Материалы по тегу: nvidia
|
25.07.2024 [10:12], Владимир Мироненко
AMD показала превосходство чипов EPYC над Arm-процессорами NVIDIA Grace в серии бенчмарков, но не всё так простоAMD провела серию тестов, чтобы доказать преимущество своих нынешних процессоров AMD EPYC над Arm-процессорами NVIDIA Grace Superchip. Как отметила AMD, в связи с растущей востребованностью ЦОД некоторые компании начали предлагать альтернативные варианты процессоров, «часто обещающие преимущества по сравнению с обычными решениями x86». «Обычно их представляют с большой помпой и заявлениями о значительных преимуществах в производительности и энергоэффективности по сравнению с x86. Слишком часто эти утверждения довольно сложно воплотить в реальные сценарии конкурентной рабочей нагрузки — с использованием устаревших, недостаточно оптимизированных альтернатив или плохо документированных предположений», — отметила AMD. С помощью серии стандартных отраслевых тестов AMD, по её словам, продемонстрировала преимущество EPYC над решениями на базе Arm. «Благодаря проверенной архитектуре x86-64, впервые разработанной AMD, вы можете получить всё это без дорогостоящего портирования или изменений в архитектуре», — подчеркнула компания. Иными словами, тесты AMD могут быть просто попыткой развеять опасения, что архитектура x86 «выдыхается» и что Arm берёт верх. 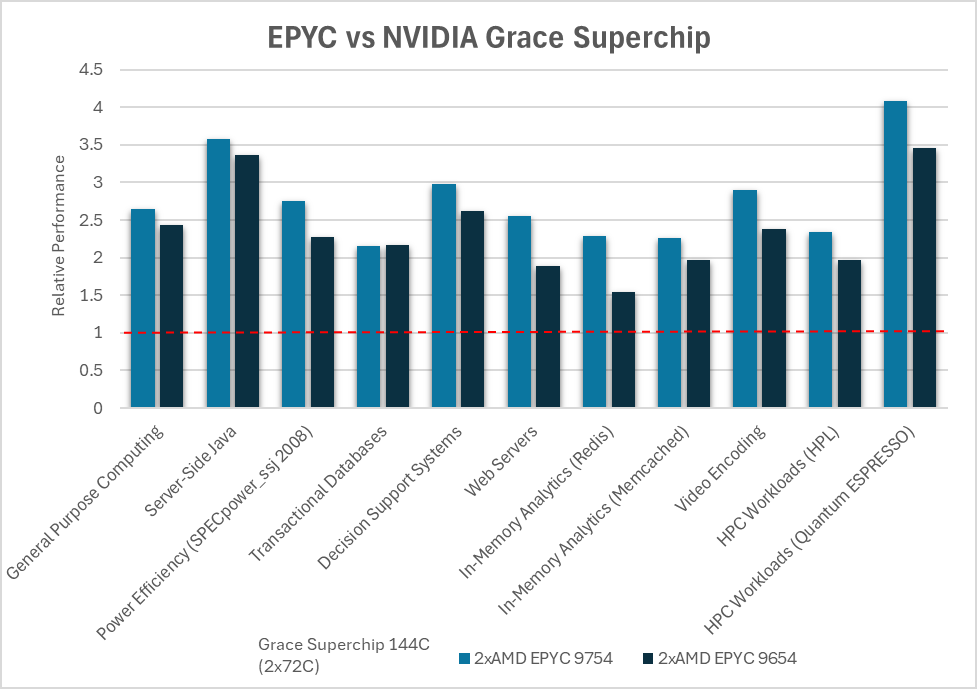
Источник изображений: AMD AMD сравнила производительность AMD EPYC и NVIDIA Grace CPU в десяти ключевых рабочих нагрузках, охватывающих вычисления общего назначения, Java, транзакционные базы данных, системы поддержки принятия решений, веб-серверы, аналитику, кодирование видео и нагрузки HPC. Согласно представленному выше графику, 128-ядерный процессор EPYC 9754 (Bergamo) и 96-ядерный EPYC 9654 (Genoa) более чем вдвое превзошли NVIDIA Grace CPU Superchip по производительности при обработке вышеуказанных нагрузок. Напомним, что Grace CPU Superchip содержит два 72-ядерных кристалла Grace, использующих ядра Arm Neoverse V2, соединённых шиной NVLink C2C с пропускной способность 900 Гбайт/с, и работает как единый 144-ядерный процессор. В свою очередь, ресурс The Register отметил, что речь идёт о версии с 480 Гбайт памяти LPDDR5x, а не с 960 Гбайт. 