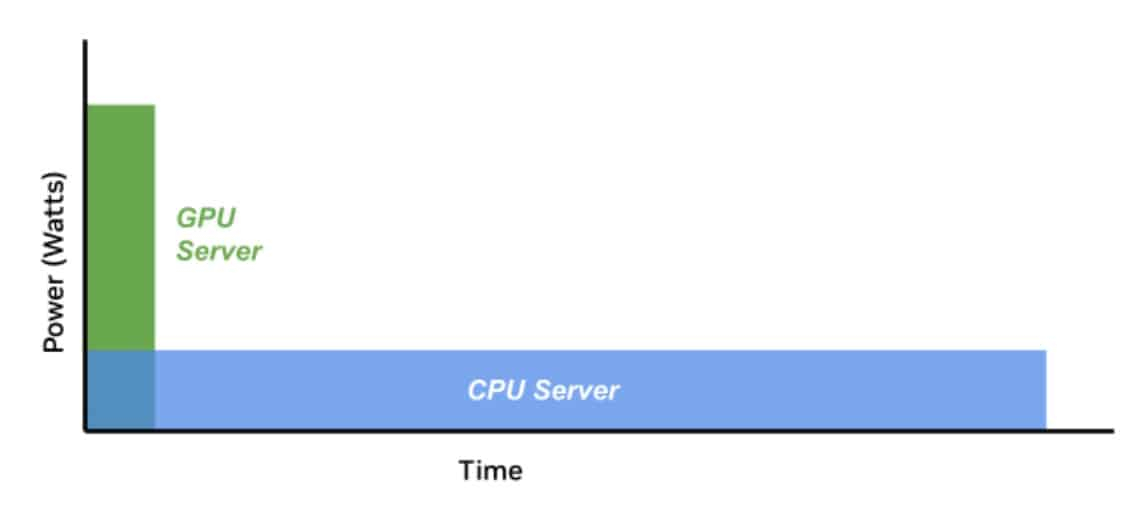 Как считают в NVIDIA, оценивать качество ЦОД можно только с учётом того, сколько энергии тратится для получения результата. Так, ЦОД для ИИ могут полагаться на MLPerf-бенчмарки, суперкомпьютеры для научных исследований могут требовать измерения других показателей, а коммерческие дата-центры для стриминговых сервисов — третьих. В идеале бенчмарки должны измерять прогресс в ускоренных вычислениях с использованием специализированных сопроцессоров, ПО и методик. Например, в параллельных вычислениях GPU намного энергоэффективнее обычных процессоров Отмечается, что с 2003 года производительность ускорителей выросла приблизительно в 7 тыс. раз, а соотношение цены и производительности стало в 5,6 тыс. раз лучше. А с учётом того, что современные ЦОД достигли PUE на уровне приблизительно 1,2, подобная метрика практически исчерпала себя, теперь стоит ориентироваться на другие показатели, релевантные актуальным проблемам. Хотя напрямую сравнить некоторые аспекты невозможно, сегментировав деятельность ЦОД на типы рабочих нагрузок, возможно, удалось бы получить некоторые результаты. В частности, операторам ЦОД нужен пакет бенчмарков, измеряющих показатели при самых распространённых рабочих ИИ-нагрузках. Например, неплохой метрикой может стать Дж/токен. Впрочем, NVIDIA грех жаловаться на недостойные оценки — в последнем рейтинге Green500 именно её системы заняли лидерские позиции.
29.03.2024 [21:54], Сергей Карасёв
Eviden увеличит производительность французского суперкомпьютера Jean Zay более чем втроеФранцузское национальное агентство по высокопроизводительным вычислениям (GENCI) и Национальный центр научных исследований (CNRS) заключили соглашение с компанией Eviden (дочерняя структура Atos) о модернизации НРС-комплекса Jean Zay. Ожидается, что производительность этого суперкомпьютера увеличится приблизительно в 3,5 раза. В рамках проекта Eviden оборудует комплекс 1456 ускорителями NVIDIA H100 в дополнение к 416 ускорителям NVIDIA A100 и 1832 ускорителям NVIDIA V100, которые задействованы в настоящее время. Модернизация предполагает использование 14 стоек суперкомпьютерной платформы Eviden BullSequana XH3000. В общей сложности будут задействованы 364 двухпроцессорных узла на базе Intel Xeon Sapphire Rapids с 48 ядрами. Каждый сервер получит 512 Гбайт оперативной памяти и четыре ускорителя NVIDIA H100 SXM5. Говорится об использовании адаптеров NVIDIA ConnectX-7. 