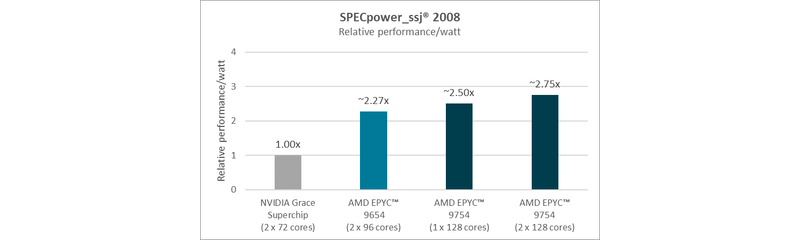 В тесте SPECpower-ssj2008, по данным AMD, одно- и двухсокетные системы на базе AMD EPYC 9754 превосходят систему NVIDIA Grace CPU Superchip по производительности на Вт примерно в 2,50 раза и 2,75 раза соответственно, а двухсокетная система AMD EPYC 9654 — примерно в 2,27 раза. Помимо производительности и эффективности, ещё одним важным фактором для операторов ЦОД является совместимость, сообщила AMD. По оценкам, во всем мире существуют триллионы строк программного кода, большая часть которого написана для архитектуры x86. EPYC основаны на архитектуре x86-64, впервые разработанной AMD, и эта архитектура является наиболее широко используемой и поддерживаемой в индустрии ЦОД, заявила компания, добавив, что изменения в архитектуре сложны, дороги и чреваты риском. AMD также отметила, что экосистема AMD EPYC включает более 250 различных конструкций серверов и поддерживает около 900 уникальных облачных инстансов. Также процессоры AMD EPYC установили более 300 мировых рекордов производительности и эффективности в широком спектре тестов. В то же время лишь немногие Arm-решения доказали свою эффективность. В свою очередь, ресурс The Register отметил, что ситуация не так проста, как AMD пытается всех убедить. В феврале сайт The Next Platform сообщил, что исследователи из университетов Стоуни-Брук и Буффало сравнили данные о производительности суперчипа NVIDIA Grace CPU Superchip и нескольких процессоров x86, предоставленные несколькими НИИ и разработчиком облачных решений. 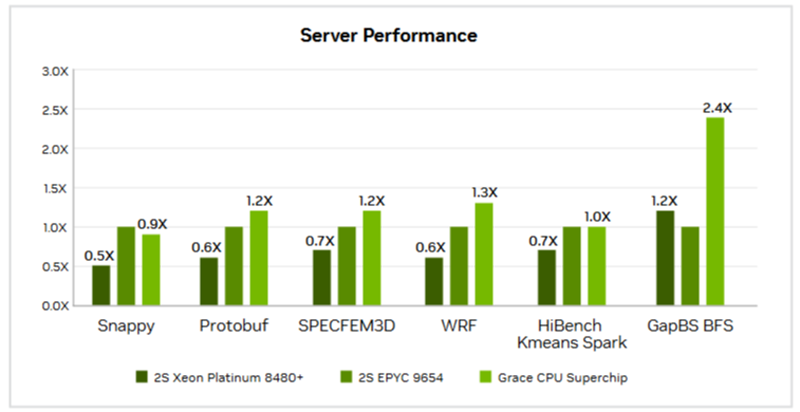
Источник изображений: NVIDIA Большинство этих тестов были ориентированы на HPC, включая Linpack, HPCG, OpenFOAM и Gromacs. И хотя производительность системы Grace сильно различалась в разных тестах, в худшем случае она находилась где-то между Intel Skylake-SP и Ice Lake-SP, превосходя AMD Milan и находясь в пределах досягаемости от показателей Xeon Max. Данные результаты отражают тот факт, что самые мощные процессоры AMD EPYC Genoa и Bergamo могут превзойти первый процессор NVIDIA для ЦОД — при правильно выбранном тесте. 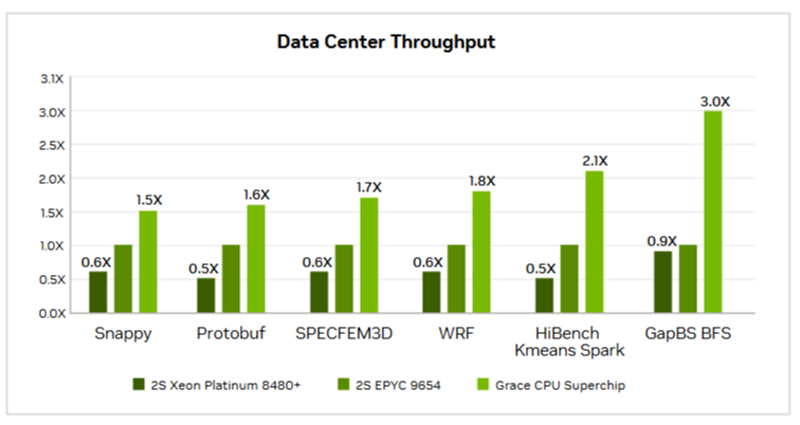 В техническом описании Grace CPU Superchip компания NVIDIA сообщает, что этот чип обеспечивает от 0,9- до 2,4-кратного увеличения производительности по сравнению с двумя 96-ядерными EPYC 9654 и предлагает до трёх раз большую пропускную способность в различных облачных и HPC-сервисах. NVIDIA отмечает, что Superchip предназначен для «обработки массивов для получения интеллектуальных данных с максимальной энергоэффективностью», говоря об ИИ, анализе данных, нагрузках облачных гиперскейлеров и приложениях HPC.
23.07.2024 [01:20], Владимир Мироненко
Стартап xAI Илона Маска запустил ИИ-кластер в Теннеси [Обновлено]Илон Маск объявил в соцсети X (ранее Twitter) о запуске стартапом xAI в дата-центре в Мемфисе «самого мощного в мире кластера для обучения ИИ», который будет использоваться для создания «самого мощного в мире по всем показателям искусственного интеллекта к декабрю этого года», пишет Tom's Hardware. Однако, судя по всему, на практике сейчас работает лишь очень небольшая часть кластера. «Отличная работа команды @xAI, команды @X, @Nvidia и компаний поддержки, которые начали обучение с кластером Memphis Supercluster примерно в 4:20 утра по местному времени. 100 тыс. H100 с жидкостным охлаждением в единой RDMA-фабрике — это самый мощный кластер обучения ИИ в мире!», — сообщил миллиардер в своём аккаунте. Как указали в xAI, новая вычислительная система будет использоваться для обучения новой версии @grok, которая будет доступна премиум-подписчикам @x. Ранее появились сообщения о том, что оборудование для ИИ-кластера будут поставлять Dell и Supermicro. Комментируя нынешнее заявление Маска, гендиректор Supermicro Чарльз Лян (Charles Liang) подтвердил, что большая часть оборудования для ИИ-кластера была поставлена его компанией. 
Источник изображений: xAI В мае этого года Маск поделился планами построить гигантский суперкомпьютер для xAI для работы над следующей версией чат-бота Grok, который будет включать 100 тыс. ускорителей Nvidia H100. А в следующем году Илон Маск планирует запустить ещё один кластер, который будет содержать 300 тыс. ускорителей NVIDIA B200. Для его создания Маск намеревался привлечь Oracle, планируя выделить $10 млрд на аренду ИИ-серверов компании, но затем отказался от этой идеи, так как его не устроили предложенные Oracle сроки реализации проекта. Как отметил ресурс Tom's Hardware, новый ИИ-кластер стартапа xAI превосходит все суперкомпьютеры из TOP500 с точки зрения количества ускорителей. Самые мощные в мире суперкомпьютеры, такие как Frontier (37 888 ускорителей AMD), Aurora (60 000 ускорителей Intel) и Microsoft Eagle (14 400 ускорителей NVIDIA), похоже, значительно уступают кластеру xAI. Впрочем, технические детали о сетевой фабрике нового кластера пока не предоставлены.  Но, как выясняется, не всё в заявлении Маска соответствует действительности. Аналитик Dylan Patel (Дилан Пател) из SemiAnalysis обвинил Маска во лжи, поскольку в настоящее время кластеру доступно 7 МВт мощности, чего хватит для работы примерно 4 тыс. ускорителей. С 1 августа будет доступно 50 МВт, если xAI наконец подпишет соглашение с властями Теннесси. А подстанция мощностью 150 МВт все ещё находится в стадии строительства, которое завершится в IV квартале 2024 года. Как отмечает местное издание commercial appeal, поскольку речь идёт об объекте мощностью более 100 МВт, для его подключения требуется разрешение коммунальных компаний Memphis Light, Gas and Water (MLGW) и Tennessee Valley Authority (TVA). Контракт на подключение ЦОД к энергосети с TVA не был подписан. Более того, для охлаждения ЦОД, по оценкам MLGW, потребуется порядка 4,9 тыс. м3 воды ежедневно. UPD: Дилан Пател удалил исходный твит, но уточнил текущее положение дел. От энергосети кластер сейчас потребляет 8 МВт, однако рядом с площадкой установлены мобильные генераторы (14 × 2,5 МВт), так что сейчас в кластере активны около 32 тыс. ускорителей, а в полную силу он зарабатает в IV квартале. Если контракт с TVA будет подписан, то к 1 августу кампус получит ещё 50 МВт от сети, а к концу году будет подведено 200 МВт. Для работы 100 тыс. H100 требуется порядка 155 МВт.