Источник изображения: Eviden Проект также предусматривает комплексное обновление подсистемы хранения данных. Она будет состоять из флеш-массива вместимостью 4,3 Пбайт со скоростями чтения/записи свыше 1 Тбайт/с и дискового массива ёмкостью 39 Пбайт со скоростями чтения/записи более 300 Гбайт/с. Компоненты СХД поставит компания DataDirect Networks (DDN). Для обоих уровней хранения предусмотрено использование файловой системы Lustre. 
Фото: Photothèque CNRS/Cyril Frésillon Ожидается, что модернизация позволит увеличить пиковую производительность Jean Zay с 36,85 до 125,9 Пфлопс. Проект получил финансирование в рамках национальной инвестиционной программы «Франция 2030». Усовершенствованный суперкомпьютер будет использоваться для решения ресурсоёмких задач, в том числе в области ИИ. Отмечается, что Jean Zay — это один из наиболее экологичных суперкомпьютеров в Европе. Отчасти это достигается благодаря использованию генерируемого машиной тепла для обогрева более 1000 зданий в кампусе Париж-Сакле.
22.03.2024 [09:09], Алексей Степин
NVIDIA представила 800G-платформы Quantum-X800 и Spectrum-X800 для InfiniBand- и Ethernet-фабрик нового поколенияДополнением к только что представленным ИИ-ускорителям NVIDIA Blackwell станут новые сетевые 800G-платформы Quantum-X800 и Spectrum-X800, а также сетевые адаптеры ConnectX-8. Именно они позволят вывести масштабирование ИИ-кластеров на новый уровень и позволят «прокормить» гигантские массивы ускорителей в дата-центрах гиперскейлеров. Платформа NVIDIA Quantum-X800 ориентирована на наиболее производительные ИИ- и HPC-кластеры. Она использует новое поколение технологии InfiniBand, всё ещё обладающей рядом преимуществ в сравнении с Ethernet, и включает в себя обновлённые SHARP-движки. Технология SHARPv4 реализует «вычисления в сети» (In-Network Computing), что позволяет не только существенно разгрузить вычислительные узлы и серверы, но и обеспечить более высокую пропускную способность интерконнекта вкупе с более серьёзными возможностями его масштабирования. 
NVIDIA Q3400-RA 4U (справа) и SN5600. Источник изображений здесь и далее: NVIDIA Основой платформы Quantum-X800 стал 4U-коммутатор Q3400-RA, впервые в индустрии, как говорит компания, использующий 200G-блоки SerDes для каждой линии InfiniBand. Коммутатор располагает 144 портами 800G в 72 OSFP-модулях и выделенным портом для Unified Fabric Manager. Новинка имеет стандартное 19″ исполнение с воздушным охлаждением, но есть и вариант Q3400-LD с жидкостным охлаждением, предназначенный для 21″ OCP-стоек. В двухуровневом варианте fat tree коммутаторы позволят объединить 10 368 NIC.  Основным адаптером для новой платформы InfiniBand является ConnectX-8 SuperNIC с интерфейсом PCIe 6.0. Он является частью SHARPv4 и предлагается в однопортовом (OSFP224) и двухпортовом (QSFP112) вариантах и в нескольких форм-факторах, включая OCP 3.0. На платах также имеется разъём SocketDirect на 16 линий PCIe. Также компания представила компоненты NVIDIA LinkX: оптические трансиверы 2xDR4/2xFR4 и активные медные кабели (LACC).  Не забыла NVIDIA и про Ethernet: здесь вывести производительность сети на новый уровень должна платформа Spectrum-X800. Её основой служит новейший коммутатор SN5600 — это, по словам NVIDIA, первый в мире Ethernet-коммутатор класса 800GbE, специально разработанный для применения гиперскейлерами в крупных облачных ИИ-комплексах. Применяемая архитектура позволяет гарантировать каждому клиенту оптимальный и постоянный уровень производительности, а потоковая телеметрия позволит находить и ликвидировать возможные «бутылочные горлышки» в сети буквально на лету.  Общая пропускная способность SN5600 составляет 51,2 Тбит/с. Коммутатор располагает 64 портами 800GbE в формате OSFP. В нём используется ASIC пятого поколения на базе архитектуры Spectrum-4. В качестве основного адаптера предлагается SuperNIC на базе DPU BlueField-3 с двумя 400GbE-портами. 
Фото: Twitter/NVIDIANetworkng Spectrum-X800 сопровождает полноценный спектр инфраструктурных компонентов, включая кабели DAC и LACC. С оптическими трансиверами длина соединения 800GbE может достигать двух километров. Начиная со следующего года, решения на базе новых сетевых платформ NVIDIA будут доступны от широкого круга поставщиков оборудования, включая Aivres, DDN, Dell Technologies, Eviden, Hitachi Vantara, HPE, Lenovo, Supermicro и VAST Data. |
|