22.07.2024 [15:57], Руслан Авдеев
Поставки суперускорителей с чипами NVIDIA GB200 могут задержаться из-за протечек СЖОNVIDIA уже готовилась начать продажи систем на базе новейших ИИ-суперускорителей GB200, однако столкнулась с непредвиденной проблемой — TweakTown сообщает, что в системах жидкостного охлаждения этих серверов начали появляться протечки. Судя по всему, серверы на основе GB200 использовали дефектные компоненты систем СЖО охлаждения, поставляемые сторонними производителями: разветвители, быстросъёмные соединители и шланги. Некорректная работа любого из этих компонентов может привести к утечке охлаждающей жидкости. В случае с моделью GB200 NVL72 стоимостью в $3 млн это может перерасти в большую проблему. К счастью, нарушения в работе новых систем NVIDIA GB200 NVL36 и NVL72 обнаружили до начала массового производства в преддверии запуска поставок ключевым покупателям ИИ-решений. Предполагается, что на сроках поставок проблема не скажется, поскольку её успеют устранить. Впрочем, по данным источников, теперь крупные провайдеры облачных сервисов «нервничают». 
Источник изображения: NVIDIA NVIDIA предлагают свою продукцию всё больше тайваньских производителей, способных заменить бракованные компоненты для серверных систем с GB200. Однако сертификация компонентов — процесс довольно сложный, поскольку многие тайваньские компании не специализировались на их выпуске ещё в недавнем прошлом. Тем не менее, когда NVIDIA объявила, что ускорители следующего поколения получат жидкостное охлаждение, многие производители решили попробовать себя в этой сфере. Тайваньские Shuanghong и Qihong уже имеют хороший опыт в выпуске водоблоков, а теперь расширили спектр разрабатываемых товаров, предлагая разветвители, быстросъемные соединители и шланги. Именно эти компании по некоторым данным сейчас предоставляют необходимые комплектующие для замены бракованных в новых суперускорителях NVIDIA GB200 NVL36 и NVL72. Лидером на рынке серверных СЖО остаётся CoolIT, но её услугами NVIDIA, видимо, решила не пользоваться.
22.07.2024 [12:51], Руслан Авдеев
NVIDIA готовит урезанную версию флагманского ИИ-чипа Blackwell для КитаяNVIDIA работает над новым вариантом представленного весной флагманского ИИ-ускорителя серии Blackwell — теперь для китайского рынка, находящегося под давлением американских санкций. По данным Reuters, вендор работает над тем, чтобы привести оборудование в соответствие с техническими требованиями властей США к поставляемым в Китай полупроводникам. Серию Blackwell компания представила в марте 2024 года. Массовое производство планируется позже в текущем году. Выпускаемый в рамках нового семейства ускоритель B200 до 30 раз производительнее своего предшественника при выполнении некоторых задач. Над выпуском и поставками упрощённого для Китая чипа B20 вендор будет работать совместно с одним из своих крупнейших дистрибьюторов в Китае — компанией Inspur. Источники Reuters пожелали остаться неизвестными, в самой NVIDIA новость пока не комментируют, предпочитают молчать и в Inspur. 
Источник изображения: NVIDIA Вашингтон в очередной раз ужесточил контроль над поставками передовых чипов в Китай в 2023 году, пытаясь предотвратить развитие в Поднебесной собственных суперкомпьютеров. С тех пор NVIDIA разработала три чипа, специально оптимизированных для китайского рынка. Примечательно, что американские санкции помогли компаниям вроде китайского техногиганта Huawei и стартапам вроде Enflame добиться некоторых успехов на китайском рынке ИИ-ускорителей. Появление версии чипа серии Blackwell для Китая, вероятно, поможет NVIDIA избавиться от конкуренции на одном из ключевых рынков. Из-за санкций США за год, закончившийся в январе, выручка NVIDIA в Китае составила 17 % от общемировой, для сравнения, двумя годами ранее на страну приходилось 26 % всех продаж компании. Изначально предназначенный для Китая чип H20, продажи которого начались в этом году, раскупался довольно слабо, поэтому вендору пришлось снизить цену, чтобы сделать его дешевле конкурирующего решения Huawei. Теперь, по данным источников, продажи растут быстрыми темпами. По оценкам экспертов SemiAnalysis, в этом году NVIDIA намерена продать в Китае более 1 млн чипов H20 на сумму свыше $12 млрд. При этом высока вероятность, что американские власти и дальше продолжат ужесточать экспортный контроль, ограничивая поставки передовых ускорителей в КНР. Более того, США хотят, чтобы Нидерланды и Япония всё активнее включались в санкционный процесс, ограничивая с Китаем сотрудничество в области оборудования для производства полупроводников. Также, как сообщают источники, имеются предварительные планы ограничить доступ к наиболее передовым ИИ-моделям. Акции полупроводниковых компаний упали на прошлой неделе на фоне новостей о том, что США оценивают целесообразность введения правила, позволяющего просто запрещать продажи продуктов, выпущенных с помощью американских технологий. UPD: Inspur отрицает совместную работу с NVIDIA над ускорителями B20.
22.07.2024 [08:57], Сергей Карасёв
Mistral AI и NVIDIA представили корпоративную ИИ-модель Mistral NeMo 12B со «здравым смыслом» и «мировыми знаниями»Корпорация NVIDIA и французская компания Mistral AI анонсировали большую языковую модель (LLM) Mistral NeMo 12B, специально разработанную для решения различных задач корпоративного уровня — чат-боты, обобщение данных, работа с программным кодом и пр. Mistral NeMo 12B насчитывает 12 млрд параметров и использует контекстное окно в 128 тыс. токенов. Для инференса применяется формат данных FP8, что, как утверждается, позволяет уменьшить размер требуемой памяти и ускорить развёртывание без какого-либо снижения точности ответов. 
Источник изображения: pixabay.com При обучении модели была задействована библиотека Megatron-LM, являющаяся частью платформы NVIDIA NeMo. При этом использовались 3072 ускорителя NVIDIA H100 на базе DGX Cloud. Утверждается, что Mistral NeMo 12B отлично справляется с многоходовыми диалогами, математическими задачами, программированием и пр. Модель обладает «здравым смыслом» и «мировыми знаниями». В целом, говорится о точной и надёжной работе применительно к широкому спектру приложений. 
Источник изображения: NVIDIA Модель выпущена под лицензией Apache 2.0 и предлагается в виде NIM-контейнера. На внедрение LLM, по словам создателей, требуются считанные минуты, а не дни. Для запуска модели достаточно одного ускорителя NVIDIA L40S, GeForce RTX 4090 или RTX 4500. Среди ключевых преимуществ развёртывания посредством NIM названы высокая эффективность, низкая стоимость вычислений, безопасность и конфиденциальность. UPD 21.08.2024: компании представили Mistral-NeMo-Minitron 8B, более компактную, но не менее эффективную, по словам создателей, версию Mistral NeMo 12B, которая может работать даже на ускорителе NVIDIA RTX.
20.07.2024 [14:40], Сергей Карасёв
Разработчик сетевых решений для гиперскейлеров Arrcus привлёк $30 млнКомпания Arrcus, разработчик программных решений для гиперскейлеров, объявила о проведении раунда финансирования на сумму $30 млн, в котором приняла участие NVIDIA. В число других инвесторов вошли Prosperity7 Ventures, Lightspeed, Hitachi Ventures, Liberty Global, Clear Ventures и General Catalyst. Arrcus была основана в 2016 году. Ранее Arrcus привлекла на развитие $138 млн от различных инвесторов. В число партнёров компании входят Amazon Web Services (AWS), Equinix, Edgecore networks, CoreSite и др. Компания специализируется на передовых сетевых технологиях: в числе её продуктов — платформа Leaf-Spine Fabric и решение ACE-AI на основе ArcOS для обслуживания распределенных рабочих нагрузок ИИ. 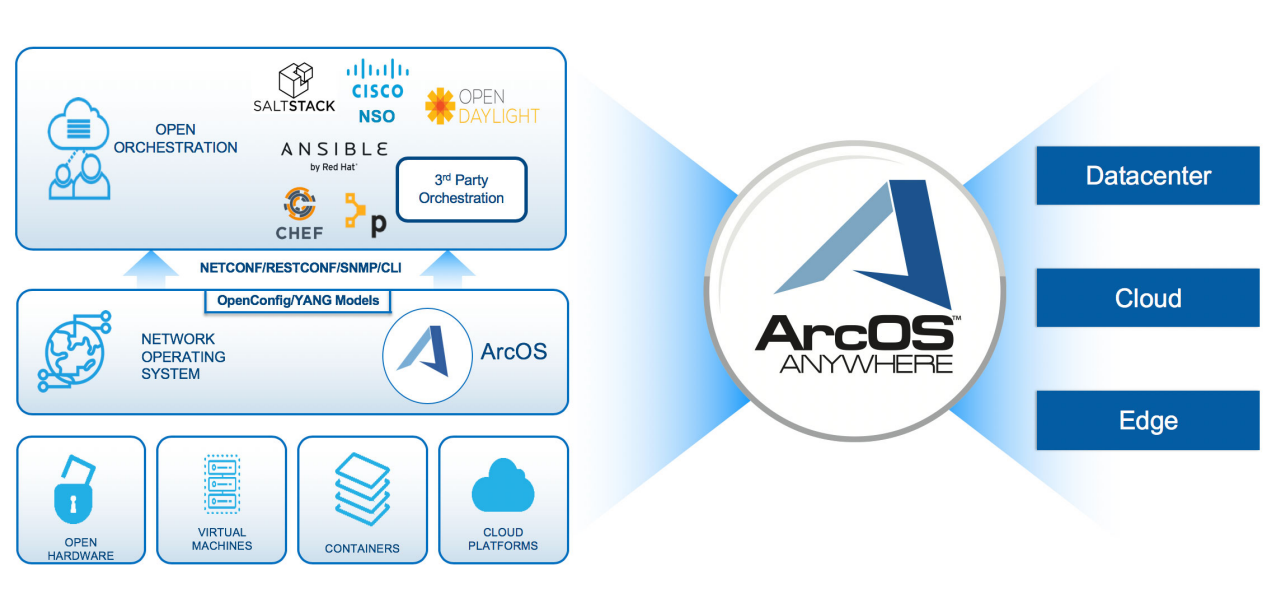
Источник изображения: Arrcus Сетевая платформа ACE (Arrcus Connected Edge), использующая NVIDIA BlueField DPU, позволяет эффективно разгружать, ускорять и изолировать ресурсоемкие приложения, такие как системы обеспечения безопасности или средства управления трафиком. По сути, Arrcus оптимизирует использование распределённой вычислительной инфраструктуры, охватывающей дата-центры, периферийные узлы и гибридные/мультиоблачные среды. Отмечается, что решения Arrcus в сочетании с ИИ-инфраструктурой на базе компонентов NVIDIA позволят обеспечить максимальную эффективность для заказчиков. Кроме того, сотрудничество компаний поможет расширить архитектуру традиционных ЦОД до распределённых конфигураций, основанных на модульной платформе NVIDIA MGX, специально разработанной для построения ИИ-систем на базе CPU, GPU и DPU.
18.07.2024 [22:35], Владимир Мироненко
TrendForce прогнозирует высокий спрос на ИИ-серверы до конца 2025 годаСогласно прогнозу аналитической компании TrendForce, высокий спрос на ИИ-серверы со стороны крупных провайдеров облачных услуг и других клиентов сохранится до конца 2024 года. Постепенное расширение производства компаниями TSMC, SK hynix, Samsung и Micron позволило значительно уменьшить дефицит во II квартале и, как следствие, время выполнения заказа на NVIDIA H100 сократилось с прежних 40–50 недель до менее чем 16. По оценкам TrendForce, поставки ИИ-серверов во II квартале выросли почти на 20 % по сравнению с предыдущим кварталом. Аналитики в своём свежем отчёте пересмотрели прогноз поставок на весь год до 1,67 млн ИИ-серверов (рост на 41,5 % в годовом исчислении). Объём рынка ИИ-серверов в 2024 году в денежном выражении, как ожидают в TrendForce, превысит $187 млрд при темпах роста 69 %, что составит 65 % от рыночной стоимости всех поставленных серверов. В отчёте также отмечено, что в этом году крупные провайдеры облачных услуг продолжают концентрироваться на закупке ИИ-серверов, что негативно отражается на темпах роста поставок серверов общего назначения. У последних ежегодные темпы роста поставок составят всего 1,9 %. Как ожидают в TrendForce, доля ИИ-серверов в штучном выражении в общем объёме поставок достигнет 12,2 %, что больше на 3,4 п.п. по сравнению с 2023 годом.  Аналитики отметили, что североамериканские гиперскейлеры постоянно расширяют выпуск собственных ASIC, впрочем, как и китайские компании, такие как Alibaba, Baidu и Huawei. Ожидается, что благодаря этому доля ASIC-серверов на рынке ИИ-серверов вырастет до 26 % в 2024 году, в то время как у ИИ-серверов с ускорителями доля будет около 71 %. При этом NVIDIA сохранит абсолютное лидерство с около 90 % рынка ИИ-серверов с ускорителями, в то время как доля AMD составит лишь около 8 %. Если же учитывать вообще все чипы, используемые в ИИ-серверах (GPU, ASIC, FPGA), то доля рынка NVIDIA в этом году составит около 64 %, ожидают в TrendForce. По оценкам аналитической фирмы Tech Insights, NVIDIA в 2023 году отгрузила приблизительно 3,76 млн серверных ускорителей на базе GPU, захватив 98 % рынка GPU для ЦОД. TrendForce считает, что спрос на передовые ИИ-серверы сохранится и в 2025 году, учитывая тот факт, что NVIDIA Blackwell (включая GB200, B100/B200) заменит Hopper. Это также будет стимулировать спрос на CoWoS (2.5D-упаковка от TSMC) и память HBM. Производственная мощность TSMC в области CoWoS, по оценкам TrendForce, достигнет 550–600 тыс. единиц к концу 2025 года, при этом темпы роста достигнут 80 %. 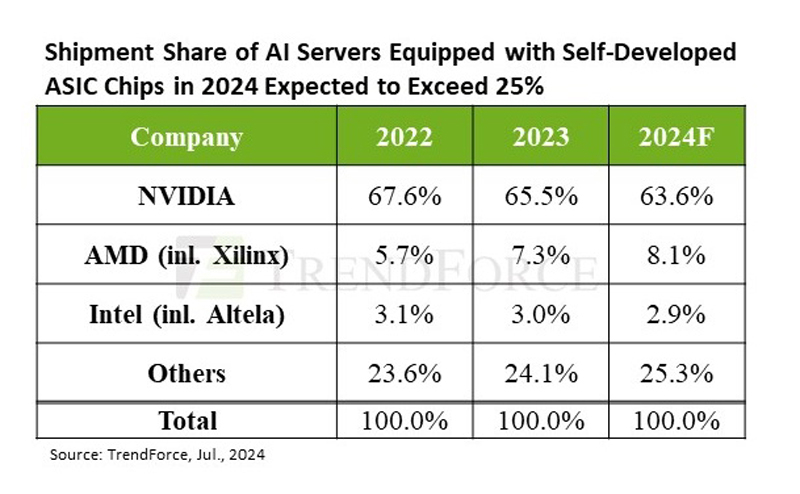
Источник изображения: TrendForce Тем не менее, ускоритель H100 получит в 2024 году наибольшее распространение. К 2025 году такие ускорители, как Blackwell Ultra от NVIDIA или MI350 от AMD, будут оснащены HBM3e ёмкостью до 288 Гбайт, что утроит количество компонентов памяти. Ожидается, что общее предложение HBM удвоится к 2025 году на фоне высокого спроса на ИИ-серверы. При этом не все уверены в светлом будущем ИИ. Так, венчурный фонд Sequoia Capital и аналитики Goldman Sachs указывают на сверхвысокие расходы на ИИ-оборудование и вместе с тем отсутсвие реальной финансовой отдачи от вложений в ИИ-решения. С другой стороны, венчурный фонд Andreessen Horowitz (a16z) уверен, что ИИ не станет очередным финансовым пузырём и сам закупает ИИ-ускорители, чтобы привлечь стартапы. А некоторые ИИ-стартапы сами приходят к крупным игрокам, поскольку не способны окупить затраты на оборудование.
18.07.2024 [18:23], Руслан Авдеев
Четвёртый за год: NVIDIA приобрела ещё один облачный стартап — Brev.devNVIDIA приобрела стартап, помогающий ИИ-разработчикам найти среди предложений облачных провайдеров наиболее подходящий по соотношению цена/качество доступ к ускорителям. Как сообщает портал CRN, это уже четвёртая заметная покупка NVIDIA с начала года. Представитель NVIDIA подтвердил, что сделка по приобретению Brev.dev действительно состоялась, но сумму и условия сделки не сообщил. Brev.dev предоставляет платформу для создания, обучения и внедрения ИИ-моделей в облаках. Целью Brev.dev, по словам самого стартапа, является поиск простейшего способа использования ускорителей для разработчиков систем ИИ и машинного обучения. Сотрудничество с NVIDIA обеспечит выполнение этой миссии, с комбинацией максимально возможно производительной аппаратной составляющей с самым передовым программным обеспечением. На сайте Brev.dev официальными партнёрами стартапа названы NVIDIA, Intel и AWS. Там же говорится, что платформа служит единым интерфейсом для взаимодействия AWS, Google Cloud Platform, Fluidstack и прочими облаками с ИИ-ускорителями. Это позволяет разработчикам искать подходящие инстансы на основе их цены и доступности. Хотя NVIDIA поставляет GPU и ИИ-ускорители облачным провайдерам более десяти лет, в последние годы компания уделяет немало внимания расширению собственного бизнеса в сфере облачных инфраструктур. 
Источник изображения: NVIDIA В прошлом году компания запустила сервис DGX Cloud, который развёрнут в облачной инфраструктуре других провайдеров и на собственных мощностях и ИИ-суперкомпьютерах. Ранее в этом году NVIDIA купила ещё два стартапа для развития возможностей DGX Cloud. В конце апреля компания анонсировала покупку израильского стартапа Run:ai, занимающегося решениями для оркестрации ИИ-инфраструктур. Его планируется интегрировать в DGX Cloud, а также с DGX- и HGX-серверами. По имеющимся данным, покупка Run:ai обошлась в $700 млн. Практически одновременно с Run:ai компания приобрела ещё один израильский стартап — Deci, предлагающий ПО, способное на любом железе ускорить инференс ИИ-моделей, сохраняя точность данных. Сделку, по слухам, оценили приблизительно в $300 млн. Наконец, месяц назад NVIDIA купила калифорнийский стартап Shoreline.io, основанный бывшим управленцем AWS — компания разрабатывает ПО для автоматического устранения проблем в инфраструктуре ЦОД. По некоторым данным, команда Shoreline присоединилась к DGX Cloud, а покупка обошлась в $100 млн.
17.07.2024 [23:33], Игорь Осколков
Суперускоритель по суперцене — NVIDIA GB200 NVL72, вероятно, будет стоить $3 млнКомпания NVIDIA значительно увеличила заказ на ускорители Blackwell у TSMC, сообщает TrendForce со ссылкой на United Daily News (UDN). По данным источника, NVIDIA намерена получить уже не 40 тыс., а 60 тыс. суперускорителей нового поколения, причём 50 тыс. из них придётся на стоечные системы GB200 NVL36. При этом Blackwell всё равно будут в дефиците, как и обещал ещё зимой глава NVIDIA Дженсен Хуанг (Jensen Huang). B200 включает два тайла, объединённых 2,5D-упаковкой CoWoS-L и соединённых интерконнектом NV-HBI. Чип имеет 208 млрд транзисторов, изготовленных по кастомному техпроцессу TSMC 4NP. GB200 объединяет два ускорителя B200 и один 72-ядерный Arm-процессор Grace. А суперускоритель GB200 NVL72, в свою очередь, объединяет в рамках одной стойки Oberon сразу 18 1U-узлов с парой GB200 в каждом (плата Bianca, 72 × B200 и 36 × Grace), провязанных шиной NVLink 5. Вся эта система потребляет порядка 120 кВт, оснащена СЖО и единой DC-шиной питания. Однако у GB200 NVL72 довольно специфические требования к окружению, поэтому NVIDIA предлагает суперускоритель попроще — GB200 NVL36, который как раз и должен стать наиболее массовым в данной серии. Эта платформа точно так же занимает целую стойку, но использует 2U-узлы с теми же платами Bianca (суммарно 36 × B200 и 18 × Grace), потребляя всего 66 кВт. При этом всё равно подразумевается использование двух стоек GB200 NVL36, объединённых интерконнектом, так что GB200 NVL72 всё равно получается более энергоэффективным решением. 
NVIDIA GB200 Как отмечает SemiAnalysis, GB200 NVL36 также будет доступен в варианте с платами Ariel, имеющими по одному чипу B200 и Grace. Наконец, во II квартале 2025 года появятся системы B200 NVL72 и B200 NVL36 с x86-процессорами (Miranda). Кроме того, NVIDIA представила и отдельные MGX-узлы GB200 NVL2 с парой GB200. В общем, ускорителей B200 компании понадобится много, чтобы наверняка удержать лидерство на рынке. 
Источник изображения: NVIDIA По словам UDN, GB200 NVL36 будет стоить порядка $1,8 млн, а GB200 NVL72 обойдётся уже в $3 млн. Одиночный GB200 будет стоить $60–$70 тыс., а самый простой ускоритель B100 оценён в $30–$35 тыс. Нужно подчеркнуть, что это оценки сторонних аналитиков. Сама компания официально не раскрывает стоимость своих продуктов. Это устоявшаяся практика на данном рынке, против которой пошла только Intel, публично назвавшая стоимость ИИ-ускорителей Gaudi. Впрочем, ранее глава NVIDIA намекнул, что B200 будет стоить приблизительно $30–$40 тыс.
15.07.2024 [09:23], Владимир Мироненко
HPE построит самый мощный в Японии ИИ-суперкомпьютер ABCI 3.0 на базе NVIDIA H200Японский национальный институт передовых промышленных наук и технологий (AIST) объявил о планах по строительству в Касива (Kashiwa, префектура Тиба) нового суперкомпьютера AI Bridging Cloud Infrastructure 3.0 (ABCI 3.0), представляющего собой очередное обновление ИИ-платформы ABCI, запущенной в 2018 году. Новый суперкомпьютер будет предлагаться в качестве облачного сервиса как государственным, так и частным организациям страны, сообщается в блоге NVIDIA. В качестве подрядчика выступает HPE, которая построит систему с использованием платформы Cray XD с ускорителями NVIDIA H200, объединённых 200G-интерконнектом NVIDIA Quantum-2 InfiniBand. HPE не стала раскрывать подробности об общем количестве узлов, стоимости системы и сроках её ввода в эксплуатацию. Как полагает ресурс The Register, речь идёт о системе с 5U-узлами Cray XD670, способными вместить восемь ускорителей NVIDIA H200/H100 и пару Intel Xeon Emerald Rapids. Кроме того, готовится машина ABCI-Q на базе ускорителей NVIDIA H100, ориентированная на исследования в области квантовых и гибридных вычислений. 
Источник изображения: AIST HPE сообщила, что ABCI 3.0, как ожидается, станет самым быстрым ИИ-суперкомпьютером в Японии — примерно 6,2 Эфлопс (FP16?) или 410 Пфлопс (FP64). Проект ABCI 3.0 реализуется при поддержке Министерства экономики, торговли и промышленности Японии (METI) с целью укрепления вычислительных ресурсов страны через Фонд экономической безопасности. Это часть более широкой инициативы METI стоимостью $1 млрд, которая включает в себя как программу ABCI, так и инвестиции в облачные вычисления на базе ИИ. |
|

